
7 способов спарсить данные из Инстаграм в 2020
Если вы читали нашу статью о родной статистике мобильного приложения Instagram, то успели заметить, что метрики там не самые классные, когда нужна глубокая аналитика. Если быть совсем точнее, хочется больше подробностей. Их открывают парсеры для сбора данных в Инстаграм.
И поскольку сама социальная сеть решительно отказывается помогать рекламодателям (не считая функций рекламного кабинета), рассмотрим лучшие парсеры для инстаграм и их возможности:
- Геолокация, пол и время пребывания в сети. Вот и все сведения о подписчиках вашего аккаунта. Да, эта информация пригодится вам при настройках на широкую аудиторию. Но если есть возможность скачать подписчиков конкурента или проверить на накрутки блогера, стоит ей воспользоваться: в Пеппер Ниндзя на тарифе Профессиональный вы сможете скачать список пользователей, подписанных на тот или иной аккаунт.
Сравните свои аккаунты и аккаунты конкурентов, найдите пересечение аудиторий (актуально, когда берете много размещений у блогеров, чтобы понять реальный охват подписчиков в итоге). Промониторить пересечения аудитории у разных инстаграм-блогеров позволяет комбинация сервисов Pepper.Ninja и Molbiotools – подробней в нашем гайде.
Какое число пользователей видит контент аккаунта? Неважно, вашего или конкурента, или блогера, которого вы хотите взять для рекламы. В родной аналитике Инстаграм вы не найдете сведений о досягаемости публикации и не узнаете, каково число лайков от подписчиков. А это значит, что вы не сможете узнать, накручены ли лайки, и правда ли посты имеют шанс попасть в разделы «Топ» и «Рекомендованное» (напоминаем, что только быстрый набор реакций от вашей подписной базы может гарантировать такое).
Но эту важную статистику можно проверить – функционал есть в сервисе TrendHero:
Можно увидеть, сколько лайков ставят именно подписчики – это и будет органический охват без накруток и таргетированной рекламы- Узнать, кто пишет вам комментарии, в Инстаграм нереально.
 Разве что вручную сидеть и проверять подписчиков. Ок, если вас комментируют не больше 10-15 человек. Но что делать, если число комментаторов увеличилось до 300 и выше? Скачать все комментарии к посту файлом Excel тоже можно в бесплатном сервисе getcommentbot:
Разве что вручную сидеть и проверять подписчиков. Ок, если вас комментируют не больше 10-15 человек. Но что делать, если число комментаторов увеличилось до 300 и выше? Скачать все комментарии к посту файлом Excel тоже можно в бесплатном сервисе getcommentbot:
 Разве что вручную сидеть и проверять подписчиков. Ок, если вас комментируют не больше 10-15 человек. Но что делать, если число комментаторов увеличилось до 300 и выше? Скачать все комментарии к посту файлом Excel тоже можно в бесплатном сервисе getcommentbot:
Разве что вручную сидеть и проверять подписчиков. Ок, если вас комментируют не больше 10-15 человек. Но что делать, если число комментаторов увеличилось до 300 и выше? Скачать все комментарии к посту файлом Excel тоже можно в бесплатном сервисе getcommentbot:Пригодится, если вы боитесь, что нерадивый подрядчик/блогер накручивают или показывают фальшивую активность.
- Кто оставляет комментарии – массфоловеры или реальные, живые пользователи? И эту статистику не отдаст Инстаграм (по крайней мере пока). Но в TrendHero можно определить качество комментариев, чтобы понимать, насколько вы или ваш конкурент/блогер востребованы у целевой аудитории:
- Увидели, кто ставит лайки и кто оставляет комментарии. Как насчет охвата от подписчиков? Только хозяин инстаграм-аккаунта может определить сколько охвата получили публикации в промоутировании и отдельные. Но нет разделения на органический и коммерческий охват. Поэтому если хочется узнать, сколько подписчиков видит ваши посты, используйте сервис getpapabot:
- Ну и вишенка на торте – вы можете не просто узнать какая часть подписчиков лайкает вас или конкурента, а сможете скачать себе живую аудиторию пользователей, которые поставили лайки с помощью Пеппер Ниндзя.
И помните! Хорошие и надежные сервисы по парсингу в Instagram не требуют авторизации через связку с вашим Инстаграм-профилем. Безопасней всего работать именно так!
Несмотря на попытки Инстаграм стать открытой площадкой для рекламодателей, на деле все обстоит плачевно. Нет никакой важной дополнительной информации, которая помогла бы вам скорректировать выбранную стратегию или понять, что вы делаете или не делаете. Не стоит обходиться скудными данными родной аналитики, пробуйте наши сервисы из подборки и делитесь мнением в комментариях!
Не стоит обходиться скудными данными родной аналитики, пробуйте наши сервисы из подборки и делитесь мнением в комментариях!
Анализировать эффективность социальных сетей, как профи, поможет бесплатный курс «Google Data Studio для SMM-щиков и аналитиков». Подробнее о нем по ссылке выше.
Автор: Лия Канарская
Скорее регистрируйтесь в SMMplanner и пробуйте описанное в статье!Способы парсинга аудитории из Инстаграма
В Pepper.Ninja появились инструменты для парсинга аудитории напрямую с Инстаграма. Теперь вы можете собирать подписчиков аккаунтов, искать аудиторию по гео и парсить по хештегам.
Как собрать подписчиков аккаунта?
Чтобы собрать подписчиков из аккаунта, переходим в раздел Instagram аккаунты и вставляем ссылку на нужный аккаунт (также можно указывать и просто id аккаунта).
Есть два варианта парсинга аудитории аккаунта: сбор всех подписчиков и парсинг аудитории, поставившей лайки за последние две недели.
В одной задаче можно указать только одну ссылку для сбора аудитории.
Выбрав нужный вариант, запускаем задачу и переходим в раздел «Задания», где будет показано число найденной аудитории.
Поиск по хештегам
Чтобы собрать аккаунты, размещавшие записи с определенными хештегами, копируем ссылку на сам хештег и вставляем ее в поле для поиска https://www.instagram.com/explore/tags/smm/
В результате найдутся все аккаунты, разместившие посты с этим хештегом, если аккаунт сделал несколько публикаций с ним, то он будет в списке столько раз, сколько публикаций с заданным хештегом содержится в нем.
Парсинг по ГЕО
Для сбора аудитории по определенной гео локации, нам как и в случае с хештегами потребуется ссылка на ГЕО точку, для этого надо нажать на нее в инстаграме и скопировать указанную ссылку. Далее останется дать название задачи и запустить поиск.
Далее останется дать название задачи и запустить поиск.
Что можно сделать с найденными аккаунтами?
Во-первых, их можно загрузить напрямую в сервис масслайкинга One Million Likes , во-вторых, можно скачать собранную базу и загрузить ее для использования в любой другой сервис для взаимодействия с этими людьми.
Наконец, инстаграмы можно конвертировать в телефоны и почты для загрузки в рекламный кабинет Фейсбука и последующей настройке рекламы.
Указываем все ссылки на Инстаграмы в столбик, задаем название отчета и запускаем задание.
P.S. Также в Pepper.Ninja можно искать Инстаграмы и по профилям ВКонтакте. Когда вы запускаете парсинг любой аудитории, то в разделе задания будет показано число найденных аккаунтов ВКонтакте и Инстаграмов.
leoneedpro/instagram-parser: Парсер аккаунтов подписчиков и подписок в Instagram
GitHub — leoneedpro/instagram-parser: Парсер аккаунтов подписчиков и подписок в InstagramПарсер аккаунтов подписчиков и подписок в Instagram
Files
Permalink Failed to load latest commit information.Type
Name
Latest commit message
Commit time
Парсер аккаунтов подписчиков и подписок в Instagram (followers-parser.js)
Парсер активной аудитории (лайки) Instagram (likes-parser.js)
Поддержать развитие проекта:
Как использовать парсер подписчиков и подписок:
- Заходим в web-браузере http://instagram. com и авторизуемся
- Выбираем интересующий аккаунт с подписчиками и подписками
- Нажимаем на просмотр подписчиков и подписок
- Нажимаем сочетание клавиш (CTRL-SHIFT-J , по умолчанию в браузере Google Chrome)
- В открывшуюся консоль браузера, копируем и вставляем код скрипта instagram-parser.js
- Нажимаем клавишу ENTER и процесс парсинга подписчиков запущен!
- После окончания работы скрипта, станет доступен список имен аккаунтов подписчиков
Изменения и новый функционал (2019):
- Изменил код прокрутки — теперь без остановки проходит «Рекомендуемое»
- Теперь можно задавать кол-во аккаунтов для сбора (строка кода 26)
- Добавил возможность собирать помимо логинов, ещё и имена аккаунтов (строка кода 30)
- Добавил возможность изменять скорость сбора (строка кода 20)
Видео пример работы:
www.leoneed.pro | www.instagram.com/leoneed.pro | www.vk.com/leovladivostok
Подписывайтесь, ставьте лайки, до новых встреч!✌️
About
Парсер аккаунтов подписчиков и подписок в Instagram
Topics
Resources
License
You can’t perform that action at this time. You signed in with another tab or window. Reload to refresh your session. You signed out in another tab or window. Reload to refresh your session.Спарсить подписчиков одного аккаунта в Инстаграм за 590 рублей
Разработать дизайн-макет наклейки
Разработать дизайн макет на стекло наклейки. Размер ширина 2,6м, высота 1м. Должна выписать в дизайн помещения. Что-то лёгкое, детское, но стильное, морское. Это детский бассейн
Размер ширина 2,6м, высота 1м. Должна выписать в дизайн помещения. Что-то лёгкое, детское, но стильное, морское. Это детский бассейн
Дарья
Нужны дизайн визиток и листовок
Нужны дизайн листовок и визиток. Четкого тех задания и цветовой гаммы нет. Фото имеющейся визитки пришлю. Текст для листовки тоже. Листовок и визиток будет два типа, отличаться будут только адресами и…
Юрий Т.
Визуальная концепция бренда
Сформировать общее представление проекта. Визуальная концепция бренда. Проект в Instagram. Есть брендбук
Ангелина М.
Раскрутка Ютуб канала
Мне нужна раскрутка канала с увеличением подсписичиков и продажами лекций, семинаров. Тематика — астрология, ЗОЖ, психология. На канале сейчас 8К подписчиков. (ссылка в приватном описании) Нужен человек…
Тематика — астрология, ЗОЖ, психология. На канале сейчас 8К подписчиков. (ссылка в приватном описании) Нужен человек…
Дарина С.
Нарисовать раскадровку-огурцы
Нужно нарисовать раскадровку для небольшого ролика. 15-20 кадров
Сергей П. Нижняя Сыромятническая улица, Москва
Как настроить рекламу на подписчиков конкурентов в Instagram
Подписчики конкурентов всегда считались одной из самых «горячих» аудиторий в соцсетях. Конечно, если они не боты, а живые заинтересованные пользователи. Настроить на них рекламу не проблема, но собрать базу подписчиков и привести ее к нужному формату может быть гораздо сложнее. Поговорим о том, как это делается.
Как собрать подписчиков конкурентов
Существует множество инструментов для парсинга (сбора) аудитории из Instagram. Некоторые реализованы в виде облачного сервиса, другие же представлены в виде компьютерных программ. В этой статье мы рассмотрим и те, и другие.
Парсинг базы с помощью Instasoft
«Инстасофт» — не просто парсер, а целый комбайн для работы с Инстаграмом. Однако нас интересует лишь функция сбора пользователей со страниц конкурентов. Программа платная, но в Сети есть старые взломанные версии в рабочем состоянии.
Допустим, вы приобрели софт или нашли его в свободном доступе. Что дальше? Запустите Instasoft. Добавьте аккаунт для сбора. Затем в боковом меню слева кликните по пункту «Сбор подписчиков конкурентов».
Что дальше? Запустите Instasoft. Добавьте аккаунт для сбора. Затем в боковом меню слева кликните по пункту «Сбор подписчиков конкурентов».
Выберите аккаунт, через который собираетесь парсить людей. Перейдите во вкладку «Настройка задачи». Если вы знаете, кто ваши конкуренты, введите логины их страниц в Инстаграме в столбик справа или загрузите файлом. Если нет, то воспользуйтесь поисковой строкой, чтобы найти конкурентов по ключевому слову.
Укажите, сколько всего нужно собрать подписчиков и сколько пользователей собирать с одного конкурента. Выберите файл для сохранения. Если хотите ускорить процесс сбора и последующей фильтрации, то загрузите аккаунты и прокси в настройках софта, в разделе «MyFastBoost», а затем поставьте галочку на соответствующий пункт в инструменте парсинга.
Не торопитесь запускать задачу. Перейдите во вкладку «Фильтрация». Активируйте фильтры, чтобы отсеять ботов, иностранцев и неактивных пользователей.
Кликните по кнопке «Запустить задачу» и дождитесь окончания парсинга.
Результаты в формате id появятся в файле, который вы ранее указали.
Парсинг базы с помощью FINDGRAM
В этом сервисе можно собрать подписчиков конкурентов ― как за деньги, так и за бонусные баллы, что выдаются при регистрации.
После авторизации нажмите на значок с тремя линиями в левом верхнем углу. Через открывшееся боковое меню перейдите в подраздел «Сбор данных», что находится в разделе «Instagram», и кликните по пункту «Пользователи».
Добавьте аккаунт, при помощи которого будете собирать базу. Он при этом не должен использоваться для продвижения.
Вернитесь в предыдущий раздел, кликните по добавленному профилю и выберите источник, откуда нужно будет собирать пользователей. Так как нас интересуют чужие подписчики, то подойдет вариант «Подписчики». Если вы уже знаете логины конкурентов, введите их в поле слева, если нет, воспользуйтесь поиском по ключевым словам.
Ниже можете добавить игнор-лист, указать количество собираемых пользователей, нужно ли парсить подписчиков с аватарами, учитывать закрытые аккаунты или только открытые.
После установки параметров нажмите на кнопку «ЗАПУСТИТЬ СБОР». Если парсинг завершился с ошибкой, зайдите в свой аккаунт Инстаграм на телефоне и подтвердите вход из другого места (сервиса). Потом запустите сбор повторно.
За один балл вы соберете одного пользователя. Если баллов меньше, чем указанное в настройках количество человек, то будет спарсено столько, на сколько хватит средств.
Кликните по кнопке «Просмотреть список». Затем нажмите на кнопку «Получить данные».
После этого пролистайте страницу вниз и нажмите на кнопку «Экспортировать». Через несколько секунд список пользователей будет сформирован. Вы сможете его скачать. В списке будут логины подписчиков ваших конкурентов.
Сбор телефонов пользователей для Ads Manager
Рекламный кабинет в Фейсбуке/Инстаграме не позволяет загружать пользователей в виде id или логинов. Здесь принимаются только телефоны или электронные адреса. Чтобы узнать телефоны собранной ранее базы подписчиков из Инстаграма, нужно сопоставить идентификационные номера или ссылки на профили с данными ВК, найдя их страницы там.
Для этого мы воспользуемся сервисом TARGETHUNTER. Нас интересует инструмент Instagram > VK, который располагается в разделе «Сбор» и подразделе «Instagram». Добавьте перед каждым логином адрес соцсети, либо конвертируйте их в id. Затем вставьте в поле и нажмите на кнопку запуска.
Задействовать этот инструмент бесплатно не получится. Придется приобрести доступ.
После того, как парсер найдет профили ВКонтакте, загрузите их в инструмент «Контакты пользователей» и запустите сбор телефонов. Либо можете воспользоваться альтернативными решениями, вроде PNSoft, NumberSteal или Lparser_VK.
Запуск рекламы на подписчиков конкурентов
Собранные телефоны загрузите в рекламный кабинет Facebook. Ведь именно через Фейсбук настраивается реклама в Инстаграм.
Ведь именно через Фейсбук настраивается реклама в Инстаграм.
В статье «Как настроить таргетированную рекламу в Instagram» мы уже описывали процесс создания и запуска рекламной кампании. Уточним, что при указании аудитории вам нужно выбрать пункт «Пользовательская» и загрузить список собранных ранее телефонов.
После этого можете запускать рекламу и переманивать подписчиков своих конкурентов.
Как собрать целевую аудиторию в Instagram. | by Дмитрий Торгов
Сбор целевой аудитории важен на любом этапе продвижения. Если неосознанно использовать сервисы по раскрутке, есть риск «наловить» множество ботов и фейковых аккаунтов. Именно поэтому нужно научиться находить свою целевую аудиторию, чтобы в дальнейшем работать с живыми людьми.
Где найти целевую аудиторию
Для начала нужно определить кто ваша целевая аудитория, кого вы ищете. А затем переходить к сервису для сбора аудитории.
Есть несколько способов сбора целевой аудитории.
По конкурентам
Ваша потенциальная целевая аудитория — это люди, которым интересна продукция ваших конкурентов. Среди множества подписчиков следует отмести коммерческие и фейковые аккаунты. Во внимание нужно брать лишь тех, кто активен — оставляет комментарии и ставит лайки, а так же тех, кто подписался дня два-три назад.
Подписчики конкурентов собираются в один список. Далее происходит отсев ненужных аккаунтов по списку стоп-слов, например, таких как цена, магазин, купить, заказать, и т.п.
По хэштегам
Собрав несколько тематических хэштегов, ищем через поиск в инстаграм публикации с наибольшим количеством лайков. Профили авторов этих публикаций собираем в единый список.
Из списка выбрасываем тех, у кого мало подписчиков, мало комментариев и лайков. Результат — база профилей подписчиков вашей возможной целевой аудитории.
Шпионы для инстаграм
Это сервисы, которые помогают найти наиболее активную аудиторию — тех, кто подписывается и лайкает. Подобранный с помощью шпионов список можно использовать для раскрутки своей страницы.
По геолокации
Актуально для регионального продвижения. Сбор целевой аудитории по геолокации позволяет собрать аудиторию, которая находится в определенном городе.
Из социальной сети ВКонтакте
Многие пользователи связывают свои аккаунты в инстаграм и ВК. Можно сперва спарсить целевую аудиторию во ВКонтакте, затем найти её аккаунты в инстаграм.
Производить сбор аудитории вручную слишком трудоёмкая работа. Поэтому, для автоматизации процесса потребуется программа — парсер, которая соберет нужную информацию за считанные минуты.
Программы и сервисы для парсинга целевой аудитории из инстаграм
SocialKit
Это платная программа, позволяющая управлять своими аккаунтами. Помимо этого в инструментарии программы присутствуют функции для сбора аудитории, различные фильтры и настраиваемые параметры.
Интересующие нас возможности:
- подбор конкурентов и хэштегов
- сбор из ВКонтакте
- шпион для сбора активной аудитории
- парсинг по геометке с установкой радиуса
SocialKit позволяет спарсить конкурентов , а затем выбрать из списка активных подписчиков. Аналогично можно собрать целевую аудиторию по хэштегам.
ТаргетХантер
Парсер для работы с сетью ВКонтакте с функцией сбора аккаунтов инстаграм, который сводит данные из профиля или со стены пользователя.
Сперва собираем целевую аудиторию в ВК, затем парсим ID или Username в инстаграм из образовавшегося списка.
Zengram
Платный сервис, который помогает собрать хэштеги и отобрать целевую аудиторию по ним, отыскать конкурентов и собрать подписчиков. Zengram может работать по геотегам. Имеется шпион, позволяющий отследить активных подписчиков у конкурентов.
DoInsta
Ещё один сервис для сбора подписчиков по хэштегам или по загруженному списку конкурентов. Имеются фильтры, позволяющие разделить аккаутны по странам, подписчикам, коммерческим аккаунтам.
Pepper.Ninja
Это парсер, который поможет найти целевую аудиторию в инстаграм.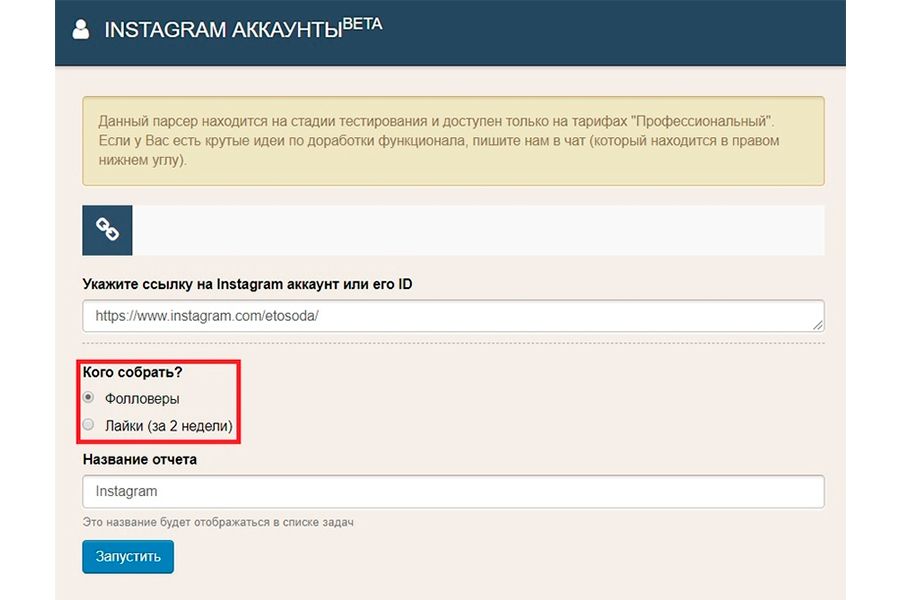 Сначала собираем в список группы ВКонтакте по ключевым словам. Далее парсим список людей из этих групп. Затем чистим базу от лишних аккаунтов, берём только активных, после чего парсим список инстаграм аккаунтов.
Сначала собираем в список группы ВКонтакте по ключевым словам. Далее парсим список людей из этих групп. Затем чистим базу от лишних аккаунтов, берём только активных, после чего парсим список инстаграм аккаунтов.
Insta.Tools
Это сервис для поиска клиентов в инстаграм. Помогает находить целевую аудиторию по тегам, по геолокации, по конкурентам — собирает подписчиков указанных пользователей, а так же находит тех, кто посетил место или мероприятие.
Важно помнить, что нужно не только собрать аудиторию, в чем нам могут помочь соответствующие программы. Нужно суметь заинтересовать целевую аудиторию своим контентом.
#Парсинг Instagram posts (photos and videos)
Этого хотят все. Направить рекламу на аудиторию конкурента.
А что, так можно?
⠀
Можно, но не нужно (исключительно мое личное мнение).
⠀
Объясню почему, по порядку:
⠀
Для того, чтобы лить рекламу на аудиторию конкурента, надо эту аудиторию спарсить, т.е. с помощью специальных автоматизированных сервисов скачать из различных групп и аккаунтов. Причем, все это — на законных основаниях.
⠀
Парсинг — в законе 😉 — это про сбор информации, находящейся в открытом доступе. И это очень нужно тем, у кого нет своей базы.
⠀
Да, безусловно парсеры позволяют ускорить процесс, который, собственно, и руками то можно сделать, но долго и риск ошибки есть. Поэтому — жирный плюс — автоматизации парсеров.
⠀
Какие сервисы используем для парсинга:
✅TargetHunter
✅Pepper ninja
✅Церебро.рф
⠀
Отличные сервисы. Кроме парсинга в чистом виде (увы!) — это кладезь полезной инфы.
⠀
Как все происходит?
⠀
Например, идем в ВКонтакте, находим нужную группу.
⠀
Ссылку на эту группу загружаем в сервис парсинга и получаем id, телефоны, емейлы пользователей, которые в этой группе.
⠀
Далее, наш любимый рекламный кабинет в Facebook — Аудитории — создаем Пользовательскую. Имеющийся список загружаем и ждем пока алгоритм найдет совпадения.
⠀
А теперь, правда жизни:
⠀
1️⃣ не надо парсить, не проверив качество аудитории: я про гивы и накрутки
2️⃣ в группе есть «мертвые души», когда то подписавшиеся и благополучно забывшие про эту группу
3️⃣ в группе есть те, кто абсолютно не вовлечен в тему, не дает реакции
⠀
И вот на такое счастье, мы делаем таргет и еще, святые ситиары! — похожую аудиторию. ⠀
Сильно сомневаюсь, в успешности и качестве такой аудитории.
⠀
Только лишь установив, при парсинге определенные критерии, можно рискнуть получить более-менее результативную аудиторию.
⠀
Сделав, несколько попыток, получила устойчивое послевкусие ненужности такой стратегии для Facebook и Instagram. Больше время не трачу.
⠀
А вот в ВКонтакте — парсинг работает отлично.
⠀
Но! всем рекомендую попробовать — ведь на вкус и цвет, как говорится….
⠀
Кто уже имел опыт работы с парсерами, как результат?
⠀
Сильно сомневаюсь, в успешности и качестве такой аудитории.
⠀
Только лишь установив, при парсинге определенные критерии, можно рискнуть получить более-менее результативную аудиторию.
⠀
Сделав, несколько попыток, получила устойчивое послевкусие ненужности такой стратегии для Facebook и Instagram. Больше время не трачу.
⠀
А вот в ВКонтакте — парсинг работает отлично.
⠀
Но! всем рекомендую попробовать — ведь на вкус и цвет, как говорится….
⠀
Кто уже имел опыт работы с парсерами, как результат?
Использование Python для очистки Instagram в поисках ответа — почему Тайлер Си так популярен? | Эмили Энгл | The Startup
Раньше я смотрел The Bachelor еженедельно и после этого быстро открыл для себя r / TheBachelor. Однажды, наблюдая за сезоном Ханны Би, я наткнулся на сообщение в сабреддите, в котором указывалось на интересный феномен — в частности, один участник, Тайлер Си, набирал популярность в социальных сетях. По сравнению с другими участницами и даже с самой ведущей шоу, его подписчики стремительно росли.
Это вызвало несколько интересных вопросов: что спровоцировало рост? Когда это началось? Было ли это постоянным или ускоряющимся? Мне стало любопытно. Если бы я хотел проследить за его последователями, чтобы понять закономерность, как бы я это сделал?
Ответ на этот вопрос оказался гораздо интереснее, чем я мог предположить, поэтому сегодня я расскажу следующее: , как я могу программно вывести количество подписчиков из Instagram? Я буду писать на Python, но решение не зависит от языка.
Итак, переходя к вопросу о том, как я могу использовать Python для программного получения количества подписчиков в Instagram, я, конечно же, первым побуждал использовать общедоступные API Instagram.
Возможно, мне не понадобился Python, чтобы ответить, почему его последователи так резко выросли. Фотографии без рубашки могут быть прямым ответом. Ты будешь судьей. Без кубиков. Instagram предлагает API для бизнес-аккаунтов и аккаунтов создателей, а также API для получения данных о вашей собственной учетной записи, но ничего, что позволяло бы получать данные из случайной учетной записи.(В то время он еще не был отмечен как создатель).
Instagram предлагает API для бизнес-аккаунтов и аккаунтов создателей, а также API для получения данных о вашей собственной учетной записи, но ничего, что позволяло бы получать данные из случайной учетной записи.(В то время он еще не был отмечен как создатель).
Следующей моей мыслью было посмотреть, смогу ли я сделать запрос на instagram.com/tylerjcameron3 и очистить полученную страницу для определения количества его подписчиков. Поскольку на странице Instagram указано количество его подписчиков (2,3 млн), информация должна присутствовать на странице. Однако вот тут-то и стало интересно.
В качестве быстрого отказа от ответственности — я не рекомендую использовать парсинг в качестве первого (или даже приемлемого) подхода, когда вам нужен доступ к данным. Как правило, это противоречит Условиям использования веб-сайтов, и я описываю это здесь исключительно как интересное упражнение, а не для того, чтобы отстаивать то, что вы это делаете.Сайты также обычно блокируют вас, если вы очищаете их слишком часто или слишком часто. Имейте в виду, что ваши действия могут привести к блокировке доступа к веб-сайту.
Но давайте перейдем к интересным вещам. Если вы собираетесь попробовать соскабливание, как бы вы это сделали? Обычно я начинаю с загрузки интересующей меня страницы и просмотра ее первоначальных сетевых вызовов в инструментах разработчика. В Chrome щелкните правой кнопкой мыши> Проверить> вкладка Сеть. Поскольку его количество подписчиков напечатано на его странице, это означает, что этот номер должен присутствовать в сетевом вызове где-то .В зависимости от его местоположения это дает мне возможность получить к нему доступ.
Начиная со страницы Тайлера С, вы можете видеть внизу журнала, что запущено довольно много запросов. В частности, семьдесят девять.
Это очень много. Итак, затем я фильтрую журнал только до запросов XHR , сокращая его до 16 из 79 вызовов — это намного удобнее просматривать. Обычно я хотел бы посмотреть, какие данные возвращаются в каждом из этих вызовов.
В идеальном мире (для нас) cURL запрос на https: // instagram.com / tylerjcameron3 приведет к легко анализируемому ответу, подобному JSON, показанному слева.
Это позволит нам в нашем коде сделать запрос к этому URL-адресу и просто проанализировать ответ для атрибута numFollowers .
К сожалению, в Instagram все не так просто. (И все равно редко производственные сайты с миллионами или миллиардами пользователей ведут себя так просто.) Проблема в том, что ни один из этих 16 сетевых запросов XHR , похоже, не содержит данных, которые мы ищем.
Мой следующий шаг — вместо этого отфильтровать до запросов Doc . Возможно, Instagram использует рендеринг на стороне сервера, и я найду там полный документ с анализируемым HTML. Здесь есть только один вызов, и он выглядит многообещающим, потому что возвращает много HTML.
Но его количество последователей не сразу видно. Итак, я попробовал еще один трюк — мы видим, что его биография содержит предложение: «Через любовь служите друг другу». Если в этом HTML-коде есть его основная информация о профиле, наверняка там будет и его биография.Итак, выполнив поиск в HTML, вуаля! Его биография находится в блоке JSON вместе с множеством другой информации профиля.
Итак, теперь мы знаем, что для получения количества подписчиков профиля нам нужно проанализировать HTML, возвращенный из Instagram, и найти атрибут edge_followed_by .
А затем в Python мы можем использовать библиотеку запросов и , чтобы сделать запрос в Instagram и проанализировать ответ, чтобы получить количество подписчиков.
И вот оно! Мы можем получить количество подписчиков для любого профиля в Instagram.
В моем теоретическом варианте использования (отслеживание количества подписчиков участника на протяжении всего шоу) я мог бы включить это в более крупный проект, который выполняется ежедневно или еженедельно, чтобы отслеживать количество подписчиков и искать тенденции.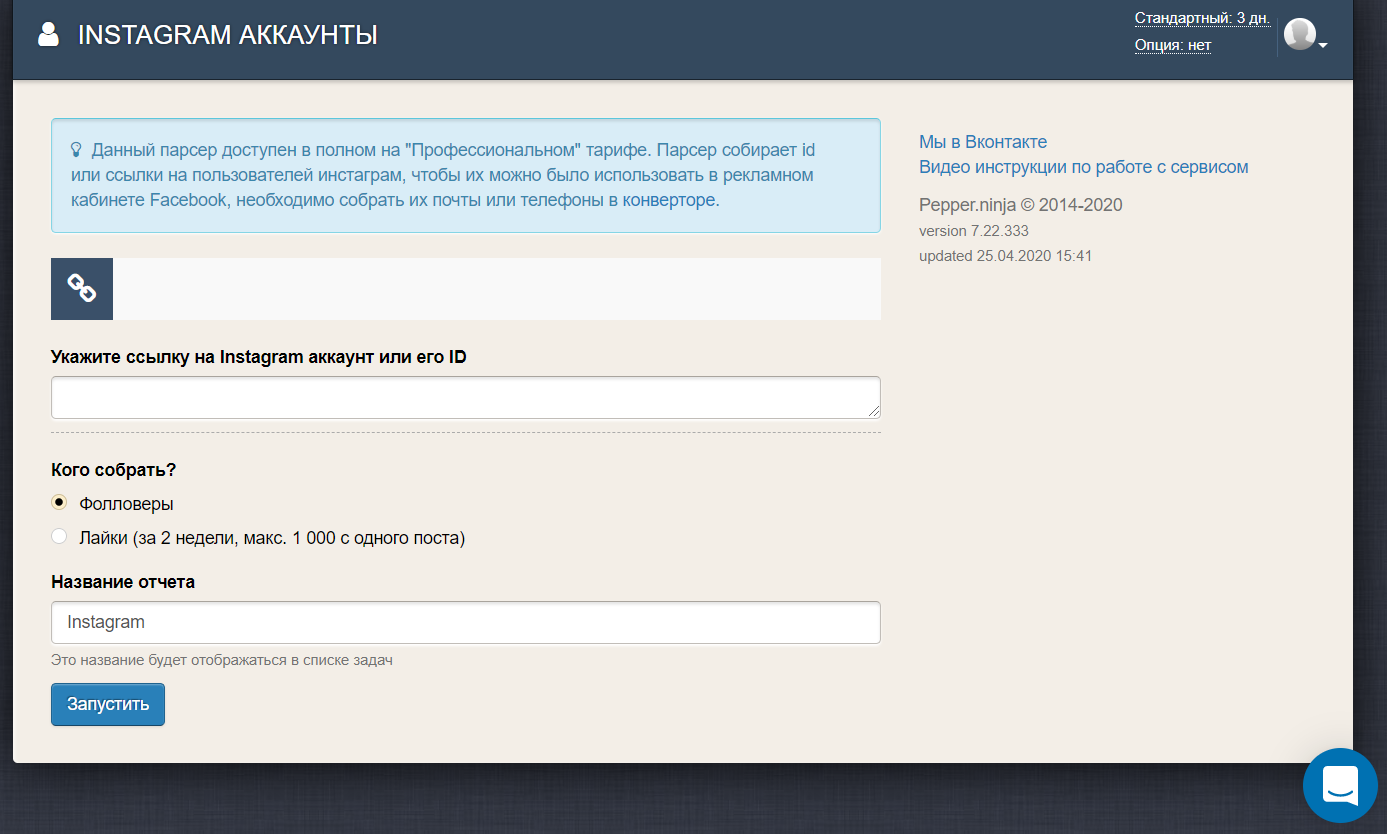
Но вы можете выбрать любое количество направлений для вашего собственного сценария использования. Удачного кодирования!
веб-парсинг — Как извлечь данные из Instagram
Вам обязательно стоит проверить API Instagram, который может предоставить вам всю общедоступную информацию, которую вы хотите очистить.Вам просто нужно написать сценарий для правильных вызовов API (см. Ниже).
С сайта Instagram:
Мы делаем все возможное, чтобы все наши URL-адреса были RESTful. Каждая конечная точка (URL) может поддерживать один из четырех разных HTTP-глаголов. Запросы GET получают информацию об объекте, запросы POST создают объекты, запросы PUT обновляют объекты и, наконец, запросы DELETE удаляют объекты.
Вам просто нужно иметь готовое значение ACCESS-TOKEN для соответствующей учетной записи, когда вы используете URL-адрес в своем коде, и иметь возможность распаковывать json, который Instagram возвращает вам с каждым запросом GET.Если данные не напрямую доступны, вы всегда можете вернуть их косвенно. — Имя пользователя — Количество подписчиков — Количество подписанных людей
Вот отличная отправная точка: https://www.instagram.com/developer/endpoints/users/#get_users
А вот как вы могли бы вызвать API в python:
#Python 2.7.6
# RestfulClient.py
запросы на импорт
из request.auth импорт HTTPDigestAuth
импортировать json
# Замените правильным URL
url = "http: // api_url"
# Рекомендуется не кодировать учетные данные жестко.Поэтому попросите пользователя ввести учетные данные во время выполнения
myResponse = requests.get (url, auth = HTTPDigestAuth (raw_input ("имя пользователя:"), raw_input ("Пароль:")), verify = True)
#print (myResponse.status_code)
# Для успешного вызова API код ответа будет 200 (OK)
если (myResponse.ok):
# Загрузка данных ответа в переменную dict
# json.loads принимает только двоичные или строковые переменные, поэтому использование содержимого для получения двоичного содержимого
# Loads (Load String) принимает файл Json и преобразует его в структуру данных python (dict или list, в зависимости от JSON)
jData = json. загружает (myResponse.content)
print ("Ответ содержит {0} свойства" .format (len (jData)))
печать ("\ п")
для ключа в jData:
ключ печати + ":" + jData [ключ]
еще:
# Если код ответа неправильный (200), вывести полученный код ошибки http с описанием
myResponse.raise_for_status ()
c # — Как очистить подписчиков Instagram?
Я считаю, что большинство страниц, которые вы видите, используют Instagram API (или метод, описанный ниже). Однако получить к нему доступ без приложения, которым они довольны, немного сложно.Насколько я понял, вам нужно будет создать приложение, прежде чем вы узнаете, будет ли у вас доступ, что немного глупо. Я предполагаю, что они пытаются помешать новым пользователям использовать его, в то время как они продолжают позволять людям, уже использующим его, продолжать его использовать.
В документации для их API, похоже, отсутствует многое из того, что было доступно ранее, и прямо сейчас нет конечной точки для получения подписчиков (это может быть что-то временно не так со страницей документации: https: //www.instagram.com / developer / endpoints /).
Вы можете получить подписчиков так же, как это делает веб-страница Instagram. Однако, похоже, это работает только в том случае, если вы запрашиваете до 5000-6000 подписчиков одновременно, и вы можете получить ограничение по скорости.
Они делают запрос GET на: https://www.instagram.com/graphql/query/ с параметрами запроса query_hash и переменных .
query_hash Я думаю, это хеш переменных.Однако я могу ошибаться, поскольку он будет продолжать работать, даже если вы измените переменные. Один и тот же хеш может не работать вечно, поэтому, возможно, вам придется получить то же самое, что и на странице Instagram. Вы получите это, даже если вы не вошли в систему, поэтому я не думаю, что это будет очень сложно.
Параметр переменных — это объект JSON с кодировкой URL, содержащий переменные поиска. JSON должен выглядеть так:
JSON должен выглядеть так:
{
"id": "305701719",
«первый»: 20
}
id — идентификатор пользователя. первые — это количество подписчиков, которое вам нужно.
URL-адрес будет выглядеть так, когда вы его закодируете. https://www.instagram.com/graphql/query/?query_hash=bfe6fc64e0775b47b311fc0398df88a9&variables=%7B%22id%22%3A%22305701719%22%2C%22first%22%3A20%7D
Это вернет такой объект json:
"данные": {
"Пользователь": {
"edge_followed_by": {
"count": 73785285,
"page_info": {
"has_next_page": правда,
"end_cursor": "AQDJzGlG3jGfM6KGYF7oOhlMqDm9_-db8DW_8gKYTeKO5eIca7cRqL1ODK1SsMA33BYBbAZz3BdC3ImMT79a1YytB1j9TIz7f"
},
"края": [
{
"узел": {}
}
]
}
}
}
Массив ребер будет содержать список узловых элементов, содержащих информацию о пользователях, которые следят за человеком, которого вы ищете.
Чтобы получить следующее x количество подписчиков, вам нужно изменить json, используемый в запросе переменных, на что-то вроде этого:
{
"id": "305701719",
«первый»: 10,
«после»: «AQDJzGlG3jGfM6KGYF7oOhlMqDm9_-db8DW_8gKYTeKO5eIca7cRqL1ODK1SsMA33BYBbAZz3BdC3ImMT79a1YytB1j9z7f-ZaTIQUE»
}
после будет тем, что вы получили как end_cursor в предыдущем запросе.
, и ваш новый URL-адрес будет выглядеть так: https: // www.instagram.com/graphql/query/?query_hash=bfe6fc64e0775b47b311fc0398df88a9&variables=%7B%22id%22%3A%22305701719%22%2C%22first%22%3A10%2C%22after%22%3A%22AQDJzGlG3jGfM6KGYF7oOhlMqDm9_-db8DW_8gKYTeKO5eIca7cRqL1ODK1SsMA33BYBbAZz3BdC3ImMT79a1YytB1j9z7f-ZaTIkQKEoBGepA%22% 7D
Таким образом, вы можете продолжать цикл до тех пор, пока has_next_page не станет false в ответе.
отслеживающих подписчиков в Instagram, как настоящий ботаник | Карлос Росо
Моя жена создает туристический контент в Instagram. Она из тех людей, которые, как и я, отслеживают все возможные данные. ” То, что не измеряешь, нельзя улучшить ” , сказали они. Она хотела отслеживать рост своей базы подписчиков, но большинство онлайн-сервисов не предлагают многое из этого бесплатно или с необходимой гибкостью.
Она из тех людей, которые, как и я, отслеживают все возможные данные. ” То, что не измеряешь, нельзя улучшить ” , сказали они. Она хотела отслеживать рост своей базы подписчиков, но большинство онлайн-сервисов не предлагают многое из этого бесплатно или с необходимой гибкостью.
Она ставила будильник каждый день в 10:00, чтобы регистрировать количество подписчиков в электронной таблице. Оказывается, это очень неудобно для путешественника, занятого полный рабочий день. В большинстве мест недостаточно данных, и ваш распорядок дня непредсказуем.
Повторяющиеся задачи — это зеленый флаг для автоматизации. Учитывая мою одержимость NIH, мне нужно было решить эту проблему самым изощренным способом.
Нам нужен способ периодически фиксировать количество подписчиков учетной записи Instagram. Затем нам нужно зарегистрировать его в Google Таблицах для дальнейшего анализа данных.
Я обнаружил, что настройка Instagram API несколько обременительна для такой простой задачи (хороший сигнал для проекта с открытым исходным кодом). Затем я скрою HTML-код профиля Instagram, прочту точное количество и запишу его в Google Sheet с помощью API.Мне также нужно будет периодически запускать это с моего сервера. Cron выполнит свою работу.
Я выберу Python для этого, потому что:
- Раньше я занимался удалением веб-страниц с помощью BeautifulSoup
- API Google Таблиц имеет отличную поддержку Python
Установка
Мы будем использовать BeautifulSoup для удаления и API Google для обработки аутентификации:
pip install --upgrade google-api-python-client google-auth-httplib2 google-auth-oauthlib beautifulsoup4 Примечание. Я рекомендую запускать команды pip в файле virtualenv.
Читать подписчики
Instagram регистрирует объект JavaScript в окне (также известном как глобальное) с количеством подписчиков в опоре edge_followed_by . Мы будем использовать группу захвата регулярных выражений, чтобы получить это число и отправить его в Google Таблицы.
Мы будем использовать группу захвата регулярных выражений, чтобы получить это число и отправить его в Google Таблицы.
запросов на импорт
импортировать json
из bs4 импорт BeautifulSoup
URL = 'https://www.instagram.com/linaestadeviaje/'
page = requests.get (URL)
soup = BeautifulSoup (page.content, 'html.parser')
followers = re.search ('"edge_followed_by": {"count": (\ d *)}', суп.prettify ()). группа (1) Запись в Google Таблицы
Вам нужно создать личный лист и получить его идентификатор из URL. Создайте новый лист и назовите его Followers .
Эта часть основана на разделе быстрого старта руководства Google Sheets Python API. Он использует OAuth для первоначального согласия пользователя, а затем сохраняет информацию об авторизации в файле ./creds/token.pickle .
Вам также потребуется загрузить свои учетные данные .json , чтобы завершить начальный поток OAuth. Получите свой, нажав «Включить API Google Таблиц» в официальной документации по API.
Собери все вместе
Вот как выглядит окончательный сценарий. Код задокументирован для облегчения навигации. Я поместил все в main () для простоты, но я рекомендую вам писать функции.
маринад импортный
импорт os.path
из сборки импорта googleapiclient.discovery
из google_auth_oauthlib.импорт потока InstalledAppFlow
из google.auth.transport.requests Запрос на импорт
импортировать json
запросы на импорт
из bs4 импорт BeautifulSoup
from datetime import datetime
SCOPES = ['https://www.googleapis.com/auth/spreadsheets']
SPREADSHEET_ID = '### ЗАМЕНИТЬ ЛИСТОМ ID ###'
WRITE_RANGE_NAME = 'Подписчики! A2: C'
CREDS_PATH = os.path.abspath ('./ creds / token.pickle')
def main ():
creds = Нет
если существует os.path. (CREDS_PATH):
с open (CREDS_PATH, 'rb') в качестве токена:
creds = рассол.загрузка (токен)
если не creds или not creds. valid:
если creds и creds.expired и creds.refresh_token:
creds.refresh (Запрос ())
еще:
flow = InstalledAppFlow.from_client_secrets_file ('credentials.json', ОБЛАСТЬ ПРИМЕНЕНИЯ)
creds = flow.run_local_server (порт = 55680)
с open (CREDS_PATH, 'wb') в качестве токена:
pickle.dump (кредиты, токен)
URL = 'https://www.instagram.com/linaestadeviaje/'
page = requests.get (URL)
soup = BeautifulSoup (стр.контент, 'html.parser')
followers = re.search ('"edge_followed_by": {"count": (\ d *)}', soup.prettify ()). group (1)
сейчас = datetime.now ()
date_string = now.strftime ("% m /% d /% Y")
time_string = now.strftime ("% H:% M:% S")
service = build ('листы', 'v4', учетные данные = кредиты)
sheet = service. spreadsheets ()
sheet.values (). append (spreadsheetId = SAMPLE_SPREADSHEET_ID,
диапазон = WRITE_RANGE_NAME,
valueInputOption = 'RAW',
body = {'значения': [[строка_даты, строка_времени, подписчики]]}).выполнять()
если __name__ == '__main__':
основной ()  valid:
если creds и creds.expired и creds.refresh_token:
creds.refresh (Запрос ())
еще:
flow = InstalledAppFlow.from_client_secrets_file ('credentials.json', ОБЛАСТЬ ПРИМЕНЕНИЯ)
creds = flow.run_local_server (порт = 55680)
с open (CREDS_PATH, 'wb') в качестве токена:
pickle.dump (кредиты, токен)
URL = 'https://www.instagram.com/linaestadeviaje/'
page = requests.get (URL)
soup = BeautifulSoup (стр.контент, 'html.parser')
followers = re.search ('"edge_followed_by": {"count": (\ d *)}', soup.prettify ()). group (1)
сейчас = datetime.now ()
date_string = now.strftime ("% m /% d /% Y")
time_string = now.strftime ("% H:% M:% S")
service = build ('листы', 'v4', учетные данные = кредиты)
sheet = service. spreadsheets ()
sheet.values (). append (spreadsheetId = SAMPLE_SPREADSHEET_ID,
диапазон = WRITE_RANGE_NAME,
valueInputOption = 'RAW',
body = {'значения': [[строка_даты, строка_времени, подписчики]]}).выполнять()
если __name__ == '__main__':
основной ()
valid:
если creds и creds.expired и creds.refresh_token:
creds.refresh (Запрос ())
еще:
flow = InstalledAppFlow.from_client_secrets_file ('credentials.json', ОБЛАСТЬ ПРИМЕНЕНИЯ)
creds = flow.run_local_server (порт = 55680)
с open (CREDS_PATH, 'wb') в качестве токена:
pickle.dump (кредиты, токен)
URL = 'https://www.instagram.com/linaestadeviaje/'
page = requests.get (URL)
soup = BeautifulSoup (стр.контент, 'html.parser')
followers = re.search ('"edge_followed_by": {"count": (\ d *)}', soup.prettify ()). group (1)
сейчас = datetime.now ()
date_string = now.strftime ("% m /% d /% Y")
time_string = now.strftime ("% H:% M:% S")
service = build ('листы', 'v4', учетные данные = кредиты)
sheet = service. spreadsheets ()
sheet.values (). append (spreadsheetId = SAMPLE_SPREADSHEET_ID,
диапазон = WRITE_RANGE_NAME,
valueInputOption = 'RAW',
body = {'значения': [[строка_даты, строка_времени, подписчики]]}).выполнять()
если __name__ == '__main__':
основной () Dockerize все вещи
Если хочешь, можешь уйти сейчас. Запустите приведенный выше код, и все будет в порядке. . В следующих нескольких разделах я расскажу, как это можно запустить на сервере.
Я использую комбинацию Docker и Digital Ocean для развертывания всех своих приложений (включая этот блог). Это означает, что мне нужно докеризовать все приложения, прежде чем перемещать их в prod. В любом случае, это фантастика, так как у меня есть полные процессы сборки на самых разных языках, и все они работают в своих собственных контейнерах докеров.
Так выглядит Dockerfile для этого приложения :
ИЗ питона: 3
RUN pip install --upgrade google-api-python-client google-auth-httplib2 google-auth-oauthlib beautifulsoup4
ENV TZ = Америка / Богота
RUN ln -snf / usr / share / zoneinfo / $ TZ / etc / localtime && echo $ TZ> / etc / timezone
ДОБАВИТЬ main. py /
CMD ["питон", "./main.py"]  py /
CMD ["питон", "./main.py"]
py /
CMD ["питон", "./main.py"] Важно: Убедитесь, что вы не зафиксировали файл token.pickle на GitHub и не отправили его в образе Docker.Он должен быть доступен только в вашей производственной среде. Вам нужно будет переместить этот файл из локального в производственный, используя предпочитаемый вами метод (например, копию ssh, частную корзину S3, временную общедоступную ссылку и т.
Выполняется периодически
Большая часть значения этого заключается в периодическом запуске сценария. Вы можете добиться этого с помощью cron на сервере Unix. Как упоминалось выше, вы хотите убрать мой token.pickle из образа Docker. Затем вам нужно будет смонтировать том с соответствующим указателем на файл pickle.
Вот как должен выглядеть ваш crontab, если вы хотите запускать процедуру каждый час:
~ $ crontab -l
0 * * * * docker rm ig_followers && docker run -d --name = ig_followers -v / root / ig_followers / creds: / creds docker-hub-username / ig-followers: последняя версия Бонус: воспользуйтесь этим удобным инструментом для создания выражений расписания cron.
Результаты
Данные прекрасны. Доступность в GSheets была легкой частью; теперь вам решать.Вы можете построить график своего роста с течением времени, скользящего среднего ежедневного роста, еженедельного изменения и т. Д.
Здесь вы можете увидеть резкий скачок ежедневного прироста (пустые посты и трендовые фото), а затем он падает в течение нескольких недель (COVID-19).
Прежде всего, наслаждайтесь и получайте удовольствие. Не зацикливайтесь на цифрах, росте и простых показателях. Будьте одержимы тем, чтобы помогать, творить и вдохновлять.
С апреля 2020 года Instagram изменил способ увеличения количества подписчиков.Я оставляю здесь предыдущий подход, основанный на JSON-LD, на всякий случай.
Наследие (
<апрель 2020 г.)Как упоминалось ранее, я решил узнать количество подписчиков, выполнив простую очистку веб-страниц. Я не хотел беспокоиться о настройке учетной записи Facebook для использования Instagram API. Оказывается, Instagram использует JSON-LD для вставки структурированных данных на страницу. Это позволяет легко прочитать количество подписчиков:
запросов на импорт
импортировать json
из bs4 импорт BeautifulSoup
URL = 'https: // www.instagram.com/linaestadeviaje/ '
page = requests.get (URL)
soup = BeautifulSoup (page.content, 'html.parser')
data = json.loads (soup.find ('script', type = 'application / ld + json'). text)
Followers = data ['mainEntityofPage'] ['InteractionStatistic'] ['userInteractionCount'] Простой способ очистки Instagram с помощью Python Scrapy и GraphQL
После мониторинга электронной коммерции создание парсеров социальных сетей для мониторинга учетных записей и отслеживания новых тенденций является следующим наиболее популярным вариантом использования парсинга веб-сайтов.
Однако любой, кто пытался создать паука-парсера для сканирования Instagram, Facebook, Twitter или TikTok, знает, что это может быть немного сложно.
Эти сайты используют сложные технологии защиты от ботов для блокировки ваших запросов и регулярно вносят изменения в схемы своих сайтов, которые могут нарушить логику парсинга ваших пауков.
Итак, в этой статье я покажу вам самый простой способ создать паука Python Scrapy, который очищает все сообщения Instagram для каждой учетной записи пользователя, которую вы ему отправляете.При этом не нужно беспокоиться о блокировке или необходимости разрабатывать селекторы XPath для очистки данных из необработанного HTML.
Код проекта доступен на GitHub здесь и настроен для очистки:
- URL сообщения
- URL изображения или видео
- Подписи к сообщениям
- Дата публикации
- Количество лайков
- Количество комментариев
За каждое сообщение в аккаунте этого пользователя. Как вы увидите, есть больше данных, которые мы могли бы легко извлечь, однако, чтобы не усложнять это руководство, я просто ограничил его наиболее важными типами данных.
Как вы увидите, есть больше данных, которые мы могли бы легко извлечь, однако, чтобы не усложнять это руководство, я просто ограничил его наиболее важными типами данных.
Этот код также можно быстро изменить, чтобы очистить все сообщения, относящиеся к определенному тегу или географическому положению, с небольшими изменениями, так что это отличная база для создания будущих пауков.
В этой статье предполагается, что вы знакомы с основами Scrapy, поэтому мы собираемся сосредоточиться на том, как очистить Instagram в большом масштабе, не будучи заблокированным.
Настройка нашего Scrapy Spider
Начать работу с Scrapy очень просто. Чтобы установить Scrapy, просто введите эту команду в командной строке:
pip install scrapy
Войти в полноэкранный режимВыйти из полноэкранного режима Затем перейдите в папку вашего проекта. Scrapy автоматически создает и запускает команду «startproject» вместе с именем проекта (в данном случае «instascraper»), и Scrapy создаст для вас папку проекта парсинга веб-страниц со всем уже настроенным:
scrapy startproject instascraper
cd instascraper
scrapy genspider instagram instagram.ком
Войти в полноэкранный режимВыйти из полноэкранного режима Вот что вы должны увидеть:
├── scrapy.cfg # файл конфигурации развертывания
└── Модуль Python учебного # проекта, вы импортируете свой код отсюда
├── __init__.py
├── items.py # файл определения элементов проекта
├── middlewares.py # файл промежуточного программного обеспечения проекта
├── pipelines.py # файл конвейера проекта
├── settings.py # файл настроек проекта
└── spiders # каталог, в котором находятся пауки
├── __init__.ру
└── amazon.py # только что созданный нами паук
Войти в полноэкранный режимВыйти из полноэкранного режима Хорошо, это настроенные шаблоны Scrapy Spider. Теперь приступим к созданию наших пауков для Instagram.
Теперь приступим к созданию наших пауков для Instagram.
Отсюда мы собираемся создать пять функций:
- start_requests — создаст URL-адрес Instagram для учетной записи пользователя и отправит запрос в Instagram.
- parse — будет извлекать все данные о сообщениях из ленты новостей пользователей.
- parse_page — , если есть более одной страницы, эта функция проанализирует все данные сообщений с этих страниц.
- get_video — , если сообщение включает видео, эта функция будет вызываться и извлекать URL видео.
- get_url — отправит запрос в Scraper API, чтобы он мог получить ответ HTML.
Приступим к работе…
Запрос учетных записей Instagram
Чтобы получить данные пользователя из Instagram, нам нужно сначала создать список пользователей, которых мы хотим отслеживать, а затем включить их идентификаторы пользователей в URL-адрес.К счастью для нас, Instagram использует довольно простую структуру URL-адресов.
У каждого пользователя есть уникальное имя и / или идентификатор пользователя, которые мы можем использовать для создания URL-адреса пользователя:
https://www.instagram.com//
Войти в полноэкранный режимВыйти из полноэкранного режима Вы также можете получить сообщения, связанные с определенным тегом или из определенного места, используя следующий формат URL:
## Теги URL
https: // www.instagram.com/explore/tags//
## URL-адрес местоположения
https://www.instagram.com/explore/locations//
# Примечание: URL-адрес местоположения представляет собой числовое значение, поэтому вам необходимо указать номер идентификатора местоположения для
# места, которые вы хотите очистить.
Войти в полноэкранный режимВыйти из полноэкранного режима Итак, для этого примера паука я собираюсь использовать Nike и Adidas в качестве двух учетных записей Instagram, которые я хочу очистить.
Используя вышеуказанную структуру, URL-адрес Nike: https: // www.instagram.com/nike/ , и мы также хотим иметь возможность указывать язык страницы с помощью параметра «hl». Например:
https://www.instagram.com/nike/?hl=en #English
https://www.instagram.com/nike/?hl=de # немецкий
Войти в полноэкранный режимВыйти из полноэкранного режимаПаук №1: получение учетных записей Instagram
Теперь мы создали проект scrapy и знакомы с тем, как Instagram отображает его данные, и можем приступить к написанию кода для пауков.
Наш паук стартовых запросов будет довольно простым, нам просто нужно отправить запросы в Instagram с URL-адресом имени пользователя, чтобы получить учетную запись пользователя:
def start_requests (самостоятельно):
для имени пользователя в user_accounts:
url = f'https: //www.instagram.com/ {username} /? hl = en '
yield scrapy.Request (get_url (url), callback = self.parse)
Войти в полноэкранный режимВыйти из полноэкранного режимаФункция start_requests выполнит итерацию по списку user_accounts, а затем отправит запрос в Instagram, используя scrapy yield .Request (get_url (url), callback = self.parse) , где ответ отправляется функции parse в обратном вызове.
Паук №2: парсинг почтовых данных
Хорошо, теперь, когда мы получили ответ от Instagram, мы можем извлечь нужные данные.
На первый взгляд, данные, которые нам нужны, такие как URL изображений, лайки, комментарии и т. Д., Похоже, не содержатся в данных HTML. Однако при более внимательном рассмотрении мы увидим, что данные представлены в форме словаря JSON в теге сценариев, который начинается с «window._sharedData ».
Это связано с тем, что Instagram сначала загружает макет и все необходимые данные из своего внутреннего API GraphQL, а затем помещает данные в правильный макет.
Мы могли бы очистить эти данные напрямую, если бы напрямую запросили конечную точку Instagrams GraphQL, добавив «/? __ a = 1» в конец URL-адреса. Например:
https://www.instagram.com/nike/?__a=1/
Войти в полноэкранный режимВыйти из полноэкранного режимаНо мы не сможем перебирать все страницы, поэтому вместо этого мы получим ответ HTML, а затем извлечем данные из окна._sharedData JSON словарь.
Поскольку данные уже отформатированы как JSON, будет очень легко извлечь нужные данные. Мы можем просто использовать простой селектор XPath, чтобы извлечь строку JSON, а затем преобразовать ее в словарь JSON.
def parse (сам, ответ):
x = response.xpath ("// сценарий [начинается с (., 'window._sharedData')] / text ()"). extract_first ()
json_string = x.strip (). split ('=') [1] [: - 1]
данные = json.loads (json_string)
Войти в полноэкранный режимВыйти из полноэкранного режима Отсюда нам просто нужно извлечь нужные данные из словаря JSON.
def parse (сам, ответ):
x = response.xpath ("// сценарий [начинается с (., 'window._sharedData')] / text ()"). extract_first ()
json_string = x.strip (). split ('=') [1] [: - 1]
данные = json.loads (json_string)
# все, что нам нужно сделать, это проанализировать имеющийся у нас JSON
user_id = data ['entry_data'] ['ProfilePage'] [0] ['graphql'] ['user'] ['id']
next_page_bool = \
data ['entry_data'] ['ProfilePage'] [0] ['graphql'] ['user'] ['edge_owner_to_timeline_media'] ['page_info'] [
'has_next_page']
Edge = data ['entry_data'] ['ProfilePage'] [0] ['graphql'] ['user'] ['edge_felix_video_timeline'] ['edge']
для i в краях:
url = 'https: // www.instagram.com/p/ '+ i [' узел '] [' короткий код ']
видео = я ['узел'] ['is_video']
date_posted_timestamp = i ['узел'] ['t_at_timestamp']
date_posted_human = datetime. fromtimestamp (date_posted_timestamp) .strftime ("% d /% m /% Y% H:% M:% S")
like_count = i ['node'] ['edge_liked_by'] ['count'] if «edge_liked_by» в i ['node']. keys () else ''
comment_count = i ['node'] ['edge_media_to_comment'] ['count'], если 'edge_media_to_comment' в i [
'узел']. ключи () еще ''
captions = ""
если я ['узел'] ['edge_media_to_caption']:
для i2 в i ['node'] ['edge_media_to_caption'] ['edge']:
captions + = i2 ['узел'] ['текст'] + "\ n"
если видео:
image_url = i ['узел'] ['display_url']
еще:
image_url = i ['узел'] ['thumbnail_resources'] [- 1] ['src']
item = {'postURL': url, 'isVideo': видео, 'date_posted': date_posted_human,
'timestamp': date_posted_timestamp, 'likeCount': like_count, 'commentCount': comment_count, 'image_url': image_url,
'captions': captions [: - 1]}
Войти в полноэкранный режимВыйти из полноэкранного режима fromtimestamp (date_posted_timestamp) .strftime ("% d /% m /% Y% H:% M:% S")
like_count = i ['node'] ['edge_liked_by'] ['count'] if «edge_liked_by» в i ['node']. keys () else ''
comment_count = i ['node'] ['edge_media_to_comment'] ['count'], если 'edge_media_to_comment' в i [
'узел']. ключи () еще ''
captions = ""
если я ['узел'] ['edge_media_to_caption']:
для i2 в i ['node'] ['edge_media_to_caption'] ['edge']:
captions + = i2 ['узел'] ['текст'] + "\ n"
если видео:
image_url = i ['узел'] ['display_url']
еще:
image_url = i ['узел'] ['thumbnail_resources'] [- 1] ['src']
item = {'postURL': url, 'isVideo': видео, 'date_posted': date_posted_human,
'timestamp': date_posted_timestamp, 'likeCount': like_count, 'commentCount': comment_count, 'image_url': image_url,
'captions': captions [: - 1]}
fromtimestamp (date_posted_timestamp) .strftime ("% d /% m /% Y% H:% M:% S")
like_count = i ['node'] ['edge_liked_by'] ['count'] if «edge_liked_by» в i ['node']. keys () else ''
comment_count = i ['node'] ['edge_media_to_comment'] ['count'], если 'edge_media_to_comment' в i [
'узел']. ключи () еще ''
captions = ""
если я ['узел'] ['edge_media_to_caption']:
для i2 в i ['node'] ['edge_media_to_caption'] ['edge']:
captions + = i2 ['узел'] ['текст'] + "\ n"
если видео:
image_url = i ['узел'] ['display_url']
еще:
image_url = i ['узел'] ['thumbnail_resources'] [- 1] ['src']
item = {'postURL': url, 'isVideo': видео, 'date_posted': date_posted_human,
'timestamp': date_posted_timestamp, 'likeCount': like_count, 'commentCount': comment_count, 'image_url': image_url,
'captions': captions [: - 1]}
Паук №3: Извлечение URL-адресов видео
Чтобы извлечь URL-адрес видео, нам нужно сделать еще один запрос к этому конкретному сообщению, поскольку эти данные не включены в ответ JSON, ранее возвращенный Instagram.
Если сообщение включает видео, тогда для флага is_video будет установлено значение true, что приведет к тому, что наш парсер запросит страницу публикации и отправит ответ функции get_video .
если видео:
yield scrapy.Request (get_url (url), callback = self.get_video, meta = {'item': item}))
еще:
элемент ['videoURL'] = ''
доходный пункт
Войти в полноэкранный режимВыйти из полноэкранного режима Затем функция get_video извлечет videoURL из ответа.
def get_video (сам, ответ):
# только с первой страницы
item = response. meta ['элемент']
video_url = response.xpath ('// meta [@ property = "og: video"] / @ content'). extract_first ()
элемент ['videoURL'] = video_url
доходный пункт
Войти в полноэкранный режимВыйти из полноэкранного режима meta ['элемент']
video_url = response.xpath ('// meta [@ property = "og: video"] / @ content'). extract_first ()
элемент ['videoURL'] = video_url
доходный пункт
meta ['элемент']
video_url = response.xpath ('// meta [@ property = "og: video"] / @ content'). extract_first ()
элемент ['videoURL'] = video_url
доходный пункт
Паук №4: Перебор доступных страниц
Последняя часть логики извлечения, которую нам нужно реализовать, — это возможность нашего поискового робота перебирать все доступные страницы в этой учетной записи пользователя и очищать все данные.
Как и функция get_video , нам нужно проверить, есть ли еще доступные страницы, прежде чем вызывать функцию parse_pages . Мы делаем это, проверяя, является ли поле has_next_page в словаре JSON истинным или ложным.
next_page_bool = \
data ['entry_data'] ['ProfilePage'] [0] ['graphql'] ['user'] ['edge_owner_to_timeline_media'] ['page_info'] [
'has_next_page']
Войти в полноэкранный режимВыйти из полноэкранного режима Если это правда, то мы извлечем значение end_cursor из словаря JSON и создадим новый запрос для конечной точки Instagrams GraphQL api вместе с user_id , query_hash и т. Д.
, если next_page_bool:
курсор = \
data ['entry_data'] ['ProfilePage'] [0] ['graphql'] ['user'] ['edge_owner_to_timeline_media'] ['page_info'] [
'end_cursor']
di = {'id': user_id, 'first': 12, 'after': cursor}
печать (ди)
params = {'query_hash': 'e769aa130647d2354c40ea6a439bfc08', 'variables': json.dumps (di)}
url = 'https://www.instagram.com/graphql/query/?' + urlencode (параметры)
урожай scrapy.Запрос (get_url (url), callback = self.parse_pages, meta = {'pages_di': di})
Войти в полноэкранный режимВыйти из полноэкранного режима Затем будет вызвана функция parse_pages , которая повторит процесс извлечения всех данных публикации и проверки, есть ли еще страницы.
Разница между этой функцией и исходной функцией синтаксического анализа заключается в том, что она не очищает URL видео каждого сообщения. Однако вы можете легко добавить это, если хотите.
def parse_pages (self, response):
di = response.meta ['pages_di']
данные = json.loads (response.text)
для i в data ['data'] ['user'] ['edge_owner_to_timeline_media'] ['edge']:
видео = я ['узел'] ['is_video']
url = 'https://www.instagram.com/p/' + i ['узел'] ['короткий код']
если видео:
image_url = i ['узел'] ['display_url']
video_url = i ['узел'] ['video_url']
еще:
video_url = ''
image_url = i ['узел'] ['thumbnail_resources'] [- 1] ['src']
date_posted_timestamp = i ['узел'] ['t_at_timestamp']
captions = ""
если я ['узел'] ['edge_media_to_caption']:
для i2 в i ['node'] ['edge_media_to_caption'] ['edge']:
captions + = i2 ['узел'] ['текст'] + "\ n"
comment_count = i ['узел'] ['edge_media_to_comment'] ['count'], если 'edge_media_to_comment' в i ['node'].ключи () еще ''
date_posted_human = datetime.fromtimestamp (date_posted_timestamp) .strftime ("% d /% m /% Y% H:% M:% S")
like_count = i ['node'] ['edge_liked_by'] ['count'] if «edge_liked_by» в i ['node']. keys () else ''
item = {'postURL': url, 'isVideo': видео, 'date_posted': date_posted_human,
'timestamp': date_posted_timestamp, 'likeCount': like_count, 'commentCount': comment_count, 'image_url': image_url,
'videoURL': video_url, 'captions': captions [: - 1]
}
доходный пункт
next_page_bool = данные ['данные'] ['пользователь'] ['edge_owner_to_timeline_media'] ['page_info'] ['has_next_page']
если next_page_bool:
курсор = данные ['данные'] ['пользователь'] ['edge_owner_to_timeline_media'] ['page_info'] ['end_cursor']
di ['после'] = курсор
params = {'query_hash': 'e769aa130647d2354c40ea6a439bfc08', 'переменные': json. свалки (ди)}
url = 'https://www.instagram.com/graphql/query/?' + urlencode (параметры)
yield scrapy.Request (get_url (url), callback = self.parse_pages, meta = {'pages_di': di})
Войти в полноэкранный режимВыйти из полноэкранного режима свалки (ди)}
url = 'https://www.instagram.com/graphql/query/?' + urlencode (параметры)
yield scrapy.Request (get_url (url), callback = self.parse_pages, meta = {'pages_di': di})
свалки (ди)}
url = 'https://www.instagram.com/graphql/query/?' + urlencode (параметры)
yield scrapy.Request (get_url (url), callback = self.parse_pages, meta = {'pages_di': di})
Going Live!
Наконец, мы почти готовы к запуску. Последнее, что нам нужно сделать, — это настроить наших пауков на использование прокси-сервера, чтобы мы могли масштабировать очистку без блокировки.
Для этого проекта я выбрал Scraper API, так как он очень прост в использовании и потому, что они имеют большой успех при парсинге Instagram.
Scraper API — это API прокси, который управляет всем, что связано с прокси за вас. Вам просто нужно отправить им URL-адрес, который вы хотите очистить, и их API направит ваш запрос через один из их пулов прокси и вернет вам ответ HTML.
Чтобы использовать Scraper API, вам необходимо зарегистрировать бесплатную учетную запись здесь и получить ключ API, который позволит вам делать 1000 бесплатных запросов в месяц и использовать все дополнительные функции, такие как рендеринг Javascript, геотаргетинг, резидентные прокси и т. Д.
Далее нам нужно интегрировать его с нашим пауком. Читая их документацию, мы видим, что есть три способа взаимодействия с API: через одну конечную точку API, через их Python SDK или через их порт прокси.
Для этого проекта я интегрировал API, настроив своих пауков для отправки всех наших запросов в их конечную точку API.
API = ‘’
def get_url (url):
payload = {'api_key': API, 'url': url}
proxy_url = 'http: // api.scraperapi.com/? ' + urlencode (полезная нагрузка)
вернуть proxy_url
Войти в полноэкранный режимВыйти из полноэкранного режима А затем измените наши функции паука, чтобы использовать прокси Scraper API, установив для параметра url в scrapy.Request значение get_url (url) . Например:
Например:
def start_requests (самостоятельно):
для имени пользователя в user_accounts:
url = f'https: //www.instagram.com/ {username} /? hl = en '
yield scrapy.Request (get_url (url), callback = self.разобрать)
Войти в полноэкранный режимВыйти из полноэкранного режима Мы также должны изменить настройки пауков, чтобы установить для allowed_domains значение api.scraperapi.com, а максимальное количество одновременных запросов на домен — равным пределу параллелизма нашего плана Scraper API. Что в случае бесплатного плана Scraper API — это 5 параллельных потоков:
класс InstagramSpider (scrapy.Spider):
name = 'instagram'
allowed_domains = ['api.scraperapi.com']
custom_settings = {'CONCURRENT_REQUESTS_PER_DOMAIN': 5}
Войти в полноэкранный режимВыйти из полноэкранного режимаКроме того, мы должны установить RETRY_TIMES , чтобы сообщить Scrapy о повторении любых неудачных запросов (например, до 5) и убедиться, что DOWNLOAD_DELAY и RANDOMIZE_DOWNLOAD_DELAY не включены, поскольку они снизят ваш параллелизм и не нужны для Scraper API.
Одним из преимуществ извлечения данных непосредственно из ответа JSON от GraphQL API является то, что нам не нужно писать какие-либо конвейеры для очистки данных, поскольку их уже можно использовать.
Теперь все готово. Вы можете протестировать паука еще раз, запустив его с помощью команды crawl.
сканирование scrapy instagram -o test.csv
Войти в полноэкранный режимВыйти из полноэкранного режимаПосле завершения паук сохранит данные учетных записей в файле csv.
Если вы хотите запустить паука для себя или изменить его для своего конкретного проекта в Instagram, не стесняйтесь делать это. Код находится здесь на GitHub. Просто помните, что вам нужно получить собственный ключ API Scraper API, зарегистрировавшись здесь.
Получение данных профиля Instagram с помощью Python
Получение данных профиля Instagram с помощью Python
Instagram — это социальная сеть для обмена фотографиями и видео, принадлежащая Facebook. В этой статье мы узнаем, как получить данные профиля Instagram с помощью веб-скрапинга.Python предоставляет мощные инструменты для парсинга веб-страниц, здесь мы будем использовать BeautifulSoup.
Требуемые модули и установка:
Запросы:
Запросы позволяют очень легко отправлять запросы HTTP / 1.1. Нет необходимости вручную добавлять строки запроса к своим URL-адресам.
запросов на установку pip
Beautiful Soup:
Beautiful Soup — это библиотека, которая упрощает очистку информации с веб-страниц. Он располагается поверх анализатора HTML или XML, предоставляя идиомы Pythonic для итерации, поиска и изменения дерева синтаксического анализа.
pip install beautifulsoup4
Explanation —
Для данного имени пользователя будет выполнено извлечение данных, а затем будет выполнен синтаксический анализ данных, чтобы выходные данные можно было прочитать. Результатом будет описание, то есть количество подписчиков, количество подписчиков, количество сообщений.
Ниже представлена реализация —
имя пользователя = «geeks_for_geeks» |
 split (
split ( {'Последователи': '120. 2k ',' Follow ':' 0 ',' Posts ':' 702 '}  2k ',' Follow ':' 0 ',' Posts ':' 702 '}
2k ',' Follow ':' 0 ',' Posts ':' 702 '} Внимание, компьютерщик! Укрепите свои основы с помощью курса Python Programming Foundation и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS .
Проголосуйте за сложность
Текущая сложность: ЛегкоЛегко Обычный Середина Жесткий Expert
парсить данные из Instagram | Octoparse
Последняя версия этого руководства доступна здесь.Пойдите, чтобы проверить сейчас!
В этом уроке мы собираемся очистить данные из Instagram, включая контент публикации, дату, URL-адрес изображения, количество лайков и местоположение.
Чтобы продолжить, вы можете использовать этот URL-адрес в учебнике:
https://www.instagram.com/izkiz/
Вот основные шаги в этом руководстве: [Загрузите демонстрационный файл задачи здесь]
1) «Перейти на веб-страницу» - открыть целевую веб-страницу.
2) Создайте цикл нумерации страниц - для очистки данных из нескольких сообщений
3) Извлечь данные - выбрать данные для извлечения
4) Настройте поле данных с помощью инструмента RegEx - чтобы изменить имя поля (необязательно)
5) Сохранить и запустить извлечение - запустить задачу и получить данные
1) «Перейти на веб-страницу» - открыть целевую веб-страницу.
· Создайте задачу в «Расширенном режиме».
· Вставьте URL-адрес в поле «URL-адрес для извлечения» и нажмите «Сохранить URL-адрес», чтобы перейти к
· Изменить встроенный браузер по умолчанию
Встроенный браузер Octoparse 7 по умолчанию несовместим с Instagram. Чтобы наша целевая страница загружалась нормально, нам нужно изменить настройки браузера.
Чтобы наша целевая страница загружалась нормально, нам нужно изменить настройки браузера.
· Нажмите «Настройка»
Если вы используете Octoparse 7.0.2, сохраните задачу перед изменением настроек
· Переключите встроенный браузер по умолчанию на Firefox 45.0.
· Нажмите «Сохранить», чтобы применить измененную настройку.
2) Создайте цикл нумерации страниц - для очистки данных из нескольких сообщений
Мы можем использовать кнопку «>» как кнопку «Следующая страница», чтобы перейти к следующему посту. Перед созданием цикла пагинации нам нужно вернуться к первому посту.
· Щелкните первое сообщение и щелкните тег «A» в нижней части «Советы по действию».
Когда вы выбираете элемент с URL-адресом, выбранный тег будет «A».Обычно изменять не нужно, поскольку Octoparse автоматически определяет теги выбранных элементов. Но в этом случае нам нужно изменить тег в нижней части «Подсказки к действию».
· Выберите «Щелкните ссылку»
У нас открылся первый пост. Однако, поскольку Instagram загружает контент с помощью AJAX, мы должны настроить загрузку AJAX для действия «Щелкните элемент».
· Снимите флажок «Автоповтор при отсутствии ответа»
· Отметьте «Загрузить страницу с помощью AJAX»
· Установить «Тайм-аут AJAX»
Теперь мы можем создать «Пагинацию»
· Нажмите кнопку ">"
· Нажмите «Цикл, щелкните следующую страницу» в «Подсказках».
Instagram использует AJAX для кнопки «>», поэтому нам также необходимо настроить загрузку AJAX для действия «Щелкните для разбивки на страницы».
· Нажмите «Загрузить страницу с помощью AJAX» в «Настроить действие».
· Настроить «Тайм-аут AJAX»
Советы! Чтобы узнать больше о работе с AJAX в Octoparse, обратитесь к разделу Работа с AJAX. |
3) Извлечь данные - выбрать данные для извлечения
Мы сейчас на втором посте.При создании «элемента цикла» мы всегда должны начинать с первого элемента на первой странице. В этом случае мы должны вернуться к первому посту.
· Щелкните «Перейти на веб-страницу» в рабочем процессе
· Нажмите «Щелкните элемент»
Octoparse откроет первый пост.
· Щелкните цикл нумерации страниц в рабочем процессе
Таким образом, мы можем помочь Octoparse определить порядок выполнения и сгенерировать шаг «Извлечь данные» в соответствующей позиции в рабочем процессе.
А теперь приступим к извлечению данных.
· Выберите данные, которые вы хотите
· Щелкните «Извлечь данные» в «Подсказках».
4) Настройте поле данных - чтобы изменить имя поля (необязательно)
· Измените название поля
Ввод или выбор из предопределенных опций.
5) Сохранить и запустить извлечение - запустить задачу и получить данные
· Нажмите «Начать извлечение»
· Выберите «Локальное извлечение», чтобы начать выполнение.
Ниже приведен пример вывода.
Была ли эта статья полезной? Свяжитесь с нами в любое время, если вам понадобится наша помощь!
.