
Использование тегов noindex и nofollow в продвижении
Рад приветствовать Вас на страницах моего блога barbadosmaney.ru! В данном посте я решил написать о том, как закрыть внешние ссылки от индексации поисковыми системами и зачем все это дело нужно делать.
Статья предназначена в основном для начинающих вебмастеров, которые только недавно начали заниматься продвижением своего сайта. Данную тему, считаю, архиважной при продвижении блога или статьи блога в Топ.
Поэтому я решил осветить несколько вопросов по данной теме:
- Для чего нужно закрывать внешние ссылки от индексации.
- Закрытие внешних ссылок вручную тегами noindex и rel=”nofollow”.
- Автоматическое закрытие внешних ссылок плагином WP-NoExternalLinks.
- Сервис для проверки исходящих ссылок.
Разберемся с первым вопросом. Закрывать чужие ссылки со своего сайта следует для того, чтобы не предавать вес вашей страницы другим ресурсам, на которые ссылаетесь. Каждая страница сайта имеет свой вес. Чем больше сайтов на нее ссылаются, тем больше ее вес в глазах поисковых систем.
Каждая страница сайта имеет свой вес. Чем больше сайтов на нее ссылаются, тем больше ее вес в глазах поисковых систем.
Практически все вебмастера, занимающиеся продвижением, закрывают внешние ссылки для того, чтобы не дарить авторитет своих вебстраниц чужим ресурсам.
Так же это во многом влияет и на траст сайта. Траст сайта – это некий уровень доверия со стороны поисковых систем к сайту. Вот поэтому нужно следить за исходящими ссылками, дабы попросту не разбазаривать авторитет страниц вашего блога. И впоследствии все это положительно скажется на такие показатели как ТИЦ и PR.
Но это вовсе не говорит о том, что абсолютно все внешние ссылки нужно закрывать. Например, если сайт авторитетный и высокотрастовый почему бы на него не сослаться.
В сети есть такое мнение, что если с сайта не исходит ни одной ссылки, то значит поисковые системы считают его мертвым.
Не знаю, правда это или нет, поэтому спорить не буду. Но то, что огромное количество открытых внешних ссылок молодому блогу в продвижении не поможет – это факт.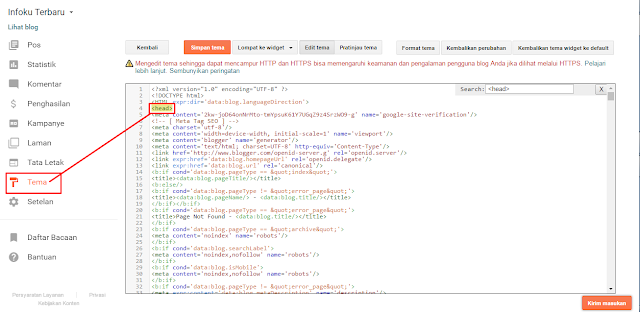
В любом случае, когда никогда придется сослаться на другой вебресурс. Что же делать, чтобы поисковые роботы таких интернет гигантов как Google и Яндекс не индексировали внешние ссылки?
Для робота Яндекса раньше закрывали ссылку атрибутом noindex, а для Google rel=”nofollow”. Но сейчас Яндекс тоже понимает тег rel=”nofollow” и не индексирует ссылку с ним.
Данный атрибут можно использовать только для ссылок, т.е. в теге <a> и не где больше. Закрытая ссылка будет выглядеть вот так:
<a href=”url” rel=”nofollow”> анкор ссылки </a>
Разберем пример обычной ссылки с названием моего сайта. До закрытия она имеет вот такой вид:
<a href=”http://barbadosmaney.ru” >Заработок в интернете</a>
После закрытия она выглядит так:
<a href=”http://barbadosmaney. ru” rel=”nofollow”>Заработок в интернете</a>
ru” rel=”nofollow”>Заработок в интернете</a>
Все, поисковые системы Яши и Гугла не будут ее индексировать. Данный атрибут надо вставлять в статью при ее написании в текстовом редакторе.
Некоторые вебмастера до сих пор используют тег noindex для ссылок, т.е. вот так:
<noindex><a href=”http://barbadosmaney.ru” >Заработок в интернете<a>< /noindex >
Не имеет ни какого смысла сейчас так делать, так как noindex запрещает индексировать только текст. То есть, в данном случае закрыт только анкор ссылки – “Заработок в интернете”, а сама ссылка остается открытой.
К такому выводу я пришел, прочитав статью от самого Яндекса. Хотя некоторые скрипты счетчиков я тегом noindex закрыл.
Автоматически закрываем исходящие ссылки от индексации плагином WP-NoExternalLinks.Данный плагин пришелся мне по душе. Он очень прост в настройке, а работа его заключается в следующем: он маскирует внешнюю ссылку под внутреннюю. Скачать плагин можно здесь.
Скачать плагин можно здесь.
После закачивания и активировании его на блоге, переходим к его настройке (редактировать в “Параметрах”). Да там и настраивать особо нечего.
Разделитель ссылок “goto” можно оставить так или изменить на “link”. В пустом окошке нужно прописать адреса сайтов, которые вы не хотите закрывать от индексации. Вот пример его работы: мы хотим сослаться на Яндекса и открытая ссылка выглядит так
http://www.yandex.ru
После работы плагина она принимает вид (на примере моего сайта)
rel=”nofollow” https://barbadosmaney.ru/goto/ http://www.yandex.ru
Ко всему прочему, по переходу по ссылке сайт открывается в новом окне. Помимо скрытия внешних ссылок в статье, маскируются также ссылки в комментариях и адреса сайтов самих комментаторов.
Самое главное, что мне нравиться в данном плагине – весь процесс автоматизирован.
Сервис для проверки внешних ссылок на сайте.Очень хороший сервис be1. ru. В нем можно проверить каждую страницу вашего сайта и провести ее анализ на количество исходящих ссылок. Закрытые ссылки помечены красным восклицательным знаком. Он показывает оба тега: noindex и rel=”nofollow”.
ru. В нем можно проверить каждую страницу вашего сайта и провести ее анализ на количество исходящих ссылок. Закрытые ссылки помечены красным восклицательным знаком. Он показывает оба тега: noindex и rel=”nofollow”.
P.S. Пользоваться или нет рекомендациями данной статьи – дело личное каждого владельца сайта.
Как использовать noindex и nofollow — Сollaborator
Как использовать noindex и nofollow
Noindex и nofollow — разные по функционалу элементы. Их часто путают, и как только не называют: тегами, метатегами, атрибутами. Расставим все точки и расскажем, чем отличается noindex от nofollow и в каких случаях их целесообразно использовать.
Теги и атрибутыТеги и атрибуты еще называют дескрипторами — это элементы разметки, с помощью которых объектам в текстовом документе придаются определенные свойства. Эти свойства зависят от языка разметки и поставленных задач. Сделать шрифт жирным, превратить кусок текста в гиперссылку или задать ей специфические визуальные характеристики.
Но есть теги, которые выполняют несколько иные функции. В их числе nofollow и noindex. В любых своих проявлениях они никак внешне не влияют на текст и ссылки. Посетитель сайта не заметит, если часть страницы обведут в тег или пометят атрибутом nofollow. Текст будет выглядеть без изменений.
Изменения произойдут на технической стороне. Отличия заметит поисковой робот, анализирующий и индексирующий веб-страницы.
Что такое noindex
Noindex (ноиндекс) – это тег и атрибут HTML-страницы, который закрывает от индексации часть страницы, которая в него заключена. Можно пометить им страницу целиком, придав ей определенные свойства, либо выбрать отдельный участок кода и применить атрибут к нему.
Функция noindex заключается в «сокрытии» контента от поисковых роботов или машин, анализирующих и индексирующих веб-сайты. Они собирают базу данных для поисковых служб и предоставляют пользователям релевантные результаты поиска.
Если какая-то часть контента на странице помечена тегом noindex, то робот ее проигнорирует и в поиске она учтена не будет, что прямо повлияет на SEO-продвижение ресурса, на котором были произведены соответствующие изменения.
Какой контент помечается этим тегом?Важно! На самом деле, робот посмотрит все, что есть на сайте. Но это правило говорит ему, что не стоит индексировать конкретную часть документа.
Любой контент. В зависимости от помеченной информации и поискового робота тег будет восприниматься по-разному.
Обычно в noindex заворачивают четыре типа текстового контента:
- Информацию с низкой уникальностью, чтобы избежать проблем с антиплагиатом.
- Коды счетчиков (типа метрики и других аналитических систем), ненужные поисковику.
- Контактные данные, номера и ссылки, которые не стоило бы показывать в поисковой выдаче.
- Постоянно меняющийся текст, индексация которого не принесет никакой пользы.
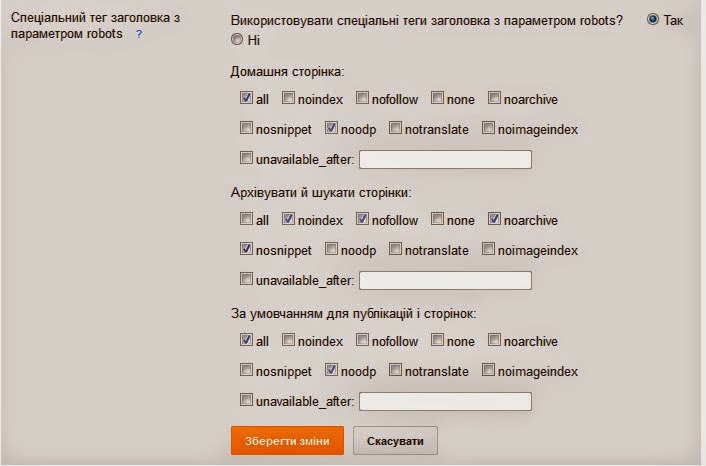
Тег можно вставить в разделе <head> страницы как мета (атрибутом), увеличив область его действия на всю страницу.
1. С таким кодом индексация страницы разрешается:
<meta name="robots" content="index"/>
2. А с таким индексация запрещается:
<meta name="robots" content="noindex"/>
3. Такое правило можно указать для конкретного робота. Например, поискового бота Google:
<meta name="googlebot" content="noindex"/>
4. Еще один способ — встраивание тегов в текст.
<noindex> кусок текста, который хотелось бы скрыть от индексации поисковиками </noindex>
Правда, такая разметка может нагородить кучю ошибок из-за того, что многие поисковики не понимают тег <noindex> и считают его наличие в тексте ошибкой. Поэтому приходится использовать его вариацию <!–noindex–>. В таком виде роботы, понимающие тег, считывают его без проблем и задают нужные свойства, а непонимающие попросту игнорируют.
Независимо от типа скрываемого контента, принцип остается тем же. Поэтому, если нужно скрыть от индексации код счетчика, ничего специфичного делать не придется. Так же оборачиваем его в <noindex> и все.
Так же оборачиваем его в <noindex> и все.
Что такое nofollow?
Nofollow — это атрибут, который вставляется перед ссылками, запрещающий по ним переходить и отдавать вес страницы.
Вес страницы — это своего рода уровень авторитетности сайтов, один из факторов, учитываемых при ранжировании страниц в поисковых запросах. Чтобы не передавать вес страницы другим сайтам по размещенным на них ссылкам, данные ссылки оборачивают в тег nofollow.
Как использовать nofollow?Атрибутом нофолов помечаются ссылки. Но не все ссылки, а те, что могут как-то негативно повлиять на вес ресурса. Это касается автоматических ссылок, появляющихся в тех или иных участках сайта. Атрибут nofollow стоило бы приписывать любым внешним ссылкам, за которые вы не можете ручаться. Например, добавленные на ресурс другими пользователями через секцию комментариев или в графу профиля БИО.
Как прописывать тег?1. С таким тегом индексирование страницы разрешается, но запрещается переход по всем ссылкам:
<meta name="robots" content="nofollow"/>
2. Как и в случае с <noindex>, правило можно задать для конкретного поискового робота:
Как и в случае с <noindex>, правило можно задать для конкретного поискового робота:
<meta name="googlebot" content="nofollow"/>
3. Если мы говорим о конкретных ссылках, то переход на них можно запретить прямо внутри разметки:
<a href="page.html" rel="nofollow"> Гиперссылка </a>
Преимущества тега noindex и атрибута nofollow
Некоторые полезные свойства тегов мы уже обсудили выше, но на эту тему можно сказать больше:
- Теги помогают сделать информацию на сайте более релевантной за счет вычленения из нее неуникального и разного рода утилитарного контента, который никак не связан с данными для посетителей. Не только пропадает текст, снижающий общую уникальность, но и увеличивается плотность вхождения ключевых слов.
- Тегами можно спрятать информацию из сквозных блоков, которые часто воспринимаются роботами как дубликаты данных.
- Мы уже упомянули выше, что за тегом <noindex> частенько прячут контактную информацию, но не пояснили зачем.
 Дело в поисковых сниппетах Яндекса и Google, в которые ненароком могут попасть номера телефонов и адреса, указанные на другом сайте или закрепленные за другой компанией в Яндекс.Справочнике.
Дело в поисковых сниппетах Яндекса и Google, в которые ненароком могут попасть номера телефонов и адреса, указанные на другом сайте или закрепленные за другой компанией в Яндекс.Справочнике. - Атрибут nofollow может прятать платные ссылки. Рекламные статьи, заметки и обзоры, размещенные на странице. Поисковикам запрещают переход по ним, чтобы избежать санкций со стороны Google или Яндекса.
- Еще nofollow нужен для распределения приоритетов сканирования. Чтобы в него не попадали всякие формы регистрации и прочие технические страницы. Сканирование этой информации никакой пользы не принесет.
 Дело в поисковых сниппетах Яндекса и Google, в которые ненароком могут попасть номера телефонов и адреса, указанные на другом сайте или закрепленные за другой компанией в Яндекс.Справочнике.
Дело в поисковых сниппетах Яндекса и Google, в которые ненароком могут попасть номера телефонов и адреса, указанные на другом сайте или закрепленные за другой компанией в Яндекс.Справочнике. Выше мы использовали <noindex> и nofollow в качестве мета-атрибутов, чтобы задать свойства всей странице целиком. Посмотрим, как разрешить для роботов весь контент и все ссылки:
<meta name="robots" content="index, follow"/>
А это полный запрет на контент и ссылки:
<meta name="robots" content="noindex, nofollow"/>
Данный тег спрячет от ботов страницу целиком, но то же самое можно сделать, указав соответствующую ссылку в графе Disallow файла robots.
Важно! Способы отличаются тем, что мета-тег разрешает поисковикам заходить на сайт и анализировать его содержимое. А вот если ссылка указана в robots.txt, то бот не сможет на нее зайти и провести индексирование.
Во избежание неадекватного поведения ботов, на уже проиндексированных страницах лучше использовать мета-теги, а в robots.txt заносите новые ссылки, неизвестные для Google и Яндекс.
Использование одного из вышеупомянутых элементов (или обоих сразу) зависит от условий, которые преследуются (сокрытие части текста, ссылки или всей страницы при использовании с мета-тегом robots).
Если нужно скрыть от робота Яндекса отдельный текст, noindex это сделает, но когда закрывается ссылка, noindex не поможет. В этом случае следует выбрать атрибут rel=nofollow.
Теперь вы знаете, какие задачи выполняют теги noindex и nofollow.
 С помощью них можно строго задать поведение поисковых ботов Google и Яндекс в отношении вашего сайта и тем самым улучшить показатели SEO.
С помощью них можно строго задать поведение поисковых ботов Google и Яндекс в отношении вашего сайта и тем самым улучшить показатели SEO.Похожие вопросы
- Что такое аутрич?
- 20 главных метатегов для сайта и как их заполнять
Ольга Горбенко
Практикующий SEO-специалист
Работа с метатегами Noindex и nofollow
27 февраля, 2019 01:14 пп 27 февраля, 2019 01:14 пп Блог Noble
Зачем нужны noindex и nofollow и как правильно пользоваться ими? Постараемся разобраться в этих вопросах поподробнее.
Атрибут rel=«nofollow» и тег – это отличающиеся элементы, используемые для создания кода страниц сайтов. Применять их будут для разных целей. Чтобы помощники оптимизаторов смогли работать правильно, стоит ознакомиться с нюансами их работы. Для начала стоит внимательно разобраться со способами использования каждого из тегов.
Тег, обозначаемый , представляет HTML-тег, который запрещает возможность индексации участка текста, закрытого в нем, для робота поисковика Яндекс. Для поисковой системы Гугл такие возможности не имеют значения, поскольку в Google не предусматривается никаких исключений для фрагментов содержащегося на странице текстов из индекса. Однако существует немало заблуждений на этот счет. Разберем наиболее распространенные.
- Первое заблуждение. Основная ошибка, допускаемая при использовании данного элемента при оптимизации сайтов: если разместить текст на участке между открывающимся и закрывающимся тегом , бот системы Яндекс не будет заниматься чтением текста и не выполняет его анализ. Тег не даст перевести содержимое в базу индексов, но стоит отметить, что оно все равно будет прочитано программой, выполняется анализ.
В качестве примера можно привести такой вариант. На странице сайта размещен текст, в котором есть предложения, выбранные из других источников в виде прямых вхождений.
 Они уменьшают уникальность, и оптимизатор пытается закрыть неугодные фрагменты тегом , полагая, что в этом случае Яндекс примет ее за 100%. Это ошибка — в любом случае текст на странице будет прочитан ботом, производится его обработка, что позволяет определить уровень настоящий уникальности.
Они уменьшают уникальность, и оптимизатор пытается закрыть неугодные фрагменты тегом , полагая, что в этом случае Яндекс примет ее за 100%. Это ошибка — в любом случае текст на странице будет прочитан ботом, производится его обработка, что позволяет определить уровень настоящий уникальности.Если задачей является техническая оптимизация сайта, стоит понимать, что тег не индексирует, следовательно, нет и запрета на проведение чтения.
Можно рассмотреть и такой вариант. Робот-поисковик посещает страницу и сканирует ее содержимого. Через некоторое время происходит открытие тега , затем текст уже не индексируется. Но для того, чтобы определить в коде участок, где будет закрываться тег, боту надо читать содержимое, расположенное после открытия. Это означает, что даже в теории нельзя давать возможность боту читать информацию, используя тег .
Зачем нужен тег ?
С ним робот получает запрет на выдачу информации в пределах какой-либо системы поиска.
- Следующая ошибка заключается в том, что ссылка, размещенная в теге , ботом не учитывается. Но все, что содержится внутри тега, робот Яндекса читает и выполняет анализ – об этом уже сказано выше. Единственное, чем отличаются ссылки, размещенные простым способом, от тех, что размещены в теге – то, что анкор не индексируется.
 Но все, что содержится внутри тега, робот Яндекса читает и выполняет анализ – об этом уже сказано выше. Единственное, чем отличаются ссылки, размещенные простым способом, от тех, что размещены в теге – то, что анкор не индексируется.
Но все, что содержится внутри тега, робот Яндекса читает и выполняет анализ – об этом уже сказано выше. Единственное, чем отличаются ссылки, размещенные простым способом, от тех, что размещены в теге – то, что анкор не индексируется.Если вебмастеру надо, чтобы робот не принимал в расчет ссылки со страниц, пользуются атрибутом rel=»nofollow». Он сработает и для Гугл, и для Яндекса. Ссылка при работе данного атрибута изучается роботом, по ней будет обязательно выполнен переход. Но без применения атрибута адресату вместе со ссылкой передается вес, который с nofollow сгорает.
Пример 1:
<noindex><a href=»https://seoprodvizheniepro.ru»>Создание и продвижение сайтов</a></noindex>Яндекс не индексирует анкор, но учитывает ссылку на seoprodvizheniepro.ru и передает по ней вес.
Пример 2:
<noindex><a href=»https://seoprodvizheniepro.ru» rel=»nofollow»>Создание и продвижение сайтов</a></noindex>Яндекс не индексирует анкор и не передает вес по ссылке на seoprodvizheniepro.
 ru
ruДля записи тега в коде есть два варианта:
- <noindex>Текст, который нельзя индексировать</noindex>
- <!—noindex—>Запрещенный текст <!—/noindex—>
Более удачным считают второй вариант. Так как тег не вошел в официальную спецификацию применяемого для разметки языка HTML, присутствие его внутри кода для других поисковиком может стать неожиданностью. Они могут посчитать его наличие за ошибочное допущение. Придание валидности коду страницы осуществляется за счет того, что для ботов выдается закомментированный вид написания. Для Яндекса распознать такое написание не составит труда, а прочие поисковики на его присутствие не обратят внимания.
Использование метатегов
Размещение в кодах страниц метатегов выступает как запрет для поисковика Яндекс выполнять индексацию текста страницы. При этом на страницах ссылки продолжают полноценно индексироваться.
Если употребляются метатеги для сайта, что это может дать? Присутствие nofollow в коде страниц не позволяет поисковикам производить индексацию. Также роботы не станут выполнять переходы по ссылкам, расположенным на страницах. В разделе «Помощь» Яндекса об этом имеется информация – сказано, что робот не станет посещать документы, на которых есть ссылки от страниц, содержащих метатеги с значением nofollow. Но может быть выполнена индексация в случаях, когда в прочих источниках есть на них ссылки без данного метатега.
Также роботы не станут выполнять переходы по ссылкам, расположенным на страницах. В разделе «Помощь» Яндекса об этом имеется информация – сказано, что робот не станет посещать документы, на которых есть ссылки от страниц, содержащих метатеги с значением nofollow. Но может быть выполнена индексация в случаях, когда в прочих источниках есть на них ссылки без данного метатега.
Заключение
Для запрещения ботам Яндекса предоставлять в выдаче информацию используем тег noindex. Nofollow (атрибут) подходит в случаях, когда необходимо, чтобы не передавался вес ссылок. Но надо помнить, что робот может все равно перейти по ссылке, если была получена информация о ней из другого источника. В этом случае страница, на которую ведет ссылка, будет проиндексирована. Работает это свойство и в Гугл, и в Яндексе.
Планируя размещение на сайта исходящих ссылок на рекламу, партнеров или клиентов, рекомендуется их закрыть в атрибут rel=”nofollow”. Это поможет не допустить, чтобы на сторонний ресурс была выполнена передача веса ссылки.
Вы можете заказать для этого наши услуги – чтобы воспользоваться возможностью технической поддержки сайта, просто обратитесь к специалистам нашей компании.
Теги:оптимизация сайта, техническая оптимизация
Что такое nofollow ссылки и зачем использовать атрибут rel nofollow
18588 2
| How-to | – Читать 9 минут |
Прочитать позже
ЧЕК-ЛИСТ: ССЫЛОЧНАЯ МАССА — ЧИСТКА
Инструкцию одобрил
Head of SEO в iProspect Ukraine
Дмитрий Клюшник
Атрибут Nofollow предназначен для запрета перехода по ссылкам ботами поисковых систем. Этот атрибут важен при добавлении ссылок на не трастовые ресурсы, либо партнерских и рекламных гиперссылок. Использование исходящих ссылок без Nofollow приводит к потере ссылочного веса.
Содержание
Что такое тег Nofollow
— В каких случаях использовать ссылки nofollow
— Когда не следует добавлять Nofollow
Как проверить ссылку на наличие атрибута Nofollow
Как найти внутренние nofollow ссылки
Как найти внешние nofollow ссылки
FAQ
Заключение
Что такое тег Nofollow
В SEO атрибут rel со значением nofollow позволяет запрещать переход поисковых роботов как по всем ссылкам страницы, так и по одной гиперссылке. Однако с 2020 года Google может учитывать ссылки с этим атрибутом и использовать их в качестве подсказок для сканирования, индексирования и ранжирования. Также теперь желательно использовать более точные варианты значений атрибутов:
Однако с 2020 года Google может учитывать ссылки с этим атрибутом и использовать их в качестве подсказок для сканирования, индексирования и ранжирования. Также теперь желательно использовать более точные варианты значений атрибутов:
- rel=»sponsored» — для размещения платных ссылок;
- rel=»ugc» — для ссылок в комментариях пользователей к каким-либо публикациям, статьям на блогах или записям на форумах.
Несмотря на то, что Google рекомендует использовать именно эти атрибуты, nofollow все так же работает, и менять значения атрибутов на старых ссылках не нужно.
Nofollow также позволяет дать указания относительной всей страницы, для этого прописывается следующая строчка кода:
<meta name="robots" content="nofollow" />
В данном случае мета-тег robots nofollow запрещает поисковикам переходить по любым ссылкам, расположенным на странице.
Во втором случае атрибут Nofollow в HTML-коде задается в теге ссылки «а»:
<a href="http://адрес-сайта" rel="nofollow">текст ссылки с атрибутом nofollow</a>
Данный атрибут предназначен для сигнала поисковикам, что по конкретной ссылке передавать ссылочный вес страницы не нужно.
В каких случаях использовать ссылки nofollow
Раньше атрибут был необходим на страницах комментариев, где пользователи могут оставлять спам и добавлять внешние ссылки на некачественные ресурсы. Наличие ссылок на сомнительные сайты приводит к снижению доверия к странице и понижению ее позиций в поисковой выдаче. Теперь на таких веб страницах можно применить атрибут rel=»ugc» или комбинацию двух значений: rel=»nofollow ugc».
Еще ранее Google рекомендовал использование тега rel-nofollow для размещения партнерских и рекламных ссылок. Теперь для таких ссылок предназначен атрибут, однако его также можно использовать в комбинации с nofollow:. Помимо того, что это рекомендует Google, вы также сможет не передавать ссылочный вес другим сайтам.
Добавьте атрибут во внутренних ссылках на неприоритетные для индексации страницы, такие как «Регистрация» или «Вход». Такая рекомендация тоже присутствует в справке Google.
Используйте базовый атрибут nofollow для любых внешних ссылок на нетрастовые ресурсы, с которыми вы не хотите ассоциировать собственный проект.
Когда не следует добавлять Nofollow
Не добавляйте Noindex и Nofollow в ссылки, используемые для внутренней перелинковки. Такие ссылки предназначены для перераспределения ссылочного веса между страницами сайта и более эффективного продвижения.
Наличие Nofollow в HTML-коде делает внутреннюю перелинковку менее результативной и усложняет продвижение.
Тег Nofollow не должен присутствовать в большинстве внешних ссылок на сайт, оплачиваемых для продвижения ресурса. Такие ссылки не передадут ссылочный вес с сайта-донора и не окажут положительного влияния на продвижение сайта.
Однако ссылки Nofollow можно использовать для того, чтобы ссылочный профиль сайта был естественным для поисковых систем. Это снижает риск санкций.
Как проверить ссылку на наличие атрибута Nofollow
Для успешной поисковой оптимизации важно контролировать внешние и внутренние ссылки на наличие атрибута nofollow, чтобы при необходимости его удалять либо наоборот добавлять. Далее рассмотрим, как найти внешние и внутренние ссылки с атрибутом nofollow.
Далее рассмотрим, как найти внешние и внутренние ссылки с атрибутом nofollow.
Как найти внутренние nofollow ссылки
Проверка ссылок осуществляется с помощью просмотра кода страницы. Кликните правой кнопкой мыши на анкоре ссылки и выберите «Просмотреть код»:
Просмотр HTML-кода для поиска атрибута rel=nofollow
Откроется HTML-код, в котором будет видно, есть ли атрибут Nofollow у ссылки:
Атрибут rel со значением Nofollow
Также в HTML-коде необходимо проверить наличие атрибута Nofollow в мета-теге Robots. В данном примере все ссылки, размещенные на странице, игнорируются краулерами:
атрибут Nofollow в мета-теге Robot
С целью более простой проверки ссылки на атрибут Nofollow используйте плагин NoFollow для Google Chrome. Для этого нужно установить данное расширение, а затем активировать его в панели инструментов:
Плагин NoFollow для браузера Chrome
Расширение выделяет ссылки с rel-nofollow на странице точечной рамкой красного цвета:
Выделение ссылок с Nofollow с помощью плагина
Как найти внешние nofollow ссылки
Чтобы узнать, какие внешние ссылки на сайт содержат атрибут nofollow, воспользуйтесь модулем «Анализ внешних ссылок» от Serpstat. Сервис позволит узнать обратные ссылки на проект, их анкорные тексты, а также тип — nofollow, dofollow, UGC, sponsored. Помимо этого, можно оценить авторитетность донора с помощью оценки Domain Rank — аналог PageRank, вычисляемый Serpstat, и узнать целевую страницу, на которую ведет ссылка.
Сервис позволит узнать обратные ссылки на проект, их анкорные тексты, а также тип — nofollow, dofollow, UGC, sponsored. Помимо этого, можно оценить авторитетность донора с помощью оценки Domain Rank — аналог PageRank, вычисляемый Serpstat, и узнать целевую страницу, на которую ведет ссылка.
Анализ обратных ссылок с помощью Serpstat
Зачем нужны внешние nofollow ссылки?
Внешние nofollow ссылки могут служить подсказкой для Google относительно сканирования, индексирования и ранжирования. Наличие nofollow-ссылок делает ссылочный профиль более естественным, поэтому не стоит использовать только dofollow-ссылки. Помимо этого, nofollow может использоваться в комплексе со значениями UGC и sponsored.
nofollow ссылки передают вес?
Nofollow ссылки не передают ссылочный вес, однако в некоторых случаях могут учитываться Google при ранжировании сайтов. Для обозначения платных ссылок и линков, добавленных пользователями в комментариях, Google рекомендует использовать атрибуты rel=»sponsored» и rel=»ugc» соответственно.
Заключение
В некоторых случаях во внешние ссылки, размещаемые на сайте, необходимо добавлять атрибут Nofollow, ugc или sponsored.
При добавлении ссылок, ведущих на сторонние сайты, используйте rel-nofollow для избежания снижения доверия к странице поисковиков и сохранения ссылочного веса.
Большинство ссылок, приобретаемых для продвижения сайта, должны быть без этого атрибута, иначе они не повлияют на позиции сайта.
Не используйте Nofollow при внутренней перелинковке, поскольку это отрицательно скажется на продвижении.
«Список задач» — готовый to-do лист, который поможет вести учет
о выполнении работ по конкретному проекту. Инструмент содержит готовые шаблоны с обширным списком параметров по развитию проекта, к которым также можно добавлять собственные пункты.
| Начать работу со «Списком задач» |
Сэкономьте время на изучении Serpstat
Хотите получить персональную демонстрацию сервиса, тестовый период или эффективные кейсы использования Serpstat?
Оставьте заявку и мы свяжемся с вами 😉
Оцените статью по 5-бальной шкале
4. 94 из 5 на основе 15 оценок
94 из 5 на основе 15 оценок
Нашли ошибку? Выделите её и нажмите Ctrl + Enter, чтобы сообщить нам.
Рекомендуемые статьи
How-to
Анастасия Сотула
Как оптимизировать видео на Youtube-канале: инструкция для новичков
How-to
Анастасия Сотула
Новый HTML атрибут Importance от Google: что это и как связано с SEO?
How-to +1
Анастасия Сотула
Retention-маркетинг: инструменты удержания клиентов
Кейсы, лайфхаки, исследования и полезные статьи
Не успеваешь следить за новостями? Не беда! Наш любимый редактор подберет материалы, которые точно помогут в работе. Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити 🙂
Нажимая кнопку, ты соглашаешься с нашей политикой конфиденциальности.
Поделитесь статьей с вашими друзьями
Вы уверены?
Спасибо, мы сохранили ваши новые настройки рассылок.
Сообщить об ошибке
Отменить
Noindex и nofollow. Что это такое и как ими пользоваться? tipsite
Всем привет! Сегодня 1 марта! УРА!!! Теплые весенние деньки уже не за горами 😀 . Но мы не будем сидеть, сложа руки, в ожидании этого времени. Мы продолжим активно работать над своими сайтами и сегодня рассмотрим, что такое noindex и nofollow, и как ими пользоваться.
Прежде всего, хочу отметить, что noindex и nofollow могут использоваться, как теги и как метатеги. На практике это будет выглядеть таким образом:
– тег <noindex> и тег, хотя точнее будет сказать атрибут rel=”nofollow”
– метатег <meta name=”robots” content=”noindex”/> и <meta name=”robots” content=”nofollow”/>
Сейчас я подробнее расскажу, для чего используются эти самые теги и метатеги.
Тег <noindex> и атрибут rel=”nofollow”
Итак, начнем с тега <noindex>, который является HTML-тегом. Он предназначен исключительно для Яндекса, то есть понимает его только Яндекс, а Google просто-напросто игнорирует. Данный тег запрещает индексировать определенную часть текста на странице. Кстати, в Google вообще нет такой возможности, чтобы убрать из индекса часть страницы.
Многие вебмастера уверены, что если обернуть какую-либо часть текста в тег <noindex> (<noindex>текст</noindex>), то Яндекс не будет его читать и индексировать, а просто пройдет мимо. Но это не так.
Яндекс обязательно прочитает весь текст на странице, единственное, что он не станет делать, так это помещать в свою индексную базу ту часть, которая находится между открывающим и закрывающим тегом .
Даже если рассуждать логически, то получается следующее: поисковый робот заходит на страницу и начинает читать (сканировать) текст. Когда он наткнется на тег <noindex>, что будет делать дальше? Правильный ответ – сканировать страницу дальше, чтобы найти закрывающий тег <noindex>. Поэтому не стоит рассчитывать на то, что можно запретить поисковикам сканировать определенную часть текста на странице. Даже сам буквальный перевод слова «noindex» – это «не индексировать», как видите, никакого запрета читать или сканировать нет.
Когда он наткнется на тег <noindex>, что будет делать дальше? Правильный ответ – сканировать страницу дальше, чтобы найти закрывающий тег <noindex>. Поэтому не стоит рассчитывать на то, что можно запретить поисковикам сканировать определенную часть текста на странице. Даже сам буквальный перевод слова «noindex» – это «не индексировать», как видите, никакого запрета читать или сканировать нет.
Зачем же тогда нам нужен тег <noindex>? Основное его предназначение в том, чтобы запрещать поисковикам показывать в поисковой выдаче какую-нибудь информацию, например, контакты или что-то еще.
Еще один распространенный миф, связанный с <noindex> состоит в том, что ссылки, находящиеся внутри этого тега, не будут учитываться поисковиками. К сожалению, это все выдумки чистой воды. Как мы уже разобрались, поисковые роботы сканируют весь текст на странице, в том числе и все ссылки. Единственное, чего мы сможем добиться, обернув ссылку тегом <noindex>, так это то, что не будет проиндексирован ее анкор, то есть текст ссылки, если он, конечно, был прописан. Ну а сама ссылка будет благополучно учитываться и по ней будет произведен переход.
Ну а сама ссылка будет благополучно учитываться и по ней будет произведен переход.
На заметку! Так как тег не входит в стандартный набор языка разметки HTML, поисковые системы, кроме Яндекса, могут посчитать его за ошибку. Поэтому прописывать его нужно не в обычном (<noindex>Текст</noindex>), а в закомментированном виде, то есть вот так: <!–noindex–>Текст<!–/noindex–>. Такой вариант Яндекс хорошо понимает, а другие поисковые роботы просто не будут обращать на него внимания.
В том случае, когда нам ну очень нужно, чтобы ссылка со страницы не учитывалась, на помощь приходит атрибут rel=”nofollow”, который, хочу заметить, понимает и Яндекс и Гугл. При использовании данного атрибута ссылка, конечно же, сканируется, но ей не передается вес страницы, на которой она находится. Напомню, что любая страница любого сайта в Интернете имеет свой вес, который равномерно распределяется на все исходящие ссылки, а точнее – на те сайты, куда ведут ссылки. Так вот, при использовании rel=”nofollow” вес страницы не будет переходить по ссылке, а просто «сгорит». В прошлой статье я рассказывал про Dofollow-блоги, которые являются противоположностью “nofollow”. Советую Вам прочитать эту статью, потому что комментирование Dofollow-блогов очень здорово помогает в продвижении сайта.
Так вот, при использовании rel=”nofollow” вес страницы не будет переходить по ссылке, а просто «сгорит». В прошлой статье я рассказывал про Dofollow-блоги, которые являются противоположностью “nofollow”. Советую Вам прочитать эту статью, потому что комментирование Dofollow-блогов очень здорово помогает в продвижении сайта.
Чтобы лучше запомнить и уяснить вышеприведенный материал, посмотрите на пару примеров, которые все наглядно объясняют.
Пример 1:
<noindex><a href=”https://tipsite.ru/”>Создание и монетизация сайтов</a></noindex>
В этом случае Яндекс не будет индексировать анкор (Создание и монетизация сайтов), но ссылку на Tipsite.ru, конечно же, учтет и передаст по ней вес страницы.
Пример 2:
<noindex><a href=”http://Tipsite.ru/” rel=”nofollow”>Создание и монетизация сайтов</a></noindex>
В этом примере Яндекс не станет индексировать анкор и не передавать вес по ссылке на Tipsite. ru.
ru.
Метатеги <meta name=”robots” content=”noindex”/> и <meta name=”robots” content=”nofollow”/>
Метатег «noindex», в отличии от тега <noindex>, прописывается в коде страницы и запрещает Яндексу (Google, опять же, игнорирует этот запрет) индексировать всё ее текстовое содержимое, а вот ссылки все равно будут проанализированы и учтены в полной мере. Как видите, метатег «noindex» отличается от полного запрета индексации страницы в robots.txt. От того, насколько правильно составлен robots.txt зависит успешное продвижение сайта и его быстрая индексация.
Что касается метатега «nofollow», то он не разрешает всем поисковым системам индексировать и учитывать ссылки на странице. Поисковые роботы также не будет делать переходы по этим ссылкам. Однако интересная фраза находится в справочнике Яндекса:
«Робот не посетит документы, если ссылки на них стоят со страницы, содержащей метатег со значением nofollow, тем не менее, они могут быть проиндексированы, если в других источниках на них указаны ссылки без nofollow».

Другими словами, при определенных условиях ссылки на нашем сайте могут быть проиндексированы, даже если мы этого не хотим, и закрыли их метатегом «nofollow».
Ну вот мы и разобрались с noindex и nofollow. Это полезные штуки. Я надеюсь, что данная статья помогла Вам разобраться с тем, когда и для чего использовать тот или иной тег или метатег. Будут вопросы – пишите об этом в комментариях. Благодарю Вас за внимание, пока!
Что это такое и как их использовать?
Главная / Noindex, Nofollow и Disallow
Узнайте, как использовать директивы сканирования и индексации для улучшения SEO. Покрытие директив nofollow, noindex и disallow.
Сэм Марсден
SEO и контент-менеджер
Теги
Управление роботами
Давайте делиться
Три приведенных выше слова могут звучать как SEO-тарабарщина, но их определенно стоит знать, поскольку понимание того, как их использовать, означает, что вы можете командовать роботом Googlebot. Что весело.
Что весело.
Итак, давайте начнем с основ: есть три способа сообщить, какие части вашего сайта поисковые системы должны сканировать и индексировать:
- Noindex : указывает поисковым системам не включать ваши страницы в результаты поиска. Чтобы боты увидели этот сигнал, страница должна быть доступна для сканирования.
- Disallow : запрещает поисковым системам сканировать ваши страницы. Это не гарантирует, что страница не будет проиндексирована.
- Nofollow : сообщает поисковым системам не переходить по ссылкам на вашей странице.
Что такое метатег
noindex ?Тег noindex указывает поисковым системам не включать страницу в результаты поиска.
Самый распространенный способ неиндексирования страницы — добавить тег в раздел заголовка HTML или в заголовки ответа. Чтобы поисковые системы могли видеть эту информацию, страница еще не должна быть заблокирована (запрещена) в файле robots. txt. Если страница заблокирована с помощью вашего файла robots.txt, Google никогда не увидит тег noindex, и страница может по-прежнему отображаться в результатах поиска.
txt. Если страница заблокирована с помощью вашего файла robots.txt, Google никогда не увидит тег noindex, и страница может по-прежнему отображаться в результатах поиска.
Чтобы запретить поисковым системам индексировать вашу страницу, просто добавьте в раздел
следующее:
Вторая часть содержимого тег здесь указывает, что все ссылки на этой странице должны быть пройдены, что мы обсудим ниже.
Кроме того, тег noindex можно использовать в X-Robots-Tag в заголовке HTTP:
X-Robots-Tag: noindex
Для получения дополнительной информации см. сообщение разработчиков Google о метатеге robots и x -robots-tag спецификация HTTP-заголовка.
Что такое директива
disallow ? Запрет страницы означает, что вы говорите поисковым системам не сканировать ее, что должно быть сделано в файле robots.txt вашего сайта. Это полезно, если у вас есть много страниц или файлов, которые бесполезны для пользователей, так как это означает, что поисковые системы не будут тратить время на сканирование этих страниц.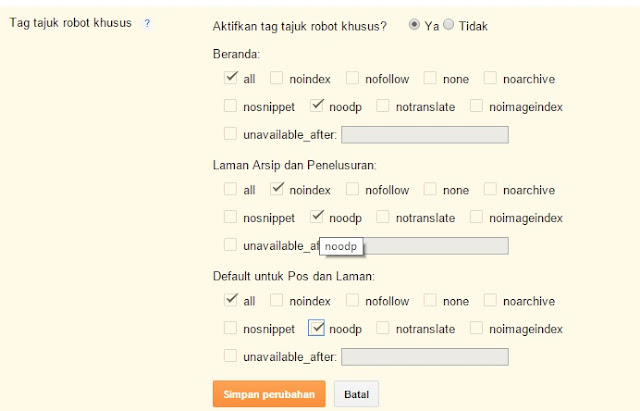 Часто это может быть полезно для максимизации краулингового бюджета.
Часто это может быть полезно для максимизации краулингового бюджета.
Чтобы добавить директиву disallow, просто объедините ее с относительным путем URL и добавьте в файл robots.txt:
Запретить: /your-page-url
Целые каталоги вашего сайта также могут быть запрещены. Завершите правило символом /, чтобы это вступило в силу:
Disallow: /directory/
Пользовательский агент должен быть указан где-то над этой строкой. Используйте звездочку в этом поле, чтобы сопоставить все поисковые роботы (кроме Adsbot, имя которого необходимо указать явно). Например:
Агент пользователя: *
Директива disallow просто запрещает ботам сканировать содержимое этих URL-адресов. Запрещенная страница все еще может появиться в индексе, например, если поисковые системы могут найти ее по входящим внешним ссылкам. Поскольку страница остается недоступной для сканирования, эти страницы обычно отображают сообщение «нет доступной информации для этой страницы», когда они появляются в поисковой выдаче.
Можно ли сочетать noindex и disallow?
Директивы Disallow не следует сочетать с тегами noindex. Это связано с тем, что предотвращение сканирования страницы поисковыми системами также не позволяет им видеть тег noindex. Страница не будет просканирована, но есть шанс, что она будет проиндексирована, если она будет найдена из других источников.
Если вы действительно не хотите, чтобы страница появлялась в поисковой выдаче, вам подойдет тег noindex.
Что такое тег nofollow?
А Тег nofollow на ссылке указывает поисковым системам не передавать ссылочный вес с исходной страницы на целевой сайт. Они также предназначены для предотвращения перехода поисковых систем по ссылке и обнаружения по ней большего количества контента.
Обычно nofollow используется для ссылок в комментариях и сообщениях на форумах, а также в любом другом контенте, который вы не контролируете. Их также можно найти во многих платных ссылках, встраиваниях, таких как виджеты или инфографика, ссылки в гостевых постах или что-то не по теме, на что вы все еще хотите связать людей, но не обязательно хотите, чтобы поисковые системы следили и сканировали.
Исторически SEO-специалисты также выборочно использовали nofollow-ссылки, чтобы направить внутренний PageRank на более важные страницы.
Теги nofollow можно добавить в одном из двух мест:
- страницы (для nofollow всех ссылок на этой странице):
- Код ссылки (для перехода по отдельной ссылке): пример страницы
Nofollow не предотвратит полное сканирование связанной страницы; это просто предотвращает его сканирование по этой конкретной ссылке. Наши собственные и другие тесты показали, что Google не будет сканировать URL-адрес, найденный по ссылке nofollow.
Google заявляет, что если другой сайт ссылается на ту же страницу без использования тега nofollow или страница появляется в карте сайта, страница может по-прежнему отображаться в результатах поиска. Точно так же, если это URL-адрес, о котором поисковые системы уже знают, добавление ссылки nofollow не удалит его из индекса.
В сентябре 2019 года Google объявил об обновлении своей директивы nofollow и ввел два новых атрибута ссылки, а именно:
- rel=»sponsored» — атрибут спонсируемый должен использоваться для идентификации ссылок, предназначенных для рекламных целей, где спонсорство и компенсационные соглашения существуют.
- rel=»ugc» — в качестве атрибута пользовательского контента это значение рекомендуется для ссылок на сайтах с пользовательским контентом, например, сообщения на форуме и комментарии в блогах.
Кроме того, все ссылки, помеченные как nofollow, спонсируемые или UGC, теперь рассматриваются как подсказки относительно того, какие ссылки следует учитывать при поиске и сканировании, а не просто как сигнал, как это использовалось ранее для nofollow. Вы можете узнать больше об этом обновлении в нашем посте, в котором также рассказывается об их влиянии, а также о экспертных выводах.
Что такое noindex, nofollow?
Как упоминалось выше, добавление тега nofollow на страницу не предотвратит ее сканирование.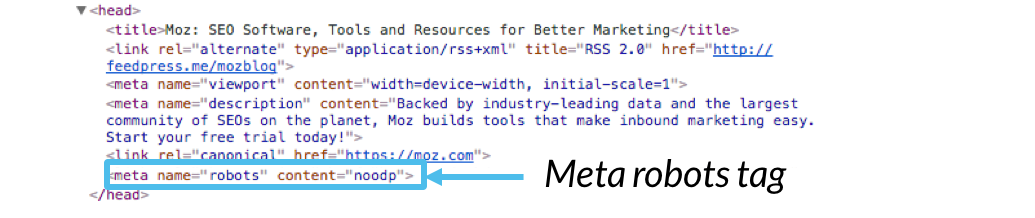 Чтобы предотвратить индексацию URL-адреса, вам также понадобится тег noindex. Это позволит Google просканировать страницу, но она не появится в индексе. Чтобы запретить Google полностью сканировать страницу, вы должны запретить это через robots.txt.
Чтобы предотвратить индексацию URL-адреса, вам также понадобится тег noindex. Это позволит Google просканировать страницу, но она не появится в индексе. Чтобы запретить Google полностью сканировать страницу, вы должны запретить это через robots.txt.
Другие директивы, которые необходимо знать: канонические теги, нумерация страниц и hreflang
Существуют и другие способы сообщить Google и другим поисковым системам, как обрабатывать URL-адреса, — их тоже стоит знать! Ознакомьтесь с приведенными ниже ресурсами, чтобы узнать больше.
- Канонические теги сообщают поисковым системам, какую страницу из группы похожих страниц следует проиндексировать. Канонизированные (т.е. вторичные страницы, направляющие поисковые системы на основную версию) не включаются в индекс. Если у вас есть отдельные мобильные и настольные сайты, вы должны канонизировать свои мобильные URL-адреса на настольные.
- Разбивка на страницы группирует несколько страниц вместе, чтобы поисковые системы знали, что они являются частью набора. Поисковые системы должны отдавать приоритет первой странице каждого набора при ранжировании страниц, но все страницы в наборе останутся в индексе.
- Hreflang сообщает поисковым системам, какие международные версии одного и того же контента относятся к какому региону, чтобы они могли отдавать приоритет правильной версии для каждой аудитории. Все эти версии останутся в индексе.
 Поисковые системы должны отдавать приоритет первой странице каждого набора при ранжировании страниц, но все страницы в наборе останутся в индексе.
Поисковые системы должны отдавать приоритет первой странице каждого набора при ранжировании страниц, но все страницы в наборе останутся в индексе.
Сколько времени вы должны потратить на сокращение краулингового бюджета?
Вы можете услышать много разговоров на форумах SEO о том, насколько важны для SEO эффективность сканирования и бюджет сканирования. Хотя общепринятой практикой является запрет и неиндексирование страниц, которые не приносят пользы поисковым системам или пользователям (например, внутренний код, который используется только для работы сайта, или некоторые типы дублированного контента), решение о том, следует ли скрывать отдельных страниц, вероятно, не лучшее использование времени и усилий. Если нет особой причины скрывать страницу от поисковых систем, обычно лучше оставить решение за ними.
Проверка ваших директив с помощью Lumar
Поиск всех неиндексируемых страниц с помощью LumarОтчет о неиндексируемых страницах включает сведения обо всех страницах с неиндексируемым статусом. Вы можете увидеть их общее количество, а также разбивку правил, которые заставляют их классифицироваться как неиндексируемые:
Отсюда погрузитесь в отдельные отчеты, чтобы убедиться, что правильные правила применяются к правильные URL-адреса.
Индексация > Страницы без индекса
В этом отчете будут показаны все страницы, содержащие тег noindex в метаинформации, заголовке HTTP или файле robots.txt.
Индексация > Запрещенные страницы
Этот отчет содержит все URL-адреса, сканирование которых невозможно из-за правила запрета в файле robots.txt.
Протестируйте новый файл robots.txt с помощью Lumar
Используйте функцию перезаписи robots. txt Lumar в дополнительных настройках, чтобы заменить текущий файл пользовательским.
txt Lumar в дополнительных настройках, чтобы заменить текущий файл пользовательским.
При следующем запуске сканирования существующий файл robots.txt будет перезаписан новыми правилами. Это позволяет вам убедиться, что нужные URL-адреса запрещены, прежде чем внедрять изменения на действующий сайт.
Для получения дополнительной информации прочитайте наше руководство по управлению изменениями robots.txt с помощью Lumar.
Дополнительные технические учебные ресурсы по SEO
Мы надеемся, что вы нашли этот пост полезным для получения дополнительной информации о noindex, nofollow и запрете на управление сканированием и индексированием вашего сайта.
Вы можете больше узнать об этих темах в нашей Технической SEO-библиотеке, а если вы хотите узнать, как проводить технический SEO-аудит, прочтите наше руководство. У нас также есть большой выбор регулярно обновляемых электронных книг по техническим темам SEO, которые помогут вам быть в курсе последних обновлений Google и лучших практик SEO.
* Примечание. Это сообщение было обновлено 26 августа 2022 г.
Сэм Марсден
SEO и контент-менеджер
Сэм Марсден — бывший менеджер Lumar по поисковой оптимизации и контенту, а в настоящее время — руководитель отдела SEO в Busuu. Сэм регулярно выступает на маркетинговых конференциях, таких как SMX и BrightonSEO, и является автором отраслевых изданий, таких как Search Engine Journal и State of Digital.
Основы SEO: мета-роботы «Noindex, Nofollow» Объяснение
Сегодня мы поговорим об одной из самых больших ошибок SEO , которую может совершить владелец веб-сайта (или веб-разработчик): без индекса . Одно упоминание об этом может вызвать у разработчика мурашки по спине.
Обновление от 29.08.2018. См. примечания к обновлению в конце сообщения.
Что такое тег
? Проще говоря, этот метатег сообщает поисковым системам, какие действия они могут выполнять (или не выполнять) на определенной странице. Основные поисковые системы будут соблюдать команды, включенные в этот тег.
Основные поисковые системы будут соблюдать команды, включенные в этот тег.
Этот метатег может быть включен где угодно между и теги в заголовке страницы, как показано ниже:
ВАЖНО: Этот тег не действует на весь сайт. Он может содержать разные значения на разных страницах одного и того же сайта.
Доступные значения для тега META ROBOTS
Ниже приведен список допустимых значений для тега META ROBOTS.
- Индекс ( значение по умолчанию )
- Без индекса
- Нет
- Подписка
- Без подписки
- Noarchive
- Nosnippet
- Noodp ( больше не актуален )
- Noydir ( больше не актуален )
Эти значения ниже 90 метатегов вполне допустимы:
Влияние NOINDEX,NOFOLLOW
Значение NOINDEX указывает поисковым системам НЕ индексировать эту страницу, поэтому в основном эта страница не должна отображаться в результатах поиска.
Значение NOFOLLOW указывает поисковым системам НЕ отслеживать (обнаруживать) страницы, на которые есть ССЫЛКИ на этой странице.
Иногда разработчики добавляют метатег роботов NOINDEX,NOFOLLOW на веб-сайты разработки, чтобы поисковые системы случайно не начали отправлять трафик на веб-сайт, который все еще находится в стадии разработки.
Или у вас может быть текущий (действующий) веб-сайт на www.example.com, но вы также храните копию для разработки на www.dev.example.com/. В этом случае рекомендуется не индексировать, не следовать версии Dev, чтобы избежать многих потенциальных проблем.
Часто бывает так, что люди случайно добавляют этот тег на живые веб-сайты, забывают добавить его в разрабатываемые копии или, что еще хуже, забывают удалить его с действующих веб-сайтов после запуска.
Да, такие же результаты и проблемы могут возникнуть из-за плохой robots.txt в корне сайта, но это выходит за рамки темы этого поста.
~3% веб-сайтов отелей затронуты индексирует свой сайт.
Это было шокирующее открытие, которое побудило нас написать эту статью.
Как проверить, содержит ли мой веб-сайт эту ошибку?
К счастью, есть очень простой способ проверить любой веб-сайт/страницу на наличие этой ошибки.
Просто откройте страницу в браузере, щелкните правой кнопкой мыши где-нибудь на странице (но не на ссылках или изображениях) и выберите «Просмотреть исходный код страницы». В большинстве браузеров для Windows вы можете просто нажать CTRL+U на клавиатуре.
При этом откроется новая вкладка с полным HTML-кодом (как его видит браузер) для текущей страницы. Как упоминалось ранее, метатеги обычно находятся в верхней части веб-сайта, как в этом примере:
Если вы видите на этой странице строку META ROBOTS со значением NOINDEX или NONE, то вам необходимо принять меры немедленно !
Как уязвимые веб-сайты выглядят в результатах поиска?
Я рад, что вы (надеюсь) спросили.
Есть очень удобный способ поиска в Google проиндексированных страниц с определенного доменного имени: [site:example.com] (без квадратных скобок).
Итак, мы идем в Google и ищем домен, который использует мета-роботов NOINDEX на их веб-сайте, и вот что мы получаем:
Надеюсь, вы понимаете, какой ущерб может быть нанесен полным удалением вашего веб-сайта из Google и других поисковых систем. Ваш органический поисковый трафик упадет до нуля в течение нескольких дней.
Как исправить/удалить строку Meta Robots?
К счастью, решить эту проблему несложно, и ее не следует откладывать. Сначала нужно определить, откуда идет эта линия.
В WordPress первое, что вы должны сделать, это перейти в Панель управления > Настройки > Чтение.
Убедитесь, что флажок для Видимость поисковой системы не отмечен .
Если это не решило проблему, то вам следует проверить, не зашита ли эта строка в тему.
Чтобы проверить это, вы должны перейти в «Внешний вид»> «Редактор», а затем выбрать «Theme Header.php» из списка файлов справа (действительно для большинства тем).
Просмотрите этот файл и убедитесь, что в нем нет тега META ROBOTS с вредоносным значением. Если есть — удалите его и нажмите синюю кнопку «Обновить файл».
В заключение
Эта строка кода может вызвать головную боль, потерю дохода и негативные долгосрочные последствия для SEO.
Ваш веб-сайт затронут NOINDEX? Проверьте сегодня!
Обновления от 29.08.2018:
Я хотел не торопиться и упомянуть новые цифры от 29 августа 2018 года.
Количество сайтов, которые я анализирую, резко увеличилось. В исходной статье упоминались данные, полученные с 50 000 веб-сайтов отелей. Сейчас я анализирую ~875 000 уникальных сайтов отелей (уникальные домены).
Результаты этих 875 000+ веб-сайтов отелей показывают, что 1,502% веб-сайтов отелей используют NOINDEX или NONE в качестве значения мета-роботов.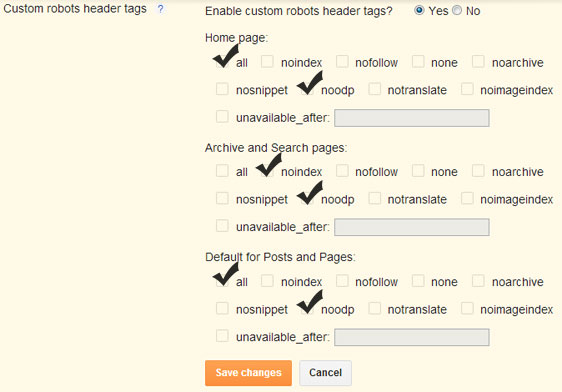
Процент не кажется высоким, но это более 13 000 веб-сайтов отелей, которые эффективно блокируют поисковые роботы от индексации своих веб-сайтов.
Конечно, некоторые из них делают это во время обслуживания своих веб-сайтов. Другие веб-сайты на самом деле пытаются вести себя сдержанно и отображать свой бизнес только через прямые ссылки.
Но я потратил время, чтобы вручную посетить более 200 случайных веб-сайтов из этого списка, и я бы быстро оценил, что 3/4 из них на самом деле используют NOINDEX по ошибке. Так вот что.
Как проверить тег X-Robots на наличие директив Noindex (инструменты Google, расширения Chrome и сторонние сканеры)
Обновлено: апрель 2022 г. тег x-robots для директив noindex. В список входят инструменты непосредственно от Google, расширения Chrome и сторонние инструменты сканирования.
——
Ранее я писал о силе (и опасности) метатега robots. Это одна строка кода, которая может препятствовать индексации страниц более низкого качества, а также говорит движкам не переходить по каким-либо ссылкам на странице (т. е. не передавать никаких сигналов ссылок на целевую страницу).
е. не передавать никаких сигналов ссылок на целевую страницу).
Это полезно, когда это необходимо, но мета-тег robots также может разрушить вашу SEO-оптимизацию при неправильном использовании. Например, если вы по ошибке добавите метатег robots на страницы, используя noindex. Если это произойдет, и если это будет широко распространено, ваши страницы могут начать выпадать из индекса Google. И когда это произойдет, вы можете потерять рейтинг этих страниц и последующий трафик. В худшем случае ваш органический поисковый трафик может резко упасть почти как у Панды. Другими словами, он может упасть с обрыва.
И прежде чем вы смеетесь над этим сценарием, я могу сказать вам, что за свою карьеру я несколько раз видел, как это случалось с компаниями. Это может быть человеческая ошибка, проблемы с CMS, возврат к старой версии сайта и т. д. Вот почему крайне важно проверять наличие метатега robots, чтобы убедиться, что используются правильные директивы.
Но вот беда. Это не единственный способ выдавать директивы noindex, nofollow. В дополнение к метатегу robots вы также можете использовать тег x-robots-tag в ответе заголовка. Используя этот подход, вам не нужно добавлять метатег к каждому URL-адресу, и вместо этого вы можете предоставлять директивы через ответ сервера.
В дополнение к метатегу robots вы также можете использовать тег x-robots-tag в ответе заголовка. Используя этот подход, вам не нужно добавлять метатег к каждому URL-адресу, и вместо этого вы можете предоставлять директивы через ответ сервера.
Вот два примера тега x-robots в действии:
Опять же, эти директивы не содержатся в html-коде. Они находятся в заголовке ответа, который невооруженным глазом не виден. Вам нужно специально проверить ответ заголовка, чтобы увидеть, используется ли тег x-robots и какие директивы используются.
Как вы можете догадаться, это может легко ускользнуть, если вы специально не ищете это. Представьте, что вы проверяете сайт на метатег robots, думая, что все в порядке, когда вы его не видите, но тег x-robots используется с «noindex, nofollow» для каждого URL-адреса. Не хорошо, мягко говоря.
Как проверить тег X-Robots в заголовке ответа
Основываясь на том, что я объяснил выше, я решил написать этот пост, чтобы объяснить несколько различных способов проверки тега x-robots. Добавив это в свой контрольный список, вы можете убедиться, что важные директивы верны и что вы не индексируете и не следите за нужными страницами на своем сайте (и не за теми важными, которые привлекают много трафика из Google и/или Bing). В приведенном ниже списке содержатся инструменты непосредственно от Google, расширения Chrome и сторонние инструменты сканирования для массовой проверки URL-адресов. Давайте прыгнем.
Добавив это в свой контрольный список, вы можете убедиться, что важные директивы верны и что вы не индексируете и не следите за нужными страницами на своем сайте (и не за теми важными, которые привлекают много трафика из Google и/или Bing). В приведенном ниже списке содержатся инструменты непосредственно от Google, расширения Chrome и сторонние инструменты сканирования для массовой проверки URL-адресов. Давайте прыгнем.
1. Инструменты непосредственно от Google
Инструмент проверки URL-адресов Google
Нет ничего лучше, чем обратиться прямо к источнику. С помощью Инструмента проверки URL-адресов Google вы можете проверить определенные URL-адреса, чтобы узнать, индексируются ли они. И, как вы можете догадаться, инструмент укажет, доставляется ли noindex через x-robots-tag (через ответ заголовка).
API проверки URL-адресов
Вы также можете использовать API проверки URL-адресов Google для массового тестирования URL-адресов. После запуска URL-адресов через API вы можете увидеть, не индексируются ли они, с помощью тега x-robots-tag. Вы можете проверить мой учебник по созданию системы мониторинга индексации нескольких сайтов, чтобы узнать больше о том, как использовать API.
После запуска URL-адресов через API вы можете увидеть, не индексируются ли они, с помощью тега x-robots-tag. Вы можете проверить мой учебник по созданию системы мониторинга индексации нескольких сайтов, чтобы узнать больше о том, как использовать API.
Тест для мобильных устройств
Тест Google для мобильных устройств также может показать вам, не индексируется ли страница с помощью тега x-robots. А поскольку инструмент может проверять любой общедоступный URL-адрес, вам не нужно проверять сайт в GSC.
2. Расширения Chrome
Плагин веб-разработчика
Плагин веб-разработчика — один из моих любимых плагинов для проверки ряда важных элементов, и он доступен как для Firefox, так и для Chrome. Просто щелкнув плагин в браузере, затем «Информация», а затем выбрав «Заголовки ответа», вы можете просмотреть значения заголовка http для имеющегося URL-адреса. И если используется тег x-robots, вы увидите перечисленные значения.
Расширение Detailed SEO для Chrome
Расширение Detailed SEO предоставляет множество SEO-информации на основе анализируемой вами страницы. И да, он включает тег x-robots. Один быстрый щелчок, и вы можете увидеть, не индексируется ли страница с помощью тега x-robots. Я настоятельно рекомендую этот плагин в целом и для проверки тега x-robots. Я думаю, вы это выкопаете.
Проверка исключения роботов
Это еще одно из моих любимых расширений Chrome. Средство проверки исключения роботов проверит статус файла robots.txt, метатега robots, x-robots-tag и тега канонического URL. Я часто использую этот плагин, и он очень хорошо работает для проверки тега x-robots.
3. Инструменты сканирования
Теперь, когда я рассмотрел инструменты Google и некоторые расширения Chrome для проверки x-robots-tag, давайте проверим некоторые надежные сторонние инструменты сканирования. Например, если вы хотите массово просканировать множество URL-адресов (например, 10 000, 100 000 или более 1 млн страниц) для проверки наличия тега x-robots, следующие инструменты могут быть чрезвычайно полезными.
DeepCrawl
Если вам нужен надежный механизм сканирования корпоративного уровня, тогда DeepCrawl для вас. Обратите внимание: я был настолько большим сторонником DeepCrawl, что много лет входил в консультативный совет клиентов. Так что да, я фанат. 🙂
После сканирования сайта вы можете легко проверить отчет «Неиндексированные страницы», чтобы просмотреть все страницы, которые не индексируются, с помощью метатега robots, ответа заголовка x-robots-tag или с помощью noindex в файле robots.txt. Вы можете экспортировать список, а затем отфильтровать в Excel, чтобы изолировать неиндексированные страницы с помощью тега x-robots.
Кричащая лягушка
Я тоже долгое время был большим поклонником Кричащей лягушки. Это важный инструмент в моем SEO-арсенале, и я часто использую Screaming Frog в сочетании с DeepCrawl. Например, я могу просканировать крупный сайт с помощью DeepCrawl, а затем изолировать определенные области для хирургического сканирования с помощью Screaming Frog.
После сканирования сайта с помощью Screaming Frog вы можете просто щелкнуть вкладку Directives и найти столбец x-robots. Если какие-либо страницы используют тег x-robots, вы увидите, какие директивы используются для каждого URL-адреса.
Sitebulb
Sitebulb — еще один отличный инструмент для сканирования, который также предоставляет информацию на основе тега x-robots. Вы можете найти эту информацию в разделе «Индексируемость», а затем в отчете об отсутствии индекса. Я часто использую Sitebulb при анализе веб-сайтов.
JetOctopus
Я также начал использовать JetOctopus для сканирования веб-сайтов, это еще один отличный инструмент для сканирования корпоративного уровня. И, как вы можете догадаться, он также сообщает о теге x-robots. Не так много людей в отрасли знают о JetOctopus, но это надежный инструмент для сканирования, который я использую все больше и больше.
Резюме. Есть несколько способов запретить индексацию страницы…
Хорошо, теперь нет оправдания отсутствию тега x-robots во время SEO-аудита. 🙂 Если вы заметили, что какие-то страницы не индексируются, а метатег robots отсутствует в html-коде, то обязательно проверьте наличие x-robots-тега. Вы просто можете обнаружить, что важные страницы не индексируются через ответ заголовка. И опять же, это может быть скрытая проблема, которая вызывает серьезные проблемы с SEO.
🙂 Если вы заметили, что какие-то страницы не индексируются, а метатег robots отсутствует в html-коде, то обязательно проверьте наличие x-robots-тега. Вы просто можете обнаружить, что важные страницы не индексируются через ответ заголовка. И опять же, это может быть скрытая проблема, которая вызывает серьезные проблемы с SEO.
В дальнейшем я рекомендую ознакомиться с различными инструментами, расширениями Chrome и поисковыми роботами, которые я перечислил в этом посте. Все это может помочь вам выявить важные директивы, которые могут повлиять на ваши усилия по SEO.
GG
Robots.txt и метатег Robots
Файл robots.txt — это одна из основ технического SEO, о которой вы всегда должны заботиться. Это помогает вам контролировать, как поисковые системы сканируют ваш сайт, чтобы все важное отображалось в результатах поиска, а все, что вы не хотите там показывать, блокировалось.
Почему так важно контролировать сканирование и индексацию страниц?
- Сохранение бюджета сканирования. Существует ограничение на количество страниц, которое поисковый бот может обработать за определенное время. Чтобы ваши самые важные страницы регулярно сканировались и повторно сканировались, вы должны исключить те страницы, которые не нужно показывать в результатах поиска.
 Существует ограничение на количество страниц, которое поисковый бот может обработать за определенное время. Чтобы ваши самые важные страницы регулярно сканировались и повторно сканировались, вы должны исключить те страницы, которые не нужно показывать в результатах поиска.
Существует ограничение на количество страниц, которое поисковый бот может обработать за определенное время. Чтобы ваши самые важные страницы регулярно сканировались и повторно сканировались, вы должны исключить те страницы, которые не нужно показывать в результатах поиска.- Запрет показа технических страниц в поиске. Ваш магазин создает множество страниц для удобства пользователей: страницы входа, оформления заказа, внутреннего поиска и т. д. Они важны для UX, но не нужны для ранжирования в поиске.
- Предотвращение проблем с дублированием контента. Говоря о технических страницах, которые мы упомянули, они могут создавать дублирование: например, разные варианты сортировки будут по разным URL-адресам, но будут показывать одни и те же продукты, только в другом порядке. Вы не хотите, чтобы эти страницы участвовали в ранжировании, поскольку поисковые системы не ценят дублированный контент.
Как вы можете контролировать индексацию страниц вашего магазина?
Чтобы повысить ценность ваших важных страниц и облегчить их индексацию поисковыми ботами, у вас всегда должна быть актуальная и правильная карта сайта. Кроме того, позаботьтесь о внутренних ссылках и о том, чтобы внешние источники ссылались на ваш контент, чтобы ваши страницы выглядели более авторитетными в глазах поисковых систем.
Эти меры в значительной степени гарантируют, что ваши страницы будут ранжироваться в поиске, хотя нет надежного способа обеспечить 100% индексацию.
Что вы можете гарантировать на 100%, так это исключение определенных страниц, которые вы не хотите показывать в поиске. Для этого вы можете используйте директиву noindex в файле robots.txt или метатег robots . На первый взгляд звучит очень технично, но на самом деле это очень просто. Особенно для продавцов Shopify, поскольку платформа автоматически заботится о большей части правильной индексации.
Итак, что вы не должны индексировать в магазине Shopify?
Для интернет-магазинов имеет смысл блокировать от индексации следующие типы страниц:
- Все, что связано с учетными записями пользователей. Эти страницы уникальны для каждого клиента и не нужны для поиска.
- Все, что связано с гостевой кассой. Даже если пользователи не входят в свою учетную запись и им разрешено совершать покупки в качестве гостей, страницы с созданными для них этапами оформления заказа не предназначены для поиска.
- Фасетная навигация и внутренний поиск. Как мы уже упоминали, предложение этих URL-адресов поисковым ботам только запутает их, истощит ваш краулинговый бюджет и создаст проблемы с дублированием контента.
- Товары, которые вы хотите скрыть от поиска. Если вы не хотите, чтобы определенные товары отображались в результатах поиска — например, товары, которых нет в наличии, или срочные товары, которые больше не актуальны, — вы можете скрыть товары из поиска в файле Shopify robots. txt.
 txt.
txt.Robots.txt в Shopify
Чтобы проверить файл robots.txt, который создается автоматически, вы можете добавить /robots.txt в домен вашего магазина:
Что обычно содержит этот файл? Указывает конкретного поискового бота (поле User-agent ) и дает директивы сканирования ( Disallow означает блокировку доступа). В приведенном выше примере первый набор правил дается всем поисковым ботам ( User-agent имеет значение *). В свою очередь директива Disallow запрещает сканирование указанных страниц. В примере мы видим, что файл запрещает сканирование технических страниц, таких как admin, cart, checkout и так далее.
Robots.txt также содержит ссылку на вашу карту сайта, которая также полезна для поисковых роботов для понимания структуры вашего сайта и приоритетов индексации.
До недавнего времени Shopify не давал никакой гибкости с этим файлом. Но в июне 2021 года продавцы Shopify получили возможность редактировать robots. txt. Предопределенных правил в большинстве случаев достаточно, но они могут не учитывать все случаи. Если вы используете приложение для внутреннего поиска, оно часто меняет URL-адрес, и правила по умолчанию не применяются. Или, если у вас многогранная навигация, URL-адрес меняется в соответствии с каждым выбранным фильтром, и правила по умолчанию могут не учитывать все. Вы можете добавить больше страниц и правил в свой файл, указать больше пользовательских агентов и т. д.
txt. Предопределенных правил в большинстве случаев достаточно, но они могут не учитывать все случаи. Если вы используете приложение для внутреннего поиска, оно часто меняет URL-адрес, и правила по умолчанию не применяются. Или, если у вас многогранная навигация, URL-адрес меняется в соответствии с каждым выбранным фильтром, и правила по умолчанию могут не учитывать все. Вы можете добавить больше страниц и правил в свой файл, указать больше пользовательских агентов и т. д.
Чтобы узнать о существующих директивах, которые вы можете применить, ознакомьтесь с руководством Google по файлу robots.txt.
Также обратите внимание, что постоянно появляются новые правила. Например, в начале 2022 года Google представила новый тег, управляющий индексацией встроенного контента: indexifembedded. Его можно применять, если в вашем магазине есть виджеты, вставленные через iframe или аналогичный HTML-тег, и вы не хотите, чтобы они индексировались.
Как отредактировать файл robots.txt на Shopify?
В коде вашей темы вы увидите набор шаблонов (перейдите в Интернет-магазин > Темы > нажмите Действия в текущей теме > выберите Редактировать код > перейдите в Шаблоны ). Список должен содержать файл robots.txt.liquid.
Если по какой-то причине у вас нет файла, вы можете создать его, нажав Добавить новый шаблон и выбрав robots.txt.
Например, запретим индексацию внутреннего поиска — в шаблоне это будет выглядеть так:
Обратитесь к странице справки Shopify по редактированию robots.txt для получения более подробной информации.
❗ Обратите внимание, что даже если страница запрещена в robots.txt, она все равно может быть проиндексирована, если на нее есть ссылки из внешних источников. Так, например, если у вас есть старая страница, которая в прошлом получала приличный объем трафика, но больше не актуальна для вашего магазина, лучше заблокировать ее с помощью метатега robots или полностью удалить.
Не индексировать Shopify контент с метатегом robots
Помимо robots.txt, 9Директиву 0037 noindex можно вставить в раздел
кода вашей темы с помощью метатега robots. Тег имеет следующий синтаксис:.Аналогично тому, как вы редактируете или создаете код Shopify robots.txt, перейдите к theme.liquid в разделе Layout . Например, вот как это будет выглядеть, если вы добавите правило для запрета индексации вашей страницы /new-collection:
Таким образом, вы навсегда скроете страницу из поиска.
❗ Обратите внимание, что вы можете использовать директивы noindex вместе с директивами nofollow или follow . С follow ваша страница будет заблокирована от индексации, но позволит поисковым роботам сканировать другие ссылки, размещенные на этой странице, а с nofollow как сама страница, так и все ссылки на ней не будут доступны для поисковых ботов.
Нет индексирования Shopify контент с помощью приложений
Если все это кажется вам слишком хлопотным, есть способы еще проще управлять индексированием вашей страницы без написания единой строки кода.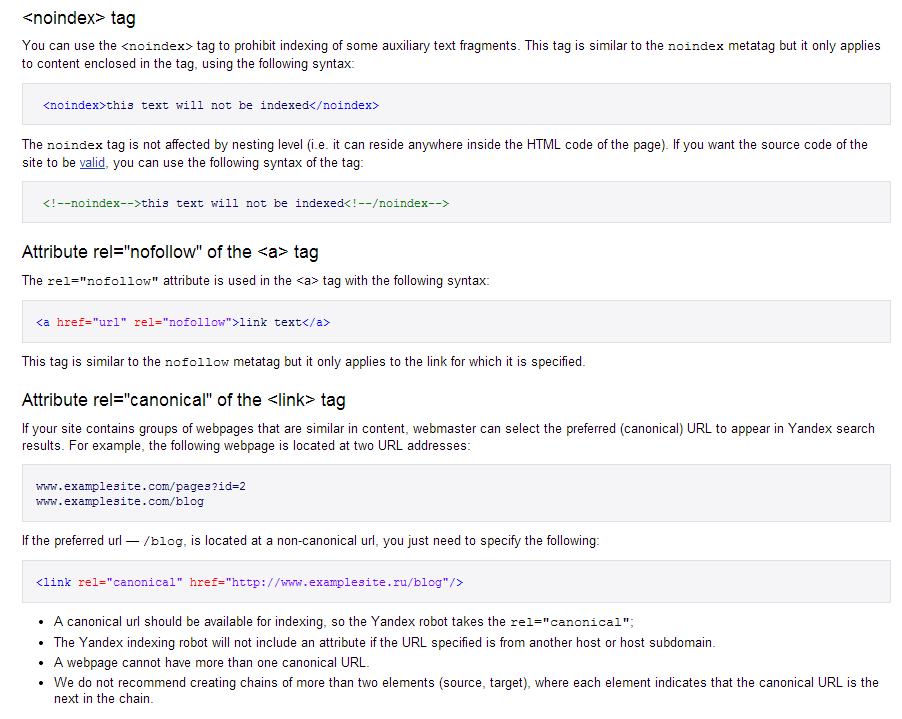 Есть несколько SEO-приложений для Shopify, которые помогут вам скрыть продукты из поиска в вашем магазине Shopify или заблокировать любые другие страницы.
Есть несколько SEO-приложений для Shopify, которые помогут вам скрыть продукты из поиска в вашем магазине Shopify или заблокировать любые другие страницы.
Взгляните на эти два:
- Карта сайта Noindex Инструменты SEO (3,49 долл. США в месяц для всех типов страниц)
- NoIndexify — Менеджер карты сайта (бесплатно для страниц продуктов, коллекций и блогов; 2,99 долл. США в месяц для других страниц: поиск, разбиение на страницы, вход и т. д.)
Вот как выглядит интерфейс NoIndexify — для каждой страницы вы можете выбрать набор директив:
Улучшите SEO, улучшив индексацию страниц
Вот и все: мы надеемся, что у вас есть лучшее понимание того, как работает файл robots.txt Shopify и как использовать его в своих интересах. С помощью robots.txt и метатега robots вы можете улучшить контроль над индексацией страниц, предотвратить проблемы с SEO и повысить ценность своих самых важных страниц, чтобы они выделялись в поиске и привлекали больше посетителей.
Если вам нужны дополнительные советы по SEO для Shopify, ознакомьтесь с нашим руководством по SEO.
Какой правильный фрагмент кода nofollow/noindex? — Пользовательский код — Forum
myonke (Майкл Йонке)
#1
Привет всем,
У меня есть два вопроса относительно noindex/nofollow для поисковых систем.
- Какой правильный фрагмент кода не позволяет поисковым системам сканировать страницу? Я видел 3 разных варианта на форумах, которые были отмечены как правильный ответ. Вот два разных примера, которые я видел:
Один включает «/» в конце и имена заключены в кавычки разных типов («против»).
На самом деле я не знаю, как проверить, что nofollow/noindex распознается, поэтому я не могу проверить каждый из них. Может кто-нибудь, дайте мне знать что правильно?
- Мой второй вопрос: правильно ли я использую noindex/nofollow. У меня есть несколько пустых страниц коллекции. Я планировал добавить код noindex/nofollow внутри тега заголовка этих страниц, так как я не хочу Google считает, что у меня есть страницы без контента. Должен ли я добавлять этот код на эти страницы? Должен ли я также включать этот код на свою страницу 404 (я видел краткое упоминание об этом на другом форуме) 9.0024
Спасибо за любую помощь, которую вы все можете предложить. Я действительно ценю это!
Вот моя ссылка для общего доступа и промежуточная ссылка, если она нужна для этого вопроса.
- Майкл
мёнке (Майкл Йонке)
#2
Просто поднимите этот вопрос, если у кого-то есть окончательный ответ
Редактировать: @samliew @vincent есть ли шанс, что вы, ребята, могли бы мне помочь, когда у вас будет такая возможность? Я был бы очень признателен!
бгарант (Брайан Гаррант)
#3
Привет, Майкл,
Вместо этого используйте файл robots.txt. Это то, что я рекомендую для ваших настроек robots.txt и sitemap.xml для Webflow. Это позволит поисковым системам проиндексировать все страницы вашего сайта. Поскольку Webflow является динамическим, и вы, вероятно, используете CMS для динамических страниц, я не рекомендую выводить список всех ваших страниц вручную. Однако вы можете использовать этот подход, если хотите.
Однако вы можете использовать этот подход, если хотите.
изображение 2324×1012 153 КБ
Если вы хотите исключить страницу или папку, вы можете использовать этот синтаксис:
изображение 1534×340 9,41 КБ
Надеюсь, это поможет!
Брайан
1 Нравится
мёнке (Майкл Йонке)
#4
@bgarrant Большое спасибо за ответ, мне очень приятно. Просто чтобы убедиться, что я не ошибаюсь и не скрываю кучу вещей от Google, не могли бы вы пояснить мою настройку:
- У меня есть группа страниц коллекции. Страницы «Команды», «Местоположения», «Отзывы» и «Галереи героев» пусты. Однако я отображаю данные CMS из этих коллекций на страницах, отличных от их отдельной страницы коллекции CMS.

изображение480×510 12,6 КБ
Итак, я хочу скрыть указанные выше 4 страницы от Google, потому что я не хочу, чтобы поисковая система думала, что у меня пустой контент. Однако я определенно хочу, чтобы Google просканировал все остальные мои страницы .
Рекомендуется также запрещать юридические страницы, такие как Политика конфиденциальности?
Мой сайт settings/robots.txt выглядит следующим образом:
User-agent: *
Disallow: /team/
Disallow: /location/
Disallow: /testimonial/
Disallow: /hero-gallery/
Disallow: /terms-and-conditions/
Disallow: /privacy-policy/
image1510×1278 88,8 КБ
Все это кажется вам правильным для целей моего конкретного проекта?
Еще раз спасибо, я очень, очень благодарен за помощь.
бгарант (Брайан Гаррант)
#5
Мне нравится, Майкл. Итак, чтобы было ясно, если вы добавите эти записи для блокировки папок, любые страницы в этих папках также должны быть заблокированы от индексации.
1 Нравится
мёнке (Майкл Йонке)
#6
Еще раз спасибо, @bgarrant. Да, я это понимаю. Поэтому, если я запретлю «/location», то «Hoss Homes» также не будет сканироваться.
Последний вопрос, лучше ли добавлять эти запреты для ваших легальных страниц, например /privacy-policy?
Спасибо!
бгарант (Брайан Гаррант)
#7
Я их обычно блокирую.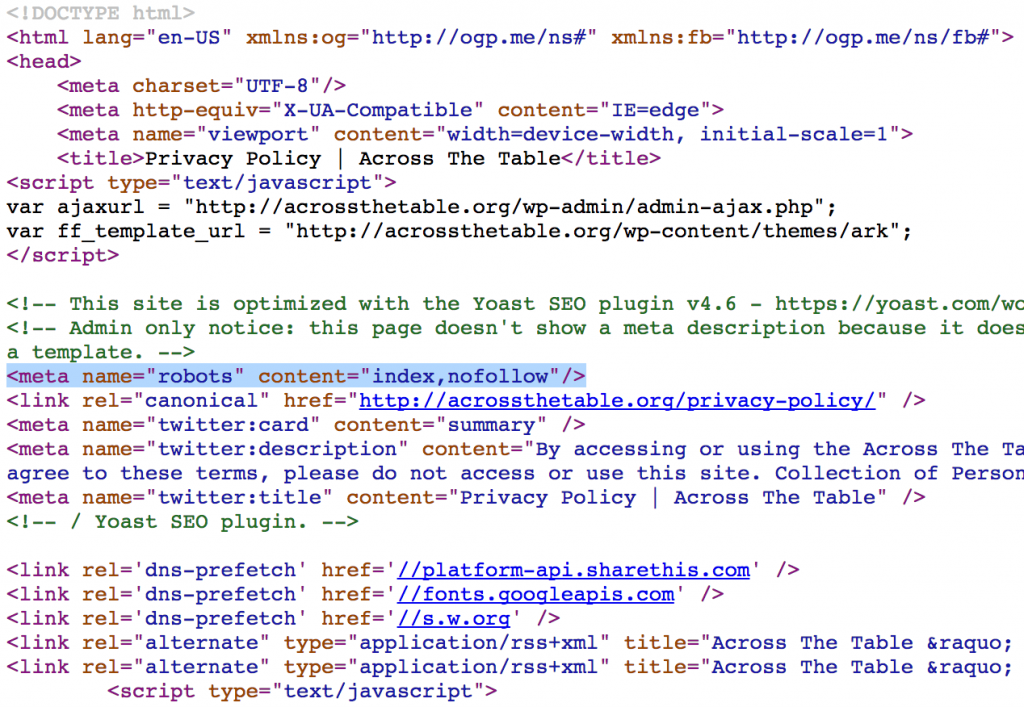 Я не могу придумать причин для их индексации.
Я не могу придумать причин для их индексации.
1 Нравится
мёнке (Майкл Йонке)
#8
@bgarrant Спасибо за помощь!
Очистка_Детализация (Мэтт Джи)
#9
Быстрый вопрос: если я хочу заблокировать динамические страницы CMS, но при этом корневая страница будет проиндексирована, как мне это сделать?
Пример: я хочу, чтобы страница mysite.com/reviews была проиндексирована, но я не хочу, чтобы каждый элемент коллекции (например, mysite. com/reviews/item-1 и т. д.) индексировался.
com/reviews/item-1 и т. д.) индексировался.
gtddesigns (Габриэла)
#10
Привет всем, Вопрос: Что касается неиндексируемых страниц коллекций или любых страниц с 2+ корнями, как правильно их не индексировать?
Пример:
Запретить: /blog/this-is-the-blog-name (с корнем)
Запретить: /this-is-the-blog-name (без root)
Как не индексировать URL-адреса с помощью Rank Math » Rank Math
Существует целый ряд причин и ситуаций, в которых вы хотели бы, чтобы сообщения и страницы не попадали в результаты поиска. Давайте посмотрим, как это сделать…
Rank Math позволяет вам установить пост/страницу/продукт/CPT на NoIndex простым способом. Для простоты мы собираемся показать вам, как установить для сообщения значение NoIndex , но этот принцип также применим к вашим страницам, продуктам, пользовательским типам сообщений или таксономиям.
Во-первых, вам нужно выбрать Advanced Mode в Rank Math:
Вам нужно использовать Advanced Mode , чтобы увидеть опцию Advanced в отдельном редакторе сообщений, если вы хотите изменить его для определенного сообщения. Вкладка «Дополнительно» в Rank Math предназначена для параметров индексирования.
Содержание
- Noindex Все сообщения определенного типа сообщений
- Сообщения и страницы Noindex в классическом редакторе
- Сообщения и страницы Noindex в Гутенберге
- Сообщения и страницы Noindex в Elementor
- Сообщения и страницы Noindex в Divi Builder
- Пометить веб-страницы как неиндексированные с помощью быстрого редактирования
- Пометка веб-страниц как неиндексируемых с помощью массовых действий
- Отметить веб-страницы как неиндексированные с помощью панели меню администратора
1 Noindex для всех сообщений определенного типа
Rank Math позволяет вам установить No Index по умолчанию для всех сообщений определенного типа, чтобы вам не приходилось вручную добавлять No Index для каждого сообщения. Вы можете настроить это в разделе Панель управления WordPress > Математика рейтинга > Плитки и метаданные > Сообщения (или любой другой тип сообщения).
Вы можете настроить это в разделе Панель управления WordPress > Математика рейтинга > Плитки и метаданные > Сообщения (или любой другой тип сообщения).
Прокрутите страницу вниз, чтобы найти параметр Post Robots Meta . Когда вы включите эту опцию, все параметры Robots Meta будут отображаться внизу. Далее выбираем Нет опции индекса .
Теперь нажмите кнопку Сохранить изменения внизу экрана, чтобы отразить изменения.
Примечание: Метароботы, настроенные в настройках Titles & Meta , являются глобальными настройками, но, тем не менее, они могут быть унаследованы одним сообщением. Это означает, что, несмотря на установку «Нет индекса» в настройках «Заголовок и метаданные», если вы вручную установите индекс для отдельного сообщения, то метаданные роботов сообщения будут переопределены и установлены на «Индекс».
2 Сообщения и страницы Noindex
В классическом редакторе Чтобы установить No Index для определенного сообщения или страницы, вам нужно отредактировать свое сообщение, а затем прокрутить вниз, чтобы найти настройки Rank Math SEO под своим сообщением. Нажмите на вкладку Advanced .
Нажмите на вкладку Advanced .
В разделе Robots Meta вы найдете флажок No Index . Отсутствие индекса предотвратит индексацию сообщения и его отображение на страницах результатов поисковой системы.
По умолчанию Rank Math позволяет вам индексировать ваши сообщения. Если вы не хотите индексировать свой пост, вам просто нужно нажать на Нет индекса флажок, как показано ниже.
3 Сообщения и страницы Noindex
В ГутенбергеВ Редакторе Гутенберга вам нужно отредактировать сообщение, которое вы хотите установить как Без индекса. Затем перейдите на вкладку «Дополнительно» и установите флажок «Нет индекса».
4 Сообщения и страницы Noindex
В ElementorЕсли вы используете Elementor, вам нужно сначала отредактировать сообщение. Затем просто перейдите на вкладку SEO > Advanced . Здесь, как показано ниже, вы сможете выбрать No Index option…
5 Noindex Posts & Pages
в Divi Builder Если вы используете Divi Builder для редактирования своего поста, щелкните значок Rank Math SEO и перейдите на вкладку Advanced в Rank Math SEO настройки. Вы сможете установить для поста значение «Без индекса», как показано ниже.
Вы сможете установить для поста значение «Без индекса», как показано ниже.
6 Отметить веб-страницы как неиндексированные с помощью Quick Edit PRO
По умолчанию интерфейс быстрого редактирования включает поля для изменения ярлыка, заголовка, таксономии и других метаданных сообщения без открытия полного редактора сообщений.
Rank Math PRO имеет мета-настройки роботов в интерфейсе быстрого редактирования, чтобы пользователи могли установить для сообщения значение «Без индекса», не открывая редактор сообщений. Чтобы установить No Index для сообщения, откройте раздел сообщений и выберите параметр Quick Edit под заголовком сообщения.
В метанастройках роботов выберите Без индекса и нажмите кнопку Обновить .
7 Отметить веб-страницы как неиндексированные с помощью массовых действий PRO
Поскольку параметр «Быстрое редактирование» может установить «Без индекса» только для одной записи за другой, вы можете использовать массовые действия для установки «Без индекса» для одной или нескольких публикаций одновременно. Пользователи Rank Math PRO могут воспользоваться этой функцией в разделах сообщений в панели меню администратора WordPress.
Пользователи Rank Math PRO могут воспользоваться этой функцией в разделах сообщений в панели меню администратора WordPress.
Из списка сообщений выберите те, которые необходимо установить с помощью метаданных No Index robots. Флажок в верхнем левом углу можно использовать для выбора всех видимых сообщений, а флажок перед каждым заголовком сообщения можно использовать для выбора определенного сообщения.
После того, как вы выбрали сообщения, выберите параметр Set to noindex в раскрывающемся меню, а затем нажмите кнопку Apply .
Теперь для всех выбранных сообщений будет установлена метамета роботов No Index.
Вы также можете установить для сообщения статус «Без индекса» с помощью панели меню администратора. Для этого просто перейдите к Rank Math SEO > Отметьте эту страницу , а затем выберите параметр As NoIndex .
Затем вернитесь к общим настройкам вашего поста и вы сможете убедиться, что настройки верны.