
Закрываем сайт от индексации в файле robots.txt
- Введение
- Для чего нужен запрет индексации
- Запрещаем индексацию сайта
- При помощи robots.txt
- При помощи тэгов
- Запрещаем индексацию страницы
- При помощи robots.txt
- При помощи тэгов
- Популярные ошибки
- Делаем выводы
Введение
Сегодня трафик из поисковых систем для многих сайтов является основным источником посетителей. Для того, что бы Ваш ресурс появился в поиске, Yandex (Google, Rambler и т.д.) должен сначала найти его, а затем скачать к себе в базу. Этот процесс и называется индексацией.
Индексация проводится не один и не два раза. Робот посещает Ваш сайт на протяжении всей его «жизни» или до момента запрета. Именно о запрете сегодня и пойдет речь.
Запретить индексацию означает не дать участвовать в поиске всему сайту или определенному списку страниц.
Для чего нужен запрет индексации
Существует множество причин для полного и частичного запрета. Разберем по порядку.
Нежелание участвовать в поиске. Самая банальная причина. Вы просто не хотите, что бы сайт участвовал в результатах поиска.
Сайт находится в разработке. Робот индексирует сайт всегда, вне зависимости от того, находится он в разработке или уже закончен.
Поэтому, если работы проводятся не на локальном хостинге, то необходимо запретить поисковым системам индексировать сайт до тех пор, пока он не будет готов. Вот лишь ряд причин, почему необходимо скрывать от поисковика все, что еще не доделали.В процессе разработки размещается демо контент, уникальность которого крайне низка. Видеть такой материал поисковая система не должна.
Сайт разрабатывается без наполнения и окончательной структуры. Не нужно вводить в заблуждение поисковую систему, иначе ресурс будет признан не интересным для пользователей еще до того, как его наполнят.

Во время технических работ появляется множество дублей страниц. Нельзя допустить попадания их в индекс.
Ряд других технических причин.
Информация не для поиска. На любом сайте существуют страницы и разделы, которые не должны участвовать в поиске. К ним относится система управления сайта, результаты вычислений, дубликаты URL, неуникальный контент, не индексируемые документы и т.д.
- Страницы в разработке. Если сайт уже давно присутствует в поиске, но часть страниц находится на стадии редактирования, то их необходимо скрыть от индексирующего робота.

Запрещаем индексацию сайта
Для того, что бы полностью запретить индексацию сайта, необходимо, что бы при обращении к нему робот получал запрет в виде инструкции. Сделать это можно двумя способами.
При помощи robots.txt
Это наиболее распространенный и менее трудозатратный способ. Для того, что бы полностью закрыть сайт необходимо прописать в файле robots.txt простую инструкцию:
Для того, что бы полностью закрыть сайт необходимо прописать в файле robots.txt простую инструкцию:
User-agent: *
Disallow: /
Таким образом вы запрещаете индексацию для любой поисковой системы. Но есть возможность запрета и для конкретного поисковика, к примеру, Яндекса.
User-agent: Yandex
Disallow: /
Подробнее о синтаксисе и работе с файлом robots.txt — https://dh-agency.ru/category/vnutrennyaya-optimizaciya/robots-txt/
При помощи тэгов
Так же, существует способ закрыть свой сайт при помощи специального тэга. Он будет «говорить» индексирующему роботу при обращении к странице, что ее загружать не надо.
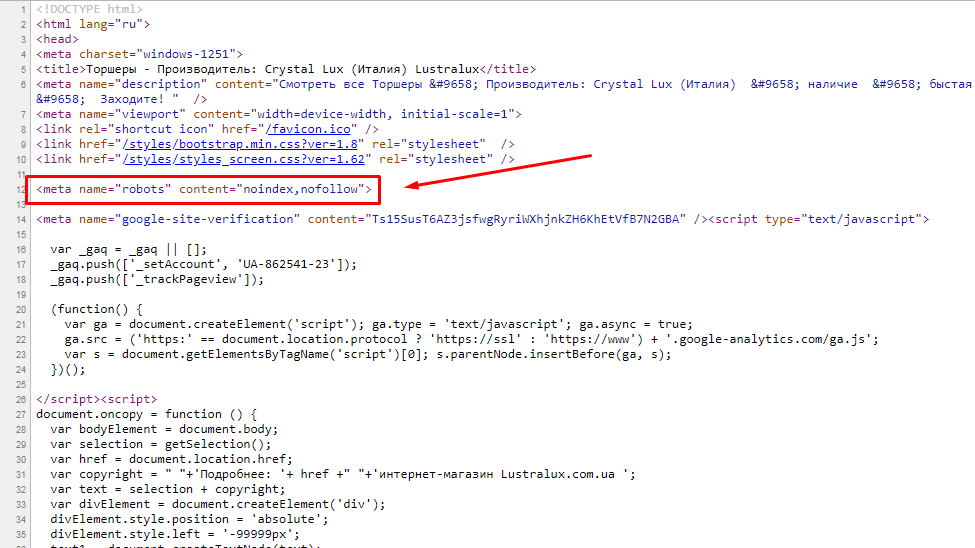
<meta name=»robots» content=»noindex»>
Данный тэг необходимо разместить на каждой странице Вашего сайта.
Параметр поля «name» зависит от робота, к которому Вы обращаетесь. К примеру, если речь идет о роботе Google, то данный тэг будет выглядеть следующим образом:
К примеру, если речь идет о роботе Google, то данный тэг будет выглядеть следующим образом:
<meta name=»googlebot» content=»noindex»>
О том, какие значения может принимать параметр «content», читайте ниже.
Запрещаем индексацию страницы
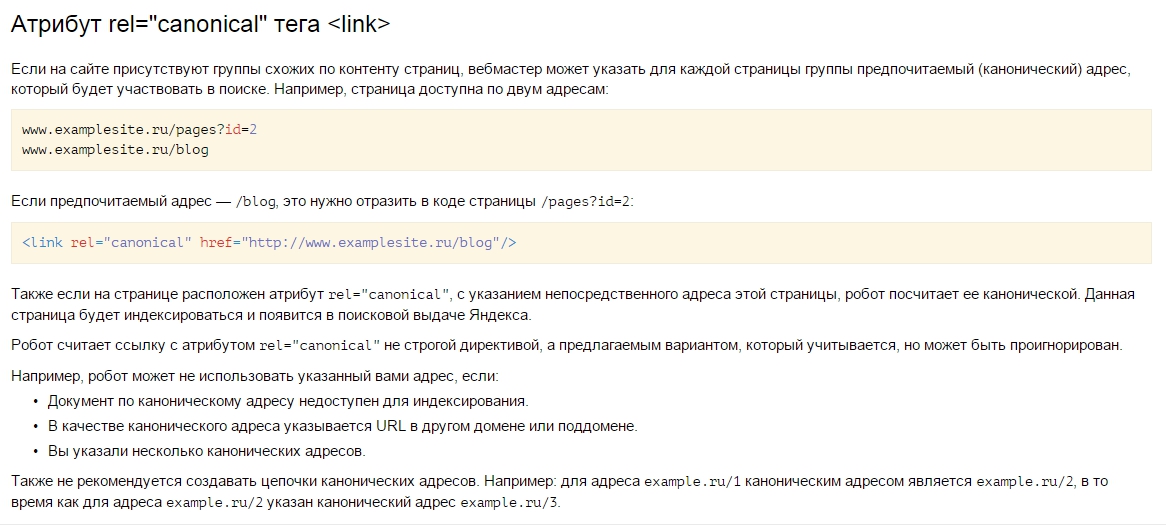
Запрет индексации одной единственной страницы отличается от запрета всего сайта только наличием дополнительной инструкции и URL адреса. Причем исключить из индекса можно не только конкретный адрес, но и маску. Однако возможность эта имеется только при работе с файлом robots.txt.
При помощи robots.txt
Для запрета конкретной страницы (спектра страниц по маске) используется инструкция «Disallow:». Синтаксис крайне простой:
Disallow: /wp-admin (исключаем всю папку wp-admin)
Disallow: /wp-content/plugins (исключаем папку plugins, которая находится в wp-content)
Disallow: /img/images. jpg (исключаем изображение images.jpg, которое находится в папке img)
jpg (исключаем изображение images.jpg, которое находится в папке img)
Disallow: /dogovor.pdf (исключаем файл /dogovor.pdf)
Disallow: */trackback (исключаем папку trackback в любой папке первого уровня)
Disallow: /*my (исключаем любую папку заканчивающуюся на my)
Все достаточно просто, не правда ли? Но это позволяет избавиться от множества проблем во время продвижения сайта. Актуализируйте robots.txt каждый месяц в зависимости от апдейтов Яндекса и Гугла.
При помощи тэгов
Исключение возможно и при помощи тэга <meta name=»robots» content=»noindex»>. Для этого необходимо просто вписать его в код конкретной страницы, которую Вы хотите закрыть от поисковиков.
Данный тэг размещается в <head> сайта, наряду с другими meta тэгами.
Стоит отметить, что значение параметра «content» может быть не только «noindex». Рассмотрим все возможные варианты.
| noindex | Самый распространенный параметр. Запрещает индексацию. |
| index | Обратный предыдущему параметр. Разрешает индексацию. Обычно не применяется, так как поисковая система по умолчанию индексирует все. |
| follow | Разрешает следовать по ссылкам, которые расположены на странице. Так же редко применяется, так как и без данного тэга краулер будет переходить по ссылкам. |
| nofollow | Запрещает переходить по ссылкам. |
Популярные ошибки
Существует множество мелких и досадных ошибок, из-за которых можно потерять кучу времени и сил.
- Запрет индексации в CMS.
У ряда CMS (к примеру, у WordPress) и шаблонов по умолчанию стоит галочка — «не индексировать сайт».
Это сделано для того, что бы разработчик не забыл закрыть сайт во время создания.К сожалению, не все вспоминают о ней по окончании работ.
- Синтаксические ошибки.
Синтаксические ошибки в файле robots.txt и тэгах часто приводят к совершенно непредсказуемым последствиям. Вам повезет, если после такого недочета в индекс просто попадут лишние страницы. Очень часто весь сайт закрывается, что в последствии приводит к полной потере органического трафика.
Для того, что бы избежать подобных ошибок, необходимо несколько раз перепроверить изменения, а так же воспользоваться инструментами валидации синтаксиса. К примеру, стандартным сервисом Яндекса.
Яндекс Вебмастер -> Инструменты -> Анализ robots.txt
- Неверное использование масок.
Неверное использование масок может привести к исключению целого дерева страниц, документов и разделов.
Если Вы сомневаетесь в правильности написания маски — лучше проконсультируйтесь у специалистов. Провести проверку при помощи online сервиса, в большинстве случаев, не получится.
 Это сделано для того, что бы разработчик не забыл закрыть сайт во время создания.
Это сделано для того, что бы разработчик не забыл закрыть сайт во время создания. Если Вы сомневаетесь в правильности написания маски — лучше проконсультируйтесь у специалистов. Провести проверку при помощи online сервиса, в большинстве случаев, не получится.
Если Вы сомневаетесь в правильности написания маски — лучше проконсультируйтесь у специалистов. Провести проверку при помощи online сервиса, в большинстве случаев, не получится.Делаем выводы
Сам по себе технический процесс исключения достаточно прост. Вся работа заключается в выяснении того, что необходимо исключить и на какой срок.
Если Вы не уверены в правильности своих действий, лучше оставьте в индексе все. Поисковая система сама выберет то, что для нее важно.
Но мы настоятельно рекомендуем обратиться за консультацией при малейших сомнениях.
что это, и как с помощью него управлять индексацией сайта
Каким бы древним ни было SEO, но такой инструмент как robots.txt всё ещё актуален, и останется таким ещё очень долго. Разберёмся, что это за инструмент и как им пользоваться правильно.
Robots.txt — это файл в корне продвигаемого сайта, в котором указываются правила для поисковых роботов по сканированию тех или иных разделов сайта.
Зачем нужен robots.txt?
👉 Разрешать или запрещать поисковым роботам сканировать конкретные папки, разделы сайта, и соответственно размещать их в индекс поисковой системы.
Основные команды в robots.txt
- User-agent: — указывает для какого робота предназначены правила сканирования ниже. Если указывается конкретное название, то правила будут работать только для указываемого робота, если указано “*” — то для всех поисковых роботов.
- Disallow: — запрет для индексации указанного раздела или папки сайта.
- Allow: — разрешение для индексации указанного раздела сайта.
- Sitemap: — указание пути к карте сайта.
- Host: — главный домен сайта.
- Crawl-delay: — команда, которая указывает на тайм-ауты загрузки страниц роботом, и как правило, задаётся для больших сайтов. По информации многих источников, эта команда сейчас не актуальна, но по старинке прописываем.
Как закрыть сайт для индексации через robots.
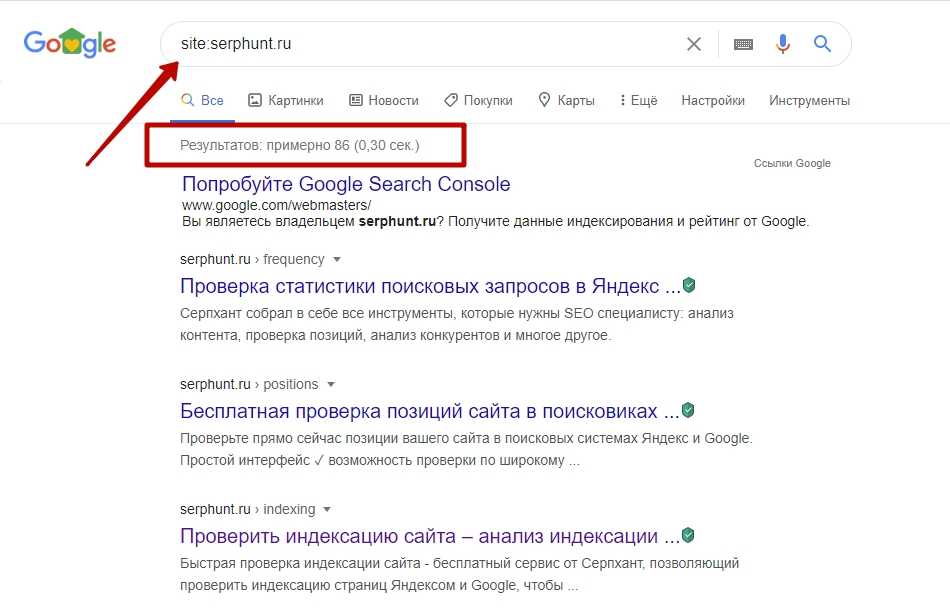 txt?
txt?User-agent: * Disallow: /
Этот “/” указывает, что всё начиная от корневой папки, закрыто для индексации.
Если Вам необходимо закрыть к индексации только конкретную папку, то указываете ее через “/”. В данном случае будет индексироваться весь сайт, кроме указанной папки.
User-agent: * Disallow: /admin
Если необходимо закрыть часть из структуры сайта, имеющую определенную закономерность в URL, то можно после «/» добавить конструкцию типа *parts_of_url*.
Это будет означать для робота, что URL сайта, которые содержат данный кусок индексироваться не будут.
Как открыть сайт для индексации через robots.txt?
User-agent: * Disallow:
Отсутствие “/”, разрешает роботу сканировать всё в границах данного домена.
Как открыть только отдельные папки для индексации через robots.txt?
User-agent: * Disallow: / Allow: /admin
В данном случае весь сайт, за исключением папки “admin”, закрыт к индексации.
Обычно, “allow” используют при сложной структуре сайта, когда внутри закрытых папок необходимо что-то открыть для робота.
Как составить robots.txt?
Robots.txt, как правило создаётся вручную, исходя из следующих составляющих:
👉 анализ корня сайта;
👉 анализ URL-структуры сайта.
Обычно это делают SEO-специалисты, при запуске сайта. Если robots.txt не создать, то сайт в любом случае будет проиндексирован.
Как протестировать robots.txt?
Тест файла robots.txt осуществляется через специальный инструмент в Google Search Console, с возможностью проверки работоспособности директив:
Стоит отметить, что директивы robots.txt на запрет индексации не всегда на 100% выполняются. Поэтому, если хотите себя подстраховать, рекомендуем воспользоваться дополнительными инъекциями в html код, типа:
<meta name="robots" content="noindex, nofollow">
Данная команда сразу принимается роботом во внимание, при загрузке html кода страницы и сканировании, даже если робот не обратится к файлу robots. txt.
txt.
Собственно, это основные важные моменты по работе с robots.txt. Это важный этап при запуске проекта и техническом SEO-аудите сайта, о котором не стоит забывать. Надеемся, этот материал был для Вас полезным. До новых встреч.
Google может индексировать заблокированные URL-адреса без сканирования
Джону Мюллеру из Google недавно «понравился» твит консультанта по поисковому маркетингу Барри Адамса (из Polemic Digital), в котором кратко излагается цель протокола исключения robots.txt. Он освежил старую тему и, вполне возможно, дал нам новый взгляд на нее.
Google может индексировать заблокированные страницы
Проблема началась, когда издатель написал в Твиттере, что Google проиндексировал веб-сайт, заблокированный файлом robots.txt.
Джон Мюллер ответил:
« URL-адреса могут быть проиндексированы без сканирования, если они заблокированы robots.txt — так задумано.
Обычно это исходит от ссылок откуда-то, судя по этому числу, я думаю, откуда-то из вашего сайта».

Как работает Robots.txt
Барри (@badams) написал в Твиттере:
«Robots.txt — это инструмент управления сканированием, а не инструмент управления индексом».
Мы часто думаем о Robots.txt как о способе запретить Google включать страницу из индекса Google. Но robots.txt — это всего лишь способ заблокировать страницы, которые сканирует Google.
Поэтому, если на другой сайт есть ссылка на определенную страницу, Google просканирует и проиндексирует эту страницу (в определенной степени).
Затем Барри объяснил, как сохранить страницу вне индекса Google:
«Используйте метадирективы robots или HTTP-заголовки X-Robots-Tag, чтобы предотвратить индексирование, и (вопреки здравому смыслу) разрешите роботу Googlebot сканировать эти страницы. страницы, которые вы не хотите индексировать, чтобы он увидел эти директивы».
Метатег NoIndex
Метатег noindex позволяет исключить просканированные страницы из индекса Google.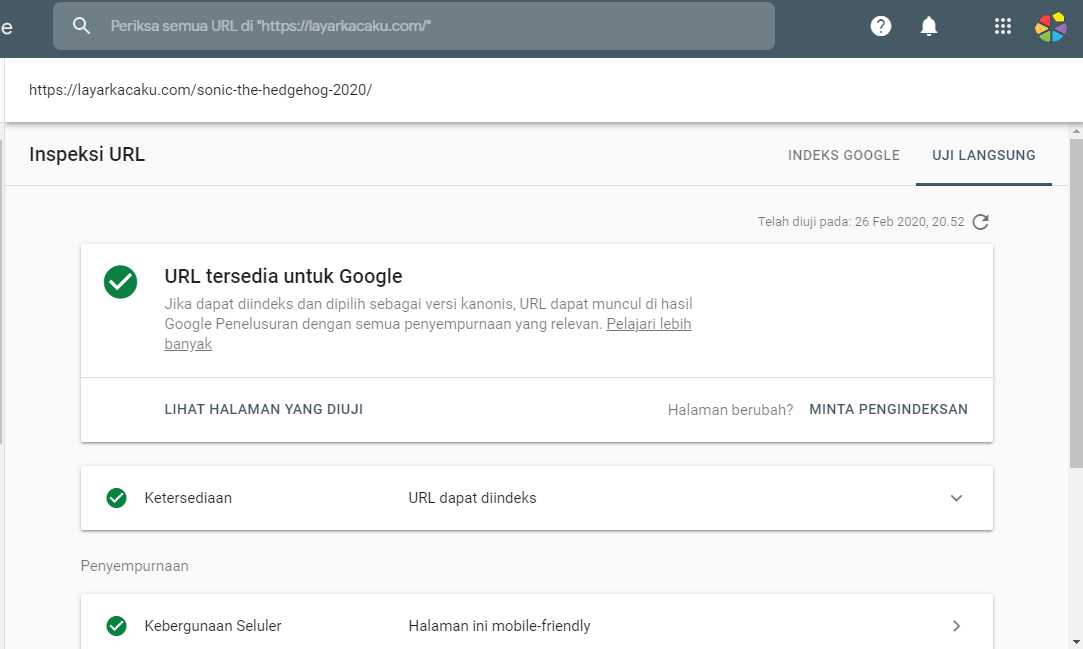 Это не останавливает сканирование страницы, но гарантирует, что страница не попадет в индекс Google.
Это не останавливает сканирование страницы, но гарантирует, что страница не попадет в индекс Google.
Метатег noindex превосходит протокол исключения robots.txt для предотвращения индексации веб-страницы.
Вот что сказал Джон Мюллер в твите от августа 2018 года
: «… если вы хотите запретить их индексацию, я бы использовал метатег noindex robots вместо запрета robots.txt».
Метатег Robots имеет множество применений
Преимущество метатега Robots в том, что его можно использовать для решения проблем, пока не появится лучшее решение.
Например, у издателя возникли проблемы с генерацией кодов ответа 404, поскольку среда angularJS продолжала генерировать 200 кодов состояния.
Его твит с просьбой о помощи гласил:
Привет @ JohnMu У меня много проблем с управлением 404 страницами в angularJS, всегда давайте мне статус 200 на них. Любой способ решить это? Спасибо
Джон Мюллер предложил использовать метатег robots noindex. Это приведет к тому, что Google исключит эту кодовую страницу ответа 200 из индекса и будет рассматривать эту страницу как мягкую 404.
Это приведет к тому, что Google исключит эту кодовую страницу ответа 200 из индекса и будет рассматривать эту страницу как мягкую 404.
«Я бы сделал обычную страницу ошибки и просто добавил бы к ней метатег noindex robots. Мы назовем его soft-404, но это нормально».
Таким образом, даже если на веб-странице отображается код ответа 200 (что означает, что страница была успешно обслужена), метатег robots не позволит этой странице попасть в индекс Google, и Google будет рассматривать ее так, как будто страница не найдена. , что является ответом 404.
Официальное описание метатега Robots
Согласно официальной документации World Wide Web Consortion, официального органа, определяющего веб-стандарты (W3C), вот что делает метатег Robots:
« Роботы и элемент META
Элемент META позволяет авторам HTML сообщать посещающим роботам, может ли документ быть проиндексирован или использоваться для сбора дополнительных ссылок».
Вот как документы W3c описывают файл Robots.txt:
«Когда робот посещает веб-сайт, он сначала проверяет … robots.txt. Если он сможет найти этот документ, он проанализирует его содержимое, чтобы увидеть, разрешено ли ему извлекать документ».
W3c интерпретирует роль Robots.txt как привратника для того, какие файлы получено. Получен – просканирован роботом, который соблюдает протокол исключения Robots.txt.
Барри Адамс правильно описал исключение Robots.txt как способ управления сканированием, а не индексированием .
Было бы полезно подумать о Robots.txt как о охранниках у дверей вашего сайта, блокирующих определенные веб-страницы. Это может немного облегчить распутывание странной активности Googlebot на заблокированных веб-страницах.
Дополнительные ресурсы
- Рекомендации по настройке тегов Meta Robots и Robots.txt
- 16 способов деиндексации Google
- Google предлагает рекомендации по кодам состояния 404 и 410
Изображения Shutterstock, измененные автором
Скриншоты автора, измененные автором
Категория Новости SEO
Почему страницы, запрещенные в robots.
 txt, по-прежнему появляются в Google — SitePoint
txt, по-прежнему появляются в Google — SitePointrobots.txt — это полезный файл, который находится в корне вашего веб-сайта и контролирует, как поисковые системы индексируют ваши страницы. Одним из самых полезных объявлений является «Запретить» — оно запрещает поисковым системам доступ к частным или нерелевантным разделам вашего сайта, например.
Запретить: /мусор/ Запретить: /temp/ Запретить: /section1/mysecretpage.html
Вы даже можете запретить поисковым системам индексировать каждую страницу вашего домена:
Пользовательский агент: * Запретить: /
Не знаю, зачем кому-то это делать, но кто-то где-то не захочет, чтобы его сайт отображался в результатах поиска.
Однако заблокированные страницы все равно могут появиться в Google. Прежде чем вы наступите на свою мыльницу, чтобы разглагольствовать о нарушении Google файла robots.txt и о злоупотреблении компанией контролем над сетью, найдите немного времени, чтобы понять, как и почему это происходит.
Предположим, у вас есть страница по адресу http://www.mysite.com/secretpage.html, содержащая конфиденциальную информацию о новом проекте Foozle вашей компании. Вы можете поделиться этой страницей с партнерами, но пока не хотите, чтобы информация стала достоянием общественности. Поэтому вы блокируете страницу с помощью объявления в http://www.mysite.com/robots.txt:
Пользовательский агент: * Запретить: /secretpage.html
Несколько недель спустя вы ищете в Google слово «Foozle», и появляется следующая запись:
mysite.com/secretpage.html
Как такое могло произойти? Первое, что нужно отметить, это то, что Google соблюдает ваши инструкции robots.txt — он не индексирует текст секретной страницы. Однако URL-адрес по-прежнему отображается, потому что Google нашел ссылку в другом месте, например.
Прочитайте о новом проекте Foozle…
Таким образом, Google связывает слово «Foozle» с вашей секретной страницей.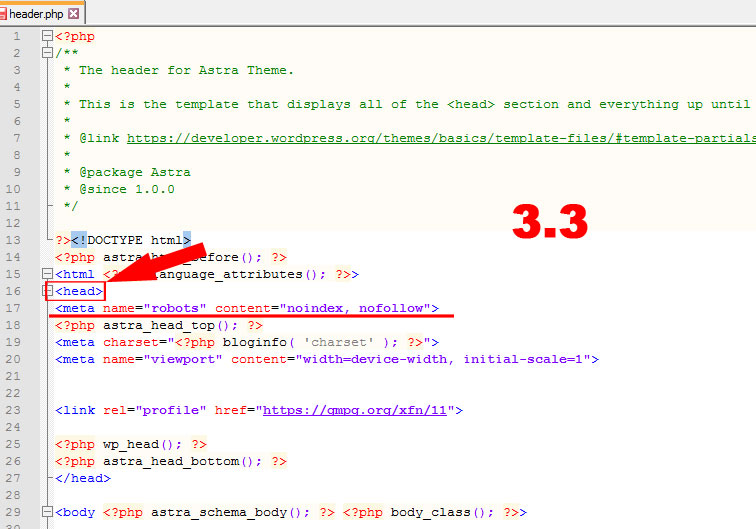 Ваш URL-адрес может оказаться на высокой позиции в результатах поиска, потому что Foozle — редко используемый термин, а ваша страница — единственный источник информации.
Ваш URL-адрес может оказаться на высокой позиции в результатах поиска, потому что Foozle — редко используемый термин, а ваша страница — единственный источник информации.
Кроме того, Google может отображать описание страницы под URL-адресом. Опять же, это не нарушение правил robots.txt — оно появляется потому, что Google нашел запись для вашей секретной страницы в признанном ресурсе, таком как Open Directory Project. Описание приходит с этого сайта, а не с содержимого вашей страницы.
Есть несколько решений, которые не позволят вашим секретным страницам появляться в результатах поиска Google.
1. Установите метатег «без индекса»
Google никогда не покажет вашу секретную страницу и не перейдет по ее ссылкам, если вы добавите следующий код в свой HTML
:2. Используйте инструмент для удаления URL
Google предлагает инструмент для удаления URL в своих Инструментах для веб-мастеров.