
Почему страницы сайта выпадают из индексации
Наверное, каждый веб-мастер сталкивался с проблемой, когда органического трафика становится все меньше, посещения сайта падают, а в поисковой выдаче страниц почти не остается. Если с подобной проблемой столкнулись и вы, то стоит проверить, не выпал ли сайт и отдельные страницы из поисковой индексации. Как это сделать и почему страницы могут перестать индексироваться — разберемся в этой статье.
Чтобы узнать, индексируется сайт или нет, веб-мастеру потребуется:
- Зайти в Яндекс Вебмастер, перейти на вкладку «Индексирование», нажать «Проверить статус URL». В поле проверки ввести ссылку на сайт, который необходимо проверить. Если будет написано, что страница обходится роботом и находится в поиске, значит, все хорошо.
Пример проверки в Яндекс Вебмастере
- Далее воспользуемся поисковиком Яндекса и оператором URL для проверки.
 Вводим запрос (url:ссылка на сайт). Если страница индексируется, то нажав «Поиск», вы увидите ее в выдаче Яндекса, если нет — страница будет отсутствовать.
Вводим запрос (url:ссылка на сайт). Если страница индексируется, то нажав «Поиск», вы увидите ее в выдаче Яндекса, если нет — страница будет отсутствовать.
 Вводим запрос (url:ссылка на сайт). Если страница индексируется, то нажав «Поиск», вы увидите ее в выдаче Яндекса, если нет — страница будет отсутствовать.
Вводим запрос (url:ссылка на сайт). Если страница индексируется, то нажав «Поиск», вы увидите ее в выдаче Яндекса, если нет — страница будет отсутствовать.Пример индексированной страницы в поиске Яндекса
- Проверим, что с сайтом в поисковой системе Google. Для проверки индексации в Google используется сервис Google Search Console. Заходим в сервис, вставляем ссылку на сайт и ждем ответа от Google.
- По окончании проверки веб-мастер получает всю информацию о странице, в том числе индексируется ли URL.
Пример отчета Google Search Console
Массовое выпадение страниц из индексацииПомимо выпадения целого сайта из индексации, могут выпадать и отдельные страницы, поэтому за этим процессом необходимо периодически следить, проверяя хотя бы основные страницы.
- Разберемся с выпадением страниц в Яндексе. Для этого опять направляемся в Яндекс Вебмастер, на вкладку «Индексирование» и переходим в раздел «Страницы в поиске».
 Для этого опять направляемся в Яндекс Вебмастер, на вкладку «Индексирование» и переходим в раздел «Страницы в поиске».
Для этого опять направляемся в Яндекс Вебмастер, на вкладку «Индексирование» и переходим в раздел «Страницы в поиске».Отчет об индексации в Яндекс Вебмастере
- Обязательно проверяйте раздел «Исключенные страницы», здесь отобразится вся информация о дате и причине исключения из индексации.
Отчет об исключенных страницах в Яндекс Вебмастере
- Для проверки исключений в Google используется Google Search Console, где после входа необходимо перейти на вкладку «Покрытие». Здесь отображается следующая информация:
- Страницы, имеющие ошибки (Google не может их проиндексировать).
- Страницы, которые имеют проблему, но индексируются.
- Страницы, не имеющие ошибок.
- Страницы, исключенные из индексации.
Отчет в Google Search Console
Причины выпадения страниц из индексацииКлючевых причин, по которым страница может пропадать из индексации, две: технические и контент.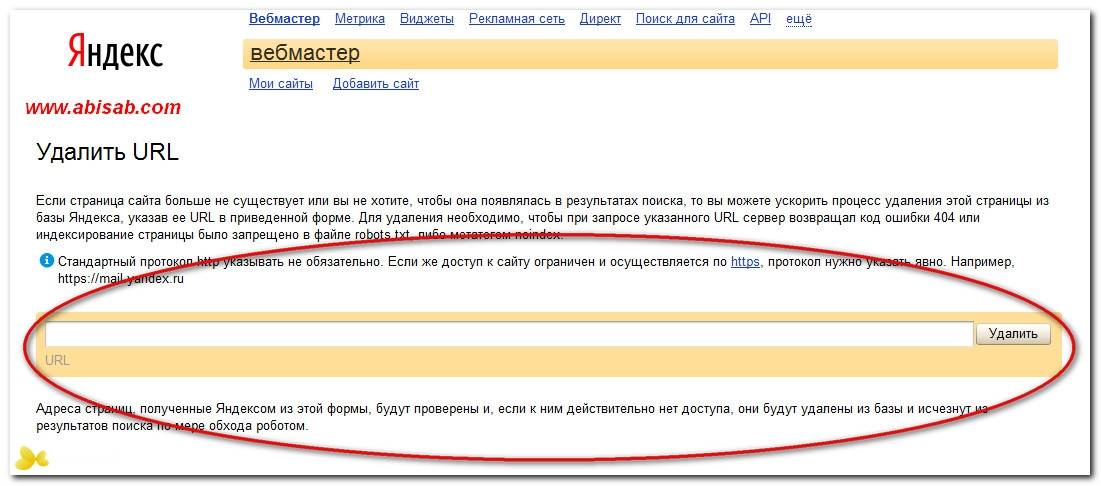 Третья причина на стороне поисковых систем, иногда Google/Yandex лагают, и сканирующий бот пропускает или просто не индексирует страницу.
Третья причина на стороне поисковых систем, иногда Google/Yandex лагают, и сканирующий бот пропускает или просто не индексирует страницу.
Решается проблема через техническую поддержку Google/Яндекса. Пишите смело, ведь помимо точной информации о сайте и его страницах вы получите рекомендации по оптимизации страниц.
Технические причины
Редиректы. Поисковые системы исключают из индексации сайты, которые имеют редирект и переводят пользователя на другие страницы. При этом конечная страница, на которую и происходит редирект, может не выпадать из индексации, если не нарушает других правил.
Пример отчета редиректов в Яндекс Вебмастере
Следовательно, если не хотите терять позиции в поисковой выдаче — исключите редирект с сайта. Но бывает и другая ситуация, когда сайт меняет основную ссылку, переезжая на другой адрес. В этом случае редирект использовать стоит, чтобы не терять клиентов, которые переходят, пользуясь ссылкой на старый сайт.
404. Страницы, при переходе на которые пользователь видит 404 ошибку, не индексируются. Если страница удалена и не работает по ошибке, то ее стоит восстановить. В случае, когда страница не нужна, на сайте следует удалить все ссылки, которые на нее вели.
Пример 404 ошибки на сайте
Иногда и по вине хостинг-провайдера на страницах сайта висит 404 ошибка — если проблема повторяется часто, то лучше сменить хостинг, чтобы не терять позиции в поисковой выдаче.
Для проверки сервера перейдите в Яндекс Вебмастер, зайдите в раздел «Инструменты» и выберите «Проверка ответа сервера».
Проверка ответа сервера в Яндекс Вебмастере
Метатег Robots (noindex) и файл Robots.txt. Каждый владелец сайта может настраивать страницы, которые не стоит включать в поисковую индексацию, делается это при помощи файла Robots.
Открываете файл Robots, направляетесь к атрибуту «name», если стоит значение «robots», а атрибут «content» имеет значение «noindex» — это означает, что индексация страницы запрещена любому роботу поисковой системы.
Настройка показа страницы с использованием метатега Robots
Следовательно, если индексировать страницу не надо, оставляете «noindex», в иных ситуациях — удаляете. Больше информации о тонкостях работы с метатегами можно найти в справке Google.
Просканированная страница еще не проиндексирована. В Google Search Console есть сайты, исключенные из индексации, имеющие статус «Страница просканирована, но пока не проиндексирована» — это означает, что поисковый робот увидел страницу, просканировал, но в индексацию она еще не попала. Стоит просто подождать и страница появится в поиске.
Пример отчета в Google Search Console просканированной страницы
С проблемой индексации можно столкнуться еще и из-за плохого хостинга или постоянных технических работ. Например, поисковый робот, обходя сайты, попадет в интервал времени, когда страница находится на технических работах или упал хостинг.
В этом случае бот вынужден исключить страницу из индексации. После того, как сайт возобновит работу, вы можете просто направить бота просканировать страницы еще раз, и тогда они вновь проиндексируются.
Чтобы направить Google-бота, необходимо подать запросы в Google Search (больше информации), а в Яндексе зайти в Вебмастер и в разделе «Индексирование» назначить переобход страниц (информация по Яндексу).
Неканоническая страница. Неканонической является страница, которая схожа по контенту с другой страницей, но имеет меньший приоритет показа, из-за чего может выпадать из поисковой выдачи. Для этого в исходном коде присутствует атрибут rel=«canonical», который позволяет выделить для поисковых систем приоритетную страницу, вследствие чего другие страницы могут исключаться из поиска.
Но проблема может возникнуть на этапе сканирования страниц ботом, если он неправильно определяет каноническую страницу, то как раз основная выпадет из поисковой выдачи, чтобы этого избежать необходимо удалить атрибут rel=«canonical» с других страниц, которые не являются приоритетными в показе.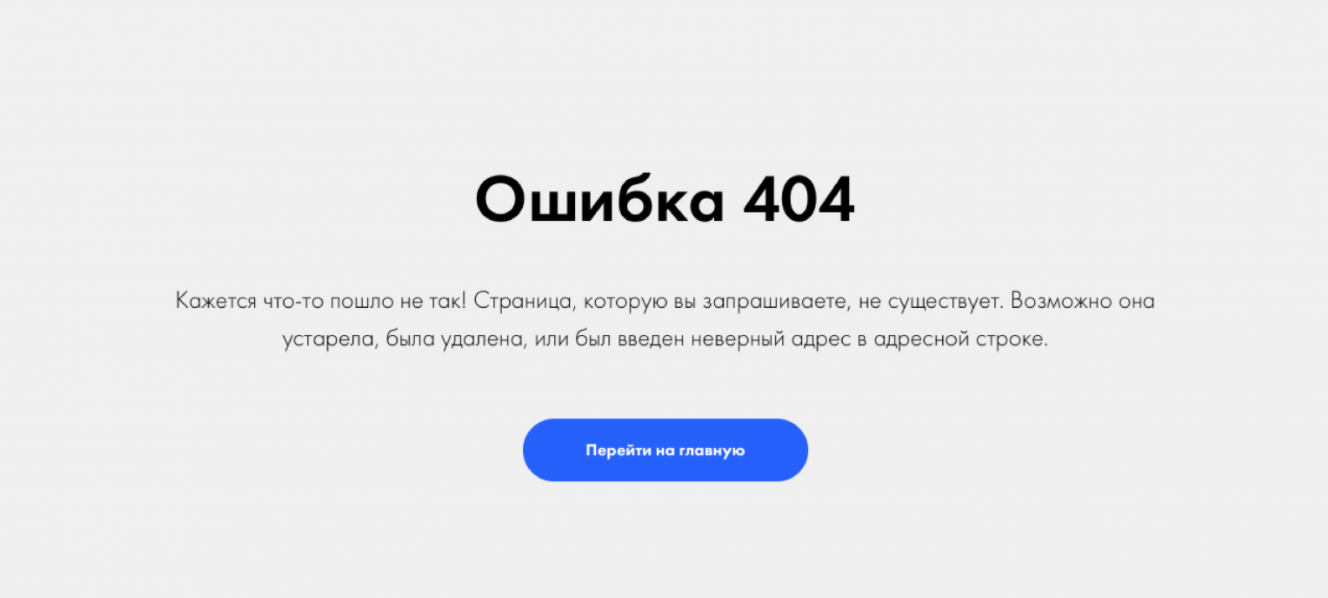
Пример отчетов в Google Search Console и Яндекс Вебмастер о канонических страницах.
Google Search Console
Яндекс Вебмастер
Вредоносный код на сайте. Сайт, который имеет вредоносный код вне зависимости от процесса появления кода (взломали сайт или вы самостоятельно изменили код) получает санкции и выпадает из индексации. Если вас взломали, то стоит сразу обратиться в техподдержку Google/Яндекса, сообщить о проблеме и восстановить работу сайта.
Причины зависящие от контентаДубли. Страницы, которые дублируют контент с других ресурсов (речь идет о полном или частичном дублировании), исключаются из поиска.
Если на сайте есть похожие друг на друга страницы — это другая ситуация, здесь одна из страниц может выпадать из индексации, поэтому за ненадобностью от второй можно отказаться.
Пример отчета с Яндекс Вебмастера о дублированных страницах
Если необходимо, чтобы похожие друг на друга страницы оставались на сайте и проходили индексацию, то их нужно максимально уникализировать. Можно изменить метатеги, сделать уникальными картинки и текст. Процент уникальности текста должен быть около 90%, чтобы уникализировать картинки — перескриньте их или скиньте в Телеграм и скачайте).
Исключенные страницы за дублирование в Яндекс Вебмастере
В ситуации, когда нет времени уникализировать вторую страницу, можно сделать одну из них каноничной.
Плохое качество контента. Под плохим качеством контента понимается низкая уникальность статей, большое количество рекламы, спам, низкое качество изображений.
Искусственный интеллект поисковых систем все время сравнивает сайты и определяет, насколько каждая страница привлекательна пользователям, сколько по времени ее читают, где пользователи останавливаются, какой процент отказов и т. п. Поэтому чем хуже ИИ оценит качество наполнения сайта, тем ниже позиция будет в выдаче.
п. Поэтому чем хуже ИИ оценит качество наполнения сайта, тем ниже позиция будет в выдаче.
Отчет в Яндекс Вебмастере о плохом качестве контента
Плохое качество страниц. Плохими называются страницы, которые не удовлетворяют поисковому запросу человека. Например, пользователь ищет «как выбрать зубную щетку», а, попадая на сайт, ему приходится читать о здоровье зубов.
Обнаружив плохую страницу, робот опускает ее в поисковой выдаче. Чаще всего сюда относятся страницы с небольшим количеством контента.
Пример Яндекс Вебмастера
Для повышения позиций необходимо наполнять сайт разносторонним контентом, указывать контактную информацию. Например, веб-мастерам интернет-магазина рекомендуется рассказать о гарантии, о процессе покупки и получении продукта.
Переоптимизированный контент. Встречается на сайтах, где статьи пишутся для поисковых систем, а не читателей. На сайте все материалы с Сео-оптимизацией, статьи кишат ключевыми словами, но при этом информационная ценность в них минимальна.
На сайте все материалы с Сео-оптимизацией, статьи кишат ключевыми словами, но при этом информационная ценность в них минимальна.
Обычно такие сайты хоть и выигрывают на Сео-оптимизации, проигрывают, когда ИИ поисковиков оценивает ресурс с точки зрения пользы читателю. По итогу подобные сайты выпадают из индексации или теряют позиции в поисковой выдаче.
Переоптимизация в Яндексе
Решение — сосредоточиться на контенте для пользователей, в перспективе такой подход имеет больше преимуществ.
Накрутка поведенческих факторов. Поисковые системы в 2021 году достаточно хорошо развиты, чтобы вычислять «фейковые» поведенческие факторы, поэтому если владелец сайта решит накрутить популярности, то поплатится плохой индексацией.
Искусственные ссылки на сайт в отчете Яндекс Вебмастера
В качестве примера можно привести накрутку кликов по ссылкам на сайте, нередко черные сайты накручивают и клики по рекламе, чтобы увеличивать свой доход, тем не менее такой путь приводит лишь к блокировке и потере доверия со стороны поисковых систем (сайт может выпадать из индексации вплоть до 9 месяцев).
Семейный фильтр. Крупные поисковые системы (как раз Google и Яндекс) имеют фильтр, исключающий из поисковой выдачи страницы, содержащие материалы 18+. Помимо этого под фильтр могут попасть сайты, которые содержат рекламные блоки или ключевые слова, связанные с адалт-тематикой.
Пример семейного фильтра в Яндекс поиске
Блокировка сайта. К блокировке могут приводят действия, запрещенные правилами поисковой системы. Например, запрещенные способы продвижения, клоакинг, скрытые и многократные повторяющиеся теги h2 и strong, большое количество «украденного» контента и редиректов.
Отчет об имитации действий пользователей в Яндекс Вебмастере
Неуникальные сниппеты. Сниппет — небольшой информационный блок, отображающий содержание сайта по поисковому запросу. Сниппет помогает сложить первостепенное представление о контенте на странице, следовательно, чем сниппет привлекательнее, тем больше трафика получит сайт.
Пример сниппета в поисковой выдаче Google
Если сниппет сайта похож на сниппет конкурента, то поисковая система вынуждена скрыть один из них. Эта ситуация достаточно часто встречается в интернет-магазинах, где находятся одинаковые товары с похожим описанием (Например, можно вспомнить продажу цветов, товар у всех одинаковый, а придумать какое-то уникальное описание не просто).
Следовательно, чтобы избежать выпадения страницы из выдачи, рекомендуется использовать уникальное описание сайта. Если замечаете, что начинаете терять органический трафик по основным запросам, то, скорее всего, вас настигла эта проблема, но, поменяв описание и просканировав страницу поисковым ботом, вы решите проблему.
Аффилированность. Если компания имеет два сайта с похожим контентом и описанием, то они будут бороться и за поисковую выдачу, причем поисковые системы здесь не будут показывать один сайт на первом месте, а другой на второй, в выдаче будет только какой-то один сайт.
Пример аффилированности
Google и Яндекс все время борются за разнообразие поисковой выдачи, поэтому и стараются, чтобы два сайта одной компании не показывались по одному и тому же набору ключевых фраз. Процесс определения аффилиатов простой, поисковый робот сравнивает информацию сайтов, начиная с контактных данных.
Как проверить, находится ли сайт под фильтром
- Для проверки в Яндексе заходите в Яндекс Вебмастер, направляетесь в раздел «Диагностика», подраздел «Безопасность и нарушения» и проверяете сайт. Если сайт получил фильтр, то информация об этом будет находиться прямо здесь.
Информация о диагностике сайта в Яндекс Вебмастере
- Для проверки в Google переходите в Google Search Console, далее направляетесь в раздел «Меры, принятые вручную», а после «Проблемы безопасности». Если в обоих разделах пусто, значит нарушений нет и поисковой индексации ничего не мешает.

Диагностика в Google Search Console
Рекомендации от поисковых систем:
- Чтобы сайты хорошо индексировались как на ПК, так и на телефонах, убедитесь, что мобильная версия сайта содержит тот же самый контент.
- Используйте одинаково информативные заголовки для всех версий сайта.
- Проверяйте качество видео и фото. Лучше индексируются страницы, где контент высокого разрешения.
- Подтвердите право собственности на сайт.
- Убедитесь, что сайт не нарушает правил безопасности.
Подводя итоги, рекомендуем чаще пользоваться сервисами Google Search Console и Яндекс Вебмастер для аналитики как сайта целиком, так и отдельных страниц, а также посвящать время технической составляющей поисковой выдачи. Ведь чем лучше вы разбираетесь в работе алгоритмом поисковиков, тем больше трафика сможете привлечь на сайт.
Основы внутренней оптимизации. Индексация страниц сайта.
Однако, определенную роль во внутренней оптимизации играют факторы, никак не связанные с контентом (назовем их неконтентными факторами). Одним из таких факторов является корректная индексация страниц сайта.
Необходимыми (но недостаточными!) условиями для попадания страницы в индекс являются следующие:
- значение HTTP-статуса страницы, отдаваемого индексирующему роботу поисковой машины, должно иметь значение 200 ОК;
- отсутствие запрета на индексацию данной страницы;
- URL страницы должен быть известен поисковой машине.
Проверить HTTP-статус страницы «глазами» индексирующего робота и отсутствие запрета на ее индексацию в файле robots.txt можно в разделе «Проверка ответа сервера» Яндекс.Вебмастера, причем эта проверка производится только для тех сайтов, права на которые подтверждены в вашем аккаунте. В Инструментах для вебмастера Google для того, чтобы проверить, доступна ли конкретная страница сайта для индексации, можно воспользоваться режимом «Посмотреть как Googlebot» в разделе «Содержимое сайта».
- с помощью файла robots.txt
- с помощью специальных директив в HTML-тегах в коде страницы
- изменяя настройки инструмента «Параметры URL» в разделе «Сканирование» Инструментов для вебмастера Google.
В файле robots.txt это можно сделать с помощью директив Disallow и Clean-param. Достаточно подробную справку по правилам составления файла robots.txt можно найти в разделе «Использование robots.txt» Помощи вебмастеру Яндекса и в разделе «Блокировка URL при помощи файла robots.txt» Справки Google.
Проверить корректность файла robots.txt можно в разделе «Анализ robots.txt» кабинета вебмастера Яндекса (причем, это можно сделать для любого сайта, а не только для тех, на которые подтверждены права) и в разделе «Инструмент проверки файла robots.txt» Инструментов для вебмастера Google (только для сайтов с подтвержденными правами).
К директивам, c помощью которых можно запрещать страницу к индексации, относятся мета-тег robots и атрибут rel=»canonical» тега . Справочную информацию по их использованию можно найти на страницах Помощи Яндекса и Справки Google. Справку по работе с инструментом «Параметры URL» раздела «Сканирование» Инструментов для вебмастера Google можно найти на странице https://support.google.com/webmasters/answer/1235687?hl=ru.
Справочную информацию по их использованию можно найти на страницах Помощи Яндекса и Справки Google. Справку по работе с инструментом «Параметры URL» раздела «Сканирование» Инструментов для вебмастера Google можно найти на странице https://support.google.com/webmasters/answer/1235687?hl=ru.
Для того, чтобы индексирующий робот нашел данную страницу, достаточно одной ссылки на неё со станицы, которая уже есть в индексе поисковика. Также о новых страницах на сайте можно сообщать поисковой машине с помощью файла Sitemap (справочную информацию по нему можно найти в Помощи Яндекса и Справке Google).
Но даже, если робот узнает о странице и посетит ее, то еще не факт, что она попадет в индекс. Проверить, знает ли индексатор Яндекса о конкретной странице, и включена ли она в поисковую базу, можно в разделе «Проверить URL» Кабинета вебмастера Яндекса. Есть несколько вариантов ответов:
В данный момент адрес страницы неизвестен роботу
- Адрес страницы уже известен роботу, но в данный момент контент страницы ещё не проиндексирован.
- Страница была проиндексирована роботом и присутствует в поиске
- Страница обходится роботом, но отсутствует в поиске
- Страница обходится роботом, но отсутствует в поиске, поскольку дублирует уже имеющиеся на вашем сайте страницы.

Первый вариант ответа говорит нам о том, что, во-первых, у индексатора нет информации о том, что данная страница существует. Поэтому необходимо убедиться, что поисковый робот видит данную страницу, и она отдает ему отклик 200 указанным выше способом, а также разместить ссылку на нее на какой-либо странице, уже ранее проиндексированной поисковой машиной. Также для того, чтобы сообщить о странице индексирующему роботу, SEO-специалисты используют размещение ссылок на нее в Твиттере. Более того, до недавнего времени информирование индексатора о новой странице через Твиттер считалось SEO-специалистами наиболее быстрым и надежным способом, позволяющим обеспечить попадание страницы в поисковый индекс Яндекса буквально за считанные дни.
Однако основную проблему, связанную с индексацией, составляют варианты 4 и 5, когда индексирующий робот обходит страницу, но не включает ее в поисковый индекс. Это может быть связано, как с техническими параметрами страницы, такими как запрет к индексации с помощью мета-тега noindex или атрибута rel=»canonical» тега . Но может иметь место и классификация алгоритмом данной страницы, как не имеющей достаточно ценного содержания. В таком случае говорят, что страница попадает в «скрытый индекс». Как с этим бороться?
Во-первых, страница может быть признана полным или нечетким (частичным) дубликатом уже имеющейся в индексе страницы (вариант ответа номер 5). Такое часто случается с однотипными страницами (например, номенклатурными единицами каталога продукции), которые отличаются друг от друга лишь незначительным по удельному объему текстом. В этом случае, необходимо повышать удельную долю уникального текста на страницах – расширять индивидуальное описание и по возможности закрывать от индексации текстовые элементы, общие для всех страниц данного типа (например, пункты меню, новостную ленту, фрагменты «шапки», «подвала» и т.п.)
Такое часто случается с однотипными страницами (например, номенклатурными единицами каталога продукции), которые отличаются друг от друга лишь незначительным по удельному объему текстом. В этом случае, необходимо повышать удельную долю уникального текста на страницах – расширять индивидуальное описание и по возможности закрывать от индексации текстовые элементы, общие для всех страниц данного типа (например, пункты меню, новостную ленту, фрагменты «шапки», «подвала» и т.п.)
Во-вторых, страница может иметь недостаточное количество статического веса. Например, она имеет достаточно глубокий уровень вложенности и имеет при этом сравнительное небольшое количество внутренних ссылок. Здесь можно посоветовать оптимизировать структуру сайта, уменьшая уровень вложенности информативных страниц, и плотнее их перелинковывая друг с другом. Также можно посоветовать использовать внешние ссылки с других сайтов.
В-третьих, сам сайт может иметь достаточно низкий уровень авторитетности в глазах поисковой машины.
Резюмируя, можно отметить, что проблема индексации сайта, конечно же, является не самой сложной из проблем современного SEO. Как правило, достаточно овладеть базовым справочным материалом по теме и тщательно следовать его рекомендациям. Однако с пренебрежением относиться к данному вопросу тоже не стоит, дабы неожиданно не столкнуться с неприятностями, которые могут существенно затормозить продвижение сайта.
Как исправить сообщение «Проиндексировано, но заблокировано robots.txt» в Google Search Console
«Проиндексировано, но заблокировано robots.txt» означает, что Google проиндексировал URL-адреса, даже если они были заблокированы вашим файлом robots. txt.
txt.
Google пометил эти URL-адреса как «Действительные с предупреждением», поскольку они не уверены, хотите ли вы, чтобы эти URL-адреса были проиндексированы. В этой статье вы узнаете, как решить эту проблему.
Вот как это выглядит в отчете об индексировании Google Search Console с указанием количества показов URL:
Перепроверьте уровень URL
Вы можете перепроверить это, выбрав Покрытие > Проиндексировано, хотя и заблокировано robots.txt , и проверьте один из перечисленных URL.
Затем под Сканирование будет написано Нет: заблокировано robots.txt для поля Сканирование разрешено и Не удалось: заблокировано robots.txt для поля Выборка страницы .
Какую часть вашего контента Google не может просканировать?
Отправьте свой веб-сайт и узнайте прямо сейчас!
Так что же случилось?
Обычно Google не проиндексировал бы эти URL-адреса, но, очевидно, они нашли ссылки на них и сочли их достаточно важными для индексации.
Скорее всего, отображаемые фрагменты не оптимальны, например:
Полезные ресурсы
- Запрещает ли robots.txt указание поисковым системам деиндексировать страницы?
- Как заставить Google проиндексировать ваш сайт
Как исправить «Проиндексирован, но заблокирован robots.txt»
- Экспортируйте список URL-адресов из Google Search Console и отсортируйте их по алфавиту.
- Просмотрите URL-адреса и проверьте, содержит ли он URL-адреса…
- Которые вы хотите проиндексировать. В этом случае обновите файл robots.txt, чтобы разрешить Google доступ к этим URL-адресам.
- К которым поисковые системы не должны иметь доступ. Если это так, оставьте файл robots.txt как есть, но проверьте, есть ли у вас какие-либо внутренние ссылки, которые следует удалить.
- Доступ к которым есть у поисковых систем, но который вы не хотите индексировать. В этом случае обновите файл robots.txt, чтобы отразить это, и примените директивы robots noindex.
- Это никому никогда не должно быть доступно. Возьмем, к примеру, промежуточную среду. В этом случае выполните действия, описанные в нашей статье Защита промежуточных сред.
- Если вам непонятно, какая часть файла robots.txt блокирует эти URL-адреса, выберите URL-адрес и нажмите кнопку
TEST ROBOTS.TXT BLOCKINGна панели, которая открывается справа. . Откроется новое окно, показывающее, какая строка в файле robots.txt не позволяет Google получить доступ к URL-адресу. - Когда вы закончите вносить изменения, нажмите кнопку
ПРОВЕРИТЬ ИСПРАВЛЕНИЕ, чтобы запросить у Google повторную оценку файла robots.txt с вашими URL-адресами.

Начните отслеживать свой сайт, прежде чем вносить изменения
Отслеживайте каждое вносимое вами изменение и следите за тем, чтобы файл robots.txt не навредил вашему сайту еще больше!
Проиндексировано, но заблокировано исправлением robots.txt для WordPress
Процесс устранения этой проблемы для сайтов WordPress такой же, как описано выше, но вот несколько советов, как быстро найти файл robots. txt в WordPress:
txt в WordPress:
WordPress + Yoast SEO
Если вы используете плагин Yoast SEO, выполните следующие действия, чтобы настроить файл robots.txt:
- Войдите в свой раздел
wp-admin. - На боковой панели перейдите к
Плагин Yoast SEO>Инструменты. - Перейти к
Редактор файлов.
WordPress + Rank Math
Если вы используете SEO-плагин Rank Math, выполните следующие действия, чтобы настроить файл robots.txt:
- Войдите в свой раздел
wp-admin. - На боковой панели выберите
Rank Math>Общие настройки. - Перейти к
Редактировать robots.txt.
WordPress + All-in-One SEO
Если вы используете плагин All-in-One SEO, выполните следующие действия, чтобы настроить файл robots.txt:
- Войдите в свой раздел
wp-admin. - На боковой панели перейдите к
All in One SEO>Robots.. txt
 txt
txt Совет для профессионалов
Если вы работаете над веб-сайтом WordPress, который еще не запущен, и не можете понять, почему ваш robots.txt содержит следующее:
User-agent: *
Запретить: /
Затем проверьте настройки в разделе: Настройки > Чтение и найдите Видимость в поисковых системах .
Если установлен флажок Запретить поисковым системам индексировать этот сайт , WordPress создаст виртуальный файл robots.txt, запрещающий поисковым системам доступ к сайту.
Проиндексировано, но заблокировано исправлением robots.txt для Shopify
Shopify не позволяет вам управлять файлом robots.txt из своей системы, поэтому вы работаете с файлом по умолчанию, который применяется ко всем сайтам.
Возможно, вы видели сообщение «Проиндексировано, но заблокировано robots.txt» в Google Search Console или получили электронное письмо от Google об этом по электронной почте «Обнаружена новая проблема индексирования».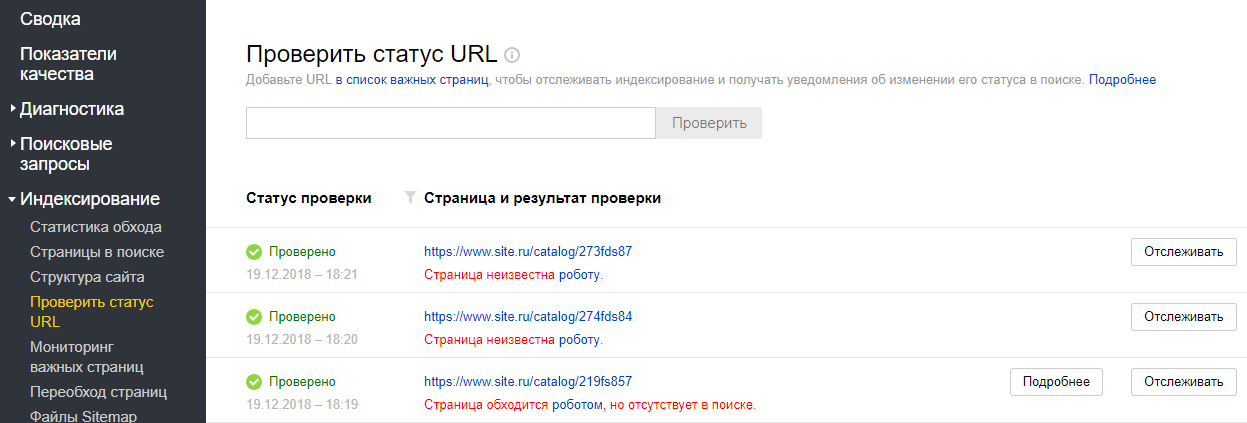 Мы рекомендуем всегда проверять, какие URL-адреса это касается, потому что вы не хотите ничего оставлять на волю случая в SEO.
Мы рекомендуем всегда проверять, какие URL-адреса это касается, потому что вы не хотите ничего оставлять на волю случая в SEO.
Просмотрите URL-адреса и посмотрите, не заблокированы ли какие-либо важные URL-адреса. Если это так, у вас есть два варианта, которые требуют некоторой работы, но позволяют изменить файл robots.txt в Shopify:
- Настроить обратный прокси-сервер
- Использовать Cloudflare Workers
Независимо от того, эти варианты того стоят для вас, зависит от потенциального вознаграждения. Если он значителен, рассмотрите возможность реализации одного из этих вариантов.
Вы можете использовать тот же подход на платформе Squarespace.
Полезные ресурсы
- Shopify Советы и лучшие практики SEO: полное руководство
Часто задаваемые вопросы
Почему Google показывает эту ошибку для моих страниц?
Google обнаружил ссылки на страницы, недоступные им из-за запрещающих директив robots. txt. Когда Google сочтет эти страницы достаточно важными, они проиндексируют их.
txt. Когда Google сочтет эти страницы достаточно важными, они проиндексируют их.
Как исправить эту ошибку?
Короткий ответ на этот вопрос: убедитесь, что страницы, которые вы хотите проиндексировать в Google, должны быть просто доступны для поисковых роботов Google. И страницы, которые вы не хотите индексировать, не должны быть связаны внутри. Подробный ответ описан в разделе «Как исправить «Проиндексировано, но заблокировано robots.txt»» этой статьи.
Могу ли я редактировать файл robots.txt в WordPress?
Популярные SEO-плагины, такие как Yoast, Rank Math и All in one SEO, например, позволяют редактировать файл robots.txt прямо из панели администратора wp.
Поделиться сведениями о статье
Почему заблокированный URL-адрес без индекса отображается в результатах поиска?
Изменено: 25.01.2021
Если вы используете robots.txt, чтобы заблокировать доступ к каталогу или определенной странице для сканеров поисковых систем, эта страница/каталог не будет просканирована или проиндексирована.
Contents
Contents
Вы можете заблокировать каталог «a-directory» и страницу «a-page.html» для вебкраулеров следующим добавлением к сайтам robots.txt:
User-agent: * Запретить: /a-каталог/ Disallow: /a-page.html
Почему я нахожу свою страницу в результатах поиска, хотя она заблокирована через robots.txt?
В некоторых случаях Google показывает страницу, которая заблокирована через файл robots.txt в поисковой выдаче (страницы результатов поисковой системы).
В таких случаях важно знать, что сканер учитывает файл robots.txt и не добавляет содержимое таких заблокированных страниц в свой индекс. Поэтому Google не имеет доступной информации, когда дело доходит до этой страницы.
Когда заблокированная страница появляется в поисковой выдаче?
Если на заблокированной странице много входящих ссылок с окончательным текстом ссылки, Google может рассматривать содержание страницы как достаточно релевантное, чтобы отображать URL-адрес, который появляется в этих текстах ссылок, в результатах поиска. Однако содержание этого URL-адреса до сих пор неизвестно Google, поскольку они не могут просканировать или проиндексировать страницу.
Однако содержание этого URL-адреса до сих пор неизвестно Google, поскольку они не могут просканировать или проиндексировать страницу.
Обычно вы можете распознать страницы в поисковой выдаче, которые были заблокированы через robots.txt от сканирования и индексации по отсутствующему фрагменту (например, описанию).
Google все больше внимания уделяет сигналам пользователей – пример
Мы используем robots.txt для блокировки доступа к нашей странице http://www.domain.com/grandmas-cakerecipe.html . Сканеры Google выполняют нашу просьбу не сканировать и не индексировать содержимое страницы. Поэтому Google понятия не имеет, какой контент находится в файле 9.0230 grandmas-cakerecipe.html .
Допустим, эта страница содержит рецепт мирового класса, и мы получаем много входящих ссылок с других страниц, многие из которых содержат текст ссылки «Рецепт пирога мирового класса от бабушки». В таких случаях наша заблокированная страница
