
Как настроить robots.txt своими руками
Правильная, грамотная настройка корневого файла robots.txt одна из важнейших задач WEB-мастера. В случае непростительных ошибок в поисковой выдаче может появиться множество ненужных страниц сайта. Или, наоборот, будут закрыты для индексирования важные документы вашего сайта, в худшем случае, можно закрыть для поисковых роботов всю корневую директорию домена.
Правильная настройка файла robots.txt своими руками, на самом деле, задача не очень сложная. Прочитав эту статью, вы научитесь премудростям директив, и самостоятельно написать правила для файла robots.txt на своём сайте.
Для создания файла robots.txt используется определённый, но не сложный синтаксис. Используемых директив не много. Рассмотрим правила, структуру и синтаксис файла robots.txt пошагово и подробно.
- Общие правила robots.txt
- Комментирование в robots.txt
- Секции в файле robots.txt
- Директивы, что это?
- Директива Disallow
- Специальные символы
- Директива Allow
- Пример одновременного использования «Allow» и «Disallow» и приоритетность
- Пустое значение параметра в директивах «Allow» и «Disallow»
- Директива Sitemap
- Директива Host
- Директива Crawl-delay
- Директива Clean-param
- Ошибки, которые часто встречаются в robots.
 txt
txt
 txt
txtОбщие правила robots.txt
Во-первых, сам файл robots.txt должен иметь кодировку ANSI.
Во-вторых, нельзя использовать для написания правил никаких национальных алфавитов, возможна только латиница.
Структурно файл robots.txt может состоять из одного или нескольких блоков инструкций, отдельно для роботов разных поисковых систем. Каждый блок или секция имеют набор правил (директив) для индексации сайта той или иной поисковой системой.
В самих директивах, блоках правил и между ними не допускаются какие-либо лишние заголовки и символы.
Директивы и блоки правил разделяются переносом строки. Единственное допущение, это комментарии.
Комментирование в robots.txt
Для комментирования используется символ ‘#’. Если вы поставите в начале строки символ «решётки», то до конца строки всё содержимое игнорируется поисковыми роботами.
User-agent: *
Disallow: /css #пишем комментарий
#Пишем ещё один комментарий
Disallow: /img
Секции в файле robots.
 txt
txt
При прочтении файла роботом, используется только секция адресованная роботу этой поисковой системы, то есть, если в секции, user-agent указано имя поисковой системы Яндекс, то его робот прочитает только адресованную ему секцию, игнорируя другие, в частности и секцию с директивой для всех роботов – User-agent:*.
Каждая из секций является самостоятельной. Секций может быть несколько, для роботов каждой или некоторых поисковых систем, так и одна универсальная, для всех роботов или роботов одной их систем. Если секция одна, то начинается она с первой строки файла и занимает все строки. Если секций несколько, то они должны разделяться пустой строкой, хотя бы одной.
Секция всегда начинается с директивы User-agent и содержит имя поисковой системы, для роботов которой предназначена, если это не универсальная секция для всех роботов. На практике это выглядит так:
User-agent:YandexBot
# юзер-агент для роботов системы Яндекс
User-agent: *
# юзер-агент для всех роботов
Перечислять несколько имён ботов запрещено.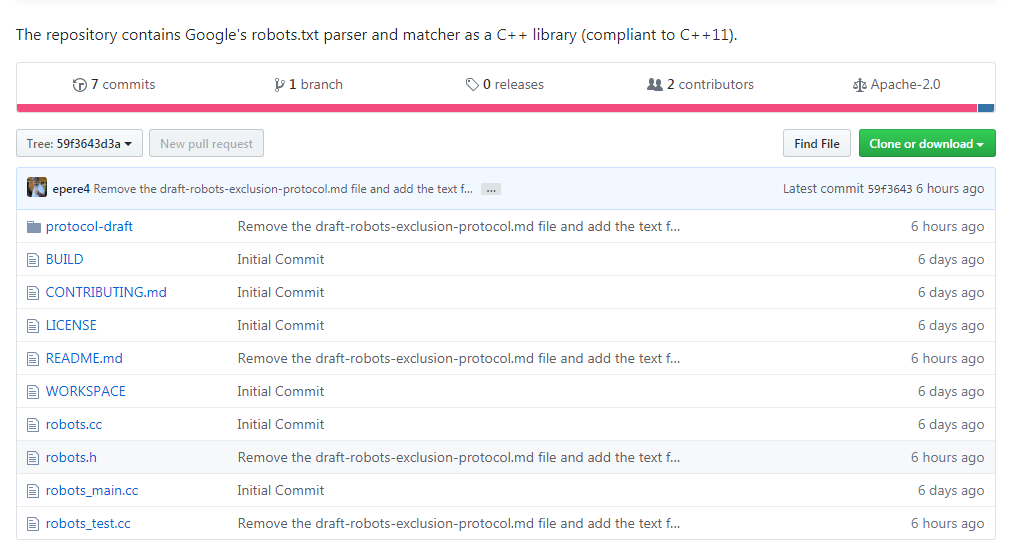 Для ботов каждой поисковой системы создаётся своя секция, свой отдельный блок правил. Если, в вашем случае, правила для всех роботов одинаковые, используйте одну универсальную, общую секцию.
Для ботов каждой поисковой системы создаётся своя секция, свой отдельный блок правил. Если, в вашем случае, правила для всех роботов одинаковые, используйте одну универсальную, общую секцию.
Директивы, что это?
Директива – это команда или правило сообщающее поисковому роботу определённую информацию. Директива сообщает поисковому боту, как индексировать ваш сайт, какие каталоги не просматривать, где находится карта сайта в формате XML, какое имя домена является главным зеркалом и некоторые другие технические подробности.Секция файла robots.txt состоит из отдельных команд,
директив. Общий синтаксис директив таков:
[Имя_директивы]:[необязательный пробел][значение][необязательный пробел]
Директива пишется в одну строку, без переносов. По принятым стандартам, между директивами в одной секции пропуск строки не допускается, то есть все директивы одной секции пишутся на каждой строке, без дополнительных пропусков строк.
Давайте опишем значения основных используемых директив.
Директива Disallow
Наиболее используемая директива в файле robots.txt, это «Disallow» — запрещающая. Директива «Disallow» запрещает индексацию указанного в ней пути. Это может быть отдельная страница, страницы, содержащие указанную «маску» в своём URL`е (пути), часть сайта, отдельная директория (папка) или сайт целиком.
User-agent: Yandex
Disallow: /
Специальные символы
Указанный выше пример запрещает индексацию всего сайта для роботов поисковой системы Яндекс.
Теперь, для лучшего понимания остальных примеров, рассмотрим и поясним, что такое специальные символы в файле robots.txt. К специальным символам относятся знаки (*)-звёздочка, ($)-доллар и (#)-решётка.
«*» — звёздочка означает – «любое количество символов». То есть, путь /folder* одинаков по своему значению с «/folders», «/folder1», «/folder111», «/foldersssss» или «/folder». Роботы, при чтении правил, автоматически дописывают знак «*». В примере, приведённом ниже, обе директивы абсолютно равнозначны:
Роботы, при чтении правил, автоматически дописывают знак «*». В примере, приведённом ниже, обе директивы абсолютно равнозначны:
Disallow: /news
Disallow: /news*
«$» — знак доллара запрещает роботам при чтении директив автоматически дописывать символ «*» (звёздочка) в конце директивы. Другими словами, символ «$» означает конец строки сравнения. То есть, в нашем примере мы запрещаем индексацию папки «/folder», но не запрещаем в папках «/folder1», «/folder111» или «/foldersssss»:
User-agent: *
Disallow: /folder$
«#» — (шарп) знак комментария. Всё, что написано после этого значка, в одной с ним строке, игнорируется поисковыми системами.
Директива Allow
Директива ALLOW файла robots.txt противоположна по своему значению директиве DISSALOW, директива ALLOW разрешающая. В примере ниже показано, что мы запрещаем индексировать весь сайт кроме папки /folder:
Allow: /folder
Disallow: /
Пример одновременного использования «Allow», «Disallow» и приоритетность
Не забывайте, о понимании приоритетности при запретах и разрешениях, при указании директив. Раньше приоритет указывался порядком объявления запретов и разрешений. Сейчас приоритет определяется указанием максимально существующего пути в пределах одного блока для робота поисковой системы (User-agent), в порядке увеличения длинны пути и месту указания директивы, чем длиннее путь, тем приоритетнее:
Раньше приоритет указывался порядком объявления запретов и разрешений. Сейчас приоритет определяется указанием максимально существующего пути в пределах одного блока для робота поисковой системы (User-agent), в порядке увеличения длинны пути и месту указания директивы, чем длиннее путь, тем приоритетнее:
User-agent: *
Allow: /folders
Disallow: /folder
В приведённом примере выше разрешена индексация URL`ов начинающихся с «/folders», но запрещена в путях, которые имеют в своих URL`ах начало «/folder», «/folderssss» или «/folder2». В случае попадания одинакового пути под обе директивы «Allow» и «Disallow», предпочтение отдаётся директиве «Allow».
Пустое значение параметра в директивах «Allow» и «Disallow»
Встречаются ошибки WEB-мастеров, когда в файле robots.txt в директиве «Disallow»забывают указать символ «/». Это является неправильным, ошибочным трактованием значений директив и их синтаксиса. В результате, запрещающая директива становится разрешающей: «Disallow:» абсолютно идентична «Allow: /».
 Правильный запрет на индексацию всего сайта выглядит так:
Правильный запрет на индексацию всего сайта выглядит так:
Disallow: /
То же самое можно сказать и об «Allow:». Директива «Allow:» без символа «/» запрещает индексацию всего сайта, так же как и «Disallow: /».
Директива Sitemap
По всем канонам SEO-оптимизации, необходимо использовать карту сайта (SITEMAP) в формате XML и предоставлять её поисковым системам.
Несмотря на функциональность «кабинетов для WEB-мастеров» в поисковых системах, необходимо заявлять о присутствии sitemap.xml и в robots.txt с помощью директивы «SITEMAP
User-agent: *
Sitemap: https://www.domainname.zone/sitemap.xml
Директива Host
Ещё одной важной директивой robots. txt является директива HOST.
txt является директива HOST.
Считается, что не все поисковые системы её распознают. Но «Яндекс» указывает, что читает эту директиву, а Яндекс в России является основным «поисковым кормильцем», поэтому не будем игнорировать директиву «host».
Эта директива говорит поисковым системам, какой домен является главным зеркалом. Все мы знаем, что сайт может иметь несколько адресов. В URL сайта может использоваться или не использоваться префикс WWW или сайт может иметь несколько доменных имён, например, domain.ru, domain.com, domen.ru, www.domen.ru. Вот именно в таких случаях мы и сообщаем поисковой системе в файле robots.txt с помощью директивы host, какое из этих имён является главным. Значением директивы является само имя главного зеркала. Приведём пример. Мы имеем несколько доменных имён (domain.ru, domain.com, domen.ru, www.domen.ru) и все они перенаправляют посетителей на сайт www.domen.ru, запись в файле robots.txt будет выглядеть так:
User-agent: *
Host: www. domen.ru
domen.ru
Если вы хотите, чтобы ваше главное зеркало было без префикса (WWW), то, соответственно, следует указать в директиве имя сайта без префикса.
Директива HOST решает проблему дублей страниц, с которой очень часто сталкиваются WEB-мастера и SEO-специалисты. Поэтому директиву HOST нужно использовать обязательно, если вы нацелены на русскоязычный сегмент и вам важно ранжирование вашего сайта в поисковой системе «Яндекс». Повторимся, на сегодня о чтении этой директивы заявляет только «Яндекс». Для указания главного зеркала в других поисковых системах необходимо воспользоваться настройками в кабинетах WEB-мастеров. Не забывайте, что имя главного зеркала должно быть указано корректно (правильность написания, соблюдение кодировки и синтаксиса файла robots.txt). В файле эта директива допускается только один раз. Если вы по ошибке укажете её несколько раз, то роботы учтут только первое вхождение.
Директива Crawl-delay
Данная директива является технической, командой поисковым роботам, как часто нужно посещать ваш сайт. Точнее, директива Crawl-delay указывает минимальный перерыв между посещениями вашего сайта роботами (краулерами поисковых систем). Зачем указывать это правило? Если роботы заходят к вам очень часто, а новая информация на сайте появляется намного реже, то со временем поисковые системы привыкнут к редкому изменению информации на вашем сайте и будут посещать вас значительно реже, чем хотелось бы вам. Это поисковый аргумент в пользу использования директивы «Crawl-delay». Теперь технический аргумент. Слишком частое посещение вашего сайта роботами создаёт дополнительную нагрузку на сервер, которая вам совсем не нужна. Значением директивы лучше указывать целое число, но сейчас некоторые роботы научились читать и дробные числа. Указывается время в секундах, например:
Точнее, директива Crawl-delay указывает минимальный перерыв между посещениями вашего сайта роботами (краулерами поисковых систем). Зачем указывать это правило? Если роботы заходят к вам очень часто, а новая информация на сайте появляется намного реже, то со временем поисковые системы привыкнут к редкому изменению информации на вашем сайте и будут посещать вас значительно реже, чем хотелось бы вам. Это поисковый аргумент в пользу использования директивы «Crawl-delay». Теперь технический аргумент. Слишком частое посещение вашего сайта роботами создаёт дополнительную нагрузку на сервер, которая вам совсем не нужна. Значением директивы лучше указывать целое число, но сейчас некоторые роботы научились читать и дробные числа. Указывается время в секундах, например:
Crawl-delay: 9
или
User-agent: Yandex
Crawl-delay: 5.5
Директива Clean-param
Необязательная директива «Clean-param» указывает поисковым роботам параметры адресов сайта, которые не нужно индексировать и следует воспринимать, как одинаковые URL. Например, у вас одни и те же страницы выводятся по разным адресам, отличающимся одним или несколькими параметрами:
Например, у вас одни и те же страницы выводятся по разным адресам, отличающимся одним или несколькими параметрами:
www.domain.zone/folder/page/
www.domain.zone/index.php?folder=folder&page=page1/
www.domain.zone/ index.php?folder=1&page=1
Поисковые роботы будут сканировать все подобные страницы и заметят, что страницы одинаковые, содержат один и тот же контент. Во-первых, это создаст путаницу в структуре сайта при индексации. Во-вторых, дополнительная нагрузка на сервер возрастёт. В третьих, скорость сканирования заметно упадёт. Чтобы избежать этих неприятностей и используется директива «Clean-param». Синтаксис следующий:
Clean-param: param1[¶m2¶m3¶m4& ... ¶m*N] [Путь]
Директиву «Clean-param», как и «Host» читают не все поисковые системы. Но Яндекс её понимает.
Ошибки, которые часто встречаются в robots.txt
- Файл robots. txt находится не в корне сайта
- Ошибка в имени файла robots.txt
- Использование недопустимых символов в robot.txt
- Ошибки синтаксиса robots.txt
- Перечисление нескольких роботов одной строкой в директиве User-agent
- User-agent с пустым значением
- Нескольких значений в директиве Disallow
- Несоблюдение приоритетов директив в robots.txt
- Поисковые системы и robots.txt
- Ошибочный синтаксис комментариев в robots.txt
- Чередование строчных и прописных букв в именах директивах
 txt находится не в корне сайта
txt находится не в корне сайтаФайл robots.txt находится не в корне сайта
Файл robots.txt должен размещаться в корне сайта, только в корневой директории. Все остальные файлы с таким же именем, но находящиеся в других папках (директориях) игнорируются поисковыми системами.
Ошибка в имени файла robots.txt
Имя файла пишется маленькими буквами (нижний регистр) и должен называться robots. txt. Все остальные варианты считаются ошибочными и поисковые стсемы будут вам сообщать об отсутствии файла. Частые ошибки выглядят так:
txt. Все остальные варианты считаются ошибочными и поисковые стсемы будут вам сообщать об отсутствии файла. Частые ошибки выглядят так:
ROBOTS.txt
Robots.txt
robot.txt
Использование недопустимых символов в robot.txt
Файл robots.txt должен быть в кодировке ANSI и содержать только латиницу. Написание директив и их значений любыми другими национальными символами недопустимо, за исключением содержимого комментариев.
Ошибки синтаксиса robots.txt
Старайтесь строго соблюдать правила синтаксиса в файле robots.txt. Синтаксические ошибки могут привести к игнорированию содержимого всего файла поисковыми системами.
Перечисление нескольких роботов одной строкой в директиве User-agent
Ошибка, часто допускаемая начинающими WEB-мастерами, скорее из-за собственной лени, не разбивать файл robots.txt на секции, а объединять команды для нескольких поисковых систем в одной секции, например:
User-agent: Yandex, Googlebot, Bing
Для каждой поисковой системы необходимо создавать свою отдельную секцию, с учётом тех директив, которые читает эта поисковая система. Исключением, в данном случае, является единая секция для всех поисковых систем:
Исключением, в данном случае, является единая секция для всех поисковых систем:
User-agent: *
User-agent с пустым значением
Директива User-agent не может иметь пустое значение. Пустыми могут быть только «Allow» и «Disallow» и то с учётом того, что меняют своё значение. Указание директивы User-agent с пустым значением является грубейшей ошибкой.
Нескольких значений в директиве Disallow
Реже встречающаяся ошибка, но, тем не менее, периодически её можно видеть на сайтах, это указание нескольких значений в директивах Allow и Disallow, например:
Disallow: /folder1 /folder2 /folder3
Делать это категорически нельзя. Если вам требуется открыть или закрыть несколько директорий, то правило для каждой из них прописывается отдельно, начиная каждую с новой строки.
Disallow: /folder1
Disallow: /folder2
Disallow: /folder3
Несоблюдение приоритетов директив в robots.
 txt
txt
Эта ошибка уже описывалась выше, но для закрепления материала повторимся. Раньше приоритет определялся порядком указания директив. На сегодняшний день правила изменились, приоритет уточняется по длине строки. Если в файле будут присутствовать две взаимоисключающих директивы, Allow и Disallow с одинаковым содержимым, то приоритет будет иметь Allow.
Поисковые системы и robots.txt
Директивы в файле robots.txt носят рекомендательный характер для поисковых систем. Это значит, что правила прочтения могут периодически меняться или дополняться. Так же помните, что каждая поисковая система по-своему обрабатывает директивы файла. И не все директивы каждая из поисковых систем читает. Например, директиву «Host» сегодня читает только Яндекс. При этом Яндекс не гарантирует, что имя домена указанное, как главное зеркало в директиве Host обязательно будет назначено главным, но утверждает, что приоритет указанному имени в директиве будет отдаваться.
Если у вас небольшой набор правил, то можно создать единую секцию для всех роботов. В противном случае, не ленитесь, создайте отдельные секции для каждой интересующей вас поисковой системы. В особенности это относится к запрещениям, если вы не хотите, чтобы какие-то определённые страницы попали в поиск.
В противном случае, не ленитесь, создайте отдельные секции для каждой интересующей вас поисковой системы. В особенности это относится к запрещениям, если вы не хотите, чтобы какие-то определённые страницы попали в поиск.
В основном, все ошибки в файле robots.txt возникают из-за неаккуратности, неряшливости пишущего директивы. Чтобы избегать основного количества ошибок, соблюдайте «правила хорошего тона». Ошибками из-за неряшливости считаются следующие ошибки:
Ошибочный синтаксис комментариев в robots.txt
Комментирование служит для напоминания WEB-мастеру, зачем и почему он закрыл или открыл определённый путь для индексации. Принято писать поясняющий комментарий после объявленной директивы с новой строки:
User-agent: *
# для всех роботов (это комментарий)
Ни в коем случае не пишите комментарий в самой директиве:
Disallow: #это комментарий / folder
В этом случае вы комментируете, то есть закрываете от роботов и содержимое директивы.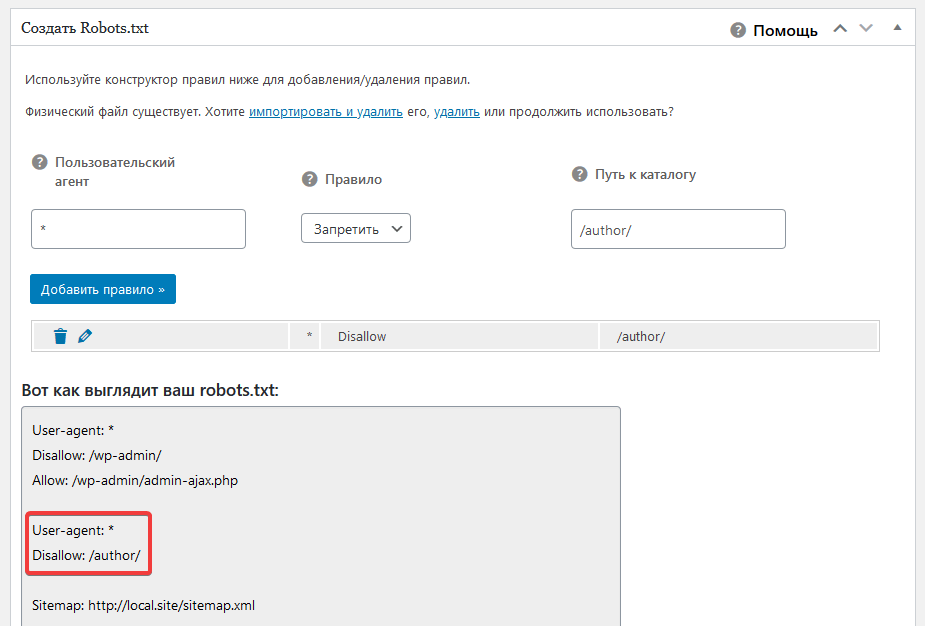 Остаётся Disallow с пустым содержанием. Что означает такая запись и как её интерпретируют поисковые системы, вы уже знаете.
Остаётся Disallow с пустым содержанием. Что означает такая запись и как её интерпретируют поисковые системы, вы уже знаете.
Чередование строчных и прописных букв в именах директивах
Если имя файла robots.txt должно быть написано именно так, как написано в этой строке, то внутри файла для объявления директив и указания их значений допускается использование как маленьких, строчных, так и заглавных, прописных букв. Ошибкой это считаться не будет. Но общепризнанные правила рекомендуют придерживаться стандартов и не увлекаться «украшением» синтаксиса.
На этом урок по созданию файла robots.txt успешно вами пройден. Теперь вы знаете все необходимые знания для заполнения этого важного файла.
Удачного Вам продвижения своих сайтов!
Знак (#) — решётка, октоторп (от латыни octothorpe — восемь концов), хеш, знак номера, диез (или шарп (английское sharp), из-за внешнего сходства этих двух символов), знак фунта (знак # часто используют, если отсутствует техническая возможность ввода символа фунта).
Файл robots.txt для joomla 2.5 Описание и назначение правил файла.
Важным моментом при самостоятельном продвижении и раскрутке сайта является повышение показателя индексации сайта. Поскольку доминируют в рунете поисковые системы Яндекс и Google, поэтому стоит уделить особое внимание индексации сайта в Яндексе и Google. Так как от этого будет зависеть успешное продвижение сайта в целом комплексе этапа раскрутки.
При обходе поисковыми роботами сайтов с целью индексации, вначале происходит проверка файла robots.txt, и в зависимости от прописанных в нем правил, осуществляются дальнейшие действия поискового робота.
При отсутствии файла robots.txt для joomla, действия поискового робота к сайту могут быть самые разные: проиндексировать, частично проиндексировать или вообще проигнорировать. При наличии файла robots.txt, причем грамотно составленного, поисковый робот будет осуществлять целенаправленную индексацию сайта.
Вот так выглядит стандартный файл robots. txt в дистрибутиве Joomla 2.5, после установки сайта на сервер.
txt в дистрибутиве Joomla 2.5, после установки сайта на сервер.
Данный файл robots.txt для joomla работоспособен, но в нем необходимо произвести изменения, которые существенно повысят эффективность индексации сайта поисковыми роботами.
Вот какие нужно произвести поправки для файла.
Правило Disallow: /images/ создает запрет на индексацию к папке для картинок на сайте. Закрытие папки images от индексирования означает отказ от участия в поиске по картинкам Яндекса и Google. Эту директиву необходимо удалить из файла robots.txt.
Для участия изображений в поиске по картинкам Яндекса и Google необходимо прописывать атрибуты Alt и Title. Так как эти атрибуты будут являться ключевыми словами для поиска по картинкам Яндекса и Google.
При работе в панели Яндекс – Вебмастер раздел “Исключенные страницы” выдается сообщение: HTTP-статус: Ресурс не найден (404) и показаны страницы намеренно запрещены к индексированию. Одной из причин такого сообщения является отсутствие правила указывающего путь к файлу Sitemap. Этот недочет должен быть восстановлен.
Этот недочет должен быть восстановлен.
Как сделать карту сайта и файл Sitemap смотрите в статье: Карта сайта для Joomla 2.5
Так же обязательно следует добавить в файл robots.txt отдельное правило
User-agent: Yandex для вставки директивы Host, определяющей главное зеркало сайта для Яндекса (зеркало сайта – это URL сайта с www или без).
Для того, чтоб закрыть директорию категории, нужно создать следующее правило:
Пример:
Disallow: */10-kategoriya.html
‘*’ – звездочка означает любые символы, то есть все то, что стоит до слэша (позиция звездочки до слэша */ или после /* — это имеет большое значение)
‘10’ – это id категории
‘kategoriya’ – это алиас категории (принадлежащей id 10)
Каким правилом можно закрыть:
- страницы для печати
- индексацию новостных каналов
- PDF файлы
- динамические ссылки
- страницы поиска и другие страницы
пояснено в статье robots. txt Как устранить дубли для сайта Joomla 2.5
txt Как устранить дубли для сайта Joomla 2.5
Для предпочтения поисковика Яндекс, необходимо User-agent: Yandex ставить в начале файла. В итоге файл robots.txt должен выглядеть так:
Данный пример не является эталоном, но его можно принять за основу.
После корректировки файла (вы также можете добавлять свои правила в robots.txt), проверка файла robots.txt для joomla обязательна. Так как в случае ошибки, истинные страницы могут быть закрыты для робота, и исчезнут из поиска.
Для удобства проверки страниц сайта на работоспособность, нужно создать текстовый документ и в него скопировать со своей страницы “Карта сайта” все существующие url-адреса, в удобочитаемом виде (каждый url-адрес с новой стрки).
Другой вариант составления списка url-адресов:
В Панели управления: открыть Компоненты ->Xmap -> нажать на ссылку XML Sitemap. Откроется окно карта сайта со всеми ссылками, которые нужно скопировать в текстовый документ.
Далее:
В Google Вебмастер: (переход по ссылкам) “Заблокированные URL” -> “Укажите URL-адреса и роботов User Agent для проверки”.
В Яндекс Вебмастер: (переход по ссылкам) “Проверить robots.txt”-> “Список URL”
нужно добавить приготовленный список и нажать кнопку “Проверить”
И вы получите результат проведенной работы.
Кстати, если вы хотите просмотреть свой файл robots.txt, то достаточно дописать в командной строке браузера к url слово: robots.txt
например: http://usersite/robots.txt.
По данной теме читайте следующие статьи:
Что такое redirect-301
Дубли страниц Joomla 2.5
robots.txt Удаление дублей в Joomla 2.5
robots.txt Ошибки и рекомендации
Источники дублей Joomla
Как читать и уважать Robots.txt
Robots.txt — это файл, используемый веб-сайтами, чтобы сообщить «поисковым ботам», должен ли и каким образом сайт сканироваться и индексироваться поисковой системой. Многие сайты просто запрещают сканирование, то есть сайт не должен сканироваться поисковыми системами или другими поисковыми роботами. Когда вы пытаетесь извлечь данные из Интернета, очень важно понимать, что такое robots.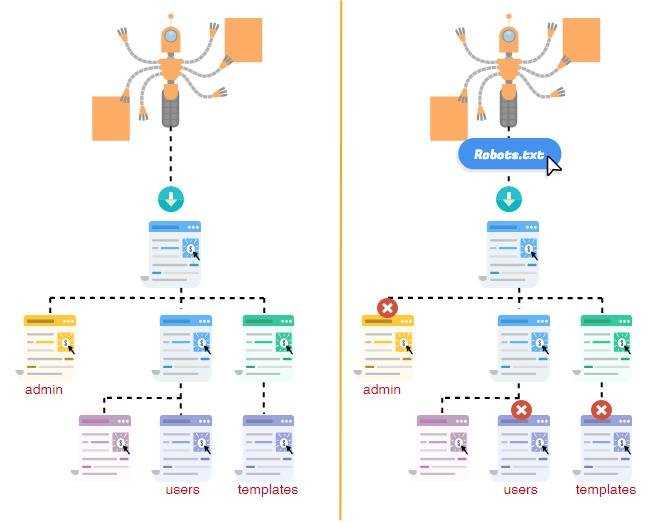 txt и как читать и уважать robots.txt , чтобы избежать юридических последствий.
txt и как читать и уважать robots.txt , чтобы избежать юридических последствий.
Почему вы должны читать и уважать файл Robots.txt?
Уважение к robots.txt нельзя списывать на то, что у нарушителей возникнут юридические осложнения. Точно так же, как вы должны соблюдать правила дорожного движения во время движения по шоссе, вы должны уважать файл robots.txt веб-сайта, который вы сканируете. Это считается стандартным поведением в Интернете и отвечает интересам веб-издателей.
Многие веб-сайты предпочитают блокировать поисковые роботы, потому что их контент носит конфиденциальный характер и мало полезен для публики. Если это недостаточно веская причина для соблюдения правил robots.txt, обратите внимание, что сканирование веб-сайта, запрещающего ботов, может привести к судебному иску и плохо закончиться для фирмы или отдельного лица. Теперь давайте перейдем к тому, как вы можете следить за файлом robots.txt, чтобы оставаться в безопасной зоне.
Правила Robots.
 txt
txt1. Разрешить полный доступ
Агент пользователя: *
Запретить:
, вам повезло. Это означает, что все страницы сайта могут быть просканированы ботами.
2. Заблокировать весь доступ
User-agent: *
Disallow: /
Вам следует держаться подальше от сайта с этим в файле robots.txt. В нем говорится, что никакая часть сайта не должна посещаться с помощью автоматического поискового робота, и нарушение этого правила может привести к проблемам с законом.
3. Частичный доступ
Пользовательский агент: *
DISLANGE: /Папка /
Пользовательский агент: *
DISLAIL сканирование только определенных разделов или файлов на своем сайте. В таких случаях вы должны приказать своим ботам оставить заблокированные области нетронутыми.
4. Ограничение скорости сканирования
Задержка сканирования: 11
Используется для ограничения слишком частого посещения сайта сканерами.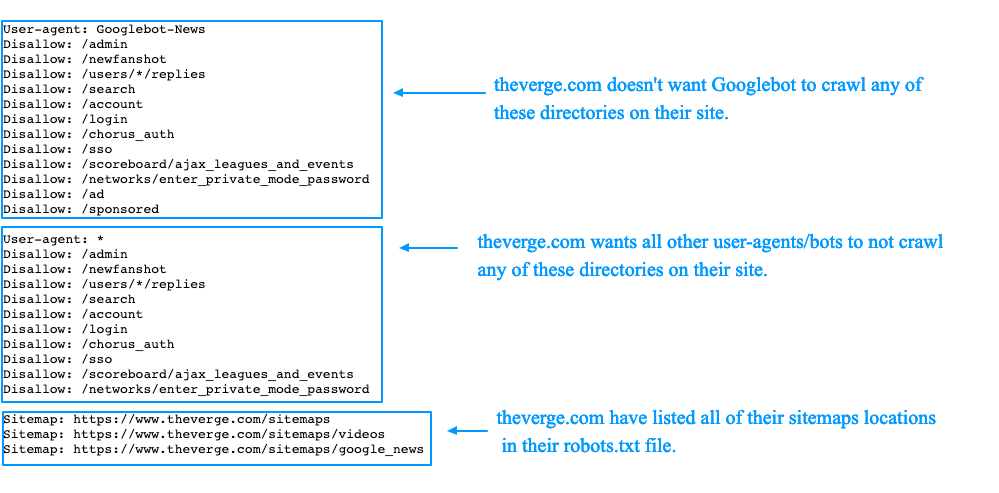 Поскольку частые обращения сканеров могут вызвать нежелательную нагрузку на сервер и замедлить работу сайта для посетителей, многие сайты добавляют эту строку в свой файл robots. В этом случае сайт может сканироваться с задержкой в 11 секунд.
Поскольку частые обращения сканеров могут вызвать нежелательную нагрузку на сервер и замедлить работу сайта для посетителей, многие сайты добавляют эту строку в свой файл robots. В этом случае сайт может сканироваться с задержкой в 11 секунд.
5. Время посещения
Время посещения: 0400-0845
Это сообщает сканерам о часах, когда сканирование разрешено. В этом примере сайт можно сканировать с 04:00 до 08:45 UTC. Сайты делают это, чтобы избежать нагрузки от ботов в часы пик.
6. Частота запросов
Частота запросов: 1/10
Некоторые веб-сайты не поддерживают ботов, пытающихся получить несколько страниц одновременно. Частота запросов используется для ограничения такого поведения. 1/10, так как это значение означает, что сайт позволяет сканерам запрашивать одну страницу каждые 10 секунд.
Будьте хорошим ботом
Хорошие боты соблюдают правила, установленные веб-сайтами в файле robots. txt, и следуют рекомендациям при сканировании и очистке. Само собой разумеется, что вы должны изучить файл robots.txt каждого целевого веб-сайта, чтобы убедиться, что вы не нарушаете никаких правил.
txt, и следуют рекомендациям при сканировании и очистке. Само собой разумеется, что вы должны изучить файл robots.txt каждого целевого веб-сайта, чтобы убедиться, что вы не нарушаете никаких правил.
Запутались?
Весьма сложный технический жаргон и правила, связанные со сканированием веб-страниц, пугают. Если вы окажетесь в ситуации, когда вам нужно извлечь веб-данные, но вы не уверены в вопросах соответствия, мы будем рады стать вашим партнером по обработке данных и полностью взять на себя ответственность за процесс.
Делиться заботой!
Связаться с нами
Пожалуйста, заполните все поля для отправки
Shopify Robots.
 txt: как его редактировать (и зачем!) в наших магазинах Shopify (как стандартных, так и Shopify Plus).
txt: как его редактировать (и зачем!) в наших магазинах Shopify (как стандартных, так и Shopify Plus).Вот как его редактировать, когда его следует настраивать и чем это полезно для SEO.
{{potential-cta}}
Что такое Robots.txt?
Robots.txt — это файл, содержащий правила доступа роботов/краулеров к вашему веб-сайту. Примером правила может быть «запретить», когда вы устанавливаете конкретный каталог или URL-адрес как запрещенный, чтобы указать, что все роботы не имеют доступа к нему.
Этот файл всегда находится по адресу:yourwebsite.com/robots.txt
Наличие правил в файле Robots.txt не обязательно «принуждает» ботов, чтобы придерживаться их, но большинство хороших ботов, включая googlebot, ahrefsbot, bingbot, duckduckbot и т. д., проверяют этот файл перед сканированием.
д., проверяют этот файл перед сканированием.
Как редактировать robots.txt на Shopify
- Откройте свой Dashboard
- Перейти к Интернет -магазину > Темы
- в Live Theme .
- В разделе шаблонов нажмите «Добавить новый шаблон»
- Изменить «Создать новый шаблон для» на
Robots.txt - Нажмите «Создать шаблон»
Будет создан файл Robots.txt.liquid со следующим кодом:
Этот файл шаблона напрямую изменяет Robots.txt файл, в то время как этот код по умолчанию добавляет все правила по умолчанию, которые Shopify использует из коробки.
Примечание: Я настоятельно рекомендую не удалять эти правила, большинство из них хорошо оптимизированы Shopify
Теперь у нас есть файл, мы можем настроить его по своему усмотрению.
Настройка Robots.txt.liquid
В этот файл можно внести 3 изменения:
- Добавить новое правило в существующую группу
- Удалить правило из существующей группы
- Добавить пользовательские правила
Группа относится к набору правил для определенных поисковых роботов.
Добавить новое правило в существующую группу
Вот файл, измененный для включения нескольких правил по умолчанию, которые мы обычно используем для клиентов:
Этот код говорит, что если user_agent (роботы name) равно *, что применимо ко всем роботам, затем запретите следующее:
-
/collections/all— это заблокирует коллекцию по умолчанию, содержащую список всех товаров ( ПРИМЕЧАНИЕ: , не используйте, если он у вас есть) -
/collections/vendors*?*q=— это заблокирует обход коллекций поставщиков по умолчанию -
/collections/types *?*q=— это заблокирует обход коллекций типов по умолчанию. -
/collections/*?*constraint*– это заблокирует другой параметр для поставщиков и типов. -
/collections/* /*- Это заблокирует сканирование тегов продуктов ( ПРИМЕЧАНИЕ: будьте осторожны с этим, это может помешать сканированию продуктов, даже если вы не настроите внутренние ссылки ) -
/collections/*?*filter*— это заблокирует сканирование общих параметров фильтра -
/collections/*?*pf_*- Это заблокирует сканирование общего параметра фильтра -
/collections/*?*view*- Это заблокирует параметр для изменения количества отображаемых продуктов -
/collections /*?*grid_list*— блокирует параметр для изменения способа отображения продуктов -
/collections/?page=*— это заблокирует сканирование пагинации коллекции по умолчанию будет применяться к каждой разбивке на страницы коллекции) -
/blogs/*/tagged— это заблокирует сканирование тегов блога

"что-нибудь здесь" например.
/collections/anything?constraint=anything будет заблокирован.
Удалить правило по умолчанию из существующей группы
Не рекомендуется, но при необходимости правила по умолчанию можно удалить из файла Robots.txt.
Вот стандартный Shopify Robots.txt и правила для справки:
Допустим, мы хотели удалить правило, блокирующее /policies/, вот пример кода, который нужно сделать что:
Все, что мы делаем, это говорим, что если есть правило «Запретить» со значением «/policies/», не показывать это. Или, точнее, показать все правила, кроме этого.
Добавить пользовательские правила
Если вы хотите применить правила, которые не применяются к группе по умолчанию (*, adsbot-google, Nutch, AhrefsBot, AhrefsSiteAudit, MJ12bot и Pinterest), вы можете добавить их внизу файла шаблона.
Например, если вы хотите заблокировать WayBackMachine, вы можете добавить следующее:
Или, если вы хотите добавить дополнительную карту сайта, вы можете добавить это:
{{potential-cta}}
Зачем настраивать Robots.
 текст?
текст?Если вы не оптимизатор, вам может быть интересно, почему это вообще имеет значение. Позволь мне объяснить.
Это сводится к обоим:
- Бюджет сканирования
- Тонкий контент
Бюджет сканирования
Существует техническая концепция SEO, известная как Бюджет сканирования , это термин, описывающий количество ресурсов, выделяемых поисковыми системами для сканирования. каждый веб-сайт.
Короче говоря:
Поисковые системы не могут регулярно сканировать каждую страницу всего Интернета (их слишком много!). Поэтому они используют алгоритмы, чтобы решить, сколько ресурсов выделить каждому веб-сайту.
Если вашему веб-сайту требуется больше ресурсов, чем ему выделено, тогда страницы будут регулярно пропускать сканирование .
Для поисковой оптимизации вы хотите, чтобы поисковые системы, такие как Google, регулярно сканировали ваш веб-сайт, чтобы отслеживать ваши улучшения. Если они не сканируют эти страницы, они понятия не имеют, как они изменились или улучшились, поэтому вы не увидите никаких улучшений рейтинга.
Если они не сканируют эти страницы, они понятия не имеют, как они изменились или улучшились, поэтому вы не увидите никаких улучшений рейтинга.
Это имеет значение, когда страницы низкого качества сканируются, а важные игнорируются.
Таким образом, когда SEO-специалисты обсуждают «кроулинг-бюджет», они имеют в виду, как лучше всего использовать краулинг-бюджет, который у нас есть.
Используя Robots.txt, мы можем специально заблокировать ботов от сканирования определенных страниц или каталогов, что сокращает потраченный впустую бюджет сканирования.
До этого единственным решением, которое у нас было, была настройка страниц на noindex, что помогает для тонкого контента (следующий раздел) , но по-прежнему требует, чтобы роботы сканировали страницы.
Тонкий контент
Тонкий контент — это термин SEO, относящийся к контенту, который не добавляет никакой ценности для пользователей поисковых систем.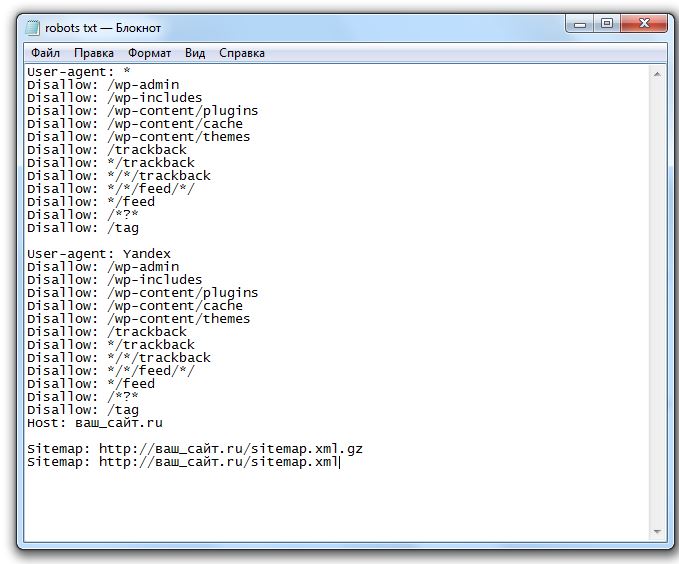
Если вы перейдете на YOURSTORE.COM/collections/vendors?q=BRAND, вы увидите страницу по умолчанию, созданную для всех поставщиков, которых вы установили в своей панели управления Shopify.
На этой странице нет ни содержания, ни описания, и ее нельзя каким-либо образом настроить. Не говоря уже об уродливом URL.
Мы бы назвали это «тонким контентом», вряд ли он будет занимать какое-либо место в Google со всеми этими недостатками.
Лучшим решением было бы удалить или заблокировать эту страницу, а затем вручную создать новую коллекцию Shopify для этого поставщика/торговой марки, которую можно полностью настроить.
Прежде чем мы смогли отредактировать Robots.txt, нашим единственным решением было установить для этих страниц значение noindex, follow. По сути, просите поисковые системы переходить по ссылкам на этой странице, но не добавляйте эту страницу в результаты своих поисковых систем.
Этот работал , но это все равно приводило к потенциальному сканированию сотен страниц в первую очередь.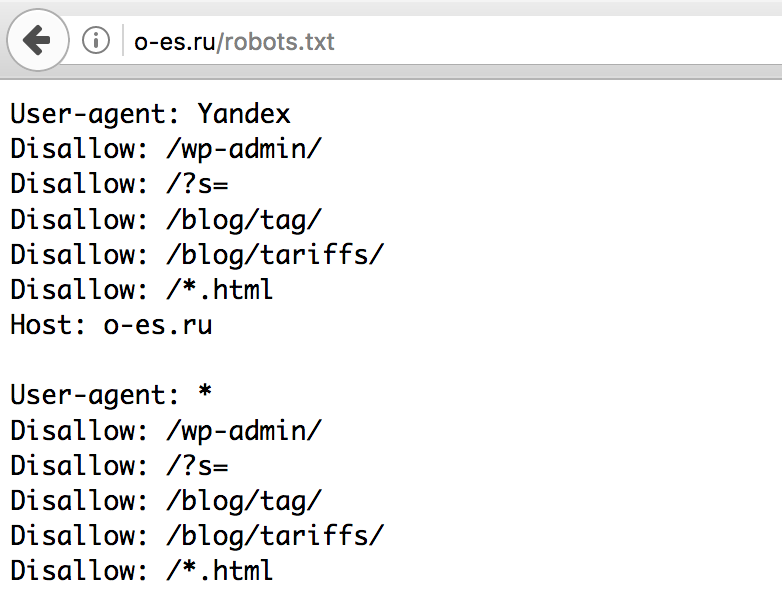
Теперь мы можем полностью запретить их сканирование, что уменьшит объем некачественного контента и сэкономит краулинговый бюджет.
Заключение
Надеюсь, последний раздел никого не потерял, это может стать довольно техническим.
Shopify, наконец, доверили нам редактировать наш собственный файл Robots.txt — это огромное обновление для магазинов Shopify, однако я призываю к осторожности тех, кто не занимается SEO и не является разработчиком, делая это.
Вполне возможно заблокировать весь ваш веб-сайт и создать серьезные проблемы с этой функциональностью.
Так что, во что бы то ни стало, настройте его, мы вносим изменения для всех наших клиентов, но будьте осторожны, чтобы сделать это правильно.
Вы также можете протестировать правила с помощью инструмента Google Robots Tester внутри GSC.
Я надеюсь, что это руководство было полезным, если вам нужна помощь с этим, не стесняйтесь свяжитесь с нами .