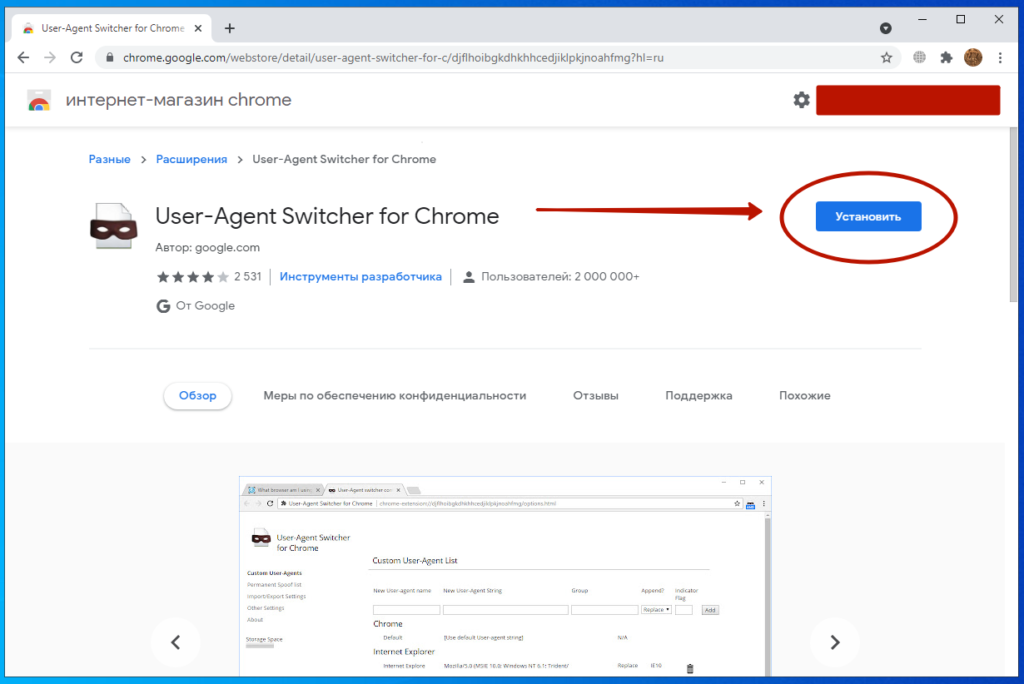
С чем едят UserAgent / Хабр
Для начала, конечно, стоило рассказать зачем едят этот самый «пользовательский агент». Ну или, вообще, начать с того что же это за агент такой. (Кстати, никто не знает какой-нибудь славянско-православный перевод этого термина?)Но рассчитывая, что хабра юзер либо уже знает и использует useragent либо ему это не нужно, я бы не хотел останавливаться на предисловиях. И так, мой совет — употребляйте useragent с регулярными выражениями!
Конечно, тебе свойственно регулярно употреблять выражения, %username%, но они другие и для души, а я о regex. Одной из основных задач в моей работе, является правильное определение возможностей устройства и браузера конечного пользователя. Так как основной упор мы делаем на мобильные устройства (сотовые телефоны), то их я и возьму в пример. В отличие от пользователей обычных компьютеров, пользователи мобильных устройств жёстко и жестоко ограничены в разрешении экрана, возможностях браузера и т.д. У нас имеется небольшая база данных собранная и автоматически обновляемая с помощью UAProf и Wurfl. Но заголовки агентов (useragent header) постоянно изменяются и количество различий постоянно растёт. О том чтобы делать поиск очередного устройства проверкой агента один к одному не может идти и речи, но как то же надо искать. Поэтому мы стали разбираться с устройством useragent и что из него можно выжать.
Но заголовки агентов (useragent header) постоянно изменяются и количество различий постоянно растёт. О том чтобы делать поиск очередного устройства проверкой агента один к одному не может идти и речи, но как то же надо искать. Поэтому мы стали разбираться с устройством useragent и что из него можно выжать.
Ингредиенты
Стандарты и формат — как обычно никто их не соблюдает. Формат useragent изменяется от производителя к производителю и от серии к серии. К тому же большинство сотовых операторов любят переписывать заголовки.
Основные блоки должны быть такие:
устройство/версия браузер/версия (поддерживаемые стандарты и технологии).
Первый же пример sonyericssonk530i/r6bc browser/netfront/3.3 profile/midp-2.0 configuration/cldc-1.1 как бы говорит нам, что скобки ожидать не приходится, а второй пример mozilla/5.0 (symbianos/9.4; u; series60/5.0 nokia5800d-1/21.0.025; profile/midp-2.1 configuration/cldc-1. 1 ) applewebkit/413 (khtml, like gecko) safari/413 мягко намекает, что и порядок никто соблюдать не будет. Но всё же мне важно знать, что разные агенты появляются у одного и того же устройства, например nokia n95:
1 ) applewebkit/413 (khtml, like gecko) safari/413 мягко намекает, что и порядок никто соблюдать не будет. Но всё же мне важно знать, что разные агенты появляются у одного и того же устройства, например nokia n95:
- mozilla/5.0 (symbianos/9.2; u; series60/3.1 nokian95/12.0.013; profile/midp-2.0 configuration/cldc-1.1 ) applewebkit/413 (khtml, like gecko) safari/413
- mozilla/5.0 (symbianos/9.2; u; series60/3.1 nokian95/31.0.017; profile/midp-2.0 configuration/cldc-1.1 ) applewebkit/413 (khtml, like gecko) safari/413 [en-us]
- mozilla/5.0 (symbianos/9.2; u; series60/3.1 nokian95/30.0.015; profile/midp-2.0 configuration/cldc-1.1 )
- mozilla/5.0 (symbianos/9.2; u; series60/3.1 nokian95_8gb/30.0.018; profile/midp-2.0 configuration/cldc-1.1 ) applewebkit/413
- mozilla/5.0 series60; nokian95;
Рецепт
Однако, как можно заметить кое какая логика есть. После слеша (/) идёт версия — динамическая часть, которая особой роли не играет. Обязательно присутствует указание на браузер. Разделение токенов с помощью пробела и/или точки с запятой. Покрутив логи мы обнаружили много мусора в заголовках агента, поэтому первым шагом стала стандартизация и выделение сегментов. Получились вот такие полезности:
Обязательно присутствует указание на браузер. Разделение токенов с помощью пробела и/или точки с запятой. Покрутив логи мы обнаружили много мусора в заголовках агента, поэтому первым шагом стала стандартизация и выделение сегментов. Получились вот такие полезности:
- Выбираем то, что действительно useragent:
([[(]?[a-z0-9._+;]\s?[/\-;:\\,*\s]*[)\]]?\s?)* - Определяем токен браузера:
((iemobile|kbrowser)\s[0-9.]+)|((up(\.link)?|netfront|obigo|opera\s?(mini|mobile)?|deckit|safari|(apple)?webkit|mozilla|openwave)/[0-9\.a-z\-]+\+?)|(browser/[a-z\-0-9]+/?[0-9\.a-z\-]+)|([a-z\.-]+browser[a-z\.-]*(/[0-9\.a-z\-]+)?) - Определяем профиль и конфигурацию:
(((profile|configuration|java(platform)?)/[a-z]+-?)|((cldc|midp|wap)[\s\-]?))[0-9\.-a-z]+ - Язык:
((?<=[\s;\[\(])[a-z]{2}[\s-][a-z]{2}(?=[\s;\]\)]))|\[([a-z]{2,3}[\-_\s]?)+\] - Версия:
[\s;/]+(v(er)?[\s.]*)?[0-9]+\.[0-9\.]+([a-z]{1,2}[0-9\.
- Иногда указывают размеры экрана в пикселях:
[0-9]{3}x[0-9]{3}
Естественно, что сто процентного результата не получилось, но прогонка по 30 000 useragent-ов показала, что правильные сегменты высветились в 97%. Так что результат вполне достойный. Но нам этого не хватило. Некоторые вещи надо проверять по базе данных и там всё тот же разброс и разнообразие моделей и агентов. Возникла простая и интуитивно понятная идея — поиск по модели. То есть несмотря на то, что существует более десятка разных useragent-ов для той же 95-ой Нокии, в каждом варианте присутствует nokian95. Задача была бы тривиальной, если бы нужно было определить/искать только одну и ту же модель (допустим узнать iPhone или нет). Но тогда вполне хватило бы if-else. В жизни всё сложней и никакого универсального стандарта для определения модели просто нет.
Десерт
Мы пошли от обратного — подчистим useragent от тех токенов, определять которые мы научились.
Используя те же выражения (с лёгкими изменениями) я стираю из useragent блоки один за другим (псевдокод while useragent ismatch replace match with string.empty). Получается остаток из неизвестных мне заранее кусков, часть которых является мусором, а какой то один — моделью. Простейшим решением стало разбиение остатка на отдельные токены — Split(' ', '/', ';') и поиск токена с производителем. Ищем в какая часть содержит одну из следующих строк:
"nokia", "motorola", "mot-", "moto-", "motorazr", "sonyericsson", "samsung", "sec-", "sgh-", "lg-", "lge", "lg", "sie-", "siemens","ipod", "iphone" ,"ipaq", "spv", "i-mate", "mobilephone", "htc", "vodafone", "palm", "rover", "gigabyte", "asus", "alcatel", "mitsu", "verizon", "apple".
Теперь из приведённых выше разных длинных useragent-ов n95 у меня остаются только nokian95 и nokian95_8gb соответственно. Вот ещё несколько примеров полных useragent-ов и результатов очистки:
- samsung-sgh-f480/f480jihh3 shp/vpp/r5 netfront/3. 4 qtv5.3 smm-mms/1.2.0 profile/midp-2.0 configuration/cldc-1.1
=samsung-sgh-f480 - sonyericssonw705/r1ea browser/netfront/3.4 profile/midp-2.1 configuration/cldc-1.1 javaplatform/jp-8.4.2
=sonyericssonw705 - lg-kc910q browser/teleca-q7.1 mms/lg-mms-v1.0/1.2 mediaplayer/lgplayer/1.0 java/asvm/1.1 profile/midp-2.1 configuration/cldc-1.1
=lg-kc910q - mozilla/5.0 (symbianos/9.3; u; series60/3.2 nokia6210navigator/03.25; profile/midp-2.1 configuration/cldc-1.1 ) applewebkit/413 (khtml, like gecko) safari/413
=nokia6210navigator - sgh-z370/1.0 netfront/3.3 profile/midp-2.0 configuration/cldc-1.1
=sgh-z370 - vodafone/1.0/sex1i/r2aa mozilla/4.0 (compatible; msie 6.0; windows ce; iemobile 7.11) up.link/6.3.1.20.0 profile/midp-2.0 configuration/cldc-1.1
=vodafone sex1i
 4 qtv5.3 smm-mms/1.2.0 profile/midp-2.0 configuration/cldc-1.1
4 qtv5.3 smm-mms/1.2.0 profile/midp-2.0 configuration/cldc-1.1На посошок
Помимо браузера вас может интересовать токен WAP (кратко WAP 1. 0 = WML, WAP 2.0 = XHTML). Версия mmp (multimedia mobile processor) должна указывать на поддержку аудио/видео кодеков — 1.0 только аудио mp3, а 2.0 поддерживает и видео 3gp. В большей части useragent-ов указанна операционная система и версия — актуально для iPhone:
0 = WML, WAP 2.0 = XHTML). Версия mmp (multimedia mobile processor) должна указывать на поддержку аудио/видео кодеков — 1.0 только аудио mp3, а 2.0 поддерживает и видео 3gp. В большей части useragent-ов указанна операционная система и версия — актуально для iPhone:
Приятного аппетита
Проверка на базе данных и подгонка (finetunning) привели к 99% результату. Это конечно явный overfitting, но это была одной из целей (максимальная точность в определённой аудитории и регионе). Кстати, вышеприведённые regex-ы более абстрактны и должны дать большую погрешность в силу своей универсальности.
Агент пользователя. Что это такое?
Часто незнакомые термины могут ввести в заблуждение обычных посетителей Интернета. Например, что подразумевает термин «агент пользователя» (user agent)? Может быть, эти слова обозначают человека, который представляет права пользователя в Интернете или отслеживает его поведение во время посещения веб-сайтов? Однако это не так. User agent – это программный элемент, который действует в сети от имени пользователя.
User agent – это программный элемент, который действует в сети от имени пользователя.
У каждого, кто просматривает Интернет, есть свой агент пользователя. User agent (UA) – это буквенно-цифровая строка, идентифицирующая программу, которая отправляет запрос на сервер и одновременно запрашивает доступ к web-сайту. Это стандартная часть веб-архитектуры, которая передается всеми веб-запросами в заголовках HTTP.
Строка содержит конкретные данные о программном и аппаратном обеспечении устройства, которое делает запрос. Эта информация обычно включает сведения о браузере, механизме веб-рендеринга, операционной системе и используемом устройстве.
Принципы работы
Чтобы лучше понять принципы работы user agent, нужно обратить внимание на эволюцию Интернета. В первые годы его существования во Всемирной паутине доминировали несколько браузеров начального поколения. В результате многие web-серверы были разработаны для взаимодействия и подключения только с ними. Это стало возможным, поскольку веб-сайты могли идентифицировать веб-браузер как пользовательский агент по текстовой строке, когда он запрашивал доступ к сайту.
Это стало возможным, поскольку веб-сайты могли идентифицировать веб-браузер как пользовательский агент по текстовой строке, когда он запрашивал доступ к сайту.
В то время посетители должны были вручную вводить команды для навигации и отправки сообщений. Современные браузеры делают эту работу сами – выполняют обязанности «агента пользователя», превращая его действия в команды.
Типы user agent
Браузеры являются простым примером user agent, однако есть и другие инструменты, выступающие в этой роли. Важно отметить, что не все пользовательские агенты контролируются людьми. Например, сканеры (роботы) поисковых систем автоматизированы и работают без вмешательства человека.
Каждый тип устройства, включая телефоны, планшеты, настольные компьютеры, может иметь свой собственный UA, что позволяет обнаруживать это устройство для любых целей. Вот список примеров пользовательских агентов для различных типов устройств, которые могут быть обнаружены:
- Браузеры (Chrome, Firefox, Internet Explorer, Safari, Edge, BlackBerry, Opera).
- Поисковые системы (Google, GoogleImages, Yahoo).
- Игровые консоли (PlayStation 3, PlayStation Portable, Wii, Nintendo Wii U).
- Офлайн-браузеры (Wget, Offline Explorer).
- Проверка ссылок (LinkChecker, W3C-checklink).
- Электронные ридеры (Amazon Kindle), валидаторы, облачные платформы, библиотеки электронной почты, скрипты.

Расшифровка строки агента пользователя HTTP
После идентификации агента пользователя на web-сервере начинается процесс согласования содержимого. Это позволяет сайтам обслуживать различные версии самих себя, основываясь на строке пользовательского агента. User agent передает свою идентификационную карту на сервер, а затем сервер согласовывает комбинацию подходящих файлов, сценариев и носителей.
Получить информацию о своем user agent можно по ссылке http://whatsmyuseragent.org/. Полученная строка UA, например, может быть такой:
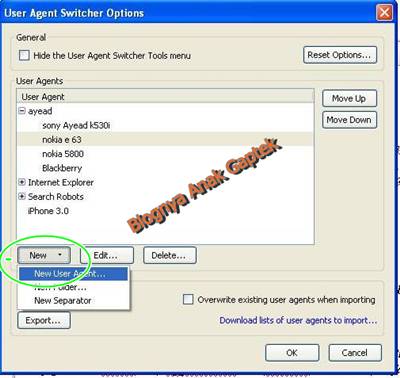 0
0В строке содержится информация:
- Приложение UA – Mozilla версии 5.0
- ОС Windows 7.
- 64-разрядная Windows (WOW64).
- Движок вывода web-страниц Gecko / 20100101.
- Релиз web-браузера Firefox 64.
Прочитать строку user agent может оказаться сложным из-за отсутствия стандартного формата. Однако Интернет содержит разнообразные руководства и аналитические инструменты, которые помогут справиться с этой задачей.
Использование строки user agent
Web-серверы используют пользовательские агенты, преследуя различные цели:
- Обслуживание разных веб-страниц в разных браузерах.
- Отображение разного контента для разных операционных систем.
- Сбор статистики, отражающей используемые посетителями браузеры и операционные системы.
Боты для веб-сканирования также используют пользовательские агенты. Например, web-сканер Google идентифицирует себя в виде строки «Googlebot / 2. 1 (+ http: //www.google.com/bot.html)».
1 (+ http: //www.google.com/bot.html)».
Заключение
User agent является центральной частью web-архитектуры и играет важную роль в согласовании контента. Когда посетитель заходит в Интернет, браузер отправляет свой user agent на каждый веб-сайт, к которому он подключается. Агенты пользователей уникальны для каждого посетителя интернета. Они показывают конкретную технологию, используемую для доступа к сайту, странице или другому контенту.
Google Crawler (агент пользователя) Обзор | Центр поиска Google | Документация
«Краулер» (иногда также называемый «роботом» или «пауком») — это общий термин для любой программы, которая
используется для автоматического обнаружения и сканирования веб-сайтов путем перехода по ссылкам с одной веб-страницы на
другой. Главный поисковый робот Google называется
Googlebot. В этой таблице указана информация
о распространенных поисковых роботах Google, которые вы можете увидеть в журналах рефереров, и о том, как указать их в
robots. txt,
роботы
txt,
роботы метатегов и X-Robots-Tag Правила HTTP.
В следующей таблице показаны поисковые роботы, используемые различными продуктами и службами Google:
- Токен пользовательского агента используется в строке
User-agent:файла robots.txt. чтобы соответствовать типу сканера при написании правил сканирования для вашего сайта. Некоторые сканеры имеют более один токен, как показано в таблице; вам нужно сопоставить только один токен сканера, чтобы правило применять. Этот список не является полным, но охватывает большинство поисковых роботов, которые вы можете увидеть на своем компьютере. Веб-сайт. - Полная строка пользовательского агента представляет собой полное описание сканера и появляется в
HTTP-запрос и ваши веб-журналы. Внимание : Строка пользовательского агента может быть подделана. Узнайте, как проверить, является ли посетитель поисковым роботом Google.
 Узнайте, как проверить, является ли посетитель поисковым роботом Google.
Узнайте, как проверить, является ли посетитель поисковым роботом Google.Краулеры | |||||
|---|---|---|---|---|---|
API-интерфейсы Google |
| ||||
AdsBot Mobile Web Android | AdsBot Mobile Web Android игнорирует подстановочный знак * . Проверяет качество рекламы на веб-странице Android.
| ||||
AdsBot Мобильный Интернет | AdsBot Mobile Web игнорирует подстановочный знак * .Проверяет качество рекламы на веб-странице iPhone.
| ||||
AdsBot | AdsBot игнорирует подстановочный знак * .Проверяет качество рекламы на настольной веб-странице.
| ||||
Адсенс |
| ||||
Изображение Googlebot |
| ||||
Новости Googlebot |
| ||||
Робот Googlebot Видео |
| ||||
Googlebot Рабочий стол |
| ||||
Googlebot Смартфон |
| ||||
Мобильный AdSense |
| ||||
Мобильные приложения Android | Мобильные приложения Android игнорирует подстановочный знак * . Проверяет рекламу на странице Android-приложения
качество. Соответствует
| ||||
Feedfetcher | Осторожно : Feedfetcher
не соблюдает правила robots. txt. txt.
| ||||
Гугл читать вслух | Осторожно : Google
Функция «Чтение вслух» не соблюдает правила robots.txt.
| ||||
Фавикон Google | Предупреждение . Для запросов, инициированных пользователями, значок Google Favicon игнорирует
правила robots.txt. Для запросов, инициированных пользователями, значок Google Favicon игнорирует
правила robots.txt.
| ||||
Google StoreBot |
| ||||
Средство проверки сайта Google | Внимание! . Google Site Verifier игнорирует правила robots.txt.
| ||||
 0 (iPhone; процессор iPhone OS 14_7_1, например, Mac OS X) AppleWebKit/605.1.15 (KHTML, например, Gecko) Version/14.1.2 Mobile/15E148 Safari/604.1 (совместимый; AdsBot-Google-Mobile; +http ://www.google.com/mobile/adsbot.html)
0 (iPhone; процессор iPhone OS 14_7_1, например, Mac OS X) AppleWebKit/605.1.15 (KHTML, например, Gecko) Version/14.1.2 Mobile/15E148 Safari/604.1 (совместимый; AdsBot-Google-Mobile; +http ://www.google.com/mobile/adsbot.html)  0
0  0
0  1 (+http://www.google.com/bot.html)
1 (+http://www.google.com/bot.html) 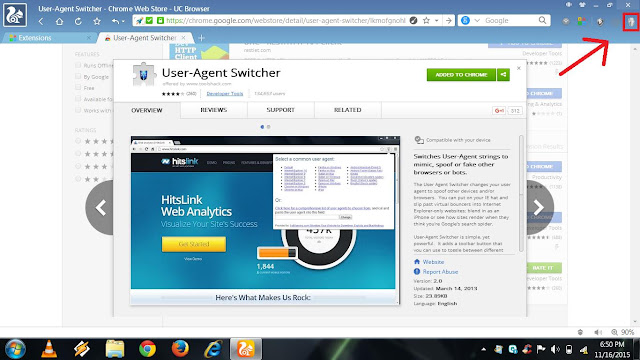 1; +http://www.google.com/bot.html)
1; +http://www.google.com/bot.html)  0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/41.0.2272.118 Safari/537.36 (совместимый; Google-Read-Aloud; +https://developers.google.com) /search/docs/crawling-indexing/overview-google-crawlers)
0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/41.0.2272.118 Safari/537.36 (совместимый; Google-Read-Aloud; +https://developers.google.com) /search/docs/crawling-indexing/overview-google-crawlers)  0 (X11; Linux x86_64; Storebot-Google/1.0) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/79.0.3945.88 Safari/537.36
0 (X11; Linux x86_64; Storebot-Google/1.0) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/79.0.3945.88 Safari/537.36 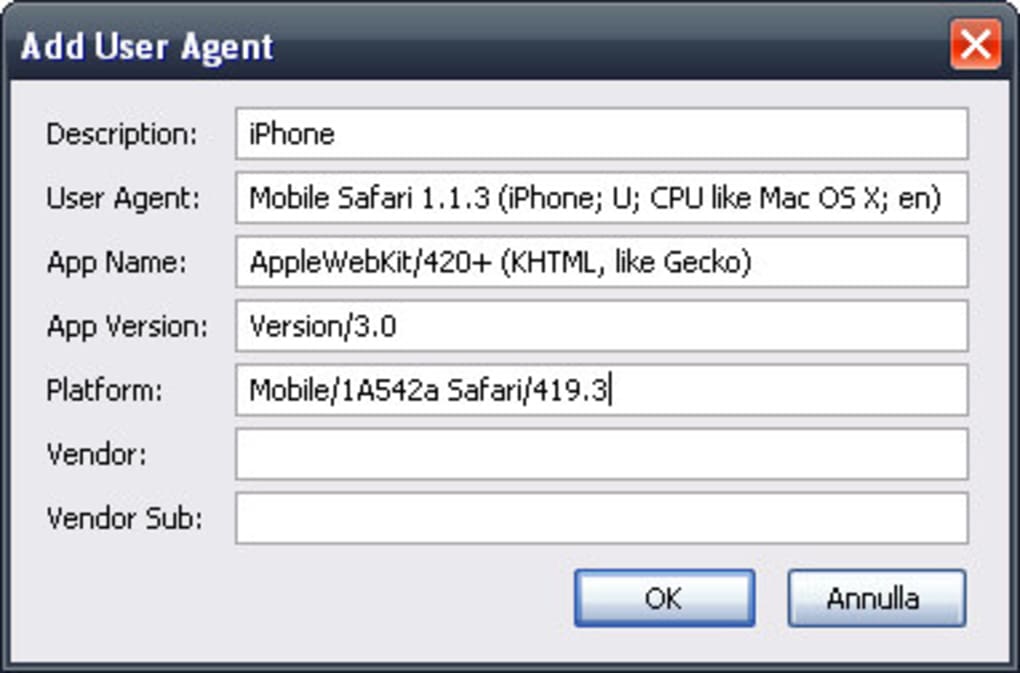 0 (совместимо; Google-Site-Verification/1.0)
0 (совместимо; Google-Site-Verification/1.0) Примечание о Chrome/
W.X.Y.Z в пользовательских агентах Везде, где вы видите строку Chrome/ W.X.Y.Z в пользовательском агенте
строк в таблице, W.X.Y.Z на самом деле является заполнителем, представляющим версию
браузера Chrome, используемого этим пользовательским агентом: например, 41.0.2272.96 . Эта версия
число будет увеличиваться со временем до
соответствовать последней версии Chromium, используемой роботом Googlebot.
Если вы просматриваете свои журналы или фильтруете свой сервер для пользовательского агента с этим шаблоном,
использовать подстановочные знаки для номера версии, а не указывать точное
номер версии.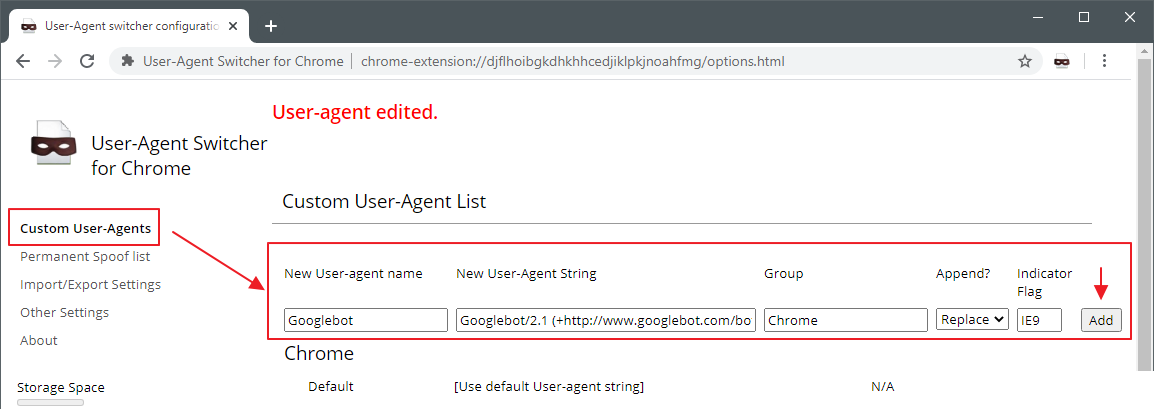
Пользовательские агенты в robots.txt
Если в файле robots.txt распознано несколько пользовательских агентов, Google будет следовать наиболее
специфический. Если вы хотите, чтобы весь Google мог сканировать ваши страницы, вам не нужен
файл robots.txt вообще. Если вы хотите заблокировать или разрешить всем поисковым роботам Google доступ
часть вашего контента, вы можете сделать это, указав Googlebot в качестве пользовательского агента. Например,
если вы хотите, чтобы все ваши страницы отображались в поиске Google, и если вы хотите, чтобы реклама AdSense появлялась
на ваших страницах вам не нужен файл robots.txt. Точно так же, если вы хотите заблокировать некоторые страницы
от Google вообще, блокируя Пользовательский агент Googlebot также заблокирует все
Другие пользовательские агенты Google.
Но если вам нужен более детальный контроль, вы можете сделать его более конкретным. Например, вы можете
хотите, чтобы все ваши страницы отображались в поиске Google, но вы не хотите, чтобы изображения отображались в личном
каталог для обхода. В этом случае используйте robots.txt, чтобы запретить
Например, вы можете
хотите, чтобы все ваши страницы отображались в поиске Google, но вы не хотите, чтобы изображения отображались в личном
каталог для обхода. В этом случае используйте robots.txt, чтобы запретить Пользовательский агент Googlebot-Image от сканирования файлов в вашем личном каталоге
(при этом позволяя роботу Googlebot сканировать все файлы), например:
Агент пользователя: Googlebot Запретить: Агент пользователя: Googlebot-Image Запретить: /personal
Возьмем другой пример. Допустим, вы хотите размещать рекламу на всех своих страницах, но не хотите,
страницы для отображения в поиске Google. Здесь вы заблокируете робота Googlebot, но разрешите
Пользовательский агент Mediapartners-Google , например:
Агент пользователя: Googlebot Запретить: / Агент пользователя: Mediapartners-Google Запретить:
Пользовательские агенты в роботах
метатеги Некоторые страницы используют несколько тегов robots meta для указания правил. для разных сканеров, например:
для разных сканеров, например:
В этом случае Google будет использовать сумму отрицательных правил, а робот Google будет следовать
правила noindex и nofollow .
Более подробная информация об управлении тем, как Google сканирует и индексирует ваш сайт.
Контроль скорости сканирования
Каждый поисковый робот Google обращается к сайтам с определенной целью и с разной скоростью. Google использует алгоритмы для определения оптимальной скорости сканирования для каждого сайта. Если поисковый робот Google сканирует ваш сайт слишком часто, вы можете уменьшить скорость сканирования.
Устаревшие поисковые роботы Google
Следующие поисковые роботы Google больше не используются и упоминаются здесь только для исторической справки.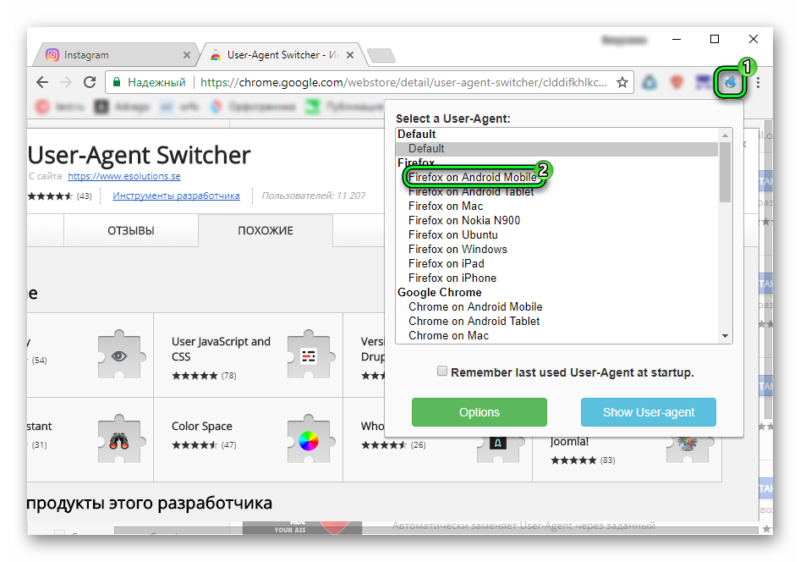
| Устаревшие поисковые роботы Google | |||||
|---|---|---|---|---|---|
Дуплекс в Интернете | Поддерживается Duplex на веб-сервисе.
* . | ||||
Веб-светильник | Проверяется наличие заголовка
| ||||
 Пользовательский агент Web Light использовался только
для явных запросов на просмотр от посетителя-человека, поэтому он игнорировал правила robots.txt,
которые используются для блокировки запросов автоматического сканирования.
Пользовательский агент Web Light использовался только
для явных запросов на просмотр от посетителя-человека, поэтому он игнорировал правила robots.txt,
которые используются для блокировки запросов автоматического сканирования.Как собираются данные пользовательского агента?
Как собираются данные пользовательского агента?Техническая библиотека | Поддержка
Как собираются данные пользовательского агента?
Справка по веб-безопасности | Решения для веб-безопасности | Версия 7.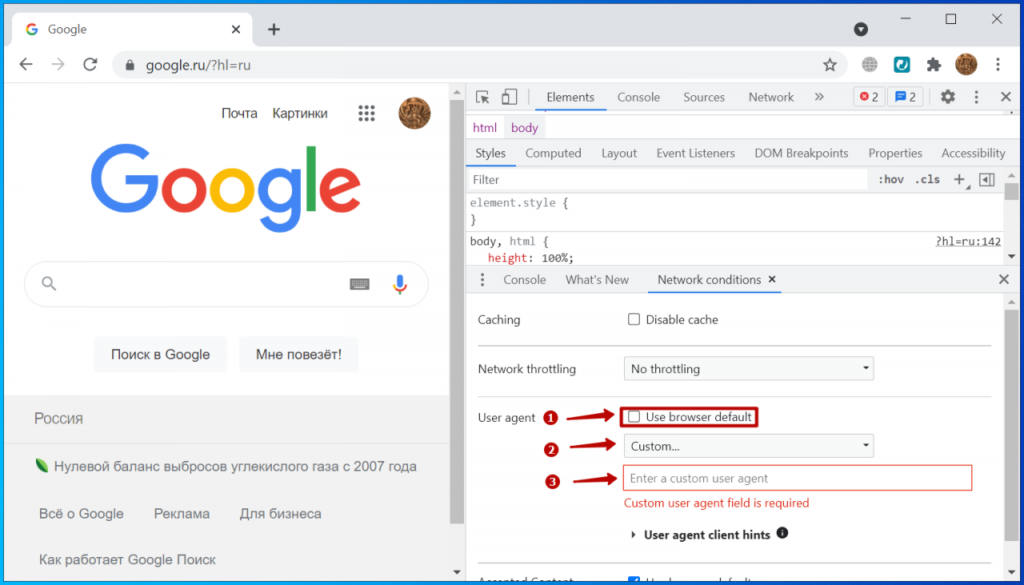 8.x
8.x
Похожие темы:
|
Пользовательский агент — это HTTP-заголовок, который веб-браузеры и другие веб-приложения используют для идентификации себя и своих возможностей. Ваше программное обеспечение для веб-безопасности собирает и регистрирует данные пользовательского агента, когда пользователи просматривают Интернет. Если данные пользовательского агента включают информацию о браузере и платформе, эта информация анализируется и отображается в отчетах приложений.
Ваше программное обеспечение для веб-безопасности собирает и регистрирует данные пользовательского агента, когда пользователи просматривают Интернет. Если данные пользовательского агента включают информацию о браузере и платформе, эта информация анализируется и отображается в отчетах приложений.
Если браузер или платформа установлены в вашей сети, но не используются для доступа в Интернет, они не отображаются в отчетах приложений. |
Поскольку общепринятых стандартов для заголовков пользовательских агентов не существует, ваше программное обеспечение веб-безопасности не может идентифицировать все приложения, имеющие доступ к Интернету. |

Некоторые приложения намеренно маскируют свои идентификационные данные в заголовке пользовательского агента, пытаясь избежать обнаружения.
Данные просмотра приложений, которые получает Websense Log Server, включают заголовок пользовательского агента, имя пользователя и исходный IP-адрес. Все запросы с одним и тем же агентом пользователя, пользователем и исходным IP-адресом в течение 60-секундного периода объединяются в одну запись, которая содержит общее количество запросов и объем полосы пропускания, связанный с этими запросами. Затем эта запись пересылается в базу данных журналов. Скорость обновления отчетов браузера и платформы данными о текущей интернет-активности зависит от того, был ли ранее замечен и проанализирован пользовательский агент:
Если пользовательский агент соответствует браузеру, версии браузера или платформе, которые ранее не анализировались и не идентифицировались, информация о запросах от этого браузера и платформы не появляется в отчетах приложений до тех пор, пока не будет выполнено ночное задание тренда (см. |