Запрет индексации страниц сайта в robots.txt
При посещении сайта, поисковый робот использует ограниченое количество ресурсов для индексации. То есть поисковый робот за одно посещение может скачать определенное количество страниц. В зависимости от частоты обновления, объема, количества документов и многих других факторов, роботы могут приходить чаще и скачивать больше страниц.
Чем больше и чаще скачиваются страницы — тем быстрее информация с Вашего сайта попадает в поисковую выдачу. Кроме того, что страницы будут быстрее появляться в поиске, изменения в содержании документов также быстрее вступают в силу.
Быстрая индексация сайта
Быстрая индексация страниц сайта помогает бороться с воровством уникального контента, позволяет повысить релевантность страницы сайта за счет ее свежести и актуальности. Но самое главное. Более быстрая индексация позволяет отслеживать как те или иные изменения влияют на позиции сайта в поисковой выдаче.
Плохая, медленная индексация сайта
Почему сайт плохо индексируется? Причин может быть множество и вот основные причины медленной индексации сайта.
- Страницы сайта медленно загружаются. Это может стать причиной полного исключения сайта из индекса.
- Сайт редко обновляется. Зачем роботу часто приходить на сайт, на котором новые страницы появляются раз в месяц.
- Неуникальный контент. Если на сайте размещен ворованый контент (статьи, фотографии), поисковая система снизит трастовость (доверие) к вашему сайту и снизит расход ресурсов на его индексацию.
- Большое количество страниц. Если на сайте много страниц и не настроен last modified, то на индексацию или переиндексацию всех страниц сайта может уйти очень много времени.
- Сложная структура сайта. Запутанная структура сайта и большие количество вложений сильно затрудняют индексацию страниц сайта.
 Если подобные страницы существуют, их как правило очень много, но в индексацию попадают далеко не все. А страницы, которые попадают — конкурируют с целевыми страницами. Все эти страницы регулярно переиндексируются, расходуя и так ограниченый ресурс, выделенный на индексацию вашего сайта.
Если подобные страницы существуют, их как правило очень много, но в индексацию попадают далеко не все. А страницы, которые попадают — конкурируют с целевыми страницами. Все эти страницы регулярно переиндексируются, расходуя и так ограниченый ресурс, выделенный на индексацию вашего сайта.- Динамические страницы. Если на сайте существуют страницы, содержимое которых не зависит от динамических параметров (пример: site.ru/page.html?lol=1&wow=2&bom=3), в результате может появиться множество дублей целевой страницы site.ru/page.html.
 Если подобные страницы существуют, их как правило очень много, но в индексацию попадают далеко не все. А страницы, которые попадают — конкурируют с целевыми страницами. Все эти страницы регулярно переиндексируются, расходуя и так ограниченый ресурс, выделенный на индексацию вашего сайта.
Если подобные страницы существуют, их как правило очень много, но в индексацию попадают далеко не все. А страницы, которые попадают — конкурируют с целевыми страницами. Все эти страницы регулярно переиндексируются, расходуя и так ограниченый ресурс, выделенный на индексацию вашего сайта.Есть и другие причины плохой индексации сайта. Однако, самой распространенной ошибкой является плохо настроенный robots.txt.
Убрать из индексации все лишнее
Существует множество возможностей рационально использовать ресурсы, которые выделяют поисковики на индексацию сайта. И широкие возможности для управления индексацией сайта открывает именно robots.txt.
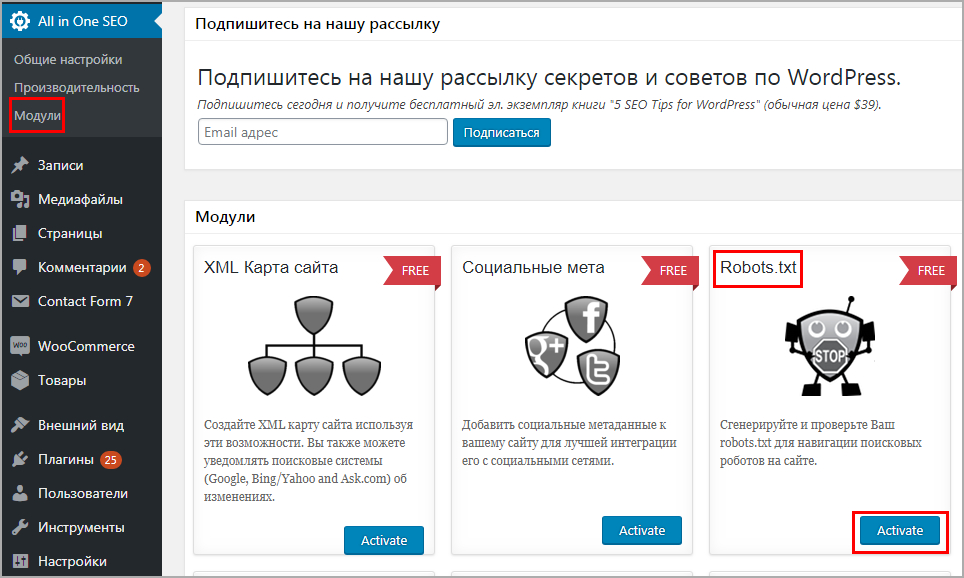
Используя дерективы Allow, Disallow, Clean-param и другие, можно эффективно распределить не только внимание поискового робота, но и существенно снизить нагрузку на сайт.
Для начала, нужно исключить из индексации все лишнее, используя дерективу Disallow.
Например, запретим страницы логина и регистрации:
Disallow: /login Disallow: /register
Запретим индексацию тегов:
Disallow: /tag
Некоторых динамических страниц:
Disallow: /*?lol=1
Или всех динамических страницы:
Disallow: /*?*
Или сведем на нет страницы с динамическими параметрами:
Clean-param: lol&wow&bom /
Подробнее про индексацию сайта, влияние индексации на выдачу, правильную настройку robots. txt, генерацию sitemap.xml, настройку last modified страниц сайта, другие способы ускорения индексации сайта и причины плохой индексации сайта читайте в следующих постах. А тем временем.
txt, генерацию sitemap.xml, настройку last modified страниц сайта, другие способы ускорения индексации сайта и причины плохой индексации сайта читайте в следующих постах. А тем временем.
Сбрасывайте ненужный баласт и быстрее идите в топ.
Получайте бесплатные уроки и фишки по интернет-маркетингу
Как использовать файл robots.txt – Статья ВебРост
О быстрой индексации молодого сайта или новых страниц старого ресурса мечтает каждый вебмастер. Достичь успехов в этом вопросе поможет robots.txt, который является навигационным маяком для поисковых систем. Мы подготовили большой гайд, который касается особенностей, функций и настройки robots.txt.
Что такое индексный файл?
В индексном файле прописана информация, указывающая поисковым ботам на страницы, разделы и папки, которые нужно и не нужно индексировать. Для создания необходимо использовать кодировку UTF-8. Применение других символов может привести к тому, что поисковые роботы просто не распознают рекомендации. Он актуален для протоколов HTTP, HTTPS и FTP. Корректная настройка рассматриваемого файла скрывает от индексации страницы, папки, разделы:
Он актуален для протоколов HTTP, HTTPS и FTP. Корректная настройка рассматриваемого файла скрывает от индексации страницы, папки, разделы:
- веб-страницы со служебной информацией;
- административная панель;
- формы регистрации, оформления заказа, сравнения товаров;
- личные кабинеты;
- персональные данные клиентов;
- корзины, иные «мусорные страницы».
Попадая на сайт, роботы начинают искать robots.txt. Если он отсутствует или оформлен неправильно, то сканирование будет выполняться произвольно. В итоге новые страницы и контент не попадут в поисковую выдачу на протяжении длительного времени. Обратите внимание на то, что некоторые конструкторы сайтов формируют файл автоматически. Для проверки наличия файла стоит дополнить доменное имя строкой «/robots.txt».
Читайте также:
Как скрыть сайт или отдельную страницу от индексации в поисковых системах Google и Яндекс?
#SEO продвижение
Зачем нужен индексный файл?
Запрет на индексацию страниц – необходимость, ведь некоторые из них не предназначены для пользователей. Использование рассматриваемого инструмента решает следующие задачи:
Использование рассматриваемого инструмента решает следующие задачи:
- составление четкого плана страниц, которые подлежат индексации;
- снижение нагрузки на сервер в то время, когда ресурс сканируют поисковые роботы;
- определение главного зеркала;
- создание корректного пути к карте сайта, что ускоряет и существенно упрощает индексацию;
- предупреждение ошибок, проблем и слишком медленной индексации.
Однако есть один нюанс: robots.txt имеет рекомендательный характер, он не может запретить ботам индексировать ту или иную страницу. Представители ПС Google указывают на то, что с помощью индексного файла нельзя выполнить блокировку страниц. Например, доступ ограничен через файл, однако на другой странице размещена ссылка на ту, которую вы хотите закрыть – в этом случае индексация может произойти. В связи с этим рекомендуется использовать не только потенциал robots.txt, но и другие методы ограничений для поисковых систем Яндекс и Google.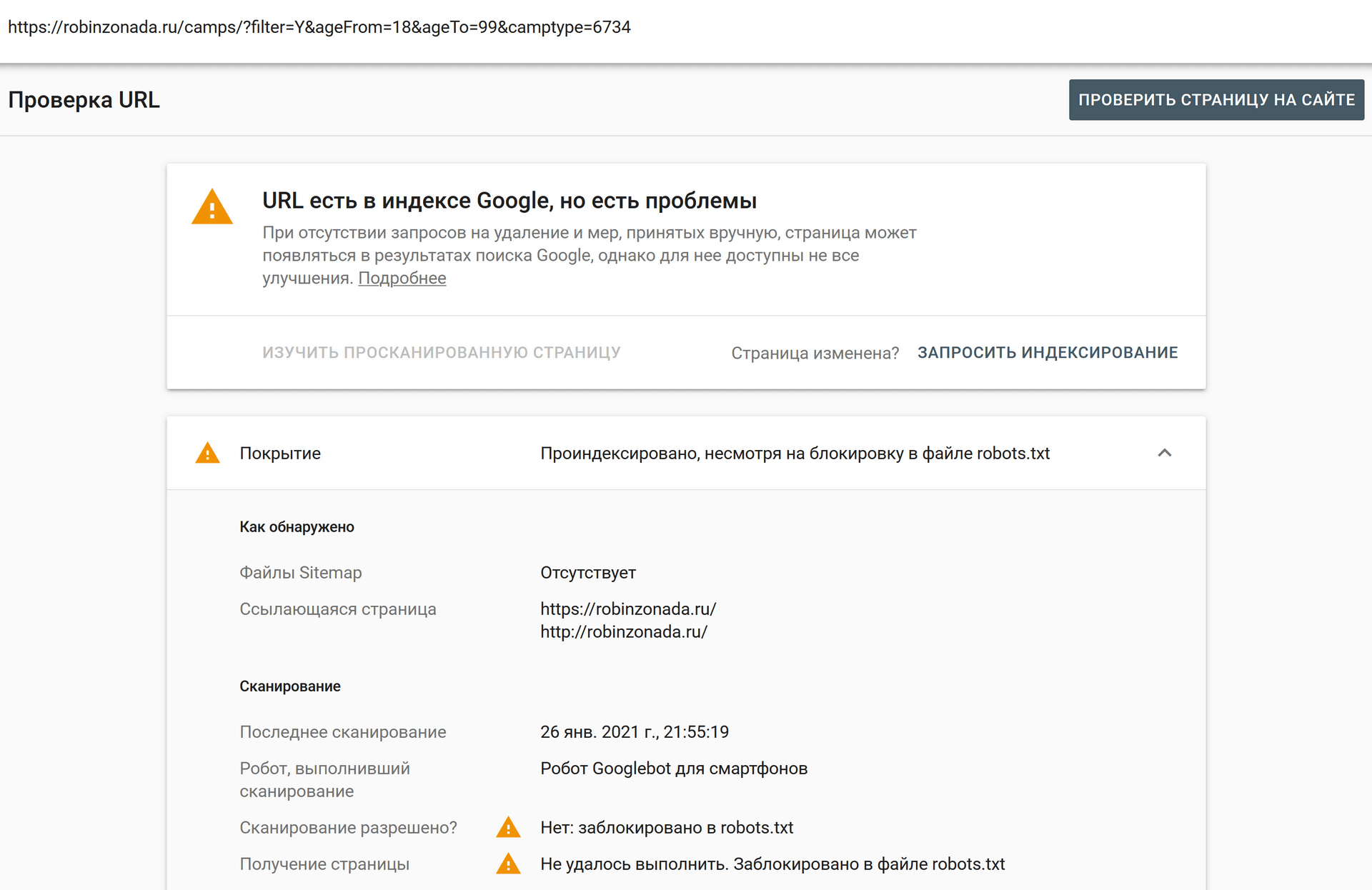
Читайте также:
Гайд по устранению проблем с индексацией сайта в Яндекс и Google: статистика, инструменты, причины и решения
#SEO продвижение #Разработка сайтов #Новичкам #Инструменты
Требования к формату
Нередко боты игнорируют рассматриваемый файл из-за ошибок, допущенных при его составлении. Во время выполнения работы нужно учитывать следующие правила и распространенные ошибки:
- размер файла определяет поисковая система: 32 Кб – Яндекс, не более 512 Кб – Google;
- наличие опечаток, ошибок в ссылках, иных проблем приводит к тому, что рекомендации остаются незамеченными или проигнорированными. Другие проблемы: во время запроса к серверу файл недоступен, формат не является текстовым, содержит запрещенные символы;
- при наполнении используется латиница. Если вы обнаружили кириллические символы, то выполните перевод, используя потенциал Punycode-конвертера.
 Если вы обнаружили кириллические символы, то выполните перевод, используя потенциал Punycode-конвертера.
Если вы обнаружили кириллические символы, то выполните перевод, используя потенциал Punycode-конвертера.Рекомендуется периодически осуществлять проверку, способ выполнения которой зависит от типа системы управления содержимым.
Синтаксис
В состав файла входят директивы, прописываемые в строгой последовательности. При работе с директивами важно не допускать ошибки, придерживаясь следующих правил:
- одна строка – одна директива;
- отсутствие пробелов, тире, лишних символов, что особенно актуально для начала строки;
- использование знака «:» после каждой директивы.
Помните о том, что для создания используются только латинские символы!
Основные директивы
- User Agent – обращение к роботам. Если используется символ «*», то страница открыта для всех ПС, Yandex – для ПС Яндекс. Для ПС для Google применяется значение Googlebot.
- Disallow – указывает на то, что поисковым роботам запрещено сканировать, папки, разделы и т. д. Если после Disallow указан знак «/», то роботам запрещено сканировать сайт, а «/page» – раздел и категории, входящие в него.
- Allow – директива, разрешающая сканирование. Если она дополнена знаком «/», то все поисковые боты смогут осуществить сканирование. Директива, лишенная описания, работает как Disallow.
- Noindex – ограничивает индексацию части контента, размещенного на странице, прописывается в коде.
- Sitemap – указывает путь к карте сайта, что обеспечивает более быстрое сканирование.
 д. Если после Disallow указан знак «/», то роботам запрещено сканировать сайт, а «/page» – раздел и категории, входящие в него.
д. Если после Disallow указан знак «/», то роботам запрещено сканировать сайт, а «/page» – раздел и категории, входящие в него.Мы описали основные директивы, но их намного больше. Например, Clean-param поддерживает только ПС Яндекс, директива указывает на динамические параметры. С помощью Host можно указать главное зеркало. Знак «#» – примечание для вебмастера, которое поисковые боты не видят.
Как выполнить проверку?
Создать robots.txt можно вручную, более простой путь – использование онлайн-инструментов, которые предупреждают человеческий фактор. Проверка результата осуществляется через панели вебмастеров в Google и Яндекс. Финишную проверку можно выполнить только после того, как robots.txt будет загружен в корневую папку вашего сайта. Если его нет, то отобразится сообщение об ошибке. Для загрузки используется FTP-клиент, после ее выполнения ожидайте результат и наблюдайте за процессом индексации. Если есть проблемы, то необходимо искать ошибку.
Проверка результата осуществляется через панели вебмастеров в Google и Яндекс. Финишную проверку можно выполнить только после того, как robots.txt будет загружен в корневую папку вашего сайта. Если его нет, то отобразится сообщение об ошибке. Для загрузки используется FTP-клиент, после ее выполнения ожидайте результат и наблюдайте за процессом индексации. Если есть проблемы, то необходимо искать ошибку.
Как выполнить проверку файла на сайте конкурентов?
Если вы хотите увидеть примеры, то сможете сделать это в несколько кликов. Используйте метод, который мы описали ранее:
- введите в поисковую строку адрес: site.ru/robots.txt, где site.ru – реальный URL-адрес ресурса, который вы хотите проверить;
- изучайте результат.
В заключение
Файл хранится в корневой папке вашего сайта. При его создании используются директивы, размещающиеся в строгой последовательности, и латинские символы. Некоторые системы управления содержимым создают robots.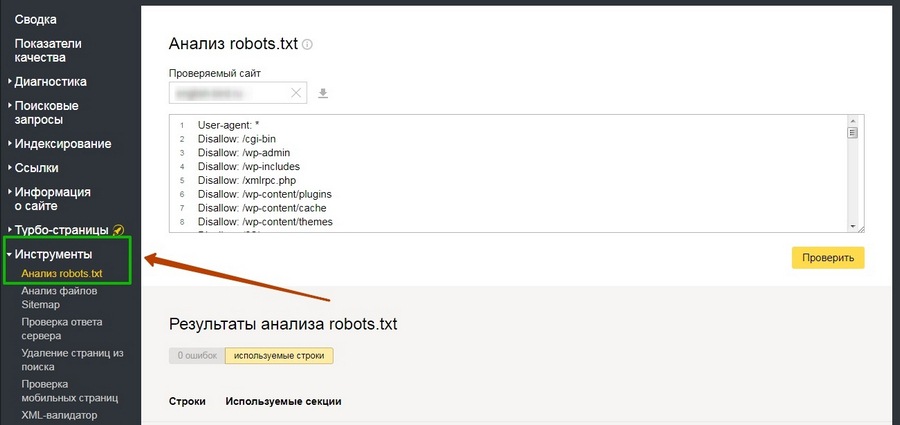 txt самостоятельно, в другом случае приходится формировать документ вручную или с помощью специального софта. В robots.txt можно добавлять рекомендации как для всех, так и для одной ПС, но это не означает, что они будут учтены. Для предупреждения попадания в индекс нежелательных страниц, вы должны внимательно проверять файл на отсутствие ошибок, а также использовать дополнительные инструменты для ограничений.
txt самостоятельно, в другом случае приходится формировать документ вручную или с помощью специального софта. В robots.txt можно добавлять рекомендации как для всех, так и для одной ПС, но это не означает, что они будут учтены. Для предупреждения попадания в индекс нежелательных страниц, вы должны внимательно проверять файл на отсутствие ошибок, а также использовать дополнительные инструменты для ограничений.
страниц запрещены в robots.txt, но проиндексированы Google. Как это возможно?
спросил
Изменено 3 года, 10 месяцев назад
Просмотрено 1к раз
Проблемы с отображением моего веб-сайта в Google Search Console. Проверьте следующее сообщение Google в GSC:
Проиндексировано, но заблокировано robots.
 txt
txt Я запрещаю страницу своей учетной записи ( https://www.joujou.com.au/account/) в robots.txt, но она индексируется Google. Можно ли проиндексировать страницу в Google, если эта страница уже запрещена в файле robots.txt?
- google-search
- robots.txt
Robots.txt просто не позволяет роботу Googlebot просматривать содержимое страницы. Однако если кто-то ссылается на вашу страницу, даже если Google не видит содержимого, Google знает, что по этому целевому URL-адресу есть веб-страница.
Если на страницу ссылается достаточное количество людей, Google может принять решение о ее добавлении и отображении в индексе. Много раз Google будет собирать контекст этой веб-страницы из контента, который ссылается на нее, и якорного текста ссылок.
Если вы действительно не хотите, чтобы URL-адрес был в индексе Google, есть 2 рекомендуемых подхода.
- Добавьте метатег robots на страницу с помощью команды NOINDEX. примечание: Вам нужно будет разрешить Google сканировать URL-адрес, чтобы он увидел команду NOINDEX. Поэтому вам придется отменить команду disallow в файле robots.txt 9.0022
- Добавить базовую HTTP-аутентификацию на страницу
 примечание: Вам нужно будет разрешить Google сканировать URL-адрес, чтобы он увидел команду NOINDEX. Поэтому вам придется отменить команду disallow в файле robots.txt 9.0022
примечание: Вам нужно будет разрешить Google сканировать URL-адрес, чтобы он увидел команду NOINDEX. Поэтому вам придется отменить команду disallow в файле robots.txt 9.0022Любой подход гарантирует, что Google не добавит URL-адрес в индекс. Однако время от времени Google по-прежнему будет сканировать URL-адрес.
Для большего контекста представитель Google Джон Мюллер недавно заявил об этом в Твиттере.
… robots.txt обязательно заблокирует сканирование контента (если запрещено), хотя это и не обязательно индексация URL-адресов. [однако] без содержание, трудно занять 9 место0005
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Обязательно, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Отключить индексацию поддоменов в robots.
 txt на виртуальных хостах — Маркетинг — Форумы SitePoint
txt на виртуальных хостах — Маркетинг — Форумы SitePointjohn_zakaria 1
я создаю субдомен для использования на моем веб-сайте, например:
example.com — test.example.com
но я использую в одном файле robots, потому что это виртуальный поддомен только
так как в моем файле robots, чтобы включить индексирование example.com, но одновременно отключить test.example.com
, потому что, когда в поиске я набираю «свяжитесь с нами», он дает результаты для example.com/contact-us и test.example.com /contact-us
я хочу отображать только результаты example.com и не индексировать test.example.com, чтобы отключить его появление в результатах поиска
поэтому я удалил ссылки в консоли поиска Google, но мне нужно отредактировать robots.txt
TechnoBear 2
Google рекомендует использовать метатеги «noindex» или каталог, защищенный паролем, чтобы страницы не сканировались.
Разработчики GoogleRobots.txt Введение и руководство | Центр поиска Google | …
Robots.txt используется для управления трафиком сканера. Изучите это вводное руководство по robots.txt, чтобы узнать, что такое файлы robots.txt и как их использовать.
джон_закария 3
это хорошее решение?
я добавил в htaccess эти строки
RewriteCond %{HTTP_HOST} test.example.com
RewriteRule /robots.txt /subdomainRobots.txt [L,NC,QSA]
и в subdomainRobots сделал запрет для всех
john_zakaria 4
и основной домен, и поддомен просматривают одни и те же файлы и один и тот же robots.txt
это только имя URL-адреса, которое использует поддомен, но веб-сайт тот же
, поэтому я не могу ставить теги, потому что он будет отражать оба ссылки на оригинал и поддомен
, не могли бы вы проверить мой другой комментарий в качестве решения? это полезно
TechnoBear 5
Если у вас есть доступ к одному и тому же контенту с двух разных URL-адресов, правильным подходом будет использование канонических URL-адресов.
Разработчики GoogleКанонизация URL и тег Canonical | Центр поиска Google…
Если на сайте есть дублированный контент, Google выбирает канонический URL. Узнайте больше о канонических URL-адресах и о том, как объединять повторяющиеся URL-адреса.