
Чем опасны ДРФ в Яндекс Директ?
Приветствую, друзья, на связи Евгений Тридчиков, и в этом видео мы поговорим про дополнительные релевантные фразы в Яндекс Директ и их опасность для Вашего бюджета.
Лень читать? Смотрите видео в конце статьи!
Что такое ДРФ?
Дополнительные релевантные фразы – функция в Яндекс Директе, которая настраивается на уровне кампании и позволяет расширить охват рекламы за счет новых ключевых фраз, которые будет подбирать сама система.
Ссылку на справку я привожу ниже:
https://yandex.ru/support/direct/keywords/related-keywords.html
Вы должны знать принцип работы данной функции. Дело в том, что при включении ДРФ, мы начинаем собирать запросы, показываться по запросам, которые являются близкими по смыслу к фразе.
Но дело в том, что эта близость определяется системой, а не нами и очень часто случается ситуация, когда данные близкие варианты совсем нерелевантны, в этом и заключается главная опасность. И прямо сейчас я покажу Вам очень убедительный пример.
И прямо сейчас я покажу Вам очень убедительный пример.
Пример работы ДРФ
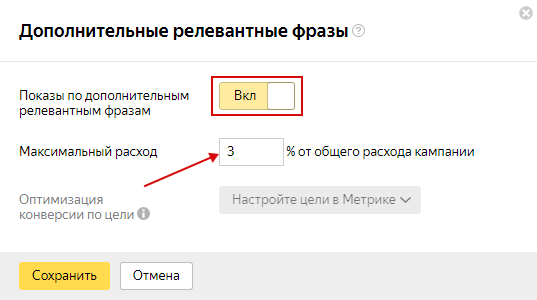
Итак, для начала перемещаемся в рекламную кампанию, в которой некоторое время работала функция дополнительных релевантных фраз. Эта функция активируется на уровне кампании в параметрах – в разделе оптимизации фраз (минус фразы).
Жмем кнопку изменить. Здесь Вы можете включить, отключить ДРФ, можете задать их максимальный расход от общего рекламного бюджета кампании, а также задать оптимизацию конверсии по цели, либо не задавать этого.
Для того, чтобы оптимизация начала работать, система должна накопить определенную статистику. То есть, Вы должны получить определенную репрезентативную выборку по конверсии.
Как оценить, релевантный трафик или нет?
Чтобы оценить трафик по дополнительным релевантным фразам идем в мастер отчетов, значит статистика кампании, затем мастер отчетов. Выбираем интересующий нас временной период. Давайте выберем за 90 дней. Здесь нас интересует тип соответствия. Жмем показать.
Жмем показать.
Это общий список, который показывает соотношение трафика по ключевым фразам, по ДРФ и по синонимам. Как Вы видите, по дополнительным релевантным фразам мы собрали столько же трафика, сколько по ключевым фразам, и примерно столько же бюджета.
Ну что ж давайте оценим на сколько релевантными оказались поисковые запросы, которые привели дополнительные релевантные фразы.
Все дело в поисковых запросах
Так, вкладка поисковые запросы. Для удобства, чтобы отчет не растягивался по горизонтали, убираем лишние столбцы. Я оставлю расход, чтобы показать Вам расход по конкретным дополнительным релевантным фразам.
В срезах убираем номер объявления, тип соответствия, подобранную фразу оставим и условия показа, то есть саму фразу, которая вызвала ДРФ, тоже оставляем.
В условиях фильтрации задаем тип соответствия – дополнительные релевантные фразы, без типа убираем. Таким образом, мы просто сейчас пытаемся вывести на экран отчет именно по дополнительным релевантным фразам без синонимов и без стандартных показов по фразам.
Итак, сортируем по расходу. Все-таки не удалось мне избежать, немножко уменьшу масштаб, я думаю, спасет. Да. Отобразилось. Чтобы не было горизонтального скрола. Итак, столбец расход. Нажмем сортировочку, чтобы сразу вопиющие случаи показать.
Итак, в чем суть? В столбце условия показа эта ключевая фраза, которая вызвала показ объявления, так как мы отфильтровали по ДРФ, то система, видя вот эту фразу «Регистрация гбо в Перми», решила подобрать фразу «академия гбо Пермь», то есть эта фраза является дополнительной, так называемая ДРФ.
Система считает, что это близкий вариант является для нас нужным и показывает объявления по запросу «академия гбо Пермь».
Таким образом, значение столбца Вы поняли. Это просто сама дополнительная релевантная фраза, которая была подобрана системой. Поисковый запрос может от нее отличаться. Ведь фраза и запрос – это разные вещи.
Таким образом, для нас сейчас интересны столбец «поисковый запрос» и «условия показа». Условия показа – это фраза. Эти фразы используются в рекламной кампании. Как видите, «регистрация газового оборудования».
Условия показа – это фраза. Эти фразы используются в рекламной кампании. Как видите, «регистрация газового оборудования».
Здесь нужно объяснить, что на сайте предлагается услуга по оформлению бумаг, именно оформление документации по изменению конструкции транспортных средств.
Например, человек ставит газовое оборудование себе на машину. Это дело надо официально задокументировать, то есть оформить. Вот как раз он едет за этим, можно сказать в бухгалтерскую контору. Они ему делают под ключ документы. И он свободно катается без штрафов. Если он будет кататься с газовым оборудованием, которое не будет зарегистрировано, то он получит штраф.
Это касается и тюнинга, переоборудование простого автомобиля в учебный, когда добавляются педали на пассажирском сидении. Эти все вещи должны регистрироваться. Это бухгалтерская работа.
Здесь нужно понимать, что работа с этими документами – это не установка самого ГБО, не установка газа, не установка переоборудования, не тонировка тачки. Есть услуга монтажа этих всех вещей, а есть услуга работы с бумагами.
Есть услуга монтажа этих всех вещей, а есть услуга работы с бумагами.
Так вот на сайте не предлагается услуга установки и так далее. Хорошо? Мы предлагаем услугу именно оформления, регистрации, лабораторные вещи, но не установки, не продажу этого оборудования.
И вот, что у нас получается, мы потратили шесть тысяч на показ объявления по следующим запросам «академия гбо пермь». Что это такое? Я в этом не силен, но что за академия такая? Там учат работать с заказанным оборудованием, или что? Дальше, «постановка на учет автомобиля», а фраза «гбо в гибдд».
«Гбо Пермь» рекламируется по фразе «регистрация газового оборудования». Мы показываемся по запросу, который даже не содержит этих слов. Гбо Пермь, ну наверняка человек ищет именно газовое оборудование.
«Замена двигателя», «академия» опять, «газовое оборудование на автомобиль пермь адреса цены», то есть он хочет понять, сколько стоит установка, но установку мы не предлагаем, мы хотим с бумагами помогать. Опять-таки, «гбо», «гбо», «не ставят на учет…», «какие нужны документы на замену двигателя» – это уже ближе.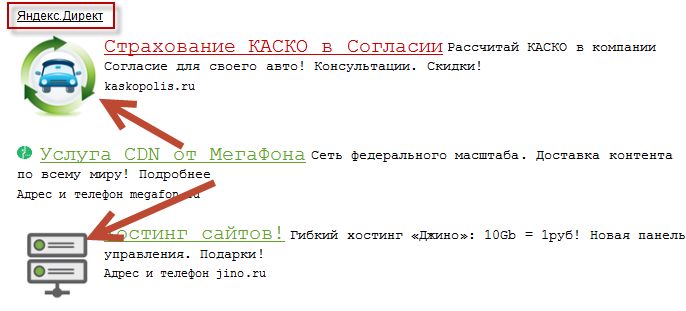
«Газобаллонное оборудование» – это вообще не по теме. Как Вы понимаете то, что человек ищет газовое оборудование, понятно, что он в будущем может стать нашим клиентом, что ему так или иначе придется оформлять это все дело, но пока он находится на другом этапе.
На наш сайт попав, он не увидит релевантного предложения, мы не сможем ему помочь. Таким образом, здесь у нас есть запрос «гбо 4 поколения», есть еще и пятого.
В чем же суть?
Короче, если вот так вот посмотреть, дополнительные релевантные фразы настолько расширяют нашу аудиторию, что начинают транслировать объявления по нерелевантным запросам.
Если так сравнивать, то можно сказать, что подключение функции дополнительные релевантные фразы аналогично широкому типу Google Adwords, когда возможны показы по близким вариантам. Эти близкие варианты вовсе неблизкие.
Какой же вывод можно сделать из всего этого, друзья? Поскольку дополнительные релевантные фразы, по умолчанию, активированы в рекламной кампании, нам нужно отключить их при запуске, и включить их только в том случае, когда нам это необходимо.

То есть работать с этим инструментом нужно аккуратно. В первую очередь, мы работаем от частного к общему. Сначала, мы окучиваем ту аудиторию, в которой мы уверены, то есть крутимся по фразам, которые мы используем.
Если нам мало трафика, или мы проводим брендинговую кампанию, то есть кампанию, в которой критерием является не количество обращений, а количество показов аудитории, то тогда мы используем ДРФ.
Так же дополнительные релевантные фразы можно активировать, когда мало трафика и мы хотим найти новые ключевые фразы, или что-то упустили, может какой-то сегмент аудитории мы не охватили, тогда мы включаем ДРФ.
Анализируем ее и вычленяем, как бы просеиваем из всего мусора и находим ключевые фразы, которые добавляем в рекламную кампанию. Но все же я рекомендую на начальном этапе отключать дополнительные релевантные фразы.
Заключение
Что ж, друзья, если Вы узнали что такое ДРФ, узнали, как сэкономить свой рекламный бюджет на старте, ставьте пальцы вверх, будет приятно.
А кроме того рекомендую пройти курс молодого бойца по контекстной рекламе. С помощью этих пошаговых видео Вы настроите свои первые рекламные кампании и ни за что не сольете бюджет. С Вами был Евгений Тридчиков. Хорошего дня!
Как добавить ключевые слова в Директ, добавление через Коммандер
Зачем нужны ключевики?
Ключевые слова расширяют количество потенциальных клиентов и охват аудитории. Так, например, для бизнеса продажа ноутбуков недостаточно рекламироваться только по основным словам. Ведь различная аудитория ищет по-разному. Так взрослые могут искать “купить ноутбук” чтобы выбрать конкретную модель с помощью консультанта, игроманы напишут “DELL G5 15 5587 цена”, а если с моделью пока не определились, то вобьют “собрать игровой ноут”.
При этом бизнес должен понимать свою аудиторию и уметь говорить на одном языке. И если не использовать в семантике жаргонные слова, артикулы и сокращения, то можно сражаться с конкурентами в ожесточенной борьбе.
А если вы будете максимально осведомлены, как ещё ищут ваш товар и будете использовать эти запросы в своей рекламе в Яндекс Директ, то вместо сражений и кликов по завышенным ценам у вас будет “голубой океан”.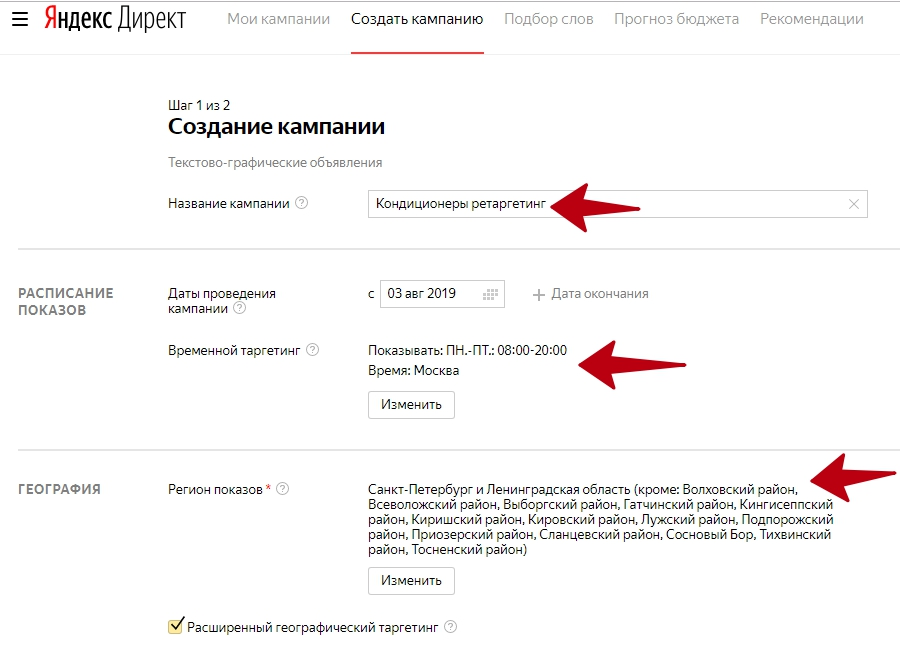
Чтобы не быть голословными на странице со всеми объявлениями мы можем посмотреть какое количество конкурентов присутствует в рекламе. Так для бизнеса по сдаче металлолома, мы нашли запрос по которому всего 3 конкурента, против 23 конкурентов по самому популярному запросу. Смысл фразы и желания клиента не теряется, а вот ваша прибыль – да. Её получает тот, кто заранее грамотно проработал ключевые слова и добавил их в рекламу.
Откуда брать новые слова для Директ?
А что делать, если вы заново создали рекламу, проработали поисковые запросы по максимуму. Воспользовались всеми советами и кажется уже добавили всё что только можно. В этом случае вам остается только следить за тем, что же на самом деле вбивают ваши клиенты в поисковую строку Яндекса, прежде чем попадут к вам на сайт.
Чтобы ответить на вопрос какие слова добавлять и откуда их брать, вам нужно будет посмотреть несколько отчетов.
Синонимы и ДРФ (дополнительные релевантные фразы).
Заходим в Мастер отчётов и настраиваем
- Группировка – за выбранный период
- Даты – например 365 дней
- Раскрываем Показать выбранные срезы, столбцы и фильтры и выбираем
- В Срезах – Условие показа (фразы, ретаргетинг и…) и Тип соответствия
- В Столбцах – Клики
- В Фильтрах – жмём + Условие фильтрации
- В поиске по фильтрам пишем “тип” и выбераем отчёт Тип соответствия
- Снимаем выделения с Без типа соответствия.
 И выделяем Синонимы и ДРФ
И выделяем Синонимы и ДРФ - Жмём показать
 И выделяем Синонимы и ДРФ
И выделяем Синонимы и ДРФТаким образом мы увидим слова, которые не использованы в нашей семантике, и мы сможем взять для себя запрос полностью или частично.
Отчёт поисковые запросы в Директ.
Теперь переходим в отчет Поисковые запросы
- В Срезах снимаем все галочки, кроме первой
- В Столбцах оставляем клики
- И по желанию можем выставить Фильтр.
- Например количество кликов от 1, чтобы сузить поле для поиска запросов и убрать совсем мусорные
- Жмём показать
Сортируем все запросы по первому столбцу, чтобы они шли в удобном порядке по алфавиту и смотрим какие запросы мы не использовали и что можем добавить в свою рекламную компанию.
Как добавить ключевые слова в Директ?
Чтобы изменить список слов в компании, вы можете воспользоваться классическим редактированием компании через браузер или сделать это в Коммандере. Поскольку этот блог предназначен, для обучения и для новичков, то для вас будет полезно постигать азы правильного и удобного управления рекламой.
Для этого открываете Direct Commander – жмёте Получить + Список компаний – затем после того как компании подгрузятся Получить + Все данные (медленнее). Выбираете компанию куда будете добавлять фразы – далее Группу – затем переходите во вкладку Фразы. Жмёте Добавить – Фразы – вставляете их и нажимаете Добавить. После этого новые фразы у вас добавляются в группу объявлений и остаются выделенными. Теперь жмём Ставки и выставляем для них нужную ставку. Теперь после того, как вы добавили поисковые фразы в группу объявлений мы должны отправить компанию Директ на сервер. Для этого нажимаем Отправить – Все данные. Всё. Осталось только дождаться модерации.
Эффективное использование сериализаторов Django REST Framework
В этой статье мы на примере рассмотрим, как более эффективно использовать сериализаторы Django REST Framework (DRF). Попутно мы углубимся в некоторые сложные концепции, такие как использование ключевого слова source , передача контекста, проверка данных и многое другое.
В этой статье предполагается, что вы уже хорошо разбираетесь в Django REST Framework.
- Что покрывается?
- Проверка пользовательских данных
- Проверка пользовательских полей
- Проверка на уровне объекта
- Функциональные валидаторы
- Пользовательские выходные данные
- to_representation()
- to_internal_value()
- Serializer Save
- Передача данных непосредственно в сохранение
- Контекст сериализатора
- Исходное ключевое слово
- Переименовать выходные поля сериализатора
- Прикрепить ответ функции сериализатора к данным
- Добавление данных из моделей один к одному
- SerializerMethodField
- Различные сериализаторы чтения и записи
- Поля только для чтения
- Вложенные сериализаторы
- Явное определение
- Использование поля глубины
- Заключение
Что покрывается?
В этой статье рассматриваются:
- Проверка данных на уровне поля или объекта
- Настройка вывода сериализации и десериализации
- Передача дополнительных данных при сохранении
- Передача контекста сериализаторам
- Переименование полей вывода сериализатора
- Присоединение ответов функции сериализатора к данным
- Извлечение данных из моделей один к одному
- Присоединение данных к сериализованному выводу
- Создание отдельных сериализаторов чтения и записи
- Установка полей только для чтения
- Обработка вложенной сериализации
Понятия, представленные в этой статье, не связаны друг с другом.
 Я рекомендую прочитать статью в целом, но не стесняйтесь оттачивать концепции, которые вас особенно интересуют.
Я рекомендую прочитать статью в целом, но не стесняйтесь оттачивать концепции, которые вас особенно интересуют.Пользовательская проверка данных
DRF обеспечивает проверку данных в процессе десериализации, поэтому вам необходимо вызвать is_valid() перед доступом к проверенным данным. Если данные недействительны, ошибки затем добавляются к свойству сериализатора error и выдается ошибка ValidationError .
Существует два типа настраиваемых валидаторов данных:
- Пользовательское поле
- Уровень объекта
Давайте рассмотрим пример. Предположим, у нас есть Movie
из моделей импорта django.db
класс Фильм (модели.Модель):
название = модели.CharField(max_length=128)
описание = модели.TextField(max_length=2048)
выпуск_дата = модели.DateField()
рейтинг = модели.PositiveSmallIntegerField()
us_gross = models.IntegerField (по умолчанию = 0)
world_gross = models. IntegerField (по умолчанию = 0)
защита __str__(я):
вернуть f'{self.title}'
 IntegerField (по умолчанию = 0)
защита __str__(я):
вернуть f'{self.title}'
IntegerField (по умолчанию = 0)
защита __str__(я):
вернуть f'{self.title}'
Наша модель имеет название , описание 9.
У нас также есть простой ModelSerializer , который сериализует все поля:
из сериализаторов импорта rest_framework
из примеров.импорт моделей Фильм
класс MovieSerializer (сериализаторы.ModelSerializer):
Мета класса:
модель = фильм
поля = '__all__'
Предположим, что модель действительна, только если верны оба этих условия:
-
рейтингнаходится между 1 и 10 -
us_grossменьшеworld_gross
Для этого мы можем использовать специальные валидаторы данных.
Проверка настраиваемого поля
Проверка настраиваемого поля позволяет нам проверять конкретное поле. Мы можем использовать его, добавив метод validate_ в наш сериализатор следующим образом:
из сериализаторов импорта rest_framework из примеров.
 импорт моделей Фильм
класс MovieSerializer (сериализаторы.ModelSerializer):
Мета класса:
модель = фильм
поля = '__all__'
def validate_rating (я, значение):
если значение < 1 или значение > 10:
поднять сериализаторы. ValidationError («Рейтинг должен быть от 1 до 10».)
возвращаемое значение
импорт моделей Фильм
класс MovieSerializer (сериализаторы.ModelSerializer):
Мета класса:
модель = фильм
поля = '__all__'
def validate_rating (я, значение):
если значение < 1 или значение > 10:
поднять сериализаторы. ValidationError («Рейтинг должен быть от 1 до 10».)
возвращаемое значение
Наш метод
Проверка на уровне объекта
Иногда вам придется сравнивать поля друг с другом, чтобы проверить их. Вот когда вы должны использовать подход проверки на уровне объекта.
Пример:
из сериализаторов импорта rest_framework
из примеров.импорт моделей Фильм
класс MovieSerializer (сериализаторы.ModelSerializer):
Мета класса:
модель = фильм
поля = '__all__'
проверка проверки (я, данные):
если данные ['us_gross'] > данные ['worldwide_gross']:
поднять сериализаторы. ValidationError («worldwide_gross не может быть больше, чем us_gross»)
возвращаемые данные
Метод validate гарантирует, что us_gross никогда не превысит world_gross .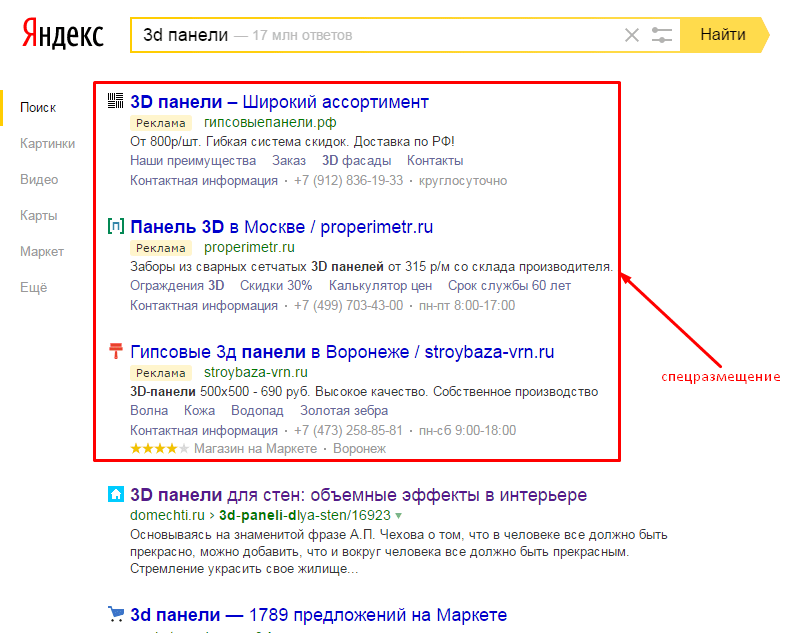
Вам следует избегать доступа к дополнительным полям в валидаторе настраиваемых полей через
self.initial_data. Этот словарь содержит необработанные данные, что означает, что ваши типы данных не обязательно будут соответствовать требуемым типам данных. DRF также добавит ошибки проверки в неправильное поле.
Функциональные валидаторы
Если мы используем один и тот же валидатор в нескольких сериализаторах, мы можем создать функциональный валидатор вместо того, чтобы писать один и тот же код снова и снова. Давайте напишем валидатор, который проверяет, находится ли число в диапазоне от 1 до 10:
по определению is_rating(значение):
если значение < 1:
поднять сериализаторы. ValidationError («Значение не может быть меньше 1».)
Элиф значение> 10:
поднять сериализаторы. ValidationError («Значение не может быть выше 10»)
Теперь мы можем добавить его к нашему MovieSerializer вот так:
из сериализаторов импорта rest_framework из примеров.импорт моделей Фильм класс MovieSerializer (сериализаторы.ModelSerializer): рейтинг = IntegerField (валидаторы = [is_rating]) ...

Пользовательские выходные данные
Две наиболее полезные функции класса BaseSerializer , которые мы можем переопределить, — это to_representation() и to_internal_value() . Переопределяя их, мы можем изменить поведение сериализации и десериализации соответственно, чтобы добавлять дополнительные данные, извлекать данные и обрабатывать отношения.
-
to_representation()позволяет нам изменить вывод сериализации -
to_internal_value()позволяет нам изменить вывод десериализации
Предположим, у вас есть следующая модель:
из django.contrib.auth.models import User
из моделей импорта django.db
Ресурс класса (модели.Модель):
название = модели.CharField(max_length=256)
содержимое = модели.TextField()
like_by = models. ManyToManyField(to=User)
защита __str__(я):
вернуть f'{self.title}'
 ManyToManyField(to=User)
защита __str__(я):
вернуть f'{self.title}'
ManyToManyField(to=User)
защита __str__(я):
вернуть f'{self.title}'
У каждого ресурса есть заголовок , контент и лайки 9поле 0004. like_by представляет пользователей, которым понравился ресурс.
Наш сериализатор определен так:
из сериализаторов импорта rest_framework
из examples.models импортировать ресурс
класс ResourceSerializer (сериализаторы.ModelSerializer):
Мета класса:
модель = ресурс
поля = '__all__'
Если мы сериализуем ресурс и получим доступ к его свойству data , мы получим следующий вывод:
{
"идентификатор": 1,
"title": "C++ с примерами",
"content": "Это контент ресурса.",
"нравится_by": [
2,
3
]
}
to_representation()
Теперь предположим, что мы хотим добавить общее количество лайков к сериализованным данным. Самый простой способ добиться этого — реализовать метод to_representation в нашем классе сериализатора:
из сериализаторов импорта rest_framework.
 из examples.models импортировать ресурс
класс ResourceSerializer (сериализаторы.ModelSerializer):
Мета класса:
модель = ресурс
поля = '__all__'
def to_representation (я, экземпляр):
представление = super().to_representation(экземпляр)
представление['лайки'] = instance.liked_by.count()
возвратное представление
из examples.models импортировать ресурс
класс ResourceSerializer (сериализаторы.ModelSerializer):
Мета класса:
модель = ресурс
поля = '__all__'
def to_representation (я, экземпляр):
представление = super().to_representation(экземпляр)
представление['лайки'] = instance.liked_by.count()
возвратное представление
Этот фрагмент кода извлекает текущее представление, добавляет к нему нравится и возвращает его.
Если мы сериализуем другой ресурс, то получим следующий результат:
{
"идентификатор": 1,
"title": "C++ с примерами",
"content": "Это контент ресурса.",
"нравится_by": [
2,
3
],
"нравится": 2
}
to_internal_value()
Предположим, сервисы, использующие наш API, добавляют ненужные данные в конечную точку при создании ресурсов:
{
"Информация": {
"дополнительно": "данные",
...
},
"ресурс": {
"идентификатор": 1,
"title": "C++ с примерами",
"content": "Это контент ресурса. ",
"нравится_by": [
2,
3
],
"нравится": 2
}
}
 ",
"нравится_by": [
2,
3
],
"нравится": 2
}
}
",
"нравится_by": [
2,
3
],
"нравится": 2
}
}
Если мы попытаемся сериализовать эти данные, наш сериализатор выйдет из строя, поскольку он не сможет извлечь ресурс.
Мы можем переопределить to_internal_value() для извлечения данных ресурса:
из сериализаторов импорта rest_framework
из examples.models импортировать ресурс
класс ResourceSerializer (сериализаторы.ModelSerializer):
Мета класса:
модель = ресурс
поля = '__all__'
def to_internal_value (я, данные):
resource_data = данные ['ресурс']
вернуть super().to_internal_value(resource_data)
Ура! Наш сериализатор теперь работает как положено.
Serializer Save
Вызов save() либо создаст новый экземпляр, либо обновит существующий экземпляр, в зависимости от того, был ли передан существующий экземпляр при создании экземпляра класса сериализатора:
# это создает новый экземпляр сериализатор = MySerializer (данные = данные) # это обновляет существующий экземпляр сериализатор = MySerializer (экземпляр, данные = данные)
Передача данных непосредственно для сохранения
Иногда вам может понадобиться передать дополнительные данные в момент сохранения экземпляра. Эти дополнительные данные могут включать такую информацию, как текущий пользователь, текущее время или данные запроса.
Эти дополнительные данные могут включать такую информацию, как текущий пользователь, текущее время или данные запроса.
Вы можете сделать это, включив дополнительные аргументы ключевого слова при вызове save() . Например:
serializer.save(владелец=request.user)
Имейте в виду, что значения, переданные в
save(), не будут проверены.
Контекст сериализатора
В некоторых случаях вам необходимо передать дополнительные данные вашим сериализаторам. Это можно сделать с помощью свойства сериализатора контекста . Затем вы можете использовать эти данные внутри сериализатора, например to_representation или при проверке данных.
Вы передаете данные в виде словаря через контекст ключевое слово:
из сериализаторов импорта rest_framework
из examples.models импортировать ресурс
ресурс = Resource.objects.get(id=1)
сериализатор = ResourceSerializer (ресурс, контекст = {'ключ': 'значение'})
Затем вы можете получить его внутри класса сериализатора из словаря self. следующим образом: context
context
из сериализаторов импорта rest_framework
из examples.models импортировать ресурс
класс ResourceSerializer (сериализаторы.ModelSerializer):
Мета класса:
модель = ресурс
поля = '__all__'
def to_representation (я, экземпляр):
представление = super().to_representation(экземпляр)
представление['ключ'] = self.context['ключ']
возвратное представление
Выходные данные нашего сериализатора теперь будут содержать ключ со значением .
Исходное ключевое слово
Сериализатор DRF поставляется с исходным ключевым словом , которое является чрезвычайно мощным и может использоваться в различных сценариях. Мы можем использовать его для:
- Переименовать поля вывода сериализатора
- Прикрепить ответ функции сериализатора к данным
- Получение данных от моделей один к одному
Допустим, вы создаете социальную сеть, и у каждого пользователя есть свои UserProfile , который имеет отношение один к одному с моделью User :
from django.
 contrib.auth.models import User
из моделей импорта django.db
класс UserProfile (модели.Модель):
user = models.OneToOneField(to=User, on_delete=models.CASCADE)
био = модели.TextField()
рождения_дата = модели.DateField()
защита __str__(я):
вернуть профиль f'{self.user.username}'
contrib.auth.models import User
из моделей импорта django.db
класс UserProfile (модели.Модель):
user = models.OneToOneField(to=User, on_delete=models.CASCADE)
био = модели.TextField()
рождения_дата = модели.DateField()
защита __str__(я):
вернуть профиль f'{self.user.username}'
Мы используем ModelSerializer для сериализации наших пользователей:
класс UserSerializer(сериализаторы.ModelSerializer):
Мета класса:
модель = пользователь
fields = ['id', 'имя пользователя', 'электронная почта', 'is_staff', 'is_active']
Сериализуем пользователя:
{
"идентификатор": 1,
"имя пользователя": "админ",
"email": "[электронная почта защищена]",
"is_staff": правда,
"is_active": правда
}
Переименовать поля вывода сериализатора
Чтобы переименовать поле вывода сериализатора, нам нужно добавить новое поле в наш сериализатор и передать его в поля свойство.
класс UserSerializer (сериализаторы.ModelSerializer):
активный = сериализаторы.BooleanField (источник = 'is_active')
Мета класса:
модель = пользователь
fields = ['id', 'имя пользователя', 'электронная почта', 'is_staff', 'активный']
Наше активное поле теперь будет называться active вместо is_active .
Прикрепить ответ функции сериализатора к данным
Мы можем использовать источник , чтобы добавить поле, равное возвращаемому функцией.
класс UserSerializer(сериализаторы.ModelSerializer):
полное_имя = сериализаторы.CharField(источник='get_full_name')
Мета класса:
модель = пользователь
fields = ['id', 'имя пользователя', 'полное_имя', 'электронная почта', 'is_staff', 'активный']
get_full_name()— это метод пользовательской модели Django, который объединяетuser.first_nameиuser.last_name.

Теперь наш ответ будет содержать full_name .
Добавление данных из моделей один к одному
Теперь давайте предположим, что мы также хотим включить bio и birth_date нашего пользователя в UserSerializer . Мы можем сделать это, добавив дополнительные поля в наш сериализатор с ключевым словом source.
Давайте изменим наш класс сериализатора:
класс UserSerializer(serializers.ModelSerializer):
био = сериализаторы.CharField (источник = 'userprofile.bio')
Birthday_date = сериализаторы.DateField (источник = 'userprofile.birth_date')
Мета класса:
модель = пользователь
поля = [
'id', 'имя пользователя', 'электронная почта', 'is_staff',
'is_active', 'био', 'дата_рождения'
] # обратите внимание, мы также добавили сюда новые поля
Мы можем получить доступ к пользовательскому профилю.<имя_поля> , потому что это отношение один к одному с нашим пользователем.
Это наш окончательный ответ JSON:
{
"идентификатор": 1,
"имя пользователя": "админ",
"электронная почта": "",
"is_staff": правда,
"is_active": правда,
"bio": "Это моя биография.",
"дата_рождения": "1995-04-27"
}
SerializerMethodField
SerializerMethodField — это поле, доступное только для чтения, которое получает свое значение путем вызова метода класса сериализатора, к которому оно прикреплено. Его можно использовать для присоединения любых данных к сериализованному представлению объекта.
SerializerMethodField получает свои данные, вызывая get_ .
Если бы мы хотели добавить атрибут full_name в наш сериализатор User , мы могли бы добиться этого следующим образом:
from django.contrib.auth.models import User
из сериализаторов импорта rest_framework
класс UserSerializer (сериализаторы.ModelSerializer):
полное_имя = сериализаторы. SerializerMethodField()
Мета класса:
модель = пользователь
поля = '__all__'
def get_full_name (я, объект):
вернуть f'{obj.first_name} {obj.last_name}'
 SerializerMethodField()
Мета класса:
модель = пользователь
поля = '__all__'
def get_full_name (я, объект):
вернуть f'{obj.first_name} {obj.last_name}'
SerializerMethodField()
Мета класса:
модель = пользователь
поля = '__all__'
def get_full_name (я, объект):
вернуть f'{obj.first_name} {obj.last_name}'
Этот фрагмент кода создает пользовательский сериализатор, который также содержит full_name , который является результатом функции get_full_name() .
Различные сериализаторы чтения и записи
Если ваши сериализаторы содержат много вложенных данных, которые не требуются для операций записи, вы можете повысить производительность API, создав отдельные сериализаторы чтения и записи.
Вы делаете это, переопределяя метод get_serializer_class() в вашем ViewSet вот так:
из rest_framework импортирует наборы представлений
из .models импортировать MyModel
из .serializers импортировать MyModelWriteSerializer, MyModelReadSerializer
класс MyViewSet(viewsets.ModelViewSet):
набор запросов = МояМодель.objects.all()
деф get_serializer_class (я):
если self. action в ["создать", "обновить", "partial_update", "уничтожить"]:
вернуть MyModelWriteSerializer
вернуть MyModelReadSerializer
 action в ["создать", "обновить", "partial_update", "уничтожить"]:
вернуть MyModelWriteSerializer
вернуть MyModelReadSerializer
action в ["создать", "обновить", "partial_update", "уничтожить"]:
вернуть MyModelWriteSerializer
вернуть MyModelReadSerializer
Этот код проверяет, какая операция REST использовалась, и возвращает MyModelWriteSerializer для операций записи и MyModelReadSerializer для операций чтения.
Поля только для чтения
Поля сериализатора поставляются с опцией только для чтения . Установив для него значение True , DRF включает поле в выходные данные API, но игнорирует его во время операций создания и обновления:
из сериализаторов импорта rest_framework
класс AccountSerializer(serializers.Serializer):
id = IntegerField (метка = 'ID', read_only = True)
имя пользователя = CharField (max_length = 32, требуется = True)
Установка таких полей, как
id,create_dateи т. д. только для чтения, повысит производительность во время операций записи.

Если вы хотите установить для нескольких полей значение read_only , вы можете указать их с помощью read_only_fields в Meta следующим образом:
из сериализаторов импорта rest_framework
класс AccountSerializer(serializers.Serializer):
id = IntegerField (метка = 'ID')
имя пользователя = CharField (max_length = 32, требуется = True)
Мета класса:
read_only_fields = ['идентификатор', 'имя пользователя']
Вложенные сериализаторы
Существует два разных способа обработки вложенной сериализации с помощью ModelSerializer :
- Явное определение
- Использование поля
глубины
Явное определение
Явное определение работает путем передачи внешнего Serializer в качестве поля нашему основному сериализатору.
Давайте рассмотрим пример. У нас есть комментарий , который определяется так:
из импорта пользователя django.
 contrib.auth.models
из моделей импорта django.db
класс Комментарий (модели.Модель):
автор = models.ForeignKey(to=User, on_delete=models.CASCADE)
datetime = models.DateTimeField (auto_now_add = True)
содержимое = модели.TextField()
contrib.auth.models
из моделей импорта django.db
класс Комментарий (модели.Модель):
автор = models.ForeignKey(to=User, on_delete=models.CASCADE)
datetime = models.DateTimeField (auto_now_add = True)
содержимое = модели.TextField()
Допустим, у вас есть следующий сериализатор:
из сериализаторов импорта rest_framework
класс CommentSerializer(serializers.ModelSerializer):
автор = UserSerializer()
Мета класса:
модель = комментарий
поля = '__all__'
Если мы сериализуем Comment , вы получите следующий вывод:
{
"идентификатор": 1,
"datetime": "2021-03-19T21:51:44.775609Z",
"content": "Это интересное сообщение.",
"автор": 1
}
Если мы также хотим сериализовать пользователя (вместо того, чтобы показывать только его идентификатор), мы можем добавить поле сериализатора author в наш комментарий :
из сериализаторов импорта rest_framework класс UserSerializer (сериализаторы.
 ModelSerializer):
Мета класса:
модель = пользователь
поля = ['id', 'имя пользователя']
класс CommentSerializer(serializers.ModelSerializer):
автор = UserSerializer()
Мета класса:
модель = комментарий
поля = '__all__'
ModelSerializer):
Мета класса:
модель = пользователь
поля = ['id', 'имя пользователя']
класс CommentSerializer(serializers.ModelSerializer):
автор = UserSerializer()
Мета класса:
модель = комментарий
поля = '__all__'
Повторите сериализацию, и вы получите следующее:
{
"идентификатор": 1,
"автор": {
"идентификатор": 1,
"имя пользователя": "админ"
},
"datetime": "2021-03-19T21:51:44.775609Z",
"content": "Это интересное сообщение."
}
Использование поля depth
Когда дело доходит до вложенной сериализации, поле depth является одной из самых мощных функций. Предположим, у нас есть три модели — ModelA , ModelB и ModelC 9.0004 . ModelA зависит от ModelB , а ModelB зависит от ModelC . Они определены так:
из моделей импорта django.db
класс ModelC (модели.Модель):
содержимое = модели. CharField(max_length=128)
класс ModelB (модели.Модель):
model_c = models.ForeignKey(to=ModelC, on_delete=models.CASCADE)
содержимое = модели.CharField(max_length=128)
класс ModelA (модели.Модель):
model_b = models.ForeignKey(to=ModelB, on_delete=models.CASCADE)
содержимое = модели.CharField(max_length=128)
 CharField(max_length=128)
класс ModelB (модели.Модель):
model_c = models.ForeignKey(to=ModelC, on_delete=models.CASCADE)
содержимое = модели.CharField(max_length=128)
класс ModelA (модели.Модель):
model_b = models.ForeignKey(to=ModelB, on_delete=models.CASCADE)
содержимое = модели.CharField(max_length=128)
CharField(max_length=128)
класс ModelB (модели.Модель):
model_c = models.ForeignKey(to=ModelC, on_delete=models.CASCADE)
содержимое = модели.CharField(max_length=128)
класс ModelA (модели.Модель):
model_b = models.ForeignKey(to=ModelB, on_delete=models.CASCADE)
содержимое = модели.CharField(max_length=128)
Наш сериализатор ModelA , который является объектом верхнего уровня, выглядит так:
из сериализаторов импорта rest_framework
класс ModelASerializer (сериализаторы.ModelSerializer):
Мета класса:
модель = МодельА
поля = '__all__'
Если мы сериализуем пример объекта, мы получим следующий вывод:
{
"идентификатор": 1,
"контент": "Контент",
"модель_б": 1
}
Теперь предположим, что мы также хотим включить содержимое ModelB при сериализации Модель А . Мы могли бы добавить явное определение в наш ModelASerializer или использовать поле depth .
Когда мы меняем depth на 1 в нашем сериализаторе следующим образом:
из сериализаторов импорта rest_framework
класс ModelASerializer (сериализаторы.ModelSerializer):
Мета класса:
модель = МодельА
поля = '__all__'
глубина = 1
Вывод изменится на следующий:
{
"идентификатор": 1,
"контент": "Контент",
"модель_б": {
"идентификатор": 1,
"контент": "Б контент",
"модель_с": 1
}
}
Если мы изменим его на 2 , наш сериализатор сериализует уровень глубже:
{
"идентификатор": 1,
"контент": "Контент",
"модель_б": {
"идентификатор": 1,
"контент": "Б контент",
"модель_с": {
"идентификатор": 1,
"content": "C-контент"
}
}
}
Недостатком является то, что вы не можете контролировать сериализацию дочерних элементов. Другими словами, при использовании глубины
будут включены все поля дочерних элементов.

Заключение
В этой статье вы узнали несколько различных советов и приемов для более эффективного использования сериализаторов DRF.
Краткое изложение того, что мы рассмотрели:
| Концепция | Метод |
|---|---|
| Проверка данных на уровне поля или объекта | validate_ или validate |
| Настройка вывода сериализации и десериализации | to_representation и to_internal_value |
| Передача дополнительных данных при сохранении | serializer.save (дополнительно = данные) |
| Передача контекста сериализаторам | SampleSerializer (ресурс, контекст = {'ключ': 'значение'}) |
| Переименование полей вывода сериализатора | источник ключевое слово |
| Присоединение ответов функции сериализатора к данным | источник ключевое слово |
| Извлечение данных из моделей один к одному | источник ключевое слово |
| Присоединение данных к сериализованному выходу | сериализаторметодфиелд |
| Создание отдельных сериализаторов чтения и записи | get_serializer_class() |
| Настройка полей только для чтения | поля только для чтения |
| Обработка вложенной сериализации | глубина поле |
Парсеры — Django REST framework
парсеры. py
py
Веб-сервисы, взаимодействующие с компьютером, как правило, используют больше структурированные форматы для отправки данных, чем закодированные в форме, поскольку они отправка более сложных данных, чем простые формы
— Малкольм Трединник, группа разработчиков Django
Платформа REST включает ряд встроенных классов Parser, которые позволяют принимать запросы с различными типами носителей. Существует также поддержка для определения ваших собственных пользовательских парсеров, что дает вам гибкость в разработке типов мультимедиа, которые принимает ваш API.
Набор допустимых парсеров для представления всегда определяется как список классов. При доступе к request.data платформа REST проверит заголовок Content-Type во входящем запросе и определит, какой синтаксический анализатор использовать для анализа содержимого запроса.
Примечание . При разработке клиентских приложений всегда помните, что при отправке данных в HTTP-запросе необходимо установить заголовок Content-Type .
Если не указать тип содержимого, большинство клиентов по умолчанию будут использовать 'application/x-www-form-urlencoded' , что может быть не тем, что вы хотели.
Например, если вы отправляете закодированные данные json с помощью jQuery с методом .ajax(), обязательно включите настройку contentType: 'application/json' .
Набор синтаксических анализаторов по умолчанию может быть установлен глобально с помощью настройки DEFAULT_PARSER_CLASSES . Например, следующие настройки разрешат только запросы с содержимым JSON вместо стандартных данных JSON или формы.
REST_FRAMEWORK = {
'DEFAULT_PARSER_CLASSES': [
'rest_framework.parsers.JSONParser',
]
}
Вы также можете установить синтаксические анализаторы, используемые для отдельного представления или набора представлений,
с использованием представлений на основе классов APIView .
из rest_framework.
 parsers импортирует JSONParser
из rest_framework.response импортировать ответ
из rest_framework.views импортировать APIView
класс ExampleView (APIView):
"""
Представление, которое может принимать запросы POST с содержимым JSON.
"""
parser_classes = [JSONParser]
сообщение о защите (я, запрос, формат = нет):
вернуть ответ ({'полученные данные': request.data})
parsers импортирует JSONParser
из rest_framework.response импортировать ответ
из rest_framework.views импортировать APIView
класс ExampleView (APIView):
"""
Представление, которое может принимать запросы POST с содержимым JSON.
"""
parser_classes = [JSONParser]
сообщение о защите (я, запрос, формат = нет):
вернуть ответ ({'полученные данные': request.data})
Или, если вы используете декоратор @api_view с представлениями на основе функций.
из rest_framework.decorators импортирует api_view
из rest_framework.decorators импортировать parser_classes
из rest_framework.parsers импортировать JSONParser
@api_view(['POST'])
@parser_classes([JSONParser])
def example_view (запрос, формат = нет):
"""
Представление, которое может принимать запросы POST с содержимым JSON.
"""
вернуть ответ ({'полученные данные': request.data})
Парсы Содержимое запроса JSON . request.data будет заполнен словарем данных.
.media_type : application/json
Разбирает содержимое формы HTML. request.data будет заполнен QueryDict данных.
Как правило, вы хотите использовать вместе FormParser и MultiPartParser , чтобы полностью поддерживать данные форм HTML.
.media_type : application/x-www-form-urlencoded
Разбирает содержимое составной HTML-формы, которая поддерживает загрузку файлов. Оба request.data будут заполнены QueryDict .
Как правило, вы хотите использовать вместе FormParser и MultiPartParser , чтобы полностью поддерживать данные форм HTML.
.media_type : multipart/form-data
Разбирает необработанный контент загружаемого файла. request.data будет словарем с одним ключом 'file' , содержащим загруженный файл.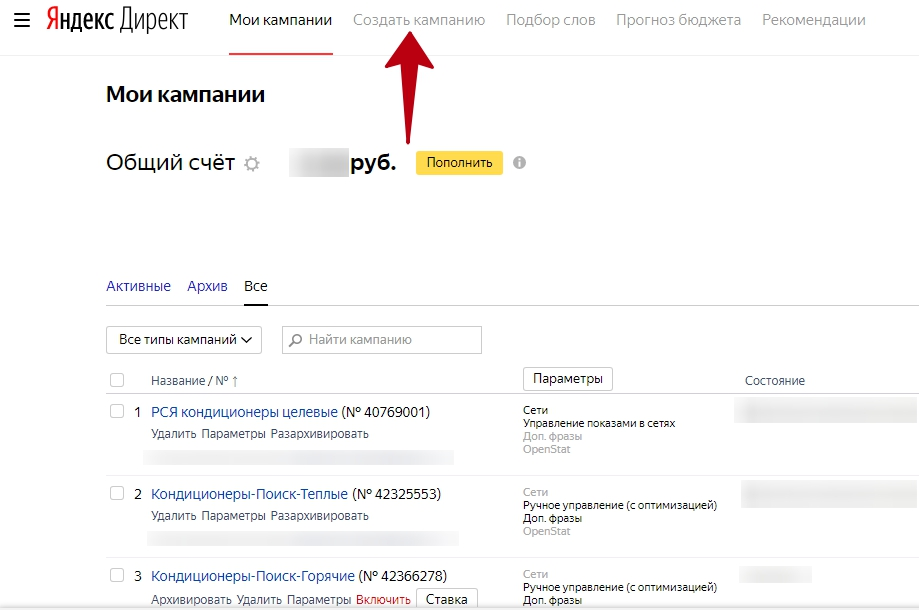
Если представление, используемое с FileUploadParser , вызывается с аргументом ключевого слова имя файла URL, то этот аргумент будет использоваться в качестве имени файла.
Если он вызывается без аргумента ключевого слова имени файла URL, то клиент должен установить имя файла в HTTP-заголовке Content-Disposition . Например, Content-Disposition: вложение; имя_файла=upload.jpg .
.media_type : */*
Примечания:
-
FileUploadParserпредназначен для использования с собственными клиентами, которые могут загружать файл как запрос необработанных данных. Для веб-загрузок или для собственных клиентов с поддержкой многокомпонентной загрузки вместо этого следует использоватьMultiPartParser. - Поскольку
media_typeэтого синтаксического анализатора соответствует любому типу контента,FileUploadParserобычно должен быть единственным синтаксическим анализатором, установленным в представлении API. /]+)$', FileUploadView.as_view())
] Чтобы реализовать собственный синтаксический анализатор, вы должны переопределить
BaseParser, установить свойство.media_typeи реализовать метод.parse(self, stream, media_type, parser_context).Метод должен возвращать данные, которые будут использоваться для заполнения свойства
request.data.Аргументы, переданные в
.parse():поток
Потоковой объект, представляющий тело запроса.
media_type
Необязательно. Если указано, это тип носителя содержимого входящего запроса.
В зависимости от заголовка запроса
Content-Type:он может быть более конкретным, чем атрибут media_type средства визуализации, и может включать параметры типа мультимедиа. Например,"text/plain; charset=utf-8".parser_context
Необязательно. Если указан, этот аргумент будет словарем, содержащим любой дополнительный контекст, который может потребоваться для анализа содержимого запроса.
По умолчанию это будет включать следующие ключи:
view,request,args,kwargs.Ниже приведен пример анализатора открытого текста, который заполняет свойство
request.dataстрокой, представляющей тело запроса.класс PlainTextParser (BaseParser): """ Парсер простого текста. """ media_type = 'текст/обычный' def parse(self, stream, media_type=None, parser_context=None): """ Просто верните строку, представляющую тело запроса. """ возвратный поток.read()Также доступны следующие сторонние пакеты.
Платформа REST YAML обеспечивает поддержку синтаксического анализа и рендеринга YAML. Ранее он был включен непосредственно в пакет инфраструктуры REST, а теперь вместо этого поддерживается как сторонний пакет.
Установка и настройка
Установить с помощью pip.
$ pip установить djangorestframework-yaml
Измените настройки среды REST.
 /]+)$', FileUploadView.as_view())
]
/]+)$', FileUploadView.as_view())
] 
