Список стоп-слов Яндекс.Директа
Стоп-слова в Яндекс.Директе — это служебные части речи и местоимения, а также любые слова, не несущие дополнительного смысла, которые автоматически исключаются из запроса пользователя при отборе объявлений для показа. Например, при запросе пользователя “Как и когда купить слона” для показа будут отобраны объявления, у которых в ключевых словах присутствует фраза “Купить слона”. “Как”, “и”, “когда” будут в этом случае являться стоп-словами. Для их принудительного включения во фразу перед ними нужно поставить знак плюс, например «+как +и +когда купить слона».
Не путайте стоп-слова и минус-слова. Минус-слова — это слова, по запросам с которыми рекламное объявление показываться не будет. Минус-слова можно указать на уровне кампании, группы объявлений или ключевой фразы. Например, если мы укажем минус-слово «скачать» на уровне кампании, то ни одно из объявлений кампании не будет показываться по любым поисковым запросам пользователя, содержащим «скачать».
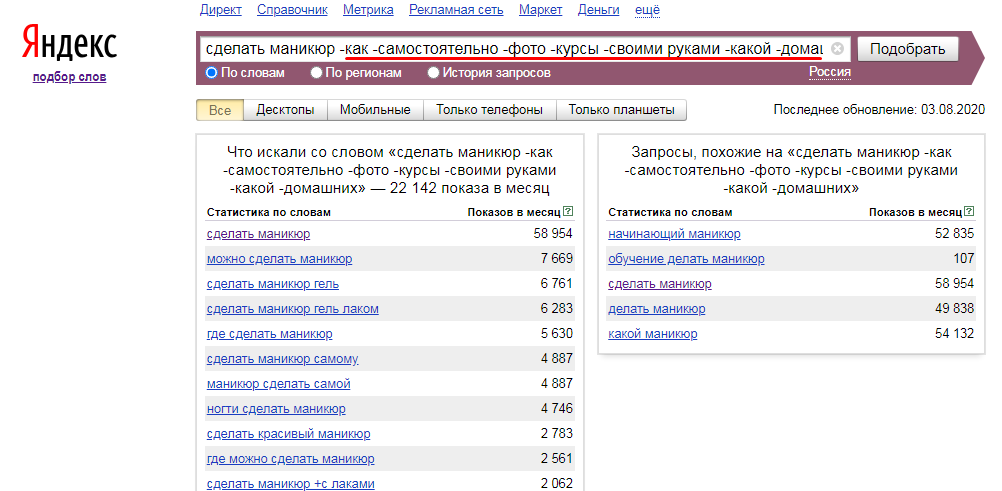
Мне понадобилось определить какие слова Яндекс.Директ считает стоп-словами. Сначала я задумал использовать для этой задачи список всех предлогов, союзов, междометий и местоимений. Но оказалось, что не все слова этих частей речи используются Директом в качестве стоп-слов. Например, союз «со» и предлог «между» к стоп-словам не относятся. Проверить это просто: если в сервис прогноза бюджета добавить предлог «в» и нажать «Посчитать», то сервис сообщит об ошибке:
А попытка рассчитать бюджет для предлога «между» закончится успехом:
Другой способ определить стоп-слова — с помощью Вордстата. Количество показов по фразам «небо земля» и «небо и земля» одинаковое. Это означает, что союз «и» не учитывается при показе объявлений в Директе:
Фраза «между небом и землей» обладает другим количеством показом, значит наличие предлога «между» во фразе уменьшает количество показов:
Вордстат при расчете количества показов для фразы, состоящей только из стоп-слова, возвращает 0. В этом он отличается от сервиса прогноза бюджета (который, напомню, выдает ошибку).
В этом он отличается от сервиса прогноза бюджета (который, напомню, выдает ошибку).
Но Вордстат возвратит тот же ноль и при запросе любого слова, у которого вообще нет показов:
Так что использовать Вордстат для определения стоп-слов не совсем надежно, поэтому я решил использовать сервис прогноза бюджета, он позволяет массово загружать несколько фраз и уведомляет о том какие именно слова не позволяют рассчитать бюджет:
Итак, я взял свой список предлогов, союзов, междометий и местоимений и начал опрашивать все слова в сервисе прогноза бюджета, но внезапно оказалось, что глагол «есть» — это тоже стоп-слово:
Значит список стоп-слов Яндекса не ограничивается одними лишь служебными словами и местоимениями. После этого открытия мне ничего не оставалось кроме как взять список кириллических униграмм (однословников) с OpenCorpora и прогнать их все в сервисе прогноза бюджета.
Следующим открытием было то, что ограничиваться одними лишь кириллическими словами было ошибкой:
Поэтому в список слов для проверки были добавлены англоязычные униграммы. Найти англоязычный корпус оказалось не так легко, но всё же удалось получить 5000 наиболее популярных англоязычных лемм.
Найти англоязычный корпус оказалось не так легко, но всё же удалось получить 5000 наиболее популярных англоязычных лемм.
Итоговый список получился таким:
| a |
| about |
| all |
| am |
| an |
| and |
| any |
| are |
| as |
| at |
| be |
| been |
| but |
| by |
| can |
| could |
| do |
| for |
| from |
| has |
| have |
| i |
| if |
| in |
| is |
| it |
| me |
| my |
| no |
| not |
| of |
| on |
| one |
| or |
| so |
| that |
| the |
| them |
| there |
| they |
| this |
| to |
| was |
| we |
| what |
| which |
| will |
| with |
| would |
| you |
| а |
| будем |
| будет |
| будете |
| будешь |
| буду |
| будут |
| будучи |
| будь |
| будьте |
| бы |
| был |
| была |
| были |
| было |
| быть |
| в |
| вам |
| вами |
| вас |
| весь |
| во |
| вот |
| все |
| всё |
| всего |
| всей |
| всем |
| всём |
| всеми |
| всему |
| всех |
| всею |
| всея |
| всю |
| вся |
| вы |
| да |
| для |
| до |
| его |
| едим |
| едят |
| ее |
| её |
| ей |
| ел |
| ела |
| ем |
| ему |
| емъ |
| если |
| ест |
| есть |
| ешь |
| еще |
| ещё |
| ею |
| же |
| за |
| и |
| из |
| или |
| им |
| ими |
| имъ |
| их |
| к |
| как |
| кем |
| ко |
| когда |
| кого |
| ком |
| кому |
| комья |
| которая |
| которого |
| которое |
| которой |
| котором |
| которому |
| которою |
| которую |
| которые |
| который |
| которым |
| которыми |
| которых |
| кто |
| меня |
| мне |
| мной |
| мною |
| мог |
| моги |
| могите |
| могла |
| могли |
| могло |
| могу |
| могут |
| мое |
| моё |
| моего |
| моей |
| моем |
| моём |
| моему |
| моею |
| можем |
| может |
| можете |
| можешь |
| мои |
| мой |
| моим |
| моими |
| моих |
| мочь |
| мою |
| моя |
| мы |
| на |
| нам |
| нами |
| нас |
| наса |
| наш |
| наша |
| наше |
| нашего |
| нашей |
| нашем |
| нашему |
| нашею |
| наши |
| нашим |
| нашими |
| наших |
| нашу |
| не |
| него |
| нее |
| неё |
| ней |
| нем |
| нём |
| нему |
| нет |
| нею |
| ним |
| ними |
| них |
| но |
| о |
| об |
| один |
| одна |
| одни |
| одним |
| одними |
| одних |
| одно |
| одного |
| одной |
| одном |
| одному |
| одною |
| одну |
| он |
| она |
| оне |
| они |
| оно |
| от |
| по |
| при |
| с |
| сам |
| сама |
| сами |
| самим |
| самими |
| самих |
| само |
| самого |
| самом |
| самому |
| саму |
| свое |
| своё |
| своего |
| своей |
| своем |
| своём |
| своему |
| своею |
| свои |
| свой |
| своим |
| своими |
| своих |
| свою |
| своя |
| себе |
| себя |
| собой |
| собою |
| та |
| так |
| такая |
| такие |
| таким |
| такими |
| таких |
| такого |
| такое |
| такой |
| таком |
| такому |
| такою |
| такую |
| те |
| тебе |
| тебя |
| тем |
| теми |
| тех |
| то |
| тобой |
| тобою |
| того |
| той |
| только |
| том |
| томах |
| тому |
| тот |
| тою |
| ту |
| ты |
| у |
| уже |
| чего |
| чем |
| чём |
| чему |
| что |
| чтобы |
| эта |
| эти |
| этим |
| этими |
| этих |
| это |
| этого |
| этой |
| этом |
| этому |
| этот |
| этою |
| эту |
| я |
| мені |
| наші |
| нашої |
| нашій |
| нашою |
| нашім |
| ті |
| тієї |
| тією |
| тії |
| теє |
Список не претендует на полную точность и вполне вероятно, что существуют еще какие-то стоп-слова. Учитывая, что у Яндекса есть турецкий поиск, то должны быть специфичные для этого языка стоп-слова.
Учитывая, что у Яндекса есть турецкий поиск, то должны быть специфичные для этого языка стоп-слова.
Немного интересных и необъяснимых аномалий:
- В список стоп-слов Яндекс.Директа входит слово «наса» (предполагаю, что это что-то вроде склонения слова «нас»).
Но Вордстат не считает его стоп-словом:
Количество показов для фраз «астронавт скотт келли» и «астронавт наса скотт келли» будет разным:
Но сервис прогноза бюджета не пропускает обе эти фразы и оставляет первую из них:
А рассчитать бюджет по фразе «что такое наса» сервис вообще не даст, так как она полностью состоит из стоп-слов (чтобы посчитать нужно добавлять плюсы перед словами):
Судя по тому, что количество показов для фраз «астронавт скотт келли» и «астронавт наса скотт келли» всё-таки разное, «наса» не является стоп-словом в том плане, что оно учитывается при показе объявлений, а уведомление об ошибке в сервисе прогноза бюджета — это баг Яндекса.
- Есть странные стоп-слова: «оне», «емъ», «комья», «томах», «имъ».

Но судя по разнице в количестве показов это всё стоп-слова только для валидатора сервиса прогноза бюджета:

Скорее всего, это тоже баг Яндекса.
- Есть некоторые слова, которые в Вордстате имеют количество показов больше 0, но прогноз бюджета Яндекс.Директа говорит о том, что слово является стоп-словом. Например, слово «будете» — это стоп-слово для сервиса прогноза бюджета:
Но не стоп-слово для Вордстата:
Если взять фразы «будете пить колу» и «пить колу», то количество показов у них различается, а значит «будете» всё же учитывается при показе объявлений:
Таких «псевдо-стоп-слов» (которые стоп-словами не являются, но на них ругается валидатор сервиса прогноза бюджета) я обнаружил довольно-таки много:
| будете |
| будучи |
| едим |
| едят |
| ел |
| ела |
| ем |
| емъ |
| ест |
| ешь |
| имъ |
| комья |
| наса |
| оне |
| сама |
| сами |
| самим |
| самими |
| самих |
| само |
| самого |
| самом |
| самому |
| саму |
| томах |
| тою |
| этою |
| am |
| could |
| me |
| them |
| мені |
| наші |
| нашої |
| нашій |
| нашою |
| нашім |
| ті |
| тієї |
| тією |
| тії |
| теє |
Фактически, эти слова учитываются при показе объявлений и стоп-словами не являются. Я включил их в список стоп-слов, так как завязывался на получение данных из API Яндекс.Директа с помощью метода CreateNewForecast. Этот метод не позволяет создать новый расчет если фраза состоит только из стоп-слов, поэтому мне нужно было точно знать список стоп-слов, которые не принимает метод. Использовать ли полный список или список без этих слов-аномалий — это зависит от решаемой задачи.
Я включил их в список стоп-слов, так как завязывался на получение данных из API Яндекс.Директа с помощью метода CreateNewForecast. Этот метод не позволяет создать новый расчет если фраза состоит только из стоп-слов, поэтому мне нужно было точно знать список стоп-слов, которые не принимает метод. Использовать ли полный список или список без этих слов-аномалий — это зависит от решаемой задачи.
UPD: Благодаря Татьяне Михальченко и Олегу Саламаха список пополнился украинскими стоп-словами.
Вступайте в группу на Facebook и подписывайтесь на мой канал в Telegram, там публикуются интересные статьи про анализ данных и не только.
О стоп-словах простым языком
Энциклопедия
- Авторазметка Яндекса
-
Анализ ключевых слов в «Яндекс. Директе»
- Анализ ключевых слов
- Контекстная и медийная реклама
- Бриф
- Видеореклама
- ВКонтакте
- Геотаргетинг
- Дополнительные ссылки
- Кликабельность
- Ключевые слова
- Код ремаркетинга
- Конверсия
- Контекстная реклама
- Контекстно-медийная сеть Google (GDN)
- Минус-слова
- Мобильная реклама
- Модерация
- Отображаемый URL
- Охват
- Период рекламной кампании
-
Подбор ключевых слов в Яндекс. Директе
- Позиция
- Поисковая реклама
- Поисковый запрос
- Показатель качества
- Показы
- Расширения рекламных объявлений на Яндексе
- Реклама в социальных сетях
- Ремаркетинг
- Российские системы контекстной рекламы
- Ротация
- РСЯ
- Сезонность
- Система контекстной рекламы
- Спецразмещение
- Ставка
- Стоп-слова
- Счетчики сайтов
- Таймтаргетинг
- Таргетинг
- Таргетированная реклама
- ТГБ
- Тематическая реклама
- Требования к тексту объявления
- Управление ставками
- Тип соответствия
- Цена контекстной рекламы
-
Яндекс. Директ
- Яндекс.Маркет
- Яндекс.Метрика
- CPA
- CPV
- Criteo
- CTR
- Look-alike
- RTB
- UTM-метки
- CR
- CPM
- Пиксель
-
Виртуальная визитка в Яндекс. Директе
- Воронка продаж
- Ассоциированные конверсии
- Атрибуция конверсии
- А/В-тестирование
- Виджеты
- Гиперлокальный таргетинг
- Динамическое рекламное объявление
- Когортный анализ
- Лид в интернет-маркетинге
- Нативная реклама
- Места размещения
- Мобильная реклама
- Призыв к действию (call to action)
- Показатель отказов
- Посадочная страница (landing page)
- Парсинг
- Семантическое ядро
- Сквозная аналитика
- Теги веб-аналитики
- Трафик
- Товарный фид
- УТП
- Умная лента
- Целевая аудитория
- Триггер
- Электронная коммерция
- Brand Lift
- Big Data
- Google Tag Manager
- Performance marketing
- Programmatic
- Pop-up
 Директе»
Директе»
 Директе
Директе
 Директ
Директ
 Директе
Директе
Стоп-слова — служебные части речи, которые не учитываются в ключевых словах, если не выделены специальным символом «!». Например, при вводе ключевого слова «он она и его друзья» показы будут осуществляться по запросу «друзья», так как «он», «она», «и», «его» будут в данном случае стоп-словами. Чтобы включить их, необходимо составить ключевое слово в таком виде: «!он !она !и !его друзья».
Например, при вводе ключевого слова «он она и его друзья» показы будут осуществляться по запросу «друзья», так как «он», «она», «и», «его» будут в данном случае стоп-словами. Чтобы включить их, необходимо составить ключевое слово в таком виде: «!он !она !и !его друзья».
Что такое стоп-слова. Как удалить стоп-слова.
Что такое стоп-слова. Как удалить стоп-слова. | MediumВсе о стоп-словах в обработке естественного языка вместе с практическими примерами.
Чтение: 6 мин.·
10 июня 2020 г. Photo by Jose Aragones on UnsplashВ этой статье мы узнаем все о стоп-словах для обработки естественного языка.
В вычислительной технике стоп-слова — это слова, которые отфильтровываются до или после обработки данных естественного языка (текста). В то время как «стоп-слова» обычно относятся к наиболее распространенным словам в…
Написано Sai Teja
106 подписчиков
Мне нравится Deep Learn.
Еще от Sai Teja
Sai Teja
in
Программирование увеличения данных
Увеличение данных — это метод, который можно использовать для создания обновленных копий изображений в наборе данных для искусственного увеличения размера …
5 минут чтения · 21 мая 2020 г.
Sai Teja
НЛП (обработка естественного языка) с TensorFlow
Учебник для изучения и практики НЛП с помощью TensorFlow.
·9 мин чтения · 2 июня 2020 г.Sai Teja
Как запустить блокнот Jupyter в облачной платформе Google (GCP)
Запустить блокнот Jupyter на облачной платформе Google (GCP) для бесплатно.
· 3 мин. Чтение · 17 августа 2020 г.Sai Teja
Трансферный обучение для глубоких нейронных сетей с использованием Tensorflow
Практический и практический пример, чтобы узнать, как использовать Transfer Learning с использованием TensorFlow.
 ·5 мин чтения·30 мая 2020 г.
·5 мин чтения·30 мая 2020 г.Просмотреть все от Sai Teja
Рекомендовано на Medium
Кэтрин Манро
в
Как сделать определение языка Использование Python, NLTK и некоторых простых статистических данных
Практическое введение в технологию, которую вы используете каждый день.
·12 минут чтения·11 январяАрун Джагота
в
Сегментация текста на предложения с помощью НЛП
Разработка признаков, статистическая модель и обучение на основе обратной связи
·Чтение за 10 минут·30 январяСписки
Обработка естественного языка
377 историй·31 сохранение
Прогнозное моделирование с Python
18 историй·79 сохранений
Практические руководства по машинному обучению
10 рассказов·89 сохранений
Кодирование и разработка
11 рассказов·34 сохранения
Андреа Д’Агостино
в
Как обучить модель Word2Vec с нуля с помощью Gensim
В этой статье мы рассмотрим Gensim, очень популярную библиотеку Python для обучения моделей машинного обучения на основе текста, для обучения Word2Vec… 06
10 Захватывающих идей для проектов с использованием больших языковых моделей (LLM) для вашего портфолио
Узнайте, как создавать приложения, и продемонстрируйте свои навыки с помощью больших языковых моделей (LLM).
 Начните сегодня! ·11 минут чтения·15 мая
Начните сегодня! ·11 минут чтения·15 маяДжей Петерман
в
Создайте средство для суммирования текста с помощью GPT-3
Краткое руководство с использованием Python, OpenAI GPT-3 и Streamlit
·11 мин. читать·23 январяThe PyCoach
in
Вы используете ChatGPT неправильно! Вот как опередить 99% пользователей ChatGPT
·Чтение за 7 мин.·17 мартаСм. дополнительные рекомендации
Статус
Карьера
Преобразование текста в речь
Предварительная обработка текста: Удаление стоп-слов | Chetna
Удобное руководство по удалению стоп-слов английского языка в Python
Опубликовано в·
Чтение: 12 мин. Нам хорошо известно, что компьютеры может легко обрабатывать числа, если хорошо запрограммирован. 🧑🏻💻 Однако большая часть информации, которой мы располагаем, представлена в виде текста. 📗 Мы общаемся друг с другом, напрямую разговаривая с ними или используя текстовые сообщения, сообщения в социальных сетях, телефонные звонки, видеозвонки и т. д. Чтобы создавать интеллектуальные системы, нам нужно использовать эту информацию, которой у нас в избытке.
д. Чтобы создавать интеллектуальные системы, нам нужно использовать эту информацию, которой у нас в избытке.
Обработка естественного языка (НЛП) — это ветвь искусственного интеллекта, которая позволяет машинам интерпретировать человеческий язык. 👍🏼 Однако то же самое не может быть использовано машиной напрямую, и нам нужно сначала предварительно обработать то же самое.
Предварительная обработка текста — это процесс подготовки текстовых данных, чтобы машины могли использовать их для выполнения таких задач, как анализ, прогнозирование и т. д. Предварительная обработка текста включает множество различных этапов, но в этой статье мы рассмотрим только познакомьтесь со стоп-словами, почему мы их удаляем и с различными библиотеками, которые можно использовать для их удаления.
Итак, приступим. 🏃🏽♀️
Что такое стоп-слова? 🤔 Слова, которые обычно отфильтровываются перед обработкой естественного языка, называются стоп-словами . На самом деле это самые распространенные слова в любом языке (такие как артикли, предлоги, местоимения, союзы и т. д.), и они не добавляют много информации к тексту. Примеры нескольких стоп-слов в английском языке: «the», «a», «an», «so», «what».
На самом деле это самые распространенные слова в любом языке (такие как артикли, предлоги, местоимения, союзы и т. д.), и они не добавляют много информации к тексту. Примеры нескольких стоп-слов в английском языке: «the», «a», «an», «so», «what».
Почему мы удаляем стоп-слова? 🤷♀️
Стоп-слова доступны в изобилии на любом человеческом языке. Удаляя эти слова, мы удаляем низкоуровневую информацию из нашего текста, чтобы уделить больше внимания важной информации. По порядку можно сказать, что удаление таких слов не оказывает негативного влияния на модель, которую мы обучаем для нашей задачи.
Удаление стоп-слов определенно уменьшает размер набора данных и, следовательно, сокращает время обучения из-за меньшего количества токенов, участвующих в обучении.
Всегда ли мы удаляем стоп-слова? Всегда ли они бесполезны для нас? 🙋♀️
Ответ — нет! 🙅♂️
Мы не всегда удаляем стоп-слова. Удаление стоп-слов сильно зависит от задачи, которую мы выполняем, и цели, которую мы хотим достичь. Например, если мы обучаем модель, которая может выполнять задачу анализа настроений, мы можем не удалять стоп-слова.
Например, если мы обучаем модель, которая может выполнять задачу анализа настроений, мы можем не удалять стоп-слова.
Обзор фильма: «Фильм совсем не понравился».
Текст после удаления стоп-слов: « фильм хороший»
Мы ясно видим, что отзыв о фильме был негативным. Однако после удаления стоп-слов отзыв стал положительным, что не соответствует действительности. Таким образом, удаление стоп-слов здесь может быть проблематичным.
В таких задачах, как классификация текста, обычно не требуются стоп-слова, поскольку другие слова, присутствующие в наборе данных, более важны и дают общее представление о тексте. Поэтому стоп-слова в таких задачах мы обычно убираем.
Короче говоря, в НЛП есть много задач, которые невозможно выполнить должным образом после удаления стоп-слов. Итак, подумайте, прежде чем выполнять этот шаг. Загвоздка здесь в том, что ни одно правило не является универсальным, и ни один список стоп-слов не является универсальным. Список, не передающий никакой важной информации одной задаче, может передать много информации другой задаче.
Список, не передающий никакой важной информации одной задаче, может передать много информации другой задаче.
Предупреждение: Прежде чем удалять стоп-слова, немного изучите свою задачу и проблему, которую вы пытаетесь решить, а затем примите решение.
Какие существуют библиотеки для удаления стоп-слов? 🙎♀️Сегодня НЛП является одной из наиболее изучаемых областей, и в этой области было сделано много революционных разработок. НЛП опирается на передовые вычислительные навыки, и разработчики по всему миру создали множество различных инструментов для работы с человеческим языком. Из такого большого количества библиотек некоторые довольно популярны и очень помогают в выполнении множества различных задач НЛП.
Некоторые из библиотек, используемых для удаления английских стоп-слов, список стоп-слов вместе с кодом приведены ниже.
Natural Language Toolkit (NLTK):
NLTK — замечательная библиотека для игры с естественным языком. Когда вы начнете свое путешествие по НЛП, это будет первая библиотека, которую вы будете использовать. Шаги для импорта библиотеки и списка английских стоп-слов приведены ниже:
Когда вы начнете свое путешествие по НЛП, это будет первая библиотека, которую вы будете использовать. Шаги для импорта библиотеки и списка английских стоп-слов приведены ниже:
07 напечатать (sw_nltk )
Вывод:
['я', 'мне', 'мой', 'сам', 'мы', 'наш', 'наш', 'нас', 'ты', 'ты', 'ты', «ты», «ты», «твой», «твой», «себя», «себя», «он», «его», «его», «сам», «она», «она». ", 'она', 'ее', 'сама', 'это', 'это', 'его', 'сама', 'они', 'их', 'их', 'их', 'себя', 'что', 'который', 'кто', 'кому', 'этот', 'тот', 'этот', 'эти', 'те', 'есть', 'есть', 'есть', 'был', 'были', 'быть', 'был', 'быть', 'иметь', 'имеет', 'иметь', 'иметь', 'делать', 'делает', 'делал', 'делает ', 'а', 'а', 'то', 'и', 'но', 'если', 'или', 'потому что', 'как', 'до', 'пока', 'из', 'в', 'по', 'за', 'с', 'о', 'против', 'между', 'в', 'через', 'во время', 'до', 'после', 'сверху' ', 'ниже', 'до', 'от', 'вверху', 'внизу', 'в', 'вне', 'вкл.', 'выкл.', 'сверху', 'под', 'снова', «дальше», «тогда», «один раз», «здесь», «там», «когда», «где», «почему», «как», «все», «каждый», «оба», «каждый».
 ', 'несколько', 'больше', 'большинство', 'другой', 'некоторые', 'такой', 'нет', 'ни', 'не', 'только', 'свой', 'такой же', 'так', 'чем', 'тоже', 'очень', 'с', 'т', 'можно', 'будет', 'просто', 'не надо', 'не надо', «должен был», «сейчас», «д», «буду», «м», «о», «ре», «ве», «у», «аин», «арен», «не ", "не мог", "не мог", "не сделал", "не сделал", "не сделал", "не сделал", "не имел", "не имел", "не имел", "не имел" ", "иметь", "не иметь", "есть", "не является", "ма", "может", "не может", "должен", "не должен", "нужно", «не нужно», «шань», «не следует», «должен», «не должен», «был», «не был», «был», «не был», «выиграл», «не будет», «будет», «не будет»]
', 'несколько', 'больше', 'большинство', 'другой', 'некоторые', 'такой', 'нет', 'ни', 'не', 'только', 'свой', 'такой же', 'так', 'чем', 'тоже', 'очень', 'с', 'т', 'можно', 'будет', 'просто', 'не надо', 'не надо', «должен был», «сейчас», «д», «буду», «м», «о», «ре», «ве», «у», «аин», «арен», «не ", "не мог", "не мог", "не сделал", "не сделал", "не сделал", "не сделал", "не имел", "не имел", "не имел", "не имел" ", "иметь", "не иметь", "есть", "не является", "ма", "может", "не может", "должен", "не должен", "нужно", «не нужно», «шань», «не следует», «должен», «не должен», «был», «не был», «был», «не был», «выиграл», «не будет», «будет», «не будет»] Проверим, сколько стоп-слов в этой библиотеке.
print ( len (sw_nltk))
Вывод:
179
Удалим из текста стоп-слова.
text = "Когда я впервые встретил ее, она была очень тихой. Она молчала все два часа пути из Стоуни-Брук в Нью-Йорк."words = [word for word in text.
новый_текст = " ". join (слова) print (new_text)
print ("Старая длина: ", len (текст))
print ("Новая длина: ", len (new_text))
 split() если слово. ниже() нет в sw_nltk]
split() если слово. ниже() нет в sw_nltk] Приведенный выше код довольно прост, но я все же объясню его для начинающих. У меня есть текст, и я разбиваю этот текст на слова, так как стоп-слова — это список слов. Затем я изменил слова на строчные, так как все слова в списке стоп-слов написаны строчными буквами. Затем я создал список всех слов, которых нет в списке стоп-слов. Затем полученный список объединяется, чтобы снова сформировать предложение.
Вывод:
сначала встретил тишину. молчал все два часа пути Стоуни-Брук в Нью-Йорк.
Старая длина: 129
Новая длина: 82
Мы можем ясно видеть, что удаление стоп-слов сократило длину предложения со 129 до 82.
Пожалуйста, обратите внимание, что я буду использовать аналогичный код для объяснения стоп-слов в каждой из библиотек.
spaCy:
spaCy — это программная библиотека с открытым исходным кодом для продвинутого НЛП. Эта библиотека сейчас довольно популярна, и практикующие НЛП используют ее для наилучшего выполнения своей работы.
import spacy
#загрузка маленькой модели spacy на английском языке
en = spacy.load ('en_core_web_sm')
sw_spacy = en. Defaults.stop_words
print (sw_spacy)
Вывод:
{'те', 'на', 'свои', ''ва', 'себя', 'вокруг', 'между', 'четыре ', 'был', 'один', 'от', 'я', 'тогда', 'другой', 'может', 'относительно', 'в дальнейшем', 'передний', 'тоже', 'использованный', 'причем', 'буду', 'делаю', 'все', 'вверх', 'на', 'никогда', 'либо', 'как', 'до', 'все равно', 'с', ' через», «количество», «сейчас», «он», «был», «иметь», «в», «потому что», «не», «поэтому», «они», «не», « даже', 'кого', 'это', 'видеть', 'где-то', 'после этого', 'ничего', 'в то время как', 'много', 'всякий раз', 'кажется', 'пока', 'почему' , 'в', 'также', 'некоторые', 'последний', 'чем', 'получить', 'уже', 'наш', 'когда-то', 'будет', 'никто', 'м', 'что', 'что', 'таким образом', 'нет', 'сам', 'вне', 'следующий', 'что угодно', 'хотя', 'хотя', 'который', 'будет', 'там ', 'ни', 'как-то', 'после этого', 'к тому же', 'кто-либо', 'нас', 'несколько', 'сделал', 'без', 'третий', 'что-нибудь', 'двенадцать', 'против', 'пока', 'двадцать', 'если', 'однако', 'сама', 'когда', 'может', 'наш', 'шесть', 'сделано', 'кажется', 'иначе ', 'позвонить', 'может быть', 'было', 'тем не менее', 'где', 'иначе', 'еще', 'внутри', 'свое', 'для', 'вместе', 'в другом месте', 'во всем', 'из', 'другие', 'показывать', ''s', 'где угодно', 'во всяком случае', 'как', 'есть', 'то', 'следовательно', 'что-то', ' при этом', 'нигде', 'в последнее время', 'говорить', 'не делает', 'ни', 'его', 'идти', 'сорок', 'ставить', 'их', 'им', 'а именно' , 'может', 'пять', 'если', 'сам', 'есть', 'девять', 'потом', 'внизу', 'дно', 'таким образом', 'такой', 'оба', ' она', 'становиться', 'целое', 'кто', 'сама', 'каждый', 'через', 'кроме', 'очень', 'несколько', 'среди', 'бытие', 'быть' , 'мой', 'дальше', 'н', 'здесь', 'во время', 'почему', 'с', 'просто', 'с', 'становится', 'будет', ' о', 'а', 'использование', 'кажущийся', 'д', 'буду', 'ре', 'из-за', 'где угодно', 'заранее', 'пятьдесят', 'становление', 'может', 'среди', 'мой', 'пустой', 'оттуда', 'после этого', 'почти', 'наименее', 'кто-то', 'часто', 'от', 'держать', 'его ', 'или', ''м', 'сверху', 'она', 'никто', 'когда-нибудь', 'поперек', ''с', ''ре', 'сотня', 'только', ' через', 'имя', 'восемь', 'три', 'назад', 'к', 'все', 'стало', 'движение', 'я', 'мы', 'ранее', 'так' , 'я', 'откуда', 'под', 'всегда', 'сам', 'в', 'здесь', 'больше', 'после', 'сами', 'вы', 'наверху', ' шестьдесят», «их», «ваш», «сделал», «действительно», «самый», «везде», «пятнадцать», «но», «должен», «вместе», «рядом», «ее» , 'боковой', 'бывший', 'кто-нибудь', 'полный', 'имеющий', 'твой', 'чей', 'за', 'пожалуйста', 'десять', 'казалось', 'иногда', ' должен', 'над', 'взять', 'каждый', 'то же самое', 'скорее', 'действительно', 'последний', 'и', 'са', 'вследствии этого', 'часть', 'за' , 'одиннадцать', 'когда-либо', ''ре', 'достаточно', 'не', 'снова', ''д', 'нас', 'еще', 'более того', 'в основном', ' один', 'тем временем', 'куда', 'там', 'по направлению', ''м', 'ве', ''д', 'дать', 'делать', 'ан', 'совсем', 'эти', 'каждый', 'к', 'этому', 'не может', 'потом', 'за', 'сделать', 'были', 'ли', 'хорошо', 'другой', 'ниже ', 'первый', 'после', 'любой', 'ничего', 'много', 'серьезный', 'различный', 'повторно', 'два', 'менее', ''ве'} Довольно длинный список. Проверим, сколько стоп-слов в этой библиотеке.
Проверим, сколько стоп-слов в этой библиотеке.
печать ( len (sw_spacy))
Вывод:
326
Ого, 326! Давайте удалим стоп-слова из нашего предыдущего текста.
слов = [слово для слов в тексте . split() если слово. ниже() нет в sw_spacy]
new_text = " ". соединение (слова)
печать (новый_текст)
печать ("Старая длина: ", длина (текст))
печать ("Новая длина: ", длина (новый_текст))
Вывод:
мет тихо. оставался тихим весь час пути в Стоуни-Брук, Нью-Йорк.
Старая длина: 129
Новая длина: 72
Мы ясно видим, что удаление стоп-слов сократило длину предложения со 129 до 72, что даже короче, чем в NLTK, потому что в библиотеке spaCy больше стоп-слов, чем в NLTK. Хотя результаты в этом случае очень похожи.
Хотя результаты в этом случае очень похожи.
Gensim:
Gensim (Generate Similar) — это программная библиотека с открытым исходным кодом, использующая современное статистическое машинное обучение. Согласно Википедии, Gensim предназначен для обработки больших текстовых коллекций с использованием потоковой передачи данных и добавочных онлайн-алгоритмов, что отличает его от большинства других пакетов программного обеспечения для машинного обучения, предназначенных только для обработки в памяти.
импорт gensim
из gensim.parsing.preprocessing import remove_stopwords, СТОП-СЛОВА
print (СТОП-СЛОВА)
Вывод:
frostset({'те', 'на', 'свои', 'ваши', 'т.е.', 'вокруг', 'между', 'четыре', 'был', 'один', 'выкл', 'ам', 'тогда', 'другой', 'может', 'плакать', 'относительно', 'в будущем', 'перед', 'слишком ', 'используется', 'при этом', 'делает', 'все', 'вверх', 'никогда', 'на', 'как', 'либо', 'до', 'все равно', 'с тех пор', 'через', 'количество', 'сейчас', 'он', 'не могу', 'был', 'против', 'иметь', 'в', 'потому что', 'вкл. ', 'не', 'поэтому ', 'они', 'даже', 'кого', 'это', 'видеть', 'где-то', 'интерес', 'вследствие этого', 'толстый', 'ничего', 'тогда как', 'много', 'всякий раз', 'найти', 'кажется', 'пока', 'в силу чего', 'в', 'лтд', 'огонь', 'также', 'некоторые', 'последний', 'чем', 'получить ', 'уже', 'наш', 'не делает', 'когда-то', 'будет', 'никто', 'тот', 'что', 'таким образом', 'нет', 'сам', 'вне', 'следующий', 'что-либо', 'хотя', 'хотя', 'и т. д.', 'который', 'будет', 'там', 'ни', 'каким-то образом', 'после этого', 'кроме того', 'кто бы ни ', 'тонкий', 'самим', 'мало', 'делал', 'третий', 'без', 'двенадцать', 'что-либо', 'против', 'пока', 'двадцать', 'если', 'однако', 'нашла', 'сама', 'когда', 'может', 'шесть', 'наш', 'сделано', 'кажется', 'иначе', 'звонок', 'может быть', 'была ', 'тем не менее', 'заполнить', 'где', 'иначе', 'еще', 'внутри', 'его', 'для', 'вместе', 'в другом месте', 'на протяжении', 'из', 'например', 'другие', 'показывать', 'искренне', 'где угодно', 'во всяком случае', 'как', 'являются', 'тот', 'следовательно', 'что-то', 'настоящим', 'нигде ', 'в последнее время', 'де', 'говорить', 'делает', 'ни', 'его', 'идти', 'сорок', 'ставить', 'их', 'им', 'а именно', 'км', 'может', 'пять', 'если', 'сам', 'есть', 'девять', 'потом', 'вниз', 'дно', 'таким образом', 'такой', 'оба ', 'она', 'становиться', 'целиком', 'кто', 'себя', 'каждый', 'через', 'кроме', 'очень', 'несколько', 'среди', 'существование', 'быть', 'моё', 'далее', 'здесь', 'во время', 'почему', 'с', 'просто', 'становится', 'о', 'а', 'ко', 'использование ', 'кажущийся', 'должной', 'где угодно', 'заранее', 'подробно', 'пятьдесят', 'становящийся', 'могущий', 'среди', 'мой', 'пустой', 'оттуда', 'после этого', 'почти', 'наименее', 'кто-то', 'часто', 'от', 'держать', 'его', 'или', 'сверху', 'ее', 'не сделал', 'никто ', 'когда-то', 'через', 'сотня', 'только', 'через', 'имя', 'восемь', 'три', 'назад', 'к', 'все', 'стал', 'двигаться', 'я', 'мы', 'раньше', 'так', 'я', 'откуда', 'описывать', 'под', 'всегда', 'сам', 'больше', 'здесь ', 'в', 'после', 'себя', 'вы', 'их', 'выше', 'шестьдесят', 'не было', 'ваш', 'сделал', 'везде', 'действительно', 'самый', 'кг', 'пятнадцать', 'но', 'должен', 'вместе', 'рядом', 'ее', 'компьютер', 'бок', 'бывший', 'полный', 'кто-нибудь ', 'имеет', 'ваш', 'чей', 'за', 'пожалуйста', 'мельница', 'среди', 'десяти', 'казалось', 'иногда', 'должен', 'над', 'взять', 'каждый', 'дон', 'тот же', 'скорее', 'действительно', 'последний', 'и', 'часть', 'вследствии этого', 'за', 'одиннадцать', 'когда-либо ', 'достаточно', 'снова', 'нас', 'еще', 'к тому же', 'в основном', 'один', 'тем временем', 'куда', 'туда', 'навстречу', 'дать', 'система', 'делать', 'совершенно', 'ан', 'эти', 'все', 'по направлению', 'это', 'счет', 'не может', 'не', 'потом', 'за пределами ', 'делать', 'были', 'ли', 'хорошо', 'другой', 'ниже', 'первый', 'над', 'любой', 'никто', 'многие', 'разные', 'серьезно', 'ре', 'два', 'меньше', 'не мог'})  ', 'не', 'поэтому ', 'они', 'даже', 'кого', 'это', 'видеть', 'где-то', 'интерес', 'вследствие этого', 'толстый', 'ничего', 'тогда как', 'много', 'всякий раз', 'найти', 'кажется', 'пока', 'в силу чего', 'в', 'лтд', 'огонь', 'также', 'некоторые', 'последний', 'чем', 'получить ', 'уже', 'наш', 'не делает', 'когда-то', 'будет', 'никто', 'тот', 'что', 'таким образом', 'нет', 'сам', 'вне', 'следующий', 'что-либо', 'хотя', 'хотя', 'и т. д.', 'который', 'будет', 'там', 'ни', 'каким-то образом', 'после этого', 'кроме того', 'кто бы ни ', 'тонкий', 'самим', 'мало', 'делал', 'третий', 'без', 'двенадцать', 'что-либо', 'против', 'пока', 'двадцать', 'если', 'однако', 'нашла', 'сама', 'когда', 'может', 'шесть', 'наш', 'сделано', 'кажется', 'иначе', 'звонок', 'может быть', 'была ', 'тем не менее', 'заполнить', 'где', 'иначе', 'еще', 'внутри', 'его', 'для', 'вместе', 'в другом месте', 'на протяжении', 'из', 'например', 'другие', 'показывать', 'искренне', 'где угодно', 'во всяком случае', 'как', 'являются', 'тот', 'следовательно', 'что-то', 'настоящим', 'нигде ', 'в последнее время', 'де', 'говорить', 'делает', 'ни', 'его', 'идти', 'сорок', 'ставить', 'их', 'им', 'а именно', 'км', 'может', 'пять', 'если', 'сам', 'есть', 'девять', 'потом', 'вниз', 'дно', 'таким образом', 'такой', 'оба ', 'она', 'становиться', 'целиком', 'кто', 'себя', 'каждый', 'через', 'кроме', 'очень', 'несколько', 'среди', 'существование', 'быть', 'моё', 'далее', 'здесь', 'во время', 'почему', 'с', 'просто', 'становится', 'о', 'а', 'ко', 'использование ', 'кажущийся', 'должной', 'где угодно', 'заранее', 'подробно', 'пятьдесят', 'становящийся', 'могущий', 'среди', 'мой', 'пустой', 'оттуда', 'после этого', 'почти', 'наименее', 'кто-то', 'часто', 'от', 'держать', 'его', 'или', 'сверху', 'ее', 'не сделал', 'никто ', 'когда-то', 'через', 'сотня', 'только', 'через', 'имя', 'восемь', 'три', 'назад', 'к', 'все', 'стал', 'двигаться', 'я', 'мы', 'раньше', 'так', 'я', 'откуда', 'описывать', 'под', 'всегда', 'сам', 'больше', 'здесь ', 'в', 'после', 'себя', 'вы', 'их', 'выше', 'шестьдесят', 'не было', 'ваш', 'сделал', 'везде', 'действительно', 'самый', 'кг', 'пятнадцать', 'но', 'должен', 'вместе', 'рядом', 'ее', 'компьютер', 'бок', 'бывший', 'полный', 'кто-нибудь ', 'имеет', 'ваш', 'чей', 'за', 'пожалуйста', 'мельница', 'среди', 'десяти', 'казалось', 'иногда', 'должен', 'над', 'взять', 'каждый', 'дон', 'тот же', 'скорее', 'действительно', 'последний', 'и', 'часть', 'вследствии этого', 'за', 'одиннадцать', 'когда-либо ', 'достаточно', 'снова', 'нас', 'еще', 'к тому же', 'в основном', 'один', 'тем временем', 'куда', 'туда', 'навстречу', 'дать', 'система', 'делать', 'совершенно', 'ан', 'эти', 'все', 'по направлению', 'это', 'счет', 'не может', 'не', 'потом', 'за пределами ', 'делать', 'были', 'ли', 'хорошо', 'другой', 'ниже', 'первый', 'над', 'любой', 'никто', 'многие', 'разные', 'серьезно', 'ре', 'два', 'меньше', 'не мог'})
', 'не', 'поэтому ', 'они', 'даже', 'кого', 'это', 'видеть', 'где-то', 'интерес', 'вследствие этого', 'толстый', 'ничего', 'тогда как', 'много', 'всякий раз', 'найти', 'кажется', 'пока', 'в силу чего', 'в', 'лтд', 'огонь', 'также', 'некоторые', 'последний', 'чем', 'получить ', 'уже', 'наш', 'не делает', 'когда-то', 'будет', 'никто', 'тот', 'что', 'таким образом', 'нет', 'сам', 'вне', 'следующий', 'что-либо', 'хотя', 'хотя', 'и т. д.', 'который', 'будет', 'там', 'ни', 'каким-то образом', 'после этого', 'кроме того', 'кто бы ни ', 'тонкий', 'самим', 'мало', 'делал', 'третий', 'без', 'двенадцать', 'что-либо', 'против', 'пока', 'двадцать', 'если', 'однако', 'нашла', 'сама', 'когда', 'может', 'шесть', 'наш', 'сделано', 'кажется', 'иначе', 'звонок', 'может быть', 'была ', 'тем не менее', 'заполнить', 'где', 'иначе', 'еще', 'внутри', 'его', 'для', 'вместе', 'в другом месте', 'на протяжении', 'из', 'например', 'другие', 'показывать', 'искренне', 'где угодно', 'во всяком случае', 'как', 'являются', 'тот', 'следовательно', 'что-то', 'настоящим', 'нигде ', 'в последнее время', 'де', 'говорить', 'делает', 'ни', 'его', 'идти', 'сорок', 'ставить', 'их', 'им', 'а именно', 'км', 'может', 'пять', 'если', 'сам', 'есть', 'девять', 'потом', 'вниз', 'дно', 'таким образом', 'такой', 'оба ', 'она', 'становиться', 'целиком', 'кто', 'себя', 'каждый', 'через', 'кроме', 'очень', 'несколько', 'среди', 'существование', 'быть', 'моё', 'далее', 'здесь', 'во время', 'почему', 'с', 'просто', 'становится', 'о', 'а', 'ко', 'использование ', 'кажущийся', 'должной', 'где угодно', 'заранее', 'подробно', 'пятьдесят', 'становящийся', 'могущий', 'среди', 'мой', 'пустой', 'оттуда', 'после этого', 'почти', 'наименее', 'кто-то', 'часто', 'от', 'держать', 'его', 'или', 'сверху', 'ее', 'не сделал', 'никто ', 'когда-то', 'через', 'сотня', 'только', 'через', 'имя', 'восемь', 'три', 'назад', 'к', 'все', 'стал', 'двигаться', 'я', 'мы', 'раньше', 'так', 'я', 'откуда', 'описывать', 'под', 'всегда', 'сам', 'больше', 'здесь ', 'в', 'после', 'себя', 'вы', 'их', 'выше', 'шестьдесят', 'не было', 'ваш', 'сделал', 'везде', 'действительно', 'самый', 'кг', 'пятнадцать', 'но', 'должен', 'вместе', 'рядом', 'ее', 'компьютер', 'бок', 'бывший', 'полный', 'кто-нибудь ', 'имеет', 'ваш', 'чей', 'за', 'пожалуйста', 'мельница', 'среди', 'десяти', 'казалось', 'иногда', 'должен', 'над', 'взять', 'каждый', 'дон', 'тот же', 'скорее', 'действительно', 'последний', 'и', 'часть', 'вследствии этого', 'за', 'одиннадцать', 'когда-либо ', 'достаточно', 'снова', 'нас', 'еще', 'к тому же', 'в основном', 'один', 'тем временем', 'куда', 'туда', 'навстречу', 'дать', 'система', 'делать', 'совершенно', 'ан', 'эти', 'все', 'по направлению', 'это', 'счет', 'не может', 'не', 'потом', 'за пределами ', 'делать', 'были', 'ли', 'хорошо', 'другой', 'ниже', 'первый', 'над', 'любой', 'никто', 'многие', 'разные', 'серьезно', 'ре', 'два', 'меньше', 'не мог'}) Опять длинный список. Проверим, сколько стоп-слов в этой библиотеке.
Проверим, сколько стоп-слов в этой библиотеке.
печать ( len (СТОП-СЛОВА))
Вывод:
337
Уммм! Такой же счет, как spaCy. Удалим стоп-слова из нашего текста.
new_text = remove_stopwords (текст)
print (new_text) print ("Старая длина: ", len (текст))
print ("Новая длина: " , лен (новый_текст ))
Мы видим, что удалить стоп-слова с помощью библиотеки Gensim довольно просто.
Вывод:
Когда я встретил Тишину. Она молчала весь час долгого путешествия Стоуни-Брук в Нью-Йорк.
Старая длина: 129
Новая длина: 83
Удаление стоп-слов уменьшило длину предложения со 129 до 83. Мы видим, что хотя длина стоп-слов в spaCy и Gensim одинакова, результирующий текст довольно другой.
Scikit-Learn:
Scikit-Learn не нуждается в представлении. Это бесплатная библиотека машинного обучения для Python. Это, пожалуй, самая мощная библиотека для машинного обучения.
Это бесплатная библиотека машинного обучения для Python. Это, пожалуй, самая мощная библиотека для машинного обучения.
из sklearn.feature_extraction.text импорт ENGLISH_STOP_WORDS
печать (ENGLISH_STOP_WORDS)
Вывод:
frostset( {'те', 'на', 'свои', 'себя', 'т.е.', 'вокруг', 'между', 'четыре', 'был', 'один', 'выкл', 'ам', 'тогда', 'другой', 'может', 'плакать', 'в будущем', 'передний ', 'тоже', 'при этом', 'все', 'вверху', 'на', 'никогда', 'либо', 'как', 'до', 'все равно', 'с', 'через', 'количество', 'сейчас', 'он', 'не может', 'было', 'против', 'иметь', 'в', 'потому что', 'вкл.', 'не', 'поэтому', 'они ', 'даже', 'кого', 'это', 'видеть', 'где-то', 'интерес', 'поэтому', 'ничего', 'толстый', 'тогда как', 'много', 'всякий раз', 'найти', 'казаться', 'пока', 'посредством чего', 'в', 'ооо', 'огонь', 'также', 'некоторые', 'последний', 'чем', 'получить', 'уже ', 'наш', 'когда-то', 'будет', 'никто', 'тот', 'что', 'таким образом', 'нет', 'сам', 'вне', 'следующий', 'что угодно', 'хотя', 'хотя', 'и т. д.', 'который', 'было бы', 'там', 'ни', 'каким-то образом', 'поскольку', 'кроме того', 'кто-либо', 'тонкий', 'мы сами ', 'мало', 'третий', 'без', 'ничего', 'двенадцать', 'против', 'пока', 'двадцать', 'если', 'однако', 'нашла', 'сама', 'когда', 'может', 'наш', 'шесть', 'сделано', 'кажется', 'иначе', 'звонить', 'возможно', 'было', 'все же', 'заполнить', 'где ', 'иначе', 'все еще', 'внутри', 'его', 'для', 'вместе', 'в другом месте', 'на протяжении', 'из', 'например', 'другие', 'показать', 'искренне', 'где угодно', 'во всяком случае', 'как', 'есть', 'то', 'следовательно', 'что-то', 'настоящим', 'нигде', 'де', 'в последнее время', 'ни ', 'его', 'идти', 'сорок', 'положить', 'их', 'по', 'а именно', 'могл', 'пять', 'сам', 'есть', 'девять', 'потому', 'внизу', 'дно', 'тем самым', 'такой', 'оба', 'она', 'становиться', 'целое', 'кто', 'себя', 'каждый', 'через ', 'кроме', 'очень', 'несколько', 'среди', 'существование', 'быть', 'моё', 'далее', 'здесь', 'во время', 'почему', 'с', 'становится', 'около', 'а', 'со', 'кажущийся', 'из-за', 'где угодно', 'заранее', 'деталь', 'пятьдесят', 'становление', 'может', 'среди ', 'мой', 'пустой', 'оттуда', 'после этого', 'почти', 'наименее', 'кто-то', 'часто', 'от', 'держать', 'его', 'или', 'сверху', 'ее', 'никто', 'когда-нибудь', 'через', 'сотню', 'только', 'через', 'имя', 'восемь', 'три', 'назад', 'к ', 'все', 'стал', 'движение', 'я', 'мы', 'прежде', 'так', 'я', 'откуда', 'описать', 'под', 'всегда', «сам», «в», «здесь», «больше», «после», «сами», «вы», «выше», «шестьдесят», «их», «не сделал», «ваш», «сделал». ', 'действительно', 'большинство', 'везде', 'пятнадцать', 'но', 'должен', 'вместе', 'рядом', 'ее', 'сторона', 'бывший', 'кто-нибудь', 'полный', 'имеет', 'твой', 'чей', 'за', 'пожалуйста', 'среди', 'мельница', 'десять', 'казалось', 'иногда', 'должен', 'более ', 'взять', 'каждый', 'тот же', 'скорее', 'последний', 'и', 'вследствии этого', 'часть', 'за', 'одиннадцать', 'когда-либо', 'достаточно', 'опять', 'нас', 'еще', 'к тому же', 'в основном', 'один', 'тем временем', 'куда', 'там', 'к', 'дать', 'система', 'делать ', 'ан', 'эти', 'все', 'по направлению', 'этот', 'билл', 'не может', 'не', 'потом', 'за', 'были', 'ли', 'ну', 'другой', 'ниже', 'первый', 'на', 'любой', 'никто', 'много', 'серьезный', 'ре', 'два', 'не мог', 'меньше '})  д.', 'который', 'было бы', 'там', 'ни', 'каким-то образом', 'поскольку', 'кроме того', 'кто-либо', 'тонкий', 'мы сами ', 'мало', 'третий', 'без', 'ничего', 'двенадцать', 'против', 'пока', 'двадцать', 'если', 'однако', 'нашла', 'сама', 'когда', 'может', 'наш', 'шесть', 'сделано', 'кажется', 'иначе', 'звонить', 'возможно', 'было', 'все же', 'заполнить', 'где ', 'иначе', 'все еще', 'внутри', 'его', 'для', 'вместе', 'в другом месте', 'на протяжении', 'из', 'например', 'другие', 'показать', 'искренне', 'где угодно', 'во всяком случае', 'как', 'есть', 'то', 'следовательно', 'что-то', 'настоящим', 'нигде', 'де', 'в последнее время', 'ни ', 'его', 'идти', 'сорок', 'положить', 'их', 'по', 'а именно', 'могл', 'пять', 'сам', 'есть', 'девять', 'потому', 'внизу', 'дно', 'тем самым', 'такой', 'оба', 'она', 'становиться', 'целое', 'кто', 'себя', 'каждый', 'через ', 'кроме', 'очень', 'несколько', 'среди', 'существование', 'быть', 'моё', 'далее', 'здесь', 'во время', 'почему', 'с', 'становится', 'около', 'а', 'со', 'кажущийся', 'из-за', 'где угодно', 'заранее', 'деталь', 'пятьдесят', 'становление', 'может', 'среди ', 'мой', 'пустой', 'оттуда', 'после этого', 'почти', 'наименее', 'кто-то', 'часто', 'от', 'держать', 'его', 'или', 'сверху', 'ее', 'никто', 'когда-нибудь', 'через', 'сотню', 'только', 'через', 'имя', 'восемь', 'три', 'назад', 'к ', 'все', 'стал', 'движение', 'я', 'мы', 'прежде', 'так', 'я', 'откуда', 'описать', 'под', 'всегда', «сам», «в», «здесь», «больше», «после», «сами», «вы», «выше», «шестьдесят», «их», «не сделал», «ваш», «сделал».
д.', 'который', 'было бы', 'там', 'ни', 'каким-то образом', 'поскольку', 'кроме того', 'кто-либо', 'тонкий', 'мы сами ', 'мало', 'третий', 'без', 'ничего', 'двенадцать', 'против', 'пока', 'двадцать', 'если', 'однако', 'нашла', 'сама', 'когда', 'может', 'наш', 'шесть', 'сделано', 'кажется', 'иначе', 'звонить', 'возможно', 'было', 'все же', 'заполнить', 'где ', 'иначе', 'все еще', 'внутри', 'его', 'для', 'вместе', 'в другом месте', 'на протяжении', 'из', 'например', 'другие', 'показать', 'искренне', 'где угодно', 'во всяком случае', 'как', 'есть', 'то', 'следовательно', 'что-то', 'настоящим', 'нигде', 'де', 'в последнее время', 'ни ', 'его', 'идти', 'сорок', 'положить', 'их', 'по', 'а именно', 'могл', 'пять', 'сам', 'есть', 'девять', 'потому', 'внизу', 'дно', 'тем самым', 'такой', 'оба', 'она', 'становиться', 'целое', 'кто', 'себя', 'каждый', 'через ', 'кроме', 'очень', 'несколько', 'среди', 'существование', 'быть', 'моё', 'далее', 'здесь', 'во время', 'почему', 'с', 'становится', 'около', 'а', 'со', 'кажущийся', 'из-за', 'где угодно', 'заранее', 'деталь', 'пятьдесят', 'становление', 'может', 'среди ', 'мой', 'пустой', 'оттуда', 'после этого', 'почти', 'наименее', 'кто-то', 'часто', 'от', 'держать', 'его', 'или', 'сверху', 'ее', 'никто', 'когда-нибудь', 'через', 'сотню', 'только', 'через', 'имя', 'восемь', 'три', 'назад', 'к ', 'все', 'стал', 'движение', 'я', 'мы', 'прежде', 'так', 'я', 'откуда', 'описать', 'под', 'всегда', «сам», «в», «здесь», «больше», «после», «сами», «вы», «выше», «шестьдесят», «их», «не сделал», «ваш», «сделал». ', 'действительно', 'большинство', 'везде', 'пятнадцать', 'но', 'должен', 'вместе', 'рядом', 'ее', 'сторона', 'бывший', 'кто-нибудь', 'полный', 'имеет', 'твой', 'чей', 'за', 'пожалуйста', 'среди', 'мельница', 'десять', 'казалось', 'иногда', 'должен', 'более ', 'взять', 'каждый', 'тот же', 'скорее', 'последний', 'и', 'вследствии этого', 'часть', 'за', 'одиннадцать', 'когда-либо', 'достаточно', 'опять', 'нас', 'еще', 'к тому же', 'в основном', 'один', 'тем временем', 'куда', 'там', 'к', 'дать', 'система', 'делать ', 'ан', 'эти', 'все', 'по направлению', 'этот', 'билл', 'не может', 'не', 'потом', 'за', 'были', 'ли', 'ну', 'другой', 'ниже', 'первый', 'на', 'любой', 'никто', 'много', 'серьезный', 'ре', 'два', 'не мог', 'меньше '})
', 'действительно', 'большинство', 'везде', 'пятнадцать', 'но', 'должен', 'вместе', 'рядом', 'ее', 'сторона', 'бывший', 'кто-нибудь', 'полный', 'имеет', 'твой', 'чей', 'за', 'пожалуйста', 'среди', 'мельница', 'десять', 'казалось', 'иногда', 'должен', 'более ', 'взять', 'каждый', 'тот же', 'скорее', 'последний', 'и', 'вследствии этого', 'часть', 'за', 'одиннадцать', 'когда-либо', 'достаточно', 'опять', 'нас', 'еще', 'к тому же', 'в основном', 'один', 'тем временем', 'куда', 'там', 'к', 'дать', 'система', 'делать ', 'ан', 'эти', 'все', 'по направлению', 'этот', 'билл', 'не может', 'не', 'потом', 'за', 'были', 'ли', 'ну', 'другой', 'ниже', 'первый', 'на', 'любой', 'никто', 'много', 'серьезный', 'ре', 'два', 'не мог', 'меньше '}) Опять длинный список. Проверим, сколько стоп-слов в этой библиотеке.
print ( len (ENGLISH_STOP_WORDS))
Вывод:
318
Удалим стоп-слова из нашего текста.
слов = [слово для слов в тексте .
new_text = " ". соединение (слова)
печать (новый_текст)
печать ("Старая длина: ", длина (текст))
печать ("Новая длина: ", длина (новый_текст))
 split() если слово. ниже() нет в ENGLISH_STOP_WORDS]
split() если слово. ниже() нет в ENGLISH_STOP_WORDS] Вывод:
мет тихо. молчал весь час долгого пути Стоуни-Брук в Нью-Йорк.
Старая длина: 129
Новая длина: 72
Удаление стоп-слов уменьшило длину предложения со 129 до 72. Мы видим, что и Scikit-learn, и spaCy дали одинаковые результаты.
Могу ли я добавить в список свои стоп-слова? ✍️
Да, мы также можем добавить собственные стоп-слова в список стоп-слов, доступных в этих библиотеках, для нашей цели.
Вот код для добавления некоторых пользовательских стоп-слов в список стоп-слов NLTK:
sw_nltk. extend (['первый', 'второй', 'третий', 'я'])
print ( len (sw_nltk))
Вывод:
183
Мы можем видеть, что длина Стоп-слов NLTK теперь 183 вместо 179. И теперь мы можем использовать тот же код для удаления стоп-слов из нашего текста.
И теперь мы можем использовать тот же код для удаления стоп-слов из нашего текста.
Могу ли я удалить стоп-слова из готового списка? 👋
Да, если мы хотим, мы также можем удалить стоп-слова из списка, доступного в этих библиотеках.
Вот код, использующий библиотеку NLTK:
sw_nltk. удалить ("не") Стоп-слово «не» теперь удалено из списка стоп-слов.
В зависимости от используемой библиотеки вы можете выполнять соответствующие операции для добавления или удаления стоп-слов из готового списка. Я указываю на это, потому что NLTK возвращает список стоп-слов, в то время как другие библиотеки возвращают набор стоп-слов.
Если мы не хотим использовать какую-либо из этих библиотек, мы также можем создать собственный список стоп-слов и использовать его в нашей задаче. Обычно это делается, когда у нас есть опыт в предметной области в нашей области и когда мы знаем, каких слов следует избегать при выполнении нашей задачи.
Посмотрите на приведенный ниже код, чтобы увидеть, насколько это просто.
# создайте свой собственный список стоп-слов
my_stop_words = ['her','me','i','she','it']words = [word for word in text .split() если слово .lower() не в my_stop_words]
new_text = " ". join (слова)
print (new_text)
print ("Старая длина: ", len (текст))
print ("Новая длина: ", len 9020 8 (новый_текст))
Результат:
При первой встрече было очень тихо. оставался тихим в течение всего двухчасового путешествия из Стоуни-Брук в Нью-Йорк.
Старая длина: 129
Новая длина: 115
Аналогичным образом вы можете создать свой список стоп-слов в соответствии с вашей задачей и использовать его. 🤟
В этой статье мы заметили, что разные библиотеки имеют разный набор стоп-слов, и мы можем четко сказать, что стоп-слова — это наиболее часто используемые слова в любом языке.