
Закрываем бесполезные страницы от индексации директивой в robots.txt
Опубликовано: 07.11.2014. Обновлено: 19.08.2019 2 431 2
Эта статья об использовании файла robots.txt на практике применительно к удалению ненужных страниц из индекса поисковых систем. Какие страницы удалять, как их искать, как убедиться, что не заблокирован полезный контент. По сути статья — об использовании одной лишь директивы — Disallow. Всесторонняя инструкция по использованию файла роботс и других директив в Помощи Яндекса.
В большинстве случаев закрываем ненужные страницы для всех поисковых роботов, то есть правила Disallow указываем для User-agent: *.
User-agent: *
Disallow: /cgi-bin
Что нужно закрывать от индексации?
При помощи директивы Disallow в файле robots.txt нужно закрывать от индексации поисковыми ботами:
Как искать страницы, которые необходимо закрыть от индексации?
ComparseR
Просканировать сайт Компарсером и справа во вкладке «Структура» построить дерево сайта:

Просмотреть все вложенные «ветви» дерева.
Получить во вкладках «Яндекс» и «Google» страницы в индексе поисковых систем. Затем в статистике сканирования просмотреть адреса страниц в «Найдено в Яндекс, не обнаружено на сайте» и «Найдено в Google не обнаружено на сайте».
Яндекс.Вебмастер
В разделе «Индексирование» — «Структура сайта» просмотреть все «ветви» структуры.

Проверить, что случайно не был заблокирован полезный контент
Перечисленные далее методы дополняют друг друга.
robots.txt
Просмотреть содержимое файла robots.txt.
Comparser (проверка на закрытие мета-тегом роботс)
В настройках Компарсера перед сканированием снять галочку:

Проанализировать результаты сканирования справа:

Search Console (проверка полезных заблокированных ресурсов)
Важно убедиться, что робот Google имеет доступ к файлам стилей и изображениям, используемым при отображении страниц. Для этого нужно выборочно просканировать страницы инструментом «Посмотреть, как Googlebot», нажав на кнопку «Получить и отобразить». Полученные в результате два изображения «Так увидел эту страницу робот Googlebot» и «Так увидит эту страницу посетитель сайта» должны выглядеть практически одинаково. Пример страницы с проблемами:

Увидеть заблокированные части страницы можно в таблице ниже:

Подробнее о результатах сканирования в справке консоли. Все заблокированные ресурсы нужно разблокировать в файле robots.txt при помощи директивы Allow (не получится разблокировать только внешние ресурсы). При этом нужно точечно разблокировать только нужные ресурсы. В приведённом примере боту Гугла запрещён доступ к папке /templates/, но открыт некоторым типам файлов внутри этой папки:
User-agent: Googlebot
Allow: /templates/*.css
Allow: /templates/*.js
Allow: /templates/*.png
Allow: /templates/*.jpg
Allow: /templates/*.woff
Allow: /templates/*.ttf
Allow: /templates/*.svg
Disallow: /templates/
Как закрыть от индексации сайт, ссылку, страницу, в robots ?
Далеко не всегда нужно, чтобы поисковые системы индексировали всю информацию на сайте.
Иногда, вебмастерам даже нужно полностью закрыть сайт от индексации, но новички не знают, как это сделать. При желании, можно скрыть от поисковиков любой контент, ресурс или его отдельные страницы.
Как закрыть от индексации сайт, ссылку, страницу? Есть несколько простых функций, которые вы сможете использовать, для закрытия любой информации от Яндекса и Гугла. В этой статье мы подскажем, как закрыть сайт от индексации через robots, и покажем, какой код нужно добавить в этот файл.

Закрываем от индексации поисковиков
Перед тем как рассказать о способе с применением robots.txt, мы покажем, как на WordPress закрыть от индексации сайт через админку. В настройках (раздел чтение), есть удобная функция:

Можно убрать видимость сайта, но обратите внимание на подсказку. В ней говорится, что поисковые системы всё же могут индексировать ресурс, поэтому лучше воспользоваться проверенным способом и добавить нужный код в robots.txt.
Текстовый файл robots находится в корне сайта, а если его там нет, создайте его через блокнот.
Закрыть сайт от индексации поможет следующий код:
User-agent: *
Disallow: /
Просто добавьте его на первую строчку (замените уже имеющиеся строчки). Если нужно закрыть сайт только от Яндекса, вместо звездочки указывайте Yandex, если закрываете ресурс от Google, вставляйте Googlebot.
Если не можете использовать этот способ, просто добавьте в код сайта строчку <meta name=»robots» content=»noindex,follow» />.
Когда проделаете эти действия, сайт больше не будет индексироваться, это самый лучший способ для закрытия ресурса от поисковых роботов.
Как закрыть страницу от индексации?
Если нужно скрыть только одну страницу, то в файле robots нужно будет прописать другой код:
User-agent: *
Disallow: /category/kak-nachat-zarabatyvat
Во второй строчке вам нужно указать адрес страницы, но без названия домена. Как вариант, вы можете закрыть страницу от индексации, если пропишите в её коде:
<META NAME=»ROBOTS» CONTENT=»NOINDEX»>
Это более сложный вариант, но если нет желания добавлять строчки в robots.txt, то это отличный выход. Если вы попали на эту страницу в поисках способа закрытия от индексации дублей, то проще всего добавить все ссылки в robots.
Как закрыть от индексации ссылку или текст?
Здесь тоже нет ничего сложного, нужно лишь добавить специальные теги в код ссылки или окружить её ими:
<noindex>
<a rel=»nofollow» href=»http://Workion.ru/»>Анкор</a>
</noindex>
Используя эти же теги noindex, вы можете скрывать от поисковых систем разный текст. Для этого нужно в редакторе статьи прописать этот тег.

К сожалению, у Google такого тега нет, поэтому скрыть от него часть текста не получится. Самый простой вариант сделать это – добавить изображение с текстом.
Скрывайте от поисковых роботов всё, что не уникально или каким-то образом может нарушать их правила. А если вы решили полностью переделать сайт, то обязательно закрывайте его от индексации, чтобы боты не индексировали внесенные изменения до того, как вы над ними поработаете и всё протестируете.
Вам также будет интересно:
— Скорость сайта – важный фактор
— Почему Яндекс не индексирует сайт?
— Оригинальные тексты для защиты от Yandex
Как настроить robots.txt? Проверить файл robots.txt, закрыть от индексации страницы на сайте

Файл robots.txt управляет индексацией сайта. В нем содержатся команды, которые разрешают или запрещают поисковым системам добавлять в свою базу определенные страницы или разделы на сайте. Например, на Вашем сайте имеется раздел с конфиденциальной информацией или служебные страницы. Вы не хотите, чтобы они находились в индексе поисковых систем, и настраиваете запрет на их индексацию в файле robots.txt.
В данной статье мы рассмотрим, как настроить robots.txt и проверить правильность указанных в нем команд. Как закрыть от индексации сайт целиком или отдельные страницы или разделы.
Чтобы поисковые системы нашли файл, он должен располагаться в корневой папке сайта и быть доступным по адресу ваш_сайт.ru/robots.txt. Если файла на сайте нет, поисковые системы будут считать, что можно индексировать все документы на сайте. Это может привести к серьезным проблемам, в частности, попаданию в базы страниц-дублей, документов с конфиденциальной информацией.
Структура файла robots.txt
В файле robots.txt для каждой поисковой системы можно прописать свои команды. Например, на скриншоте ниже Вы можете увидеть команды для робота Яндекса, Google и для всех остальных поисковых систем:
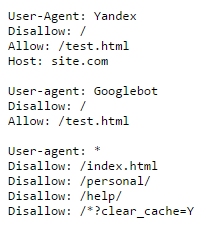
Каждая команда начинается с новой строки. Между блоками команд для разных поисковых систем оставляют пустую строку.
Настройка файла robots.txt: основные директивы
Чтобы правильно настроить файл robots.txt, необходимо знать директивы – команды, которые воспринимают роботы поисковых систем. Ниже рассмотрим основные директивы для настройки индексации сайта в файле robots.txt:
| Директива | Назначение |
| User-agent: | Указывает робота поисковой системы, для которого предназначены команды ниже. Названия роботов можно посмотреть в справочной информации, которую предоставляют поисковые системы. |
| Disallow: | Данная директива в файле robots.txt закрывает индексацию определенной страницы или раздела на сайте. Сама страница или раздел указываются от корневой папки сайта, без домена (см. скриншот в начале статьи). |
| Allow: | Разрешает индексацию определенной страницы или раздела на сайте. Директивы Allow необходимо располагать ниже директив Disallow. |
| Host: | Указывает главное зеркало сайта (либо с www, либо без www). Учитывается только Яндексом. |
| Sitemap: | В данной директиве необходимо прописать путь к карте сайта, если она имеется на сайте. |
Существуют другие директивы, которые используется реже. Посмотреть информацию обо всех директивах, которые можно настроить в файле robots.txt, можно здесь.
Частные случаи команд в файле robots.txt
Разберем некоторые команды, которые потребуются Вам в работе:
| Команда | Что обозначает |
| User-agent: Yandex | Начало блока команд для основного робота поисковой системы Яндекс. |
| User-agent: Googlebot | Начало блока команд для основного робота поисковой системы Google. |
| User-agent: * Disallow: / | Данная команда в файле robots.txt полностью закрывает сайт от индексации всеми поисковыми системами. |
| User-agent: * Disallow: / Allow: /test.html | Данные команды закрывают все документы на сайте от индексации, кроме страницы /test.html |
| Disallow: /*.doc | Данная команда запрещает индексировать файлы MS Word на сайте. Если на сайте содержится конфиденциальная информация в файлах определенного типа, имеет смысл закрыть такие файлы от индексации. |
| Disallow: /*.pdf | Данная команда в robots.txt запрещает индексировать на сайте файлы в формате PDF. Если Вы выкладываете на сайте какие-либо файлы, доступные для скачивания после оплаты или после авторизации, имеет смысл закрыть их от индексации. В ином случае данные файлы смогут найти в поисковых системах. |
| Disallow: /basket/ | Команда запрещает индексировать все документы в разделе /basket/. |
| Host: www.yandex.ru | Команда задает для сайта yandex.ru основным зеркалом адрес сайта с www. Соответственно, в поиске с высокой вероятностью будут выводиться адреса страниц с www. |
| Host: yandex.ru | Данная команда задает для сайта yandex.ru в качестве основного зеркала адрес yandex.ru (без www). |
Использование спецсимволов в командах robots.txt
В командах robots.txt может использоваться два спецсимвола: * и $:
- Звездочка * заменяет собой любую последовательность символов.
- По умолчанию в конце каждой команды добавляется *. Чтобы отменить это, в конце строки необходимо поставить символ $.
Допустим, у нас имеется сайт с адресом site.com, и мы хотим настроить файл robots.txt для нашего проекта. Разберем действие спецсимволов на примерах:
| Команда | Что обозначает |
| Disallow: /basket/ | Запрещает индексацию всех документов в разделе /basket/, например: site.com/basket/ |
| Disallow: /basket/$ | Запрещает индексацию только документа: site.com/basket/ Документы: остаются открытыми для индексации. |
Пример настройки файла robots.txt
Давайте разберем на примере, как настроить файл robots.txt. Ниже находится пример файла, значение команд из которого будет подробно рассмотрено в статье.
В данном файле мы видим, что от поисковых систем Яндекс и Google закрыты от индексации все документы на сайте, кроме страницы /test.html
Остальные поисковые системы могут индексировать все документы, кроме:
- документов в разделах /personal/ и /help/
- документа по адресу /index.html
- документов, адреса которых включают параметр clear_cache=Y
Последние две команды требуют отдельного внимания.
Командой /index.html закрыт от индексации дубль главной страницы сайта. Как правило, главная страница доступна по двум адресам:
- site.com
- site.com/index.html или site.com/index.php
Если не закрыть второй адрес от индексации, то в поиске может появиться две главных страницы!
Команда Disallow: /*?clear_cache=Y закрывает от индексации все страницы, в адресах которых используется последовательность символов ?clear_cache=Y. Часто различный функционал на сайте, например, сортировки или формы подбора добавляют к адресам страниц различные параметры, из-за чего генерируется множество страниц-дублей. Закрывая дубли с параметрами от индексации, Вы решаете проблему попадания дублей в базу поисковых систем.
Посмотрите, какие страницы необходимо закрывать от индексации, в статье про проведение технического аудита сайта.
Как проверить файл robots.txt?
После добавления файла robots.txt на сайт Вы можете проверить корректность его настройки. Для этого поисковые системы предлагают специальные инструменты. В статье рассмотрим инструмент от Яндекса, который позволяет проверить правильность настройки robots.txt. Он доступен в сервисе Яндекс.Вебмастер во вкладке «Инструменты» – «Анализ robots.txt».
В верхней части страницы Вы можете увидеть проверяемый сайт (на скриншоте затерт), содержание файла robots.txt, известное Яндексу. Обязательно проверьте, что содержание файла указано корректно. Если в Яндекс.Вебмастер выводятся старые команды, нажмите на кнопку «Загрузить» (серый значок справа от ссылки на проверяемый сайт, выделен на скриншоте рамкой):

В нижней части страницы добавьте в поле «Разрешены ли URL?» список страниц, по которым Вы хотите проверить, разрешена их индексация или нет. Нажмите кнопку «Проверить», и ниже выведутся результаты. Красный значок означает, что страница запрещена к индексации, зеленый – разрешена:
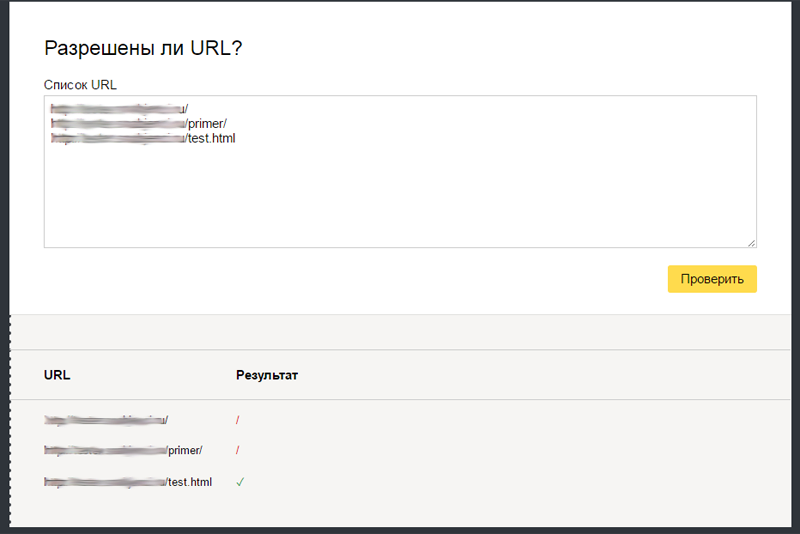
Аналогичные инструменты проверки файла имеются в Центре вебмастеров Google.
Время от времени в структуру сайта вносятся изменения. Поэтому необходимо периодически проверять, какие страницы и документы находятся в индексе поисковых систем. При появлении в индексе документов, которые не должны там быть, их индексацию необходимо закрыть в файле robots.txt.
Рекомендуем

Один из самых важных вопросов в продвижении сайта – какие тексты ссылок использовать? На этот счет существует множество мнений, я изложу только …

В данной статье рассмотрим, как поисковые системы учитывают внешние ссылки, какие ссылки приносят пользу сайту и как правильно развивать ссылочный …
Как закрыть сайт от индексации с noindex/robots.txt?
Когда вы занимаетесь SEO для сайт, то часто нужно скрыть какую-либо часть сайта или же целую страницу целиком. В этой записи я расскажу о том как это можно сделать.Если вам нужно закрыть какую-либо определенную страницу сайта, то можно воспользоваться meta тэгом, который запретить индексацию целой страницы.
Чтобы запретить индексацию страницы для всех ботов, то вы можете воспользоваться HTML кодом ниже.
<meta name="robots" content="noindex">
Если вы нацелены на определенный поисковик (например: Google), то вы можете это сделать как показано ниже.
<meta name="googlebot" content="noindex">
Официального источника можно найти по этой ссылке.
Если вам нужно спрятать из индексации определенную часть страницы вашего сайта, то вы можете воспользоваться <noindex> тэгом.. Как в примере ниже.
<noindex> <p>Боты не будут этого считывать</p> </noindex>
Все что указано внутри noindex остается вне видимости бота. В целом, информация внутри все равно читается им, но остается проигнорирована при поиске какой-либо информации через поисковик.
robots.txt является самым распространенным видом установки ограничения для просмотра контента ботами. Другими словами, данный файл устанавливает инструкции для ботов (что можно смотреть, а что нет).
Идеального варианта этого файла не существует. Для каждого проекта должен иметься свой собственный robots.txt файл, который правильно настроен и скрывает нежелательные папки/разделы сайта.
Имейте ввиду, что не все боты будут следовать этому файлу. Есть множество других плохих и хороших ботов, которые просто путешествуют по вебу, собирают информацию и тд.
Что я точно вам могу сказать: robots.txt не будет проигнорирован известными поисковыми системами.
Некоторые из примеров я использовал с этого источника. Если кому интересно, зайдите и посмотрите (достаточно не плохой ресурс).
Пример 1
Данный пример имеет два свойства.
User-agent— которое говорит роботу, что любой тип может посетить страницуDisallow— запрещает индексировать какие-либо страницы на сайте, который установит этотrobots.txt
User-agent: * Disallow: /
А вот этот пример (ниже), разрешить посещать любые страницы сайта.
User-agent: * Disallow:
Пример 2
Пример ниже запрещает ботам посещать папку cgi-bin и tmp в корне сайта. Вы можете прописывать сколько захотите Disallow, чтобы полностью расписать инструкции для бота.
User-agent: * Disallow: /cgi-bin/ Disallow: /tmp/
Пример 3
Данный пример использует два разных правила.
Первое — это устанавливает правила только для User-agent: Google бота. И разрешает ему анализировать любые страницы сайта.
Второе — это все остальные боты User-agent: *, которые не могут смотреть никакие страницы сайта.
User-agent: Google Disallow: User-agent: * Disallow: /
Чтобы запретить индексаю для определенного файла, можно просто прописать полный путь до файла, от корня сайта. Например, у вас есть файл main.hml, который находится в /src/ папку, то ваш robots будет выглядеть как на примере ниже:
User-agent: * Disallow: /src/main.html