
Правильный robots.txt для WordPress | Как сделать robots.txt
Содержание:
- Что такое robots.txt
- Для чего нужен robots.txt
- Как редактировать robots txt
- Правильный robots.txt для CMS WordPress
- Проверка robots.txt
Вебмастера и маркетологи знают насколько важна индексация сайта поисковыми системами. Именно поэтому они делают все возможное, чтобы помочь поисковикам типа Google и Yandex правильно сканировать и индексировать свои сайты.
Большое количество времени и ресурсов тратятся на внутреннюю и внешнюю оптимизацию, такую как контент, ссылки, теги, оптимизация изображений и структуры сайта.
Всё это играет огромную роль в продвижении. Однако если вы забыли сделать техническую оптимизацию сайта, если вы не слышали о файлах robots.txt и sitemap.xml могут возникнуть проблемы с правильным сканированием и индексацией вашего сайта.
к содержанию ↑
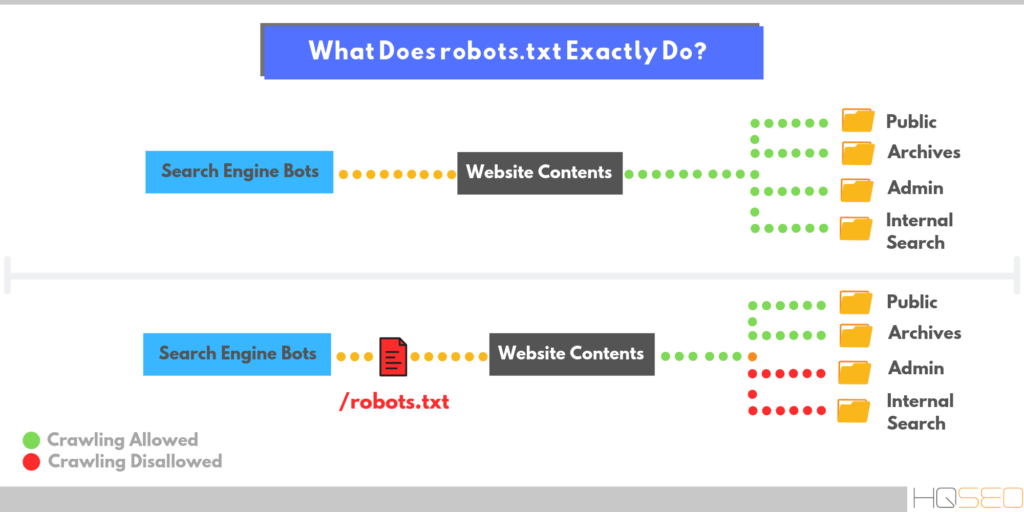
Что такое robots.txt
Robots.txt – это текстовый файл, который используется в качестве инструкции для роботов поисковых систем (также известных как сканеры, боты или пауки), как сканировать и индексировать страницы сайта.
Простыми словами, robots.txt говорит роботам, какие страницы или файлы сайта мы хотим видеть в поиске, а какие нет.
В идеале файл robots.txt размещается в корневом каталоге вашего веб-сайта (https://site.com/robots.txt), чтобы роботы могли сразу получить доступ к его инструкциям.
Если вы используете CMS WordPress, то вы сможете увидеть ваш файл по вышеуказанному адресу, однако вы не найдете сам файл в общей папке с вашим сайтом. Это потому что WordPress автоматически создает виртуальный файл robots.txt (с параметрами по-умолчанию), если не находит данный файл в корневом каталоге сайта.
Это потому что WordPress автоматически создает виртуальный файл robots.txt (с параметрами по-умолчанию), если не находит данный файл в корневом каталоге сайта.
Виртуальный файл robots.txt CMS WordPress не решает всех необходимых задач, в связи с этим крайне желательно написать свой.
к содержанию ↑
Для чего нужен robots.txt
Файл robots.txt нужен, для того чтобы запретить поисковым роботам посещать определенные разделы вашего сайта, например:
- страницы пагинации;
- страницы с результатами поиска на сайте;
- административные файлы;
- служебные страницы;
- ссылки с utm-метками;
- данные о параметрах сортировки, фильтрации, сравнении;
- страница личного кабинета и т.п.
Важно! Файл robots.txt не является обязательным к исполнению поисковыми роботами. В связи с этим, если вы хотите на 100% быть уверенными в том что какая-либо из страниц вашего сайта не появится в поисковой выдаче – используйте мета-тег robots.
Согласно Cправке Google файл robots.txt не предназначен для того, чтобы запрещать показ веб-страниц в результатах поиска Google.
Если вы не хотите чтобы какая-то страница вашего сайта появилась в поиске вставьте в <head> страницы атрибут noindex:
<meta name=“robots” content=“noindex,nofollow”>
к содержанию ↑
Как редактировать robots txt
Редактировать файл robots.txt в CMS WordPress можно двумя способами. Добавить необходимый код в файл functions.php, или при помощи плагина.
В нашей компании мы предпочитаем второй способ.
Устанавливаем плагин Virtual Robots.txt из репозитория CMS WordPress, открываем его в админ. панеле во вкладке Настройки. В открывшееся поле плагина вносим необходимый код, жмем кнопку Save и вуаля – ваш файл robots.txt готов.
к содержанию ↑
Правильный robots.txt для CMS WordPress
Взял с сайта seogio.ru и немного подкорректировал. Вот что получилось:
Вот что получилось:
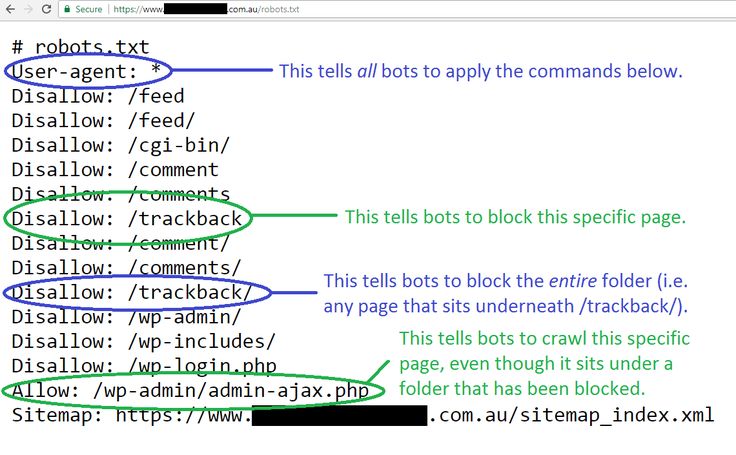
User-agent: * # общие правила для роботов всех поисковых систем
Disallow: /cgi-bin # служебная папка для хранения серверных скриптов
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет,
# правило можно удалить)
Disallow: *?s= # поиск по сайту
Disallow: *&s= # поиск по сайту
Disallow: /search/ # поиск по сайту
Disallow: /author/ # архив автора
Disallow: /users/ # архив пользователей
Disallow: */trackback # трекбеки, уведомления в комментариях о ссылке на веб-документ
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: */embed # все встраивания
Disallow: */wlwmanifest.
xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
Allow: /*/*.js # открываем файлы скриптов js
Allow: /*/*.css # открываем фалы css
Allow: /wp-*.png # разрешаем индексировать изображения
Allow: /wp-*.jpg # разрешаем индексировать изображения
Allow: /wp-*.jpeg # разрешаем индексировать изображения
Allow: /wp-*.gif # разрешаем индексировать гифки
Allow: /wp-admin/admin-ajax.php # разрешаем ajax
# Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS
# то пишем протокол, если нужно указать порт, указываем). Команда стала необязательной. Ранее Host понимал
# Яндекс и Mail. RU. Теперь все основные поисковые системы команду Host не учитывают.
Host: www.site.ru
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz

к содержанию ↑
Проверка robots.txt
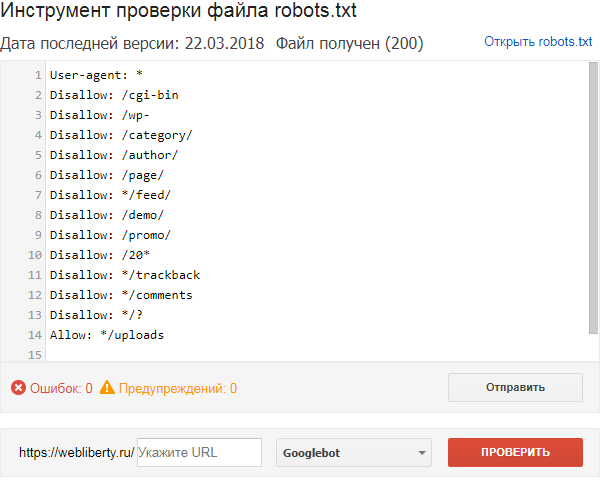
Если файл robots.txt настроен неправильно это может привести к множественным ошибкам в индексации сайта. Проверить правильность настройки вашего robots.txt можно с помощью бесплатного инструмента Google Robots Testing Tool
Выбираем наш сайт:
Вводим в строку путь к нашему файлу robots.txt и жмем кнопку Проверить:
В результате не должно быть ошибок и предупреждений и файл должен быть Доступен для роботов:
Если файл robots.txt настроен правильно, это значительно ускорит процесс индексации вашего сайта.
Правильный robots.
 txt для WordPress — 2023
txt для WordPress — 2023- 1. Оптимальный robots.txt
- 2. Расширенный вариант (разделенные правила для Google и Яндекса)
- 3. Оптимальный Robots.txt для WooCommerce
- 4. Где находится файл robots.txt в WordPress
- 5. Часто задаваемые вопросы
Robots.txt – текстовой файл, который сообщает поисковым роботам, какие файлы и папки следует сканировать (индексировать), а какие сканировать не нужно.
Поисковые системы, такие как Яндекс и Google сначала проверяют файл robots.txt, после этого начинают обход с помощью веб-роботов, которые занимаются архивированием и категоризацией веб сайтов.
Файл robots.txt содержит набор инструкций, которые просят бота игнорировать определенные файлы или каталоги. Это может быть сделано в целях конфиденциальности или потому что владелец сайта считает, что содержимое этих файлов и каталогов не должны появляться в выдаче поисковых систем.
Если веб-сайт имеет более одного субдомена, каждый субдомен должен иметь свой собственный файл robots.txt. Важно отметить, что не все боты будут использовать файл robots.txt. Некоторые злонамеренные боты даже читают файл robots.txt, чтобы найти, какие файлы и каталоги Вы хотели скрыть. Кроме того, даже если файл robots.txt указывает игнорировать определенные страницы на сайте, эти страницы могут по-прежнему появляться в результатах поиска, если на них ссылаются другие просканированные страницы. Стандартный роботс тхт для вордпресс открывает весь сайт для интдекса, поэтому нам нужно закрыть не нужные разделы WordPress от индексации.
Оптимальный robots.txt
User-agent: * # общие правила для роботов, кроме Яндекса и Google,
# т.к. для них правила ниже
Disallow: /cgi-bin # системная папка на хостинге, закрывается всегда
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет,
# правило можно удалить)
Disallow: *?s= # запрос поиска
Disallow: *&s= # запрос поиска
Disallow: /search/ # запрос поиска
Disallow: /author/ # архив автора, если у Вас новостной блог с авторскими колонками, то можно открыть
# архив автора, если у Вас новостной блог с авторскими колонками, то можно открыть
Disallow: /users/ # архив авторов
Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой
# ссылки на статью
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: */embed # все встраивания
Disallow: */wlwmanifest. xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
# Host прописывать больше не нужно.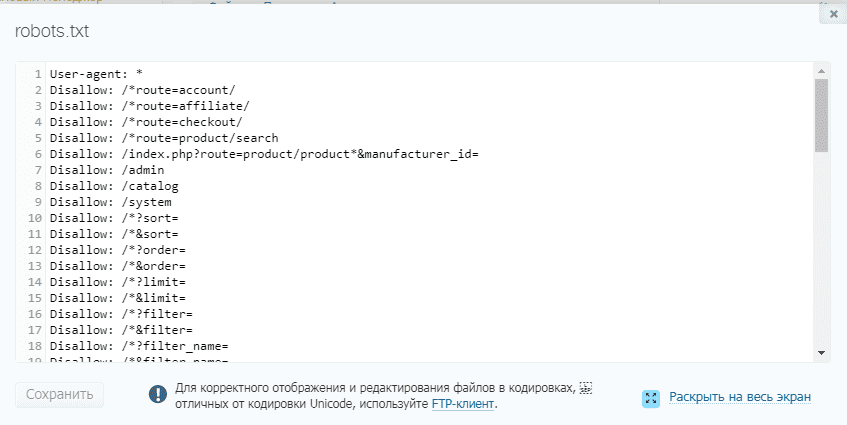
Скачать оптимальную версию robots.txt
Расширенный вариант (разделенные правила для Google и Яндекса)
User-agent: * # общие правила для роботов, кроме Яндекса и Google,
# т.к. для них правила ниже
Disallow: /cgi-bin # папка на хостинге
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет,
# правило можно удалить)
Disallow: *?s= # поиск
Disallow: *&s= # поиск
Disallow: /search/ # поиск
Disallow: /author/ # архив автора
Disallow: /users/ # архив авторов
Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой
# ссылки на статью
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: */embed # все встраивания
Disallow: */wlwmanifest. xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
User-agent: GoogleBot # правила для Google (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Disallow: *utm*=
Disallow: *openstat=
Allow: */uploads
Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ - для приоритета)
Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ - для приоритета)
Allow: /wp-*.png # картинки в плагинах, cache папке и т.д.
Allow: /wp-*. jpg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д.
Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS
User-agent: Yandex # правила для Яндекса (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать
# от индексирования, а удалять параметры меток,
# Google такие правила не поддерживает
Clean-Param: openstat # аналогично
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
# Host прописывать больше не нужно. xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
User-agent: GoogleBot # правила для Google (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Disallow: *utm*=
Disallow: *openstat=
Allow: */uploads
Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ - для приоритета)
Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ - для приоритета)
Allow: /wp-*.png # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.
xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
User-agent: GoogleBot # правила для Google (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Disallow: *utm*=
Disallow: *openstat=
Allow: */uploads
Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ - для приоритета)
Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ - для приоритета)
Allow: /wp-*.png # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.
 Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
# Host прописывать больше не нужно.
Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
# Host прописывать больше не нужно.Скачать Расширенный вариант robots.txt
Оптимальный Robots.txt для WooCommerce
Владельцы интернет-магазинов на WordPress – WooCommerce также должны позаботиться о правильном robots.txt. Мы закроем от индексации корзину, страницу оформления заказа и ссылки на добавление товара в корзину.
User-agent: * Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: */wlwmanifest.xml Disallow: /xmlrpc.php Disallow: *utm*= Disallow: *openstat= Disallow: /cart/ Disallow: /checkout/ Disallow: /*add-to-cart=* Allow: */uploads Allow: /*/*.js Allow: /*/*.css Allow: /wp-*.png Allow: /wp-*.jpg Allow: /wp-*.jpeg Allow: /wp-*.gif Allow: /wp-admin/admin-ajax.
 php
Sitemap: https://site.ru/sitemap_index.xml
php
Sitemap: https://site.ru/sitemap_index.xmlСкачать robots.txt для WooCommerce
Где находится файл robots.txt в WordPress
Обычно robots.txt располагается в корне сайта. Если его нет, то потребуется создать текстовой файл и загрузить его на сайт по FTP или панель управления на хостинге. Если Вы не смогли найти robots.txt в корне сайта, но при переходе по ссылке вашсайт.ру/robots.txt он открывается, значит какой то из SEO плагинов сам генерирует его.
К примеру плагин Yoast SEO создает виртуальный файл, которого нет в корне сайта.
Как редактировать robots.txt с помощью Yoast SEO
- Зайдите в админ панель сайта
Админа панель находится по следующему адресу вашсайт.ру/wp-admin/
- Слева в консоли наведите на кнопку SEO и в выпадающем окне выберите “Инструменты”. Перейдите в раздел, как указано на картинке.
- Зайдите в редактор файлов
Этот инструмент позволит быстро отредактировать такие важные для вашего SEO файлы, как robots.
txt и .htaccess (при его наличии). - Если файла robots.txt нет, нажмите на кнопку создать, либо вставьте нужное содержимое.
Содержимое файла для WordPress и WooCommerce можно взять из примеров выше.
- Сохраните изменения в robots.txt
После сохранения файла вы можете проверить правильность через сервисы проверки.
 txt и .htaccess (при его наличии).
txt и .htaccess (при его наличии).Чтобы установить плагин Yoast SEO воспользуйтесь данной статьей – ссылка.
Часто задаваемые вопросы
Как проверить правильность работы robots.txt?
У Google и Яндекс есть средства для проверки файла robots.txt:
Яндекс – https://webmaster.yandex.ru/tools/robotstxt/
Google – https://support.google.com/webmasters/answer/6062598?hl=ru
Закрывать ли feed в robots.txt?
По умолчанию мы рекомендуем закрывать feed от индексации в robots.txt. Открытие feed может потребоваться, если вы например настраиваете Турбо-страницы от Яндекса или выгружаете свою ленту в другой сервис.
Как разрешить индексировать feed Турбо-страниц
Добавьте директиву: Allow: /feed/turbo/, тогда Яндекс сможет проверять ваши турбо-страницы и обновлять их.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Как использовать robots.txt для разрешения или запрета всего
Файл robots.txt — это файл, расположенный в корневом домене.
Это простой текстовый файл, основной целью которого является указание поисковым роботам и поисковым роботам файлов и папок, от которых следует держаться подальше.
Роботы поисковых систем — это программы, которые посещают ваш сайт и переходят по ссылкам на нем, чтобы узнать о ваших страницах. Примером может служить поисковый робот Google, который называется Googlebot.
Обычно боты проверяют файл robots.txt перед посещением вашего сайта. Они делают это, чтобы узнать, разрешено ли им сканировать сайт и есть ли вещи, которых следует избегать.![]()
Файл robots.txt следует поместить в каталог верхнего уровня вашего домена, например, example.com/robots.txt.
Лучший способ отредактировать его — войти на свой веб-хост через бесплатный FTP-клиент, такой как FileZilla, а затем отредактировать файл с помощью текстового редактора, такого как Блокнот (Windows) или TextEdit (Mac).
Если вы не знаете, как войти на свой сервер через FTP, обратитесь в свою хостинговую компанию за инструкциями.
Некоторые плагины, такие как Yoast SEO, также позволяют редактировать файл robots.txt из панели управления WordPress.
Как запретить всем использовать robots.txt
Если вы хотите, чтобы все роботы держались подальше от вашего сайта, то этот код вы должны поместить в свой robots.txt, чтобы запретить все:
User-agent: * Disallow: /
Часть «User-agent: *» означает, что применяется ко всем роботам. Часть «Запретить: /» означает, что она применяется ко всему вашему сайту.
По сути, это сообщит всем роботам и поисковым роботам, что им не разрешен доступ к вашему сайту или его сканирование.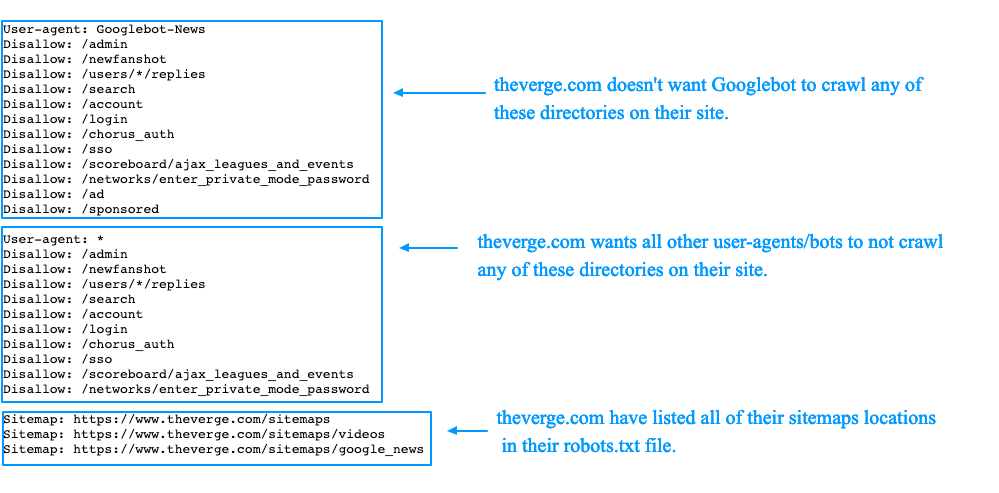
Важно: Запрет всех роботов на действующем веб-сайте может привести к удалению вашего сайта из поисковых систем и потере трафика и доходов. Используйте это, только если вы знаете, что делаете!
Как разрешить все
Robots.txt работает преимущественно путем исключения. Вы исключаете файлы и папки, к которым не хотите получать доступ, все остальное считается разрешенным.
Если вы хотите, чтобы боты могли сканировать весь ваш сайт, вы можете просто иметь пустой файл или вообще не иметь файла.
Или вы можете поместить это в свой файл robots.txt, чтобы разрешить все:
Агент пользователя: * Disallow:
Это интерпретируется как запрещение ничего, поэтому фактически разрешено все.
Как запретить определенные файлы и папки
Вы можете использовать команду «Запретить:», чтобы заблокировать отдельные файлы и папки.
Вы просто помещаете отдельную строку для каждого файла или папки, которые хотите запретить.
Вот пример:
User-agent: * Запретить: /topsy/ Запретить: /crets/ Запретить: /hidden/file.html
В этом случае разрешено все, кроме двух подпапок и одного файла.
Как запретить определенным ботам
Если вы просто хотите заблокировать сканирование одного конкретного бота, сделайте это следующим образом:
Агент пользователя: Bingbot Запретить: / Пользовательский агент: * Disallow:
Это заблокирует поисковый робот Bing от сканирования вашего сайта, но другим ботам будет разрешено сканировать все.
Вы можете сделать то же самое с Googlebot, используя «User-agent: Googlebot».
Вы также можете запретить определенным ботам доступ к определенным файлам и папкам.
Хороший файл robots.txt для WordPress
Следующий код — это то, что я использую в своем файле robots.txt. Это хорошая настройка по умолчанию для WordPress.
Агент пользователя: * Запретить: /wp-admin/ Разрешить: /wp-admin/admin-ajax.
 php
Карта сайта: https://searchfacts.com/sitemap.xml
php
Карта сайта: https://searchfacts.com/sitemap.xml Этот файл robots.txt сообщает ботам, что они могут сканировать все, кроме папки /wp-admin/. Однако им разрешено сканировать один файл в папке /wp-admin/ с именем admin-ajax.php.
Причиной этого параметра является то, что Google Search Console раньше сообщала об ошибке, если не могла просканировать файл admin-ajax.php.
Googlebot — единственный бот, который понимает «Разрешить:» — он используется для разрешения обхода определенного файла внутри запрещенной папки.
Вы также можете использовать строку «Карта сайта:», чтобы сообщить ботам, где найти вашу XML-карту сайта. Эта карта сайта должна содержать список всех страниц вашего сайта, чтобы поисковым роботам было легче найти их все.
Когда использовать noindex вместо robots
Если вы хотите заблокировать показ всего сайта или отдельных страниц в поисковых системах, таких как Google, то robots.txt — не лучший способ сделать это.
Поисковые системы по-прежнему могут индексировать файлы, заблокированные роботами, просто они не будут показывать некоторые полезные метаданные.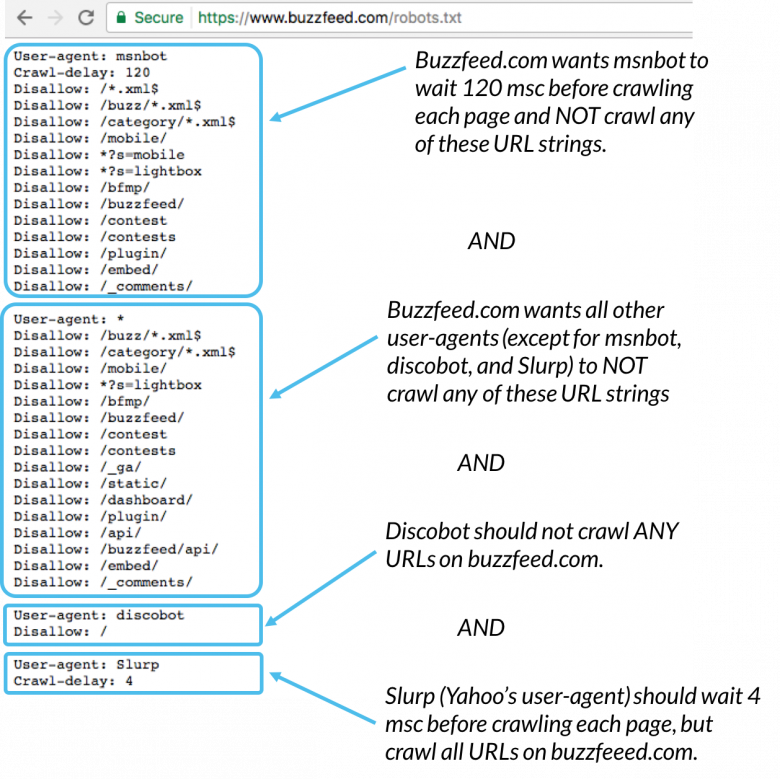
Вместо этого в описании результатов поиска будет указано: «Описание этого результата недоступно из-за файла robots.txt этого сайта».
Источник: Круглый стол поисковой системыЕсли вы скрываете файл или папку с robots.txt, но потом кто-то ссылается на него, Google с большой долей вероятности покажет его в результатах поиска только без описания.
В этих случаях лучше использовать тег noindex, чтобы запретить поисковым системам отображать его в результатах поиска.
В WordPress, если вы перейдете в «Настройки» -> «Чтение» и отметите «Запретить поисковым системам индексировать этот сайт», на все ваши страницы будет добавлен тег noindex.
Выглядит так:
Вы также можете использовать бесплатный SEO-плагин, такой как Yoast или The SEO Framework, чтобы не индексировать определенные сообщения, страницы или категории на вашем сайте.
В большинстве случаев noindex лучше блокирует индексирование, чем robots. txt.
txt.
Когда вместо этого заблокировать весь сайт
В некоторых случаях может потребоваться заблокировать доступ ко всему сайту как для ботов, так и для людей.
Лучше всего для этого установить пароль на свой сайт. Это можно сделать с помощью бесплатного плагина WordPress под названием «Защищено паролем».
Важные факты о файле robots.txt
Имейте в виду, что роботы могут игнорировать ваш файл robots.txt, особенно вредоносные боты, такие как те, которыми управляют хакеры, ищущие уязвимости в системе безопасности.
Кроме того, если вы пытаетесь скрыть папку со своего веб-сайта, просто поместить ее в файл robots.txt может быть неразумным подходом.
Любой может увидеть файл robots.txt, если введет его в свой браузер, и может понять, что вы пытаетесь скрыть таким образом.
На самом деле, вы можете посмотреть на некоторых популярных сайтах, как настроены их файлы robots.txt. Просто попробуйте добавить /robots.txt к URL-адресу домашней страницы ваших любимых веб-сайтов.
Если вы хотите убедиться, что ваш файл robots.txt работает, вы можете протестировать его с помощью Google Search Console. Вот инструкции.
Сообщение на вынос
Файл robots.txt сообщает роботам и поисковым роботам, какие файлы и папки они могут и не могут сканировать.
Его использование может быть полезно для блокировки определенных областей вашего веб-сайта или для предотвращения сканирования вашего сайта определенными ботами.
Если вы собираетесь редактировать файл robots.txt, то будьте осторожны, ведь небольшая ошибка может иметь катастрофические последствия.
Например, если вы неправильно поместите одну косую черту, она может заблокировать всех роботов и буквально удалить весь ваш поисковый трафик, пока это не будет исправлено.
Я работал с большим сайтом до того, как однажды случайно поставил «Disallow: /» в их живой файл robots.txt. Из-за этой маленькой ошибки они потеряли много трафика и доходов.
Файл robots.txt очень мощный, поэтому обращайтесь с ним с осторожностью.
Как запретить всем использовать robots.txt?
Если вы хотите, чтобы все роботы держались подальше от вашего сайта, то этот код вы должны поместить в свой robots.txt, чтобы запретить все:
User-agent: *
Disallow: /
Как разрешить все с помощью robots.txt?
Если вы хотите, чтобы боты могли сканировать весь ваш сайт, вы можете просто иметь пустой файл или вообще не иметь файла.
Или вы можете поместить это в свой файл robots.txt, чтобы разрешить все:
User-agent: *
Disallow:
Как запретить определенные файлы и папки с robots.txt?
Вы просто помещаете отдельную строку для каждого файла или папки, которые хотите запретить.
Вот пример:
User-agent: *
Disallow: /topsy/
Disallow: /crets/
Disallow: /hidden/file.html
Как запретить определенных ботов с помощью robots.txt?
Если вы просто хотите заблокировать сканирование одного конкретного бота, например Bing, то вы делаете это так:
User-agent: Bingbot
Disallow: /
Какой файл robots.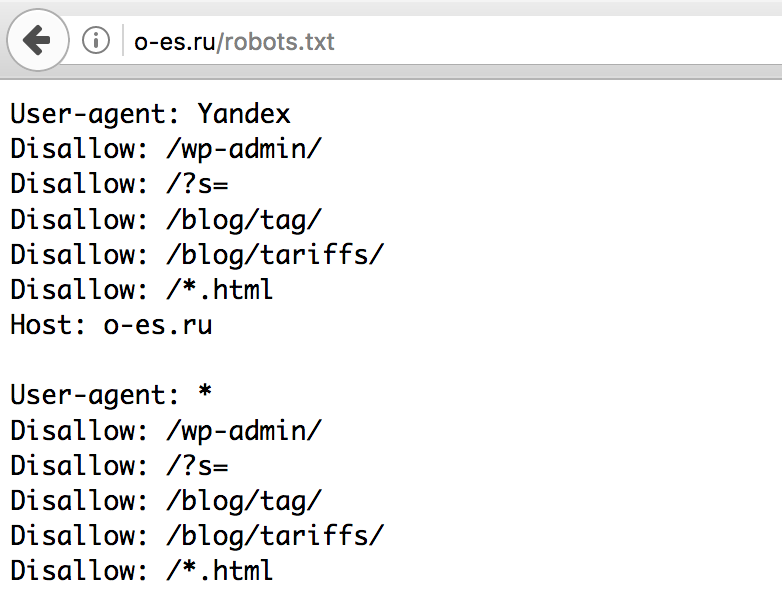 txt подходит для WordPress?
txt подходит для WordPress?
Следующий код — это то, что я использую в своем файле robots.txt. Это хорошая настройка по умолчанию для WordPress.
Агент пользователя: *
Запретить: /wp-admin/
Разрешить: /wp-admin/admin-ajax.php
Карта сайта: https://searchfacts.com/sitemap.xml
Шаблон Robots.txt — белый список
Простой шаблон robots.txt. Не допускать нежелательных роботов (запретить). Белые списки (разрешить) законных пользовательских агентов. Полезно для всех веб-сайтов.
Стандарт исключения роботов [1], также известный как протокол исключения роботов или просто robots.txt , — это стандарт, используемый веб-сайтами для связи с поисковыми роботами и другими веб-роботами. Стандарт определяет, как информировать веб-робота о том, какие области веб-сайта не должны обрабатываться или сканироваться.
Исключение роботов Стандартные шаблоны файлов
Этот веб-сайт содержит 2 шаблона файлов robots.txt (обычный и минимизированный), чтобы помочь веб-мастерам защитить себя от нежелательных веб-роботов (например, роботов-скребков, поисковых систем, инструментов SEO, маркетинговых инструментов и т.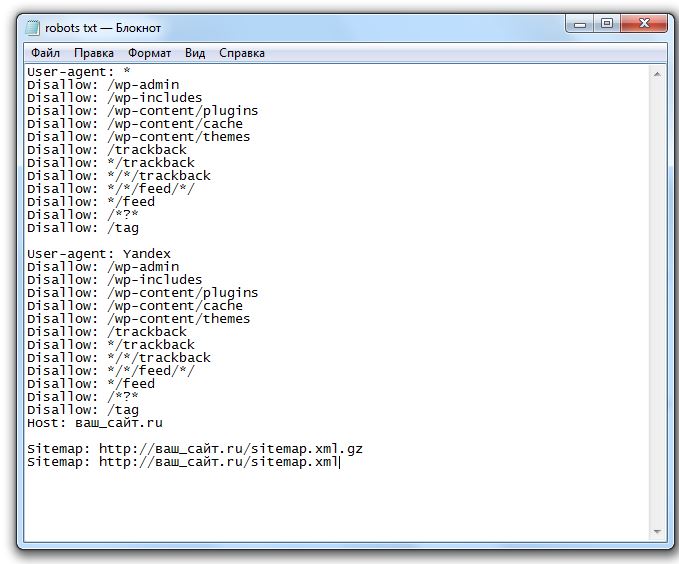 д.). своих веб-сайтов, разрешая доступ законным роботам (например, сканерам поисковых систем).
д.). своих веб-сайтов, разрешая доступ законным роботам (например, сканерам поисковых систем).
Чтобы быть законными и попасть в список, роботы должны полностью соответствовать стандарту исключения роботов. Шаблоны файлов robots.txt содержат белый список. В соответствии с соглашениями Стандарта исключения роботов доступ к незарегистрированным роботам (агентам пользователя) запрещен.
Шаблоны
Файлы шаблонов robots.txt содержат в алфавитном порядке белый список законных веб-роботов . В версии с комментариями каждый бот кратко описан в комментарии над (списком) пользовательских агентов. Раскомментируйте или удалите ботов (агентов пользователей), которым вы не хотите разрешать доступ к вашему веб-сайту.
Существует две версии файла robots.txt, которые можно просто скопировать и вставить для использования. ################################ ROBOTS.TXT ################ #####################
# #
# Белые списки законных веб-роботов в алфавитном порядке, которые подчиняются #
# Стандарт исключения роботов (robots. txt). Каждый бот кратко описан в #
# комментарий над (списком) пользовательских агентов. Закомментируйте или удалите строки, которые #
# содержат пользовательские агенты, которые вы не хотите разрешать на своем веб-сайте. #
# Важно: Пустые строки не допускаются в итоговом файле robots.txt! #
# Обновления можно получить по адресу: https://www.ditig.com/robots-txt-template #
# #
# Этот документ находится под лицензией CC BY-NC-SA 4.0. #
# #
# Последнее обновление: 2021-11-04 #
# #
################################################### ###############################
# so.com китайская поисковая система
Агент пользователя: 360Spider
Агент пользователя: 360Spider-Image
Агент пользователя: 360Spider-Video
# проверка качества целевой страницы google.com
Агент пользователя: AdsBot-Google
Агент пользователя: AdsBot-Google-Mobile
# сборщик ресурсов приложения google.com
Агент пользователя: AdsBot-Google-Mobile-Apps
# рекламный бот bing
Агент пользователя: adidxbot
# поисковая система apple.com
Агент пользователя: Applebot
пользовательский агент: AppleNewsBot
# baidu.
txt). Каждый бот кратко описан в #
# комментарий над (списком) пользовательских агентов. Закомментируйте или удалите строки, которые #
# содержат пользовательские агенты, которые вы не хотите разрешать на своем веб-сайте. #
# Важно: Пустые строки не допускаются в итоговом файле robots.txt! #
# Обновления можно получить по адресу: https://www.ditig.com/robots-txt-template #
# #
# Этот документ находится под лицензией CC BY-NC-SA 4.0. #
# #
# Последнее обновление: 2021-11-04 #
# #
################################################### ###############################
# so.com китайская поисковая система
Агент пользователя: 360Spider
Агент пользователя: 360Spider-Image
Агент пользователя: 360Spider-Video
# проверка качества целевой страницы google.com
Агент пользователя: AdsBot-Google
Агент пользователя: AdsBot-Google-Mobile
# сборщик ресурсов приложения google.com
Агент пользователя: AdsBot-Google-Mobile-Apps
# рекламный бот bing
Агент пользователя: adidxbot
# поисковая система apple.com
Агент пользователя: Applebot
пользовательский агент: AppleNewsBot
# baidu. com китайская поисковая система
Агент пользователя: Baiduspider
Пользовательский агент: Baiduspider-image
Пользовательский агент: Baiduspider-news
Пользовательский агент: Baiduspider-video
# международная поисковая система bing.com
Агент пользователя: bingbot
Агент пользователя: BingPreview
# bublup.com предложение/поисковая система
Агент пользователя: BublupBot
# commoncrawl.org открытый репозиторий данных веб-сканирования
Агент пользователя: CCBot
# cliqz.com немецкая поисковая система по товарам
Агент пользователя: Cliqzbot
# coccoc.com вьетнамская поисковая система
Агент пользователя: coccoc
Пользовательский агент: coccocbot-image
Агент пользователя: coccocbot-web
# корейская поисковая система daum.net
Агент пользователя: Daumoa
# dazoo.fr французский поисковик
Агент пользователя: Дазообот
# deusu.de немецкая поисковая система
Агент пользователя: DeuSu
# Duckduckgo.com международная поисковая система конфиденциальности
Агент пользователя: DuckDuckBot
Агент пользователя: DuckDuckGo-Favicons-Bot
# eurip.
com китайская поисковая система
Агент пользователя: Baiduspider
Пользовательский агент: Baiduspider-image
Пользовательский агент: Baiduspider-news
Пользовательский агент: Baiduspider-video
# международная поисковая система bing.com
Агент пользователя: bingbot
Агент пользователя: BingPreview
# bublup.com предложение/поисковая система
Агент пользователя: BublupBot
# commoncrawl.org открытый репозиторий данных веб-сканирования
Агент пользователя: CCBot
# cliqz.com немецкая поисковая система по товарам
Агент пользователя: Cliqzbot
# coccoc.com вьетнамская поисковая система
Агент пользователя: coccoc
Пользовательский агент: coccocbot-image
Агент пользователя: coccocbot-web
# корейская поисковая система daum.net
Агент пользователя: Daumoa
# dazoo.fr французский поисковик
Агент пользователя: Дазообот
# deusu.de немецкая поисковая система
Агент пользователя: DeuSu
# Duckduckgo.com международная поисковая система конфиденциальности
Агент пользователя: DuckDuckBot
Агент пользователя: DuckDuckGo-Favicons-Bot
# eurip. com европейская поисковая система
Агент пользователя: EuripBot
# exploratodo.com латинский поисковик
Агент пользователя: Exploratodo
# facebook.com социальная сеть
Агент пользователя: Facebot
# сборщик каналов feedly.com
Пользовательский агент: Feedly
# findx.com европейская поисковая система
Агент пользователя: Findxbot
# goo.ne.jp японская поисковая система
Агент пользователя: gooblog
# международная поисковая система google.com
Агент пользователя: Googlebot
Агент пользователя: Googlebot-Image
Агент пользователя: Googlebot-Mobile
Агент пользователя: Googlebot-Новости
Агент пользователя: Googlebot-Video
# so.com китайская поисковая система
Агент пользователя: HaoSouSpider
# goo.ne.jp японская поисковая система
Агент пользователя: ichiro
# istella.it итальянская поисковая система
Агент пользователя: istellabot
# jike.com / chinaso.com китайская поисковая система
Агент пользователя: JikeSpider
# международная поисковая система lycos.com и hotbot.com
Агент пользователя: Lycos
# русская поисковая система mail.
com европейская поисковая система
Агент пользователя: EuripBot
# exploratodo.com латинский поисковик
Агент пользователя: Exploratodo
# facebook.com социальная сеть
Агент пользователя: Facebot
# сборщик каналов feedly.com
Пользовательский агент: Feedly
# findx.com европейская поисковая система
Агент пользователя: Findxbot
# goo.ne.jp японская поисковая система
Агент пользователя: gooblog
# международная поисковая система google.com
Агент пользователя: Googlebot
Агент пользователя: Googlebot-Image
Агент пользователя: Googlebot-Mobile
Агент пользователя: Googlebot-Новости
Агент пользователя: Googlebot-Video
# so.com китайская поисковая система
Агент пользователя: HaoSouSpider
# goo.ne.jp японская поисковая система
Агент пользователя: ichiro
# istella.it итальянская поисковая система
Агент пользователя: istellabot
# jike.com / chinaso.com китайская поисковая система
Агент пользователя: JikeSpider
# международная поисковая система lycos.com и hotbot.com
Агент пользователя: Lycos
# русская поисковая система mail. ru
Агент пользователя: Mail.Ru
# бот google.com AdSense
Агент пользователя: Mediapartners-Google
# поисковая система mojeek.com
Агент пользователя: MojeekBot
# международная поисковая система bing.com
Агент пользователя: msnbot
Агент пользователя: msnbot-media
# международная поисковая система Orange.com
Агент пользователя: OrangeBot
# социальная сеть pinterest.com
Агент пользователя: Pinterest
# botje.nl голландская поисковая система
Агент пользователя: Плакки
# qwant.com французский поисковик
Агент пользователя: Qwantify
# rambler.ru русский поисковик
Пользователь-агент: Рамблер
# seznam.cz чешская поисковая система
Агент пользователя: SeznamBot
# soso.com китайская поисковая система
Агент пользователя: Sosospider
# международная поисковая система yahoo.com
Агент пользователя: Slurp
# sogou.com китайский поисковик
Пользовательский агент: блог Sogou
Агент пользователя: Sogou inst spider
Агент пользователя: Sogou News Spider
Пользовательский агент: паук Sogou Orion
Агент пользователя: Sogou Spider2
Пользовательский агент: веб-паук Sogou
# sputnik.
ru
Агент пользователя: Mail.Ru
# бот google.com AdSense
Агент пользователя: Mediapartners-Google
# поисковая система mojeek.com
Агент пользователя: MojeekBot
# международная поисковая система bing.com
Агент пользователя: msnbot
Агент пользователя: msnbot-media
# международная поисковая система Orange.com
Агент пользователя: OrangeBot
# социальная сеть pinterest.com
Агент пользователя: Pinterest
# botje.nl голландская поисковая система
Агент пользователя: Плакки
# qwant.com французский поисковик
Агент пользователя: Qwantify
# rambler.ru русский поисковик
Пользователь-агент: Рамблер
# seznam.cz чешская поисковая система
Агент пользователя: SeznamBot
# soso.com китайская поисковая система
Агент пользователя: Sosospider
# международная поисковая система yahoo.com
Агент пользователя: Slurp
# sogou.com китайский поисковик
Пользовательский агент: блог Sogou
Агент пользователя: Sogou inst spider
Агент пользователя: Sogou News Spider
Пользовательский агент: паук Sogou Orion
Агент пользователя: Sogou Spider2
Пользовательский агент: веб-паук Sogou
# sputnik. ru российская поисковая система
Агент пользователя: SputnikBot
# международная поисковая система ask.com
Агент пользователя: Теома
# бот twitter.com
Агент пользователя: Twitterbot
# международная поисковая система wotbox.com
Агент пользователя: wotbox
# программа для поиска p2p yacy.net
Агент пользователя: yacybot
# yandex.com русская поисковая система
User-agent: Яндекс
User-agent: YandexMobileBot
# search.naver.com южнокорейская поисковая система
пользовательский агент: Йети
# международная поисковая система yioop.com
Агент пользователя: YioopBot
# yooz.ir иранская поисковая система
Агент пользователя: yoozBot
# youdao.com китайская поисковая система
Агент пользователя: YoudaoBot
# правила сканирования для вышеперечисленных ботов
Запретить:
# запрещаем всех остальных ботов
Пользовательский агент: *
Запретить: /
ru российская поисковая система
Агент пользователя: SputnikBot
# международная поисковая система ask.com
Агент пользователя: Теома
# бот twitter.com
Агент пользователя: Twitterbot
# международная поисковая система wotbox.com
Агент пользователя: wotbox
# программа для поиска p2p yacy.net
Агент пользователя: yacybot
# yandex.com русская поисковая система
User-agent: Яндекс
User-agent: YandexMobileBot
# search.naver.com южнокорейская поисковая система
пользовательский агент: Йети
# международная поисковая система yioop.com
Агент пользователя: YioopBot
# yooz.ir иранская поисковая система
Агент пользователя: yoozBot
# youdao.com китайская поисковая система
Агент пользователя: YoudaoBot
# правила сканирования для вышеперечисленных ботов
Запретить:
# запрещаем всех остальных ботов
Пользовательский агент: *
Запретить: /
Минимизированный шаблон (без комментариев)
################################ ROBOTS.TXT #### ################################ # Обновления можно получить по адресу: https://www.
 ditig.com/robots-txt-template #
# Этот документ находится под лицензией CC BY-NC-SA 4.0. #
# Последнее обновление: 2021-11-04 #
################################################### ###############################
Агент пользователя: 360Spider
Агент пользователя: 360Spider-Image
Агент пользователя: 360Spider-Video
Агент пользователя: AdsBot-Google
Агент пользователя: AdsBot-Google-Mobile
Агент пользователя: AdsBot-Google-Mobile-Apps
Агент пользователя: adidxbot
Агент пользователя: Applebot
Агент пользователя: AppleNewsBot
Агент пользователя: Baiduspider
Пользовательский агент: Baiduspider-image
Пользовательский агент: Baiduspider-news
Пользовательский агент: Baiduspider-video
Агент пользователя: bingbot
Агент пользователя: BingPreview
Агент пользователя: BublupBot
Агент пользователя: CCBot
Агент пользователя: Cliqzbot
Агент пользователя: coccoc
Пользовательский агент: coccocbot-image
Агент пользователя: coccocbot-web
Агент пользователя: Daumoa
Агент пользователя: Дазообот
Агент пользователя: DeuSu
Агент пользователя: DuckDuckBot
Агент пользователя: DuckDuckGo-Favicons-Bot
Агент пользователя: EuripBot
Агент пользователя: Exploratodo
Агент пользователя: Facebot
Пользовательский агент: Feedly
Агент пользователя: Findxbot
Агент пользователя: Googlebot
Агент пользователя: Googlebot-Image
Агент пользователя: Googlebot-Mobile
Агент пользователя: Googlebot-Новости
Агент пользователя: Googlebot-Video
Агент пользователя: HaoSouSpider
Агент пользователя: ichiro
Агент пользователя: istellabot
Агент пользователя: JikeSpider
Агент пользователя: Lycos
Агент пользователя: Mail.
ditig.com/robots-txt-template #
# Этот документ находится под лицензией CC BY-NC-SA 4.0. #
# Последнее обновление: 2021-11-04 #
################################################### ###############################
Агент пользователя: 360Spider
Агент пользователя: 360Spider-Image
Агент пользователя: 360Spider-Video
Агент пользователя: AdsBot-Google
Агент пользователя: AdsBot-Google-Mobile
Агент пользователя: AdsBot-Google-Mobile-Apps
Агент пользователя: adidxbot
Агент пользователя: Applebot
Агент пользователя: AppleNewsBot
Агент пользователя: Baiduspider
Пользовательский агент: Baiduspider-image
Пользовательский агент: Baiduspider-news
Пользовательский агент: Baiduspider-video
Агент пользователя: bingbot
Агент пользователя: BingPreview
Агент пользователя: BublupBot
Агент пользователя: CCBot
Агент пользователя: Cliqzbot
Агент пользователя: coccoc
Пользовательский агент: coccocbot-image
Агент пользователя: coccocbot-web
Агент пользователя: Daumoa
Агент пользователя: Дазообот
Агент пользователя: DeuSu
Агент пользователя: DuckDuckBot
Агент пользователя: DuckDuckGo-Favicons-Bot
Агент пользователя: EuripBot
Агент пользователя: Exploratodo
Агент пользователя: Facebot
Пользовательский агент: Feedly
Агент пользователя: Findxbot
Агент пользователя: Googlebot
Агент пользователя: Googlebot-Image
Агент пользователя: Googlebot-Mobile
Агент пользователя: Googlebot-Новости
Агент пользователя: Googlebot-Video
Агент пользователя: HaoSouSpider
Агент пользователя: ichiro
Агент пользователя: istellabot
Агент пользователя: JikeSpider
Агент пользователя: Lycos
Агент пользователя: Mail. Ru
Агент пользователя: Mediapartners-Google
Агент пользователя: MojeekBot
Агент пользователя: msnbot
Агент пользователя: msnbot-media
Агент пользователя: OrangeBot
Агент пользователя: Pinterest
Агент пользователя: Плакки
Агент пользователя: Qwantify
Пользователь-агент: Рамблер
Агент пользователя: SeznamBot
Агент пользователя: Sosospider
Агент пользователя: Slurp
Пользовательский агент: блог Sogou
Агент пользователя: Sogou inst spider
Агент пользователя: Sogou News Spider
Пользовательский агент: паук Sogou Orion
Агент пользователя: Sogou Spider2
Пользовательский агент: веб-паук Sogou
Агент пользователя: SputnikBot
Агент пользователя: Теома
Агент пользователя: Twitterbot
Агент пользователя: wotbox
Агент пользователя: yacybot
User-agent: Яндекс
User-agent: YandexMobileBot
Агент пользователя: Йети
Агент пользователя: YioopBot
Агент пользователя: yoozBot
Агент пользователя: YoudaoBot
Запретить:
Пользовательский агент: *
Запретить: /
Ru
Агент пользователя: Mediapartners-Google
Агент пользователя: MojeekBot
Агент пользователя: msnbot
Агент пользователя: msnbot-media
Агент пользователя: OrangeBot
Агент пользователя: Pinterest
Агент пользователя: Плакки
Агент пользователя: Qwantify
Пользователь-агент: Рамблер
Агент пользователя: SeznamBot
Агент пользователя: Sosospider
Агент пользователя: Slurp
Пользовательский агент: блог Sogou
Агент пользователя: Sogou inst spider
Агент пользователя: Sogou News Spider
Пользовательский агент: паук Sogou Orion
Агент пользователя: Sogou Spider2
Пользовательский агент: веб-паук Sogou
Агент пользователя: SputnikBot
Агент пользователя: Теома
Агент пользователя: Twitterbot
Агент пользователя: wotbox
Агент пользователя: yacybot
User-agent: Яндекс
User-agent: YandexMobileBot
Агент пользователя: Йети
Агент пользователя: YioopBot
Агент пользователя: yoozBot
Агент пользователя: YoudaoBot
Запретить:
Пользовательский агент: *
Запретить: / Гарантия и ответственность
Автор не делает абсолютно никаких претензий и заверений в отношении гарантий относительно точности или полноты предоставленной информации.