
Запрет индексации страниц/директорий через robots.txt
Все поисковые роботы при заходе на сайт в первую очередь ищут файл robots.txt. Это текстовый файл, находящийся в корневой директории сайта (там же где и главный файл index., для основного домена/сайта, это папка public_html), в нем записываются специальные инструкции для поисковых роботов.
Эти инструкции могут запрещать к индексации папки или страницы сайта, указать роботу на главное зеркало сайта, рекомендовать поисковому роботу соблюдать определенный временной интервал индексации сайта и многое другое
Если файла robotx.txt нет в каталоге вашего сайта, тогда вы можете его создать.
Чтобы запретить индексирование сайта через файл robots.txt, используются 2 директивы: User-agent и Disallow.
- User-agent: УКАЗАТЬ_ПОИСКОВОГО_БОТА
- Disallow: / # будет запрещено индексирование всего сайта
- Disallow: /page/ # будет запрещено индексирование директории /page/
Запретить индексацию вашего сайта ботом MSNbot
User-agent: MSNBot
Disallow: /
Запретить индексацию вашего сайта ботом Yahoo
User-agent: Slurp
Disallow: /
Запретить индексацию вашего сайта ботом Yandex
User-agent: Yandex
Disallow: /
Запретить индексацию вашего сайта ботом Google
User-agent: Googlebot
Disallow: /
Запретить индексацию вашего сайта для всех поисковиков
User-agent: *
Disallow: /
Запрет индексации папок cgi-bin и images для всех поисковиков
User-agent: *
Disallow: /cgi-bin/
Disallow: /images/
Теперь как разрешить индексировать все страницы сайта всем поисковикам (примечание: эквивалентом данной инструкции будет пустой файл robots.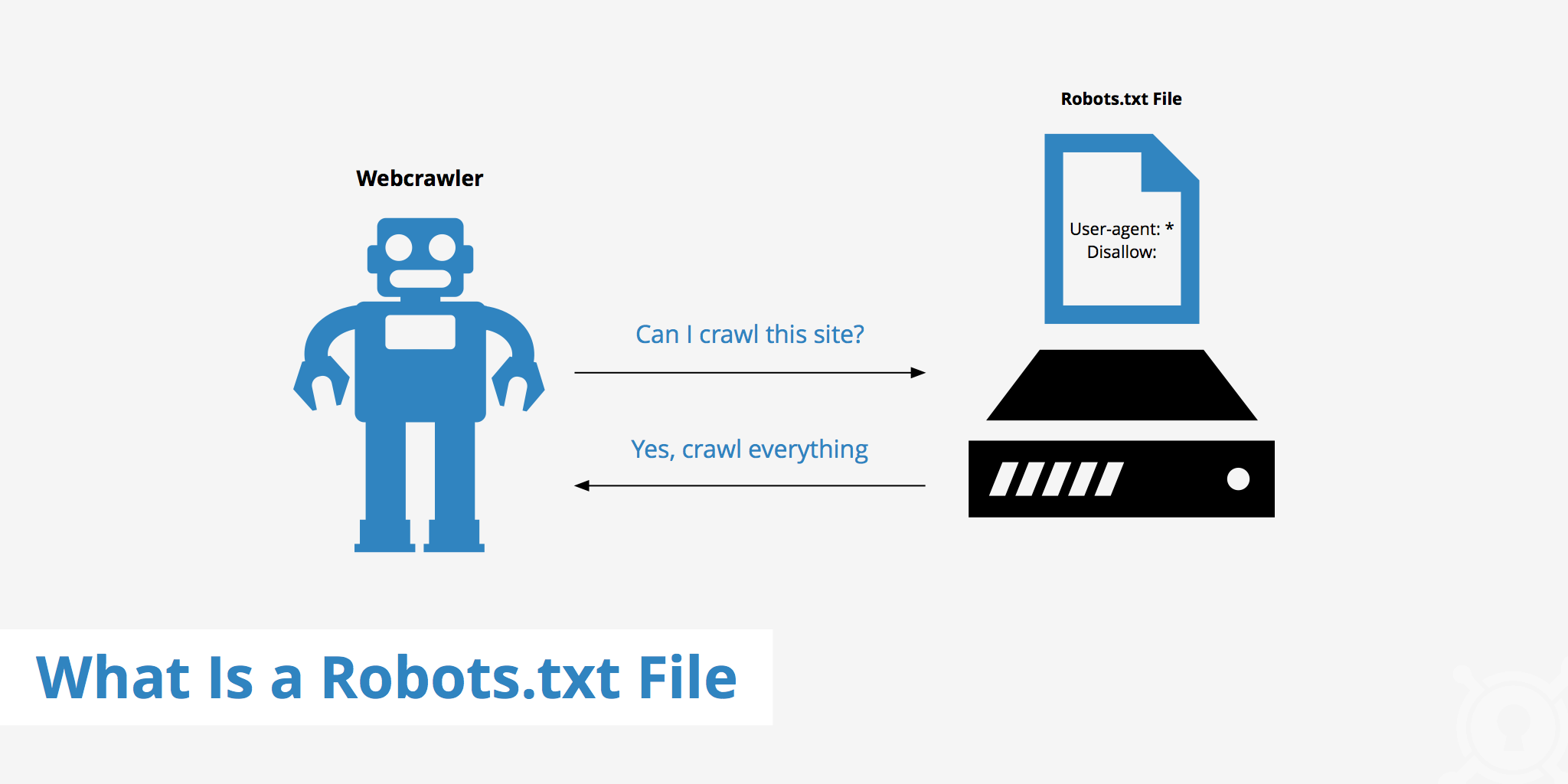
User-agent: *
Disallow:
Пример:
Разрешить индексировать сайт только ботам Yandex, Google, Rambler с задержкой 4сек между опросами страниц.
User-agent: *
Disallow: /
User-agent: Yandex
Crawl-delay: 4
Disallow:
User-agent: Googlebot
Crawl-delay: 4
Disallow:
User-agent: StackRambler
Crawl-delay: 4
Disallow:
Запретить индексацию страниц/директорий (robots.txt) — База знаний
Все поисковые роботы при заходе на сайт в первую очередь ищут файл robots.txt. Это текстовый файл, находящийся в корневой директории сайта (там же где и главный файл index., для основного домена/сайта, это папка public_html), в нем записываются специальные инструкции для поисковых роботов. Эти инструкции могут запрещать к индексации папки или страницы сайта, указать роботу на главное зеркало сайта, рекомендовать поисковому роботу соблюдать определенный временной интервал индексации сайта и многое другое
Если файла robotx.txt нет в каталоге вашего сайта, тогда вы можете его создать.
Чтобы запретить индексирование сайта через файл robots.txt, используются 2 директивы: User-agent и Disallow.
User-agent: УКАЗАТЬ_ПОИСКОВОГО_БОТА
Disallow: / # будет запрещено индексирование всего сайта
Disallow: /page/ # будет запрещено индексирование директории /page/
Примеры:
1. Запретить индексацию вашего сайта ботом MSNbot
User-agent: MSNBot
Disallow: /
2. Запретить индексацию вашего сайта ботом Yahoo
User-agent: Slurp
Disallow: /
3. Запретить индексацию вашего сайта ботом Yandex
User-agent: Yandex
Disallow: /
4. Запретить индексацию вашего сайта ботом Google
User-agent: Googlebot
Disallow: /
5. Запретить индексацию вашего сайта для всех поисковиков
User-agent: *
Disallow: /
6. Усложняем задачу и например Яндексу запрещаем индексировать папки cgi-bin и images, а Апорту файлы myfile1.htm и myfile2.htm в директории subdir (название папки где расположены файлы myfile1.htm и myfile2.htm)
User-agent: Yandex
Disallow: /cgi-bin/
Disallow: /images/
User-agent: Aport
Disallow: /subdir/myfile1.htm
Disallow: /subdir/myfile2.htm
7. Запрет индексации папок cgi-bin и images для всех поисковиков
User-agent: *
Disallow: /cgi-bin/
Disallow: /images/
Теперь как разрешить индексировать все страницы сайта всем поисковикам (примечание: эквивалентом данной инструкции будет пустой файл robots.txt):
User-agent: *
Disallow:
P.S. Для различных CMS, в интернете можно найти рекомендации, какие директории лучше закрыть от индексации поисковиками., в большей степени это нужно ради безопасности и уменьшения нагрузки на сервер.
Как закрыть сайт от индексации в robots.txt
Автор wbooster На чтение 3 мин Просмотров 1693 Опубликовано
В процессе проведения редизайна или же разработки ресурса нередко бывают ситуации, когда требуется предотвратить посещение поисковых роботов и по сути, закрыть ресурс от индексации. Сделать это можно посредством закрытия сайта в коне сайта. в данном случае используется текстовый файл robots.txt.
Файл находится на файловом хранилище Вашего сайта, найти его можно с помощью файловых менеджеров, через хостинг (файловый менеджер на хостинге) или через админку сайта (доступно не во всех CMS).
kak-zakryt-sajt-v-robots-txt.img
Данные строки закроют сайт от индексации поисковым роботом Google:
User-agent: Google
Disallow: /
А с помощью данных строк, мы закроем сайт для всех поисковых систем.
User-agent: *
Disallow: /
Закрытие отдельной папки
Также существует возможность в указанном файле осуществить процесс закрытия конкретной папки. Посредством таких действий осуществляется закрытие всех файлов, которые присутствуют в указанной папке. Прописывается следующее:User-agent: *
Disallow: /papka/
Можно будет в такой ситуации отдельно указать на те файлы в папке, которые могут быть открыты для дальнейшей индексации.
Если же вы хотите закрыть не только конкретную папку, а также все вложенные внутри папки, то используйте звездочку на конце папке:
User-agent: *
Disallow: /papka/*
Если же у вас 2 правила, которые могут конфликтовать между собой, то в данном случае поисковые роботы выставят приоритет по наиболее длинной строчке. То есть, для роботов, нет последовательности строчек.
Цифрами мы обозначили, по какому приоритету будет идти строчки:
То есть, в данном случае папка /papka/kartinki/logotip/ будет закрыта, однако остальные файлы и папки в /papka/kartinki/ будут открыты.
Закрытие отдельного файла
Тут все производится в том же формате, как и при закрытии папки, но в процессе указания конкретных данных, нужно четко определить файл, который вы хотели бы скрыть от поисковой системы.
User-agent: *
Disallow: /papka/kartinka.jpg
Если же вы хотите закрыть папку, однако открыть доступ к файлу, то используйте директиву Allow:
User-agent: *
Allow: /papka/kartinka.jpg
Disallow: /papka/
Проверка индекса документа
Чтобы осуществить проверку нужно воспользоваться специализированным сервисом Яндекс.Вебмастер.
Скрытие картинок
Чтобы картинки, расположенные на страницах вашего интернет ресурса, не попали в индекс, рекомендуется в robots.txt, ввести команду – Disallow, а также указать четкий формат картинок, которые не должны посещаться поисковым роботом.
User-Agent: *
Disallow: *.jpg
Disallow: *.png
Disallow: *.gif
Можно ли закрыть поддомен?
Опять же используется директория Disallow, при этом указания на закрытие должно осуществляться исключительно в файле robots.txt конкретного поддомена. Дубли на поддоменне при использовании CDN могут стать определенной проблемой. В данном случае обязательно нужно использовать запрещающий файл с указанием четко определенных дублей, чтобы они не появлялись в индексе и не влияли на продвижение интернет ресурса.
Чтобы осуществить блокировку других поисковых систем вместо Yandex, нужно будет указать данные поискового робота. Для этого можно воспользоваться специализированными программами, чтобы иметь четкие назначения роботов той или же иной системы.
Закрытие сайта или же страницы при помощи мета-тега
Можно процесс закрытия осуществить посредством применения мета-тега robots. В определенных ситуациях данный вариант закрытия считается более предпочтительным, так как он влияет на различные поисковые системы и требует введение определенного кода (в коде обязательно прописываются данные конкретного поискового робота).
Как правило, данную строку пишут в теге <head> или </footer>:
<meta name=”robots” content=”noindex, nofollow”/>
Или
<meta name=”robots” content=”none”/>
Также, мы можем написать отдельное правило для каждого поискового паука:
Google:
<meta name=”googlebot” content=”noindex, nofollow”/>
Яндекс:
<meta name=”yandex” content=”none”/>
Работа с файлом robots.txt
Когда происходит создание сайта, то оптимизация его содержания происходит в двух направлениях :
- Оптимизируют дизайн и тексты для посетителей веб-ресурса
- Оптимизации подвергается программная часть сайта, которая важна для поисковых систем
Файл robots.txt имеет неоднозначную оценку в среде веб-программистов и специалистов по продвижению веб-сайтов. Этот файл существует во всех сайтах, его готовят специалисты для поисковых систем в ходе оптимизации веб-ресурса для раскрутки. Но все же не до конца понятно то, важен ли в наше время этот файл. Нужно заметить, что файл robots.txt представляет собой неисполняемый файл, который имеет содержание сугубо для поисковых систем. Причем те инструкции, которые указываются в файле robots.txt могут быть применены и без него, если установить в CMS сайта нужные функциональные плагины.
Например, через файл robots.txt имеется возможность запретить индексирование сайта, однако та же функция имеется и в специальных плагинов для seo, которые можно установить бесплатно через магазин плагинов для любой CMS, а также запретить индексировать сайт или отдельные страницы сайта можно и через панель управления служб Яндекс Вебмастер и Google Вебмастер. Также через эти службы, как и через файл robots.txt, можно запретить индексирование, например, версий страниц сайта для печати.
Когда начинается процесс индексирования контента сайта поисковыми системами, те в первую очередь ищут в корневом каталоге файл robots.txt, который должен с самого начала указать поисковым ботом то, какие страницы разрешено индексировать, а какие все же нет. Но, как указывают специалисты, поисковые боты индексируют все страницы сайтов, даже если их запрещает владелец сайта через файл robots.txt, только запрещенные к индексации страницы не попадут в поисковую выдачу. И вот опять можно задать вопрос- зачем тогда нужен файл robots.txt? Его функции заменяют панель управления сайтами через службы вебмастера от крупнейших поисковиков, и даже при запрещении индексирования некоторого контента через этот файл, все равно поисковики индексируют весь контент сайта.
Не стоит забывать, что файл robots.txt не исполняемый, то есть его можно только читать. Править этот файл можно разными способами. И через обычный бесплатный редактор Notepad, установленный на компьютер, либо через панель управления контентом CMS, где также есть возможность управлять записями этого файла. Конечно, не стоит забывать, что хоть файл robots.txt это всего лишь читаемый файл, содержание его обращено к поисковым ботам, а значит информация в этом файле должна быть написана на понятном языке для всех поисковых ботов в мире, и иметь ясную и четкую структуру.
Структура файла robots.txt
Начинается записать в файле robots.txt всегда с упоминания того поискового бота, к которому будет обращены команды. Обращаться к поисковому боту можно с помощью директивы User-agent. Стоит отметить и то, что если после директивы User-agent стоит звездочка *, то значит команда директивы обращена ко всем поисковым ботам. Также не стоит забывать и о том, что текст в файле robots.txt не чувствителен к регистру, то есть можно писать как с большой буквы. Так и большими буквами. Но лучше всего, раз уж этот традиционный файл используется на сайте, лучше соблюдать все традиции. После директивы user-agent используется название поискового бота, к которому и обращено послание. Если к поисковому боту от Google, то после директивы первой стоит добавить googlebot, если к поисковой системе Яндекс, то Yandex. Таким образом, первая запись всегда в файле robots.txt имеет первую строку :
User-agent: googlebot
После обращению к поисковому боту стоит указать те папки или файлы, которые запрещено индексировать. Используется для этого простая директива Disallow. После ее объявления, нужно указать запрещенные к индексированию папки или файлы, как указано в примере ниже:
Disallow: /feedback.php Disallow: /cgi-bin/
В данном примере показано, что в файле robots.txt были запрещены к индексированию файл feedback.php и папка cgi-bin/ , которые находятся в корневом каталоге сайта. Для особо ленивых предусмотрена возможность блокировки по начальным символам, поэтому стоит всегда быть аккуратней с директивой
Disallow : prices
То поисковой бот не будет индексировать и имеющиеся файлы http://site.ru/prices.php и даже папку http://site.ru/prices/
Также не стоит забывать, что после директивы Disallow ничего не находится, то полностью все содержание сайта будет проиндексировано. Если же после директивы Disallow стоит символ /, то абсолютно полностью все содержимое сайта запрещено индексировать.
Если вдруг возникла свободная минутка и есть желание пообщаться с поисковыми ботами, но нет желание ничего запрещать для индексирования, то можно создать файл robots.txt с командой :
User-agent: * Disallow:
Поисковой бот любой поймет, что владелец сайта имеет много свободного времени, раз тратить свое время на создание файла robots.txt, в котором разрешает всем ботам индексировать все содержание сайта. Если не будет такой записи или даже вообще будет отсутствовать файл robots.txt, то любой поисковик так и сделает.
Директива Allow и ее магические свойства
Не все волшебство файла robots.txt заключено в запрете индексирования файлов сайта, также можно разрешать индексировать. Все точно также, как и с директивой Disallow, только используется директива Allow, которая разрешает индексацию всего, что указано. Вот пример :
User-agent: Yandex Allow: /prices Disallow: /
Все ясно и понятно – Поисковому боту от Яндекса запрещается индексировать на сайте все, кроме папки prices. Стоит отметить, что директиву Allow используют всегда перед директивой Disallow. Если после Allow в файле robots.txt будет пусто , то это означает, что поисковому боту Яндекса запрещена индексация всех файлов :
User-agent: Yandex Allow:
Иными словами, в файле robots.txt директивы Disallow / и Allow равнозначны, запрещающие индексацию.
Все поисковые системы, по крайней мере речь если идет о крупнейших, понимают содержание записей файла robots.txt одинаково. Если есть опасения запутаться в директивах данного файла, то лучше всего использовать службы Яндекс Вебмастер и Google Вебмастер, через которые можно начать индексацию страниц сайта, а также без труда управлять индексацией страниц, разрешая или запрещая те или иные страницы для поисковых ботов. Эти службы помогают также загрузить карту сайта.
Специальные регулярные выражения для robots.txt
С помощью всемогущего файла robots.txt можно запретить индексировать не только отдельные страницы сайта или какие-то папки с файлами, но и отдельно файлы. Это очень удобно бывает в том случае, если сайт достаточно крупный, и в нем находится большое количество файлов различного содержания. Тут нужно отдельно указать, что регулярные выражение $ означает окончание ссылки, указанной в файле, а звездочка * на любой адрес ссылки или название файла в указанном формате. Вот пример :
User-agent: Yandex Allow: /prices/*.html$ Disallow: /
Ценителям магии файла robots.txt все понятно с этой записью, точно также, как и поисковому боту от Яндекса. Поисковик должен индексировать все файлы в папке prices в html формате, но запрещена индексация любых других файлов на сайте. Или еще один пример с регулярными выражениями для robots.txt :
User-agent: Yandex Disallow: *.pdf$
Запись говорит, что Яндекс-боту запрещена индексация всех файлов в формате pdf.
Путь к карте сайта
Файл robots.txt многофункциональный читаемый файл, которые также указывает и направление поисков поисковыми ботами карты сайта. Стоит отметить, что карта сайта, если веб-ресурс действительно обширен, очень важна для того, чтобы поисковые системы могли проиндексировать все нужные страницы и файлы сайта. Послать поисковой бот можно с помощью директивы Sitemap :
User-agent: googlebot Disallow: Sitemap: http://site.ru/sitemap.xml
Загрузить карту сайта можно и с помощью служб Яндекс Вебмастер и Google Вебмастер, не работая с директивами robots.txt.
Работа с зеркалами сайта в файле robots.txt
Не так давно поисковой гигант Google решил начать борьбу за повышенную защищенность посетителей сайтов в интернете, и решил оценивать сайты с шифрованном трафиком с https протоколом выше сайтов, которые были всегда с стандартным http протоколом. И многие владельцы сайтов, даже если они не работали с платежными системами, должны были перейти на https протокол для того, чтобы поднять свой рейтинг в поисковой выдачи. Но как это сделать?
Начать нужно с того, что для поисковых систем сайты http://site.ru/ и https://site.ru/ являются различными, хотя имеют одинаковое название, и являются по сути зеркалами друг друга, но поисковые системы будут их по-разному индексировать и оценивать. Чтобы указать поисковым ботам, что нужно индексировать только одно главное зеркало сайта, требуется использовать директиву Hosts в файле robots.txt. Выглядеть это будет так :
User-agent: googlebot Disallow: /prices.php Host: https://site.(.*)$ http://www.site.ru/$1 [R=301,L]
Использование комментариев в robots.txt
Зачем комментировать что-то для поисковых ботов в файле robots.txt? Сложно сказать, но если кому-то захочется это делать, стоит использовать символ #. Вот пример :
User-agent: googlebot Disallow: /prices/ # тут нет ничего интересного
Краткое описание работы с файлом robots.txt
1.Как разрешить всем поисковым ботам индексацию всех файлов на сайте?
User-agent: * Disallow:
2.Как запретить всем поисковым ботам индексацию всех файлов на сайте?
User-agent: * Disallow: /
3.Как запретить поисковому боту от Google индексировать файл prices.html?
User-agent: googlebot Disallow: prices.html
4.Как разрешить всем поисковым ботам индексировать весь сайта, а боту от Google запрещаем индексацию папки prices?
User-agent: googlebot Disallow: /prices/ User-agent: * Disallow:
Какие ошибки могут возникнуть при работе с файлом robots.txt?
Нужно сказать, что поисковые боты не чувствительны к регистру букв при написании директив, но с названием файлов и папок нужно быть осторожнее. Также проблем между директивами не стоит делать просто так для красоты, ведь для файла robots.txt проблем означает разделение команд для разных поисковых ботов.
Для каждого поискового бота нужно создавать свою директиву user-agent, а не пытаться в одну вписать несколько ботов. Очень часто забывают использовать символ / перед названием папок, что приведет к недопониманию поисковым ботом директивы. Также админка сайта исключается всегда поисковыми ботами из индексации и ее не следует указывать в файле. Есть мнение специалистов, что большой размер файла robots.txt с огромным списком страниц сайта и файлов, исключаемых из индексации, просто игнорируются поисковыми системами.
Поэтому надежней всего удалять ненужные файлы, а не указывать запрет на их индексацию.
Как проверить файл robots.txt на фатальные ошибки?
Если файл robots.txt отличается многословием, то есть в нем указаны команды для поисковых ботов для множества файлов и страниц сайта, то лучше провести проверку качества файла robots.txt с помощью ресурсов Яндекс Вебмастер и Google Вебмастер.
Закрыть сайт от индексации ᐈ Способы запретить индексацию
Содержание:
Индексация и способы закрыть информацию сайта
Индексация. Закрыть домен (или поддомен)
Индексация. Закрыть информацию по частям
Индексация. Закрыть отдельные страницы ресурса
Индексация и использование URL
Индексация и сомнительные способы закрытия контента
Индексация. Итоги
Индексация очень полезная вещь, однако бывают случаи, когда владельцам сайтов или вебмастерам нужно закрыть часть информации от индексации поисковых систем. Или же запретить обращение к ней. Часть из таких ситуаций можно перечислить:
- Необходимость закрыть техническую информацию.
- Запрещение индексации неуникальной информации.
- Закрыть страницы, которые для поискового робота выглядят как дубль другой страницы. При этом такие адреса могут быть полезны рядовому пользователю.
- Часто сайт может использовать на разных страницах повторяющуюся информацию. Для лучшей оптимизации сайта ее нужно закрыть от постороннего взгляда.
Есть несколько способов закрыть сайт от взгляда поисковика.
Используем robots.txt
В этом файле нужно прописать такие ряды:
User-agent: *
Disallow: /
От этого закрывается отображение домена для абсолютно всех поисковиков. Но если есть желание исключить лишь одну систему, следует указать ее название. Пример:
User-agent: Yahoo
Disallow: /
Также существует возможность запретить доступ всем поисковикам, кроме одного. Тогда оставляем строки без изменений, как в первом примере и ниже добавляем еще два ряда:
User-agent: Yahoo
Allow: /
Минусом такого способа является не стопроцентная гарантия отсутствия индексации. Это маловероятно, но все же возможно. Для правильной корректировки роботс.txt используем онлайн-инструмент от Yandex. Держите ссылку http://webmaster.yandex.ru/robots.xml. Загружаем свой файл и сканируем его.
Использование мета-тега
Это очень легкий, но довольно затратный по времени метод. Особенно, если на вашем сайте существует большое количество страниц. Для его реализации необходимо в head нужных адресов указать ряды:
META NAME=»ROBOTS» CONTENT=»NOINDEX, NOFOLLOW»
Такой способ абсолютно защищает ваш сайт от взгляда поисковиков. Его плюсом является отсутствия необходимости лезть роботс.
Индексация. Изменение атрибутов файла .htaccess
Этот способ позволяет закрыть доступ к ресурсу за паролем. В htaccess указываем ряды:
Такой способ также полностью закрывает доступ поисковикам к контенту сайта. Однако из-за наличия пароля сайт становится очень тяжело просканировать на наличие ошибок. Поскольку не все сервисы имеют возможность вводить пароль.
Есть множество вещей, доступ к которым следует закрыть (код, отдельный текст, ссылку на другие сайты, элементы меню), не закрывая при этом сам адрес. Сейчас очень популярный ранее метод с помощью noindex уже не используется. Его суть состояла в том, что в отдельный тег существовала возможность скопировать всю информацию, которую нужно было закрыть. Теперь мегапопулярным стал другой способ.
Использование JavaScript
В этом способе снова нужно использовать файл роботс. Его суть предполагает, что вся нужная информация кодируется с помощью яваскрипт, а после копируется в роботс и скрывается от индексации с помощью нужных тегов. Этот метод уменьшает «вес» ресурса, при его использовании быстродействие сайта увеличивается. Поэтому возможно улучшение ранжирования. Но есть один существенный минус. Google не одобряет данный способ и регулярно отсылает владельцам сайтов письма с просьбой открыть для индексации сокрытую информацию. По его заверениям информация должна быть идентичной и для пользователя, и для поискового робота.
Но несмотря на все усилия корпорации, этот способ остается достаточно популярным из-за эффективности.
Есть два способа, которые используются, чтобы закрыть ссылку на страницу от индексации.
Robots.txt
Для реализации первого способа добавляем в файл robots.txt такие строки:
User-agent: ag
Disallow: http://example.com/main
Это простой способ, но он не отличается надежностью. Страницы могут продолжать индексироваться. Но чтобы запретить их отображение, можно использовать еще один способ:
Мета-тег noindex
Второй способ является лучшим вариантом, поскольку в нем исключается воздействие роботс. Для его реализации в head всеx адресов, которые нужно закрыть от взгляда поисковых систем, вставляем тег:
META NAME=»ROBOTS» CONTENT=»NOINDEX, NOFOLLOW»
Такой способ намного эффективнее использовать большим ресурсам, которым нужно закрывать больше сотни страниц. Однако, тогда у них отсутствует общий параметр.
Robots.txt
И снова вмешательство в этот файл поможет нам избежать индексации страниц. Добавляя в тег Disallow названия разделов и папок, мы можем исключать их из индексации. Примеры:
Disallow: /название папки/
Disallow: /название раздела/
Такой способ удобный, быстрый и простой в применении. Но он также полностью не гарантирует отсутствие индексирования нужных страниц. Поэтому мы рекомендуем использование мета-тега noidex в способе, описанном выше.
Редактирование файла robots.txt однозначно остается самым легким способом закрытия контента от индексации. Но в любом случае он больше нагружает файл, что скажется на быстродействии ресурса и его ранжировании. Тем более, чаще всего эти способы не гарантируют стопроцентную эффективность.
Есть возможность закрыть доступ для поисковых систем на уровне сервера.
Добавляем в бан отдельных User Agents
Такой способ позволяет заблокировать пользователя или робота, указав его нежелательным или опасным. Это позволяет запретить доступ к контенту своим конкурентам.
Способ используется для того, чтобы закрыть информацию от роботов онлайн-сервисов, которые анализируют источники трафика сайта, а также сео-оптимизации.
Это очень опасный метод, который часто приводит к нежелательным последствиям. Поэтому если вы не уверены в своих силах, следует обратиться к профессионалу.
Изменение HTTP-заголовка
Существует возможность прописать тег X-Robots как заголовок отдельной страницы. Такие методы идентичны тем, которые мы использовали при редактировании файла robots.txt. Нужно только указать имя пользователя (название поисковой системы).
Конкуренция в интернете с каждым днем вырастает все выше и напоминает промышленное шпионство больших корпораций. Поэтому владельцы сайтов и вебмастера вынуждены использовать любые способы, чтобы закрыть от посторонних глаз свою стратегию продвижения и способы сео-оптимизации.
Однако подобные методы используются и в банальных целях. Например, чтобы закрыть от индексации «мусор» на страницах ресурса. Как видим, индексация имеет две стороны.
Перечисленные выше методы не панацея, поэтому при недостаточных знаниях лучше обращаться к профессионалу.
robots txt: что это такое за файл и как использовать его
1. Введение
Технические аспекты созданного сайта играют не менее важную роль для продвижения сайта в поисковых системах, чем его наполнение. Одним из наиболее важных технических аспектов является индексирование сайта, т. е. определение областей сайта (файлов и директорий), которые могут или не могут быть проиндексированы роботами поисковых систем. Для этих целей используется robots.txt – это специальный файл, который содержит команды для роботов поисковиков. Правильный файл robots.txt для Яндекса и Google поможет избежать многих неприятных последствий, связанных с индексацией сайта.
2. Понятие файла robots.txt и требования, предъявляемые к нему
Файл /robots.txt предназначен для указания всем поисковым роботам (spiders) индексировать информационные сервера так, как определено в этом файле, т.е. только те директории и файлы сервера, которые не описаны в /robots.txt. Этот файл должен содержать 0 или более записей, которые связаны с тем или иным роботом (что определяется значением поля agent_id) и указывают для каждого робота или для всех сразу, что именно им не надо индексировать.
Синтаксис файла позволяет задавать запретные области индексирования, как для всех, так и для определенных, роботов.
К файлу robots.txt предъявляются специальные требования, не выполнение которых может привести к неправильному считыванию роботом поисковой системы или вообще к недееспособности данного файла.
Основные требования:
- все буквы в названии файла должны быть прописными, т. е. должны иметь нижний регистр:
- robots.txt – правильно,
- Robots.txt или ROBOTS.TXT – неправильно;
- файл robots.txt должен создаваться в текстовом формате Unix. При копировании данного файла на сайт ftp-клиент должен быть настроен на текстовый режим обмена файлами;
- файл robots.txt должен быть размещен в корневом каталоге сайта.
3. Содержимое файла robots.txt
Файл robots.txt включает в себя две записи: «User-agent» и «Disallow». Названия данных записей не чувствительны к регистру букв.
Некоторые поисковые системы поддерживают еще и дополнительные записи. Так, например, поисковая система «Yandex» использует запись «Host» для определения основного зеркала сайта (основное зеркало сайта – это сайт, находящийся в индексе поисковых систем).
Каждая запись имеет свое предназначение и может встречаться несколько раз, в зависимости от количества закрываемых от индексации страниц или (и) директорий и количества роботов, к которым Вы обращаетесь.
Предполагается следующий формат строк файла robots.txt:
имя_записи[необязательные
пробелы]:[необязательные
пробелы]значение[необязательные пробелы]
Чтобы файл robots.txt считался верным, необходимо, чтобы, как минимум, одна директива «Disallow» присутствовала после каждой записи «User-agent».
Полностью пустой файл robots.txt эквивалентен его отсутствию, что предполагает разрешение на индексирование всего сайта.
Запись «User-agent»
Запись «User-agent» должна содержать название поискового робота. В данной записи можно указать каждому конкретному роботу, какие страницы сайта индексировать, а какие нет.
Пример записи «User-agent», где обращение происходит ко всем поисковым системам без исключений и используется символ «*»:
User-agent: *
Пример записи «User-agent», где обращение происходит только к роботу поисковой системы Rambler:
User-agent: StackRambler
Робот каждой поисковой системы имеет свое название. Существует два основных способа узнать его (название):
на сайтах многих поисковых систем присутствует специализированный§ раздел «помощь веб-мастеру», в котором часто указывается название поискового робота;
при просмотре логов веб-сервера, а именно при просмотре обращений к§ файлу robots.txt, можно увидеть множество имен, в которых присутствуют названия поисковых систем или их часть. Поэтому Вам остается лишь выбрать нужное имя и вписать его в файл robots.txt.
Запись «Disallow»
Запись «Disallow» должна содержать предписания, которые указывают поисковому роботу из записи «User-agent», какие файлы или (и) каталоги индексировать запрещено.
Рассмотрим различные примеры записи «Disallow».
Пример записи в robots.txt (разрешить все для индексации):
Disallow:
Пример (сайт полностью запрещен к индексации. Для этого используется символ «/»):Disallow: /
Пример (для индексирования запрещен файл «page.htm», находящийся в корневом каталоге и файл «page2.htm», располагающийся в директории «dir»):
Disallow: /page.htm
Disallow: /dir/page2.htm
Пример (для индексирования запрещены директории «cgi-bin» и «forum» и, следовательно, все содержимое данной директории):
Disallow: /cgi-bin/
Disallow: /forum/
Возможно закрытие от индексирования ряда документов и (или) директорий, начинающихся с одних и тех же символов, используя только одну запись «Disallow». Для этого необходимо прописать начальные одинаковые символы без закрывающей наклонной черты.
Пример (для индексирования запрещены директория «dir», а так же все файлы и директории, начинающиеся буквами «dir», т. е. файлы: «dir.htm», «direct.htm», директории: «dir», «directory1», «directory2» и т. д.):
Запись «Allow»
Опция «Allow» используется для обозначения исключений из неиндексируемых директорий и страниц, которые заданы записью «Disallow».
Например, есть запись следующего вида:
Disallow: /forum/
Но при этом нужно, чтобы в директории /forum/ индексировалась страница page1. Тогда в файле robots.txt потребуются следующие строки:
Disallow: /forum/
Allow: /forum/page1
Запись «Sitemap»
Эта запись указывает на расположение карты сайта в формате xml, которая используется поисковыми роботами. Эта запись указывает путь к данному файлу.
Пример:
Sitemap: http://site.ru/sitemap.xml
Запись «Host»
Запись «host» используется поисковой системой «Yandex». Она необходима для определения основного зеркала сайта, т. е. если сайт имеет зеркала (зеркало – это частичная или полная копия сайта. Наличие дубликатов ресурса бывает необходимо владельцам высокопосещаемых сайтов для повышения надежности и доступности их сервиса), то с помощью директивы «Host» можно выбрать то имя, под которым Вы хотите быть проиндексированы. В противном случае «Yandex» выберет главное зеркало самостоятельно, а остальные имена будут запрещены к индексации.
В целях совместимости с поисковыми роботами, которые при обработке файла robots.txt не воспринимают директиву Host, необходимо добавлять запись «Host» непосредственно после записей Disallow.
Пример: www.site.ru – основное зеркало:
Host: www.site.ru
Запись «Crawl-delay»
Эту запись воспринимает Яндекс. Она является командой для робота делать промежутки заданного времени (в секундах) между индексацией страниц. Иногда это бывает нужно для защиты сайта от перегрузок.
Так, запись следующего вида обозначает, что роботу Яндекса нужно переходить с одной страницы на другую не раньше чем через 3 секунды:
Crawl-delay: 3
Комментарии
Любая строка в robots.txt, начинающаяся с символа «#», считается комментарием. Разрешено использовать комментарии в конце строк с директивами, но некоторые роботы могут неправильно распознать данную строку.
Пример (комментарий находится на одной строке вместе с директивой):
Disallow: /cgi-bin/ #комментарий
Желательно размещать комментарий на отдельной строке. Пробел в начале строки разрешается, но не рекомендуется.
4. Примеры файлов robots.txt
Пример (комментарий находится на отдельной строке):
Disallow: /cgi-bin/#комментарий
Пример файла robots.txt, разрешающего всем роботам индексирование всего сайта:
User-agent: *
Disallow:
Host: www.site.ru
Пример файла robots.txt, запрещающего всем роботам индексирование сайта:
User-agent: *
Disallow: /
Host: www.site.ru
Пример файла robots.txt, запрещающего всем роботам индексирование директории «abc», а так же всех директорий и файлов, начинающихся с символов «abc».
User-agent: *
Disallow: /abc
Host: www.site.ru
Пример файла robots.txt, запрещающего индексирование страницы «page.htm», находящейся в корневом каталоге сайта, поисковым роботом «googlebot»:
User-agent: googlebot
Disallow: /page.htm
Host: www.site.ru
Пример файла robots.txt, запрещающего индексирование:
– роботу «googlebot» – страницы «page1.htm», находящейся в директории «directory»;
– роботу «Yandex» – все директории и страницы, начинающиеся символами «dir» (/dir/, /direct/, dir.htm, direction.htm, и т. д.) и находящиеся в корневом каталоге сайта.
User-agent: googlebot
Disallow: /directory/page1.htm
User-agent: Yandex
Disallow: /dir
Host: www.site.ru
5. Ошибки, связанные с файлом robots.txt
Одна из самых распространенных ошибок – перевернутый синтаксис.
Неправильно:
User-agent: /
Disallow: Yandex
Правильно:
User-agent: Yandex
Disallow: /
Неправильно:
User-agent: *
Disallow: /dir/ /cgi-bin/ /forum/
Правильно:
User-agent: *
Disallow: /dir/
Disallow: /cgi-bin/
Disallow: /forum/
Если при обработке ошибки 404 (документ не найден), веб-сервер выдает специальную страницу, и при этом файл robots.txt отсутствует, то возможна ситуация, когда поисковому роботу при запросе файла robots.txt выдается та самая специальная страница, никак не являющаяся файлом управления индексирования.
Ошибка, связанная с неправильным использованием регистра в файле robots.txt. Например, если необходимо закрыть директорию «cgi-bin», то в записе «Disallow» нельзя писать название директории в верхнем регистре «cgi-bin».
Неправильно:
User-agent: *
Disallow: /CGI-BIN/
Правильно:
User-agent: *
Disallow: /cgi-bin/
Ошибка, связанная с отсутствием открывающей наклонной черты при закрытии директории от индексирования.
Неправильно:
User-agent: *
Disallow: dir
User-agent: *
Disallow: page.HTML
Правильно:
User-agent: *
Disallow: /dir
User-agent: *
Disallow: /page.HTML
Чтобы избежать наиболее распространенных ошибок, файл robots.txt можно проверить средствами Яндекс.Вебмастера или Инструментами для вебмастеров Google. Проверка осуществляется после загрузки файла.
6. Заключение
Таким образом, наличие файла robots.txt, а так же его составление, может повлиять на продвижение сайта в поисковых системах. Не зная синтаксиса файла robots.txt, можно запретить к индексированию возможные продвигаемые страницы, а так же весь сайт. И, наоборот, грамотное составление данного файла может очень помочь в продвижении ресурса, например, можно закрыть от индексирования документы, которые мешают продвижению нужных страниц.
Как избавиться от дубликатов страниц сайта на Joomla
Дубликаты страниц усложняют структуру сайта и мешают его качественному ранжированию в поисковых системах. Чтобы найти и удалить дубли готовых страниц в Joomla, можно использовать один из способов в этой статье.Применение мета-тега «Robots»
Самый простой способ запретить индексировать страницу-дубликат — это выставить мета тег с атрибутом name=»robots». Это специальный тег, с помощью которого можно приказать роботу индексировать или не индексировать текущую страницу:<meta name=”robots” content=”noindex”>Запрет в файле «Robots.txt»
Второй способ не менее надёжный — запрет индексации в файле robots.txt. Этот файл специально сделан для поисковых роботов. В нём содержатся правила индексации сайта. Каждый день поисковые роботы считывают этот файл и корректируют свою поисковую выдачу.Попробуем добавить в этот файл запрет на индексирование страницы сайт.ру/папка/страница.html. Откройте файл «robots.txt», который находится в корневой папке сайта, и добавить в самый конец такую строчку:
Disallow: /папка/страница.htmlУ этой директивы есть одна особенность. Она будет запрещать индексирование страниц, у которых в адресе есть запрещённое выражение. Таким образом можно запрещать целые папки. К примеру, после сохранения нашего пример будет запрещена не только индексация файла /папка/страница.html, но и страниц с параметрами от неё /папка/страница.html?param=1.
Аналогично и с папками. Если написать такой запрет:
Disallow: /папка//папка/страница.html
/папка/подпапка/страница.html
/папка/кулинария/еда.html
/папка/сыр/молоко.htmlПолитика индексации сайта | Integral Ad Science
Возможно, вы заметили «IAS Crawler (ias_crawler; https://integralads.com/site-indexing-policy/)» и «IAS Wombles (ias_wombles; https://integralads.com/site-indexing- policy /) »и вам интересно, почему эти сканеры посещают ваш сайт, или вы можете пригласить одного или обоих этих роботов для сканирования вашего сайта. Integral использует машинное обучение и другой анализ для предоставления услуг по оценке контента и сертификации для брендов, агентств, рекламных сетей и издателей.Разрешение нашим роботам сканировать ваш сайт важно для того, чтобы мы могли давать точную оценку содержания вашего сайта и дорабатывать наши услуги сертификации для оценки содержания и недействительного трафика. Если наш робот «IAS Crawler» заблокирован, мы не сможем дать точную оценку вашего сайта, и, таким образом, ваш сайт будет недоступен для любого из наших партнерских рекламодателей. Если наш робот «IAS Wombles» заблокирован, мы не сможем собирать дополнительную информацию для анализа наших недействительных моделей трафика.
Чтобы пригласить нашего робота сканировать ваш сайт, свяжитесь с нами: crawling@integralads.com, и мы внесем URL вашего сайта в нашу очередь сканирования.
Чтобы заблокировать «IAS Crawler (ias_crawler; https://integralads.com/site-indexing-policy/)» и «IAS Wombles (ias_wombles; http://intergralads.com/site-indexing-policy/)» от сканирование вашего сайта, пожалуйста, прочтите ниже. Дополнительную информацию о нашей политике конфиденциальности и технологиях можно найти на следующих страницах Политика конфиденциальности и страницы продуктов.
Если на вашем сайте есть области, в которых вы хотели бы запретить роботам сканирование, просто сообщите нам о своих параметрах сканирования через Стандарт исключения роботов (SRE). Стандарт SRE регулирует работу большинства основных групп веб-сканирования, и Integral строго придерживается этого стандарта.
При сканировании вашего сайта сканеры Integral ищут файл с именем «robots.txt», который администраторы веб-сайта могут разместить на верхнем уровне сайта, чтобы управлять поведением роботов, сканирующих веб-страницы.
Сканеры Integral всегда выбирают копию файла robots.txt перед соответствующим сканированием Интернета. Если вы измените файл robots.txt во время сканирования вашего сайта, сообщите нам об этом, чтобы мы могли проинструктировать сканеры получить обновленные инструкции, содержащиеся в файле robots.txt.
Чтобы исключить всех роботов, файл robots.txt должен выглядеть так:
User-agent: *
Disallow: /
Чтобы исключить только один каталог (и его подкаталоги), скажем, каталог / images /, файл должен выглядеть так:
User-agent: *
Disallow: / images /
Администраторы веб-сайта могут разрешить или запретить определенным роботам посещать часть или весь свой сайт.Интегральные сканеры идентифицируют себя как ias_crawler и ias_wombles, и поэтому, чтобы разрешить посещение ias_crawler и / или ias_wombles (при предотвращении всех остальных), ваш файл robots.txt должен выглядеть следующим образом:
User-agent: ias_crawler
Disallow:
To Чтобы предотвратить посещение ias_crawler (разрешив всем остальным), ваш файл robots.txt должен выглядеть следующим образом:
User-agent: ias_crawler
Disallow: /
Для получения дополнительной информации о роботах, сканировании и роботах.txt посетите страницы веб-роботов по адресу www.robotstxt.org, отличный источник последней информации о Стандарте исключения роботов.
Есть несколько причин, по которым Integral не зашел на ваш сайт. Ваш сайт может быть новым, или мы могли не быть перенаправлены на ваш сайт нашим брендом, агентством или партнерами по рекламной сети. Также возможно, что администратор вашего веб-сайта запретил поисковым роботам посещать ваш сайт. Пожалуйста, прочтите информацию о robots.txt, которую мы предоставили выше, чтобы убедиться, что ваши предпочтения учтены.
Вернуться на портал защиты данных IAS ›
Запретить поисковым системам индексировать ваши веб-сайты
Обзор
Веб-роботы, также известные как веб-странники, краулеры или пауки, — это программы, которые автоматически перемещаются по сети. Поисковые системы, такие как Google или Yahoo, используют их для индексации веб-содержания вашего сайта. Однако они также могут использоваться ненадлежащим образом, например, спамеры, использующие их для сканирования адресов электронной почты. Ниже приведены несколько методов, которые можно использовать для предотвращения этого.
ПРОЧИТАЙТЕ Вначале
Публикация данной информации не означает поддержку данной статьи. Эта статья предоставлена исключительно из уважения к нашим клиентам. Найдите минутку, чтобы просмотреть Заявление о поддержке.
ПРОЧИТАЙТЕ МЕНЯ ПЕРВЫЙ
Публикация данной информации не означает поддержку данной статьи. Эта статья предоставлена исключительно из уважения к нашим клиентам. Найдите минутку, чтобы просмотреть Заявление о поддержке.
Инструкции
WordPress
Если вы используете WordPress в качестве CMS, есть встроенная функция, позволяющая отговорить поисковые системы от индексации вашего сайта.
- Войдите в панель администратора WordPress.
- Щелкните Настройки >> Чтение.
- Убедитесь, что Search Engine Visibility отмечен.
Как следует из описания, это будет препятствовать поисковым системам индексировать ваш сайт, но поисковая система должна выполнить этот запрос.
Robots.txt
В качестве альтернативы описанному выше решению WordPress вы также можете использовать файл robots.txt, чтобы сканеры поисковых систем не запрашивали ваш сайт.
- Используйте диспетчер файлов файлового менеджера или FTP FTP FTP для перехода к корневому каталогу вашего веб-сайта.
- Отредактируйте файл robots.txt или создайте новый, если его в настоящее время нет.
- Введите в robots.txt следующее:
Агент пользователя: * Disallow: / - Сохраните изменения. Вот и все!
Если вам нужны дополнительные директивы для robots.txt, ознакомьтесь с информацией ниже. Не забудьте удалить знак # для любой команды, которой вы хотите, чтобы роботы следовали, но не оставляйте комментарий в описании команд. Для получения подробной информации обо всех правилах, которые вы можете создать, посетите: http://www.robotstxt.org/
# Пример файла robots.txt из (mt) Media Temple
# Узнайте больше на http://mediatemple.net
# (mt) Форумы - http://forum.mediatemple.net/
# (mt) Состояние системы - http://status.mediatemple.net
# (mt) Заявление о поддержке - http: // mediatemple.сеть / поддержка / заявление /
# Как проверить, что мой файл robots.txt работает должным образом
# http://www.google.com/support/webmasters/bin/answer.pyanswer=35237
# Список роботов можно найти на сайте: http://www.robotstxt.org/db.html
# Инструкции
# Удалите символ "#", чтобы раскомментировать любую строку, которую вы хотите использовать, но не раскомментируйте описание.
# Предоставить доступ роботам
########################################################################## ###################################
# В этом примере все роботы могут посещать все файлы, потому что подстановочный знак «*» указывает всех роботов:
# User-agent: *
#Disallow:
# Чтобы разрешить использование одного робота, вы должны использовать следующее:
# User-agent: Google
#Disallow:
# User-agent: *
#Disallow: /
# Запретить доступ роботам
########################################################################## ###################################
# В этом примере не допускаются все роботы:
# User-agent: *
#Disallow: /
# Следующий пример говорит всем поисковым роботам не заходить в четыре каталога веб-сайта:
# User-agent: *
#Disallow: / cgi-bin /
#Disallow: / images /
#Disallow: / tmp /
#Disallow: / private /
# Пример, указывающий определенному поисковому роботу не заходить в один конкретный каталог:
# User-agent: BadBot
#Disallow: / private /
# Пример, указывающий всем сканерам не вводить один конкретный файл с именем foo.html
# User-agent: *
#Disallow: /domains/example.com/html//var/www/vhosts/example.com/httpdocs/
Защита паролем ваших страниц / веб-сайта
Поисковые системы и сканеры не имеют доступа к страницам, защищенным паролем. Таким образом, он довольно эффективен для предотвращения индексации. Однако этот метод потребует от пользователей ввода пароля для просмотра вашего контента. Это можно реализовать на отдельных страницах или на всем сайте. Подробные инструкции см. В статье ниже:
Изменений для предотвращения индексации сайтов поисковыми системами.- Сделайте WordPress Core
В WordPress 5.3 метод, используемый для предотвращения индексации, будет изменен на сайтах, включив опцию «препятствовать индексированию этого сайта поисковыми системами» на панели инструментов WordPress. Эти изменения были внесены как часть тикета Created как для отчетов об ошибках, так и для разработки функций в системе отслеживания ошибок. # 43590.
Эти изменения предназначены для того, чтобы лучше препятствовать поисковым системам отображать сайт, а не только предотвращать сканирование сайта.
robots.txt изменения файла. В предыдущих версиях WordPress Disallow: / был добавлен в файл robots.txt , чтобы предотвратить сканирование сайта поисковыми системами. Это было удалено для закрытых веб-сайтов в WordPress 5.3.
Как пишет Йуст де Валк в объяснении исключения из поисковых систем, запрет на сканирование может привести к разрешению индексации сайта:
Сайт не должен быть [просканирован], чтобы быть в списке.Если ссылка указывает на страницу, домен или другое место, Google перейдет по этой ссылке. Если файл robots.txt в этом домене предотвращает [сканирование] этой страницы поисковой системой, он все равно будет показывать URL. Определенный веб-адрес веб-сайта или веб-страницы в Интернете, например URL-адрес веб-сайта www.wordpress. org в результатах, если он сможет собрать… на него стоит взглянуть.
Мета Мета — это термин, относящийся к внутренней работе группы. Для нас это команда, которая работает над внутренними сайтами WordPress, такими как WordCamp Central и Make WordPress.tag Каталог в Subversion. WordPress использует теги для хранения одного снимка версии (3.6, 3.6.1 и т. Д.), Что является обычным условием использования тегов в системах контроля версий. (Не путать с тегами постов.) Изменения.
Сайты с включенной опцией «препятствовать индексированию этого сайта поисковыми системами» будут отображать обновленный метатег robots, чтобы сайт не отображался в поисковых системах: .
Этот метатег запрашивает у поисковых систем исключение страницы из индексации и отговаривает их от дальнейшего сканирования сайта.
Исключение серверов разработки из поисковых систем.
Наиболее эффективным методом исключения сайтов разработки из индексации поисковыми системами является включение HTTP HTTP — это аббревиатура от Hyper Text Transfer Protocol. HTTP — это базовый протокол, используемый во всемирной паутине, и этот протокол определяет, как сообщения форматируются и передаются, и какие действия веб-серверы и браузеры должны выполнять в ответ на различные команды. Заголовок Заголовок вашего сайта — это обычно первое, с чем сталкиваются люди.Заголовок или заголовок, расположенный в верхней части страницы, является частью внешнего вида вашего веб-сайта. Это может повлиять на мнение посетителей о вашем контенте и о бренде вашей организации. Он также может выглядеть по-разному на экранах разных размеров. X-Robots-Tag: noindex, nofollow при обслуживании всех ресурсов вашего сайта: изображений, PDF-файлов, видео и других ресурсов.
Как большинство языков разметки гипертекста, отличных от HTML. Язык семантических сценариев, который в основном используется для вывода контента в веб-браузерах.ресурсы обслуживаются непосредственно веб-сервером на сайте WordPress, ядро Core — это набор программного обеспечения, необходимого для работы WordPress. Основная команда разработчиков создает WordPress. программное обеспечение не может установить этот заголовок HTTP. Вам следует проконсультироваться с документацией вашего веб-сервера или вашего хоста, чтобы убедиться, что эти ресурсы исключены на сайтах разработки.
# 5-3, # dev-notes
WordPress 5.3 изменит способ блокирования индексации
WordPress объявил о важном изменении того, как он будет блокировать поисковые системы от индексации веб-сайтов.Это изменение отказывается от традиционного решения Robots.txt в пользу подхода Robots Meta Tag. Это изменение приводит WordPress в соответствие с причиной блокировки Google, которая заключается в том, чтобы заблокированные страницы не отображались в результатах поиска Google.
Это метатег роботов, который будет использовать WordPress:
Блокировка Google от индексации
Это давно было стандартная практика использования роботов.txt, чтобы заблокировать «индексацию» веб-сайта.
Слово «индексация» означало сканирование сайта роботом GoogleBot. Используя функцию блокировки Robots.txt, вы могли помешать Google загружать указанную веб-страницу, и предполагалось, что Google не сможет отображать ваши страницы в результатах поиска.
Реклама
Продолжить чтение ниже
Но эта директива robots.txt только помешала Google сканировать страницу. Google по-прежнему может добавить его в свой индекс, если сможет обнаружить URL.
Итак, чтобы заблокировать отображение сайта в индексе, издатель заблокировал бы Google от «индексации» страниц. Что не всегда было эффективным.
WordPress 5.3 действительно предотвратит индексацию
WordPress адаптировал подход Robots.txt. Но это изменилось в версии 5.3.
Когда издатель в настоящее время выбирает « препятствовать поисковым системам индексировать этот сайт », он добавляет запись в robots.txt сайта, которая запрещает Google сканировать сайт.
Реклама
Продолжить чтение ниже
Начиная с WordPress 5.3, WordPress будет применять более надежный подход с метатегами роботов для предотвращения индексации веб-сайта.
Это изменение повлияет на настройку «запретить поисковым системам индексировать этот сайт».
Это изменение является улучшением. Издатели WordPress могут быть в большей безопасности, зная, что заблокированные веб-страницы не будут отображаться в результатах поиска Google.
Скриншот объявления об изменении WordPress 5.3.Почему WordPress использовал Robots.txt?
WordPress использовал Robots.txt для блокировки индексации веб-сайта, потому что именно так все не позволяли страницам отображаться в результатах поиска Google. Это был стандартный способ сделать это.
Тем не менее, хотя все так поступали, как уже объяснялось, это был ненадежный подход.
Слово «индексирование» имеет два значения:
- Индексирование означает сканирование, например, когда робот Googlebot посещает и загружает веб-страницы.
- Индексирование также может означать добавление веб-страницы в базу данных веб-страниц Google (которая называется The Index) .
Блокировка Google от «индексации» веб-страницы не позволит ему видеть веб-страницу, но Google все равно может проиндексировать веб-страницу и добавить ее в индекс Google. Есть смысл?
Реклама
Продолжить чтение ниже
Robots.txt по сравнению с метатегом «Роботы»
Роботы не собирались убирать веб-страницу из индекса Google.txt решение. Это работа метатега роботов.
Так что приятно видеть, что WordPress использует метатег Robots как решение, блокирующее отображение веб-страниц в поисковых системах.
WordPress 5.3 планируется выпустить в ноябре 2019 года.
Прочтите объявление WordPress:Изменения, предотвращающие индексацию сайтов поисковыми системами
Прочтите официальную документацию Google- Метатег роботов и X- Спецификации HTTP-заголовка Robots-Tag
- Блокировать поисковую индексацию с помощью noindex
Запрещает поисковому роботу Amazon Kendra индексировать ваш веб-сайт
Amazon Kendra — это интеллектуальный поисковый сервис, который клиенты AWS могут использовать для индексации и искать документы по своему выбору.Чтобы индексировать документы в Интернете, клиенты могут использовать веб-сканер Amazon Kendra, указывая, какие URL-адреса следует проиндексирован и другие рабочие параметры. Клиенты Amazon Kendra должны получить авторизация перед индексированием того или иного сайта.
Вы можете запретить поисковому роботу Amazon Kendra индексировать ваш веб-сайт с помощью Disallow , как показано ниже.Вы также можете контролировать, какие
веб-страницы индексируются, а какие веб-страницы не сканируются.
Веб-сканер Amazon Kendra соблюдает стандартные директивы robots.txt, например Разрешить и Запретить . Каждый клиент Amazon Kendra, использующий Интернет
поисковый робот имеет уникальный пользовательский агент или идентификатор клиента. Вы можете идентифицировать пользовательский агент или
идентификатор клиента, который
вы хотите контролировать и настраивать его в файле robots.txt директивы.
Например, приведенные ниже директивы не позволяют клиенту Amazon Kendra
для индексации каталога ваших веб-страниц под / do-not-crawl / , но
разрешить индексирование подкаталога / do-not-crawl / except-this / :
User-agent: amazon-kendra-customer-id- [ id ] # Пользовательский агент / идентификатор клиента Amazon
Disallow: / do-not-crawl / # запретить этот каталог
Разрешить: / do-not-crawl / except-this / # разрешить этот подкаталог
User-agent: * # любой робот
Disallow: / not-allowed / # запретить этот каталог
User-agent: amazon-kendra-web-crawler- * # все клиенты веб-сканера Amazon Kendra
Disallow: / confidential / # disallow this directory Веб-сканер Amazon Kendra также поддерживает роботов noindex и nofollow директивы в метатегах на HTML-страницах.Эти
директивы запрещают поисковому роботу индексировать веб-страницу и перестают следовать
любые ссылки на веб-странице. Вы помещаете метатеги в раздел
документ для определения правил роботов.
Например, приведенная ниже веб-страница включает директивы robots noindex и nofollow :
...
...
Если у вас есть какие-либо вопросы или опасения относительно поискового робота Amazon Kendra, вы можете может достигать в службу поддержки AWS.
Как предотвратить индексирование вашего веб-сайта разработки
Во время создания нового веб-сайта или при внедрении новой разработки на существующем сайте обычно рекомендуется блокировать сканирование поисковыми системами и предотвращать индексацию вашего веб-сайта.
Очевидная проблема заключается в дублировании контента и в том, как это может негативно повлиять на SEO вашего действующего веб-сайта. Если разрабатываемая версия индексируется поисковыми системами, это может привести именно к этой проблеме. Но, что, возможно, более важно, для совершенно новых веб-сайтов весь этот новый контент и дизайн будут просачиваться в сеть, прежде чем вы будете готовы к своему большому раскрытию. Даже если ваш сайт создается на непонятном URL, который не могут найти даже программы для взлома кода Enigma Machine, Google найдет его, если вы не заблокируете индексирование.
Новая веб-разработка | Прячась на виду
Если вы работаете над своим новым веб-сайтом в среде онлайн-разработки или если у вас есть копия действующего сайта для целей подготовки / разработки, крайне важно, чтобы вы случайно не позволили Google (или любой поисковой системе для этого имеет значение) просканируйте ваш сайт разработки.
Разрешение поисковым системам сканировать как рабочую, так и разрабатываемую версию вашего сайта, может нанести вашему SEO вред, иногда значительно.Это происходит из-за ряда факторов, но не в последнюю очередь из-за разделения вашей оценки SEO между двумя сайтами и возникновения проблем с дублированием контента.
Noindex — заблокировать всех агентов в вашем файле robots.txt
Самый простой способ помешать поисковым системам индексировать ваш сайт разработки — добавить файл robots.txt в основной каталог домена (т. Е. В родительский веб-каталог для вашего сайта). Этот файл роботов должен содержать единственную директиву, указанную ниже:
Пользовательский агент: *
Disallow: /
Самые авторитетные поисковые системы будут уважать директивы в ваших файлах robots.txt, поэтому описанного выше метода будет достаточно для блокировки сканирования и индексации во время разработки. Однако эти надоедливые боты, которые любят безумно сканировать сайты по менее чем добродетельным причинам, ничего не уважают. так что не ждите, что они снимут шляпу и пройдут мимо.
Конечно, они не совсем то, чем мы здесь занимаемся; в этом случае мы просто хотим избежать, например, Google, от индексации нашего сайта разработки. Вы можете узнать больше о robots.txt в Moz.com.
Блокировка поисковых систем на WordPress
На сайте WordPress вам не нужно беспокоиться о ручном редактировании и загрузке файла robots.txt. Вы можете просто зайти на страницу настроек -> читать страницу управления и поставить галочку в поле, в котором говорится: препятствуйте поисковым системам индексировать этот сайт.
Обратите внимание, что комментарий под флажком на скриншоте выше: Поисковые системы должны выполнить этот запрос .Это то, о чем мы говорили ранее, и хотя большинство поисковых систем будут выполнять запрос, некоторые из менее благородных будут.
Вот почему вы найдете в Интернете ссылки на защиту паролем всего сайта WordPress на уровне сервера, чтобы предотвратить индексацию каких-либо элементов вообще. Однако, по нашему опыту, это, вероятно, излишне и не обязательно, но помните об этом, если вы начнете замечать изображения или фрагменты контента, попадающие в результаты поиска.
Не забудьте удалить директиву при выходе в эфир
Если в конечном итоге ваш сайт разработки будет развернут как действующий веб-сайт, не забудьте соответствующим образом отредактировать файл robots.txt и / или отменить выбор этого параметра в WordPress. В противном случае вы будете ломать голову, недоумевая, почему не происходит индексирование, и тупо уставитесь на экран консоли поиска Google, в то время как ваш веб-сайт не получит никакой поддержки в поисковой выдаче.
Руководство для новичков по блокировке URL-адресов в роботах.txt файл | Ignite Visibility
Файл robots.txt, также известный как исключение роботов, является ключом к предотвращению сканирования роботами поисковых систем ограниченных областей вашего сайта.
В этой статье я рассмотрю основы того, как блокировать URL-адреса в robots.txt.
Что мы расскажем:
Что такое файл Robots.txt?
Robots.txt — это текстовый файл, который веб-мастера создают, чтобы научить роботов сканировать страницы веб-сайтов и позволяет сканерам узнать, обращаться к файлу или нет.
Вы можете заблокировать URL-адреса в robots txt, чтобы Google не индексировал личные фотографии, просроченные специальные предложения или другие страницы, к которым вы не готовы для пользователей. Использование его для блокировки URL-адреса может помочь в SEO.
Он может решить проблемы с дублированным контентом (однако могут быть более эффективные способы сделать это, о чем мы поговорим позже). Когда робот начинает сканирование, он сначала проверяет наличие файла robots.txt, который не позволяет им просматривать определенные страницы.
Когда мне следует использовать файл Robots.txt?
Вам нужно будет использовать его, если вы не хотите, чтобы поисковые системы индексировали определенные страницы или контент. Если вы хотите, чтобы поисковые системы (например, Google, Bing и Yahoo) получали доступ и индексировали весь ваш сайт, вам не нужен файл robots.txt. Хотя стоит упомянуть, что в некоторых случаях люди все же используют его, чтобы направлять пользователей на карту сайта.
Однако, если другие сайты ссылаются на страницы вашего сайта, заблокированные, поисковые системы могут по-прежнему индексировать URL-адреса, и в результате они по-прежнему могут отображаться в результатах поиска.Чтобы этого не произошло, используйте x-robots-tag , метатег noindex или относительный канонический к соответствующей странице.
Эти типы файлов помогают веб-сайтам в следующих случаях:
- Сохраняйте конфиденциальность частей сайта — например, страницы администратора или изолированную программную среду вашей команды разработчиков.
- Предотвратить появление дублирующегося контента в результатах поиска.
- Избегайте проблем с индексацией
- блокирует URL
- Запретить поисковым системам индексировать определенные файлы, такие как изображения или PDF-файлы
- Управляйте обходным трафиком и предотвращайте появление медиафайлов в результатах поиска.
- Используйте его, если вы размещаете платные объявления или ссылки, требующие специальных инструкций для роботов.
Тем не менее, если на вашем сайте нет каких-либо областей, которые вам не нужно контролировать, то она вам и не нужна. В рекомендациях Google также упоминается, что вам не следует использовать robots.txt для блокировки веб-страниц из результатов поиска.
Причина в том, что если другие страницы ссылаются на ваш сайт с описательным текстом, ваша страница все равно может быть проиндексирована благодаря отображению на этом стороннем канале.Здесь лучше использовать директивы Noindex или защищенные паролем страницы.
Начало работы с Robots.txt
Прежде чем вы начнете собирать файл, убедитесь, что у вас его еще нет. Чтобы найти его, просто добавьте «/robots.txt» в конец любого доменного имени — www.examplesite.com/robots.txt. Если он у вас есть, вы увидите файл со списком инструкций. В противном случае вы увидите пустую страницу.
Затем проверьте, не блокируются ли какие-либо важные файлы
Зайдите в консоль поиска Google, чтобы узнать, не блокирует ли ваш файл какие-либо важные файлы.Тестер robots.txt покажет, препятствует ли ваш файл поисковым роботам Google доступ к определенным частям вашего веб-сайта.
Также стоит отметить, что вам может вообще не понадобиться файл robots.txt. Если у вас относительно простой веб-сайт, и вам не нужно блокировать определенные страницы для тестирования или для защиты конфиденциальной информации, вы обойдетесь без веб-сайта. И на этом учебник заканчивается.
Настройка файла Robots.Txt
Эти файлы можно использовать по-разному.Однако их главное преимущество заключается в том, что маркетологи могут разрешать или запрещать использование нескольких страниц одновременно, не обращаясь к коду каждой страницы вручную.
Все файлы robots.txt приведут к одному из следующих результатов:
- Полное разрешение — все содержимое можно сканировать
- Полное запрещение — сканирование контента невозможно. Это означает, что вы полностью блокируете доступ сканеров Google к любой части вашего веб-сайта.
- Условное разрешение — правила, описанные в файле, определяют, какой контент открыт для сканирования, а какой заблокирован.Если вам интересно, как запретить использование URL-адреса, не заблокировав для поисковых роботов доступ ко всему сайту, то вот оно.
Если вы хотите создать файл, процесс на самом деле довольно прост и включает два элемента: «пользовательский агент», который является роботом, к которому применяется следующий блок URL, и «запретить», который является URL-адресом. вы хотите заблокировать. Эти две строки рассматриваются как одна запись в файле, что означает, что вы можете иметь несколько записей в одном файле.
Как заблокировать URL-адреса в роботах txt:
Для строки пользовательского агента вы можете указать конкретного бота (например, Googlebot) или применить блок URL txt ко всем ботам, используя звездочку.Ниже приведен пример того, как пользовательский агент блокирует всех ботов.
Пользовательский агент: *
Во второй строке записи, disallow, перечислены конкретные страницы, которые вы хотите заблокировать. Чтобы заблокировать весь сайт, используйте косую черту. Для всех остальных записей сначала используйте косую черту, а затем укажите страницу, каталог, изображение или тип файла
Disallow: / блокирует весь сайт.
Disallow: / bad-directory / блокирует как каталог, так и все его содержимое.
Disallow: /secret.html блокирует страницу.
После создания пользовательского агента и запрета выбора одна из ваших записей может выглядеть так:
Агент пользователя: *
Запретить: / bad-directory /
Посмотреть другие примеры записей из Google Search Console .
Как сохранить файл
- Сохраните файл, скопировав его в текстовый файл или блокнот и сохранив как «robots.текст».
- Обязательно сохраните файл в каталоге верхнего уровня вашего сайта и убедитесь, что он находится в корневом домене с именем, точно соответствующим «robots.txt».
- Добавьте файл в каталог верхнего уровня кода вашего веб-сайта для упрощения сканирования и индексации.
- Убедитесь, что ваш код имеет правильную структуру: User-agent → Disallow → Allow → Host → Sitemap. Это позволяет поисковым системам получать доступ к страницам в правильном порядке.
- Поместите все URL-адреса, для которых требуется «Разрешить:» или «Запретить:», в отдельной строке.Если несколько URL-адресов отображаются в одной строке, сканерам будет сложно разделить их, и у вас могут возникнуть проблемы.
- Всегда используйте строчные буквы для сохранения файла, так как имена файлов чувствительны к регистру и не содержат специальных символов.
- Создавать отдельные файлы для разных поддоменов. Например, «example.com» и «blog.example.com» имеют отдельные файлы со своим собственным набором директив.
- Если вы должны оставлять комментарии, начните с новой строки и поставьте перед комментарием символ #.Знак # позволяет сканерам знать, что эту информацию нельзя включать в свою директиву.
Как проверить свои результаты
Проверьте свои результаты в своей учетной записи Google Search Console, чтобы убедиться, что боты сканируют те части сайта, которые вам нужны, и блокируют URL-адреса, которые вы не хотите, чтобы поисковики видели.
- Сначала откройте инструмент тестера и просмотрите свой файл на предмет предупреждений или ошибок.
- Затем введите URL-адрес страницы вашего веб-сайта в поле внизу страницы.
- Затем выберите user-agent , который вы хотите смоделировать, из раскрывающегося меню.
- Щелкните ТЕСТ.
- Кнопка ТЕСТ должна читать ПРИНЯТО или ЗАБЛОКИРОВАНО, , что укажет, заблокирован файл поисковыми роботами или нет.
- При необходимости отредактируйте файл и повторите попытку.
- Помните, любые изменения, которые вы вносите в тестере GSC, не будут сохранены на вашем веб-сайте (это симуляция).
- Если вы хотите сохранить изменения, скопируйте новый код на свой веб-сайт.
Имейте в виду, что это будет тестировать только Googlebot и другие пользовательские агенты, связанные с Google. Тем не менее, использование тестера имеет огромное значение, когда дело доходит до SEO. Видите ли, если вы все же решите использовать файл, вам обязательно нужно правильно его настроить. Если в вашем коде есть какие-либо ошибки, робот Google может не проиндексировать вашу страницу или вы можете случайно заблокировать важные страницы из результатов поиска.
Наконец, убедитесь, что вы не используете его вместо реальных мер безопасности. Когда дело доходит до защиты вашего сайта от хакеров, мошенников и посторонних глаз, лучше использовать пароли, брандмауэры и зашифрованные данные.
Завершение
Готовы начать работу с robots.txt? Большой!
Если у вас есть какие-либо вопросы или вам нужна помощь в начале работы, дайте нам знать!
.