
Что такое robots.txt — создание файла роботс.txt
Довольно часто вебмастера и разработчики сталкиваются с вопросами как правильно создать файл robots.txt, что прописывать в файле роботс.txt и как закрыть ту или другую страницу от индексации с помощью robots.txt. Давайте рассмотрим все по порядку.
Что такое файл robots.txt
Иногда бывает нужно скрыть некоторые страницы сайта от приходящих на него поисковых роботов и таким образом закрыть эти страницы от индексации. Сам файл robots.txt должен лежать на сервере в корневом каталоге сайта. Если его там нет или он лежит в любой другой папке эффекта не будет, т.к. робот поисковой системы его попросту не найдет, а если и найдет, то не поймет что с ним делать.
Как правильно создать файл robots.txt и что в нем прописывать
Создать robots.txt очень просто — открываем Блокнот или любой другой текстовый редактор (Word, Notepad++, Sublime Text и т.д.) и создаем новый текстовый файл с названием robots и расширением .. Само содержание файла являет собой перечень команд, обращенных к тому или иному поисковому роботу или универсальные команды сразу для всех. Первая строка — это имя робота, вторая — страницы, разделы или подразделы, которые мы хотим закрыть от видимости поисковых систем. Если нужно чтобы поисковики видели весь сайт, то хватит и одной универсальной команды, а содержание файла роботс.txt примет вид: txt
txt
User-agent: * Disallow: Host: www.site.com
В данном примере User-agent и звездочка после двоеточия означают, что команда действует для роботов всех поисковых систем. Слово Disallow c двоеточием, после которого ничего не указано значит, что весь сайт полностью открыт для индексации. Строка Host
Как закрыть страницу или сайт от индексации с помощью robots.txt
Для того, чтобы закрыть от индексации весь сайт и чтобы поисковики его не видели, нужно прописать в robots.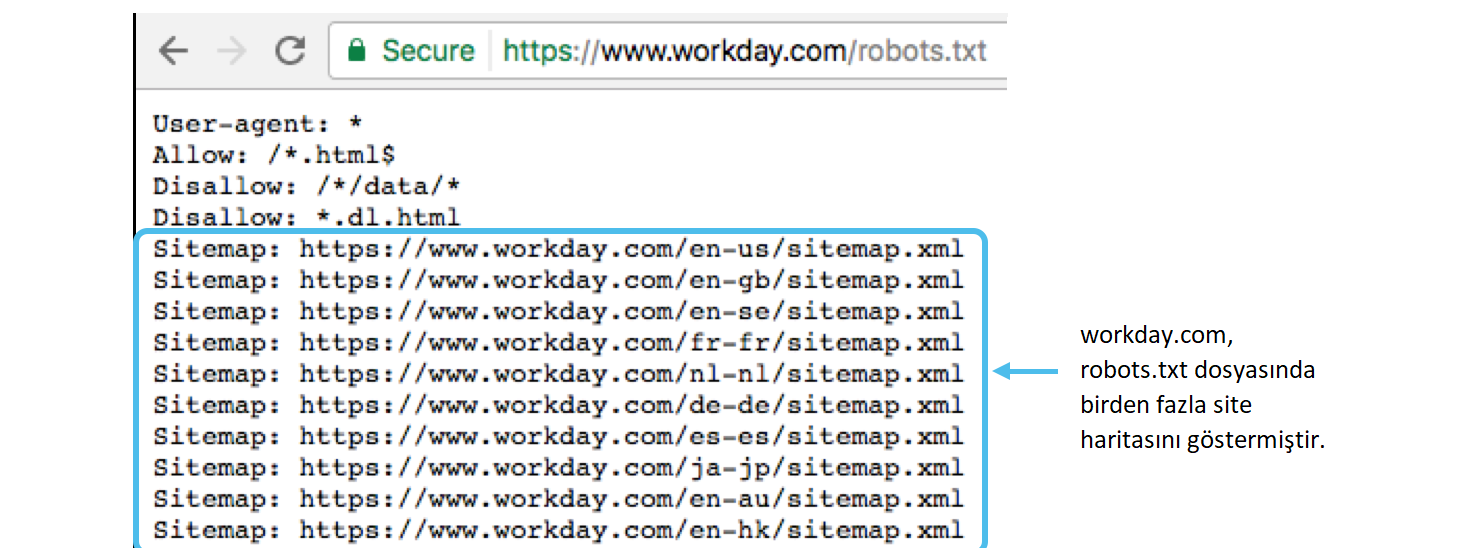 txt следующие команды:
txt следующие команды:
User-agent: * Disallow: / Host: www.site.com
Чтобы закрыть от индексации любую страницу, нужно прописать в robots.txt после Disallow: путь к ней без учета адреса самого сайта — к примеру мы хотим закрыть страницу http://www.site.com/admin.php, тогда нам нужно указать адрес /admin.php. Также можно закрыть директорию (папку) — после ее адреса нужно добавить «/» (как мы это сделали с директорией api). При этом все страницы, которые находятся в данной директории (к примеру http://www.site.com/api/sample-page.php) тоже индексироваться не будут.
User-agent: * Disallow: /admin.php Disallow: /api/ Host: www.site.com
Также в файле robots.txt можно использовать регулярные выражения (RegExp). Проверить как сейчас настроен этот файл и какие страницы он блокирует вы всегда можете в Google Webmaster Tools -> Crawl -> Blocked URLs.
Что такое файл robots.txt? — Тюлягин
Здравствуйте, уважаемые читатели проекта «Тюлягин»! Сегодня мы с вами поговорим об одном из трех базовых первостепенных настроек по оптимизации вашего сайта — файле robots. txt. После прочтения этой статьи вы узнаете для чего нужен данный файл и что такое robots.txt. Я расскажу вам как создать и правильно настроить файл robots.txt для сайта на движке WordPress. Также мы рассмотрим с вами основные способы настройки индексации сайта через файл robots.txt, включая запрет индексации отдельных страниц и всего сайта поисковыми системами.
txt. После прочтения этой статьи вы узнаете для чего нужен данный файл и что такое robots.txt. Я расскажу вам как создать и правильно настроить файл robots.txt для сайта на движке WordPress. Также мы рассмотрим с вами основные способы настройки индексации сайта через файл robots.txt, включая запрет индексации отдельных страниц и всего сайта поисковыми системами.
Содержание статьи:
- Что такое файл robots.txt и зачем он нужен?
- Как создать файл robots.txt
- Синтаксис и символы файла robots.txt
- Настройка индексации с помощью правильного файла robots.txt для WordPress
- Как проверить файл robots.txt
Что такое файл robots.txt и зачем он нужен?
Файл robots.txt или другими словами индексный файл — это файл в текстовом формате txt, создающий ограничения индексирования поисковым роботам на серверах http, https и ftp. Именно из-за того что файл robots.txt предназначен для поисковых роботов он носит такое созвучное название. Данный стандарт был принят в 1994 году, то есть ему уже 25 лет, и используется большинством крупных поисковых систем. Файл robots.txt содержит строгий синтаксис, который выражает набор исключений и инструкций для поисковых систем, а точнее для их алгоритмов и роботов, сканирующих сайты. Файл robots.txt должен обязательно записан в кодировке UTF-8, иначе поисковые роботы его не поймут. Файл robots.txt загружается в корневой каталог вашего сайта и должен быть доступен по адресу https://ваш_сайт.ru/robots.txt. Если все правильно и файл доступен, то содержимое роботс отобразится в вашем браузере, при вводе адреса в браузерную строку. Все правила индексации и исключения, записанные в файле robots.txt действуют только в отношении того протокола и хоста, где он размещен. То есть файл роботс ти икс ти никак не влияет на сканирование внешних ссылок на другие сайты.
Данный стандарт был принят в 1994 году, то есть ему уже 25 лет, и используется большинством крупных поисковых систем. Файл robots.txt содержит строгий синтаксис, который выражает набор исключений и инструкций для поисковых систем, а точнее для их алгоритмов и роботов, сканирующих сайты. Файл robots.txt должен обязательно записан в кодировке UTF-8, иначе поисковые роботы его не поймут. Файл robots.txt загружается в корневой каталог вашего сайта и должен быть доступен по адресу https://ваш_сайт.ru/robots.txt. Если все правильно и файл доступен, то содержимое роботс отобразится в вашем браузере, при вводе адреса в браузерную строку. Все правила индексации и исключения, записанные в файле robots.txt действуют только в отношении того протокола и хоста, где он размещен. То есть файл роботс ти икс ти никак не влияет на сканирование внешних ссылок на другие сайты.
Файл robots нужен для правильного сканирования поисковыми роботами вашего сайта. Поисковые роботы, или как их также называют краулеры, с помощью инструкций, записанных в файле robots. txt узнают какие разделы сайта не надо сканировать. То есть для управления индексацией сайта помимо карты сайта в формате xml, у нас есть в наличии такой инструмент как файл robots.txt. Если карта сайта помогала нам указать какой важный контент есть на сайте и как часто он обновляется для поисковых роботов, то инструмент индексации robots.txt наоборот позволяет ограничить доступ к неважному контенту, который не надо индексировать.
txt узнают какие разделы сайта не надо сканировать. То есть для управления индексацией сайта помимо карты сайта в формате xml, у нас есть в наличии такой инструмент как файл robots.txt. Если карта сайта помогала нам указать какой важный контент есть на сайте и как часто он обновляется для поисковых роботов, то инструмент индексации robots.txt наоборот позволяет ограничить доступ к неважному контенту, который не надо индексировать.
Какой же контент не стоит индексировать поисковым системам для успешного продвижения вашего сайта? В первую очередь не стоит индексировать все внутренние файлы вашего сайта, то есть те файлы которые обеспечивают функционирования движка сайта. Также рекомендуется ограничивать индексацию дублирующего контента, то есть тех страниц или разделов сайта которые частично или полностью дублируют более важные разделы сайта. Как пример дублирующего контента являются страницы тегов, на которых находятся ваши записи, которые уже есть на главной странице и в рубриках. Также вы можете ограничить от индексации какие-то личные страницы с контактами или другими приватными данными, чтобы они не попали в выдачу поиска. Также я рекомендую ограничить страницы с внутреннем поиском сайта и страницы с любой формой отправки информации и контактных данных.
Также вы можете ограничить от индексации какие-то личные страницы с контактами или другими приватными данными, чтобы они не попали в выдачу поиска. Также я рекомендую ограничить страницы с внутреннем поиском сайта и страницы с любой формой отправки информации и контактных данных.
Если не ограничивать данную информацию от поисковых систем и их роботов, то она попадет в поисковую выдачу, что сильно повлияет на успешное продвижение вашего сайта, так как снизит вес остальных страниц с более важным контентом. Кроме того попадание личной информации и другой внутренней информации устройства вашего сайта может навредить лично вам и функционированию сайта и его безопасности.
Как создать файл robots.txt
Создать файл robots.txt весьма легко, так как этот текстовый фал с популярным разрешением txt. Cделать это можно с помощью Notepad++ или любого другого текстового редактора, включая обычный блокнот. Если вы не планируете запрещать что либо на своем сайте от индексации вы можете оставить файл robots. txt пустым и закончить на этом его создание. Однако останавливаться на этом я бы вам не советовал. Сам процесс создания файла не должен вызвать сложности даже у новичков, а вот с наполнением и синтаксисом robots.txt есть что обсудить. Именно от правильного написания инструкций и синтаксиса файла роботс зависит успешная индексация вашего сайта поисковыми системами.
txt пустым и закончить на этом его создание. Однако останавливаться на этом я бы вам не советовал. Сам процесс создания файла не должен вызвать сложности даже у новичков, а вот с наполнением и синтаксисом robots.txt есть что обсудить. Именно от правильного написания инструкций и синтаксиса файла роботс зависит успешная индексация вашего сайта поисковыми системами.
Синтаксис и символы файла robots.txt
Любой правильный файл robots.txt начинается с директивы User-agent, которая указывает к какому поисковому роботу обращены нижеследующие инструкции. Так на текущий момент существует 302 общепризнанных поисковых робота, со списком которых можно ознакомится на сайте robotstxt.org. Если вы указываете инструкции для всех поисковых роботов сразу, то имеет смысл поставить в директиве символ * ( User-agent: * ). Либо указать конкретного работа, например:
- User-agent: Yandex или User-agent: Googlebot
После директивы User-agent вы расставляете команды для текущего робота на запрет или разрешение индексации тех или иных разделов, страниц и записей вашего сайта.
- Данная запись приведет к индексированию всего сайта:
User-agent: *
Disallow:
- А эта наоборот к запрету индексации всего сайта или закрытию сайта для всех роботов
User-agent: *
Disallow: /
Также для правильного заполнения robots.txt, вам необходимо понимать что такое уровни сайта:
- Для уровня страницы сайта директива запрета индексации страницы выглядит так: Disallow: /primer_stranici.html
- Уровень папки сайта. Запрет индексации конкретной папки выглядит так: Disallow: /primer-papki/
- Уровень типа контента или файла.
 Так, если вы не хотите, чтобы роботы индексировали все файлы в формате .jpg, используйте следующую команду: Disallow: /*.jpg
Так, если вы не хотите, чтобы роботы индексировали все файлы в формате .jpg, используйте следующую команду: Disallow: /*.jpg
 Так, если вы не хотите, чтобы роботы индексировали все файлы в формате .jpg, используйте следующую команду: Disallow: /*.jpg
Так, если вы не хотите, чтобы роботы индексировали все файлы в формате .jpg, используйте следующую команду: Disallow: /*.jpgПомимо перечисленных команд вы также можете указать в своем файле robots.txt несколько дополнительных, например указать карту сайта и основное зеркало сайта. Раньше это было обязательной составляющей каждого файла robots, теперь же вы можете указывать это по своему желанию. Для того чтобы указать карту сайта в фале robots.txt вам необходимо написать команду Sitemap:
Sitemap: https://ваш_сайт.ru/sitemap.xml
Директива зеркала сайта или Host поддерживается поисковым роботом Яндекса, и не понимается Гуглом. Не так давно ее отменил как обязательную Яндекс, но можете ее указать на всякий случай. Эта директива сообщает поисковому роботу Яндекса какое из зеркал вашего сайта нужно учитывать для индексации (Зеркало — копия вашего сайта, доступная по другому адресу). Если сайт работает по протоколу https, то в адресе хоста следует его указать:
User-agent: Yandex
Allow: /catalog
Disallow: /
Host: https://mysite.
 ru
ruТакже есть и ряд других директив которые можно указать в вашем файле robots:
- Директива Crawl-delay необходима для слабых серверов, чтобы снизить нагрузку во время индексации страниц сайта роботом. Параметр указывается в секундах. Чем большее число вы укажете тем меньшая нагрузка на сервер будет. По умолчанию рекомендую ставить Crawl-delay: 3 для слабых серверов. Если с вашим сервером все ок, то можете пропустить команду.
- Директива Clean-param нужна для исключения страниц сайта с динамическими адресами. Данная команда учитывается только роботами Яндекса и служат для удаления лишних динамических ссылок. Пример синтаксиса для данной команды:
Clean-param: param1[¶m2¶m3¶m4&..¶mn] [Путь]
Первая часть param1[¶m2¶m3¶m4&..¶mn] описывает ненужный динамический адрес который требуется очистить, а вторая часть [Путь] указывает на страницу или раздел сайта к которому применяется директива Clean-param.
Помимо директив в синтаксисе файла robots.txt важно также учитывать и специальные символы — «/, *, $, #»:
- С помощью слэша / мы запрещаем индексацию для поисковых роботов. Мы уже показывали, что если стоит один слеш в директиве Disallow, то мы запрещаем индексировать весь сайт. С помощью двух знаков слэш мы запрещаем индексирование отдельно директории: /tmp/.
- Звездочка * подразумевает любую последовательность знаков в названии файла. Если мы хотим запретить индексацию jpg картинок в папке image мы должны указать следующую команду: Disallow: /image/*.jpg$
- Последний знак доллара $ в команде выше ограничивает действия знака звездочки. Если необходимо закрыть от индекса содержимое папки image, но нельзя запретить ссылки, которые включают /image, команда в файле роботс будет следующей: Disallow: /image$
- И наконец, знак решетки # используется в файле роботс для комментариев, которые можно оставить для коллег, которые также работают с вашим сайтом. Все записи со знаком решетки # поисковые роботы не учитывают.
 Все записи со знаком решетки # поисковые роботы не учитывают.
Все записи со знаком решетки # поисковые роботы не учитывают.Настройка индексации с помощью правильного файла robots.txt для WordPress
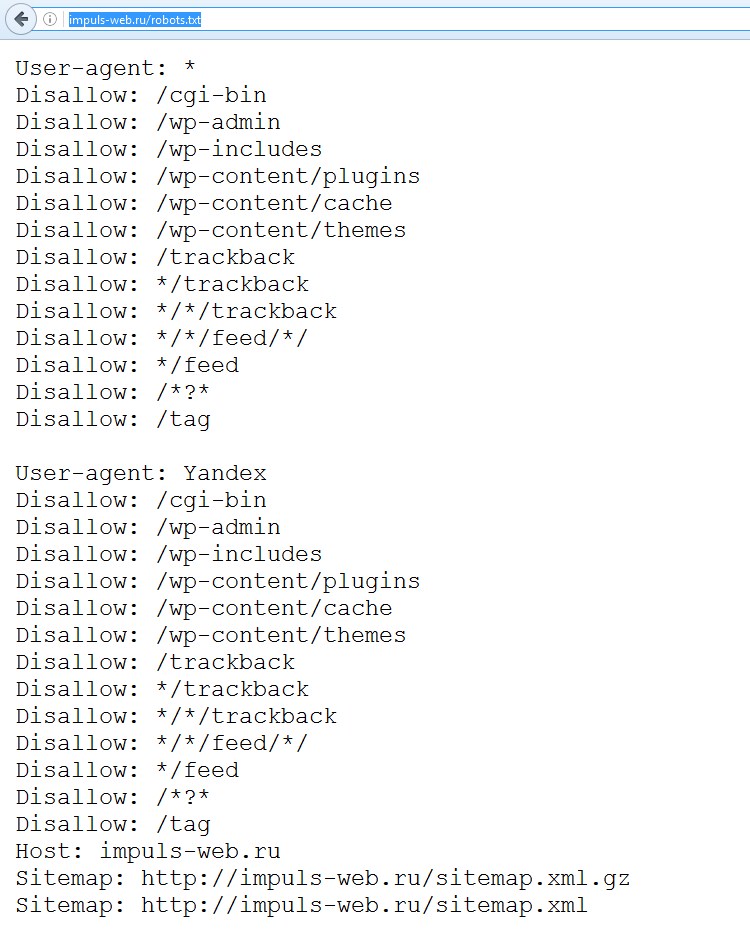
В качестве примера правильно составленного файла robots.txt я решил выбрать сайт на движке WordPress. На это есть как минимум две причины, во-первых, данный сайт написан на данном движке, и я уже имею опыт составления правильных фалов robots.txt чтобы с полной компетентностью показывать его на примере. А во-вторых, большинство сайтов в интернете функционирует именно на движке WordPress, поэтому данный пример файла robots.txt будет востребован у большинства читателей.
Первый правильный robots.txt для WordPress более короткий, так как включает директивы индексации для всех поисковых роботов в общем:
User-agent: *
Disallow: *utm*=
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.
Disallow: /xmlrpc.php
Disallow: *openstat=
Allow: */uploads# Не будет лишним указать адрес карты сайта
Sitemap: https://ваш_сайт.ru/sitemap.xml
Sitemap: https://ваш_сайт.ru/sitemap.xml.gz# Также можно указать хост (зеркало) сайта для Яндекса, хотя теперь это необязательно.
Host: https://ваш_сайт.ru
 xml
xmlВторой пример правильного файла robots.txt для WordPress является расширенным и содержит отдельные директивы для поисковых роботов Гугла и Яндекса:
User-agent: *
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Disallow: *utm*=
Disallow: *openstat=
Allow: */uploadsUser-agent: GoogleBot # директивы для поисковых роботов Google
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.
Disallow: /xmlrpc.php
Disallow: *utm*=
Disallow: *openstat=
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.phpUser-agent: Yandex # директивы для поисковых роботов Яндекса
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php# Как и для предыдущего варианта файла robots.txt можете указать основное зеркало сайта для робота Яндекса
# а также расположение карты сайта для поисковых роботов
 xml
xmlКак проверить файл robots.
 txt
txtДля того чтобы проверить правильно ли составлен файл robots.txt для вашего сайта, вы можете использовать специальные инструменты вебмастера Яндекс и Гугл. Так с помощью данного инструмента в личном кабинете вебмастера Яндекса или Гугл поисковика вы сможете проверить текущий и предыдущие версии вашего файла robots.txt, можете сразу же в режиме онлайн внести любые изменения и проверить какие страницы и раздела запрещены для индексации в текущем файле robots.txt. В случае наличия каких-либо ошибок или предупреждений связанных с неправильным файлом robots.txt вы будете уведомлены в кабинете вебмастера, кроме того сервис даже подчеркнуть ту строку или участок синтаксиса который ведет к ошибке.
Ну а на этом сегодня все о файле robots.txt для вашего сайта. Добавляйте статью и сайт в закладки! Удачного вам сайтостроения и до новых встреч на страницах проекта Тюлягин!
Редактирование файла robots.txt вашего сайта | Справочный центр
Файл robots.txt сообщает поисковым системам, какие страницы вашего сайта включать или пропускать в результатах поиска. Поисковые системы проверяют файл robots.txt вашего сайта, когда сканируют и индексируют ваш сайт. Это не гарантирует, что поисковые системы будут или не будут сканировать страницу или файл, но может помочь предотвратить менее точные попытки индексации.
Поисковые системы проверяют файл robots.txt вашего сайта, когда сканируют и индексируют ваш сайт. Это не гарантирует, что поисковые системы будут или не будут сканировать страницу или файл, но может помочь предотвратить менее точные попытки индексации.Если вы хотите лучше контролировать запросы на сканирование вашего сайта, вы можете отредактировать файл robots.txt.
Из этой статьи вы узнаете больше о:
Что такое файл robots.txt
Файл robots.txt содержит инструкции по разрешению или запрещению определенных запросов от поисковых систем. Команда «разрешить» сообщает сканерам ссылки, по которым они могут переходить, а команда «запретить» сообщает сканерам ссылки, по которым они не могут переходить. Он также включает URL-адрес файла карты сайта вашего сайта.
Вы можете просмотреть файл robots.txt своего сайта, добавив «/robots.txt» к корневому домену. Например: https://www.mystunningwebsite.com/robots.txt .
Редактирование файла robots.txt
Вы можете редактировать файл robots.txt своего сайта с помощью редактора Robots.txt на панели SEO вашего сайта. Файл robots.txt вашего сайта по умолчанию позволяет роботам поисковых систем получать доступ ко всем страницам вашего сайта. Боты могут не иметь доступа к определенным страницам, если они:
Прежде чем вносить изменения в файл robots.txt, мы рекомендуем ознакомиться с рекомендациями и ограничениями Google для файлов robots.txt.
Чтобы отредактировать файл robots.txt:
- Перейдите на панель инструментов SEO.
- Выберите Перейдите в редактор Robots.txt в разделе Инструменты и настройки .
- Нажмите Просмотреть файл .
- Добавьте информацию о файле robots.txt, написав директивы под Это ваш текущий файл .
- Нажмите Сохранить изменения .
- Щелкните Сохранить .

Сброс файла robots.txt
Если вы изменили файл robots.txt своего сайта и хотите вернуть его обратно, вы можете восстановить его состояние по умолчанию с помощью редактора Robots.txt на панели инструментов SEO вашего сайта.
Чтобы сбросить файл robots.txt:
- Перейдите на панель инструментов SEO.
- Выберите Перейдите в редактор Robots.txt в разделе Инструменты и настройки .
- Нажмите Просмотреть файл .
- Нажмите Восстановить настройки по умолчанию .
- Нажмите Сброс .
Ошибка robots.txt в Wix Site Inspection или Google Search Console
Иногда вы можете видеть такие ошибки, как Blocked by robots.txt , в своем отчете Wix Site Inspection или в своей учетной записи Google Search Console.
Если вы видите подобную ошибку, вам не нужно редактировать файл robots.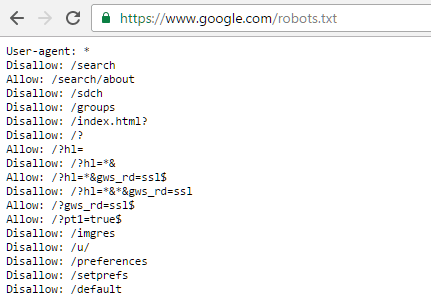 txt, особенно если вы никогда не редактировали его раньше. Вместо этого вы должны проверить свои страницы на наличие следующих настроек:
txt, особенно если вы никогда не редактировали его раньше. Вместо этого вы должны проверить свои страницы на наличие следующих настроек:
Если вам нужно обновить страницу, Wix автоматически обновит файл robots.txt после публикации страницы. Если вы измените настройки своего сайта, ваш файл robots.txt будет немедленно обновлен.
После внесения изменений поисковые системы обновят свою кешированную версию файла robots.txt при следующем сканировании вашего сайта. Если вам нужно обновить ее раньше, вы можете попробовать отправить свою домашнюю страницу в поисковые системы для переиндексации.
Как создать файл robots.txt (4 основных шага)
Contents
Toggle Файл robots.txt повышает эффективность роботов поисковых систем при оценке SEO вашего сайта. Хорошая метафора заключается в том, что файл robots.txt помогает указать Google, куда вы хотите, чтобы они направлялись, как указатель к вашему контенту. Эта статья покажет вам, как создавать файлы robots. txt для оптимизации SEO вашего сайта и увеличения трафика. Исторически сложилось так, что сайты robots.txt имеют немного лучший SEO и веб-трафик, чем сайты, не использующие файлы robots.txt.
txt для оптимизации SEO вашего сайта и увеличения трафика. Исторически сложилось так, что сайты robots.txt имеют немного лучший SEO и веб-трафик, чем сайты, не использующие файлы robots.txt.
1. Создайте файл
Начните с создания файла .txt с помощью блокнота или любого текстового редактора, сохранив новый файл как «роботы» в нижнем регистре.
2. Добавьте строки текста в файл
Введите следующие две строки текста в файл robots.txt, который вы только что сохранили:
User-agent: *
Disallow:
сайт, что эта строка текста относится ко всем из них.
3. Используйте линии запрета для управления поиском бота
Используя строки запрета для ограничения частей вашего сайта, которые боты Google могут сканировать, вы можете сделать SEO более эффективным, вырезав любые страницы, на которых вы не хотите, чтобы они фокусировались, оставив их для прямого доступа. к вашему контенту. Примером строки запрета может быть:
к вашему контенту. Примером строки запрета может быть:
Запретить: /database/
Вырезание раздела базы данных вашего сайта и упрощение поиска по вашему сайту.
4. Сохраните файл robots.txt на своем веб-сайте
Последний шаг — сохранить только что созданный файл robots.txt в корневой каталог вашего веб-сайта. Перейдите в корневую директорию сервера хостинга веб-сайта и сохраните там файл robots.txt.
Структура и содержимое файла robots.txt
Файл robots.txt состоит из двух элементов. Во-первых, вы должны назвать пользовательский агент. После этого вы даете команды, какие каталоги на вашем сайте следует читать или игнорировать. Файл sitemap.xml вашего сайта может храниться в файле robots.txt, чтобы сканер обращался ко всему сайту. Ниже приведена правильная структура файла robots.txt:
- Команда, которая обращается к боту, идет первой.
Агент пользователя:
- После агента пользователя: вы можете назвать каждого бота отдельно или использовать звездочку *, чтобы включить всех ботов.
- Далее идет командная строка. Запретить: это для предотвращения доступа ботов к определенным областям. В то время как команда Разрешить: разрешает доступ к перечисленным областям.

Ниже приведены несколько примеров файлов robots.txt:
Образец 1:
Агент пользователя: seobot
Disallow: /nothere/
В этом примере бот с именем «seobot» не будет сканировать папку http://www.test.com/nothere/ и все последующие подкаталоги.
Пример 2:
Агент пользователя: *
Разрешить: /
В этом примере все агенты пользователя могут получить доступ ко всему сайту. Однако боты все равно будут искать по всему сайту, если нет команды disallow, поэтому команда Allow:/ не нужна.
Образец 3:
Агент пользователя: seobot
ПОСЛЕДНИЕ ПОСТЫ
Ошибка 502 Bad Gateway является довольно распространенной, но раздражающей проблемой для большинства пользователей Интернета. Это один из кодов состояния HTTP, указывающих на наличие . ..
..
SMTP-сервер может сбивать с толку, но вы должны научиться использовать его для своего бизнеса. Вместо использования переносного SMTP-сервера или стороннего почтового клиента…
Disallow: /directory2/
Disallow: /directory3/
В этом примере имя бота ‘seobot’ сообщает, что он не может просматривать каталоги 2 и 3. Обратите внимание, что каждая команда Disallow: должна располагаться на отдельной строке.
Другие инструкции, которые может использовать файл robots.txt
Выше мы упомянули несколько командных инструкций. Вот описательный список инструкций;
- User-agent: Используется для присвоения имен ботам, которым вы хотите отдавать команды. Использование *, чтобы позволить всем агентам следовать командам.
- Disallow: запрещает ботам доступ к каким-либо каталогам, расположенным по указанному пути к файлу. / косая черта относится ко всем страницам сайта, поэтому Disallow: / предотвратит доступ ботов к любой странице.
- Разрешить: по умолчанию каждая страница на сайте помечена как разрешенная. Однако его можно использовать для предоставления доступа к определенным путям к файлам, даже если они ранее были заблокированы командой Disallow:. Эта функция полезна, если вы хотите заблокировать доступ к поддомену и получить доступ к определенной странице в этом заблокированном поддомене.
- Карта сайта: используется для предоставления местоположения вашей карты сайта ботам поисковых систем.

Как файл robots.txt влияет на поисковую оптимизацию?
При правильном использовании файл robots.txt может существенно повлиять на поисковую оптимизацию (SEO). Крайне важно не ограничивать ботов поисковых систем слишком сильно с помощью команды disallow. Если они слишком ограничены, это отрицательно скажется на рейтинге ваших веб-страниц. Прежде чем сохранять файл в корневой каталог, обязательно проверьте его на наличие ошибок. Если есть ошибка, это может означать, что важные области вашего сайта не включены или включены области, которые должны быть проигнорированы.
У Google есть удобный инструмент для проверки правильности работы файла robots.txt. Используйте консоль поиска Google, так как она перечислит все заблокированные страницы из ваших инструкций по запрету под заголовками «текущее состояние» и «ошибки сканирования». поисковые системы, которые его посещают.
Преимущества использования файла robots.txt на вашем веб-сайте
Поисковые роботы, индексирующие веб-сайты в Интернете, имеют заранее установленное количество страниц, которые они могут сканировать, известное как краулинговый бюджет. Основное преимущество файла robots.txt заключается в том, что он позволяет заблокировать их в различных частях сайта и сосредоточиться на более дружественных к SEO разделах. Например, если на вашем сайте продаются футболки разных цветов и размеров, у каждой из них есть действительный URL-адрес для сканирования ботом. Заблокировав их, бот может сосредоточиться на основных важных страницах и пропустить разделы с несколькими цветами и размерами, если вы запретите эту область. Поэтому, если вы создадите файл robots.txt для своего сайта, вы сможете воспользоваться этими преимуществами.
Поэтому, если вы создадите файл robots.txt для своего сайта, вы сможете воспользоваться этими преимуществами.
Недостатки использования файла robots.txt
Поисковые системы не обязаны следовать командам, содержащимся в файле robots.txt. Так что в будущем файл robots.txt может полностью игнорироваться. Другим недостатком является то, что даже если вы запретите раздел своего сайта, он будет проиндексирован в результатах поиска независимо от файла robots.txt, если будет найдено достаточно ссылок на этот раздел. Это означает, что результат Google для этой страницы будет выглядеть пустым, потому что ботам не разрешено просматривать ее, но они знают, что она есть. Файл robots.txt также не обеспечивает никакой защиты от других людей, хотя настоятельно рекомендуется использовать защиту паролем на веб-сервере. Если вы беспокоитесь об этом, вы не можете создать файл robots.txt для своего сайта.
Завершение файла robots.txt
Мы объяснили, как создать файл robots. txt. В целом, файл robots.txt легко создать и внедрить, и он может помочь повысить удобство SEO, а также увеличить веб-трафик для вашего сайта. Тот факт, что поисковые системы могут полностью игнорировать этот файл в будущем, не умаляет преимуществ реализации файла сегодня. Тот факт, что крошечный файл может помочь направить поисковые системы в определенные области вашего сайта, является слишком большой возможностью, чтобы его игнорировать. Надеюсь, вам понравилось читать эту статью, и вы узнали кое-что о файлах robots.txt и о том, как их использовать. Если вы хотите узнать, что такое файл robots.txt, у нас есть более подробная статья о нем.
txt. В целом, файл robots.txt легко создать и внедрить, и он может помочь повысить удобство SEO, а также увеличить веб-трафик для вашего сайта. Тот факт, что поисковые системы могут полностью игнорировать этот файл в будущем, не умаляет преимуществ реализации файла сегодня. Тот факт, что крошечный файл может помочь направить поисковые системы в определенные области вашего сайта, является слишком большой возможностью, чтобы его игнорировать. Надеюсь, вам понравилось читать эту статью, и вы узнали кое-что о файлах robots.txt и о том, как их использовать. Если вы хотите узнать, что такое файл robots.txt, у нас есть более подробная статья о нем.
Часто задаваемые вопросы
Нужен ли мне файл robots.txt для моего сайта WordPress?
Нет, файл robots. txt использовать не нужно. Тем не менее, это может помочь вашему сайту стать более оптимизированным для SEO и увеличить посещаемость сайта.
txt использовать не нужно. Тем не менее, это может помочь вашему сайту стать более оптимизированным для SEO и увеличить посещаемость сайта.
Где сохранить файл robots.txt?
Файл robots.txt всегда следует сохранять в корневом каталоге вашего домена. В нашем предыдущем примере вы должны найти файл robots.txt по адресу https://www.test.com/robots.txt. Имя файла чувствительно к регистру и всегда должно быть строчным; в противном случае это не сработает.
Как включить карту сайта в robots.txt?
Вы должны включить файл sitemap.xml в файл robots.txt, так как это считается хорошей практикой. Вы можете использовать команду sitemap: для ссылки на вашу карту сайта. В файле robots.txt можно указать несколько файлов Sitemap. Не забудьте также отправить карту сайта через консоль поиска Google и инструменты Bing для веб-мастеров.
Как найти файл robots.txt вашего сайта?
Если на вашем сайте уже есть файл robots.