Как в dle запретить индексацию страниц? Что написать в robot.txt?
- Сообщество
- Как в dle запретить индексацию страниц? Что написать в robot.txt?
Ответы на пост (20) Написать ответ
Зачем нагружать robot.txt? это же dle не плодите ненужные стр и всё.
User-agent: *
Disallow: /engine/
Host: site.ru
Sitemap: http://site.ru/sitemap.xml
Должен быть такой, остальное в /engine/engine.php
перед
if ($config[‘allow_rss’]) $metatags .= <<<HTML
добавь
if (
(intval($_GET[‘cstart’]) > 1 ) OR /* Любые страницы пагинации */
) $metatags .= <<<HTML
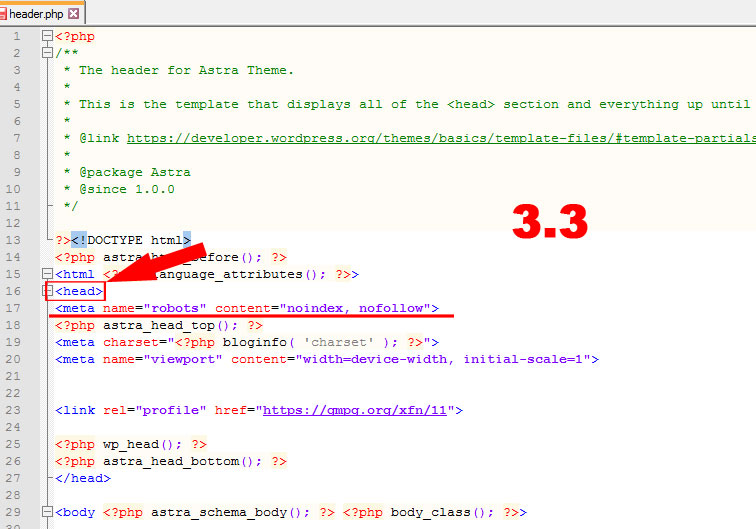
\n<meta name=»robots» content=»noindex,nofollow» />
HTML;
Можно там же и другие ненужные стр закрыть, например — Стр просмотра списка тегов, формы обратной связи закладок пользователей и прочие
0
Решение
Disallow: /page/*
и все? все страницы выпадут ? хм .
выпадут.
Ответ на такой вопрос можно было уже поискать и в гугле… Привыкли на блюдечке да с каёмочкой, блин… лодыри, тунеядцы…
Оно так и есть, лень, но не лень сайт создавать и им заниматься. Где надо мозг работает, а на самом элементарном и простом его нет.
topbux
26
26.09.2017 10:32
Не надо велосипед изобретать 🙂
Disallow: */page/*/
Disallow: */page/
topbux
26
26.09.2017 10:36
И еще используй хак для DLE Тег canonical для страниц DLE что бы отбить все возможные ее дубли https://dleshka.org/hacks/6003-teg-canonical-dlya-stranic-dle.html
Я бы посоветовал сделать так.
 Порыться по Нету и выбрать все запреты страниц типа:
Порыться по Нету и выбрать все запреты страниц типа:Disallow: */page/*/
Disallow: */page/
Disallow: /page/*
и.т.д
2. Затем зайти в Яндекс Вебмастер, в раздел — «Инструменты» — «Анализ robots.txt». Там отобразится ваш действующий robots.txt. Ниже будет поле «Разрешены ли URL?» Добавляете команды (Disallow: */page/*/, Disallow: */page/, Disallow: /page/* и им подобные) в ваш robots.txt тот, что в окне выше. Затем в окно «Разрешены ли URL?» вставляете списком те страницы page, либо другие страницы и жмете «Проверить». Если урл разрешен будет зеленая галочка — тогда в команде предположим Disallow: */page/*/ убираете наклонные и звездочки. Делаете пока ваш урл — не будет красным (Запрещен)!
3. Аналогично, есть проверка robots.txt в гугл вебмастере.
С ув. Сергей.
P.S. Насчет грузить robots.txt как советовали выше — не согласен! Сам закрывал в дле, в /engine/engine.php — остался недоволен. Да и сами Яндекс-представители советуют, закрывать именно в файле robots.
как бы не ставил в вебмастере
Disallow: */page/*/
Disallow: */page/
Disallow: /page/*
Все равно горит зеленая галочка …
Почитайте мой 1 пункт и полазьте по нету. Вот вам нашел еще пару команд — пробуйте.
Disallow: */page/*
Disallow: /page*
С ув. Сергей
порылся.. добавил = зеленая галочка …
1. Вот вставил в свой роботс две строки:
User-agent: *
Disallow: */page/*
Disallow: /page*
Host: ****.ru
Sitemap: http://****.ru/sitemap.xml
2. В итоге страницы типа ****.ru/page/2/ — результат */page/* — Закрыт к индексации!!!
Попробуйте еще раз.
Вот результат — http://s018.radikal.ru/i519/1709/78/6cdef03aa8fd.jpg
С ув. Сергей
GreenRed, ну что получилось?
нет… не работает =) зеленая горит ….
Из вот этих двух команд
Disallow: */page/*
Disallow: /page*
достаточно и этой одной
Disallow: */page/*
Вот скрин на закрытие всех вами указанных выше страниц — http://radikal. ru/lfp/s013.radikal.ru/i324/1709/6f/dea45e8cac01.jpg/htm
ru/lfp/s013.radikal.ru/i324/1709/6f/dea45e8cac01.jpg/htm
С ув. Сергей
вставил Disallow: */page/* — зеленая!
Для robots.txt запрет будет выглядеть так
Disallow: /*page/
Запрет на индексацию идет по всем возможным страницам пагинации, т.е. как только в адресе появляется page на эту страницу ставится запрет индексации.
Прописал, но яндекс даже если вручную пробовать удалить — пишет, что нет оснований для удаления!
Похожие посты
- запрет в robots.txt
4 - Удаление страниц в яндекс вебмастер
6 - Запретить индексацию сайта либо показывать недоделки
3 - Удаление страницы с Яндекса
6 - Robots.txt. разница в disallow со слэшем и без
1
Анализ сайта
Поможем улучшить ваш сайт.
Как запретить индексацию страницы сайта в robots.txt
Как запретить индексацию страницы сайта в robots. txt
txt
Во время разработки собственного сайта нередко возникает необходимость скрыть ту или иную страницу от вездесущих глаз поисковых ботов. Связано это бывает с плановыми профилактическими работами, наличием всевозможных дублей и тому подобными проблемами. Банальный редизайн интерфейса вынуждает скрывать все неоптимизированные страницы, которые требуют ручной настройки.
В зависимости от специфики ресурса, может быть проще попросту спрятать от ботов его целиком. А ещё вы можете разрабатывать закрытый проект, доступ к которому предоставляется только определённой группе лиц. Тогда его и открывать для поисковых систем нет никакого смысла. Ведь пользователи из поиска попросту не смогут на него зайти.
Но наиболее часто скрываются страницы с морально устаревшей информацией. Нет никакого смысла продолжать держать в индексе страницы с древними новостями, событиями или другими активностями. Возможность найти их через поисковую выдачу лишь введёт в заблуждение вашу аудиторию.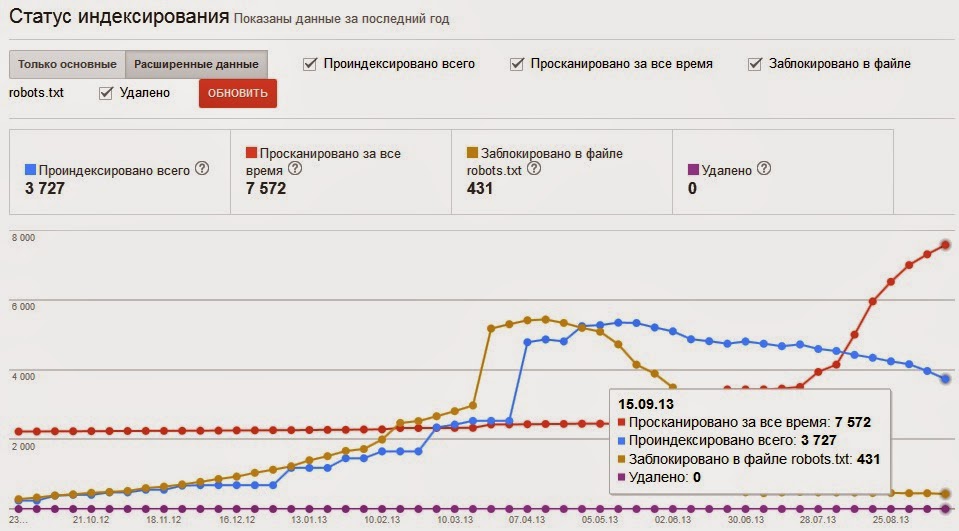
Вы также можете скрывать отдельные элементы страницы. Например, всплывающие окна, баннеры, различные скрипты и графику. Таким образом удаётся получить более высокие оценки Time to First Bite. Кроме того, это снижает нагрузку на сервер и позволяет улучшить общий индекс качества вашего сайта.
Что значит закрыть сайт от индексации?
Запрещение поисковым ботам переходить на страницы вашего сайта приводит к тому, что он закрывается от индексации. К таким кардинальным мерам можно прибегать в том случае, если у вас небольшой проект с ограниченным количеством страниц, а проведение необходимого обслуживания затрагивает их все или почти все.
Разумеется, для старых и массивных сайтов, закрывать все страницы от индексации – равносильно вылету из топа поисковой выдачи. После того, как доступ к страницам будет восстановлен, они вернут себе свой вес, но далекоидущие последствия подобных действий могут быть непредсказуемыми.
Закрытие ресурса от индексации означает, что ни одна его страница не будет присутствовать в поисковой выдачи. То есть сайт в Глобальной сети присутствовать будет, вот только отыскать его через Яндекс или Google не получится.
То есть сайт в Глобальной сети присутствовать будет, вот только отыскать его через Яндекс или Google не получится.
Нужно ли закрывать сайт от индексации?
Закрывать сайт от индексации целиком может потребоваться только в каких-то исключительных случаях. В подавляющем большинстве ситуаций, достаточно скрывать только отдельно взятые страницы, над которыми вы в настоящее время работаете.
Однако полная трансформация проекта, в случае его покупки новыми владельцами или кардинальной смены курса текущим хозяином, требует его сокрытия.
Если вы взялись за семантику с нуля и собираетесь полностью перелопатить ядро ресурса, то закройте его на всё время работ. В противном случае поисковые алгоритмы могут неправильно вас понять и наложить различных фильтров, отмыться от которых окажется непосильной задачей.
Разумеется, резкая смена тематики или подхода к работе над контентом – также не лучшая идея, с точки зрения поисковых систем. Ведь это означает, что вы больше не соответствуете пользовательским намерениям той аудитории, которая приходит из органической выдачи. А значит страницы нужно оценивать с нуля.
Ведь это означает, что вы больше не соответствуете пользовательским намерениям той аудитории, которая приходит из органической выдачи. А значит страницы нужно оценивать с нуля.
В любом случае, кардинальные изменения проекта требуют его закрытия на время проведения работ. Тогда обновления пройдут более мягко и приведут к меньшим потерям.
Как запретить роботам индексировать сайт целиком?
Инструментов для сокрытия сайта от поисковых ботов придумано предостаточно. Выбор того или иного зависит от конкретной ситуации и тех задач, которые стоят перед разработчиком:
Каждый из вариантов сокрытия сайта отличается своими особенностями, а также имеет достоинства и недостатки. Каждый из них нужно рассматривать отдельно.
Файл robots.txt
Поисковые краулеры, путешествуя по просторам Глобальной сети, воспринимают сайты не так, как обычные пользователи. Они заглядывают в технические файлы и читают карту ресурса оттуда.
Robots.txt при посещении является их первой целью. Именно здесь прописываются различные указания о том, каким образом нужно читать страницы. Фактически, этот файл содержит набор директив и во многом именно от него зависит то, как ресурс воспримут алгоритмы.
К самому файлу robots.txt также предъявляются определённые требования:
-
Название должно быть написано в нижнем регистре. Никаких прописных букв тут быть не должно.
-
Формат .txt является обязательным требованием. Требование строгое и обмануть бота вам не удастся.
-
Максимально допустимый размер файла составляет 500 Кбайт. Это достаточно серьёзное ограничение. Но оно имеет под собой основания.
-
Файл должен лежать в корневом каталоге. Нет смысла заставлять бота сканировать всё содержимое в поисках злосчастного списка директив.

-
А ещё этот файл должен быть доступен по адресу: «URL сайта/robots.txt». После запроса этого файла, сервер должен отправить в ответ код 200 OK.

Теперь, когда формат файла robots.txt представляется более определённым, перейдём к его содержанию. Оно, как и следовало ожидать от технического документа, также должно быть строго регламентированным:
-
User-agent – директива, которая содержит в себе информацию о том, для каких конкретно ботов предназначен этот список указаний.
-
Allow – информация, открытая для индексации. Сюда попадают все элементы ресурса, которые могут сканировать поисковые алгоритмы.
-
Disallow – директива, соответственно, закрывающая доступ к информации. Закрывайте ею всё, что не должно попасть под сканирование.
-
Sitemap – прямой адрес карты вашего сайта, упрощающей процесс взаимодействия ботов с ресурсом.
-
Clean-param – директива, которая призвана помочь поисковым ботам Яндекса правильно определять страницы, требующие индексации.
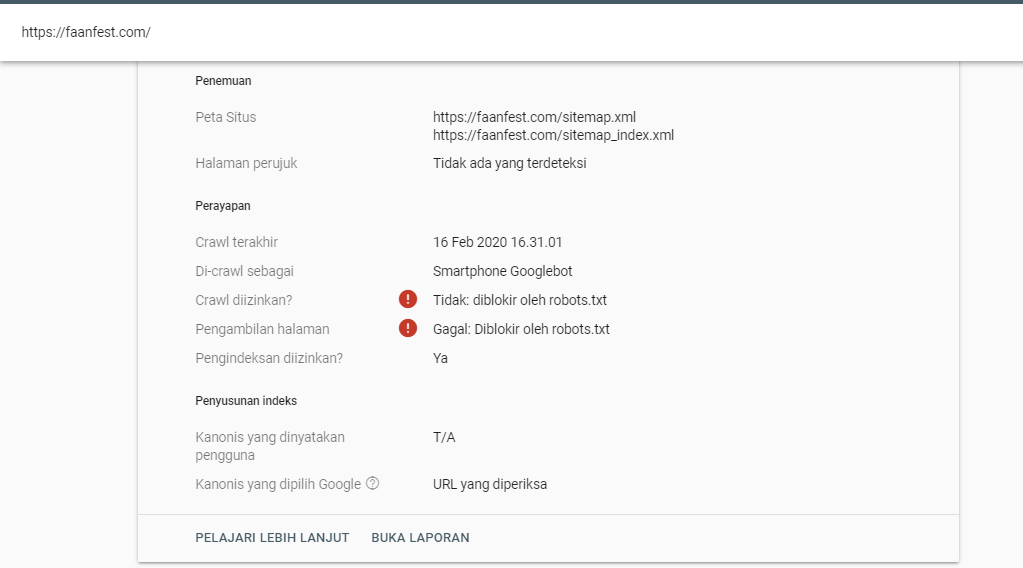
Помните, что даже идеально настроенный robots.txt не избавляет от возможных неприятностей в результате сканирования. Поисковые алгоритмы, в некоторых случаях, могут попросту проигнорировать всё его содержимое и отправить в индекс вообще всё. Такие ситуации, к сожалению, встречаются чаще, чем хотелось бы.
Всё, что остаётся вебмастеру – отправляться в службу технической поддержки и пытаться отыскать ответы там. Правда, в 95% случаев вам ничем не помогут, а лишь предложат дежурные ответы со стандартными цитатами из внутренних правил поисковой системы.
Полный запрет индексации в robots.txt
Запретить индексацию вашего сайта можно конкретным ботам, а не сразу всем. У поисковых систем есть отдельные алгоритмы, сканирующие конкретные формы информации. Например, YandexImages отвечает за работу с изображениями.
Например, YandexImages отвечает за работу с изображениями.
User-agent: YandexImages
Disallow: /
Закрыв ему доступ к сайту, вы скроете только изображения, оставив в индексе остальную информацию. Соответственно можно поступить с конкретной поисковой системой. Закрыть доступ для Google или Яндекса и продолжать работать в другой.
User-agent: *
Disallow: /
Вот так выглядит запрет на индексацию для всех ботов вообще. Таким образом можно полностью скрыть сайт от посещения извне.
User-agent: *
Disallow: /
User-agent: Yandex
Allow: /
Этот вариант включает в себя закрытие сайта для всех ботов, за исключением указанного. Ресурс останется доступен для ботов Яндекса, но скроется от всех остальных.
Полный запрет через HTML-код
Существует возможность закрыть страницу метатегами в блоке . Технический код страницы имеет широкий спектр возможностей. В зависимости от того, что вы укажите в атрибуте «content», эффект может существенно различаться:
Технический код страницы имеет широкий спектр возможностей. В зависимости от того, что вы укажите в атрибуте «content», эффект может существенно различаться:
-
index – разрешение на полное индексирование контента страницы;
-
noindex – закроет от индексации всё, за исключением ссылок;
-
follow – отдельный атрибут для разрешения индексирования ссылок;
-
nofollow – соответственно, запрещает ботам сканировать ссылки;
-
all – ещё один вариант открыть всё содержимое страницы для индексации.
Как и в случае файла robots.txt, вы можете задать конкретных ботов, которым закрываете доступ к странице. Недостаток данного способа очевиден – вы работаете только с одной страницей за раз. У каждой из них собственный HTML-код, который придётся править вручную. Googlebot» search_bot
Googlebot» search_bot
Как запретить индексацию отдельных страниц?
Намного более перспективными выглядят возможности скрыть отдельные страницы или типы контента. Запрещая ботам искать определённый тип контентам в рамках всего вашего сайта, можно решить проблему намного быстрее.
Прописывается запрет всё так же в файле robots.txt. Вам нужно просто прописать в директиве Disallow: тип контента или относительный адрес страницы/раздела, которые необходимо скрыть. Прекрасный способ спрятать конкретные данные, разбросанные по всему сайту.
HTML-код более предрасположен к работе с отдельными страницами. Нужно лишь прописать noindex в блоке , и страница выпадет из индекса. Разумеется, произойдёт это не мгновенно. Поисковые системы выкинут её из выдачи спустя некоторое время.
Помните и о том, что вы потеряете часть или весь индекс качества, который приносила сайту эта страница, даже после её возвращения. Возврат к изначальным параметрам крайне маловероятен.
Какие именно страницы стоит скрыть от индексации?
Выставлять на всеобщее обозрение в индексе стоит только полезные целевые страницы. Они должны содержать качественный контент и соответствовать пользовательским намерениям. Исходя из этого можно охарактеризовать все страницы, которые не стоит отправлять в индекс:
-
Административные страницы, которые не содержат полезный для посетителей контент.
-
Страницы с внутренней информацией. Сюда относятся различные базы данных, содержащие личную информацию, оставляему при регистрации.
-
Дубли страниц. Они встречаются куда чаще, чем можно было бы подумать. Дубли нужны для работы с различными форматами URL-адресов и безопасным соединением.
-
Различные виды форм. Сюда относятся окошки оформления заказа или заявок, регистрации, корзины или тому подобные инструменты.
-
Неактуальная информация. Весь, морально устаревший и ставший бесполезным, контент необходимо закрывать от индексации.
-
Многие ресурсы предоставляют варианты страниц для печати. Разумеется, в индекс их отправлять не нужно.
-
RSS-лента – это не подходящий для индексации контент.
-
Страницы, на которых ведутся технические работы. Или страницы, которые находятся на этапе разработки и ещё не доведены до своего финального вида.
-
Разделы сайта, содержащие информацию для внутреннего круга лиц. Особенно актуально в тех случаях, когда разработка ведётся группой специалистов, а не одним человеком.
-
Сайты-аффилиаты. Их поисковые системы особенно не любят. Так что, если не хотите выпасть из выдачи, отправлять в индекс такой контент не стоит.

Как закрыть от индексации поддомен?
Поисковые системы распознают каждый отдельно взятый поддомен, как самостоятельный сайт. А значит каждый из них нуждается в собственном файле robots.txt. Поэтому всё, что от вас требуется – добавить в этот файл директиву, закрывающую его от глаз поисковых ботов.
В общем, если рассматривать каждый поддомен, как самостоятельный сайт, то это поможет вам существенно упростить все работы по его разработке. Разумеется, в плане продвижения он будет зависим от основного.
Как запретить индексацию сайта на WordPress?
Будучи наиболее широко распространённой CMS, WordPress уже давно обзавёлся собственными инструментами на все случаи жизни. Причём, скрыть сайт целиком можно буквально в пару кликов:
-
Вам нужно зайти в панель администратора.
-
Перейдите в раздел «Настройки». Выберите там «Чтение».
-
Теперь нужно лишь кликнуть на пункт «Попросить поисковые системы не индексировать сайт».

Плагины для WordPress
Закрыть отдельные страницы вашего сайта помогут плагины, широко представлены во внутренней библиотеке. В качестве примера можно взять Yoast SEO. Он как раз-таки и создан, дабы упростить процесс настройки индексации ваших страниц.
Страницы закрываются от сканирования буквально в пару действий:
-
Откройте нужную страницу и войдите в режим редактирования. Пролистайте её до конца и перейдите к окну плагина.
-
Режим индексации настраивается во вкладке «Дополнительно».
Как открыть сайт для индексации?
Наиболее актуальным будет открытие сайта через файл robots.txt. Будучи основным элементом управления действиями поисковых ботов, он позволяет быстро решить проблему с отсутствием страниц в выдаче. Воспользуйтесь директивой Allow, дабы открыть всё содержимое для сканирования.
Воспользуйтесь директивой Allow, дабы открыть всё содержимое для сканирования.
Если вы не уверены, открыт ли сайт для индексации, или какие его части закрыты для посещения ботами, можно воспользоваться внутренними службами поисковых систем. Это Яндекс.Вебмастер и Google Search Console. Через них вы сможете точно узнать – какие URL-адреса вашего сайта находятся в индексе. Это позволит составить начальное представление о положении дел конкретного ресурса и решить, что с ним делать дальше.
Как проверить свой Robots.txt?
Составление технического файла – дело достаточно сложное, особенно если вам приходится заниматься этим впервые.
Чтобы убедиться, что всё было сделано правильно и в соответствии с требованиями поисковых систем, необходимо воспользоваться внутренними инструментами Яндекса и Google.
Помните о том, что поисковики по-разному подходят к процессу проверки этого файла. Поэтому каждый раз нужно проводить две проверки.
Яндекс.Вебмастер
После добавления сайта в сервис и подтверждения прав владения, вы получите доступ ко всем необходимым инструментам. Для проверки файла robots.txt нужно обратиться к валидатору Яндекса:
-
Перейдите в личный кабинет Яндекс.Вебмастер.
-
В разделе «Инструменты» найдите пункт «Анализ robots.txt».
-
Как правило, проверка происходит автоматически. Скрипт самостоятельно находит нужный файл и оценивает его на соответствие. Но если по какой-то причине сканирование не началось, вы можете скопировать код и вручную вставить его в поле для проверки.
-
В отчёте, составленном по итогам проверки, будут указаны директивы, в которых допущены ошибки. Сервис также даст рекомендации по их устранению.
Google Search Console
Самый популярный поисковик в мире оказывает полное содействие всем вебмастерам, которые работают над продвижением своих ресурсов. Если вы хотите просканировать файл robots.txt, вам потребуется сделать следующее:
Если вы хотите просканировать файл robots.txt, вам потребуется сделать следующее:
-
Зайдите в личный кабинет и перейдите к инструменту проверки.
-
На открывшейся странице будет отображаться информация из нужного файла. Если она содержит неактуальную версию, всё равно нажмите отправить и следуйте дальнейшим инструкциям поисковой системы.
-
Спустя несколько минут обновите страницу и ещё раз проверьте содержимое на соответствие актуальной версии файла robots.txt.
Помните о том, что вносить правки в окне проверки можно, но они не приведут к автоматическому изменению в файле robots.txt вашего сайта. Исправлять код придётся вручную через админку.
Как закрыть страницы от индексации?
Поисковым роботам закрывают доступ к ресурсам, которые находятся в разработке или процессе редизайна. Запрет на индексацию накладывают также на сайты, где вебмастера тестируют доработки и проводят эксперименты. Из поиска стоит убрать служебные разделы блога, страницы с личными кабинетами, неактуальные данные, версии для печати, страницы различных фильтраций. Чтобы уменьшить нагрузку на сервер и ускорить индексацию, рекомендуем закрыть от поисковых ботов скрипты информеров и онлайн-консультантов, pop-up-окна, баннеры и тяжелые файлы, например, фотографии.
Из поиска стоит убрать служебные разделы блога, страницы с личными кабинетами, неактуальные данные, версии для печати, страницы различных фильтраций. Чтобы уменьшить нагрузку на сервер и ускорить индексацию, рекомендуем закрыть от поисковых ботов скрипты информеров и онлайн-консультантов, pop-up-окна, баннеры и тяжелые файлы, например, фотографии.
В статье расскажем, как закрыть от индексации сайт целиком и его отдельные элементы с помощью файла robots.txt.
Закрываем сайт
Создайте файл robots.txt и загрузите его в корневую папку сайта. Включите в файл строчку вида:
User-agent: *
Disallow: /
Так вы наложите вето на индексацию сайта всем поисковикам без исключения.
Если вы хотите закрыть сайт только от Яндекса, строчка будет выглядеть так:
User-agent: Yandex
Disallow: /
Аналогичным образом, подставляя вместо Yandex имена других поисковых ботов, вы можете запретить индексацию и для них:
Googlebot.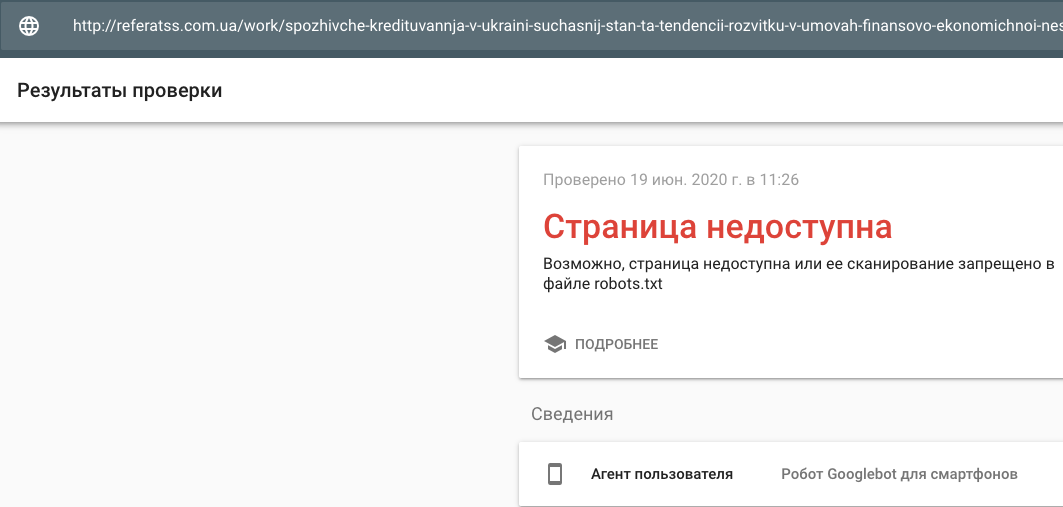 Из имени видно, что этот робот принадлежит системе Google.
Из имени видно, что этот робот принадлежит системе Google.
Slurp. Индексирует сайты в системе Yahoo!.
MSNBot. Работает в поисковике Bing.
SputnikBot. Поисковый бот системы «Спутник» .
Закрываем папку и файлы
Чтобы закрыть конкретную папку, пропишите ее название в строке, которая запрещает индексацию. Например, вы хотите спрятать от поисковиков папку «papka1». Пропишите в файле robots.txt:
User-agent: *
Disallow: /papka1/
В этом случае она будет недоступна для поисковых ботов вместе со всеми файлами, которые в нее входят.
Если вы хотите один из файлов в закрытой папке сделать открытым для индексации, используйте одновременно две директивы — Allow (разрешить) и Disallow (запретить):
User-agent: *
Allow: /papka1/file1.php
Disallow: /papka1/
Закрываем картинки
Если вы хотите закрыть все картинки из конкретной папки, в robots. txt пропишите директиву Disallow для этой папки, например:
txt пропишите директиву Disallow для этой папки, например:
User-agent: *
Disallow: /imgpapka/
Если вам нужно закрыть только одну картинку, укажите путь к ней:
User-Agent: *
Disallow: /img/pixel23.gif
Для запрещения картинок определенного формата используйте строчки:
User-Agent: *
Disallow: *.jpg
В зависимости от задачи вместо *.jpg можно указать *.png или *.gif.
Закрываем поддомен
Как правило, файл robots.txt есть у каждого поддомена в его корневой папке. Если файла нет, создайте его. Далее выполните процедуру таким же образом, как это описано для сайта.
Если вы используете Content Distribution Network (CDN), то дубль на поддомене может ухудшить результаты по SEO. Есть два варианта решения проблемы.
Первый — создать на поддомене с CDN отдельный файл robots.txt, в котором прописать запрет на индексацию. Однако в этом случае пострадают поведенческие факторы. Поисковая система не будет учитывать посетителей сайта, если они посещают страницы, размещенные на поддомене.
Второй — выполнить настройку атрибута rel=»canonical» тега <link> с отсылкой к основному домену. В этом случае данные о поведенческих факторах на сайте и поддомене будут суммироваться.
Закрываем сайт или страницу мета-тегом «robots»
Поисковые боты с большей вероятностью обойдут ваш сайт стороной, если вы запретите индексацию путем использования тега robots. Его прописывают в начале кода между тегами <head> и </head>.
Запись для всех роботов:
<meta name=»robots» content=»noindex, nofollow»/>
Или:
<meta name=»robots» content=»none»/>
Для конкретного робота robots заменяется на имя робота, например:
<meta name=»yandex» content=»noindex, nofollow»/>
Другие директивы в robots.
 txt для робота Яндекс
txt для робота ЯндексВы можете использовать дополнительные параметры для бота поисковой системы Яндекс:
-
Установить минимальный промежуток времени между концом загрузки одной страницы и началом загрузки следующей. Это позволяет снизить нагрузку на сервер сайта. Например:
Crawl-delay: 0.3
где 0,3 — время в секундах. -
Отказаться от многократной перезагрузки дублирующихся данных для повышения эффективности обхода сайта. Рекомендовано использовать в том случае, если страницы блога содержат ref-ссылки, идентификаторы сессий, UTM-метки или другие GET-параметры. Записывается в виде:
Clean-param: utm/catalog/get_book.p1
-
Подсказать поисковым роботам, какие страницы сайта нужно проиндексировать. Запись выглядит следующим образом:
Sitemap: https://site.ru/sitemap.xml
2 Апреля 2019
Запретить поисковым системам индексировать ваш сайт
Если вы запретите поисковым системам индексировать ваш сайт WordPress, он не будет сканироваться, индексироваться и отображаться где-либо в результатах поиска. Вы разработали веб-сайт и оптимизировали его, чтобы повысить шансы на ранжирование в результатах поиска. Итак, почему вы хотите заблокировать поисковые роботы и индексаторы?
Вы разработали веб-сайт и оптимизировали его, чтобы повысить шансы на ранжирование в результатах поиска. Итак, почему вы хотите заблокировать поисковые роботы и индексаторы?
К концу поста вы узнаете 5 самых важных причин, по которым ваш сайт не индексируется, а также способы отключения индексации поисковыми системами.
- Зачем отговаривать поисковые системы от индексации вашего сайта WordPress
- Запретить поисковым системам индексировать сайты WordPress
- Защита паролем веб-сайтов с помощью cPanel
- Использовать плагин для защиты паролем WordPress Pro
- Использовать функцию видимости поисковой системы WordPress
- 3 распространенных мифа о robots.txt
- Ограничения файла robots.txt
- Запретить Google индексировать страницы и сообщения WordPress
- Использовать метатег robots
- Использовать HTTP-заголовок x-robots-tag
- Используйте плагин защиты страниц и сообщений WordPress
- Запрет поисковым системам индексировать файлы WordPress
- Редактировать robots. txt
- Запретить Google индексировать страницы вложений
- Использовать плагин Yoast SEO
- Используйте плагин Prevent Direct Access Gold
- Редактировать robots.
 txt
txtПочему не рекомендуется поисковым системам индексировать ваш сайт WordPress
Существует 5 распространенных случаев, когда вы можете потребовать, чтобы поисковые системы прекратили сканирование и индексирование вашего сайта WordPress и его контента:
1. Обслуживание и скоро будут страницыСтраница обслуживания сообщает пользователям, что ваш сайт все еще находится в разработке. Эта страница не должна быть проиндексирована и отображаться в результатах поиска, потому что она не будет предоставлять никаких значений после того, как сайт будет запущен.
2. Дублированный контент Вы создаете клон веб-сайта в целях разработки. Однако вы не хотите, чтобы этот сайт конкурировал с существующим. Само собой разумеется, что Google может рассматривать их как повторяющиеся веб-сайты и отображать один из этих двух в результатах поиска. Что, если он ранжирует ваш тестовый сайт вместо основного? Хранение дублирующего сайта вдали от Google оказывается полезным для более высокого рейтинга более важного веб-сайта.
Что, если он ранжирует ваш тестовый сайт вместо основного? Хранение дублирующего сайта вдали от Google оказывается полезным для более высокого рейтинга более важного веб-сайта.
Посетители могут искать URL-адреса страницы заказа и благодарности, которые включают ценные предложения, чтобы украсть ваши продукты. Если это так, эти страницы не должны индексироваться и показываться в результатах поиска публично.
4. Личный контентКогда вы пишете журналы или дневники и размещаете их на своем веб-сайте блога, у вас есть веская причина сделать его недоступным для поиска. В результате никто даже не узнает о существовании вашего блога.
5. Управление проектами Пока ваша команда работает над проектом, вы можете создать неиндексируемый сайт для обмена внутренней информацией с членами команды. Этот веб-сайт будет скрыт от поисковых роботов Google. Только члены команды могут искать и получать доступ к сайту.
Теперь мы покажем вам конкретные решения для отключения индексации поиска в зависимости от областей сайта, которые вы хотите защитить.
Запретить поисковым системам индексировать сайты WordPress
Существует 3 распространенных способа запретить поисковым системам индексировать сайты WordPress:
- Пароль, защищающий каталог с помощью cPanel
- Использование плагина для защиты паролем всего сайта
- Включение функции видимости поисковой системы WordPress
Прежде чем углубляться во встроенную функцию WordPress, давайте начнем с метода защиты паролем. Вы можете либо указать пароль для инструмента панели управления вашего сайта, либо установить пароль через плагин. Каждый метод защищает ваш сайт по-своему.
1. Защита паролем веб-сайтов с помощью cPanelcPanel предлагает один из самых популярных и удобных инструментов веб-хостинга для управления всеми веб-сайтами. Чтобы защитить паролем свой сайт, выполните следующие 5 шагов:
- Войдите в панель управления cPanel и откройте Защитить паролем каталоги
- Выберите каталог, в котором размещен ваш сайт WordPress на
- Выберите Пароль Защитить этот каталог опция
- Создайте учетную запись пользователя с именем пользователя и паролем
- Сохраните изменения
Если веб-сайт защищен паролем через cPanel, пользователи должны вводить имя пользователя и пароль при доступе к веб-сайту. Вот почему вы можете рассмотреть возможность использования плагина защиты паролем.
Вот почему вы можете рассмотреть возможность использования плагина защиты паролем.
Password Protect WordPress Pro защищает ваш сайт WordPress с помощью одного пароля, защищая его от поисковых роботов и индексаторов. Этот метод дает вам больший контроль над инструментом защищенных паролем каталогов cPanel, поскольку он не требует имени пользователя.
После активации вам необходимо:
- Перейти на страницу настроек
- Убедитесь, что расширенная функция Block Search Indexing включена
- Перейдите на вкладку Весь сайт и введите пароль для защиты вашего сайта
- Сохраните изменения
После защиты паролем ваш сайт становится невидимым для поисковых роботов и нигде не отображается в результатах поиска. Только те, у кого есть правильные пароли, могут разблокировать частный сайт.
Кроме того, плагин позволяет исключить некоторые страницы из общей защиты сайта. Другими словами, эти страницы будут доступны для поиска, в то время как остальная часть веб-сайта скрыта от поисковых систем.
3. Используйте функцию видимости для поисковых систем WordPress. Чтобы включить опцию, вам необходимо:- Найти Настройки в панели управления WordPress
- Нажмите на опцию Чтение под
- Включить параметр « Запретить поисковым системам индексировать этот сайт »
Как только вы установите флажок Запретить поисковым системам индексировать этот сайт , WordPress использует файл robots.txt и метатег, чтобы защитить ваш сайт от поисковых роботов и индексаторов.
WordPress редактирует файл robots.txt, используя следующий синтаксис:
Агент пользователя: * Запретить: /
В то же время он добавляет эту строку в заголовок вашего веб-сайта:
Вы можете задаться вопросом, является ли это хорошим решением, чтобы отговорить поисковые системы от индексация вашего сайта. Это влияет на SEO-рейтинг вашего сайта. Вашему контенту сложно подняться в рейтинге.
Это влияет на SEO-рейтинг вашего сайта. Вашему контенту сложно подняться в рейтинге.
3 распространенных мифа о Robots.txt
Robots.txt — это текстовый файл, созданный веб-мастерами, чтобы запретить поисковым системам сканировать страницы вашего веб-сайта. Многие люди, в том числе WordPress, рекомендуют использовать его для ограничения индексации веб-сайтов, контента и файлов.
Однако не все из нас знают, как правильно использовать файлы robots.txt. Ниже приведены 3 распространенных мифа о robots.txt, которые большинство пользователей неправильно понимают.
1. Robots.txt помогает блокировать поисковое индексирование Владельцы сайтов WordPress считают, что правила запрета robots.txt широко используются для предотвращения индексации вашего сайта поисковыми системами. Однако это не предназначено для блокировки поисковых индексаторов, а для управления сканирующим трафиком на ваш сайт. Например, вы используете robots.txt, чтобы избежать сканирования неважных или похожих страниц. Более того, вы можете использовать robots.txt, когда к вашему серверу поступает много запросов от поисковых роботов Google.
Более того, вы можете использовать robots.txt, когда к вашему серверу поступает много запросов от поисковых роботов Google.
Чтобы запретить поисковым системам индексировать ваш сайт, вам следует рассмотреть возможность использования метатега robots и HTTP-заголовка x-robots-tag.
2. Контент не будет проиндексирован без сканированияGoogle выполняет 3 основных шага для получения результатов от веб-страниц, а именно сканирование, индексирование и обслуживание.
- Во-первых, сканирование — это когда Google обнаруживает все страницы, существующие на вашем сайте. Он использует множество методов для поиска страницы, таких как чтение карты сайта или переход по ссылкам с других сайтов и страниц.
- Затем Google индексирует ваши страницы, анализируя и понимая, о чем страница. Эта информация будет храниться в огромной базе данных под названием Google index.
- Наконец, Google начинает ранжировать ваш контент. Всякий раз, когда кто-то вводит ключевое слово в строку поиска, Google находит и предоставляет результаты с наиболее релевантным содержанием из своего индекса. Эти результаты будут основаны на более чем 200 факторах, включая качество контента страницы, местоположение пользователя, язык, устройство и т. д.
 Всякий раз, когда кто-то вводит ключевое слово в строку поиска, Google находит и предоставляет результаты с наиболее релевантным содержанием из своего индекса. Эти результаты будут основаны на более чем 200 факторах, включая качество контента страницы, местоположение пользователя, язык, устройство и т. д.
Всякий раз, когда кто-то вводит ключевое слово в строку поиска, Google находит и предоставляет результаты с наиболее релевантным содержанием из своего индекса. Эти результаты будут основаны на более чем 200 факторах, включая качество контента страницы, местоположение пользователя, язык, устройство и т. д.Таким образом, вы можете подумать, что если ваш контент не просканирован, он не будет проиндексирован. Поскольку файл robots.txt блокирует поисковые роботы Google, он также предотвратит индексацию поиска?
На самом деле страницы, заблокированные robots.txt, не будут сканироваться, но все равно будут проиндексированы, если на них ссылаются с других сайтов. Скорее всего, ваши страницы все еще появляются в результатах поиска.
3. Robots.txt используется для сокрытия контента Люди часто используют файл robots.txt, чтобы контент не отображался в результатах поиска. Однако файл robots.txt указывает Google не читать, анализировать и понимать содержание. Таким образом, поисковые системы не будут знать, должны ли они индексировать ваши страницы или нет. В результате Google не предоставляет метаописание для страницы. Вместо этого пользователи увидят строку «Для этой страницы нет доступной информации. Узнайте, почему».
Таким образом, поисковые системы не будут знать, должны ли они индексировать ваши страницы или нет. В результате Google не предоставляет метаописание для страницы. Вместо этого пользователи увидят строку «Для этой страницы нет доступной информации. Узнайте, почему».
Robots.txt НЕ используется для сокрытия контента. На самом деле robots.txt затрудняет для Google анализ и защиту вашего личного контента. Чтобы эффективно скрыть контент, вы должны использовать другие методы, такие как защита паролем или метатег «noindex».
Как уже упоминалось, функция WordPress Search Engine Visibility работает на основе файла robots.txt. Вот почему это не мешает поисковым системам индексировать ваш контент.
Ограничения файла robots.txtСуществуют некоторые ограничения, которые следует учитывать при использовании robots.txt.
1. Файл robots.txt общедоступен
Файл robots. txt доступен всем. На самом деле файлы robots.txt всех сайтов находятся в корневом домене, а /robots.txt, например. www.example.com/robots.txt . Помещая URL-адреса страниц и файлов в файл robots.txt, вы случайно открываете непреднамеренный доступ. Боты и пользователи будут знать, какие страницы следует скрыть. Затем они могут получить URL-адреса и легко получить доступ к этим страницам 9.0003
txt доступен всем. На самом деле файлы robots.txt всех сайтов находятся в корневом домене, а /robots.txt, например. www.example.com/robots.txt . Помещая URL-адреса страниц и файлов в файл robots.txt, вы случайно открываете непреднамеренный доступ. Боты и пользователи будут знать, какие страницы следует скрыть. Затем они могут получить URL-адреса и легко получить доступ к этим страницам 9.0003
Чтобы преодолеть этот недостаток, вам нужно сгруппировать все файлы, для которых вы хотите отключить поисковое индексирование, в отдельной папке. Затем поместите свои файлы в эту папку и сделайте ее невидимой в Интернете. После этого укажите только имя папки в /robots.txt.
2. Другие роботы поисковых систем могут игнорировать ваш файл robots.txt
Хотя большинство роботов следуют вашему файлу robots.txt, вредоносные программы и сборщики адресов электронной почты, используемые спамерами, могут игнорировать его. Эти вредоносные роботы могут посещать ваш сайт и сканировать его на наличие такой информации, как электронные письма и формы для рассылки спама.
Вы должны использовать брандмауэры, блокировщики IP-адресов и плагины безопасности для повышения безопасности вашего сайта WordPress.
3. Каждый поисковый робот может читать синтаксис по-разному
Синтаксис в файле robots.txt применяется для большинства веб-сканеров. Тем не менее, каждый из них может читать и следовать правилам файла по-разному. Это объясняет, почему некоторые поисковые роботы не соблюдают правила запрета файлов и продолжают сканировать ваш сайт.
Не следует слишком полагаться на файл robots.txt для управления сканирующим трафиком.
Важность robots.txt Файл robots.txt оказывается полезным, когда вы четко понимаете, как он работает. Это не мешает контенту индексироваться. Файл robots.txt используется для управления сканирующим трафиком и предотвращения отображения загрузок в результатах поиска Google. Эта функция будет обсуждаться в разделе «Запретить поисковым системам индексировать файлы » ниже.
Запретить Google индексировать страницы и сообщения WordPress
Вместо того, чтобы защищать весь сайт от поисковых роботов и индексаторов, вы можете деиндексировать только некоторые определенные страницы, например страницы с конфиденциальной информацией или страницы с благодарностью.
Чтобы запретить Google индексировать ваш контент, выберите один из этих 3 отдельных путей: редактирование метатега robots, использование HTTP-заголовка X-Robots-Tag или использование плагина Protect WordPress Pages and Posts.
1. Используйте метатег robotsДобавление метатега noindex к страницам (X)HTML запрещает Google индексировать и делать ваш контент доступным в результатах поиска.
Поместите метатег robots в раздел
выбранной страницы, например:<заголовок> (…) (…)
Значение « robots » после мета-имени указывает, что страница или запись применимы ко всем поисковым роботам.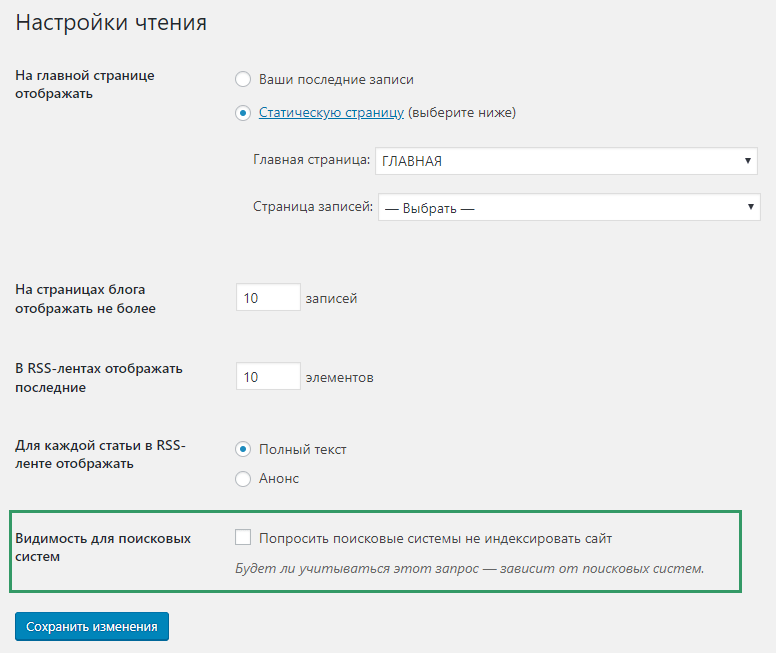 Замените « robots » на имя конкретного бота, индексацию которого вы собираетесь заблокировать, например Googlebot — поисковый робот Google. Посетители смогут найти ваш контент не в результатах поиска Google, а через другие поисковые системы, такие как Bing или Ask.com.
Замените « robots » на имя конкретного бота, индексацию которого вы собираетесь заблокировать, например Googlebot — поисковый робот Google. Посетители смогут найти ваш контент не в результатах поиска Google, а через другие поисковые системы, такие как Bing или Ask.com.
Более того, вы можете использовать несколько метатегов robots одновременно, если вы хотите указать разные поисковые роботы по отдельности. Например:
Подобно метатегу robots, вы также можете использовать HTTP-заголовок X-Robots-Tag, чтобы запретить поисковым системам индексировать контент на уровне страницы. Поместите следующий синтаксис в заголовок HTTP:
HTTP/1.1 200 ОК Дата: вторник, 25 мая 2010 г., 21:42:43 по Гринвичу (…) X-Robots-Tag: noindex (…)
Методы метатегов robots и x-robots-tag HTTP-заголовков кажутся слишком сложными для тех, у кого нет хороших навыков программирования.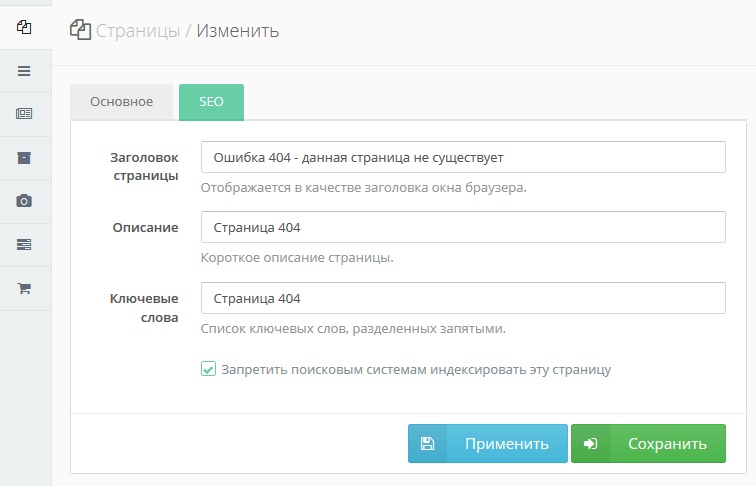 К счастью, Protect Pages and Posts WordPress упрощает использование метатега robots и HTTP-заголовка x-robots-tag.
К счастью, Protect Pages and Posts WordPress упрощает использование метатега robots и HTTP-заголовка x-robots-tag.
«Защита страниц и сообщений WordPress» скрывает ваш контент от индексаторов на основе того, как работают метатеги robots и HTTP-заголовки x-robots-tag.
Пользователи не могут найти ваши исходные URL-адреса контента. Вместо этого плагин автоматически генерирует уникальные частные ссылки, которые позволяют вам делиться защищенными страницами и сообщениями с другими. Вы можете настроить эти ссылки, чтобы сделать их значимыми, запоминающимися и законными.
Чтобы контент не был широко распространен среди других, срок действия частных ссылок может истечь в течение нескольких дней или кликов. Например, вы можете установить использование ссылки на один раз. Пользователи будут видеть страницу 404 после загрузки каждой страницы.
Запретить поисковым системам индексировать файлы WordPress
Существует ряд способов сделать ваши файлы невидимыми для поисковых роботов, например, редактирование файлов robots. txt, защита страниц вложений или использование плагина Prevent Direct Access.
txt, защита страниц вложений или использование плагина Prevent Direct Access.
Как упоминалось выше, файл robots.txt не препятствует индексации отдельных веб-страниц поисковыми системами. Он удерживает только медиафайлы, кроме PDF и HTML, подальше от глаз Google. Поместите следующий синтаксис в данный файл, который вы хотите исключить поисковые системы:
Агент пользователя: Googlebot-Image Disallow: /[slug]/
Обновите ярлык с конкретными URL-адресами файлов, которые вы хотите заблокировать при поиске. Вы также можете добавить символ доллара ($), чтобы заблокировать все файлы, оканчивающиеся на определенную строку URL. Например:
Агент пользователя: Googlebot Disallow: /*.xls$
Все файлы, заканчивающиеся на .xls, теперь заблокированы для индексации Google.
2. Запретить Google индексировать страницы вложений Другой способ запретить поисковым системам индексировать файлы — использовать страницы вложений.
Вложения относятся к любым типам загрузки веб-сайта, таким как изображения, видео и аудио. Как только файл загружается, WordPress создает страницу вложения, которая включает файл, а также соответствующие подписи и описания.
Вы должны запретить поисковым системам находить и ранжировать эти страницы, поскольку они содержат очень мало контента или вообще не содержат его. Эти страницы могут разочаровать посетителей, желающих найти информативные статьи.
Существуют различные способы сделать так, чтобы Google не смог проиндексировать ваши страницы вложений WordPress, либо вручную отредактировав метатег robots и HTTP-заголовок x-robots-tag, либо используя плагин Yoast SEO.
Редактирование метатега robots и HTTP-заголовка x-robots-tag для страниц вложений выполняется так же, как и редактирование метатега и HTTP-заголовка x-robots-tag для стандартных страниц. Однако этот метод кажется слишком сложным и трудоемким, если вы хотите предотвратить одновременную индексацию нескольких файлов.
Вы также можете использовать Yoast SEO, чтобы защитить ваши файлы от поисковых роботов и индексаторов Google. Активируйте плагин и выполните следующие 5 шагов:
- Перейдите к Настройки SEO в раскрывающемся списке Yoast
- Выбрать Внешний вид поиска
- Головка Носитель Вкладка
- Включить параметр « Перенаправить URL-адреса вложений на само вложение »
- Сохраните изменения
Prevent Direct Access Gold блокирует поисковые системы от индексации ваших файлов. В отличие от метатегов robots и HTTP-заголовков x-robots-tag, плагин не требует никакого технического кодирования.
После активации плагин автоматически поместит метатег noindex в
каждой страницы вложений, чтобы отключить поисковое индексирование.
Более наглядное руководство можно найти в этом обучающем видео.
Готовы заблокировать поисковую систему от индексации вашего сайта?
Вручную запретить поисковым системам индексировать сайты, контент и файлы WordPress непросто. Нужно искать решения для упрощения процесса.
Вы можете установить Password Protect WordPress Pro, чтобы защитить весь ваш сайт от поисковых роботов. Это связано с тем, что встроенная функция чтения по-прежнему позволяет поисковым роботам заходить и индексировать ваш сайт, если на него есть ссылки с других сайтов и страниц.
Считаете редактирование метатега и HTTP-заголовка X-Robots-Tag слишком сложным? Плагин Protect WordPress Pages and Posts автоматически делает страницы и сообщения невидимыми для поисковых систем.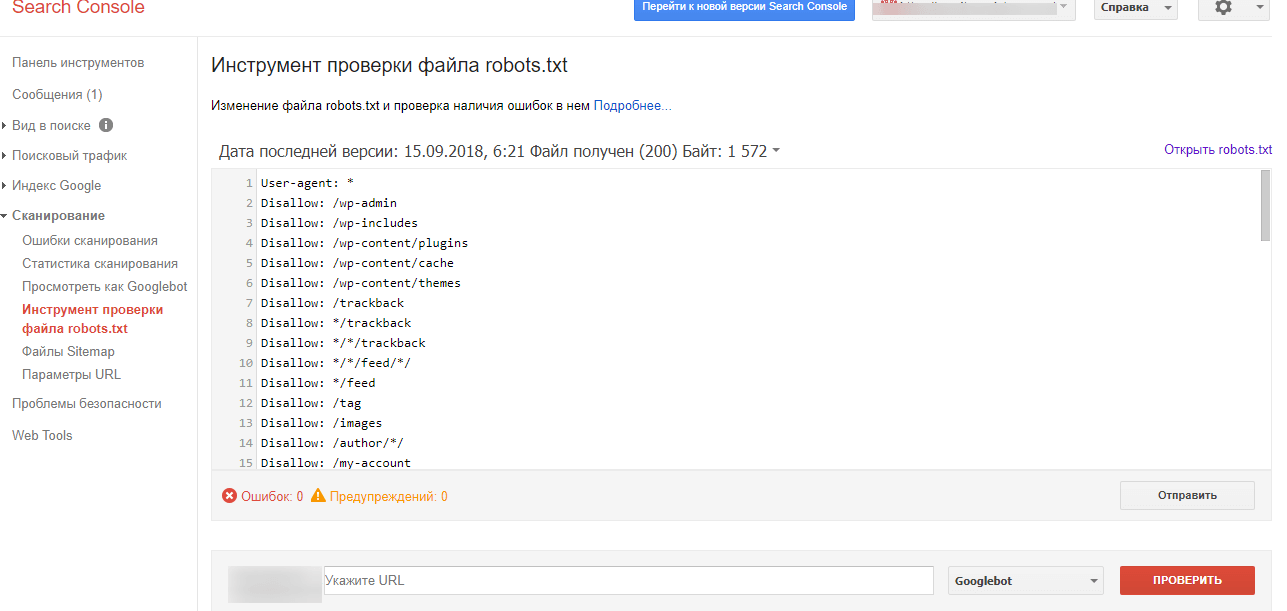
Плагин Prevent Direct Access Gold экономит вам много времени, отключая поисковые системы от индексации файлов WordPress и страниц вложений. Это быстрее, чем блокировать отдельные файлы с помощью метатега robots или HTTP-заголовка X-Robots-Tag.
Пожалуйста, оставьте комментарий ниже, если у вас есть какие-либо вопросы о том, как предотвратить сканирование и индексацию вашего сайта WordPress.
Проиндексировано, хотя и заблокировано robots.txt: как исправить
Содержание
Основная функция ботов — сканирование поисковыми системами и архивирование истории веб-страниц. Иногда вы хотите, чтобы части вашего веб-сайта, содержащие важную информацию, были доступны для ботов в поисковой системе. Здесь robots.txt — это один из методов, который вы можете использовать для достижения этой цели. Однако неправильно созданный robots.txt может означать, что важные части вашего сайта недоступны для поисковых систем. Так что страницы, заблокированные в файле robots. txt таким образом, могут быть проблемными. Основная причина в том, что Google рассматривает страницы так, как будто на них нет контента, потому что они заблокированы для сканирования.
txt таким образом, могут быть проблемными. Основная причина в том, что Google рассматривает страницы так, как будто на них нет контента, потому что они заблокированы для сканирования.
Что такое Robots.txt?
Robots.txt — это простой текст, сообщающий поисковой системе, какие части вашего сайта могут быть идентифицированы, какой индекс сканировать, к какой поисковой системе есть доступ или нет. Когда на ваш сайт заходит поисковая программа, также называемая пауком, она сканирует файл и идентифицирует разрешенные части сайта в соответствии с инструкциями в файле. Проще говоря, robots.txt похож на исследование шлюзов вашего сайта. Это позволяет вам решить, в какие шлюзы могут входить роботы, а какие роботы в поисковых системах могут входить, а какие нет. Если файл robots.txt и его инструкции настроены правильно, поисковые системы следуют этим правилам и сканируют ваш сайт в соответствии с предоставленными вами инструкциями. Этот процесс называется стандартом блокировки роботов (или протоколом блокировки роботов).
Если файл robots.txt и его инструкции настроены правильно, поисковые системы следуют этим правилам и сканируют ваш сайт в соответствии с предоставленными вами инструкциями. Этот процесс называется стандартом блокировки роботов (или протоколом блокировки роботов).
Файл robots.txt должен быть файлом на сайте, и он должен быть правильно настроен. Файл robots.txt, не измененный с помощью соответствующих команд, не будет рассматриваться поисковыми системами, а направления, которые вы не хотите сканировать, также могут быть проигнорированы. Поэтому этот небольшой, но очень важный файл следует правильно отформатировать.
Как создать файл robots.txt?
Скрипт robots.txt должен быть настроен в рамках определенных уровней и таким образом загружен в корневую директорию вашего сайта. Во-первых, необходимо, чтобы ваш файл robots.txt находился в корневом каталоге вашего сайта, а не в подпапке или на отдельных страницах, где создается файл. Если нам нужно подать пример для правильного использования; Можно сказать, что можно в виде https://www. Abcd.Com/robots.txt. Однако использование https://www.Abcd.Com/main/robots.txt может быть неправильным использованием robots.Txt. Файл robots.txt должен быть текстовым. Поскольку файл постоянно обновляется, вы должны хранить его в формате, с которым вы можете работать в любое время, скрывая или удаляя его. Если вы хотите узнать больше о создании файла robots.txt, ознакомьтесь с нашей статьей по теме.
Abcd.Com/robots.txt. Однако использование https://www.Abcd.Com/main/robots.txt может быть неправильным использованием robots.Txt. Файл robots.txt должен быть текстовым. Поскольку файл постоянно обновляется, вы должны хранить его в формате, с которым вы можете работать в любое время, скрывая или удаляя его. Если вы хотите узнать больше о создании файла robots.txt, ознакомьтесь с нашей статьей по теме.
Размещенный URL-адрес заблокирован Файл robots.txt Что это значит?
Эта ошибка произошла, когда вы отправили свою страницу для идентификации, и боты Google не смогли получить доступ к вашему сайту из-за команды в файле robots.txt. Очень часто встречается на новых сайтах или сайтах доставки.
Как это исправить: Удалите строку кода, которая препятствует идентификации сайта в вашем файле Robots.txt. Чтобы проверить это, используйте тестовый инструмент robots.txt, установленный в старой версии. Новый Google SC не сразу обнаружит ваш файл robots.txt, поэтому используйте тестовый инструмент.
Что означает индексирование сообщений?
При использовании SQL-запросов доступ к данным с диска может занять некоторое время. Здесь он указывает на структуру данных, которая помогает быстро найти и получить доступ к оглавлению, содержащемуся в базе данных. Метод идентификации уменьшает количество дисков, доступных для транзакционных запросов. Руководство состоит из двух частей; ключ поиска и ссылка на данные. Ключ просмотра содержит ключ или ключ таблицы-кандидата. Таким образом, ссылка на данные содержит адрес диска со значением, соответствующим этому ключу. Также существует несколько типов индикаторов.
Вот некоторые из них:
- Отфильтрованный индекс
Отфильтрованные индексы позволяют осуществлять быстрый поиск данных.
- Индекс ключа
Использует комбинацию двух или более столбцов для создания индекса. Группа записей содержит записи с похожей структурой.
И эти группы образуют подсказки. - Комбинированный индекс
Использует комбинацию двух или более столбцов для создания индекса. Группа записей содержит записи с похожей структурой. И эти группы образуют подсказки.
- Ввод второго индекса
Включает другой уровень индекса для уменьшения размера совпадения.
 И эти группы образуют подсказки.
И эти группы образуют подсказки.Кратко проиндексировано, но заблокировано robots.txt
Если вы просто создаете свой веб-сайт или хотите изменить существующий дизайн, первое, что вам нужно, это файл robots.txt. Если на вашем работающем веб-сайте нет файла robots.txt, рекомендуется немедленно создать файл robots.txt. Мы можем честно сказать, что более половины сайтов, на которых мы делали SEO-проект, не имели файла robots.txt, что создавало массу сложностей. Однако при быстром вмешательстве можно создать файл robots.txt с нужными уровнями и устранить недостатки. Итак, если вам понравилась наша статья про проиндексированный, но заблокированный robots. txt случай, обязательно ознакомьтесь с другими нашими статьями на эту тему. Например, вам также может понравиться наш технический контрольный список SEO.
txt случай, обязательно ознакомьтесь с другими нашими статьями на эту тему. Например, вам также может понравиться наш технический контрольный список SEO.
Часто задаваемые вопросы
Зачем мне нужен файл robots.txt?
Все основные поисковые системы ищут файлы robots.txt, как только они попадают на ваш сайт. Всегда полезно иметь файл robots.txt в любой части вашего сайта, хотите вы этого или нет, чтобы предотвратить проникновение пауков.
Зачем мне останавливать пауков?
Возможно, сайт еще не готов. Или он может содержать незавершенные страницы. В этом случае вы можете не захотеть, чтобы ваш сайт или страницы индексировались посередине. У вас может быть контент или категория на вашем сайте, которые не требуют шифрования, но все же важны для вас, и вы можете не хотеть, чтобы они регистрировались в поисковых системах и отображались в поиске. А причин может быть еще много.
А причин может быть еще много.
Как защитить конкретный файл от банка с помощью robots.txt?
Например, вы создаете раздел под названием «Новости» и не хотите, чтобы роботы приходили и записывали до того, как они закончат. В этом случае вы должны использовать звездочку «*» вместо прямого указания имени робота, потому что целью является робот.
Что означает индекс Google?
Каталог Google создается с помощью инструмента поиска Google для веб-мастеров. Если вам важен живой трафик из Google, то есть если вы хотите, чтобы ваши посетители находили вас в результате поиска Google и переходили на ваш сайт, вам обязательно следует зарегистрироваться в Search Console.
Как отредактировать отправленный URL, помеченный как «noindex»?
Удалите метатег «noindex» со страниц, которые вы хотите. Кроме того, если вы используете настраиваемую CMS, такую как WordPress, и есть плагин XML Sitemap, снимите флажок «Включить карту сайта в формате HTML».
Как исправить «Проиндексировано, но заблокировано robots.
 txt» в Google Search Console
txt» в Google Search Console26 ноя
26 ноя
Содержание
Краткий обзор
Определите затронутые страницы или URL-адреса
Определите причину уведомления
Неверный формат URL-адреса
Страницы, которые следует проиндексировать
Как проверить правильность файла Robots.txt в WordPress?
страниц, которые не должны быть индексированы
Старые URLS
Виртуальные роботы. уведомление в Google Search Console, вы захотите исправить это как можно скорее, так как это может повлиять на способность ваших страниц вообще занимать место на страницах результатов поисковой системы (SERPS).
Файл robots.txt — это файл, который находится в каталоге вашего веб-сайта и содержит некоторые инструкции для сканеров поисковых систем, таких как бот Google, относительно того, какие файлы они должны и не должны просматривать.
«Проиндексировано, хотя и заблокировано robots.txt» означает, что Google нашел вашу страницу, но также нашел указание игнорировать ее в вашем файле robots (что означает, что она не будет отображаться в результатах).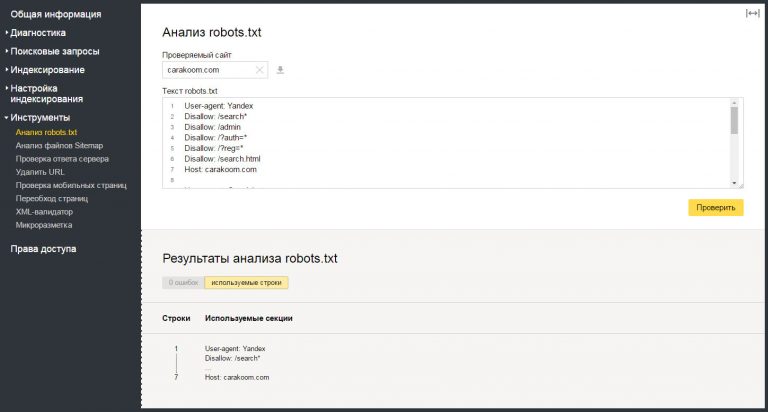
Иногда это делается намеренно, а что-то случайно, по ряду причин, изложенных ниже, и их можно исправить.
Скриншот уведомления:
Определите затронутые страницы или URL-адреса
Если вы получили уведомление от Google Search Console (GSC), вам необходимо идентифицируйте конкретную страницу (страницы) или URL (адреса), о которых идет речь.
Вы можете просматривать страницы с пометкой «Проиндексировано, но заблокировано robots.txt» в Google Search Console>>Coverage. Если вы не видите предупреждающую метку, то вы свободны и чисты.
Проверить файл robots.txt можно с помощью нашего тестера robots.txt. Вы можете обнаружить, что у вас все в порядке с тем, что все, что блокируется, остается «заблокированным». Поэтому никаких действий предпринимать не нужно.
Вы также можете перейти по этой ссылке GSC. Далее вам необходимо:
- Откройте список заблокированных ресурсов и выберите домен.
- Щелкните по каждому ресурсу. Вы должны увидеть это всплывающее окно:

Определите причину уведомления
Уведомление может быть вызвано несколькими причинами. Вот наиболее распространенные из них:
Но, во-первых, это не обязательно проблема, если есть страницы, заблокированные robots.txt. Он может быть разработан по причинам, таким как желание разработчика заблокировать ненужные страницы / страницы категорий или дубликаты. Итак, в чем расхождения?
Неверный формат URL-адреса
Иногда проблема может возникать из-за URL-адреса, который на самом деле не является страницей. Например, если URL-адрес https://www.seoptimer.com/?s=digital+marketing, вам необходимо знать, на какую страницу он указывает.
Если это страница, содержащая важный контент, который вам действительно нужно, чтобы ваши пользователи увидели, вам нужно изменить URL-адрес. Это возможно в системах управления контентом (CMS), таких как WordPress, где вы можете редактировать ярлык страницы.
Если страница не важна, или в нашем примере /?s=digital+marketing это поисковый запрос из нашего блога, то ошибку GSC исправлять не нужно.
Не имеет значения, проиндексирован он или нет, так как это даже не настоящий URL, а поисковый запрос. Кроме того, вы можете удалить страницу.
Страницы, которые должны быть проиндексированы
Существует несколько причин, по которым страницы, которые должны быть проиндексированы, не индексируются. Вот некоторые из них:
- Вы проверили свои директивы для роботов? Возможно, вы включили в файл robots.txt директивы, запрещающие индексацию страниц, которые действительно должны быть проиндексированы, например теги и категории. Теги и категории — это фактические URL-адреса на вашем сайте.
- Вы указываете роботу Googlebot цепочку переадресации? Робот Google просматривает каждую ссылку, которую может найти, и делает все возможное, чтобы прочитать ее для индексации. Однако, если вы настроите многократную, длинную, глубокую переадресацию или если страница просто недоступна, робот Googlebot перестанет искать.
- Правильно ли реализована каноническая ссылка? Тег canonical используется в заголовке HTML, чтобы сообщить роботу Googlebot, какая страница является предпочтительной и канонической в случае дублирования контента. Каждая страница должна иметь канонический тег. Например, у вас есть страница, переведенная на испанский язык. Вы сами сделаете каноническим URL-адрес на испанском языке и захотите вернуть страницу к английской версии по умолчанию.
 Однако, если вы настроите многократную, длинную, глубокую переадресацию или если страница просто недоступна, робот Googlebot перестанет искать.
Однако, если вы настроите многократную, длинную, глубокую переадресацию или если страница просто недоступна, робот Googlebot перестанет искать.
Как проверить правильность файла Robots.txt в WordPress?
Для WordPress: если ваш файл robots.txt является частью установки сайта, используйте плагин Yoast для его редактирования. Если вызывающий проблемы файл robots.txt находится на другом сайте, который не принадлежит вам, вам необходимо связаться с владельцами сайта и попросить их отредактировать файл robots.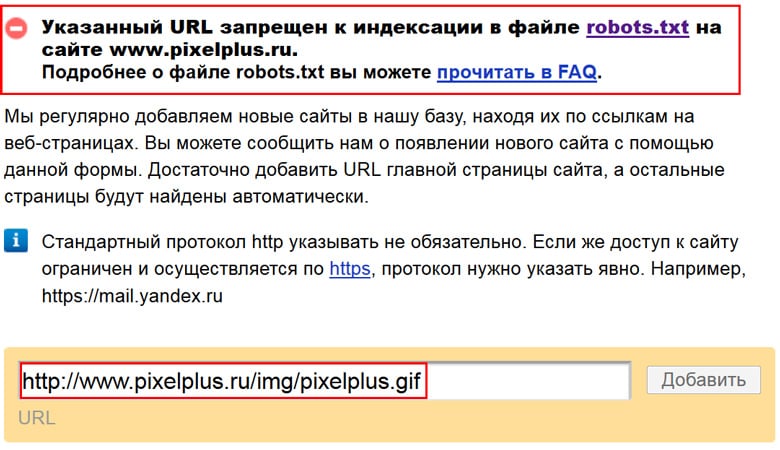 txt.
txt.
Страницы, которые не следует индексировать
Есть несколько причин, по которым страницы, которые не должны быть проиндексированы, индексируются. Вот некоторые из них:
Директивы robots.txt, которые «говорят», что страницу не следует индексировать . Обратите внимание, что вам нужно разрешить сканирование страницы с директивой noindex, чтобы роботы поисковых систем «знали», что ее нельзя индексировать.
В файле robots.txt убедитесь, что:
- Строка «disallow» не следует сразу за строкой «user-agent».
- Существует не более одного блока «агент пользователя».
- Невидимые символы Unicode — вам нужно запустить файл robots.txt через текстовый редактор, который преобразует кодировки. Это удалит любые специальные символы.
Страницы, на которые ведут ссылки с других сайтов . Страницы могут быть проиндексированы, если на них есть ссылки с других сайтов, даже если это запрещено в файле robots. txt. Однако в этом случае в результатах поиска отображаются только URL-адрес и текст привязки. Вот как эти URL-адреса отображаются на странице результатов поисковой системы (SERP):
txt. Однако в этом случае в результатах поиска отображаются только URL-адрес и текст привязки. Вот как эти URL-адреса отображаются на странице результатов поисковой системы (SERP):
источник изображения Webmasters StackExchange
Одним из способов решения проблемы блокировки robots.txt является защита паролем файлов на вашем сервере.
В качестве альтернативы удалите страницы из robots.txt или используйте следующий метатег, чтобы заблокировать
их:
Если вы создали новый контент или новый сайт и использовали директиву noindex в файле robots.txt, чтобы убедиться, что он не проиндексирован, или недавно зарегистрировались в GSC, есть два варианта устранения заблокированного Ошибка robots.txt: В первом случае Google в конечном итоге удаляет URL-адреса из своего индекса, если все, что они делают, — это возвращают 404 (это означает, что страницы не существуют). Есть возможность получения уведомления, даже если у вас нет файла robots.txt. Это связано с тем, что сайты на основе CMS (Customer Management Systems), например WordPress, имеют виртуальные файлы robots.txt. Плагины также могут содержать файлы robots.txt. Это могут быть те, которые вызывают проблемы на вашем сайте. Эти виртуальные файлы robots.txt необходимо перезаписать вашим собственным файлом robots.txt. Убедитесь, что в файле robots.txt есть директива, позволяющая всем ботам поисковых систем сканировать ваш сайт. Это единственный способ указать URL-адресам индексировать их или нет. Вот директива, позволяющая всем ботам сканировать ваш сайт: User-agent: * Disallow: / Это означает «ничего не запрещать».
00054 00054 URL-адреса Не рекомендуется использовать плагины для перенаправления ошибок 404. Плагины могут вызвать проблемы, которые могут привести к тому, что GSC отправит вам предупреждение «заблокировано robots.txt».
Не рекомендуется использовать плагины для перенаправления ошибок 404. Плагины могут вызвать проблемы, которые могут привести к тому, что GSC отправит вам предупреждение «заблокировано robots.txt». Виртуальные файлы robots.txt