
Канонические URL адреса страниц или link rel=»canonical»
- Что такое канонические URL адреса?
- Примеры канонических адресов
- Роль канонических адресов в SEO
- Правильно устанавливаем канонические URL адреса
- Понятие «каноническая ссылка»
- 301 редирект это замена rel=»canonical»?
- Яндекс Вебмастер — статус «Неканоническая»
- Что это значит?
- Что с этим делать?
Что такое канонические URL адреса?
В широком смысле слова, канонический означает «принятый за образец», «твердо установленный». То есть, канонический URL это, грубо говоря, основной адрес страницы.
Обычно, один материал имеет один URL адрес, к примеру www.example.ru/1.html. Но иногда одна и так же страница может быть доступна по нескольким адресам. К примеру: www.example.ru/1.html и www.example.ru/1/1. html. В таком случае, необходимо определить, какой из 2-х адресов является основным или каноническим.
html. В таком случае, необходимо определить, какой из 2-х адресов является основным или каноническим.
Предположим, что www.example.ru/1.html был выбран в качестве основного URL. Тогда на странице с данным адресом (а так же, других страницах с копией контента) необходимо разместить следующий элемент:
<link rel="canonical" href="www.example.ru/1.html" />
Размещается он в шапке сайта, между тегов <head></head>.
Внимание! Что бы снизить вероятность ошибки, внутри элемента link rel=»canonical» необходимо использовать абсолютные, а не относительные адреса. То есть, добавлять к ссылке домен.
Убедитесь, что в технической карте сайта sitemap.xml размещены именно канонические ссылки. Иначе это может привести к ошибкам индексирования.
Примеры канонических адресов
Предположим, что мы создали статью о продвижении Интернет-магазина одежды, для которой сделали красивый, понятный для человека URL.
Но статья осталась доступна по техническому адресу, который мы больше видеть не хотим.
В этом случае, на странице со статьей, нам необходимо прописать элемент <link rel=»canonical» href=»https://dh-agency.ru/prodvijenie-magazina-odejdy/» />, в котором указан основной, канонический адрес.
Вот таким образом:
Теперь адрес https://dh-agency.ru/prodvijenie-magazina-odejdy/ будет считаться основным.
Роль канонических адресов страниц в SEO
С точки зрения поисковой оптимизации, наличие одного основного URL адреса страницы просто необходимо. Во-первых, это позволяет сэкономить время, так как роботу не приходится загружать копии контента. Во-вторых, не остается никаких сомнений, какой адрес должен участвовать в поисковой выдаче. В-третьих, снижается нагрузка на сайт, что так-же важно для посещаемого ресурса.
Нужно понимать, что краулер отводит ограниченное количество времени на индексацию сайта, поэтому многочисленные дубли страниц могут сильно ударить по эффективности его работы.
Правильно устанавливаем канонические URL адреса
Правильно установленный канонический адрес отвечает следующим требованиям:
Каноническая страница, указанная в элементе link rel=»canonical», обязательно должна существовать и быть доступна для пользователей;
Канонический адрес должен быть указан только для одного домена и поддомена. Грубо говоря, не должно быть ссылок на другие ресурсы;
Для страницы может быть указан один единственный канонический адрес;
Убедитесь, что на сайте отсутствуют рекурсии или «цепочки» канонических адресов. То есть, одна страница не должна ссылаться на другую, которая, в свою очередь, ссылается на третью или первую;
Элемент link rel=»canonical» должен находится между тегами <head></head>.
Уверены, что Ваши канонические адреса соответствуют всем вышеуказанным требованиям? Тогда можете считать их просто превосходными!
Понятие «каноническая ссылка»
Те, кто только начал окунаться в основы поисковой оптимизации, иногда разделяют понятия «канонический адрес» и «каноническая ссылка». На самом деле, речь идет об одном и том же — о главном URL адресе страницы.
На самом деле, речь идет об одном и том же — о главном URL адресе страницы.
Нет никаких канонических <a href=»»> </a> и «главных ссылок ссылок для перелинковки».
301 редирект — замена rel=»canonical»?
Когда речь заходит о выборе между 301 редиректом и элементом link rel=»canonical», мы обычно советуем использовать именно переадресацию. Все дело в том, что тег link rel=»canonical» не является обязательным, то есть, может быть проигнорирован поисковой системой.
Использование link rel=»canonical» актуально только тогда, когда сделать 301 редирект невозможно или проблематично.
Есть и еще один плюс link rel=»canonical» перед 301 редиректом — его простановку возможно сделать автоматической при создании страницы. К примеру, в WordPress эта функция уже реализована. То есть, заранее указав канонический адрес, Вы можете избавить себя от будущих проблем с индексацией.
Яндекс Вебмастер — статус «неканоническая»
В Яндекс Вебмастере есть раздел «Исключенные страницы«, добраться туда можно из меню «Индексирование» -> «Страницы в поиске» -> «Исключенные страницы«.
Перейдя в этот раздел, Вы увидите все материалы, которые были по какой либо причине загружены в базу, но исключены из поиска.
Среди прочих причин исключения Вы можете увидеть статус «Неканоническая». Нажав на троеточие, отроется сообщение следующего вида:
«Страница проиндексирована по каноническому адресу https://dh-agency.ru/category/vnutrennyaya-optimizaciya/design/, который был указан в атрибуте rel=»canonical» в исходном коде. Исправьте или удалите атрибут canonical, если он указан некорректно. Робот отследит изменения автоматически.»
Что это значит?
Ничего страшного не произошло. Робот Яндекса проиндексировал страницу по первому (написанному синем шрифтом) URL, при этом на самой странице стоял элемент link rel=»canonical», в котором, в качестве канонического, был указан другой адрес (написанный серым шрифтом).
Пользуясь данной инструкцией, робот исключил неканонический URL.
Переживать, что материал был полностью исключен из поиска не стоит, он находится в выдаче, но по другому URL адресу.
Что с этим делать?
Если Вас не устраивает URL, который был выбран в качестве основного, необходимо поменять адрес в элементе link rel=»canonical» на предпочтительный. После изменения, страницу желательно отправить на переобход индексирующему роботу.
(«Индексирование» -> «Переобход страниц«)
Так изменения будут загружены в базу в самое ближайшее время.
Только не забудьте изменить адрес в файле sitemap.xml.
Страница просканирована, но не проиндексирована: что это значит?
Содержание- Определение Google
- 1. Ложная тревога
- 2.
 Адреса RSS-каналов
Адреса RSS-каналов - 3. Разбитые на страницы URL-адреса
- 4. Отсутствующие продукты
- 5. Переадресация 301
- 6. Контент низкого качества
- 7. Дублированный (неуникальный) контент
- Пример: дублированный пользовательский контент
- Заключение
 Адреса RSS-каналов
Адреса RSS-каналов Скрытый контент
Скрытый контентНет времени читать?
Отправить статью на почтуПеревод статьи с портала MOZ
Отчет об индексировании от Google дает SEO-специалистам уникальную возможность понять, как происходит краулинг и индексирование страниц. Эта функция очень удобна для диагностики технических проблем, возникающих у клиентов.
В отчете встречается много разных «статусов», которые предоставляют веб-мастерам подробную информацию о том, как Google обрабатывает контент их сайта. И хотя большинство статусов дают понимание о решениях Google по краулингу и индексированию, один из них остается неясным.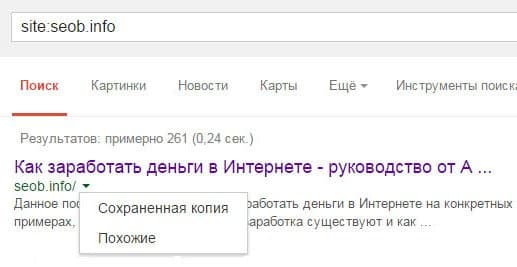
Обращая внимание на подобные отчеты и выявив причины возникновения ошибок, можно будет с уверенностью ответить на вопрос «Почему сайт не индексируется в Google?».
Появления статуса «Crawled — currently not indexed» вызывает у владельцев сайтов много вопросов. Одно из преимуществ крупной компании — это возможность работать с большим объемом данных. Поэтому после появления этого статуса в нескольких учетных записях мы начали отслеживать тенденции по указанным URL-адресам.
Определение Google
Для начала давайте посмотрим, какое определение этому статусу дает сам Google. Согласно официальным документам Google, за непонятной фразой скрывается следующее: «Страница была просканирована Google, но не проиндексирована. Возможно, она будет проиндексирована в будущем; нет необходимости повторно отправлять этот URL для краулинга».
Итак, мы можем сделать следующие выводы:
1. Google может получить доступ к странице.
Google может получить доступ к странице.
2. Google потратил время на сканирование страницы.
3. После сканирования Google решил не индексировать страницу.
Чтобы лучше понять этот статус, нужно подумать о причинах, по которым Google решил отказать странице в индексации. Очевидно, что Google без труда находит страницу, но почему-то не считает ее достаточно полезной для включения в поисковую выдачу.
Получать отказ в индексировании от Google всегда неприятно, особенно если вы не понимаете, что сделали не так. Ниже мы рассмотрим несколько наиболее распространенных причин, по которым этот загадочный статус может быть присвоен вашему сайту.
1. Ложная тревога
Приоритет: низкий
Прежде всего нелишним будет сделать несколько выборочных проверок URL-адресов, получивших статус «Crawled — currently not indexed». Нередко можно найти URL-адреса, которые отмечены как исключенные, но тем не менее присутствуют в поисковой выдаче Google.
Например, вот URL-адрес, получивший такой статус в отчете для нашего веб-сайта: https://gofishdigital. com/meetup/
com/meetup/
Однако, используя оператор поиска по сайту, мы обнаруживаем, что URL по-прежнему включен в индекс Google. Вы можете сделать это, добавив site: перед URL, как показано на рисунке ниже.
Таким образом, если вы обнаружили статус «Crawled — currently not indexed» у URL-адреса, рекомендуется начать с оператора поиска по сайту, чтобы наверняка убедиться, проиндексирован он или нет. Иногда появление такого статуса — ложная тревога о статусе индексации в Google.
Решение: ничего делать не нужно. Все хорошо.
2. Адреса RSS-каналов
Приоритет: низкий
Один из достаточно распространенных случаев, с которыми нам приходилось сталкиваться. Если на вашем сайте используется RSS-канал, возможно, вы обнаружите у URL-адресов статус «Crawled — currently not indexed». Часто к этим URL-адресам будет добавлена строка /feed/. В отчете это выглядит следующим образом:
Google нашел эти URL-адреса RSS-каналов, связанных с основной страницей, затем просканировал, но не проиндексировал.
Связывание часто происходит с использованием элемента rel=alternate. Плагины WordPress, такие как Yoast, могут автоматически генерировать подобные URL.
Решение: ничего делать не нужно. Все хорошо.
Скорее всего, Google выборочно не индексирует эти URL-адреса, и вовсе не напрасно. Если вы перейдете по адресу RSS-канала, то увидите XML-документ, подобный приведенному ниже:
Хотя этот документ полезен для RSS-каналов, обычным пользователям он совершенно без надобности. Именно поэтому Google не индексирует такие URL-адреса.
3. Разбитые на страницы URL-адреса
Приоритет: низкий
Еще одна распространенная причина появления статуса «Crawled — currently not indexed» — разбивка на страницы. В отчете мы часто наблюдаем большое количество разбитых на страницы URL-адресов. На рисунке ниже приведено несколько URL-адресов с крупного сайта интернет-магазина:
Решение: ничего делать не нужно. Все хорошо.
Для полного краулинга сайта Google должен сканировать все разбитые на страницы URL-адреса. Это могут быть страницы с довольно важным контентом, например, с категориями или описанием продуктов. Однако поисковой системе вовсе не обязательно индексировать все подобные URL-адреса.
Тем не менее нужно удостовериться, что вы сами не препятствуете сканированию отдельных страниц. Убедитесь, что все ваши страницы имеют самореферентный канонический тег и не содержат nofollow-тегов. Подобная разбивка позволяет Google сканировать другие ключевые страницы вашего сайта.
4. Отсутствующие продукты
Приоритет: средний
После выборочной проверки отдельных страниц, перечисленных в отчете, мы обнаружили еще одну общую проблему многих клиентов. Речь идет об URL-адресах, содержащих текст «товары с истекшим сроком годности» или «нет в наличии». Похоже, что на сайтах интернет-магазинов Google проверяет наличие определенного продукта. Если выясняется, что продукта нет в наличии, Google убирает страницу из индекса.
С точки зрения пользовательского опыта, это действительно имеет смысл, поскольку Google сканирует и исключает из индекса товары, которые пользователи не могут приобрести.
Однако, если данные продукты доступны на вашем сайте, исключение из индекса сулит неприятные последствия. Если страница не была проиндексирована, ваш контент не получает никакого рейтинга.
Кроме того, Google не просто проверяет видимый контент на странице. Бывали случаи, когда видимый контент никоим образом не указывал на отсутствие того или иного продукта. Однако при проверке структурированных данных мы видим, что для свойства Availability («Доступность») установлено значение OutOfStock («Нет на складе»).
Похоже, что Google использует не только видимый контент, но и структурированные данные о доступности того или иного продукта. Поэтому важно проверять оба источника данных. Если проблема имеет массовый характер, Google не проиндексирует не только страницы, но и сайт в целом.
Решение: проверьте наличие продуктов на складе.
Если вы обнаружите, что ваш продукт, который на самом деле есть в наличии, почему-то исключен из индекса, это повод проверить и другие продукты, указанные в отчете. Проведите сканирование своего сайта с помощью инструментов извлечения, таких как Screaming Frog SEO Spider.
Например, если вы хотите увидеть все ваши URL-адреса, где присутствует значение OutOfStock, используйте регулярное выражение «availability»:».
С помощью «class=»redactor-autoparser-object»>http://schema.org/OutOfStock» автоматически отобразятся все URL-адреса с этим значением:
Вы можете экспортировать этот список и перекрестные ссылки с данными о наличии товара, используя Excel или инструменты бизнес-аналитики. Это позволит вам быстро найти расхождения между структурированными данными на вашем сайте и продуктами, которые действительно есть в наличии. Аналогичным образом можно обнаружить случаи, когда ваш видимый контент указывает, что срок годности продуктов истек.
5.
 Переадресация 301
Переадресация 301Приоритет: средний
Конечный URL — еще один тип адресов в зоне риска. Мы часто видим, что Google сканирует конечный URL, но не включает его в индекс. Однако, посмотрев на поисковую выдачу, мы обнаружим, что Google индексирует перенаправленный URL. Поскольку перенаправленный URL индексируется, конечный URL-адрес добавляется в отчет «Crawled — currently not indexed».
Проблема в том, что Google, вероятно, еще не распознает переадресацию. В результате он рассматривает конечный URL как «дубликат» перенаправленного URL.
Решение: создайте временный файл sitemap.xml.
Если подобное происходит на большом количестве URL-адресов или сайт полностью не индексируется в Google, стоит принять меры для отправки в Google более сильных сигналов консолидации. Проблема может указывать на то, что Google своевременно не распознает ваши переадресации, что приводит к появлению сигналов о неконсолидированном контенте.
Одним из вариантов может стать создание временного файла sitemap. Это поможет значительно ускорить сканирование перенаправленных URL-адресов. Именно такую стратегию рекомендовал Джон Мюллер в одной из предыдущих статей.
Это поможет значительно ускорить сканирование перенаправленных URL-адресов. Именно такую стратегию рекомендовал Джон Мюллер в одной из предыдущих статей.
Как сделать временную карту сайта с конечными URL адресами для редиректов:
1. Экспортируйте все URL-адреса из отчета «Crawled — currently not indexed».
2. Сопоставьте их в Excel с предварительно настроенными редиректами.
3. Найдите все переадресации, у которых в области «Crawled — currently not indexed» находится конечный URL.
4. С помощью Screaming Frog создайте статический файл sitemap.xml этих URL-адресов.
5. Загрузите sitemap и просмотрите отчет в Search Console.
Google будет сканировать URL-адреса во временном файле sitemap.xml чаще, что приведет к более быстрой консолидации редиректов.
6. Контент низкого качества
Приоритет: средний
Иногда мы видим в отчете URL-адреса с контентом очень низкого качества. На таких страницах могут быть правильно настроены все технические элементы и внутренние ссылки, однако им недостает фактического контента, что также замечает Google. Ниже приведен пример страницы с информацией о продукте, на которой очень мало уникального текста:
Ниже приведен пример страницы с информацией о продукте, на которой очень мало уникального текста:
Этой странице был присвоен статус «Crawled — Currently Not Indexed». Наиболее вероятная причина — низкое качество контента.
Google посчитал ее либо недостаточно полезной, либо дубликатом другой страницы. В результате страница была удалена из индекса.
Вот еще один пример: Google просканировал страницу с отзывом на сайте Go Fish Digital (рисунок выше). Хотя этот контент является уникальным для нашего сайта, но Google, вероятно, не считает, что страница из одного предложения с рекомендацией заслуживает индексации.
Поэтому Google принял решение исключить страницу из индекса по причине низкого качества контента.
Решение: добавьте больше контента или настройте сигналы индексации.
Следующие шаги зависят от того, насколько важно для вас проиндексировать те или иные страницы.
Если вы считаете, что страница обязательно должна попасть в индекс, добавьте больше уникального контента. В этом случае Google посчитает страницу достаточно полезной и проиндексирует ее.
В этом случае Google посчитает страницу достаточно полезной и проиндексирует ее.
Если тот или иной контент, на ваш взгляд, не нуждается в индексации, встает совершенно другой вопрос: следует ли вам предпринять дополнительные меры и убедительно показать, что данный контент не следует индексировать. Ведь, как мы помним, статус «Crawled —currently not indexed» указывает на то, что контент был просканирован и мог быть включен в индекс, но Google решил этого не делать.
Однако Google применяет эту логику не ко всем страницам низкого качества. Вы можете выполнить общий поиск по сайту с помощью оператора site:, чтобы найти проиндексированный контент, который соответствует приведенным выше критериям низкого качества. Если обнаружится, что большое количество таких страниц появляется в индексе, вы можете предпринять ряд мер, таких как тег noindex, ошибка 404 или полное удаление внутренних ссылок.
7. Дублированный (неуникальный) контент
Приоритет: высокий
Среди наших клиентов данная проблема встречается наиболее часто. Если Google посчитает ваш контент дублированным, он может сканировать его, но не включать в индекс. Это один из способов, с помощью которых Google избегает дублирования поисковой выдачи. Удаляя подобный контент, Google обеспечивает пользователям широкий выбор уникальных страниц. Иногда в отчете URL-адреса получают статус «дубликатов» (Duplicate, Google chose different canonical than user). Тем не менее не каждая страница является дублирующей в строгом смысле этого слова.
Эта проблема особенно актуальна для интернет-магазинов. Ключевые страницы, например, с описанием продукта, часто содержат контент, аналогичный или похожий на многие другие страницы в интернете. Если Google обнаружит, что по содержанию или структуре ваши страницы слишком похожи на страницы других сайтов, он может исключить их из индекса.
Решение: добавьте в дублированный контент уникальные элементы.
Если вы считаете, что это относится к вашему сайту, проведите следующую проверку:
1. Скопируйте сниппет потенциального дублированного текста и вставьте его в Google.
2. Добавьте в конец URL-адреса (в браузере) следующую строку: &num=100. Отобразятся первые 100 результатов.
3. Используйте функцию «Поиск», чтобы увидеть, появляется ли ваш результат среди первой сотни. Если нет, вероятно, он был удален из индекса.
4. Вернитесь к URL-адресу (в браузере) и добавьте следующую строку: &filter=0. Это должно показать вам нефильтрованные результаты Google (спасибо Патрику Стоксу за совет).
5. Используйте функцию «Поиск», чтобы найти ваш URL. Если теперь ваша страница появляется в выдаче, это говорит о том, что ваш контент удаляется фильтром из индекса.
6. Повторите процесс для нескольких URL-адресов с потенциально дублированным или очень похожим контентом, которые получили статус «Crawled — currently not indexed».
Если вы продолжаете замечать, что URL-адреса удаляются фильтром из индекса, необходимо сделать контент более уникальным.
Универсального средства для таких случаев не существует, но мы можем предложить несколько вариантов:
1. Перепишите контент на самых важных страницах, чтобы сделать его более уникальным.
2. Используйте динамические свойства для автоматической вставки уникального контента на страницу.
3. Удалите большие куски шаблонного текста. Иногда страница признается дубликатом именно по этой причине.
4. Если ваш сайт зависит от пользовательского контента, повысьте требования к уникальности текстов. Это может помочь предотвратить случаи, когда пользователи размещают один и тот же контент на нескольких страницах или доменах.
8. Скрытый контент
Приоритет: высокий
В некоторых случаях Google может сканировать контент, к которому у него не должно быть доступа. Если Google находит URL-адреса, на которых ведется разработка, он может включить их в отчет. Однажды мы столкнулись с тем, что Google сканировал субдомен, предназначенный для задач JIRA. Это вызвало тотальный обход сайта, содержащего страницы, совершенно не предназначенные для индексации.
Таким образом, Google тратит время на сканирование (и, возможно, индексацию) URL-адресов, которые не предназначены для обычных пользователей. Это может иметь серьезные последствия для краулингового бюджета сайта.
Решение: примите меры для краулинга и индексации.
Это решение будет полностью зависеть от ситуации и того, к чему Google может получить доступ. Как правило, первым делом необходимо выяснить, как Google смог обнаружить скрытые URL-адреса, особенно если это произошло через структуру внутренних ссылок.
Начните сканирование с домашней страницы основного субдомена и проверьте, может ли Screaming Frog получить доступ к скрытым субдоменам стандартным способом. Если да, то можно с уверенностью сказать, что робот Google мог использовать аналогичную лазейку. Вы можете ограничить доступ Google, удалив все внутренние ссылки на этот контент.
Следующим шагом может стать проверка статусов URL-адресов, которые должны быть исключены из индекса. Справляется ли Google с этой задачей, или некоторые из адресов все же были проиндексированы? Если Google не индексирует большой объем данного контента, вы можете настроить файл robots.txt так, чтобы он сразу блокировал сканирование. В противном случае используйте теги noindex, атрибуты canonical и страницы, защищенные паролем.
Пример: дублированный пользовательский контент
В качестве живого примера можно привести случай, когда мы диагностировали проблему на сайте клиента. Этот сайт очень похож на интернет-магазин, поскольку большая часть его контента состоит из страниц с описанием продуктов. Тем не менее все такие описания являются пользовательским контентом.
Третьим лицам разрешено создавать листинги продуктов на этом сайте. Однако очень часто пользователи составляют слишком короткие описания, что расценивается как контент низкого качества. По этой причине страницы с описанием продуктов от пользователей стали попадать в отчет «Crawled — currently not indexed». Таким образом, страницы, способные генерировать органический трафик, были вовсе исключены из индекса, что имело ряд неприятных последствий.
Таким образом, страницы, способные генерировать органический трафик, были вовсе исключены из индекса, что имело ряд неприятных последствий.
После проведения диагностики мы обнаружили, что страницам с описанием продуктов существенно не хватало уникального контента. Все исключенные страницы содержали не более одного абзаца уникального текста. Кроме того, основное содержание всех страниц представляло собой один и тот же шаблон. Из-за недостатка уникальности шаблонного текста Google мог рассматривать страницы как дубликаты. В результате они были исключены из индекса с присвоением статуса «Crawled — currently not indexed».
Совместно с клиентом мы решили, какой неуникальный контент необходимо убрать со страниц описания продукта. Мы удалили одинаковое содержание с тысяч страниц. Это привело к значительному уменьшению URL-адресов со статусом «Crawled — currently not indexed», так как Google начал рассматривать каждую страницу как более уникальную.
Заключение
Надеюсь, наша статья поможет SEO-специалистам лучше понять загадочный статус «
 Конечно, могут быть и другие причины, по которым Google классифицирует URL-адреса подобным образом, однако мы привели наиболее распространенные среди наших клиентов случаи.
Конечно, могут быть и другие причины, по которым Google классифицирует URL-адреса подобным образом, однако мы привели наиболее распространенные среди наших клиентов случаи.Таким образом, Отчет об индексации является одним из самых мощных инструментов Search Console. Мы настоятельно рекомендуем с ним ознакомиться, поскольку во многом благодаря этому инструменту мы своевременно обнаруживаем все аномалии краулинга и индексирования, особенно на крупных сайтах. Если вы сталкивались с другими причинами попадания URL-адресов в отчет «Crawled — currently not indexed», сообщите об этом в комментариях!
Об авторе:
Крис Лонг -— старший SEO-менеджер в Go Fish Digital
. Крис работает с уникальными проблемами и сложными ситуациями, чтобы через глубокое понимание алгоритмов Google и веб-технологий помочь своим клиентам улучшить органический трафик. Крис сотрудничает с Moz, Search Engine Land и The Next Web. Он также выступает на тематических конференциях, таких как SMX East и State Of Search. Вы можете связаться с Крисом в Twitter и LinkedIn.
Он также выступает на тематических конференциях, таких как SMX East и State Of Search. Вы можете связаться с Крисом в Twitter и LinkedIn.Автор: Кристофер Лонг
Ссылка на оригинал: https://moz.com/blog/crawled-currently-not-indexed-coverage-status
P.s. Мы стараемся регулярно готовить для вас полезный контент. Для того чтобы не пропустить очередную статью в нашем блоге, подписывайтесь на наш telegram-канал: T.me/seoantteam
Спасибо, что подписались на рассылку!
Мы будем отправлять вам только полезный контент не чаще 2 раз в месяц.
Остались вопросы или хотите заказать продвижение?
Имя
Phone
Я ознакомлен и согласен с Политикой в отношении обработки персональных данных
Спасибо, что подписались на рассылку!
Мы будем отправлять вам только полезный контент не чаще 2 раз в месяц.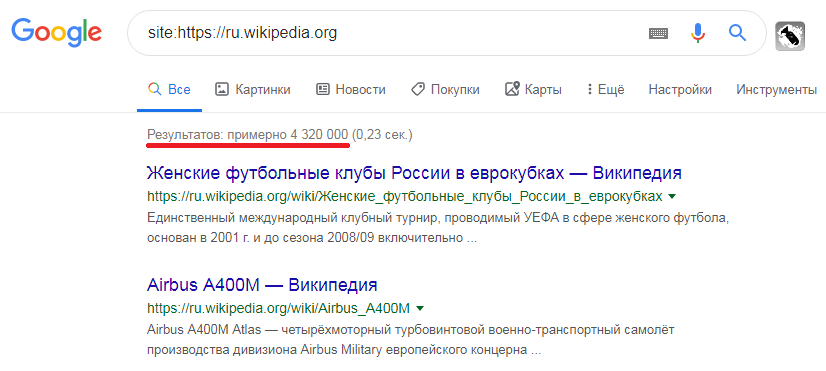
Подпишитесь на рассылку
Мы будем отправлять вам письма с самыми интересными и полезными статьями 2 раза в месяц.Имя
Я ознакомлен и согласен с Политикой в отношении обработки персональных данных
Когда канонизировать, запретить индексирование или ничего не делать с похожим контентом
Представьте себе свой контент так, как вы это делаете. У вас есть какой-то багаж, от которого вы могли бы избавиться? Вы носите с собой что-то, что хотите сохранить, но, возможно, хотите перепрофилировать или увидеть по-другому?
То же самое и с контентом веб-сайта. Мы все, вероятно, сидели вместе, как группа умов, думая о контенте, который мы хотели бы отрезать от нашего веб-сайта, но понимаем, что он все еще нужен, будь то конкретный потенциальный клиент, внутренняя команда и т. д.
Мы все, вероятно, сидели вместе, как группа умов, думая о контенте, который мы хотели бы отрезать от нашего веб-сайта, но понимаем, что он все еще нужен, будь то конкретный потенциальный клиент, внутренняя команда и т. д.
Пока мы ищем способы сделать наши веб-сайты максимально компактными для целей управления контентом, мы также хотим сделать то же самое, чтобы успокоить сканирующих роботов поисковых систем.
Мы хотим, чтобы их ежедневное посещение наших веб-сайтов было быстрым и лаконичным.
Надеюсь, это покажет им, кто мы такие, чем мы занимаемся и, в конечном счете, — если у нас должен быть контент, который нельзя удалить, — как мы его помечаем для них.
К счастью, сканеры поисковых систем хотят понять наш контент так же, как мы хотим этого от них. Нам даны шансы канонизировать контент и неиндексируемый контент.
Однако имейте в виду, что неправильное выполнение этого действия может привести к тому, что важные элементы веб-сайта будут неправильно поняты роботами поисковых систем или вообще не прочитаны.
Снимок экрана, сделанный автором, июль 2022 г.
Канонические теги — отличный способ проинструктировать поисковые системы: «Да, мы знаем, что этот контент не такой уж уникальный или ценный, но он должен быть у нас».
Это также может быть отличным способом показать ценность контента из другого домена или наоборот.
Тем не менее, пришло время показать сканирующим ботам, как вы воспринимаете контент веб-сайта.
Для использования вы должны поместить этот тег в раздел заголовка исходного кода.
Тег canonical может быть отличным способом борьбы с контентом, который, как вы знаете, дублируется или похож, но он должен существовать для нужд пользователей на сайте или медленной команды обслуживания сайта.
Если вы считаете, что этот тег идеально подходит для вашего веб-сайта, просмотрите свой веб-сайт и обратитесь к разделам сайта, которые имеют отдельные URL-адреса, но имеют схожее содержание (например, текст, изображение, заголовки, элементы заголовка и т. д.).
д.).
Средства аудита веб-сайтов, такие как Screaming Frog и раздел Semrush Site Audit, позволяют быстро выявить сходство контента.
Если вы считаете, что могут быть какие-то другие виновники похожего контента, вы можете глубже изучить его с помощью таких инструментов, как средство проверки похожих страниц и Siteliner, которые проверят ваш сайт на наличие похожего контента.
Теперь, когда вы хорошо чувствуете случаи сходства, вам нужно понять, заслуживает ли это отсутствие уникальности канонизации. Вот несколько примеров и решений:
Пример 1: Ваш сайт существует как в HTTP-, так и в HTTPS-версиях страниц сайта, или ваш веб-сайт существует в обеих версиях www. и без www. версии страницы.
Решение: Ставьте канонический тег на версию страницы с наибольшим количеством ссылок, внутренних ссылок и т.д., пока не сможете перенаправить все дублирующиеся страницы один к одному.
Пример 2: Вы продаете товары, которые очень похожи, если на этих страницах нет уникальной копии, но есть небольшие различия в названии, изображении, цене и т. д. Если вы канонически указываете определенные страницы продукта на родительский продукт страница?
д. Если вы канонически указываете определенные страницы продукта на родительский продукт страница?
Решение: Здесь мой совет — ничего не делать. Эти страницы достаточно уникальны, чтобы их можно было проиндексировать. У них есть уникальные имена, которые их отличают, и это может помочь вам с экземплярами ключевых слов с длинным хвостом.
Пример 3: Вы продаете футболки, но у вас есть страницы для каждого цвета и каждой рубашки.
Решение: Canonical пометьте страницы цвета для ссылки на родительскую страницу рубашки. Каждая страница — это не конкретный продукт, а очень похожая вариация.
Вариант использования: каноническая маркировка контента, который достаточно уникален для успехаКак и в примере, представленном выше, я хотел объяснить, что иногда немного похожий контент все же может быть индексирован.
Что, если бы это были рубашки с дочерними страницами для разных типов рубашек, таких как рубашки с длинными рукавами, майки и т. д.? Теперь это становится другим продуктом, а не просто вариацией. Как уже упоминалось ранее, это может быть успешным для поиска в Интернете с длинным хвостом.
д.? Теперь это становится другим продуктом, а не просто вариацией. Как уже упоминалось ранее, это может быть успешным для поиска в Интернете с длинным хвостом.
Вот отличный пример: сайт по продаже автомобилей, на котором есть страницы, посвященные маркам автомобилей, связанным с ними моделям и вариациям этих моделей (2Dr, 4Dr, V8, V6, роскошная версия и т. д.). Первоначальная мысль об этом сайте заключается в том, что все варианты просто почти дублируют типовые страницы.
Вы можете подумать, зачем нам раздражать поисковые системы этим почти дублирующимся контентом, когда мы можем канонизировать эти страницы, чтобы они указывали на типовую страницу как на репрезентативную?
Мы двигались в этом направлении, но беспокойство по поводу того, смогут ли эти страницы быть успешными, заставило нас перейти к канонической маркировке каждой соответствующей страницы модели.
Предположим, вы канонически помечаете страницу родительской модели. Даже если вы покажете поисковым системам важность/иерархию контента, они все равно могут ранжировать канонизированную страницу, если поиск относительно специфичен.
Итак, что мы увидели?
Мы обнаружили, что органический трафик увеличился как на дочерние, так и на родительские страницы. По моему мнению, когда вы отдаете должное дочерним страницам, родительская страница выглядит более авторитетной, поскольку у нее есть много дочерних страниц, которым теперь возвращается «кредит».
Ежемесячный трафик всех этих страниц вместе вырос в пять раз.
С сентября этого года, когда мы пересмотрели канонические теги, ежемесячный органический трафик на эту область сайта увеличился в 5 раз, при этом 754 страницы обеспечивают органический трафик по сравнению со 154, признанными ранее в предыдущем году.
Скриншот автора с Semrush, июль 2022 г.
Не совершайте этих ошибок канонизации- Установка канонических тегов, которые выдерживают перенаправление до разрешения на финальную страницу, может оказать большую медвежью услугу. Это замедлит поисковые системы, поскольку вынуждает их пытаться понять важность контента, но теперь они пропускают URL-адреса.
- Точно так же, если вы указываете канонические теги на целевые URL-адреса, которые являются страницами с ошибкой 404, то вы, по сути, указываете им на стену.
- Каноническая пометка неверной версии страницы (например, www./без www., HTTP/HTTPS). Мы обсудили обнаружение с помощью инструментов сканирования веб-сайтов того, что у вас может быть непреднамеренное дублирование веб-сайтов. Не ошибитесь, указывая важность страницы на более слабую версию страницы.

Вы также можете использовать тег метатега robots noindex, чтобы полностью исключить похожий или повторяющийся контент.
Размещение тега noindex в разделе head вашего исходного кода остановит поисковые системы от индексации этих страниц.
Осторожно: хотя тег метатега robots noindex — это быстрый способ удалить дублированный контент из рейтинга, он может быть опасен для вашего органического трафика, если вы не используете его должным образом.
В прошлом этот тег использовался для отсеивания крупных сайтов, чтобы представить только критически важные для поиска страницы сайта, чтобы расходы на сканирование сайта были максимально эффективными.
Однако вы хотите, чтобы поисковые системы видели все релевантное содержимое сайта, чтобы понимать таксономию сайта и иерархию страниц.
Однако, если этот тег вас не слишком пугает, вы можете использовать его, чтобы позволить поисковым системам сканировать и индексировать только то, что вы считаете свежим, уникальным контентом.
Вот несколько вариантов решения проблемы отсутствия индексации:
Пример 1: Чтобы помочь своим клиентам, вы можете предоставить документацию от производителя, даже если они уже размещают ее на своем веб-сайте.
Решение: Продолжайте предоставлять документацию, чтобы помочь вашим клиентам на месте, но не индексируйте эти страницы.
Они уже принадлежат производителю и проиндексированы им, у которого, вероятно, гораздо больше полномочий в домене, чем у вас. Другими словами, вы, скорее всего, не будете рейтинговым веб-сайтом для этого контента.
Другими словами, вы, скорее всего, не будете рейтинговым веб-сайтом для этого контента.
Пример 2: Вы предлагаете несколько разных, но похожих товаров. Единственная разница — это цвет, размер, количество и т. д. Мы не хотим тратить деньги на сканирование.
Решение: Решить с помощью канонических тегов. Поиск с длинным хвостом может привлечь квалифицированный трафик, поскольку данная страница по-прежнему будет проиндексирована и сможет занимать высокие позиции.
Пример 3: У вас есть много старых продуктов, которые вы больше не продаете и которые больше не являются вашим основным направлением.
Решение: Этот идеальный сценарий, вероятно, можно найти в аудите контента или продаж. Если продукты мало приносят компании пользы, рассмотрите возможность выхода на пенсию.
Рассмотрите возможность канонического указания этих страниц на страницы соответствующих категорий или перенаправления их на страницы соответствующих категорий. Эти страницы имеют возраст/доверие, могут иметь ссылки и могут иметь рейтинг.
Эти страницы имеют возраст/доверие, могут иметь ссылки и могут иметь рейтинг.
Что касается нашего веб-сайта, мы знаем, что хотим сделать все возможное для поисковых систем.
Мы не хотим тратить их время на сканирование и не хотим создавать впечатление, что большей части нашего контента не хватает уникальности.
В приведенном ниже примере, чтобы уменьшить раздувание несколько похожего содержимого страницы продукта из обзоров поисковых систем, теги meta robots noindex были помещены на дочерние страницы вариантов продукта во время перехода/перезапуска домена.
На приведенном ниже графике показано общее количество ключевых слов, перешедших из одного домена в другой.
После удаления метатегов robots noindex общее количество терминов ранжирования выросло на 50%.
Скриншот автора с Semrush, июль 2022 г.
- Не размещайте тег метатега robots noindex на странице со значением входящей ссылки. Если это так, вы должны навсегда перенаправить рассматриваемую страницу на другую соответствующую страницу сайта. Размещение тега устранит ценный ссылочный вес, который у вас есть.
- Если вы не индексируете страницу, которая включена в основную часть, нижний колонтитул или вспомогательную навигацию, убедитесь, что указана директива не «noindex, nofollow», а «noindex, follow», чтобы поисковые системы, сканирующие сайт, могли по-прежнему переходить по ссылкам на неиндексируемой странице.
Иногда трудно расстаться с содержанием веб-сайта.
Канонические и мета-теги robots noindex — отличный способ сохранить функциональность веб-сайта для всех пользователей, а также инструктировать поисковые системы.
В конце концов, будьте осторожны с тегами! Легко потерять присутствие в поиске, если вы не полностью понимаете процесс тегирования.
Дополнительные ресурсы:
- Когда использовать Rel Canonical или Noindex… или оба варианта
- Что происходит, когда Google выбирает неправильный канонический URL?
- Продвинутое техническое SEO: полное руководство
Рекомендуемое изображение: Джек Фрог/Shutterstock
Категория SEO Техническое SEO
Альтернативная страница с правильным каноническим тегом в Google Search Console » Rank Math
Видите ли вы статус «Альтернативная страница с правильным каноническим тегом» в своей Google Search Console? Обычно вы можете увидеть это сообщение, если на вашем веб-сайте есть несколько версий страницы.
В этой статье базы знаний мы объясним, что означает это сообщение, и дадим вам советы, как это исправить, если это необходимо.
1 Что означает «Альтернативная страница с правильным каноническим тегом»?
Сообщение о статусе «Альтернативная страница с правильным каноническим тегом» в Google Search Console означает, что на вашем веб-сайте есть две версии страницы с одинаковым каноническим URL-адресом. Google просто исключит повторяющуюся версию и проиндексирует основную версию страницы.
Google просто исключит повторяющуюся версию и проиндексирует основную версию страницы.
В идеале это означает, что Google правильно распознает эти канонизированные URL-адреса, и вам не нужно ничего делать с вашей стороны.
Но, тем не менее, вы все равно должны время от времени просматривать их и проверять, предназначены ли эти страницы для канонизации. В противном случае вы можете потерять потенциальный трафик с ценных страниц, которые могли быть проиндексированы.
2 Что такое канонический тег?
Канонический тег сообщает поисковым системам, какая версия веб-страницы является «главной» или «канонической» и должна быть проиндексирована. Это поможет вам указать, какую версию URL вы хотите отображать в результатах поиска. Это полезно, потому что в некоторых случаях, когда у вас может быть контент, доступный через несколько URL-адресов или разных веб-сайтов, вы можете использовать канонические URL-адреса, чтобы избежать негативного влияния дублированного контента на рейтинг.
Допустим, у вас есть две страницы на вашем сайте, которые очень похожи:
- rankmath.com/page1
- rankmath.com/page2
Обе страницы имеют одинаковое содержание, но вы хотите, чтобы поисковые системы индексировали только каноническую версию страницы (в данном случае rankmath.com/page1).
Для этого вы должны добавить канонический тег в HTML-код rankmath.com/page2, а также в HTML-код rankmath.com/page1, например:
Это сообщает поисковым системам, что rankmath.com/page1 — это каноническая версия страницы, которая должна быть проиндексирована.
Чтобы узнать канонический URL-адрес веб-страницы, вставьте URL-адрес веб-страницы в консоль поиска Google, как показано ниже.
После этого нажмите Индексирование страницы и прокрутите вниз до Канонический, выбранный Google , , как показано ниже. Термин Inspected URL указывает на то, что URL-адрес, который вы вставили в Search Console, является каноническим URL-адресом.
Термин Inspected URL указывает на то, что URL-адрес, который вы вставили в Search Console, является каноническим URL-адресом.
3 Как исправить сообщение о состоянии «Альтернативная страница с правильным каноническим тегом»
3.1 Обновление канонического URL-адреса в Rank Math
Первый шаг — найти дубликаты страниц на вашем сайте. Для этого перейдите в раздел Страницы Google Search Console и нажмите на вкладку Не проиндексировано .
Затем нажмите на статус «Альтернативная страница с правильным каноническим тегом».
Это покажет вам список всех страниц вашего сайта, которые отмечены этим статусом.
Когда у вас есть список затронутых страниц в Google Search Console или на вкладке «Статус индекса» в Rank Math, вам нужно проверить, содержат ли они правильный канонический URL-адрес. Если нет, вам нужно будет изменить их с помощью Rank Math.
Лучше всего то, что плагин Rank Math SEO WordPress позволяет легко изменить канонический URL-адрес с помощью мета-поля (как показано на рисунке ниже).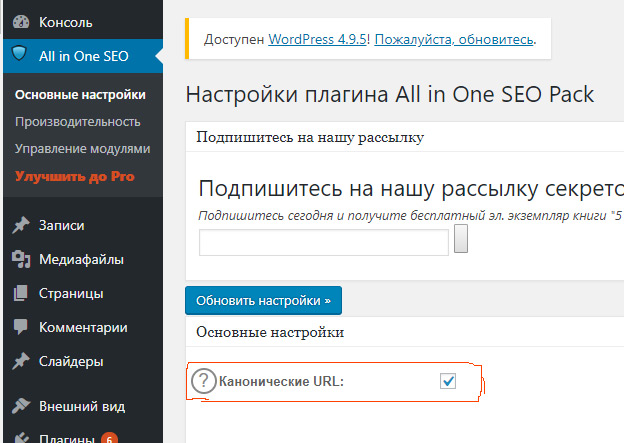
По умолчанию Rank Math использует текущий URL-адрес публикации/страницы в качестве канонического URL-адреса, поэтому вам нужно изменить этот параметр только в том случае, если вы хотите изменить его на что-то другое. Это также известно как самоссылающийся канонический .
Примечание: Если вы не можете найти вкладку «Дополнительно», включите расширенный режим из Панель инструментов WordPress > Математика рангов > Панель инструментов .
На вкладке «Дополнительно» в мета-окне Rank Math вы можете изменить поле «Канонический URL-адрес», чтобы оно указывало на основной источник вашего контента. Канонический URL-адрес сообщает поисковым роботам главной страницы, если у вас есть страницы или сообщения с похожим содержанием.
Приведенный ниже снимок экрана приведен только для справки.
Когда вы закончите настройку своего канонического URL-адреса, просто обновите страницу, как обычно, после внесения изменений или нажмите Опубликовать , если это только что созданная страница.
С другой стороны, если вы не используете WordPress, вам может потребоваться обратиться к вашей системе управления контентом для получения информации о том, как они обрабатывают канонические URL-адреса.
Если вы используете специально созданный веб-сайт, вы можете добавить тег canonical непосредственно в элемент заголовка веб-страницы. Для этого скопируйте приведенный ниже фрагмент кода, замените https://rankmath.com/canonical-url своим каноническим URL-адресом и вставьте его в тег заголовка страницы.
3.2
Используйте переадресацию 301 Вы должны добавлять канонические URL-адреса только к нужным дубликатам страниц. хранить. Если вы не хотите, чтобы страница больше появлялась на вашем сайте, вам следует использовать вместо этого перенаправление 301 . Вы можете обратиться к этой статье базы знаний о настройке одиночной и множественной переадресации 301 в Rank Math.