Instagram рассказал, как устроена рекомендательная система соцсети
Разработчик алгоритма Instagram Амог Махапатра опубликовал статью, в которой рассказал о ценности разнообразных рекомендаций и о том, как работает рекомендательная система соцсети.
Главная дилемма таких систем – оценивать их по предсказательной точности или сосредоточить внимание на расширении предпочтений пользователей.
Другими словами – показывать только то, что нравится пользователям или расширять их опыт, предлагая меньше того, что они любят?
Амог Махапатра рассмотрел 2 смоделированных сценария в динамической обстановке.
Предпочтения пользователей в динамической обстановке
Например, пользователь одинаково предпочитает боевики и комедии. Эти предпочтения обозначены двумя шариками в урне, красным (боевики) и серым (комедии). Предположим, что изначально они одинаково предпочтительны для пользователя. Далее рассматриваются две простые модели того, как предпочтения могут динамически развиваться.
Персонализация
В этой модели пользователь случайным образом вытягивает шарик из урны и смотрит фильм соответствующего жанра. После просмотра кладет его обратно и добавляет еще один шарик того же цвета. Если человек выбрал красный шарик в первом случае, на следующем этапе в урне будет два красных шарика и один серый шарик.
Эта модель положительно подкрепляет выбор пользователя, то есть показывает больше того, что ему нравится.
После тысяч таких манипуляций урна будет заполнена одним цветом, и в нее будет очень сложно добавить другой цвет, даже случайным образом.
Этот процесс известен как «Модель урны Polya» (Pólya urn model). Это отличная игрушечная модель для понимания самоусиливающихся динамических систем. У них одинаково вероятные результаты, зависящие от пути. Но независимо от того, какой путь выбран, в состоянии равновесия (после бесконечных манипуляций) один вариант сильно доминирует над другим.
По аналогии, если пользователю просто показывают больше того, что он предпочитает в настоящее время, он может застрять в небольшом пространстве выбора.
Баланс
Во второй модели случайным образом извлекается шарик из урны, помещается обратно и добавляется еще один шарик противоположного цвета. Например, если был выбран красный шарик, в следующем случае в урне будет один красный шарик и два серых шарика.
Эта модель негативно подкрепляет выбор пользователя, то есть показывает меньше того, что ему нравится.
В конце концов, после бесконечного количества манипуляций в урне находятся равные пропорции каждого цвета. Этот процесс известен как балансировка.
Процессы балансировки – отличная игрушечная модель для самобалансирующихся динамических систем. В такой системе пользователю предоставляется больший набор возможных вариантов.
Получаются две противоположные системы, первая из которых основана на предпочтениях пользователя. Она сильнее вовлекает, но в конечном итоге приводит к скуке и потере вовлеченности и расширения предпочтений.
Другая система не ведет к немедленному взаимодействию, но хороша, для поддержания долгосрочного разнообразия.
Какой модели придерживается рекомендательная система Instagram?
Как выбрать «средний путь» между этими крайностями в создании полезного опыта в долгосрочной перспективе с небольшими краткосрочными компромиссами.
Прежде необходимо понять некоторые основы.
Предпочтения в реальном мире
В игрушечных моделях, можно обозначать предпочтения просто как шарики в урне: статические, точные и одномерные. В реальности предпочтения имеют следующие сложности:
Многомерность: пользователь с одинаковой вероятностью будет более глубоко вовлечен в «черную комедию», которая содержит как элементы триллера, так и общей комедии.
Мягкость: пользователь может демонстрировать различную степень привязанности к типам контента, например, 35% относятся к комедии и 99% – к спорту.
Контекстуальность: предпочтения зависят от контекста с точки зрения предыдущего набора сделанных выборов, способа их представления, текущих тенденций и множества других факторов.
Динамичность: что наиболее важно, предпочтения меняются с течением времени. Человек, который любит исторические документальные фильмы в настоящее время, может не интересоваться ими через месяц.
Чтобы помочь обеспечить более разнообразный пользовательский опыт с учетом строгих количественных и качественных оценок, Амог Махапатра рассмотрел несколько практических методов диверсификации.
Практические методы диверсификации Instagram
1. Разнообразие на уровне авторов: что делать, если один и тот же автор продолжает появляться в сеансе одного пользователя несколько раз? Простая стратификация для выбора ранжируемых кандидатов среди разных авторов может улучшить общий пользовательский опыт.
2. Уровень типа мультимедиа: для разнородной платформы, которая поддерживает множество типов мультимедиа, таких как фотографии, альбомы, короткие видеоролики, длинные видеоролики и т.д. По возможности лучше диверсифицировать типы мультимедиа с точки зрения последовательности.
Например, если алгоритм ранжирования выбирает 3 видео, а затем 2 фотографии для показа, рекомендуется смешивать фотографии и видео, если это не влияет на общие количественные/качественные показатели.
3. Семантическое разнообразие: пользователь может получать рекомендуемые видео о баскетболе от нескольких авторов за один сеанс. Этот вид разнообразия наиболее сложно поддерживать. Лучший способ диверсификации на уровне контента – это сначала разработать систему понимания контента высокого качества. В Instagram были созданы системы понимания фотографий, видео и текста в любом масштабе. Они могут обеспечить как детальное, так и общее понимание медиа-элемента.
4. Изучение подобных семантических узлов: большинство систем понимания контента представляют знания в форме графа или дерева.
Например, фотография дикой природы может быть концепцией более низкого уровня, которая, в свою очередь, ведет к искусству и ремеслам. Как только система узнает основные концепции, которые обычно интересуют пользователя, она может углублять исследование в разных направлениях:
а) Изучение родственных концептов. Образно говоря, если пользователь заинтересовался фотографией дикой природы, скорее всего, его может заинтересовать главная концепция фотографии либо родственные концепции: живопись, уличная фотография, или концепции «дальних родственников» например, объектив, камера и т.д.
Образно говоря, если пользователь заинтересовался фотографией дикой природы, скорее всего, его может заинтересовать главная концепция фотографии либо родственные концепции: живопись, уличная фотография, или концепции «дальних родственников» например, объектив, камера и т.д.
б) Концепция «длинного хвоста»: пользователь, возможно, никогда не сталкивался с тысячами нишевых концепций (например, манга, фестивали народных танцев, тяжелая научная фантастика), которые могли быть интересны подобным людям. Их изучение может привести к более разнообразному опыту.
в) Мультимодальные элементы – элементы, которые охватывают несколько типов интересов. Например, если пользователь сильно интересуется машинным обучением и фотографией дикой природы, возможно пост о применении методов машинного обучения для сохранения дикой природы может быть для него очень интересным.
Так может выглядеть Граф знаний пользователя с учетом подбора семантических узлов
5. Сохранение долгосрочных и краткосрочных предпочтений: у всех людей есть вещи, интересующие их всегда и те, которые интересны в данный момент времени. Поддержание двух отдельных очередей приоритетов, обозначающих долгосрочные и краткосрочные интересы пользователя, может привести к лучшей диверсификации в долгосрочной перспективе.
Сохранение долгосрочных и краткосрочных предпочтений: у всех людей есть вещи, интересующие их всегда и те, которые интересны в данный момент времени. Поддержание двух отдельных очередей приоритетов, обозначающих долгосрочные и краткосрочные интересы пользователя, может привести к лучшей диверсификации в долгосрочной перспективе.
6. Использование алгоритмов компромисса: компромиссные методы исследования и использования, основанные на обучении с подкреплением, могут обеспечить систематический механизм для разнообразия предпочтений пользователей. Вот пара примеров:
а) эпсилон-жадный алгоритм (или алгоритм «Многоруких бандитов»): в этом методе система персонализирует без семантической диверсификации, но время от времени пользователю рандомно показывается почти аналогичный элемент.
б) верхняя граница уверенности: допустим, система знает, что пользователь проявил умеренную заинтересованность в некоторых концепциях, но недостаточно ознакомился с ними. Таким образом, система могла бы исследовать все концепции умеренного интереса пользователя достаточное количество раз, прежде чем у нее будет достаточно уверенности в их исключении.
Таким образом, система могла бы исследовать все концепции умеренного интереса пользователя достаточное количество раз, прежде чем у нее будет достаточно уверенности в их исключении.
7. Вычисление качественного компромисса: Instagram ценит качественные показатели, такие как удовлетворенность и настроения пользователей, не меньше, чем количественные показатели, такие как ROC-кривая или NDCG (метрика качества ранжирования).
Разработчики проводят качественные исследования, опросы пользователей, дневниковые исследования и т. д., чтобы определить лояльность и терпимость к повторяемости и стремление к разнообразию.
8. Негативные ограничения: пользователи сами не любят повторения и иногда (не всегда) будут давать явные отрицательные отзывы. Отрицательная обратная связь связана с такими действиями пользователя, как: нажатие кнопки «не интересно» или «показывать меньше таких видео».
Система учитывает эти негативные сигналы и использует их. Для этого были созданы специальные модели машинного обучения, которые уменьшают количество негативных отзывов. Настройка этих моделей происходит на автономных симуляторах и на выводах, полученных в результате опросов пользователей.
Настройка этих моделей происходит на автономных симуляторах и на выводах, полученных в результате опросов пользователей.
Заключение
Амог Махапатра рекомендует помнить об этих факторах и оптимизировать контент так, чтобы он мог долгосрочно удовлетворять пользователей. Использование исключительно метрик, ориентированных на ранжирование (NDCG), или показателей, ориентированных на продукт (количество лайков), может привести к скуке пользователя и отпискам.
Читайте также:
Instagram назвал 4 метрики, которые влияют на ранжирование постов в ленте
Instagram рассказал, как алгоритмы соцсети выбирают посты для показа в ленте.
Источник: Блог Instagram
CRM-система для Instagram ➤ подбор, внедрение, настройка
CRM системы
Вывести свой маркетинг на новый уровень легко! Конвертируйте все обращений клиентов с Instagram в заказы.
Ваши менеджеры смогут в режиме реального времени отвечать из CRM-системы клиентам на Instagram Директ и комментарии. Подключайте множество аккаунтов.
Подключайте множество аккаунтов.
CRM для инстаграм Украина
Последние годы инстаграм является не только одной из самых популярных соцсетей в мире, но и перспективной площадкой для продажи товаров, по сути маркетплейсом. Поэтому вести огромное количество обращений с директа и комментариев становится не очень удобно. Наша страна не исключение и возникает потребность в crm системе для инстаграм Украина. Но прежде чем внедрить и настроить систему нужно понять — CRM для инстаграм что это? И какие преимущества…
Преимущества CRM для инстаграм:
Рост продаж
Оформляйте заказы не выходя из чата. Продавать удобней и быстрее
Клиентская база в CRM
Все клиенты и заказы остаются в СРМ системе.
Безопасность
Полная безопасность от кражи сотрудниками паролей и доступов
Легкая настройка воронки продаж. Интуитивно понятное заполнение карточки контакта, сделки
Подробнее CRM для Instagram
Консультация ➝
Конвертируйте подписчиков Instagram в клиентов
CRM система — идеальное решение для Instagram
Единое окно для обработки Direct сообщений, комментариев и взаимодействий в Stories
Клиент актуализирует информацию и предоставляет данные для оформления заказа в онлайн режиме. Продажи в чатах предусматривают возможность онлайн оплаты заказа или услуги. Таким образом осуществляется прием заказов в инстаграм.
Продажи в чатах предусматривают возможность онлайн оплаты заказа или услуги. Таким образом осуществляется прием заказов в инстаграм.
После оформления продажи у клиента есть номер заказа и актуальная ссылка для оплаты. У Вас есть возможность формировать базу клиентов для повторных продаж
У Вас есть возможность формировать базу клиентов для повторных продаж
Возможность подключения нескольких аккаунтов.
Вы можете вести любое количество аккаунтов в социальных сетях и мессенджерах. Все диалоги с клиентами будут равномерно распределены между менеджерами, что позволит ускорить процесс обработки обращений.
Подключение служб доставки
Оформляйте доставку клиенту в один клик.
Отслеживайте трек-номера и статуса заказа в CRM
Сообщайте клиенту актуальную информацию о статусе заказов в sms, email или чатах.
Используйте автоматические ответы в сообщениях для максимально быстрой и качественной коммуникации с клиентом.
CRM-система для Инстаграм поможет собрать все данные о клиентах
- телефон
- заметки
- пол
- история покупок и предпочтений
Все данные о клиенте, история заказов остаются в СРМ-системе и сохраняеться история переписки.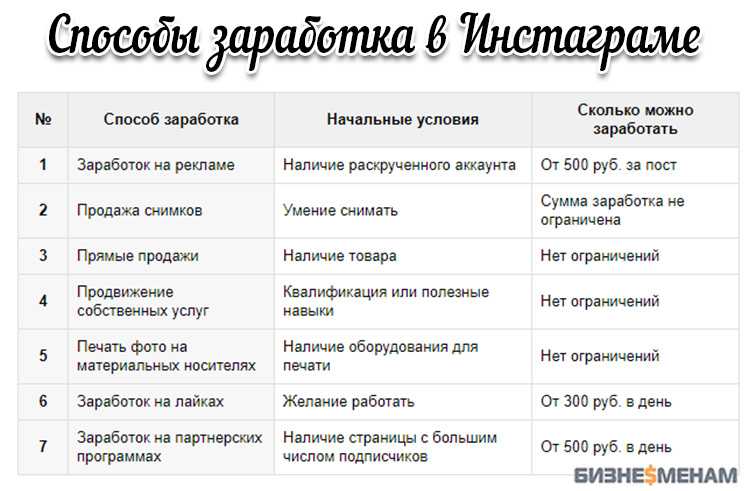
ТОП CRM для инстаграм
На данный момент существует немало CRM для инстаграм магазина. И по сути все эти системы закрывают основные задачи — вести переписку с клиентом, отвечать на комментарии, на основании диалогов создавать Контакт, оформлять Заказ и т.д.
ТОП срм для instagram в Украине:
- OneBox OS
- KeyCRM
- SalesDrive
CRM-интегратор Украина
ProfiCRM-UA — команда профессиональных интеграторов. Мы не привязываемся к CRM, но знаем какая лучше подойдет для вашего бизнеса. У нас в команде опытные специалисты:
- бизнес-аналитики
- crm-специалисты
- разработчики
- 1С-программисты
Подобрать CRM
Консультация ➝
Интеграция CRM с инстаграм. Кейсы
Maribella
Продажа одежды в Instagram
- Настройка системы и воронки продаж
- Импорт базы клиентов в CRM
- Интеграция CRM с Instagram
- Интеграция CRM с Новой Почтой
- Внедрение 1С
- Интеграция 1С с CRM
- Интеграция с SMS рассыльщиком
- Настройка автоматических действий
Beauty Space by Elena Romanova
- Настройка воронки продаж (3 направления)
- Интеграция CRM с инстаграмом
- Интеграция CRM с Фейсбук
- Интеграция с новой почтой
- Автоматизация бизнес-процесса на отдельных стадиях сделки
BS Romanova
Оставьте нам заявку на интеграцию инстаграм с CRM
* Нажимая на кнопку, вы согласны на обработку персональных данных.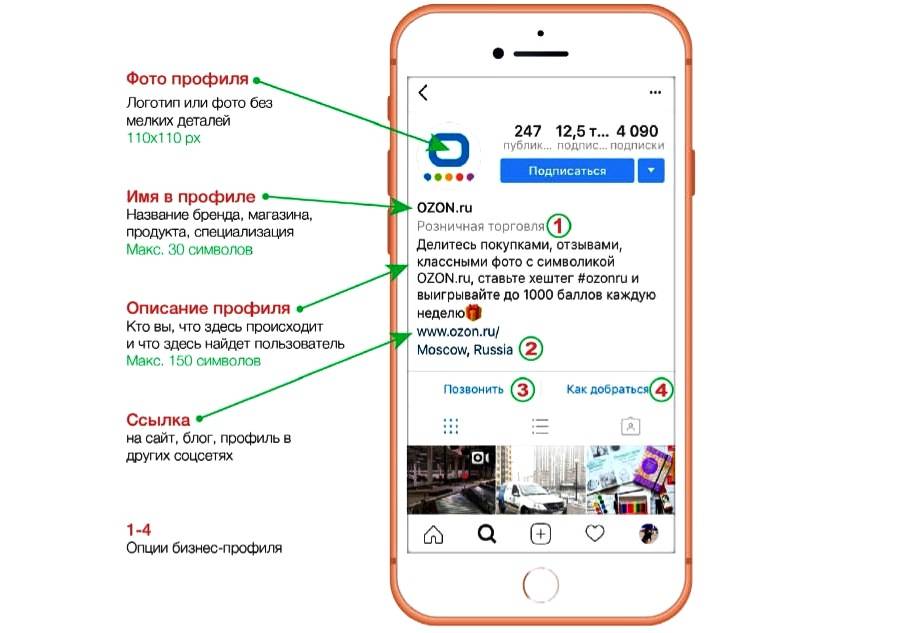
Instagram System Design
Instagram — это платформа социальных сетей, которая позволяет пользователям обмениваться фотографиями и видео с другими. На платформе создатели контента могут установить видимость своих сообщений (фотографий/видео) как частную или общедоступную, а другие пользователи могут взаимодействовать с сообщениями, ставя лайки или комментируя их.
Instagram также предлагает ряд других функций, в том числе возможность для пользователей подписываться друг на друга, просматривать ленты новостей друг друга и искать контент по всей платформе. Другие функции, доступные в Instagram, включают редактирование изображений, пометку местоположения, личные сообщения, push-оповещения, групповые сообщения, хэштеги, фильтры и многое другое.
В этом блоге мы рассмотрим, как разработать упрощенную версию системы Instagram с такими функциями, как обмен фотографиями, подписка и новостные ленты.
Требования к системе
Функциональные требования- Пользователи должны иметь возможность загружать и просматривать фотографии.

- Система должна позволять пользователям искать фотографии по их названиям.
- Пользователи должны иметь возможность подписываться друг на друга.
- У каждого пользователя должна быть настраиваемая лента новостей, в которой отображаются лучшие фотографии пользователей, на которых они подписаны.
- Система должна отдавать приоритет высокой доступности и низкой задержке при просмотре фотографий. Чтобы улучшить доступность, мы можем отказаться от согласованности, что означает, что допустимо, если пользователь не видит изображение сразу.
- Система должна быть хорошо масштабируемой и оптимизированной для рабочих нагрузок с большим объемом операций чтения с высоким соотношением операций чтения и записи.
- Система должна быть надежной и гарантировать, что загруженные фотографии или видео не будут потеряны.
- Система должна быть оптимизирована для доступа к популярным сообщениям.
- Система должна быть совместима с широким спектром устройств, поддерживать несколько языков и хорошо работать с различной пропускной способностью Интернета.

Оценка емкости
Важно учитывать, что запросы на чтение будут значительно более частыми, чем запросы на запись, с соотношением примерно 100 к 1.
- Предположим, что на платформе зарегистрировано 500 миллионов пользователей, из которых 1 миллион активных пользователей в день.
- Если ежедневно публикуется 5 миллионов изображений, это означает, что в среднем загружается 57 фотографий в секунду (5M / (246060)).
- Если средний размер фотографии составляет 150 КБ, то ежедневное использование хранилища составляет 716 ГБ (5 М * 150 КБ).
- Если предположить, что служба будет активна в течение десяти лет, общее необходимое пространство составит примерно 2,6 ПБ (716 ГБ * 365 * 10).
High Level Design
Пользовательская служба отвечает за управление входом пользователя в систему, входом в систему и действиями, связанными с профилем. Он работает в базе данных MySQL, которая была выбрана потому, что данные структурированы относительно реляционным образом, а система оптимизирована для рабочих нагрузок с большим объемом чтения, с которыми MySQL хорошо справляется.
Он работает в базе данных MySQL, которая была выбрана потому, что данные структурированы относительно реляционным образом, а система оптимизирована для рабочих нагрузок с большим объемом чтения, с которыми MySQL хорошо справляется.
Пользовательская служба подключена к базе данных Redis, в которой хранятся все пользовательские данные. Когда пользовательский сервис получает запрос, он сначала проверяет Redis на наличие запрошенной информации и возвращает ее пользователю, если она найдена. Если данные отсутствуют в Redis, пользовательский сервис проверит базу данных MySQL, извлечет данные и вставит их в Redis, прежде чем вернуть их пользователю. Кроме того, аналогичный процесс можно выполнять всякий раз, когда в базу данных добавляются новые пользователи или информация.
Этот подход позволяет пользовательской службе быстро получать доступ к самым последним данным и возвращать их пользователю, поддерживая кэш часто используемой информации в Redis для повышения производительности.
Компоненты системы
Наша система будет состоять из нескольких микрослужб, каждая из которых отвечает за определенную задачу. Для хранения данных мы будем использовать графовую базу данных, например Neo4j. Мы выбрали эту модель данных, потому что наши данные содержат сложные отношения между такими элементами, как пользователи, публикации и комментарии, которые можно представить в виде узлов на графике. Края графика можно использовать для записи отношений, таких как подписки, лайки и комментарии. Мы также можем использовать столбцовые базы данных, такие как Cassandra, для хранения такой информации, как каналы пользователей, действия и т. д.
Поток данных и дизайн API
Поток данных
- Пользователь отправляет запрос к API.
- Балансировщик нагрузки получает запрос и перенаправляет его на сервер приложений.
- Сервер приложений получает запрос и выполняет проверку ввода.
- Если вход верен, сервер приложений пытается выполнить запрос.
- В случае успеха сервер приложений возвращает ответ OK с запрошенными данными или без них. Если есть проблема, он возвращает указанный ответ об ошибке.
Дизайн API
- регистрация (имя пользователя, первое имя , фамилия , пароль с солью, хэш пароля , номер телефона, электронная почта, биография, фото): добавляет пользователя в таблицу пользователей
- логин (имя пользователя, пароль с солью хэш): регистрирует пользователя и обновляет время последнего входа
- search_user (строка поиска , токен аутентификации ): возвращает общедоступные данные пользователя для заданной строки поиска (можно искать по имени, фамилии и имени пользователя)
- получить пользователя by_id (идентификатор пользователя , токен аутентификации ): возвращает общедоступные данные пользователя для данного идентификатора пользователя
- follow_user (идентификатор пользователя , идентификатор пользователя цели , токен аутентификации ): добавляет данные отслеживания в базу данных
- add_post (файл, заголовок, идентификатор пользователя , токен аутентификации ): загружает файл на сервер хранения файлов
- delete_post (идентификатор пользователя , идентификатор сообщения , auth_token): удаляет данное сообщение данного пользователя вместе с его метаданными (используя мягкое удаление)
- get_feed (идентификатор пользователя , количество, смещение, метка времени, токен аутентификации ): возвращает первые сообщения после заданной метки времени пользователей, за которыми следует данный пользователь в соответствии с количеством и смещением
- получить пользователя сообщения (идентификатор пользователя , количество, смещение, токен аутентификации ): возвращает сообщения данного пользователя в соответствии с количеством и смещением
- post_like (идентификатор пользователя , идентификатор сообщения , auth_token): добавляет данный идентификатор сообщения в лайки данного пользователя
- post_unlike (идентификатор пользователя , идентификатор сообщения , auth_token): удаляет данный идентификатор сообщения из лайков данного пользователя
- add_comment
- delete_comment (идентификатор пользователя , идентификатор комментария ): удаляет комментарий данного пользователя с данным идентификатором комментария
Дизайн базы данных
Важно четко определить структуру базы данных в начале процесса интервью, чтобы понять поток данных между различными компонентами и определить, как сегментировать данные.
Нам нужно хранить данные о пользователях, размещенных ими изображениях и людях, на которых они подписаны. Чтобы эффективно извлекать последние фотографии из таблицы фотографий, в которой хранятся все данные, связанные с фотографией, мы создадим индекс для (PhotoID, CreationDate).
Одним из вариантов хранения описанных выше данных, требующих объединения, является использование системы управления реляционными базами данных (RDBMS), такой как MySQL. Однако у реляционных СУБД могут возникнуть проблемы с масштабированием. Вместо этого мы могли бы хранить фотографии в распределенной файловой системе, такой как HDFS или S3.
Чтобы воспользоваться преимуществами NoSQL, мы можем сохранить схему, описанную выше, в распределенном хранилище ключей и значений. Мы можем создать таблицу с «ключом» «PhotoID» и «значением» объекта, содержащего все метаданные для фотографии, такие как PhotoLocation, UserLocation, CreationTimestamp и т. д. Это позволяет нам хранить и извлекать данные с помощью простой интерфейс ключ-значение.
Чтобы узнать, кому принадлежит какая фотография, нам нужно сохранить отношения между пользователями и фотографиями. Нам также нужно отслеживать, за кем следит пользователь. Мы можем использовать хранилище данных с широкими столбцами, такое как Cassandra 28, для обеих этих таблиц. «Ключом» для таблицы «UserPhoto» будет «UserID», а «значением» будет пользовательский список «PhotoID», хранящийся в отдельных столбцах. Таблица «UserFollow» будет следовать аналогичному шаблону.
Как и другие хранилища ключей и значений, Cassandra поддерживает определенное количество реплик для обеспечения надежности. Удаление также не выполняется немедленно в хранилищах «ключ-значение», поскольку данные обычно хранятся в течение определенного количества дней, чтобы их можно было восстановить, прежде чем они будут безвозвратно удалены из системы. Это помогает обеспечить согласованность данных и возможность восстановления.
Генерация новостной ленты
Создание новостной ленты
Разработка индивидуальной новостной ленты для каждого пользователя, которая демонстрирует самые последние сообщения от каждого пользователя, на которого они подписаны, является важным аспектом службы, подобной Instagram. Для простоты предположим, что каждый пользователь и его подписчики загружают 200 уникальных фотографий в день. Это означает, что новостная лента пользователя будет состоять из комбинации этих 200 уникальных фотографий, за которыми следует репутация предыдущих материалов. Это позволяет пользователю видеть самый последний и актуальный контент от пользователей, на которых он подписан.
Для простоты предположим, что каждый пользователь и его подписчики загружают 200 уникальных фотографий в день. Это означает, что новостная лента пользователя будет состоять из комбинации этих 200 уникальных фотографий, за которыми следует репутация предыдущих материалов. Это позволяет пользователю видеть самый последний и актуальный контент от пользователей, на которых он подписан.
Чтобы сгенерировать новостную ленту для пользователя, мы сначала получим метаданные (такие как лайки, комментарии, время, местоположение и т. д.) самых последних 200 фотографий и передадим их алгоритму ранжирования. Этот алгоритм будет использовать метаданные для определения порядка, в котором фотографии должны отображаться в ленте новостей. Это позволяет пользователю видеть наиболее актуальный и привлекательный контент в верхней части своей ленты.
Одним из недостатков описанного выше подхода к созданию ленты новостей является то, что он требует одновременного запроса большого количества таблиц и ранжирования их на основе заранее определенных критериев. Это может привести к более высокой задержке, а это означает, что для создания новостной ленты требуется больше времени. Для повышения производительности нам может потребоваться оптимизировать запросы и алгоритмы ранжирования или рассмотреть альтернативные подходы, такие как предварительное вычисление и кэширование результатов.
Это может привести к более высокой задержке, а это означает, что для создания новостной ленты требуется больше времени. Для повышения производительности нам может потребоваться оптимизировать запросы и алгоритмы ранжирования или рассмотреть альтернативные подходы, такие как предварительное вычисление и кэширование результатов.
Чтобы устранить проблемы с задержкой с помощью описанного выше алгоритма генерации новостных лент, мы можем настроить сервер, который заранее создает уникальную новостную ленту для каждого пользователя и сохраняет ее в отдельной таблице новостных лент. Когда пользователь хочет получить доступ к своей ленте новостей, мы можем просто запросить эту таблицу, чтобы получить самый последний контент. Такой подход снижает потребность в запросах и ранжировании большого количества таблиц в режиме реального времени, повышая производительность и скорость отклика системы.
Обслуживание ленты новостей
Теперь мы обсудили, как создать ленту новостей. Следующей задачей при разработке архитектуры службы, подобной Instagram, является определение того, как доставлять сгенерированную новостную ленту пользователям.
Следующей задачей при разработке архитектуры службы, подобной Instagram, является определение того, как доставлять сгенерированную новостную ленту пользователям.
Один из подходов заключается в использовании механизма push , когда сервер оповещает всех подписчиков пользователя всякий раз, когда они загружают новую фотографию. Это можно сделать с помощью метода, называемого длинным опросом. Однако этот подход может быть неэффективным, если пользователь подписан на большое количество людей, поскольку серверу потребуется часто отправлять обновления и доставлять уведомления.
Альтернативным подходом является использование механизма pull , когда пользователи обновляют свои новостные ленты (отправляя запрос на сервер), чтобы увидеть новое содержимое. Однако это может быть проблематично, поскольку новые сообщения могут быть невидимы до тех пор, пока пользователь не обновит страницу, а многие обновления могут возвращать пустые результаты.
Гибридный подход сочетает в себе преимущества как толкающего, так и тянущего механизмов. Для пользователей с большим количеством подписчиков (например, знаменитостей) сервер может использовать подход на основе извлечения. Для всех остальных пользователей сервер может использовать подход, основанный на проталкивании. Это позволяет эффективно доставлять обновления, сводя к минимуму нагрузку на сервер.
Для пользователей с большим количеством подписчиков (например, знаменитостей) сервер может использовать подход на основе извлечения. Для всех остальных пользователей сервер может использовать подход, основанный на проталкивании. Это позволяет эффективно доставлять обновления, сводя к минимуму нагрузку на сервер.
Балансировка нагрузки
Для обработки пользовательских запросов нам необходимо использовать балансировщик нагрузки для распределения запросов между серверами приложений. Один из способов сделать это — использовать метод циклического перебора, при котором запросы распределяются по очереди. Однако этот подход может быть проблематичным, если сервер недоступен, так как на него все еще могут отправляться запросы. Чтобы предотвратить это, мы можем реализовать систему «сердцебиения», в которой каждый сервер проверяет балансировщик нагрузки с заданным интервалом, чтобы указать, что он не отключен.
Балансировщики нагрузки также необходимы для серверов баз данных и кэшей, которые также могут быть распределенными. Чтобы направить запросы на соответствующий сервер, мы можем использовать технику, называемую согласованным хешированием. Это включает в себя сопоставление каждого запроса с конкретным сервером на основе информации о пользователе. Это помогает обеспечить маршрутизацию запросов на правильный сервер и равномерное распределение нагрузки.
Чтобы направить запросы на соответствующий сервер, мы можем использовать технику, называемую согласованным хешированием. Это включает в себя сопоставление каждого запроса с конкретным сервером на основе информации о пользователе. Это помогает обеспечить маршрутизацию запросов на правильный сервер и равномерное распределение нагрузки.
Чтобы равномерно распределить нагрузку между серверами, мы можем использовать алгоритм балансировки нагрузки, который называется «Метод наименьшей пропускной способности». Этот алгоритм выбирает сервер с наименьшим объемом трафика (измеряется в мегабитах в секунду) для обработки запроса.
Балансировщики нагрузки могут быть размещены в двух точках системы: между клиентом и сервером и между базой данных и сервером. Это обеспечивает эффективную маршрутизацию запросов и гарантирует, что система сможет обрабатывать большой объем трафика.
Спасибо Навтошу Кумару за его вклад в создание первой версии этого контента. В случае каких-либо вопросов и отзывов, не стесняйтесь писать нам по адресу contact@enjoyalgorithms. com. Наслаждайтесь обучением, наслаждайтесь дизайном системы!
com. Наслаждайтесь обучением, наслаждайтесь дизайном системы!
Анализ дизайна системы Instagram | Ашис Чакраборти
Как вы разрабатываете сервис для обмена фотографиями, такой как Instagram?
Photo by Zane Lee on UnsplashПроектирование системы — одна из наиболее важных частей разработки программного обеспечения. Страшно начинать проектировать систему. Одна из основных причин заключается в том, что терминология, описанная в книгах по архитектуре программного обеспечения, сложна для понимания. И нет никаких фиксированных ориентиров. Везде, где вы проверяете, кажется, есть другой подход. Это становится запутанным для нового ученика.
Итак, я решил спроектировать систему, основываясь на своем опыте изучения архитектурных курсов. Это часть серии статей о проектировании систем для начинающих (ссылка приведена ниже). Для этого давайте разработаем сервис обмена фотографиями, такой как Instagram.
Определение Системы:
Нам нужно уточнить цель системы. Проектирование системы — очень обширная тема; если мы не сузим его до конкретной цели, будет сложно спроектировать систему, особенно для новичков.
Проектирование системы — очень обширная тема; если мы не сузим его до конкретной цели, будет сложно спроектировать систему, особенно для новичков.
Instagram — это служба обмена фотографиями, которая позволяет пользователям загружать и делиться своими фотографиями и видео с другими пользователями, в основном со своими подписчиками. Поскольку это упражнение, мы разработаем более простую версию основного сервиса Instagram.
В этом сервисе пользователь может делиться фотографиями и подписываться на других пользователей. Для каждого пользователя будет новостная лента. Лента новостей состоит из лучших фотографий всех людей, на которых подписан пользователь.
Требования к системе:
В этой части мы выбираем функции системы. Системные требования разделены на две части:
Функциональные требования:
Это тип требований, которые должна обеспечивать система. Можно сказать, что это главная цель системы.
Во-первых, для Instagram пользователи должны иметь возможность загружать/скачивать/просматривать фотографии. Пользователи могут выполнять поиск изображений по названиям фото/видео. Один пользователь может подписываться на других пользователей. Еще одна важная функция заключается в том, что система должна отображать новостную ленту пользователя, состоящую из фотографий всех людей, на которых подписан пользователь.
Поскольку это практика для системы, мы не рассматриваем теги на фотографиях, поиск по тегам, функции лайков и комментариев и т. д.
Нефункциональные требования
Производительность, доступность, согласованность, масштабируемость, надежность и т. д., являются важными требованиями к качеству при проектировании системы. Нам нужно проанализировать эти требования к системе.
Как системный разработчик, мы могли бы захотеть иметь проект, который будет высокодоступным, очень высокопроизводительным, первоклассной согласованности в системе, высокозащищенной системой и т. д. Но невозможно достичь всех этих целей в одной системе. . Нам нужны требования, которые будут работать как ограничения при проектировании системы. Итак, давайте определим наши NFR:
д. Но невозможно достичь всех этих целей в одной системе. . Нам нужны требования, которые будут работать как ограничения при проектировании системы. Итак, давайте определим наши NFR:
Наша система должна быть высокодоступной. В случае любого веб-сервиса это обязательное требование. Задержка генерации домашней страницы должна быть не более 200 мс. Если генерация домашней страницы занимает слишком много времени, пользователи будут недовольны, что недопустимо.
Выбирая высокую доступность системы, мы должны помнить, что это может помешать согласованности в системе. Система также должна быть очень надежной, а это означает, что любые загруженные пользователями фото или видео никогда не должны быть потеряны.
В этой системе поиск и просмотр фотографий будет больше, чем загрузка. Поскольку в системе будет больше операций чтения, мы сосредоточимся на создании системы, которая может быстро извлекать фотографии. При просмотре фотографий задержка должна быть как можно меньше.
Поток данных:
Если вы не знаете, с чего начать проектирование системы, всегда начинайте с системы хранения данных. Это поможет держать ваш фокус в соответствии с требованиями системы.
Нам нужно поддерживать два сценария на высоком уровне, один для загрузки фотографий, а другой для просмотра/поиска фотографий. Нашей системе потребуются серверы хранения объектов для хранения фотографий и серверы баз данных для хранения метаданных.
Определение схемы базы данных — это первый этап понимания потока данных между различными компонентами системы. Нам нужно хранить данные профиля пользователя, такие как список подписчиков, загруженные пользователями фотографии. Должна быть таблица, в которой хранятся все данные о фотографиях. Если мы хотим сначала показать последние фотографии, нам нужно проиндексировать (PhotoID, CreationDate). Таблиц в БД может быть:
Имя таблицы: таблица indexe1,index2 и т. д.
Фото: PhotoID (pk), UserID, PhotoLocation, CreationDate
Follow: UserID1, UserID2 (парный pk)
FeedItem: FeedID(pk), UserID, Contents, PhotoID ,CreationDate
**pk = первичный ключ

Мы можем хранить указанные выше таблицы в СУБД, такой как MySQL так как нам потребуются соединения между таблицами. Но у реляционных баз данных есть свои проблемы. Хотя реляционную базу данных можно масштабировать на несколько серверов, это сложный процесс. Мы можем хранить фотографии в распределенном файловом хранилище, таком как HDFS или S3.
Когда пользователи загружают фотографии, сохранение их в базе данных является медленным процессом, поскольку они хранятся на диске. Но в случае чтений процесс будет быстрее, особенно если мы будем обслуживать их из кеша.
Рисунок: Отдельная служба загрузки и выгрузки (Изображение автора) Поскольку загрузка — медленный процесс, если мы поместим фотографии для записи и чтения на один и тот же сервер, система может быть слишком занята всеми запросами на «запись». Мы должны учитывать, что веб-серверы имеют ограничение на количество подключений, прежде чем разрабатывать нашу систему.
Мы должны учитывать, что веб-серверы имеют ограничение на количество подключений, прежде чем разрабатывать нашу систему.
Допустим, сервер может иметь максимум 5000 подключений в любое время. Таким образом, он не может иметь более 5000 одновременных загрузок или скачиваний. Чтобы справиться с этим типом узких мест, мы можем использовать разделение ответственности .
Мы можем разделить операции чтения и записи на две отдельные службы. Итак, у нас будет несколько серверов для чтения и разные серверы для записи. Это разделение также даст нам возможность независимо масштабировать каждую операцию.
Доступность и надежность:
Мы не можем потерять фотографии, загруженные пользователями. Надежность является огромным фактором для этой системы. Итак, нам нужно иметь более одной копии каждого файла. В этом случае, если один сервер мертв, у нас все еще есть другие копии этих фотографий.
В системе не может быть единой точки отказа. Если мы храним несколько копий компонента, это может устранить единую точку отказа в системе. Для создания высокодоступной системы нам необходимо хранить несколько реплик служб в системе. Таким образом, даже если некоторые из серверов не работают, система может оставаться доступной. Создание избыточности в системе также обеспечивает резервную копию в кризисной ситуации.
Для создания высокодоступной системы нам необходимо хранить несколько реплик служб в системе. Таким образом, даже если некоторые из серверов не работают, система может оставаться доступной. Создание избыточности в системе также обеспечивает резервную копию в кризисной ситуации.
Масштабируемость:
Для поддержки миллионов пользователей нам необходимо разделить нашу базу данных, чтобы разделить и хранить наши данные на разных серверах БД. Мы можем использовать сегментирование базы данных для метаданных.
Разделение на основе UserID:
Если мы разделим базу данных метаданных на основе UserID, мы можем хранить все фотографии пользователей в одном сегменте. Кажется, у одного пользователя почти 3 ТБ данных. Если один сегмент БД составляет 1 ТБ, нам потребуется три сегмента данных каждого пользователя.
Для повышения производительности и масштабируемости мы можем оставить десять осколков. В таком случае мы можем найти номер шарда по UserId%10 и хранить там данные.
В таком случае мы можем найти номер шарда по UserId%10 и хранить там данные.
При таком подходе мы можем столкнуться с некоторыми проблемами, если пользователь является популярной знаменитостью. Эта часть осколков будет часто подвергаться ударам.
Кроме того, некоторые пользователи могут загружать больше фотографий, чем другие. В этом случае распределение может быть неравномерным.
Что еще более важно, если мы не можем хранить все изображения пользователей в одном сегменте, нам может потребоваться распределить фотографии по разным сегментам.
И если сегмент не работает, мы можем столкнуться с проблемой недоступности для пользователя.
Разделение на основе PhotoID:
Другим способом разделения БД может быть использование PhotoID. Нам нужно создать уникальный идентификатор для каждой фотографии. Каждый сегмент БД должен иметь свою последовательность автоинкремента для PhotoID, но тогда каждый сегмент будет иметь один и тот же идентификатор фотографии в своей части. Мы можем добавить ShardId к каждому фотоID; это может сделать фотоID уникальным в системе.
Мы можем добавить ShardId к каждому фотоID; это может сделать фотоID уникальным в системе.
Балансировщик нагрузки:
Поскольку мы используем несколько копий сервера, нам необходимо эффективно распределять пользовательский трафик на эти серверы. Балансировщик нагрузки будет равномерно распределять пользовательские запросы на различные серверы. Мы можем использовать маршрутизацию на основе IP для службы новостей, поскольку одни и те же запросы пользователей отправляются на один и тот же сервер, а кэширование можно использовать для получения более быстрого ответа.
Если таких требований нет, циклический перебор должен быть простым и хорошим решением для стратегии выбора серверов балансировщиков нагрузки.
Шлюз API:
У нас есть много сервисов для нашей системы. Некоторые будут генерировать новостную ленту, некоторые помогут хранить фотографии, некоторые будут просматривать фотографии и т. д. Нам нужна единая точка входа для всех клиентов. Эта точка входа — шлюз API.
Он будет обрабатывать все запросы, отправляя их в несколько служб. А для некоторых запросов он просто будет перенаправляться на конкретный сервер. Шлюз API также может обеспечивать безопасность, например проверку разрешения клиента на выполнение запроса.
Генерация новостной ленты:
Новостная лента для любого пользователя содержит самые свежие, самые популярные и актуальные фотографии людей, на которых подписан пользователь. Если мы будем генерировать новостную ленту в режиме реального времени, это будет очень большая задержка. Итак, попробуем предварительно сгенерировать новостную ленту. Таким образом, почтовый сервис будет хранить фотографии в базе данных. Служба новостных лент предварительно вычисляет ленту для всех пользователей.
Нам нужны определенные серверы, которые бы постоянно генерировали пользовательские новостные ленты и сохраняли их в базе данных. Итак, когда пользователю нужны последние фотографии для ленты новостей, нам нужно запросить таблицу.
Теперь, как пользователь получает последнюю ленту новостей с сервера? Мы можем рассмотреть следующие подходы:
Подход на основе извлечения
В этом подходе каждый пользователь может опросить сервер через регулярные промежутки времени, чтобы проверить, есть ли у кого-либо из друзей новое обновление. Сервер должен найти все подключения пользователей и проверить каждого друга, чтобы создать новый пост. Если есть новые сообщения, запрос к базе данных получит все последние сообщения, созданные соединениями пользователя, и покажет их на своей домашней странице.
Пользователи могут пинговать серверы новостных лент для предварительно сгенерированных лент через регулярные промежутки времени. Чем меньше временной интервал, тем более свежие данные будут найдены в ленте.
Этот подход требует много времени. Поскольку пользователи опрашивают базу данных через регулярные промежутки времени, это создаст огромную ненужную нагрузку на базу данных.
Подход, основанный на отправке
В этом подходе серверы могут отправлять новые данные пользователям, как только они становятся доступными. Пользователи должны поддерживать длинный запрос на опрос сервера для получения обновлений.
Поскольку служба новостей предварительно создает каналы, служба уведомлений будет уведомлять активных пользователей о новых сообщениях. БД сессий будет хранить данные о подключениях пользователей, которые находятся в сети.
Вы можете ознакомиться с различными способами уведомления по этой ссылке.
Мы можем внедрить модель на основе вытягивания для всех пользователей с большим количеством подписчиков. И мы можем использовать push-подход для тех, у кого есть несколько сотен подписчиков.
Пагинация:
Лента новостей пользователей может быть большим откликом. Таким образом, мы можем разработать API для возврата одной страницы фида. Допустим, мы отправляем не более 50 сообщений каждый раз, когда делается запрос фида.