
Как связать Метрику и Директ: руководство по синхронизации
Если у вас уже есть рекламные кампании, или вы планируете их создавать, то нужно помнить о том, что для полной картины по анализу рекламы вам необходимо синхронизировать Яндекс Директ c Яндекс Метрикой.
Зачем это нужно?
В Яндекс Директе вы закупаете трафик на поиске Яндекса, в РСЯ и т.д.
Вы получаете данные о количестве показов, кликов, CTR, CPC, расход. В Мастере отчетов можно посмотреть уже более интересные отчеты по позиции показа и % трафика и т.д., но без Яндекс Метрики мы не получим самой важной информации.
Яндекс Метрика сможет ответить на эти вопросы.
После того, как вы свяжете Яндекс Директ и Яндекс Метрику, вам будет доступно:
- Показатели % отказа по рекламным кампаниям, группам, ключевым словам
- Отслеживание конверсий
- Настройка ключевых целей в настройках рекламных кампаний
- Настройка ретаргетинга по целям и сегментам в Яндекс Метрике
- Настройка автоматических стратегий, где целью РК является достижение конверсий
Как связать Яндекс Директ и Яндекс Метрику если они под одним логином?
Если рекламные кампании Яндекс Директа и счетчик Яндекс Метрики находятся под одним логином, то, необходимо только указать номер счетчика в Настройках рекламы.
Для этого нужно перейти в https://metrika.yandex.ru и на вкладке «Счетчики» → «Мои счетчики» найти номер своего счетчика (напротив доменного имени сайта) и скопировать:
После этого переходим в Яндекс Директ: https://direct.yandex.ru
На вкладке «Мои кампании» → «Редактировать» → перейти в блок «Целевые действия и бюджет кампании» → «Счётчики целевых действий» → Вставить номер своего счетчика Метрики → «Применить» → Внизу страницы настроек нажать «Сохранить»
Теперь вы связали Яндекс Директ и Янедкс Метрику и сможете лучше анализировать свою рекламу.
Как связать Яндекс Директ и Яндекс Метрику если они под разными логинами?
В случае, если рекламные кампании Яндекс Директа и счетчик Яндекс Метрики находится под разными логинами, то номер счетчика будет невозможно добавить, а в поле «Счётчики целевых действий» появится информация об отсутствии доступа:
Поэтому сначала их надо будет связать, предоставив доступ в Яндекс Метрике логину Яндекс Директа.
Для этого мы опять заходим в Яндекс Метрику: https://metrika.yandex.ru
Выбираем свой счетчик и переходим в «Настройки».
В левой части меню → переходим в «Доступ» → нажимаем «Добавить пользователя» → Вводим логин, под которым РК в Яндекс Директе → «Сохранить»
Теперь можем просто добавить номер счетчика Яндекс Метрики в настройки рекламной кампании. Данные будут синхронизироваться.
Лайфхаки и полезности
Одновременное добавление многих РК
При добавлении многих рекламных кампаний, у которых по умолчанию будет один и тот же счетчик Яндекс Метрики, можно добавить на главной странице Яндекс Директа.
Необходимо нажать на логин и выбрать «Мои настройки».
После этого добавить номер счетчика в пункт «Счетчик Метрики для новых кампаний»
И теперь при создании новых кампаний у них будет автоматически продублирован счетчик Яндекс Метрики, который вы здесь указали.
Настройка целей без Вебмастеров
Если вы хотите сразу же начать отслеживать такие действия как клик по e-mail, скачивание файлов, отправка форм, поиск по сайту и т. д., то теперь это можно сделать без веб-мастера, а в Яндекс Метрике в пункте «Цели».
д., то теперь это можно сделать без веб-мастера, а в Яндекс Метрике в пункте «Цели».
При переходе, выбираете необходимое действие и создаете цель.
Очень удобно и сразу позволяет собирать данные по действиям.
До 5 счетчиков Яндекс Метрики
В параметры Яндекс Директа в блоке «Счётчики целевых действий» можно добавлять до 5 счетчиков Яндекс Метрики.
Метка ycid
В блоке «Счётчики целевых действий» ниже есть возможность подключить метку yclid.
Эта метка связывает визиты Яндекс Директа и Яндекс Метрики. Эту метку понимает только Яндекс Метрика (другие системы аналитики не смогут расшифровать).
Yclid-метка — это резервный способ для системы найти источник клика по вашей рекламе. Самое интересное, что она всегда подставляется в URL перехода по рекламе, поэтому отключить подстановку метки со стороны Директа не получится.
Можете на тему подключения этой функции не переживать. Она по умолчанию включена, даже без включения.
Подключение автостратегий
Подключать автостратегии с оптимизацией по кликам есть смысл только когда есть достаточное количество осуществленных конверсий и система будет понимать, на что ей ориентироваться.
Публикация статистики из Яндекс.Метрики в Telegram
Всем привет, в этой статье я расскажу, как создать удобный инструмент для автоматической отправки статистики из Яндекс.Метрики в Telegram.
В рамках этой статьи мы будем:
- создавать счётчик Яндекс.Метрики
- настраивать и встраивать его на сайт
- работать с API Яндекс.Метрики
- работать с Telegram Bot Api
- программировать на Python получение статистики от Метрики и отправку в Telegram
Создаём счётчик в Метрике
Переходим на сайт Яндекс.Метрики и регистрируемся, если у вас еще нет аккаунта в Яндексе. После этого нужно создать счётчик, настроить его и встроить на сайт. Нажимаем кнопку «Добавить счётчик».
Заполняем все необходимые поля и нажимаем «Создать счётчик». Теперь нам нужно его настроить.
Переходим на страницу счётчика и нажимаем «Настройки», во вкладке «Код счётчика» отмечаем нужные нам функции.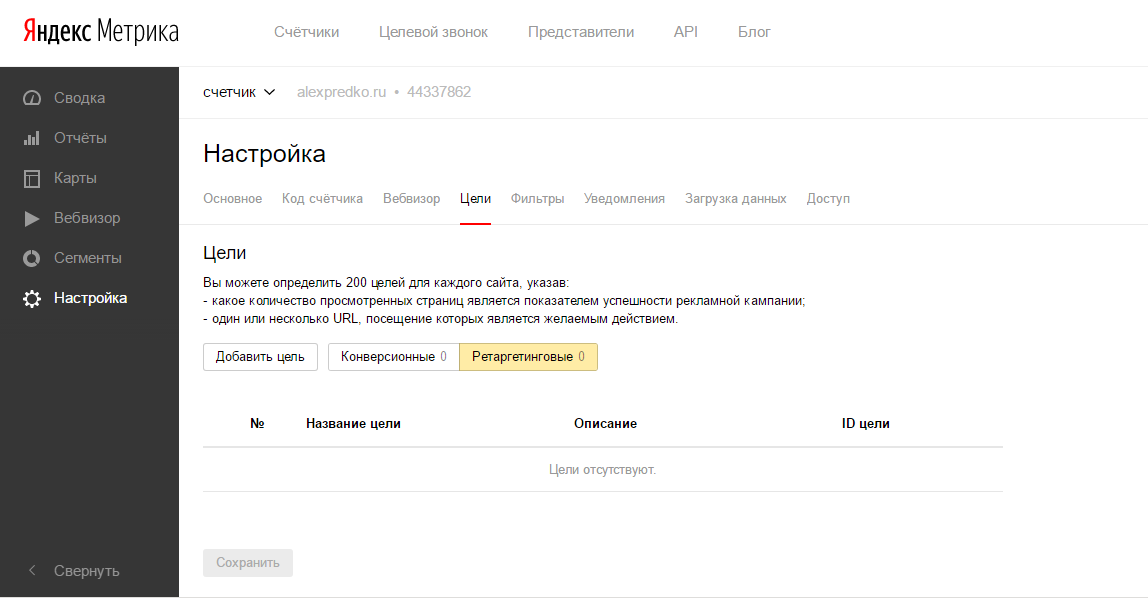
Создаём приложение в Метрике
Заходим в личный кабинет Яндекс.Метрики, во вкладку API , там находится вся необходимая документация. Приложение нам нужно, чтобы получать данные от Яндекс.Метрики с помощью Python.
Для начала нам нужно получить OAuth-токен, с которым мы будем отправлять запросы к нашему приложению. Нажимаем на «Получить OAuth-токен» и регистрируем приложение. Заполняем все необходимые поля, в поле «Права» выбираем «Яндекс.Метрика».
Выставляем необходимые права приложению. Рядом с полем «Callback URL» нажимаем «Подставить URL для разработки» — это адрес, на который нас перенаправит Яндекс для получения токена, но об этом позже. После подтверждения откроется новая страница с данными нашего приложения.
https://oauth.yandex.ru/authorize?response_type=&client_id=
Вместо подставляем ID со страницы нашего приложения. В ответ Яндекс перенаправит нас на страницу, которую мы указали в Callback URL и там будет токен. Вот документация, в которой объяснено, как делать запросы к API Яндекс.Метрики с помощью своего приложения.
Создаём бота для Telegram
Теперь нужно создать бота в Telegram, который будет присылать сообщения нам в чат. Я не буду расписывать поэтапно как создать бота, эту тему отлично раскрыл Александр Менщиков в своей статье. А так же официальная документация от Telegram.
Работаем с API Яндекс.Метрики с помощью Python
Нам нужно написать программу на Python, которая будет обращаться за данными к API Яндекс. Метрики. Есть два способа это реализовать. Первый — это использовать open source библиотеки для работы с Telegram Bot API и API Яндекс.Метрика. Второй — это написать необходимую реализацию самому. Я выберу второй вариант, итак, приступим. Нам нужно выбрать библиотеку для работы с HTTP запросами. Я предлагаю использовать одну из самых популярных — requests. Так же можно использовать urllib2 или httplib2.
Метрики. Есть два способа это реализовать. Первый — это использовать open source библиотеки для работы с Telegram Bot API и API Яндекс.Метрика. Второй — это написать необходимую реализацию самому. Я выберу второй вариант, итак, приступим. Нам нужно выбрать библиотеку для работы с HTTP запросами. Я предлагаю использовать одну из самых популярных — requests. Так же можно использовать urllib2 или httplib2.
Качаем requests с помощью pip в терминале:
sudo pip install requests
Python-код:
import requests
url = "https://api-metrika.yandex.ru/stat/traffic/summary.json"
r = request.get(url, {"id":"12345678","oauth_token":"00504030535435345"})
res = r.json()
В данном участке кода я импортирую библиотеку requests, затем присваиваю переменной url строку со структурой запроса к API Яндекс.Метрике. С помощью функции get из модуля requests производим GET-запрос и передаем необходимые параметры. Метод r.json()преобразует JSON в словарь и возвращает его. Советую поделать запросы в браузере, чтобы изучить структуру ответов. Также необходимо передавать параметр «pretty=1«, чтобы JSON ответ был читабелен.
Метод r.json()преобразует JSON в словарь и возвращает его. Советую поделать запросы в браузере, чтобы изучить структуру ответов. Также необходимо передавать параметр «pretty=1«, чтобы JSON ответ был читабелен.
Отправляем полученную статистику в Telegram с помощью бота
Для этой задачи нам потребуется уже созданный бот в Telegram, токен от него для работы с Telegram Bot API и всё та же библиотека requests. После того как мы создали бота и получили токен, нам нужно создать личный чат с ботом либо добавить его в уже существующий общий чат, в который хотим отправлять статистику. Создаем чат с ботом или добавляем в существующий, затем делаем запрос в адресной строке браузера:
https://api.telegram.org/bot/getupdates
В полученном JSON ответе нам нужно найти поле «chat». У этого поля будет вложенное поле «id» — это уникальный идентификатор чата, в котором мы начали переписку с ботом. Переходим к Python.
import requests
from urllib import urlencode
api_token = "ваш_токен"
chat_id = "122512369"
text = "статистика от API Яндекс.Метрики"
query = "https://api.telegram.org/bot%s/sendMessage?text=%s&chat_id=%s" % (api_token, text, chat_id)
requests.get(query)
Здесь импортируем requests и функцию urlencode из модуля urllib. Затем создаем необходимые переменные, api_token — токен от Telegram Bot, chat_id — уникальный идентификатор чата, в который будем отправлять статистику. В переменной query формируем строку запроса. Request.get(query) — производит сам GET запрос, в данном случае отправляет сообщение в Telegram.
На этом все. Для автоматического перезапуска скрипта можно использовать Supervisor. Советую прочитать статью Александра Менщикова на эту тему.
Понимание типов метрик | Прометей
- Счетчик
- Датчик
- Гистограмма
- Резюме
Prometheus поддерживает четыре типа метрик, это — Прилавок — Измерять — Гистограмма — Сводка
Счетчик
Счетчик — это метрическое значение, которое может только увеличиваться или сбрасываться, т.
Введите приведенный ниже запрос в строке запроса и нажмите «Выполнить».
go_gc_duration_seconds_count
Функция rate() в PromQL берет историю показателей за определенный период времени и вычисляет, насколько быстро значение увеличивается в секунду. Ставка применима только к значениям счетчика.
скорость (go_gc_duration_seconds_count [5 м])
Манометр
Датчик — это число, которое может увеличиваться или уменьшаться. Его можно использовать для таких показателей, как количество модулей в кластере, количество событий в очереди и т. д.
go_memstats_heap_alloc_bytes
Функции PromQL, такие как max_over_time
min_over_time и avg_over_time можно использовать для метрик датчикаГистограмма
Гистограмма представляет собой более сложный тип метрики по сравнению с двумя предыдущими. Гистограмму можно использовать для любого расчетного значения, которое подсчитывается на основе значений корзины. Границы корзины могут быть настроены разработчиком. Типичным примером может служить время, необходимое для ответа на запрос, называемое задержкой.
Гистограмму можно использовать для любого расчетного значения, которое подсчитывается на основе значений корзины. Границы корзины могут быть настроены разработчиком. Типичным примером может служить время, необходимое для ответа на запрос, называемое задержкой.
Пример: Предположим, мы хотим отслеживать время, затрачиваемое на обработку запросов API. Вместо того, чтобы хранить время запроса для каждого запроса, гистограммы позволяют нам хранить их в сегментах. Мы определяем сегменты для затраченного времени, например, меньше или равно 0,3 , ле 0,5 , ле 0,7 , ле 1 и
Допустим, запрос 1 для конечной точки «/ping» занимает 0,25 с. Значения счетчика для сегментов будут.
/пинг
| Ведро | Граф |
|---|---|
| 0 — 0,3 | 1 |
| 0 — 0,5 | 1 |
| 0 — 0,7 | 1 |
| 0 — 1 | 1 |
| 0 — 1,2 | 1 |
| 0 — +Инф | 1 |
Примечание. По умолчанию добавляется сегмент +Inf.
По умолчанию добавляется сегмент +Inf.
(Поскольку гистограмма представляет собой кумулятивную частоту, 1 добавляется ко всем корзинам, превышающим значение)
Запрос 2 для конечной точки «/ping» занимает 0,4 с. Значения счетчика для корзин будут следующими.
/пинг
| Ведро | Граф |
|---|---|
| 0 — 0,3 | 1 |
| 0 — 0,5 | 2 |
| 0 — 0,7 | 2 |
| 0 — 1 | 2 |
| 0 — 1,2 | 2 |
| 0 — +Инф | 2 |
Поскольку 0,4 меньше 0,5, все сегменты до этой границы увеличивают свои значения.
Давайте изучим метрику гистограммы из пользовательского интерфейса Prometheus и применим несколько функций.
prometheus_http_request_duration_seconds_bucket{handler="/graph"}
histogram_quantile() function can be used to calculate quantiles from histogram
histogram_quantile(0.
The graph shows that the 90th percentile is 0.09 , Чтобы найти histogram_quantile за последние 5 минут, вы можете использовать rate() и временной интервал
histogram_quantile(0,9, rate(prometheus_http_request_duration_seconds_bucket{handler="/graph"}[5m]))
Сводка
Сводки также измеряют события и являются альтернативой гистограммам. Они дешевле, но теряют больше данных. Они рассчитываются на уровне приложения, поэтому агрегирование показателей из нескольких экземпляров одного и того же процесса невозможно. Они используются, когда сегменты метрики заранее неизвестны, но настоятельно рекомендуется по возможности использовать гистограммы вместо сводок.
В этом руководстве мы подробно рассмотрели типы метрик и несколько операций PromQL, таких как rate, histogram_quantile и т. д.
Эта документация является открытым исходным кодом. Пожалуйста, помогите улучшить его, зарегистрировав проблемы или запросы на включение.
Пожалуйста, помогите улучшить его, зарегистрировав проблемы или запросы на включение.
Глубокое погружение в четыре типа метрик Prometheus
📖
Добро пожаловать в нашу серию статей о метриках! В этом первом посте мы подробно рассмотрели четыре типа метрик Prometheus; затем мы рассмотрели, как работают метрики в OpenTelemetry; и, наконец, мы соединяем их вместе, объясняя различия, сходства и интеграцию метрик в обеих системах.
Метрики измеряют производительность, потребление, производительность и многие другие свойства программного обеспечения с течением времени. Они позволяют инженерам отслеживать развитие ряда измерений (таких как использование ЦП или памяти, продолжительность запросов, задержки и т. д.) с помощью предупреждений и информационных панелей. Метрики имеют долгую историю в мире ИТ-мониторинга и широко используются инженерами вместе с журналами и трассировками, чтобы обнаруживать, когда системы работают не так, как ожидалось.
В своей основной форме точка данных метрики состоит из:
- Имя метрики
- Отметка времени сбора точки данных
- Измерение, представленное числовым значением
То есть появились метрики, которые также включают набор тегов или меток (т. е. измерений) для обеспечения дополнительного контекста. Системы мониторинга, поддерживающие многомерные метрики, позволяют инженерам легко агрегировать и анализировать метрику по нескольким компонентам и измерениям, запрашивая конкретное имя метрики, а также фильтруя и группируя по меткам.
е. измерений) для обеспечения дополнительного контекста. Системы мониторинга, поддерживающие многомерные метрики, позволяют инженерам легко агрегировать и анализировать метрику по нескольким компонентам и измерениям, запрашивая конкретное имя метрики, а также фильтруя и группируя по меткам.
Для современных динамических систем, состоящих из многих компонентов, Prometheus, проект Cloud Native Computing Foundation (CNCF), стал самым популярным программным обеспечением для мониторинга с открытым исходным кодом и фактически отраслевым стандартом для мониторинга показателей. Prometheus определяет формат представления метрик и протокол удаленной записи, которые сообщество и многие поставщики приняли для предоставления и сбора метрик, ставших стандартом де-факто. OpenMetrics — это еще один проект CNCF, основанный на формате представления Prometheus, чтобы предложить независимую от поставщика стандартизированную модель для сбора метрик, которая призвана стать частью Инженерной группы Интернета (IEFT).
Совсем недавно появился еще один проект CNCF, OpenTelemetry, с целью предоставления нового стандарта, объединяющего набор метрик, трассировок и журналов, что упрощает инструментирование и корреляцию сигналов телеметрии.
Имея на выбор несколько различных вариантов, вы можете задаться вопросом, какой стандарт лучше всего подходит для вас. Чтобы помочь вам ответить на этот вопрос, мы подготовили серию сообщений в блоге, состоящую из трех частей, в которых мы подробно рассмотрим метрические стандарты, принятые CNCF. В этом первом посте мы рассмотрим метрики Prometheus; в следующем мы рассмотрим метрики OpenTelemetry; и в последнем сообщении блога мы сравним оба формата напрямую, предоставив некоторые рекомендации по улучшению взаимодействия.
Мы надеемся, что после прочтения этих сообщений в блоге вы поймете различия между каждым стандартом и сможете решить, какой из них лучше всего соответствует вашим текущим (и будущим) потребностям.
Метрики Prometheus
Обо всем по порядку. Существует четыре типа метрик, собираемых Prometheus как часть формата презентации:
Существует четыре типа метрик, собираемых Prometheus как часть формата презентации:
- Счетчики
- Измерители
- Гистограммы
- Сводки
Prometheus использует модель извлечения для сбора этих метрик; то есть Prometheus очищает конечные точки HTTP, которые предоставляют метрики. Эти конечные точки могут быть изначально доступны отслеживаемым компонентом или доступны через один из сотен экспортеров Prometheus, созданных сообществом. Prometheus предоставляет клиентские библиотеки на разных языках программирования, которые вы можете использовать для инструментирования своего кода.
Модель вытягивания отлично работает при мониторинге кластера Kubernetes благодаря обнаружению сервисов и общему сетевому доступу внутри кластера, но ее сложнее использовать для мониторинга динамического парка виртуальных машин, контейнеров AWS Fargate или функций Lambda с Prometheus. Почему? Трудно определить конечные точки метрик, которые необходимо очистить, и доступ к этим конечным точкам может быть ограничен политиками сетевой безопасности. Чтобы решить некоторые из этих проблем, в конце 2021 года сообщество выпустило режим агента Prometheus, который только собирает метрики и отправляет их на сервер мониторинга с использованием протокола удаленной записи.
Чтобы решить некоторые из этих проблем, в конце 2021 года сообщество выпустило режим агента Prometheus, который только собирает метрики и отправляет их на сервер мониторинга с использованием протокола удаленной записи.
Prometheus может очищать метрики как в формате Prometheus, так и в формате OpenMetrics. В обоих случаях метрики предоставляются через HTTP с использованием простого текстового формата (более часто используемого и широко поддерживаемого) или более эффективного и надежного формата буфера протокола. Одним из больших преимуществ текстового формата является то, что он удобочитаем, что означает, что вы можете открыть его в своем браузере или использовать такой инструмент, как curl, для получения текущего набора доступных метрик.
Prometheus использует очень простую метрическую модель с четырьмя типами метрик, которые поддерживаются только в клиентских библиотеках. Все типы метрик представлены в формате представления с использованием одного или комбинации одного базового типа данных. Этот тип данных включает имя метрики, набор меток и значение с плавающей запятой. Временная метка добавляется серверной частью мониторинга (например, Prometheus) или агентом, когда они очищают метрики.
Этот тип данных включает имя метрики, набор меток и значение с плавающей запятой. Временная метка добавляется серверной частью мониторинга (например, Prometheus) или агентом, когда они очищают метрики.
Каждая уникальная комбинация имени метрики и набора меток определяет ряд, а каждая отметка времени и значение с плавающей запятой определяют выборку (т. е. точку данных) в ряду.
Некоторые соглашения используются для представления различных типов метрик.
Очень полезной функцией формата представления Prometheus является возможность связать метаданные с метриками, чтобы определить их тип и предоставить описание. Например, Prometheus делает эту информацию доступной, а Grafana использует ее для отображения дополнительного контекста пользователю, который помогает ему выбрать правильную метрику и применить правильные функции PromQL:
Браузер метрик в Grafana, отображающий список метрик Prometheus и отображающий дополнительный контекст о них.Пример метрики, представленной с использованием формата представления Prometheus:
# HELP http_requests_total Общее количество запросов http API
# ТИП счетчика http_requests_total
http_requests_total{api="add_product"} 4633433 # HELP используется для предоставления описания метрики, а # TYPE — тип метрики.
Теперь подробнее о каждой метрике Prometheus в формате изложения.
Счетчики
Показатели счетчика используются для измерений, которые только возрастают. Поэтому они всегда кумулятивны — их стоимость может только расти. Единственным исключением является перезапуск счетчика, когда его значение обнуляется.
Фактическое значение счетчика само по себе обычно не очень полезно. Значение счетчика часто используется для вычисления разницы между двумя временными метками или скорости изменения во времени.
Например, типичным вариантом использования счетчиков является измерение вызовов API, которое всегда будет увеличиваться:
# ПОМОЩЬ http_requests_total Общее количество запросов http API
# ТИП счетчика http_requests_total
http_requests_total{api="add_product"} 4633433 Метрика имеет имя http_requests_total , у нее есть одна метка с именем api со значением add_product и значением счетчика 4633423 . Это означает, что API
Это означает, что API add_product вызывался 4 633 433 раза с момента последнего запуска службы или сброса счетчика. По соглашению метрики счетчика обычно имеют суффикс 9.0021 _всего .
Абсолютное число не дает нам много информации, но при использовании с функцией PromQL rate (или аналогичной функцией в другом сервере мониторинга) оно помогает нам понять количество запросов в секунду, которые получает API. Приведенный ниже запрос PromQL вычисляет среднее количество запросов в секунду за последние пять минут:
rate(http_requests_total{api="add_product"}[5m]) Чтобы вычислить абсолютное изменение за период времени, мы будем использовать дельта-функцию. который в PromQL называется увеличением():
увеличение(http_requests_total{api="add_product"}[5m]) Это вернет общее количество запросов, сделанных за последние пять минут, и это будет то же самое, что умножение скорости в секунду на количество секунд в интервале (пять минут в нашем случае):
rate(http_requests_total{api="add_product"}[5m]) * 5 * 60 Другими примерами, где вы хотели бы использовать метрику счетчика, было бы измерение числа заказов на сайте электронной коммерции, количество байтов, отправленных и полученных через сетевой интерфейс, или количество ошибок в приложении. Если это метрика, которая всегда будет расти, используйте счетчик.
Если это метрика, которая всегда будет расти, используйте счетчик.
Ниже приведен пример создания и увеличения метрики счетчика с помощью клиентской библиотеки Prometheus для Python:
из prometheus_client import Counter
api_requests_counter = Счетчик(
'http_requests_total',
'Общее количество запросов http API',
['апи']
)
api_requests_counter.labels(api='add_product').inc() Обратите внимание, что, поскольку счетчики могут быть сброшены на ноль, вы хотите убедиться, что серверная часть, которую вы используете для хранения и запроса ваших метрик, будет поддерживать этот сценарий и по-прежнему предоставлять точные данные. результаты в случае перезапуска счетчика. Prometheus и системы удаленного хранения Prometheus, совместимые с PromQL, такие как Promscale, корректно перезапускают счетчик.
Датчики
Показатели датчиков используются для измерений, которые могут произвольно увеличиваться или уменьшаться. Это тип метрики, с которым вы, вероятно, лучше знакомы, поскольку фактическое значение без дополнительной обработки имеет смысл, и они часто используются. Например, метрики для измерения температуры, использования ЦП и памяти или размера очереди являются датчиками.
Это тип метрики, с которым вы, вероятно, лучше знакомы, поскольку фактическое значение без дополнительной обработки имеет смысл, и они часто используются. Например, метрики для измерения температуры, использования ЦП и памяти или размера очереди являются датчиками.
Например, чтобы измерить использование памяти на хосте, мы могли бы использовать метрику, например:
# HELP node_memory_used_bytes Общая память, используемая в узле в байтах
# Датчик TYPE node_memory_used_bytes
node_memory_used_bytes{hostname="host1.domain.com"} 943348382 Приведенная выше метрика показывает, что объем памяти, используемый узлом host1.domain.com во время измерения, составляет около 900 мегабайт. Значение метрики имеет смысл без каких-либо дополнительных вычислений, потому что оно говорит нам, сколько памяти потребляется на этом узле.
В отличие от использования счетчиков, функции скорости и дельта не имеют смысла с датчиками. Однако функции, которые вычисляют среднее, максимальное, минимальное значение или процентили для определенного ряда, часто используются с датчиками. В Prometheus имена этих функций 9.0021 avg_over_time ,
В Prometheus имена этих функций 9.0021 avg_over_time , max_over_time , min_over_time и quantile_over_time . Чтобы вычислить среднее значение памяти, используемой на host1.domain.com за последние десять минут, вы можете сделать это: метрика датчика с использованием клиентской библиотеки Prometheus для Python, вы должны сделать что-то вроде этого:
из prometheus_client import Gauge
memory_used = Датчик(
'node_memory_used_bytes',
«Общая память, используемая узлом в байтах»,
['имя хоста']
)
memory_used.labels(hostname='host1.domain.com').set(943348382) Гистограммы
Показатели гистограмм полезны для представления распределения измерений. Они часто используются для измерения продолжительности запроса или размера ответа.
Гистограммы делят весь диапазон измерений на набор интервалов, называемых сегментами, и подсчитывают, сколько измерений попадает в каждый сегмент.
Метрика гистограммы включает несколько элементов:
- Счетчик с общим количеством измерений. Имя метрики использует
_countсуффикс. - Счетчик с суммой значений всех измерений. В имени метрики используется суффикс
_sum. - Сегменты гистограммы отображаются как счетчики с использованием имени метрики с суффиксом
_bucketи меткой файламетка файла) включает все точки данных со значением, меньшим или равным N.
Например, сводная метрика для измерения времени отклика экземпляра конечной точки API add_product , работающей на host1.domain.com , может быть представлена следующим образом:
# HELP http_request_duration_seconds Время ответа запросов API в секундах
# TYPE http_request_duration_seconds гистограмма
http_request_duration_seconds_sum{api="add_product" instance="host1. domain.com"} 8953,332
http_request_duration_seconds_count{api="add_product" instance="host1.domain.com"} 27892
http_request_duration_seconds_bucket{api="add_product" instance="host1.domain.com" le="0"}
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0.01"} 0
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0,025"} 8
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0.05"} 1672
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0.1"} 8954
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0.25"} 14251
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0.5"} 24101
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="1"} 26351
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="2.5"} 27534
http_request_duration_seconds_bucket{api="add_product", instance="host1. domain.com", le="5"} 27814
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="10"} 27881
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="25"} 27890
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="+Inf"} 27892
domain.com"} 8953,332
http_request_duration_seconds_count{api="add_product" instance="host1.domain.com"} 27892
http_request_duration_seconds_bucket{api="add_product" instance="host1.domain.com" le="0"}
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0.01"} 0
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0,025"} 8
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0.05"} 1672
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0.1"} 8954
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0.25"} 14251
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0.5"} 24101
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="1"} 26351
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="2.5"} 27534
http_request_duration_seconds_bucket{api="add_product", instance="host1. domain.com", le="5"} 27814
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="10"} 27881
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="25"} 27890
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="+Inf"} 27892  domain.com"} 8953,332
http_request_duration_seconds_count{api="add_product" instance="host1.domain.com"} 27892
http_request_duration_seconds_bucket{api="add_product" instance="host1.domain.com" le="0"}
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0.01"} 0
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0,025"} 8
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0.05"} 1672
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0.1"} 8954
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0.25"} 14251
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0.5"} 24101
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="1"} 26351
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="2.5"} 27534
http_request_duration_seconds_bucket{api="add_product", instance="host1.
domain.com"} 8953,332
http_request_duration_seconds_count{api="add_product" instance="host1.domain.com"} 27892
http_request_duration_seconds_bucket{api="add_product" instance="host1.domain.com" le="0"}
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0.01"} 0
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0,025"} 8
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0.05"} 1672
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0.1"} 8954
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0.25"} 14251
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0.5"} 24101
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="1"} 26351
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="2.5"} 27534
http_request_duration_seconds_bucket{api="add_product", instance="host1. domain.com", le="5"} 27814
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="10"} 27881
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="25"} 27890
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="+Inf"} 27892
domain.com", le="5"} 27814
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="10"} 27881
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="25"} 27890
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="+Inf"} 27892 Пример выше включает сумму , количество и 12 сегментов. Сумма и счет могут использоваться для вычисления среднего значения измерения с течением времени. В PromQL средняя продолжительность за последние пять минут будет вычисляться следующим образом:
rate(http_request_duration_seconds_sum{api="add_product", instance="host1.domain.com"}[5m]) / rate(http_request_duration_seconds_count{api= "add_product", instance="host1.domain.com"}[5m]) Его также можно использовать для вычисления средних значений по сериям. Следующий запрос PromQL будет вычислять среднюю продолжительность запроса за последние пять минут для всех API и экземпляров: может вычислять процентили во время запроса для отдельных рядов, а также для рядов. В PromQL мы будем использовать функцию
В PromQL мы будем использовать функцию histogram_quantile . Prometheus использует квантили вместо процентилей. По сути, это одно и то же, но квантили представлены по шкале от 0 до 1, а процентили представлены по шкале от 0 до 100. Чтобы вычислить 99-й процентиль (квантиль 0,99) времени отклика для API add_product , работающего на host1.domain.com , вы должны использовать следующий запрос:
histogram_quantile(0,99, rate(http_request_duration_seconds_bucket{api="add_product", instance= "host1.domain.com"}[5m])) Одним из больших преимуществ гистограмм является то, что их можно агрегировать. Следующий запрос возвращает 99-й процентиль времени отклика для всех API и экземпляров:
histogram_quantile(0,99, sum by (le) (rate(http_request_duration_seconds_bucket[5m])))
В облачных средах, где обычно работает много экземпляров одного и того же компонента, ключевым моментом является возможность агрегирования данных между экземплярами.
Гистограммы имеют три основных недостатка:
- Во-первых, сегменты должны быть предварительно определены, что требует предварительной разработки. Если ваши сегменты не определены должным образом, вы не сможете вычислить нужные процентили или будете потреблять ненужные ресурсы. Например, если у вас есть API, который всегда занимает более одной секунды, то наличие сегментов с верхней границей (
le label) менее одной секунды будет бесполезным и будет потреблять только вычислительные ресурсы и ресурсы хранения на сервере мониторинга. С другой стороны, если 99,9 % ваших запросов к API занимают менее 50 миллисекунд, наличие начального сегмента с верхней границей в 100 миллисекунд не позволит вам точно измерить производительность API. - Во-вторых, они предоставляют приблизительные, а не точные процентили. Обычно это нормально, если ваши сегменты рассчитаны на получение результатов с разумной точностью.
- И в-третьих, поскольку процентили должны рассчитываться на стороне сервера, их вычисление может быть очень дорогим, когда нужно обработать много данных. Один из способов смягчить это в Prometheus — использовать правила записи для предварительного вычисления требуемых процентилей.
 Один из способов смягчить это в Prometheus — использовать правила записи для предварительного вычисления требуемых процентилей.
Один из способов смягчить это в Prometheus — использовать правила записи для предварительного вычисления требуемых процентилей.В следующем примере показано, как можно создать метрику гистограммы с пользовательскими сегментами с помощью клиентской библиотеки Prometheus для Python:
из prometheus_client import Histogram
api_request_duration = Гистограмма(
имя = 'http_request_duration_seconds',
documentation='Время ответа на запросы API в секундах',
labelnames=['API', 'экземпляр'],
ведра = (0,01, 0,025, 0,05, 0,1, 0,25, 0,5, 1, 2,5, 5, 10, 25)
)
api_request_duration.labels(
API = 'добавить_продукт',
instance='host1.domain.com'
).наблюдать(0,3672) Сводки
Как и гистограммы, сводные метрики полезны для измерения длительности запросов и размеров ответов.
Сводная метрика включает следующие элементы:
- Счетчик с общим количеством измерений. Имя метрики использует суффикс
_count. - Счетчик с суммой значений всех измерений. В имени метрики используется суффикс
_sum. Необязательно, количество квантилей измерений, представленных в виде датчика с использованием имени метрики с меткой квантиля. Поскольку вы не хотите, чтобы эти квантили измерялись за все время работы приложения, клиентские библиотеки Prometheus используют потоковые квантили, которые вычисляются в течение скользящего временного окна (которое обычно настраивается).
 Имя метрики использует суффикс
Имя метрики использует суффикс Например, сводная метрика для измерения времени отклика экземпляра конечной точки API add_product , работающей на host1.domain.com , может быть представлена следующим образом:
# HELP http_request_duration_seconds Время ответа запросов API в секундах
# TYPE http_request_duration_seconds сводка
http_request_duration_seconds_sum{api="add_product" instance="host1.domain.com"} 8953,332
http_request_duration_seconds_count{api="add_product" instance="host1. domain.com"} 27892
http_request_duration_seconds{api="add_product" instance="host1.domain.com" quantile="0"}
http_request_duration_seconds{api="add_product" instance="host1.domain.com" quantile="0,5"} 0,232227334
http_request_duration_seconds{api="add_product" instance="host1.domain.com" quantile="0,90"} 0,821139321
http_request_duration_seconds{api="add_product" instance="host1.domain.com" quantile="0,95"} 1,528948804
http_request_duration_seconds{api="add_product" instance="host1.domain.com" quantile="0,99"} 2,829188272
http_request_duration_seconds{api="add_product" instance="host1.domain.com" quantile="1"} 34.283829292  domain.com"} 27892
http_request_duration_seconds{api="add_product" instance="host1.domain.com" quantile="0"}
http_request_duration_seconds{api="add_product" instance="host1.domain.com" quantile="0,5"} 0,232227334
http_request_duration_seconds{api="add_product" instance="host1.domain.com" quantile="0,90"} 0,821139321
http_request_duration_seconds{api="add_product" instance="host1.domain.com" quantile="0,95"} 1,528948804
http_request_duration_seconds{api="add_product" instance="host1.domain.com" quantile="0,99"} 2,829188272
http_request_duration_seconds{api="add_product" instance="host1.domain.com" quantile="1"} 34.283829292
domain.com"} 27892
http_request_duration_seconds{api="add_product" instance="host1.domain.com" quantile="0"}
http_request_duration_seconds{api="add_product" instance="host1.domain.com" quantile="0,5"} 0,232227334
http_request_duration_seconds{api="add_product" instance="host1.domain.com" quantile="0,90"} 0,821139321
http_request_duration_seconds{api="add_product" instance="host1.domain.com" quantile="0,95"} 1,528948804
http_request_duration_seconds{api="add_product" instance="host1.domain.com" quantile="0,99"} 2,829188272
http_request_duration_seconds{api="add_product" instance="host1.domain.com" quantile="1"} 34.283829292 Этот пример выше включает сумму и количество, а также пять квантилей. Квантиль 0 соответствует минимальному значению, а квантиль 1 соответствует максимальному значению. Квантиль 0,5 — это медиана, а квантили 0,90, 0,95 и 0,99 соответствуют 90-му, 95-му и 99-му процентилю времени отклика для конечной точки API add_product , работающей на host1. . domain.com
domain.com
Как и гистограммы, сводки включают сумму и количество, которые можно использовать для вычисления среднего значения измерения во времени и во временном ряду.
Сводки обеспечивают более точные квантили, чем гистограммы, но эти квантили имеют три основных недостатка:
- Во-первых, вычисление квантилей требует больших затрат на стороне клиента. Это связано с тем, что клиентская библиотека должна постоянно хранить отсортированный список точек данных, чтобы выполнить этот расчет. Реализация в клиентских библиотеках Prometheus использует методы, которые ограничивают количество точек данных, которые необходимо хранить и сортировать, что снижает точность в обмен на повышение эффективности. Обратите внимание, что не все клиентские библиотеки Prometheus поддерживают квантили в сводных метриках. Например, библиотека Python не поддерживает его.
- Во-вторых, квантили, которые вы хотите запросить, должны быть предварительно определены клиентом. Только те квантили, для которых уже есть метрика, могут быть возвращены запросами. Невозможно вычислить другие квантили во время запроса. Добавление нового квантиля требует изменения кода, и с этого момента метрика будет доступна.
- И, в-третьих, что наиболее важно, невозможно агрегировать сводки по нескольким сериям, что делает их бесполезными для большинства случаев использования в динамических современных системах, где вас интересует представление всех экземпляров данного компонента. Поэтому представьте, что в нашем примере
add_productКонечная точка API работала на десяти хостах, находящихся за балансировщиком нагрузки. Не существует функции агрегирования, которую мы могли бы использовать для вычисления 99-го процентиля времени отклика конечной точки APIadd_productпо всем запросам, независимо от того, на какой хост они попали. Мы могли видеть только 99-й процентиль для каждого отдельного хоста. То же самое, если вместо 99-го процентиля времени отклика для конечной точки APIadd_productмы хотели получить 99-й процентиль времени отклика для всех запросов API, независимо от того, в какую конечную точку они попали.
 Только те квантили, для которых уже есть метрика, могут быть возвращены запросами. Невозможно вычислить другие квантили во время запроса. Добавление нового квантиля требует изменения кода, и с этого момента метрика будет доступна.
Только те квантили, для которых уже есть метрика, могут быть возвращены запросами. Невозможно вычислить другие квантили во время запроса. Добавление нового квантиля требует изменения кода, и с этого момента метрика будет доступна.
В приведенном ниже коде создается сводная метрика с использованием клиентской библиотеки Prometheus для Python:
из prometheus_client import Summary
api_request_duration = Сводка(
'http_request_duration_seconds',
'Время ответа на запросы API в секундах',
['апи', 'экземпляр']
)
api_request_duration.labels(api='add_product', instance='host1.domain.com').observe(0.3672) Приведенный выше код не определяет ни одного квантиля и будет производить только суммирование и подсчет метрик. Клиентская библиотека Prometheus для Python не поддерживает квантили в сводных метриках.
Гистограммы или сводки, что мне использовать?
В большинстве случаев предпочтительны гистограммы, поскольку они более гибкие и позволяют использовать агрегированные процентили.
Сводки полезны в тех случаях, когда процентили не нужны и достаточно средних значений, или когда требуются очень точные процентили. Например, в случае договорных обязательств по выполнению критической системы.
Например, в случае договорных обязательств по выполнению критической системы.
В таблице ниже приведены плюсы и минусы гистограмм и сводок.
Таблица сравнения различных свойств гистограмм и сводок в Prometheus.Заключение
В первой части этой серии статей о метриках мы рассмотрели четыре типа метрик Prometheus: счетчики, датчики, гистограммы и сводки. В следующей части серии мы рассмотрим метрики OpenTelemetry.
Ищете долгосрочное хранилище для ваших метрик Prometheus? Ознакомьтесь с Promscale, серверной частью для наблюдения, построенной на PostgreSQL и TimescaleDB. Он легко интегрируется с Prometheus, обеспечивая 100% соответствие требованиям PromQL, мультиарендность и поддержку экземпляров OpenMetrics.
- Promscale — это проект с открытым исходным кодом, и вы можете использовать его совершенно бесплатно. Инструкции по установке в Kubernetes, Docker или виртуальной машине см. в нашей документации.
- Если у вас есть вопросы, присоединяйтесь к каналу #promscale в Slack сообщества Timescale.
