Как добавить robots.txt на свой сайт Django | Статьи о Django
robots.txt — это стандартный файл для связи со сканерами-роботами, такими как Googlebot, которые не должны сканировать страницы. Вы размещаете его на своем сайте по корневому URL /robots.txt, например https://example.com/robots.txt.
Чтобы добавить такой файл в приложение Django, у вас есть несколько вариантов.
Вы можете обслуживать его с помощью веб-сервера без использования вашего приложения, такого как nginx. Недостатком этого подхода является то, что если вы перенесете свое приложение на другой веб-сервер, вам придется переделать эту конфигурацию. Также вы можете отслеживать код своего приложения в Git, но не конфигурацию вашего веб-сервера, и лучше всего отслеживать изменения в правилах ваших роботов.
Подход, который я одобряю, заключается в том, чтобы использовать его как обычный URL из Django. Это становится другим видом, который вы можете тестировать и обновлять с течением времени. Вот несколько подходов для этого.
Вот несколько подходов для этого.
С шаблоном
Это самый простой подход. Он сохраняет файл robots.txt в шаблоне и просто отображает его по URL-адресу.
Сначала добавьте новый шаблон robots.txt в корневой каталог шаблонов или в каталог шаблонов «основного» приложения:
User-Agent: *
Disallow: /private/
Disallow: /junk/Во-вторых, добавьте запись urlconf:
from django.urls import path
from django.views.generic.base import TemplateView
urlpatterns = [
# ...
path(
"robots.txt",
TemplateView.as_view(template_name="robots.txt", content_type="text/plain"),
),
]Это создает новый вид непосредственно внутри URLconf, а не импортирует его из views.py. Это не лучшая идея, поскольку она смешивает слои в одном файле, но часто это делается прагматично, чтобы избежать лишних строк кода для простых представлений.
Нам нужно установить для content_type значение text/plain, чтобы он служил в качестве текстового документа, а не по умолчанию text/html.
После этого вы сможете запустить python manage.py runserver и увидеть файл, размещенный по адресу http://localhost: 8000/robots.txt (или аналогичный для вашего URL-адреса сервера запуска).
С пользовательским видом
Это немного более гибкий подход. Используя представление, вы можете добавить собственную логику, такую как проверка заголовка хоста и обслуживание различного контента для каждого домена. Это также означает, что вам не нужно беспокоиться о том, что в шаблоне экранированы HTML-переменные, которые могут оказаться неверными для текстового формата.
Сначала добавьте новый вид в ваше «основное» приложение:
from django.http import HttpResponse
from django.views.decorators.http import require_GET
@require_GET
def robots_txt(request):
lines = [
"User-Agent: *",
"Disallow: /private/",
"Disallow: /junk/",
]
return HttpResponse("\n". join(lines), content_type="text/plain")
join(lines), content_type="text/plain") join(lines), content_type="text/plain")
join(lines), content_type="text/plain")We’re using Django’s require_GET decorator to restrict to only GET requests. Class-based views already do this, but we need to think about it ourselves for function-based views.
Мы используем декоратор require_GET в Django, чтобы ограничивать только запросы GET. Представления на основе классов уже делают это, но нам нужно подумать об этом самим для представлений на основе функций.
Мы генерируем содержимое robots.txt внутри Python, комбинируя список строк с помощью str.join().
Во-вторых, добавьте запись urlconf:
from django.urls import path
from core.views import robots_txt
urlpatterns = [
# ...
path("robots.txt", robots_txt),
]Опять же, вы должны быть в состоянии проверить это на runserver.
Тестирование
Как я писал выше, одним из преимуществ обслуживания этого из Django является то, что мы можем проверить это. Автоматические тесты защитят от случайного взлома кода или удаления URL.
Автоматические тесты защитят от случайного взлома кода или удаления URL.
Вы можете добавить некоторые базовые тесты в файл, например, core/tests/test_views.py:
from http import HTTPStatus
from django.test import TestCase
class RobotsTxtTests(TestCase):
def test_get(self):
response = self.client.get("/robots.txt")
self.assertEqual(response.status_code, HTTPStatus.OK)
self.assertEqual(response["content-type"], "text/plain")
lines = response.content.decode().splitlines()
self.assertEqual(lines[0], "User-Agent: *")
def test_post_disallowed(self):
response = self.client.post("/robots.txt")
self.assertEqual(HTTPStatus.METHOD_NOT_ALLOWED, response.status_code) Запустите тесты с помощью python manage.py test core.tests.test_views. Это также хорошая идея проверить, что они запускаются, заставляя их терпеть неудачу, например, закомментировав запись в URL conf.
Django-Robots
If you want to control your robots.txt rules in your database, there’s a Jazzband package called django-robots. I haven’t used it, but it seems well maintained. It also adds some less standard rules, like directing to the sitemap.
Если вы хотите контролировать свои правила robots.txt в своей базе данных, есть пакет от Jazzband под названием django-robots. Я не использовал его, но, кажется, в хорошем состоянии. Он также добавляет некоторые менее стандартные правила, такие как перенаправление на карту сайта.
Итог
Не забывайте проверять файл robots.txt через соответствующие инструменты в интернет.
https://adamj.eu/tech/2020/02/10/robots-txt/
Вернуться на верх
Создаем правильный Robots.txt для WordPress
В этом руководстве я поделюсь методикой составления правильного robots.txt для сайтов на базе WordPress. Вы узнаете все об основных параметрах и допустимых значениях этого файла, а так же способах манипулирования поведением поисковых роботов для ускорения индексации сайта.
Robots.txt — это текстовый файл, который содержит директивы и их значения для управления индексированием сайта в поисковых системах.
В базовый набор директив (параметров) для поисковой системы Яндекс входят:
| Директива | Описание |
|---|---|
| User-agent | Указывает на робота, для которого действуют правила (например, Yandex). |
| Allow | Разрешает обход и индексирование разделов, страниц, файлов. |
| Disallow | Запрещает обход и индексирование разделов, страниц, файлов. |
| Clean-param | Указывает роботу, какие параметры URL (например, UTM-метки) не следует учитывать при индексировании. |
| Sitemap | Указывает путь к файлу Sitemap, который размещен на сайте. |
Все директивы, кроме Clean-param одинаково интерпретируются в других поисковых системах и помогают решить 90% задач связанных с индексированием сайтов на WordPress.
Краулинговый бюджет: что это и как им управлять
Важно понимать, что файл robots.txt не является инструментом для запрета индексирования сайта. Поисковая система Google может не учитывать значения директив и индексировать страницы по своему усмотрению.
Crawler (веб-паук, краулер) или поисковой бот. Его задачи: найти, прочитать и внести в поисковую базу данных веб-страницы найденные в Интернете.
Владельцы сайтов могут управлять поведением краулера. Для этого достаточно разместить инструкции в robots.txt с помощью указанных директив в исходном коде страниц.
От правильности настройки будет зависеть частота сканирования вашего сайта. Основная цель такого управления — это снижение нагрузки на краулер и экономия квоты обхода страниц.
Где находится robots.txt в WordPress
Согласно требованиям поисковых систем файл robots.txt должен быть расположен в корневой директории. Если у вас он отсутствует, убедитесь, что вы не используете SEO-плагины.
Плагины позволяют редактировать robots.txt из панели администратора WordPress и не создают копию файла в корневой папке сайта (например, в режиме Multisite).
Если вы не используете плагин, создайте файл заново и проверьте его доступность. Ручная проверка доступности должна выявить:
- Наличие файла в корневой директории,
- Правильный ответ сервера (код 200 ОК),
- Допустимый размер файла (не более 500 Кб).
После проверки сообщите поисковым системам о внесении изменений.
Стандартный robots.txt для WordPress
После инсталляции WordPress 5.9.3 по умолчанию robots.txt выглядит так:
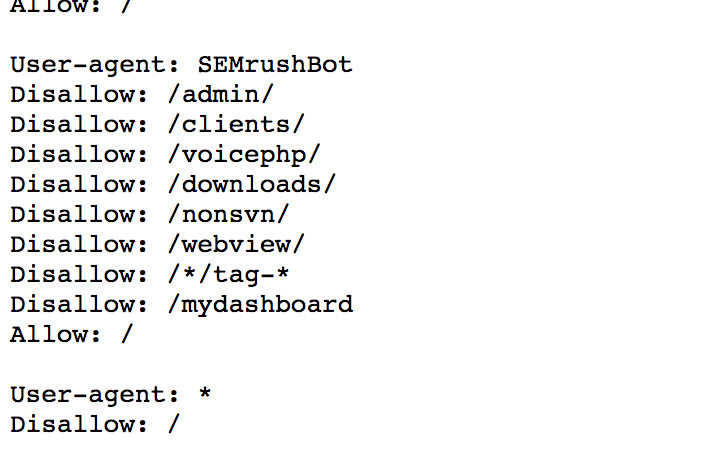
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php Sitemap: https://example.com/wp-sitemap.xml
Из содержания следует, что разработчики рекомендуют закрывать от поисковых машин раздел административной панели, кроме сценария  txt для любого проекта под управлением WordPress это необходимо учитывать.
txt для любого проекта под управлением WordPress это необходимо учитывать.
Правильный robots.txt для WordPress
В WordPress имеется набор системных директорий, файлов и параметров, которые любят сканировать поисковые системы. Все они должны быть запрещены к индексированию за исключением редких случаев.
Системные директории и файлы
| Директория / Файл | Описание |
|---|---|
| /wp-admin | Панель администратора |
| /wp-json | JSON REST API |
| /xmlrpc.php | Протокол XML-RPC |
Параметры URL
| Параметр | Описание |
|---|---|
| s | Стандартная функция поиска |
| author | Личная страница пользователя |
| p&preview | Просмотр черновика записи |
| customize_theme | Изменение внешнего вида темы оформления |
| customize_autosaved | Автосохранение состояния кастомайзера |
Для более гибкой настройки мы рекомендуем разделять robots.
Примечательно, что системные каталоги, файлы и параметры URL можно запретить с помощью директивы Disallow без использования Clean-param. В результате правильный robots.txt для WordPress выглядит так:
User-agent: * Allow: /wp-admin/admin-ajax.php Disallow: /*? Disallow: /wp-admin Disallow: /wp-json Disallow: /xmlrpc.php User-agent: Yandex Allow: /wp-admin/admin-ajax.php Disallow: /*? Disallow: /wp-admin Disallow: /wp-json Disallow: /xmlrpc.php Sitemap: https://example.com/wp-sitemap.xml
Не забудьте изменить значение директивы Sitemap.
Это универсальная конфигурация robots.txt для сайтов под управлением WordPress.
Значение /*? директивы Disallow запрещает к индексированию все параметры URL для главной страницы, записей и категорий..png)
Отлично! Теперь перейдем к индивидуальной настройке.
Несколько примеров из практики
Запрет индексирования AMP страниц в поиске Яндекса
Сайт использует плагин для генерации мобильных страниц в формате AMP для поисковой системы Google. Яндекс их не поддерживает, но умеет сканировать. Для экономии квоты, запрещаем обход AMP страниц для Яндекса с помощью директивы Disallow:
User-agent: * Allow: /wp-admin/admin-ajax.php Disallow: /*? Disallow: /wp-admin Disallow: /wp-json Disallow: /xmlrpc.php User-agent: Yandex Allow: /wp-admin/admin-ajax.php Disallow: /*? Disallow: /amp Disallow: /wp-admin Disallow: /wp-json Disallow: /xmlrpc.php Sitemap: https://example.com/wp-sitemap.xmlНе забудьте изменить значение директивы Sitemap.
Запрет индексирования служебных URL
Сайт использует плагин кастомной авторизации. Ссылки на страницы входа, регистрации и восстановления пароля выглядят так:
Ссылки на страницы входа, регистрации и восстановления пароля выглядят так:
- https://example.com/login,
- https://example.com/register,
- https://example.com/reset-password.
Предварительно, исключим страницы из wp-sitemap.xml и добавим запрет на их сканирование с помощью директивы Disallow в файле robots.txt:
User-agent: * Allow: /wp-admin/admin-ajax.php Disallow: /*? Disallow: /login Disallow: /register Disallow: /reset-password Disallow: /wp-admin Disallow: /wp-json Disallow: /xmlrpc.php User-agent: Yandex Allow: /wp-admin/admin-ajax.php Disallow: /*? Disallow: /amp Disallow: /login Disallow: /register Disallow: /reset-password Disallow: /wp-admin Disallow: /wp-json Disallow: /xmlrpc.php Sitemap: https://example.com/wp-sitemap.xml
Не забудьте изменить значение директивы Sitemap.
Использование директивы Clean-param
Директива Clean-param позволяет гибко настроить индексирование страниц с параметрами URL, которые влияют на содержание страниц.
Она поддерживается только поисковой системой Яндекса. Поисковые роботы Google теперь работают с параметрами URL автоматически.
Например, в торговом каталоге WooCommerce имеется фильтр, который сортирует товары по различным характеристикам: цвету, бренду, размеру.
| Параметр | Описание |
|---|---|
| orderby | Функция сортировки |
| add-to-cart | Функция добавления товара в корзину |
| removed_item | Функция удаления товара из корзины |
Чтобы разрешить индексирование каталога с сортировками в Яндексе без ущерба квоте на переобход сайта, потребуется сделать несколько корректировок.
Разрешим сканирование параметров URL в каталоге, где установлен Woocommerce. Определим лишние параметры — это add-to-cart и removed_item. Воспользуемся директивой Clean-param и внесем изменения:
User-agent: * Allow: /wp-admin/admin-ajax.php Disallow: /*? Disallow: /login Disallow: /register Disallow: /reset-password Disallow: /wp-admin Disallow: /wp-json Disallow: /xmlrpc.
 php
User-agent: Yandex
Allow: /catalog/?
Allow: /wp-admin/admin-ajax.php
Disallow: /*?
Disallow: /amp
Disallow: /login
Disallow: /register
Disallow: /reset-password
Disallow: /wp-admin
Disallow: /wp-json
Disallow: /xmlrpc.php
Clean-param: add-to-cart
Clean-param: removed_item
Sitemap: https://example.com/wp-sitemap.xml
php
User-agent: Yandex
Allow: /catalog/?
Allow: /wp-admin/admin-ajax.php
Disallow: /*?
Disallow: /amp
Disallow: /login
Disallow: /register
Disallow: /reset-password
Disallow: /wp-admin
Disallow: /wp-json
Disallow: /xmlrpc.php
Clean-param: add-to-cart
Clean-param: removed_item
Sitemap: https://example.com/wp-sitemap.xml
Не забудьте изменить значение директивы Sitemap.
Сканирование сортировок товара разрешено в рамках экономии квоты переобхода страниц. Поисковой бот Яндекса не будет сканировать параметры URL предназначенные для манипуляций с корзиной товаров.
Отслеживание лишних страниц в поисковой консоли
Для получения максимального эффекта регулярно отслеживайте сканирование страниц в поисковой консоли Яндекса (разд. Статистика обхода) и запрещайте обход лишних страниц в robots.txt.
При настройке robots.txt я не рекомендую:
- Запрещать обход страниц пагинации записей и разделов (используйте атрибут
rel="canonical"), - Исключать из поиска комментарии пользователей к записям,
- Запрещать сканирование системных папок, где хранятся изображения, скрипты и стили тем оформления WordPress: wp-content, wp-includes и пр.

Как сообщить об изменениях поисковикам
Для отправки изменений используйте инструменты для анализа robots.txt в Яндекс.Вебмастер и Google Search Console.
Правильный Robots.txt для WordPress (базовый и расширенный) [2022]
Правильный Robots.txt для WordPress в 2022-м году. Несколько версий под разные нужды: простая базовая и расширенная — с проработкой под каждую поисковую систему.
Одной из важнейших вещей при создании и оптимизации сайта для поисковых систем считают Robots.txt. Небольшой файлик, где прописаны правила индексирования для поисковых роботов.
Если файл будет настроен неправильно, то сайт может неправильно индексироваться и терять большие доли трафика. Грамотная настройка наоборот позволяет улучшить SEO, и вывести ресурс в топы.
Сегодня мы поговорим о настройке Robots.txt для WordPress. Я покажу вам правильный вариант, который сам использую для своих проектов.
✅ Содержание
Что такое Robots.txt
Как я уже и сказал, robots. txt — текстовой файлик, где прописаны правила для поисковых систем. Стандартный robots.txt для WordPress выглядит следующим образом:
txt — текстовой файлик, где прописаны правила для поисковых систем. Стандартный robots.txt для WordPress выглядит следующим образом:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php
Именно в таком виде он создается плагином Yoast SEO. Некоторые считают, что этого хватит для правильной индексации. Я же считаю, что нужна более детальная проработка. А если речь идет о нестандартных проектах, то проработка нужна и подавно. Давайте разберемся в основных директивах:
| Директива | Значение | Пояснение |
| User-agent: | Yandex, Googlebot и т.д. | В этой директиве можно указать к какому конкретно роботу мы обращаемся. Обычно используются те значения, которые я указал. |
| Disallow: | Относительная ссылка | Директива запрета. Ссылки, указанные в этой директиве будут игнорироваться поисковыми системами. |
| Allow: | Относительная ссылка | Разрешающая директива. Ссылки, которые указаны с ней будут проиндексированы. Ссылки, которые указаны с ней будут проиндексированы. |
| Sitemap: | Абсолютная ссылка | Здесь указывается ссылка на XML-карту сайта. Если в файле не указать эту директиву, то придется добавлять карту вручную (через Яндекс.Вебмастер или Search Console). |
| Crawl-delay: | Время в секундах (пример: 2.0 — 2 секунды) | Позволяет указать таймаут между посещениями поисковых роботов. Нужна в случае, если эти самые роботы создают дополнительную нагрузку на хостинг. |
| Clean-param: | Динамический параметр | Если на сайте есть параметры вида site.ru/statia?uid=32, где ?uid=32 — параметр, то с помощью этой директивы их можно скрыть. |
В принципе, ничего сложного. Дам дополнительные пояснения по директивам Clean-param (откройте вкладку).
Подробнее о Clean-param
Параметры, как правило, используются на динамических сайтах. Они могут передавать поисковым системам лишнюю информацию — создавать дубли. Чтобы избежать этого, мы должны указать в Robots.txt директиву Clean-param с указанием параметра и ссылки, к которой это параметр применяется.
Чтобы избежать этого, мы должны указать в Robots.txt директиву Clean-param с указанием параметра и ссылки, к которой это параметр применяется.
В нашем примере site.ru/statia?uid=32 — site.ru/statia — ссылка, а все, что после знака вопроса — параметр. Здесь это uid=32. Он динамический, и это значит, что параметр uid может принимать другие значения.
Например, uid=33, uid=34…uid=123434. В теории их может быть сколько угодно, поэтому мы должны закрыть от индексации все параметры uid. Для этого директива должна принять такой вид:
Clean-param: uid /statia # все параметры uid для statia будут закрыты
Более подробно о том, что такое Robots.txt можно узнать из Яндекс.Помощи. Или из этого видеоролика:
Базовый Robots.
 txt для WordPress
txt для WordPressСовсем недавно я приобрел плагин Clearfy Pro для своих проектов. Там очень много разных функций, и одна из них — создание идеального Robots.txt. На самом деле насколько он идеален — я не знаю, вебмастера расходятся во мнениях.
Кто-то предпочитает делать более краткие версии роботса, указывая правила для всех поисковых систем сразу. Другие прописывают отдельные правила для каждого поисковика (в основном для Яндекса и Гугла).
Что из этого правильно — точно сказать не могу. Однако я предлагаю вам ознакомиться с базовой версией Robots.txt для WordPress от Clearfy Pro. Я немного подредактировал ее — указал директиву Sitemap. Удалил директиву Host.
User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-json/ Disallow: /xmlrpc.php Disallow: /readme.html Disallow: /*? Disallow: /?s= Allow: /wp-includes/*.css Allow: /wp-includes/*.js Allow: /wp-content/plugins/*.
 css
Allow: /wp-content/plugins/*.js
Allow: /*.css
Allow: /*.js
Sitemap: https://site.ru/sitemap.xml
css
Allow: /wp-content/plugins/*.js
Allow: /*.css
Allow: /*.js
Sitemap: https://site.ru/sitemap.xmlНе могу сказать, что это лучший вариант для блогов на ВП. Но во всяком случае, он лучше, чем то, что нам предлагает Yoast SEO по умолчанию.
Расширенный Robots.txt для WordPress
Теперь посмотрим на расширенную версию Robots.txt для WordPress. Наверняка вы знаете, что все сайты на WP имеют одинаковую структуру. Одинаковые названия папок, файлов и т.д. позволяют специалистам выявить наиболее приемлемый вариант роботса.
Читайте также: Самые лучшие SEO-оптимизированные шаблоны для WordPress
В этой статье я хочу представить вам свой вариант Robots.txt. Его я использую как для своих сайтов, так и для клиентских. Вы могли видеть такой вариант и на других сайтах, т.к. он обладает некоторой популярностью.
Итак, правильный Robots.txt для WordPress выглядит следующим образом:
User-agent: * # Для всех поисковых систем, кроме Яндекса и Гугла Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: /xmlrpc.
 php
Disallow: *utm=
Disallow: *openstat=
Disallow: /tag/ # Закрываем метки
Disallow: /readme.html # Закрываем бесполезный мануал по установке WordPress (лежит в корне)
Disallow: *?replytocom
Allow: */uploads
User-agent: GoogleBot # Для Гугла
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: /xmlrpc.php
Disallow: *utm=
Disallow: *openstat=
Disallow: /tag/ # Закрываем метки
Disallow: /readme.html
Disallow: *?replytocom
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
User-agent: Yandex # Для Яндекса
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: /xmlrpc.
php
Disallow: *utm=
Disallow: *openstat=
Disallow: /tag/ # Закрываем метки
Disallow: /readme.html # Закрываем бесполезный мануал по установке WordPress (лежит в корне)
Disallow: *?replytocom
Allow: */uploads
User-agent: GoogleBot # Для Гугла
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: /xmlrpc.php
Disallow: *utm=
Disallow: *openstat=
Disallow: /tag/ # Закрываем метки
Disallow: /readme.html
Disallow: *?replytocom
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
User-agent: Yandex # Для Яндекса
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: /xmlrpc. php
Disallow: /tag/ # Закрываем метки
Disallow: /readme.html
Disallow: *?replytocom
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign
Clean-Param: openstat
Sitemap: https://site.com/sitemap_index.xml # Карта сайта, меняем site.com на нужный адрес.
php
Disallow: /tag/ # Закрываем метки
Disallow: /readme.html
Disallow: *?replytocom
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign
Clean-Param: openstat
Sitemap: https://site.com/sitemap_index.xml # Карта сайта, меняем site.com на нужный адрес.Ранее в Robots.txt использовалась директива Host. Она указывала главное зеркало сайта. Теперь это делается при помощи редиректа. Подробнее об этом можно почитать в блоге Яндекса.
Комментарии (текст после #) можно удалить. Указываю Sitemap с https протоколом, т.к. большинство сайтов сейчас используют защищенное соединение. Если у вас нет SSL, то измените протокол на http.
Читайте также: Как правильно настроить WordPress
Обратите внимание на то, что я закрываю метки (теги). Делаю это потому, что они создают большое количество дублей. Это плохо сказывается на SEO, но если вы хотите открыть метки, тогда уберите строчку disallow: /tag/ из файла.
Это плохо сказывается на SEO, но если вы хотите открыть метки, тогда уберите строчку disallow: /tag/ из файла.
Заключение
В общем-то, вот так выглядит правильный Robots.txt для WordPress. Смело копируйте данные в файл и пользуйтесь. Отмечу, что этот вариант подходит только для стандартных информационных сайтов.
В других ситуациях может потребоваться индивидуальная проработка. На этом все. Спасибо за внимание. Буду благодарен, если вы подпишитесь на мой телеграм-канал и мою группу ВК.
Видео на десерт: Фермер Хотел Найти Воду, но То Что Случилось Удивило Весь Мир
( 30 оценок, среднее 5 из 5 )
Шаблон файла Robots.txt для WordPress
Шаблон robots.txt для WordPress
Подробная инструкция
Практически каждый этап и элемент играет не последнюю роль в создании и дальнейшей оптимизации сайта в поисковой системе, но, одним из наиболее важных считается Robots. txt. Это небольшой файл, в котором прописываются правила индексирования для поисковых роботов.
txt. Это небольшой файл, в котором прописываются правила индексирования для поисковых роботов.
При неправильной настройке, сайт будет терять львиную долю трафика из-за неправильного индексирования, чего вам естественно не надо. Более ответственно подходите к настройке Robots.txt. ведь от этого зависит будет ли ваш сайт пробиваться топ или нет.
В этой статье я расскажу о том, как правильно настроить Robots.txt для WordPress. Помимо этого, поделюсь с вами вариантами, которые лично использую на своих проектах.
Время на чтение 2 минуты
509
0
Содержание
Robots.txt, что это такое?Подробнее о Clean-paramБазовый вид Robots.txt для WPВам будет интересноРасширенная версия Robots.txt. для WPЗаключение
Robots.txt, что это такое?
Как говорилось выше, это ничто иное как текстовый файл с прописанными в нем правилами для поисковых систем. Обратите внимание, стандартный Robots. txt для WordPress выглядит именно так:
txt для WordPress выглядит именно так:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Вот в таком виде, плагин Yoast SEO создает файл. Многие пользователи ошибочно полагают, что этого вполне достаточно, возможно в каких-то случаях это работает. Но, мое мнение таково: если хочешь хороших показателей роста, стандартные приемы стоит забыть. Если ты со мной согласен, и считаешь что необходима детальная проработка файла, давай глубже разбираться в вопросе. Для начала, мы разберемся в основных директивах:
Как вы успели заметить, сложного здесь ничего нет.
| Директива | Значение | Пояснение |
|---|---|---|
| User-agent: | Yandex, Googlebot и т.д. | Указываем к какому работу обращаемся |
| Disallow: | Относительная ссылка | Выписываем ссылки, которые будут игнорироваться |
| Allow: | Относительная ссылка | Выписываем ссылки, которые будут проиндексированы |
| Sitemap: | Абсолютная ссылка | Указываем ссылки на XML-карту сайта. Если их не прописать в файле, то в дальнейшем придется добавлять карту в ручную через Яндекс.Вебмастер Если их не прописать в файле, то в дальнейшем придется добавлять карту в ручную через Яндекс.Вебмастер |
| Crawl-delay: | Время в секундах | Указываем таймаут между посещениями роботов. Это необходимо в тех |
Как вы успели заметить, сложного здесь ничего нет.
Подробнее о Clean-param
Как правило, параметры используются в динамических сайтах. Проблема в том, что они могут дублироваться и передавать поисковым системам лишнюю информацию. Во избежании этого, как раз и прописывается директива Clean-param в Robots.txt.
Рассмотрим такой пример: site.ru/statia?uid=32 — site.ru/statia — это ссылка, а все что находится после знака “?” является параметром. В данном случае, uid=32 является динамическим параметром, это значит что он может принимать другое значения.
Например, uid=33, uid=34 и так далее. Закрываем индексацию, ведь этот параметр может меняться до бесконечности. Приводим директиву вот в такой вид:
Clean-param: uid /statia # все параметры uid для statia будут закрыты
Базовый вид Robots.
 txt для WP
txt для WPБуквально на днях, я стал обладателем плагина Clearfy Pro, в котором есть огромное разнообразие функций. Сейчас мы рассмотрим одну из них, а именно, функции для создания идеального файла Robots.txt. На сколько же он идеален? Все очень просто, я не знаю! Нет однозначного ответа на этот вопрос.
Люди делятся на два лагеря, одни делают более короткую версию, в которой прописывают правила для всех роботов сразу, другие же расписывают правила для каждого поисковика в отдельности.
Что из этого правильно а что нет, ответа также нет. Вы можете поделиться своими мыслями в комментариях. А сейчас, я вам дам для ознакомления базовую версию Robots.txt. для WordPress, которую я немного подредактировал. Я указал директиву Sitemap и удалил директиву Host.
User-agent: *
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-json/
Disallow: /xmlrpc.php
Disallow: /readme.
Disallow: /*?
Disallow: /?s=
Allow: /*.css
Allow: /*.js
Sitemap: https://site.ru/sitemap.xml
 html
htmlНе возьмусь утверждать, что это самый лучший вариант. Но, он однозначно лучше того, что предлагает нам Yoast SEO.
Вам будет интересно
Расширенная версия Robots.txt. для WP
Для вас наверняка не будет откровением то, что все сайты на WP имеют единую структуру. Этот факт, позволяет специалистам разрабатывать наиболее оптимальные варианты robots.
Я, не стал исключением. За долго подбирал для себя тот вид роботса, который мог бы полностью меня удовлетворить. И сейчас я хочу с вами им поделиться.
User-agent: * # Для всех поисковых систем, кроме Яндекса и Гугла
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: /xmlrpc.
Disallow: *utm=
Disallow: *openstat=
Disallow: /tag/ # Закрываем метки
Disallow: /readme.html # Закрываем бесполезный мануал по установке WordPress (лежит в корне)
Disallow: *?replytocom
Allow: */uploads
User-agent: GoogleBot # Для Гугла
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: /xmlrpc.php
Disallow: *utm=
Disallow: *openstat=
Disallow: /tag/ # Закрываем метки
Disallow: /readme.html
Disallow: *?replytocom
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
User-agent: Yandex # Для Яндекса
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: /xmlrpc.
Disallow: /tag/ # Закрываем метки
Disallow: /readme.html
Disallow: *?replytocom
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign
Clean-Param: openstat
Sitemap: https://site.com/sitemap_index.xml # Карта сайта, меняем site.com на нужный адрес.
 php
php php
phpРанее, в Robots.txt. использовалась директива Host, которая указывала на главное зеркало сайта. Сейчас в этом нет нужды, так как это делается при помощи редиректа.
Sitemap с протоколом https указывается по причине того, что большая часть сайтов использует защищенное соединение. Если у вас нет SSL, просто измените протокол на http.
Хочу заострить ваше внимание на том, что я закрываю теги, ведь они создают огромное количество дублей, что плохо сказывается на SEO. В том случае, если вы хотите их открыть, тогда вам необходимо удалить строку disallow: /tag/ из файла.
Заключение
Собственно, вы наглядно познакомились с тем, как выглядит Robots.txt. “здорового человека” для WP. Берите в пользование и ни в чем себе не отказывайте.
P.S. данный вариант подходит для стандартных информационных сайтов. В иных случаях, вам придется индивидуально прорабатывать файл.
Оцените статью
- 5
- 4
- 3
- 2
- 1
5
Нам очень важно знать ваше мнение,
чтобы писать о том что вам интересно.
Robots.TXT — инструкция
Что такое robots.txt
Robots.txt — это стандартный текстовый файл в кодировке UTF-8 с расширением .txt, который содержит директивы и инструкции индексирования сайта, его страниц или разделов. Он необходим для роботов поисковых систем. В статье расскажем, зачем он нужен, какие инструменты используются для его проверки и настройки под Яндекс и Google, а также представим рекомендации по созданию.
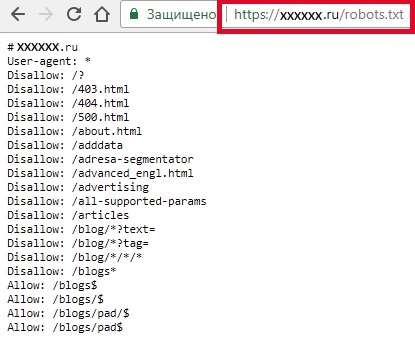
Это первый файл, к которому обращаются поисковые системы, чтобы определить, может ли проводиться индексация сайта. Файл располагается в корневой директории сайта. Разместить его можно через FTP-клиент. Файл должен быть доступен в браузере по ссылке вида site.ru/robots.txt. На него нужно смотреть в первую очередь, если на сайт “упал трафик”.
Рассмотрим наиболее простой пример содержимого robots.txt (кстати, в названии должен быть строго нижний регистр букв), которое позволяет поисковым системам индексировать все разделы сайта:
User-agent: *
Allow: /
Эта инструкция дословно говорит: роботы, которые читают данную инструкцию (User-agent: *), могут индексировать весь сайт (Allow: /).
Зачем он вообще необходим? Чтобы это понять, достаточно представить, как работает поисковый робот. Им по умолчанию приходится просматривать миллиарды страниц по всему интернету, а затем определить для каждой страницы запросы, которым они могут соответствовать. В конце они ранжируют общую массу в поисковой выдаче. Конечно, это задача не из легких. Для работы поисковых алгоритмов задействуются колоссальные ресурсы, которые, конечно, ограничены.
В конце они ранжируют общую массу в поисковой выдаче. Конечно, это задача не из легких. Для работы поисковых алгоритмов задействуются колоссальные ресурсы, которые, конечно, ограничены.
Если кроме страниц, которые содержат полезный контент и которые по задумке владельца сайта должны попадать в выдачу, роботу придется просматривать еще множество технических страниц, которые не представляют никакой ценности для пользователей, его ресурсы будут растрачиваться впустую. Лишь один сайт может генерировать тысячи страниц результатов поиска по сайту, повторяющихся страниц или таких страниц, которые не содержат контента вообще. А если этот объем масштабировать на всю сеть, то получатся огромные цифры и соответствующие ресурсы, которые придется тратить поисковикам.
Наличие огромного количества бесполезного контента на сайте может отрицательно сказаться на его представлении в поиске.
Помимо этого, существует такое понятие, как краулинговый бюджет. Условно говоря, это объем страниц, который может участвовать в поисковой выдаче от одного сайта. Этот объем, конечно, ограничен, хоть по мере роста проекта и повышения его качества краулинговый бюджет может увеличиваться. Главная мысль в том, в выдаче должны участвовать лишь страницы, которые содержат полезные записи, а весь технический «мусор» не должен засорять выдачу.
Этот объем, конечно, ограничен, хоть по мере роста проекта и повышения его качества краулинговый бюджет может увеличиваться. Главная мысль в том, в выдаче должны участвовать лишь страницы, которые содержат полезные записи, а весь технический «мусор» не должен засорять выдачу.
Зачем Robots.txt нужен для SEO?
Если на сайте нет robots.txt, то роботы из поисковых систем будут беспорядочно блуждать по всему сайту. Роботы могут попасть в корзину с мусором, после чего они «сделают вывод», что на сайте слишком грязно. А с помощью robots.txt можно скрыть определенные страницы от индексации. Его нужно создавать для каждого поддомена.
Правильно заполненный файл robots.txt с верной последовательностью позволит роботу создать представление, что на сайте всегда чисто и убрано. Важно регулярно проверять содержимое.
Где находится и как создать?
Файл robots.txt размещается в корневой директории сайта: путь к файлу robots станет таким: site.ru/robots.txt.
Принцип настройки и как редактировать.
 Техническая часть
Техническая частьПосле написания файла Robots его текст можно редактировать в процессе оптимизации ресурса, например, в Notepad. Делать это нужно в текстовом файле robots.txt с соблюдением правил и синтаксиса файла, но не в HTML редакторе. После редактирования на сайт можно выгрузить обновленную версию файла. Кстати, для определенны CMS есть специальные плагины и дополнения, которые дают возможность редактировать файл прямо в админ панели.
Подробнее рассмотрим список директив, используемые символы и принципы настройки.
User-Agent
Это обязательная директива, которая определяет, к какому роботу будут применяться прописанные ниже в файле правила. Иными словами, это обращение к конкретному роботу или всем поисковым ботам. Все файлы должны начинаться именно с этой строчки. Пустой эту строку оставлять нельзя. Регистр символов в значениях директивы User-agent (пользовательский агент) не принимается во внимание.
Disallow
Disallow. Наиболее распространенная директива, запрещающая индексировать определенные страницы или целые разделы веб-сайта. В этой строке можно использовать спец символы * и $. Точка с запятой не используются. Пробел в начале строки ставить можно, но не рекомендуется.
Наиболее распространенная директива, запрещающая индексировать определенные страницы или целые разделы веб-сайта. В этой строке можно использовать спец символы * и $. Точка с запятой не используются. Пробел в начале строки ставить можно, но не рекомендуется.
Что нужно исключить из индекса?
- В первую очередь роботу необходимо запретить включать в индекс любые дубли страниц. Доступ к странице должен осуществляться лишь по одному URL. Обращаясь к сайту, поисковый бот по каждому URL должен получить в ответ страницу строго с уникальным содержанием. Дубли нередко появляются у CMS в процессе создания страниц. Так, один и тот же документ можно найти по техническому домену в формате http:// site.ru/?p=391&preview=true и “человекопонятному” URL http:// site.ru/chto-takoe-seo. Часто дубли появляются и из-за динамических ссылок. Важно их все скрывать от индекса с помощью масок (писать каждую команду нужно с новой строки):
Disallow: /*?*
Disallow: /*%
Disallow: /index.
Disallow: /*?page=
Disallow: /*&page=
 php
php2. Все страницы с неуникальным контентом, например, статьями, новостями, а также политикой конфиденциальности, картинками, изображениями и проч. Такие документы стоит скрыть от поисковых машин, прежде чем они начнут индексироваться.
3. Все страницы, которые используются при работе сценариев. К примеру, это те, где есть сообщения наподобие “Спасибо за ваш отзыв!”.
4. Страницы, которые включают индикаторы сессий. Для подобных страниц тоже рекомендуется использовать директиву Disallow с соответствующими символами. В строке указывается:
Disallow: *PHPSESSID=
Disallow: *session_id=
5. Все файлы движка управления сайтом. Это файлы шаблонов, администраторской панели, тем, баз и другие. Возможные исключения:
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
6. Бесполезные для пользователей страницы и разделы. К примеру, не имеющие какого-либо содержания, с неуникальным контентом, несуществующие и так далее. Их роботу видеть не стоит. Кроме этого, для робота Googlebot при необходимости можно заблокировать выдачу сайта в новостях через Googlebot-News, а через Googlebot-Image — запретить показ изображений в Гугл Картинках.
Бесполезные для пользователей страницы и разделы. К примеру, не имеющие какого-либо содержания, с неуникальным контентом, несуществующие и так далее. Их роботу видеть не стоит. Кроме этого, для робота Googlebot при необходимости можно заблокировать выдачу сайта в новостях через Googlebot-News, а через Googlebot-Image — запретить показ изображений в Гугл Картинках.
Рекомендуем держать файл robots.txt всегда в порядке и в чистоте, и тогда ваш сайт будет индексироваться значительно быстрее и лучше, а ранжироваться выше.
Запрет конкретного раздела сайта
User-agent: *
Disallow: /admin/
Запрет на сканирование определенного файла
User-agent: *
Disallow: /admin/my-embarrassing-photo.png
Полная блокировка доступа к хосту
User-agent: *
Disallow: /
Разрешить полный доступ
Разрешает полный доступ:
User-agent: *
Disallow:
Allow
С помощью такой директивы можно, напротив, допустить каталог или конкретный адрес для того, чтобы он индексировался. В некоторых случаях быстрее и легче запретить к сканированию весь сайт и с помощью строки Allow открыть роботу необходимые разделы.
В некоторых случаях быстрее и легче запретить к сканированию весь сайт и с помощью строки Allow открыть роботу необходимые разделы.
User-agent: *#
Блокируем весь раздел /admin
Disallow: /admin#
Кроме файла /admin/css/style.css
Allow: /admin/css/style.css#
Открываем все файлы в папке /admin/js. Например:
# /admin/js/global.js
# /admin/js/ajax/update.js
Allow: /admin/js/
Директива Crawl-delay
Директива, которая не актуальна в случае Goolge, но очень полезна для работы с другими поисковиками, например, Яндекс или даже Yahoo..
С ее помощью можно замедлить сканирование, если сервер бывает перегружен. Она задает интервал времени для обхода страниц в секундах (актуально для Яндекса). Чем выше значение, тем медленнее краулер станет обходить страницы сайта.
User-agent: *
Crawl-delay: 5
Хотя Googlebot игнорирует подобные правила, настроить скорость сканирования можно в Google Search Console проекта.
Важно, что китайским Baidu тоже не учитывается наличие Crawl-delay в robots.txt, а Bing воспринимает команду как «временное окно», в рамках которого BingBot будет сканировать сайт лишь единожды.
Стоит учитывать: если установлено высокое значение Crawl-delay, самое главное — убедиться, что сайт своевременно индексируется. В сутках 86 400 секунд, при Crawl-delay: 30 будет просканировано менее 2880 страниц в день, и этот показатель не слишком велик для крупных сайтов.
Директива Clean-param
Директива Clean-param дает возможность запрещать поисковому роботу обход страниц с динамическими параметрами, контент которых не имеет отличий от основной страницы. Например, многие интернет-магазины используют параметры в url-адресах, которые отправляют данные по источникам сессий, в том числе персональные идентификаторы пользователей.
Чтобы поисковые роботы не заходили на данные страницы и лишний раз не создавали нагрузку на сервер, можно использовать директиву Clean-param, которая поможет оставить в выдаче только исходный документ.
Давайте рассмотрим использование данной директивы на примере. Например, что сайт собирает информацию по пользователям на страницах:
https:// site.ru/get_book/?userID=1&source=site_2&book_id=3
https:// site.ru/get_book/?userID=5&source=site_4&book_id=5
https:// site.ru/get_book/?userID=9&source=site_11&book_id=2
Параметр userID, который есть в каждом url-адресе, показывает персональный идентификатор пользователя, а параметр source показывает источник, из которого посетитель попал на сайт. По трем разным url-адресам пользователи видят один и тот же контент book_id=3. В этом случае нам необходимо использовать директиву Clean-param таким образом:
User-agent: Yandex
Clean-param: userID /books/get_book.pl
Clean-param: source /books/get_book.pl
Данные директивы позволяют поисковому роботу Яндекса свести все динамические параметры в единую страницу:
https:// site. ru/books/get_book.pl?&book_id=3
ru/books/get_book.pl?&book_id=3
Если на сайте есть такая страница, то именно она станет индексироваться и участвовать в выдаче.
Главное зеркало сайта в robots.txt — Host
С марта 2018 года Яндекс отказался от директивы Host. Ее функции полностью перешли на раздел «Переезд сайта в Вебмастере» и 301-редирект.
Директива Host указывает поисковому роботу Яндекса на главное зеркало сайта. Если сайт был доступен сразу по нескольким разным URL адресам, например, с www и без www, требовалось настроить 301 редирект на главный URL адрес и указать его в директиве Host, поддержка Host прекращена.
Эта директива была полезна при установке SSL-сертификата и переезде сайта с http на https. В директиве Host адрес сайта при наличии SSL-сертификата указывался с https.
Директива Host указывалась в User-agent: Yandex только 1 раз. Например для нашего сайта это выглядело таким образом:
User-agent: Yandex
Host: https:// site.
 ru
ru
В этом примере указано, что главным зеркалом сайта oparinseo.ru является ни www.oparinseo.ru, ни http://oparinseo.ru, а именно https://oparinseo.ru.
Для указания главного зеркала сайта в Google требуется использовать инструменты вебмастера в Google Search Console.
Комментарии в robots.txt
Комментарии в файле robots.txt можно оставлять после символа # — они будут игнорироваться поисковыми системами. Чаще всего они необходимы для обозначения причин открытия или закрытия для индексации определенных страниц, чтобы в будущем оптимизатор мог точно понять причины тех или иных правок в файле.
Один из примеров:
#Это файл robots.txt. Все, что прописывают в данной строке, роботы не прочтут
User-agent: Yandex #Правила для Яндекс-бота
Disallow: /pink #закрыл от индексации, т.к. на странице есть неуникальный контент
Карта сайта в robots.
 txt — Sitemap.xml
txt — Sitemap.xmlДиректива Sitemap позволяет показать поисковому роботу путь на xml карту сайта. Этот файл очень важен для поисковых систем, так как при обходе сайта они в самом начале обращаются к нему. В этом файле представлена структура сайта со всем внутренними ссылками, датами создания страниц, приоритетами индексирования.
Пример robots.txt с указанием адреса карты сайта в строке:
User-agent: *
Sitemap: https:// site.ru/sitemal.xml
Благодаря наличию xml карты сайта представление сайта в поисковой выдаче улучшается. Она является стандартом, который должен использоваться на каждом сайте. Частота обновления и актуальность поддержания sitemap.xml сможет значительно увеличить скорость индексирования страниц, особенно у относительно молодого сайта.
Как проверить Robots.txt?
После того, как готовый файл robots.txt был загружен на сервер, обязательно необходима проверка его доступности, корректности и наличия ошибок в нем.
Как проверить robots.txt на сайте?
Если файл составлен правильно и загружен в корень сервера, то после загрузки он будет доступен по ссылке типа site.ru/robots.txt. Он является публичным, поэтому посмотреть и провести анализ robots.txt можно у любого сайта.
Как проверить robots.txt на наличие ошибок — доступные инструменты
Можно провести проверку robots.txt на наличие ошибок, используя для этой цели специальные инструменты Гугл и Яндекс:
- В панели Вебмастера Яндекс — https://webmaster.yandex.ru/tools/robotstxt/
- В Google Search Console — https://www.google.com/webmasters/tools/robots-tes…
Эти инструменты покажут все ошибки данного файла, предупредят об ограничениях в директивах и предложат провести проверку доступности страниц сайта после настройки robots.txt.
Частая ошибка Robots.txt
Обычной распространенной ошибкой является установка индивидуальных правил для User-Agent без дублирования инструкций Disallow.
Как мы уже выяснили, при указании директивы User-Agent соответствующий краулер будет следовать лишь тем правилам, что установлены именно для него, а остальные проигнорирует. Важно не забывать дублировать общие директивы для всех User-Agent.
Правильный robots.txt для WordPress
Внешний вид Robots.txt на платформе WordPress
Ниже представлен универсальный пример кода для файла robots.txt. Для каждого конкретного сайта его нужно менять или расширять, чтобы страницы могли проиндексироваться корректно.
В представленном варианте нет опасности запретить индексацию каких-либо файлов внутри ядра WordPress либо папки wp-content.
User-agent: *
# Нужно создать секцию правил для роботов. * означает для всех роботов. Чтобы указать секцию правил для отдельного робота, вместо * укажите его имя: GoogleBot (mediapartners-google), Yandex.
Disallow: /cgi-bin # Стандартная папка на хостинге.
Disallow: /wp-admin/ # Закрываем админку.
Disallow: /? # Все параметры запроса на главной.
Disallow: *?s= # Поиск.
Disallow: *&s= # Поиск.
Disallow: /search # Поиск.
Disallow: /author/ # Архив автора.
Disallow: */embed$ # Все встраивания. Символ $ — конец строки.
Disallow: */page/ # Все виды пагинации.
Disallow: */xmlrpc.php # Файл WordPress API
Disallow: *utm*= # Ссылки с utm-метками
Disallow: *openstat= # Ссылки с метками openstat #
Одна или несколько ссылок на карту сайта (файл Sitemap). Это независимая # директива и дублировать её для каждого User-agent не нужно. Например, # Google XML Sitemap создает две карты сайта:
Sitemap: http:// example.com/sitemap.xml
Sitemap: http:// example.com/sitemap.xml.gz
Правильный robots.
 txt для Joomla
txt для JoomlaВнешний вид Robots.txt на платформе Joomla
User-agent: *
Disallow: /administrator/
Disallow: /bin/
Disallow: /cache/
Disallow: /cli/
Disallow: /components/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /layouts/
Disallow: /libraries/
Disallow: /logs/
Disallow: /media/
Disallow: /tmp/
Sitemap: https:// site.ru/sitemap.xml
Здесь указаны другие названия директорий, однако суть остается одной: таким образом закрываются мусорные и служебные страницы, чтобы показать поисковым системам лишь то, что они должны увидеть
Правильный robots.txt для Tilda
Оба файла — роботс и карта сайта — генерируются Тильдой автоматически.
Чтобы просмотреть их, добавьте к вашему адресу сайта /robots. txt или /sitemap.xml, например:
txt или /sitemap.xml, например:
http:// mysite.com/robots.txt
http:// mysite.com/sitemap.xml
Правда, единственный вариант внести кардинальные изменения в эти файлы для сайта на Тильде — экспортировать проект на собственных хостинг и произвести нужные изменения.
Правильный robots.txt для Bitrix
Внешний вид Robots.txt на платформе Bitrix
Код для Robots, который представлен ниже, является базовым, универсальным для любого сайта на Битриксе. В то же время важно понимать, что у каждого сайта могут быть свои индивидуальные особенности, и этот файл может потребоваться корректировать и дополнять в вашем конкретном случае. После этого его нужно сохранить.
User-agent: * # правила для всех роботов
Disallow: /cgi-bin # папка на хостинге
Disallow: /bitrix/ # папка с системными файлами битрикса
Disallow: *bitrix_*= # GET-запросы битрикса
Disallow: /local/ # папка с системными файлами битрикса
Disallow: /*index.
Disallow: /auth/ # авторизацияDisallow: *auth= # авторизация
Disallow: /personal/ # личный кабинет
Disallow: *register= # регистрация
Disallow: *forgot_password= # забыли пароль
Disallow: *change_password= # изменить пароль
Disallow: *login= # логин
Disallow: *logout= # выход
Disallow: */search/ # поиск
Disallow: *action= # действия
Disallow: *print= # печать
Disallow: *?new=Y # новая страница
Disallow: *?edit= # редактирование
Disallow: *?preview= # предпросмотр
Disallow: *backurl= # трекбеки
Disallow: *back_url= # трекбеки
Disallow: *back_url_admin= # трекбеки
Disallow: *captcha # каптча
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: *?FILTER*= # здесь и ниже различные популярные параметры фильтров
Disallow: *?ei=
Disallow: *?p=
Disallow: *?q=
Disallow: *?tags=
Disallow: *B_ORDER=
Disallow: *BRAND=
Disallow: *CLEAR_CACHE=
Disallow: *ELEMENT_ID=
Disallow: *price_from=
Disallow: *price_to=
Disallow: *PROPERTY_TYPE=
Disallow: *PROPERTY_WIDTH=
Disallow: *PROPERTY_HEIGHT=
Disallow: *PROPERTY_DIA=
Disallow: *PROPERTY_OPENING_COUNT=
Disallow: *PROPERTY_SELL_TYPE=
Disallow: *PROPERTY_MAIN_TYPE=
Disallow: *PROPERTY_PRICE[*]=
Disallow: *S_LAST=
Disallow: *SECTION_ID=
Disallow: *SECTION[*]=
Disallow: *SHOWALL=
Disallow: *SHOW_ALL=
Disallow: *SHOWBY=
Disallow: *SORT=
Disallow: *SPHRASE_ID=
Disallow: *TYPE=
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Disallow: *from= # ссылки с метками from
Allow: */upload/ # открываем папку с файлами uploads
Allow: /bitrix/*.
Allow: /bitrix/*.css
Allow: /local/*.js
Allow: /local/*.css
Allow: /local/*.jpg
Allow: /local/*.jpeg
Allow: /local/*.png
Allow: /local/*.gif
# Укажите один или несколько файлов Sitemap
Sitemap: http:// site.ru/sitemap.xml
Sitemap: http:// site.ru/sitemap.xml.gz
 php$ # дубли страниц index.php
php$ # дубли страниц index.php js # здесь и далее открываем для индексации скрипты
js # здесь и далее открываем для индексации скриптыRobots.txt в Яндекс и Google
Многие оптимизаторы, делая только первые шаги в работе с robots.txt, задаются логичным вопросом о том, почему нельзя указать общий User-agent: * и не указывать роботу каждого поисковика — Яндекс и Google — одни и те же инструкции.
Все дело в том, что поисковая система Google более позитивно воспринимает директиву User-agent: Googlebot в файле robots, а Яндекс — отдельную директиву User-agent: Yandex.
Прописывая ключевые правила отдельно для Google и Яндекс, можно управлять индексацией страниц и разделов веб-ресурса посредством Robots. Кроме того, применение персональных User-agent, поможет запретить индексацию некоторых файлов Google, но при этом оставить их доступными для роботов Яндекса, и наоборот.
Кроме того, применение персональных User-agent, поможет запретить индексацию некоторых файлов Google, но при этом оставить их доступными для роботов Яндекса, и наоборот.
Максимально допустимый размер текстового документа robots составляет 32 КБ (если он больше, файл считается открытым и полностью разрешающим). Это позволяет почти любому сайту указать все необходимые для индексации инструкции в отдельных юзер-агентах для Google и Яндекс.. Поэтому лучше не проводить эксперименты и указывать правила, которые относятся к каждому поисковику.
Кстати, Googlebot-Mobile — робот, индексирующий сайты для мобильных устройств.
Правильно настроенный файл robots.txt может позитивно влиять на SEO-продвижение сайта в Яндекс и Google, улучшение позиций. Если вы хотите избавиться от “мусора” и навести порядок на сайте, улучшить его индексацию, в первую очередь нужно работать именно с robots.txt. И если самостоятельно справиться с этим из-за отсутствия опыта и достаточных знаний сложно, лучше доверить эту задачу SEO-специалисту.
Правильный robots.txt для WordPress — 2021
- 1. Оптимальный robots.txt
- 2. Расширенный вариант (разделенные правила для Google и Яндекса)
- 3. Оптимальный Robots.txt для WooCommerce
- 4. Где находится файл robots.txt в WordPress
- 5. Часто задаваемые вопросы
Robots.txt – текстовой файл, который сообщает поисковым роботам, какие файлы и папки следует сканировать (индексировать), а какие сканировать не нужно.
Поисковые системы, такие как Яндекс и Google сначала проверяют файл robots.txt, после этого начинают обход с помощью веб-роботов, которые занимаются архивированием и категоризацией веб сайтов.
 youtube.com/embed/NOU6O8GbmMU?feature=oembed» frameborder=»0″ allow=»accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»>
youtube.com/embed/NOU6O8GbmMU?feature=oembed» frameborder=»0″ allow=»accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»> Файл robots.txt содержит набор инструкций, которые просят бота игнорировать определенные файлы или каталоги. Это может быть сделано в целях конфиденциальности или потому что владелец сайта считает, что содержимое этих файлов и каталогов не должны появляться в выдаче поисковых систем.
Если веб-сайт имеет более одного субдомена, каждый субдомен должен иметь свой собственный файл robots.txt. Важно отметить, что не все боты будут использовать файл robots.txt. Некоторые злонамеренные боты даже читают файл robots.txt, чтобы найти, какие файлы и каталоги Вы хотели скрыть. Кроме того, даже если файл robots.txt указывает игнорировать определенные страницы на сайте, эти страницы могут по-прежнему появляться в результатах поиска, если на них ссылаются другие просканированные страницы. Стандартный роботс тхт для вордпресс открывает весь сайт для интдекса, поэтому нам нужно закрыть не нужные разделы WordPress от индексации.
Оптимальный robots.txt
User-agent: * # общие правила для роботов, кроме Яндекса и Google,
# т.к. для них правила ниже
Disallow: /cgi-bin # системная папка на хостинге, закрывается всегда
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет,
# правило можно удалить)
Disallow: *?s= # запрос поиска
Disallow: *&s= # запрос поиска
Disallow: /search/ # запрос поиска
Disallow: /author/ # архив автора, если у Вас новостной блог с авторскими колонками, то можно открыть
# архив автора, если у Вас новостной блог с авторскими колонками, то можно открыть
Disallow: /users/ # архив авторов
Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой
# ссылки на статью
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: */embed # все встраивания
Disallow: */wlwmanifest. xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
# Host прописывать больше не нужно. xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
# Host прописывать больше не нужно.
xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
# Host прописывать больше не нужно.Скачать оптимальную версию robots.txt
Расширенный вариант (разделенные правила для Google и Яндекса)
User-agent: * # общие правила для роботов, кроме Яндекса и Google,
# т.к. для них правила ниже
Disallow: /cgi-bin # папка на хостинге
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет,
# правило можно удалить)
Disallow: *?s= # поиск
Disallow: *&s= # поиск
Disallow: /search/ # поиск
Disallow: /author/ # архив автора
Disallow: /users/ # архив авторов
Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой
# ссылки на статью
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: */embed # все встраивания
Disallow: */wlwmanifest. xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
User-agent: GoogleBot # правила для Google (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Disallow: *utm*=
Disallow: *openstat=
Allow: */uploads
Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ - для приоритета)
Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ - для приоритета)
Allow: /wp-*.png # картинки в плагинах, cache папке и т.д.
Allow: /wp-*. jpg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д.
Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS
User-agent: Yandex # правила для Яндекса (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать
# от индексирования, а удалять параметры меток,
# Google такие правила не поддерживает
Clean-Param: openstat # аналогично
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
# Host прописывать больше не нужно. xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
User-agent: GoogleBot # правила для Google (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Disallow: *utm*=
Disallow: *openstat=
Allow: */uploads
Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ - для приоритета)
Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ - для приоритета)
Allow: /wp-*.png # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.
xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
User-agent: GoogleBot # правила для Google (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Disallow: *utm*=
Disallow: *openstat=
Allow: */uploads
Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ - для приоритета)
Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ - для приоритета)
Allow: /wp-*.png # картинки в плагинах, cache папке и т.д.
Allow: /wp-*. jpg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д.
Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS
User-agent: Yandex # правила для Яндекса (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать
# от индексирования, а удалять параметры меток,
# Google такие правила не поддерживает
Clean-Param: openstat # аналогично
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно).
jpg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д.
Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS
User-agent: Yandex # правила для Яндекса (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать
# от индексирования, а удалять параметры меток,
# Google такие правила не поддерживает
Clean-Param: openstat # аналогично
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
# Host прописывать больше не нужно.
Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
# Host прописывать больше не нужно.Скачать Расширенный вариант robots.txt
Оптимальный Robots.txt для WooCommerce
Владельцы интернет-магазинов на WordPress – WooCommerce также должны позаботиться о правильном robots.txt. Мы закроем от индексации корзину, страницу оформления заказа и ссылки на добавление товара в корзину.
User-agent: * Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: */wlwmanifest.xml Disallow: /xmlrpc.php Disallow: *utm*= Disallow: *openstat= Disallow: /cart/ Disallow: /checkout/ Disallow: /*add-to-cart=* Allow: */uploads Allow: /*/*.js Allow: /*/*.css Allow: /wp-*.png Allow: /wp-*.jpg Allow: /wp-*.jpeg Allow: /wp-*.gif Allow: /wp-admin/admin-ajax.
 php
Sitemap: https://site.ru/sitemap_index.xml
php
Sitemap: https://site.ru/sitemap_index.xmlСкачать robots.txt для WooCommerce
Где находится файл robots.txt в WordPress
Обычно robots.txt располагается в корне сайта. Если его нет, то потребуется создать текстовой файл и загрузить его на сайт по FTP или панель управления на хостинге. Если Вы не смогли найти robots.txt в корне сайта, но при переходе по ссылке вашсайт.ру/robots.txt он открывается, значит какой то из SEO плагинов сам генерирует его.
К примеру плагин Yoast SEO создает виртуальный файл, которого нет в корне сайта.
Как редактировать robots.txt с помощью Yoast SEO
- Зайдите в админ панель сайта
Админа панель находится по следующему адресу вашсайт.ру/wp-admin/
- Слева в консоли наведите на кнопку SEO и в выпадающем окне выберите “Инструменты”. Перейдите в раздел, как указано на картинке.
- Зайдите в редактор файлов
Этот инструмент позволит быстро отредактировать такие важные для вашего SEO файлы, как robots.
txt и .htaccess (при его наличии). - Если файла robots.txt нет, нажмите на кнопку создать, либо вставьте нужное содержимое.
Содержимое файла для WordPress и WooCommerce можно взять из примеров выше.
- Сохраните изменения в robots.txt
После сохранения файла вы можете проверить правильность через сервисы проверки.
 txt и .htaccess (при его наличии).
txt и .htaccess (при его наличии).Чтобы установить плагин Yoast SEO воспользуйтесь данной статьей – ссылка.
Часто задаваемые вопросы
Как проверить правильность работы robots.txt?
У Google и Яндекс есть средства для проверки файла robots.txt:
Яндекс – https://webmaster.yandex.ru/tools/robotstxt/
Google – https://support.google.com/webmasters/answer/6062598?hl=ru
Закрывать ли feed в robots.txt?
По умолчанию мы рекомендуем закрывать feed от индексации в robots.txt. Открытие feed может потребоваться, если вы например настраиваете Турбо-страницы от Яндекса или выгружаете свою ленту в другой сервис.
Как разрешить индексировать feed Турбо-страниц
Добавьте директиву: Allow: /feed/turbo/, тогда Яндекс сможет проверять ваши турбо-страницы и обновлять их.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Как написать хороший robots.txt
Файл robots.txt похож на привратника вашего веб-сайта, который пропускает одних ботов и поисковых роботов, а других нет. Плохо написанный файл robots.txt может привести к проблемам с доступностью для поисковых роботов и падению трафика.
Протокол исключения роботов
Файл robots.txt был впервые определен в исходном документе «Стандарт для исключения роботов» 1994 года, а затем обновлен в спецификации Internet Draft 1996 года «Метод управления веб-роботами». Оба определяют очень строгий и, следовательно, подверженный ошибкам синтаксический анализ, который побудил основные поисковые системы, такие как Google, использовать, а затем указать более расслабленный метод синтаксического анализа и работать над тем, чтобы сделать его интернет-стандартом. Новые документы для протокола исключения роботов находятся в стадии разработки и получили некоторые последние обновления с 2019 года..
Новые документы для протокола исключения роботов находятся в стадии разработки и получили некоторые последние обновления с 2019 года..
При строгом анализе неточные файлы robots.txt могут привести к неожиданному сканированию. Новый, более простой синтаксический анализ позволяет решить ряд проблем, обнаруженных в файлах robots.txt. Непринужденный синтаксический анализ, скорее всего, имел в виду веб-мастер, когда писал robots.txt.
Рассмотрим пример:
Файл robots.txt с
User-agent: * Disallow: /
можно интерпретировать как
User-agent: * Disallow:
со строгим толкованием оригинальных и обновленных документов и как
Агент пользователя: * Disallow: /
с использованием парсинга, указанного в последнем документе.
В этом крайнем примере обе интерпретации приводят к прямо противоположным результатам, и пользователь, вероятно, имел в виду смягченную интерпретацию. Как веб-мастер, вы хотите убедиться, что оба анализа идентичны. Вы можете сделать это, работая над проблемами, описанными ниже.
Вы можете сделать это, работая над проблемами, описанными ниже.
Базовый файл robots.txt
Написание файла robots.txt может быть очень простым, если вы не запрещаете сканирование и обрабатываете всех роботов одинаково. Это позволит всем роботам сканировать сайт без ограничений:
Агент пользователя: * Disallow:
Общие проблемы с файлами robots.txt
Проблемы начинаются, когда все становится сложнее. Например, вы можете обращаться к нескольким роботам, добавлять комментарии и использовать такие расширения, как задержка сканирования или подстановочные знаки. Не все роботы все понимают, и здесь все очень быстро становится запутанным.
Пустые строки
Черновик описывает формат файла следующим образом:
Формат логически состоит из непустого набора или записей, разделенных пустыми строками. Записи состоят из набора строк вида: <Поле> «:» <значение>
Это означает, что записи разделены пустыми строками, и вам не разрешено иметь пустые строки в записи.
Агент пользователя: * Disallow: /
Если строго применять черновик, то это будет интерпретироваться как две записи. Обе записи неполные, первая не имеет правил, вторая не имеет пользовательского агента. Оба набора можно игнорировать, что приведет к созданию пустого файла robots.txt, который фактически будет таким же, как:
User-agent: * Disallow:
Это полностью противоположно тому, что было задумано. Однако некоторые роботы, такие как Googlebot, используют другой подход к разбору файлов robots.txt, удаляя пустые строки и интерпретируя их так, как это, вероятно, придумал веб-мастер:
Агент пользователя: * Disallow: /
Если вы хотите сэкономить, мы настоятельно рекомендуем не использовать пустые строки в записи. Таким образом, больше ботов будет интерпретировать файл robots.txt так, как он был создан.
С другой стороны, это тоже плохо, если у вас нет пустых строк для разделения записей:
User-agent: a Запретить: /путь2/ Пользовательский агент: b Disallow: /path3/
Это неубедительно.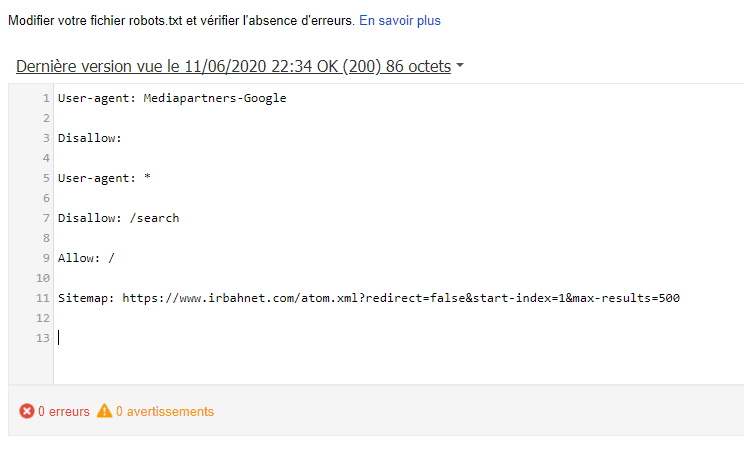 Его можно интерпретировать как:
Его можно интерпретировать как:
User-agent: a Запретить: /путь2/ Запретить: /path3/
или
Агент пользователя: a Пользовательский агент: b Запретить: /путь2/ Disallow: /path3/
Веб-мастер, вероятно, имел в виду:
User-agent: a Запретить: /путь2/ Пользовательский агент: b Disallow: /path3/
Если вы хотите сэкономить, мы настоятельно рекомендуем разделить записи в этом случае.
Проанализируйте проблемы с разбором robots.txt в несколько кликов с Audisto
Наше программное обеспечение будет систематически проверять все хосты на соответствие файлам robots.txt и предупреждать вас о многих обнаруженных распространенных проблемах. Убедитесь, что ваши директивы robots управляют ботами, как задумано.
Заказать демонстрацию
Неполный набор записей
В черновике запись описана следующим образом:
Запись начинается с одной или нескольких строк агента пользователя, указывающих, к каким роботам относится запись, за которыми следуют инструкции «Запретить» и «Разрешить» для этого робота.

Это означает, что запись состоит из строки User-agent и директивы. Даже если вы хотите разрешить сканирование всего вашего сайта, вы должны добавить инструкцию.
Вместо использования:
Агент пользователя: *
Следует использовать:
Агент пользователя: * Disallow:
Многие плохо запрограммированные роботы имеют проблемы с комментариями. Черновик допускает комментарии в конце строки и в виде отдельных строк.
# robots.txt версия 1 User-agent: * # обрабатывать всех ботов Disallow: /
Есть несколько роботов, которые полностью запутались в разборе этого и обрабатывают его как:
User-agent: * Disallow:
Мы настоятельно рекомендуем не оставлять комментарии в файле robots.txt, чтобы он правильно обрабатывался большим количеством роботов.
Записи с более чем одним агентом пользователя
Черновик позволяет обращаться к нескольким агентам пользователя и иметь набор правил, которые применяются ко всем из них:
Агент пользователя: bot1 Агент пользователя: bot2 Disallow: /
Для некоторых ботов этот синтаксис слишком сложен, и мы видели, что это интерпретируется как:
User-agent: bot1 Запретить: Агент пользователя: bot2 Disallow: /
или еще хуже
User-agent: bot1 Запретить: Агент пользователя: bot2 Disallow:
Настоятельно рекомендуется адресовать каждому боту отдельную запись для повышения совместимости с плохо запрограммированными роботами. Если вы обращаетесь к более чем одному роботу с отдельным набором записей, вам необходимо использовать пустые строки для разделения записей.
Если вы обращаетесь к более чем одному роботу с отдельным набором записей, вам необходимо использовать пустые строки для разделения записей.
Перенаправление на другой хост или протокол
В черновике очень конкретно указаны перенаправления:
При ответе сервера, указывающем перенаправление (код состояния HTTP 3XX), робот должен следовать перенаправлениям, пока не будет найден ресурс.
Однако в некоторых роботах это вообще не реализовано. Мы настоятельно рекомендуем вам не перенаправлять файл robots.txt в другое место. У вас должен быть отдельный файл robots.txt на каждом хосте и для каждого протокола/порта, который доступен напрямую, потому что это диапазон допустимости.
Проанализируйте проблемы с разбором robots.txt в несколько кликов с Audisto
Наше программное обеспечение будет систематически проверять все хосты на соответствие файлам robots.txt и предупреждать вас о многих обнаруженных распространенных проблемах. Убедитесь, что ваши директивы robots управляют ботами, как задумано.
Убедитесь, что ваши директивы robots управляют ботами, как задумано.
Заказать демонстрацию
Усовершенствования чернового варианта, сделанные основными поисковыми системами
В дополнение к черновому варианту основные поисковые системы согласовали несколько улучшений, таких как подстановочные знаки, задержка сканирования и возможность ссылаться на карты сайта.
Проблема, конечно, в том, что некоторые роботы не поддерживают эти улучшения и не могут корректно с ними работать:
Агент пользователя: * Запретить: /*/secret.html Crawl-delay: 5
Мы настоятельно рекомендуем использовать улучшения только в записях для ботов, которые могут их обрабатывать, чтобы предотвратить ошибки синтаксического анализа.
Усовершенствования подстановочных знаков
Как упоминалось выше, подстановочные знаки поддерживаются основными поисковыми системами. Всякий раз, когда вы хотите заблокировать доступ к URL-адресам с определенным суффиксом, их невозможно обойти. Мы часто видим наборы правил, подобные этому:
Мы часто видим наборы правил, подобные этому:
Агент пользователя: * Disallow: .doc
Не блокирует доступ к файлам .doc, поскольку совпадает с
User-agent: * Disallow: /.doc
, и это блокирует доступ только к URL-адресам, начинающимся с /.doc. Чтобы заблокировать доступ ко всем файлам, заканчивающимся на .doc, вам нужно использовать:
User-agent: * Disallow: /*.doc
При использовании подстановочных знаков для блокировки параметров следует использовать что-то вроде этого:
User-agent: * Запретить: /*?параметр1 Запретить: /*&параметр1
в противном случае правило не соответствует, если параметр не является первым:
http://www.example.com/?parameter2¶meter1
Порядок записей
В черновике очень конкретно указано, в каком порядке применяются записи :
Эти маркеры имени используются в строках агента пользователя в файле /robots.txt, чтобы определить, к каким конкретным роботам относится запись.
Чтобы оценить, разрешен ли доступ к URL-адресу, робот должен попытаться сопоставить пути в строках «Разрешить» и «Запретить» с URL-адресом в том порядке, в котором они встречаются в записи. Используется первое найденное совпадение. Если совпадений не найдено, предполагается, что URL-адрес разрешен.
 Робот должен подчиняться первой записи в /robots.txt, которая содержит строку User-Agent, значение которой содержит токен имени робота в качестве подстроки. Сравнение имен не зависит от регистра. Если такой записи не существует, она должна подчиняться первой записи со строкой User-agent со значением «*», если оно присутствует. Если ни одна запись не удовлетворяет ни одному из условий, или записи вообще отсутствуют, доступ неограничен.
Робот должен подчиняться первой записи в /robots.txt, которая содержит строку User-Agent, значение которой содержит токен имени робота в качестве подстроки. Сравнение имен не зависит от регистра. Если такой записи не существует, она должна подчиняться первой записи со строкой User-agent со значением «*», если оно присутствует. Если ни одна запись не удовлетворяет ни одному из условий, или записи вообще отсутствуют, доступ неограничен. Однако существует множество ботов, которые не справляются с этим корректно. Мы настоятельно рекомендуем предварительно сортировать записи и разрешать и запрещать строки, чтобы уменьшить количество проблем во время синтаксического анализа.
Записи никогда не складываются
Некоторые веб-мастера считают, что записи складываются. Это фатально:
User-Agent: * Запретить: /url/1 Пользовательский агент: кто-то Запретить: /url/2 Пользовательский агент: кто-то Crawl-delay: 5
не приводит к тому, что «somebot» интерпретирует это как
User-Agent: somebot Запретить: /url/1 Запретить: /url/2 Crawl-delay: 5
, но обычно интерпретируется как
User-Agent: somebot Disallow: /url/2
Вам нужно продублировать правила, если вы хотите, чтобы бот применил их все.
Кодирование символов, отличных от US-ASCII
Кажется, многие упускают из виду тот факт, что путь к строке правил имеет ограниченный набор разрешенных символов. Символы, не входящие в набор символов US-ASCII, необходимо кодировать. Вместо использования
User-agent: * Disallow: /ä
вы должны использовать закодированную версию. Эта версия может отличаться для разных кодировок. Если вы используете UTF-8, вы должны использовать:
Если вы используете UTF-8, вы должны использовать:
User-agent: * Запретить: /%C3%A4
Если вы используете ISO-8859-1 вы бы использовали:
Агент пользователя: * Disallow: /%E4
Из-за того, что пользователи могут копировать ваши URL-адреса в другие наборы символов, вам необходимо обрабатывать оба URL-адреса в вашем приложении и обязательно использовать обе закодированные версии, чтобы правильно их заблокировать:
User- агент: * Запретить: /%C3%A4 Disallow: /%E4
Формат файла, только символы US-ASCII
В черновике очень четко указан формат файла. Файл должен быть текстовым и содержать подробное описание в стиле BNF. Однако мы часто видим, что люди упускают эту часть.
В файле robots.txt разрешены только символы US-ASCII. Вам даже не разрешено использовать символы, отличные от US-ASCII, в комментариях.
Мы настоятельно рекомендуем использовать только символы US-ASCII, чтобы избежать проблем с анализом.
Кодировка Unicode и метка порядка байтов (BOM)
В черновике не указана кодировка содержимого.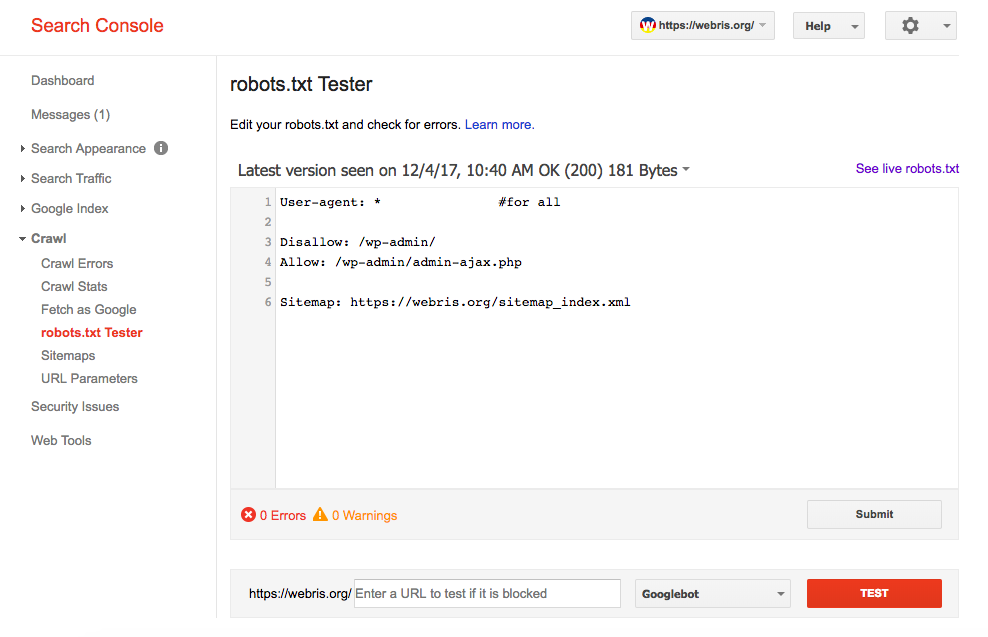 Мы видим много разных кодировок для файлов robots.txt. Однако это может привести к проблемам синтаксического анализа, особенно если файл robots.txt содержит символы, отличные от US-ASCII.
Мы видим много разных кодировок для файлов robots.txt. Однако это может привести к проблемам синтаксического анализа, особенно если файл robots.txt содержит символы, отличные от US-ASCII.
Во избежание проблем настоятельно рекомендуется использовать для файла robots.txt обычный текст в кодировке UTF-8. Это также формат файла, который ожидает Google.
Иногда люди также используют метку порядка байтов (BOM) в начале файла, и это может быть проблемой для парсеров robots.txt. Метка порядка байтов — это необязательный невидимый символ Unicode, используемый для обозначения порядка байтов текстового файла или потока.
Мы рекомендуем не использовать метку порядка байтов для повышения совместимости.
Размер файла
Даже крупные поисковые системы не обрабатывают большие файлы robots.txt. Google, например, имеет ограничение в 500 КБ, другие могут иметь меньшие ограничения. Имейте это в виду и постарайтесь свести размер к минимуму.
Другие проблемы с файлами robots.
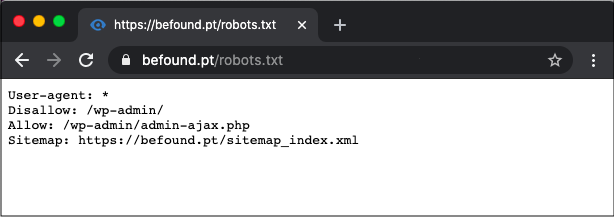 txt
txtНекоторые люди также склонны сталкиваться с проблемами, которые возникают из-за того, что некоторые роботы демонстрируют определенное поведение.
Коды состояния HTTP 401 и 403 для файлов robots.txt
Отправка кода состояния 401 или 403 для файла robots.txt, скорее всего, приведет к неожиданному сканированию, особенно если вы хотите ограничить доступ с помощью этих кодов состояния.
Роботы с реализацией, основанной на спецификации A Method for Web Robots Control от 1996 года, вероятно, будут рассматривать коды состояния 401 и 403 как ограничение доступа. В документе в разделе 3.1 указано:
При ответе сервера с указанием ограничений доступа (код состояния HTTP 401 или 403) робот должен считать доступ к сайту полностью ограниченным.
Однако это только рекомендация, а не требование. Требования касаются только явного существования (коды состояния 2xx) и явного отсутствия (код состояния 404) файла robots.txt. Это оставляет много случаев открытыми для интерпретации.
Роботы с реализацией, основанной на спецификации протокола исключения роботов, будут рассматривать 401 и 403 как недоступные коды состояния, что может разрешить сканирование. В документе в разделе 2.3.1.3 указано:
Недоступно означает, что сканер пытается получить файл robots.txt, а сервер отвечает кодами состояния недоступности. Например, в контексте HTTP недоступные коды состояния находятся в диапазоне 400–499.
Если код состояния сервера указывает на то, что файл robots.txt недоступен для клиента, сканеры МОГУТ получить доступ к любым ресурсам на сервере или МОГУТ использовать кэшированную версию файла robots.txt на срок до 24 часов.
Здесь четко указано, что сканирование разрешено для кодов состояния 401 и 403, но поисковые роботы по-прежнему могут рассматривать это как ограничение доступа.
Рекомендация в старом документе и спецификация в новом документе противоречат друг другу. Использование кодов состояния HTTP для разрешения или ограничения доступа является плохой практикой и не имеет четкого определения. Вместо этого следует реализовать правильный файл robots.txt с кодом состояния 200.
Вместо этого следует реализовать правильный файл robots.txt с кодом состояния 200.
Обработка запланированных простоев
Когда вы доставляете файл robots.txt с кодом состояния 503, роботы некоторых основных поисковых систем перестают сканировать веб-сайт. Даже во время запланированного простоя рекомендуется сохранить файл robots.txt с кодом состояния 200 и предоставлять только коды состояния 503 для всех остальных URL-адресов.
Изменение файла robots.txt на
User-agent: * Disallow: /
— худшее, что вы можете сделать во время простоя, и обычно вызывает проблемы, которые длятся довольно долго.
Блокировать контент, который не должен индексироваться
Блокировать URL-адреса, которые не должны индексироваться или сканироваться ботом, также не рекомендуется. Поисковые системы склонны перечислять известные страницы даже после того, как они были заблокированы. Вы должны использовать noindex в качестве заголовка или метатега, чтобы сначала удалить сайты из индекса.
Файлы robots.txt для каталогов
Некоторые также считают, что для каждого каталога можно создать отдельный файл robots.txt. Это не тот случай!
Инструкции должны быть доступны через HTTP с сайта, к которому должны быть применены инструкции, как ресурс интернет-медиа. Введите «text/plain» по стандартному относительному пути на сервере: «/robots.txt».
Файл robots.txt необходимо поместить в корневой каталог хоста.
Проанализируйте проблемы с разбором robots.txt в несколько кликов с Audisto
Наше программное обеспечение будет систематически проверять все хосты на соответствие файлам robots.txt и предупреждать вас о многих обнаруженных распространенных проблемах. Убедитесь, что ваши директивы robots управляют ботами, как задумано.
Заказать демонстрацию
Шаблон robots.txt — белый список
Простой шаблон robots.txt. Не допускать нежелательных роботов (запретить). Белые списки (разрешить) законных пользовательских агентов. Полезно для всех веб-сайтов.
Белые списки (разрешить) законных пользовательских агентов. Полезно для всех веб-сайтов.
Стандарт исключения роботов [1], также известный как протокол исключения роботов или просто robots.txt , — это стандарт, используемый веб-сайтами для связи с поисковыми роботами и другими веб-роботами. Стандарт определяет, как информировать веб-робота о том, какие области веб-сайта не должны обрабатываться или сканироваться.
Исключение роботов Стандартные шаблоны файлов
Этот веб-сайт содержит 2 шаблона файлов robots.txt (обычный и минимизированный), чтобы помочь веб-мастерам защитить себя от нежелательных веб-роботов (например, роботов-скребков, поисковых систем, инструментов SEO, маркетинговых инструментов и т. д.). своих веб-сайтов, разрешая доступ законным роботам (например, сканерам поисковых систем).
Чтобы быть законными и попасть в список, роботы должны полностью соответствовать стандарту исключения роботов. Шаблоны файлов robots.txt содержат белый список. В соответствии с соглашениями Стандарта исключения роботов доступ к незарегистрированным роботам (агентам пользователя) запрещен.
В соответствии с соглашениями Стандарта исключения роботов доступ к незарегистрированным роботам (агентам пользователя) запрещен.
Шаблоны
Файлы шаблонов robots.txt содержат упорядоченный в алфавитном порядке белый список законных веб-роботов . В версии с комментариями каждый бот кратко описан в комментарии над (списком) пользовательских агентов. Раскомментируйте или удалите ботов (агентов пользователей), которым вы не хотите разрешать доступ к вашему веб-сайту.
Существует две версии файла robots.txt, которые можно просто скопировать и вставить для использования. ################################ ROBOTS.TXT ################ #####################
# #
# Белые списки законных веб-роботов в алфавитном порядке, которые подчиняются #
# Стандарт исключения роботов (robots.txt). Каждый бот кратко описан в #
# комментарий над (списком) пользовательских агентов. Закомментируйте или удалите строки, которые #
# содержат пользовательские агенты, которые вы не хотите разрешать на своем веб-сайте. #
# Важно: Пустые строки не допускаются в итоговом файле robots.txt! #
# Обновления можно получить по адресу: https://www.ditig.com/robots-txt-template #
# #
# Этот документ находится под лицензией CC BY-NC-SA 4.0. #
# #
# Последнее обновление: 2021-11-04 #
# #
################################################### ###############################
# so.com китайская поисковая система
Агент пользователя: 360Spider
Агент пользователя: 360Spider-Image
Агент пользователя: 360Spider-Video
# проверка качества целевой страницы google.com
Агент пользователя: AdsBot-Google
Агент пользователя: AdsBot-Google-Mobile
# сборщик ресурсов приложения google.com
Агент пользователя: AdsBot-Google-Mobile-Apps
# рекламный бот bing
Агент пользователя: adidxbot
# поисковая система apple.com
Агент пользователя: Applebot
пользовательский агент: AppleNewsBot
# baidu.com китайская поисковая система
Агент пользователя: Baiduspider
Пользовательский агент: Baiduspider-image
Пользовательский агент: Baiduspider-news
Пользовательский агент: Baiduspider-video
# международная поисковая система bing.
#
# Важно: Пустые строки не допускаются в итоговом файле robots.txt! #
# Обновления можно получить по адресу: https://www.ditig.com/robots-txt-template #
# #
# Этот документ находится под лицензией CC BY-NC-SA 4.0. #
# #
# Последнее обновление: 2021-11-04 #
# #
################################################### ###############################
# so.com китайская поисковая система
Агент пользователя: 360Spider
Агент пользователя: 360Spider-Image
Агент пользователя: 360Spider-Video
# проверка качества целевой страницы google.com
Агент пользователя: AdsBot-Google
Агент пользователя: AdsBot-Google-Mobile
# сборщик ресурсов приложения google.com
Агент пользователя: AdsBot-Google-Mobile-Apps
# рекламный бот bing
Агент пользователя: adidxbot
# поисковая система apple.com
Агент пользователя: Applebot
пользовательский агент: AppleNewsBot
# baidu.com китайская поисковая система
Агент пользователя: Baiduspider
Пользовательский агент: Baiduspider-image
Пользовательский агент: Baiduspider-news
Пользовательский агент: Baiduspider-video
# международная поисковая система bing.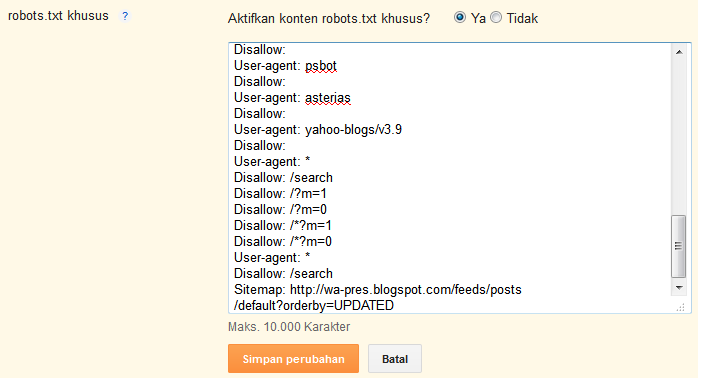 com
Агент пользователя: bingbot
Агент пользователя: BingPreview
# bublup.com предложение/поисковая система
Агент пользователя: BublupBot
# commoncrawl.org открытый репозиторий данных веб-сканирования
Агент пользователя: CCBot
# cliqz.com немецкая поисковая система по товарам
Агент пользователя: Cliqzbot
# coccoc.com вьетнамская поисковая система
Агент пользователя: coccoc
Пользовательский агент: coccocbot-image
Агент пользователя: coccocbot-web
# корейская поисковая система daum.net
Агент пользователя: Daumoa
# dazoo.fr французский поисковик
Агент пользователя: Дазообот
# deusu.de немецкая поисковая система
Агент пользователя: DeuSu
# Duckduckgo.com международная поисковая система конфиденциальности
Агент пользователя: DuckDuckBot
Агент пользователя: DuckDuckGo-Favicons-Bot
# eurip.com европейская поисковая система
Агент пользователя: EuripBot
# exploratodo.com латинский поисковик
Агент пользователя: Exploratodo
# facebook.com социальная сеть
Агент пользователя: Facebot
# сборщик каналов feedly.
com
Агент пользователя: bingbot
Агент пользователя: BingPreview
# bublup.com предложение/поисковая система
Агент пользователя: BublupBot
# commoncrawl.org открытый репозиторий данных веб-сканирования
Агент пользователя: CCBot
# cliqz.com немецкая поисковая система по товарам
Агент пользователя: Cliqzbot
# coccoc.com вьетнамская поисковая система
Агент пользователя: coccoc
Пользовательский агент: coccocbot-image
Агент пользователя: coccocbot-web
# корейская поисковая система daum.net
Агент пользователя: Daumoa
# dazoo.fr французский поисковик
Агент пользователя: Дазообот
# deusu.de немецкая поисковая система
Агент пользователя: DeuSu
# Duckduckgo.com международная поисковая система конфиденциальности
Агент пользователя: DuckDuckBot
Агент пользователя: DuckDuckGo-Favicons-Bot
# eurip.com европейская поисковая система
Агент пользователя: EuripBot
# exploratodo.com латинский поисковик
Агент пользователя: Exploratodo
# facebook.com социальная сеть
Агент пользователя: Facebot
# сборщик каналов feedly.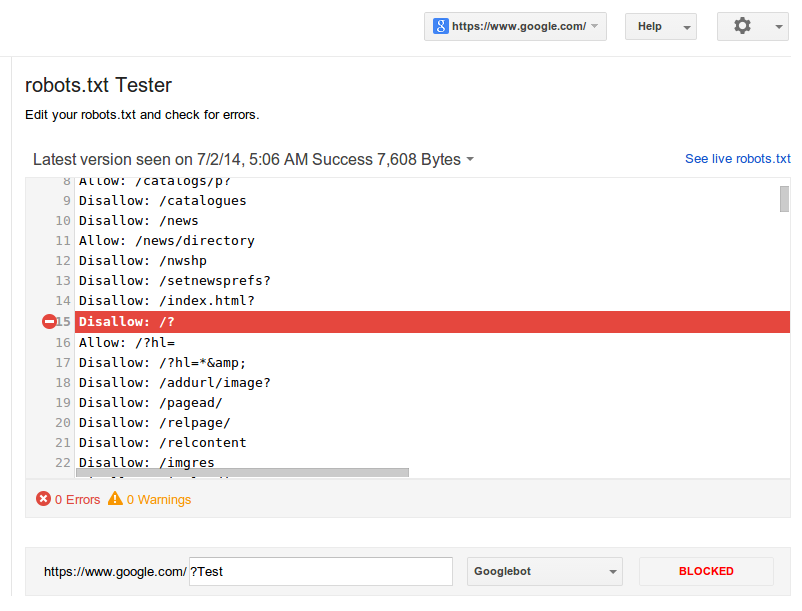 com
Пользовательский агент: Feedly
# findx.com европейская поисковая система
Агент пользователя: Findxbot
# goo.ne.jp японская поисковая система
Агент пользователя: gooblog
# международная поисковая система google.com
Агент пользователя: Googlebot
Агент пользователя: Googlebot-Image
Агент пользователя: Googlebot-Mobile
Агент пользователя: Googlebot-Новости
Агент пользователя: Googlebot-Video
# so.com китайская поисковая система
Агент пользователя: HaoSouSpider
# goo.ne.jp японская поисковая система
Агент пользователя: ichiro
# istella.it итальянская поисковая система
Агент пользователя: istellabot
# jike.com / chinaso.com китайская поисковая система
Агент пользователя: JikeSpider
# международная поисковая система lycos.com и hotbot.com
Агент пользователя: Lycos
# русская поисковая система mail.ru
Агент пользователя: Mail.Ru
# бот google.com AdSense
Агент пользователя: Mediapartners-Google
# поисковая система mojeek.com
Агент пользователя: MojeekBot
# международная поисковая система bing.
com
Пользовательский агент: Feedly
# findx.com европейская поисковая система
Агент пользователя: Findxbot
# goo.ne.jp японская поисковая система
Агент пользователя: gooblog
# международная поисковая система google.com
Агент пользователя: Googlebot
Агент пользователя: Googlebot-Image
Агент пользователя: Googlebot-Mobile
Агент пользователя: Googlebot-Новости
Агент пользователя: Googlebot-Video
# so.com китайская поисковая система
Агент пользователя: HaoSouSpider
# goo.ne.jp японская поисковая система
Агент пользователя: ichiro
# istella.it итальянская поисковая система
Агент пользователя: istellabot
# jike.com / chinaso.com китайская поисковая система
Агент пользователя: JikeSpider
# международная поисковая система lycos.com и hotbot.com
Агент пользователя: Lycos
# русская поисковая система mail.ru
Агент пользователя: Mail.Ru
# бот google.com AdSense
Агент пользователя: Mediapartners-Google
# поисковая система mojeek.com
Агент пользователя: MojeekBot
# международная поисковая система bing. com
Агент пользователя: msnbot
Агент пользователя: msnbot-media
# международная поисковая система Orange.com
Агент пользователя: OrangeBot
# социальная сеть pinterest.com
Агент пользователя: Pinterest
# botje.nl голландская поисковая система
Агент пользователя: Плакки
# qwant.com французский поисковик
Агент пользователя: Qwantify
# rambler.ru русский поисковик
Пользователь-агент: Рамблер
# seznam.cz чешская поисковая система
Агент пользователя: SeznamBot
# soso.com китайская поисковая система
Агент пользователя: Sosospider
# международная поисковая система yahoo.com
Агент пользователя: Slurp
# sogou.com китайский поисковик
Пользовательский агент: блог Sogou
Агент пользователя: Sogou inst spider
Агент пользователя: Sogou News Spider
Пользовательский агент: паук Sogou Orion
Агент пользователя: Sogou Spider2
Пользовательский агент: веб-паук Sogou
# sputnik.ru российская поисковая система
Агент пользователя: SputnikBot
# международная поисковая система ask.com
Агент пользователя: Теома
# бот twitter.
com
Агент пользователя: msnbot
Агент пользователя: msnbot-media
# международная поисковая система Orange.com
Агент пользователя: OrangeBot
# социальная сеть pinterest.com
Агент пользователя: Pinterest
# botje.nl голландская поисковая система
Агент пользователя: Плакки
# qwant.com французский поисковик
Агент пользователя: Qwantify
# rambler.ru русский поисковик
Пользователь-агент: Рамблер
# seznam.cz чешская поисковая система
Агент пользователя: SeznamBot
# soso.com китайская поисковая система
Агент пользователя: Sosospider
# международная поисковая система yahoo.com
Агент пользователя: Slurp
# sogou.com китайский поисковик
Пользовательский агент: блог Sogou
Агент пользователя: Sogou inst spider
Агент пользователя: Sogou News Spider
Пользовательский агент: паук Sogou Orion
Агент пользователя: Sogou Spider2
Пользовательский агент: веб-паук Sogou
# sputnik.ru российская поисковая система
Агент пользователя: SputnikBot
# международная поисковая система ask.com
Агент пользователя: Теома
# бот twitter.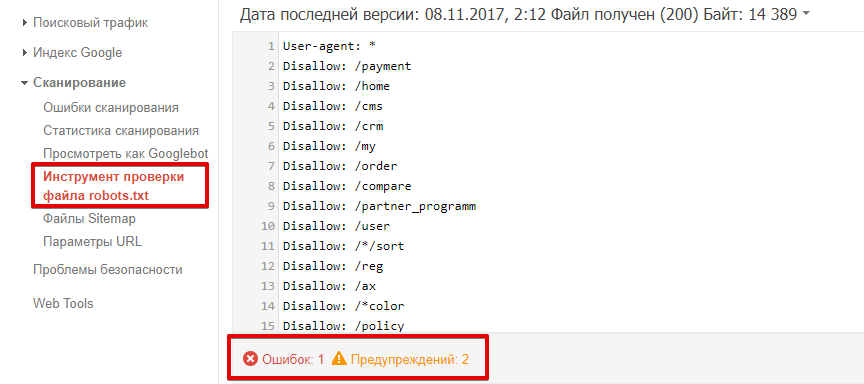 com
Агент пользователя: Twitterbot
# международная поисковая система wotbox.com
Агент пользователя: wotbox
# программа для поиска p2p yacy.net
Агент пользователя: yacybot
# yandex.com русская поисковая система
User-agent: Яндекс
User-agent: YandexMobileBot
# search.naver.com южнокорейская поисковая система
пользовательский агент: Йети
# международная поисковая система yioop.com
Агент пользователя: YioopBot
# yooz.ir иранская поисковая система
Агент пользователя: yoozBot
# youdao.com китайская поисковая система
Агент пользователя: YoudaoBot
# правила сканирования для вышеперечисленных ботов
Запретить:
# запрещаем всех остальных ботов
Пользовательский агент: *
Запретить: /
com
Агент пользователя: Twitterbot
# международная поисковая система wotbox.com
Агент пользователя: wotbox
# программа для поиска p2p yacy.net
Агент пользователя: yacybot
# yandex.com русская поисковая система
User-agent: Яндекс
User-agent: YandexMobileBot
# search.naver.com южнокорейская поисковая система
пользовательский агент: Йети
# международная поисковая система yioop.com
Агент пользователя: YioopBot
# yooz.ir иранская поисковая система
Агент пользователя: yoozBot
# youdao.com китайская поисковая система
Агент пользователя: YoudaoBot
# правила сканирования для вышеперечисленных ботов
Запретить:
# запрещаем всех остальных ботов
Пользовательский агент: *
Запретить: / Минимизированный шаблон (без комментариев)
################################ ROBOTS.TXT #### ################################
# Обновления можно получить по адресу: https://www.ditig.com/robots-txt-template #
# Этот документ находится под лицензией CC BY-NC-SA 4.0. #
# Последнее обновление: 2021-11-04 #
################################################### ###############################
Агент пользователя: 360Spider
Агент пользователя: 360Spider-Image
Агент пользователя: 360Spider-Video
Агент пользователя: AdsBot-Google
Агент пользователя: AdsBot-Google-Mobile
Агент пользователя: AdsBot-Google-Mobile-Apps
Агент пользователя: adidxbot
Агент пользователя: Applebot
Агент пользователя: AppleNewsBot
Агент пользователя: Baiduspider
Пользовательский агент: Baiduspider-image
Пользовательский агент: Baiduspider-news
Пользовательский агент: Baiduspider-video
Агент пользователя: bingbot
Агент пользователя: BingPreview
Агент пользователя: BublupBot
Агент пользователя: CCBot
Агент пользователя: Cliqzbot
Агент пользователя: coccoc
Пользовательский агент: coccocbot-image
Агент пользователя: coccocbot-web
Агент пользователя: Daumoa
Агент пользователя: Дазообот
Агент пользователя: DeuSu
Агент пользователя: DuckDuckBot
Агент пользователя: DuckDuckGo-Favicons-Bot
Агент пользователя: EuripBot
Агент пользователя: Exploratodo
Агент пользователя: Facebot
Пользовательский агент: Feedly
Агент пользователя: Findxbot
Агент пользователя: Googlebot
Агент пользователя: Googlebot-Image
Агент пользователя: Googlebot-Mobile
Агент пользователя: Googlebot-Новости
Агент пользователя: Googlebot-Video
Агент пользователя: HaoSouSpider
Агент пользователя: ichiro
Агент пользователя: istellabot
Агент пользователя: JikeSpider
Агент пользователя: Lycos
Агент пользователя: Mail.
 Ru
Агент пользователя: Mediapartners-Google
Агент пользователя: MojeekBot
Агент пользователя: msnbot
Агент пользователя: msnbot-media
Агент пользователя: OrangeBot
Агент пользователя: Pinterest
Агент пользователя: Плакки
Агент пользователя: Qwantify
Пользователь-агент: Рамблер
Агент пользователя: SeznamBot
Агент пользователя: Sosospider
Агент пользователя: Slurp
Пользовательский агент: блог Sogou
Агент пользователя: Sogou inst spider
Агент пользователя: Sogou News Spider
Пользовательский агент: паук Sogou Orion
Агент пользователя: Sogou Spider2
Пользовательский агент: веб-паук Sogou
Агент пользователя: SputnikBot
Агент пользователя: Теома
Агент пользователя: Twitterbot
Агент пользователя: wotbox
Агент пользователя: yacybot
User-agent: Яндекс
User-agent: YandexMobileBot
Агент пользователя: Йети
Агент пользователя: YioopBot
Агент пользователя: yoozBot
Агент пользователя: YoudaoBot
Запретить:
Пользовательский агент: *
Запретить: /
Ru
Агент пользователя: Mediapartners-Google
Агент пользователя: MojeekBot
Агент пользователя: msnbot
Агент пользователя: msnbot-media
Агент пользователя: OrangeBot
Агент пользователя: Pinterest
Агент пользователя: Плакки
Агент пользователя: Qwantify
Пользователь-агент: Рамблер
Агент пользователя: SeznamBot
Агент пользователя: Sosospider
Агент пользователя: Slurp
Пользовательский агент: блог Sogou
Агент пользователя: Sogou inst spider
Агент пользователя: Sogou News Spider
Пользовательский агент: паук Sogou Orion
Агент пользователя: Sogou Spider2
Пользовательский агент: веб-паук Sogou
Агент пользователя: SputnikBot
Агент пользователя: Теома
Агент пользователя: Twitterbot
Агент пользователя: wotbox
Агент пользователя: yacybot
User-agent: Яндекс
User-agent: YandexMobileBot
Агент пользователя: Йети
Агент пользователя: YioopBot
Агент пользователя: yoozBot
Агент пользователя: YoudaoBot
Запретить:
Пользовательский агент: *
Запретить: / Гарантия и ответственность
Автор не делает абсолютно никаких претензий и заверений относительно гарантий относительно точности или полноты предоставленной информации. Тем не менее, вы можете использовать шаблоны на этом сайте НА СВОЙ СОБСТВЕННЫЙ РИСК.
Тем не менее, вы можете использовать шаблоны на этом сайте НА СВОЙ СОБСТВЕННЫЙ РИСК.
Решение о том, какой бот нужен/нежелателен, принимается автором, который очень консервативен и самоуверен, когда дело доходит до блокировки ботов. Впрочем, решения автора должно хватить на многих. Не забудьте настроить список разрешенных/запрещенных каталогов под свои нужды.
Лицензия
Шаблон Robots.txt изначально был написан Йонасом Яцеком, который предоставил его по лицензии Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
Ссылки
- Википедия — стандарт исключения роботов
7+ рекомендаций по Robots.txt, которые должен попробовать каждый блоггер
351
АКЦИИ
Со временем поисковые системы обычно сканируют все страницы и файлы вашего веб-сайта, если не указано иное.
Пока есть хотя бы одна ссылка, указывающая на страницу, поисковые системы найдут ее.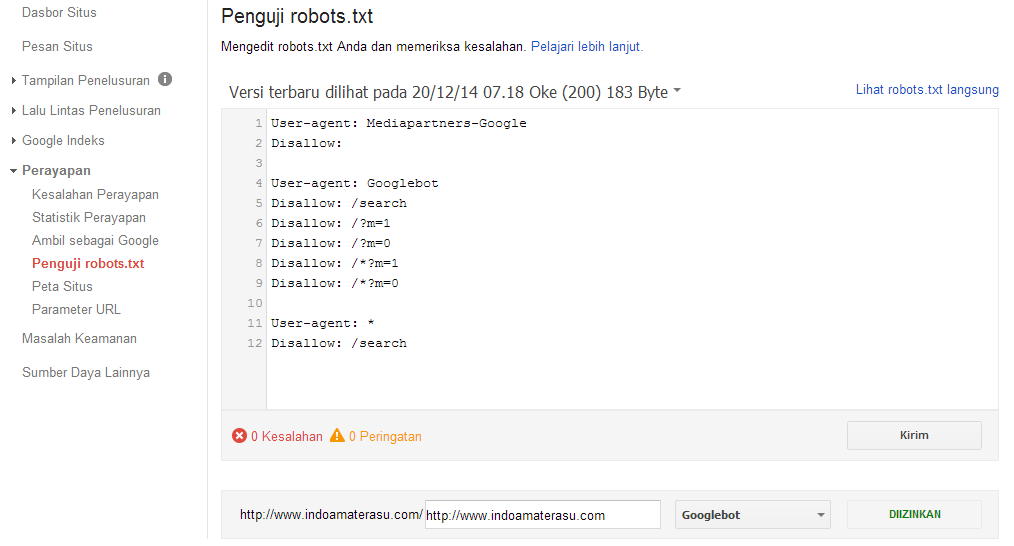.png)
Не вдаваясь в подробности, самая важная концепция, которую вы должны знать, заключается в том, что они используют информацию, собранную во время сканирования, для присвоения поискового рейтинга.
Чтобы определить место страницы, поисковые системы должны ее просканировать.
Однако некоторые страницы вашего веб-сайта, вероятно, более ценны, чем другие.
На вашем веб-сайте могут быть, например, страницы с дублирующимся контентом или целевые страницы, предназначенные для платных рекламных кампаний.
Разрешение поисковым системам сканировать эти нежелательные страницы только отвлечет их от более ценных страниц вашего сайта.
Чтобы запретить поисковым системам сканировать нежелательные страницы, вам необходимо создать файл robots.txt.
Содержание
- Что такое файл robots.txt?
- Добавление файла robots.txt в блог или веб-сайт WordPress
- Подведение итогов
Что такое файл robots.txt?
Файл robots. txt, также известный как стандартный протокол исключения роботов, представляет собой компьютерный файл, содержащий инструкции о том, как поисковые системы должны сканировать веб-сайт, с которым он используется.
txt, также известный как стандартный протокол исключения роботов, представляет собой компьютерный файл, содержащий инструкции о том, как поисковые системы должны сканировать веб-сайт, с которым он используется.
Вы можете использовать его, чтобы сообщить поисковым системам, какие страницы, файлы или каталоги вашего сайта им не следует сканировать.
При первом посещении вашего веб-сайта поисковые системы проверяют его на наличие файла robots.txt.
Если присутствует файл robots.txt, они будут соблюдать его директивы, избегая указанных мест.
Итак, как вы можете сделать это в своем собственном блоге или на сайте WordPress?
Добавление файла robots.txt в блог или веб-сайт WordPress
[su_youtube url=»https://youtu.be/Fee4DY5gvLg»]
Еще один шаг вперед в видеоруководстве. Вот несколько рекомендаций по добавлению файла robots.txt на ваш сайт.
1) Загрузить в корневой каталог
Поисковые системы будут искать файл robots. txt вашего веб-сайта в его корневом каталоге.
txt вашего веб-сайта в его корневом каталоге.
Если вы поместите его в подкаталог, они могут его не найти.
Даже если поисковые системы найдут файл robots.txt, они не будут подчиняться его директивам, поскольку стандарт специально требует размещения в корневом каталоге.
После создания файла robots.txt загрузите его в корневой каталог, где находится домашняя страница вашего сайта.
2) Создать один файл
Для вашего веб-сайта следует создать только один файл robots.txt.
Если вы хотите запретить поисковым системам сканировать одну страницу или 1000 страниц, вы можете поместить все необходимые директивы в один файл.
Распределение директив по нескольким файлам robots.txt не сработает.
Вы должны назвать файл «robots.txt» и поместить его в корневую папку вашего веб-сайта.
Поскольку у вас не может быть нескольких файлов с одинаковым именем в одном каталоге, вы не можете использовать несколько файлов robots.txt.
3) Сохранить в текстовом формате
Чтобы поисковые системы могли распознавать и учитывать файл robots. txt вашего веб-сайта, вы должны сохранить его в текстовом формате.
txt вашего веб-сайта, вы должны сохранить его в текстовом формате.
Он не должен содержать код языка разметки гипертекста (HTML), код препроцессора гипертекста (PHP) или код каскадных таблиц стилей (CSS).
Все, что нужно для передачи инструкций по сканированию поисковым системам, — это обычный текст.
Таким образом, вы можете создать файл robots.txt с помощью обычного текстового редактора, такого как Блокнот для Windows или TextEdit для macOS.
Только не забудьте проверить расширение файла перед сохранением, чтобы убедиться, что он показывает «.txt», что означает формат простого текста.
4) Размещайте по одной директиве в строке
При создании файла robots.txt размещайте по одной директиве в строке.
Чтобы запретить роботу Googlebot сканировать, например, две страницы, необходимо создать две отдельные директивы, каждая из которых размещена на отдельной строке.
Вам не нужно указывать робота Googlebot дважды.
Вместо этого вы можете указать Googlebot один раз прямо над парой директив.
Стандарт исключения роботов требует использования групп.
Каждая группа должна содержать строку с упоминанием пользовательского агента или агентов, для которых предназначены директивы, за которыми следуют сами директивы, разделенные строкой.
Если вы используете несколько групп, разделите их пустой строкой.
Вот пример группы директив, запрещающей Google сканировать две страницы:
[su_note note_color=”#E5E5E5″]
Агент пользователя: Googlebot
Запретить: /category/page-one.html
Запретить: /category/page-two.html
[/su_note]
5) Остерегайтесь использования заглавных букв
При создании файла robots.txt для веб-сайта необходимо учитывать использование заглавных букв.
В то время как имена пользовательских агентов — имена сканеров поисковых систем — не чувствительны к регистру, пути к файлам учитываются.
Если путь к файлу, указанный в директиве, использует строчные буквы, тогда как фактический путь использует прописные буквы, поисковые системы не будут подчиняться этому правилу.
Путь к файлу — это место в группе директив, указывающее на страницу, файл или каталог.
Все пути к файлам должны начинаться с косой черты, за которой следует точное местоположение страницы, файла или каталога, которые вы хотите, чтобы поисковые системы избегали сканирования.
Неверное использование заглавных букв сделает директиву недействительной, а это означает, что поисковые системы все равно будут ее сканировать.
6) Проверка на наличие ошибок
Рекомендуется проверить файл robots.txt вашего веб-сайта на наличие ошибок.
Google предлагает инструмент для тестирования файла robots.txt, который может выявить распространенные ошибки.
Чтобы использовать его, добавьте свой веб-сайт в Google Search Console, перейдите по URL-адресу инструмента тестирования и выберите свой сайт в раскрывающемся меню проверенных свойств.
Инструмент тестирования файла robots.txt от Google отобразит файл robots.txt вашего веб-сайта.
Если есть какие-либо ошибки, такие как неправильный синтаксис, они будут выделены.
Вы также можете использовать инструмент тестирования файла robots.txt от Google, чтобы проверить блокировку URL-адресов.
Если вы создали директиву, запрещающую роботу Googlebot сканировать страницу, введите путь к файлу страницы в поле в нижней части инструмента тестирования и нажмите кнопку «ТЕСТ».
7) Укажите карту сайта
Хотя его основная цель — запретить поисковым системам сканировать определенные страницы, файлы или каталоги, вы также можете использовать файл robots.txt для указания карты сайта вашего веб-сайта.
После загрузки карты сайта в корневой каталог вашего веб-сайта вы можете создать уникальный тип директивы в файле robots.txt вашего сайта, указывающий на его местоположение.
Поисковые системы посетят карту сайта, где смогут найти удобный для чтения список всех страниц вашего веб-сайта.
Директива карты сайта использует следующий формат:
[su_note note_color=”#E5E5E5″]
Карта сайта: https://example.com/sitemap. xml
xml
[/su_note]
Имейте в виду, что путь к файлу вашего сайта Карта сайта должна содержать домен вашего сайта и его префикс.
Эту информацию можно опустить при создании традиционных директив запрета.
Подведение итогов
С файлом robots.txt у вас будет больший контроль над тем, как поисковые системы сканируют ваш сайт.
Вы можете использовать этот простой текстовый файл, чтобы указать поисковым системам не сканировать определенные страницы, файлы или целые каталоги, а также предоставить им карту сайта.
Поисковым системам это не требуется, но стоит создать файл robots.txt, если вы хотите, чтобы поисковые системы сканировали одни части вашего сайта, а не другие.
Нужен ли файл Robots.txt для моего веб-сайта?
Файл robots.txt похож на забор вокруг вашей собственности. Заборы предназначены для защиты от опасности, но они также могут позволить другим видеть сквозь них. Для веб-сайта файл robots.txt находится в корневой папке вашего веб-сайта и указывает, какие части вашего веб-сайта вы хотите или не хотите, чтобы поисковые роботы видели или получали к ним доступ. Вы можете настроить таргетинг на отдельные файлы, типы файлов, папки и IP-адреса и ботов, которых следует избегать на вашем сайте.
Вы можете настроить таргетинг на отдельные файлы, типы файлов, папки и IP-адреса и ботов, которых следует избегать на вашем сайте.
Зачем вам файл robots.txt?
- Неправильное использование файла robots.txt может повредить вашему рейтингу в поисковой системе*
- Файл robots.txt управляет тем, как некоторые боты и поисковые роботы видят ваш веб-сайт и взаимодействуют с ним
- Этот файл содержит инструкции для ботов по взаимодействию с вашим сайтом и является фундаментальной частью работы поисковых систем.
*Google прекратит поддержку NoIndex для Robots.txt в сентябре 2019 года.
Что такое файл robots.txt?
Файл robots.txt представляет собой отдельный файл, в котором используется стандарт исключения роботов, который представляет собой протокол с небольшим набором команд, которые можно использовать для указания доступа к вашему сайту по разделам и определенным типам поисковых роботов (например, мобильным сканеры против настольных сканеров). Robots.txt позволяет вам попытаться заблокировать области вашего веб-сайта, которые вы, возможно, не хотите, чтобы поисковые роботы находили (например, области только для членов). Использование файла Robots.txt — это шаг, но не единственный шаг, который вы должны предпринять, чтобы пометить области вашего сайта, в которые не должны попадать поисковые роботы.
Robots.txt позволяет вам попытаться заблокировать области вашего веб-сайта, которые вы, возможно, не хотите, чтобы поисковые роботы находили (например, области только для членов). Использование файла Robots.txt — это шаг, но не единственный шаг, который вы должны предпринять, чтобы пометить области вашего сайта, в которые не должны попадать поисковые роботы.
Веб-страницы (HTML/PHP)
Для файлов, не являющихся изображениями (то есть веб-страниц), файл robots.txt используется для управления сканирующим трафиком, обычно потому, что вы не хотите, чтобы ваш сервер был перегружен поисковым роботом. .
Файлы изображений
Файл robots.txt предотвращает появление файлов изображений в результатах поиска Google. Это может быть хорошим способом уберечь ваши изображения от поиска изображений Google, если вы, например, фотограф, который продает свои работы в Интернете. Это не мешает другим страницам или пользователям ссылаться на ваше изображение. Это хорошо, потому что вы хотите, чтобы люди делились вашими страницами и работали с друзьями в социальных сетях.
Файлы ресурсов
Вы можете использовать robots.txt для блокировки файлов ресурсов, таких как неважные файлы изображений, сценариев или стилей. Имейте в виду, что если эти файлы необходимы для отображения вашего веб-сайта, это может повлиять на возможности поиска по вашему сайту. Если файлы заблокированы, то краулер не загрузит их, даже если их вызовет страница. Будет ли ваш сайт выглядеть так же на мобильных устройствах, если вы удалите CSS, предназначенный для мобильных устройств? Как Google решит, что ваш сайт выглядит, если он не видит CSS?
Примечание от Google
Вы не должны использовать robots.txt, чтобы скрыть свои веб-страницы от результатов поиска Google. Это связано с тем, что другие страницы могут указывать на вашу страницу, и ваша страница может быть проиндексирована таким образом, избегая файла robots.txt. Если вы хотите заблокировать свою страницу в результатах поиска, используйте другой метод, например, защиту паролем или метатеги или директивы noindex непосредственно на каждой странице.
Основные примеры robots.txt
Вот некоторые распространенные настройки robots.txt.
Разрешить полный доступ
Агент пользователя: *
Запретить:
Блокировать полный доступ
Агент пользователя: *
Запретить: *
Блокировать одну папку
Агент пользователя: *
Запретить: /папка/
Блокировать один файл
Агент пользователя: *
Запретить: /file.html
На вашем сайте уже есть файл robots.txt?
Вы можете проверить наличие файла robots.txt в любом онлайн-браузере. Файл robots.txt всегда находится в одном и том же месте на любом сайте, поэтому легко определить, есть ли он на сайте. Просто добавьте «/robots.txt» в конец доменного имени, как показано ниже.
https://www.yourwebsite.com/robots.txt
Если у вас есть файл, это ваш файл robots.txt. Вы либо найдете файл со словами, либо найдете файл без слов, либо вернете страницу с ошибкой 404.
Проверка файла robots.
 txt
txtЕсли у вас есть доступ и разрешение, вы можете использовать консоль поиска Google для проверки файла robots.txt. Инструкции по тестированию файла Robots.txt можно найти здесь.
Чтобы полностью понять, не блокирует ли ваш файл robots.txt то, что вы не хотите, чтобы он блокировал, вам необходимо понять, о чем он говорит. Я расскажу об этом ниже.
Вам нужен файл robots.txt?
Возможно, вам даже не понадобится файл robots.txt на вашем сайте. На самом деле, часто бывает так, что он вам не нужен.
Причины, по которым вам может понадобиться файл robots.txt:
- У вас есть контент, который вы хотите заблокировать от поисковых систем
- Вы разрабатываете работающий сайт, но не хотите, чтобы поисковые системы его индексировали новые страницы еще
- Вы хотите точно настроить доступ к вашему сайту от авторитетных ботов и поисковых роботов
- Вы используете платные ссылки или рекламные объявления, требующие специальных инструкций для ботов
- Они помогают вам следовать некоторым рекомендациям Google в некоторых ситуациях
Причины, по которым вы можете не захотеть иметь файл robots. txt:
txt:
- Ваш сайт проста и безошибочна, и вы хотите, чтобы все индексировалось
- У вас нет файлов, которые вы хотите или должны заблокировать от поисковых систем
- .txt файл
- Можно не иметь файла robots.txt.
Если у вас нет файла robots.txt, роботы поисковых систем, такие как Googlebot, будут иметь полный доступ к вашему сайту. Это нормальный и простой метод, который очень распространен.
Ключи к robots.txt
- Если вы используете файл robots.txt, убедитесь, что он используется правильно
- Неправильный файл robots.txt может помешать ботам и поисковым роботам обнаружить все страницы вашего сайта вы не блокируете страницы или элементы, которые нужны Google для чтения, отображения и ранжирования ваших страниц 9
- Стандарт исключения роботов текст
WWW 2007, 8-12 мая 2007, Банф, Альберта, Канада.
2007 г.
978-1-59593-654-7/07/0005
1
Ян Сунь, Цзымин Чжуан и К.
Ли Джайлз Университет штата Пенсильвания
Юниверсити-Парк, Пенсильвания, США
{ysun, zzhuang, giles}@ist.psu.edu
Реферат:
Поисковые системы в основном полагаются на веб-роботов для сбора информации. из Интернета. В связи с нерегулируемым характером открытого доступа Интернет, деятельность роботов чрезвычайно разнообразна. Такое ползание деятельность может регулироваться со стороны сервера путем развертывания Протокол исключения роботов в файле robots.txt. Хотя это не является стандартом правоприменения, этичные роботы (и многие коммерческие) будут следовать правилам, указанным в robots.txt. С наш сфокусированный сканер, мы исследуем 7,593 сайта из сферы образования, правительство, новости и деловые домены. Было проведено пять обходов проводится последовательно для изучения временных изменений. Через статистический анализ данных, мы представляем обзор использования правил веб-роботов в веб-масштабе.
Результаты также показывают, что
использование robots.txt со временем увеличилось.Эксперимент, измерение.
сканер, протокол исключения роботов, robots.txt, поиск двигатель.
Без роботов, вероятно, не было бы поисковых систем. Интернет поисковые системы, электронные библиотеки и многие другие веб-приложения таких как автономные браузеры, программное обеспечение для интернет-маркетинга и интеллектуальные поисковые агенты в значительной степени зависят от роботов для получения документы. Роботы, также называемые «пауками», «сканерами» или «ботами». являются самодействующими агентами, которые круглосуточно перемещаются по гиперссылки в Интернете, собирая тематические ресурсы без каких-либо затрат управление людьми [4]. Из-за высокой степени автоматизации роботов, должны быть созданы правила, регулирующие такое ползание действия для предотвращения нежелательного воздействия на сервер нагрузка или доступ к закрытой информации.
Протокол исключения роботов был предложен [3] для предоставить рекомендательные правила для роботов.
Файл с именем
robots.txt, содержащий политики доступа для роботов, размещается на
корневой каталог веб-сайта и доступен для всех роботов. Этический
роботы читают этот файл и соблюдают правила во время посещения
Веб-сайт. Несмотря на критичность соглашения robots.txt для
поставщиков контента и сборщиков, мало работы было сделано для
подробно изучить его использование, особенно в масштабах Интернета.
Исследование использования файла robots.txt в университетах и колледжах Великобритании.
исследовали 163 веб-сайта и 53 файла robots.txt [2]. Роботы.txt
файлы были проверены с точки зрения размера файла и использования роботов
Протокол исключения в университетских доменах Великобритании. Дротт
[1] изучали использование файла robots.txt в качестве вспомогательного средства для индексации.
для защиты информации на 60 образцах от компании Fortune Global 500
сайты.В этом постере мы представляем первое крупномасштабное исследование файла robots.txt. файлы, охватывающие области образования, правительства, новостей и бизнес.
Мы представляем наши наблюдения в значительно большем масштабе.
данные, чем предыдущие исследования.Наш основной источник для сбора начальных URL-адресов для подачи нашего поискового робота. это проект открытого каталога (DMOZ). Наша коллекция от DMOZ охватывает три области: образование, новости и правительство. университетский домен далее разбит на американский, Европейские и азиатские домены университетов. Мы используем Fortune Top 1000 Company List в качестве нашего источника данных в сфере бизнеса. Наш сканер выполнил пять обходов одного и того же набора веб-сайтов с декабря 2005 г. по октябрь 2006 г.
Статистика: Просканировано и исследовано 7593 уникальных веб-сайты, в том числе 600 государственных веб-сайтов, 2047 газетных веб-сайты, 1487 веб-сайтов университетов США, 1420 веб-сайтов европейских университетов веб-сайты, 1039 веб-сайтов азиатских университетов и 1000 веб-сайтов компаний. сайты.
В целом процент веб-сайтов с файлом robots.txt увеличился с 35% до 38,5% за последние 11 месяцев (см. 1). Поскольку поисковые системы и интеллектуальный поиск агенты становятся все более важными для доступа к веб-информации, это результат ожидается. Протокол исключения роботов чаще принято правительством (44%), газетой (46%) и университетом веб-сайты в США (45,9%). Широко используется для защиты информации, не подлежащей публичному разглашению, и сбалансировать рабочую нагрузку для эти сайты.Рисунок 1: Вероятность наличия веб-сайта с файлом robots. txt в каждом домене.В нашем наборе данных найдено 1056 именованных роботов. Универсальный робот «*» — наиболее часто используемый робот в поле User-Agent. и использовался 2744 раза, что означает, что 93,8% файлов robots.txt имеют правила для универсальных роботов. Появилось 72,4% названных роботов только один или два раза.
Размер и длина: Интересно наблюдение, что размеры и длина файлов robots.txt на правительственных веб-сайтах значительно больше, чем у других исследованных домены.
Имеется 26 файлов длиной 68 строк и 4 по 253 строки.
линии. Разумным объяснением является то, что правительственные веб-сайты, как правило,
принять более сложные ограничения для роботов, что приводит к большему
и более длинные файлы robots.txt (см. Таблицу 1).Таблица 1: Средний размер (в байтах) и средняя длина (в числах строк) собранных файлов robots.txt. средний размер со стандартным отклонением США образование 625.1 1#1 Европейское образование 422,5 2#2 Азиатское образование 270,1 3#3 Бизнес 895,8 4#4 Правительство 1551. 2 5#5Новости 509,7 6#6 Задержка сканирования: Имя поля «Crawl-Delay» в файле robots.txt. files недавно использовался веб-администраторами. веб сервер администраторы, скорее всего, используют это поле в своем файле robots.txt. файлов для организации доступной рабочей нагрузки. Использование Crawl-Delay увеличилось с 40 случаев (1,5%) в декабре 2005 г. до 140 случаев (4,8%) в октябре 2006 г. Частота правил Crawl-Delay для разных роботы представлены в таблице 2.
Таблица 2: Частота правил Crawl-Delay для разных роботов. Имя робота Количество правил задержки msnbot 42 чавкать 36 yahooseker/cafekelsa 12 гуглбот 7 теома 6 Неправильное использование: Когда мы изучаем содержимое собраны файлы robots.
txt, значительное количество некорректных использований
Протокол исключения роботов был обнаружен. Эти неправильные
использование включает файлы с неправильными именами, неправильные местоположения и конфликтующие
правила. Из-за неправильного использования политика доступа будет
игнорируются роботами. Мы наблюдаем 13 случаев неправильного названия robots.txt.
файлы и найдите 23 файла, в которых есть конкретное имя, такое
как «краулер», «робот» или «веб-сканеры» появляются в User-Agent
поле. Общее имя в поле User-Agent является неправильным использованием
Протокол исключения роботов. Мы также нашли 282 файла robots.txt.
с неоднозначными правилами и 18 файлов с конфликтующими правилами (например,
каталог сначала запрещен, а затем разрешен или разрешен сначала
а потом запретили).Фактический метод доступа роботов к файлу robots.txt не указано в протоколе исключения роботов. Поисковые роботы с открытым исходным кодом например, Websphinx, Jspider и Nutch проверяет файл robots.
txt.
файл прямо перед сканированием каждого URL-адреса по умолчанию. Мы наблюдаем
«Googlebot», «Yahoo! Slurp» и «MSNbot» кэшируют файл robots.txt.
файлы для веб-сайта. Во время модификации файла robots.txt,
эти роботы могут не подчиняться правилам. В результате имеется несколько
запрещенные ссылки, появляющиеся в этих поисковых системах.Комментарии В robots.txt: Мы обнаружили случаи, когда комментарии в файлах robots.txt не пишутся для версии или объяснение, но написано для пользователей или робота администраторы 1 . Даже блог был найден в файле robots.txt файл 2 .
Проблемы: Правило «Запретить:» можно понимать как соответствие всему или ничего. Означает ли это правило, что роботы могут ползать что-либо или ничего? Другой вопрос касается Поле Crawl-Delay. Так как этого поля нет в исходном Протокол исключения роботов, не каждый робот распознает это правило. Как веб-мастерам оформить robots.txt, если у них нет знание того, распознает ли робот правило или нет? Есть никаких дальнейших обсуждений в Протоколе об исключении роботов об этих вопросы.
Мы представили обзор использования исключения роботов Протокол в Интернете посредством статистического анализа большой выборки файлов robots.txt. Наше исследование показывает, что использование robots.txt увеличился за последние 11 месяцев, в которых 2662 Файлы robots.txt были обнаружены при первом сканировании, и 2925 файлов были найдено за последнее сканирование. Мы наблюдаем, что 46,02% газет веб-сайты в настоящее время внедрили файлы robots.txt и газетный домен — это домен, в котором исключение роботов Наиболее часто принимается протокол. 45,93% университета США веб-сайты в нашей выборке используют протокол исключения роботов, значительно больше, чем европейские (37,8%) и азиатские (15,4%) сайты. Было обнаружено много некорректного использования протокола исключения роботов. Это, в дополнение к потенциальной двусмысленности в robots.txt файлов, подразумевает, что необходим более конкретизированный официальный стандарт. Авторы хотели бы выразить частичную поддержку Национальный научный фонд и полезные предложения от Исаака Советл и Андрей Бродер.- 1
- М. Дротт.
Вспомогательные средства индексирования на корпоративных веб-сайтах: использование файла robots.txt и метаданных теги.
Обработка информации и управление , 38(2):209-219, 2002. - 2
- Б. Келли и И. Пикок.
Интернет-сообщества Великобритании: Заключительный отчет для веб-сайтов проект.
Отчет Британской библиотеки об исследованиях и инновациях , 1999 г. - 3
- М. Костер.
Способ управления веб-роботами.
В Internet Draft, Инженерная рабочая группа Интернета (IETF) , 1996. - 4
- Г. Пант, П. Шринивасан и Ф. Менцер.
Crawling the Web , глава Web Dynamics.
Спрингер-Верлаг, 2004 г.
Сноски
- … администраторы 1
- http://www.ebay.com/robots.txt
- … файл 2
- http://www. webmasterworld.com/robots.txt
Как устранять угрозы безопасности с помощью файлов robots.txt
Стандарту исключения роботов уже почти 25 лет, но риски безопасности, создаваемые неправильным использованием стандарта, малопонятны.
Сохраняется путаница в отношении цели стандарта исключения роботов.
Читайте дальше, чтобы узнать, как правильно использовать его, чтобы избежать угроз безопасности и обеспечить защиту ваших конфиденциальных данных.
Что такое стандарт исключения роботов и что такое файл robots.txt?
Файл robots.txt используется, чтобы сообщать поисковым роботам и другим благонамеренным роботам некоторые сведения о структуре веб-сайта. Он находится в открытом доступе, а также может быть легко и быстро прочитан и понят людьми.
Файл robots.txt может сообщить поисковым роботам, где найти XML-файл(ы) карты сайта, как быстро можно сканировать сайт и (что наиболее известно), какие веб-страницы и каталоги , а не сканировать.
Перед тем, как хороший робот просканирует веб-страницу, он сначала проверяет наличие файла robots.txt и, если он существует, обычно соблюдает содержащиеся в нем директивы.
Файл robots.txt — это первое, о чем узнают начинающие специалисты по SEO. Он кажется простым в использовании и мощным. Этот набор условий, к сожалению, приводит к использованию файла с благими намерениями, но с высоким риском.
Чтобы запретить роботу сканировать веб-страницу или каталог, стандарт исключения роботов основан на объявлениях «Запретить», в которых роботу «запрещено» доступ к странице (страницам).
Угроза безопасности Robots.txt
Файл robots.txt не является жесткой директивой, это просто предложение. Хорошие роботы, такие как Googlebot, соблюдают директивы в файле.
Плохие роботы, однако, могут полностью игнорировать это или того хуже. На самом деле, некоторые недобросовестные роботы и роботы для тестирования на проникновение специально ищут файлы robots.
txt именно для того, чтобы посетить запрещенные разделы сайта.Если злоумышленник — будь то человек или робот — пытается найти личную или конфиденциальную информацию на веб-сайте, список запретов в файле robots.txt может служить картой. Это первое, самое очевидное место для поиска.
Таким образом, если администратор сайта думает, что использует файл robots.txt для защиты своего контента и сохранения конфиденциальности страниц, он, скорее всего, делает прямо противоположное.
Также во многих случаях файлы, исключаемые с помощью стандарта исключения роботов, не являются по-настоящему конфиденциальными по своей природе, но конкуренту нежелательно находить эти файлы.
Например, файлы robots.txt могут содержать сведения о шаблонах URL-адресов A/B-тестов или разделах веб-сайта, которые являются новыми и находятся в стадии разработки.
В этих случаях это может не представлять реальной угрозы безопасности, но тем не менее существуют риски, связанные с упоминанием этих конфиденциальных областей в доступном документе.
Рекомендации по снижению рисков, связанных с файлами robots.txt
Существует несколько рекомендаций по снижению рисков, связанных с файлами robots.txt.
1. Понять, для чего предназначен файл robots.txt и для чего он не предназначен
Стандарт исключения роботов не поможет удалить URL-адрес из индекса поисковой системы и не помешает поисковой системе добавить URL к его индексу.
Поисковые системы обычно добавляют URL-адреса в свой индекс, даже если им было приказано не сканировать URL-адрес. Сканирование и индексирование URL-адресов — это разные действия, и файл robots.txt никак не препятствует индексированию URL-адресов.
2. Будьте осторожны при одновременном использовании Noindex и Robots.txt Disallow
Это чрезвычайно редкий случай, когда страница должна иметь тег noindex и директиву запрета роботов. На самом деле такого варианта использования может и не быть.
Раньше Google показывал это сообщение в результатах для этих страниц, а не описание: «Описание этого результата недоступно из-за robots.
txt этого сайта».В последнее время это, похоже, изменилось на «Для этой страницы нет доступной информации».
3. Используйте Noindex, а не Disallow, для страниц, которые должны быть приватными, но общедоступными
Делая это, вы можете гарантировать, что если хороший поисковый робот найдет URL-адрес, который не должен быть проиндексирован, он не будет проиндексирован.
Для контента с этим требуемым уровнем безопасности поисковый робот может посетить URL-адрес, но не может проиндексировать контент.
Для страниц, которые должны быть закрытыми, а , а не общедоступными, наилучшим решением является защита паролем или белый список IP-адресов.
4. Запретить каталоги, а не определенные страницы
Указывая определенные страницы для запрещения, вы просто упрощаете злоумышленникам поиск страниц, которые вы хотите, чтобы они не находили.
Если вы запретите каталог, мошенник или робот все равно сможет найти «скрытые» страницы в каталоге с помощью грубой силы или оператора поиска inurl, но точная карта страниц не будет для них выложена .
Обязательно включите индексную страницу, перенаправление или 404 на уровне индекса каталога, чтобы гарантировать, что ваши файлы не будут случайно раскрыты через «индексную» страницу. Если вы создаете индексную страницу на уровне каталога, обязательно не включайте ссылки на приватный контент!
5. Настройте приманку для внесения в черный список IP-адресов
Если вы хотите поднять свою безопасность на новый уровень, подумайте о настройке приманки с помощью файла robots.txt. Включите директиву disallow в robots.txt, которая звучит привлекательно для злоумышленников, например «Disallow: /secure/logins.html».
Затем настройте ведение журнала IP для запрещенного ресурса. Любые IP-адреса, которые пытаются загрузить «logins.html», должны быть занесены в черный список для доступа к любой части вашего веб-сайта в будущем.
Заключение
Файл robots.txt является важным SEO-инструментом для обучения хороших роботов тому, как себя вести, но обращаться с ним как с протоколом безопасности ошибочно и опасно.
 Ли Джайлз
Ли Джайлз  Результаты также показывают, что
использование robots.txt со временем увеличилось.
Результаты также показывают, что
использование robots.txt со временем увеличилось.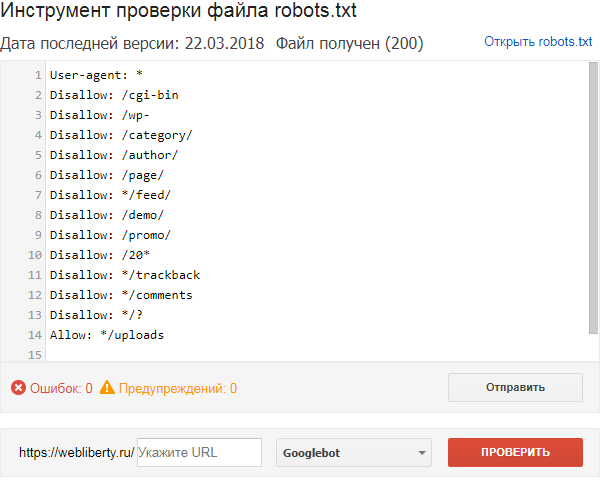 Файл с именем
robots.txt, содержащий политики доступа для роботов, размещается на
корневой каталог веб-сайта и доступен для всех роботов. Этический
роботы читают этот файл и соблюдают правила во время посещения
Веб-сайт. Несмотря на критичность соглашения robots.txt для
поставщиков контента и сборщиков, мало работы было сделано для
подробно изучить его использование, особенно в масштабах Интернета.
Исследование использования файла robots.txt в университетах и колледжах Великобритании.
исследовали 163 веб-сайта и 53 файла robots.txt [2]. Роботы.txt
файлы были проверены с точки зрения размера файла и использования роботов
Протокол исключения в университетских доменах Великобритании. Дротт
[1] изучали использование файла robots.txt в качестве вспомогательного средства для индексации.
для защиты информации на 60 образцах от компании Fortune Global 500
сайты.
Файл с именем
robots.txt, содержащий политики доступа для роботов, размещается на
корневой каталог веб-сайта и доступен для всех роботов. Этический
роботы читают этот файл и соблюдают правила во время посещения
Веб-сайт. Несмотря на критичность соглашения robots.txt для
поставщиков контента и сборщиков, мало работы было сделано для
подробно изучить его использование, особенно в масштабах Интернета.
Исследование использования файла robots.txt в университетах и колледжах Великобритании.
исследовали 163 веб-сайта и 53 файла robots.txt [2]. Роботы.txt
файлы были проверены с точки зрения размера файла и использования роботов
Протокол исключения в университетских доменах Великобритании. Дротт
[1] изучали использование файла robots.txt в качестве вспомогательного средства для индексации.
для защиты информации на 60 образцах от компании Fortune Global 500
сайты. Мы представляем наши наблюдения в значительно большем масштабе.
данные, чем предыдущие исследования.
Мы представляем наши наблюдения в значительно большем масштабе.
данные, чем предыдущие исследования. txt в каждом домене.
txt в каждом домене. Имеется 26 файлов длиной 68 строк и 4 по 253 строки.
линии. Разумным объяснением является то, что правительственные веб-сайты, как правило,
принять более сложные ограничения для роботов, что приводит к большему
и более длинные файлы robots.txt (см. Таблицу 1).
Имеется 26 файлов длиной 68 строк и 4 по 253 строки.
линии. Разумным объяснением является то, что правительственные веб-сайты, как правило,
принять более сложные ограничения для роботов, что приводит к большему
и более длинные файлы robots.txt (см. Таблицу 1). 2 5#5
2 5#5 txt, значительное количество некорректных использований
Протокол исключения роботов был обнаружен. Эти неправильные
использование включает файлы с неправильными именами, неправильные местоположения и конфликтующие
правила. Из-за неправильного использования политика доступа будет
игнорируются роботами. Мы наблюдаем 13 случаев неправильного названия robots.txt.
файлы и найдите 23 файла, в которых есть конкретное имя, такое
как «краулер», «робот» или «веб-сканеры» появляются в User-Agent
поле. Общее имя в поле User-Agent является неправильным использованием
Протокол исключения роботов. Мы также нашли 282 файла robots.txt.
с неоднозначными правилами и 18 файлов с конфликтующими правилами (например,
каталог сначала запрещен, а затем разрешен или разрешен сначала
а потом запретили).
txt, значительное количество некорректных использований
Протокол исключения роботов был обнаружен. Эти неправильные
использование включает файлы с неправильными именами, неправильные местоположения и конфликтующие
правила. Из-за неправильного использования политика доступа будет
игнорируются роботами. Мы наблюдаем 13 случаев неправильного названия robots.txt.
файлы и найдите 23 файла, в которых есть конкретное имя, такое
как «краулер», «робот» или «веб-сканеры» появляются в User-Agent
поле. Общее имя в поле User-Agent является неправильным использованием
Протокол исключения роботов. Мы также нашли 282 файла robots.txt.
с неоднозначными правилами и 18 файлов с конфликтующими правилами (например,
каталог сначала запрещен, а затем разрешен или разрешен сначала
а потом запретили). txt.
файл прямо перед сканированием каждого URL-адреса по умолчанию. Мы наблюдаем
«Googlebot», «Yahoo! Slurp» и «MSNbot» кэшируют файл robots.txt.
файлы для веб-сайта. Во время модификации файла robots.txt,
эти роботы могут не подчиняться правилам. В результате имеется несколько
запрещенные ссылки, появляющиеся в этих поисковых системах.
txt.
файл прямо перед сканированием каждого URL-адреса по умолчанию. Мы наблюдаем
«Googlebot», «Yahoo! Slurp» и «MSNbot» кэшируют файл robots.txt.
файлы для веб-сайта. Во время модификации файла robots.txt,
эти роботы могут не подчиняться правилам. В результате имеется несколько
запрещенные ссылки, появляющиеся в этих поисковых системах.


 txt именно для того, чтобы посетить запрещенные разделы сайта.
txt именно для того, чтобы посетить запрещенные разделы сайта.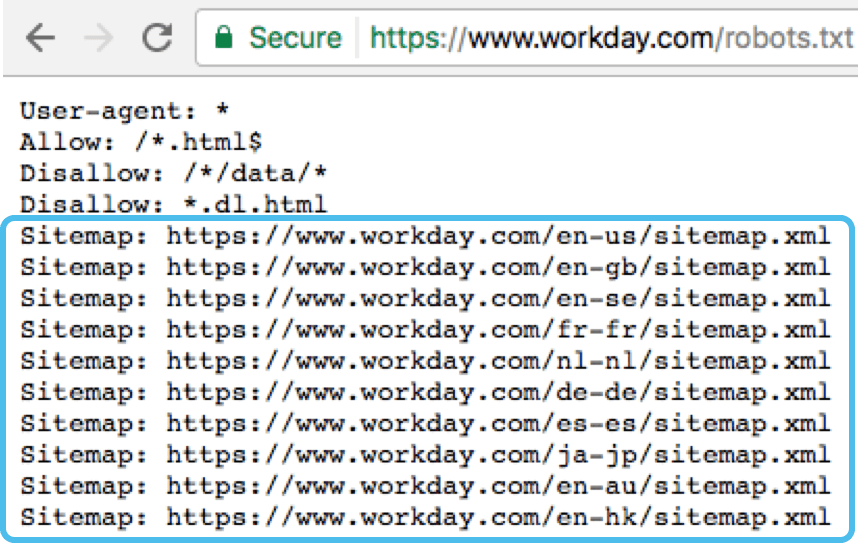
 txt этого сайта».
txt этого сайта».