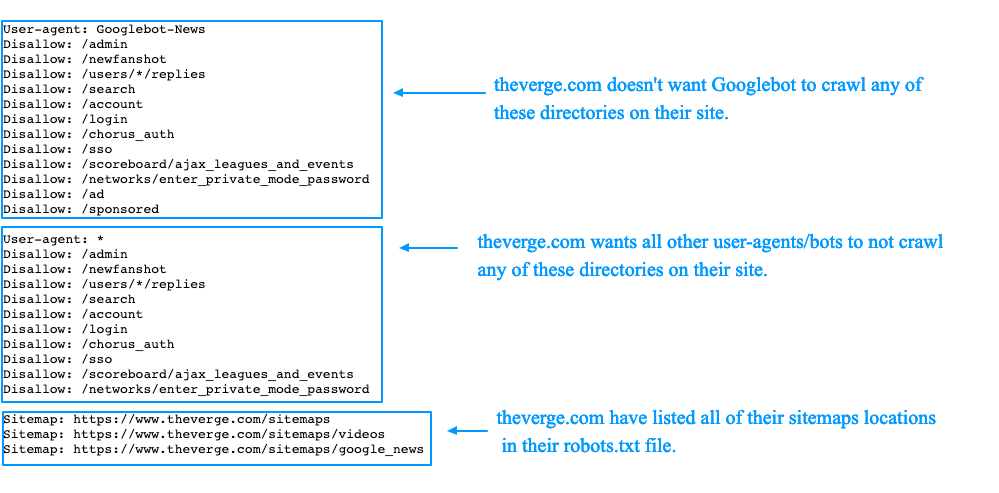
Как управлять роботом (зеркала, sitemap, robots txt)
- Eye 4 547
- Chatbubbles 0
- CategoriesSEO, Яндекс
Содержание
Как управлять роботом
Сейчас мы с вами поговорим, как можно повлиять на робота, чтобы он индексировал то, что нам было нужно, или наоборот не индексировал.
Robots.txt – строгая инструкция для робота.
Мне кажется, самая популярная тема, о которой уже говорилось много раз, но она всегда считает актуальной, это файл robots.txt. Сам по себе robots.txt – это определенный набор инструкций, строгих инструкций для индексирующего робота, которые показывают, что можно индексировать, а что нет.
Этот файл находится в корне вашего сайта, имеет имя robots. txt и обязательно начинается со строки User-Agent – эта директива показывает то, какие правила, перечисленные ниже, будут предназначены для того или другого робота.
txt и обязательно начинается со строки User-Agent – эта директива показывает то, какие правила, перечисленные ниже, будут предназначены для того или другого робота.
Самая распространенная директива – Disallow/Allow, которая запрещает или разрешает индексирование тех или иных страниц. Здесь можно запрещать и дублирующие страницы, и служебные, и скрипты, и все, что угодно. Особенно важна эта директива, если у вас на сайте хранятся какие-то пользовательские данные.
Например, договор, адрес доставки, мобильный телефон и прочее. Эту информацию, естественно, нужно закрыть от индексирующего робота, чтобы она не включилась в результаты поиска.
Следующая директива – это директива Clean-param, которая позволит вам удалить ненужные параметры из URL-адресов страниц, если вы используете их, например, для отслеживания того, откуда именно пришел на ваш сайт индексирующий робот.
Директива Crawl-delay задает интервал между окончанием запроса одной страницы роботом и началом запроса другой страницы.
Следующая директива – это директива Sitemap, которая указывает на наличие и адрес соответствующего файла на вашем сайте.
Директива Host покажет на адрес главного зеркала.
Файл robots.txt
Давайте посмотрим пример типичного файла robots.txt. Начинается файл с директивы «User-agent: *», показывая то, что используется для всех индексирующих роботов, если не указано иначе.
Во втором блоке, как раз, указано иначе «User-agent: Yandex», предназначен для наших индексирующих роботов. Директива «Disallow: /admin» показывает на то, что нужно запретить обход всех страниц, которые начинаются с админа. «Disallow: */cart=*» запрещает любые действия, любые get-параметры, содержащие этот адрес.
Так же дополнительные директивы: «Clean-param», как раз, например, очищает идентификатор сессии, «Crawl-delay», в данном случае робот будет запрашивать две страницы за одну секунду.
Директивы «Host» и «Sitemap». Директива «Sitemap» является межсекционной, она может находиться в любой части вашего файла robots.txt.
Какие самые распространенные ошибки допускаются веб-мастерами при работе с файлом robots.txt? Сюда относятся неправильные указания или, когда запретили какие-то страницы к обходу.
Ошибки при работе с robots.txt
Действительно, самые популярные проблемы – это ошибки в содержимом файла. Даже самые опытные вебмастера допускают такие ошибки, допускают вылеты сайта из результатов поиска, поскольку сайт полностью становится недоступен для индексирующего робота.
Вторая по популярности проблема при работе с robots.txt – это код ответа отличный от кода 200. Самый распространенный случай в данной ситуации. Например, у вас есть служебный домен, служебный домен вылез в результаты поиска, что вы делаете? Вы закрываете «Disallow: /all» на служебном домене, при этом настраиваете индексирующему роботу HTTP-код ответа 403.
Робот приходит, запрашивает ваш файл robots.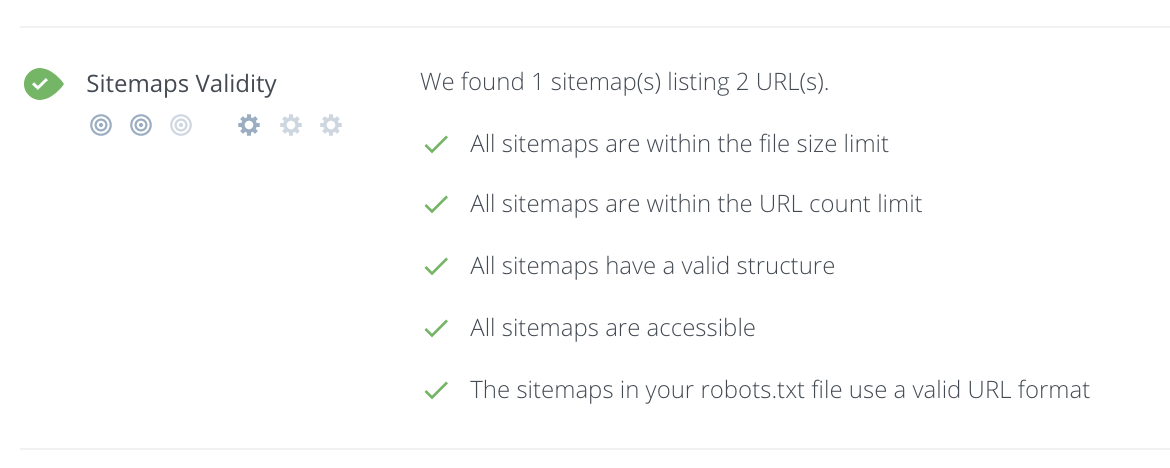 txt и видит код ответа отличный от кода 200, он игнорирует эту инструкцию и считает, что тут находится полностью разрешающий файл, что все адреса, которые ему известны, можно индексировать и включать в результаты поиска. И на переобход вашего запрещенного сайта, на удаление его из выдачи потребуется очень много времени, гораздо больше, чем если бы robots.txt возвращал код ответа 200.
txt и видит код ответа отличный от кода 200, он игнорирует эту инструкцию и считает, что тут находится полностью разрешающий файл, что все адреса, которые ему известны, можно индексировать и включать в результаты поиска. И на переобход вашего запрещенного сайта, на удаление его из выдачи потребуется очень много времени, гораздо больше, чем если бы robots.txt возвращал код ответа 200.
Следующая распространенная ошибка – это наличие кириллических символов в файле robots.txt. Да, такие символы использовать нельзя, потому что робот тоже их проигнорирует.
Самый распространенный случай ошибки – это, например, если условные лютикицветочки.рф в директиве «Host» вы указали не в закодированном виде, хотя нужно указывать в закодированном в Punycode. То есть вот правильный и неправильный вариант.
И последнее, наверное, не по популярности из этого топа – это размер файла превышающий 32Кб. Робот, получая такой файл, считает, что здесь находится не файл текстового типа, а обычная страничка и то, что эту страничку не нужно учитывать при обходе сайта, поэтому будет ее игнорировать.
Вот самые популярные проблемы. Само по себе наличие файла robots.txt не обязательно. Если у вас действительно landing page какой-нибудь, да, то есть у вас одна только страница физически находится на сайте, то вы можете не создавать файл robots.txt, либо оставить его совершенно пустым.
Все эти ошибки в любом случае можно предотвратить если пользоваться простейшим инструментом в Яндекс.Вебмастере – «Анализатор robots.txt». Вставляете адрес вашего сайта, нажимаете кнопочку «загрузить robots.txt» и видите то, что сейчас уже там находится, затем добавляете список url-адресов страниц и нажимаете кнопочку проверить.
Можно редактировать, посмотреть, как робот воспримет то или иное, в любом случае, если вносите какие-то серьезные изменения в файл robots.txt, даже если вы знаете и делали это много раз, перестрахуйтесь, используйте этот инструмент, в любом случае он будет полезен и поможет предотвратить все, о чем мы до этого говорили.
- Помощь вебмастеру (Использование robots.
 txt)
txt)
 txt)
txt)И полезным в работе вам в любом случае будет – это стандарт файла robots.txt и раздел помощи вебмастеру. Там обо всех директивах, то, что я рассказывал, все это указано, написаны примеры, можно посмотреть.
Sitemap – карта вашего сайта
Мы с вами запретили посещать те или иные страницы на сайте, теперь нужно показать роботу какие все-таки страницы нужно индексировать и включать в поисковую выдачу. Для этого существует специальный файл – файл Sitemap.
Как правило, это либо текстовый документ, либо XML-файл, который, собственно, содержит адреса страниц и, возможно, какую-то дополнительную информацию. Пример файла Sitemap вы можете сейчас наблюдать на данном слайде.
Файл должен обязательно начинаться со служебной строки, указывающей на кодировку – «UTF-8», обязательно стандарт, в соответствии с которым он составлен, и обязательные теги: тег «url» и тег «loc», соответственно, он показывает адрес страницы.
Это самый простой файл Sitemap, здесь всего одна страница – это морда, плюс есть необязательные теги, которые также можно передавать роботу, и, которые, робот может учитывать.
«lastmod» показывает последнюю дату изменения страницы, «changfreq» — периодичность ее изменения и «priority» — приоритет при обходе вашего сайта в целом. Эти теги можно передавать индексирующему роботу, они могут им учитываться при обходе вашего сайта, но они являются необязательными.
В файле Sitemap нет строгой инструкции, но в любом случае хорошо, когда он есть.
Ошибки при работе с Sitemap
И плохо, когда мы в Sitemap допускаем, опять-таки, какие-либо ошибки. Самая распространенная ошибка, с которой сталкиваются веб-мастера – это когда индексирующему роботу указывают файл Sitemap, который находится на другом сайте.
Например, если вы используете бесплатный генератор файлов Sitemap, который автоматически размещает этот файл Sitemap у себя на сайте. Робот не будет обрабатывать такой файл просто потому, что в соответствии со стандартом, файл должен находиться на том хосте, на том сайте, ссылки которого указаны внутри самого сайта.
Вторая по популярности проблема – это установленные перенаправления файла Sitemap. Например, у вас файл находится по стандартному адресу Sitemap.xml, и там находится редирект, который ведет уже на какую-то внутреннюю страницу, какой-то внутренний адрес. Робот тоже не обрабатывает такие файлы Sitemap. Обязательно файл Sitemap должен возвращать код ответа 200.
И, последнее – это какие-то ошибки внутри, критические ошибки внутри самого файла, которые тоже влияют на его обработку. Например, если отсутствует служебная строка с указанием кодировки, робот просто проигнорирует такой файл и не будет использовать его при обходе.
Sitemap:
- Валидатор в Яндекс.Вебмастере
- Помощь Вебмастеру (Использование файла Sitemap)
В работе с файлом Sitemap вам пригодится валидатор в Яндекс. Вебмастере, где можно проверить все эти ошибки, проверить ваш готовый файл, размещенный на сервере либо на компьютере. Также поможет стандарт файлов Sitemap, переведенный на русский язык и, соответственно, раздел помощи вебмастеру.
Вебмастере, где можно проверить все эти ошибки, проверить ваш готовый файл, размещенный на сервере либо на компьютере. Также поможет стандарт файлов Sitemap, переведенный на русский язык и, соответственно, раздел помощи вебмастеру.
Зеркала сайта
Как правило, любой сайт в Интернете доступен по двум адресам: www и без www. Для индексирующего робота в первоначальном виде это два независимых ресурса, они индексируются независимо и участвуют в поиске независимо друг от друга.
Что это значит? Что у вас у одного сайта может быть проиндексировано определенное количество страниц, а не находиться по таким-то запросам, а у второго сайта может быть совсем другая ситуация. Для того, чтобы избежать такого дублирования, перемешивания и непонимания, мы используем такое понятие, как «зеркала сайтов».
В общем понимании зеркала сайтов – это несколько сайтов, которые обладают одинаковым контентом. В данном случае, это с www, без www, это сайт, например, по протоколу https и адрес сайта на кириллице. Это самые распространенные случаи.
Это самые распространенные случаи.
Зачем вообще все это нужно? Основная причина, для которой сейчас используются зеркала сайтов, это перенос сайта со старого адреса на новый. Например, вы решили изменить доменное имя по каким-либо причинам, потому что выбрали его десять лет назад и сейчас оно кажется вам каким-то несовременным, потому что сложно писать пользователям, которые вбивают его в адресную строку и постоянно делают какие-то ошибки, появляется какое-то недопонимание.
И во-вторых, это как раз для того, чтобы предотвратить ошибочные переходы по другим адресам. В первом случае, если мы совершаем переезд с использованием зеркал, мы сохраняем все характеристики нашего старого сайта для нового сайта. Соответственно мы минимизируем какие-либо возможные проблемы.
Каким образом сайты можно сделать зеркалами?
- Указать роботу на адрес вашего главного зеркала, которое должно находиться в результатах поиска, можно с помощью директивы «Host» в вашем файле robots. txt. Указали адрес и это будет прямое направление роботу о том, что нужно подключать адрес по определенному адресу в поиске.
- Сообщить роботу об изменениях, например, если у вас уже есть сайты с www, без www, можно с помощью соответствующего инструмента в Яндекс.Вебмастере. Но сам по себе инструмент не позволяет изменить адрес главного зеркала, это делает именно директива «Host».
- И последний пункт, который я хотел бы порекомендовать использовать, но только очень аккуратно и в крайнем случае – это серверное перенаправление, допустим, не главного зеркала на новый адрес сайта. Почему? Потому что самая распространенная ошибка при использовании зеркал – это наличие этого перенаправления, как основного указания для переклейки имеющейся группы зеркал.
 txt. Указали адрес и это будет прямое направление роботу о том, что нужно подключать адрес по определенному адресу в поиске.
txt. Указали адрес и это будет прямое направление роботу о том, что нужно подключать адрес по определенному адресу в поиске.Допустим у нас есть два сайта. Сайт А – сейчас главное зеркало. Он у нас индексируется, находится в результатах поиска, участвует по запросам. А сайт Б – сейчас он не главное зеркало, в выдаче мы его не видим. Теперь мы принимаем решение, что нам нужно включать в результаты поиска именно сайт Б и устанавливаем перенаправление с сайта А на сайт Б.
Что происходит дальше? Главное наше зеркало, сайт А, перестает участвовать в результатах поиска просто потому, что на нем сейчас установлено перенаправление, и его страницы сейчас недоступны для робота, поэтому они начинают исключаться из поисковой выдачи. Сайт Б при этом, поскольку является неглавным зеркалом, в поиске не участвует, не индексируется и не показывается по каким-либо запросам.
Хочу привести небольшой пример из сервиса Яндекс.Метрика с установленным перенаправлением.
Я думаю, что тут все понятно – это количество переходов. Мы видим, что после установки, буквально в течение двух недель, страницы сайта начали исключаться из поисковой выдачи. Продолжалось это продолжительное время, до того момента, как изменился адрес главного зеркала.
Ошибки при работе с зеркалами
Выделяют типичные ошибки при работе с зеркалами, помимо установки редиректа для смены адреса главного зеркала:
- Это разное содержимое на ваших сайтах при попытке склеить их, объединить в группы зеркал. Например, вы хотите объединить и сделать одновременно: изменить дизайн на вашем сайте и изменить адрес главного зеркала. Чтобы сайты были зеркалами, на них одновременно для робота должен находиться один и тот же контент. В данном случае я советую вам делать поэтапно. Либо сначала делать редизайн, потом менять главное зеркало, либо наоборот, размещать по новому адресу старый контент, ждать склейки, потом делать редизайн сайта, чтобы не было каких-либо проблем. Если контент будет разный, вы не склеите, потеряете время и посетителей.
- Вторая распространенная проблема – это частный случай, наверное, разного содержимого, это переезд вашего какого-либо сайта в раздел другого ресурса. Например, у вас есть два сайта: один сайт занимается, например, роботами-пылесосами, а второй бытовой техникой. Вы решаете, что роботы-пылесосы это тоже относится к бытовой технике, поэтому можно объединить их в один большой ресурс. Каким образом? Устанавливаете директиву «Host» и ждете. Ничего не происходит, просто потому, что у вас на одном адресе находится один сайт, а на другом другой. Директива «Host» здесь не поможет, и объединить такие сайты в группу зеркал не получится. В подобных ситуациях можно открывать раздел на вашем большом ресурсе, после того, как эти страницы начнут индексироваться, можно установить 301 редирект с вашего маленького сайта на этот раздел. К сожалению, склеить в такой ситуации сайты не получится.
- Еще одна из самых распространенных проблем – это запрет или недоступность вашего старого зеркала. Бывает так, что веб-мастера забывают продлевать доменные имена, спустя какое-то время они покупают новое доменное имя, хотят объединить данные сайты в группу зеркал. Поскольку доступ к вашему старому сайту уже утерян, то склеить данные сайты не получится. Их нельзя склеить как-то вручную, как-то применить какие-то настройки. Чтобы сайты могли быть склеены, они должны быть доступны для индексирования и находиться в вашем управлении.
- И последняя по популярности – это противоречивые указания для индексирующего робота о том, по какому адресу сайт должен индексироваться и находиться в поисковой выдаче. Например, директивой «Host» указали один адрес, редирект поставили по другому адресу, робот автоматически выберет на свое усмотрение, соответственно, с определенным алгоритмом выберет адрес главного зеркала. Иногда бывает, что это не тот адрес, который вы хотели. Тут нужно внимательнее, если вы решаете переезд на новый домен, все указания должны вести именно на этот домен.
 Например, вы хотите объединить и сделать одновременно: изменить дизайн на вашем сайте и изменить адрес главного зеркала. Чтобы сайты были зеркалами, на них одновременно для робота должен находиться один и тот же контент. В данном случае я советую вам делать поэтапно. Либо сначала делать редизайн, потом менять главное зеркало, либо наоборот, размещать по новому адресу старый контент, ждать склейки, потом делать редизайн сайта, чтобы не было каких-либо проблем. Если контент будет разный, вы не склеите, потеряете время и посетителей.
Например, вы хотите объединить и сделать одновременно: изменить дизайн на вашем сайте и изменить адрес главного зеркала. Чтобы сайты были зеркалами, на них одновременно для робота должен находиться один и тот же контент. В данном случае я советую вам делать поэтапно. Либо сначала делать редизайн, потом менять главное зеркало, либо наоборот, размещать по новому адресу старый контент, ждать склейки, потом делать редизайн сайта, чтобы не было каких-либо проблем. Если контент будет разный, вы не склеите, потеряете время и посетителей. Директива «Host» здесь не поможет, и объединить такие сайты в группу зеркал не получится. В подобных ситуациях можно открывать раздел на вашем большом ресурсе, после того, как эти страницы начнут индексироваться, можно установить 301 редирект с вашего маленького сайта на этот раздел. К сожалению, склеить в такой ситуации сайты не получится.
Директива «Host» здесь не поможет, и объединить такие сайты в группу зеркал не получится. В подобных ситуациях можно открывать раздел на вашем большом ресурсе, после того, как эти страницы начнут индексироваться, можно установить 301 редирект с вашего маленького сайта на этот раздел. К сожалению, склеить в такой ситуации сайты не получится. Например, директивой «Host» указали один адрес, редирект поставили по другому адресу, робот автоматически выберет на свое усмотрение, соответственно, с определенным алгоритмом выберет адрес главного зеркала. Иногда бывает, что это не тот адрес, который вы хотели. Тут нужно внимательнее, если вы решаете переезд на новый домен, все указания должны вести именно на этот домен.
Например, директивой «Host» указали один адрес, редирект поставили по другому адресу, робот автоматически выберет на свое усмотрение, соответственно, с определенным алгоритмом выберет адрес главного зеркала. Иногда бывает, что это не тот адрес, который вы хотели. Тут нужно внимательнее, если вы решаете переезд на новый домен, все указания должны вести именно на этот домен.В работе вам так же поможет раздел помощи, и всегда вы можете, если не уверены в каких-либо настройках, написать в службу поддержки для того, чтобы проверили, что действительно указания верны и зеркала склеятся.
- Помощь Вебмастеру (Зеркала сайтов)
- Обратная связь
Полезное:
- Настройка индексирования сайта в Яндексе: от теории к практике
- Как поиск находит страницу сайта? Описание процесса индексации страниц сайта
Источник (видео): Как управлять роботом (зеркала, sitemap, robots txt) – Александр Смирнов
Магомед Чербижев
Поделиться:
Об авторе
Никита Пасечник
Эксперт в области продвижения и интернет-маркетинга. Специалист по бизнес-решениям. Опыт работы более 10 лет. Более 5 000 часов активных тренингов и практик.
Специалист по бизнес-решениям. Опыт работы более 10 лет. Более 5 000 часов активных тренингов и практик.
Подробнее
Нужно ли загружать файл robots.txt и sitemap.html в Гугл Search Consolе? — Вопрос от Александр Кузьмин #2
- Вопросы
- Горячие
- Пользователи
- Вход/Регистрация
>
Категории вопросов
Задать вопрос +
Основное
- Вопросы новичков (16476)
- Платные услуги (2118)
- Вопросы по uKit (81)
Контент-модули
- Интернет-магазин (1431)
- Редактор страниц (236)
- Новости сайта (498)
- Каталоги (805)
- Блог (дневник) (111)
- Объявления (295)
- Фотоальбомы (433)
- Видео (255)
- Тесты (60)
- Форум (576)
Продвижение сайта
- Монетизация сайта (219)
- Раскрутка сайта (2451)
Управление сайтом
- Работа с аккаунтом (5311)
- Поиск по сайту (426)
- Меню сайта (1765)
- Домен для сайта (1531)
- Дизайн сайта (13464)
- Безопасность сайта (1474)
- Доп. функции (1307)
 функции (1307)
функции (1307)Доп. модули
- SEO-модуль (225)
- Опросы (63)
- Гостевая книга (99)
- Пользователи (431)
- Почтовые формы (318)
- Статистика сайта (197)
- Соц. постинг (212)
- Мини-чат (91)
 постинг (212)
постинг (212)Вебмастеру
- JavaScript и пр. (644)
- PHP и API на uCoz (235)
- SMS сервисы (10)
- Вопросы по Narod. ru (427)
- Софт для вебмастера (39)
 ru (427)
ru (427)…
Карта сайта в формате XML и файл robots.txt
Вот что вам нужно знать о настройке карты сайта в формате XML и файла robots.txt. Посмотрите несколько примеров и как начать.
Любой, кто разбирается в сложности поисковой оптимизации (SEO), знает, что важная часть повышения рейтинга веб-сайта в поисковых системах включает в себя разрешение сканирования и индексации его страниц чем-то, известному как бот или робот.
Эти боты предназначены для проверки удобства использования и актуальности определенных веб-сайтов для пользователей поисковых систем, предоставления и ранжирования результатов в соответствии с их выводами.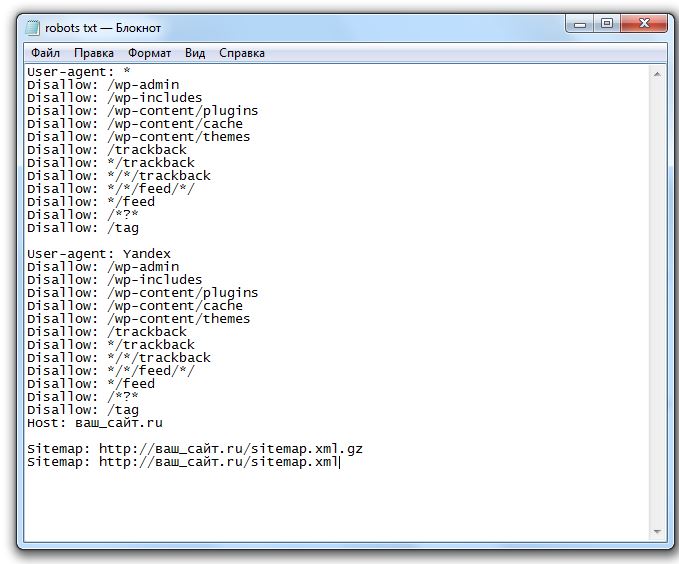
Чтобы убедиться, что ваш веб-сайт предоставляет ботам всю информацию, необходимую им для быстрого и эффективного чтения вашего веб-сайта, вам необходимо сосредоточиться на двух важных файлах: файле robots.txt и XML-карте сайта.
Что такое файл robots.txt?
Этот файл известен как директива сканирования. Другими словами, он указывает ботам поисковых систем сканировать веб-сайт определенным образом, следуя строгому синтаксису. Цель файла — сообщить поисковым системам, какие URL-адреса им разрешено индексировать на данном веб-сайте.
Для компаний важно размещать этот файл на своих веб-сайтах, так как это первое, что бот будет искать при входе на ваш сайт. Даже если вы хотите, чтобы бот просканировал все страницы вашего сайта, вам понадобится файл robots.txt по умолчанию, чтобы направить его так, чтобы это приносило пользу вашему SEO.
Куда следует поместить файл robots.txt?
Файл robot.txt всегда должен располагаться в корне домена веб-сайта. Другими словами, если у вас есть веб-сайт, такой как https://www.segmentseo.com, файл будет находиться по адресу https://www.segmentseo.com/robots.txt.
Другими словами, если у вас есть веб-сайт, такой как https://www.segmentseo.com, файл будет находиться по адресу https://www.segmentseo.com/robots.txt.
Каковы преимущества использования robots.txt?
Вообще говоря, поисковые роботы заходят на веб-сайт с заранее определенным «допуском», определяющим, сколько страниц им разрешено сканировать в зависимости от размера или репутации сайта. Это также известно как «краулинговый бюджет».
С помощью файла robot.text вы можете запретить поисковым системам вводить проблемные части вашего сайта, которые могут быть недостаточно оптимизированы для маркетинговых целей. Если вы решите оптимизировать содержимое позже, вы можете отредактировать файл и снова разрешить его.
Что такое карта сайта в формате XML?
Карта сайта XMP — это документ, в котором перечислены все страницы веб-сайта. Разработанный для поисковых систем, он предлагает информацию о доступном контенте и способах его доступа. Иногда он также предоставляет информацию о том, когда в последний раз обновлялись отдельные страницы и насколько важны определенные части сайта для пользователей или потенциальных клиентов.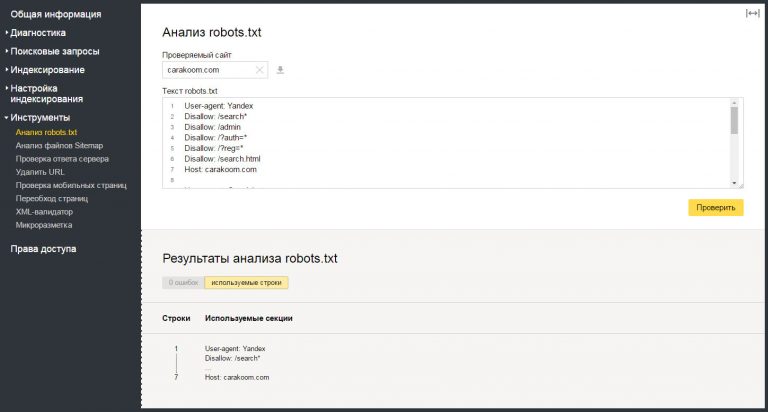
Проще говоря, XML-карта сайта предлагает поисковым системам моментальный снимок всего доступного содержимого веб-сайта одновременно. Это позволяет им молниеносно находить недавно добавленный контент и упрощает понимание содержания сайта.
Важно не путать карты сайта в формате XML с картами сайта, с которыми регулярно сталкиваются обычные пользователи Интернета (известными как карты сайта в формате HTML). В то время как последний предназначен для обучения пользователей веб-сайта, первый предназначен исключительно для использования поисковыми системами.
Почему файлы Sitemap в формате XML важны?
XML-карты сайта — это эффективный способ оповещения поисковых систем при создании или обновлении содержимого. Действительно, они являются жизненно важной частью любой достойной стратегии SEO, особенно если ваш сайт может похвастаться большим количеством страниц.
Где должен находиться файл Sitemap в формате XML?
Важно разместить XML-карту сайта на специальном URL-адресе. Обычно разработчики веб-сайтов размещают карту сайта, например, по адресу https://www.segmentseo.com/sitemap.xml. Однако, если это невозможно, вы можете выделить другое местоположение, если оно указано в вашем файле robots.txt через директиву sitemap. Это гарантирует, что он останется доступным для поисковых систем.
Обычно разработчики веб-сайтов размещают карту сайта, например, по адресу https://www.segmentseo.com/sitemap.xml. Однако, если это невозможно, вы можете выделить другое местоположение, если оно указано в вашем файле robots.txt через директиву sitemap. Это гарантирует, что он останется доступным для поисковых систем.
XML Sitemap и Robots.txt для оптимальной структуры сайта
Брайан Туми, генеральный директор JB Analytics
Карта сайта и robots.txt
Что такое карты сайта и robots.txt?Два основных инструмента, помогающих поисковым системам понять и правильно проиндексировать ваш веб-сайт, — это XML-файл карты сайта и файл Robots.txt.
- XML-карта сайта: XML-документ, который показывает поисковым системам общую структуру и взаимосвязь контента на вашем сайте.
- Robots.txt: файл, определяющий, что следует исключить из индексации.
В сочетании оба файла должны давать полную и точную картину того, какой контент вы хотите, чтобы поисковая система проиндексировала, и как он организован.
Вкратце: используйте карту сайта, в которой указано, что вы хотите проиндексировать, и не указано то, что вы не хотите индексировать. Перечислите папки или файлы, которые вы не хотите индексировать, в файле robots.txt.
Дополнительные технические элементы:
- Содержимое. Мы рекомендуем перечислять все и только разрешимые HTML-страницы, исключая параметризованное содержимое и архивные файлы.
- Архивные страницы, основанные на дате, такие как приведенные ниже, не имеют большого значения для органического поиска /07/
- https://www.yoursite.com/2010/05/14/
- Хостинг: храните карты сайта на подтвержденном домене.
- Размер: размер отдельных карт сайта в несжатом виде не должен превышать 50 МБ, и каждый из них должен содержать не более 50 000 отдельных URL-адресов.
- Размещение: Карта сайта должна быть размещена либо в /sitemap. xml, либо в месте, указанном в файле robots.txt.
 xml, либо в месте, указанном в файле robots.txt.
xml, либо в месте, указанном в файле robots.txt.Несколько карт сайта могут быть перечислены в файле индекса карты сайта (в /sitemap_index.xml) для облегчения анализа поисковыми системами.
JB Analytics сочетает в себе страсть к данным и аналитике для повышения производительности с оплатой за клик. Они дружелюбны, нацелены на результат, и мы искренне рекомендуем их .
Тони Сирна, координатор по данным и стратегии, Citizens’ Climate Lobby
Локализованный контент и теги Hreflang
Что это такоеТеги Hreflang показывают отношения между страницами одной темы для разных регионов или языков.
В приведенном выше примере показаны поисковые системы, у которых эквивалентные домашние страницы представлены на разных языках.
- На главной странице на немецком языке
- hreflang=»en-us» />
- На домашней странице на английском языке в США
 com/» hreflang=»de-de» />
com/» hreflang=»de-de» />
Теги Hreflang также можно использовать на разные домены. Например:
- На главной странице на немецком языке
- hreflang=»en-us» />
- 5 5 5 5 На домашней странице на английском языке в США
- hreflang=»de-de» />
Установка тегов hreflang помогает поисковым системам предоставлять пользователям нужный контент в нужном месте. Это также помогает поисковым системам понять, как может выглядеть дублированный контент, который на самом деле нацелен на аудиторию из разных мест.
Что делать- При размещении контента на нескольких языках используйте теги hreflang для обозначения связи между страницами в разных доменах или в одном домене.