
Noindex не спасет. Google Учитывает Скорость Загрузки на Закрытых страницах
Ваш браузер не поддерживает HTML5 аудио. Вот взамен ссылка на аудио
1X
Длительность: 8:49
В новом аудиоподкасте №383 Николай Шмичков рассказал про то, что Noindex не спасет.
Google Учитывает Скорость Загрузки на Закрытых страницах.
Текстовая версия выступления:
«Всем привет!
Вы на канале SEOquick.
Меня зовут Николай Шмичков.
И это обзор свежих новостей и свежей онлайн прессы, относительно Google Core Web Vitals.
Того самого фильтра, который выходит буквально вот-вот скоро.
На самом деле, по поводу него идут огромные споры.
И первый же вопрос который задали, действительно, у всех был на слуху, но его никто не задавал.
Крутился, как говорится, на языке.
Это: “А если у меня страница медленная и я её закрою от индексации – это улучшит мое ранжирование?
Да или нет?”
На самом деле Core Web Vitals может принимать во внимание не индексируемые странице.
Google утверждает, что не индексируемые страницы по-прежнему можно использовать для оценки Core Web Vitals, которые вскоре действительно станут факторами ранжирования в поиске.
Иными словами: страницы, которые намеренно вы исключили из поискового индекса, могут быть использованы для оценки показателей, которые влияют на ваш рейтинг в выдаче.
Конечно же, это нормальная причина для беспокойства.
Потому что, мы же скрываем часто от индексации какие-то внутренние тяжелые страницы, которые находится внутри нашего сайта.
И оказывается, что это будет влиять на рейтинг.
И как же с этим бороться?
Этот вопрос задали Джону Мюллеру 4 декабря и он на него ответил, буквально недавно.
Задали вопрос, связанный с использованием в Google агрегированных данных для измерения Core Web Vitals.
Google берёт страницы группы, анализирует их, использует данные для расчета Core Web Vitals вашего сайта, представляющих весь сайт.
И его спросили в таком формате.
Core Web Vitals учитывает не индексированные страницы и объекты, заблокированные в robots.txt.
Выходит, что страницы, которые попадают в индекс анализа Search Console, получаются довольно-таки обширные.
И некоторые из них могут попадать туда, даже заблокированные для robots.txt.
И, собственно, Джон Мюллер ответил, что он считает что не индексированные страницы являются частью вашего веб сайта.
Поэтому, если вы используете какие-то дополнительные функции, которые не индексируются, люди по-прежнему видит их как часть вашего веб-сайта.
Говорят, что этот ваш сайт медленный или же сайт быстрый.
На самом деле, User Experience Google считает на основе данных, которые он берёт основываясь на тех страницах, которые попали на его анализ.
Вероятно, эти страницы будут проиндексированы в будущем.
Либо эти страницы не проиндексированы по какой-то ошибке.
И поэтому эти данные Google берёт в основу.
Самое обидное, получается, что просто закрыться robots. txt или тегом noindex для того, чтобы скрыть медленную страницу, у вас попросту не выйдет.
txt или тегом noindex для того, чтобы скрыть медленную страницу, у вас попросту не выйдет.
Обоснования нужны для изменения восприятия страницы.
Потому что, таким образом пользователь должен знать, что есть внутренние страницы, которые находятся на вашем сайте.
И на которые он может попасть, уже переходя из той страницы, которая находится в индексе.
И таким образом Core Web Vitals сказывается в целом и на весь сайт, а не только по страничным факторам ранжирования.
Поэтому, я бы выделил Core Web Vitals все-таки алгоритмом, который является не постраничным, а именно частично их остовом.
Потому что, общий показатель сайта будет сказываться в зависимости от того, как Google просканирует и ваши внутренние страницы.
Что делать дальше?
Я бы прогнал весь ваш сайт на анализ PageSpeed.
Прогнал бы все страницы, которые у вас есть, на скорость загрузки.
Сделал бы это как-то массово.
Проверил бы медленные страницы и, действительно, занялся их исправлением.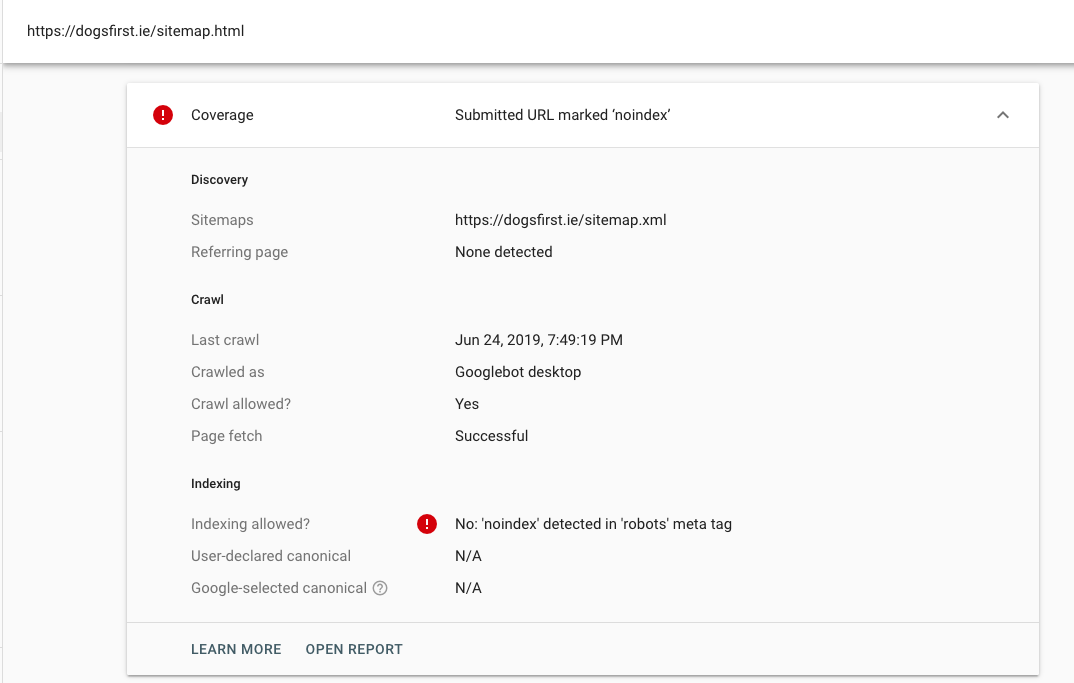
Я понимаю, что в Search Console можно вытащить данные по пейджспиду, и по мобильным ошибкам.
Но иногда, эти данные могут приходить не вовремя и недостаточно их просто проверять для сайта, который ещё не вышел в индекс.
Поэтому, я бы в этом плане посоветовал воспользоваться какими-то сторонними сервисами анализа PageSpeed.
Мы сейчас разрабатываем аналогичный, словно знали куда смотреть, где подстелить.
И вы можете воспользоваться нашим инструментом “Веб-сайт аудит”.
Вскоре он будет доступен для массового анализа PageSpeed для списков страниц, которые вы ему скормите.
Следующее, на что я хотел бы обратить внимание – это то, что индексируемый контент, который вы отдаете в Google на анализ PageSpeed, иногда им могут манипулировать.
Могут сделать страницы заглушки.
Вам могут показывать красивый PageSpeed, просто за счет того, чтобы вставлять пару строчек кода, которые обманывают пользователя.
Я побоялся бы сейчас экспериментировать с такими трюками, по одной простой причине.
Google может всерьез взяться за этот метод обмана.
Побанить те сайты, которые пользовались таким методом обхода его собственного алгоритма PageSpeed.
Поэтому закрывать не индексируемый контент массово каким-то дешевыми методами, я бы точно не советовал.
Лучше сделать хороший, грамотный технический аудит.
Именно уделить внимание скорости загрузки.
Всем этим ключевым 6 показателям, который я обсуждал в прошлом видео, по поводу скорости сайта.
И действительно выписать список ошибок программисту.
У вас фактически три месяца на закрытие всех этих проблем.
Почему?
Потому что, я уверен что Core Web Vitals выкатят в следующем апдейте ядра.
Про него сейчас в основном идут только разговоры.
А как мы знаем, раз Google ведет какие-то разговоры – он это выкатывает в следующем большом, либо через одно, обновлении.
А про Core Web Vitals мы уже говорим полгода.
Значит, если считать, условно говоря, что декабрьский вышел апдейт.
Январь, февраль, март…
У нас получается будет, вероятно, мартовский или апрельский апдейт.
Вот он примерно выйдет в тот период.
Формально, у вас три месяца на то, чтобы улучшить показатели скорости своего сайта.
Нужно смотреть не только индексируемые странице, но еще и те, которые находятся внутри.
Это касается странички регистрации, оформления заказа, внутреннего личного кабинета, и всего контента, который доступен только после регистрации.
Всему контенту нужно будет уделить внимание: он должен быстро загружаться.
И я видел сайты, который снаружи выглядят быстрыми, а после регистрации – начинают жутко тормозить и долго прогружаться.
Это действительно проблема, с которой Google будет бороться.
Если вам понравился разбор этих новостей, то напишите, что вы думаете по поводу этой новости в комментариях.
Хотелось бы услышать ваше мнение.
Мое мнение, что в целом идея достаточно разумная.
Но, конечно, несправедливая для тех сайтов, у которых куча технических багов.
Потому что они могут очень сильно посыпаться, если у них есть внутренние страницы, которые они забыли позакрывать, поудалять.
Которые являются не индексируемыми, но являются старыми.
Допустим, глюки темы после переезда, какие-то глючные страницы после загрузки.
Их всех нужно, получается, выкопать и изучить.
Оптимальный вариант, как выкопать список страниц, которые находятся не в индексе.
Зайти в собственной webmaster, посмотреть какие там страницы находятся.
Выкачать список этих страниц из Google Вебмастера.
Он будет ориентироваться, в первую очередь, только на них.
И конечно же разобраться с ними: либо убить, либо редиректить.
Сделать с ними что-то такое, чтобы те страницы, которые являются бесполезными…
А чаще всего такой мусор бесполезный там и находится – его нужно как-то убрать.
Именно из-за него могут быть у вас и большие проблемы в следующем обновление ядра.
Делайте технический Аудит.
Вовремя исправляйте.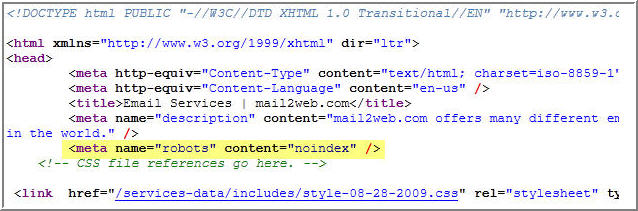
Берете в команду толковых программистов.
И, как говорится, первых мест вам и органики из Google.
Всем спасибо и с наступающими праздниками!»
Если у тебя есть вопросы, мы с радостью ответим в нашей группе в телеграмме — https://t.me/seoquick_com_ua
Что такое Noindex ᐈ Хочу знать?!
Как использовать Noindex
Если вам необходимо, чтобы некоторые фрагменты странички были скрыты от процесса индексации, просто заключите этот самый фрагмент в тег Noindex. В итоге Яндексом данный фрагмент будет проигнорирован, но другими поисковыми системами он все-равно будет учтен.
Поскольку данный тег состоит в классе нестандартных, для соблюдения «валидности» всего текстового контента можно использовать его как комментарий.
Noindex можно использовать исключительно с текстовым контентом. Картинки или ссылки с его помощью спрятать у вас не выйдет. Любой веб-мастер знает об этом. Если вы закрываете ссылку, имеющую анкор, то поисковая система Яндекс проигнорирует только само описание. Линк все-равно будет проиндексирован.
Линк все-равно будет проиндексирован.
Как прописывать Noindex с метатегом роботс
Существует метод, с помощью которого можно спрятать страницу от индексации не только Яндексом, но и другими поисковыми системами. Для этого следует воспользоваться метатегом роботс. Но если в случае с Яндексом закрывается только определенная часть страницы, то для любой другой поисковой системы документ будет невидимым полностью.
Страницы для установки на noindex
1 Авторские архивы в блоге с одним автором
Поисковый бот трепетно относится к уникальности контента. Но домашняя страница блога часто выглядит как нарезка из разных публикаций статей, размещенных на сайте в разное время. Решить задачу можно разными способами. Опубликовать на Главной странице большую статью, посвященную тематике сайта. Можно отключить от индексирования архив авторов или наоборот, запретить индексировать некоторые элементы главной страницы. Перечисленное реализуется с помощью noindex.
2 Определенные (настраиваемые) типы сообщений
Иногда плагин или веб-разработчик добавляют пользовательский тип сообщения не желательный к индексированиюь. Изображение продукта, фильтры размеров и технических характеристик на вкладке рядом с описанием. Поэтому обычные страницы продуктов закрывают от индексации, которые выводит WooCommerce и используем наши собственные записи.
Решения для электронной коммерции, которые добавляют такие характеристики, как размеры и вес, в качестве настраиваемого типа публикации, считаются некачественным контентом . Эти страницы бесполезны для посетителей и ботов Google, поэтому их тоже нужно держать подальше от результатов поиска.
3 Страницы благодарности
Запись служит одной цели — поблагодарить клиента/подписчика на новостную рассылку/комментатора. Надо помнить, что подобный контент считается тонким, хотя и предоставляет возможность продавать из социальных сетей.
4 Страницы администратора и входа
Большинство страниц входа не должны находиться в Google. Но это так. Не допускайте их попадания в индекс, добавив noindex. Исключением являются страницы входа, которые обслуживают сообщество, например Dropbox или аналогичные службы. Пользователи вряд ли станут искать страницы входа через поиск Гугл. Поэтому Google не нужно индексировать эти записи. В WordPress CMS автоматически не индексирует страницу входа на ваш сайт.
5 Результаты внутреннего поиска
Результаты внутреннего поиска — это в значительной степени последние страницы, на которые Google хотел бы отправлять своих посетителей. Если вы хотите испортить поиск, можно ссылаться на другие страницы поиска вместо фактического результата. Но ссылки на странице результатов поиска по-прежнему очень ценны, вы определенно хотите, чтобы Google следил за ними. Итак, все ссылки должны быть пройдены, а мета-настройка robots должна быть:
Но ссылки на странице результатов поиска по-прежнему очень ценны, вы определенно хотите, чтобы Google следил за ними. Итак, все ссылки должны быть пройдены, а мета-настройка robots должна быть:
<meta name=»robots» content=»noindex, follow»>
Уважает ли Google Noindex в Robots.txt? 2019 Case Study
TL;DRЯ провел это исследование в качестве продолжения тематического исследования Stone Temple еще в 2015 году. 3 года — это очень долгий срок для SEO лет. И да, в 2019 году все еще работает как шарм:
Давайте углубимся в детали.
Почему Google не рекомендует добавлять noindex в robots.txt?
Во-первых, его нет ни в одной официальной документации Google. Google рекомендует блокировать индексацию только с помощью директивы Meta Robots или x-robots.
Во-вторых, сам Джон Мюллер из Google неоднократно упоминал, что на самом деле избегал бы его использования.
https://twitter.com/JohnMu/status/638644112359604224?ref_src=twsrc%5Etfw%7Ctwcamp%5Etweetembed%7Ctwterm%5E638644112359604224&ref_url=https%3A%2F%2F-donot-use-google%2www.seroundtable.com noindex-in-robots-txt-20873.html
С другой стороны, это не противоречит рекомендациям Google для веб-мастеров, или, по крайней мере, об этом никогда не говорилось.
Я думаю, что эта директива может просто не работать в 100% случаев, и если сами Google не могут поручиться за такую важную директиву (noindex), они не будут ее рекомендовать.
Вот и все.
Кроме того, вот объяснение Гэри Иллиса:
Технически robots.txt предназначен для сканирования. Метатеги предназначены для индексации. Во время индексации они будут применяться на одном и том же этапе, поэтому нет веской причины использовать их оба
.— Гэри «鯨理» Иллиес (@methode) 18 апреля 2019 г.
В некоторых случаях они не должны мешать вам экспериментировать с ним.
Также Гэри намекнул, что Google может изменить принцип работы noindex в robots.txt. На данный момент это работает, но я обещаю держать вас в курсе.
Также важно отметить, что Google — единственная поисковая система, которая поддерживает эту директиву (пусть и не официально).
Почему я решил провести этот эксперимент?
По правде говоря, у меня было мало времени, это мое оправдание.
через GIPHY
Давайте углубимся в детали —
Мой местный SEO-клиент имел тысячи проиндексированных страниц, ориентированных на все возможные варианты городов США.
Например, если бы это был сантехник, это выглядело бы примерно так: сантехник в Нью-Йорке, сантехник в Чикаго, сантехник в Вашингтоне, округ Колумбия и т. д. Вы поняли.
Дело в том, что, кроме трех реальных местных отделений моего клиента, все другие города были просто дубликатами целевых страниц, нацеленных на каждое заданное местное ключевое слово. Иглы, чтобы сказать, что это не сработало так хорошо.
Иглы, чтобы сказать, что это не сработало так хорошо.
Итак, проведя исследование, я составил окончательный список примерно из 3000 избыточных страниц, которые не должны быть проиндексированы. Еще одна проблема заключалась в том, что весь веб-сайт имел единую инфраструктуру URL без иерархии. Что-то вроде этого:
- example.com/plumber-in-nyc/
- example.com/сантехник в Чикаго/
- example.com/сантехник в Остине/
- example.com/plumber-in-cincinnati/
и т.д.
Было бы намного проще, если бы все локальные страницы находились в одном каталоге, например:
- example.com/cities/nyc/
- example.com/cities/chicago/
- example.com/cities/austin/
- example.com/cities/cincinnati/
Если бы это было так, я бы посоветовал запретить всю папку /cities/ в файле robots.txt и разрешить только несколько релевантных списков, которые мы хотели бы сохранить (самое простое и быстрое решение).
Но, к сожалению, это было не так.
Мне пришлось мыслить нестандартно и быстро. Почему? Потому что до отпуска у меня оставалось меньше суток, а деиндексация тысяч страниц может занять довольно много времени, по крайней мере, несколько недель.
Кроме того, имейте в виду, что этот конкретный клиент был очень ограничен в своих ресурсах для разработки, поэтому найти разработчика, который решит эту проблему в течение 24 часов, было все равно, что попросить жирафа отрастить крылья.
Итак, какие у меня были основные варианты?
- Просить разработчиков переходить на каждую страницу одну за другой и обновлять директиву Meta Robots на noindex,nofollow в WordPress – исключено и нереально
- Отправка разработчикам длинного списка тегов роботов HTACESS x и реализации noindex,nofollow через HTTP-заголовок. Недостаток — помимо того факта, что несколько тысяч строк в файле HTACESS могут повлиять на производительность сайта, это то, что эта задача очень чувствительна, и каждая маленькая ошибка может привести к падению всего сайта — это то, чего я не могу допустить, пока я прочь.

- Disallow vs. noindex в robots.txt — во-первых, важно подчеркнуть разницу между ними: когда запрещает через robots.txt, это не означает, что URL-адрес будет удален из индекса. Это означает, что Google просто прекратит сканирование URL-адреса и больше не будет тратить на него краулинговый бюджет. С другой стороны, noindex означает, что Google полностью удалит URL-адрес из индекса, но его все еще можно будет сканировать. Если конкретный URL-адрес имеет как правило запрета, так и правило noindex (будь то через мета-роботы или файл robots.txt), робот Googlebot не сможет увидеть noindex, поскольку существует ограничение на сканирование этой страницы! Таким образом, сумма вверх, я выбрал нетрадиционный подход noindex через robots.txt по следующим причинам:
- У меня было мало времени, и мне было нечего терять – в худшем случае ничего не произойдет.
- Мне было очень любопытно провести этот эксперимент 🙂
Продолжим?

Почему я считаю это важным?
Каждый опытный SEO-специалист, имеющий некоторый опыт работы с клиентами, знает, что независимо от того, насколько они велики, ресурсы для разработки иногда бывает трудно найти, и в основном задачи разработки требуют времени для реализации.
Итак, когда я думаю о данной рекомендации по SEO, я также должен учитывать время и ресурсы, которые потребуются для ее выполнения. Например, загрузка файла robots.txt — одна из самых простых задач (не должна занимать меньше минуты при доступе к серверу сайта) по сравнению с развертыванием метатега robots в коде веб-сайта для определенных страниц, что может быть сложно. и потребуется разработчик.
Обновление файла robots.txt — одно из самых экономичных известных мне изменений. Независимо от того, сколько работы у меня есть на моей стороне, она не потребует ресурсов разработки.
Если мы можем использовать его, пока он работает и не противоречит рекомендациям Google для веб-мастеров, почему бы и нет?
В чем разница между двумя экспериментами SEO?
Два тематических исследования не совсем похожи по нескольким аспектам:
- Stone Temple экспериментировал с 13 различными доменами, но это было только на 13 отдельных URL-адресах в этих заданных доменах. В нашем эксперименте у нас был только один домен, но с 957 разных страниц запрещены в robots.txt
- По сравнению с 2015 годом, в 2019 году мы получили новую консоль поиска Google, поэтому будет интересно посмотреть, как Google обрабатывает эти URL-адреса в новом покрытии индекса.
- Как я уже упоминал, последний эксперимент был проведен в ноябре 2015 года. С тех пор я не нашел никаких обновлений. Кажется, самое время снова протестировать его.
 В нашем эксперименте у нас был только один домен, но с 957 разных страниц запрещены в robots.txt
В нашем эксперименте у нас был только один домен, но с 957 разных страниц запрещены в robots.txtМы сопоставили 957 URL-адресов из одного основного домена.
Затем я добавил строку Noindex для каждого URL-адреса в рассматриваемой папке. по папкам и подстановочным знакам (например, *) Noindex в robots.txt предполагает обработку только определенных URL-адресов. Кроме того, как я уже упоминал, иерархия URL-адресов была плоской, так что она все равно не пригодилась.
Мы загрузили новый файл robots.txt 20 февраля. И ждал.
Результаты
Как я уже упоминал выше, одно из ключевых отличий между двумя экспериментами заключается в том, что новая консоль поиска Google не была доступна 3 года назад. Поэтому было интересно посмотреть, как покрытие индекса обрабатывает эти директивы в robots.txt
Поэтому было интересно посмотреть, как покрытие индекса обрабатывает эти директивы в robots.txt
Во-первых, было интересно посмотреть, как Google относится к noindex как к представленному URL-адресу, заблокированному robots.txt:
Более того, Я проверил несколько заданных URL-адресов с новым URL-адресом проверки:
Интересно посмотреть, как Google трактует запрет как директиву, не позволяющую роботу Googlebot сканировать страницу (напоминаем: noindex — это не то же самое, что запретить). Возможно, Google не будет показывать эту опцию, потому что они не хотят ее поощрять или поддерживать.
Хорошо, а на практике? Эти страницы были удалены из индекса? (или хотя бы некоторые из них?)
Взгляните на следующий график:
Важные выводы из данных:
- Новый файл robots.txt был опубликован 22 февраля. Первая партия страниц, удаленных из индекса, была удалена 1 марта.
- 23 марта мы достигли 814 страниц, которые были удалены из индекса. Другими словами, за один месяц нам удалось удалить 85% рассматриваемых страниц. Неплохо, не так ли? Важно отметить, что, вероятно, было бы полезнее и намного быстрее иметь файл sitemap.xml, содержащий URL-адреса, которые мы хотели удалить. Таким образом, робот Google может иметь быстрый доступ для сканирования этих URL-адресов, прежде чем они будут удалены из индекса.
- Но подождите, это еще не все. 2 апреля графа уменьшилась с 814 страниц до 660. Почему? Честно говоря, я пока не совсем уверен. Это еще больше усложняет понимание того, какие страницы не проиндексированы и были ли некоторые из них переиндексированы, потому что у нас только что есть образец ULS, поэтому у нас нет полных данных. Означает ли это, что некоторые URL-адреса были переиндексированы? Мне ОЧЕНЬ трудно в это поверить, но я буду следить за этим в течение следующих недель и обещаю обновлять соответственно.
- После того, как Google обновил график, число увеличилось до 905, то есть почти 95% отправленных URL были удалены из индекса .
- Также важно отметить, что я вручную проверил URL-адреса в списке, чтобы убедиться, что они были удалены из индекса, а не просто заблокированы robots.txt (как в случае с Disallow). Как это проверить? Поиск оператора сайта с помощью конкретный URL-адрес. Если вы видите это: Обычно это означает, что URL-адрес есть в индексе, но он заблокирован robots.txt. Если вы вообще не видите его в результатах поиска, это означает, что он был удален из индекса
 Другими словами, за один месяц нам удалось удалить 85% рассматриваемых страниц. Неплохо, не так ли? Важно отметить, что, вероятно, было бы полезнее и намного быстрее иметь файл sitemap.xml, содержащий URL-адреса, которые мы хотели удалить. Таким образом, робот Google может иметь быстрый доступ для сканирования этих URL-адресов, прежде чем они будут удалены из индекса.
Другими словами, за один месяц нам удалось удалить 85% рассматриваемых страниц. Неплохо, не так ли? Важно отметить, что, вероятно, было бы полезнее и намного быстрее иметь файл sitemap.xml, содержащий URL-адреса, которые мы хотели удалить. Таким образом, робот Google может иметь быстрый доступ для сканирования этих URL-адресов, прежде чем они будут удалены из индекса.
Каков ваш опыт?
В ближайшие несколько недель и месяцев я снова проверю эти результаты, используя еще несколько веб-сайтов и, возможно, с другим восприятием.
Я призываю вас провести свои собственные эксперименты на эту тему, будет действительно интересно увидеть больше результатов, не стесняйтесь поделиться ими
Вот так:
Нравится Загрузка…
Когда Google не соблюдает собственные правила !
Если есть место, где Google должен соблюдать собственные правила Google, помощь Search Console, вероятно, должна быть первой, поскольку Google предоставляет рекомендации…
Тем не менее, я покажу вам, что это не всегда так.
Проблема:
Если вы сегодня ищете « your money your life google site:google.com » в Google.ch, вы, вероятно, найдете страницу справки Google Search Console, как показано ниже.
Удивительно, но это внутренняя страница результатов поиска с веб-сайта Google для веб-мастеров: https://support.google.com/webmasters/search?q=YMYL
Конечно, мы можем думать, что Google разрешает индексировать собственные результаты поиска, что строго противоречит Официальным рекомендациям Google:
Не позволяйте Google сканировать ваши страницы результатов внутреннего поиска. Пользователям не нравится нажимать на результат поисковой системы только для того, чтобы попасть на другую страницу результатов поиска на вашем сайте.
Но на самом деле Google старается не проводить эту индексацию… Как вы можете видеть ниже, файл Robots.txt настроен правильно и запрещает любую индексацию страницы поиска:
И Google правильно устанавливает значение Meta Robots на « noindex,nofollow » в HTML страницы поиска…
Итак, что не так и почему Google пытается индексировать собственный контент внутреннего поиска?
Мы можем видеть 2 возможности:
Первая возможность: сигналы индексации противоречивы…
На самом деле, нам нужно еще немного покопаться, чтобы обнаружить, что HTML страницы содержит каноническую ссылку…
Это именно то, что Google просит не делать … Джон Мюллер из Google советует владельцам сайтов не смешивать такие сигналы, как noindex и rel=canonical, поскольку эти сигналы представляют собой противоречивые фрагменты информации: «не индексировать» и «индексировать контент по определенному URL». .
.
В большинстве случаев Google выберет rel=canonical вместо noindex в тех случаях, когда используются оба сигнала. Именно по этой причине мы можем видеть очень неожиданные результаты поиска, возвращаемые Google.
Но… как вы можете заметить, ссылка Canonical указывает на главную страницу раздела поиска: https://support.google.com/webmasters/search?hl=fr … Это создает непредвиденную ситуацию, потому что Google не « обычно » имеют доступ к этой странице (ограничения Robots.txt)… Таким образом, возможный сценарий: Google поймет, что страницу необходимо проиндексировать, но, поскольку Google «застрял посередине», алгоритм не будет следовать исходной директиве тега Canonical. , и, наконец, решите проиндексировать страницу поиска с исходным URL…
Второй вариант: Google не будет соблюдать Robots.txt
Google может принять решение не соблюдать ограничения Robots.txt. Это то, что Google объясняет на этой странице: https://developers.google.com/search/docs/advanced/robots/intro?hl=en.
- Роботизированная страница по-прежнему может быть проиндексирована, если на нее есть ссылки с других сайтов
Хотя Google не будет сканировать или индексировать контент, заблокированный файломrobots.txt, мы все равно можем найти и проиндексировать запрещенный URL-адрес, если он связан с другие места в сети. В результате URL-адрес и, возможно, другая общедоступная информация, такая как текст привязки в ссылках на страницу, по-прежнему может отображаться в результатах поиска Google. Чтобы ваш URL не отображался в результатах поиска Google, вы должны защитить паролем файлы на своем сервере или использовать метатег noindex или заголовок ответа (или полностью удалить страницу).
Итак, если Google обнаружит внешние ссылки на «роботизированную» страницу, Google просканирует страницу, сохранит и проанализирует контент и использует его для построения результатов поиска…
Мы также можем представить сценарий, в котором есть исходный внешний ссылка (на странице, удаленной Google), но перенаправленная (302 или 301) на страницу справки по внутреннему поиску…
Решения
Чтобы устранить эту проблему, группе поддержки Google для веб-мастеров необходимо удалить тег Canonical, чтобы избежать конфликтов алгоритма Google , быть «совместимым с Google» и очищать результаты поиска.