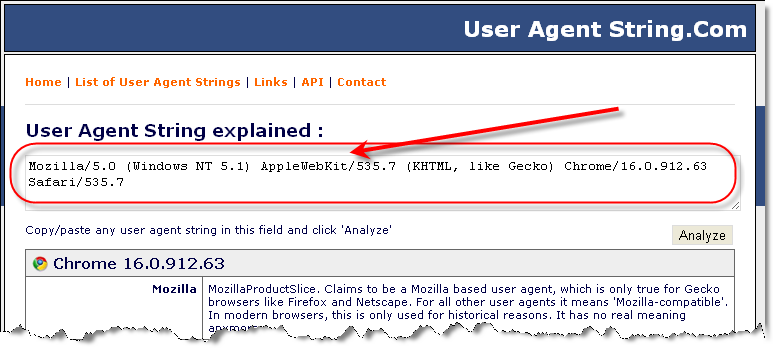
Google убирает из браузера Chrome строку ‘user-agent’ / Хабр
При посещении веб-сайта браузер или другое клиентское приложение обычно посылает веб-серверу информацию о себе. Эта текстовая строка является частью HTTP-запроса. Она начинается с User-agent: или User-Agent: и обычно содержит название и версию приложения, операционную систему компьютера и язык. Например, Chrome под Android посылает что-то вроде такого:
User-Agent: Mozilla/5.0 (Linux; Android 9; Pixel 2 XL Build/PPP3.180510.008) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Mobile Safari/537.36
Но разработчики Chrome считают, что это слишком подробная информация. Они объявили о решении отказаться от user-agent в браузере Chrome. Вместо этого Chrome предложит новый API под названием Client Hints, который позволит лучше контролировать, какая информация передаётся веб-сайтам.
Это делается для защиты приватности, поскольку злоумышленники сейчас активно используют
user-agent для фингерпринтинга и профилирования пользователей. Вообще ненормальна ситуация, когда user-agent транслируется всем подряд в автоматическом режиме.Строка
User-Agent впервые появилась в Mosaic, популярном браузере начала 90-х. Тогда браузер отправлял просто строку с названием и версией браузера. Строка выглядела примерно так:Mosaic/0.9
В первое время от этой информации было мало практической пользы. Через несколько лет вышел браузер Netscape, он перенял у предшественника строку user-agent и добавил к неё дополнительные детали, такие как операционная система, язык и т. д. Примерно с этого времени веб-сайты начали учитывать user-agent, чтобы выдавать клиенту правильный контент.
Поскольку Mosaic и Netscape поддерживали разный набор функций, веб-сайты должны были использовать строку
user-agent, чтобы определить тип браузера и избежать использования неподдерживаемых функций (например, фреймы поддерживались только Netscape, но не Mosaic).
В течение многих лет определение версии браузера продолжало играть значительную роль в веб-разработке. Это вызвало неприятные побочные эффекты, когда мелким разработчикам браузеров приходилось имитировать популярные user-agent’ы для корректного отображения веб-сайта, поскольку некоторые компании поддерживали только основные типы user-agent.
С ростом популярности JavaScript большинство разработчиков начали использовать библиотеки вроде Modernizer, которые определяют конкретный список функций HTML, CSS и JavaScript, которые поддерживает конкретный браузер, обеспечивая гораздо более точные результаты, чем user-agent.
В результате основными пользователями user-agent

По иронии, Google считается одним из главных нарушителей приватности. Именно эта компания собирает самые подробные профили пользователей, собирая данные из электронной почты, GPS-трекеров, операционной системы Android и десятков своих веб-сервисов.
Более того, именно Google в последнее время чаще всех злоупотребляла user-agent, блокируя доступ к своим сервисам пользователей с альтернативными браузерами. Чтобы открыть эти сервисы, альтернативным браузерам приходилось подделывать строку user-agent и выдавать себя за Chrome. Например, см. список поддельных user-agent для браузера Microsoft Edge, который тоже вынужден выдавать себя за Chrome на десятках сайтов.
Gmail, Google Maps и другие сервисы работают медленнее во всех браузерах, кроме Chrome.
Но бывает, что интересы отдельных разработчиков идут вразрез с интересами работодателя. Возможно, здесь как раз такой случай. Мы и раньше видели, как разработчики Chrome выражали протест некорректными действиями компании, когда она выкатывала сервисы «только для Chrome». Они выражали недовольство в твиттере и во внутренней корпоративной рассылке. Это действительно грамотные специалисты, у которых неадекватные решения руководства Google не могли вызвать ничего, кроме недоумения и фейспалма. Похоже, сейчас пришло время для конкретных действий.
Они выражали недовольство в твиттере и во внутренней корпоративной рассылке. Это действительно грамотные специалисты, у которых неадекватные решения руководства Google не могли вызвать ничего, кроме недоумения и фейспалма. Похоже, сейчас пришло время для конкретных действий.
Команда разработчиков браузера Chrome начала поэтапный отказ от user-agent, начиная с версии Chrome 81. Отказ от
user-agent значительно затруднит Google некорректные практики по продвижению своего браузера.Полностью удалить user-agent пока проблематично, поскольку многие сайты ещё полагаются на эту строку, но Chrome больше не будет обновлять версию браузера и укажет одинаковую версию ОС в user-agent для всех устройств.
В частности, со всех мобильных устройств Chrome будет отправлять такую строку:
Mozilla/5.0 (Linux; Android 9; Unspecified Device) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/71.1.2222.33 Mobile Safari/537. 36
36 36
36Со всех настольных компьютеров строка будет выглядеть следующим образом, независимо от устройства и версии браузера:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.1.2222.33 Safari/537.36
Переход с user-agent на Client Hints планируется завершить к версии Chrome 85, которая должна выйти в сентябре 2020 года. Другие разработчики браузеров, включая Mozilla Firefox, Microsoft Edge и Apple Safari, выразили поддержку этому шагу, хотя пока не огласили свои планы по аналогичным действиям.
Подробнее о предлагаемой альтернативе Client Hints можно почитать в официальном репозитории Github. Это предложение пока не оформлено в виде стандарта, поэтому точная реализация может измениться к моменту выпуска официальных рекомендаций. Разработчикам рекомендуется следить за изменениями в репозитории, а также за примечаниями, которые публикуются с новыми версиями Chrome.
Главное отличие Client Hints от user-agent в том, что сайты больше не будут пассивно получать информацию о браузере пользователя. Они будут вынуждены активно запрашивать её, а браузер может отказать в таком запросе, примерно так же, как сейчас некоторые браузеры блокируют сторонние куки.
Про user-agent. Что это и зачем? Для начинающего тестировщика. 2023 — Василий Волгин на vc.ru
{«id»:13929,»url»:»\/distributions\/13929\/click?bit=1&hash=278952ad87803f3f218904bec511e12e0af0771c282b5c14278379ae8fde671e»,»title»:»\u0423\u0437\u043d\u0430\u0442\u044c, \u043a\u0430\u043a\u0438\u043c \u0442\u0435\u0445\u043d\u043e\u043b\u043e\u0433\u0438\u044f\u043c \u0431\u0438\u0437\u043d\u0435\u0441 \u043e\u0442\u0434\u0430\u0451\u0442 \u043f\u0440\u0435\u0434\u043f\u043e\u0447\u0442\u0435\u043d\u0438\u0435 \u0441\u0435\u0433\u043e\u0434\u043d\u044f»,»buttonText»:»»,»imageUuid»:»»,»isPaidAndBannersEnabled»:false}
Как «обмануть» браузер и протестировать с других устройств веб приложение? Варианты есть разные и предлагаю рассмотреть user agent для данной деятельности.
478 просмотров
❤Поставь лайк полезному материалу и дочитай до конца.
User-Agent — это строка, которую ваш браузер отправляет на сервер при запросе веб-страницы, и она содержит информацию о вашей операционной системе, браузере и его версии, а также другие данные, такие как тип устройства и язык. Веб-сервер использует эту информацию для того, чтобы предоставить вам оптимизированную версию веб-страницы для вашего устройства и браузера.
Найти его можно во вкладке Network перейдя по любому запросу.
User-agent может использоваться для:
- Определения типа устройства и настройки веб-страницы для наилучшего отображения на экране устройства.
- Определения возможностей браузера и включения или отключения функций веб-страницы в зависимости от них.
- Сбора статистики посещаемости веб-сайта и анализа поведения пользователей в зависимости от типа браузера и устройства.
- Предотвращения злоупотребления доступом к веб-серверу и защиты от вредоносных программ.
- Улучшения качества сервиса и удобства использования веб-приложений.

Есть много полезных приложений, которые могут в этом помочь, например:
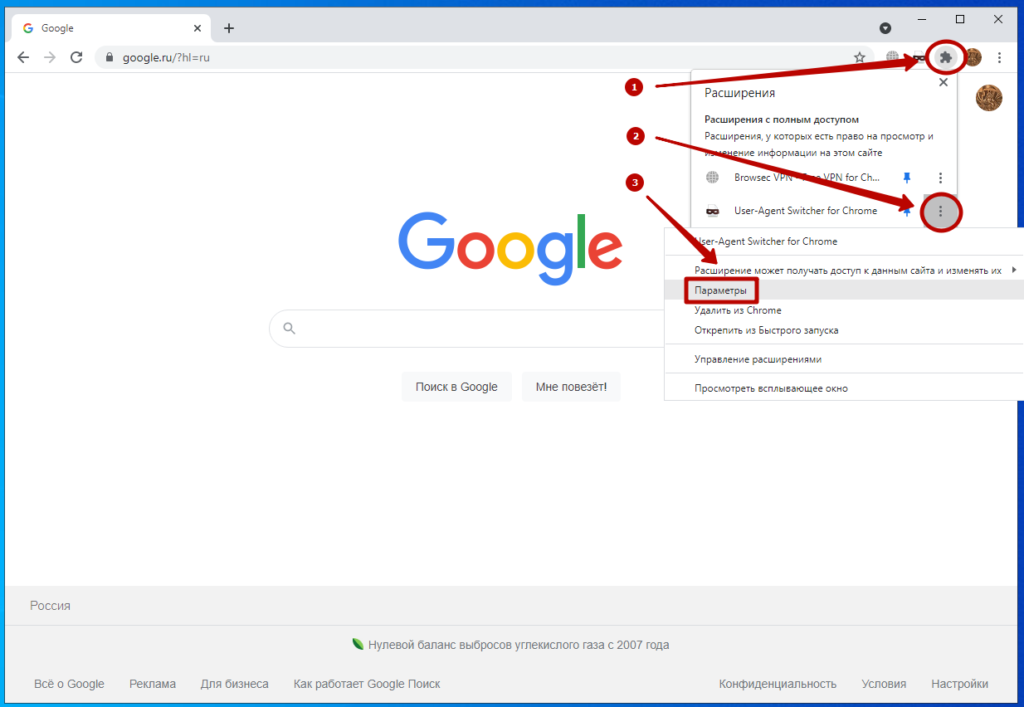
По сути это расширения для браузера, которое позволяет изменять User-Agent, который отправляется вашим браузером при запросе веб-страницы.
Они позволяют вам изменить User-Agent, который отправляется серверу, чтобы вы могли посмотреть, как выглядит веб-страница на разных устройствах или браузерах.
Пример панели из одного приложения
Например, вы можете использовать User-Agent Switcher, чтобы проверить, как выглядит ваш сайт на мобильном устройстве или на другом браузере, таком как Firefox или Safari. Это может быть полезно для разработчиков веб-сайтов и приложений, чтобы убедиться, что их продукты выглядят и работают корректно на разных устройствах и браузерах.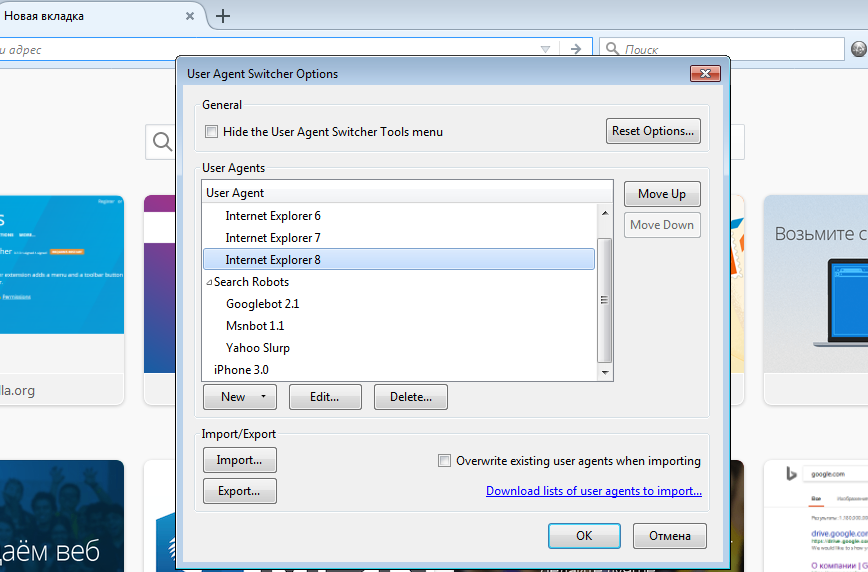
Подпишись: Канал для будущих тестировщиков
Василий Волгин — full stack тестировщик
Google Crawler (агент пользователя) Обзор | Центр поиска Google | Документация
Google использует сканеры и сборщики для выполнения действий со своими продуктами, либо автоматически, либо срабатывает по запросу пользователя.
«Краулер» (иногда также называемый «роботом» или «пауком») — это общий термин для любой программы, которая используется для автоматического обнаружения и сканирования веб-сайтов путем перехода по ссылкам с одной веб-страницы на другой. Главный поисковый робот Google называется Googlebot.
Сборщики, как и браузер, — это инструменты, которые запрашивают один URL-адрес по запросу пользователя.
В следующих таблицах показаны сканеры и сборщики данных Google, используемые различными продуктами и службами.
как вы можете увидеть в своих журналах реферера, и как указать их в
robots. txt.
txt.
- Токен пользовательского агента используется в строке
User-agent:файла robots.txt. чтобы соответствовать типу сканера при написании правил сканирования для вашего сайта. Некоторые сканеры имеют более один токен, как показано в таблице; вам нужно сопоставить только один токен сканера, чтобы правило применять. Этот список не является полным, но охватывает большинство поисковых роботов, которые вы можете встретить на своем веб-сайте. - Полная строка пользовательского агента представляет собой полное описание сканера и появляется в HTTP-запрос и ваши веб-журналы. Внимание : Строка пользовательского агента может быть подделана. Узнайте, как проверить, является ли посетитель поисковым роботом Google.
Обыкновенные гусеницы
Обычные поисковые роботы Google используются для построения поисковых индексов Google, выполнения других продуктов. определенные сканирования и для анализа. Они всегда соблюдают правила robots.txt и обычно ползают с
Диапазоны IP-адресов, опубликованные в
объект googlebot.json.
определенные сканирования и для анализа. Они всегда соблюдают правила robots.txt и обычно ползают с
Диапазоны IP-адресов, опубликованные в
объект googlebot.json.
| Общие сканеры | |||||
|---|---|---|---|---|---|
Смартфон Googlebot |
| ||||
Googlebot Desktop |
| ||||
Googlebot Изображение | Используется для сканирования байтов изображения для картинок Google и продуктов, зависящих от изображений.
| ||||
Новости Googlebot | Googlebot News использует робота Googlebot для сканирования новостных статей, однако соблюдает его
исторический токен пользовательского агента
| ||||
Робот Googlebot | Используется для сканирования байтов видео для Google Video и продуктов, зависящих от видео.
| ||||
Фавикон Google | Предупреждение . Для запросов, инициированных пользователями, значок Google Favicon игнорирует
robots.txt, и в этом случае он будет делать запрос из другого диапазона IP-адресов.
| ||||
Google StoreBot | Google Storebot сканирует определенные типы страниц, включая, помимо прочего, страницы сведений о продукте, страницы корзины и страницы оформления заказа.
| ||||
GoogleДругое | Универсальный поисковый робот, который может использоваться различными продуктовыми группами для получения общедоступных данных. контент с сайтов. Например, его можно использовать для разового сканирования для внутренних исследований и разработка.
| ||||
 0 AppleWebKit/537.36 (KHTML, как Gecko; совместимо; Googlebot/2.1; +http://www.google.com/bot.html) Chrome/ W.X.Y.Z Сафари/537.36
0 AppleWebKit/537.36 (KHTML, как Gecko; совместимо; Googlebot/2.1; +http://www.google.com/bot.html) Chrome/ W.X.Y.Z Сафари/537.36 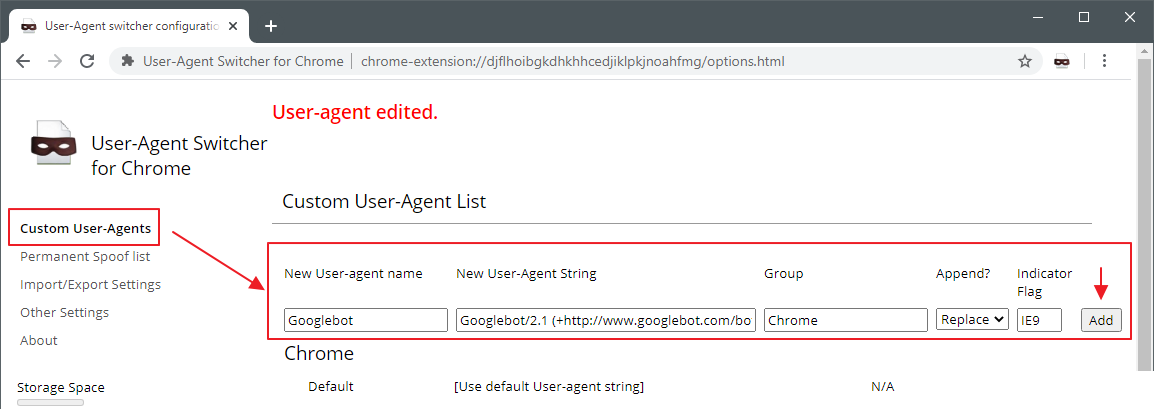 0
0 
 0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/49.0.2623.75 Safari/537.36 Google Favicon
0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/49.0.2623.75 Safari/537.36 Google Favicon  0 (Linux; Android 8.0; Pixel 2 Build/OPD3.170816.012; Storebot-Google/1.0) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/81.0.4044.138 Mobile Safari/537.36
0 (Linux; Android 8.0; Pixel 2 Build/OPD3.170816.012; Storebot-Google/1.0) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/81.0.4044.138 Mobile Safari/537.36 Специальные гусеничные тележки
Искатели специального назначения используются конкретными продуктами, для которых существует соглашение между
просканированный сайт и продукт о процессе сканирования. Например,
Например, AdsBot игнорирует
глобальный пользовательский агент robots.txt ( * ) с разрешения издателя рекламы.
поисковые роботы в особых случаях могут игнорировать правила robots.txt и работать с другого диапазона IP-адресов.
чем обычные краулеры. Диапазоны IP-адресов публикуются в
объект special-crawlers.json.
| Специальные гусеничные тележки | |||||
|---|---|---|---|---|---|
API-интерфейсы Google | Используется API Google для доставки push-уведомлений. Игнорирует глобальный пользовательский агент
(
| ||||
AdsBot Mobile Web Android | Проверяет Android
качество рекламы на веб-странице.
Игнорирует глобальный пользовательский агент (
| ||||
AdsBot Mobile Web | Проверяет iPhone
качество рекламы на веб-странице.
| ||||
AdsBot | Проверяет рабочий стол
качество рекламы на веб-странице.
Игнорирует глобальный пользовательский агент (
| ||||
AdSense | Сканер AdSense посещает ваш сайт, чтобы определить его содержание и предоставить релевантные
Объявления. Игнорирует глобальный пользовательский агент (
| ||||
Мобильный AdSense | Сканер Mobile AdSense посещает ваш сайт, чтобы определить его содержание, чтобы предоставить
релевантные объявления.
| ||||
 google.com/webmasters/APIs-Google.html)
google.com/webmasters/APIs-Google.html)  Игнорирует глобальный пользовательский агент (
Игнорирует глобальный пользовательский агент (  google.com/adsbot.html)
google.com/adsbot.html)  Игнорирует глобальный пользовательский агент (
Игнорирует глобальный пользовательский агент ( Пользовательские сборщики
Инициируемые пользователем сборщики запускаются пользователями для выполнения определенной функции продукта. Для
пример,
Верификатор сайта Google
действует по запросу пользователя. Поскольку выборка была запрошена пользователем, эти сборщики обычно
игнорировать правила robots.txt. Диапазоны IP-адресов, которые используют сборщики, запускаемые пользователем, публикуются в
пользователь-триггеры-fetchers. json
объект.
json
объект.
| Пользовательские сборщики | |||||
|---|---|---|---|---|---|
Сборщик фидов | Feedfetcher используется для сканирования каналов RSS или Atom для Google Podcasts, Google News и ПабСубХаббуб.
| ||||
Центр издателей Google | Выборки и процессы
фиды, явно предоставленные издателями
через Центр издателей Google для использования на целевых страницах Новостей Google.
| ||||
Гугл читать вслух | По запросу пользователя Google Read Aloud извлекает и читает веб-страницы, используя преобразование текста в речь. (ТТС).
| ||||
Верификатор сайта Google | Google Site Verifier извлекает токены подтверждения Search Console по запросу пользователя.
| ||||

 0 (Linux; Android 7.0; SM-G930V Build/NRD90M) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/59.0.3071.125 Mobile Safari/537.36 (совместимый; Google-Read-Aloud; +https ://developers.google.com/search/docs/crawling-indexing/overview-google-crawlers)
0 (Linux; Android 7.0; SM-G930V Build/NRD90M) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/59.0.3071.125 Mobile Safari/537.36 (совместимый; Google-Read-Aloud; +https ://developers.google.com/search/docs/crawling-indexing/overview-google-crawlers)  X.Y.Z in user agents»> Примечание о Chrome/ W.X.Y.Z в пользовательских агентах
X.Y.Z in user agents»> Примечание о Chrome/ W.X.Y.Z в пользовательских агентах
Везде, где вы видите строку Chrome/ W.X.Y.Z в пользовательском агенте
строк в таблице, W.X.Y.Z на самом деле является заполнителем, представляющим версию
браузера Chrome, используемого этим пользовательским агентом: например, 41.0.2272.96 . Эта версия
число будет увеличиваться со временем до
соответствовать последней версии Chromium, используемой роботом Googlebot.
Если вы просматриваете свои журналы или фильтруете свой сервер для пользовательского агента с этим шаблоном, использовать подстановочные знаки для номера версии, а не указывать точное номер версии.
Пользовательские агенты в robots.txt
Если в файле robots.txt распознано несколько пользовательских агентов, Google будет следовать наиболее
специфический. Если вы хотите, чтобы весь Google мог сканировать ваши страницы, вам не нужен
файл robots. txt вообще. Если вы хотите заблокировать или разрешить всем поисковым роботам Google доступ
часть вашего контента, вы можете сделать это, указав Googlebot в качестве пользовательского агента. Например,
если вы хотите, чтобы все ваши страницы отображались в поиске Google, и если вы хотите, чтобы реклама AdSense появлялась
на ваших страницах вам не нужен файл robots.txt. Точно так же, если вы хотите заблокировать некоторые страницы
от Google вообще, блокируя
txt вообще. Если вы хотите заблокировать или разрешить всем поисковым роботам Google доступ
часть вашего контента, вы можете сделать это, указав Googlebot в качестве пользовательского агента. Например,
если вы хотите, чтобы все ваши страницы отображались в поиске Google, и если вы хотите, чтобы реклама AdSense появлялась
на ваших страницах вам не нужен файл robots.txt. Точно так же, если вы хотите заблокировать некоторые страницы
от Google вообще, блокируя Пользовательский агент Googlebot также заблокирует все
Другие пользовательские агенты Google.
Но если вам нужен более детальный контроль, вы можете сделать его более конкретным. Например, вы можете
хотите, чтобы все ваши страницы отображались в поиске Google, но вы не хотите, чтобы изображения отображались в личном
каталог для обхода. В этом случае используйте robots.txt, чтобы запретить Пользовательский агент Googlebot-Image от сканирования файлов в вашем личном каталоге
(при этом позволяя роботу Googlebot сканировать все файлы), например:
Агент пользователя: Googlebot Запретить: Агент пользователя: Googlebot-Image Запретить: /personal
Возьмем другой пример. Допустим, вы хотите размещать рекламу на всех своих страницах, но не хотите,
страницы для отображения в поиске Google. Здесь вы заблокируете робота Googlebot, но разрешите
Пользовательский агент
Допустим, вы хотите размещать рекламу на всех своих страницах, но не хотите,
страницы для отображения в поиске Google. Здесь вы заблокируете робота Googlebot, но разрешите
Пользовательский агент Mediapartners-Google , например:
Агент пользователя: Googlebot Запретить: / Агент пользователя: Mediapartners-Google Запретить:
Контроль скорости сканирования
Каждый поисковый робот Google обращается к сайтам с определенной целью и с разной скоростью. Google использует алгоритмы для определения оптимальной скорости сканирования для каждого сайта. Если поисковый робот Google сканирует ваш сайт слишком часто, вы можете уменьшить скорость сканирования.
Устаревшие поисковые роботы Google
Следующие поисковые роботы Google больше не используются и упоминаются здесь только для исторической справки.
| Устаревшие поисковые роботы Google | |||||
|---|---|---|---|---|---|
Дуплекс в Интернете | Поддерживается Duplex на веб-сервисе.
* . | ||||
Веб-светильник | Проверяется наличие заголовка
| ||||
Мобильные приложения Android | Проверяет страницу приложения Android
качество рекламы.
Повинуется
| ||||
 Пользовательский агент Web Light использовался только
для явных запросов на просмотр от посетителя-человека, поэтому он игнорировал правила robots.txt,
которые используются для блокировки запросов автоматического сканирования.
Пользовательский агент Web Light использовался только
для явных запросов на просмотр от посетителя-человека, поэтому он игнорировал правила robots.txt,
которые используются для блокировки запросов автоматического сканирования. txt.
txt.Что такое Googlebot | Центр поиска Google | Документация
Googlebot — это общее название для двух типов роботов Google. поисковые роботы:
- Рабочий стол Googlebot : сканер рабочего стола, который имитирует пользователя на рабочем столе.
- Googlebot Смартфон : мобильный поисковый робот, имитирующий пользователя на мобильном устройстве.
Вы можете определить подтип робота Googlebot, взглянув на
строка пользовательского агента в
запрос.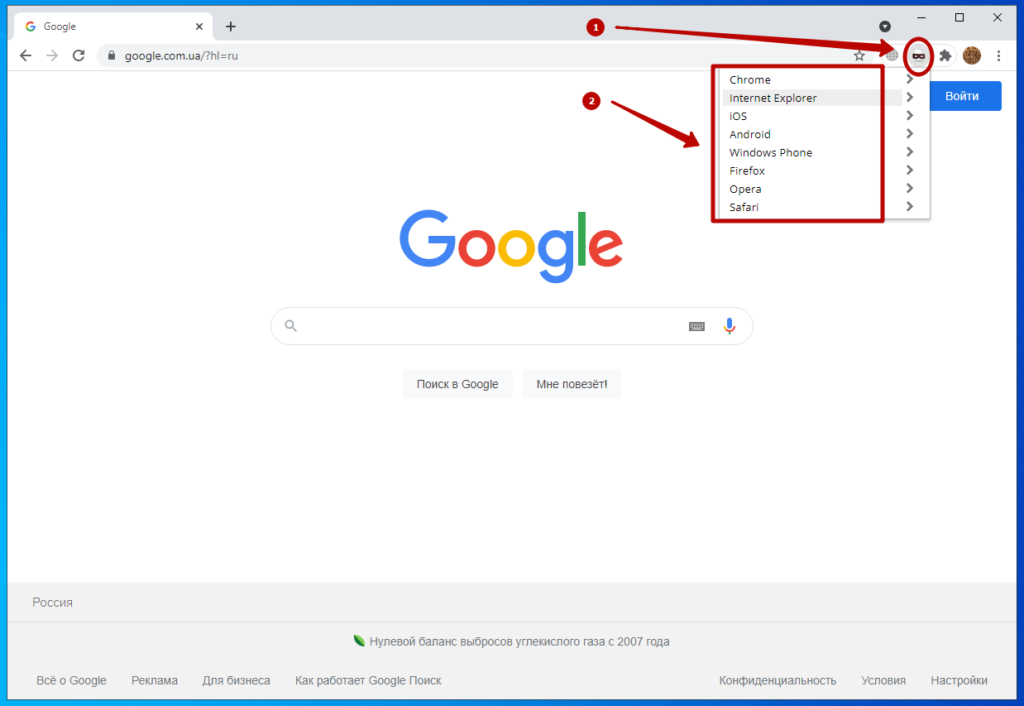 Однако оба типа искателей подчиняются одному и тому же токену продукта (токен агента пользователя) в
robots.txt, поэтому вы не можете выборочно настроить таргетинг ни на Googlebot Smartphone, ни на Googlebot.
Рабочий стол с помощью robots.txt.
Однако оба типа искателей подчиняются одному и тому же токену продукта (токен агента пользователя) в
robots.txt, поэтому вы не можете выборочно настроить таргетинг ни на Googlebot Smartphone, ни на Googlebot.
Рабочий стол с помощью robots.txt.
Для большинства сайтов Google в первую очередь индексирует мобильную версию содержания. Таким образом, большинство запросов на сканирование робота Googlebot будет выполняться с мобильных устройств. сканер, и меньшинство использует сканер для настольных компьютеров.
Как робот Googlebot получает доступ к вашему сайту
Для большинства сайтов робот Googlebot не должен заходить на ваш сайт чаще, чем раз в несколько секунд в средний. Однако из-за задержек возможно, что ставка будет немного выше. в течение коротких периодов.
Робот Google был разработан для одновременной работы на тысячах машин, чтобы улучшить
производительность и масштабируемость по мере роста Интернета. Кроме того, чтобы сократить использование полосы пропускания, мы запускаем множество
сканеры на машинах, расположенных рядом с сайтами, которые они могут сканировать. Поэтому ваши журналы могут
показать посещения с нескольких IP-адресов, все с пользовательским агентом Googlebot. Наша цель
состоит в том, чтобы сканировать как можно больше страниц вашего сайта при каждом посещении, не перегружая ваш
сервер. Если ваш сайт не справляется с запросами на сканирование Google, вы можете
уменьшить скорость сканирования.
Кроме того, чтобы сократить использование полосы пропускания, мы запускаем множество
сканеры на машинах, расположенных рядом с сайтами, которые они могут сканировать. Поэтому ваши журналы могут
показать посещения с нескольких IP-адресов, все с пользовательским агентом Googlebot. Наша цель
состоит в том, чтобы сканировать как можно больше страниц вашего сайта при каждом посещении, не перегружая ваш
сервер. Если ваш сайт не справляется с запросами на сканирование Google, вы можете
уменьшить скорость сканирования.
Googlebot сканирует в основном с IP-адресов в США. Если робот Googlebot обнаружит что сайт блокирует запросы из США, он может пытаться сканировать с IP адреса, находящиеся в других странах. Список используемых в настоящее время блоков IP-адресов, используемых Googlebot доступен в формат JSON.
Робот Googlebot сканирует HTTP/1.1 и, если это поддерживается сайтом,
HTTP/2. Нет никаких
преимущество ранжирования в зависимости от того, какая версия протокола используется для сканирования вашего сайта; однако ползать
через HTTP/2 может сэкономить вычислительные ресурсы (например, ЦП, ОЗУ) для вашего сайта и робота Googlebot.
Чтобы отказаться от сканирования по HTTP/2, попросите сервер, на котором размещен ваш сайт, ответить
с кодом состояния HTTP 421 , когда робот Googlebot пытается просканировать ваш сайт
HTTP/2. Если это невозможно, вы
может отправить сообщение команде Googlebot
(однако это решение временное).
Робот Googlebot может сканировать первые 15 МБ HTML-файла или поддерживаемый текстовый файл. Каждый ресурс, указанный в HTML, такой как CSS и JavaScript, извлекается отдельно, и каждая выборка связана с одним и тем же ограничением размера файла. После первых 15 МБ файла робот Googlebot останавливает сканирование и рассматривает для индексации только первые 15 МБ файла. Ограничение размера файла применяется к несжатым данным. Другие поисковые роботы Google, например Googlebot Video и Изображение Googlebot может иметь другие ограничения.
Блокировка доступа робота Googlebot к вашему сайту
Почти невозможно сохранить веб-сервер в секрете, не публикуя ссылки на него. Для
например, как только кто-то перейдет по ссылке с вашего «секретного» сервера на другой веб-сервер,
ваш «секретный» URL-адрес может отображаться в теге реферера и может храниться и публиковаться другим
веб-сервер в своем журнале рефереров. Точно так же в Интернете есть много устаревших и неработающих ссылок.
Всякий раз, когда кто-то публикует неверную ссылку на ваш сайт или не обновляет ссылки, чтобы отразить
изменений на вашем сервере, робот Googlebot попытается просканировать неправильную ссылку с вашего сайта.
Для
например, как только кто-то перейдет по ссылке с вашего «секретного» сервера на другой веб-сервер,
ваш «секретный» URL-адрес может отображаться в теге реферера и может храниться и публиковаться другим
веб-сервер в своем журнале рефереров. Точно так же в Интернете есть много устаревших и неработающих ссылок.
Всякий раз, когда кто-то публикует неверную ссылку на ваш сайт или не обновляет ссылки, чтобы отразить
изменений на вашем сервере, робот Googlebot попытается просканировать неправильную ссылку с вашего сайта.
Если вы хотите, чтобы робот Googlebot не сканировал содержание вашего сайта, у вас есть количество опций. Быть понимают разницу между предотвращением сканирования страницы роботом Googlebot и предотвращением Googlebot не может индексировать страницу и вообще запрещает доступ к странице обоими пользователями. поисковые роботы или пользователи.
Проверка робота Googlebot
Прежде чем вы решите заблокировать робота Googlebot, имейте в виду, что строка пользовательского агента, используемая роботом Googlebot,
часто подделывается другими поисковыми роботами.