
оптимизация — Как запретить индексацию всех страниц с определенным get-параметром в robots.txt?
Яндекс пожаловался на то, что присутствует некоторое кол-во дубликатов страниц с get-параметром.
Ссылка на подобную страницу выглядит примерно так: site.ru/blog/article?layout=new Параметр всегда одинаков, но его значение меняется. Как запретить индексацию всех ссылок с layout=»»? Насколько правильным будет Disallow: *?*layout=
- оптимизация
- seo
- индексация
- robots.txt
Эта конструкция абсолютно верная:
Disallow: *?*layout=
Однако надо учитывать, что она запретит индексацию всех страниц, которые содержат параметр layout, независимо от его положения в списке параметров и наличия других параметров в адресе. Т.е. все указанные ниже примеры страниц не будут индексироваться:
site.ru/blog/article?layout=new site.ru/blog/article?layout=old site.ru/blog/article?layout=old&author=Example site.ru/blog/article?page=1&layout=fashion site.ru/blog/article?page=2&layout=new&author=Example
 ru/blog/article?page=1&layout=fashion
site.ru/blog/article?page=2&layout=new&author=Example
ru/blog/article?page=1&layout=fashion
site.ru/blog/article?page=2&layout=new&author=Example
1
Я делаю это через Clean-param: в robots.txt по двум причинам:
- Снижается нагрузка на сервер обхода.
- Если закрывать от индекса с помощью Disallow или тега noindex, тогда поисковики так же не будут индексировать и учитывать обратные ссылки на такие страницы. А если закрывать от индекса этим методом, тогда беклинки учтутся сайту.
Эти плюсы относятся только к Yandex!
А в Google получите ошибку в robots.txt, что-то не совмещаются в этом моменте. Но я ее игнорирую и всё нормально.
Для гугла, с моей точки зрения решать проблему таких дублей с помощью этого чудесного инструмента, почитайте, поймете все плюсы. А если не поймете, то лучше не трогайте!
Зарегистрируйтесь или войдите
Регистрация через GoogleРегистрация через Facebook
Регистрация через почту
Отправить без регистрации
Почта
Необходима, но никому не показывается
Отправить без регистрации
Почта
Необходима, но никому не показывается
Нажимая на кнопку «Отправить ответ», вы соглашаетесь с нашими пользовательским соглашением, политикой конфиденциальности и политикой о куки
Как в dle запретить индексацию страниц? Что написать в robot.
 txt? – QA PR-CY
txt? – QA PR-CY- Сообщество
- Как в dle запретить индексацию страниц? Что написать в robot.txt?
Ответы на пост (20) Написать ответ
Зачем нагружать robot.txt? это же dle не плодите ненужные стр и всё.
User-agent: *
Disallow: /engine/
Host: site.ru
Sitemap: http://site.ru/sitemap.xml
Должен быть такой, остальное в /engine/engine.php
перед
if ($config[‘allow_rss’]) $metatags .= <<<HTML
добавь
if (
(intval($_GET[‘cstart’]) > 1 ) OR /* Любые страницы пагинации */
) $metatags .= <<<HTML
\n<meta name=»robots» content=»noindex,nofollow» />
HTML;
Можно там же и другие ненужные стр закрыть, например — Стр просмотра списка тегов, формы обратной связи закладок пользователей и прочие
0
Решение
Disallow: /page/*
и все? все страницы выпадут ? хм .
выпадут.
Ответ на такой вопрос можно было уже поискать и в гугле… Привыкли на блюдечке да с каёмочкой, блин… лодыри, тунеядцы…
Оно так и есть, лень, но не лень сайт создавать и им заниматься. Где надо мозг работает, а на самом элементарном и простом его нет.
topbux
26
26.09.2017 10:32
Не надо велосипед изобретать 🙂
Disallow: */page/*/
Disallow: */page/
topbux
26
26.09.2017 10:36
И еще используй хак для DLE Тег canonical для страниц DLE что бы отбить все возможные ее дубли https://dleshka.org/hacks/6003-teg-canonical-dlya-stranic-dle.html
Я бы посоветовал сделать так.
1.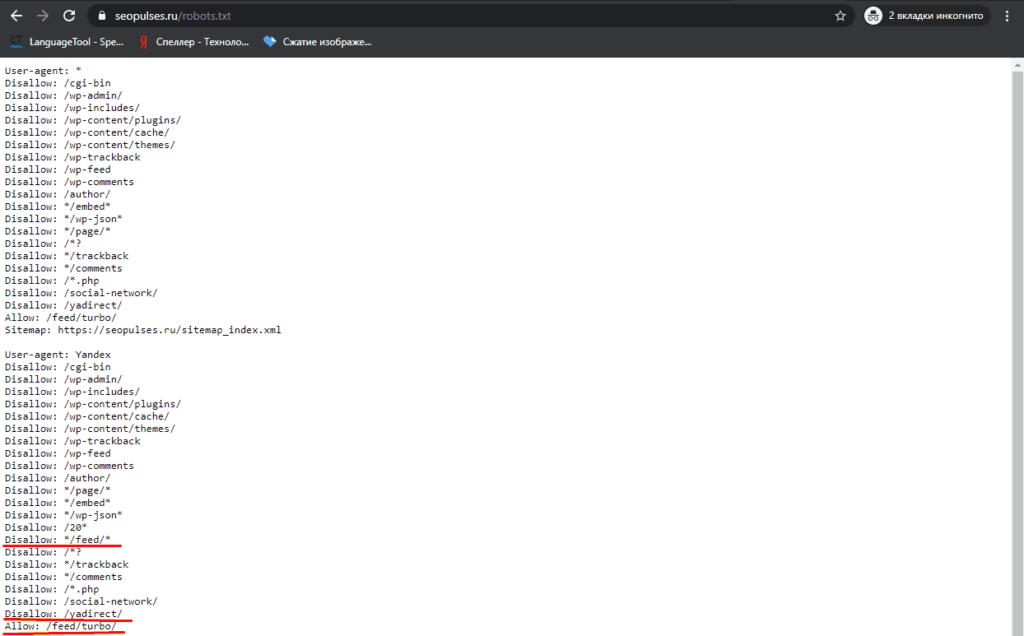 Порыться по Нету и выбрать все запреты страниц типа:
Порыться по Нету и выбрать все запреты страниц типа:
Disallow: */page/*/
Disallow: */page/
Disallow: /page/*
и.т.д
2. Затем зайти в Яндекс Вебмастер, в раздел — «Инструменты» — «Анализ robots.txt». Там отобразится ваш действующий robots.txt. Ниже будет поле «Разрешены ли URL?» Добавляете команды (Disallow: */page/*/, Disallow: */page/, Disallow: /page/* и им подобные) в ваш robots.txt тот, что в окне выше. Затем в окно «Разрешены ли URL?» вставляете списком те страницы page, либо другие страницы и жмете «Проверить». Если урл разрешен будет зеленая галочка — тогда в команде предположим Disallow: */page/*/ убираете наклонные и звездочки. Делаете пока ваш урл — не будет красным (Запрещен)!
3. Аналогично, есть проверка robots.txt в гугл вебмастере.
P.S. Насчет грузить robots.txt как советовали выше — не согласен! Сам закрывал в дле, в /engine/engine.php — остался недоволен. Да и сами Яндекс-представители советуют, закрывать именно в файле robots. txt.
txt.
как бы не ставил в вебмастере
Disallow: */page/*/
Disallow: */page/
Disallow: /page/*
Все равно горит зеленая галочка …
Почитайте мой 1 пункт и полазьте по нету. Вот вам нашел еще пару команд — пробуйте.
Disallow: */page/*
Disallow: /page*
С ув. Сергей
порылся.. добавил = зеленая галочка …
1. Вот вставил в свой роботс две строки:
User-agent: *
Disallow: */page/*
Disallow: /page*
Host: ****.ru
Sitemap: http://****.ru/sitemap.xml
2. В итоге страницы типа ****.ru/page/2/ — результат */page/* — Закрыт к индексации!!!
Попробуйте еще раз.
Вот результат — http://s018.radikal.ru/i519/1709/78/6cdef03aa8fd.jpg
С ув. Сергей
GreenRed, ну что получилось?
нет… не работает =) зеленая горит ….
Из вот этих двух команд
Disallow: */page/*
Disallow: /page*
достаточно и этой одной
Disallow: */page/*
Вот скрин на закрытие всех вами указанных выше страниц — http://radikal. ru/lfp/s013.radikal.ru/i324/1709/6f/dea45e8cac01.jpg/htm
ru/lfp/s013.radikal.ru/i324/1709/6f/dea45e8cac01.jpg/htm
С ув. Сергей
вставил Disallow: */page/* — зеленая!
Для robots.txt запрет будет выглядеть так
Disallow: /*page/
Запрет на индексацию идет по всем возможным страницам пагинации, т.е. как только в адресе появляется page на эту страницу ставится запрет индексации.
Прописал, но яндекс даже если вручную пробовать удалить — пишет, что нет оснований для удаления!
Похожие посты
- запрет в robots.txt
6 - Удаление страниц в яндекс вебмастер
9 - Запретить индексацию сайта либо показывать недоделки
8 - Удаление страницы с Яндекса
9 - robots.txt и геморрой с движком, как запретить?
1
Анализ сайта
Поможем улучшить ваш сайт.
php — достаточно ли тегов robots.txt и метаданных, чтобы запретить поисковым системам индексировать динамические страницы, зависящие от переменных $_GET?
спросил
Изменено 7 лет, 2 месяца назад
Просмотрено 964 раза
Я создал php-страницу, доступную только с помощью токена/пароля, полученного через $_GET
Поэтому, если вы перейдете по следующему URL-адресу, вы получите общую или пустую страницу
http://fakepage11.
 com/secret_page.php
com/secret_page.phpОднако, если вы использовали ссылку с токеном, она показывает вам специальный контент
http://fakepage11.com/secret_page.php?token=344ee833bde0d8fa008de206606769e4
Конечно, это не так безопасно, как страница входа, но моя единственная забота — создать динамическую страницу, которая не индексируется и доступна только по предоставленной ссылке.
Индексируются ли динамические страницы, зависящие от переменных $_GET, Google и другими поисковыми системами?
Если да, будет ли достаточно включить следующее, чтобы скрыть это?
Даже если я наберу в гугле:
сайт:fakepage11.com/
Спасибо!
- php
- get
- web-crawler
- robots.txt
- google-crawlers
Если бот поисковой системы находит ссылку с токеном, он может каким-то образом просканировать и проиндексировать ее¹.
Если вы используете robots.txt , чтобы запретить сканирование страницы, соответствующие боты поисковых систем не будут сканировать страницу, но они все равно могут проиндексировать ее URL-адрес (который затем может появиться на сайте : поиск).
Если вы используете мета — роботов , чтобы запретить индексирование страницы, соответствующие поисковые роботы не будут индексировать страницу, но они все равно смогут ее сканировать.
Вы не можете иметь и то, и другое : Если вы запретите сканирование, соответствующие боты никогда не узнают, что вы также запрещаете индексирование, потому что им не разрешено посещать страницу, чтобы увидеть ваши мета — роботов элемент.
¹ Поисковые системы могут найти ссылку бесчисленным множеством способов. Например, пользователь, который посещает страницу, может использовать панель инструментов браузера, которая автоматически отправляет все посещенные URL-адреса в поисковую систему.
1
Если ваша страница недоступна для обнаружения, она не будет проиндексирована.
под «обнаруживаемым» мы подразумеваем:
- это стандартная веб-страница, т.е. индекс.*
- на него ссылается другая ссылка либо ваша, либо с другого сайта
Таким образом, в вашем случае, используя параметр get для доступа, вы получаете 1, но не обязательно 2, поскольку кто-то может ссылаться на эту ссылку и, следовательно, на «скрытую» страницу.
Вы можете использовать robots.txt , который вы дали, и в этом случае страница не будет проиндексирована ботом, который это соблюдает (не все подойдут). Отсутствие индексации вашей страницы, конечно, не означает, что «скрытый» URL-адрес страницы не будет находиться в открытом доступе.
Кроме того, еще одна проблема — в зависимости от ваших требований — заключается в том, что вы используете незашифрованный HTTP, что означает, что ваши «скрытые» URL-адреса и содержимое страниц видны каждому серверу между вашим сервером и пользователем.
Помимо поисковых систем, позаботьтесь о том, чтобы определенные службы кэшировали/разрешали контент при обмене URL-адресами, например, в мессенджерах Skype или Facebook. В этом случае они посетят URL-адрес и попытаются извлечь метаданные и, возможно, кэшировать их, если это применимо. Конечно, этот сценарий не раскрывает ваш URL-адрес публике, но он предоставляется системам этих служб, а вместе с ними и контенту, который вы «спрятали».
ОБНОВЛЕНИЕ : Еще одна проблема, которую следует учитывать, — это раскрытие «скрытой» страницы путем ссылки на другую страницу. В этом случае в журналах сервера, на котором размещен связанный URL-адрес, ваша страница будет рассматриваться как реферальная и, следовательно, будет видна, что также распространяется на Google Analytics и т. д. Таким образом, если вы хотите оставаться незаметным, не ссылайтесь на другие страницы из скрытая страница.
3
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Обязательно, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Как запретить страницы поиска из robots.
 txt
txtспросил
Изменено 10 лет, 6 месяцев назад
Просмотрено 23 тысячи раз
Мне нужно запретить индексацию http://example.com/startup?page=2 поисковых страниц.
Я хочу, чтобы http://example.com/startup индексировался, но не http://example.com/startup?page=2 и page3 и так далее.
Кроме того, запуск может быть случайным, например, http://example.com/XXXXX?page
- robots.txt
Что-то вроде этого работает, как подтверждает функция Google Webmaster Tools «test robots.txt»:
Агент пользователя: * Запретить: /startup?page=
Запретить Значение этого поля указывает частичный URL-адрес, который не быть посещенным. Это может быть полный путь, или частичный путь; любой URL, который начинается с этим значением не будет получено.

Однако, , если первая часть URL-адреса изменится на , необходимо использовать подстановочные знаки:
User-Agent: * Запретить: /startup?page= Запретить: *страница= Запретить: *?page=
0
Вы можете поместить это на страницы, которые вы не хотите индексировать:
<МЕТА-ИМЯ="РОБОТЫ" СОДЕРЖИМОЕ="НЕТ">
Это говорит роботам не индексировать страницу.
На странице поиска может быть интереснее использовать:
Указывает роботам не индексировать текущую страницу, но по-прежнему переходить по ссылкам на этой странице, что позволяет им попадать на страницы, найденные в поиске.
- Создайте текстовый файл и назовите его: robots.txt
- Добавить пользовательские агенты и запретить разделы (см. пример ниже)
- Поместите файл в корень вашего сайта
Пример:
################################ #Мой файл robots.
