
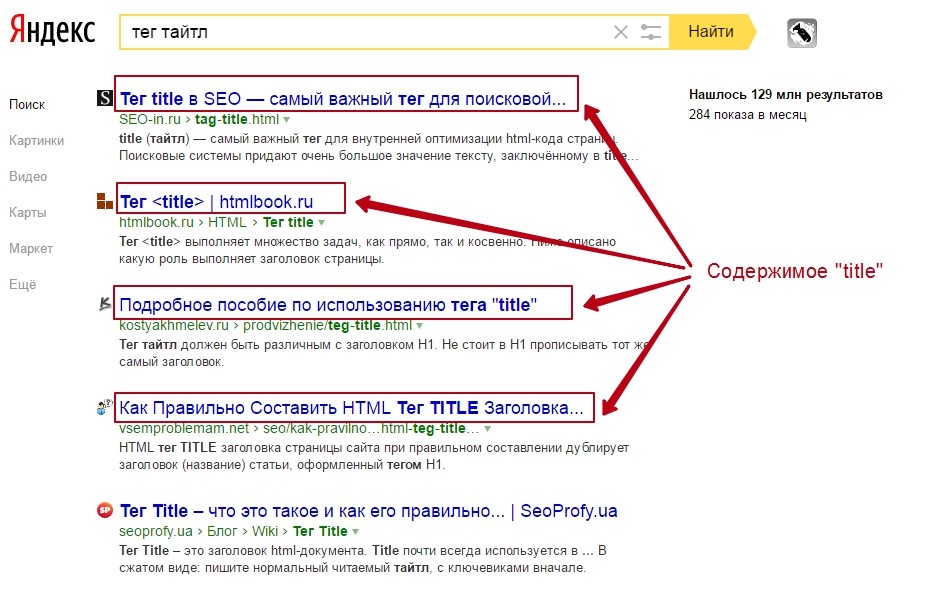
как Яндекс применил тяжёлые нейросети для поиска по смыслу / Хабр
Привет, Хабр. Меня зовут Саша Готманов, я руковожу группой нейросетевых технологий в поиске Яндекса. На YaC 2020 мы впервые рассказали о внедрении трансформера — новой нейросетевой архитектуры для ранжирования веб-страниц. Это наиболее значимое событие в нашем поиске за последние 10 лет.
Сегодня я расскажу читателям Хабра, в чём заключается иллюзия «поиска по смыслу», какой путь прошли алгоритмы и нейросети в ранжировании и какие основные сложности стоят перед теми, кто хочет применить для этой задачи трансформеры и даже заставить их работать в рантайме.
Задача поиска
Чтобы хорошо ранжировать результаты поиска, надо научиться оценивать семантическую (то есть смысловую) связь между запросом пользователя и документом (веб-страницей) из интернета. Иначе говоря, нужно построить алгоритм, который сможет предсказать, содержит ли данный документ ответ на запрос пользователя, есть ли в нём релевантная запросу информация.
С точки зрения пользователя это совершенно естественная задача. Смысл запроса ему очевиден; дальше достаточно лишь прочитать документ, понять его и либо найти в нём нужное содержание (тогда документ релевантен), либо нет (не релевантен).
Алгоритм, в отличие от человека, оперирует словами из запроса и текста документа чисто математически, как строчками из символов. Например, алгоритмически легко посчитать число совпадающих слов в запросе и документе или длину самой длинной подстроки из запроса, которая присутствует и в документе. Можно также воспользоваться накопленной историей поиска и достать из заранее подготовленной таблицы сведения о том, что запрос уже задавался в поиск много раз, а документ получил по нему много кликов (или наоборот, получил их очень мало, или вообще ещё ни разу не был показан). Каждый такой расчёт приносит полезную информацию о наличии семантической связи, но сам по себе не опирается на какое-либо смысловое понимание текста. Например, если документ отвечает на запрос, то правдоподобно, что у запроса и документа должны быть общие слова и подстроки. Алгоритм может использовать этот статистический факт, чтобы лучше оценить вероятность смысловой связи, а на основе большого числа таких расчётов уже можно построить достаточно хорошую модель. При её использовании на практике у человека будет возникать ощущение, что алгоритм «понимает» смысл текста.
Алгоритм может использовать этот статистический факт, чтобы лучше оценить вероятность смысловой связи, а на основе большого числа таких расчётов уже можно построить достаточно хорошую модель. При её использовании на практике у человека будет возникать ощущение, что алгоритм «понимает» смысл текста.
По такому принципу и работал поиск Яндекса до 2016 года. За годы разработки для повышения качества было придумано множество остроумных эвристических алгоритмов. Одних только способов посчитать общие слова запроса и документа было предложено и внедрено несколько десятков. Вот так, к примеру, выглядит один из сравнительно простых:
Здесь каждому «хиту» t (то есть вхождению слова из запроса в документ, от англ. hit, попадание) присваивается вес с учётом частотности слова в корпусе (IDF, Inverse Document Frequency) и расстояний до ближайших вхождений других слов запроса в документ слева и справа по тексту (LeftDist и RightDist). Затем полученные значения суммируются по всем найденным хитам. Каждая такая эвристика при внедрении позволяла получить небольшой, но статистически значимый прирост качества модели, то есть чуть лучше приблизить ту самую смысловую связь. Суммарный эффект от простых факторов постепенно накапливался, и внедрения за длительный период (полгода-год) уже заметно влияли на ранжирование.
Затем полученные значения суммируются по всем найденным хитам. Каждая такая эвристика при внедрении позволяла получить небольшой, но статистически значимый прирост качества модели, то есть чуть лучше приблизить ту самую смысловую связь. Суммарный эффект от простых факторов постепенно накапливался, и внедрения за длительный период (полгода-год) уже заметно влияли на ранжирование.
Немного другой, но тоже хорошо работающий способ принести качество с помощью простого алгоритма — придумать, какие еще тексты можно использовать в качестве «запроса» и «документа» для уже существующих эвристик. Слова запроса можно расширить близкими им по смыслу (синонимичными) словами или фразами. Либо вместо исходного запроса пользователя взять другой, который сформулирован иначе, но выражает схожую информационную потребность. Например, для запроса [отдых на северном ледовитом океане] похожими могут быть:
[можно ли купаться в баренцевом море летом]
[путешествие по северному ледовитому океану]
[города и поселки на побережье северного ледовитого океана]
(Это реальные примеры расширений запроса, взятые из поиска Яндекса. )
)
Как найти похожие слова и запросы — тема отдельного рассказа. Для этого в нашем поиске тоже есть разные алгоритмы, а решению задачи очень помогают логи запросов, которые нам задают пользователи. Сейчас важно отметить, что если похожий запрос найден, то его можно использовать во всех эвристических расчётах сразу; достаточно взять уже готовый алгоритм и заменить в нём один текст запроса на другой. Таким методом можно получить сразу много полезной информации для ранжирования. Что может быть чуть менее очевидно — аналогично запросу можно «расширять» и документ, собирая для него «альтернативные» тексты, которые в Яндексе называют словом стримы (от англ. stream). Например, стрим для документа может состоять из всех текстов входящих ссылок или из всех текстов запросов в поиск, по которым пользователи часто выбирают этот документ на выдаче. Точно так же стрим можно использовать в любом готовом эвристическом алгоритме, заменив на него исходный текст документа.
Говоря более современным языком, расширения и стримы — это примеры дополнительных контентных признаков, которые поиск Яндекса умеет ассоциировать с запросом и документом. Они ничем не отличаются от обычных числовых или категориальных признаков, кроме того, что их содержимое — это неструктурированный текст. Интересно, что эвристики, для которых эти признаки изначально разрабатывались, уже утратили большую часть своей актуальности и полезности, но сами расширения и стримы продолжают приносить пользу, только теперь уже в качестве входов новых нейронных сетей.
В результате многих лет работы над качеством поиска у нас накопились тысячи самых разных факторов. При решении задачи ранжирования все они подаются на вход одной итоговой модели. Для её обучения мы используем нашу открытую реализацию алгоритма GBDT (Gradient Boosting Decision Trees) — CatBoost.
Нейросети в ранжировании
Современные поисковые системы развиваются и улучшают своё качество за счёт всё более точных приближений семантической связи запроса и документа, так что иллюзия понимания становится полнее, охватывает новые классы запросов и пользовательских задач. Основным инструментом для этого в последние годы стали нейронные сети всё более возрастающей сложности. Впрочем, начало (как нам теперь кажется) было довольно простым.
Основным инструментом для этого в последние годы стали нейронные сети всё более возрастающей сложности. Впрочем, начало (как нам теперь кажется) было довольно простым.
Первые нейронные сети в поиске обладали простой feed-forward-архитектурой. На вход сети подаётся исходный текст в виде «мешка слов» (bag of words). Каждое слово превращается в вектор, вектора затем суммируются в один, который и используется как представление всего текста. Взаимный порядок слов при этом теряется или учитывается лишь частично с помощью специальных технических трюков. Кроме того, размер «словаря» у такой сети ограничен; неизвестное слово в лучшем случае удаётся разбить на частотные сочетания букв (например, на триграммы) в надежде сохранить хотя бы часть его смысла. Вектор мешка слов затем пропускается через несколько плотных слоёв нейронов, на выходе которых образуется семантический вектор (иначе эмбеддинг, от англ. embedding, вложение; имеется в виду, что исходный объект-текст вкладывается в n-мерное пространство семантических векторов).
Замечательная особенность такого вектора в том, что он позволяет приближать сложные «смысловые» свойства текста с помощью сравнительно простых математических операций. Например, чтобы оценить смысловую связь запроса и документа, можно каждый из них сначала превратить в отдельный вектор-эмбеддинг, а затем вектора скалярно перемножить друг на друга (или посчитать косинусное расстояние).
В этом свойстве семантических векторов нет ничего удивительного, ведь нейронная сеть обучается решать именно такую задачу, то есть приближать смысловую связь между запросом и документом на миллиардах обучающих примеров. В качестве таргета (то есть целевого, истинного значения релевантности) при этом используются предпочтения наших пользователей, которые можно определить по логам поиска. Точнее, можно предположить, что определённый шаблон поведения пользователя хорошо коррелирует с наличием (или, что не менее важно, с отсутствием) смысловой связи между запросом и показанным по нему документом, и собрать на его основе вариант таргета для обучения. Задача сложнее, чем может показаться на первый взгляд, и допускает различные решения. Если в качестве положительного примера обычно подходит документ с «кликом» по запросу, то найти хороший отрицательный пример гораздо труднее. Например, оказывается, что почти бесполезно брать в качестве отрицательных документы, для которых был показ, но не было «клика» по запросу. Здесь снова открывается простор для эвристических алгоритмов, а их правильное использование позволяет на порядок улучшить качество получающейся нейронной сети в задаче ранжирования. Алгоритм, который лучше всего показал себя на практике, называется в Яндексе «алгоритмом переформулировок» и существенно опирается на то, что пользователям свойственно при решении поисковой задачи задавать несколько запросов подряд, постепенно уточняя формулировку, то есть «переформулировать» исходный запрос до тех пор, пока не будет найден нужный документ.
Задача сложнее, чем может показаться на первый взгляд, и допускает различные решения. Если в качестве положительного примера обычно подходит документ с «кликом» по запросу, то найти хороший отрицательный пример гораздо труднее. Например, оказывается, что почти бесполезно брать в качестве отрицательных документы, для которых был показ, но не было «клика» по запросу. Здесь снова открывается простор для эвристических алгоритмов, а их правильное использование позволяет на порядок улучшить качество получающейся нейронной сети в задаче ранжирования. Алгоритм, который лучше всего показал себя на практике, называется в Яндексе «алгоритмом переформулировок» и существенно опирается на то, что пользователям свойственно при решении поисковой задачи задавать несколько запросов подряд, постепенно уточняя формулировку, то есть «переформулировать» исходный запрос до тех пор, пока не будет найден нужный документ.
Пример архитектуры сети в подходе с семантическими эмбеддингами. Более подробное описание этого подхода — тут.
Важное ограничивающее свойство такой сети: весь входной текст с самого начала представляется одним вектором ограниченного размера, который должен полностью описывать его «смысл». Однако реальный текст (в основном это касается документа) обладает сложной структурой — его размер может сильно меняться, а смысловое содержание может быть очень разнородным; каждое слово и предложение обладают своим особым контекстом и добавляют свою часть содержания, при этом разные части текста документа могут быть в разной степени связаны с запросом пользователя. Поэтому простая нейронная сеть может дать лишь очень грубое приближение реальной семантики, которое в основном работает для коротких текстов.
Тем не менее, использование плотных feed-forward-сетей в своё время позволило существенно улучшить качество поиска Яндекса, что легло в основу двух крупных релизов: «Палех» и «Королёв». В значительной степени этого удалось добиться за счёт длительных экспериментов с обучающими выборками и подбором правильных контентных признаков на входе моделей. То есть ключевыми вопросами для нас были: «На какой (кликовый) таргет учить?» и «Какие данные и в каком виде подавать на вход?»
То есть ключевыми вопросами для нас были: «На какой (кликовый) таргет учить?» и «Какие данные и в каком виде подавать на вход?»
Интересно, что хотя нейронная сеть обучается предсказывать связь между запросом и документом, её затем можно легко адаптировать и для решения других смысловых задач. Например, уже готовую сеть можно на сравнительно небольшом числе примеров дообучить для различных вариантов запросной или документной классификации, таких как выделение потока порнозапросов, товарных и коммерческих, навигационных (то есть требующих конкретного сайта в ответе) и так далее. Что ещё более важно для ранжирования, такую же сеть можно дообучить на экспертных оценках. Экспертные оценки в ранжировании — это прямые оценки смысловой связи запроса и документа, которые ставятся людьми на основе понимания текста. В сложных случаях правильная оценка требует специальных знаний в узкой области, например в медицине, юриспруденции, программировании, строительстве. Это самый качественный и самый дорогой из доступных нам таргетов, поэтому важно уметь его выучивать максимально эффективно.
Нейронная сеть, сначала обученная на миллиардах «переформулировок», а затем дообученная на сильно меньшем количестве экспертных оценок, заметно улучшает качество ранжирования. Это характерный пример применения подхода transfer learning: модель сначала обучается решать более простую или более общую задачу на большой выборке (этот этап также называют предварительным обучением или предобучением, англ. pre-tain), а затем быстро адаптируется под конкретную задачу уже на сильно меньшем числе примеров (этот этап называют дообучением или настройкой, англ. fine-tune). В случае простых feed-forward-сетей transfer learning уже приносит пользу, но наибольшего эффекта этот метод достигает с появлением архитектур следующего поколения.
Нейросети-трансформеры
Долгое время самой активно развивающейся областью применения для сложных алгоритмов анализа текста была задача машинного перевода. Результат работы переводчика — это полностью сгенерированный текст, и даже небольшие смысловые ошибки сразу заметны пользователю. Поэтому для решения задач перевода всегда использовались самые сложные модели, которые могли учесть порядок слов в тексте и их взаимное влияние друг на друга. Сначала это были рекуррентные нейронные сети (Recurrent Neural Networks, RNN), а затем трансформеры. Далее речь пойдёт только о трансформерах, которые по сути являются более технологически совершенным развитием идеи рекуррентных сетей.
Поэтому для решения задач перевода всегда использовались самые сложные модели, которые могли учесть порядок слов в тексте и их взаимное влияние друг на друга. Сначала это были рекуррентные нейронные сети (Recurrent Neural Networks, RNN), а затем трансформеры. Далее речь пойдёт только о трансформерах, которые по сути являются более технологически совершенным развитием идеи рекуррентных сетей.
В сетях с архитектурой трансформеров каждый элемент текста обрабатывается по отдельности и представляется отдельным вектором, сохраняя при этом своё положение. Элементом может быть отдельное слово, знак пунктуации или частотная последовательность символов, например BPE-токен. Сеть также включает механизм «внимания» (англ. attention), который позволяет ей при вычислениях «концентрироваться» на разных фрагментах входного текста.
Применительно к задаче ранжирования, по запросу [купить кофеварку] такая нейронная сеть может выделить часть документа (e.g. страницы интернет-магазина), в которой речь идёт именно о нужном пользователю товаре. Остальные части тоже могут быть учтены, но их влияние на результат будет меньше. Трансформеры могут хорошо выучивать сложные зависимости между словами и активно используются для генерации естественных текстов в таких задачах, как перевод и ответы на вопросы (англ. question answering). Поэтому в Яндексе они применяются уже достаточно давно. В первую очередь, конечно, в Яндекс.Переводчике.
Остальные части тоже могут быть учтены, но их влияние на результат будет меньше. Трансформеры могут хорошо выучивать сложные зависимости между словами и активно используются для генерации естественных текстов в таких задачах, как перевод и ответы на вопросы (англ. question answering). Поэтому в Яндексе они применяются уже достаточно давно. В первую очередь, конечно, в Яндекс.Переводчике.
В ранжировании трансформеры позволяют добиться нового уровня качества при моделировании семантической связи запроса и документа, а также дают возможность извлекать полезную для поиска информацию из более длинных текстов. Но одних только ванильных трансформеров для этой задачи мало.
Transformers + transfer learning
Глубокие нейронные сети достаточно требовательны к объёму примеров для обучения. Если данных мало, то никакого выигрыша от применения тяжёлой архитектуры не получится. При этом практических задач всегда много, и они несколько отличаются друг от друга. Собрать миллиарды примеров для каждый задачи просто невозможно: не хватит ни времени, ни бюджета. На помощь снова приходит подход transfer learning. Как мы уже разобрались на примере feed-forward-сетей, суть в том, чтобы переиспользовать информацию, накопленную в рамках одной задачи, для других задач. В Яндексе этот подход применяется повсеместно, особенно он хорош в компьютерном зрении, где обученная на поиске изображений базовая модель легко дообучается почти на любые задачи. В трансформерах transfer learning тоже ожидаемо заработал.
На помощь снова приходит подход transfer learning. Как мы уже разобрались на примере feed-forward-сетей, суть в том, чтобы переиспользовать информацию, накопленную в рамках одной задачи, для других задач. В Яндексе этот подход применяется повсеместно, особенно он хорош в компьютерном зрении, где обученная на поиске изображений базовая модель легко дообучается почти на любые задачи. В трансформерах transfer learning тоже ожидаемо заработал.
В 2018-м команда OpenAI показала, что если обучить трансформер на сыром корпусе текстов большого размера в режиме языковой модели, а затем дообучать модель на малых данных для конкретных задач, то результат оказывается существенно лучше, чем раньше. Так родился проект GPT (Generative Pre-trained Transformer). Похожая идея чуть позже легла в основу проекта BERT (Bidirectional Encoder Representations from Transformers) от Google.
Такой же метод мы решили применить и в качестве поиска Яндекса. Но для этого нам потребовалось преодолеть несколько технологических трудностей.
Трансформеры в поиске Яндекса
Проект BERT замечателен тем, что каждый может взять в открытом доступе уже готовую предобученную модель и применить её к своей задаче. Во многих случаях это даёт отличный результат. Но, к сожалению, поиск Яндекса — не такой случай. Простое дообучение готовой модели приносит лишь небольшое улучшение качества, совершенно непропорциональное затратам ресурсов, которые необходимы для применения такой модели в рантайме. Чтобы раскрыть реальные возможности трансформера для поиска, нужно было обучать свою модель с нуля.
Для иллюстрации приведу несколько результатов из наших экспериментов. Давайте возьмём открытую модель BERT-Base Multilingual и обучим на наши экспертные оценки. Можно измерить полезность такого трансформера как дополнительного фактора в задаче ранжирования; получим статистически значимое уменьшение ошибки предсказания релевантности на 3-4%. Это хороший фактор для ранжирования, который мы бы немедленно внедрили, если бы он не требовал применения 12-слойного трансформера в рантайме. Теперь возьмём вариант модели BERT-Base, который мы обучили с нуля, и получим уменьшение ошибки предсказания почти на 10%, то есть более чем двукратный рост качества по сравнению с ванильной версией, и это далеко не предел. Это не значит, что модель Multilingual от Google — низкого качества. С помощью открытых моделей BERT уже было получено много интересных результатов в разных задачах NLP (Natural Language Processing, то есть в задачах обработки текстов на естественном языке). Но это значит, что она плохо подходит для ранжирования веб-страниц на русском языке.
Теперь возьмём вариант модели BERT-Base, который мы обучили с нуля, и получим уменьшение ошибки предсказания почти на 10%, то есть более чем двукратный рост качества по сравнению с ванильной версией, и это далеко не предел. Это не значит, что модель Multilingual от Google — низкого качества. С помощью открытых моделей BERT уже было получено много интересных результатов в разных задачах NLP (Natural Language Processing, то есть в задачах обработки текстов на естественном языке). Но это значит, что она плохо подходит для ранжирования веб-страниц на русском языке.
Первая трудность, которая возникает на пути к обучению своего трансформера, — это вычислительная сложность задачи. Новые модели хорошо масштабируются по качеству, но при этом в миллионы раз сложнее, чем те, которые применялись в поиске Яндекса раньше. Если раньше нейронную сеть удавалось обучить за один час, то трансформер на таком же графическом ускорителе Tesla v100 будет учиться 10 лет. То есть без одновременного использования хотя бы 100 ускорителей (с возможностью быстрой передачи данных между ними) задача не решается в принципе. Необходим запуск специализированного вычислительного кластера и распределённое обучение на нём.
Необходим запуск специализированного вычислительного кластера и распределённое обучение на нём.
Нам потребовалось немного времени, пара сотен GPU-карт, место в одном из дата-центров Яндекса и классные инженеры. К счастью, всё это у нас было. Мы собрали несколько версий кластера и успешно запустили на нём обучение. Теперь модель одновременно обучается примерно на 100 ускорителях, которые физически расположены в разных серверах и общаются друг с другом через сеть. И даже с такими ресурсами на обучение уходит около месяца.
Несколько слов про само обучение. Нам важно, чтобы получившаяся модель решала с оптимальным качеством именно задачу ранжирования. Для этого мы разработали свой стек обучения. Как и BERT, модель сначала учится свойствам языка, решая задачу MLM (Masked Language Model), но делает это сразу на текстах, характерных для задачи ранжирования. Уже на этом этапе вход модели состоит из запроса и документа, и мы с самого начала обучаем модель предсказывать ещё и вероятность клика на документ по запросу. Удивительно, но тот же самый таргет «переформулировок», который был разработан ещё для feed-forward-сетей, отлично показывает себя и здесь. Обучение на клик существенно увеличивает качество при последующем решении семантических задач ранжирования.
Удивительно, но тот же самый таргет «переформулировок», который был разработан ещё для feed-forward-сетей, отлично показывает себя и здесь. Обучение на клик существенно увеличивает качество при последующем решении семантических задач ранжирования.
В дообучении мы используем не одну задачу, а последовательность задач возрастающей сложности. Сначала модель учится на более простых и дешёвых толокерских оценках релевантности, которыми мы располагаем в большом количестве. Затем на более сложных и дорогих оценках асессоров. И наконец, обучается на итоговую метрику, которая объединяет в себе сразу несколько аспектов и по которой мы оцениваем качество ранжирования. Такой метод последовательного дообучения позволяет добиться наилучшего результата. По сути весь процесс обучения выстраивается от больших выборок к малым и от простых задач к более сложным и «семантическим».
На вход модели мы подаём всё те же контентные признаки, о которых шла речь в самом начале. Здесь есть текст запроса, его расширения и фрагменты содержимого документа. Документ целиком всё ещё слишком большой, чтобы модель могла справиться с ним полностью сама, без предварительной обработки. Стримы тоже содержат полезную информацию, но с ними нам ещё надо поработать, чтобы понять, как её эффективно донести до поиска. Сложнее всего оказалось выделить хорошие фрагменты текста документа. Это вполне ожидаемо: чтобы выделить наиболее важную часть веб-страницы, уже нужно многое понимать про её смысловое содержание. Сейчас нам на помощь опять приходят простые эвристики и алгоритмы автоматической сегментации, то есть разметки страницы на структурные зоны (основное содержание, заголовки и так далее). Стоимость ошибки достаточно велика, иногда для правильного решения задачи необходимо, чтобы модель «увидела» одно конкретное предложение в длинном тексте статьи, и здесь ещё остается потенциал для улучшений.
Документ целиком всё ещё слишком большой, чтобы модель могла справиться с ним полностью сама, без предварительной обработки. Стримы тоже содержат полезную информацию, но с ними нам ещё надо поработать, чтобы понять, как её эффективно донести до поиска. Сложнее всего оказалось выделить хорошие фрагменты текста документа. Это вполне ожидаемо: чтобы выделить наиболее важную часть веб-страницы, уже нужно многое понимать про её смысловое содержание. Сейчас нам на помощь опять приходят простые эвристики и алгоритмы автоматической сегментации, то есть разметки страницы на структурные зоны (основное содержание, заголовки и так далее). Стоимость ошибки достаточно велика, иногда для правильного решения задачи необходимо, чтобы модель «увидела» одно конкретное предложение в длинном тексте статьи, и здесь ещё остается потенциал для улучшений.
Итак, мы научились обучать модели в офлайне, но вот работать им уже нужно в онлайне, то есть в реальном времени в ответ на тысячи пользовательских запросов в секунду. Тут заключается вторая принципиальная трудность. Применение трансформера — это тяжелая для рантайма задача; модели такой сложности можно применять только на GPU-картах, иначе время их работы окажется чрезмерным и легко может превысить время работы всего поиска. Потребовалось разработать с нуля и развернуть несколько сервисов для быстрого применения («инференса», англ. inference) трансформеров на GPU. Это новый тип инфраструктуры, который до этого не использовался в поиске.
Тут заключается вторая принципиальная трудность. Применение трансформера — это тяжелая для рантайма задача; модели такой сложности можно применять только на GPU-картах, иначе время их работы окажется чрезмерным и легко может превысить время работы всего поиска. Потребовалось разработать с нуля и развернуть несколько сервисов для быстрого применения («инференса», англ. inference) трансформеров на GPU. Это новый тип инфраструктуры, который до этого не использовался в поиске.
Непосредственно для применения мы доработали внутреннюю библиотеку для инференса трансформеров, которая разработана нашими коллегами из Яндекс.Переводчика и, по нашим замерам, как минимум не уступает другим доступным аналогам. Ну и конечно, всё считается в FP16 (16-битное представление чисел с плавающей точкой).
Однако, даже с учетом использования GPU и оптимизированного кода для инференса, модель с максимальным уровнем качества слишком большая для внедрения в рантайм поиска. Для решения этой проблемы есть классический приём — knowledge distillation (или dark knowledge). В Яндексе мы используем менее пафосный термин «пародирование». Это обучение более простой модели, которая «пародирует» поведение более сложной, обучаясь на её предсказания в офлайне.
В Яндексе мы используем менее пафосный термин «пародирование». Это обучение более простой модели, которая «пародирует» поведение более сложной, обучаясь на её предсказания в офлайне.
В результате пародирования сложность модели удаётся уменьшить в разы, а потери качества остаются в пределах ~10%.
Это не единственный способ оптимизации. Мы также научились делать многозадачные модели, когда одна модель «подражает» сразу нескольким сложным моделям, обученным на разные задачи. При этом суммарная полезность модели для ранжирования существенно возрастает, а её сложность почти не увеличивается.
Если же хочется добиться максимального качества, то возможностей одной дистилляции недостаточно. Приходится поделить модель на несколько частей, каждая из которых применяется независимо. Часть модели применяется только к запросу; часть — только к документу; а то, что получилось, затем обрабатывается финальной связывающей моделью. Такой метод построения «раздельной» или split-модели распределяет вычислительную нагрузку между разными компонентами системы, что позволяет сделать модель более сложной, увеличить размер её входа и заметно повысить качество.
Внедрение split-модели опять приводит нас к новым и интересным инженерным задачам, но рассказать обо всём в одном посте, увы, невозможно. Хотя архитектура нейросетей-трансформеров известна уже достаточно давно, а их использование для задач NLP приобрело огромную популярность после появления BERT в 2018 году, внедрение трансформера в современную поисковую систему невозможно без инженерной изобретательности и большого числа оригинальных технологических улучшений в обучении и рантайме. Поэтому мы назвали нашу технологию YATI — Yet Another Transformer (with Improvements), что, как нам кажется, хорошо отражает её суть. Это действительно «ещё один трансформер», архитектурно похожий на другие модели (а их в последние годы появилось великое множество), но уникальный тем, что благодаря совокупности улучшений он способен работать и приносить пользу в поиске — самом сложном сервисе Яндекса.
Что в итоге? У нас появилась своя инфраструктура обучения и дистилляции тяжёлых моделей, адаптированная под наш стек задач ранжирования. С её помощью мы сначала обучили большие модели-трансформеры высокого качества, а затем дистиллировали их в многозадачную split-модель, которая внедрена в рантайм на GPU в виде нескольких частей, независимо применяемых к запросу и документу.
С её помощью мы сначала обучили большие модели-трансформеры высокого качества, а затем дистиллировали их в многозадачную split-модель, которая внедрена в рантайм на GPU в виде нескольких частей, независимо применяемых к запросу и документу.
Это внедрение принесло нам рекордные улучшения в ранжировании за последние 10 лет (со времён внедрения Матрикснета). Просто для сравнения: Палех и Королёв вместе повлияли на поиск меньше, чем новая модель на трансформерах. Более того, в поиске рассчитываются тысячи факторов, но если выключить их все и оставить только новую модель, то качество ранжирования по основной офлайн-метрике упадёт лишь на 4-5%!
В таблице ниже сравнивается качество нескольких нейросетевых алгоритмов в задаче ранжирования. “% NDCG” — это нормированное значение обычной метрики качества DCG по отношению к идеальному ранжированию на нашем датасете. 100% означает, что модель располагает документы в порядке убывания их истинных офлайн-оценок. Худший результат ожидаемо даёт подход предыдущего поколения, то есть просто обучение feed-forward-сети на кликовый таргет. Дообучение готовых моделей BERT существенно проигрывает по качеству специализированной версии, которая показывает рекордный результат в 95,4% — сравнимо с качеством дистилляции YATI в feed-forward-сеть. Все модели, кроме первой, дообучались на одном и том же множестве экспертных оценок.
Дообучение готовых моделей BERT существенно проигрывает по качеству специализированной версии, которая показывает рекордный результат в 95,4% — сравнимо с качеством дистилляции YATI в feed-forward-сеть. Все модели, кроме первой, дообучались на одном и том же множестве экспертных оценок.
Приводимые числа показывают: несмотря на универсальность нейросетей последнего поколения, их адаптация к конкретным задачам на практике даёт существенный прирост эффективности. Это особенно важно для промышленных применений под высокой нагрузкой. Тем не менее очевидная ценность универсальных моделей в том, что они позволяют добиться достаточно хороших результатов на широком круге NLP-задач при минимальном вложении времени и ресурсов.
В начале поста я рассказал про ощущение поиска по смыслу. Применение тяжёлых (как мы сейчас о них думаем) нейросетевых моделей, которые точнее приближают структуру естественного языка и лучше учитывают семантические связи между словами в тексте, поможет нашим пользователям встречаться с этим эффектом ещё чаще, чем раньше. И может быть, однажды нам уже будет непросто отличить иллюзию от реальности. Но до этого, я уверен, в качестве поиска ещё предстоит сделать много нового и интересного.
И может быть, однажды нам уже будет непросто отличить иллюзию от реальности. Но до этого, я уверен, в качестве поиска ещё предстоит сделать много нового и интересного.
Спасибо за внимание.
Работа с сайтом ИСК «Память народа»
ИСК «Память народа» является информационным ресурсом открытого доступа и содержит информацию по интерактивным картам и оперативным документам, а также предоставляет возможность поиска и работы с информацией из ОБД «Мемориал» и ОБД «Подвиг народа» в Великой Отечественной войне 1941-1945 годов.
Быстрый переход:
- Описание главной страницы
- Участники войны
- Боевые операции
- Воинские захоронения
- Воинские части
- Документы частей
- RSS подписка
- Истории пользователей
- Личный архив
- Регистрация
- Авторизация
- Восстановление пароля
- Выход пользователя из системы
Описание главной страницы сайта ИСК «Память народа»
Главная страница сайта содержит следующие области: основные тематические разделы сайта, поисковую форму,
блоки отображающие информацию разделов проекта и доступ к личному архиву.
Для просмотра сайта c поддержкой основных нововведений рекомендуется использовать приложение-обозреватель Microsoft Internet Explorer 10, Mozilla Firefox 4, Google Chrome 5, Opera 11.5, Safari 5.0 и выше.
Для того чтобы начать поиск введите в форме поиска текст запроса и нажмите клавишу «Enter» или щелкните кнопку «Найти».
Обратите внимание
Поиск по персоналиям (награды, потери, оперативные документы) производится на главной странице и страницах раздела «Участники войны», поиск по боевым операциям — в разделе «Боевые операции», поиск по воинским частям и военачальникам — в разделе «Воинские части», поиск по документам частей — в одноименном разделе «Документы частей», а поиск по воинским захоронениям — на страницах раздела «Воинские захоронения».
Раздел «Участники войны»
На главной странице раздела «Участники войны», в верхней части страницы расположена строка поиска:
Поиск осуществляется по следующим данным: Фамилия, Имя, Отчество, Год рождения.
Для осуществления поиска укажите данные в поисковой строке, нажмите кнопку «Найти» или клавишу «Enter» на клавиатуре.
Если данные в поисковой строке были введены на главной странице, автоматически произойдет переход к разделу «Участники войны».
Указанные данные из поисковой строки будут добавлены в поля блока «Дополнительные параметры», и на страницу будут выведены результаты поиска. Если для одной персоналии будет найдено несколько документов, результаты поиска будут сгруппированы по персоналии.
Если Вы хотите исключить группировку найденных документов по персоналии, нажмите кнопку «Уточнить»,
расположенную справа от строки поиска, снимите «флажок», поставленный в поле «Группировать документы
одного человека», при необходимости, можете ввести уточняющие параметры поиска и нажмите кнопку
«Уточнить и найти».
При переходе на интересующее Вас ФИО героя, Вы попадаете на страницу героя, на которой можете видеть все документы, связанные с ним из различных источников (документы о потерях, документы о награждениях, паспорта захоронений и т.д.).
На вкладке «Сводная информация» доступна информация о дате и месте рождения, месте призыва, местах службы и наградах героя, собранная из документов, в которых упоминается герой.
На странице героя, в левой стороне расположена область с перечисленными документами героя, в правой стороне находится область просмотра выбранного документа.
Для перемещения между документами, связанными с выбранным документом о награждении,
используйте вкладки переключения, например: Подвиг, Подвиг2, Первая страница приказа
или указа, Строка в наградном списке, Наградной лист. Вкладки отображаются в случае
наличия соответствующей информации.
Для перемещения между типами данных: «Сводная информация», «Документы», «Боевой путь героя» и «Дополнительная информация» — используйте вкладки переключения:
Для отображения боевого пути героя, нажмите на одноименную вкладку «Боевой путь». Будет выполнен переход на страницу, на которой изображена карта с точками боевого пути, а также воинские части в составе которых был пройден боевой путь:
Раздел «Боевые операции»
В верхней части страницы расположена поисковая строка. Поиск осуществляется по следующим полям: Название операции, Военачальник, Воинская часть.
Первоначально в данном разделе слева от карты Вы увидите список всех боевых операций за весь период Великой отечественной войны.
Для уточнения запроса воспользуйтесь дополнительным поиском, нажав кнопку «Уточнить». В открывшейся форме введите уточняющие условия поиска и нажмите кнопку «Уточнить и найти»:
Также Вы можете уточнить поиск по периоду выполнения боевых операций, воспользовавшись инструментом «таймлайн» и установив год и месяц начала и/или окончания боевых операций:
После задания всех уточняющих условий поиска в левой части страницы данного раздела будет показан список всех боевых операций, удовлетворяющих заданным условиям со ссылками на подробную страницу, а справа –интерактивная карта боевых действий, в которой Вы можете:
— масштабировать карту с помощью инструмента масштабирования
— переключать режим отображения боевых операций: по схеме операции или по линии
фронта
— перемещаться между операциями с помощью меток
На странице выбранной операции вы увидите описание боевой операции; ее этапы и схему
операции; расположение частей, участвующих в данной операции; список военачальников; список
военнослужащих, получивших высшую награду Героя за сражение в боевой операции, документы
воинских частей, документы сражения; захоронения, мемориалы и памятники в районе проведения
операции; фотографии и другие материалы; журналы боевых действий.
Героя боевой операции, воинской части, принимавшей участие в данной боевой операции.
Вы можете переключать режимы отображения доступной информации по:
1) Cхеме операции
С помощью инструмента «таймлайн» в данном режиме Вы можете посмотреть расположение частей в ходе боевой операции за любую дату в период действия.
2) Расположению частей
С помощью инструмента «таймлайн» в данном режиме вы можете посмотреть расположение частей в ходе боевой операции за любую дату в период действия.
3) Историческим картам
С помощью инструмента «таймлайн» в данном режиме Вы можете посмотреть исторические карты боевой операции за любую дату в период действия.
4) Выбор области на карте
В выбранной области на карте будут отображены воинские части, места захоронений, госпитали, лагеря,
исторические карты и военные операции.
Раздел «Воинские захоронения»
В верхней части страницы расположена поисковая строка. Поиск осуществляется по следующим полям: Населенный пункт или регион, тип захоронения.
Вы также можете воспользоваться дополнительными параметрами поиска:
В центральной части страницы слева выведен список найденных записей (каждое из наименований в списке является ссылкой на страницу захоронения, места выбытия, госпиталя или лагеря), справа показана интерактивная карта с метками, показывающими количество объектов (захоронений, мест выбытия, госпиталей или лагерей) в данной области при выбранном масштабе. Вы можете просто увеличивать масштаб карты или дважды нажать на одну из меток для автоматического приближения к региональной привязке:
После увеличения масштаба будут показаны новые метки с более точной привязкой
к местности, и в левой части окна изменится отображаемый список найденных записей. При нажатии на метку Вы увидите окно с информацией о выбранном объекте и ссылкой
на страницу с более подробной информацией:
При нажатии на метку Вы увидите окно с информацией о выбранном объекте и ссылкой
на страницу с более подробной информацией:
Для отображения на карте определенных типов данных: «Все результаты», «Современные захоронения», «Первичные захоронения», «Места выбытия», «Госпитали» и «Лагеря» — используйте вкладки переключения:
Раздел «Истории пользователей»
В новом разделе размещены истории и воспоминания людей, чьи судьбы затронула война 1941–1945 года. Возможность опубликовать истории о войне близких вам людей, сохранив их имена для истории России.
Главная страница
Страница определенной истории
Раздел Воинские части
Поиск осуществляется по названию воинской части.
Для осуществления поиска — укажите данные в поисковой строке, нажмите кнопку «Найти» или клавишу
«Enter» на клавиатуре.
Раздел Документы частей
Поиск осуществляется по следующим данным: Боевая операция, Воинская часть, Автор документа, Номер документа, Дата начала, Дата окончания.
Для осуществления поиска — укажите данные в поисковой строке, нажмите кнопку «Найти» или клавишу «Enter» на клавиатуре.
При переходе к разделу «Документы частей» открывается следующая страница:
На странице раздела «Документы частей» даны краткие рекомендации по работе с данным разделом.
Строка поискаНа странице раздела «Документы частей», в верхней части страницы расположена строка поиска.
Поиск осуществляется по следующим данным о документах:
- Операция;
- Воинская часть;
- Автор документа.
Для осуществления поиска необходимо:
1) указать данные в поисковой строке;
2) нажать кнопку «Найти» или клавишу
на клавиатуре.
На экран пользователя будет выведен результат поиска.
Для перехода к расширенному поиску необходимо нажать на кнопку «Уточнить».
Расширенный поискЧтобы осуществить расширенный поиск, необходимо:
1) перейти к разделу «Документы частей»;
2) нажать кнопку «Уточнить»;
Откроется блок для введения дополнительных параметров поиска.
Блок дополнительных параметров включает в себя следующие поля: Боевая операция, Воинская часть, Автор документа, Номер документа, Дата начала, Дата окончания, Номер документа, Фонд, Опись, Дело.
3) заполнить поля поисковой формы;
Примечание. Поле Боевая операция заполняется выбором значения из списка операций, отображаемого при нажатии кнопки , стоящей в правой части поля, или вводом значения с помощью клавиатуры.
В последнем случае, по мере ввода значения, отображаются записи, в которых содержатся вводимые символы.
4) для получения результата поиска нажать кнопку «Уточнить и найти».
После чего на экране отобразятся результаты поиска, соответствующие введенным критериям поиска:
Результаты поискаРезультаты поиска отображаются на экране в форме списка:
Перед списком предложены категории данных, в которых осуществлялся поиск:
С правой стороны от списка найденных документов отображается область для выбора типа документов, среди которых осуществляется поиск.
Доступ к выбору типа документа зависит от выбранной категории. Например, при нажатии на категорию «Руководящие и направляющие документы», в области «Типы документов» для выбора будут доступны только параметры, относящиеся к типу «Руководящие и направляющие документы».
Для просмотра документа необходимо нажать левой кнопкой мыши по строке найденного документа в результатах поиска. Откроется страница содержащая данные по выбранному документу.
В левой части экрана будет показан список страниц документа, выбранная страница в данной области
подсвечена красным. Для перехода к просмотру другой страницы необходимо нажать левой кнопкой мыши по
нужной странице. Также выбранную страницу из списка возможно добавить в личный архив, для этого
необходимо нажать кнопку «В архив».
Для перехода к просмотру другой страницы необходимо нажать левой кнопкой мыши по
нужной странице. Также выбранную страницу из списка возможно добавить в личный архив, для этого
необходимо нажать кнопку «В архив».
В правой части экрана отобразится электронный образ страницы выбранного документа.
Личный архив
Личный архив предоставляет пользователям возможность работы с сохраненными страницами сайта и электронными образами документов.
Доступ к личному архиву возможен с любой из страниц сайта в правой части экрана. Для того чтобы открыть область личного архива, необходимо нажать левой кнопкой мыши по серой полосе с надписью «Личный архив» в правой части экрана.
Регистрация
Для доступа к личному архиву и корректного сохранения всех добавленных в личный архив данных необходимо зарегистрироваться на ИСК «Память народа».
Нажмите ссылку «Зарегистрируйтесь», расположенную в верхей части открытой области «Личный
архив».
Окно регистрации
Заполните необходимые поля и нажмите на кнопку «Зарегистрироваться»
Стоит учесть, что нажимая кнопку «Зарегистрироваться» пользователь принимает правила и условия пользовательского соглашения, скоторымы необходимо ознакомиться.
На адрес электронной почты, указанный в соответствующем поле окна регистрации, будет отправлено письмо с сылкой для подтверждения регистрации.
Примечание – также можно авторизоваться, используя учетные данные социальных сетей.
Окно авторизации (вход)
Для использования всех возможностей работы с личным архивом следует авторизоваться на ИСК «Память народа».
Заполните поля Логин и Пароль и нажмите кнопку «Войти».
Примечание – также можно авторизоваться, используя учетные данные социальных сетей.
Восстановление пароля
Нажмите на ссылку «Забыли пароль?»
Заполнить поля;
Нажать кнопку «Восстановить».
На указанный адрес электронной почты будет выслано письмо, содержащее новый пароль.
Рекомендуется сменить данный пароль при следующем входе в систему.
Выход из Личного архива
Для выхода пользователем из системы нажать на ссылку «Выход»
Добавление материала в Личный кабинет
В личном кабинете предусмотрена типизированная подборка История героя и произвольная Мои подборки. При выборе типизированной подборки создается папка верхнего уровня, в которую добавляются все необходимые документы на героя, на основе которых формируется страница героя. Произвольная подборка Мои подборки используется для структурированного хранения документов, выбранных пользователем (предусмотрена возможность создания до 5 уровней вложенности папок).
Для созданных подборок предусмотрены возможности:
- — перемещения информации из одной подборки в другую;
- — изменения названия;
- — удаления.

Для того, чтобы подписаться на RSS канал необходимо нажать на ссылку расположенную в нижней части сайта (в подвале):
Нажмите правой кнопкой мыши по ссылке RSS и скопируйте адрес ссылки. Если вы используете Mozilla Firefox, щёлкните «Копировать ссылку» в контекстном меню. Если вы используете Google Chrome, щёлкните «Копировать адрес ссылки».
Откройте Microsoft Outlook. Нажмите правой кнопкой мыши по пункту «RSS-каналы». Выберите «Добавить новый RSS-канал». Вставить ссылку в строку расположения и нажмите «Добавить»:
идентификаторов мест | Places API
Выберите платформу: Андроид iOS JavaScript Web Service
Идентификаторы мест однозначно идентифицируют место в базе данных Google Places и на Google Maps. Идентификаторы мест принимаются в запросах к следующим API Карт:
- Получение адреса для идентификатора места в веб-службе API геокодирования и
Служба геокодирования, Maps JavaScript API.
- Указание исходной, конечной и промежуточных путевых точек в Directions API веб-служба и служба маршрутов, Maps JavaScript API.
- Указание пунктов отправления и назначения в веб-службе API матрицы расстояний и службе матрицы расстояний, Maps JavaScript API.
- Получение сведений о месте в веб-службе API Places, SDK Places для Android, SDK Places для iOS и библиотеке Places.
- Использование параметров Place ID в Maps Embed API.
- Получение поисковых запросов в URL-адресах Карт.
- Отображение ограничений скорости в Roads API.
- Поиск и оформление полигонов границ в управляемом данными стиле для границ.

Уведомление: 30 марта 2022 г.,
все API платформы Google Карт перестанут принимать некоторые устаревшие
разместить идентификаторы.
Начиная с 30 марта 2022 года все запросы, сделанные с использованием устаревших
Идентификаторы мест будут отклонены и вернут код ошибки INVALID_REQUEST . Чтобы предотвратить ухудшение пользовательского опыта, пожалуйста,
обновить все
размещать идентификаторы старше 12 месяцев до 30 марта 2022 года.
Чтобы предотвратить ухудшение пользовательского опыта, пожалуйста,
обновить все
размещать идентификаторы старше 12 месяцев до 30 марта 2022 года.
Найти идентификатор определенного места
Вы ищете ID определенного места? Используйте идентификатор места Искатель ниже, чтобы найти место и получить его ID:
В качестве альтернативы вы можете вид поиск идентификатора места с его кодом в Maps JavaScript API документация.
Обзор
Идентификатор места — это текстовый идентификатор, который однозначно идентифицирует место. длина идентификатора может варьироваться (максимальной длины идентификаторов мест нет). Примеры:
-
ЧIJgUbEo8cfqokR5lP9_Wh_DaM -
GhIJQWDl0CIeQUARxks3icF8U8A -
EicxMyBNYXJrZXQgU3QsIFdpbG1pbmd0b24sIE5DIDI4NDAxLCBVU0EiGhIYChQKEgnRTo6ixx-qiRHo_bbmkCm7ZRAN -
EicxMyBNYXJrZXQgU3QsIFdpbG1pbmd0b24sIE5DIDI4NDAxLCBVU0E -
IhoSGAOUCHIJ0U6OoscfqokR6P225pApu2UQDQ
Идентификаторы мест доступны для большинства местоположений, включая предприятия, достопримечательности,
парки и перекрестки. Возможно, в одном и том же месте или месте
иметь несколько разных идентификаторов места. Идентификаторы мест могут меняться со временем.
Возможно, в одном и том же месте или месте
иметь несколько разных идентификаторов места. Идентификаторы мест могут меняться со временем.
Вы можете использовать один и тот же идентификатор места в Places API и количество API платформы Google Maps. Например, вы можете использовать один и тот же идентификатор места для указать место в API мест, Карты JavaScript API, API геокодирования, API встраивания Карт и API дорог.
Получение сведений о месте с помощью идентификатора места
Идентификаторы мест освобождаются от ограничений кэширования, указанных в Раздел 3.2.3(б) Условия использования платформы Google Карт. Как только вы определили идентификатор места для места, вы можете повторно использовать это значение при следующем поиске этого место. Для получения дополнительной информации см. Сохраните идентификаторы мест для последующего использования ниже.
Обычный способ использования идентификаторов мест — поиск места
(используя Places API
или Места
библиотеку в Maps JavaScript API, например), затем используйте
возвращенный идентификатор места для получения сведений о месте. Вы можете сохранить идентификатор места и
используйте его, чтобы получить информацию о том же месте позже. Прочитать о
сохранение идентификаторов мест ниже.
Вы можете сохранить идентификатор места и
используйте его, чтобы получить информацию о том же месте позже. Прочитать о
сохранение идентификаторов мест ниже.
Пример использования Places API
Используя Places API, вы можете найти идентификатор места, выполнив Разместить поисковый запрос.
Примечание: Вы должны заменить ключ в этих примеры со своим ключом, чтобы запрос работал в вашем приложение.Следующий пример представляет собой запрос на поиск мест типа «ресторан». в радиусе 1500 м от точки в Сиднее, Австралия, содержащей слово «круиз»:
https://maps.googleapis.com/maps/api/place/nearbysearch/json?location=-33.8670522,151.1957362&radius=1500&type=restaurant&keyword=cruise&key=YOUR_API_KEY
Ответ включает идентификатор места в поле place_id , т.к.
показано в этом фрагменте:
{
"html_атрибуции": [],
"Результаты" : [
{
"геометрия" : {
"расположение" : {
"широта": -33. 870775,
"длинный": 151,199025
}
},
...
"place_id": "ЧIJrTLr-GyuEmsRBfy61i59si0",
...
}
],
"Статус": "ОК"
}
 870775,
"длинный": 151,199025
}
},
...
"place_id": "ЧIJrTLr-GyuEmsRBfy61i59si0",
...
}
],
"Статус": "ОК"
}
870775,
"длинный": 151,199025
}
},
...
"place_id": "ЧIJrTLr-GyuEmsRBfy61i59si0",
...
}
],
"Статус": "ОК"
}
Описание всех полей ответа см. Место поиска документация.
Теперь вы можете отправить запрос сведений о месте,
размещение идентификатора места в параметре place_id :
https://maps.googleapis.com/maps/api/place/details/json?place_id=ChIJrTLr-GyuEmsRBfy61i59si0&key=YOUR_API_KEY
Сохранение идентификаторов мест для последующего использования
Идентификаторы мест освобождены от ограничений кэширования, указанных в Раздел 3.2.3(а) Условия использования платформы Google Карт. Таким образом, вы можете сохранить значения идентификатора места для последующего использования. использовать.
Обновление сохраненных идентификаторов мест
Мы рекомендуем обновлять идентификаторы мест, если они старше 12 месяцев. Ты
можно бесплатно обновить идентификаторы мест , создав
Запрос сведений о месте,
указав только
Ты
можно бесплатно обновить идентификаторы мест , создав
Запрос сведений о месте,
указав только place_id поле в параметре fields .
Например:
https://maps.googleapis.com/maps/api/place/details/json?place_id=ChIJ05IRjKHxEQ0RJLV_5NLdK2w&fields=place_id&key=YOUR_API_KEY
Этот вызов вызовет
Сведения о местах – обновление идентификатора
Артикул. Однако этот запрос также может возвращать статус NOT_FOUND .
код. Одна из стратегий состоит в том, чтобы сохранить исходный запрос, возвращающий каждое место.
ИДЕНТИФИКАТОР. Если идентификатор места становится недействительным, вы можете повторно отправить этот запрос, чтобы получить новый
Результаты. Эти результаты могут включать или не включать исходное место. Запрос
является платным.
NOT_FOUND , когда исходный используемый запрос
запрос автозаполнения места или запроса.
Коды ошибок при использовании идентификаторов мест
Код состояния INVALID_REQUEST указывает, что указанный
идентификатор места недействителен. INVALID_REQUEST может быть возвращено, когда
идентификатор места был усечен или иным образом изменен и больше не является правильным.
Код состояния NOT_FOUND указывает, что указанный идентификатор места
устарел. Идентификатор места может устареть, если предприятие закроется или переедет в другое место.
новое место. Идентификаторы мест могут измениться из-за масштабных обновлений в Google
База данных карт. В таких случаях место может получить новый идентификатор места, а старый
ID возвращает ответ NOT_FOUND .
В частности, некоторые типы идентификаторов места могут иногда вызывать Ответ NOT_FOUND , или API может вернуть другой идентификатор места в
ответ. Эти типы идентификаторов мест включают:
Эти типы идентификаторов мест включают:
- Адреса улиц, которые не существуют в Картах Google как точные адреса, но выводятся из диапазона адресов.
- Участки длинного маршрута, где в запросе также указан город или местонахождение.
- Перекрестки.
- Места с компонентом адреса типа
подпомещение.
Эти идентификаторы часто представляют собой длинную строку (максимальной длины нет). для идентификаторов мест). Например:
EpID4LC14LC_4LCo4LCv4LGN4LCo4LCX4LCw4LGNIC0g4LC44LGI4LCm4LGN4LCs4LC-4LCm4LGNIOCwsOCxi-CwoeCxjeCwoeCxgSAmIOCwteCwv-CwqOCwr-CxjSDgsKjgsJfgsLDgsY0g4LCu4LGG4LCv4LC_4 LCo4LGNIOCwsOCxi-CwoeCxjeCwoeCxgSwg4LC14LC_4LCo4LCv4LGNIOCwqOCwl-CwsOCxjSDgsJXgsL7gsLLgsKjgsYAsIOCwsuCwleCxjeCwt-CxjeCwruCwv-CwqOCwl-CwsOCxjSDgsJXgsL7gsLLgsKjgsYAs IOCwuOCwsOCxguCwsOCxjSDgsKjgsJfgsLDgsY0g4LC14LGG4LC44LGN4LCf4LGNLCDgsLjgsK_gsYDgsKbgsL7gsKzgsL7gsKbgsY0sIOCwueCxiOCwpuCwsOCwvuCwrOCwvuCwpuCxjSwg4LCk4LGG4LCy4LCC4 LCX4LC-4LCjIDUwMDA1OSwg4LCt4LC-4LCw4LCk4LCm4LGh5LC24LCCImYiZAoUChIJ31l5uGWYyzsR9zY2qk9lDiASFAoSCd9ZebhlmMs7Efc2NqpPZQ4gGhQKEglDz61OZpjLOxHgDJCFY-o1qBoUChIJi37TW2-YyzsRr_uv50r7tdEiCg1MwFcKFS_dyy4
EarthExplorer
Критерии поиска
Наборы данных
Дополнительные критерии
Результаты
1.
 Введите критерии поиска
Введите критерии поискаЧтобы сузить область поиска: введите адрес или название места, введите координаты или нажмите на карту, чтобы определить область поиска (для расширенных картографических инструментов см. справочная документация), и/или выберите диапазон дат.
Геокодер
Загрузка KML/шейп-файла
Выбор пути/строки метода геокодирования (GNIS)Установка типа WRS Точка Полигон
Тип: WRS2WRS1Путь: Ряд:
Пределы поиска: Максимальное количество результатов поиска — 100 записей; выберите страну, класс объекта и/или тип объекта, чтобы снизить вероятность превышения этого ограничения.Тип функции Особенности США Особенности мира
Название элементаШтатВсеALABAMAALASKAAАМЕРИКАНСКОЕ САМОААРИЗОНААРКАНСАКАЛИБОРНИАКОЛОРАДОКОННЕКТИКУТДЕЛАВАРЕДСКИЙ РАЙОН КОЛУМБИЯФЕДЕРАТИВНЫЕ ШТАТЫ МИКРОНЕЗИИФЛОРИДАЖОРГИЯГУАМГАВАIIIДАХИЛЛИНОИСИНДИАНАЙОВАКАНСАККЕНТУККИЛУИЗИАНАМАЙНМАРШАЛЛ-ИСЛАНДСМЭРИ ЛАНДМАССАЧУСЕТСМИЧИГАНМИННЕСОТАМИССИСИПМИССУРИМОНТАНАНЕБРАСКАНЕВАДАНЬЮ-ГЭМПШИРЕНЬЮ-ДЖЕРСИНЬЮ-МЕКСИКАНЬЮ-ЙОРКСЕВЕРНАЯ КАРОЛИНАСЕВЕРНАЯ ДАКОТАСЕВЕРНАЯ МАРИАНСКАЯ ОСТРОВА ОФИООКЛАХОМАОРЕГОНПАЛАУПЕННСИЛЬВАНИЯ ОСТРОВ ПУЭРТО-РИКОРОДЮЖНАЯ КАРОЛИНАЮЖНАЯ ДАКОТАТ NNESSEETEXASU. S. МАЛЫЕ ОТДАЛЕННЫЕ ОСТРОВАЮТАВЕРМОНТВИРГИНИЯВИРЖИНСКИЕ ОСТРОВАВАШИНГТОНЗАПАДНАЯ ВИРГИНИЯВИСКОНСИНВАЙОМИНГТип объектаВсеPPL*ГОРОД*НАСЕЛЕННОЕ МЕСТО*PPL*ПОСЕЛЕНИЕ*ГОРОД*ДЕРЕВНЯПочтовый индекс (5 цифр)HIST LANDMARK*NAT PARK*PARK*State Park*WLDERNESS AREABOROUGH *ГРАЖДАНСКОЕ*ОКРУГ*МИНИСИПИО*ПРИХОД*ГОРОД*ГОРОДСКОЕ ПОЛЕ* АЭРОПОРТ*ВЗЛЕТНАЯ ПОЛОСА*ВЗЛЕТНАЯ ПЛОЩАДКА*ЗЕМЛЯ ПОЛОСА*МОСТ*ПРЕДПРИНИМАТЕЛЬНЫЙ МОСТ*МОРСКОЙ АРХАРЬ*БАДЗЕМЬ*БАРРЕН*ДЕЛЬТА*ВЕНТИЛЯТОР*САДАРРОЙО*КУЛИ*РИЧАС*ВОРАГ*РАМЫВАЛЬНИК*РИФ*ОТМЕЛЬ*ОТМЕЛЬКА*СПИТАМФИТЕАТР*БАССЕЙН*ЦИРК* ЯМА*СИНКАРМ*ЗАЛИВ*БУХТА*БУХТА*ЭСТУАРИЙ*ГОЛЬФ*ВХОД*ЗВУКОВОЙ ПЛЯЖ*ПОБЕРЕЖЬЕ*БЕРЕГ*БЕРЕГ*БЕРЕГ*ДНО*ПЕТЛЯ*МЕАНДЕРМОСТ*МОЛИННАЯ ПУТЬ*Эстакада*ЗДАНИЕ ЭСТЕЛЫ*КАПИТОЛИЙ*ГОСУДАРСТВЕННАЯ КАПИТОЛИЯ*БИБЛИОТЕКА*ПОЧТАКАНАЛ*КАНАЛ*ЛАТЕРАЛКАП*ЛЕА* ШЕЯ*ПОЛУОСТРОВ*МОГИЛЬНИКИ*МОГИЛЬНИКИ*КЛАДБИЩЕ*МОГИЛЫ*МЕМОРИАЛЬНЫЙ САДКАНАЛ*ПРОХОД*ДОХОД*ПРОЛИВ*ПРОХОД*ЧЕРЕЗ ЧАСОВНЯ*ЦЕРКОВЬ*МЕЧЕТЬ*СИНАГОГА*ТАБЕРНАКЛ*ХРАМБУФ*СКАЛ*СКАЛ*ГОЛОВА*ПОРТ*НОС*ПАЛИСАДЫ … КАЛЬДЕРА*КРАТЕР*ПЕРЕХОД ЛУ*Эстакада*ПЛОЩАДКАВОЛОН*ПЛАТИНА*ПАЛИНА*КАСКАД*КАТАРАКТ*ВОДОПАД*ПОЛЯНА*ПЛОСКАЯ*ПОЛЯНА*ЛЕС-ПЛОЩАДКА*НАТ.
S. МАЛЫЕ ОТДАЛЕННЫЕ ОСТРОВАЮТАВЕРМОНТВИРГИНИЯВИРЖИНСКИЕ ОСТРОВАВАШИНГТОНЗАПАДНАЯ ВИРГИНИЯВИСКОНСИНВАЙОМИНГТип объектаВсеPPL*ГОРОД*НАСЕЛЕННОЕ МЕСТО*PPL*ПОСЕЛЕНИЕ*ГОРОД*ДЕРЕВНЯПочтовый индекс (5 цифр)HIST LANDMARK*NAT PARK*PARK*State Park*WLDERNESS AREABOROUGH *ГРАЖДАНСКОЕ*ОКРУГ*МИНИСИПИО*ПРИХОД*ГОРОД*ГОРОДСКОЕ ПОЛЕ* АЭРОПОРТ*ВЗЛЕТНАЯ ПОЛОСА*ВЗЛЕТНАЯ ПЛОЩАДКА*ЗЕМЛЯ ПОЛОСА*МОСТ*ПРЕДПРИНИМАТЕЛЬНЫЙ МОСТ*МОРСКОЙ АРХАРЬ*БАДЗЕМЬ*БАРРЕН*ДЕЛЬТА*ВЕНТИЛЯТОР*САДАРРОЙО*КУЛИ*РИЧАС*ВОРАГ*РАМЫВАЛЬНИК*РИФ*ОТМЕЛЬ*ОТМЕЛЬКА*СПИТАМФИТЕАТР*БАССЕЙН*ЦИРК* ЯМА*СИНКАРМ*ЗАЛИВ*БУХТА*БУХТА*ЭСТУАРИЙ*ГОЛЬФ*ВХОД*ЗВУКОВОЙ ПЛЯЖ*ПОБЕРЕЖЬЕ*БЕРЕГ*БЕРЕГ*БЕРЕГ*ДНО*ПЕТЛЯ*МЕАНДЕРМОСТ*МОЛИННАЯ ПУТЬ*Эстакада*ЗДАНИЕ ЭСТЕЛЫ*КАПИТОЛИЙ*ГОСУДАРСТВЕННАЯ КАПИТОЛИЯ*БИБЛИОТЕКА*ПОЧТАКАНАЛ*КАНАЛ*ЛАТЕРАЛКАП*ЛЕА* ШЕЯ*ПОЛУОСТРОВ*МОГИЛЬНИКИ*МОГИЛЬНИКИ*КЛАДБИЩЕ*МОГИЛЫ*МЕМОРИАЛЬНЫЙ САДКАНАЛ*ПРОХОД*ДОХОД*ПРОЛИВ*ПРОХОД*ЧЕРЕЗ ЧАСОВНЯ*ЦЕРКОВЬ*МЕЧЕТЬ*СИНАГОГА*ТАБЕРНАКЛ*ХРАМБУФ*СКАЛ*СКАЛ*ГОЛОВА*ПОРТ*НОС*ПАЛИСАДЫ … КАЛЬДЕРА*КРАТЕР*ПЕРЕХОД ЛУ*Эстакада*ПЛОЩАДКАВОЛОН*ПЛАТИНА*ПАЛИНА*КАСКАД*КАТАРАКТ*ВОДОПАД*ПОЛЯНА*ПЛОСКАЯ*ПОЛЯНА*ЛЕС-ПЛОЩАДКА*НАТ. ЛЕС*НАТ. ЛУГА*ГОСУДАРСТВЕННЫЙ ЛЕСКОЛ*ПРОБЕЛ*НОТЧ*ПЕРАСС*СЕДЛО*ВОДНЫЙ ПРОСТРАНСТВО*ВЕТР ГАПГЕЙСЕРГЕЙСЕРГЛЯСЬ*ЛЕДЯНОЕ ПОЛЕ*ЛЕДЯНОЕ ПАТЧ*СНЕЖНЫЙ ПАТЧКРЕК*ВХОД*СЛАУХАРБОР*ХОНО*ПОРТ*ДОРОГИ*ДОРОГАБОЛЬНИЦА*ИНФИРМАРЬАРХИПЕЛАГ*АТОЛЛ*КЕЙ*ГАМОК*ХАММОК*ИС Лос-Анджелес *ОСТРОВ*КЛЮЧ…ИСТМУСБАКВТР*ЛАК*ЛАГУНА*ЛАГУНА*ОЗЕРО*ПРУД*БАССЕЙН*RESACAKEPULA*ЛАВА*ЛАВА ПОТОК*БЕРМА*ЛЕВИБАТТЛФИЛД*ПЕРЕКРЕСТОК*ЛАГЕРЬ*ФЕРМА*ГОРОД-ПРИЗРАК*ПОСАДКА…ВОЕННАЯШАХТА*ЯМА*КАРЬЕР *SHAFTOIL FIELDOTHERBENCH*LEVELCHIMNEY*ПАМЯТНИК*СТОЛБ*ПИНАКЛ*POHAKU*ROCK TOWERGRASSLAND*Highland*KULA*РАВНИНА*ПЛАТО*UPLANDCORDILLERA*ДИАПАЗОН*SIERRARAPIDS*RIFFLE*RIPPLERESERVATION*ЗАПОВЕДНИК*ЗОНА УПРАВЛЕНИЯ ДИКОЙ ПРИРОДОЙ*RESERVOIR*TANKCR ЭСТ*КУЭСТА*ОТСТУП*ХОГБАК *LAE*RIDGE*RIM*SPURACADEMY*COLLEGE*HIGH SCHOOL*SCHOOL*UNIVERSITYGULF*OCEAN*SEAGRADE*PITCH*SLOPESEEP*SPRINGANABRANCH*AWAWA*BAYOU*BRANCH*BROOK*CREEK*FORK…AHU*BERG*BALD*BUTTE* CERRO*COLINA*CONE*CUMBRE*DOME…BOG*CIENEGA*MARAIS*MARSH*POCOSIN*SWAMPTOWER*Искусственные сооружения*LOOKOUT-TRANSMISSION TOWERSJEEP TRAIL*ПУТЬ*ЛЫЖНАЯ ТРЕЙЛ*TRAILPORTAL*TUBE*TUNNELUNKNOWNBARRANCA*CANION*CHASM*COVE* РИСОВАТЬ*ГЛЕН*УЩЕЛЬЕ*Ущелье*ГАЛФИСКУССТВЕННЫЙ ШАФТ*WELLFOREST*NAT.
ЛЕС*НАТ. ЛУГА*ГОСУДАРСТВЕННЫЙ ЛЕСКОЛ*ПРОБЕЛ*НОТЧ*ПЕРАСС*СЕДЛО*ВОДНЫЙ ПРОСТРАНСТВО*ВЕТР ГАПГЕЙСЕРГЕЙСЕРГЛЯСЬ*ЛЕДЯНОЕ ПОЛЕ*ЛЕДЯНОЕ ПАТЧ*СНЕЖНЫЙ ПАТЧКРЕК*ВХОД*СЛАУХАРБОР*ХОНО*ПОРТ*ДОРОГИ*ДОРОГАБОЛЬНИЦА*ИНФИРМАРЬАРХИПЕЛАГ*АТОЛЛ*КЕЙ*ГАМОК*ХАММОК*ИС Лос-Анджелес *ОСТРОВ*КЛЮЧ…ИСТМУСБАКВТР*ЛАК*ЛАГУНА*ЛАГУНА*ОЗЕРО*ПРУД*БАССЕЙН*RESACAKEPULA*ЛАВА*ЛАВА ПОТОК*БЕРМА*ЛЕВИБАТТЛФИЛД*ПЕРЕКРЕСТОК*ЛАГЕРЬ*ФЕРМА*ГОРОД-ПРИЗРАК*ПОСАДКА…ВОЕННАЯШАХТА*ЯМА*КАРЬЕР *SHAFTOIL FIELDOTHERBENCH*LEVELCHIMNEY*ПАМЯТНИК*СТОЛБ*ПИНАКЛ*POHAKU*ROCK TOWERGRASSLAND*Highland*KULA*РАВНИНА*ПЛАТО*UPLANDCORDILLERA*ДИАПАЗОН*SIERRARAPIDS*RIFFLE*RIPPLERESERVATION*ЗАПОВЕДНИК*ЗОНА УПРАВЛЕНИЯ ДИКОЙ ПРИРОДОЙ*RESERVOIR*TANKCR ЭСТ*КУЭСТА*ОТСТУП*ХОГБАК *LAE*RIDGE*RIM*SPURACADEMY*COLLEGE*HIGH SCHOOL*SCHOOL*UNIVERSITYGULF*OCEAN*SEAGRADE*PITCH*SLOPESEEP*SPRINGANABRANCH*AWAWA*BAYOU*BRANCH*BROOK*CREEK*FORK…AHU*BERG*BALD*BUTTE* CERRO*COLINA*CONE*CUMBRE*DOME…BOG*CIENEGA*MARAIS*MARSH*POCOSIN*SWAMPTOWER*Искусственные сооружения*LOOKOUT-TRANSMISSION TOWERSJEEP TRAIL*ПУТЬ*ЛЫЖНАЯ ТРЕЙЛ*TRAILPORTAL*TUBE*TUNNELUNKNOWNBARRANCA*CANION*CHASM*COVE* РИСОВАТЬ*ГЛЕН*УЩЕЛЬЕ*Ущелье*ГАЛФИСКУССТВЕННЫЙ ШАФТ*WELLFOREST*NAT. ЛЕС*НАТ. ЛУГА*ГОСУДАРСТВЕННЫЙ ЛЕС*ЛЕСНАЯ СТОПОГРАФИЧЕСКАЯ КАРТА НАЗВАНИЯ ИЗ 7,5-МИНУТНОЙ КАРТЫСтранаВсеАФГАНИСТАНАЛБАНИЯАЛЖИРАМЕРИКАНСКОЕ САМОААНДОРРААНГОЛАНГИЛЬЯАНТАРКТИКААНТИГУА И БАРБУДААРГЕНТИНААРМЕНИЯОСТРОВ АРУБААСМОР И КАРТЬЕСАВСТРАЛИЯАВСТРИЯАЗЕРБАЙДЖАНБАГАМАС, БАГАМА ОСТРОВ ХРЕЙНБЕЙКЕР БАНГЛАДЕШБАРБАДОСБАССАС ДА ИНДИЯБЕЛАРУСБЕЛЬБЕЛЬГИЯБЕЛИЗБЕНИНБЕРМУДАБХУТАНБОЛИВИАБОСНИЯ И ГЕРЦЕГОВИНАБОТВАБОНСИЯ ОСТРОВ БУВЕТБРАЗИЛИЯБРИТАНСКАЯ ТЕРРИТОРИЯ В ИНДИЙСКОМ ОКЕАНЕБРИТАНСКИЕ ВИРГИНСКИЕ ОСТРОВАБРРУНЕЙБОЛГАРИЯБУРКИНА ФАСОБУРМАБУРУНДИКАМБОДИЯКАМЕР ООНКАНАДАКАП-ВЕРДЕКАЙМАН ОСТРОВ ЦЕНТРАЛЬНО-АФРИКАНСКАЯ РЕСПУБЛИКАЧАДЧИЛЬЧИЧАЙСКИЙ ОСТРОВ КРИСТМАСОСТРОВ КЛИППЕРТОНКОКОС (КИЛИНГ) ОСТРОВАКОЛУМБИЯКОМОРОСКОНГО, ДЕМОКРАТИЧЕСКАЯ РЕСПУБЛИКА КОНГО, РЕСПУБЛИКА ОСТРОВА КУКАОСТРОВА КОРАЛЬСКОГО МОРЕКОСТА-РИКАКОТА-Д’ИВУАРЭКОРАТИЯКУБАКИПРЧЕХИЯДАНИЯДАНИЯДЖИБУТИДОМИНИКАДОМИНИКАНСКАЯ РЕСПУБЛИКАКВАДОРЕГИПТЕЛЬ САЛЬВАДОРАЭКВАТОРИАЛЬНАЯ ГВИНЕАЭРИТРИЯЭСТОНИЯЭФИОПИЯОСТРОВ ЕВРОПАФОЛКЛЕНДФАРЕРСКИЕ ОСТРОВАФИДЖИНЛАН DФРАНЦИЯФРАНЦУЗСКАЯ ГВИАНАФРАНЦУЗСКАЯ ПОЛИНЕЗИЯФРАНЦУЗСКИЕ ЮЖНЫЕ И АНТАРКТИДСКИЕ ЗЕМЛИГАБОНГАМБИЯ, ПОЛОСА ГАЗАГРУЗИЯГЕРМАНИЯМАНИГАНАГИБРАЛТАРГЛОРИОЗО ОСТРОВАГРЕЦИЯГРЕНЛАНДГРЕНАДАГВАДЕЛУПЕГУАМГВАМАЛАГЕРНСЕЙГВИНЕАГВИНЕЯ-БИССАУГЯНААИТИ ОСТРОВ ХЕРД И МАКДОНАЛЬД ОСТРОВХОНДУРАШОНГ КОНГХУЛЭНД ВЕНГРИЯИСЛАНДИЯИНДОНЕЗИЯАИРРАНИРАКИРЕЛАНДИСРАЭЛИТАЛИЯМАЙКАДЖАН МАЙЕНЯПОНИЯ ПАНДЖАРВИС ОСТРОВ ДЖЕРСЕЙДЖОНСТОН АТОЛЛЙОРДАНХУАН-ДЕ-НОВА ОСТРОВКАЗАХСТАНКЕНЯКИНЬМАН РИФКИРИБАТИКОРЕЙСКАЯ НАРОДНАЯ РЕФЕРАЦИЯ ГОСУДАРСТВЕННАЯ КОРЕЯ, РЕСПУБЛИКА КУВЕЙТ, БЫВШАЯ ЮГОСЛАВСКАЯ РЕСПУБЛИКА МАДАГАСКАРМАЛАВИМАЛАЙСКАЯ МАЛДИВСКАЯ МАЛИМАЛТАМАН, ОСТРОВ МАРШАЛЛОВЫХ ОСТРОВСМАРТИНИКЕМАВРИТАНИЯМАВРИКИЙМАЙОТТЕМАЭКСИКОМИКРОНЕЗИЯ, ФЕДЕРАТИВНЫЕ ШТАТЫ ОСТРОВ МИДУЭЙСМОЛДОВАМОНАКОМОНГОЛИЯМОНТЕНЕГРОМОНТСЕРРАТМОРОККОМОЗАМБИКЕНАМИБИ АНАУРУНАВАССА ОСТРОВНЕПАЛНИДЕРЛАНДЫ НИДЕРЛАНДЫ АНТИЛЬСКИЕ ЛЕСНИДЕРЛАНДЫ АНТИЛЬСКИЕ ЛЕСАНОВАЯ КАЛЕДОНИЯНОВАЯ ЗЕЛАНДИЯ НИКАРАГУАНГЕРНИГЕРИЯНИУЭНО МАНС ЛАНДНОРФОЛК ОСТРОВСЕВЕРНЫЕ МАРИАНСКИЕ ОСТРОВА НОРВЕГИЯОКЕАНСОМАН ПАКИСТАНПАЛАУ, РЕСПУБЛИКА ПАЛЬМИРА АТОЛЛПАНАМАПАПУА НОВАЯ ГВИНЕАПАРАСЕЛЬ ОСТРОВА ПАРАГВАЙПЕРУФИЛИППИНЫСПИТКЭРН ОСТРОВ ПОЛЬШАПОРТУГАЛПУЭРТО-РИКОКАТАРРЕЮНИОНРУМАНИЯРОССИЯРУМЫНИЯРУМЫНИЯРУМЫНИЯ САМОАСАН-МАРИНОСАО ТОМЕ И ПРИНЦИПЕСАУДОВСКАЯ АРАБИЯНЕГАЛСЕРБИЯСЕЙЧЕЛЛЕСЬЕРРА-ЛЕОНЕСИНГАПОРЕСЛОВАКИЯСЛОВЕНИЯСОЛОМОНОВЫ ОСТРОВАСОМАЛИЮЖНАЯ АФРИКАЮЖНАЯ ГРУЗИЯ И ЮЖНЫЕ СЭНДВИЧОВЫЕ ОСТРОВАЮЖНЫЙ СУДАНСКАЯ ОСТРОВА ПРАТЛИШРИ-ЛАНКАСТЬ .
ЛЕС*НАТ. ЛУГА*ГОСУДАРСТВЕННЫЙ ЛЕС*ЛЕСНАЯ СТОПОГРАФИЧЕСКАЯ КАРТА НАЗВАНИЯ ИЗ 7,5-МИНУТНОЙ КАРТЫСтранаВсеАФГАНИСТАНАЛБАНИЯАЛЖИРАМЕРИКАНСКОЕ САМОААНДОРРААНГОЛАНГИЛЬЯАНТАРКТИКААНТИГУА И БАРБУДААРГЕНТИНААРМЕНИЯОСТРОВ АРУБААСМОР И КАРТЬЕСАВСТРАЛИЯАВСТРИЯАЗЕРБАЙДЖАНБАГАМАС, БАГАМА ОСТРОВ ХРЕЙНБЕЙКЕР БАНГЛАДЕШБАРБАДОСБАССАС ДА ИНДИЯБЕЛАРУСБЕЛЬБЕЛЬГИЯБЕЛИЗБЕНИНБЕРМУДАБХУТАНБОЛИВИАБОСНИЯ И ГЕРЦЕГОВИНАБОТВАБОНСИЯ ОСТРОВ БУВЕТБРАЗИЛИЯБРИТАНСКАЯ ТЕРРИТОРИЯ В ИНДИЙСКОМ ОКЕАНЕБРИТАНСКИЕ ВИРГИНСКИЕ ОСТРОВАБРРУНЕЙБОЛГАРИЯБУРКИНА ФАСОБУРМАБУРУНДИКАМБОДИЯКАМЕР ООНКАНАДАКАП-ВЕРДЕКАЙМАН ОСТРОВ ЦЕНТРАЛЬНО-АФРИКАНСКАЯ РЕСПУБЛИКАЧАДЧИЛЬЧИЧАЙСКИЙ ОСТРОВ КРИСТМАСОСТРОВ КЛИППЕРТОНКОКОС (КИЛИНГ) ОСТРОВАКОЛУМБИЯКОМОРОСКОНГО, ДЕМОКРАТИЧЕСКАЯ РЕСПУБЛИКА КОНГО, РЕСПУБЛИКА ОСТРОВА КУКАОСТРОВА КОРАЛЬСКОГО МОРЕКОСТА-РИКАКОТА-Д’ИВУАРЭКОРАТИЯКУБАКИПРЧЕХИЯДАНИЯДАНИЯДЖИБУТИДОМИНИКАДОМИНИКАНСКАЯ РЕСПУБЛИКАКВАДОРЕГИПТЕЛЬ САЛЬВАДОРАЭКВАТОРИАЛЬНАЯ ГВИНЕАЭРИТРИЯЭСТОНИЯЭФИОПИЯОСТРОВ ЕВРОПАФОЛКЛЕНДФАРЕРСКИЕ ОСТРОВАФИДЖИНЛАН DФРАНЦИЯФРАНЦУЗСКАЯ ГВИАНАФРАНЦУЗСКАЯ ПОЛИНЕЗИЯФРАНЦУЗСКИЕ ЮЖНЫЕ И АНТАРКТИДСКИЕ ЗЕМЛИГАБОНГАМБИЯ, ПОЛОСА ГАЗАГРУЗИЯГЕРМАНИЯМАНИГАНАГИБРАЛТАРГЛОРИОЗО ОСТРОВАГРЕЦИЯГРЕНЛАНДГРЕНАДАГВАДЕЛУПЕГУАМГВАМАЛАГЕРНСЕЙГВИНЕАГВИНЕЯ-БИССАУГЯНААИТИ ОСТРОВ ХЕРД И МАКДОНАЛЬД ОСТРОВХОНДУРАШОНГ КОНГХУЛЭНД ВЕНГРИЯИСЛАНДИЯИНДОНЕЗИЯАИРРАНИРАКИРЕЛАНДИСРАЭЛИТАЛИЯМАЙКАДЖАН МАЙЕНЯПОНИЯ ПАНДЖАРВИС ОСТРОВ ДЖЕРСЕЙДЖОНСТОН АТОЛЛЙОРДАНХУАН-ДЕ-НОВА ОСТРОВКАЗАХСТАНКЕНЯКИНЬМАН РИФКИРИБАТИКОРЕЙСКАЯ НАРОДНАЯ РЕФЕРАЦИЯ ГОСУДАРСТВЕННАЯ КОРЕЯ, РЕСПУБЛИКА КУВЕЙТ, БЫВШАЯ ЮГОСЛАВСКАЯ РЕСПУБЛИКА МАДАГАСКАРМАЛАВИМАЛАЙСКАЯ МАЛДИВСКАЯ МАЛИМАЛТАМАН, ОСТРОВ МАРШАЛЛОВЫХ ОСТРОВСМАРТИНИКЕМАВРИТАНИЯМАВРИКИЙМАЙОТТЕМАЭКСИКОМИКРОНЕЗИЯ, ФЕДЕРАТИВНЫЕ ШТАТЫ ОСТРОВ МИДУЭЙСМОЛДОВАМОНАКОМОНГОЛИЯМОНТЕНЕГРОМОНТСЕРРАТМОРОККОМОЗАМБИКЕНАМИБИ АНАУРУНАВАССА ОСТРОВНЕПАЛНИДЕРЛАНДЫ НИДЕРЛАНДЫ АНТИЛЬСКИЕ ЛЕСНИДЕРЛАНДЫ АНТИЛЬСКИЕ ЛЕСАНОВАЯ КАЛЕДОНИЯНОВАЯ ЗЕЛАНДИЯ НИКАРАГУАНГЕРНИГЕРИЯНИУЭНО МАНС ЛАНДНОРФОЛК ОСТРОВСЕВЕРНЫЕ МАРИАНСКИЕ ОСТРОВА НОРВЕГИЯОКЕАНСОМАН ПАКИСТАНПАЛАУ, РЕСПУБЛИКА ПАЛЬМИРА АТОЛЛПАНАМАПАПУА НОВАЯ ГВИНЕАПАРАСЕЛЬ ОСТРОВА ПАРАГВАЙПЕРУФИЛИППИНЫСПИТКЭРН ОСТРОВ ПОЛЬШАПОРТУГАЛПУЭРТО-РИКОКАТАРРЕЮНИОНРУМАНИЯРОССИЯРУМЫНИЯРУМЫНИЯРУМЫНИЯ САМОАСАН-МАРИНОСАО ТОМЕ И ПРИНЦИПЕСАУДОВСКАЯ АРАБИЯНЕГАЛСЕРБИЯСЕЙЧЕЛЛЕСЬЕРРА-ЛЕОНЕСИНГАПОРЕСЛОВАКИЯСЛОВЕНИЯСОЛОМОНОВЫ ОСТРОВАСОМАЛИЮЖНАЯ АФРИКАЮЖНАЯ ГРУЗИЯ И ЮЖНЫЕ СЭНДВИЧОВЫЕ ОСТРОВАЮЖНЫЙ СУДАНСКАЯ ОСТРОВА ПРАТЛИШРИ-ЛАНКАСТЬ .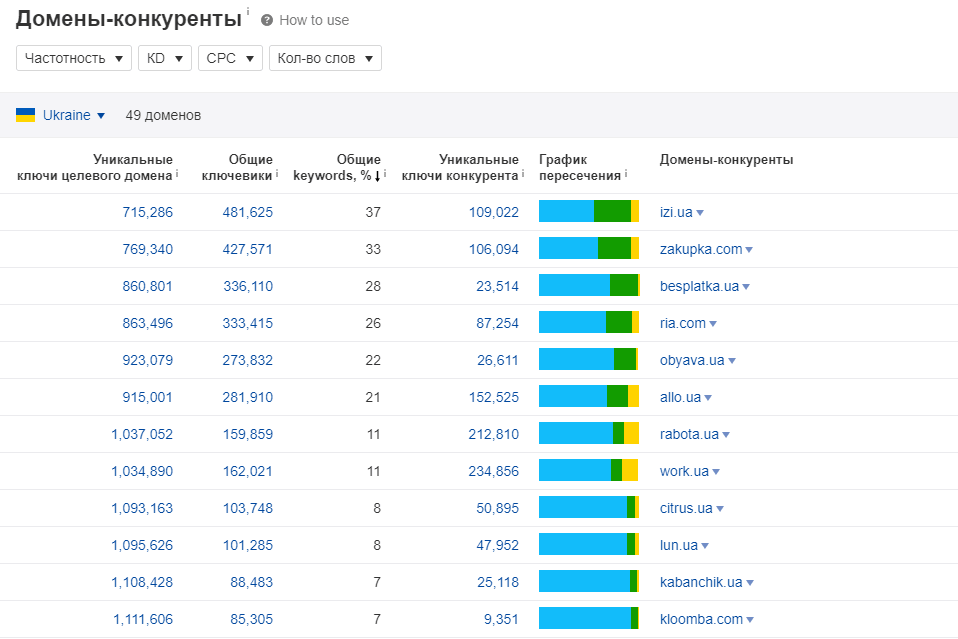 ЭЛЕНАСТ. КИТС И НЕВИССТ. ЛЮЦИАСТ. ПЬЕР И МИКЕЛОН. ВИНСЕНТ И ГРЕНАДИНЕСУДАНСУРИНАМВАЛЬБАРДСВАЗИЛАНДШВЕЦИЯСИРИЯТАЙВАНТАДЖИКИСТАНТАНЗАНИЯ, ОБЪЕДИНЕННАЯ РЕСПУБЛИКА ТАИЛАНДТОГОТОКЕЛАВТОНГАТРИНИДАД И ТОБАГОТРОМЕЛИНЮНИСИАТТУРКМЕНИСТАНТУРКИ И ОСТРОВА КАЙКОСТУВАЛУУГАНДАУКРАИНАПОД МОРЕМ F EATURESОБЪЕДИНЕННЫЕ АРАБСКИЕ ЭМИРАТЫСОЕДИНЕННОЕ КОРОЛЕВСТВОМУРУГВАЮЗБЕКИСТАНВАНУАТУВАТИКАНСКИЙ ГОРОДВЕНЕСУЭЛАВЬЕТНАМВИРГИНСКИЕ ОСТРОВАУЭЙК-ИСЛАНДУАЛЛИС И ФУТУНАВЕСТ-БАНКЗАПАДНАЯ САХАРАЙЭМЕНЬЮГОСЛАВИЯАЗАМБИАЗИМБАБВЕКласс объектовВсеАдминистративные границы ОсобенностиГидрографические объектыОбласти местностиОсобенности населенных пунктовДорога или железная дорога ХарактеристикиТочечные характеристикиГипсографические особенностиПодводные особенностиОсобенности растительностиТип объектаВсе
ЭЛЕНАСТ. КИТС И НЕВИССТ. ЛЮЦИАСТ. ПЬЕР И МИКЕЛОН. ВИНСЕНТ И ГРЕНАДИНЕСУДАНСУРИНАМВАЛЬБАРДСВАЗИЛАНДШВЕЦИЯСИРИЯТАЙВАНТАДЖИКИСТАНТАНЗАНИЯ, ОБЪЕДИНЕННАЯ РЕСПУБЛИКА ТАИЛАНДТОГОТОКЕЛАВТОНГАТРИНИДАД И ТОБАГОТРОМЕЛИНЮНИСИАТТУРКМЕНИСТАНТУРКИ И ОСТРОВА КАЙКОСТУВАЛУУГАНДАУКРАИНАПОД МОРЕМ F EATURESОБЪЕДИНЕННЫЕ АРАБСКИЕ ЭМИРАТЫСОЕДИНЕННОЕ КОРОЛЕВСТВОМУРУГВАЮЗБЕКИСТАНВАНУАТУВАТИКАНСКИЙ ГОРОДВЕНЕСУЭЛАВЬЕТНАМВИРГИНСКИЕ ОСТРОВАУЭЙК-ИСЛАНДУАЛЛИС И ФУТУНАВЕСТ-БАНКЗАПАДНАЯ САХАРАЙЭМЕНЬЮГОСЛАВИЯАЗАМБИАЗИМБАБВЕКласс объектовВсеАдминистративные границы ОсобенностиГидрографические объектыОбласти местностиОсобенности населенных пунктовДорога или железная дорога ХарактеристикиТочечные характеристикиГипсографические особенностиПодводные особенностиОсобенности растительностиТип объектаВсеНажмите на адрес/место, чтобы показать местоположение на карте и добавить координаты в зону интереса контроля.
| Номер | Адрес/Место | Широта | Долгота |
|---|
Щелкните элемент, чтобы отобразить
местоположение на карте и добавить координаты
в зону интереса контроля.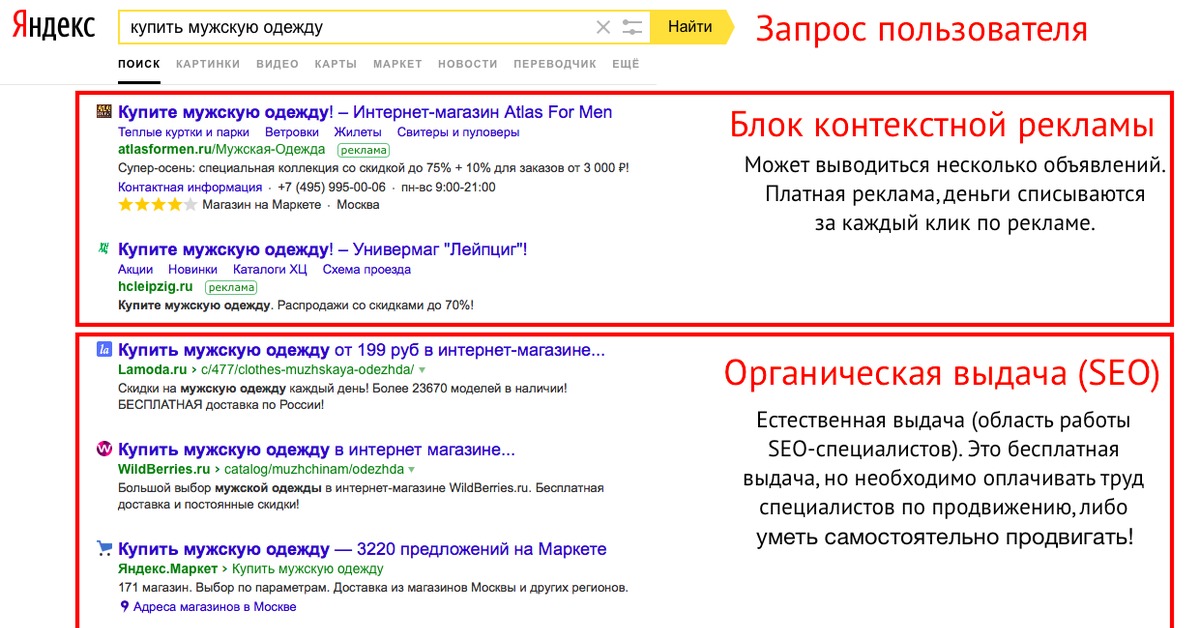
| Топоним | Тип | Регион | Широта | Долгота |
|---|
Вы должны войти в систему, чтобы загрузить файл.
Тип Select OneAERONETNEON Relocatable TerrestrialNEON Core TerrestrialUSCRNSURFRADEOS Базовые сайты проверки землиСправочные сайты CEOSСуперсайты CEOS
Калибр/Вал Сайт
Многоугольник
Окружность
Предопределенная область
Формат координат Градус/минута/секунда Десятичная дробь
.
лат: , Лон:
лат: , Лон:
- Координаты не выбраны.
Центр Широта:
Радиус: МетрыКилометрыМили
Центральная долгота:
Форма не загружена.
Диапазон дат
Облачность
Параметры результата
Искать от: до:Месяцы поиска:
(все) Выберите месяцы(все)
Январь
9 февраля0003
марта
апрель
май
июнь
июль
августа
сентября
октябрь
ноябрь
декабрь
Диапазон облачности:
Unknown Cloud Cover ValuesIncludedExcluded Этот фильтр будет применяться только к наборам данных, которые поддерживают фильтрацию облачности ( в списке наборов данных обозначает поддержку облачности).