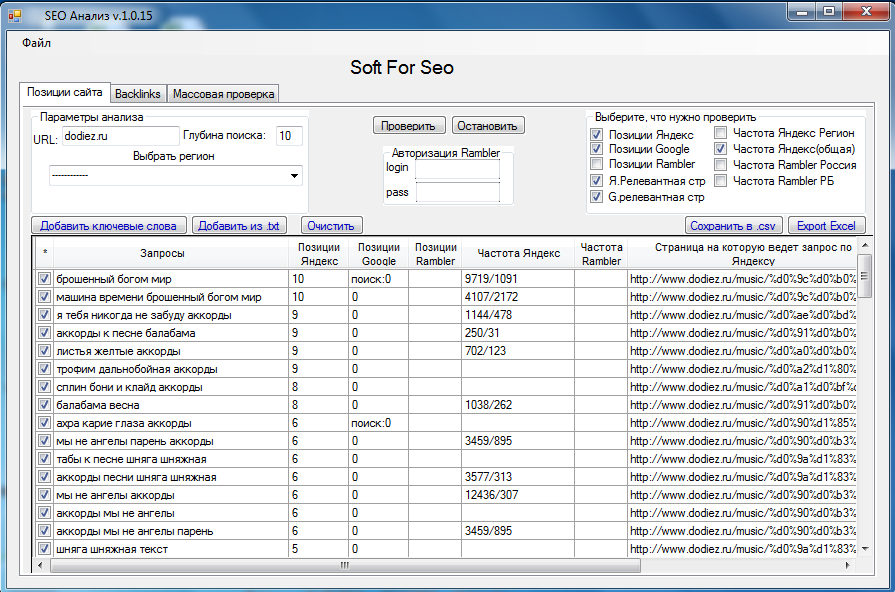
Управление запросами (Power Query)
Excel
Импорт и анализ данных
Импорт данных
Импорт данных
Управление запросами (Power Query)
Excel для Microsoft 365 Excel для Интернета Excel 2021 Excel 2019 Excel 2016 Excel 2013 Excel 2010 Еще…Меньше
Вы можете управлять запросами в области «Запросы» Редактор Power Query или на вкладке «Запросы» на панели «Запросы & подключения» в Excel. Это особенно полезно, если у вас много запросов и вы хотите быстро найти запрос. После поиска запроса можно выполнить ряд дополнительных действий, таких как дублирование, ссылка, слияние, добавление, совместное использование и удаление запроса.
При создании запроса сведения о подключении создаются в фоновом режиме. Роль запроса — формирование данных. Сведения о подключении должны поддерживать сведения об источнике данных и обновлять их в соответствии с параметрами обновления, такими как частота.
Не все запросы могут быть загружены на лист. Это может произойти, когда вы импортируете данные из внешнего источника данных, формируете данные в Редактор Power Query, выбираете home> Load To, а затем используете диалоговое окно «Импорт данных», чтобы поместить запрос в модель данных или ODC-файл.
Ниже приведена сводка команд, которые можно использовать в том порядке, в котором они отображаются в соответствующих контекстных меню на вкладке «Запросы» на панели «Запросы & Подключение» в Excel или на панели «Запросы» Редактор Power Query. Некоторые команды доступны только на одной панели. Многие из этих команд также доступны на вкладке «Запрос контекста» на ленте. Все запросы в книге отображаются и сортируются по дате и времени последнего изменения, начиная с последнего.
-
Выберите команду управления запросом:
Edit Edits the query in the Редактор Power Query. Доступно только на вкладке » Запросы » & «Подключения «.
Удалить Удаляет запрос.
Переименовать Изменяет имя запроса.
Обновить Предоставляет актуальные данные из внешних источников данных. Доступно только на вкладке « Запросы » & «Подключения «. Дополнительные сведения см. в разделе «Обновление подключения к внешним данным» в Excel.

Загрузить в Отображает диалоговое окно «Импорт данных», в котором можно выбрать способ просмотра данных, место их размещения и добавить в модель данных. Доступно только на вкладке » Запросы » & «Подключения «.
Дублировать Создает копию выбранного запроса с тем же именем, что и исходный запрос, добавленный (2). Вы можете переименовать запрос, чтобы упростить его идентификацию. Последующие изменения исходного запроса не влияют на новый запрос.
Ссылки Создает новый запрос, который использует шаги предыдущего запроса без необходимости дублировать запрос. Новый запрос следует тому же соглашению об именовании, что и команда Duplicate . Вы можете переименовать новый запрос, чтобы его было проще идентифицировать. Последующие изменения исходного запроса, которые приводят к изменению выходных данных, влияют на новый запрос.
Объединить Объединение столбцов в запросе с соответствующими столбцами в других запросах.
Дополнительные сведения о слиянии см. в разделе «Запросы на слияние». Доступно только на вкладке » Запросы » & «Подключения «.Добавить Добавление столбцов в запрос с соответствующими столбцами в других запросах. Дополнительные сведения о добавлении см. в разделе «Запросы на добавление». Доступно только на вкладке » Запросы » & «Подключения «.
Переместить в группу Перемещает запрос в группу в списке или, если группы отсутствуют,
Вверх Перемещает запрос вверх в списке запросов.
Переместить вниз Перемещает запрос вниз в списке запросов.
В диалоговом окне «Создание функции » отображается диалоговое окно «Создание функции». Доступно только на панели запросов в Редактор Power Query.
Дополнительные сведения см. в Power Query функции M.Преобразование в параметр Преобразует запрос в параметр и отображает его в предварительной версии данных. Если текущий дисплей является параметром, команда переключается на преобразование в запрос. Доступно только на панели запросов в Редактор Power Query. Дополнительные сведения см. в разделе «Создание запроса параметров Power Query».
Расширенный редактор открывает окно Расширенный редактор окна. Дополнительные сведения см. в статье «Создание Power Query в Excel». Доступно только на панели запросов в Редактор Power Query.
Экспорт файла подключения Сохраняет запрос в виде ODC-файла подключения. ODC-файл содержит определение запроса, сведения о подключении к источнику данных и все шаги преобразования. Это полезно, если вы хотите поделиться запросами с другими пользователями и книгами. Кроме того, можно использовать команду «Свойства» на вкладке «Контекст запроса» Power Query ленты.
Дополнительные сведения см. в статье «Создание, изменение подключений к внешним данным и управление ими». Доступно только на вкладке » Запросы » & «Подключения «.Вариантов размещения Используйте эту команду для управления запросом и сведениями о подключении к источнику данных. На вкладке « Запросы » на панели & connections (Запросы) откроется диалоговое окно «Свойства запроса». На панели «Запросы» в Редактор Power Query откроется диалоговое окно «Параметры запроса».
 org/ListItem»>
org/ListItem»>
Выполните одно из следующих действий:
в Excel выберите запросы> данных & подключения> запросы.
В разделе Редактор Power Query Выбор данных> получить > запуска Редактор Power Query и просмотреть область запросов слева.

 Дополнительные сведения о слиянии см. в разделе «Запросы на слияние». Доступно только на вкладке » Запросы » & «Подключения «.
Дополнительные сведения о слиянии см. в разделе «Запросы на слияние». Доступно только на вкладке » Запросы » & «Подключения «. Дополнительные сведения см. в Power Query функции M.
Дополнительные сведения см. в Power Query функции M. Дополнительные сведения см. в статье «Создание, изменение подключений к внешним данным и управление ими». Доступно только на вкладке » Запросы » & «Подключения «.
Дополнительные сведения см. в статье «Создание, изменение подключений к внешним данным и управление ими». Доступно только на вкладке » Запросы » & «Подключения «.Вы можете включить или отключить отображение всплывающего элемента запроса при наведении указателя мыши на имя запроса на вкладке «Запрос» на панели «Запросы & подключения».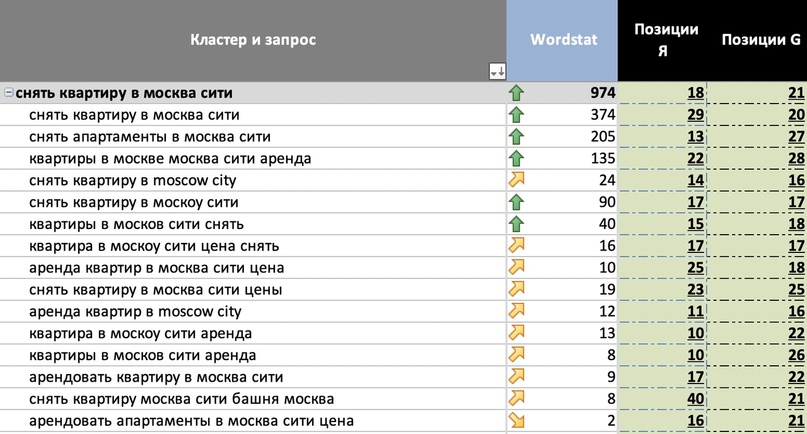
-
Выберите параметры > «Получение > данных».
-
Слева в разделе GLOBAL выберите » Общие».
-
Справа в разделе » Предварительный просмотр запроса» снимите флажок рядом с кнопкой
 Действие по умолчанию — отображение всплывающего меню при наведении указателя мыши.
Действие по умолчанию — отображение всплывающего меню при наведении указателя мыши.
Excel для Интернета включает Power Query (также называемую get & Transform) для повышения производительности при работе с импортируемыми источниками данных. Запросы и связанные сведения можно просмотреть в области задач «Запросы».
Примечание: Следите за дальнейшими объявлениями об улучшениях Excel для Интернета и Power Query интеграции.
Запросы и связанные сведения можно просмотреть на панели запросов.
-
Убедитесь, что вы в режиме правки ( выберите «Просмотр > редактирование»).
 org/ListItem»>
org/ListItem»>
Выберите запросы > данных.
Результат
Excel отображает область задач » Запросы» и все запросы в текущей книге, а также сведения о запросах, такие как количество строк, дата последнего обновления, расположение и состояние загрузки. Если запрос загружается в модель данных, а не в сетку, в Excel отображается значение «Только подключение».
Вы можете выполнять различные задачи группирования, чтобы лучше упорядочить запросы.
-
Убедитесь, что вы в режиме правки ( выберите «Просмотр > редактирование»).
-
Выполните одно или несколько из указанных ниже действий.
Создание группы
-
В правом верхнем углу области » Запросы» выберите «Дополнительные параметры» > «Создать группу».
-
Введите имя (при необходимости описание) и нажмите кнопку » Сохранить».
Перемещение запроса или группы в другую группу
-
Рядом с запросом или именем группы выберите «Дополнительные параметры» >«Переместить в группу».
-
Выберите группу, в которую нужно переместить, а затем нажмите кнопку «Сохранить».
Перемещение группы на верхний уровень
Развертывание или свертывание групп
 org/ListItem»>
org/ListItem»>
Чтобы развернуть или свернуть все группы, в правом верхнем углу области «Запросы» выберите «Дополнительные параметры» > «Развернуть все» или «Свернуть все».
-
-
Чтобы развернуть или свернуть определенную группу, щелкните стрелку рядом с ее именем.
-
Рядом с именем группы выберите » Дополнительные параметры» >«Обновить».
Примечание Обновление работает только для поддерживаемых источников данных.
Дополнительные сведения см. в Power Query источниках данных в версиях Excel. -
Рядом с именем группы выберите » Дополнительные параметры»… > переименовать.
-
Введите новое имя и нажмите клавишу RETURN.
-
Рядом с именем группы выберите «Дополнительные параметры… >«.
-
Переименуйте группу или измените ее описание, а затем нажмите кнопку «Сохранить».
 org/ListItem»>
org/ListItem»>
Выберите запросы > данных.
Обновление всех запросов в группе
 Дополнительные сведения см. в Power Query источниках данных в версиях Excel.
Дополнительные сведения см. в Power Query источниках данных в версиях Excel.Разгруппировка запросов в группе
Переименование группы
Удаление группы
Изменение свойств группы
 org/ItemList»>
org/ItemList»>Совет Чтобы просмотреть описание группы, наведите на нее указатель мыши.
См. также
Справка по Power Query для Excel
Изменение свойств параметров запроса
Использование панели «Запросы» (docs.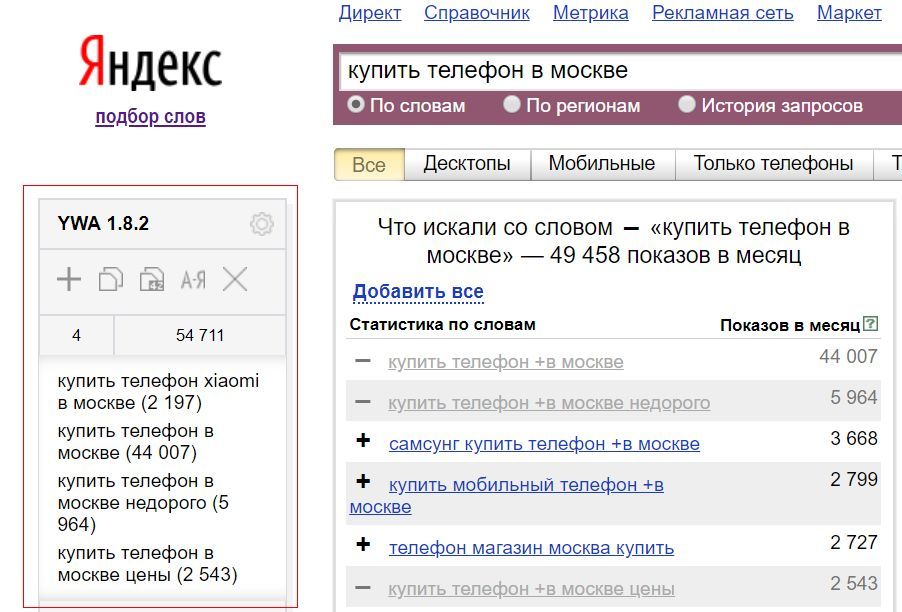 com)
com)
Характеристики поисковых запросов
На первоначальном этапе в вашем списке окажутся десятки и сотни тысяч (а может и миллионы) запросов. Но большая их часть не будет представлять интереса в плане продвижения, поэтому вы неизбежно столкнетесь с задачей анализа и фильтрации полученного списка.
Эту работу надо выполнить в три этапа:
- понять, какие характеристики запросов важны;
- собрать данные по нужным характеристикам;
- отобрать целевые запросы.
Рассмотрим важнейшие характеристики ключевых слов , а также определим взаимосвязи между характеристиками и целесообразностью продвижения сайта по конкретному запросу.
Навигационные, коммерческие и информационные запросы
Запрос относят:
- к навигационным, если пользователю нужна конкретная информация: адрес, время работы, место, сайт;
- коммерческим (трансакционным), если пользователю нужно что-то купить (запрос подразумевает проведение финансовой трансакции трансакции),
- информационным, если нужна общая информация, не подразумевающая конкретного действия.
Запрос может также быть нечетким, а поисковая выдача по нему — смешанной, так как у поисковика нет возможности точно определить намерение пользователя. Например, по запросу «стул» поисковики будут показывать и интернет-магазины стульев, и информационные статьи про стулья.
Необходимо проанализировать каждый запрос и понять, стоит ли его брать в работу. Для продвижения контентных проектов нужно ориентироваться на информационные запросы, для интернет-магазинов и корпоративных сайтов — на коммерческие. Однако разделение это условное: интернет-магазин может привлекать дополнительный трафик на информационные статьи в блоге, а информационный портал предлагать полезный каталог с выбором товаров и последующей его покупкой на сайтах-партнерах.
Характеристики частотности и конкурентности
По частотности (количеству запросов в месяц) можно разделить ключевые слова на высоко-, средне- и низкочастотные, а по уровню конкуренции — на высоко-, средне- и низкоконкурентные.
Определить частотность запроса не всегда просто, так как здесь нужно учесть много факторов: базовую частотность, влияние сезонности и моды, всплески актуальности запроса в соц. сетях и прочее.
Однако для практических задач высокая точность не нужна. Поэтому проще всего воспользоваться следующим алгоритмом.
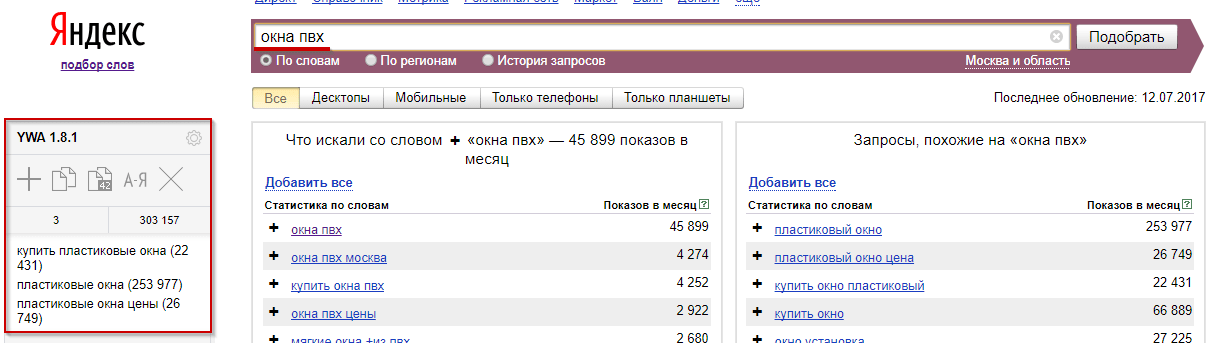
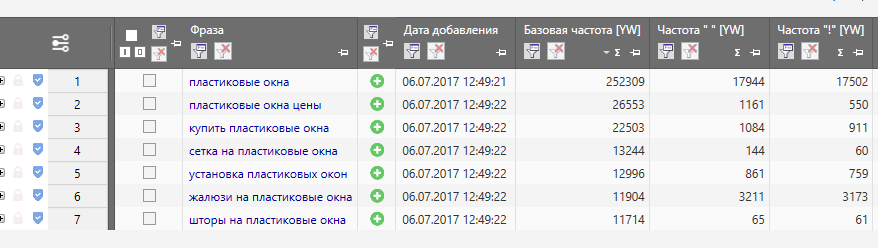
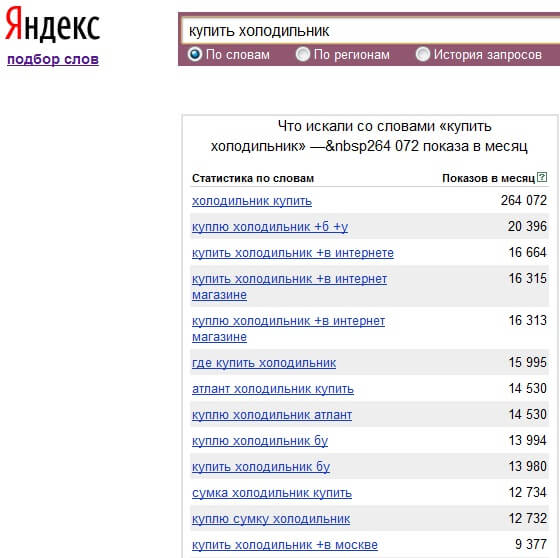
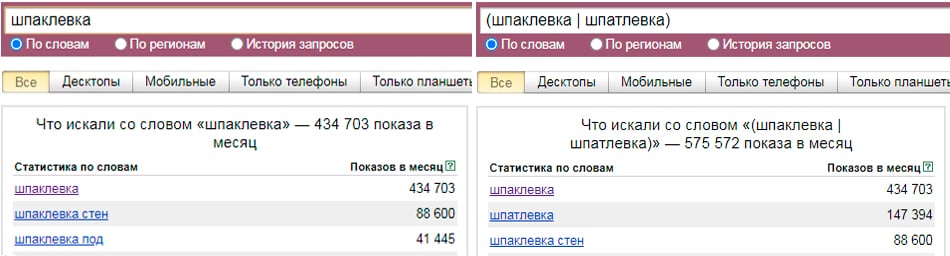
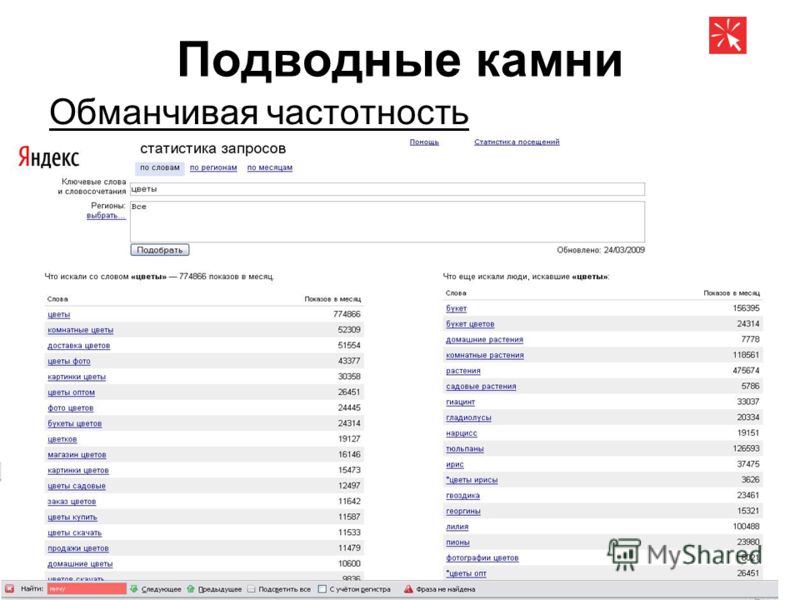
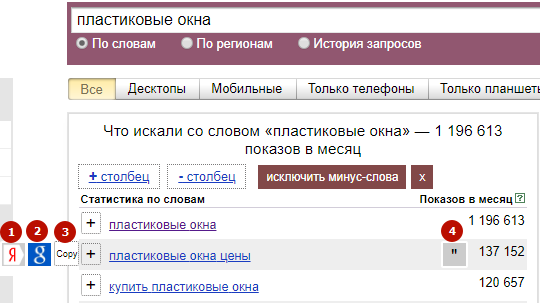
Идем в сервис Яндекс.Вордстат. Вводим туда целевой запрос (например, «велосипед») и получаем базовую частотность (4 092 821 показ в месяц). Базовая частотность показывает количество всех запросов, содержащих целевой запрос, которое пользователи запрашивали в Яндексе в последний месяц. Например, для «велосипеда» это «велосипеды», «купить велосипед», «детский велосипед» и далее по списку.
Можно уточнить цифры, введя в сервисе Вордстат целевой запрос в кавычках («велосипед»). Так мы получим фразовую частотность (59 993 показа в месяц), которая показывает, сколько раз пользователи вводили в поисковик запросы, содержащие только слова из нашего целевого запроса (в нашем случае это «велосипед» и «велосипеды»).
Если нужна еще более точная информация, поставьте перед каждым или некоторым словами целевого запроса восклицательный знак («!велосипед» — не забудьте кавычки). Так вы получите точную частотность (29 634 показа в месяц), которая покажет, сколько раз пользователи Яндекса запрашивали именно такие слова за последний месяц.
Чтобы прикинуть общую частотность по всем поисковикам, нужно полученные цифры умножить в соответствии с долей Яндекса на поисковом рынке (информацию о ней легко найти в сети).
Разделение по частотности условное: на одном рынке высокочастотный ключевик будет иметь десятки тысяч («пластиковые окна»), а на другом — всего сотни запросов в месяц («ледяная рыба купить»).
Понятно, что продвижение по более частотным запросам может привлечь больше трафика, но тут не все так просто. За хорошие места по высокочастотным запросам борются многие сайты, поэтому бюджет продвижения по высокочастотникам выше.
На практике это часто означает, что лучше взять в работу менее частотные, но более простые в продвижении запросы.

Для расчета конкурентности существуют разные методы, но суть их одна: надо проанализировать поисковую выдачу по целевому запросу и составляющие ее сайты. Основные параметры:
— количество оптимизированных главных страниц,
— количеству оптимизированных страниц,
— возрасту сайтов,
— количеству рекламы по запросу,
— оптимизированность каждого отдельного сайта и т.д.
Всю эту информацию обычно сводят к показателю KEI (Keyword Effectiveness Index, придуман Самантой Рой), чтобы было удобно сравнивать запросы между собой. Классическая формула этого показателя:
KEI = F2/Q,
где F — это частотность за последние 60 дней, а Q — это количество сайтов в выдаче, оптимизированных под данный ключевик. Как правило, чем выше KEI, тем выше частотность и конкурентность запроса.
Рассчитать параметры конкуренции для большого количества запросов в ручном режиме нереально, поэтому процесс надо автоматизировать с помощью специальных сервисов и программ (например, Key Collector).
Можно использовать другие методы. Например, сравнить ставки контекстной рекламы: у более конкурентных запросов они будут выше. Или проверить запросы в сервисах так называемого «автоматического» продвижения: чем выше бюджет — тем сильнее конкуренция по запросу.
При этом надо понимать, что любые полученные цифры будут условными. Но они помогут принять правильное решение и выстроить стратегию продвижения, при которой в работу в первую очередь надо брать запросы с высокими показателями частотности и умеренной конкуренцией.
Геозависимость
Если поисковая выдача меняется в зависимости от региона, то запрос является геозависимым, если нет — геонезависимым.
Для понимания того, какие запросы являются геозависимыми, можно воспользоваться специальными сервисами в интернете или вбить запрос в поисковую систему два-три раза, при этой не забывая менять регион.
Учитывать геозависимость запросов необходимо для того, чтобы понимать специфику поисковой выдачи. Если вы продвигаетесь в конкретном регионе, приоритет стоит отдать геозависимым запросам — так у вас будет больше шансов в сравнении с федеральными брендами.
Если же продвижение идет на федеральном уровне, то лучше сосредоточиться на геонезависимых запросах, так как вам может быть сложно конкурировать с региональными игроками без дополнительных расходов (например, открытия филиала).
В такой ситуации может помочь лайфхак. Попробуйте договориться с региональной компанией о представительстве в регионе — это повысит ваши шансы в гонке, даже если «представительство» будет номинальным.
Главное — указать на продвигаемом сайте физический адрес представительства и его контактные данные в нужном регионе.
Zero-click запросы
Согласно свежим данным более половины мобильных и около трети десктопных поисковых сессий в Гугле заканчиваются без перехода на контент других сайтов. То есть на многие запросы поисковики стараются дать ответ уже на странице поисковой выдачи.
Это касается информации об отдельных фактах, таблицах, расписаниях и других запросах, ответ на который легко «упаковать» в специальный формат на странице выдачи.
Со временем таких специальных форматов будет становиться все больше, а конкурировать за трафик станет сложнее.
С zero-click запросами можно и нужно работать, но они явно не будут в приоритете при планировании стратегии продвижения.
Витальные запросы
Витальные запросы — поисковые запросы, состоящие строго из названия сайта, компании или бренда. В выдаче по ним на первых местах будут исключительно соответствующие ресурсы — официальный сайт компании, его популярные страницы или поддомены.
Обратите внимание: витальными являются запросы без уточняющих слов. Например, запрос «купить samsung» не витальный, а коммерческий, а запрос «как перепрошить самсунг гелакси 2» — информационный.
Категорийные или товарные запросы
Данная характеристика важна для проектирования структуры сайта. Запрос считается категорийным, если в выдаче по нему большую часть позиций занимают категории товаров (листинги). Если же большую часть выдачи занимают страницы конкретных товаров, запрос считается товарным.
Больше информации:
- продвижение сайтов
- создание продающих сайтов
Подбор ключевых слов для оптимизации сайта и рекламы
Каждый SEO-оптимизатор знает, что от того, насколько правильно подобраны ключевые запросы, зависит успешность продвижения. А именно: место в поисковой выдаче, объем и качество трафика, эффективность контекстной рекламы и не только.
Ключевые запросы – это слова, которые вбивают пользователи в поисковую строку. Очень важный параметр для раскрутки сайта.
Сайт без семантики подобен машине без двигателя – автомобиль-то есть, а толку от него нет. А плохо подобранная семантика как неисправный двигатель – она как бы и существует, но до назначенной цели никак «не довезет».
Семантика (семантическое ядро, СЯ) – это список ключевых запросов, точно характеризующих деятельность сайта, предлагаемые товары и услуги. Это тот пласт ключевых слов, по которым вы хотите, чтобы пользователи находили ваш сайт.
Семантическое ядро важно любому сайту, будь это интернет-магазин, сайт-визитка компании по ремонту квартир или кулинарный блог. Эффективные ключевые слова необходимы любому проекту, ведь только они помогут добиться вам нужных целей – вывести сайт на хорошие позиции в поисковике, привести целевого покупателя или читателя блога, совершить целевое действие (купить, подписаться на блог, скачать книгу) и т.д.
В этой статье я постараюсь простыми словами рассказать вам о правилах подбора ключевых слов.
Подбор ключевых слов для сайта
Ключевые запросы в первую очередь собираются для оптимизации самого сайта. Их необходимо использовать:
- В текстах на сайте. В этой статье мы рассказали, как правильно подбирать ключевые слова для своего контента и как их грамотно распределять по тексту, чтобы оптимизация была эффективной.
- В тегах Title и И об этом есть статья в нашем блоге.
- В заголовках Н1-Н6. Очень подробная статья с примерами представлена здесь.
- В описаниях к изображениям. Отличная статья на эту тему – советуем прочесть.
- В URL страниц. Включение ключевых слов в адрес страницы тоже увеличивает релевантность страницы по запросу.
- В хлебных крошках на сайте. Статья в помощь здесь.
- В ссылках. Влияет включение запросов как во внешние ссылки, так и при внутренней перелинковке сайта.
 Очень подробная статья с примерами представлена здесь.
Очень подробная статья с примерами представлена здесь.Чем больше вы задействуете ключевых слов на странице (в текстах, тегах, заголовках и пр.), тем выше будет ее релевантность по этим ключам, что улучшает ранжирование, увеличивает шансы на попадание в ТОП и приведение посетителей, ищущих информацию по этим запросам.
Но помните, что не так страшно «не доборщить» как «переборщить». Переспам текстов ключевыми словами карается поисковиками, оптимизация страницы должна быть умеренной. Подробнее про тошноту читайте в этой статье.
Как подбирать ключевые слова для сайта?
Для начала дам очень важный совет для тех, кто еще не создал сайт: семантическое ядро лучше всего собирать до разработки сайта, а не после. Предварительный сбор ключевых слов позволит вам определить структуру сайта – вы сможете изначально понять, какие страницы нужно создать, чтобы не упустить важные запросы. Иначе потом, когда сайт будет создан, а структура готова, вносить коррективы будет сложнее, и подходящие запросы придется «распихивать как попало», или вовсе не задействовать их в продвижении.
Этапы подбора ключевых запросов для сайта
Покажу наиболее распространенный способ подбора семантического ядра, который не требует особых знаний, финансовых затрат, привлечения дополнительных специалистов и задействования платных сервисов. Даже начинающему SEO-оптимизатору или новичку в создании сайтов он будет под силу.
1 этап. Подбор первичного списка запросов
Самостоятельно или вместе с коллегами соберите первоначальный список фраз, по которым, на ваш взгляд, пользователи должны находить ваш сайт.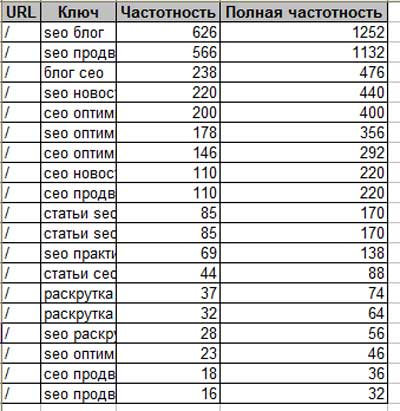 Подумайте, как бы вы искали вашу компанию, товары или услуги, будь вы потенциальным клиентом. Составьте список – это и будет начальный вариант семантического ядра.
Подумайте, как бы вы искали вашу компанию, товары или услуги, будь вы потенциальным клиентом. Составьте список – это и будет начальный вариант семантического ядра.
Допустим, мы подбираем запросы для сайта гостиницы на Байкале:
Рис.1. Первоначальный список запросов для сайта гостиницы на Байкале
Первоначальный список получился совсем коротким – ну что ж поделаешь, столько фраз пришло на ум без обращения к поиску или сервисам. Переходим к следующему этапу.
2 Этап. Расширение списка ключевых слов
На этом этапе вы можете пользоваться разными сервисами и программами, подсказками поисковиков.
Очень удобный и простой в использовании сервис по подбору ключевых слов – Яндекс.Вордстат. Сервис помогает оценить востребованность пользователей к определенным тематикам, узнать частоту искомых запросов.
В строку поиска вводите поочередно запросы из первоначального списка – это позволит значительно его расширить, выбирайте все «Уточненные запросы», они будут показываться в столбце слева «Что искали со словом. ..».
..».
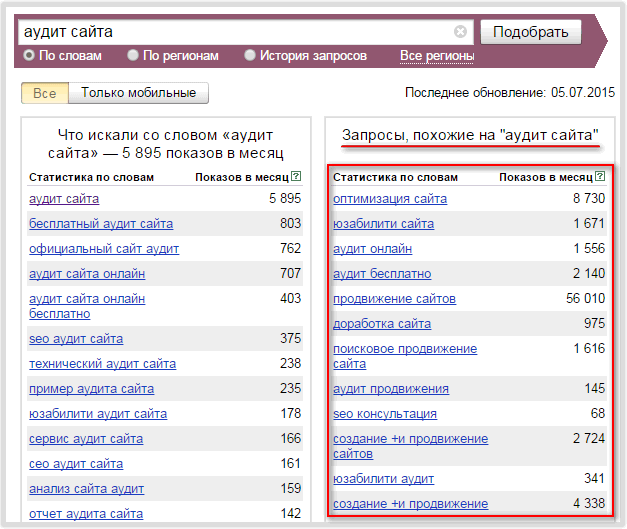
Но и ассоциативные запросы из столбца справа упускать не стоит – среди них будут подсказки от поисковика. Это те запросы, которые похожи на вводимый вами запрос, и большинство из них подойдут вам.
Рис 2. Расширение списка запросов в Яндекс.Вордстат
Еще можно расширить список запросов и найти подходящие для вас ключи с помощью поисковых подсказок. Вот, что подсказал мне Яндекс при поиске фразы «гостиница на Байкале».
Рис.3. Поисковые подсказки от Яндекса.
Этап 3. Зачистка
Как только вы собрали окончательный большой список ключевых фраз, следует выбрать только те, что действительно подходят вам, и продвижение по которым принесет эффект.
Исключите запросы:
-
Неподходящие по частоте. Все запросы классифицируются по частотности (высокочастотные, средне- и низкочастотные). Углубляться в анатомию ключевых слов сейчас я не буду, для всех, кому интересно советую очень подробную статью про классификацию ключевых фраз с детальным разбором.
Рекомендую при отсеивании ключевых слов исключать слишком высокочастотные запросы, запросы с совсем низкой или нулевой частотой, запросы-пустышки. Но помните, для каждой тематики все индивидуально.
Например, для стартующего интернет-магазина запрос «купить телефон» с частотой 1 298 609 использовать не стоит, шансов продвинуться по нему практически нет.
А вот для завода криогенного оборудования запрос «криогенные емкости для СПГ» с, казалось бы, низкой частотой 12 исключать не стоит – отрасль не настолько востребованная и запрос с таким показателем очень даже эффективен в продвижении.
Частоту запросов лучше всего оценивать через Яндекс.Вордстат. Сервис подходит российским сайтам, для проектов из Украины, Беларуси подойдет планировщик ключевых слов от Google.Adwords.
Выберите регион продвижения:
Рис.4. Выбор региона продвижения в Яндекс.Вордстат
Для оценки фразы по частоте вам достаточно смотреть на общую статистику и статистику с оператором «„.
Общая частота покажет вам, сколько людей искало данную фразу в месяц. Причем общая частота учитывает и ключ в составе других запросов с минус-словами. Например, вы смотрите общую частоту фразы „ремонт велосипедов“, в показатель частотности будут входить и фразы „инструменты для ремонта велосипедов“, „ремонт велосипедов своими руками“, „мастерская по ремонту велосипедов“ и пр.
Рис.5. Общая частота запроса по Яндекс.Вордстату
Частота же в кавычках (“») покажет только число вводимых запросов исключительно фразы «ремонт велосипедов», без минус-слов.
Рис.6. Частота в кавычках по Яндекс.Вордстату
Чем выше запрос в кавычках, тем лучше, значит его точно нужно включать в список семантического ядра. Как правило, мы советуем брать фразы с частотой в «» не меньше 3.
Часто встречаются запросы, у которых общая частота большая, а в кавычках совсем низкая или вовсе 0 – это и есть запросы-пустышки, которые лучше избегать.
Вот пример такого запроса, общая частота фразы «чайник недорого в Москве» – 1256:
Рис.7. Общая частота запроса с хорошим показателем
А вот в кавычках всего 1:
Рис.8. Пример запроса-пустышки
Но повторюсь: для каждой тематики все индивидуально – бывают настолько узкие отрасли, что даже низкочастотные или запросы-пустышки подойдут для продвижения.
Выше я дала вам совсем краткую инструкцию по подбору ключевых слов через сервис Яндекс.Вордстат, в этой статье вы узнаете намного больше.
-
Слишком общие фразы. Некоторые фразы неэффективны для продвижения, потому что являются слишком общими, чаще информационными. К примеру, «вкусная пицца» для пиццерии – не лучший запрос для продвижения, по нему могут искать рецепт вкусной пиццы. А вот «вкусная пицца в Екатеринбурге» – запрос точно хороший и отсеивать его не стоит.
Если вы сомневаетесь, стоит ли брать ключ или нет, информационный ли он или можно использовать его для продаж, обратитесь за помощью к поисковику. Например, по запросу «вязаный плед» поисковая выдача в основном информационная: это идеи, схемы узоров, инструкции по вязанию спицами или крючком.
Рис.9. Информационная выдача по запросу
Следовательно, для интернет-магазина такой запрос не самый удачный и продвижение по нему не будет эффективным, а вот с приставкой «купить» шансы привлечь потенциального клиента, а не рукодельницу, ищущую статью «как связать вязаный плед», увеличиваются.
-
Запросы, неподходящие по направлению. Исключайте все запросы, которые не подходят вам по специфике. Например, вы продаете дорогую мебель премиум-класса из Италии, следовательно, запросы с «дешево» и «недорого» исключайте не задумываясь – нужный контингент они на сайт не приведут.
Или вы занимаетесь ремонтом автокондиционеров, значит, в вашем списке ключевых слов не должно быть запросов «ремонт бытового кондиционера», «заправка кондиционера в квартире» и т.п.
-
Запросы со стоп-словами. Возьмем снова пример с «вязаным пледом» – если вы интернет-магазин, избегайте фразы со словами «своими руками», «как связать», «схемы», «инструкции» и пр.
А для магазинов электроники стоит исключить фразы со словами «обзор», «отзывы», «технические характеристики» – они подойдут вам в том случае, если у вас есть блог, и вы пишете статьи, где эти ключевые слова можно и даже нужно использовать.
Откинув все вышеперечисленные запросы, у вас будет итоговая, годная для продвижения база ключевых фраз.



Основные правила по подбору ключевых слов для сайта, которые нужно запомнить
-
Используйте в среднем 5 запросов на одну страницу.
Не нужно для одной страницы использовать много запросов, это приведет к переспаму и снижению «веса» ключевых слов.Рис.10. Переспамленный текст
Согласитесь, лучше взять 4-5 ключевых слов и понемногу распределить их по всей странице, чем, пытаясь «втиснуть» несколько десятков ключей, сделать текст переоптимизированным, как на примере выше?
-
Используйте 1-2 запроса высокой частоты и 3-4 средне- и низкочастотные. Упускать ВЧ фразы нельзя! Как говорится, и «на вашей улице может перевернуться грузовик с пряниками», и у вас получится выйти в ТОП по высокочастотным фразам.
А вот средне- и низкочастотные ключевые слова очень важны, конкуренция по ним ниже, соответственно, и шансов выйти по ним в ТОП больше.
На практике я не раз встречала оптимизаторов, которые вовсе не используют ВЧ запросы, а создают дополнительные страницы под НЧ, и, знаете, такой метод приносит хорошие результаты при этом ресурсов нужно тратить гораздо меньше.
-
Используйте наиболее коммерческие запросы. Если ваш сайт не блог и не портал, и ваша задача – транзакции (продажа, заказ, скачивание и пр.), то уделяйте больше внимания коммерческим ключевым словам.
Это слова с «магазин», «купить», «недорого», «заказать», «продажа», «цены» и прочие. Т.е. ключи со словами, которые пользователи вводят, чтобы, вероятнее всего, выполнить нужное действие.
Геозависимые запросы тоже считаются коммерческими, например, «пицца с доставкой», «ресторан с летней верандой» и пр. Такие запросы обычно вводят, чтобы найти нужный объект в своем городе или районе.
-
Берите все варианты названия товара или услуги. Максимально используйте разные вариации запросов. Например, татуировки с дополненной реальностью, ищут по запросам «тату с анимацией», «живые татуировки», «оживающие тату» и пр.
-
Используйте переводы, аббревиатуры, сокращения.
К примеру, запросы с «Фольксваген», ищут чаще чем с «Volkswagen», а «МГИМО» чаще чем «Московский государственный институт международных отношений». -
Используйте профессиональные, сленговые названия, сокращенные или простонародные. К примеру, «ЗИЛ 5301» в простонародье называют бычком и многие даже так ищут для него запчасти:
Рис.11. Пример сленгового запроса
-
Используйте ошибочные названия, не бойтесь орфографических ошибок. В строительстве существуют так называемые «топпинговые полы», так вот 1585 пользователей ищут «топпинговые полы», 1828 – «топинговые полы», даже появляются сомнения, как все-таки правильно.
-
Не используйте фразы, относящиеся к конкурентам. Многие до сих пор полагают, что продвижение по запросам конкурентов – это хорошо и эффективно. Может быть, но крайне редко.
Чаще всего это приводит к тому, что пользователь, не найдя то, что искал, покидает страницу, тем самым ухудшает показатели поведенческих факторов на сайте.Нет ничего хорошего, в том, что агентства недвижимости пытаются продвинуть сайт по запросам с «Авито», а мебельные магазины с «Икеа».
 Не нужно для одной страницы использовать много запросов, это приведет к переспаму и снижению «веса» ключевых слов.
Не нужно для одной страницы использовать много запросов, это приведет к переспаму и снижению «веса» ключевых слов.
 К примеру, запросы с «Фольксваген», ищут чаще чем с «Volkswagen», а «МГИМО» чаще чем «Московский государственный институт международных отношений».
К примеру, запросы с «Фольксваген», ищут чаще чем с «Volkswagen», а «МГИМО» чаще чем «Московский государственный институт международных отношений».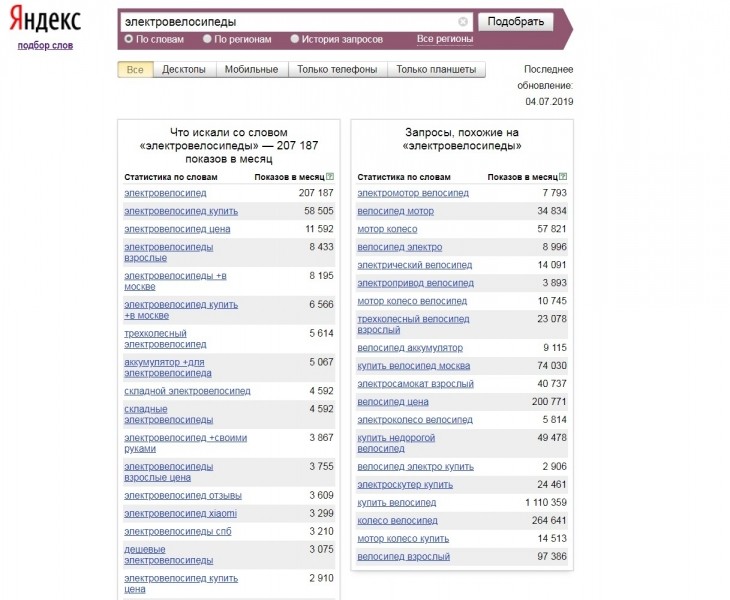 Чаще всего это приводит к тому, что пользователь, не найдя то, что искал, покидает страницу, тем самым ухудшает показатели поведенческих факторов на сайте.
Чаще всего это приводит к тому, что пользователь, не найдя то, что искал, покидает страницу, тем самым ухудшает показатели поведенческих факторов на сайте.Подбор ключевых слов для рекламы
Ключевые слова для контекстной и таргетинговой рекламы в социальных сетях – это основа. Чем точнее вы определите список фраз, тем лучше будет результат рекламной кампании. Правильно подобранные ключевые слова для Яндекс.Директа и Google.Adwords помогут найти вам потенциального клиента, а настройка минус-слов избавит вас от лишних расходов бюджета.
Скажу сразу, основы подбора семантического ядра для рекламы не сильно отличаются от тех, которые следует соблюдать при сборе ключевых фраз для оптимизации сайта, но все же здесь нужно быть более внимательным и дальновидным, ведь на кону стоят ваши деньги.
Далее я расскажу вам, какие ключевые слова лучше всего подбирать для рекламы, а после рекомендую прочесть о прогнозе бюджета в этой статье.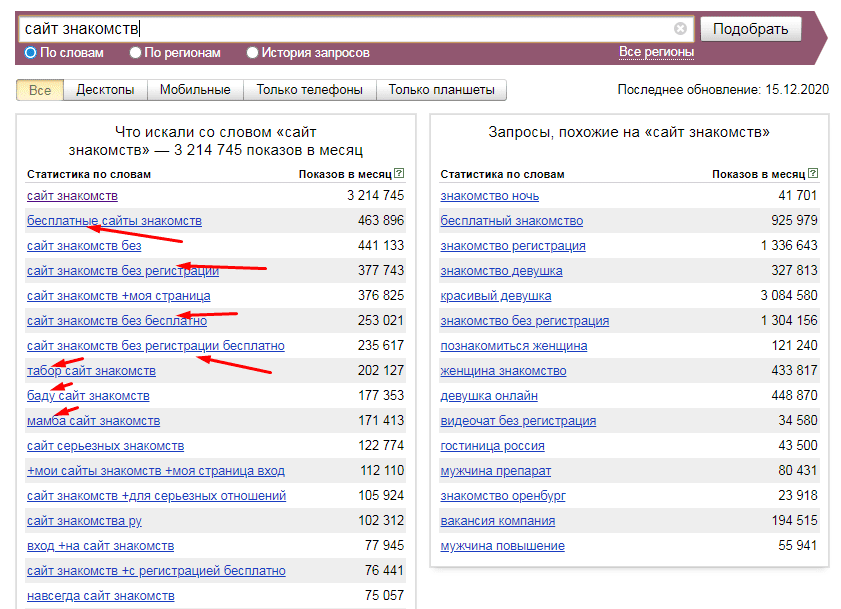
Рекомендации по подбору ключевых слов для контекстной рекламы
-
Выберите фразы, которые наиболее точно характеризуют вашу деятельность, описывающие товары и услуги.
Например, клининговой компании следует включить все виды услуг: уборка помещений, мойка окон, химчистка мебели и пр.
-
Уточните ключевые слова. Если фраза имеет совсем общий смысл, ее следует уточнить, например, компании по ремонту квартир нельзя использовать фразы «ремонт в Москве», пользователи могут искать «ремонт принтеров в Москве», «ремонт телефонов в Москве» и т.п.
-
Укажите синонимы, сленг, профессиональные термины. Вспомните, пример с «бычком ЗИЛом», здесь точно также, «АКБ» = «аккумуляторные батареи», «балонный ключ» = «балонник» и т.д.
-
Используйте ключи на иностранном языке. «Купить телефон Samsung Galaxy» ищут чаще, чем на кириллице «купить телефон Самсунг Галакси».
-
Не забывайте, что часто пользователи делают опечатки. Например, запрос «отдельно стоящие посудомоечные машины» нельзя проигнорировать из-за неправильного написания, т.к. многие вводят его именно в таком виде:
Рис.12. Ошибка в ключевой фразе
-
Ну и помните, что коммерческие запросы в приоритете.

Как отобрать минус-слова?
Многие фразы не будут релевантны вашим запросам, и их необходимо будет исключить, чтобы не тратить впустую бюджет на клики. В этом вам поможет добавление минус-слов и минус-фраз.
Разберем на примере: допустим, вы продаете стиральные машинки с сушкой от LG, Candy и Bosch.
Рис.13. Выбор минус-слов
Исключаем фразы с «отзывы», «рейтинг», «лучшие», «обзор», поскольку по ним пользователи ищут информацию, касающуюся выбора стиральных машин с сушкой.
Исключаем фразы с «Haier», «Electrolux» и другими брендами, т. к. их мы не продаем.
к. их мы не продаем.
Исключаем запросы с «инструкция», т.к. их вводят пользователи, чтобы найти информацию по эксплуатации.
Исключаем фразы с названиями городов, в которых мы не работаем.
Таким образом настроенная ключевая фраза с минус-словами: «стиральные машины с сушкой -отзывы -рейтинг -лучшие -обзор -инструкция – Haier – Electrolux -Екатеринбург –СПб» значительно сэкономит ваш бюджет.
Это была краткая инструкция по подбору ключевых слова для Яндекс.Директа и других рекламных площадок, более подробно о сборе СЯ рассказал специалист по интернет-рекламе в этой статье.
Сервисы и программы для подбора ключевых запросов
В статье я уже упоминала, что при подборе семантического ядра помогают разные онлайн-сервисы и программы. В этом разделе я постараюсь объединить наиболее популярные инструменты в единый список.
Яндекс.Вордстат
Рис.14. Сервис Яндекс.Вордстат
Сервис от поисковой системы Яндекса, который бесплатно поможет вам подобрать ключевые слова, узнать их частотность по региону, оценить сезонность.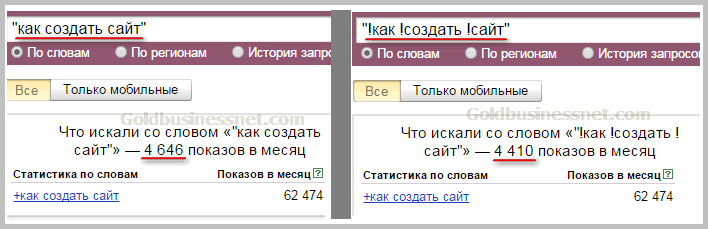
Планировщик ключевых слов от Google
Рис.15. Google.Планировщик ключевых слов
Аналогичный Яндекс.Вордстату сервис. Помогает анализировать и собирать ключевые запросы, эффективные для продвижения в Google. Так же, как и Яндекс.Вордстат, сервис совершенно бесплатный.
Topvisor.com
Рис.16. Топвизор
Продукт платный, но очень многофункциональный. Сервис помогает подбирать ключевые слова, собирает поисковые подсказки. Вся информация берется из поисковых систем.
Вы можете не только собрать семантику, но и доработать список уже имеющихся запросов, анализировать фразы, приводящие на сайт трафик, кластеризировать их по группам и не только.
Semrush.com
Рис.17. Semrush
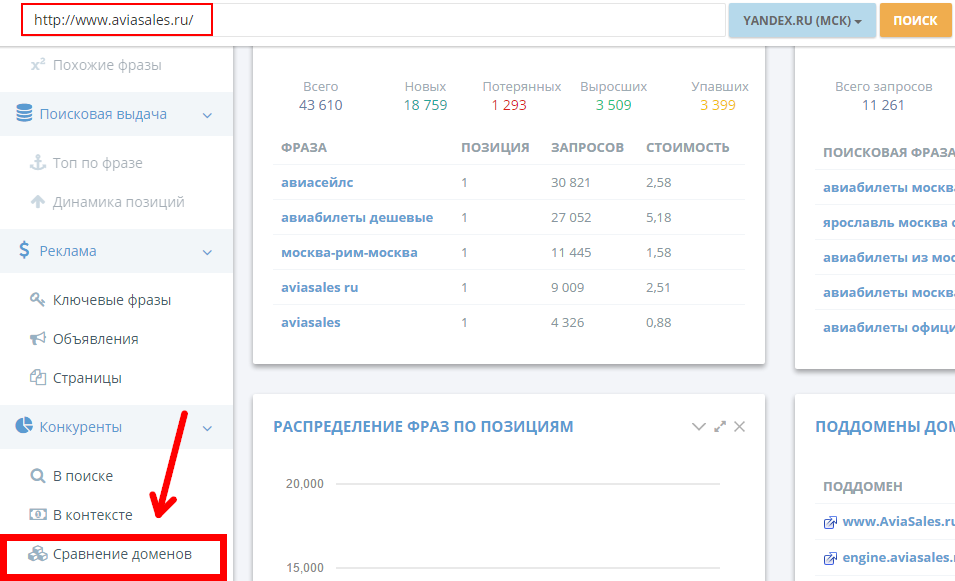
Отличный сервис для комплексного интернет-маркетинга. Среди множества функций выделим возможность анализа ключевых слов сайтов-конкурентов в органической выдаче и рекламе.
Имеется инструмент обзора ключевых слов, который позволяет находить ключевые слова, релевантные искомой фразе.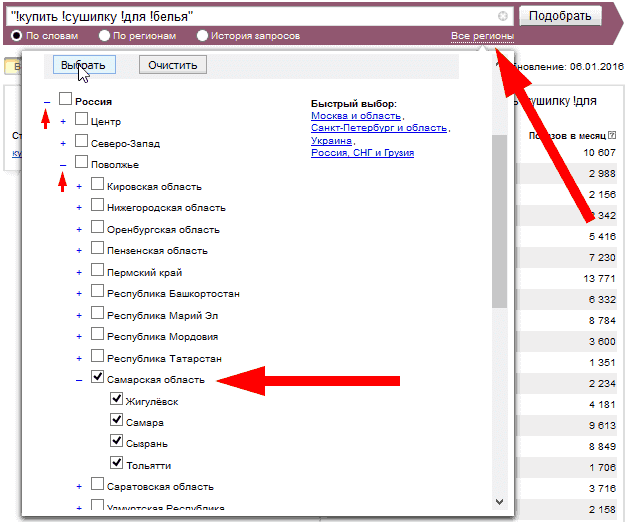
Megaindex.com
Рис.18. MegaIndex
Отличный платный продукт для анализа собранной семантики и ее дополнения. Сервис поможет анализировать сайты конкурентов, чтобы получать их семантику, которая пригодится в доработке вашего СЯ. Кроме того, инструмент дает прогноз трафика по определенным ключевым словам.
Rush-analytics.ru
Рис.19. Rush-Analytics
Платный сервис, который помогает с кластеризацией ключевых запросов. Помимо группировки семантики, вы сможете собирать ключевые запросы и поисковые подсказки из Яндекса.
Spywords.ru
Рис.20. SpyWords
Отличный российский инструмент для анализа ключевых запросов конкурентов в органическом поиске и в контекстной рекламе.
Помимо списка ключевых запросов и их частоты, инструмент показывает динамику их популярности, подбирает страницы конкурентов, ранжирующиеся по этим ключам в ТОП-10, и показывает сниппеты этих страниц.
Seranking.ru
Рис. 21. SeRanking
21. SeRanking
Инструмент с большим набором функций, в том числе и с возможностью работы с ключевыми запросами. Вы сможете собирать ключевые запросы и определять их частоту, а также кластеризовать собранную семантику. Имеется функция автоматического распределения ключевых слов на группы по частоте: высоко-, средне- и низкочастотные.
Keys.so
Рис.22. Keys.So
Один из самых популярных инструментов для анализа конкурентов и подбора ключевых слов. Keys.so дает возможность узнать список поисковых слов конкурентов и их частоту, адреса сайтов, которые находятся в ТОПе по искомому ключевому запросу, узнать динамику популярности ключей и конкурентов.
Конечно, список инструментов, помогающих работать с семантикой, гораздо больше – это лишь небольшая часть сервисов, с которыми мы работаем сами и можем смело рекомендовать вам.
Вывод
Подбор ключевых запросов – это первый шаг в SEO-продвижении для любого сайта. Если семантическое ядро составлено некорректно, сколько бы денег и сил вы ни тратили, желаемого успеха вы вряд ли добьетесь.
Если вы хотите, чтобы сайт выходил в ТОП и приводил нужный трафик, а контекстная реклама приносила свои плоды, позаботьтесь о качестве семантики. Надеюсь, после рекомендаций в этой статье вам станет легче подбирать ключевые слова. А если в своих силах вы не уверены, то подбор СЯ вы всегда можете доверить нашим специалистам.
# google adwords # ключевые слова # контекстная реклама # контентное продвижение # оптимизация сайта # оптимизированные тексты # поисковые запросы # семантическое ядро # яндекс директ
TF-IDF с нуля в Python на реальном наборе данных. | Уильям Скотт
- Что такое TF-IDF?
- Предварительная обработка данных.
- Вес заголовка и тела.
- Поиск документа с использованием оценки соответствия TF-IDF .
- Поиск документа с использованием косинусного подобия TF-IDF .
TF-IDF расшифровывается как «Term Frequency — Inverse Document Frequency» Это метод количественной оценки слов в наборе документов. Обычно мы подсчитываем баллы для каждого слова, чтобы обозначить его важность в документе и корпусе. Этот метод широко используется в информационном поиске и анализе текста.
Обычно мы подсчитываем баллы для каждого слова, чтобы обозначить его важность в документе и корпусе. Этот метод широко используется в информационном поиске и анализе текста.
Если я дам вам предложение, например, «Это здание такое высокое». Нам легко понять предложение, поскольку мы знаем семантику слов и предложения. Но как любая программа (например, Python) может интерпретировать это предложение? Любому языку программирования проще понимать текстовые данные в виде числового значения. Итак, по этой причине нам нужно векторизовать весь текст, чтобы он был лучше представлен.
Путем векторизации документов мы можем дополнительно выполнять несколько задач, таких как поиск соответствующих документов, ранжирование, кластеризация и т. д. Именно этот метод используется при выполнении поиска в Google (теперь они обновлены до новых методов преобразования). Веб-страницы называются документами, а поисковый текст, с помощью которого вы ищете, называется запросом. Поисковая система поддерживает фиксированное представление всех документов. Когда вы выполняете поиск по запросу, поисковая система находит соответствие запроса всем документам, ранжирует их в порядке релевантности и показывает вам k лучших документов. Весь этот процесс выполняется с использованием векторизованной формы запроса и документов.
Когда вы выполняете поиск по запросу, поисковая система находит соответствие запроса всем документам, ранжирует их в порядке релевантности и показывает вам k лучших документов. Весь этот процесс выполняется с использованием векторизованной формы запроса и документов.
Теперь вернемся к нашему TF-IDF,
TF-IDF = Частота термина (TF) * Обратная частота документа (IDF)
Терминология
- t — термин (слово)
- d — документ (набор слов) )
- N — количество корпусов
- корпусов — общий набор документов
Измеряет частоту встречаемости слова в документе. Это сильно зависит от длины документа и общего характера слова, например, очень распространенное слово, такое как «был» может встречаться в документе несколько раз. Но если мы возьмем два документа со 100 словами и 10 000 слов соответственно, есть большая вероятность, что общее слово «было» присутствует больше в документе из 10 000 слов. Но мы не можем сказать, что более длинный документ важнее более короткого. Именно по этой причине мы выполняем нормализацию значения частоты, мы делим частоту на общее количество слов в документе.
Но мы не можем сказать, что более длинный документ важнее более короткого. Именно по этой причине мы выполняем нормализацию значения частоты, мы делим частоту на общее количество слов в документе.
Напомним, что нам нужно окончательно векторизовать документ. Когда мы планируем векторизовать документы, мы не можем просто учитывать слова, присутствующие в этом конкретном документе. Если мы это сделаем, то длина вектора будет разной для обоих документов, и вычислить сходство будет невозможно. Итак, что мы делаем, так это векторизируем документы на словарь . Vocab — это список всех возможных миров в корпусе.
Нам нужно количество слов во всех словарных словах и длина документа для вычисления TF. Если термин не существует в конкретном документе, это конкретное значение TF будет равно 0 для этого конкретного документа. В крайнем случае, если все слова в документе одинаковы, то TF будет равен 1. Окончательное значение нормализованного значения TF будет находиться в диапазоне от [0 до 1].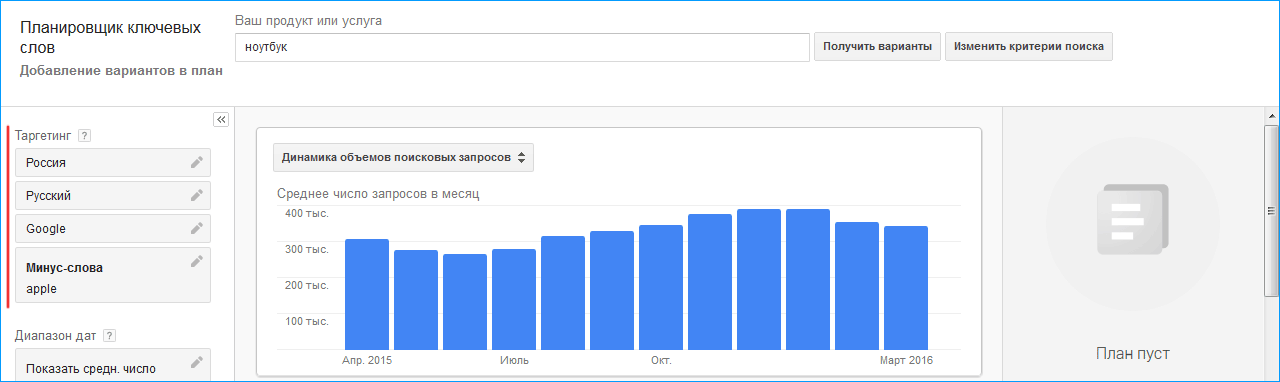 0, 1 включительно.
0, 1 включительно.
ТФ индивидуален для каждого документа и слова, следовательно, мы можем сформулировать ТФ следующим образом:
tf(t,d) = количество t в d / количество слов в d
Если мы уже вычислили значение TF и если это создает векторизованную форму документа, почему бы не использовать только TF для поиска соответствие между документами? Зачем нам ЦАХАЛ?
Позвольте мне объяснить, что наиболее распространенные слова, такие как «есть», «являются», будут иметь очень высокие значения, что придает этим словам очень большое значение. Но использование этих слов для вычисления релевантности приводит к плохим результатам. Такие общеупотребительные слова называются стоп-словами. Хотя мы удалим стоп-слова позже на этапе предварительной обработки, поиск присутствия слова в документах и каким-то образом уменьшим их вес является более идеальным.
Частота документов Этот измеряет важность документов во всей совокупности корпуса. Это очень похоже на TF, но с той лишь разницей, что TF — это счетчик частоты для термина t в документе d, тогда как DF — это подсчет вхождений термина t в наборе документов N. Другими словами, DF — это счетчик частоты. количество документов, в которых присутствует это слово. Мы считаем одно вхождение, если термин присутствует в документе хотя бы один раз, нам не нужно знать, сколько раз термин присутствует.
Это очень похоже на TF, но с той лишь разницей, что TF — это счетчик частоты для термина t в документе d, тогда как DF — это подсчет вхождений термина t в наборе документов N. Другими словами, DF — это счетчик частоты. количество документов, в которых присутствует это слово. Мы считаем одно вхождение, если термин присутствует в документе хотя бы один раз, нам не нужно знать, сколько раз термин присутствует.
df(t) = встречаемость t в N документах
Чтобы сохранить это также в диапазоне, мы нормализуем путем деления на общее количество документов. Наша главная цель — узнать информативность терма, а DF — точная обратная ей. вот почему мы инвертируем DF
Обратная частота документа IDF является обратной частотой документа, которая измеряет информативность термина t. Когда мы вычисляем IDF, он будет очень низким для наиболее часто встречающихся слов, таких как стоп-слова (поскольку они присутствуют почти во всех документах, и N/df даст очень низкое значение этому слову).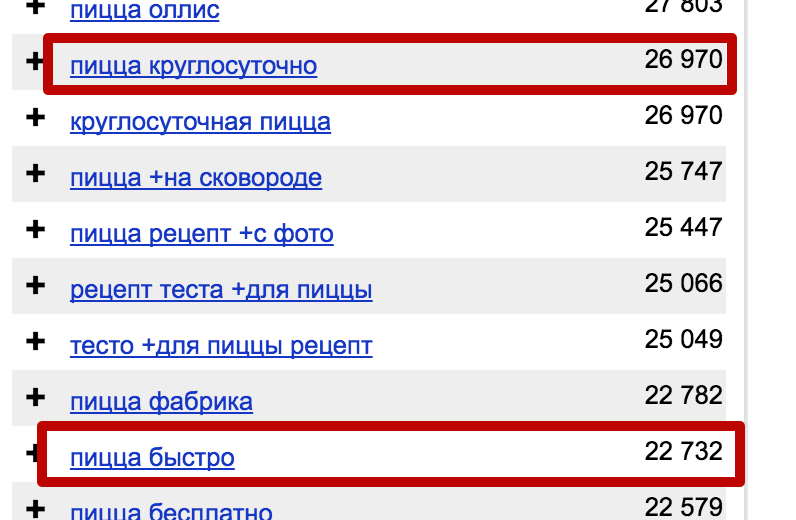 Это, наконец, дает то, что мы хотим, относительный вес.
Это, наконец, дает то, что мы хотим, относительный вес.
idf(t) = N/df
Теперь есть несколько других проблем с IDF, когда у нас большой размер корпуса, скажем, N=10000, значение IDF резко возрастает. Так что для гашения эффекта берем лог IDF.
Во время запроса, когда слово отсутствует в нет в словаре, оно будет просто проигнорировано. Но в некоторых случаях мы используем фиксированный словарь, и несколько слов словаря могут отсутствовать в документе, в таких случаях df будет равен 0. Поскольку мы не можем делить на 0, мы сглаживаем значение, добавляя 1 к знаменателю. .
idf(t) = log(N/(df + 1))
Наконец, взяв мультипликативное значение TF и IDF, мы получим показатель TF-IDF. Существует множество различных вариантов TF-IDF, но пока давайте сосредоточимся на этой базовой версии.
tf-idf(t, d) = tf(t, d) * log(N/(df + 1))
Я старший специалист по данным и исследователь ИИ в области NLP и DL.
Свяжитесь со мной: Twitter, LinkedIn.
Теперь, когда мы узнали, что такое TF-IDF, давайте вычислим показатель подобия для набора данных.
Набор данных, который мы собираемся использовать, представляет собой архив нескольких историй, этот набор данных содержит множество документов в разных форматах. Загрузите набор данных и откройте свои блокноты, я имею в виду блокноты Jupyter 😜.
Ссылка на набор данных: http://archives.textfiles.com/stories.zip
Шаг 1. Анализ набора данных
Первым шагом любой задачи машинного обучения является анализ данных. Итак, если мы посмотрим на набор данных, на первый взгляд мы увидим все документы со словами на английском языке. Каждый документ имеет разные имена и в нем есть две папки.
Сейчас одной из важных задач является выявление заголовка в теле, если проанализировать документы, то есть разные закономерности выравнивания заголовка. Но большинство заголовков выравниваются по центру. Теперь нам нужно найти способ извлечь заголовок. Но прежде чем мы накачаемся и начнем кодировать, давайте немного проанализируем набор данных.
Но прежде чем мы накачаемся и начнем кодировать, давайте немного проанализируем набор данных.
Потратьте несколько минут, чтобы самостоятельно проанализировать набор данных. Попробуйте изучить…
При более тщательном осмотре мы можем заметить, что в каждой папке (включая корень) есть файл index.html, который содержит все имена документов и их заголовки. Так что будем считать, что нам повезло, так как заголовки даны нам, без исчерпывающего извлечения заголовков из каждого документа.
Шаг 2: Извлечение заголовка и тела:
Нет конкретного способа сделать это, это полностью зависит от имеющейся постановки задачи и анализа, который мы проводим с набором данных.
Поскольку мы уже обнаружили, что заголовки и имена документов находятся в index.html, нам нужно извлечь эти имена и заголовки. Нам повезло, что в index.html есть теги, которые мы можем использовать в качестве шаблонов для извлечения необходимого содержимого.
Прежде чем мы начнем извлекать заголовки и имена файлов, так как у нас разные папки, сначала просканируем папки, чтобы потом сразу прочитать все файлы index. html.
html.
[x[0] for x in os.walk(str(os.getcwd())+'/stories/')]
os.walk дает нам файлы в каталоге, os.getcwd дает нам текущий каталог и заголовок, и мы собираемся искать в текущем каталоге + папке историй, так как наши файлы данных находятся в папке историй.
Всегда предполагайте , что вы имеете дело с огромным набором данных, это помогает автоматизировать код.
Теперь мы можем обнаружить, что папок дают дополнительные / для корневой папки, поэтому мы собираемся ее удалить.
folders[0] = folders[0][:len(folders[0])-1]
Приведенный выше код удаляет последний символ для 0-го индекса в папках, который является корневой папкой
Теперь давайте просканируем через все index.html, чтобы извлечь их заголовки. Для этого нам нужно найти шаблон, чтобы убрать заголовок. Так как это в html, наша работа будет немного проще.
давайте посмотрим…
Мы можем ясно видеть, что имя каждого файла заключено между ( > Следующий код дает список всех значений, соответствующих этому шаблону. поэтому переменные имен и заголовков имеют список всех имен и заголовков.
Следующий код дает список всех значений, соответствующих этому шаблону. поэтому переменные имен и заголовков имеют список всех имен и заголовков.
name = re.findall('>', text)
titles = re.findall('
(.*)\n', text) Теперь, когда у нас есть код для извлечения значений из индекса, нам просто нужно выполнить итерацию по всем папкам и получить заголовок и имя файла из всех файлов index.html
— прочитать файл из индексных файлов
— извлечь заголовок и имена
— перейти к следующей папке
набор данных = []for i в папках:
file = open(i+"/index.html", ' r')
text = file.read().strip()
file.close() file_name = re.findall('>', text)
file_title = re.findall ('
(.*)\n', текст) для j в диапазоне (len(file_name)):
dataset.append((str(i) + str(file_name[j]), file_title [ж]))
Это подготавливает индексы набора данных, который представляет собой кортеж местоположения файла и его заголовка. Есть небольшая проблема, в корневой папке index.html также есть папки и ссылки на них, нам нужно их удалить.
просто используйте условную проверку, чтобы удалить его.
if c == False:
имя_файла = имя_файла[2:]
c = True
Предварительная обработка — один из основных шагов, когда мы имеем дело с любой текстовой моделью. На этом этапе мы должны посмотреть на распределение наших данных, какие методы необходимы и насколько глубоко мы должны очищать.
Этот шаг никогда не имеет однозначного правила и полностью зависит от постановки задачи. Немногие обязательные предварительные обработки: преобразование в нижний регистр, удаление знаков препинания, удаление стоп-слов и лемматизация/выделение корней. В нашей постановке задачи кажется, что основных шагов предварительной обработки будет достаточно.
Нижний регистр
Во время обработки текста каждое предложение разбивается на слова, и после предварительной обработки каждое слово считается токеном. Языки программирования считают текстовые данные конфиденциальными, а это означает, что отличается от . мы, люди, знаем, что они оба принадлежат одному и тому же токену, но из-за кодировки символов они считаются разными токенами. Преобразование в нижний регистр является обязательным этапом предварительной обработки. Поскольку у нас есть все наши данные в списке, у numpy есть метод, который может сразу преобразовать список списков в нижний регистр.
np.char.lower(data)
Стоп-слова
Стоп-слова — это наиболее часто встречающиеся слова, которые не придают никакого дополнительного значения вектору документа. на самом деле их удаление повысит эффективность вычислений и пространства. В библиотеке nltk есть метод для загрузки стоп-слов, поэтому вместо того, чтобы явно указывать все стоп-слова, мы можем просто использовать библиотеку nltk, перебрать все слова и удалить стоп-слова. Есть много эффективных способов сделать это, но я приведу простой метод.
мы будем перебирать все стоп-слова и не добавлять их в список, если это стоп-слова
new_text = ""
для слова в словах:
если слово не в стоп-словах:
new_text = new_text + " " + слово
Пунктуация
Пунктуация — это набор ненужных символов, которые есть в наших корпусных документах. Мы должны быть немного осторожны с тем, что мы делаем с этим, может быть несколько проблем, таких как США — мы, «Соединенные Штаты», преобразуются в «нас» после предварительной обработки. дефис, и обычно с ним следует обращаться с небольшой осторожностью. Но для этой постановки задачи мы просто удалим эти 9_`{|}~\n»
для i в символах:
data = np.char.replace(data, i, ‘ ‘)
Мы собираемся хранить все наши символы в переменной и повторять эту переменную, удаляя это
Апостроф
Обратите внимание, что в знаках препинания нет апострофа. Потому что, когда мы сначала удалите знаки препинания, он преобразует «не» в «не», и это стоп-слово, которое не будет удалено Вместо этого мы будем удалять стоп-слова, сначала следуют символы, а затем, наконец, повторяем удаление стоп-слов, поскольку несколько слов могут все еще имеют апостроф, который не является стоп-словом. 0021
return np.char.replace(data, "'", "")
Одиночные символы
Отдельные символы не очень полезны для понимания важности документа, и несколько последних одиночных символов могут быть нерелевантными символами, поэтому всегда хорошо удалять отдельные символы.
new_text = ""
for w в словах:
if len(w) > 1:
new_text = new_text + " " + w
Нам просто нужно перебрать все слова и не добавлять слово, если длина не более 1,
Стемминг
Это последняя и самая важная часть предварительной обработки. стемминг преобразует слова в их основу.
Например, play и play — это слова одного типа, которые в основном обозначают действие play. Stemmer делает именно это, он сводит слово к его основе. мы собираемся использовать библиотеку под названием porter-stemmer, основанную на правилах. Портер-Стеммер идентифицирует и удаляет суффикс или аффикс слова. Слова, заданные стеммером, не обязательно должны быть осмысленными несколько раз, но они будут идентифицированы как один токен для модели.
Лемматизация
Лемматизация — это способ сведения слова к корневому синониму слова. В отличие от стемминга, лемматизация гарантирует, что сокращенное слово снова станет словарным словом (словом, присутствующим в том же языке). WordNetLemmatizer можно использовать для лемматизации любого слова.
Stemming vs Lemmatization
Stemming — не обязательно словарное слово, удаляет префикс и аффикс на основе нескольких правил
lemmatization — будет словарным словом. сводится к корневому синониму.
Более эффективный способ — сначала лемматизировать, а затем сформулировать, но одно стеммирование также подходит для некоторых задач, здесь мы не будем лемматизировать.
Преобразование чисел
Когда пользователь вводит запрос, например 100 долларов или сто долларов. Для пользователя оба условия поиска одинаковы. но наша модель IR рассматривает их отдельно, так как мы храним 100 долларов, сто как разные токены. Итак, чтобы сделать наш ИК-режим немного лучше, нам нужно преобразовать 100 в сто. Для этого мы будем использовать библиотеку под названием 9.0010 число2слово .
Если мы внимательно посмотрим на вышеприведенный вывод, он даст нам несколько символов и предложений, таких как «сто и два», но, черт возьми, мы только что очистили наши данные, тогда как мы с этим справимся? Не беспокойтесь, мы просто снова запустим пунктуацию и стоп-слова после преобразования чисел в слова.
Предварительная обработка
Наконец, мы поместим все эти методы предварительной обработки выше в другой метод и назовем этот метод предварительной обработки.
def preprocess(data):
data = convert_lower_case(data)
data = remove_punctuation(data)
data = remove_apostrophe(data)
data = remove_single_characters(data)
data = convert_numbers(data)
data = remove_stop_words(data)
данные = основа(данные)
данные = удалить_пунктуация(данные)
данные = преобразовать_числа(данные)
Если присмотреться, некоторые методы предварительной обработки повторяются снова. Как уже говорилось, это просто помогает очистить данные немного глубже. Теперь нам нужно прочитать документы и сохранить их заголовок и тело отдельно, так как мы собираемся использовать их позже. В нашей постановке задачи у нас очень разные типы документов, это может вызвать несколько ошибок при чтении документов из-за совместимости кодировок. чтобы решить эту проблему, просто используйте encoding=»utf8″, errors=’ignore’ в методе open().
Шаг 3: Расчет TF-IDF
Напомним, что нам нужно присвоить разные веса заголовку и телу. Теперь, как мы собираемся решить эту проблему? как в этом случае будет работать расчет TF-IDF?
Придание разного веса заголовку и основной части является очень распространенным подходом. Нам просто нужно рассматривать документ как тело + заголовок, используя это, мы можем найти словарный запас. И нам нужно придать разный вес словам в заголовке и разный вес словам в теле. Чтобы лучше объяснить это, давайте рассмотрим пример.
title = «Это новая статья»
body = «Эта статья состоит из обзора многих статей»
Теперь нам нужно рассчитать TF-IDF для тела и заголовка. Пока давайте рассмотрим только слово paper и забудем об удалении стоп-слов.
Что такое TF слова бумаги в названии? 1/4?
Нет, это 13 марта. Как? word paper появляется в заголовке и теле 3 раза, а общее количество слов в заголовке и теле равно 13. Как я упоминал ранее, нас всего считать слово в заголовке иметь разные веса, но тем не менее, мы учитываем весь документ при расчете TF-IDF.
Тогда ТФ бумаги и в заголовке, и в теле одинаковы? Да, это то же самое! это просто разница в весе, который мы собираемся дать. Если слово присутствует и в заголовке, и в теле, то никакого уменьшения значения TF-IDF не будет. Если слово присутствует только в названии, то вес тела для этого конкретного слова не будет добавляться к ТФ этого слова, и наоборот.
документ = тело + заголовок
TF-IDF(документ) = TF-IDF(заголовок) * альфа + TF-IDF(тело) * (1-альфа)
Расчет DF
предварительно рассчитать ДФ. Нам нужно перебрать все слова во всех документах и сохранить идентификатор документа для каждого слова. Для этого мы будем использовать словарь, так как мы можем использовать слово в качестве ключа и набор документов в качестве значения. Я упомянул набор, потому что, даже если мы пытаемся добавить документ несколько раз, набор не будет просто принимать повторяющиеся значения.
DF = {}
для i в диапазоне (len(processed_text)):
токенов = обрабатываемый_текст[i]
для w в токенах:
попытка:
DF[w].add(i)
за исключением:
DF[ w] = {i} Мы создадим набор, если у слова еще нет набора, иначе добавим его в набор. Это условие проверяется блоком try. Здесь обрабатываемый_текст — это тело документа, и мы собираемся повторить то же самое и для заголовка, так как нам нужно учитывать DF всего документа.
len(DF) даст уникальные слова
DF будет иметь слово в качестве ключа и список идентификаторов документов в качестве значения. но для DF нам на самом деле не нужен список документов, нам просто нужно количество. поэтому мы собираемся заменить список его счетчиком.
Вот и все необходимое для всех слов. Чтобы найти общее количество уникальных слов в нашем словаре, нам нужно взять все ключи DF.
Вычисление TF-IDF
Напомним, что нам необходимо поддерживать разные веса для заголовка и основного текста. Чтобы рассчитать TF-IDF тела или названия, нам нужно учитывать и название, и тело. Чтобы немного облегчить нашу работу, давайте воспользуемся словарем с числом 9.0289 (документ, токен) Пара в качестве ключа и любая оценка TF-IDF в качестве значения. Нам просто нужно перебрать все документы, мы можем использовать Coutner, который может дать нам частоту токенов, вычислить tf и idf и, наконец, сохранить как пару (doc, token) в tf_idf. Словарь tf_idf предназначен для тела, мы будем использовать ту же логику для создания словаря tf_idf_title для слов в заголовке.
tf_idf = {}
для i в диапазоне (N):
токены = обрабатываемый_текст[i]
счетчик = счетчик(токены + обработанный_название[i])
для токена в np. unique(токены):
tf = counter[token]/words_count
df = doc_freq(token)
idf = np.log(N/(df+1))
tf_idf[doc, token] = tf*idf Приступаем к расчету разных весов. Во-первых, нам нужно поддерживать значение альфа, которое является весом для тела, тогда, очевидно, 1-альфа будет весом для заголовка. Теперь давайте немного углубимся в математику, мы обсуждали, что значение слова в TF-IDF будет одинаковым как для тела, так и для заголовка, если слово присутствует в обоих местах. Мы будем поддерживать два разных словаря tf-idf, один для тела и один для заголовка.
То, что мы собираемся сделать, немного умнее, мы рассчитаем TF-IDF для тела; умножить значения TF-IDF всего тела на альфа; повторять токены в заголовке; заменить значение заголовка TF-IDF в теле значения TF-IDF пары (документ, токен) существует. Потратьте некоторое время, чтобы обработать это: P
Поток:
— Рассчитать TF-IDF для тела для всех документов
— Рассчитать TF-IDF для заголовка для всех документов
— умножить TF-IDF тела на альфа-канал
— Итерация заголовка IF-IDF для каждого (документа, токена)
— если токен находится в теле, замените значение Body(doc, token) значением в Title(doc, token)
Я знаю, что сначала это не просто понять, но все же позвольте мне объяснить, почему выше поток работает, так как мы знаем, что tf-idf для тела и заголовка будет одинаковым, если токен находится в обоих местах. Веса, которые мы используем для тела и заголовка, суммируются до одного
TF-IDF = body_tf-idf * body_weight + title_tf-idf*title_weight
body_weight + title_weight = 1
: Когда токен находится в обоих местах, окончательный TF-IDF будет таким же, как если бы он принимал тело или заголовок tf_idf. Это именно то, что мы делаем в приведенном выше потоке. Итак, наконец, у нас есть словарь tf_idf со значениями в виде пары (doc, token).
Оценка совпадения — это самый простой способ расчета сходства, в этом методе мы добавляем значения tf_idf токенов, которые находятся в запросе, для каждого документа . Например, для запроса «привет, мир» нам нужно проверить в каждом документе, существуют ли эти слова, и если слово существует, то значение tf_idf добавляется к оценке соответствия этого конкретного doc_id. В конце мы отсортируем и выберем k лучших документов.
Упомянутое выше является теоретической концепцией, но поскольку мы используем словарь для хранения нашего набора данных, мы собираемся сделать итерацию по всем значениям в словаре и проверить, присутствует ли значение в токене. Поскольку наш словарь является ключом (документ, токен), когда мы находим токен, который находится в запросе, мы добавим идентификатор документа в другой словарь вместе со значением tf-idf. Наконец, мы просто снова возьмем первые k документов.
определение match_score(запрос):
query_weights = {}
для ключа в tf_idf:
if key[1] в tokens:
query_weights[key[0]] += tf_idf[key]
key[0] — это documentid, key[1] — это токен.
Когда у нас есть идеально работающий Matching Score , зачем нам снова нужно косинусное сходство? хотя Matching Score дает соответствующие документы, он совершенно не работает, когда мы даем длинные запросы, он не сможет правильно их ранжировать. Косинус аналогично делает то, что он помечает все документы как векторы токенов tf-idf и измеряет сходство в косинусном пространстве (угол между векторами. Несколько раз длина запроса будет небольшой, но она может быть тесно связана с документом. в таких случаях косинусное сходство лучше всего подходит для поиска релевантности.0021
Обратите внимание на приведенный выше график, синие векторы — это документы, а красный вектор — это запрос, как мы можем ясно видеть, хотя манхэттенское расстояние (зеленая линия) очень велико для документа d1, запрос все еще близок к документу d1. . В таких случаях косинусное сходство было бы лучше, поскольку оно учитывает угол между этими двумя векторами. Но Matching Score вернет документ d3, но это не очень тесно связано.
Matching Score вычисляет манхэттенское расстояние (прямая линия от наконечников)
Оценка косинуса учитывает угол векторов.
Векторизация
Чтобы вычислить что-либо из вышеперечисленного, самый простой способ — преобразовать все в вектор, а затем вычислить косинусное сходство. Итак, давайте преобразуем запрос и документы в векторы. Мы собираемся использовать переменную total_vocab, которая содержит весь список уникальных токенов, для создания индекса для каждого токена, и мы будем использовать numpy of shape (docs, total_vocab) для хранения векторов документов.
# Векторизация документа
D = np.zeros((N, total_vocab_size))
для i в tf_idf:
ind = total_vocab.index(i[1])
D[i[0]][ind] = tf_idf[i]
For вектор, нам нужно вычислить значения TF-IDF, TF мы можем вычислить из самого запроса, и мы можем использовать DF, который мы создали для частоты документа. Наконец, мы будем хранить в массиве numpy (1, vocab_size) значения tf-idf, индекс токена будет определяться из списка total_voab
Q = np.zeros((len(total_vocab)))
counter = Счетчик (жетонов)
words_count = len(токены)
query_weights = {}
для токена в np.unique(токены):
tf = counter[token]/words_count
df = doc_freq(token)
idf = math.log((N+1 )/(df+1))
Теперь все, что нам нужно сделать, это вычислить косинусное сходство для всех документов и вернуть максимум k документов. Косинусное сходство определяется следующим образом.
np.dot(a, b)/(norm(a)*norm(b))
Я взял текст из doc_id 200 (для себя) и вставил некоторый контент с длинным запросом и коротким запросом в как совпадающая оценка, так и косинусное сходство.
Короткий запрос
Длинный запрос
Как видно из вышеприведенного документа, число 200 всегда имеет более высокую оценку в косинусном методе, чем в методе сопоставления, потому что косинусное сходство лучше изучает контекст.
Обо мне:
Я старший специалист по данным и исследователь ИИ в области NLP и DL.
Хотел бы подключиться: Twitter, LinkedIn.
Попробуйте сами. Нажмите здесь, чтобы открыть репозиторий git.
Используемые библиотеки
- nltk, numpy, re, mat, num2words
- 1. ВВЕДЕНИЕ
- 2. Индексирование и индексация Unigram
- 3. TF-IDF
- Подробнее …
Антенна SQL Урок: Acque и частота
Предложите Edits
Antenna
Предложите Edits
Antenna
Edits
Antenna
EDITS
Antenna
. метод получения беспрепятственного доступа к вашим данным на уровне журнала для запросов в интерфейсе SQL без необходимости приема, очистки и преобразования ваших файлов журнала.
В этом руководстве мы рассмотрим несколько способов использования данных уровня журнала, которые предоставляет Antenna, для анализа ваших данных способами, недоступными для вас в инструменте запросов Beeswax. На протяжении всего этого процесса мы будем продвигаться от базовых запросов к более сложным запросам.
Пока мы будем работать над повышением сложности, это руководство предполагает базовые практические знания SQL. Одним из ресурсов для обучения основам SQL является Учебник W3Schools по SQL.
Давайте начнем с относительно простого анализа: определения охвата и частоты наших кампаний. Для этого анализа нам нужны только данные о выигранных показах, поэтому мы будем использовать таблицу, в которой содержится это: SHARED_IMPRESSION_DETAILS_VIEW .
Давайте начнем с базовой структуры запроса, выбрав нужные поля и получив базовое количество показов, прежде чем мы добавим охват и частоту. Мы объединимся в течение кампания_id и параметры line_item_id за последние 30 дней данных. Здесь мы подсчитываем количество всех строк, так как эта таблица представляет показы.
ВЫБОР
идентификатор_кампании,
line_item_id,
COUNT(*) КАК показы
ОТ shared_impression_details_view
ГДЕ bid_time >= CURRENT_DATE() - 30
СГРУППИРОВАТЬ ПО id_кампании, id_элемента_строки
ЗАКАЗАТЬ ПО ПОКАЗАМ DESC
Теперь все наши кампании разбиты по позициям, отсортированным по показам в порядке убывания. Впрочем, в этом нет ничего особенного — вы можете получить это в Инструменте запросов уже сегодня!
Давайте начнем приближаться к тому анализу, который нам действительно нужен, с расчетами охвата и частоты показов. Для расчета Reach мы будем использовать функцию HLL Snowflake, которая запускает приблизительный анализ количества HyperLogLog. Это снизит небольшую степень точности (+/- 1,62%) на гораздо более экономичный запрос.
ВЫБОР
идентификатор_кампании,
line_item_id,
COUNT(*) КАК показы,
HLL(user_id) AS охват,
-- Приведенное ниже можно использовать вместо HLL с худшей производительностью, но точным подсчетом. Мы пока закомментировали это.
-- COUNT(DISTINCT user_id) КАК alt_reach_calculation
СУММ(СЛУЧАЙ, КОГДА user_id НЕ равен нулю, ТОГДА 1, ИНАЧЕ 0 КОНЕЦ) AS measurable_reach_impressions,
HLL(user_id)/SUM(СЛУЧАЙ, КОГДА user_id НЕ равен null THEN 1 ELSE 0 END) КАК частота
ОТ shared_impression_details_view
ГДЕ bid_time >= CURRENT_DATE() - 30
СГРУППИРОВАТЬ ПО id_кампании, id_элемента_строки
ЗАКАЗАТЬ ПО DESC
Отлично! Теперь у нас есть отчет, в котором вычисляется охват и частота показов по нашим позициям. Однако на всякий случай заменим его параметром, недоступным сегодня в Инструменте запросов — Deal_id .
ВЫБОР
ID_сделки,
COUNT(*) КАК показы,
HLL(user_id) AS охват,
СУММ(СЛУЧАЙ, КОГДА user_id НЕ равен нулю, ТОГДА 1, ИНАЧЕ 0 КОНЕЦ) AS measurable_reach_impressions,
HLL(user_id)/SUM(СЛУЧАЙ, КОГДА user_id НЕ равен null THEN 1 ELSE 0 END) КАК частота
ОТ shared_impression_details_view
ГДЕ bid_time >= CURRENT_DATE() - 30
СГРУППИРОВАТЬ ПО Deal_id
ЗАКАЗАТЬ ПО DESC
С помощью нескольких небольших шагов в Antenna мы перешли от запроса, который можно было полностью выполнить в Инструменте запросов, к запросу, который содержит параметры и показатели частотного анализа, ранее недоступные для вас.
Давайте сделаем одно последнее изменение, которое может дать немного больше понимания. Выясним распределение частоты показов для конвертеров. Давайте начнем с получения частоты для каждого user_id , но ограничимся только показами с конверсией. Мы будем использовать немного другую методологию, чем раньше. Этот анализ не охватывает все нишевые случаи, но будет отображать частоту показов для любого пользователя, который совершил хотя бы одну конверсию и видел хотя бы один показ за последние 30 дней.
ВЫБОР
ID пользователя,
COUNT(*) КАК показы
ОТ shared_impression_details_view
ГДЕ конверсии > 0
И bid_time >= CURRENT_DATE() - 30
СГРУППИРОВАТЬ ПО user_id
Закрыть, но мы еще не закончили получение частотного распределения. Давайте завернем это в подзапрос, чтобы получить эти результаты и получить распределение. Потому что может быть длинный хвост пользователей с большим количеством показов. Сгруппируем всех пользователей с 10+ показами в одну корзину. Для этого нам нужно также бросить impressions_per_user в строковый тип данных с использованием TO_CHAR .
ВЫБОР
КЕЙС
КОГДА показов_на_пользователя >= 10, ТО '10+'
ELSE TO_CHAR(количество показов_на_пользователя)
КОНЕЦ показов_на_пользователя,
COUNT(*) как частота
ИЗ
(ВЫБРАТЬ
ID пользователя,
COUNT(*) КАК показов_на_пользователя
ОТ shared_impression_details_view
ГДЕ конверсии > 0
И bid_time_utc >= CURRENT_DATE() - 30
СГРУППИРОВАТЬ ПО user_id)
СГРУППИРОВАТЬ ПО показам_на_пользователя
ЗАКАЗАТЬ ПО показам_на_пользователя
С этими результатами мы можем перенести результаты в программу электронных таблиц и создать хорошую визуализацию частотного распределения (логарифмическая шкала).
Частота на пользователя в логарифмической шкале
Обновлено более 2 лет назад
- Учебное пособие по Antenna SQL: Пользовательская модель атрибуции
- Учебное пособие по Antenna SQL. Ads Data Hub
Вы можете использовать Ads Data Hub для создания аудиторий и управления ими, которыми затем можно поделиться со своими связанными аккаунтами Google Рекламы и Дисплея и Видео 360. Данные из связанных аккаунтов Google Реклама, Дисплея и Видео 360 и Менеджера кампаний 360 можно использовать для создания аудиторий, но окончательные списки можно использовать только для ремаркетинга в Google Рекламе и Дисплее и Видео 3609.0021
Ads Data Hub позволяет создавать 2 типа списков аудитории:
- Списки ремаркетинга показывают ваши кампании или позиции пользователям, которые ранее нажимали на ваши объявления.
- Списки ограничения частоты показов ограничивают количество показов ваших кампаний или позиций потенциальным клиентам. (Доступно только для использования в Дисплее и Видео 360.)
Примечание. Списки ограничения частоты показов, созданные (в Ads Data Hub) после 31 августа 2021 г., будут автоматически обновляться каждые 24 часа для добавления или ограничения количества пользователей. Для всех других списков вы должны выполнять запросы, чтобы поддерживать свои списки. Ремаркетинг позволяет стратегически ориентироваться на пользователей, которые ранее взаимодействовали с вашими объявлениями. Оптимизация закупок рекламы на основе предыдущих действий пользователя с вашими объявлениями может повысить вовлеченность и лояльность к бренду. Кроме того, Ads Data Hub позволяет объединять данные из нескольких учетных записей и включать собственные данные для дальнейшего обогащения вашей аудитории.
В Ads Data Hub для целей ремаркетинга вы можете создавать аудитории только из пользователей, которые совершили клик или конверсию по одному из ваших объявлений.
Ads Data Hub рекомендует поддерживать соотношение 1:1 между запросами аудитории и списками аудитории.
После написания запроса аудитории вам нужно будет выполнить запрос, чтобы заполнить список аудитории.
- Перейдите на вкладку Запросы в Ads Data Hub.
- Нажмите + Создать запрос .
- В разделе «Аудитория» выберите Создать пустой запрос .
- Запись SQL, совместимого с BigQuery.
- Дайте вашему запросу имя.
- При необходимости добавьте в запрос параметры.
- Щелкните Сохранить .
Запросы аудитории можно запускать либо для заполнения вновь созданного списка аудитории, либо для добавления пользователей в существующий список. Оба этих действия имеют схожие шаги. Новый запрос аудитории может содержать только одну аудиторию — аудиторию, созданную при первом запуске запроса. Запрос аудитории может заполнить все аудитории, которые он ранее заполнил.
Примечание. Новые списки аудитории появляются (или обновляются) в сервисе «Дисплей и Видео 360» в течение 10 часов. Однако новые пользователи, добавленные в существующие списки аудитории, доступны для ремаркетинга сразу после выполнения запроса.- Перейдите на вкладку Запросы в Ads Data Hub.
- При необходимости отфильтруйте по типу запроса, чтобы отобразить только запросы аудитории.
- Щелкните имя запроса, который вы хотите выполнить.
- Щелкните Выполнить .
- Если запрос никогда ранее не заполнял аудиторию:
- Выберите источник данных с помощью поля «Данные рекламы из».
- Если применимо, укажите учетную запись, которую следует использовать для сопоставления, в поле «Сопоставить таблицу из».
- Введите имя и описание новой аудитории.
- Если запрос уже заполнил аудиторию:
- Если применимо, укажите учетную запись, которую следует использовать для сопоставления, в поле «Сопоставить таблицу из».
- Если запрос ранее заполнил более 1 аудитории, выберите аудиторию для заполнения.
- Введите диапазон дат и часовой пояс.
- Щелкните Выполнить .
Приемлемость событий
В целях защиты конфиденциальности конечных пользователей не все события доступны для использования в запросах аудитории. События, не соответствующие этому критерию, будут автоматически отфильтрованы. Допустимые события ограничены:
- Показы с последующими событиями, такими как клики или конверсии. Примечание. Вы не можете выбирать напрямую из таблиц показов. В таблицах Google Рекламы есть предварительно объединенные данные о показах, доступные через
google_ads_clicks_audience.joined_impression.* и google_ads_conversions_audience.joined_impression.* . Клики и действия на основе передачи данных имеют доступные данные о показах в полях событий. - Доступные поля. (См. список заблокированных полей ниже.)
- События, связанные с файлом cookie IDE (doubleclick.net).
- События с выходом из системы. (Кроме YouTube.)
Кроме того, события могут быть отфильтрованы, если существует риск раскрытия конфиденциальной информации о пользователях.
Таблицы adh. cm_dt_impressions , adh_dv360_dt_impressions и adh.google_ads_impressions нельзя использовать в запросах аудитории.
Приемлемость полей
Следующие поля из Ads Data Hub могут иметь идентификаторы, которые могут быть привязаны к одному пользователю, но не должны содержать личную информацию; поэтому их можно использовать в запросах аудитории ремаркетинга:
-
u_value -
ord_value -
значение_транзакции -
другие_данные
Следующие поля из таблиц Ads Data Hub нельзя использовать в запросах аудитории ремаркетинга:
-
match_targeted_keywords -
site_id -
идентификатор_местоположения -
dv360_url -
dv360_site_id -
издатель_домен -
content_url
Ограничение частоты показов
Аудитории с ограничением частоты показов дают вам лучший контроль над воздействием ваших кампаний на пользователей за счет отрицательного перенацеливания пользователей в зависимости от того, сколько раз они видели вашу рекламу. Вот как это работает: вы указываете список кампаний или позиций, для которых вы хотите вычислить частоту, а также порог показов. Когда пользователь достигает порога показов и вы выполняете запрос ограничения частоты показов, он добавляется в аудиторию ограничения частоты показов.
Поскольку пользователи активно добавляются в списки ограничения частоты показов (благодаря выполненным вами запросам), пользователи могут видеть ваши объявления чаще, чем позволяет ваш порог. Убедитесь, что вы регулярно выполняете запросы на ограничение частоты показов, чтобы поддерживать точность ваших списков.
Примеры использования API для создания аудитории с ограничением частоты показов см. в примерах API.
Вы можете использовать исходные данные из Google Рекламы, Менеджера кампаний 360 или Дисплея и Видео 360, но ваши аудитории с ограничением частоты показов можно использовать только в Дисплее и Видео 360.
Создайте аудиторию с ограничением частоты показов
- Перейдите на вкладку Аудитории в Ads Data Hub.
- Перейдите на вкладку Ограничение частоты показов в верхней части навигации.
- Нажмите + Создать аудиторию .
- Детали аудитории:
- Добавьте имя и (необязательно) описание.
- Конфигурация:
- Введите максимальное количество показов объявления, которое может иметь данный пользователь, прежде чем кампания или позиция перестанут показываться ему.
- Введите период (в днях), в течение которого подсчитываются показы объявлений пользователя. Это окно ретроспективного анализа, называемое «Продолжительность», также указывает, как долго пользователь будет оставаться в списке аудитории.
- Данные:
- Выберите учетную запись Ads Data Hub, в которую вы хотите добавить список аудитории.
- В разделе «Источники» выберите кампании, заказы на размещение или идентификаторы позиций, которые будут использоваться для заполнения списка аудитории.
- В разделе «Места назначения» выберите учетные записи, которым следует предоставить общий доступ к списку.
- Нажмите Сохранить.
Обновление аудитории с ограничением частоты показов
Вы можете добавить дополнительные кампании, позиции или заказы на размещение к существующей аудитории с ограничением частоты показов.
- Перейдите на вкладку Audiences в Ads Data Hub.
- Перейдите на вкладку Ограничение частоты показов в верхней части навигации.
- Нажмите на список, который вы хотите обновить.
- В разделе «Данные > Источники» выберите кампании, порядок размещения или идентификаторы позиций, которые будут использоваться для заполнения списка аудитории. Вы не можете удалить источники, которые уже есть в списке.
- Щелкните Выполнить , чтобы применить изменения.
- Щелкните Сохранить .
Совместное использование аудиторий
По умолчанию созданные вами аудитории не будут передаваться в ваши связанные учетные записи. Чтобы использовать списки, которые вы заполнили с помощью Ads Data Hub, вы должны выборочно поделиться этими списками со своими связанными учетными записями.
Чтобы поделиться списком аудитории:
- Перейдите к списку, которым хотите поделиться.
- Google Реклама:
- Нажмите Выберите клиентов в разделе «Назначения».
- Установите флажок рядом с рекламодателем или партнером, с которым вы хотите поделиться списком.
- Нажмите Готово .
- Дисплей и Видео 360:
- Нажмите Выберите рекламодателей и партнеров в разделе «Направления».
- Установите флажок рядом с рекламодателем или партнером, с которым вы хотите поделиться списком.
- Нажмите Готово .
- Нажмите Сохранить .
Вы также можете закрыть общий доступ к списку пользователей для определенной учетной записи. Чтобы обновить конфигурацию общего доступа:
- Перейдите к списку, в котором вы хотите обновить настройки общего доступа.
- Google Реклама:
- Нажмите Выберите клиентов в разделе «Назначения».
- Установите флажок рядом с рекламодателем или партнером, которому вы хотите предоставить общий доступ, или запретите общий доступ к списку.
- Нажмите Готово .
- Дисплей и Видео 360:
- Нажмите Выберите рекламодателей и партнеров в разделе «Направления».
- Установите флажок рядом с рекламодателем или партнером, которому вы хотите предоставить общий доступ, или запретите общий доступ к списку.
- Нажмите Готово .
- Щелкните Сохранить .
Ограничения и соображения конфиденциальности
В дополнение к перечисленным ниже требованиям, создаваемые вами списки также должны соответствовать требованиям и политикам таргетинга платформы, на которой используется этот список.
Требования к агрегированию
Списки аудитории должны содержать 100 или более активных пользователей за 30 дней. Это означает, что созданные вами списки аудитории не будут использоваться для таргетинга в Google Рекламе и Дисплее и Видео 360, если за последние 30 дней в списке было менее 100 пользователей.
Собственные данные
Данные, которые вы загрузили в свою учетную запись BigQuery, можно использовать для дополнения данных о рекламных событиях, но их нельзя использовать в качестве источника идентификаторов пользователей, используемых для таргетинга. Собственные данные можно объединить с помощью сопоставления файлов cookie или пользовательских переменных Floodlight.
Примечание. Сторонние данные не поддерживаются для активации аудитории. Недавность
Идентификаторы пользователей имеют срок действия 30 дней в списках аудитории. Вы можете обновить этот срок, повторно добавив идентификаторы пользователей в аудиторию.
Приемлемость места для идентификатора
В настоящее время активация аудитории ограничивается рекламными событиями, отслеживаемыми с помощью файлов cookie.
(События, происходящие в контекстно-медийной сети Google или на партнерских видеосайтах Google.)
Наконец, убедитесь, что вы создаете аудитории в соответствии с Ads Data Hub.
политики.
Примеры запросов
Создайте аудиторию всех пользователей, которые нажали на объявление для определенного идентификатора кампании:
выберите user_id
от adh.google_ads_clicks_audience
гдеjoin_impression.campaign_id в (@campaign_ids)
;
Создайте аудиторию всех пользователей, которые взаимодействовали с определенным идентификатором кампании и сопоставьте данные клиентов с помощью таблицы соответствия:
выберите user_id
из adh.google_ads_clicks_audience_match
гдеjoin_impression.
 Есть небольшая проблема, в корневой папке index.html также есть папки и ссылки на них, нам нужно их удалить.
Есть небольшая проблема, в корневой папке index.html также есть папки и ссылки на них, нам нужно их удалить. Языки программирования считают текстовые данные конфиденциальными, а это означает, что отличается от . мы, люди, знаем, что они оба принадлежат одному и тому же токену, но из-за кодировки символов они считаются разными токенами. Преобразование в нижний регистр является обязательным этапом предварительной обработки. Поскольку у нас есть все наши данные в списке, у numpy есть метод, который может сразу преобразовать список списков в нижний регистр.
Языки программирования считают текстовые данные конфиденциальными, а это означает, что отличается от . мы, люди, знаем, что они оба принадлежат одному и тому же токену, но из-за кодировки символов они считаются разными токенами. Преобразование в нижний регистр является обязательным этапом предварительной обработки. Поскольку у нас есть все наши данные в списке, у numpy есть метод, который может сразу преобразовать список списков в нижний регистр.
 0021
0021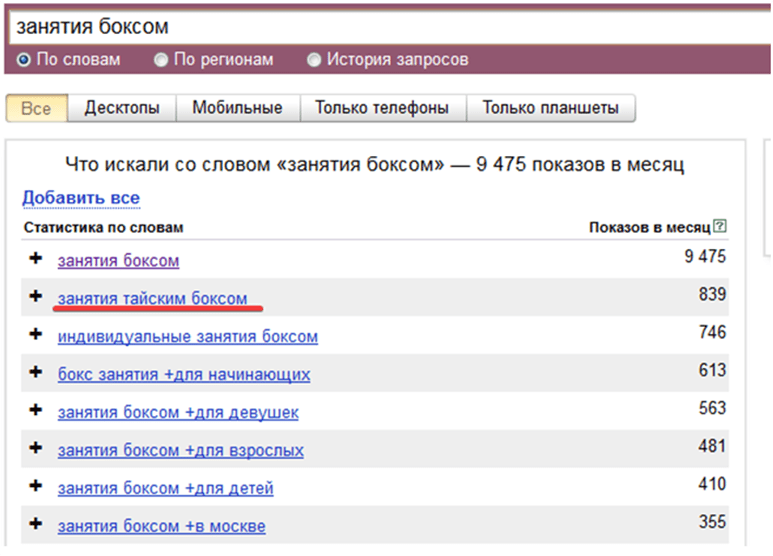
 Итак, чтобы сделать наш ИК-режим немного лучше, нам нужно преобразовать 100 в сто. Для этого мы будем использовать библиотеку под названием 9.0010 число2слово .
Итак, чтобы сделать наш ИК-режим немного лучше, нам нужно преобразовать 100 в сто. Для этого мы будем использовать библиотеку под названием 9.0010 число2слово . Как уже говорилось, это просто помогает очистить данные немного глубже. Теперь нам нужно прочитать документы и сохранить их заголовок и тело отдельно, так как мы собираемся использовать их позже. В нашей постановке задачи у нас очень разные типы документов, это может вызвать несколько ошибок при чтении документов из-за совместимости кодировок. чтобы решить эту проблему, просто используйте encoding=»utf8″, errors=’ignore’ в методе open().
Как уже говорилось, это просто помогает очистить данные немного глубже. Теперь нам нужно прочитать документы и сохранить их заголовок и тело отдельно, так как мы собираемся использовать их позже. В нашей постановке задачи у нас очень разные типы документов, это может вызвать несколько ошибок при чтении документов из-за совместимости кодировок. чтобы решить эту проблему, просто используйте encoding=»utf8″, errors=’ignore’ в методе open().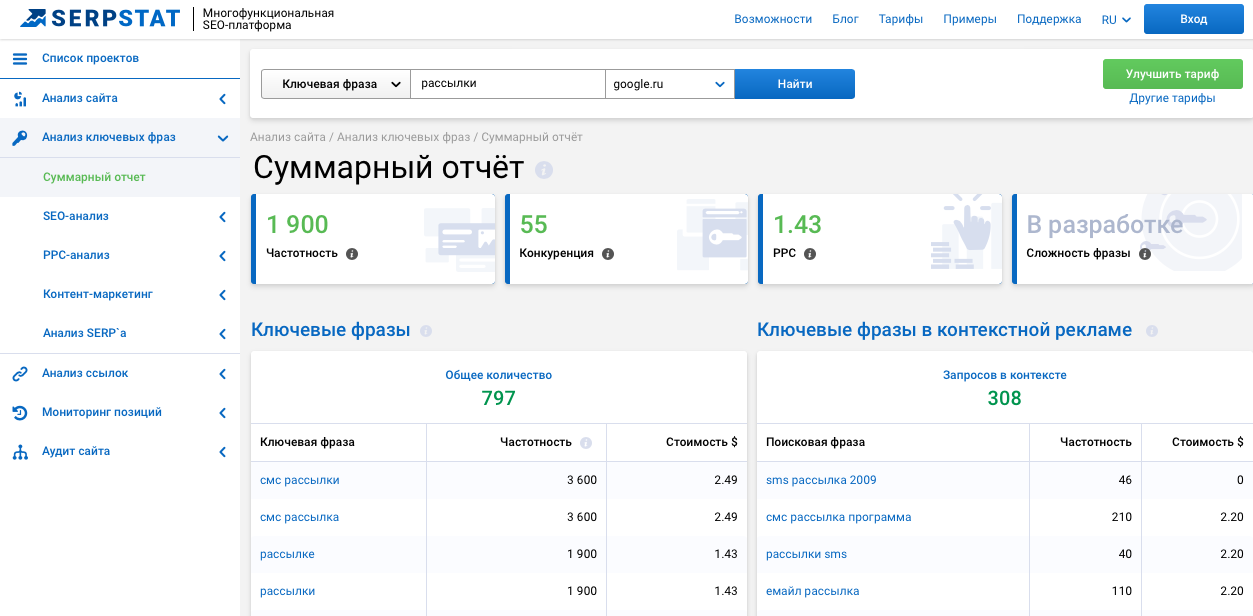 Пока давайте рассмотрим только слово paper и забудем об удалении стоп-слов.
Пока давайте рассмотрим только слово paper и забудем об удалении стоп-слов.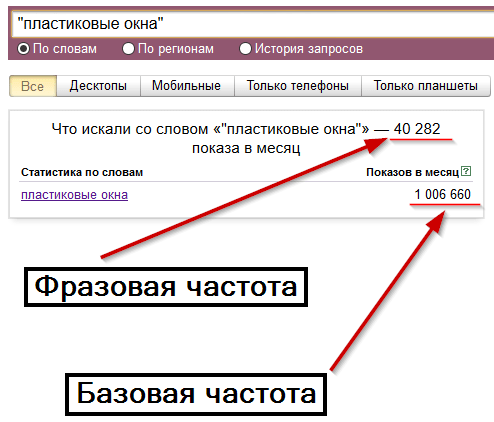 Нам нужно перебрать все слова во всех документах и сохранить идентификатор документа для каждого слова. Для этого мы будем использовать словарь, так как мы можем использовать слово в качестве ключа и набор документов в качестве значения. Я упомянул набор, потому что, даже если мы пытаемся добавить документ несколько раз, набор не будет просто принимать повторяющиеся значения.
Нам нужно перебрать все слова во всех документах и сохранить идентификатор документа для каждого слова. Для этого мы будем использовать словарь, так как мы можем использовать слово в качестве ключа и набор документов в качестве значения. Я упомянул набор, потому что, даже если мы пытаемся добавить документ несколько раз, набор не будет просто принимать повторяющиеся значения.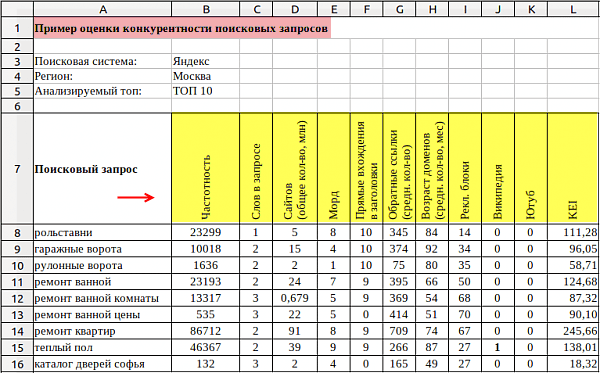 но для DF нам на самом деле не нужен список документов, нам просто нужно количество. поэтому мы собираемся заменить список его счетчиком.
но для DF нам на самом деле не нужен список документов, нам просто нужно количество. поэтому мы собираемся заменить список его счетчиком. unique(токены):
unique(токены):  Веса, которые мы используем для тела и заголовка, суммируются до одного
Веса, которые мы используем для тела и заголовка, суммируются до одного Поскольку наш словарь является ключом (документ, токен), когда мы находим токен, который находится в запросе, мы добавим идентификатор документа в другой словарь вместе со значением tf-idf. Наконец, мы просто снова возьмем первые k документов.
Поскольку наш словарь является ключом (документ, токен), когда мы находим токен, который находится в запросе, мы добавим идентификатор документа в другой словарь вместе со значением tf-idf. Наконец, мы просто снова возьмем первые k документов. в таких случаях косинусное сходство лучше всего подходит для поиска релевантности.0021
в таких случаях косинусное сходство лучше всего подходит для поиска релевантности.0021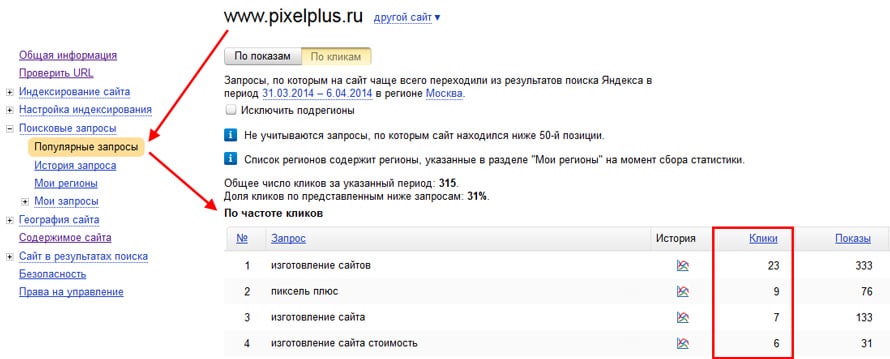
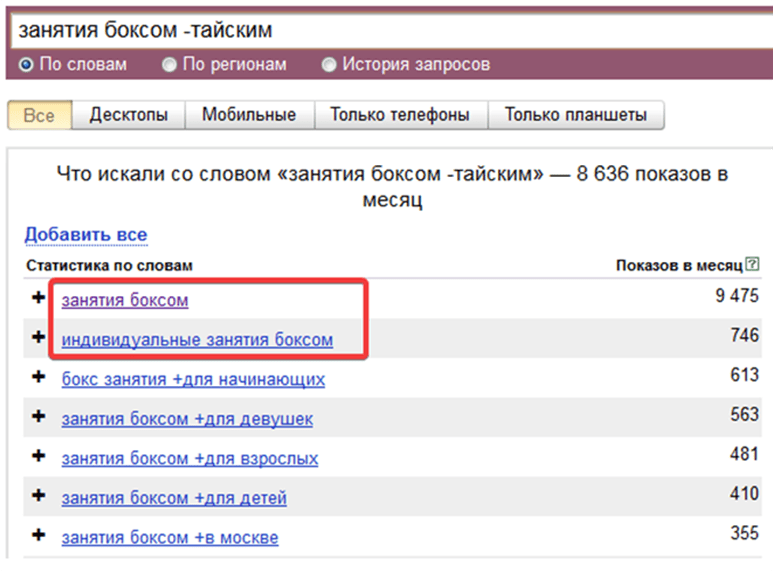

 Здесь мы подсчитываем количество всех строк, так как эта таблица представляет показы.
Здесь мы подсчитываем количество всех строк, так как эта таблица представляет показы.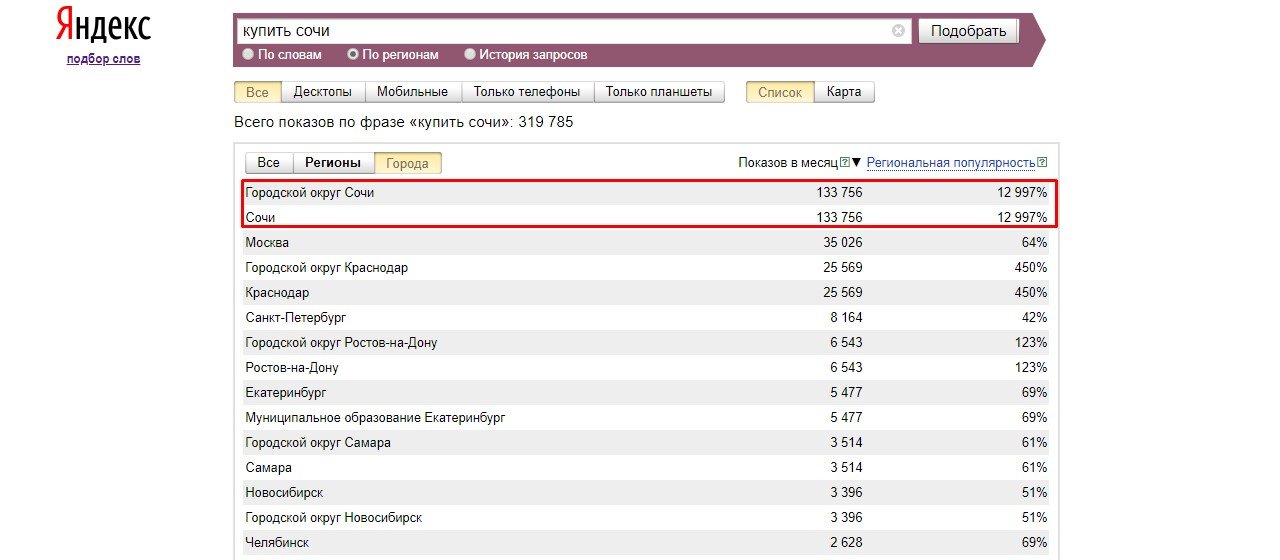 Мы пока закомментировали это.
-- COUNT(DISTINCT user_id) КАК alt_reach_calculation
СУММ(СЛУЧАЙ, КОГДА user_id НЕ равен нулю, ТОГДА 1, ИНАЧЕ 0 КОНЕЦ) AS measurable_reach_impressions,
HLL(user_id)/SUM(СЛУЧАЙ, КОГДА user_id НЕ равен null THEN 1 ELSE 0 END) КАК частота
ОТ shared_impression_details_view
ГДЕ bid_time >= CURRENT_DATE() - 30
СГРУППИРОВАТЬ ПО id_кампании, id_элемента_строки
ЗАКАЗАТЬ ПО DESC
Мы пока закомментировали это.
-- COUNT(DISTINCT user_id) КАК alt_reach_calculation
СУММ(СЛУЧАЙ, КОГДА user_id НЕ равен нулю, ТОГДА 1, ИНАЧЕ 0 КОНЕЦ) AS measurable_reach_impressions,
HLL(user_id)/SUM(СЛУЧАЙ, КОГДА user_id НЕ равен null THEN 1 ELSE 0 END) КАК частота
ОТ shared_impression_details_view
ГДЕ bid_time >= CURRENT_DATE() - 30
СГРУППИРОВАТЬ ПО id_кампании, id_элемента_строки
ЗАКАЗАТЬ ПО DESC
 Для этого нам нужно также бросить
Для этого нам нужно также бросить  Ads Data Hub
Ads Data Hub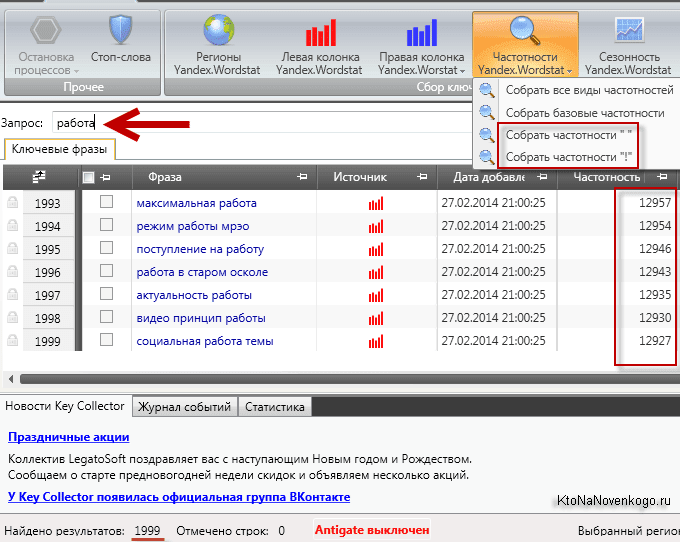 Для всех других списков вы должны выполнять запросы, чтобы поддерживать свои списки.
Для всех других списков вы должны выполнять запросы, чтобы поддерживать свои списки.

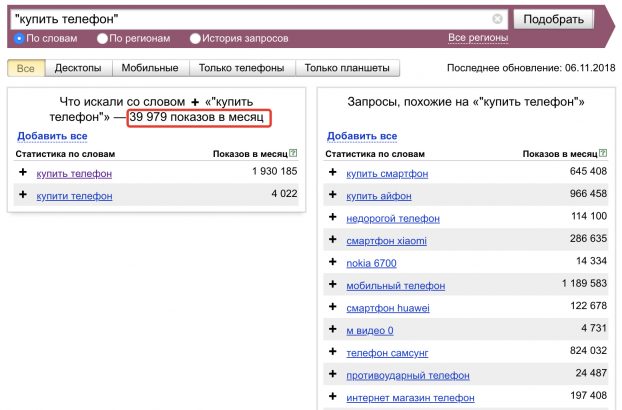 События, не соответствующие этому критерию, будут автоматически отфильтрованы. Допустимые события ограничены:
События, не соответствующие этому критерию, будут автоматически отфильтрованы. Допустимые события ограничены: cm_dt_impressions
cm_dt_impressions  Вот как это работает: вы указываете список кампаний или позиций, для которых вы хотите вычислить частоту, а также порог показов. Когда пользователь достигает порога показов и вы выполняете запрос ограничения частоты показов, он добавляется в аудиторию ограничения частоты показов.
Вот как это работает: вы указываете список кампаний или позиций, для которых вы хотите вычислить частоту, а также порог показов. Когда пользователь достигает порога показов и вы выполняете запрос ограничения частоты показов, он добавляется в аудиторию ограничения частоты показов.

 Чтобы использовать списки, которые вы заполнили с помощью Ads Data Hub, вы должны выборочно поделиться этими списками со своими связанными учетными записями.
Чтобы использовать списки, которые вы заполнили с помощью Ads Data Hub, вы должны выборочно поделиться этими списками со своими связанными учетными записями.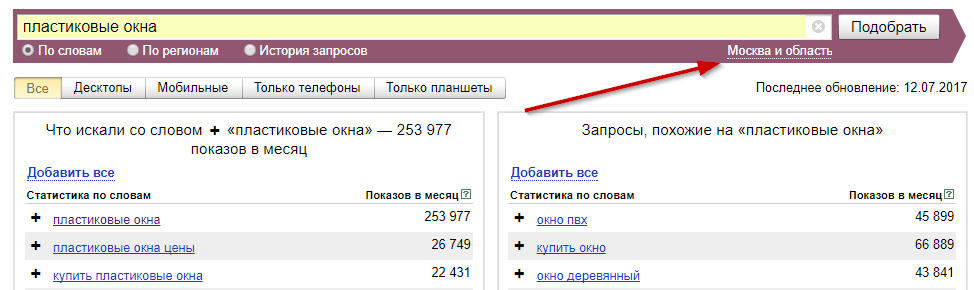 Чтобы обновить конфигурацию общего доступа:
Чтобы обновить конфигурацию общего доступа: