
Robots.txt — как настроить и загрузить на сайт
Михаил Шумовский
07 октября, 2022
Кому нужен robots.txt Как настроить robots.txt Как создать robots.txt Требования к файлу robots.txt Как проверить правильность Robots.txt
Читайте наc в Telegram
Разбираемся, что происходит в мире рассылок и digital-маркетинга. Публикуем анонсы статей, обзоры, подборки, мнения экспертов.
Смотреть канал
Станьте email-рокером 🤘
Пройдите бесплатный курс и запустите свою первую рассылку
Подробнее
Robots.txt — документ, который нужен для индексирования и продвижения сайта.
Если у сайта нет robots.txt, поисковые роботы считают все страницы ресурса открытыми для индексирования. Если файл есть, владелец сайта может запретить роботам индексировать определённые страницы.
Например, контентным ресурсам или медиа можно работать без robots.txt — тут все страницы участвуют в индексации.
На других ресурсах могут быть страницы, которые не нужно показывать поисковым роботам:
- Админ-панели сайта: пути, которые начинаются с /user, /admin, /administrator и т.д.
- Пустые страницы ресурса: если на них нет контента, в индексации они не помогут.
- Формы регистрации.
- Личные страницы в интернет-магазинах: кабинеты пользователей, корзины и т.
 д.
д.
 д.
д.Начну с основных параметров.
User-agent: Yandex
Disallow: catalog/
Allow: /catalog/cucumbers/
Sitemap: http://www.example.com/sitemap.xml
User-agent — указывает название робота, к которому применяется правило. Например, User-agent: Yandex означает, что правило применяется к роботу Яндекса.
А user-agent: * означает, что правило применяется ко всем роботам. Но о звёздочках поговорим ниже.
Основные типы роботов, которые можно указать в User-agent:
- Yandex. Все роботы Яндекса.
- YandexBot. Основной робот Яндекса
- YandexImages. Индексирует изображения.
- YandexMedia. Индексирует видео и другие мультимедийные данные.
- Google. Все роботы Google.
- Googlebot-Image. Индексирует изображения.
 Индексирует изображения.
Индексирует изображения.Disallow. Указывает на каталог или страницу ресурса, которые роботы индексировать не будут. Если нельзя индексировать конкретную страницу, например, определённый раздел в каталоге, нужно указывать полный путь к ней — как в поисковой строке браузера.
В начале строки должен быть символ /. Если правило касается каталога, строка должна заканчиваться символом /.
Например, disallow: /catalog/gloves. Так мы запретим индексацию раздела с перчаткам.
Если оставить disallow пустым, роботы будут индексировать все страницы сайта.
Allow. Указывает на каталог или страницу, которые можно сканировать роботу. Его используют, чтобы внести исключения в пункт disallow
и разрешить сканирование подкаталога или страницы в каталоге, который закрыт для обработки.Если требуется индексировать конкретную страницу, нужно указывать к ней полный путь. Как и в disallow. Например, allow: /story/marketing. Так мы разрешили индексировать статью о маркетинге.
Так мы разрешили индексировать статью о маркетинге.
Если правило касается каталога, строка должна заканчиваться символом /.
Если allow пустой, робот не будет индексировать никакие страницы.
Sitemap. Необязательная директива, которая может повторяться несколько раз или не использоваться совсем. Её используют, чтобы описать структуру сайта и помочь роботам индексировать страницы.
Лендингам и небольшим сайтам sitemap не нужен. А вот таким ресурсам без sitemap не обойтись:
- Cайтам без хлебных крошек (навигационных цепочек).
- Сайтам с глубокой вложенностью. Например, «Главная/Каталог/Перчатки/Резиновые».
- Молодым ресурсам, на которые мало внешних ссылок, — их роботам сложно найти.
- Сайтам с большим архивом страниц, которые изолированы или не связаны друг с другом.

Файл нужно прописывать в XML-формате. Создание sitemap — тема для отдельной статьи. Подробную инструкцию читайте на Google Developers или в Яндекс.Справке.
Основные моменты robots.txt разобрали. Теперь расскажу про дополнительные параметры, которые используют в коде.
Для начала посмотрим на robots.txt Unisender. Для этого в поисковой строке браузера пишем Unisender.com/robots.txt.
По такой же формуле можно проверять файлы на всех сайтах: URL сайта + домен/robots.txt.
Robots.txt Unisender отличается от файла, который я приводил в пример. Дело в том, что здесь использованы дополнительные параметры:
Директива # (решётка) — комментарий. Решётки прописывают для себя, а поисковые роботы комментариев не видят.
User-agent: Yandex
Allow: /example/* # разрешает ‘/example/blog’
# разрешает ‘/example/blog/test’
Звёздочку роботы видят, а решётку — нет
Директива * (звёздочка) — любая последовательность символов после неё.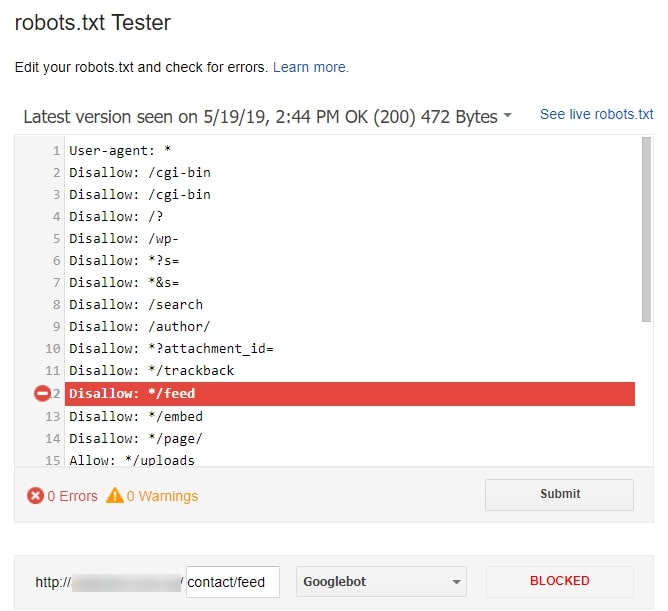
Например, если поставить звёздочку в поле disallow, то всё, что находится на её месте, будет запрещено.
User-agent: Yandex
Disallow: /example/* # запрещает ‘/example/blog’
# запрещает ‘/example/blog/test’
Disallow: */shop # запрещает не только ‘/shop’,
Также и с полем allow: всё, что стоит на месте звёздочки, — разрешено для индексации.
User-agent: Yandex
Allow: /example/* # разрешает ‘/example/blog’
# разрешает ‘/example/blog/test’
Allow: */shop # разрешает не только ‘/shop’,
# но и ‘/example/shop’
Например, у Google есть особенность: компания рекомендует не закрывать от поисковых роботов файлы с css-стилями и js-скриптами. Вот как это нужно прописывать:
User-agent: Googlebot
Disallow: /site
Allow: *.css
Allow: *. js
js
Директива $ (знак доллара) — точное соответствие указанному параметру.
User-agent: Yandex
Disallow: /example # запрещает ‘/example’,
# запрещает ‘/example.html’
Disallow: /example$ # запрещает ‘/example’,
# не запрещает ‘/example.html’
# не запрещает ‘/example1’
# не запрещает ‘/example-new’
Таким способом можно исключить из сканирования все файлы определённого типа, например, GIF или JPG. Для этого нужно совместить * и $. Звёздочку ставим до расширения, а $ — после.
User-agent: Yandex
Disallow: / *.gif$ # вместо * могут быть любые символы,
# $ запретит индексировать файлы gif
Директива Clean-param — новый параметр Яндекс-роботов, который не будет сканировать дублированную информацию и поможет быстрее анализировать ресурс.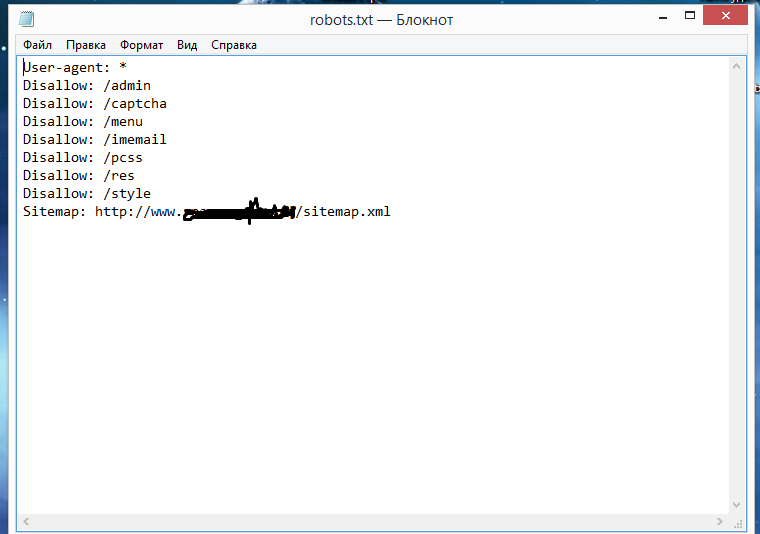
Дело в том, что из-за повторяющейся информации роботы медленнее проверяют сайт, а изменения на ресурсе дольше попадают в результаты поиска. Когда роботы Яндекса увидят эту директиву, не будут несколько раз перезагружать дубли информации и быстрее проверят сайт, а нагрузка на сервер снизится.
www.example.com/dir/get_card.pl?ref=site_1&card_id=10
www.example.com/dir/get_card.pl?ref=site_2&card_id=10
Параметр ref нужен, чтобы отследить, с какого ресурса сделан запрос. Он не меняет содержимое страницы, значит два адреса покажут одну и ту же страницу с книгой card_id=10. Поэтому директиву можно указать так:
User-agent: Yandex
Disallow:
Clean-param: ref /dir/get_card.pl
Робот Яндекса сведёт страницы к одной: www.example.com/dir/get_card.pl?card_id=10
Чтобы директива применялась к параметрам на страницах по любому адресу, не указывайте адрес:
User-agent: Yandex
Disallow:
Clean-param: utm
Директива Crawl-delay — устанавливает минимальный интервал в секундах между обращениями робота к сайту. Это помогает снизить нагрузку на сервер ресурса. Чем выше указанное значение, тем меньше страниц робот загрузит за сессию.
Это помогает снизить нагрузку на сервер ресурса. Чем выше указанное значение, тем меньше страниц робот загрузит за сессию.
Значения можно указывать целыми или дробными числами через точку.
User-agent: Yandex
Disallow:
Crawl-delay: 0.5
Для Яндекса максимальное значение в crawl-delay — 2. Более высокое значение можно установить инструментами Яндекс.Вебмастер.
Для Google-бота можно установить частоту обращений в панели вебмастера Search Console.
Директива Host — инструкция для робота Яндекса, которая указывает главное зеркало сайта. Нужна, если у сайта есть несколько доменов, по которым он доступен. Вот как её указывают:
User-agent: Yandex
Disallow: /example/
Host: example.ru
Если главное зеркало сайта — домен с протоколом HTTPS, его указывают так:
Host: https://site.ru
Как создать robots.txtСпособ 1. Понадобится текстовый редактор: блокнот, TextEdit, Vi, Emacs или любой другой. Не используйте приложения Microsoft Office, потому что они сохраняют файлы в неподходящем формате или добавляют в них лишние символы, которые не распознаются поисковыми роботами.
Не используйте приложения Microsoft Office, потому что они сохраняют файлы в неподходящем формате или добавляют в них лишние символы, которые не распознаются поисковыми роботами.
Способ 2. Создать на CMS с помощью плагинов — в этом случае robots.txt установится сам.
Если вы используете CMS хостинга, редактировать файл robots.txt не потребуется. Скорее всего, у вас даже не будет такой возможности. Вместо этого провайдер будет указывать поисковым системам, нужно ли сканировать контент, с помощью страницы настроек поиска или другого инструмента.
Способ 3. Воспользоваться генератором robots.txt — век технологий всё-таки.
Сгенерировать файл можно на PR-CY, IKSWEB, Smallseotools.
Требования к файлу robots.txtКогда создадите текстовый файл, сохраните его в кодировке utf-8. Иначе поисковые роботы не смогут прочитать документ. После создания загрузите файл в корневую директорию на сайте хостинг-провайдера. Корневая директория — это папка public. html.
html.
Папка, в которой нужно искать robots.txt. Источник
Если файла нет, его придётся создавать самостоятельно.
Требования, которым должен соответствовать robots.txt:
- Каждая директива начинается с новой строки.
- Одна директива в строке, сам параметр также написан в одну строку.
- В начале строки нет пробелов.
- Нет кавычек в директивах.
- Директивы не нужно закрывать точкой или точкой с запятой.
- Файл должен называться robots.txt. Нельзя называть его Robots.txt или ROBOTS.TXT.
- Размер файла не должен превышать 500 КБ.
- robots.txt должен быть написан на английском языке. Буквы других алфавитов не разрешаются.
Если файл не соответствует одному из требований, весь сайт считается открытым для индексирования.
Как проверить правильность Robots.txtПроверить robots. txt помогают сервисы от Яндекс и Google. В Яндексе можно проверять файл даже без сайта — например, если вы написали robots.txt, но пока не загрузили его на сайт.
txt помогают сервисы от Яндекс и Google. В Яндексе можно проверять файл даже без сайта — например, если вы написали robots.txt, но пока не загрузили его на сайт.
Вот как это сделать:
- Перейдите на Яндекс.Вебмастер.
- В открывшееся окно вставьте текст robots.txt и нажмите проверить.
Если файл написан правильно, Яндекс.Вебмастер не увидит ошибок.
А если увидит ошибку — подсветит её и опишет возможную проблему.
На Яндекс.Вебмастер можно проверить robots.txt и по URL сайта. Для этого нужно указать запрос: URL сайта/robots.txt. Например, unisender.com/robots.txt.
Ещё один вариант — проверить файл robots.txt через Google Search Console. Но сначала нужно подтвердить владение сайтом. Пошаговый алгоритм проверки robots.txt описан в видеоинструкции:
Поделиться
СВЕЖИЕ СТАТЬИ
Другие материалы из этой рубрики
Не пропускайте новые статьи
Подписывайтесь на соцсети
Делимся новостями и свежими статьями, рассказываем о новинках сервиса
Статьи почтой
Раз в неделю присылаем подборку свежих статей и новостей из блога. Пытаемся
шутить, но получается не всегда
Пытаемся
шутить, но получается не всегда
Наш юрист будет ругаться, если вы не примете 🙁
Как запустить email-маркетинг с нуля?
В бесплатном курсе «Rock-email» мы за 15 писем расскажем, как настроить email-маркетинг в компании. В конце каждого письма даем отбитые татуировки об email ⚡️
*Вместе с курсом вы будете получать рассылку блога Unisender
Оставляя свой email, я принимаю Политику конфиденциальностиНаш юрист будет ругаться, если вы не примете 🙁
Robots.
 txt — как настроить и загрузить на сайт
txt — как настроить и загрузить на сайтМихаил Шумовский
07 октября, 2022
Кому нужен robots.txt Как настроить robots.txt Как создать robots.txt Требования к файлу robots.txt Как проверить правильность Robots.txt
Читайте наc в Telegram
Разбираемся, что происходит в мире рассылок и digital-маркетинга. Публикуем анонсы статей, обзоры, подборки, мнения экспертов.
Смотреть канал
Станьте email-рокером 🤘
Пройдите бесплатный курс и запустите свою первую рассылку
Подробнее
Robots.txt — документ, который нужен для индексирования и продвижения сайта. С помощью этого файла владелец сайта подсказывает поисковым системам, какие разделы ресурса нужно учитывать, а какие — нет. Объясняю особенности его составления и настройки такого текстового файла.
С помощью этого файла владелец сайта подсказывает поисковым системам, какие разделы ресурса нужно учитывать, а какие — нет. Объясняю особенности его составления и настройки такого текстового файла.
Если у сайта нет robots.txt, поисковые роботы считают все страницы ресурса открытыми для индексирования. Если файл есть, владелец сайта может запретить роботам индексировать определённые страницы.
Например, контентным ресурсам или медиа можно работать без robots.txt — тут все страницы участвуют в индексации.
На других ресурсах могут быть страницы, которые не нужно показывать поисковым роботам:
- Админ-панели сайта: пути, которые начинаются с /user, /admin, /administrator и т.д.
- Пустые страницы ресурса: если на них нет контента, в индексации они не помогут.
- Формы регистрации.
- Личные страницы в интернет-магазинах: кабинеты пользователей, корзины и т. д.
 д.
д.Начну с основных параметров.
User-agent: Yandex
Disallow: catalog/
Allow: /catalog/cucumbers/
Sitemap: http://www.example.com/sitemap.xml
User-agent — указывает название робота, к которому применяется правило. Например, User-agent: Yandex означает, что правило применяется к роботу Яндекса.
А user-agent: * означает, что правило применяется ко всем роботам. Но о звёздочках поговорим ниже.
Основные типы роботов, которые можно указать в User-agent:
- Yandex. Все роботы Яндекса.
- YandexBot. Основной робот Яндекса
- YandexImages. Индексирует изображения.
- YandexMedia. Индексирует видео и другие мультимедийные данные.
- Google. Все роботы Google.
- Googlebot. Основной робот Google.
- Googlebot-Image. Индексирует изображения.
 Индексирует изображения.
Индексирует изображения.Disallow. Указывает на каталог или страницу ресурса, которые роботы индексировать не будут. Если нельзя индексировать конкретную страницу, например, определённый раздел в каталоге, нужно указывать полный путь к ней — как в поисковой строке браузера.
В начале строки должен быть символ /. Если правило касается каталога, строка должна заканчиваться символом /.
Например, disallow: /catalog/gloves. Так мы запретим индексацию раздела с перчаткам.
Если оставить disallow пустым, роботы будут индексировать все страницы сайта.
Allow. Указывает на каталог или страницу, которые можно сканировать роботу. Его используют, чтобы внести исключения в пункт disallow и разрешить сканирование подкаталога или страницы в каталоге, который закрыт для обработки.
Если требуется индексировать конкретную страницу, нужно указывать к ней полный путь. Как и в disallow. Например, allow: /story/marketing. Так мы разрешили индексировать статью о маркетинге.
Так мы разрешили индексировать статью о маркетинге.
Если правило касается каталога, строка должна заканчиваться символом /.
Если allow пустой, робот не будет индексировать никакие страницы.
Sitemap. Необязательная директива, которая может повторяться несколько раз или не использоваться совсем. Её используют, чтобы описать структуру сайта и помочь роботам индексировать страницы.
Лендингам и небольшим сайтам sitemap не нужен. А вот таким ресурсам без sitemap не обойтись:
- Cайтам без хлебных крошек (навигационных цепочек).
- Большим ресурсам. Например, если сайт содержит большой объём мультимедиа или новостного контента.
- Сайтам с глубокой вложенностью. Например, «Главная/Каталог/Перчатки/Резиновые».
- Молодым ресурсам, на которые мало внешних ссылок, — их роботам сложно найти.
- Сайтам с большим архивом страниц, которые изолированы или не связаны друг с другом.

Файл нужно прописывать в XML-формате. Создание sitemap — тема для отдельной статьи. Подробную инструкцию читайте на Google Developers или в Яндекс.Справке.
Основные моменты robots.txt разобрали. Теперь расскажу про дополнительные параметры, которые используют в коде.
Для начала посмотрим на robots.txt Unisender. Для этого в поисковой строке браузера пишем Unisender.com/robots.txt.
По такой же формуле можно проверять файлы на всех сайтах: URL сайта + домен/robots.txt.
Robots.txt Unisender отличается от файла, который я приводил в пример. Дело в том, что здесь использованы дополнительные параметры:
Директива # (решётка) — комментарий. Решётки прописывают для себя, а поисковые роботы комментариев не видят.
User-agent: Yandex
Allow: /example/* # разрешает ‘/example/blog’
# разрешает ‘/example/blog/test’
Звёздочку роботы видят, а решётку — нет
Директива * (звёздочка) — любая последовательность символов после неё.
Например, если поставить звёздочку в поле disallow, то всё, что находится на её месте, будет запрещено.
User-agent: Yandex
Disallow: /example/* # запрещает ‘/example/blog’
# запрещает ‘/example/blog/test’
Disallow: */shop # запрещает не только ‘/shop’,
# но и ‘/example/shop’
Также и с полем allow: всё, что стоит на месте звёздочки, — разрешено для индексации.
User-agent: Yandex
Allow: /example/* # разрешает ‘/example/blog’
# разрешает ‘/example/blog/test’
Allow: */shop # разрешает не только ‘/shop’,
# но и ‘/example/shop’
Например, у Google есть особенность: компания рекомендует не закрывать от поисковых роботов файлы с css-стилями и js-скриптами. Вот как это нужно прописывать:
User-agent: Googlebot
Disallow: /site
Allow: *.css
Allow: *. js
js
Директива $ (знак доллара) — точное соответствие указанному параметру.
Например, использование доллара в disallow запретит доступ к определённому пути.
User-agent: Yandex
Disallow: /example # запрещает ‘/example’,
# запрещает ‘/example.html’
Disallow: /example$ # запрещает ‘/example’,
# не запрещает ‘/example.html’
# не запрещает ‘/example1’
# не запрещает ‘/example-new’
Таким способом можно исключить из сканирования все файлы определённого типа, например, GIF или JPG. Для этого нужно совместить * и $. Звёздочку ставим до расширения, а $ — после.
User-agent: Yandex
Disallow: / *.gif$ # вместо * могут быть любые символы,
# $ запретит индексировать файлы gif
Директива Clean-param — новый параметр Яндекс-роботов, который не будет сканировать дублированную информацию и поможет быстрее анализировать ресурс.
Дело в том, что из-за повторяющейся информации роботы медленнее проверяют сайт, а изменения на ресурсе дольше попадают в результаты поиска. Когда роботы Яндекса увидят эту директиву, не будут несколько раз перезагружать дубли информации и быстрее проверят сайт, а нагрузка на сервер снизится.
www.example.com/dir/get_card.pl?ref=site_1&card_id=10
www.example.com/dir/get_card.pl?ref=site_2&card_id=10
Параметр ref нужен, чтобы отследить, с какого ресурса сделан запрос. Он не меняет содержимое страницы, значит два адреса покажут одну и ту же страницу с книгой card_id=10. Поэтому директиву можно указать так:
User-agent: Yandex
Disallow:
Clean-param: ref /dir/get_card.pl
Робот Яндекса сведёт страницы к одной: www.example.com/dir/get_card.pl?card_id=10
Чтобы директива применялась к параметрам на страницах по любому адресу, не указывайте адрес:
User-agent: Yandex
Disallow:
Clean-param: utm
Директива Crawl-delay — устанавливает минимальный интервал в секундах между обращениями робота к сайту. Это помогает снизить нагрузку на сервер ресурса. Чем выше указанное значение, тем меньше страниц робот загрузит за сессию.
Это помогает снизить нагрузку на сервер ресурса. Чем выше указанное значение, тем меньше страниц робот загрузит за сессию.
Значения можно указывать целыми или дробными числами через точку.
User-agent: Yandex
Disallow:
Crawl-delay: 0.5
Для Яндекса максимальное значение в crawl-delay — 2. Более высокое значение можно установить инструментами Яндекс.Вебмастер.
Для Google-бота можно установить частоту обращений в панели вебмастера Search Console.
Директива Host — инструкция для робота Яндекса, которая указывает главное зеркало сайта. Нужна, если у сайта есть несколько доменов, по которым он доступен. Вот как её указывают:
User-agent: Yandex
Disallow: /example/
Host: example.ru
Если главное зеркало сайта — домен с протоколом HTTPS, его указывают так:
Host: https://site.ru
Как создать robots.txtСпособ 1. Понадобится текстовый редактор: блокнот, TextEdit, Vi, Emacs или любой другой. Не используйте приложения Microsoft Office, потому что они сохраняют файлы в неподходящем формате или добавляют в них лишние символы, которые не распознаются поисковыми роботами.
Не используйте приложения Microsoft Office, потому что они сохраняют файлы в неподходящем формате или добавляют в них лишние символы, которые не распознаются поисковыми роботами.
Способ 2. Создать на CMS с помощью плагинов — в этом случае robots.txt установится сам.
Если вы используете CMS хостинга, редактировать файл robots.txt не потребуется. Скорее всего, у вас даже не будет такой возможности. Вместо этого провайдер будет указывать поисковым системам, нужно ли сканировать контент, с помощью страницы настроек поиска или другого инструмента.
Способ 3. Воспользоваться генератором robots.txt — век технологий всё-таки.
Сгенерировать файл можно на PR-CY, IKSWEB, Smallseotools.
Требования к файлу robots.txtКогда создадите текстовый файл, сохраните его в кодировке utf-8. Иначе поисковые роботы не смогут прочитать документ. После создания загрузите файл в корневую директорию на сайте хостинг-провайдера. Корневая директория — это папка public. html.
html.
Папка, в которой нужно искать robots.txt. Источник
Если файла нет, его придётся создавать самостоятельно.
Требования, которым должен соответствовать robots.txt:
- Каждая директива начинается с новой строки.
- Одна директива в строке, сам параметр также написан в одну строку.
- В начале строки нет пробелов.
- Нет кавычек в директивах.
- Директивы не нужно закрывать точкой или точкой с запятой.
- Файл должен называться robots.txt. Нельзя называть его Robots.txt или ROBOTS.TXT.
- Размер файла не должен превышать 500 КБ.
- robots.txt должен быть написан на английском языке. Буквы других алфавитов не разрешаются.
Если файл не соответствует одному из требований, весь сайт считается открытым для индексирования.
Как проверить правильность Robots.txtПроверить robots. txt помогают сервисы от Яндекс и Google. В Яндексе можно проверять файл даже без сайта — например, если вы написали robots.txt, но пока не загрузили его на сайт.
txt помогают сервисы от Яндекс и Google. В Яндексе можно проверять файл даже без сайта — например, если вы написали robots.txt, но пока не загрузили его на сайт.
Вот как это сделать:
- Перейдите на Яндекс.Вебмастер.
- В открывшееся окно вставьте текст robots.txt и нажмите проверить.
Если файл написан правильно, Яндекс.Вебмастер не увидит ошибок.
А если увидит ошибку — подсветит её и опишет возможную проблему.
На Яндекс.Вебмастер можно проверить robots.txt и по URL сайта. Для этого нужно указать запрос: URL сайта/robots.txt. Например, unisender.com/robots.txt.
Ещё один вариант — проверить файл robots.txt через Google Search Console. Но сначала нужно подтвердить владение сайтом. Пошаговый алгоритм проверки robots.txt описан в видеоинструкции:
Поделиться
СВЕЖИЕ СТАТЬИ
Другие материалы из этой рубрики
Не пропускайте новые статьи
Подписывайтесь на соцсети
Делимся новостями и свежими статьями, рассказываем о новинках сервиса
Статьи почтой
Раз в неделю присылаем подборку свежих статей и новостей из блога. Пытаемся
шутить, но получается не всегда
Пытаемся
шутить, но получается не всегда
Наш юрист будет ругаться, если вы не примете 🙁
Как запустить email-маркетинг с нуля?
В бесплатном курсе «Rock-email» мы за 15 писем расскажем, как настроить email-маркетинг в компании. В конце каждого письма даем отбитые татуировки об email ⚡️
*Вместе с курсом вы будете получать рассылку блога Unisender
Оставляя свой email, я принимаю Политику конфиденциальностиНаш юрист будет ругаться, если вы не примете 🙁
Памяти: Роботы доставки Яндекса ушли, но не забыты
Пришли в среду, и пришли с миром.
17 ноября 2021 года ознаменовалось появлением роботов-доставщиков еды Яндекса в кампусе Университета Аризоны. Они были мгновенным культурным феноменом.
Студенты не могли не смотреть на роботов, когда они проезжали мимо, некоторые даже останавливали автоматы на своем пути, прыгая на их пути.
«Мы видим огромный интерес со стороны студентов. Чаще всего в кампусах мы сталкиваемся с тем, что студенты хотят с ними сфотографироваться. Им также нравится бросать вызов роботу, чтобы увидеть, что произойдет, если они встанут перед ним. Так что студенческое любопытство действительно поражает, и я думаю, что они в восторге от этих роботов», — рассказала в предыдущей статье Wildcat руководитель отдела по связям с общественностью «Яндекса» Юлия Швейко.
БОЛЬШЕ ИЗ ЕЖЕДНЕВНОГО ДИКОГО КОТА
UA стал вторым университетом в стране, который стал партнером Яндекса и Grubhub, чтобы предоставить альтернативный способ доставки еды голодным студентам. Хотя роботы помогли уменьшить объем заказов на доставку, казалось, что бремя было переложено на работников ресторана, обрабатывающих большее количество заказов.
Хотя роботы помогли уменьшить объем заказов на доставку, казалось, что бремя было переложено на работников ресторана, обрабатывающих большее количество заказов.
Томас Наджор учится на первом курсе экономического факультета и работал в Einstein’s Bagels в Мемориальном центре студенческого союза, пока роботы Яндекса еще доставляли товары. Наджор сказал, что заказы на доставку от роботов накапливались в существующем количестве заказов, которые должны были обрабатывать рабочие Эйнштейна, что могло стать непосильным.
«С одной стороны, мне очень нравится работать с ними в качестве парня, раздающего заказы, — сказал Наджор. «Я бы сказал, что более сложная часть работы с ними связана с самой линией, потому что мы получаем все заказы одновременно. Таким образом, мы будем получать заказы в магазине одновременно с самовывозом, который уже осуществляется из Grubhub, а затем, помимо этого, у нас будут поставки от реальных доставщиков Grubhub, а затем роботы».
Наджор оценил, основываясь на собственном опыте, что использование роботов значительно выросло с момента их внедрения в ноябре.
«Действительно, за последние два месяца мы перешли от шести в день к, вероятно, по меньшей мере сотне», — сказал Наджор.
Роботы оставили в UA больше, чем просто экономический след. У некоторых студентов установилась эмоциональная связь.
«Приятно видеть их здесь», — сказала Ананья Шах, студентка-первокурсник биологического факультета. «Они милые.»
Еще одним привлекательным аспектом роботов было их удобство.
«Если они предлагают, я честно предпочитаю [роботов]», — сказала Кэти Смит, первокурсница и студентка бизнес-школы в Колледже управления Эллера. «Я просто в половине случаев не люблю разговаривать с людьми, когда заказываю доставку еды. Мне они очень нравятся, если честно, так намного проще».
У других появилось необъяснимое отвращение к катящимся по тротуару большим белым кубам и выражаемому им сочувствию.
«Я думаю, что это просто странно, вроде как сочувствовать машине и называть ее милой», — сказал Ян Макартур, первокурсник, изучающий архитектурное проектирование и самопровозглашенный антиботтер. «Что-то в этом меня раздражает, и я думаю: «Нет, это металлический ящик, который катится мне по тротуару».
МакАртур был участником сервера Discord на базе UA, который участвует в дискуссиях Яндекса. Пользователи сервера обычно делятся на два лагеря: сторонники ботов и противники ботов.
СВЯЗАННЫЕ: Представитель Пол Госар выступает на мероприятии College Republicans United в кампусе
Возражения против роботов также распространялись на их потенциально вредные социальные и политические последствия.
«Это машины, созданные безмозглой мегакорпорацией, управляемой русскими олигархами, чтобы отнимать рабочие места у честных работников, которым, возможно, недоплачивают, но недоплата лучше, чем буквальное отсутствие работы, что они и пытаются сделать. . Мы продолжаем поддерживать такие вещи, как Яндекс, не говоря об этических и социальных соображениях», — сказал Зейн Ландерс, еще один откровенный противник ботов на сервере Discord.
. Мы продолжаем поддерживать такие вещи, как Яндекс, не говоря об этических и социальных соображениях», — сказал Зейн Ландерс, еще один откровенный противник ботов на сервере Discord.
«Я полностью согласна с мнением, но я сторонник ботов, потому что я думаю, что мы можем создать систему доставки еды с очаровательными роботами с соблюдением этических норм», — сказала Фарида Бауаб, студентка-второкурсник психологии, которая также является членом Дискорд. «Просто надо менять систему. Так что проблема не в роботах. Это система, в которой они работают».
Как бы то ни было, антиботтеры добьются своего.
3 марта из кампуса прекратили работу роботы-доставщики еды Яндекса из-за продолжающейся войны в Украине.
«В связи с вторжением России в Украину, Arizona Student Unions и Arizona Dining прекратят вести дела с Яндексом, российской многонациональной публичной компанией и поставщиком оборудования для роботов-курьеров в кампусе, с сегодняшнего дня, 3 марта, 2022», — написали в Instagram Студенческие союзы Аризоны.
Роботов спас Discord-сервер «Яндекспостинга».
Следите за Кристианом Барняком на Twitter
Пойдемте к вам. The Daily Wildcat, прямо в ваш почтовый ящик. Новости. Наука/Здоровье. Спортивный. Искусство/Образ жизни. Твой выбор. Вы отмените в любое время.
Зарегистрируйтесь сейчас
Grubhub прекращает отношения мобильной доставки с российской интернет-компанией Яндекс
Robotics 24/7 Темы Мобильные роботы Служба доставки
Grubhub не уточнил, почему прекращает деловые отношения.
Яндекс
Соглашение о роботизированной доставке Яндекса с Grubhub продлилось менее года.
Автор Cesareo Contreras
· 5 марта 2022 г.
Гигант онлайн-заказов еды Grubhub объявляет о прекращении сотрудничества с российской интернет-компанией Yandex N.V. по доставке мобильных роботов, согласно недавнему сообщению агентства Reuters.
«Мы прекращаем сотрудничество с Яндексом», — заявил Grubhub агентству Reuters в пятницу. «Мы работаем с нашими партнерами по кампусу над альтернативными вариантами обслуживания, поскольку со временем мы отказываемся от Яндекса».
Недолгое партнерство
В июле 2021 года Яндекс заключил соглашение с Grubhub о развертывании своих автономных мобильных роботов в кампусах колледжей по всей стране. Grubhub принадлежит голландской транснациональной компании Just Eat Takeaways. Компания заявила, что сотрудничает с более чем 250 кампусами колледжей по всей территории США. время. «Мы рады предложить эти экономичные, масштабируемые и быстрые возможности заказа и доставки еды колледжам и университетам по всей стране, которые хотят адаптироваться к уникальным потребностям студентов в питании».
В августе 2021 года Яндекс запустил свою первую коллегиальную службу доставки в Университете штата Огайо. В ноябре он начал поставки в Аризонский университет.
В ноябре Яндекс представил последнюю версию своего робота-доставщика. Источник: Яндекс
Источник: Яндекс
Российские компании столкнулись с негативной реакцией
Grubhub не уточнил, почему прекращает отношения с компанией, но это происходит на фоне вторжения России в Украину. Агентство Reuters отметило, что многие российские компании «во всем мире избегают» в связи с конфликтом.
Яндекс — многонациональная компания, предлагающая различные интернет-услуги и продукты, включая поиск. Его описывают как российскую версию Google. Компания заявила, что ей грозит дефолт в ответ на негативную реакцию России, сообщает CNN.
Последние достижения Яндекса
Компания запустила своего первого робота-доставщика в 2019 году, но с 2017 года разрабатывает технологию автономного вождения. Компания утверждает, что ее роботы-доставщики осуществили более 10 000 доставок по всему миру.
В ноябре компания представила третье поколение своего робота-доставщика. В дополнение к новому дизайну беспилотный носитель был оснащен большим объемом памяти, съемной батареей и большим количеством камер.
В том же месяце Яндекс объявил о партнерстве с Majid Al Futtaim, чтобы предлагать услуги беспилотного вождения в торговых центрах и других торговых точках Дубая.
Об автореЧезарео Контрерас
Чезарео Контрерас — помощник редактора журнала Robotics 24/7. До работы в Peerless Media он был отмеченным наградами репортером в газетах Metrowest Daily News и Milford Daily News в Массачусетсе. Контрерас является выпускником Университета штата Фрамингем и проявляет большой интерес к человеческой стороне новых технологий.
Следите за робототехникой 24/7 на Facebook
Электронная почта РегистрацияПолучайте новости, документы, СМИ и исследования с доставкой
Будьте в курсе новостей и ресурсов, необходимых для работы.