
Какие страницы следует закрывать от индексации — SEO
Индексирование сайта – это процесс, с помощью которого поисковые системы, подобные Google и Yandex, анализируют страницы веб-ресурса и вносят их в свою базу данных. Индексация выполняется специальным ботом, который заносит всю необходимую информацию о сайте в систему – веб-страницы, картинки, видеофайлы, текстовый контент и прочее. Корректное индексирование сайта помогает потенциальным клиентам легко найти нужный сайт в поисковой выдаче, поэтому важно знать обо всех тонкостях данного процесса.
Почему важно ограничивать индексацию страниц
Заинтересованность в индексации есть не только у собственника веб-ресурса, но и у поисковой системы – ей необходимо предоставить релевантную и, главное, ценную информацию для пользователя. Чтобы удовлетворить обе стороны, требуется проиндексировать только те страницы, которые будут интересны и целевой аудитории, и поисковику.
Прежде чем переходить к списку ненужных страниц для индексации, давайте рассмотрим причины, из-за которых стоит запрещать их выдачу.
- Уникальность контента – важно, чтобы вся информация, передаваемая поисковой системе, была неповторима. При соблюдении данного критерия выдача может заметно вырасти. В противном случае поисковик будет сначала искать первоисточник – только он сможет получить доверие.
- Краулинговый бюджет – лимит, выделяемый сайту на сканирование. Другими словами, это количество страниц, которое выделяется каждому ресурсу для индексации. Такое число обычно определяется для каждого сайта индивидуально. Для лучшей выдачи рекомендуется избавиться от ненужных страниц.
В краулинговый бюджет входят: взломанные страницы, файлы CSS и JS, дубли, цепочки редиректов, страницы со спамом и прочее.
Что нужно скрывать от поисковиков
В первую очередь стоит ограничить индексирование всего сайта, который еще находится на стадии разработки. Именно так можно уберечь базу данных поисковых систем от некорректной информации.
PDF и прочие документы
Часто на сайтах выкладываются различные документы, относящиеся к контенту определенной страницы (такие файлы могут содержать и важную информацию, например, политику конфиденциальности).
Рекомендуется отслеживать поисковую выдачу: если заголовки PDF-файлов отображаются выше в рейтинге, чем страницы со схожим запросом, то их лучше скрыть, чтобы открыть доступ к наиболее релевантной информации. Отключить индексацию PDF и других документов вы можете в файле robots.txt.
Разрабатываемые страницы
Стоит всегда избегать индексации разрабатываемых страниц, чтобы рейтинг сайта не снизился. Используйте только те страницы, которые оптимизированы и наполнены уникальным контентом. Настроить их отображение можно в файле robots.txt.
Копии сайта
Если вам потребовалось создать копию веб-ресурса, то в этом случае также необходимо все правильно настроить. В первую очередь укажите корректное зеркало с помощью 301 редиректа. Это позволит оставить прежний рейтинг у исходного сайта: поисковая система будет понимать, где оригинал, а где копия. Если же вы решитесь использовать копию как оригинал, то делать это не рекомендуется, так как возраст сайта будет обнулен, а вместе с ним и вся репутация.
Веб-страницы для печати
Иногда контент сайта требует уникальных функций, которые могут быть полезны для клиентов. Одной из таких является «Печать», позволяющая распечатать необходимые страницы на принтере. Создание такой версии страницы выполняется через дублирование, поэтому поисковые роботы могут с легкостью установить копию как приоритетную. Чтобы правильно оптимизировать такой контент, необходимо отключить индексацию веб-страниц для печати. Сделать это можно с использованием AJAX, метатегом <meta name=»robots» content=»noindex, follow»/> либо в файле robots.
Формы и прочие элементы сайта
Большинство сайтов сейчас невозможно представить без таких элементов, как личный кабинет, корзина пользователя, форма обратной связи или регистрации. Несомненно, это важная часть структуры веб-ресурса, но в то же время она совсем бесполезна для поисковых запросов. Подобные типы страниц необходимо скрывать от любых поисковиков.
Страницы служебного пользования
Формы авторизации в панель управления и другие страницы, используемые администратором сайта, не несут никакой важной информации для обычного пользователя. Поэтому все служебные страницы следует исключить из индексации.
Личные данные пользователя
Вся персональная информация должна быть надежно защищена – позаботиться о ее исключении из поисковой выдачи нужно незамедлительно. Это относится к данным о платежах, контактам и прочей информации, идентифицирующей конкретного пользователя.
Страницы с результатами поиска по сайту
Как и в случае со страницами, содержащими личные данные пользователей, индексация такого контента не нужна: веб-страницы результатов полезны для клиента, но не для поисковых систем, так как содержат неуникальное содержание.
Контент на таких веб-страницах обычно дублируется, хоть и частично. Однако индексация таких страниц посчитается поисковыми системами как дублирование. Чтобы снизить риск возникновения таких проблем, рекомендуется отказаться от подобного контента в поисковой выдаче.
Пагинация на сайте
Пагинация – без нее сложно представить существование любого крупного веб-сайта. Чтобы понять ее назначение, приведу небольшой пример: до появления типичных книг использовались свитки, на которых прописывался текст. Прочитать его можно было путем развертывания (что не очень удобно). На таком длинном холсте сложно найти нужную информацию, нежели в обычной книге. Без использования пагинации отыскать подходящий раздел или товар также проблематично.
Пагинация позволяет разделить большой массив данных на отдельные страницы для удобства использования. Отключать индексирование для такого типа контента нежелательно, требуется только настроить атрибуты rel=»canonical», rel=»prev» и rel=»next».
Помимо всего вышесказанного, рекомендуется закрывать такие типы страниц, как лендинги для контекстной рекламы, страницы с результатами поиска по сайту и поиск по сайту в целом, страницы с UTM-метками.
Какие страницы нужно индексировать
Ограничение страниц для поисковых систем зачастую становится проблемой – владельцы сайтов начинают с этим затягивать или случайно перекрывают важный контент. Чтобы избежать таких ошибок, рекомендуем ознакомиться с нижеуказанным списком страниц, которые нужно оставлять во время настройки индексации сайта.
- В некоторых случаях могут появляться страницы-дубликаты. Часто это связано со случайным созданием дублирующих категорий, привязкой товаров к нескольким категориям и их доступность по различным ссылкам. Для такого контента не нужно сразу же бежать и отключать индексацию: сначала проанализируйте каждую страницу и посмотрите, какой объем трафика был получен.
 И только после этого настройте 301 редиректы с непопулярных страниц на популярные, затем удалите те, которые совсем не эффективны.
И только после этого настройте 301 редиректы с непопулярных страниц на популярные, затем удалите те, которые совсем не эффективны. - Страницы смарт-фильтра – благодаря им можно увеличить трафик за счет низкочастотных запросов. Важно, чтобы были правильно настроены мета-теги, 404 ошибки для пустых веб-страниц и карта сайта.
 И только после этого настройте 301 редиректы с непопулярных страниц на популярные, затем удалите те, которые совсем не эффективны.
И только после этого настройте 301 редиректы с непопулярных страниц на популярные, затем удалите те, которые совсем не эффективны.Соблюдение индексации таких страниц может значительно улучшить поисковую выдачу, если ранее оптимизация не проводилась.
Как закрыть страницы от индексации
Мы детально рассмотрели список всех страниц, которые следует закрывать от поисковых роботов, но о том, как это сделать, прошлись лишь вскользь – давайте это исправлять. Выполнить это можно несколькими способами: с помощью файла robots.txt, добавления специальных метатегов, кода, сервисов для вебмастеров, а также с использованием дополнительных плагинов. Рассмотрим каждый метод более детально.
Скачать robots.txt для Invision Community
Способ 1: Файл robots. txt
txt
Данный текстовый документ – это файл, который первым делом посещают поисковики. Он предоставляет им информацию о том, какие страницы и файлы на сайте можно обрабатывать, а какие нет. Его основная функция – сократить количество запросов к сайту и снизить на него нагрузку. Он должен удовлетворять следующим критериям:
- наименование прописано в нижнем регистре;
- формат указан как .txt;
- размер не должен превышать 500 Кб;
- местоположение – корень сайта;
- находится по адресу URL/robots.txt, при запросе сервер отправляет в ответ код 200.
Прежде чем переходить к редактированию файла, рекомендую обратить внимание на ограничивающие факторы.
- Директивы robots.txt поддерживаются не всеми поисковыми системами. Большинство поисковых роботов следуют тому, что написано в данном файле, но не всегда придерживаются правил. Чтобы полностью скрыть информацию от поисковиков, рекомендуется воспользоваться другими способами.
- Синтаксис может интерпретироваться по-разному в зависимости от поисковой системы. Потребуется узнать о синтаксисе в правилах конкретного поисковика.
- Запрещенные страницы в файле могут быть проиндексированы при наличии ссылок из прочих источников. По большей части это относится к Google – несмотря на блокировку указанных страниц, он все равно может найти их на других сайтах и добавить в выдачу. Отсюда вытекает то, что запреты в robots.txt не исключают появление URL и другой информации, например, ссылок. Решить это можно защитой файлов на сервере при помощи пароля либо директивы noindex в метатеге.

Файл robots.txt включает в себя такие параметры, как:
- User-agent – создает указание конкретному роботу.
- Disallow – дает рекомендацию, какую именно информацию не стоит сканировать.
- Allow – аналогичен предыдущему параметру, но в обратную сторону.
- Sitemap – позволяет указать расположение карты сайта sitemap. xml. Поисковый робот может узнать о наличии карты и начать ее индексировать.
- Clean-param – позволяет убрать из индекса страницы с динамическими параметрами. Подобные страницы могут отдавать одинаковое содержимое, имея различные URL-страницы.
- Crawl-delay – снижает нагрузку на сервер в том случае, если посещаемость поисковых ботов слишком велика. Обычно используется на сайтах с большим количеством страниц.
 xml. Поисковый робот может узнать о наличии карты и начать ее индексировать.
xml. Поисковый робот может узнать о наличии карты и начать ее индексировать.Теперь давайте рассмотрим, как можно отключить индексацию определенных страниц или всего сайта. Все пути в примерах – условные.
Пропишите, чтобы исключить индексацию сайта для всех роботов:
User-agent: * Disallow: /
User-agent: * Disallow: /
Закрывает все поисковики, кроме одного:
User-agent: * Disallow: / User-agent: Google Allow: /
Запрет на индексацию одной страницы:
User-agent: * Disallow: /page.html
Закрыть раздел:
User-agent: * Disallow: /category
Все разделы, кроме одного:
User-agent: * Disallow: / Allow: /category
Все директории, кроме нужной поддиректории:
User-agent: * Disallow: /direct Allow: /direct/subdirect
Скрыть директорию, кроме указанного файла:
User-agent: * Disallow: /category Allow: photo.
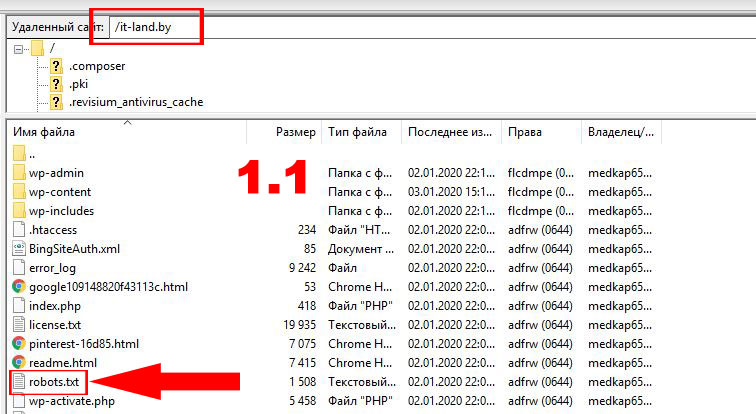 png
pngЗаблокировать UTM-метки:
User-agent: * Disallow: *utm=
Заблокировать скрипты:
User-agent: * Disallow: /scripts/*.js
Мы рассмотрели один из главных файлов, просматриваемых поисковыми роботами. Он использует лишь рекомендации, и не все правила могут быть корректно восприняты.
Способ 2: HTML-код
Отключение индексации можно осуществить также с помощью метатегов в блоке <head>. Обратите внимание на атрибут «content», он позволяет:
- активировать индексацию всей страницы;
- деактивировать индексацию всей страницы, кроме ссылок;
- разрешить индексацию ссылок;
- индексировать страницу, но запрещать ссылки;
- полностью индексировать веб-страницу.
Чтобы указать поискового робота, необходимо изменить атрибут «name», где устанавливается значение yandex для Яндекса и googlebot – для Гугла.
Пример запрета индексации всей страницы и ссылок для Google:
<html>
<head>
<meta name="googlebot" content="noindex, nofollow" />
</head>
<body>. Yandex" search_bot Yandex" search_bot
Yandex" search_botСпособ 4: Сервисы для вебмастеров
В Google Search Console мы можем убрать определенную страницу из поисковика. Для этого достаточно перейти в раздел «Индекс Google» и удалить выбранный URL.
Процедура запрета на индексацию выбранной страницы может занять некоторое время. Аналогичные действия можно совершить в Яндекс.Вебмастере.
Как закрыть от индексации страницу, сайт, ссылки, текст. Что нужно запрещать индексировать в robots.txt
Наш аналитик Александр Явтушенко недавно поделился со мной наблюдением, что у многих сайтов, которые приходят к нам на аудит, часто встречаются одни и те же ошибки. Причем эти ошибки не всегда можно назвать тривиальными – их допускают даже продвинутые веб-мастера. Так возникла идея написать серию статей с инструкциями по отслеживанию и исправлению подобных ошибок. Первый в очереди – гайд по настройке индексации сайта. Передаю слово автору.
Для хорошей индексации сайта и лучшего ранжирования страниц нужно, чтобы поисковик обходил ключевые продвигаемые страницы сайта, а на самих страницах мог точно выделить основной контент, не запутавшись в обилие служебной и вспомогательной информации.
У сайтов, приходящих к нам на анализ, встречаются ошибки двух типов:
1. При продвижении сайта их владельцы не задумываются о том, что видит и добавляет в индекс поисковый бот. В этом случае может возникнуть ситуация, когда в индексе больше мусорных страниц, чем продвигаемых, а сами страницы перегружены.
2. Наоборот, владельцы чересчур рьяно взялись за чистку сайта. Вместе с ненужной информацией могут прятаться и важные для продвижения и оценки страниц данные.
Сегодня мы хотим рассмотреть, что же действительно стоит прятать от поисковых роботов и как это лучше делать. Начнём с контента страниц.
Контент
Проблемы, связанные с закрытием контента на сайте:
Страница оценивается поисковыми роботами комплексно, а не только по текстовым показателям. Увлекаясь закрытием различных блоков, часто удаляется и важная для оценки полезности и ранжирования информация.
Приведём пример наиболее частых ошибок:
– прячется шапка сайта. В ней обычно размещается контактная информация, ссылки. Если шапка сайта закрыта, поисковики могут не узнать, что вы позаботились о посетителях и поместили важную информацию на видном месте;
Если шапка сайта закрыта, поисковики могут не узнать, что вы позаботились о посетителях и поместили важную информацию на видном месте;
– скрываются от индексации фильтры, форма поиска, сортировка. Наличие таких возможностей у интернет-магазина – важный коммерческий показатель, который лучше показать, а не прятать.
– прячется информация об оплате и доставке. Это делают, чтобы повысить уникальность на товарных карточках. А ведь это тоже информация, которая должна быть на качественной товарной карточке.
– со страниц «вырезается» меню, ухудшая оценку удобства навигации по сайту.
Зачем на сайте закрывают часть контента?
Обычно есть несколько целей:
– сделать на странице акцент на основной контент, убрав из индекса вспомогательную информацию, служебные блоки, меню;
– сделать страницу более уникальной, полезной, убрав дублирующиеся на сайте блоки;
– убрать «лишний» текст, повысить текстовую релевантность страницы.
Всего этого можно достичь без того, чтобы прятать часть контента!
У вас очень большое меню?
Выводите на страницах только те пункты, которые непосредственно относятся к разделу.
Много возможностей выбора в фильтрах?
Выводите в основном коде только популярные. Подгружайте остальные варианты, только если пользователь нажмёт кнопку «показать всё». Да, здесь используются скрипты, но никакого обмана нет – скрипт срабатывает по требованию пользователя. Найти все пункты поисковик сможет, но при оценке они не получат такое же значение, как основной контент страницы.
На странице большой блок с новостями?
Сократите их количество, выводите только заголовки или просто уберите блок новостей, если пользователи редко переходят по ссылкам в нём или на странице мало основного контента.
Поисковые роботы хоть и далеки от идеала, но постоянно совершенствуются. Уже сейчас Google показывает скрытие скриптов от индексирования как ошибку в панели Google Search Console (вкладка «Заблокированные ресурсы»). Не показывать часть контента роботам действительно может быть полезным, но это не метод оптимизации, а, скорее, временные «костыли», которые стоит использовать только при крайней необходимости.
Мы рекомендуем:
– относиться к скрытию контента, как к «костылю», и прибегать к нему только в крайних ситуациях, стремясь доработать саму страницу;
– удаляя со страницы часть контента, ориентироваться не только на текстовые показатели, но и оценивать удобство и информацию, влияющую на коммерческие факторы ранжирования;
– перед тем как прятать контент, проводить эксперимент на нескольких тестовых страницах. Поисковые боты умеют разбирать страницы и ваши опасения о снижение релевантности могут оказаться напрасными.
Давайте рассмотрим, какие методы используются, чтобы спрятать контент:
Тег noindex
У этого метода есть несколько недостатков. Прежде всего этот тег учитывает только Яндекс, поэтому для скрытия текста от Google он бесполезен. Помимо этого, важно понимать, что тег запрещает индексировать и показывать в поисковой выдаче только текст. На остальной контент, например, ссылки, он не распространяется.
Это видно из самого описания тега в справке Яндекса.
Поддержка Яндекса не особо распространяется о том, как работает noindex. Чуть больше информации есть в одном из обсуждений в официальном блоге.
Вопрос пользователя:
«Не до конца понятна механика действия и влияние на ранжирование тега <noindex>текст</noindex>. Далее поясню, почему так озадачены. А сейчас — есть 2 гипотезы, хотелось бы найти истину.
№1 Noindex не влияет на ранжирование / релевантность страницы вообще
При этом предположении: единственное, что он делает — закрывает часть контента от появления в поисковой выдаче. При этом вся страница рассматривается целиком, включая закрытые блоки, релевантность и сопряженные параметры (уникальность; соответствие и т. п.) для нее вычисляется согласно всему имеющему в коде контенту, даже закрытому.
№2 Noindex влияет на ранжирование и релевантность, так как закрытый в тег контент не оценивается вообще. Соответственно, все наоборот. Страница будет ранжироваться в соответствии с открытым для роботов контентом.
 »
»Ответ:
В каких случаях может быть полезен тег:
– если есть подозрения, что страница понижена в выдаче Яндекса из-за переоптимизации, но при этом занимает ТОПовые позиции по важным фразам в Google. Нужно понимать, что это быстрое и временное решение. Если весь сайт попал под «Баден-Баден», noindex, как неоднократно подтверждали представители Яндекса, не поможет;
– чтобы скрыть общую служебную информацию, которую вы из-за корпоративных ли юридических нормативов должны указывать на странице;
– для корректировки сниппетов в Яндексе, если в них попадает нежелательный контент.
Скрытие контента с помощью AJAX
Это универсальный метод. Он позволяет спрятать контент и от Яндекса, и от Google. Если хотите почистить страницу от размывающего релевантность контента, лучше использовать именно его. Представители ПС такой метод, конечно, не приветствую и рекомендуют, чтобы поисковые роботы видели тот же контент, что и пользователи.
Технология использования AJAX широко распространена и если не заниматься явным клоакингом, санкции за её использование не грозят. Недостаток метода – вам всё-таки придётся закрывать доступ к скриптам, хотя и Яндекс и Google этого не рекомендуют делать.
Страницы сайта
Для успешного продвижения важно не только избавиться от лишней информации на страницах, но и очистить поисковый индекс сайта от малополезных мусорных страниц.
Во-первых, это ускорит индексацию основных продвигаемых страниц сайта. Во-вторых, наличие в индексе большого числа мусорных страниц будет негативно влиять на оценку сайта и его продвижение.
Сразу перечислим страницы, которые целесообразно прятать:
– страницы оформления заявок, корзины пользователей;
– результаты поиска по сайту;
– личная информация пользователей;
– страницы результатов сравнения товаров и подобных вспомогательных модулей;
– страницы, генерируемые фильтрами поиска и сортировкой;
– страницы административной части сайта;
– версии для печати.
Рассмотрим способы, которыми можно закрыть страницы от индексации.
Закрыть в robots.txt
Это не самый лучший метод.
Во-первых, файл robots не предназначен для борьбы с дублями и чистки сайтов от мусорных страниц. Для этих целей лучше использовать другие методы.
Во-вторых, запрет в файле robots не является гарантией того, что страница не попадёт в индекс.
Вот что Google пишет об этом в своей справке:
Работе с файлом robots.txt посвящена статья в блоге Siteclinic «Гайд по robots.txt: создаём, настраиваем, проверяем».
Метатег noindex
Чтобы гарантированно исключить страницы из индекса, лучше использовать этот метатег.
Рекомендации по синтаксису у Яндекса и Google отличаются.
Ниже приведём вариант метатега, который понимают оба поисковика:
<meta name="robots" content="noindex, nofollow">
Важный момент!
Чтобы Googlebot увидел метатег noindex, нужно открыть доступ к страницам, закрытым в файле robots. txt. Если этого не сделать, робот может просто не зайти на эти страницы.
txt. Если этого не сделать, робот может просто не зайти на эти страницы.
Выдержка из рекомендаций Google:
Рекомендации Google.
Рекомендации Яндекса.
Заголовки X-Robots-Tag
Существенное преимущество такого метода в том, что запрет можно размещать не только в коде страницы, но и через корневой файл .htaccess.
Этот метод не очень распространён в Рунете. Полагаем, основная причина такой ситуации в том, что Яндекс этот метод долгое время не поддерживал.
В этом году сотрудники Яндекса написали, что метод теперь поддерживается.
Ответ поддержки подробным не назовёшь))). Прежде чем переходить на запрет индексации, используя X-Robots-Tag, лучше убедиться в работе этого способа под Яндекс. Свои эксперименты на эту тему мы пока не ставили, но, возможно, сделаем в ближайшее время.
Подробные рекомендации по использованию заголовков X-Robots-Tag от Google.
Защита с помощью пароля
Этот способ Google рекомендует, как наиболее надёжный метод спрятать конфиденциальную информацию на сайте.
Если нужно скрыть весь сайт, например, тестовую версию, также рекомендуем использовать именно этот метод. Пожалуй, единственный недостаток – могут возникнуть сложности в случае необходимости просканировать домен, скрытый под паролем.
Исключить появление мусорных страниц c помощью AJAX
Речь о том, чтобы не просто запретить индексацию страниц, генерируемых фильтрами, сортировкой и т. д., а вообще не создавать подобные страницы на сайте.
Например, если пользователь выбрал в фильтре поиска набор параметров, под которые вы не создавали отдельную страницу, изменения в товарах, отображаемых на странице, происходит без изменения самого URL.
Сложность этого метода в том, что обычно его нельзя применить сразу для всех случаев. Часть формируемых страниц используется для продвижения.
Например, страницы фильтров. Для «холодильник + Samsung + белый» нам нужна страница, а для «холодильник + Samsung + белый + двухкамерный + no frost» – уже нет.
Поэтому нужно делать инструмент, предполагающий создание исключений. Это усложняет задачу программистов.
Это усложняет задачу программистов.
Использовать методы запрета индексации от поисковых алгоритмов
«Параметры URL» в Google Search Console
Этот инструмент позволяет указать, как идентифицировать появление в URL страниц новых параметров.
Директива Clean-param в robots.txt
В Яндексе аналогичный запрет для параметров URL можно прописать, используя директиву Clean-param.
Почитать об этом можно в блоге Siteclinic.
Канонические адреса, как профилактика появления мусорных страниц на сайте
Этот метатег был создан специально для борьбы с дублями и мусорными страницами на сайте. Мы рекомендуем прописывать его на всём сайте, как профилактику появления в индексе дубле и мусорных страниц.
Рекомендации Яндекса.
Рекомендации Google.
Инструменты точечного удаления страниц из индекса Яндекса и Google
Если возникла ситуация, когда нужно срочно удалить информацию из индекса, не дожидаясь, пока ваш запрет увидят поисковые работы, можно использовать инструменты из панели Яндекс. Вебмастера и Google Search Console.
Вебмастера и Google Search Console.
В Яндексе это «Удалить URL»:
В Google Search Console «Удалить URL-адрес»:
Внутренние ссылки
Внутренние ссылки закрываются от индексации для перераспределения внутренних весов на основные продвигаемые страницы. Но дело в том, что:
– такое перераспределение может плохо отразиться на общих связях между страницами;
– ссылки из шаблонных сквозных блоков обычно имеют меньший вес или могут вообще не учитываться.
Рассмотрим варианты, которые используются для скрытия ссылок:
Тег noindex
Для скрытия ссылок этот тег бесполезен. Он распространяется только на текст.
Атрибут rel=”nofollow”
Сейчас атрибут не позволяет сохранять вес на странице. При использовании rel=”nofollow” вес просто теряется. Само по себе использование тега для внутренних ссылок выглядит не особо логично.
Представители Google рекомендуют отказаться от такой практики.
Рекомендацию Рэнда Фишкина:
Скрытие ссылок с помощью скриптов
Это фактически единственный рабочий метод, с помощью которого можно спрятать ссылки от поисковых систем. Можно использовать Аjax и подгружать блоки ссылок уже после загрузки страницы или добавлять ссылки, подменяя скриптом тег <span> на <a>. При этом важно учитывать, что поисковые алгоритмы умеют распознавать скрипты.
Можно использовать Аjax и подгружать блоки ссылок уже после загрузки страницы или добавлять ссылки, подменяя скриптом тег <span> на <a>. При этом важно учитывать, что поисковые алгоритмы умеют распознавать скрипты.
Как и в случае с контентом – это «костыль», который иногда может решить проблему. Если вы не уверены, что получите положительный эффект от спрятанного блока ссылок, лучше такие методы не использовать.
Заключение
Удаление со страницы объёмных сквозных блоков действительно может давать положительный эффект для ранжирования. Делать это лучше, сокращая страницу, и выводя на ней только нужный посетителям контент. Прятать контент от поисковика – костыль, который стоит использовать только в тех случаях, когда сократить другими способами сквозные блоки нельзя.
Убирая со страницы часть контента, не забывайте, что для ранжирования важны не только текстовые критерии, но и полнота информации, коммерческие факторы.
Примерно аналогичная ситуация и с внутренними ссылками. Да, иногда это может быть полезно, но искусственное перераспределение ссылочной массы на сайте – метод спорный. Гораздо безопаснее и надёжнее будет просто отказаться от ссылок, в которых вы не уверены.
Да, иногда это может быть полезно, но искусственное перераспределение ссылочной массы на сайте – метод спорный. Гораздо безопаснее и надёжнее будет просто отказаться от ссылок, в которых вы не уверены.
Со страницами сайта всё более однозначно. Важно следить за тем, чтобы мусорные, малополезные страницы не попадали в индекс. Для этого есть много методов, которые мы собрали и описали в этой статье.
Вы всегда можете взять у нас консультацию по техническим аспектам оптимизации, или заказать продвижение под ключ, куда входит ежемесячный seo-аудит.
ОТПРАВИТЬ ЗАЯВКУ
Автор: Александр, SEO аналитик SiteClinic.ru
Какие страницы сайта должны быть закрыты от индексации?
Автор: Бабар Икбал (старший автор блога)
Цифровой маркетинг, электронная коммерция, локальное SEO, SEO, веб-дизайн, разработка веб-сайтов
Оптимизация веб-сайта | Какие страницы сайта следует закрыть от индексации? Вручную или автоматически сайты могут создавать страницы, полезные пользователям или необходимые для обеспечения нормальной работы, но которые не нужно «отдавать» поисковым роботам для индексации. Таких страниц должно быть быть принудительно закрыть от индексации чтобы они не могли попасть в результаты поиска. Как это можно сделать и какие страницы следует закрыть, более подробно рассмотрено ниже.
Таких страниц должно быть быть принудительно закрыть от индексации чтобы они не могли попасть в результаты поиска. Как это можно сделать и какие страницы следует закрыть, более подробно рассмотрено ниже.
Если страницы сайта дублируют существующие тексты или содержат только официальные данные, такие страницы могут быть не только бесполезными в поисковом продвижении, но даже вредными . Действительно, эти страницы за неуникальный или малоинформативный контент могут быть признаны поисковыми системами плохими, в результате чего общая производительность сайта может быть занижена.
Конечно, полностью удалить страницы с сайта нельзя. Во первых этот может привести к появлению ошибки 404, что тоже вредно для поискового продвижения, а во вторых эти страницы могут быть нужны пользователям или администрации. В этом случае выход — закрыть страницы сайта от индексации: пользователи увидят нужные страницы, а поисковые роботы — нет.
Когда отдельные страницы сайта закрыты от индексации, важно тщательно выбирать такие страницы. В противном случае можно случайно закрыть «нужные» страницы, и это ни к чему хорошему не приведет: если поисковые роботы не смогут проиндексировать страницы с уникальным тематическим содержанием, то сайт не сможет добиться высоких позиций в поисковой выдаче.
Содержание
Страницы административной части сайта.Страницы административной части предназначены строго для служебного пользования и уж точно не должны индексироваться поисковыми роботами. Как правило, такие страницы изначально закрываются в файле robots.txt, автоматически сгенерированном различными готовыми CMS с использованием директивы Disallow. Если файл robots.txt создан вручную или претерпевал изменения, важно проверить, что запрет на индексацию стоит на всех страницах, связанных с управлением сайтом.
Страницы личной информации.
Подобные страницы есть на сайтах разного типа, в том числе, в частности, на форумах, блог-платформах, социальных сетях. Эти страницы имеют практическую пользу для посетителей сайта, однако допускать их к индексации вредно из-за неуникального содержания, поскольку содержание таких страниц отличается лишь незначительно.
Страницы результатов поиска по сайту.Как и в случае со страницами, содержащими персональные данные пользователей, индексация поисковыми роботами не обязательна: страницы результатов полезны для посетителей, но с точки зрения поисковых систем являются «мусором», поскольку содержат не -уникальный контент.
Дублирование страниц сайта. На сайте возможно создание страниц с одинаковой информацией в связи с особенностями его системы управления (CMS). Например, такая ситуация особенно часто наблюдается в интернет-магазинах, где отдельные страницы могут формироваться для фильтров и сортировки, а также для тегов и тегов.
Разумеется, страницы корзины и страницы оформления заказа есть в интернет-магазинах, а страницы запросов можно найти и на других типах сайтов. Эти страницы не несут смысловой нагрузки, а потому их нужно закрывать от индексации поисковыми роботами.
Как именно можно закрыть различные страницы сайта от индексации поисковыми системами? Существует различных способов , включая прописывание запрещающих директив в файле robots.txt, добавление метатега robots в код страницы, использование так называемого 301 редиректа и запрет индексации в .htaccess. Выбор нужного метода зависит от особенностей закрываемых страниц, и решение лучше предоставить специалистам по оптимизации сайта для максимально эффективного результата.
Для получения профессиональной помощи Свяжитесь с нами сегодня, профессиональное агентство SEO в Дубае.
Позвонить по номеру 00971567300683
Создать и обновить указатель
В указателе перечислены термины и темы, обсуждаемые в документе, а также страницы, на которых они появляются. Чтобы создать указатель, вы помечаете записи указателя, указывая имя основной записи и перекрестную ссылку в своем документе, а затем строите указатель.
Чтобы создать указатель, вы помечаете записи указателя, указывая имя основной записи и перекрестную ссылку в своем документе, а затем строите указатель.
Вы можете создать запись указателя для отдельного слова, фразы или символа для темы, которая охватывает диапазон страниц или которая ссылается на другую запись, например, «Транспорт». См. Велосипеды». Когда вы выбираете текст и помечаете его как элемент указателя, Word добавляет специальное поле XE (элемент указателя), которое включает отмеченную основную запись и любую информацию о перекрестных ссылках, которую вы решите включить.
После того, как вы пометите все записи указателя, вы выбираете схему указателя и создаете готовый указатель. Word собирает элементы указателя, сортирует их в алфавитном порядке, ссылается на номера страниц, находит и удаляет повторяющиеся элементы с одной и той же страницы и отображает указатель в документе.
Отметить записи
В этих шагах показано, как помечать слова или фразы для указателя, но вы также можете пометить элементы указателя для текста, охватывающего диапазон страниц.
Выберите текст, который вы хотите использовать в качестве элемента указателя, или просто щелкните в том месте, где вы хотите вставить элемент.
О ссылках , в группе Index нажмите Mark Entry .
Вы можете редактировать текст в диалоговом окне Mark Entry .
Вы можете добавить второй уровень в поле Subentry . Если вам нужен третий уровень, поставьте после текста подзаписи двоеточие.
Чтобы создать перекрестную ссылку на другую запись, щелкните Перекрестная ссылка в разделе Параметры , а затем введите в поле текст для другой записи.
Чтобы отформатировать номера страниц, которые будут отображаться в указателе, установите флажок Жирный или Курсив под Формат номера страницы .
Щелкните Отметить , чтобы отметить элемент указателя. Чтобы пометить этот текст везде, где он появляется в документе, нажмите Отметить все .

 org/ListItem»>
org/ListItem»>Чтобы пометить дополнительные элементы указателя, выделите текст, щелкните в диалоговом окне Пометить элемент указателя и повторите шаги 3 и 4.
Создать индекс
После того, как вы отметите записи, вы готовы вставить индекс в свой документ.
Щелкните место, где вы хотите добавить указатель.
На вкладке References в группе Index щелкните Insert Index .
В диалоговом окне Index можно выбрать формат для текстовых записей, номеров страниц, знаков табуляции и надстрочных знаков.
Вы можете изменить общий вид указателя, выбрав в раскрывающемся меню Форматы . Предварительный просмотр отображается в окне слева вверху.
Щелкните OK .

Отредактируйте или отформатируйте запись указателя и обновите указатель
Если вы отметите больше записей после создания указателя, вам потребуется обновить указатель, чтобы увидеть их.
Если поля XE не отображаются, нажмите Показать/скрыть в группе Абзац на вкладке Главная .
Чтобы отредактировать или отформатировать элемент указателя, измените текст в кавычках.
Чтобы обновить индекс, щелкните его и нажмите F9. Или щелкните Обновить индекс в группе Индекс на вкладке Ссылки .
 org/ListItem»>
org/ListItem»>Найдите поле XE для записи, которую вы хотите изменить, например, { XE «Callisto» \t » See Moons» } .
Если вы обнаружите ошибку в указателе, найдите запись указателя, которую вы хотите изменить, внесите изменение, а затем обновите указатель.
Удалить запись индекса и обновить индекс
