
«Какие самые популярные запросы в Яндексе?» — Яндекс Кью
ПопулярноеСообществаЯндексПопулярные запросы в яндексеПопулярные поисковые запросы
Анонимный вопрос ·91,2 KОтветить1УточнитьУправление репутацией, Seciva-1Комплексный подход к управлению репутацией в Екатеринбурге. · 12 нояб 2020 · seciva.ru
ОтвечаетЕвгений ДатураПриветствую, выше уже ответили на основной вопрос и привели различные варианты топ запросов, я же хочу показать как искать такие запросы и получать точную информацию с помощью сервиса Яндекс.Вордстат (Статистика показов заданного пользователем слова или словосочетания, а также запросов, которые делали искавшие его люди)
Открываем Вордстат по ссылке и вводим любое ключевое слово или словосочетание в поисковую строку. Я ввел интересующий меня запрос «Управление репутацией»
На картинке мы видим что данную услугу ищут 5986 раз в месяц, ниже приведены схожие запросы по тематике и разновидности ключевых слов и словосочетаний.
Таким образом можно находить точные значения поисковых запросов в Яндексе. Я их использую для продвижения своих ресурсов в сети интернет и предлагаю услуги нашей организации, ниже приведен пример.
Бесплатный аудит онлайн-репутацииПерейти на seciva.ru/auditКомментировать ответ…Комментировать…Otzyvmarketing.ru8,9 KСервисы для маркетологов. 2000+ инструментов, 20000+ отзывов экспертов, кейсы и рейтинги… · 25 нояб 2019 · otzyvmarketing.ru
ОтвечаетАнастасия КузнецоваОтвет на ваш вопрос, скорее всего, покажется вам очень скучным. Дело в том, что самые популярные поисковые запросы в большинстве поисковых систем – банальны и предсказуемы. Например, вполне ожидаемо, что среди таких запросов будет «скачать», «видео» и так далее. Ежегодно «Яндекс» и Google приводят список из десяти самым популярных запросов. В целом все запросы занимают… Читать далееОтзывы о сервисах для бизнеса мы собираем тут. Перейти на otzyvmarketing.ru22,6 KСергей Гарбузов
11 декабря 2019Вы еще не упомянули запросы — «порно» и иже с нми. .. )))
.. )))
Увлекаюсь путешествиями, спортом, здоровым образом жизни. Люблю расширять свой кругозор и… · 16 апр 2018
В 2017 году популярными были запросы о Марии Максаковой, введении штрафа за отсутствие знака Ш, урагане в Москве, парке Зарядье, Юлии Самойлове, криптовалюте и спиннере.
Валентина Кутузова
8 апреля 2020Самый и вечно популярный — это где взять деньги!
Комментировать ответ…Комментировать…ПервыйДмитрий Кулаков
16 мар 2020
Самый популярный запрос на данный момент-это коронавирус! Введу того что вирус распространяется на колосальном уровне, я бы даже сказал со скоростью ветра.
Миланья Снег
27 марта 2020КоронАвирус😉 остальные ошибки перечислять не буду. Кол Вам, Дмитрий, за «русский язык».
Комментировать ответ…Комментировать…Вы знаете ответ на этот вопрос?
Поделитесь своим опытом и знаниями
Войти и ответить на вопрос1 ответ скрыт(Почему?)
Косметичка
Декабрь 12, 2022
By: Marina Dianova
Продолжая свою ежегодную традицию, компания Google опубликовала обзор Year in Search, в котором собраны самые актуальные (trending*) поисковые запросы, объем которых значительно увеличился в 2022 году по сравнению с 2020 годом. Исходя из поисковых запросов, сделанных в Латвии, можно сделать вывод, что пандемия в этом
Исходя из поисковых запросов, сделанных в Латвии, можно сделать вывод, что пандемия в этом
году не потеряла своей актуальности, однако поменялись акценты – в этом году наибольший интерес вызывали сертификаты Covid-19 и возможности вакцинации. Геополитическая ситуация, в свою очередь, резко повысила интерес жителей Латвии к Украине, поставив поиск этой соседней страны на второе место.
Ежегодный обзор от Google отражает темы, события и вопросы, которые попали в поле зрения и заслужили внимание общества. В этом году, например, такие крупные спортивные события, как чемпионат мира по футболу, хоккейный чемпионат и Олимпийские игры, интересовали людей больше, чем фестиваль Positivus или выборы Сейма, свидетельствуют результаты поисковика.
Среди брендов, которые латвийские пользователи Google стали чаще искать, – иностранные новостные источники CNN и BBC News, а также торговая сеть Lidl, которая недавно вышла на местный рынок. Кинотеатры вернули свою актуальность после ограничений, связанных с пандемией: в списке самых популярных поисковых запросов появились Apollo Kino и Forum Cinemas.
Что касается фильмов, то внимание жителей Латвии привлекли телесериалы с элементами мистики – сериалы “Stranger things” и «Перевал Дятлова» обогнали по частоте запросов подростковую драму «Euphoria» и музыкальный мультфильм «Encanto». Смерть королевы Великобритании Елизаветы II и эксцентричного российского политика Владимира Жириновского также не оставила равнодушными жителей Латвии. Мы скорбели и об уходе из жизни шеф-повара Мартиньша Ритиньша (Mārtiņš Rītiņš) и легендарного актера Арниса Лициша (Arnis Līcītis).
На первом месте в списке запросов, которые начинаются со слова «как» стоит вопрос о подаче заявления на получение пособия на дрова, а также отопление, что, несомненно, является одним из самых актуальных вопросов для большого количества жителей в этом году. Люди также регулярно интересуются темами здоровья, ищут информацию о том, как подать заявку на Covid-тест, как лечить коронавирус, снизить уровень холестерина или подать больничный лист в электронном виде. Кроме того, в этом году актуален был вопрос о том, как правильно голосовать на выборах Сейма.
Топ поисковых запросов Google в Латвии в 2022 году:
1. Covid sertifikāts
2. Ukraina
3. manavakcina
4. World Cup 2022
5. CNN
6. EUR to RUB
7. Wordle
8. Degvielas cenas
9. Lidl loterija
10. Hokejs 2022
События:
1. World Cup 2022
2. Hokejs 2022
3. Olimpiāde 2022
4. Positivus 2022
5. Vēlēšanas 2022
6. Summer Sound
7. Eurobasket 2022
8. Eurovision 2022
9. Muzeju nakts 2022
10. Latvijas Republikas proklamēšanas diena 2022
Бренды:
1. CNN
2. Lidl
3. BBC News
4. Apollo Kino
5. Flightradar24
6. Zalando
7. Rutube
8. Forum Cinemas
9. Nexta
10. Swedbank
Личности, ушедшие из жизни:
1. Queen Elizabeth
2. Vladimirs Žirinovskis (Владимир Жириновский)
3. Jurijs Šatunovs (Юрий Шатунов)
4. Mārtiņš Rītiņš
5. Arnis Līcītis
6. Ivo Goldmanis
7. Technoblade
8. Valdis Bērziņš
Valdis Bērziņš
9. Betty White
10. Ausma Kantāne
Фильмы:
1. Stranger Things
2. Djatlova pāreja
3. Eiforija
4. Encanto
5. Жизнь по вызову
6. Tinder Swindler
7. Пацанки
8. День Труда
9. Smile
10. The Summer I Turned Pretty
Запросы, начинающиеся с “Kак…”:
1. Kā pieteikties malkas pabalstam
2. Kā pieteikties uz Covid testu
3. Kā labāk dzīvot
4. Kā iesniegt B lapu VSAA elektroniski
5. Kā balsot Saeimas vēlēšanās
6. Kā pieteikties apkures pabalstam
7. Kā ārstēt Covid
8. Kā aprēķināt procentus
9. Kā samazināt holesterīnu
10. Kā pagatavot garneles
* Самые актуальные поисковые запросы (Trending Searches) — это результаты поиска Google, объем которых значительно вырос в 2022 году по сравнению с 2020 годом на длительный период времени.
Дополнительная информация об обзоре Year in Search 2022 доступна ЗДЕСЬ
Coinspeaker на Binance Feed: Российская поисковая система Яндекс добавляет криптовалюты в свой конвертер валют
Coinspeaker Российская поисковая система Яндекс добавляет криптовалюты в свой конвертер валют . Теперь, помимо данных о различных национальных валютах, пользователи также могут просматривать информацию о 143 самых популярных криптовалютах, включая биткойны (BTC), Ethereum (ETH), Binance USD (BUSD) и другие.
Теперь, помимо данных о различных национальных валютах, пользователи также могут просматривать информацию о 143 самых популярных криптовалютах, включая биткойны (BTC), Ethereum (ETH), Binance USD (BUSD) и другие.
Криптовалюты в конвертере валют Яндекса
После того, как вы введете поисковый запрос, содержащий ключевые слова, связанные с определенной криптовалютой, вы увидите ценовой график и инструмент быстрой конвертации прямо над результатами поиска. По данным Яндекса, программное обеспечение, используемое поисковой системой, способно распознавать в запросе даже сленг или ненормативную лексику.
Яндекс полагается на Coingecko, платформу ранжирования криптовалют, которая обеспечивает фундаментальный анализ рынка криптовалют, для получения данных, связанных с криптовалютами. На данный момент стоимость криптовалюты может отображаться в российских рублях, долларах США, евро и других фиатных валютах. В дальнейшем Яндекс планирует добавить больше пар, а также предложить возможность посмотреть цену той или иной монеты в другой криптовалюте.
Инициатива последовала за бумом поисковых запросов, связанных с криптовалютой, в Яндексе в 2022 году. По данным компании, в пятерку крупнейших криптовалют вошли биткойн, эфириум, лайткоин (LTC), догекоин (DOGE) и солана (SOL).
Ранее аналогичная функция была запущена в Twitter. Начиная с декабря 2022 года, пользователи Твиттера могут искать котируемые акции компаний и цены на криптовалюту, вводя тикеры криптовалюты или акций в строку поиска, чтобы получить текущую стоимость и график цен. Результат также включает ссылку на торговое приложение Robinhood. Примечательно, что эта функция недоступна в России, поскольку Twitter был заблокирован в стране, поскольку российское правительство приняло закон, предусматривающий уголовную ответственность за «фейковые» сообщения о российско-украинской войне.
Как регулируется криптовалюта в России?
Еще в январе 2021 года вступил в силу закон «О цифровых финансовых активах». Закон определил криптовалюту как «совокупность электронных данных, которые могут быть приняты в качестве платежного средства, не являющегося денежной единицей Российской Федерации или иностранного государства, а также в качестве инвестиций». Он узаконил операции с криптовалютой, но запретил их использование в качестве оплаты за товары и услуги.
Он узаконил операции с криптовалютой, но запретил их использование в качестве оплаты за товары и услуги.
Кроме того, в 2022 году Министерство финансов России продвигало свой план регулирования криптовалют в стране. В июле президент России Владимир Путин утвердил закон, запрещающий использование цифровых активов в качестве формы оплаты в стране. Однако подход немного отличается, когда речь идет о майнинге. Банк России поддержал идею легализации майнинга криптовалюты в России, но только при одном условии: майнеры должны продавать свою криптовалюту только на иностранных биржах и нерезидентам России.
Кроме того, существует вероятность того, что Россия одобрит криптовалюты для трансграничных транзакций. Это вызывает много вопросов, поскольку позиция страны в отношении криптографии весьма неоднозначна. Однако ожидается, что в 2023 году Россия внесет больше ясности в регулирование отрасли.
next
Русский поисковик Яндекс добавляет криптовалюту в свой конвертер валют
YTsaurus: Эксабайтная система хранения и обработки теперь с открытым исходным кодом | Максим Бабенко | Яндекс
Опубликовано в·
Чтение: 15 мин.
·
20 мартаЗдравствуйте, меня зовут Максим Бабенко, я руководитель отдела технологий распределенных вычислений в Яндексе. Сегодня мы рады сообщить, что выпустили платформу YTsaurus с открытым исходным кодом. YTsaurus — одна из ключевых инфраструктурных систем больших данных, разработанная в Яндексе и ранее известная как YT.
После почти десятилетия напряженной работы мы хотим поделиться YTsaurus со всем миром. В этой статье мы познакомим вас с историей развития YT, объясним, зачем нужен YTsaurus, опишем его основные возможности и наметим области, для которых он лучше всего подходит.
Репозиторий GitHub содержит серверный код для YTsaurus, инфраструктуру развертывания с использованием k8s, веб-интерфейс для системы и клиентские SDK для популярных языков программирования, таких как C++, Java, Go и Python. Все распространяется под лицензией Apache 2.0, что означает, что каждый может загрузить и модифицировать его в соответствии со своими потребностями.
История начинается в 2006 году. К тому времени Яндекс стал достаточно крупной компанией. Вопрос о том, где хранить и как обрабатывать данные компании, перестал быть простым. В то время основное внимание уделялось журналам из нескольких сервисов. Обработка журналов включала в себя множество аналитических средств, которые могли решать широкий спектр задач, от улучшения моделей машинного обучения до анализа поведения пользователей при внесении функциональных или интерфейсных изменений в сервисы.
Идея масштабируемой и эластичной системы хранения данных, которая могла бы выполнять параллельные вычисления, не заботясь о физическом расположении данных и отказоустойчивости физических компонентов кластера, уже витала в воздухе.
В 2004 году Джеффри Дин и Санджай Гемават из Google опубликовали книгу MapReduce: Simplified Data Processing on Large Clusters. Он во многом предсказал эволюцию индустрии распределенных вычислений на следующее десятилетие. Неудивительно, что похожая реализация парадигмы MapReduce появилась в Яндексе под названием YAMR — Yet Another MapReduce.
ЯМР был построен с нуля в рекордно короткие сроки и, несомненно, оказал огромное влияние на развитие внутренней инфраструктуры компании. Однако со временем стало ясно, что многие варианты дизайна, первоначально сделанные в YAMR, не позволяли системе эффективно развиваться и масштабироваться. Например, главный сервер YAMR был единственной точкой отказа и не масштабировался.
На первый взгляд может показаться, что решение построить собственную инфраструктуру — типичный случай синдрома НИЗ, а вариант использования готового решения вроде Apache Hadoop даже не рассматривался. Но это не совсем так. В сентябре 2015 года группа инженеров Яндекса отправилась в Калифорнию, чтобы встретиться с теми, кто использует стек Hadoop в продакшене. Они задавали вопросы об ограничениях, особенностях работы и ожидаемом развитии Hadoop.
Но потом стало ясно, что стек Hadoop значительно отстает, даже по сравнению с YAMR, который уже поддерживал кодирование с затиранием и подключение по IPv6. Это были далеко не единственные проблемы.
Это были далеко не единственные проблемы.
Проанализировав всё, мы решили отказаться от использования Hadoop. При этом нам пришлось выбирать между эволюционным развитием ЯМР и революционным написанием новой системы, и мы выбрали последнее решение. За пять лет до этих событий небольшая группа энтузиастов, частью которой мне посчастливилось быть, начала работу над проектом под кодовым названием YT. При должной доработке YT имел все шансы заменить YAMR.
Важно понимать, что не было возможности немедленно заменить YAMR. На пике своего развития эта система управляла кластерами, насчитывающими в общей сложности тысячи узлов, и большое количество кода приложений было основано на API YAMR. В результате процесс доработки YT и миграции с YAMR занял много лет. Подробности этой истории интересны сами по себе и, вероятно, заслуживают отдельного поста.
С 2017 года в Яндексе действует единая система MapReduce, развитие которой как по масштабам, так и по возможностям продолжается и по сей день. Сегодня компания управляет несколькими кластерами YT размером от нескольких машин до десятков тысяч серверов. Крупнейшие установки хранят эксабайты данных, используя миллионы ядер ЦП и тысячи видеокарт для круглосуточных вычислений.
Сегодня компания управляет несколькими кластерами YT размером от нескольких машин до десятков тысяч серверов. Крупнейшие установки хранят эксабайты данных, используя миллионы ядер ЦП и тысячи видеокарт для круглосуточных вычислений.
Нам потребовалось почти семь лет, чтобы ответить на вопрос: «Будет ли YT открытым исходным кодом?» Но вот оно: YT не будет с открытым исходным кодом, но YTsaurus будет!
Первоначально разработанная нами система называлась «YT». Та же аббревиатура появляется во многих частях кодовой базы. Из уст в уста в Яндексе говорят, что аббревиатура «YT» предназначалась для обозначения «Яндекс-таблицы», возможно, вдохновленной известной системой Google Big Table, но мы не смогли найти никаких надежных доказательств в поддержку этой теории. .
Когда мы решили выпустить систему с открытым исходным кодом, нам было сложно сохранить исходное название. Проблема заключалась не только в том, что это двухбуквенное сочетание часто ассоциируется с определенной популярной платформой для видеохостинга, но и в том, что сложно найти короткие названия для продуктов, которые выставлены на продажу.
В конце концов мы остановились на имени YTsaurus. У него такая же родная и знакомая приставка «YT», и наша команда всегда относилась к проекту как к живому существу. Теперь мы наконец-то знаем его расу!
В нашей кодовой базе и текстах мы часто сокращаем «YTsaurus» до «YT». Сами пока привыкаем к полному названию 🙂
Мы проектировали систему гибкой и масштабируемой, и на данный момент ее возможности не ограничиваются классической технологией MapReduce. В этом разделе я опишу основные технические возможности, доступные в версии YTsaurus с открытым исходным кодом, от низкоуровневого хранилища до высокоуровневых вычислительных примитивов.
Cypress: надежное и эффективное хранилище данных
Ядром любой системы больших данных является хранилище различных журналов, статистики, индексов и других структурированных или неструктурированных данных. YTsaurus построен на основе Cypress, отказоустойчивого хранилища на основе дерева, возможности которого можно кратко описать следующим образом: данные) в виде узлов
В основе Cypress лежит реплицированный и масштабируемый по горизонтали главный сервер, на котором хранятся метаданные о древовидной структуре Cypress, а также о составе и расположении реплик фрагментов для всех таблиц в кластере. Главные серверы реализованы как реплицированные конечные автоматы на основе Hydra, проприетарного алгоритма консенсуса, похожего на Raft.
Главные серверы реализованы как реплицированные конечные автоматы на основе Hydra, проприетарного алгоритма консенсуса, похожего на Raft.
Cypress реализует отказоустойчивый эластичный уровень данных, который используется практически во всех аспектах системы, описанных ниже.
Вычисления MapReduce и планировщик общего назначения
Несмотря на то, что технология MapReduce уже не считается новой и необычной, ее реализация в нашей системе заслуживает внимания. Мы по-прежнему используем его для вычислений с петабайтами данных, где требуется высокая пропускная способность.
MapReduce в YTsaurus имеет следующие особенности:
- Богатая базовая модель операций: классический MapReduce (с различными стратегиями перетасовки и поддержкой многоэтапного разбиения), Map, Erase, Sort и некоторые расширения классической модели, учитывающие «сортированность» входных данных
- Горизонтальная масштабируемость вычислений: операции разбиты на задания, которые выполняются на отдельных серверах
- Поддержка сотен тысяч заданий в одной операции
- Гибкая модель иерархических вычислительных пулов с мгновенными и целостными гарантиями, а также справедливой долевое распределение недоиспользованных ресурсов между потребителями без гарантий
- Модель векторных ресурсов, позволяющая запрашивать различные вычислительные ресурсы (ЦП, ОЗУ, ГП) в разных пропорциях
- Выполнение заданий на вычислительных узлах в контейнерах, изолированных ЦП, ОЗУ, файловой системой и пространством имен процессов с использованием механизма контейнеризации Porto
- Масштабируемый планировщик, способный обслуживать кластеры с числом одновременных задач до миллиона
- Практически весь ход вычислений сохраняется в случае обновлений или отказов узлов планировщика
YT поддерживает не только выполнение операций MapReduce, но и развертывание в кластере произвольного пользовательского кода.
В терминологии YT запуск произвольного кода с неопределенными побочными эффектами достигается с помощью «ванильных» операций. Мы используем эту возможность для ряда других компонентов нашей платформы, о которых я расскажу ниже.
Динамические таблицы хранения k-v
Парадигма MapReduce практически не подходит для создания конвейеров интерактивных вычислений с временем отклика менее секунды. Проблема заключается не только в том, как данные обрабатываются, но и в том, как они хранятся.
Статические таблицы YT, как и набор файлов в HDFS, могут служить входными и выходными данными для вычислений MapReduce. Однако их нельзя использовать в интерактивном сценарии, поскольку они привязаны к медленному постоянному носителю данных. Для интерактивных сценариев приложения обычно используют хранилища ключей и значений. Они могут масштабироваться горизонтально, обеспечивая доступ для чтения и записи с малой задержкой.
К счастью, в 2014 году мы начали работать над динамическими таблицами в рамках YT.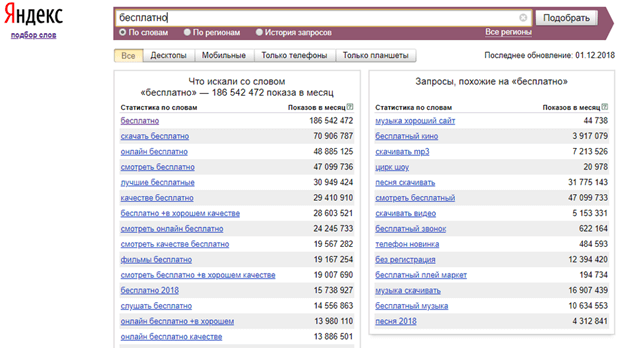 Они частично основаны на модели Apache HBase. Они масштабируются горизонтально и используют нашу распределенную файловую систему в качестве базового хранилища. Однако, в отличие от Apache HBase, динамические таблицы органично интегрированы в общую экосистему: они представляют собой узлы Cypress и могут использоваться во многих сценариях, где ожидаются статические таблицы.
Они частично основаны на модели Apache HBase. Они масштабируются горизонтально и используют нашу распределенную файловую систему в качестве базового хранилища. Однако, в отличие от Apache HBase, динамические таблицы органично интегрированы в общую экосистему: они представляют собой узлы Cypress и могут использоваться во многих сценариях, где ожидаются статические таблицы.
Например, в YT можно создать динамическую таблицу в результате операции MapReduce и использовать ее для быстрого поиска и вставки на основе ключа. В то же время вы можете создать фоновый процесс MapReduce, который обрабатывает выборку данных из динамической таблицы и вычисляет по ней некоторую статистику.
- Хранение данных в модели MVCC. Пользователи могут искать значения по ключу или временной метке
- Масштабируемость: динамические таблицы разбиты на планшеты (сегменты по диапазонам ключей), которые обслуживаются отдельными серверами
- Транзакционность: динамические таблицы представляют собой хранилище OLTP, которое может изменять множество строк в разных сегментах из разных таблиц
- Отказоустойчивость: отказ одного узла, обслуживающего планшет, приводит к перемещению этого планшета на другой узел без потери данных
- Изоляция : узлы, обслуживающие планшеты, сгруппированы в пакеты, расположенные на отдельных машинах, что обеспечивает изоляцию нагрузки
- Проверка конфликтов на уровне отдельных ключей или даже отдельных значений
- Горячие ответы данных из ОЗУ
- Встроенный SQL-подобный язык для сканирования и анализа запросов
Помимо динамических таблиц с интерфейсом хранилища k-v, система поддерживает динамические таблицы, реализующие абстракцию очереди сообщений, а именно темы и потоки. Эти очереди также можно считать таблицами, поскольку они состоят из строк и имеют собственную схему. В транзакции вы можете одновременно изменять строки как в динамической таблице k-v, так и в очереди. Это позволяет вам строить потоковую обработку поверх динамических таблиц YT с семантикой ровно один раз.
Эти очереди также можно считать таблицами, поскольку они состоят из строк и имеют собственную схему. В транзакции вы можете одновременно изменять строки как в динамической таблице k-v, так и в очереди. Это позволяет вам строить потоковую обработку поверх динамических таблиц YT с семантикой ровно один раз.
YQL
YQL — это язык запросов на основе SQL; это первый высокоуровневый примитив, созданный поверх YT. YQL занимает примерно такое же положение по отношению к YT, как Hive по отношению к Hadoop. Эта технология позволяет пользователям писать простые запросы на языке SQL, а не создавать последовательность операций MapReduce с помощью пользовательского кода. Вот пример такого запроса:
SELECT
region,
AVG(age) AS avg_age_in_region,
COUNT(DISTINCT ip) AS ips_count
FROM `//home/production/users`
ГРУППИРОВАТЬ ПО региону
ORDER BY avg_age_in_region;
Сегодня многие задачи с большими данными можно кратко сформулировать в виде SQL-запросов. Без YQL наша экосистема была бы неполной. Это один из самых популярных инструментов как для специального анализа больших наборов данных, так и для регулярных производственных расчетов.
Без YQL наша экосистема была бы неполной. Это один из самых популярных инструментов как для специального анализа больших наборов данных, так и для регулярных производственных расчетов.
Преимущества YQL:
- Мощный механизм выполнения графов, который может создавать конвейеры MapReduce с сотнями узлов и адаптироваться во время вычислений
- Возможность построения сложных конвейеров обработки данных с помощью SQL путем хранения подзапросов в переменных в виде цепочек зависимых запросов и транзакций
- Предсказуемое параллельное выполнение запросов любой сложности
- Эффективная реализация объединений, подзапросов и оконных функций без ограничений на их топология или вложение
- Обширная библиотека функций
- Поддержка пользовательских функций на C++, Python и JavaScript
- Поддержка использования моделей машинного обучения через CatBoost и TensorFlow
- Автоматическое выполнение небольших частей запросов на подготовленных вычислительных инстансах в обход MapReduce для уменьшения задержки
CHYT
Само собой разумеется, что большинство моих читателей слышали о ClickHouse. В 2016 году эта СУБД стала пионером среди открытых технологий Яндекса и оказалась настолько успешной, что в 2021 году была выделена в отдельную компанию под названием ClickHouse Inc. исполнительный движок и множество интеграций с системами BI. Одной из приятных особенностей ClickHouse является хорошее разделение частей хранения и вычислений в исходном коде, что позволило нам построить CHYT в 2018 году — интеграцию вычислительного движка ClickHouse с YTsaurus в качестве хранилища.
В 2016 году эта СУБД стала пионером среди открытых технологий Яндекса и оказалась настолько успешной, что в 2021 году была выделена в отдельную компанию под названием ClickHouse Inc. исполнительный движок и множество интеграций с системами BI. Одной из приятных особенностей ClickHouse является хорошее разделение частей хранения и вычислений в исходном коде, что позволило нам построить CHYT в 2018 году — интеграцию вычислительного движка ClickHouse с YTsaurus в качестве хранилища.
В экосистеме YTsaurus CHYT предоставляет следующие возможности
- Быстрые аналитические запросы к статическим таблицам в YT с задержкой менее секунды
- Повторное использование существующих данных в кластере YTsaurus без необходимости их копирования в отдельный кластер ClickHouse
- Возможность для интеграции (например, со сторонними системами визуализации) через собственные драйверы ODBC и JDBC ClickHouse
Отмечу, что интеграция выполнена на достаточно низком уровне. Это позволяет нам использовать весь потенциал как YTsaurus, так и ClickHouse, а именно:
Это позволяет нам использовать весь потенциал как YTsaurus, так и ClickHouse, а именно:
- Поддержка для чтения как статических, так и динамических таблиц
- Частичная поддержка транзакционной модели Ytsaurus
- Поддержка распределенных вставки
- CPU-эффективное преобразование Agagestive Data Agagestive
- 818181818181 818181 818181818181818181 гг. кэширование данных, которое в некоторых случаях позволяет считывать данные выполнения запроса исключительно из памяти экземпляра
Код сервера ClickHouse выполняется в вышеупомянутых ванильных операциях, используя те же вычислительные ресурсы, которые могут использоваться для вычислений MapReduce. В этом смысле кластер YTsaurus действует как вычислительное облако по отношению к кластерам CHYT внутри.
Это позволяет разным пользователям или командам пользователей запускать несколько кластеров CHYT в одном кластере YT, полностью изолированных друг от друга, решая проблему разделения ресурсов облачным способом.
SPYT
В 2019 году Яндекс представил SPYT, систему, которая интегрирует Apache Spark в качестве вычислительного механизма для данных, хранящихся в YT. Подобно CHYT, ванильные операции YTsaurus предоставляют вычислительные ресурсы для кластера Spark. Apache Spark изначально был разработан для упрощения подключения к стороннему хранилищу в качестве источника данных.
SPYT также хорошо зарекомендовал себя в экосистеме YTsaurus. Это один из основных способов написания процессов ETL благодаря богатым возможностям интеграции со сторонними системами. Под капотом Spark используется гибкий оптимизатор распределенных вычислений, который максимально увеличивает объем памяти для промежуточных данных и может реализовывать вычислительные конвейеры с несколькими соединениями.
Различные SDK
Часто SDK для системы на определенном языке автоматически генерируются или пишутся кем-то из сообщества пользователей и давно не поддерживаются. В нашем случае мы сами разрабатываем все API на популярных языках (C++, Python, Java, Go).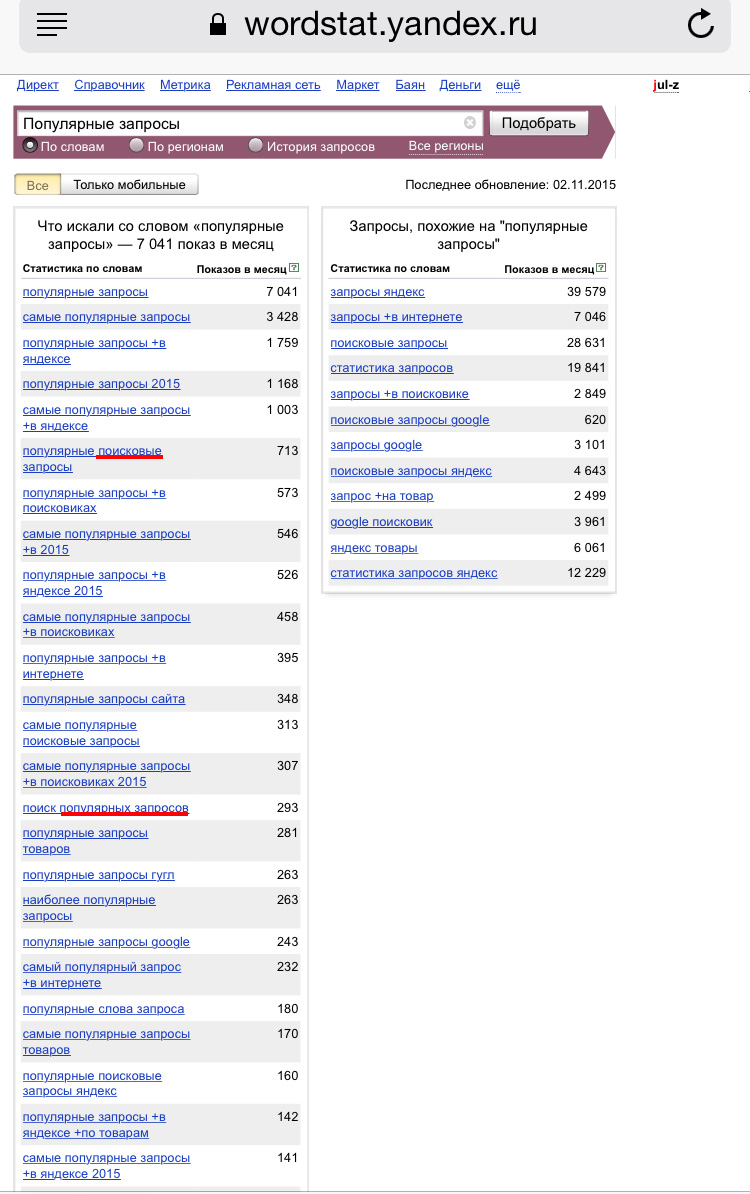 В каждом случае учитываются и продуманы все нюансы взаимодействия с системой.
В каждом случае учитываются и продуманы все нюансы взаимодействия с системой.
Наши клиентские библиотеки, написанные на разных языках, могут повторять запросы, включая чтение или запись больших объемов данных, несмотря на возможные сбои сети и другие ошибки. При создании каждой библиотеки мы учитывали особенности языков и использовали их, чтобы сделать взаимодействие с системой максимально удобным и простым.
Веб-интерфейс
Удобный веб-интерфейс является обязательным условием для системы, используемой тысячами пользователей. Более того, мы намеренно не стали создавать отдельные веб-интерфейсы для пользователей и администраторов, что уберегло нас от распространенной ситуации, когда административный веб-интерфейс делается наспех энтузиастами: ведь пользовательская сторона важнее, и незачем стыдно перед админами 🙂
Вот что вы можете делать с веб-интерфейсом YTsaurus:
- Навигация по Cypress для просмотра файлов, таблиц и других объектов
- Создание, переименование или удаление объектов Cypress и изменение их атрибутов
- Выполнение и просмотр MapReduce вычисления
- Выполнение и просмотр истории SQL-запросов по всем механизмам — YQL, CHYT, динамические таблицы SQL
- Администрирование системы: мониторинг работоспособности компонентов кластера, создание, удаление или блокировка пользователей, управление правами доступа и квотами, просмотр компонентов кластера версии и многое другое
Большая часть серверного кода написана на C++.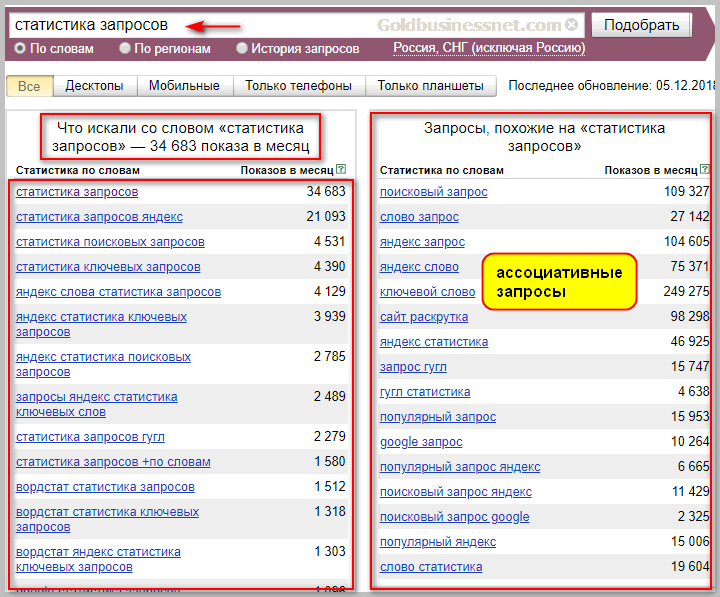 Мы любим этот язык за его богатую функциональность и эффективный код. После выпуска YTsaurus с открытым исходным кодом мы надеемся поделиться большим количеством разработок, которые могут быть полезны в виде отдельных примитивов C++.
Мы любим этот язык за его богатую функциональность и эффективный код. После выпуска YTsaurus с открытым исходным кодом мы надеемся поделиться большим количеством разработок, которые могут быть полезны в виде отдельных примитивов C++.
Серверный код создается с помощью компилятора clang и системы сборки CMake.
Отдельные части системы написаны на Go, Python и Java. Существует также API для разработки приложений, которые работают с YTsaurus на четырех упомянутых выше языках программирования.
База кода автоматически синхронизируется с внутренним хранилищем. Таким образом, актуальная версия YTsaurus всегда доступна извне.
YTsaurus работает на Linux x86–64.
Развертывание и администрирование
Внутри Яндекса установлено более 20 установок YTsaurus. Они сильно различаются по размеру и конфигурации: от 5 до 20 000+ хостов в одном кластере. YTsaurus также интегрирован с несколькими внутренними системами Яндекса, включая аутентификацию, контроль доступа, аудит, мониторинг, управление оборудованием и оркестрацию контейнеров. Все эти системы позволяют нам управлять кластерами с минимальными усилиями.
Все эти системы позволяют нам управлять кластерами с минимальными усилиями.
Для удобства пользователей мы вложили средства в разработку нашего оператора второго уровня для автоматизированного развертывания кластера YTsaurus в Kubernetes с поддержкой стандартных механизмов обновления до новой версии с даунтаймом. Оператор позволяет за несколько минут развернуть ваш кластер YTsaurus на локальной машине в миникубе, общедоступном облаке или собственной локальной установке Kubernetes.
Конфигурацией кластера можно управлять «на лету», изменяя системные узлы в дереве метаданных (Cypress). Используя основные команды Cypress, такие как list, get, set и remove, вы можете создать учетную запись, добавить пользователя или вычислительный пул, предоставить доступ к каталогу или удалить узлы кластера.
Особо следует отметить возможность динамической настройки отдельных компонентов: изменяя специальные атрибуты, вы можете настроить размеры кэша, периоды такта или параметры ведения журналов на узлах.
YTsaurus — это вычислительная платформа, поэтому подразумевается выполнение пользовательского кода. Для запуска и изоляции ненадежного кода YTsaurus использует Porto — систему контейнеризации, разработанную в Яндексе. Для полной изоляции пользователей в мультитенантном кластере рекомендуется установить Porto в качестве CRI Kubernetes. Это откроет весь спектр возможностей YTsaurus для изоляции заданий и использования настраиваемых сред в различных операциях.
И, конечно же, работа большой распределенной системы невозможна без инструментов наблюдаемости — логирования, количественного мониторинга и трассировки. YTsaurus ведет структурированные журналы для аудита и мониторинга действий пользователей, а также подробные журналы отладки для более глубокой диагностики проблем. Кроме того, система поддерживает экспорт метрик в формате Prometheus и доставку трассировки по протоколу Jaeger gRPC.
Давайте рассмотрим несколько вариантов использования нашей системы в Яндексе.
Одним из наиболее показательных и типичных вариантов использования YTsaurus является создание DWH. Например, заказы от Яндекс Такси, Яндекс Еда, Яндекс Гастроном и Яндекс Доставка поступают в динамические таблицы YTsaurus в необработанном виде с минимальной задержкой. Объем данных достигает сотен терабайт в месяц.
Затем заказы обрабатываются с помощью различных инструментов: например, большинство аналитических витрин данных готовятся с использованием YQL и SPYT. Общий объем данных превышает 6 ПБ. CHYT используется для специального анализа, а в Yandex DataLens создаются различные визуализации. Аналогичные варианты использования существуют и для других сервисов Яндекса, таких как Яндекс Маркет, Яндекс Музыка и Яндекс Путешествия.
Существуют также очень специфические варианты использования. Например, все три суперкомпьютера Яндекса управляются планировщиком YTsaurus. Многие узлы с различными типами графических процессоров подключены к YT и распределены по разным деревьям пулов.