
Как удалить URL адреса из поисковой выдачи Google и Яндекс
Переходим сразу от слов к делу. Для того, чтобы удалить URL адреса из поисковой выдачи в Google необходимо обратиться к сервису вебмастер и выяснить в каких случаях нужно пользоваться сервисом — удалить URL адреса, а в каких не следует:
Прежде всего хочу предупредить о том, что если у Вас присутствуют древовидные комментарии, необходимо обратить внимание на удаление внутренних ссылок. Прежде, чем удалять параметры URL и полностью запрещать поисковому роботу обращаться к внутренним ссылкам страниц содержащих: /?replytocom=, следует обязательно удалить из поисковой выдачи — эти страницы содержащие /?replytocom= .
Для удаления URL адреса из поисковой выдачи Google необходимо перейти по адресу https://www.google.com/webmasters/tools/, выбрать значение — оптимизация -> удалить URL адреса:

Далее создаете запрос на удаление, вводите URL (например: http://abisab.com/?replytocom=53) и нажимаете кнопку продолжить, тем самым создав запрос на удаление URL адреса. Через некоторое время URL будет удален.
Если же Вы сначала удалите Параметры URL, то при обращении в сервис удалить URL адреса из поисковой выдачи Google, будет появляться следующее окно, тем самым говоря, что Вы уже внесли replytocom в Параметры URL. Нажимаем — отправить запрос и удаляем необходимый URL страницы:
После удаления URL адреса, можно посмотреть список удаленных страниц:

Там, где стрелка указывает на кнопку «ожидание», при нажатии на нее — появится список вариантов, в котором есть «удаленные» — проверить удалился ли адрес, можете вставив данный URL в строчку браузера.
Когда НЕ следует использовать инструмент удаления URL
Инструмент удаления URL предназначен для срочного удаления страниц, например в тех случаях, если на них случайно оказались конфиденциальные данные. Использование этого инструмента не по назначению может привести к негативным последствиям для вашего сайта.
Не используйте инструмент удаления URL в следующих случаях:
- Для удаления «мусора», например старых страниц, отображающих ошибку 404. Если вы изменили структуру своего сайта и некоторые URL в индексе Google устарели, поисковые роботы обнаружат это и повторно просканируют их, а старые страницы постепенно будут исключены из результатов поиска. Вам не нужно запрашивать срочное удаление.
- Для удаления ошибок сканирования из аккаунта Инструментов для веб-мастеров.
Инструмент удаления URL исключает URL из результатов поиска Google, а не из вашего аккаунта Инструментов для веб-мастеров. Вам не нужно вручную удалять URL из этого отчета. Со временем они будут исключены автоматически.
- Для создания сайта «с чистого листа». Если вы обеспокоены тем, что к вашему сайту могут быть применены штрафные санкции, или хотите начать все сначала после покупки домена у прежнего владельца, рекомендуем подать запрос на повторную проверку, в котором нужно описать, какие изменения вы внесли и в чем состоит причина вашего беспокойства.
- Для перевода сайта в автономный режим после взлома. Если ваш сайт был взломан и вы хотите удалить из индекса страницы с вредоносным кодом, используйте инструмент удаления URL для удаления новых URL, созданных злоумышленником, например http://www.example.com/buy-cheap-cialis-skq3w598.html. Однако мы не рекомендуем удалять все страницы сайта или те URL, которые нужно будет проиндексировать в будущем. Вместо этого удалите вредоносный код, чтобы роботы Google могли повторно просканировать ваш сайт. Подробнее о работе со взломанными сайтами…
- Для индексации правильной версии своего сайта. На многих сайтах одно и то же содержание можно найти по разным URL. Если вы не хотите, чтобы дублирующееся содержание отображалось в результатах поиска, ознакомьтесь с рекомендуемыми методами назначения канонических версий страниц. Не используйте инструмент удаления URL для удаления нежелательных версий URL. Это вам не поможет сохранить предпочтительную версию страницы. Ведь при удалении одной из версий URL (http/https, с префиксом www или без него) будут удалены и все остальные.
Для удаления URL адреса из Яндекса, набираем в поисковой строке http://webmaster.yandex.ua/delurl.xml

Надеюсь, данная статья помогла Вам лучше понять тему удаления URL адреса.
abisab.com
Как удалить страницу из поиска — Онлайн-курсы Яндекса
1. Немного теории
Многих владельцев сайтов интересует, как удалить веб-страницу из поиска. Причины для этого бывают разные. Например, нужно убрать из поиска страницу, которой уже нет на самом сайте. Или в поиск попала конфиденциальная информация, которую владелец сайта забыл закрыть с помощью файла robots.txt. Давайте разберемся, как поступить в том и в другом случае.
Убрать страницу из поиска, не удаляя её с сайта, можно несколькими способами.
Например, указать в файле robots.txt, что страница запрещена к индексированию. Другой способ — закрыть контент страницы с помощью мета-тега noindex. При очередном обходе робот обнаружит, что страницу нельзя индексировать, и уберёт её из поисковой базы. О том, как правильно сделать запись в robots.txt, рассказано в уроке «Как управлять индексированием сайта».
Часто бывает так, что страница удалена с сайта, но по-прежнему доступна в поиске. Это значит, что поисковый робот ещё не добрался до страницы и не знает, что она удалена. Вы можете попросить робота зайти на эту страницу — с помощью инструмента «Удалить URL» на сервисе Яндекс.Вебмастер. Этот инструмент можно использовать и в том случае, если вы закрыли страницу для поисковой системы тегами или в файле robots.txt.
Инструмент «Удалить URL» позволяет сообщить роботу, что страница изменилась и её нужно переобойти как можно скорее. Например, вы можете сообщить роботу, что страница была удалена или запрещена к индексированию.
Сделать это очень просто. Достаточно указать адрес страницы и нажать на кнопку «Удалить». Страница исчезнет из поиска, когда поисковый робот убедится в том, что страница удалена (то есть возвращает код 404) или запрещена к индексированию.
Совет
Если на сайте удалено сразу много страниц, то робот будет обнаруживать их постепенно — по мере обхода. Чтобы эти страницы быстрее исчезли из поиска, можно закрыть их для индексации в файле robots.txt.
yandex.ru
4 способа удалить страницу из поискового индекса Яндекс и Google

Практически каждый вебмастер, особенно на начальном этапе создания проекта, сталкивался с необходимостью удаления страниц веб-сайта из индекса поисковиков. Даже не взирая на то, что процедура, на первый взгляд, довольно простая, у многих все же возникают трудности.
Зачем нужно убирать страницы из индекса?
Порой владельцу веб-ресурса приходиться скрывать документ от поисковиков по следующим причинам:
- сайт находится в стадии разработки и попал в выдачу совершенно случайно;
- контент на странице больше неактуален;
- документ дублирует другую страницу, которая уже есть на сайте;
- в индекс попали служебные страницы, где размещены личные данные клиентов.
Во избежание таких случаев, сегодня мы поговорим о 4 эффективных способах удаления страницы из индекса поисковых систем.
Как закрыть страницу от поисковиков с помощью панели вебмастера?
Данный метод закрытия доступа к страницам вашего сайта для поисковых роботов считается одним из самых легких. Причем этот инструмент идеально подходит для тех случаев, когда определенные URL нужно удалить срочно.
Yandex
Для этого вам понадобится сервис Яндекс.Вебмастер. Как добавлять сайт на эту площадку для ускорения индексации, мы рассказывали здесь. Перейдите по ссылке https://webmaster.yandex.ru/tools/del-url/ и добавьте в соответствующее поле адрес конкретной страницы, затем нажмите «Удалить».

С большой долей вероятности Yandex попросит вас ускорить процесс удаления страницы из базы данных системы. Для этого вам нужно предварительно закрыть ее от ботов через файл либо мета-тег robots, или сделать так, чтобы сервер выдавал ошибку 404. Про то, как это сделать, мы поговорим чуть позже.

Понадобится несколько часов или даже дней, прежде чем боты удалят документ из базы. Это связано с тем, что системе нужно будет отслеживать его статус и убедиться, что он уже не изменится.
Авторизируйтесь на площадке Google Webmaster Tools. Предварительно добавьте свой сайт в индекс, если вы еще этого не сделали. Затем найдите там вкладку «Индекс Google», и под ним «Удалить URL адреса». В появившемся окне выберите опцию создания запроса на удаление, и укажите в поле адрес удаляемого документа. Затем отправьте запрос.

Дальше сверху экрана появится сообщение о том, что указанный URL был добавлен в список удаляемых. Вам остается только ждать. Как правило, документ из индекса Google удаляется в течение 2-24 часов.
Ошибка 404 на сервере
Наверняка каждый пользователь, ища нужную информацию в Интернете, попадал на страницу, где выдавало ошибку 404 – «Страница не найдена». Это значит, что искомый по вашему запросу документ был удален с ресурса.
Сделать это вебмастер может в панели управления сайтом, например, WordPress. Для поисковиков это означает, что вы настраиваете ответ сервер этой страницы так, чтобы на определенном адресе появился код
К характерным особенностям данного способа можно отнести:
- Простую настройку всего за несколько кликов.
- Полное исчезновение документа из веб-ресурса. Из-за этого не рекомендуется использовать данный метод в случае, когда из индекса нужно убрать служебную страницу (конфиденциальную информацию клиентов и пр.).
- Также стоит прибегнуть к другому варианту скрытия страницы, например, 301 редирект, если на нее ведут входящие ссылки.
Важно! Страница выпадает из поискового индекса не за счет ее удаления с ресурса, а за счет дальнейшей переиндексации. Поэтому для ее удаления вам придется ждать около 2ух недель, пока бот вновь не посетит ресурс.
Для вебмастеров такой метод является одним из самых удобных, а вот посетителю ошибка 404 может не понравиться, и есть риск того, что пользователь, увидев ее, перестанет заходить на сайт. Но выход есть и из этой ситуации.
На заметку. Очень часто сайтостроители занимаются интересным оформлением страницы, на которой вылетает ошибка 404 not found. Они выкладывают туда полезную информацию и
webmasterie.ru
Как удалить URL-адреса, предлагаемые при вводе в адресную строку?
При вводе адреса сайта адресую строку браузера мы можем видеть предлагаемые адреса, на которые вы уже заходили, то есть вы можете стрелочками сразу перейти на этот ресурс и сразу оказаться на нужно сайте. Это, конечно, убыстряет процесс ввода и перехода, но иногда могут показаться такие сайты из вашей истории, которые не должны видеть ваши знакомые. Есть еще один случай, когда вы однажды ввели сайт неверно и теперь о будет постоянно выскакивать при вводе. Естественно, надоедливые адреса можно удалить, чтобы они вас не беспокоили.
В данной статьей я не буду разбирать браузер Microsoft Edge, потому что в нем нет функции удаления URL. Но все необходимые функции в будущем должны быть реализованы.
Автозаполнение URL адресов в Google Chrome
Огромное количество пользователей пользуется браузером Chrome. Чтобы очистить адреса, которые предлагаются после ввода каких букв или фраз, то всё, что вам нужно сделать – дойти стрелочками до этого адреса и нажать комбинацию Shift+Delete. Нежелательный адрес мгновенно удалится.

Как удалить автозаполнение URL-адресов в Firefox?
При пользовании браузеров Mozilla Firefox удалить адреса сайтов, появляющихся в адресной строке при вводе можно удалить точно так же, как и в Google Chrome. Набираете несколько букв интересующего вас адреса, стрелками переходите на появившейся нежелательный и нажимаете Shift+Delete.

Как удалить автозаполнение URL-адресов в Internet Explorer?
Пока еще есть пользователи, которые пользуются Internet Explorer, поэтому я буду во многих статьях упоминать этот браузер.
Когда вы начинаете набирать URL-адрес, ниже появляются предложения. Чтобы какое-то из них удалить направляете на него мышкой, и справа появляется красный крестик, отвечающий за удаление.

Таким же образом вы можете работать и с другими браузерами. При возникновении трудностей у вас есть возможность обратиться к автору через комментарии.
Похожее:
Как отключить в браузере запрос местоположения?
9 Способов ускорить Google Chrome
Internet Explorer для Windows 10 находим браузер в системе
Как очистить куки браузера (Cookie)?
computerinfo.ru
Удаляем URL’ы из дополнительного индекса Google
 Ведя борьбу с дублями страниц, провела настоящую «чистку» блога. Настроила редиректы, прописала noindex для технических дублей своего сайта. Довольная своей работой, стала ждать, когда же наконец все дубли вылетят из индекса.
Ведя борьбу с дублями страниц, провела настоящую «чистку» блога. Настроила редиректы, прописала noindex для технических дублей своего сайта. Довольная своей работой, стала ждать, когда же наконец все дубли вылетят из индекса.
Однако, хоть их число заметно сократилось, значительная часть их так и осталась «болтаться». Время от времени проверяя дополнительный индекс Google, убедилась, что ждать придется очень долго, пока поисковик сам все это удалит. Конечно, в вебмастере есть инструмент «Удалить URL-адреса», однако при этом возникает проблема: как узнать эти самые урлы?
Как узнать URL-адреса дублей?
Если вбить комбинацию site:incomeeasily.ru (для каждого сайта конечно же свой домен), можно узнать количество страниц в индексе Гугла. Пройдя в конец списка и нажав «показать скрытые результаты», мы увидим, что же там в Supplemental results, или как уже многие говорят, в «соплях».
А у меня там болтались удаленные давно страницы, дубли комментариев к ним, даже страницы админки(!), файлы темы, копии мобильной версии сайта (кстати давно удаленные) и прочий мусор. Некоторые адреса я могла узнать, пройдя по ссылке и открыв сам сайт. Но большинство не открывалось благодаря настроенным редиректам.
Вот тут и возник вопрос: что же делать? Как всегда ответ пришел сам собой. «Метод научного тыка» — самый лучший метод для ленивых. Я себя отношу к числу лентяев. Болея последнюю неделю, не нашла в себе силы писать новые статьи, но вот поковыряться в этих каверзах почему-то захотелось. Стала отправлять запросы на удаление тех адресов, которые смогла определить.
Потом пришла идея посмотреть исходный код ссылки, которую дает поисковик. Если кто не знает, для этого достаточно клацнуть по ссылке правой кнопкой мыши и в выпавшем меню выбрать «просмотр кода элемента».
После чего увидим «развернутую картину», как переадресовывается ссылка из архива поисковика на нашу страницу. Но вот беда: как я не пыталась ее выделить, никак не получалось, а перепечатывать длиннющую ссылку — это очень долго. Промучившись с полчаса, все же «методом тыка» обнаружила: ссылка выделяется двойным щелчком левой кнопки. Элементарно! 
Как удалить URL-адреса
Теперь достаточно сделать запросы на удаление URL-адресов в вебмастере Гугла (Инструменты для веб-мастеров — Индекс Google — Удалить URL-адреса). Пару вечеров по полчаса «скопировал-вставил-подтвердил» — и никаких дублей в индексе Google больше не будет! При условии конечно, что вы поработали над тем, чтобы они не создавались заново.  Думаю, информация очень доступная и даже школьник разберется, как удалить URL-адреса из дополнительного индекса Google!
Думаю, информация очень доступная и даже школьник разберется, как удалить URL-адреса из дополнительного индекса Google!
incomeeasily.ru
9 рабочих способов деиндексировать страницу в Google и избежать раздувания индекса
SEO-специалисты стремятся ускорить индексацию целевых страниц сайта, Google идёт на встречу, но также легко добавляет в поиск и нежелательные для нас страницы.
SearchEngineJournal опубликовали актуальные методы деиндексации, их влияние на SEO и почему меньшее количество страниц в поиске может привести к увеличению трафика. Давайте посмотрим!
Что такое «раздутый» индекс?
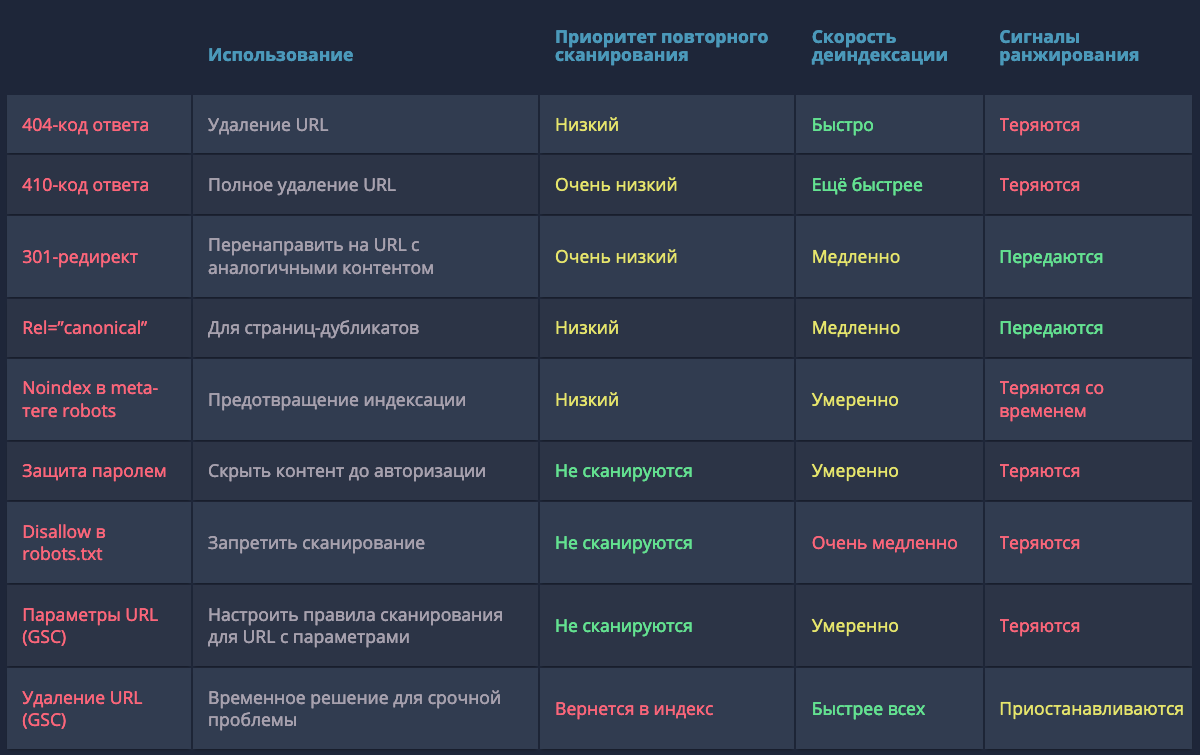
Index Bloat (раздутый индекс) возникает, когда в поиск попадает большее количество малополезных страниц сайта с небольшим количеством уникального контента или вовсе без него. Такие URL в индексе могут оказывать негативный каскадный эффект на SEO, примеры документов:
-
Страницы результатов фильтрации.
-
Неупорядоченные архивные страницы с неактуальным контентом.
-
Неограниченные страницы тегов.
-
Страницы с GET-параметрами.
-
Неоптимизированные страницы результатов поиска по сайту.
-
Автоматически сгенерированные страницы.
-
Трекинг-URL с метками для отслеживания.
-
http / https или www / non-www страницы без переадресации.
В чём вред? Googlebot обходит бесполезные для привлечения трафика страницы, тратит на них краулинговый бюджет и замедляет сканирование целевых URL. Повышается вероятность дублирование контента, каннибализации по запросам, релевантные страницы теряют позиции и вообще на сайте начинает царить плохо контролируемый беспорядок.
Кроме того, URL ранжируются в контексте репутации всего сайта и Google Webmaster Center недвусмысленно заявляет:
Низкокачественный контент на отдельных страницах веб-сайта может повлиять на рейтинг всего сайта, и, следовательно, удаление некачественных страниц… может помочь ранжированию высококачественного контента.
Как отслеживать количество проиндексированных страниц?
В Google Search Console на вкладке Индекс > Покрытие:
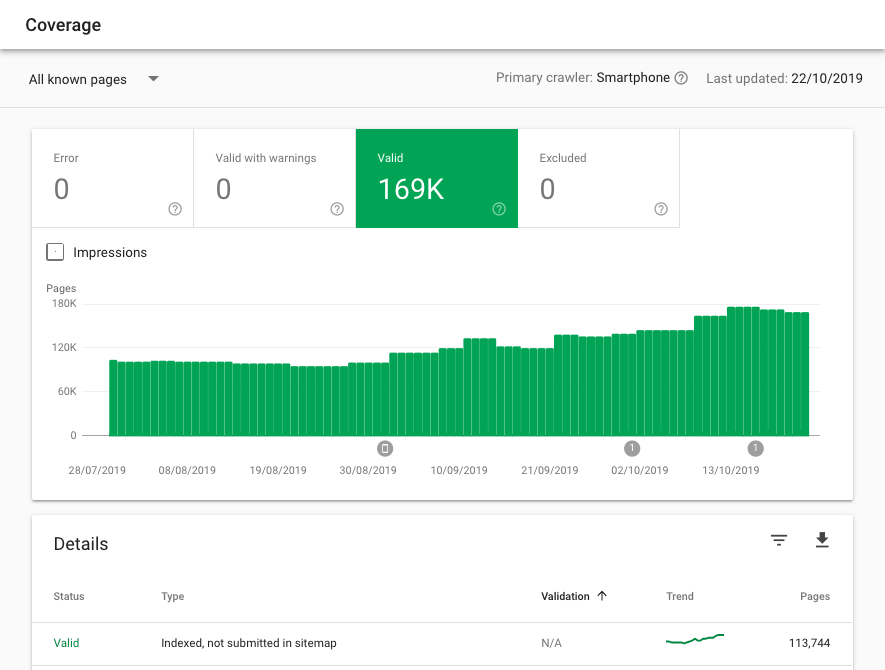
С помощью отдельных инструментов, например в «Модуле ведения проектов» на вкладке «Аудит»
Или, используя оператор site: в поиске Google (не самый надёжный и не очень точный способ):

Если количество страниц в индексе превышает число URL, которое вы хотели отдать на индексацию (скажем, из файла Sitemap.xml), вероятно имеет место проблема «раздутого» индекса и пора освежить правила запрета на сканирование.
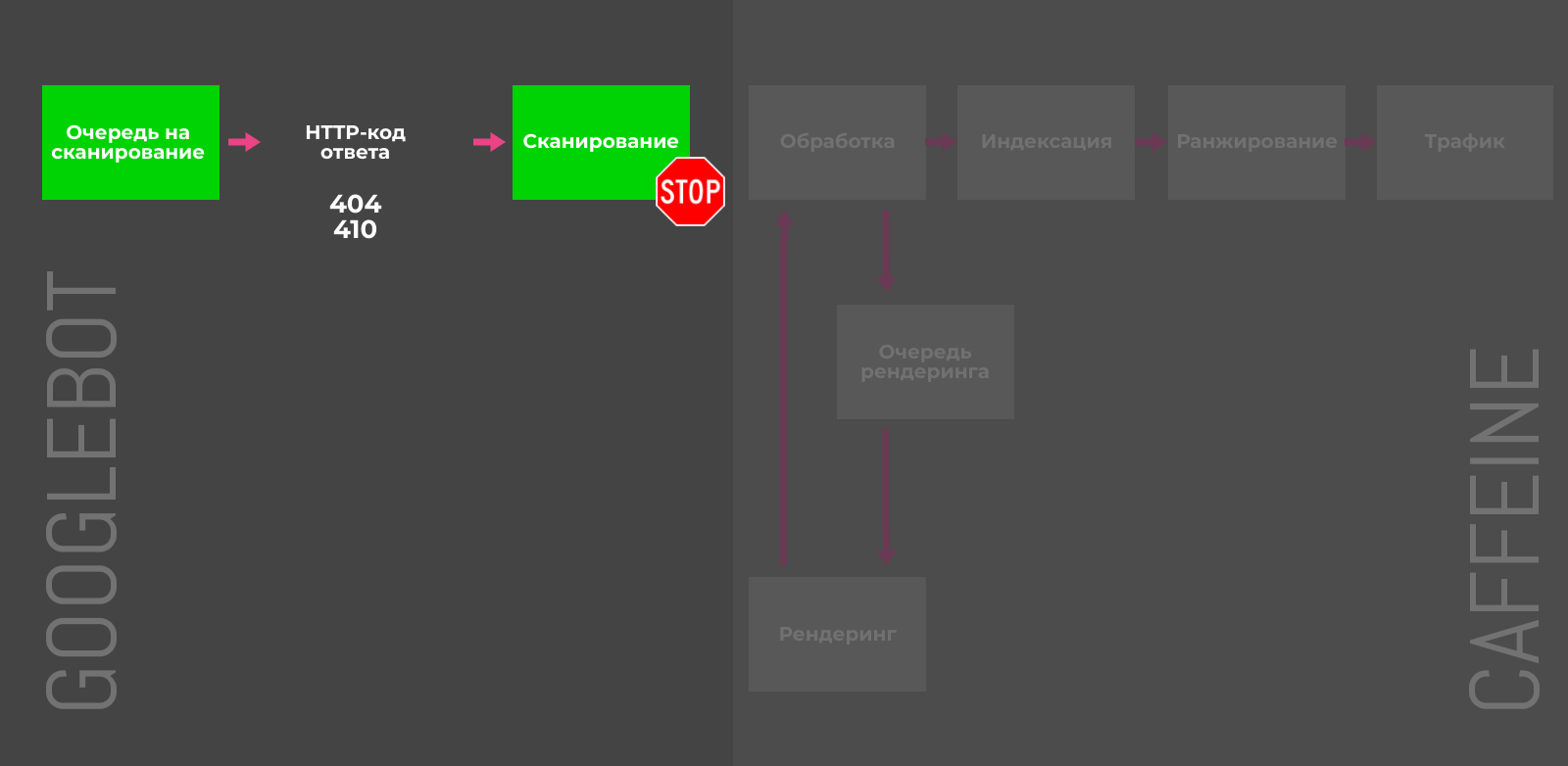
-
410 Gone — быстрый способ сообщить Google о том, что страница была намеренно удалена, и вы не планируете её заменить.
-
404-код ответа («страница не найдена») указывает на то, что страница может быть восстановлена, поэтому Googlebot может вернуться и проверить страницу на доступность через некоторое время.
При проверках в Search Console Google 410-код ответа помечается как 404-й. Джон Мюллер подтвердил, что это сделано с целью «упрощения», но разница всё-таки есть.
Также специалисты Google успокаивают — количество 4xx-ошибок на сайте не вредит вашему сайту. Проверить код ответа и размер документа для списка URL можно с помощью бесплатного инструмента.
Предотвращение «раздувания» индекса: 1/5
Борьба с последствиями «раздувания»: 4/5
301-редирект
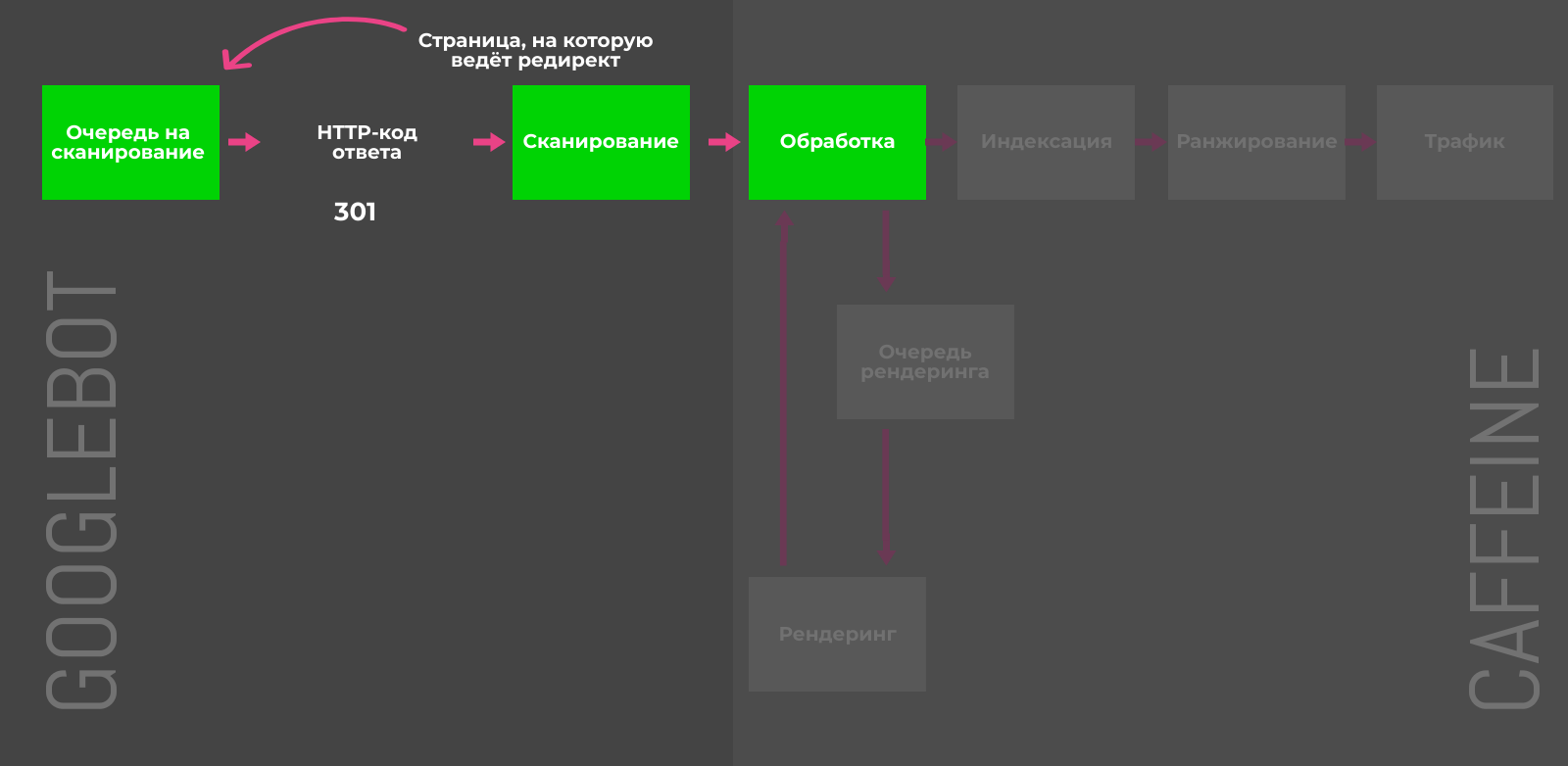
Если множество малополезных страниц можно переадресовать на целевой URL с похожим контентом и таким образом объединить их сигналы ранжирования, то 301-редирект самое верное решение. Например, в случае удалённых товаров или неактуальных новостей, можно перенаправить пользователя на схожие позиции или свежие посты по теме.
Деиндексирование перенаправляемых страниц требует времени: сначала Googlebot должен дойти до исходного URL, добавить целевой адрес в очередь для сканирования и затем обработать контент, чтобы убедиться в его тематической связи с первичным документом. В обратном случае (например, редирект на главную страницу сайта) 301-код ответа будет расцениваться Google как SOFT-404 и никаких сигналов для ранжирования (например, ссылочная масса) передано не будет.
Предотвращение «раздувания» индекса: 1/5
Борьба с последствиями «раздувания»: 3/5
Атрибут rel=”canonical” тега link
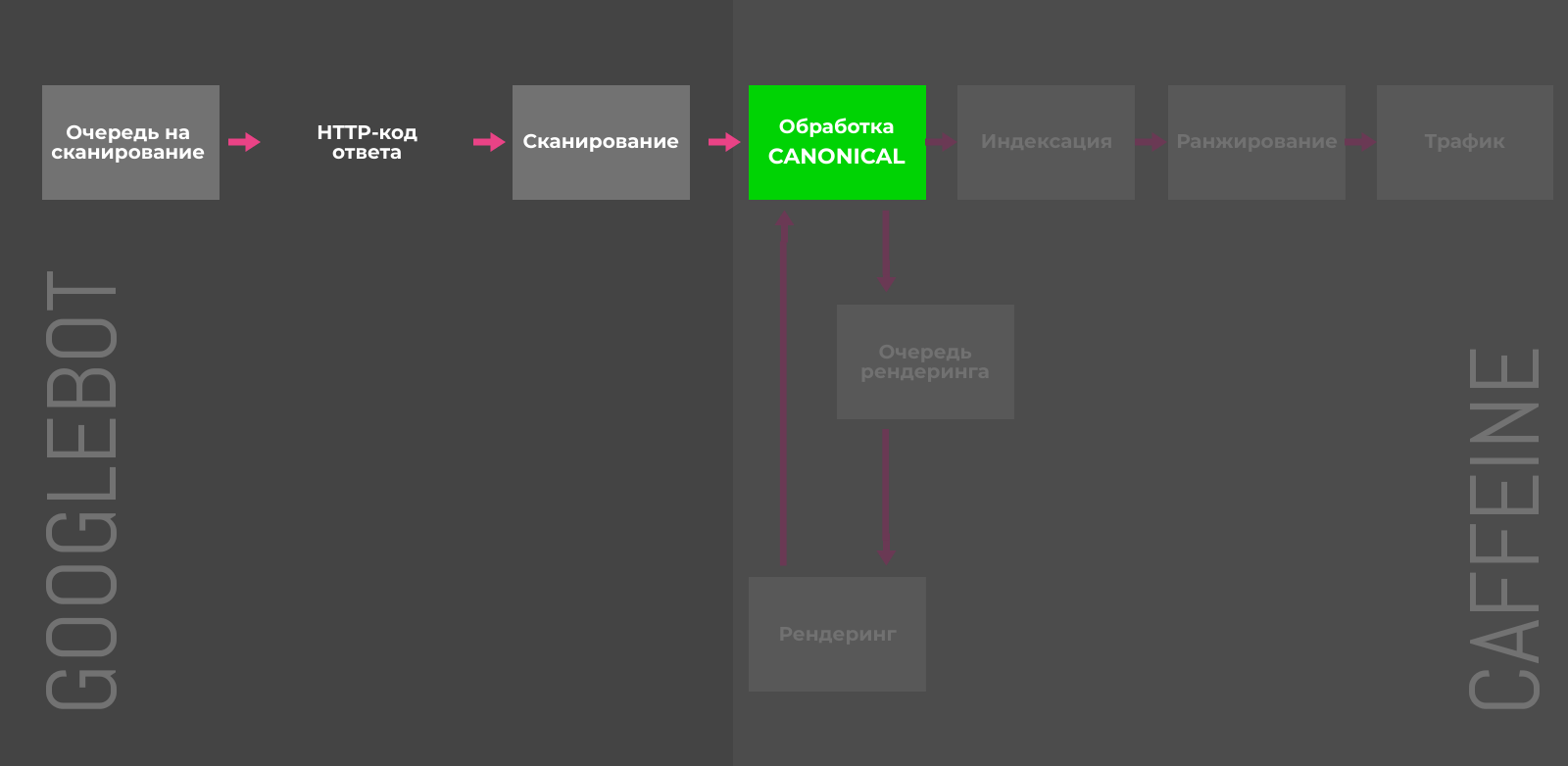
В случае дубликатов, атрибут rel=”canonical” сообщает краулеру какую именно страницу нужно индексировать. Альтернативные версии будут сканироваться, но гораздо реже и постепенно исчезнут из индекса. Чтобы учитывались и передавались сигналы ранжирования, контент на дубликатах и оригинальных страницах должен быть почти идентичным.
Предотвращение «раздувания» индекса: 4/5
Борьба с последствиями «раздувания»: 2/5
GSC-инструмент «Параметры URL»
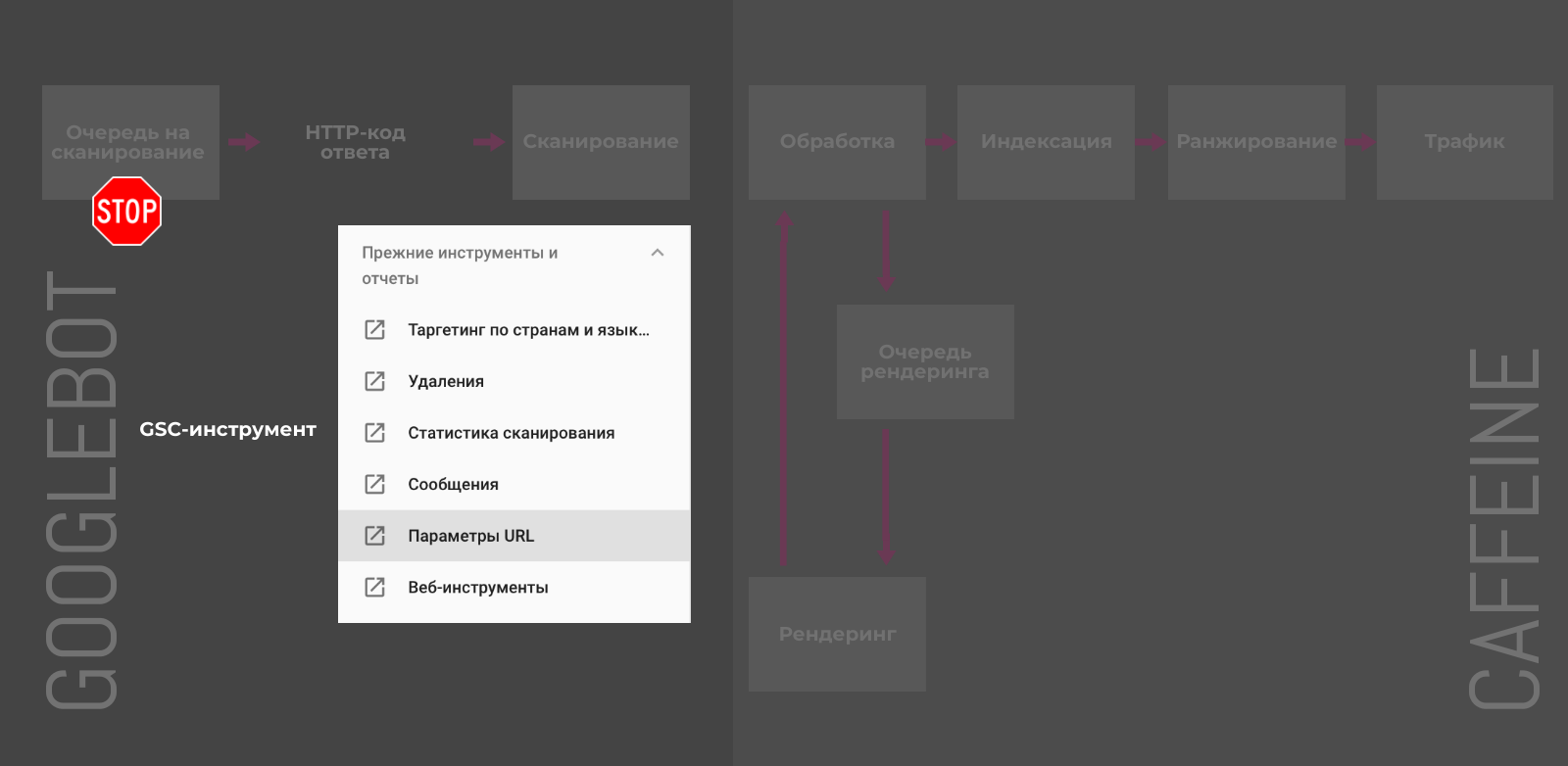
В старой версии Google Search Console можно настроить обработку и задать правила сканирования для URL с различными параметрами.
У этого способа есть несколько недостатков:
-
Работает только для URL с наличием параметров в адресе.
-
Актуально только для Googlebot и не повлияет на сканирование другими поисковыми роботами.
-
Позволяет контролировать только краулинг и не управляет индексацией напрямую.
Хотя Джон Мюллер уверяет, что в конечном счёте, попавшие под исключения, URL также будут удалены из индекса. Не самый быстрый, но также способ деиндексации.
Предотвращение «раздувания» индекса: 3/5
Борьба с последствиями «раздувания»: 1/5
Robots.txt
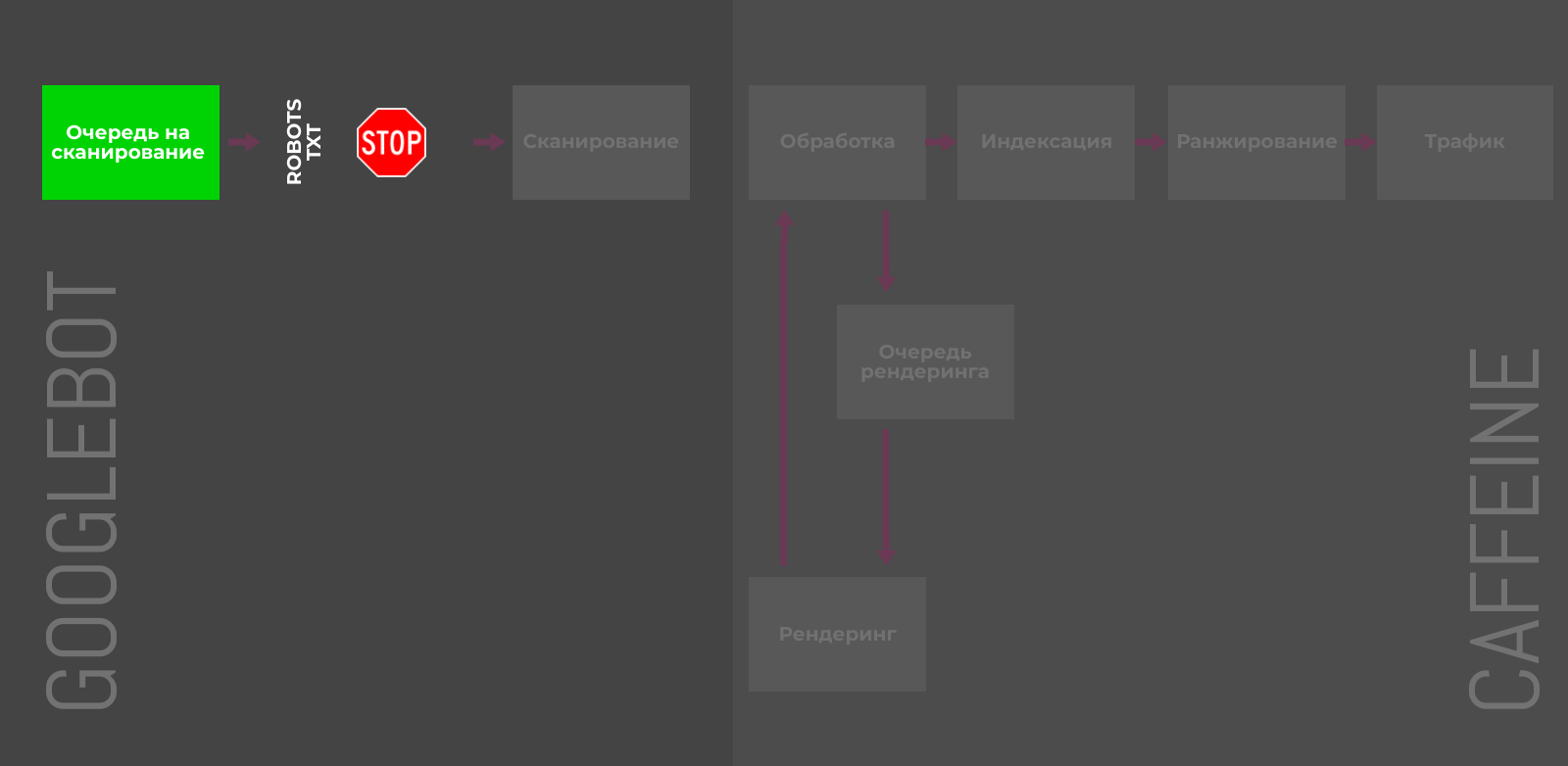
Директива Disallow в файле robots.txt позволяет блокировать отдельные страницы, разделы или полностью весь сайт. Пригодятся для закрытия служебных, временных или динамических страниц.
Тем не менее, директива не управляет индексацией напрямую, и некоторые адреса Google может отправить в индекс, если на них ссылаются сторонние ресурсы. Более того, правило не даёт четких инструкций краулерам, как поступать со страницами, которые уже попали в индексе, что замедляет процесс деиндексации.
Предотвращение «раздувания» индекса: 2/5
Борьба с последствиями «раздувания»: 1/5
Noindex в meta-теге robots
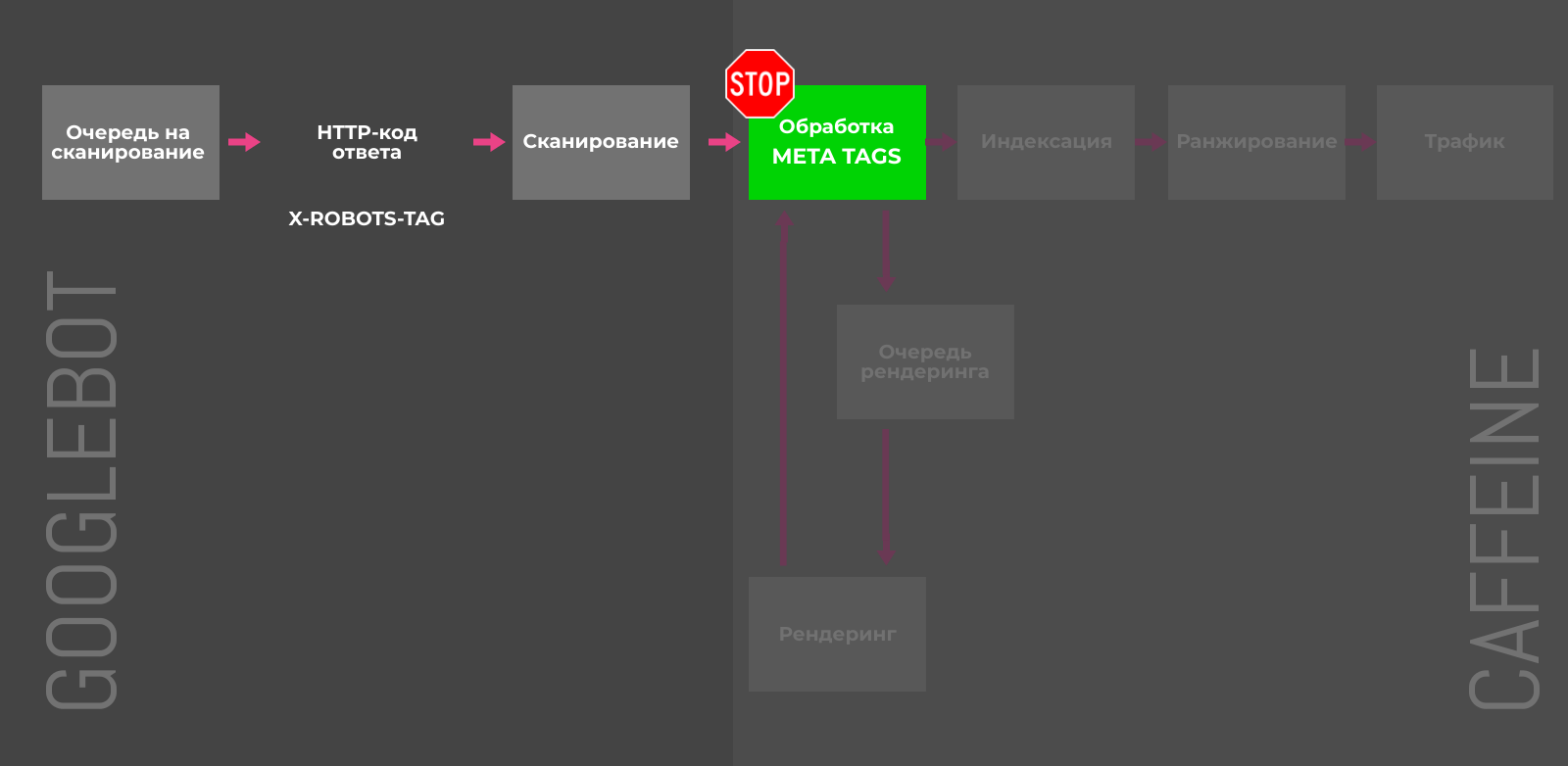
Для полной блокировки индексации отдельных страниц можно использовать мета-тег robots с атрибутом content=»noindex» или HTTP-заголовок X-Robots-Tag с директивой noindex. Напомним, что noindex, прописанный в robots.txt, игнорируется поисковыми краулерами.
X-Robots-Tag и мета-тег robots на страницах имеют каскадный эффект и возможны следующие последствия:
-
Предотвращают индексацию или исключают страницу из индекса в случае добавления постфактум.
-
Сканирование таких URL будет происходить реже.
-
Любые факторы ранжирования перестают учитываться для заблокированных страниц.
-
Если параметры используются продолжительное время, ссылки на страницах обретают статус «nofollow».
Предотвращение «раздувания» индекса: 4/5
Борьба с последствиями «раздувания»: 4/5
Защита с помощью пароля / авторизации
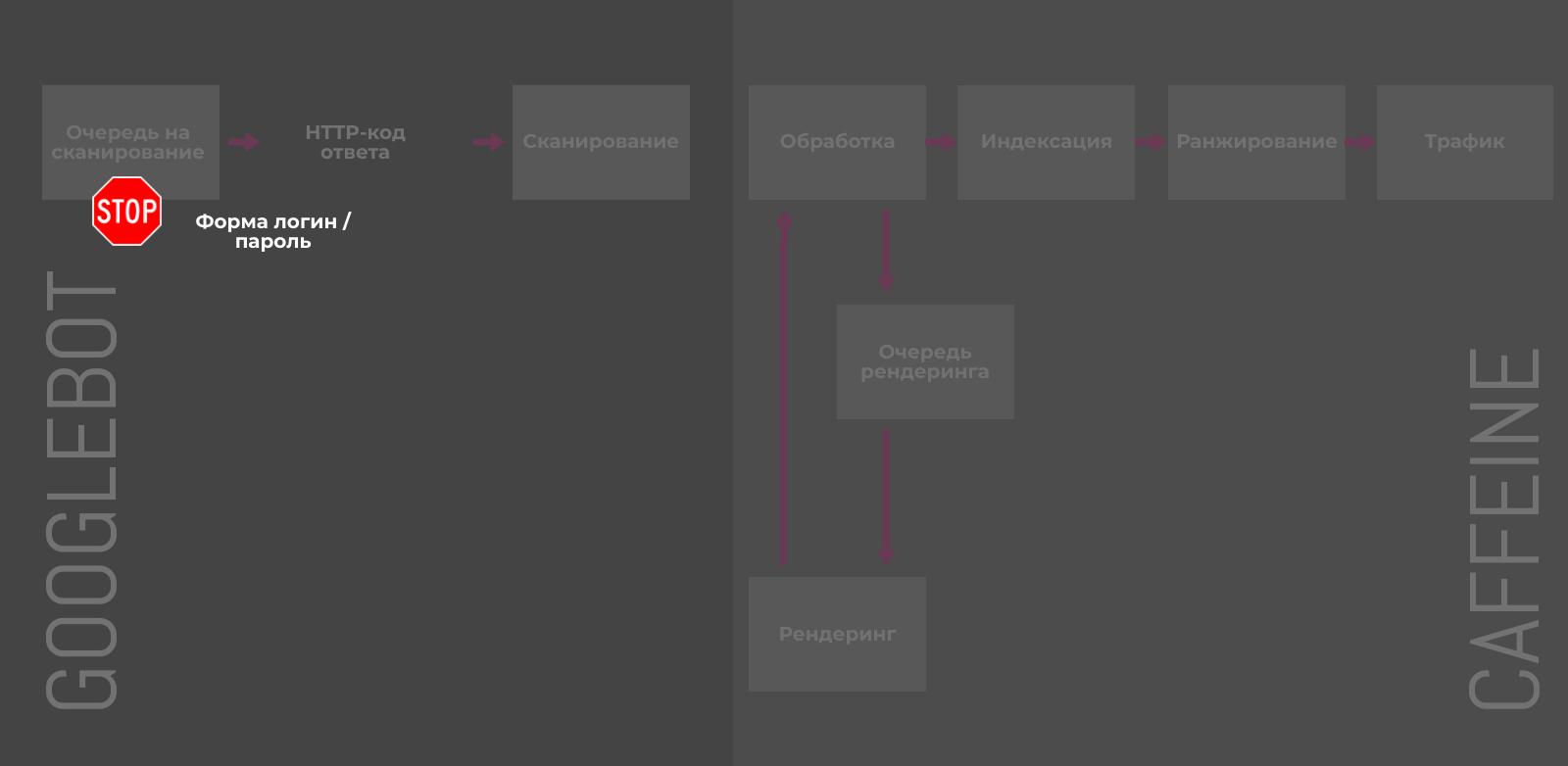
Все файлы на вашем сервере, защищенные паролем и требующие авторизации, будут недоступны для поисковых систем. Такие URL нельзя просканировать и проиндексировать. Очевидно, для пользователей контент на закрытых паролем страницах также будет недоступен до авторизации.
Предотвращение «раздувания» индекса: 2/5
Борьба с последствиями «раздувания»: 1/5
Инструмент Google для удаления URL
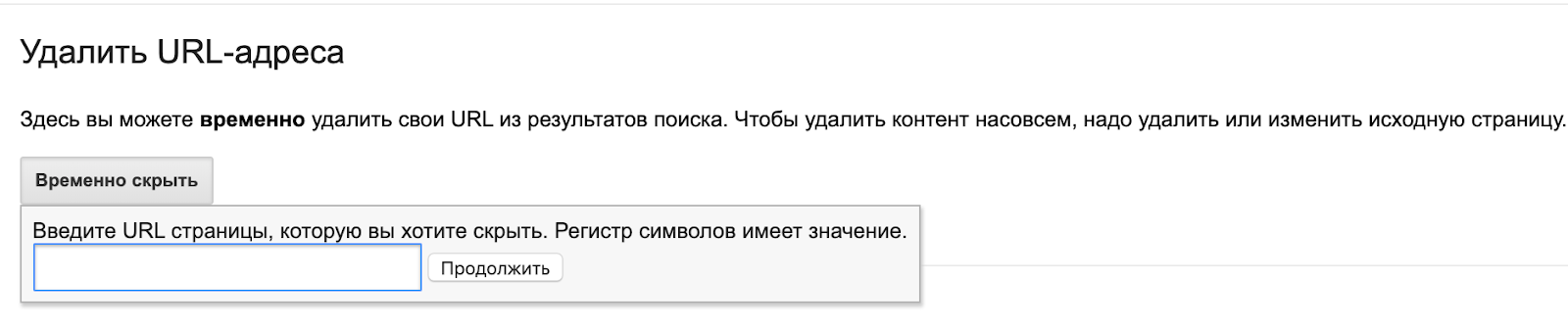
Если необходимо срочно удалить из индекса какую-либо страницу, можно использовать инструмент в старой версии Search Console. Как правило, запросы обрабатываются в день заявки. Главное, нужно понимать — это временная блокировка. По истечении 90 дней URL снова может оказаться в поисковой выдаче, если не будут применены способы для блокировки индексации, описанные выше.
Предотвращение «раздувания» индекса: 1/5
Борьба с последствиями «раздувания»: 3/5
Краткие выводы
Как всегда, профилактика гораздо эффективнее лечения. У Google слишком хорошая память и деиндексации может занять неприлично много времени. Всем терпения и целевых страниц в индексе!
tools.pixelplus.ru
Удаление страниц из индекса поисковых систем Яндекс и Google
Здравствуйте! Сегодня пост о наболевшем для большинства из начинающих сайтостроителей. Мне приходилось очень часто в комментариях отвечать на один и тот же вопрос — как удалить страницы из поиска, которые были проиндексированы ранее, но в силу сложившихся обстоятельств были удалены и больше не существуют, но по-прежнему находятся в индексе поисковых систем. Или же в поиске находятся страницы запрещенные к индексации.

В комментариях особо не развернешься, поэтому после очередного вопроса решил уделить данной теме отдельное внимание. Для начала давайте разберемся, каким образом такие страницы могли оказаться в поиске. Примеры буду приводить исходя из собственного опыта, так что если я что-то забуду, то прошу дополнить.
Почему закрытые и удаленные страницы есть в поиске
Причин может быть несколько и некоторые из них я постараюсь выделить в виде небольшого списка с пояснениями. Перед началом дам пояснение что подразумеваю под «лишними» (закрытыми) страницами: служебные или иные страницы, запрещенные к индексации правилами файла robots.txt или мета-тегом.
Несуществующие страницы находятся в поиске по следующим причинам:
- Самое банальное — страница удалена и больше не существует.
- Ручное редактирование адреса web-страницы, вследствие чего документ который уже находится в поиске становится не доступным для просмотра. Особое внимание этому моменту нужно уделить новичкам, которые в силу своих небольших знаний пренебрежительно относятся к функционированию ресурса.
- Продолжая мысль о структуре напомню, что по-умолчанию после установки WordPress на хостинг она не удовлетворяет требованиям внутренней оптимизации и состоит из буквенно-цифровых идентификаторов. Приходится менять структуру страниц на ЧПУ, при этом появляется масса нерабочих адресов, которые еще долго будут оставаться в индексе поисковых систем. Поэтому применяйте основное правило: надумали менять структуру — используйте 301 редирект со старых адресов на новые. Идеальный вариант — выполнить все настройки сайта ДО его открытия, в этом может пригодиться локальный сервер.
- Не правильно настроена работа сервера. Несуществующая страница должна отдавать код ошибки 404 или редирект с кодом 3хх.
Лишние страницы появляются в индексе при следующих условиях:
- Страницы, как Вам кажется, закрыты, но на самом деле они открыты для поисковых роботов и находятся в поиске без ограничений (или не правильно написан robots.txt). Для проверки прав доступа ПС к страницам воспользуйтесь соответствующими инструментами для вебмастеров.
- Они были проиндексированы до того как были закрыты доступными способа.
- На данные страницы ссылаются другие сайты или внутренние страницы в пределах одного домена.
Итак, с причинами разобрались. Стоит отметить, что после устранения причины несуществующие или лишние страницы еще долгое время могут оставаться в поисковой базе — все зависит от апдейтов или частоты посещения сайта роботом.
Как удалить страницу из поисковой системы Яндекс
Для удаления URL из Яндекс достаточно пройти по ссылке и в текстовое поле формы вставить адрес страницы, которую нужно удалить из поисковой выдачи.
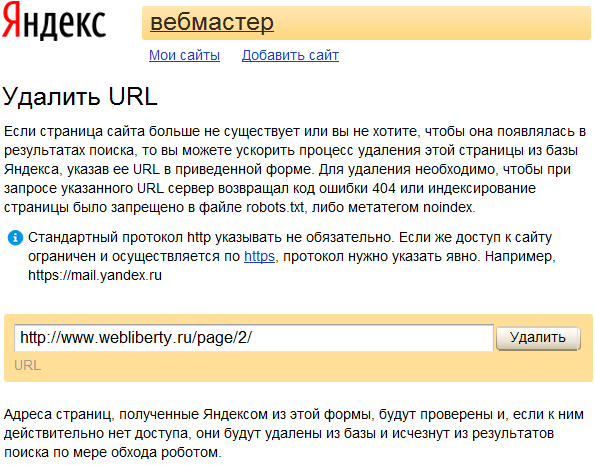
Главное условие успешного запроса на удаление:
- страница должна быть закрыта от индексации правилами robots или мета-тегом noindex на данной странице — в том случае если страница существует, но не должна участвовать в выдаче;
- при попытке обращения к странице сервер должен возвращать ошибку 404 — если страница удалена и более не существует.
При следующем обходе сайта роботом запросы на удаление будут выполнены, а страницы исчезнут из результатов поиска.
Как удалить страницу из поисковой системы Google
Для удаления страниц из Гугла поступаем аналогичным образом. Открываем инструменты для веб-мастеров и находим в раскрывающемся списке Оптимизация пункт Удалить URL-адреса и переходим по ссылке.
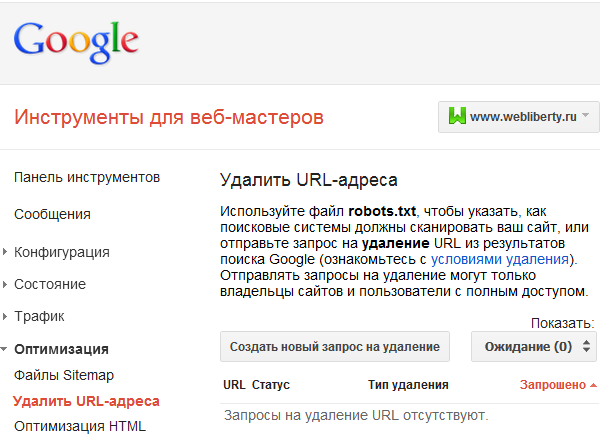
Перед нами специальная форма с помощью которой создаем новый запрос на удаление:
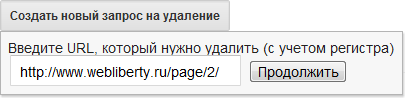
Нажимаем продолжить и следуя дальнейшим указаниям выбираем причину удаления. По-моему мнению слово «причина» не совсем подходит для этого, но это не суть…
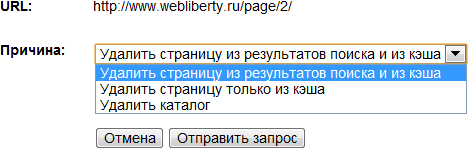
Из представленных вариантов нам доступно:
- удаление страницы страницы из результатов поиска Google и из кэша поисковой системы;
- удаление только страницы из кэша;
- удаление каталога со всеми входящими в него адресами.
Очень удобная функция удаления целого каталога, когда приходится удалять по несколько страниц, например из одной рубрики. Следить за статусом запроса на удаление можно на этой же странице инструментов с возможностью отмены. Для успешного удаления страниц из Google необходимы те же условия, что и для Яндекса. Запрос обычно выполняется в кратчайшие сроки и страница тут же исчезает из результатов поиска.
webliberty.ru