
Как выглядел сайт раньше
Говорят, прогресс не остановить. Проходят месяцы и годы, технологии становятся всё лучше и совершеннее, уже никого не удивишь с мобильным телефоном со спутниковой навигацией. А сеть Интернет позволяет нам общаться в реальном времени находясь на противоположных концах планеты. Время летит так быстро, что подчас мы не замечаем существенных изменений во многих вещах, с которыми имеем дело. Касается это и сети Интернет, в которой развитие сетевых протоколов, стандартов и технологий просто преобразило внешний вид и функционал имеющихся сайтов. В этом материале я предлагаю вам поднять покров времени и заглянуть в прошлое, посмотреть, как выглядел сайт раньше, каков был внешний вид и функционал ресурсов тех лет, и, возможно, это поможет понять, как далеко мы шагнули вперёд в развитии цифровых технологий наших дней.

Просмотр истории сайтов
Содержание статьи:
История архива Интернета
Итак, как же выглядел сайт в прошлом, и какие инструменты могут нам помочь заглянуть в веб-историю 5-10 летней давности? Более 20 лет назад, в 1996 году энтузиаст Кейл Брюстер основал цифровой архив под названием «Архив Интернета» («The Internet Archive»), слоганом которого был провозглашён «Всеобщий доступ к знаниям». С того времени указанный архив собирает и хранит копии веб-страниц, графики, аудио и видео, различных программ, обеспечивая свободный доступ к накопленной информации для всех желающих.
На состояние октября 2016 года архив уже имел 15 петабайт информации, а веб-архив проекта содержал уже более 150 миллиардов веб-страниц различных сайтов.

Примерно так выглядят серверы архива
Именно благодаря данному архиву сегодня мы имеем возможность посмотреть, как выглядели многие ресурсы 10-15-20 лет тому назад. Историю действий на вашем компьютере можно узнать в статье написанной мной ранее.
Смотрим каким был сайт ранее
Итак, как же посмотреть сохранённые копии сайтов? Воспользуемся возможностями данного проекта и попробуем приоткрыть покровы времени.
Перейдите на данный сервис (он носит название Wayback Machine), введите в поисковой строке адрес интересующего вас сайта (например, www.youtube.com) и нажмите на кнопку «Browse history» (просмотреть историю) справа.

Сервис архив сайтов Wayback Machine
Система обработает запрос и выдаст вам результат. Сверху будет располагаться разбивка по годам, и вы увидите, в каком году впервые была отслежена активность данного сайта и сделан его снимок.

История сайта за 2005 год

Выбираем дату сохранённого скриншота сарвисом
Кликните, к примеру, на самый ранний год (в случае Ютуб это 2005 год), внизу отобразится полный календарь данного года по месяцам. Дни, когда были сделаны «снимки» сайта будут подсвечены голубоватым цветом, в нашем случае первый «снимок» был сделан 28 апреля данного года.
Кликаем на 28 апреля и просматриваем, как выглядел сервис Youtube 28 апреля 2005 года.

Так выглядел сайт Ютуба ранее
Соответствующим образом вы можете просмотреть любой из интересующих вас сайтов.
http://web.archive.org/web/*/http://url нужного сайта
Например:
http://web.archive.org/web/*/http://google.com
Соответственно, введя данную строку в адресной строке браузера и нажав на ввод, вы сразу попадёте в отображение снимков нужного вам сайта по годам, месяцам и днём.
Смотрим как выглядели сайты ранее
С помощью ресурса archive.org каждый желающий может получить доступ к миллиардам страниц сохранённого веб-контента, буквально по дням, месяцам и годам наблюдая, как менялся внешний облик множества популярных ресурсов. Воочию видя, как развивалась визуальная составляющая сети, мы можем отчётливо понять, какой скачок сделали интернет технологии за эти годы, и в какое великое время расцвета технического прогресса нам выпала удача жить.
Вконтакте
Одноклассники
lifehacki.ru
Где посмотреть, как выглядел сайт раньше?
Время идет, а интернет постепенно становится всё более современным и оформление сайтов меняется.
Интересно, как выглядели сайты раньше, многие уже забыли, что был старый дизайн, а некоторые и вовсе его не видели. Но вспомнить прошлое не так сложно, так как есть специальная база, в которую добавляются почти все сайты.
Где посмотреть, как выглядел сайт раньше? Через виртуальный архив Archive.org. Он ведется уже много лет и в него попадают все сайты после индексации.
Сохраняются не просто скриншоты, а полностью страницы с HTML кодом, поэтому вы сможете не только посмотреть на старые версии сайтов, но и частично ими воспользоваться.

Виртуальный архив — Web Archive
Пользуются Web архивом для различных целей. Некоторые пытаются найти старую информацию, кто-то только ради развлечения, а иногда он используется даже для восстановления ресурса.
Никаких денег с пользователей не берется, можно посмотреть сколько угодно сайтов. А также в него можно всегда сохранить свой проект, чтобы он остался в памяти.
Когда-то и наш блог создавался и находился на этапе разработки. Давайте вместе посмотрим, как он выглядел 17 мая 2013 года:
1. Переходим на страницу Archive.org/web/, где необходимо ввести адрес сайта:
 2. После этого открывается страница, где можно выбрать год. На календаре ниже отмечены все даты, когда проводилось сохранение страниц сайта:
2. После этого открывается страница, где можно выбрать год. На календаре ниже отмечены все даты, когда проводилось сохранение страниц сайта:  3. Нажав на одно из чисел, обведенных синим кружком, вы попадаете на сохраненную в архиве копию:
3. Нажав на одно из чисел, обведенных синим кружком, вы попадаете на сохраненную в архиве копию:  Вот мы и добрались до первой сохраненной копии блога Workion. Как видите, никакого дизайна, первая запись создана для примера и в рубриках есть только одна категория.
Вот мы и добрались до первой сохраненной копии блога Workion. Как видите, никакого дизайна, первая запись создана для примера и в рубриках есть только одна категория.Именно так выглядел сайт чуть больше 2х лет назад, а сейчас на нем тысячи полезных сайтов, сотни комментариев и каждый день к нам приходят тысячи людей за качественной информацией.
Попробуйте провести проверки сайтов, которыми вы активно пользуетесь, это довольно интересно. К примеру, все кто работает в сети, знают о существовании почтовика Wmmail. Сейчас его оформление современное:
 Мало кто помнит, как выглядел этот ресурс сразу после его запуска в 2004 году. Дизайн, мягко говоря «Не очень», но не забывайте, что тогда было всё по-другому, за последние 10 лет много изменилось:
Мало кто помнит, как выглядел этот ресурс сразу после его запуска в 2004 году. Дизайн, мягко говоря «Не очень», но не забывайте, что тогда было всё по-другому, за последние 10 лет много изменилось:  Современные технологии позволяют создавать красочные и красивые сайты. Убедитесь в этом, проверив несколько других популярных ресурсов.
Современные технологии позволяют создавать красочные и красивые сайты. Убедитесь в этом, проверив несколько других популярных ресурсов.Проверить, как выглядела страница сайта раньше совсем не сложно и теперь вы знаете, какой инструмент для этого потребуется. Просмотр старых версий разных ресурсов – это увлекательно занятие, так же как и интересные места в Google Maps, которые вы можете увидеть прямо сейчас.
Вам также будет интересно:
— Сайт не приносит прибыли, почему?
— Как создать Wiki сайт?
— Почему без интернета сейчас никуда
workion.ru
как пользоваться вебархивом, как восстановить сайт и узнать, как он выглядел раньше
Мы увеличиваем посещаемость и позиции в выдаче. Вы получаете продажи и платите только за реальный результат, только за целевые переходы из поисковых систем

Мы выпустили новую книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!

Веб-архив (Webarchive) – это бесплатная платформа, где собраны все сайты, созданные когда-либо, и на которые не наложен запрет для их сохранения.
Больше видео на нашем канале — изучайте интернет-маркетинг с SEMANTICA

Это настоящая библиотека, в которой каждый желающий может открыть интересующий его веб-ресурс, и посмотреть на его содержимое, на ту дату, в которую вебархив посетил сайт и сохранил копию.
Знакомство с archive org или как Валерий нашел старые тексты из веб-архива
В 2010-м году, Валерий создал сайт, в котором он писал статьи про интернет-маркетинг. Одну из них он написал о рекламе в Гугл (AdWords) в виде краткого конспекта. Спустя несколько лет ему понадобилась эта информация. Но страница с текстами, некоторое время назад, была им ошибочно удалена. С кем не бывает.
Однако, Валерий знал, как выйти из ситуации. Он уверенно открыл сервис веб-архива, и в поисковой строке ввел нужный ему адрес. Через несколько мгновений, он уже читал нужный ему материал и еще чуть позже восстановил тексты на своем сайте.
История создания Internet Archive
В 1996 году Брюстер Кайл, американский программист, создал Архив Интернета, где он начал собирать копии веб-сайтов, со всей находящейся в них информацией. Это были полностью сохраненные в реальном виде страницы, как если бы вы открыли необходимый сайт в браузере.
Данными веб-архива может воспользоваться каждый желающий совершенно бесплатно. Создавая его, у Брюстера Кайла была основная цель – сохранить культурно-исторические ценности интернет-пространства и создать обширную электронную библиотеку.
В 2001 году был создан основной сервис Internet Archive Wayback Machine, который и сегодня можно найти по адресу https://archive.org. Именно здесь находятся копии всех веб-сервисов в свободном доступе для просмотра.
Чтобы не ограничиваться коллекцией сайтов, в 1999 году начали архивировать тексты, изображения, звукозаписи, видео и программные обеспечения.
В марте 2010 года, на ежегодной премии Free Software Awards, Архив Интернета был удостоен звания победителя в номинации Project of Social Benefit.
С каждым годом библиотека разрастается, и уже в августе 2016 года объем Webarchive составил 502 миллиарда копий веб-страниц. Все они хранятся на очень больших серверах в Сан-Франциско, Новой Александрии и Амстердаме.
Все про archive.org: как пользоваться сервисом и как достать сайт из веб-архива
Брюстер Кайл создал сервис Internet Archive Wayback Machine, без которого невозможно представить работу современного интернет-маркетинга. Посмотреть историю любого портала, увидеть, как выглядели определенные страницы раньше, восстановить свой старый веб-ресурс или найти нужный и интересный контент — все это можно сделать с помощью Webarchive.
Как на archive.org посмотреть историю сайта
Благодаря веб-сканеру, в библиотеке веб-архива, хранится большая часть интернет-площадок со всеми их страницами. Также, он сохраняет все его изменения. Таким образом, можно просмотреть историю любого веб-ресурса, даже если его уже давно не существует.
Для этого, необходимо зайти на https://web.archive.org/ и в поисковой строке ввести адрес веб-ресурса.
 После, некоторого времени, веб-архив выдаст календарь с датами изменений данной страницы и информацию о его создании и количестве изменений за весь период.
После, некоторого времени, веб-архив выдаст календарь с датами изменений данной страницы и информацию о его создании и количестве изменений за весь период.
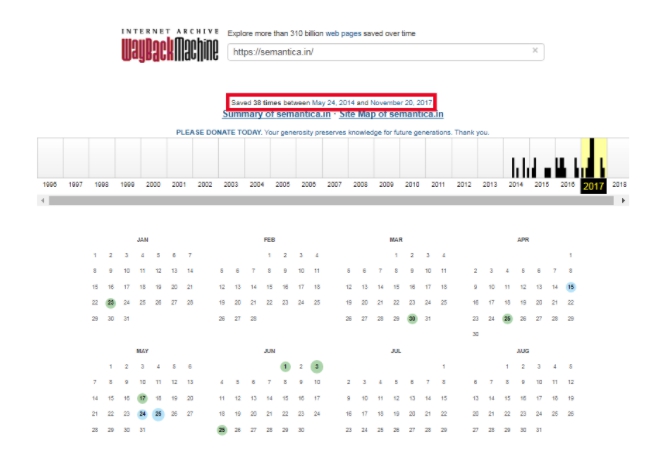 Согласно полученной информации, можно узнать, что главная страница нашего сайта была впервые найдена сервисом 24 мая 2014 года. И, с этого времени, по сегодняшний день, ее копия сохранялась 38 раз. Даты изменений на странице отмечены на календаре голубым цветом. Для того, чтобы посмотреть историю изменений и увидеть как выглядел определенный участок веб-ресурса в интересующий вас день, следует выбрать нужный период в ленте с предыдущими годами, и дату в календаре из тех, что предлагает сервис.
Согласно полученной информации, можно узнать, что главная страница нашего сайта была впервые найдена сервисом 24 мая 2014 года. И, с этого времени, по сегодняшний день, ее копия сохранялась 38 раз. Даты изменений на странице отмечены на календаре голубым цветом. Для того, чтобы посмотреть историю изменений и увидеть как выглядел определенный участок веб-ресурса в интересующий вас день, следует выбрать нужный период в ленте с предыдущими годами, и дату в календаре из тех, что предлагает сервис.
 Через мгновение, веб-архив откроет запрашиваемую версию на своей платформе, где можно увидеть как выглядел наш сайт в самом первоначальном виде.
Через мгновение, веб-архив откроет запрашиваемую версию на своей платформе, где можно увидеть как выглядел наш сайт в самом первоначальном виде.
 Далее, с помощью календаря со стрелками, в самом верху экрана, можно перелистывать страницы, по хронологии их изменений, чтобы отследить, как изменялся внешний вид и их содержание.
Далее, с помощью календаря со стрелками, в самом верху экрана, можно перелистывать страницы, по хронологии их изменений, чтобы отследить, как изменялся внешний вид и их содержание.
 Таким образом, можно нырнуть в прошлое и увидеть все его перемены, которые с ним происходили за все время его существования.
Таким образом, можно нырнуть в прошлое и увидеть все его перемены, которые с ним происходили за все время его существования.
Почему вы можете не узнать на Webarchive, как выглядел сайт раньше
Случается такое, что веб-площадка не может быть найден с помощью сервиса Internet Archive Wayback Machine. И происходит это по нескольким причинам:
- правообладатель решил удалить все копии;
- веб-ресурс закрыли, согласно закону о защите интеллектуальной собственности;
- в корневую директорию интернет-площадки, внесен запрет через файл robots.txt
Для того, чтобы сайт в любой момент был в веб-архиве, рекомендуется принимать меры предосторожности и самостоятельно сохранять его в библиотеке Webarchive. Для этого в разделе Save Page Now введите адрес веб-ресурса, который нужно заархивировать, нажмите кнопку Save Page.
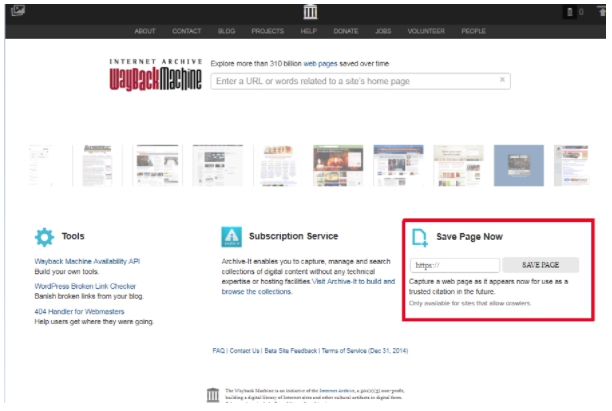 Таким образом, для безопасности и сохранности всей информации, необходимо такую процедуру повторять с каждым изменением. Это даст 100% гарантию сохранения ваших страниц на долгое время.
Таким образом, для безопасности и сохранности всей информации, необходимо такую процедуру повторять с каждым изменением. Это даст 100% гарантию сохранения ваших страниц на долгое время.
Как недействующий сайт восстановить из веб-архива
Бывают разные ситуации, когда браузер выдает, что такого-то веб-сервиса больше нет. Но данные нужно извлечь. Поможет Webarchive.
И для этого существует два варианта. Первый подходит для старых площадок небольшого размера и хорошо проиндексированных. Просто извлеките данные нужной версии. Далее просматривается код страницы и дошлифовываются вручную ссылки. Процесс несколько трудозатратный по времени и действиям. Поэтому существует другой, более оптимальный способ.
Второй вариант идеален для тех, кто хочет сэкономить время и решить вопрос скачивания, максимально быстро и легко. Для этого нужно открыть сервис восстановления сайта из Webarchive – RoboTools. Ввести доменное имя интересующего портала и указать дату сохраненной его версии. Через некоторое время, задача будет выполнена в полном объеме, с наполнением всех страниц.
Как найти контент из веб-архива
Webarchive является замечательным источником для наполнения полноценными текстами веб-ресурсов. Есть множество площадок, которые по ряду причин прекратили свое существование, но содержат в себе полезную и нужную информацию. Которая не попадает в индексы поисковых систем, и по сути есть неповторяющейся.
Так, существует свободные домены, которые хранят много интересного материала. Все что нужно, это найти подходящее содержание, и проверить его уникальность. Это очень выгодно, как финансово – ведь не нужно будет оплачивать работу авторов, так и по времени – ведь весь контент уже написан.
Как сделать так, чтобы сайт не попал в библиотеку веб-архива
Случаются такие ситуации, когда владелец интернет-площадки дорожит информацией, размещенной на его портале, и он не хочет, чтобы она стала доступной широкому кругу. В таких ситуациях есть один простой выход – в файле robots.txt, прописать запретную директиву для Webarchive. После этого изменения в настройках, веб-машина больше не будет создавать копии такого веб-ресурса.
semantica.in
как пользоваться, чем полезен [Инструкция]

Интернет в привычном для нас виде появился 36 лет назад — за это время он развивался семимильными шагами, а сайты тысячи раз меняли свой дизайн и контент. Web archive представляет собой своеобразную машину времени, которой может воспользоваться каждый пользователь.
Что такое Web Archive?
Это бесплатный сервис, где собраны истории многих интернет ресурсов — их архивные копии. Причем речь идет не о скриншотах, а о полноценных страницах с изображениями, рабочими ссылками и стилевым оформлением.
Получение информации о том или ином домене предполагает не только интересное времяпровождение с отслеживанием эволюции веб-проекта, но еще и возможность:
- узнать тематику сайта — архив интернета демонстрирует содержимое, благодаря чему легко определить нишу проекта;
- посмотреть, как выглядел сайт раньше — это находка для охотников за б/у доменами;
- определить, регистрировался ли до этого анализируемый домен — полезный инструмент для тех, кому принципиальна «стерильность» домена или для того чтобы избежать санкций поисковиков;
- восстановить свой сайт, если вы почему-то не сделали резервное копирование.
- отыскать уникальный контент — трудоемкая задача, которая может подарить вам десятки бесплатных статей;
- увидеть удаленный текст из закладок — шансы найти нужную страницу достаточно высоки.
История создания архива интернета
Wayback Machine является одним из двух главных проектов archive.org. Этот некоммерческий сервис был создан в 1996 году Брюстером Кейлом. Машина времени сайтов имеет четкую цель: сбор и хранение копий ресурсов вместе со всем контентом для возможности свободного просмотра несуществующих или неподдерживающихся страниц в будущем. С 1999-го робот стал фиксировать еще и аудио, видео, иллюстрации, программное обеспечение.
База современного архива собиралась в течение 20 лет, у нее не существует аналогов. Статистика впечатляет: на сегодняшний день в сервисе находится 279 миллиардов страниц, 11 миллионов книг и статей, 100 тысяч программ и миллион картинок.
А знаете ли вы? Веб-архив сайтов часто имеет проблемы на законодательном уровне из-за нарушения авторских прав. По требованию правообладателей библиотека удаляет материалы из публичного доступа.
Как пользоваться веб-архивом?
Сервис очень удобный в применении. Пошаговая инструкция такова:
- Зайдите на главную страницу платформы.
- Введите в поле название интересующего вас сайта и нажмите Enter (в нашем случае это https://livepage.pro).

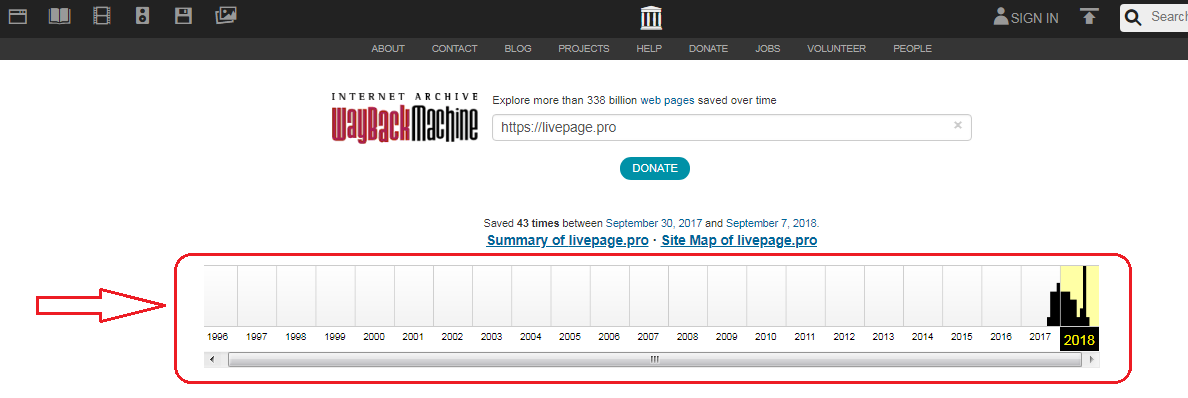
- Под указанным доменным именем демонстрируется основная информация: когда начинается история проекта, сколько слепков имеет сайт. В примере видно, что ресурс был впервые архивирован 30 сентября 2017 года, библиотека хранит его 43 архивные копии.
- Дальше мы обращаем внимание на календарь — голубым цветом в нем отмечены даты создания слепков.Каждый из них доступен для просмотра: нужно лишь выбрать год, месяц и день сохранения. Мы хотим посмотреть, как выглядел сайт раньше: допустим, 3 февраля текущего года. Наводим курсор на голубой кружок и жмем на время сохранения. Проще не бывает!
- При желании можно получить общие данные о web-проекте — надо нажать на кнопку Summary над хронологической таблицей и календарем или же ознакомиться с картой сайта (кнопка Site Map).
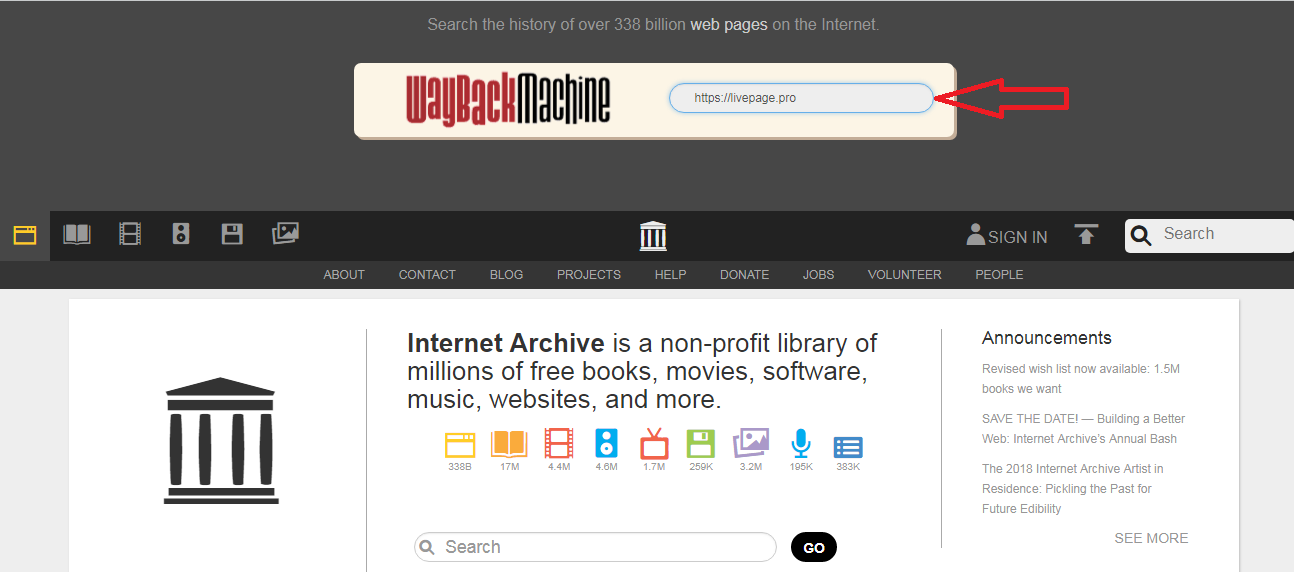

 Каждый из них доступен для просмотра: нужно лишь выбрать год, месяц и день сохранения. Мы хотим посмотреть, как выглядел сайт раньше: допустим, 3 февраля текущего года. Наводим курсор на голубой кружок и жмем на время сохранения. Проще не бывает!
Каждый из них доступен для просмотра: нужно лишь выбрать год, месяц и день сохранения. Мы хотим посмотреть, как выглядел сайт раньше: допустим, 3 февраля текущего года. Наводим курсор на голубой кружок и жмем на время сохранения. Проще не бывает!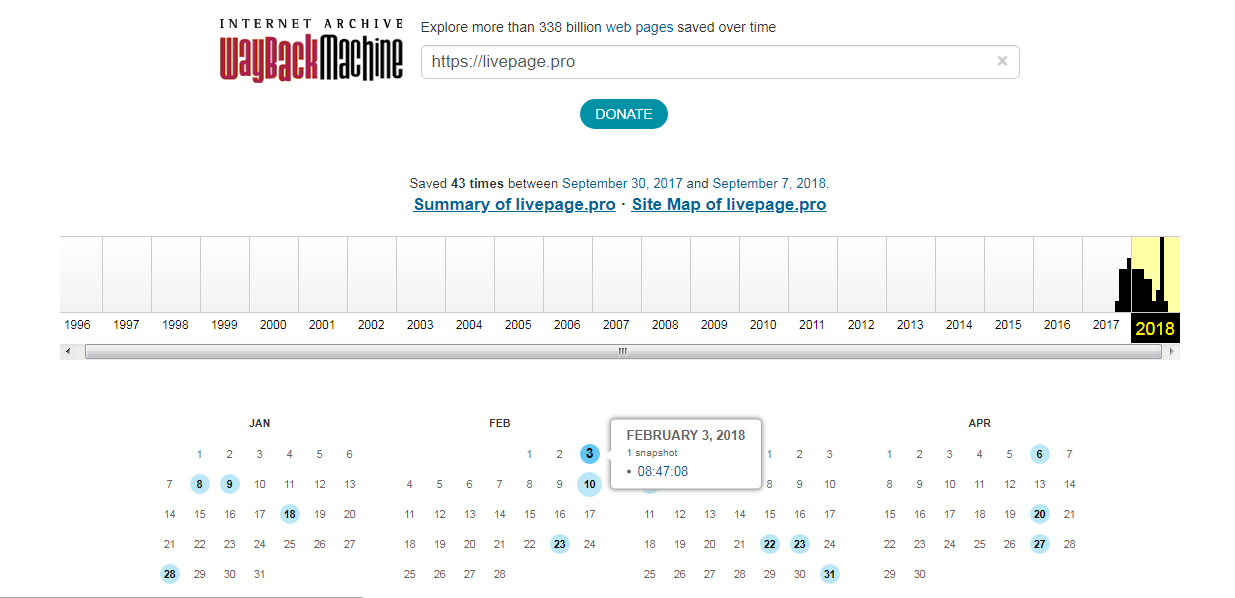
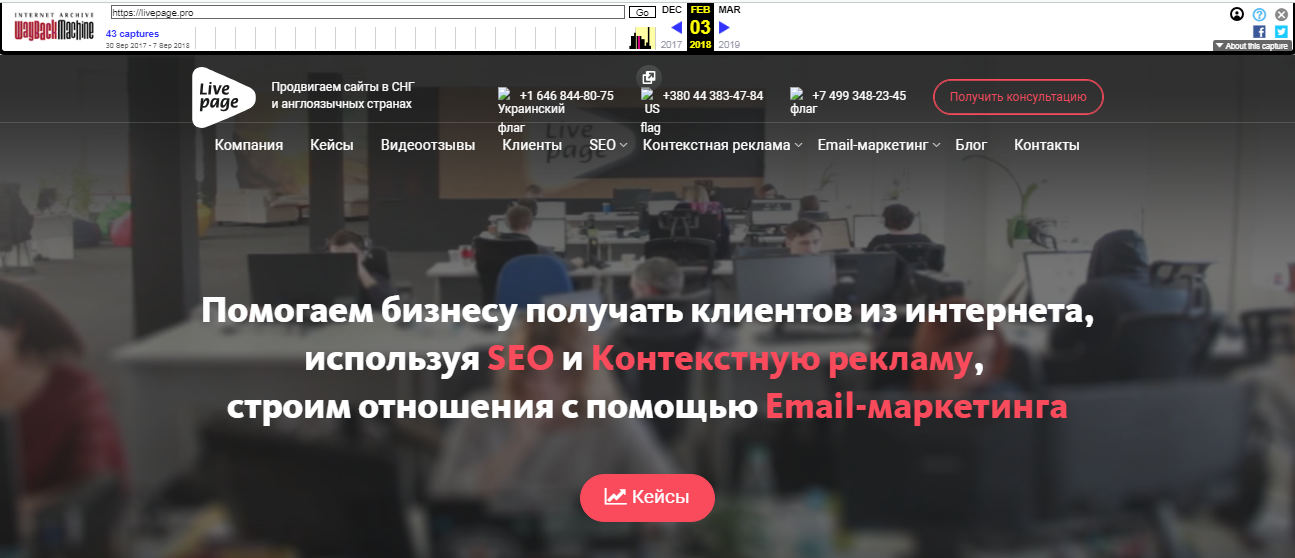

Алгоритм действий можно сократить. Для работы с сервисом напрямую, введите в строке своего браузера
http://web.archive.org/web/*/http://url.
В нашем случае это
http://web.archive.org/web/*/https://livepage.pro.
Как восстановить сайт из веб-архива?
Плохая новость для тех, кто планирует просто найти архив сайта и скачать его привычным способом: страницы имеют вид статических html-файлов, к тому же их слишком много для того, чтобы заниматься этим вручную. Решить проблему можно при помощи специальных программ, к примеру, приложения на ruby. Необходимо лишь установить все на сервер и запустить восстановление страниц.
- Установите «Руби».
apt-get install ruby

- Добавьте саму программу, необходимую для работы.
gem install wayback_machine_downloader
- Запустите выкачивание сайта из web archive.

wayback_machine_downloader http://www.site.ru -timestamp 20131209110704
Для удобства можно указать отметку снапшота — утилита определит число страниц и выведет выкачиваемые файлы на консоль. После скачивания и сохранения мы получим набор статических данных.
- Разместите файлы в выбранной папке. Подойдет rsync:
rsync -avh./websites/www.site.com/ /var/www/site.com/
- Создайте конфигурацию в nginx и дождитесь обновления dns. На этом все!

Как восстановить сайт без бэкапа?
Вернуть ресурс из небытия можно даже без резервного копирования.
- Как уже говорилось раньше, можно восстановить сайт из веб-архива https://archive.org. Чтобы получить все страницы, введите в специальное поле имя ресурса с добавлением /* (https://livepage.pro/*). Здесь же предусмотрена возможность фильтрации файлов по подстроке в URL. Для скачивания файлов подойдут многие программы, например, Teleport Pro.
- Страницы интернет-проектов часто хранятся в кэше поисковых систем. По причине того что у каждого поисковика свои параметры, для лучшего эффекта промониторьте не только Google и Яндекс, но и Bing, Rambler:
http://www.google.ru/advanced_search
http://yandex.ru/search/advanced
http://www.bing.com/
http://nova.rambler.ru/srch/advanced
Войдите в режим расширенного поиска и укажите имя сайта. Получив результаты, кликайте по ссылкам «cached» или «копия».
- Если вы отдаете полный RSS, тогда стоит проверить еще и ридеры, агрегаторы.
Учтите!
Нужный вам проект может и не входить в архив сайтов интернета. Если вы его не нашли в библиотеке — значит, правообладатель потребовал удаления копий или же ресурс закрыли в соответствии с законом о защите интеллектуальной собственности. Возможен и другой вариант: через файл robots.txt был банально внесен соответствующий запрет.
Как найти уникальный контент из веб-архива для вашего сайта?
Статьи, расположенные на заброшенных ресурсах, обычно не представляют никакой ценности для их бывших владельцев. А ведь в мир иной ежедневно уходят десятки сайтов. И среди кучи хлама, выброшенного на помойку истории, можно найти настоящие самородки — приличные тексты, которые достанутся вам бесплатно.
Поисковики хорошо относятся к любому актуальному и уникальному контенту — можно не бояться попасть в их немилость только из-за того, что статьи взяты из веб-архива чужого сайта.
Итак, последовательность действий следующая:
- Найдите подходящие вам блоги. Для этого следует зайти на Reg.ru и скачать оттуда список недавно освободившихся доменов.
- Посетите архив интернета с целью поиска сохраненных копий.
- Проверьте понравившиеся тексты через антиплагиат (контент может быть уже скопирован на другие сайты).
- Опубликуйте уникальные статьи на своем ресурсе.
При разумном подходе такой способ пополнения сайта контентом можно поставить на поток. Поиски материалов на мертвых блогах оправданы экономией времени на написание текстов и денег, которые бы вам пришлось заплатить авторам.
Как сделать так, чтобы сайт не попал в библиотеку веб-архива?
Если вы дорожите контентом и не хотите видеть свою онлайн-площадку в электронной библиотеке, пропишите запретную директиву в файле robots.txt:
User-agent: ia_archiver
Disallow: /
User-agent: ia_archiver-web.archive.org
Disallow: /
После изменения в настройках веб-сканер перестанет создавать архивные копии вашего сайта, к тому же удалит уже сделанные слепки. Однако учтите, что ваш запрет действует лишь до тех пор, пока доступен robots.txt — когда закончится срок регистрации доменного имени, машина времени сайтов станет демонстрировать статьи всем желающим.
Важно! Если вы, наоборот, желаете активно пользоваться веб-архивом, введите соответствующий запрос на главной странице сервиса. Просто укажите адрес проекта в разделе Save Page Now, после чего нажмите кнопку Save Page. Повторяйте процедуру после внесения любых правок.

Аналоги Webarchive
Альтернативой рассматриваемой в обзоре электронной библиотеке может стать:
Принцип работы тот же, как и у archive.org.
livepage.pro
Как выглядели сайты раньше: 20 примеров
Karina | 17.08.2016
С тех пор, как родился Интернет (более 25 лет назад), веб-сайты претерпели тысячи изменений, и их развитие ушло далеко вперёд благодаря стремительно прогрессирующим технологиям. Уже сложно вспомнить, как выглядели сайты в прошлом, а ведь ранние версии многих известных ресурсов были совершенно другими. Давайте взглянем на них.
Вид раньше и сейчас
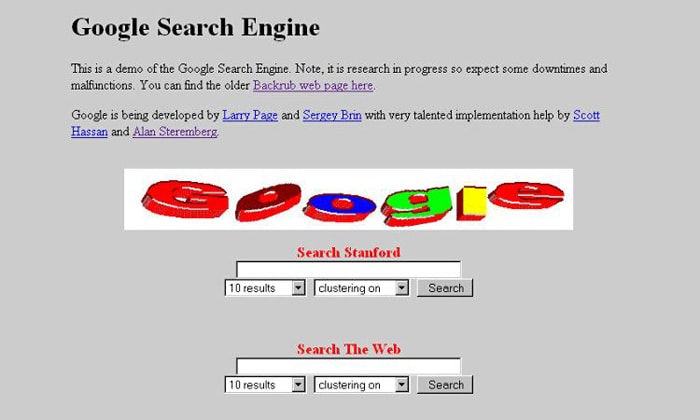
1. Google.com: старт в 1996 году
Поисковая система Google, созданная в 1996 году в качестве учебного проекта студентами Стэнфордского университета Ларри Пейджем и Сергеем Брином, сегодня является крупнейшей компанией в мире. На первом скриншоте изображен один из самых ранних вариантов внешнего вида Google, а на втором — современный дизайн:
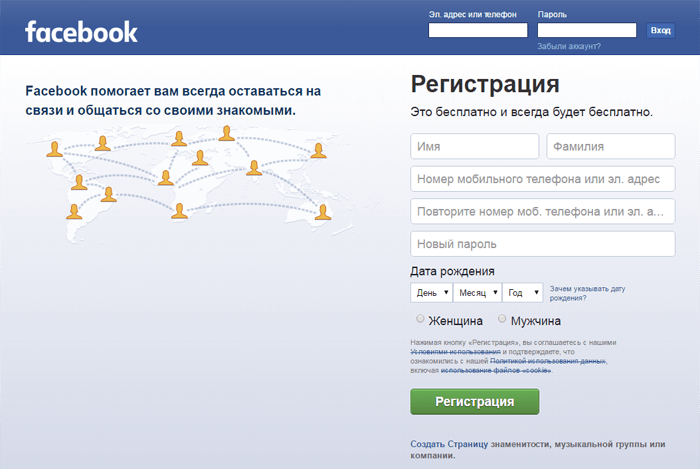
2. Facebook.com: старт в 2004
Спустя 8 лет после Google был изобретён Facebook — Марком Цукербергом в Гарвардском университете. Известный как TheFacebook, изначально проект был доступен только однокурсникам Гарварда. Сегодня же посещаемость данной социальной сети составляет 1,71 млрд активных пользователей в месяц.

3. MySpace.com: старт в 2003
Прежде чем появился Facebook, популярной социальной сетью была площадка MySpace. Она является одной из первых соцсетей, но с лидирующего места её уже вытеснили такие сайты как Twitter и Facebook. В 2005 году Руперт Мердок выкупил MySpace за $580 млн у основателей Криса Девульфа и Тома Андерсона. После того, как MySpace стал стремительно терять аудиторию, Мердок, по слухам, продал его за $35 млн, назвав покупку «огромной ошибкой».


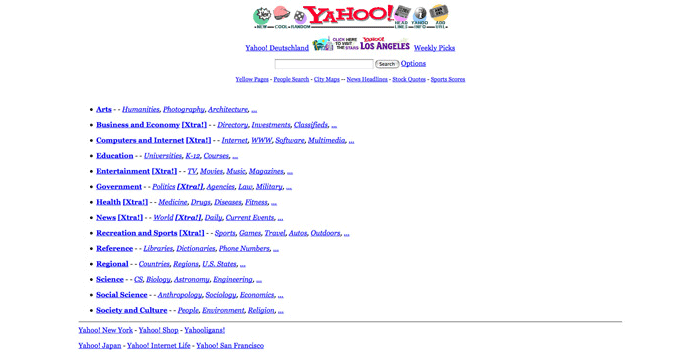
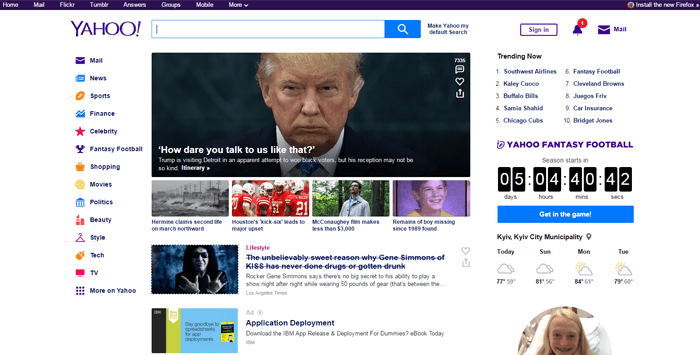
4. Yahoo.com: старт в 1994
В начале 1994 года аспиранты Стэнфордского университета Дэвид Фило и Джерри Янг создали портал под названием «Путеводитель Джерри по Всемирной Паутине», представляющий собой каталог других веб-сайтов. Позже, в этом же году сайт был переименован в Yahoo!.
Версий происхождения данного имени существует несколько. Одни утверждают, что Yahoo! является акронимом фразы «Yet Another Hierarchical Officious Oracle». Другие же считают, что название было позаимствовано из книги «Путешествия Гулливера» Д. Свифта, где словом «yahoo» называются грубые человекообразные существа. Кстати, именно вторую версию основатели компании называют правильной.
5. YouTube.com: старт в 2005
Если у компании Yahoo! есть две версии появления её названия, то у сервиса YouTube существует две версии появления его самого. В первом варианте утверждается, что автором идеи был программист Джавед Карим, которого посетила мысль создать такой сервис, когда он не смог найти в Сети видео с участием Джанет Джексон и Джастина Тимберлейка. По второй версии, YouTube возник, когда его будущие основатели Стив Чен, Чад Хёрли и Джавед Карим захотели поделиться друг с другом видеороликами с вечеринки, но не нашли в Интернете удобного сервиса для этого. После чего было решено создать сайт, куда пользователи смогут легко загружать видео, а оно будет автоматически конвертироваться в нужный для просмотра в браузерах формат.


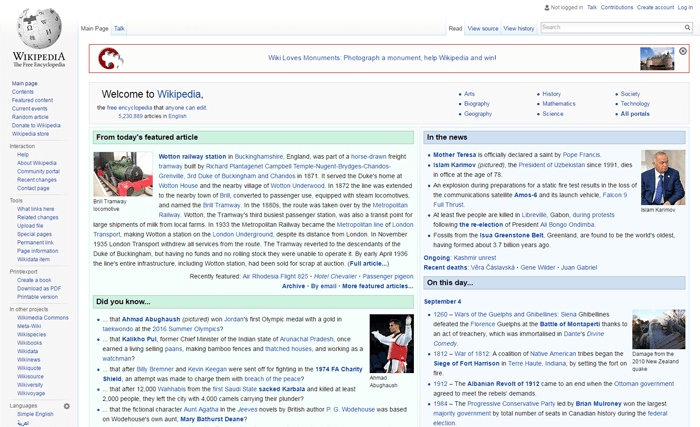
6. Wikipedia.org: старт в 2001
Объёмная онлайн-энциклопедия Wikipedia навсегда изменила подход к получению информации для целых поколений. И хотя с момента запуска в 2001 Википедия мало изменилась в плане внешнего вида, за это время она сильно разрослась: на сайте насчитывается уже более 30 млн статей.

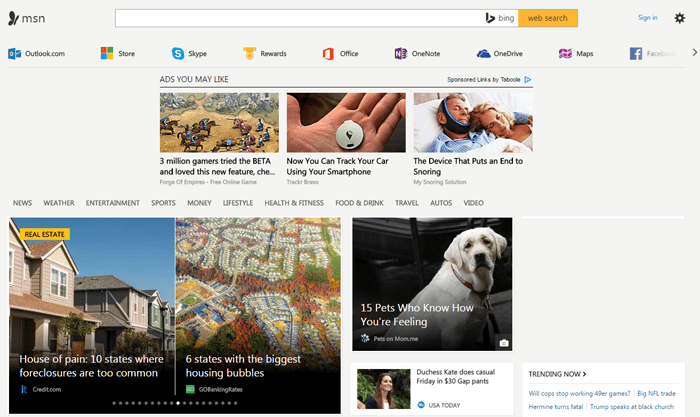
7. MSN.com: старт в 1995
MSN (Microsoft Network) был запущен в 1995 году. В начале 2000-х компания MSN являлась вторым по популярности интернет-провайдером (после AOL LLC). Сам сайт msn.com представляет собой новостной портал с видео, акциями и опросами.

8. Apple.com: старт в 1997
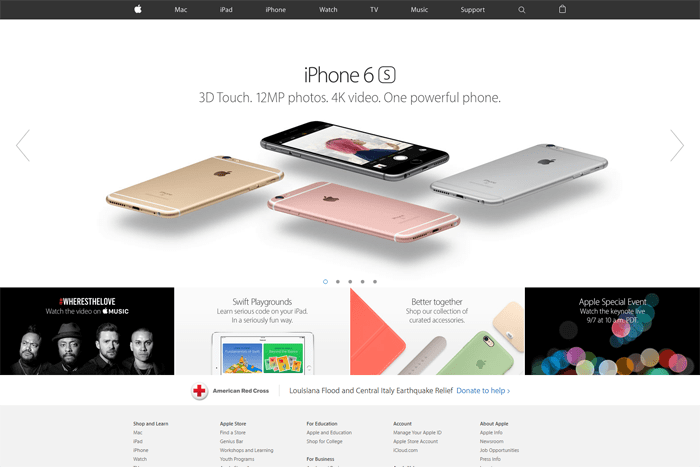
Нынешний вид сайта Apple кардинально отличается от его ранней версии с заманчивым предложением получить бесплатный CD-ROM. Однако уже тогда компания демонстрировала свою любовь к белому цвету. А Apple eMate 300, рекламирующийся в правой части страницы, одно время был популярным КПК (с 1997 по 1998 год).

9. Twitter.com: старт в 2006
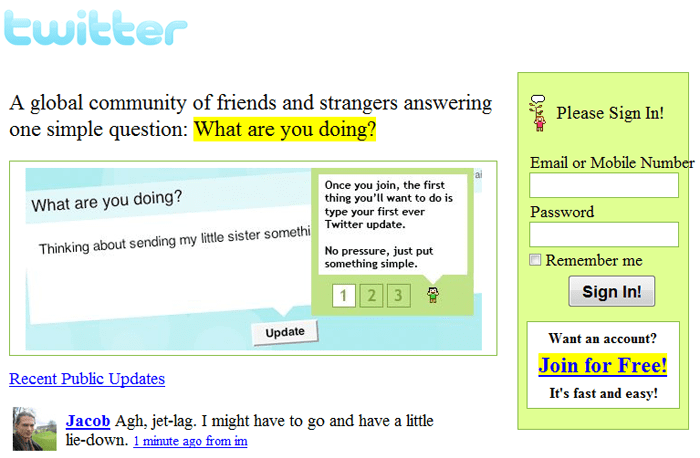
Сайт Twitter был запущен в марте 2006 года и, по сравнению со своей старой версией, стал практически неузнаваем. В настоящее время Твиттер входит в десятку самых посещаемых ресурсов в мире и считается одним из самых успешных стартапов всех времён с точки зрения рыночной капитализации.

10. eBay.com (ранее известный как AuctionWeb): старт в 1995
Кто бы мог подумать, что этот серый, мало чем примечательный сайт превратится в крупнейший онлайн-аукцион в мире? Его основатель, программист Пьер Омидьяр, изначально хотел зарегистрировать доменное имя EchoBay.com, но, как оказалось, им уже владела одна золотодобывающая компания, поэтому название было решено сократить до eBay.com.


11. LinkedIn.com: старт в 2003
Сайт LinkedIn был создан в 2003 году предпринимателем Ридом Хоффманом и позиционировался как социальная сеть для поиска и установления деловых контактов. В одном только США насчитывается 93 млн пользователей данной сети. С самого начала сайт обладает достаточно сложной структурой.


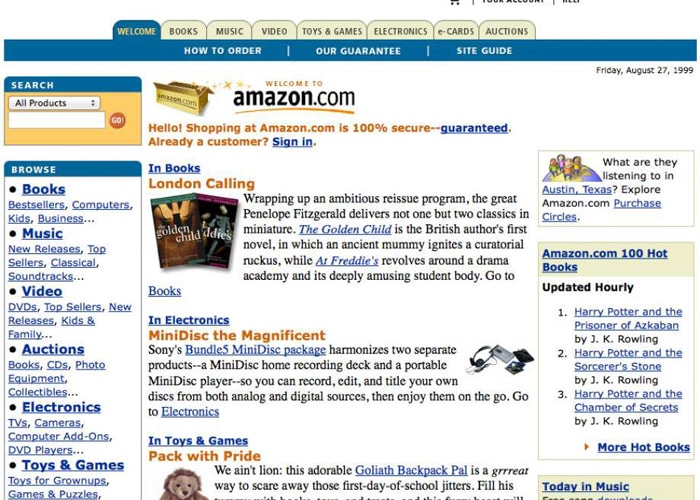
12. Amazon.com: старт в 1995
Изначально на сайте Amazon продавались только книги. Придумывая название своему проекту, Джефф Безос просматривал словарь и остановился на слове «Amazon», поскольку Амазонка является экзотической, непохожей на другие и самой большой рекой в мире. Именно таким он хотел сделать и свой магазин.
Интересно и то, что ранее, в сентябре 1994, Безос приобрел домен Relentless.com и планировал назвать своё детище словом Relentless (рус. безжалостный, неустанный), но друзья сказали ему, что такое имя звучит немного зловеще. Домен всё ещё принадлежит Безосу — с него идёт перенаправление на Amazon.com.

13. Instagram.com: старт в 2010
Такой популярный нынче сайт Instagram начинал своё существование под названием Burbn. Создатели проекта, Кевин Систром и Майк Кригер, в какой-то момент поняли, что их сервис стал сильно напоминать Foursquare, и приняли решение сделать его более специализированным, сделав упор на мобильную фотографию. Так появился Instagram. Название представляет собой объединение двух выражений — «instant camera» и «telegram».
С тех пор проект признан одним из самых успешных в мире. В 2012 году Facebook купил Instagram за $1 млрд.


Все вышеперечисленные ресурсы на сегодняшний день уже имеют абсолютно другой дизайн, и узнать, как выглядели эти сайты раньше, можно лишь благодаря сохранившимся скриншотам. Но есть некоторые сайты, которые сохранились в первозданном виде! Если вам мало одного скриншота, и вы хотите устроить настоящий сёрфинг по сайтам в стиле 90-х, взгляните на список ниже.
Рабочие сайты в стиле 90-х
На момент публикации этой статьи все сайты рабочие.
14. Space Jam: старт в 1996
Забавный кусочек истории: подсайт Space Jam домена warnerbros.com, который никак не изменялся с момента своего запуска в 1996 году. Здесь можно переходить по ссылкам и ощутить перемещение во времени!

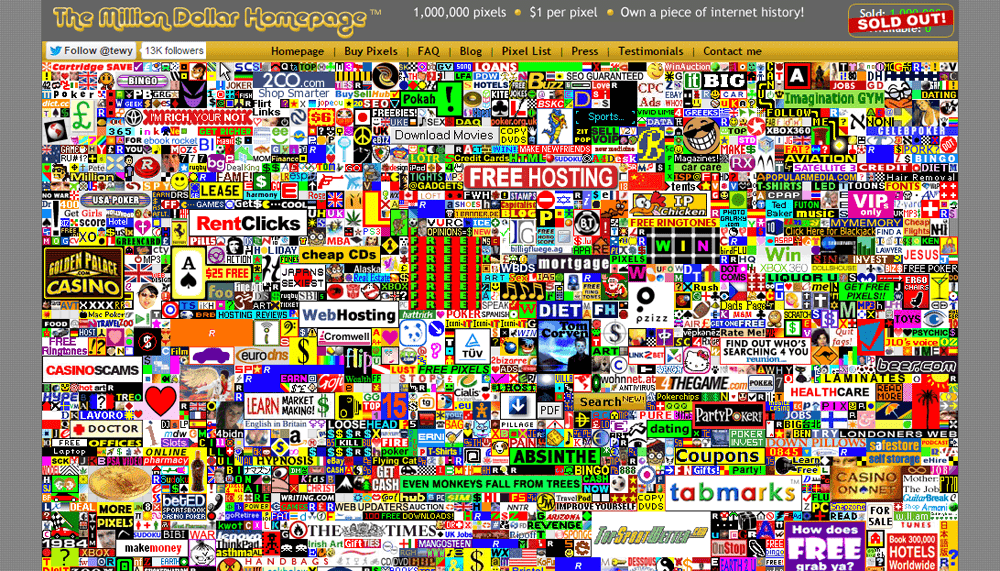
15. MillionDollarHomepage.com: старт в 2005
Этот сайт принёс своему создателю, 21-летнему студенту из Великобритании Алексу Тью, заработок в размере $1 037 100. Главная страница имеет размер 1000×1000 = 1 млн пикселей. Каждый пиксель продавался за $1, а минимальным размером покупки был блок 10×10 пикселей. В распоряжении покупателя была та площадь, которую он купил — он мог разместить на ней картинку и сделать из неё ссылку.
Целью автора сайта была продажа всех пикселей, следовательно, заработок должен был составить 1 миллион долларов. Но заработал Алекс Тью немного больше, поскольку последнюю тысячу пикселей он выставил на аукцион eBay, заработав на продаже $38 100. Вид сайта сохранён для истории и доступен для просмотра.
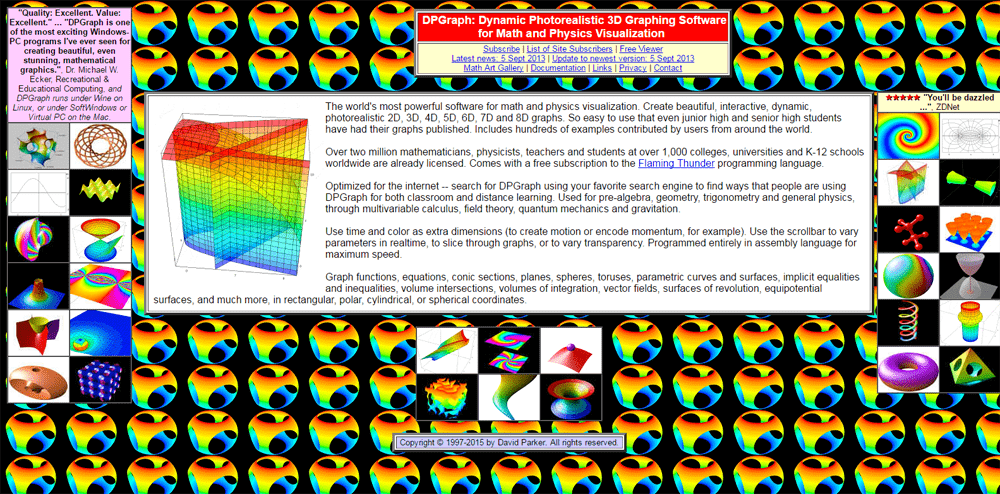
16. DPGraph.com: старт в 1997
Сайт программного обеспечения для математической и физической 3D-визуализации. Здесь поражает не только тематика, но и внешний вид страницы — анимированные gif-ки объемных графиков, раскрашенные во все цвета радуги, и дизайн в стиле 90-х — что может быть более психоделичным?…
17. Aliweb.com: запуск в 1993
ALIWEB (Archie Like Indexing for the WEB) — одна из первых поисковых систем в мире. Её запуск состоялся в ноябре 1993 года. К счастью, спустя 23 года у нас есть возможность полюбоваться таким раритетом в нетронутом виде.

18. Taco.com: старт в 1997
«Мы не продаем тако. Мы не готовим тако. По правде говоря, некоторые из нас даже не очень их любят», — сказано на одной из страниц сайта taco.com, принадлежащего компании, которая предлагает различную компьютерную помощь. Название TACO произошло от сокращения Technical Advisors Company. Этот сайт 90-х годов до сих пор блистает благодаря чувству юмора сисадминов.

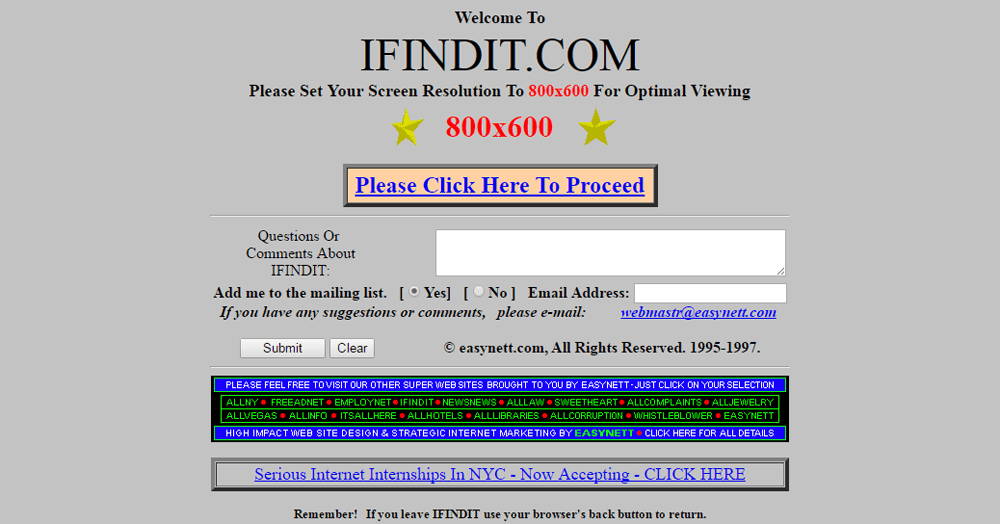
19. IFindIt.com: старт в 1995
I Find It — огромное руководство по поиску в Интернете. Год создания — 1995. На сайте размещен совет: «Пожалуйста, задайте разрешение экрана 800×600 для оптимального просмотра»…
Google, а где был ты в 1995? По-видимому, ещё играл с погремушками.
20. Instanet.com: старт в 1995
Если бы страницы HTML 2.0 (версия, одобренная как стандарт 22 сентября 1995 года) можно было продавать на аукционах, то сайт instanet.com сейчас стоил бы миллионы. Вы только взгляните на этот исходный код:
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0 plus SQ/ICADD Tables//EN" "html.dtd">
Вау.

idg.net.ua
Архив Интернета или как выглядел любой сайт в прошлом
Вам когда-нибудь хотелось посмотреть, как выглядел любой популярный ресурс в интернете 2-5 лет назад, а может и более? У вас есть такая возможность!
Привет, дорогие друзья!
Сегодня статья будет скорее развлекательная, но не менее познавательная и ценная.
Вам когда-нибудь хотелось посмотреть, как выглядел любой популярный ресурс в интернете 2-5 лет назад, а может и более? У вас есть такая возможность!
Вы можете изучить историю интернет-ресурсов с помощью архива Wayback Machine, который начал работать с 1996 г.
Ссылка на архив сайтов: https://archive.org/web/web.php
Данный архив собирает копии веб-страниц и даже целых сайтов. Архив обеспечивает долгосрочное архивирование собранного материала и бесплатный доступ к своим базам данных для широкой публики.
Содержание веб-страниц фиксируется с временным промежутком c помощью бота. Таким образом, можно посмотреть, как выглядела та или иная страница раньше, даже если она больше не существует.
Конечно, первое, что хочется проверить, это сайт Вконтакте) Просто впишите название сайта в поле и жмите «Take Me Back».

Вот так выглядела главная страница сайта Вконтакте 9 ноября 2006 года:

Для справки: Вконтакте начал работать с 10 октября 2006 года.
А вот так выглядел известный мегамаркет Ozon.ru 19 июня 2000 года:

Для справки: Российский интернет-магазин начал работать с 1998 года.
Остальные сайты, которые вас интересуют, можете проверить уже сами. Инструмент я вам показал. Возможно вы найдете какое-нибудь применение данному сервису.
Оставляйте отзывы к этой статье ниже. Если вы нашли интересный сайт в прошлом – поделитесь с нами ссылкой в комментариях.
Статьи по темеКомментарии
stasbykov.ru
Как узнать историю сайта и домена или назад в прошлое.
Прошлое должно оставаться в прошлом, но иногда нужно вернуться, чтобы рассмотреть детали…
Здравствуйте, дорогие мои читатели!
Я очень люблю узнавать что-то новое. Ведь так здорово, когда наш багаж знаний пополняется. И самое хорошее здесь то, что такой багаж знаний нести совсем не тяжело. Наоборот, это придаёт нам уверенности в жизни. Естественно, всё знать невозможно, но здоровая любознательность это очень хорошее качество.
Пару лет назад я совершенно случайно узнала об одном сервисе. Привело меня к этому простое любопытство. Просто захотелось узнать, как выглядел определённый сайт на самом первом этапе развития, и каков был его первоначальный дизайн.
Разве это не интересно?
А ещё интересно это не просто как банальное любопытство. Если человек захотел купить себе уже готовый, используемый раньше домен, то не мешало бы посмотреть, какой на нём был раньше сайт, какой тематики он был и как он выглядел. Это очень важно. Так надо делать, чтобы быть уверенным в том, что вы покупаете на самом деле. Ведь кота в мешке покупать не очень то хочется.
И ещё. Нам нравятся не все сайты подряд, даже если они выглядят аккуратно и всё там реализовано так, как положено.
Мы посещаем самые различные сайты, и на одних сайтах мы бываем мимолетом, а на других задерживаемся и ставим на них закладки, чтобы возвращаться вновь и вновь.
От чего это зависит?
У всех по разному, и как бы блогер или администрация сайта не старались, всем понравится не возможно. И не стоит расстраиваться по этому поводу, если ваш блог кому то не понравился.
Кому не нравится,те пройдут мимо. А если уж блог понравился, то у человека возникает естественное чувство любопытства, особенно если это веб. мастер:
КАК УЗНАТЬ ИСТОРИЮ САЙТА И ДОМЕНА?
То, какими мы сейчас видим сайты в интернете, на это влияет мода, прогресс и просто удобство для читателей. Это всё изучает каждый веб. мастер, ведь для того чтобы быть любимым и интересным, надо соответствовать.
А любому веб.мастеру всегда интересен вопрос:
Как же все-таки можно узнать историю сайта блоггера, живущего по соседству в интернете=)?
Всё просто. Это узнать можно быстро. Для этого сядем поудобнее перед компьютером и переместимся на специальной машине времени назад, в прошлое.
В интернете существует специальный веб-архив и в нем сохраняются все изменения сайта на протяжении нескольких лет. Просто делаются скриншоты (фотографии) всех страниц сайта.
Стоит отметить, что история сайта сохраняется не в виде простых скриншотов, а в виде работающих веб-страниц со всеми файлами.
Если сайт достаточно популярный, то фотографии делаются чаще, если нет, то бот-фотограф заходит туда реже или не заходит совсем, если сайт перестал обновляться. Это из личных наблюдений. Так как этот сайт веб- архив работает по своим правилам, и не всегда поддаётся логике.
Этот сайт, на который мы сейчас попадём, некоммерческий проект, и он уже достаточно долгое время работает на благо всех интернет пользователей.
Этот факт заслуживает к нему уважения. Это как Википедия, только немного с другими целями.
Как посмотреть историю сайта в архиве?
Нам нужно перейти по ссылке:
http://www.archive.org/web/web.php
Откроется страница, с формой поиска, в которую нужно вписать адрес сайта.
Далее, нажимаем: ПРОСМОТРЕТЬ ИСТОРИЮ.
Например, вот один из известных сайтов:
http://www.fast-torrent.ru/
Вписываем адрес сайта и смотрим, что получилось:
Перед вами откроется новая страница, где будет показан календарь и указаны даты, когда это сайт был сфотографирован. Вы сможете проследить всю историю развития сайта, исходя из сохранённых фотографий.
В календаре голубыми кружочками отмечены даты, когда был создан снимок данного сайта.
Нужно просто нажать на число, выделенное голубым цветом. Вы увидите скриншот, как выглядел сайт в тот момент. Будет виден дизайн, и последние статьи и новости.
Кстати, если вы по каким-либо причинам не сделали бэкап сайта, то не стоит совсем отчаиваться от потерянной навеки информации. Данный ресурс поможет вам восстановить сайт.
Понятно, что восстановление таким образом своего сайта займет огромное количество времени, но когда другого варианта нет, как бы это не звучало, то любая возможность будется казаться самой лучшей.
К тому же, такая беда может случится обычно у начинающих веб мастеров, и значит контента будет не так то много, так что берите в руки своё терпение и по детально восстанавливайте свои статьи.
Хотя всем желаю, чтобы таким образом этот ресурс вам не пригодился никогда!
Как можно посмотреть страницы определённого сайта?
Итак, надо ввести в адресную строку Яндекса или Гугла такой адрес:
http://wayback.archive.org/web/*/internetkapusta.ru/*
Вместо моего введите тот, что надо для просмотра.
Вы попадёте на машине времени назад, где можно посмотреть все сохранённые страницы, если они были запротоколированы.
Вот такие адреса у меня были в начале ведения блога:
А вот такие, красивые, уже впоследствии:
Нажимаем на любую ссылку и смотрим, какой был сайт в это время по этой ссылке:
Мы попадём на страницу, где будет показано, сколько раз был сделан снимок сайта:
Даже фавикон будет тот, что был на тот момент:)
Немного истории:
Вот представьте масштаб этого хранилища на данный момент времени!!! Это сколько нужно места!!!
Некоторые сайты всё же не попадают в историю веб. архива, потому что владельцы сайта могут не захотеть, чтобы было разрешение на сканирование веб-сайта боту этого ресурса: The Wayback Machine.
Для этого в robots.txt.ставят запрет на просмотр страниц ботом. Приблизительно это будет так:
User-agent: ia_archiver
Disallow: /
Как посмотреть нужную копию сайта?
Чтобы посмотреть архивы, надо обратить внимание на временную шкалу, расположенную вверху страницы, где вертикальными черными черточками отмечены имеющиеся для этого сайта копии. Иногда, при неудачной фотографии сайта, например, когда у вас были технические работы или ещё что то и снимок получился битым, тогда следует обратится к другой копии и открыть снимок.
Нажав на голубой кружок, вы увидете ссылки на несколько архивов, отличающихся временем их снятия. Это делается во избежании потери данных за счет форс мажорных обстоятельств на сайте.
И вот, именно 25 июня 2014 года мы смотрим фотографию:
В итоге, перейдя к просмотру вы увидите копию нужного сайта с работающими внутренними ссылками и подключенным стилевым оформлением.
Стоит заметить, что эта машина работает иногда не совсем корректно, но этих случаев немного на практике и это скорее всего это временное явление.
Теперь вы знаете:
КАК УЗНАТЬ ИСТОРИЮ САЙТА И ДОМЕНА.
Всем пока! До новых встреч!
С уважением, автор блога, Интернет Капуста, Лара Мазурова.
Прочитайте ещё очень интересные статьи из рубрик:
internetkapusta.ru