
Robots.txt Generator — Создание файла robots.txt мгновенно
Robots.txt Проведи для Краулеров – Использование Google Роботы Txt Генератор
Robots.txt это файл, который содержит инструкции о том, как сканировать веб-сайт. Он также известен как протокол исключений для роботов, и этот стандарт используется сайтами сказать боты, какая часть их веб-сайта нуждается индексацией. Кроме того, вы можете указать, какие области вы не хотите, чтобы обрабатываемого этих гусеничные; такие области содержат дублированный контент или находятся в стадии разработки. Поисковые системы, такие как вредоносные детекторы, почтовые комбайны не следует этому стандарту и будут проверять слабые места в ваших ценных бумагах, и существует значительная вероятность того, что они начнут рассмотрение вашего сайта из областей, которые не хотят быть проиндексированы.
Полный Robots.txt файл содержит «User-Agent», а под ним, вы можете написать другие директивы, такие как «Разрешить», «Disallow», «Crawl-Delay» и т. д., если написано вручную это может занять много времени, и вы можете ввести несколько строк команд в одном файле. Если вы хотите исключить страницы, вам нужно будет написать «Disallow: ссылка не хотите ботов посетить» То же самое касается разрешительной атрибута. Если вы думаете, что это все есть в файле robots.txt, то это не так просто, одна неправильная линия может исключить страницу из очереди индексации. Таким образом, это лучше оставить задачу профи, пусть наш Robots.txt генератор Заботьтесь файла для вас.
д., если написано вручную это может занять много времени, и вы можете ввести несколько строк команд в одном файле. Если вы хотите исключить страницы, вам нужно будет написать «Disallow: ссылка не хотите ботов посетить» То же самое касается разрешительной атрибута. Если вы думаете, что это все есть в файле robots.txt, то это не так просто, одна неправильная линия может исключить страницу из очереди индексации. Таким образом, это лучше оставить задачу профи, пусть наш Robots.txt генератор Заботьтесь файла для вас.
Что такое робот Txt в SEO?
Вы знаете, это небольшой файл, это способ, чтобы разблокировать более ранг для вашего сайта?
Первые поиска файлов двигатели боты посмотреть на это текстовый файл робота, если он не найден, то есть вероятность того, что массовый сканерам не будет индексировать все страницы вашего сайта. Этот крошечный файл может быть изменен позже, когда вы добавляете больше страниц с помощью маленьких инструкций, но убедитесь, что вы не добавляете главную страницу в Disallow directive. Google работает на бюджете ползания; этот бюджет основан на пределе ползать. Предел ползать является количество времени гусеничном будет тратить на веб-сайте, но если Google узнает, что ползает ваш сайт встряхивая опыт пользователя, то он будет сканировать сайт медленнее. Это означает, что медленнее, каждый раз, когда Google посылает паук, он будет проверять только несколько страниц вашего сайта и самого последнего поста потребуется время, чтобы получить индексироваться. Для снятия этого ограничения, ваш сайт должен иметь карту сайта и файл robots.txt.
Google работает на бюджете ползания; этот бюджет основан на пределе ползать. Предел ползать является количество времени гусеничном будет тратить на веб-сайте, но если Google узнает, что ползает ваш сайт встряхивая опыт пользователя, то он будет сканировать сайт медленнее. Это означает, что медленнее, каждый раз, когда Google посылает паук, он будет проверять только несколько страниц вашего сайта и самого последнего поста потребуется время, чтобы получить индексироваться. Для снятия этого ограничения, ваш сайт должен иметь карту сайта и файл robots.txt.
Так как каждый бот имеет ползать котировку на веб-сайт, это делает необходимым иметь лучший файл робот для сайта WordPress, а также. Причина заключается в том, что содержит много страниц, которые не нуждаются в индексации вы можете даже генерировать WP роботов текстовый файл с нашими инструментами. Кроме того, если у вас нет робототехники текстового файла, сканеры все равно будет проиндексировать ваш сайт, если это блог и сайт не имеет много страниц, то это не обязательно иметь один.
Цель директив в файле robots.txt
Если вы создаете файл вручную, то вы должны быть осведомлены о руководящих принципах, используемых в файле. Вы даже можете изменить файл позже, после обучения, как они работают.
- Crawl-оттянуть
Эту директива используются для предотвращения сканеров от перегрузки хозяина, слишком много запросов могут перегрузить сервер , который приведет к плохому опыту пользователя. Crawl задержка трактуется по- разному различными ботами из поисковых систем, Bing, Google, Яндекс лечить эту директиву по – разному. Для Яндекса это между последовательными визитами, для Bing, это как временное окно , в котором боты будут посещать сайт только один раз, и для Google, вы можете использовать поисковую консоль для управления визитами бот. - Разрешение
Позволяющей директивы используются для включения индексации по следующему адресу. Вы можете добавить столько же URL , как вы хотите , особенно если это торговый сайт , то ваш список может быть большим. Тем не менее, использовать только файл роботов , если ваш сайт имеет страницы , которые вы не хотите , чтобы получить индексироваться.
Тем не менее, использовать только файл роботов , если ваш сайт имеет страницы , которые вы не хотите , чтобы получить индексироваться. - Запрет
Основное назначение файла роботов является мусоровозов гусеничном от посещения указанных ссылок, каталоги и т.д. Эти каталоги, однако, доступ к другим роботам , которые необходимо проверить на наличие вредоносных программ , потому что они не сотрудничают со стандартом.
 Тем не менее, использовать только файл роботов , если ваш сайт имеет страницы , которые вы не хотите , чтобы получить индексироваться.
Тем не менее, использовать только файл роботов , если ваш сайт имеет страницы , которые вы не хотите , чтобы получить индексироваться.Разница между файлом Sitemap и robots.txt,
Карта сайт имеет жизненно важное значение для всех сайтов, так как он содержит полезную информацию для поисковых систем. Карта сайт говорит ботам, как часто вы обновляете свой сайт, какой контент вашего сайта предоставляет. Его основным мотивом является извещением в поисковых системах всех страниц вашего сайта имеет, что нужно просматривать в то время как робототехника TXT файл для поисковых роботов. Он сообщает сканерам, какие страницы ползать и которые не в. Карта сайта необходима для того, чтобы ваш сайт индексируется, тогда как TXT робота нет (если у вас нет страниц, которые не должны быть проиндексированы).
Как сделать робота, используя Google роботов генератор файлов?
Роботы текстового файла легко сделать, но люди, которые не знают о том, как они должны следовать следующим инструкциям, чтобы сэкономить время.
- Когда вы приземлились на странице новых роботов тхт генератора , вы увидите несколько вариантов, не все параметры являются обязательными, но вам нужно тщательно выбирать. Первая строка содержит значение по умолчанию для всех роботов , и если вы хотите сохранить ползания задержки. Оставьте их , как они, если вы не хотите , чтобы изменить их , как показано на рисунке ниже:
- Вторая строка о карте сайта, убедитесь, что у вас есть один и не забудьте упомянуть об этом в текстовом файле робота.
- После этого, вы можете выбрать один из нескольких вариантов для поисковых систем, если вы хотите, чтобы поисковые системы роботов сканировать или нет, второй блок для изображений, если вы собираетесь разрешить их индексации третьего столбца для мобильной версии Веб-сайт.
- Последний вариант для запрещая, где вы будете ограничивать искатель индексировать области страницы. Убедитесь в том, чтобы добавить слэш перед заполнением поля с адресом каталога или страницы.

Другие языки: English, русский, 日本語, italiano, français, Português, Español, Deutsche, 中文
Проверка файла robots.txt | REG.RU
Файл robots.txt — это инструкция для поисковых роботов. В ней указывается, какие разделы и страницы сайта могут посещать роботы, а какие должны пропускать. В фокусе этой статьи — проверка robots.txt. Мы рассмотрим советы по созданию файла для начинающих веб-разработчиков, а также разберем, как делать анализ robots.txt с помощью стандартных инструментов Яндекс и Google.
Зачем нужен robots.txt
Поисковые роботы — это программы, которые сканируют содержимое сайтов и заносят их в базы поисковиков Яндекс, Google и других систем. Этот процесс называется индексацией.
robots.txt содержит информацию о том, какие разделы нельзя посещать поисковым роботам. Это нужно для того, чтобы в выдачу не попадало лишнее: служебные и временные файлы, формы авторизации и т. п. В поисковой выдаче должен быть только уникальный контент и элементы, необходимые для корректного отображения страниц (изображения, CSS- и JS-код).
Это нужно для того, чтобы в выдачу не попадало лишнее: служебные и временные файлы, формы авторизации и т. п. В поисковой выдаче должен быть только уникальный контент и элементы, необходимые для корректного отображения страниц (изображения, CSS- и JS-код).
Если на сайте нет robots.txt, роботы заходят на каждую страницу. Это занимает много времени и уменьшает шанс того, что все нужные страницы будут проиндексированы корректно.
Если же файл есть в корневой папке сайта на хостинге, роботы сначала обращаются к прописанным в нём правилам. Они узнают, куда нельзя заходить, а какие страницы/разделы обязательно нужно посетить. И только после этого начинают обход сайта по инструкции.
Веб-разработчикам следует создать файл, если его нет, и наполнить его правильными директивами (командами) для поисковых роботов. Ниже кратко рассмотрим основные директивы для robots.txt.
Основные директивы robots.txt
Структура файла robots.txt выглядит так:
- Директива User-agent. Обозначает, для каких поисковых роботов предназначены правила в документе. Здесь можно указать все поисковые системы (для этого используется символ «*») или конкретных роботов (Yandex, Googlebot и другие).
- Директива Disallow (запрет индексации). Указывает, какие разделы не должны сканировать роботы. Даже если на сайте нет служебного контента, который необходимо закрыть от индексации, директиву нужно прописывать (не указывая значение). Если не сделать этого, robots.txt может некорректно читаться поисковыми роботами.
- Директива Allow (разрешение). Указывает, какие разделы или файлы должны просканировать поисковые роботы. Здесь не нужно указывать все разделы сайта: все, что не запрещено к обходу, индексируется автоматически. Поэтому следует задавать только исключения из правила Disallow.
- Sitemap (карта сайта). Полная ссылка на файл в формате .xml. Sitemap содержит список всех страниц, доступных для индексации, а также время и частоту их обновления.
 Обозначает, для каких поисковых роботов предназначены правила в документе. Здесь можно указать все поисковые системы (для этого используется символ «*») или конкретных роботов (Yandex, Googlebot и другие).
Обозначает, для каких поисковых роботов предназначены правила в документе. Здесь можно указать все поисковые системы (для этого используется символ «*») или конкретных роботов (Yandex, Googlebot и другие).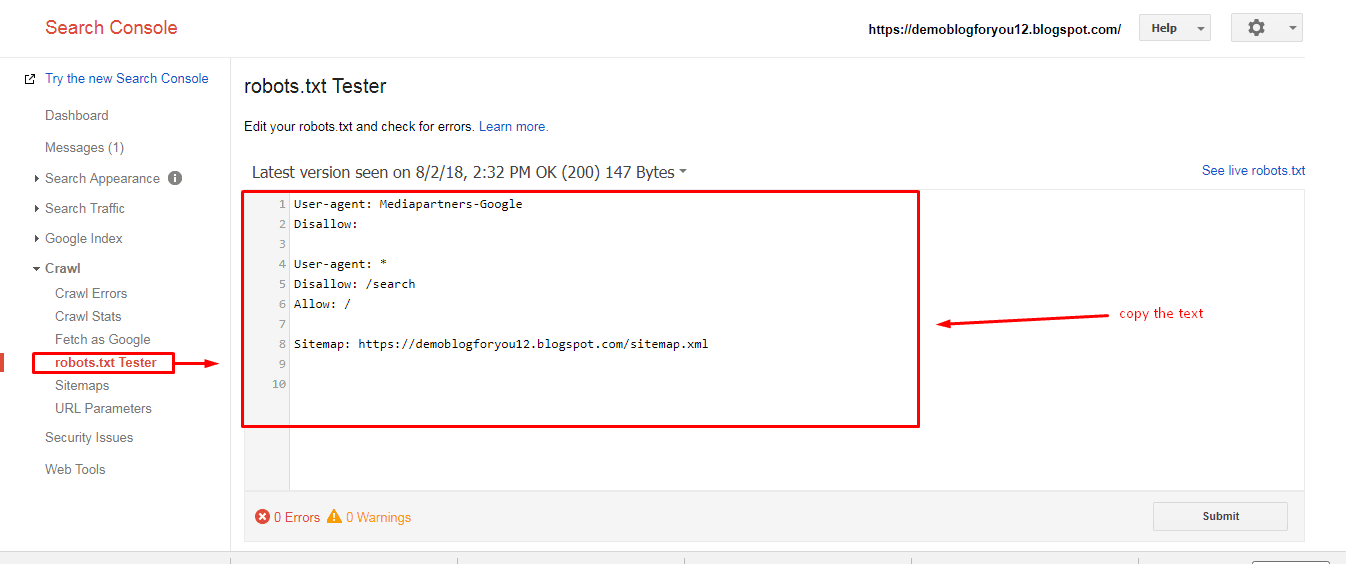
Пример простого файла robots.txt (после # указаны пояснительные комментарии к директивам):
User-agent: * # правила ниже предназначены для всех поисковых роботов Disallow: /wp-admin # запрет индексации служебной папки со всеми вложениями Disallow: /*? # запрет индексации результатов поиска на сайте Allow: /wp-admin/admin-ajax.php # разрешение индексации JS-скрипты темы WordPress Allow: /*.jpg # разрешение индексации всех файлов формата .jpg Sitemap: http://site.ru/sitemap.xml # адрес карты сайта, где вместо site.ru — домен сайта
Советы по созданию robots.txt
Для того чтобы файл читался поисковыми программами корректно, он должен быть составлен по определенным правилам. Даже детали (регистр, абзацы, написание) играют важную роль. Рассмотрим несколько основных советов по оформлению текстового документа.
Группируйте директивы
Если требуется задать различные правила для отдельных поисковых роботов, в файле нужно сделать несколько блоков (групп) с правилами и разделить их пустой строкой.
User-agent: Yandex # правила только для ПС Яндекс Disallow: # раздел, файл или формат файлов Allow: # раздел, файл или формат файлов # пустая строка User-agent: Googlebot # правила только для ПС Google Disallow: # раздел, файл или формат файлов Allow: # раздел, файл или формат файлов Sitemap: # адрес файла
Учитывайте регистр в названии файла
Для некоторых поисковых систем не имеет значение, какими буквами (прописными или строчными) будет обозначено название файла robots.txt. Но для Google, например, это важно. Поэтому желательно писать название файла маленькими буквами, а не Robots.txt или ROBOTS.TXT.
Не указывайте несколько каталогов в одной директиве
Для каждого раздела/файла нужно указывать отдельную директиву Disallow.
Disallow: /cgi-bin/ Disallow: /authors/ Disallow: /css/
Убирайте лишние директивы
Часть директив robots.txt считается устаревшими и необязательными: Host (зеркало сайта), Crawl-Delay (пауза между обращением поисковых роботов), Clean-param (ограничение дублирующегося контента). Вы можете удалить эти директивы, чтобы не «засорять» файл.
Как проверить robots.txt онлайн
Чтобы убедиться в том, что файл составлен грамотно, можно использовать веб-инструменты Яндекс, Google или онлайн-сервисы (PR-CY, Website Planet и т. п.). В Яндекс и Google есть собственные правила для проверки robots.txt. Поэтому файл необходимо проверять дважды: и в Яндекс, и в Google.
Яндекс.Вебмастер
Если вы впервые пользуетесь сервисом Яндекс.Вебмастер, сначала добавьте свой сайт и подтвердите права на него. После этого вы получите доступ к инструментам для анализа SEO-показателей сайта и продвижения в ПС Яндекс.
Чтобы проверить robots.txt с помощью валидатора Яндекс:
- 1.
Зайдите в личный кабинет Яндекс.Вебмастер.
- 2.
Выберите в левом меню раздел Инструменты → Анализ robots.txt.
- 3.
Содержимое нужного файла подставиться автоматически. Если по какой-то причине этого не произошло, скопируйте код, вставьте его в поле и нажмите Проверить:
- 4.
Ниже будут указаны результаты проверки. Если в директивах есть ошибки, сервис покажет, какую строку нужно поправить, и опишет проблему:
Google Search Console
Чтобы сделать проверку с помощью Google:
- 2.
Если на открывшейся странице отображается неактуальная версия robots.txt, нажмите кнопку Отправить и следуйте инструкциям Google:
- 3.
Через несколько минут вы можете обновить страницу. В поле будут отображаться актуальные директивы. Предупреждения/ошибки (если система найдет их) будут перечислены под кодом.
Проверка robots.txt Google не выявила ошибок
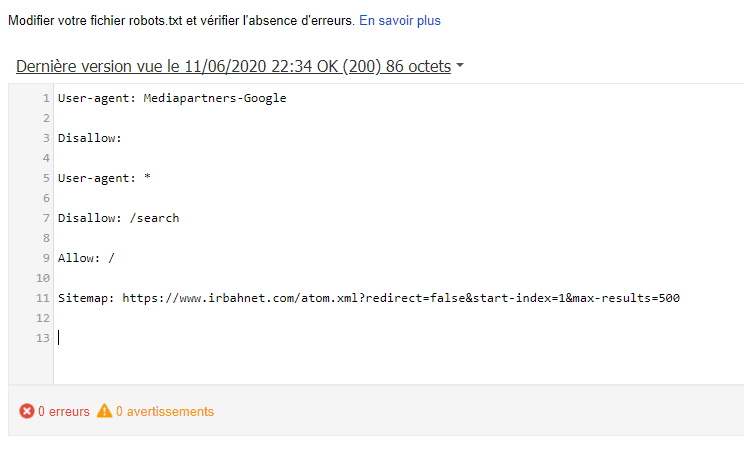
Перейдите на страницу инструмента проверки.
Обратите внимание: правки, которые вы вносите в сервисе проверки, не будут автоматически применяться в robots.txt. Вам нужно внести исправленный код вручную на хостинге или в административной панели CMS и сохранить изменения.
Помогла ли вам статья?
Да
2 раза уже помогла
Создать robots.
 txt онлайн
txt онлайн
Чтобы активировать
PRO версию программы достаточно только нажать и поделиться страницей через социальные сети выше.
Настройки
|
Ссылка на сайт |
Домен сайта, если на сайт заходите с WWW укажите сайт с www. |
|
Ссылка на карту сайт [ Создать карту сайта онлайн ] |
Обычно это sitemap.xml файл который содержит древо сайта Только файл (без http:// и домена Добавить еще |
|
Ссылка на карту сайт (1) |
Добавить еще |
|
Ссылка на карту сайт (2) |
Добавить еще |
|
Ссылка на карту сайт (3) |
Добавить еще |
|
Ссылка на карту сайт (4) |
Добавить еще |
|
Ссылка на карту сайт (5) |
Добавить еще |
| Все роботы могут заходить на сайт |
Рекомендовано разрешить.
разрешитьзапретить |
|
Задержка индексации |
Скорость перехода (в секундах) на другу страницу На усмотрение поисковика5 сек.10 сек.20 сек.60 сек.120 сек. |
Запретить этим роботам индексировать сайт:
| Яндекс | Mail.Ru | Rambler | Google Картинки | |
| Google Мобильный | Aport | MSN Поиск | MSN Картинки | Yahoo |
Запретить индексировать пути
Robots. txt является обыкновенным текстовым файлом, располагающимся в корне вашего сайта, просмотреть и отредактировать его можно используя любой текстовый редактор. В данном файлике записаны инструкции, которыми должны руководствоваться поисковые машины (роботы). Собственно, отсюда и пошло название этого документа. Инструкции эти указывают поисковику, что подлежит индексированию, а что трогать не нужно. Наверное, каждый вебмастер хотел бы, чтобы созданный им сайт как можно быстрее был проиндексирован поисковой системой, причем чтобы этот процесс прошел правильно и без ошибок. Поэтому, нужно понимать, что без грамотно составленного файла robots.txt это маловероятно, следовательно, нужно позаботиться о его создании.
Конечно же вы можете самостоятельно написать данный файл, к тому же примеров в сети очень много. Но, намного правильнее и быстрее будет воспользоваться нашим инструментом создания robots.txt – это самый эффективный способ. Все что от Вас требуется это заполнить форму на нашем сайте и все. В результате вы получите уже готовый текст, который нужно просто вставить в документ и сохранить в корне вашего сайта под именем Robots.txt. При этом у вас есть возможность полностью запретить индексирование своего сайта, хотя вряд ли это кому-то понадобится. Здесь вам нужно будет указать местонахождение карты вашего сайта, а если у вас ее нету, то можно просто не заполнять данное поле. Далее вы можете выбрать поисковые системы, которым дадите право проводить индексирование страниц вашего ресурса. Рекомендуется выбирать все, это даст наиболее положительный эффект в плане посещаемости сайта. В перечне присутствуют все основные поисковые машины. Далее вам предлагается указать те страницы, которые вы бы не хотели видеть в индексе поисковиков. На этом все, ваш файлик готов, можете выкладывать его к себе на сайт.
Есть ли какие-то отличия Robots.txt для Яндекса в сравнении с файлами для других роботов?
На самом деле каждая поисковая машина использует разные методы индексирования, и вообще работают они по-разному. Каждый поисковик имеет свои методики ранжирования, присвоения сайтам определенного места в своем списке. Однако, практически все они одинаково индексируют и понимают файл Robots.txt. Практика свидетельствует, что один файл Robots.txt подходит абсолютно ко всем поисковым системам и с ним не возникает никаких проблем.
Есть ли возможность проверить существующий файл Robots.txt?
Если вы сами писали данный файл, или использовали другой генератор, и сомневаетесь в его работоспособности, то можете проверить его с помощью специального сервиса на нашем сайте. Если в ходе такой проверки обнаружатся те или иные проблемы, то вы с легкостью сможете сгенерировать новый файлик воспользовавшись нашим инструментом. Специалисты всегда рекомендуют проверять самодельные файлы Robots.txt с помощью уже проверенных генераторов, чтобы избежать возможных проблем в будущем.
Бесплатный онлайн генератор файла Robots.
txt для сайта | SEOГенератор Robots.txt
| По умолчанию — для всех роботов: | ДопуститьОтказать | |
| Задержка обхода: | По умолчанию — без задержки5 Секунд10 Секунд20 Секунд60 Секунд120 Секунд | |
| Карта сайта: (оставьте поле пустым, если у вас нет карты) | ||
| Поисковые роботы: | По умолчаниюДопуститьОтказать | |
| Google Image | По умолчаниюДопуститьОтказать | |
| Google Mobile | По умолчаниюДопуститьОтказать | |
| MSN Search | По умолчаниюДопуститьОтказать | |
| Yahoo | По умолчаниюДопуститьОтказать | |
| Yahoo MM | По умолчаниюДопуститьОтказать | |
| Yahoo Blogs | По умолчаниюДопуститьОтказать | |
| Ask/Teoma | По умолчаниюДопуститьОтказать | |
| GigaBlast | По умолчаниюДопуститьОтказать | |
| DMOZ Checker | По умолчаниюДопуститьОтказать | |
| Nutch | По умолчаниюДопуститьОтказать | |
| Alexa/Wayback | По умолчаниюДопуститьОтказать | |
| Baidu | По умолчаниюДопуститьОтказать | |
| Naver | По умолчаниюДопуститьОтказать | |
| MSN PicSearch | По умолчаниюДопуститьОтказать | |
| Запрещенные каталоги: |
Путь указывается относительно корня и должен содержать косую черту в конце. «/» |
|
Теперь создайте файл robots.txt в корневом каталоге. Скопируйте указанный выше текст и вставьте в текстовый файл.
Подробно о Генератор Robots.txt
Когда поисковые системы сканируют сайт, они сначала ищут файл robots.txt в корне домена. Если обнаружено, они читают список директив файла, чтобы увидеть, какие каталоги и файлы, если таковые имеются, заблокированы от сканирования. Этот файл можно создать с помощью нашего генератора файлов robots. txt. Когда вы используете генератор robots.txt, Google и другие поисковые системы могут определить, какие страницы вашего сайта следует исключить а какие нет. Другими словами, файл, созданный генератором robots.txt, похож на противоположность карты сайта, которая указывает, какие страницы нужно включить.
Файл robots.txt сообщает поисковой системе, какие подстраницы вашего сайта индексировать, а какие нет.
- Пакетные настройки для всех команд в генераторе
- Robots.txt можно создать как текст, так и файл
- Доступны все основные поисковые роботы
Настройка параметров в генераторе
Генератор облегчает вашу работу, запрашивая всю важную информацию. Ниже приведено пошаговое руководство по использованию генератора robots.txt:
- В первом поле пауки могут быть полностью исключены или вообще разрешены (рекомендованы). Если вы запретите всем поисковым роботам индексировать ваш сайт, все остальные поля генератора станут лишними.
- Выберите, должна ли быть задержка сканирования. Если это так, соответствующему сканеру разрешено посещать ваш сайт только каждые 5, 10, 20, 60 или 120 секунд.
- В третье поле введите XML-карту сайта. Если на вашем сайте нет карты сайта, оставьте это поле пустым или создайте карту сайта XML с помощью нашего бесплатного генератора карты сайта XML.
- Генератор предоставляет вам список всех распространенных поисковых систем. Если вас интересуют только определенные поисковые системы, вы можете разрешить или запретить доступ к ним по отдельности.
- Наконец, укажите все страницы и папки, которые не следует индексировать. Убедитесь, что каждый путь имеет собственное поле и заканчивается косой чертой. Если в процессе работы вы заметили, что допустили ошибку или вообще хотите действовать по-другому, вы, конечно, можете в любой момент изменить свои записи в генераторе robots.txt. Внизу также есть синяя кнопка с надписью «Сброс», поэтому вы можете начать все сначала в любое время.
2. Создайте файл бесплатно
После того, как вы введете всю информацию в инструмент, генератор создаст для вас файл robots.txt. Вы можете выбрать один из двух вариантов:
- После нажатия на зеленую кнопку с надписью «Создать robots.txt» в белом поле под кнопкой создается файл robotos.txt. Вы можете просматривать, просматривать и копировать файл там.
- Нажатие на красную кнопку с надписью «Создать и сохранить как robots.txt» приводит к тому же результату. Однако вдобавок вы получите готовый файл, который сможете сохранить прямо на жесткий диск.
3. robots.txt хранение в корневом каталоге через ваш FTP
После создания файла robots.txt его необходимо реализовать. Обычно это очень просто: сохраните файл как robots.txt и загрузите его через FTP-сервер или Хостинг в корневой каталог домена.
Как только это будет сделано, каждый сканер должен сначала интерпретировать этот файл. Это говорит ему, разрешено ли ему посещать и индексировать ваш сайт или отдельные подстраницы. Если у вас есть какие-либо вопросы или проблемы с хранением robots.txt, пожалуйста, не стесняйтесь обращаться к нам.
Часто задаваемые вопросы о файле robots.txt:
Для чего нужен robots.txt?
Файл robots.txt используется для управления поведением роботов поисковых систем. Если, например, вы не хотите, чтобы боты имели доступ к определенной подстранице, эта подстраница блокируется для роботов через файл robots.txt командой «Запретить».
Где я могу найти файл robots.txt?
Файл robots.txt находится на первом уровне дерева вашего сайта. Вы можете вызвать файл, введя www.домен.ru/robot.txt в адресную строку браузера. Вы можете найти файл через FTP-доступ у вашего хостера.
Можно ли создать файл robots.txt самостоятельно?
Да. С помощью нашего бесплатного генератора robots.txt вы можете легко создать и настроить файл самостоятельно.
Как проверить, правильно ли настроен файл?
Вы можете проверить это, просмотрев все сайты, упомянутые в файле robots. txt. Здесь вы должны решить, может ли соответствующая страница быть включена в индекс или нет. Все страницы вашего сайта должны быть перечислены в разделе «Разрешить», а только те области вашей страницы, которые не разрешены в индексе, — в разделе «Запретить».
Является ли файл robots.txt обязательным?
Нет Файл robots.txt является необязательным, но дает некоторые преимущества с точки зрения поисковой оптимизации.
Почему XML-карта сайта должна быть в файле robots.txt?
При вызове вашего сайта поисковая система всегда сначала натыкается на файл robots.txt. Если вы сохранили там свой sitemap.xml, есть большая вероятность, что ваша страница будет проиндексирована без ошибок.
Может вас заинтересуют и эти инструменты:
- Генератор мета тегов
- Анализатор мета-тегов
- Генератор Robots.txt
- Генератор Sitemap XML
- Генератор Md5 онлайн
- Генератор перенаправления Htaccess
- Конвертер CSV в JSON
- HTML редактор
- Генератор кредитных карт
- Генератор поддельных данных
- Генератор schema org
Что такое Robots.
txt и как его настроитьrobots.txt — это текстовый файл с инструкциями для поисковиков.
В этом файле можно закрыть сайт от поисковых систем или же закрыть отдельные страницы / разделы сайта. Можно прописывать правила как для конкретного поисковика, так и для всех поисковиков сразу.
Найти роботс можно по адресу: https://site.ru/robots.txt (где site.ru — это ваш домен).
robots.txt — это обязательный файл. Его отсутствие или кривая настройка могут вырасти в нереальный геморрой и сильно усложнить продвижение сайта.
Пример robots.txt моего сайта
Разберем базовые директивы:
- User-agent: обращаемся к поисковому роботу по имени, либо ко всем роботам сразу
- Disallow: нужен для закрытия от индексации страниц, разделов, либо всего сайта
- Allow: разрешить индексацию отдельного раздела или страницы сайта
- Sitemap.xml: указать место расположения xml карты сайта
Дополнительные директивы для яндекса:
- Clean-param: очистить адреса от параметров (динамических переменных)
- Crawl-delay: поставить задержку при ответе поисковому роботу (если вдруг ваш сервак не справляется и поисковик кладёт сайт).
Как настраивать robots.txt
1. Создаем .txt файл с именем robots.txt и вписываем первой строкой:
User-agent: *
Эта директива указывает на то, что любой поисковой робот может воспользоваться ниже указанными правилами, если не найдет определенных правил, конкретно для себя.
2. Скрываем от поисковиков технические страницы:
- Панель администрирования сайта
- Поиск по сайту
- Страницы с неуникальной информацией (политика конфиденциальности и т.д.)
В моем случае, нужно закрыть:
- Disallow: /register
- Disallow: /password/reset
- Disallow: /login
Просто подставьте свои адреса вместо адресов из примера. По необходимости добавьте еще несколько директив Disallow (если таких страниц у вас больше 3-х)
3. Закрываем от индексации URL с параметрами:
URL с параметрами — это страницы, в адрес которых дописываются атрибуты в результате работы сортировок, фильтров, и других элементов.
Наример, когда вы переходите по пагинации на моем сайте.
Наример, — когда вы переходите по пагинации на моем сайте.
В синий прямоугольник я выделил постоянный адрес,
а в красный — подставляемые параметры при переходе по пагинации.
Чтобы закрыть от индексации всю пагинацию на моем сайте, нужно воспользоваться следующей директивой:
Disallow: *page=*
Символ * указывает роботу, что нет значения, что идет перед началом и концом записи нашей константы.
URL, которые будут закрыты в результате работы директивы:
- https://kondrashov.online/?page=любой_текст
- https://kondrashov.online/любой_текст?page=3/любой_текст
- https://kondrashov.online/любой_текст/?page=21231231
Если робот найдет в адресе страницы фрагмент «page=«, то он не станет индексировать эту страницу. Сама же страница может быть любого уровня вложенности.
Рассмотрим работу переменных в интернет магазине
Возьмем случайный интернет магазин, отправимся на страницу каталога и кликнем в какую-нибудь сортировку товаров:
По умолчанию у нас статические адрес страницы, без переменных в адресе.
При использовании каких-либо сортировок и фильтраций адрес начинает меняться. К нему добавляются переменные (красный прямоугольник на скриншоте).
Страница при этом остается прежней, на ней меняется только порядок товаров.
Такие страницы не являются полезными для поисковика, они воспринимаются как дубли основной страницы.
- Подробнее читайте тут: некачественные страницы yandex
- И еще тут: поиск и удаление дублей на сайте
Наша задача — понять, какие есть способы образования таких страниц, и закрыть их от индексирования!
В моем примере я отсортировал товары по актуальности, и адрес изменился.
В нем появился вот такой тест: ?sort=ACTIVE_TO&order=asc
Параметры генерируются через переменную ?sort. Понимая это, я могу дописать в наш robots.txt новую директиву:
Disallow: *?sort*
Тем самым я закрою от индексации все страницы, в которых встречается переменная ?sort, по аналогии с первым примером.
Любые динамические адреса генерируются через символы: ?, $, &, =, %
Если закрыть все адреса, в которых встречаются эти символы, то мы избавимся от всех дублей страниц с параметрами.
- Disallow: *?*
- Disallow: *$*
- Disallow: *&*
- Disallow: *=*
- Disallow: *%*
Но такая глобальная зачистка может зацепить и важные страницы сайта!
4. Открываем доступ к файлам стилей сайта CSS
Директива: Allow: *css* решит проблему доступности всех CSS файлов на сайте.
Адреса до CSS файлов могут содержать параметры. Есть риск, что при закрытии дублей страниц, мы можем закрыть и доступ к CSS. Поэтому после закрытия динамических страниц дописываем директиву Allow: *css*.
5. Указываем ссылку на Sitemap.xml
Самый простой пункт настройки — нужно поставить ссылку на карту сайта через директиву:
Sitemap: https://site.ru/sitemap. xml
Где site.ru — домен вашего сайта.
Все! Настройка закончена.
Мы настроили базовый robots.txt, который подойдет для любой CMS системы.
Если есть вопросы, пишите в комменты, разберем 😉
Некоторые важные моменты про robots.txt
- Robots.txt кешируется поисковиками, краткосрочно, но все же кешируется!
- Кодировка для robots.txt — UTF8
- Размер файла — не более 500кб.
- Код ответа сервера должен быть 200. Проверить можно тут: https://webmaster.yandex.ru/tools/server-response/
- Использование кириллицы запрещено в файле robots.txt и HTTP-заголовках сервера. Для указания имен доменов в зоне РФ используйте Punycode!
- Не закрывайте страницы пагинации от индексации в robots.txt (в своем примере я делаю в точности наоборот, но у меня есть свои причины на это). Для закрытия страниц пагинации используйте теги: noindex, follow или rel=»canonical».
создание, настройка, проверка и индексация сайта
Здравствуйте!
В SEO мелочей не бывает. Иногда на продвижение сайта может оказать влияние всего лишь один небольшой файл — Robots.txt. Если вы хотите, чтобы ваш сайт зашел в индекс, чтобы поисковые роботы обошли нужные вам страницы, нужно прописать для них рекомендации.
«Разве это возможно?», — спросите вы. Возможно. Для этого на вашем сайте должен быть файл robots.txt. Как правильно составить файл роботс, настроить и добавить на сайт – разбираемся в этой статье.
Что такое robots.txt и для чего нужен
Robots.txt – это обычный текстовый файл, который содержит в себе рекомендации для поисковых роботов: какие страницы нужно сканировать, а какие нет.
Важно: файл должен быть в кодировке UTF-8, иначе поисковые роботы могут его не воспринять.
Зайдет ли в индекс сайт, на котором не будет этого файла? Зайдет, но роботы могут «выхватить» те страницы, наличие которых в результатах поиска нежелательно: например, страницы входа, админпанель, личные страницы пользователей, сайты-зеркала и т. п. Все это считается «поисковым мусором»:
Если в результаты поиска попадёт личная информация, можете пострадать и вы, и сайт. Ещё один момент – без этого файла индексация сайта будет проходить дольше.
В файле Robots.txt можно задать три типа команд для поисковых пауков:
- сканирование запрещено;
- сканирование разрешено;
- сканирование разрешено частично.
Все это прописывается с помощью директив.
Как создать правильный файл Robots.txt для сайта
Файл Robots.txt можно создать просто в программе «Блокнот», которая по умолчанию есть на любом компьютере. Прописывание файла займет даже у новичка максимум полчаса времени (если знать команды).
Также можно использовать другие программы – Notepad, например. Есть и онлайн сервисы, которые могут сгенерировать файл автоматически. Например, такие как CY-PR.com или Mediasova.
Вам просто нужно указать адрес своего сайта, для каких поисковых систем нужно задать правила, главное зеркало (с www или без). Дальше сервис всё сделает сам.
Лично я предпочитаю старый «дедовский» способ – прописать файл вручную в блокноте. Есть ещё и «ленивый способ» — озадачить этим своего разработчика 🙂 Но даже в таком случае вы должны проверить, правильно ли там всё прописано. Поэтому давайте разберемся, как составить этот самый файл, и где он должен находиться.
Где должен находиться файл Robots
Готовый файл Robots.txt должен находиться в корневой папке сайта. Просто файл, без папки:
Хотите проверить, есть ли он на вашем сайте? Вбейте в адресную строку адрес: site.ru/robots.txt. Вам откроется вот такая страничка (если файл есть):
Файл состоит из нескольких блоков, отделённых отступом. В каждом блоке – рекомендации для поисковых роботов разных поисковых систем (плюс блок с общими правилами для всех), и отдельный блок со ссылками на карту сайта – Sitemap.
Внутри блока с правилами для одного поискового робота отступы делать не нужно.
Каждый блок начинается директивой User-agent.
После каждой директивы ставится знак «:» (двоеточие), пробел, после которого указывается значение (например, какую страницу закрыть от индексации).
Нужно указывать относительные адреса страниц, а не абсолютные. Относительные – это без «www.site.ru». Например, вам нужно запретить к индексации страницу www.site.ru/shop. Значит после двоеточия ставим пробел, слэш и «shop»:
Disallow: /shop.
Звездочка (*) обозначает любой набор символов.
Знак доллара ($) – конец строки.
Вы можете решить – зачем писать файл с нуля, если его можно открыть на любом сайте и просто скопировать себе?
Для каждого сайта нужно прописывать уникальные правила. Нужно учесть особенности CMS. Например, та же админпанель находится по адресу /wp-admin на движке WordPress, на другом адрес будет отличаться. То же самое с адресами отдельных страниц, с картой сайта и прочим.
Читайте также: Как найти и удалить дубли страниц на сайте
Настройка файла Robots.
txt: индексация, главное зеркало, диррективыКак вы уже видели на скриншоте, первой идет директива User-agent. Она указывает, для какого поискового робота будут идти правила ниже.
User-agent: * — правила для всех поисковых роботов, то есть любой поисковой системы (Google, Yandex, Bing, Рамблер и т.п.).
User-agent: Googlebot – указывает на правила для поискового паука Google.
User-agent: Yandex – правила для поискового робота Яндекс.
Для какого поискового робота прописывать правила первым, нет никакой разницы. Но обычно сначала пишут рекомендации для всех роботов.
Рекомендации для каждого робота, как я уже писала, отделяются отступом.
Disallow: Запрет на индексацию
Чтобы запретить индексацию сайта в целом или отдельных страниц, используется директива Disallow.
Например, вы можете полностью закрыть сайт от индексации (если ресурс находится на доработке, и вы не хотите, чтобы он попал в выдачу в таком состоянии). Для этого нужно прописать следующее:
User-agent: *
Disallow: /
Таким образом всем поисковым роботам запрещено индексировать контент на сайте.
А вот так можно открыть сайт для индексации:
User-agent: *
Disallow:
Потому проверьте, стоит ли слеш после директивы Disallow, если хотите закрыть сайт. Если хотите потом его открыть – не забудьте снять правило (а такое часто случается).
Чтобы закрыть от индексации отдельные страницы, нужно указать их адрес. Я уже писала, как это делается:
User-agent: *
Disallow: /wp-admin
Таким образом на сайте закрыли от сторонних взглядов админпанель.
Что нужно закрывать от индексации в обязательном порядке:
- административную панель;
- личные страницы пользователей;
- корзины;
- результаты поиска по сайту;
- страницы входа, регистрации, авторизации.
Можно закрыть от индексации и отдельные типы файлов. Допустим, у вас на сайте есть некоторые .pdf-файлы, индексация которых нежелательна. А поисковые роботы очень легко сканируют залитые на сайт файлы. Закрыть их от индексации можно следующим образом:
User-agent: *
Disallow: /*. pdf$
Как отрыть сайт для индексации
Даже при полностью закрытом от индексации сайте можно открыть роботам путь к определённым файлам или страницам. Допустим, вы переделываете сайт, но каталог с услугами остается нетронутым. Вы можете направить поисковых роботов туда, чтобы они продолжали индексировать раздел. Для этого используется директива Allow:
User-agent: *
Allow: /uslugi
Disallow: /
Главное зеркало сайта
До 20 марта 2018 года в файле robots.txt для поискового робота Яндекс нужно было указывать главное зеркало сайта через директиву Host. Сейчас этого делать не нужно – достаточно настроить постраничный 301-редирект.
Что такое главное зеркало? Это какой адрес вашего сайта является главным – с www или без. Если не настроить редирект, то оба сайта будут проиндексированы, то есть, будут дубли всех страниц.
Карта сайта: robots.txt sitemap
После того, как прописаны все директивы для роботов, необходимо указать путь к Sitemap. Карта сайта показывает роботам, что все URL, которые нужно проиндексировать, находятся по определённому адресу. Например:
Sitemap: site.ru/sitemap.xml
Когда робот будет обходить сайт, он будет видеть, какие изменения вносились в этот файл. В итоге новые страницы будут индексироваться быстрее.
Директива Clean-param
В 2009 году Яндекс ввел новую директиву – Clean-param. С ее помощью можно описать динамические параметры, которые не влияют на содержание страниц. Чаще всего данная директива используется на форумах. Тут возникает много мусора, например id сессии, параметры сортировки. Если прописать данную директиву, поисковый робот Яндекса не будет многократно загружать информацию, которая дублируется.
Прописать эту директиву можно в любом месте файла robots.txt.
Параметры, которые роботу не нужно учитывать, перечисляются в первой части значения через знак &:
Clean-param: sid&sort /forum/viewforum. php
Эта директива позволяет избежать дублей страниц с динамическими адресами (которые содержат знак вопроса).
Директива Crawl-delay
Эта директива придёт на помощь тем, у кого слабый сервер.
Приход поискового робота – это дополнительная нагрузка на сервер. Если у вас высокая посещаемость сайта, то ресурс может попросту не выдержать и «лечь». В итоге робот получит сообщение об ошибке 5хх. Если такая ситуация будет повторяться постоянно, сайт может быть признан поисковой системой нерабочим.
Представьте, что вы работаете, и параллельно вам приходится постоянно отвечать на звонки. Ваша продуктивность в таком случае падает.
Так же и с сервером.
Вернемся к директиве. Crawl-delay позволяет задать задержку сканирования страниц сайта с целью снизить нагрузку на сервер. Другими словами, вы задаете период, через который будут загружаться страницы сайта. Указывается данный параметр в секундах, целым числом:
Crawl-delay: 2
Комментарии в robots.
txtБывают случаи, когда вам нужно оставить в файле комментарий для других вебмастеров. Например, если ресурс передаётся в работу другой команде или если над сайтом работает целая команда.
В этом файле, как и во всех других, можно оставлять комментарии для других разработчиков.
Делается это просто – перед сообщением нужно поставить знак решетки: «#». Дальше вы можете писать свое примечание, робот не будет учитывать написанное:
User-agent: *
Disallow: /*. xls$
#закрыл прайсы от индексации
Как проверить файл robots.txt
После того, как файл написан, нужно узнать, правильно ли. Для этого вы можете использовать инструменты от Яндекс и Google.
Через Яндекс.Вебмастер robots.txt можно проверить на вкладке «Инструменты – Анализ robots.txt»:
На открывшейся странице указываем адрес проверяемого сайта, а в поле снизу вставляем содержимое своего файла. Затем нажимаем «Проверить». Сервис проверит ваш файл и укажет на возможные ошибки:
Также можно проверить файл robots. txt через Google Search Console, если у вас подтверждены права на сайт.
Для этого в панели инструментов выбираем «Сканирование – Инструмент проверки файла robots.txt».
На странице проверки вам тоже нужно будет скопировать и вставить содержимое файла, затем указать адрес сайта:
Потом нажимаете «Проверить» — и все. Система укажет ошибки или выдаст предупреждения.
Останется только внести необходимые правки.
Если в файле присутствуют какие-то ошибки, или появятся со временем (например, после какого-то очередного изменения), инструменты для вебмастеров будут присылать вам уведомления об этом. Извещение вы увидите сразу, как войдете в консоль.
Частые ошибки в заполнении файла robots.txt
Какие же ошибки чаще всего допускают вебмастера или владельцы ресурсов?
1. Файла вообще нет. Это встречается чаще всего, и выявляется при SEO-аудите ресурса. Как правило, на тот момент уже заметно, что сайт индексируется не так быстро, как хотелось бы, или в индекс попали мусорные страницы.
2. Перечисление нескольких папок или директорий в одной инструкции. То есть вот так:
Allow: /catalog /uslugi /shop
Называется «зачем писать больше…». В таком случае робот вообще не знает, что ему можно индексировать. Каждая инструкция должна иди с новой строки, запрет или разрешение на индексацию каждой папки или страницы – это отдельная рекомендация.
3. Разные регистры. Название файла должно быть с маленькой буквы и написано маленькими буквами – никакого капса. То же самое касается и инструкций: каждая с большой буквы, все остальное – маленькими. Если вы напишете капсом, это будет считаться уже совсем другой директивой.
4. Пустой User-agent. Нужно обязательно указать, для какой поисковой системы идет набор правил. Если для всех – ставим звездочку, но никак нельзя оставлять пустое место.
5. Забыли открыть ресурс для индексации после всех работ – просто не убрали слеш после Disallow.
6. Лишние звездочки, пробелы, другие знаки. Это просто невнимательность.
Регулярно заглядывайте в инструменты для вебмастеров и вовремя исправляйте возможные ошибки в своем файле robots.txt.
Удачного вам продвижения!
Robots.txt Tester & Validator 2022: БЕСПЛАТНЫЙ онлайн-инструмент
Это поле обязательно к заполнению URL-адрес недействителенПример: www.websiteplanet.com/robots.txt
ПРОВЕРЬТЕ01
Простота использования:
Проверить точность файла robots.txt еще никогда не было так просто. Просто вставьте свой полный URL-адрес с /robots.txt, нажмите «Ввод», и ваш отчет будет готов быстро.
02
Точность 100%:
Наша программа проверки robots.txt не только найдет ошибки, связанные с опечатками, синтаксическими и «логическими» ошибками, но и даст вам полезные советы по оптимизации.
03
Точно:
Принимая во внимание стандарт исключения роботов и специальные расширения для поисковых роботов, наша программа проверки robots. txt создаст удобный для чтения отчет, который поможет исправить любые ошибки, которые могут быть в вашем файле robots.txt. .
Часто задаваемые вопросы
Что такое средство проверки и проверки robots.txt?
Инструмент проверки robots.txt предназначен для проверки правильности файла robots.txt и отсутствия ошибок. Robots.txt — это файл, который является частью вашего веб-сайта и содержит правила индексации для роботов поисковых систем, чтобы убедиться, что ваш веб-сайт сканируется (и индексируется) правильно, а самые важные данные на вашем веб-сайте индексируются в первую очередь. Этот инструмент прост. для использования и дает вам отчет за считанные секунды — просто введите полный URL-адрес своего веб-сайта, а затем /robots.txt (например, yourwebsite.com/robots.txt) и нажмите кнопку «Проверить». Наше средство проверки robots.txt найдет любые ошибки (например, опечатки, синтаксические и «логические» ошибки) и даст вам советы по оптимизации файла robots.txt. Зачем мне проверять файл robots. txt?
Проблемы с файлом robots.txt — или вообще отсутствие файла robots.txt — могут негативно повлиять на ваши показатели SEO, ваш веб-сайт может ухудшиться в рейтинге на страницах результатов поисковой системы (SERP). Это связано с риском сканирования нерелевантного контента раньше или вместо важного контента. Проверка файла перед сканированием вашего веб-сайта означает, что вы можете избежать таких проблем, как сканирование и индексирование всего контента вашего веб-сайта, а не только страниц. Вы хотите индексацию. Например, если у вас есть страница, доступ к которой вы хотите получить только после заполнения формы подписки, или страница входа участника, но вы не исключили ее в файле robot.txt, она может оказаться проиндексированной. Что делать? Имеются в виду ошибки и предупреждения?
Существует ряд ошибок, которые могут повлиять на ваш файл robots.txt, а также некоторые «рекомендуемые» предупреждения, которые вы можете увидеть при проверке файла. Это вещи, которые могут повлиять на SEO и должны быть исправлены. Предупреждения менее важны и служат советом о том, как улучшить файл robots.txt. Вы можете увидеть следующие ошибки: Неверный URL-адрес — вы увидите эту ошибку, если ваш файл robots.txt полностью отсутствует Потенциальная ошибка с подстановочными знаками — Хотя технически это скорее предупреждение, чем ошибка, если вы видите это сообщение, обычно это означает, что ваш файл robots.txt содержит подстановочный знак (*) в поле Disallow (например, Disallow: /*.rss). Это проблема передовой практики — Google разрешает использовать подстановочные знаки в поле «Запретить», но это не рекомендуется. Общие и специальные пользовательские агенты в одном блоке кода — это синтаксическая ошибка в вашем файле robots.txt, которую следует исправить, чтобы избежать проблем со сканированием вашего веб-сайта. Предупреждения, которые вы можете увидеть, включают: Разрешить: / — Использование разрешающего порядка не повредит вашему рейтингу или не повлияет на ваш сайт, но это не стандартная практика. Основные роботы, включая Google и Bing, примут эту директиву, но не все поисковые роботы — и, вообще говоря, лучше всего сделать файл robots.txt совместимым со всеми поисковыми роботами, а не только с большими. Использование заглавных букв в именах полей — Хотя имена полей не обязательно чувствительны к регистру, некоторым поисковым роботам может потребоваться использовать заглавные буквы, поэтому рекомендуется использовать заглавные буквы в именах полей для определенных пользовательских агентов Поддержка карты сайта — Многие файлы robots.txt содержат сведения sitemap для веб-сайта, но это не считается лучшей практикой. Однако Google и Bing поддерживают эту функцию. Как исправить ошибки в файле My Robots.txt?
Исправление ошибок в файле robots.txt зависит от используемой платформы. Если вы используете WordPress, рекомендуется использовать плагин, такой как WordPress Robots.txt Optimization или Robots.txt Editor. Если вы подключите свой веб-сайт к Google Search Console, вы также сможете редактировать файл robots. txt там. Некоторые конструкторы веб-сайтов, такие как Wix, не позволяют вам напрямую редактировать файл robots.txt, но позволяют добавлять индексные теги для определенных страниц.
49094
49094
Нравится этот инструмент? Оцените это!
4.7 (Проголосовало 978 пользователей)
Вы уже проголосовали! Отменить
Вам нужно использовать этот инструмент, чтобы оценить его
Это поле обязательно к заполнению Максимальная длина комментария равна 80000 символов Минимальная длина комментария равна 10 символам Электронная почта обязательна Электронная почта невернаГенератор Robots.txt — Создайте файл Robot.txt онлайн бесплатно
Опишите, какие области вашего веб-сайта должны и не должны посещаться поисковым роботом в файле robots.txt. Предоставьте нашему инструменту всю необходимую информацию и позвольте ему создать нужный файл, нажав кнопку «Создать Robots. txt».
Robots.txt — это краткая форма, используемая SEO-специалистами и технически подкованными веб-мастерами для описания стандарта исключения роботов. Это означает, что robots.txt инструктирует роботов поисковых систем, какие области веб-сайта им не следует посещать. Для размещения этих инструкций на веб-сайте можно использовать простой и удобный в использовании текстовый генератор robots.
Этот стандарт был предложен в 1994 году Мартином Костером после того, как поисковый робот, написанный Чарльзом Строссом, нанес ущерб сайту Мартейна. Robots.txt стал стандартом де-факто, которому следуют современные поисковые роботы. Однако ложные веб-сканеры, которые нацелены на веб-сайты для распространения вирусов и вредоносных программ, игнорируют файл robots.txt и посещают каталоги веб-сайтов, которые роботы.txt запрещает посещать сканерам. Эти вредоносные роботы будут не только игнорировать инструкции robots.txt, но и посещать страницы и каталоги, посещение которых запрещено. Именно так они распространяют вредоносное ПО и портят сайты.
Например, когда робот поисковой системы хочет посетить веб-сайт, предположим, что URL-адрес веб-сайта http://www.examples.com/Greetings.html/, но прежде чем поисковая система начнет оценивать сайт, она проверяет, http: //www.examples.com/robots.txt существует. Он существует и находит эти две строки:
User-agent: *
Disallow: /
Сайт не проверяется и не индексируется. В первой строке файла robots.txt «User-agent: *» содержится указание всем поисковым системам следовать его инструкциям, а во второй строке «Disallow: /» — указание им не посещать какие-либо каталоги сайта.
ВАЖНЫЕ СООБРАЖЕНИЯ
Есть два важных фактора, о которых вы должны знать, а именно:
- Помните, что если вы щелкните правой кнопкой мыши на любом веб-сайте, вы сможете просмотреть его исходный код. Поэтому помните, что ваш файл robots.txt будет виден всем, и любой сможет его увидеть и увидеть, какие каталоги вы запретили поисковому роботу посещать.
- Веб-роботы могут игнорировать файл robots. txt, особенно вредоносные роботы и сборщики адресов электронной почты. Они будут искать уязвимости на сайте и игнорировать инструкции robots.txt.
Типичный robots.txt, предписывающий поисковым роботам не посещать определенные каталоги на веб-сайте, будет выглядеть так:
User-agent: *
Disallow: /aaa-bin/
Disallow: /tmp/
Disallow: / ~mike/
Этот текст указывает роботам поисковых систем не посещать сайт. Вы не можете поместить две функции запрета в одну строку, например, вы не можете написать: Disallow: /aaa-bin/tmp/. Вы должны явно указать, какие каталоги вы хотите игнорировать. Вы не можете использовать общие имена, такие как Disallow: *.gif.
Не забудьте использовать строчные буквы для имени файла robots.txt, а не «ROBOTS.TXT».
ГДЕ РАЗМЕСТИТЬ ROBOTS.TXT НА ВИРТУАЛЬНОМ ХОСТИ
Виртуальный хост имеет разные значения для разных вещей. Виртуальный веб-хост различает с помощью доменного имени разные сайты, использующие один и тот же IP-адрес. Файл robots.txt можно поместить в код вашего домена, он будет прочитан и выполнен поисковым роботом.
Если вы делите хост с другими пользователями, вам придется попросить администратора хоста помочь вам.
КАК СОЗДАТЬ ROBOTS.TXT
Если вы являетесь SEO-специалистом или технически подкованным веб-мастером, вы можете создать файл robots.txt на компьютере Microsoft, используя notepad.exe или textpad.exe и даже Microsoft Word. Только не забудьте сохранить его как обычный текст.
На Apple Macintosh вы можете использовать TextEdit, используя формат «сделать обычный текст» и сохранить как западный.
В Linux можно использовать vi или emacs.
Создав файл robots.txt, вы можете скопировать/вставить его в раздел заголовка кода заголовка вашего веб-сайта.
ИСПОЛЬЗОВАНИЕ ГЕНЕРАТОРА ROBOTS.TXT ДЛЯ СОЗДАНИЯ ФАЙЛА
Если вы оптимизатор, веб-мастер или разработчик, вы можете получить помощь на сайте searchenginereports. net. Посетите веб-сайт и нажмите «Бесплатные инструменты SEO». Прокрутите список инструментов SEO, пока не нажмете генератор Robots.txt.
Нажмите на значок этого инструмента, и он откроет страницу, отображающую: Генератор Robots.txt.
- По умолчанию — все роботы: По умолчанию «Разрешено».
- Crawl-Delay: по умолчанию — «Без задержки».
- Карта сайта: (оставьте пустым, если у вас ее нет)
- Поисковые роботы: здесь все роботы будут перечислены в отдельных строках, и значение по умолчанию будет таким же, как и значение по умолчанию, то есть «Разрешено».
- Запрещенные каталоги: Здесь вы укажете каталоги, которые вы хотите запретить поисковым роботам. Не забудьте указать один каталог в каждом поле.
После того, как вы ввели свои ограничения; вы можете нажать «Создать Robots.txt» или выбрать «Очистить». Если вы допустили ошибку при вводе требований, нажмите «Очистить» и повторно заполните поля.
Если выбрать параметр «Создать Robots. txt», система создаст файл robots.txt. Затем вы можете скопировать и вставить его в заголовок HTML-кода вашего сайта.
Нет никаких ограничений на количество раз, когда вы можете использовать этот отличный бесплатный инструмент. Если вы забыли добавить каталог для ограничения или хотите добавить новый каталог. Вы можете использовать инструмент генератора txt Robots, чтобы создать новый файл.
Помните, что если вы хотите добавить новый каталог, просто укажите его в списке ограниченных каталогов инструмента генератора txt для роботов. После создания файла скопируйте/вставьте только строку каталога с ограничениями в существующий файл robots.txt в формате HTML.
Вы можете войти во все каталоги с ограниченным доступом, включая старые и новые, и создать новый файл robots.txt, который можно вырезать и вставить после удаления предыдущего файла robots.txt из источника HTML.
ВЫВОД
Поскольку вы собираетесь вмешиваться в исходный код своего веб-сайта, будьте очень осторожны. Не пытайтесь экспериментировать с созданием robots.txt, вы можете непреднамеренно сломать свой сайт.
Если вы разработали свой веб-сайт в WordPress, вы можете обратиться за помощью к плагину WordPress robots.txt, как создать robots.txt в WordPress и на нескольких других сайтах, включая WordPress.
В HTML вы также можете получить справку из примера robot.txt.
Помните, что файл robots.txt — это часть, в которой вы указываете роботам поисковых систем, какие каталоги им не следует посещать. Также в файле robots.txt вы можете указать им не переходить по внешним ссылкам вашего сайта. Но вы не можете сгенерировать это с помощью searchenginereports.exe, если только они не помещены в отдельный каталог.
Пользовательский генератор robots.txt (создание текстового файла Google Robots)
Почему и как генерировать robots.txt с помощью нашего инструмента
Прежде чем перейти к тому, как работает генератор файлов robots.txt, давайте немного углубимся в то, почему он вам вообще нужен. Не все страницы вашего сайта представляют ценность для SEO. Подумайте о страницах подтверждения оформления заказа, страницах входа в систему, дублирующемся контенте, административных и промежуточных областях сайта и т. д. Дело не только в том, что такие страницы не улучшают SEO, если они включены в сканирование, но и в том, что они могут активно работать против ваших усилий по поисковой оптимизации, занимая драгоценный краулинговый бюджет. Это может означать отсутствие действительно ценного контента в пользу страниц, которые на самом деле не имеют значения. Более того, не только Google сканирует ваш сайт, исключая другие сторонние сканеры, которые могут помочь сохранить скорость вашего сайта.
Генератор txt для роботов позволяет блокировать части сайта от индексации, чтобы Google шел именно туда, куда вы хотите. Без лишних слов, вот как создать текстовый файл robots.
- 1.
- Выберите «разрешено» или «отказано». По умолчанию для нашего генератора файлов txt для роботов разрешены все роботы или поисковые роботы. 0169 Установите задержку сканирования
- 4.
- Введите любые каталоги, которые вы хотите исключить из сканирования, будьте очень осторожны с регистром букв и символами
- 5.
- Добавьте URL-адрес вашей карты сайта 6
- 1 9.1671 9.1671 9.1671
- Загрузите файл и, имея в руках файл txt для робота, добавьте его в корневой каталог. Кроме того, вы можете скопировать содержимое и вставить его в существующий файл robots.txt
Объяснение выходных данных нашего генератора текстовых файлов robots
После того, как вы создадите файл robots.txt, вы можете задаться вопросом, что же это за жаргон, который вы видите во всех этих группах текста. Давайте разберем выходные директивы нашего текстового генератора robots онлайн.
| Вывод | Объяснение |
|---|---|
| User-agent | Это текст поисковой системы, к которому будут применяться следующие строки сканера. Существует множество пользовательских агентов, но одними из наиболее распространенных являются Googlebot, Bingbot, Slurp и Baiduspider (все с учетом регистра). Единственным исключением является файл *. Звездочка применяется ко всем поисковым роботам (кроме поисковых роботов AdsBot, которые должны быть названы отдельно). |
| Запретить | Второе, что вы увидите в каждой группе, это запретить список того, к чему вы не хотите, чтобы сканер обращался или индексировал. Если вы оставите это поле пустым, это означает, что вы ничего не запрещаете сканеру этого пользовательского агента, и они могут проиндексировать весь ваш сайт. С другой стороны, если вы хотите, чтобы этот поисковый робот заблокировал весь ваш сайт, вы увидите «/». У вас также могут быть определенные каталоги или страницы, перечисленные здесь, и все они должны быть перечислены в отдельных строках. |
| Разрешить | По сути, это позволяет создавать исключения из директивы запрета для определенных каталогов, подкаталогов или страниц. |
| Crawl-delay | Как бы это ни звучало, число, которое вы здесь видите, представляет собой задержку в секундах перед тем, как краулер получит доступ к вашему сайту в попытке сэкономить пропускную способность и не создавать пик трафика. Google больше не поддерживает это, т. е. Google игнорирует это, но другие поисковые системы могут по-прежнему следовать этой директиве. |
| Карта сайта | Хотя отправлять карту сайта непосредственно в Google Search Console разумно, существуют и другие поисковые системы, и эта директива генератора файлов txt для роботов сообщает их поисковым роботам, где находится ваша карта сайта. |
Рекомендации по созданию файла robots.txt для целей SEO внести изменения в будущем или хотите узнать, как создать файл robots.txt, который сделает работу самостоятельно.
- 1.
- Файл должен находиться на верхнем уровне, в корневом каталоге вашего сайта.
- 2.
- При создании файлов robots.txt учитывайте регистр символов. Если вы создадите директиву txt для роботов, например, чтобы заблокировать каталог «Фото», но введете «фото», он все равно будет просканирован.
- 3.
- Обратите особое внимание на символы, такие как обратная косая черта, в обоих доменах и при заполнении полей директив, таких как disallow. Например, если вы случайно оставите disallow полностью пустым, это означает, что вы разрешаете этому сканеру доступ к
- 4.
- Каждая директива должна быть на отдельной строке.
- 5.
- Директивы, созданные генератором robot.txt, не блокируют страницу, домен или каталог от Google. Если вы хотите, чтобы что-то вообще не отображалось, вам следует использовать тег «noindex», а не файл robots.txt.
- 6.
- Избегайте конфликтующих правил, так как они могут привести к проблемам со сканированием, из-за которых важный контент будет пропущен.
Часто задаваемые вопросы о нашем конструкторе robots.txt
Что такое генератор текстовых сообщений для роботов?
Генератор текста для роботов — это инструмент, который избавляет от догадок о том, как создать файл robots.txt. Это упрощает процесс ввода различных пользовательских агентов, директив и каталогов или страниц в несколько кликов и копий / вставок, устраняя возможность дорогостоящих ошибок SEO.
Как узнать, действительно ли я создаю txt-файл robots?
Последнее, что вы хотите сделать, это создать файл robots.txt только для того, чтобы обнаружить, что он даже не работает. К счастью, есть способ проверить, работает ли вывод генератора Google robots.txt. На самом деле, у Google есть тестер именно для этой цели.
Является ли robots txt уязвимостью?
Вроде как может быть, да. Поскольку файл robots.txt доступен всем, его можно использовать для идентификации закрытых областей вашего сайта или контента с ограниченным доступом.
Иными словами, файл сам по себе не является уязвимостью, но он может указать злоумышленникам на уязвимые области вашего сайта.
10 Best Robots txt Generator Tools- PageTraffic
Когда дело доходит до вашего веб-сайта, важно сделать все возможное (цифровое). Это может означать скрытие некоторых страниц от робота Googlebot при сканировании вашего сайта. Файлы robots.txt, к счастью, позволяют вам это сделать. Мы рассмотрим актуальность файлов robots.txt и способы их создания с помощью бесплатных инструментов генератора txt для роботов в разделах ниже.
Что такое файл robots.txt и зачем он мне нужен?
Давайте поговорим о , что такое файл robots.txt и почему он необходим, прежде чем мы перейдем к невероятно полезным (и бесплатным!) инструментам генератора robots.txt, которые вы должны проверить.
На вашем веб-сайте могут быть страницы, которые вы не хотите или не должны сканировать роботом Googlebot. Файл robots. txt сообщает Google, какие страницы и файлы на вашем веб-сайте следует сканировать, а какие игнорировать. Считайте это практическим руководством для робота Googlebot, которое поможет вам сэкономить время.
Вот как это работает
Робот хочет просканировать URL-адрес веб-сайта, например http://www.coolwebsite.com/welcome.html. Сначала он сканирует http://www.coolwebsite.com/robots.txt и находит:
Раздел запрета информирует поисковых роботов о том, что некоторые веб-страницы или элементы веб-сайта не должны сканироваться.
Какое значение имеет файл Robots.txt?
Файл robots.txt полезен для различных целей SEO. Во-первых, это позволяет Google быстро и четко определить, какие страницы на вашем сайте более значимы, чем другие.
Файлы robots.txt можно использовать для предотвращения отображения некоторых элементов веб-сайта, таких как аудиофайлы, в результатах поиска. Обратите внимание, что, хотя файл robots. txt не следует использовать для сокрытия страниц от Google, его можно использовать для контроля трафика поисковых роботов.
В соответствии с рекомендациями Google по бюджету сканирования, вы не хотите, чтобы сканер Google перегружал ваш сервер или тратил деньги на сканирование неважных или похожих страниц на вашем сайте.
Что такое файл robots.txt и как его создать?
Для Google файлы robots.txt должны быть отформатированы определенным образом. На каждом веб-сайте разрешен один файл robots.txt. Первое, что нужно помнить, это то, что файл robots.txt вашего домена должен быть размещен в корневом каталоге.
Подробные инструкции по созданию файлов robots.txt вручную см. в Центре поиска Google. Мы составили список из 10 лучших инструментов для создания robots.txt, которые вы можете использовать бесплатно!
1. SEO Optimer
Приложение от Seo Optimer позволяет бесплатно создать файл robots. txt. Инструмент предлагает надежный интерфейс для бесплатного создания файла robots.txt. Вы можете выбрать период задержки сканирования и каким ботам разрешено или запрещено сканировать ваш сайт.
2. Ryte
Разрешить все, запретить все и настроить — это три варианта создания файла robots.txt в бесплатном генераторе Ryte. Вы можете выбрать, на каких ботов вы хотите повлиять, с помощью параметра настройки, содержащего пошаговые инструкции.
Ryte поможет вам провести SEO-аудит для выявления содержания вашего сайта, технических и структурных ошибок. Начните анализ одним щелчком мыши или запланируйте частые сканирования для автоматизации потоков данных. Вы можете настроить сканирование с более чем 15 конфигурациями или использовать надежный API для интеграции данных непосредственно в ваш обычный рабочий процесс. С помощью этого инструмента вы получите всю необходимую информацию для повышения UX вашего сайта.
Вы можете легко создавать интригующий контент с рекомендациями ключевых слов Ryte, которые помогут вашему веб-сайту отображаться в верхней части поисковой выдачи. Как только вы поймете рекомендации по ключевым словам, вы сможете изменить свой веб-контент с помощью структурированных данных и тегов schema.org. Вы можете экспортировать готовый текст в HTML, а затем скопировать и вставить в свою CMS.
3. Better Robots.txt (WordPress)
Плагин Better Robots.txt для WordPress улучшает SEO и скорость загрузки вашего сайта. Он может защитить ваши данные и контент от вредоносных ботов и доступен на семи языках. Плагин Better Robots.txt работает с плагином Yoast SEO и другими генераторами карт сайта. Плагин может определить, используете ли вы в настоящее время Yoast SEO или доступны ли какие-либо другие карты сайта на вашем веб-сайте. Чтобы добавить карту сайта, вам нужно всего лишь скопировать и вставить URL-адрес карты сайта. Затем Better Robots.txt добавит его в ваш файл Robots.txt.
Плагин Better Robots.txt поможет вам заблокировать вредоносных ботов, сканирующих ваши данные и влияющих на них. Плагин защищает ваш сайт WordPress от парсеров и пауков. Он также предоставляет обновления и время с более полным списком плохих ботов, заблокированных инструментом.
4. Virtual Robots.txt (WordPress)
Плагин WordPress Virtual Robots.txt — это простое и автоматизированное решение для создания и управления файлом robots.txt для вашего файла robots.txt. Вам нужно только загрузить и активировать плагин, прежде чем использовать его по максимуму.
Плагин Virtual Robots.txt по умолчанию предоставляет доступ к элементам WordPress, доступ к которым необходим хорошим загрузчикам, таким как Google. В то время как другие части WordPress остаются заблокированными. Когда плагин обнаруживает предыдущий XML-файл карты сайта, ссылка на него автоматически добавляется в файл robots.txt.
5. Small SEO Tools
Еще одним простым инструментом для создания файла robot. txt является бесплатный генератор Small SEO Tools. Он использует выпадающие меню для настроек каждого бота. Для каждого бота вы можете выбрать, разрешен он или нет.
6. Web Nots
Из-за своего минималистского внешнего вида инструмент генерации robots.txt Web Nots похож на генератор Small SEO Tools. Он также включает раскрывающиеся меню и раздел для ограниченных каталогов. Когда вы закончите, вы можете скачать файл robots.txt.
7. Отчеты поисковых систем
Генератор отчетов поисковых систем предоставляет части для карты вашего сайта и любых ограниченных каталогов. Это бесплатное приложение — прекрасный способ быстро создать файл robots.txt.
С помощью отчетов поисковых систем вы проверяете фрагмент контента, содержащий 2000 слов за раз. Вы можете вставить содержимое в поле и нажать кнопку отправки. Интеграция с Dropbox позволяет напрямую загружать контент с этой платформы.
Вы также можете загрузить файлы, хранящиеся в вашей системе, щелкнув опцию «Загрузить файл» в отчетах поисковой системы. Вы можете добавить URL-адрес в поле с онлайн-проверкой на плагиат, и программное обеспечение выполнит подробные операции.
8. Инструменты SEO
Бесплатный генератор robots.txt от SEO Tools — это простой и быстрый способ создать файл robots.txt для вашего веб-сайта. Если хотите, вы можете определить задержку сканирования и ввести карту сайта. Когда вы завершите выбор нужных параметров, нажмите «Создать и сохранить как Robots.txt».
9. SEO To Checker
Еще одним полезным инструментом для создания файла robots.txt является генератор SEO To Checker robot.txt. Вы можете настроить все параметры поисковых роботов и добавить свою карту сайта.
10. Консоль поиска Google Robots.txt Tester
Вы можете использовать тестер robots.txt консоли поиска Google после создания файла robots.txt. Чтобы определить, правильно ли составлен ваш URL-адрес, чтобы запретить роботу Googlebot доступ к определенным разделам, которые вы хотите скрыть, отправьте его в инструмент тестирования.
Подводим итоги!
Перечисленные выше инструменты упрощают и ускоряют создание файла robots.txt. С другой стороны, здоровый, хорошо работающий веб-сайт выходит за рамки файла robots.txt. Улучшение технического SEO имеет решающее значение для придания вашему веб-сайту необходимой видимости и успеха SEO, которого он заслуживает.
- Автор
- Последние сообщения
Навнит Каушал
Генеральный директор PageTraffic
Автор — предприниматель первого поколения. Он является основателем и генеральным директором наиболее отмеченного наградами индийского SEO-агентства PageTraffic. Он также работает советником и консультантом многих крупных компаний. Он помогает компаниям, заботящимся о ценности, наращивать посещаемость сайта, увеличивать базу пользователей, повышать продажи через Интернет и повышать удовлетворенность клиентов. С ним можно связаться @navneetkaushal в Твиттере
Последние сообщения Навнит Каушал (посмотреть все)
10 лучших бесплатных онлайн-сайтов-генераторов Robots.
txtВот список из лучших бесплатных онлайн-сайтов-генераторов Robots.txt . Поисковые системы используют веб-сканеры, также известные как поисковые роботы, для проверки содержимого веб-страниц. Если у вас есть веб-сайт, страницы веб-сайта сканируются поисковыми роботами. Файл Robots.txt помогает вам определить правила для веб-сканирования на вашем веб-сайте. Этот файл содержит директивы с разрешениями до разрешить/запретить поисковым роботам сканирование сайта. Вы можете установить разрешение по умолчанию для всех поисковых роботов и индивидуально разрешать/запрещать популярных поисковых роботов. Точно так же вы можете определить каталогов/страниц с ограниченным доступом , которые вы не хотите, чтобы роботы сканировали, как панель администратора. Кроме того, этот файл также может содержать время задержки сканирования и карту сайта в формате XML.
Файл Robots.txt помещается в корневой каталог веб-сайта. Поисковая система читает этот файл и продолжает или избегает сканирования веб-страниц, как описано в этом файле. Помимо сканирования, файл robots.txt также может помочь поисковой системе лучше индексировать веб-сайт. Сделать файл robots.txt довольно просто. Вот 10 веб-сайтов, на которых вы можете сделать это онлайн за пару минут.
Эти 10 веб-сайтов предлагают инструменты для создания файла robots.txt. Все эти инструменты охватывают популярные поисковые роботы. Вы можете установить разрешения на сканирование для этих роботов по отдельности. Затем вы можете установить разрешения по умолчанию для всех других сканирующих роботов, которые не охвачены. Некоторые из этих инструментов позволяют ограничить доступ к определенным каталогам для всех поисковых роботов. В то время как некоторые позволяют вам настроить, какие каталоги или страницы (URL-адреса) вы хотите запретить для какого поискового робота. Таким образом, вы можете изучить пост, чтобы подробно проверить эти инструменты. Я надеюсь, что это поможет вам найти инструмент для создания собственного файла robots. txt.
Мой любимый онлайн-генератор Robots.txt
SEOptimer.com — мой любимый генератор Robots.txt в этом списке. Этот инструмент содержит все параметры, необходимые для создания настраиваемого файла Robots.txt для ваших веб-сайтов. Он также включает в себя сканирование сделок и каталогов с ограниченным доступом. И, наконец, вы можете либо скопировать содержимое Robots.txt напрямую, либо экспортировать его, чтобы сохранить файл локально.
Вы можете ознакомиться с другими нашими списками лучших бесплатных онлайн-сайтов с инструментами для создания UUID, онлайн-сайтов с генераторами записей DMARC и онлайн-сайтов с генераторами записей DKIM.
SEOptimer.com
SEOptimer предлагает бесплатный генератор robots.txt . Этот инструмент охватывает 15 поисковых роботов, включая Google, Google Image, Google Mobile, MSN, Yahoo, Yahoo MM, Asks, GigaBlast, Nutch и другие. Вы можете начать с установки статуса по умолчанию для поисковых роботов. Таким образом, вам не нужно настраивать его индивидуально для каждого поискового робота. Кроме того, вы можете добавить несколько каталогов, сканирование которых вы хотите запретить. При этом вы можете создать файл Robots.txt. Этот инструмент имеет два варианта; Создать и Создать и загрузить . Опция Создать показывает содержимое файла на экране. Вы можете скопировать его в буфер обмена оттуда. Принимая во внимание, что опция Create & Download создает файл и загружает его на ваш компьютер.
Как сгенерировать Robots.txt онлайн на SEOptimer?
- Перейдите к бесплатному генератору Robots.txt , используя ссылку, указанную ниже.
- Установите Статус по умолчанию на Разрешено или Отказано .
- Выберите Crawl-Delay и добавьте URL-адрес карты сайта (если доступен).
- Затем установите статус поисковых роботов в соответствии с вашими потребностями.
- Определите ограниченные каталоги , которые вы освобождаете от сканирования.
- Затем используйте кнопку Создать/Загрузить для создания и сохранения файла Robots.txt.
Особенности:
- Этот инструмент охватывает 15 поисковых роботов, которым вы можете разрешить или запретить.
- Позволяет добавить несколько каталогов с ограниченным доступом.
- Параметры для копирования и загрузки сгенерированного файла Robots.txt.
Домашняя страница
En.ryte.com
En.ryte.com содержит бесплатный инструмент Robots.txt Generator . С помощью этого инструмента вы можете быстро создать файл Robots.txt для своего веб-сайта. Этот инструмент начинается с трех опций; Разрешить все, Запретить все или Настроить . первые два варианта просто генерируют файл Robots.txt, в котором все разрешено или запрещено соответственно. И с Настроить параметр , вы можете выбрать, каких поисковых роботов вы хотите разрешить/запретить на своем веб-сайте. Наряду с этим вы также получаете возможность добавить, какие URL-адреса вы хотите разрешить и запретить для сканирования. Таким образом, вы сможете быстро получить файл robots.txt для своего сайта.
Как сгенерировать Robots.txt онлайн на En.ryte.com?
- Перейдите по ссылке, указанной ниже, чтобы открыть этот генератор Robots.txt .
- Выберите вариант разрешения для создания файла. Перейти с Разрешить Все , Запретить все или Настроить .
(Для «Разрешить все» и «Запретить все» вы получите файл сразу, для «Настроить» следуйте инструкциям) - Установите статус поисковых роботов в соответствии с вашими требованиями.
- Введите корневой каталог веб-сайта вместе с разрешенным URL-адресом и запрещенным URL-адресом .
- Затем установите флажок и нажмите кнопку «Создать», чтобы загрузить файл Robots. txt.
Особенности:
- Этот инструмент охватывает 11 поисковых роботов, которых вы можете разрешить или запретить на своем веб-сайте.
- Позволяет определить разрешенный URL-адрес и запрещенный URL-адрес (каталоги с ограниченным доступом).
- Нет возможности добавить задержку сканирования.
- Параметры для копирования и загрузки сгенерированного файла Robots.txt.
Домашняя страница
DigitalScholar.in
DigitalScholar предлагает бесплатный онлайн-инструмент Robots.txt Generator . Этот инструмент также охватывает 15 популярных поисковых роботов. Вы можете выбрать статус для каждого поискового робота отдельно. Или вы можете установить статус по умолчанию, а затем изменить его только для определенных поисковых роботов в соответствии с вашими потребностями. Если вы хотите добавить задержку сканирования на свой веб-сайт, вы можете это сделать. Кроме того, вы можете указать папки, которые вы не хотите сканировать поисковыми роботами, и создать файл robots. txt. Этот инструмент показывает содержимое файла на экране с кнопкой копирования рядом с ним. Он также предлагает возможность экспортировать файл локально.
Как создать Robots.txt онлайн на DigitalScholar?
- Откройте этот генератор Robots.txt , используя ссылку, указанную ниже.
- Установите Статус по умолчанию на Разрешено или Запретить .
- Выберите Crawl-Delay и добавьте URL-адрес карты сайта .
- Затем установите статус поисковых роботов в соответствии с вашими потребностями.
- Добавьте Disallow Folders , которые вы исключили из сканирования.
- Затем нажмите кнопку Создать , чтобы получить файл Robots.txt.
Особенности:
- Этот инструмент охватывает 15 поисковых роботов, которых вы можете разрешить или запретить.
- Позволяет добавить несколько папок для удаления из сканирования.
- Параметры для копирования и экспорта сгенерированного файла Robots.txt.
Домашняя страница
DupliChecker.com
DupliChecker — еще один бесплатный веб-сайт, на котором можно создать файл Robots.txt. Он начинается с запроса разрешения по умолчанию для всех поисковых роботов. Вы можете установить это разрешение в соответствии с вашими потребностями. Наряду с этим вы получаете возможность настроить задержку сканирования и добавить карту сайта. После этих основных требований он позволяет добавлять директивы. Эта функция позволяет выдавать разрешение индивидуально для поискового робота. Он охватывает 25 поисковых роботов. Вы можете выбрать робота, определить разрешения и соответственно добавить каталог. Таким образом, вы можете легко создать файл Robots.txt на этом веб-сайте.
Как сгенерировать Robots.txt онлайн на DupliChecker?
- Используйте приведенную ниже ссылку, чтобы получить доступ к этому инструменту в вашем браузере.
- Установите статус по умолчанию для всех поисковых роботов и при необходимости выберите задержку сканирования.
- Затем с помощью опции «Добавить директиву» задайте разрешение и выберите поискового робота из списка.
- При желании добавьте каталог с ограниченным доступом.
- Аналогичным образом выполните 2 шага выше, чтобы добавить дополнительные настраиваемые разрешения.
- В конце нажмите Создайте кнопку Robots.txt , чтобы получить файл.
Особенности:
- Этот инструмент охватывает 25 поисковых роботов, которых вы можете разрешить или запретить на своем веб-сайте.
- Возможность добавления директив с разрешением и каталогом.
- Параметры для копирования и загрузки сгенерированного файла Robots.txt.
Домашняя страница
IPLocation.io
IPLocation — еще один бесплатный веб-сайт, на котором можно создать файл Robots.txt. Он имеет простой инструмент, в котором вы можете добавить свои настройки и создать файл. Вы можете установить статус по умолчанию для поисковых роботов и пометить тех, которым вы не хотите сканировать ваш сайт. Вы также можете добавить задержку сканирования, если хотите, и определить каталоги, которые вы хотите ограничить для сканирования. При этом вы можете создать файл Robots.txt. Вы можете либо скопировать содержимое файла напрямую, либо экспортировать его, чтобы сохранить файл локально.
Как сгенерировать Robots.txt онлайн на IPLocation?
- Перейдите по приведенной ниже ссылке на этот инструмент Robots.txt Generator на IPLocation .
- Установите Статус по умолчанию на Разрешено или Отказано .
- Выберите Crawl-Delay и добавьте URL-адрес карты сайта.
- Затем установите статус поисковых роботов в соответствии с вашими потребностями.
- Определите ограниченные каталоги , которые вы освобождаете от сканирования.
- Затем нажмите кнопку СОЗДАТЬ СЕЙЧАС , чтобы получить файл Robots. txt.
Особенности:
- Этот инструмент охватывает 15 поисковых роботов, которым вы можете разрешить или запретить.
- Позволяет добавить доступ для обхода и несколько каталогов с ограниченным доступом.
- Параметры для копирования и экспорта сгенерированного файла Robots.txt.
Домашняя страница
InternetMarketingNinjas.com
InternetMarketingNinjas предлагает бесплатный генератор Robots.txt. Этот инструмент позволяет создать файл robots.txt для вашего веб-сайта. Если у вас уже есть файл robots.txt, вы можете загрузить этот файл и внести в него изменения. Процесс прост. В нем перечислены более 20 поисковых роботов. Вы можете выбрать робота и установить разрешение вместе с каталогом. Таким образом, вы можете добавить желаемых robots в свой файл. И если вы хотите удалить робота, который присутствует в файле, вы также можете сделать это, используя опцию «Удалить Dievtive». Точно так же вы можете создать или обновить файл robots. txt.
Как сгенерировать Robots.txt онлайн на InternetMarketingNinjas?
- Перейдите по ссылке, приведенной ниже, чтобы получить доступ к этому инструменту в вашем браузере.
- Загрузите или получите файл robots.txt, если хотите его обновить.
- Установите разрешение и выберите поискового робота из списка. Добавьте каталог, если необходимо.
- Затем нажмите кнопку Добавить директиву и выполните те же действия, чтобы добавить больше роботов.
- В конце нажмите Create Robots.txt , чтобы получить файл.
Особенности:
- Этот инструмент может обновить существующий файл Robots.txt или создать новый файл.
- Он охватывает более 20 поисковых роботов, которых вы можете разрешить или запретить.
- Возможность добавления директив с разрешением и каталогом.
- Нет возможности настроить задержку сканирования.
- Параметры для копирования и сохранения сгенерированного файла Robots. txt.
Домашняя страница
SEOImage.com
SEOImage предлагает бесплатный инструмент для создания файла Robotos.txt онлайн. Этот инструмент довольно прост и охватывает 15 популярных поисковых роботов. Вы можете установить, какие поисковые роботы вы хотите разрешить и запретить на своем сайте. Вы также можете установить разрешение по умолчанию для поисковых роботов. Если вы не хотите, чтобы поисковый робот сканировал определенные файлы вашего сайта, вы можете добавить этот каталог в каталоги с ограниченным доступом. При этом вы можете создать файл Robots.txt для своего веб-сайта.
Как сгенерировать Robots.txt онлайн на SEOImage?
- Перейдите по приведенной ниже ссылке на этот инструмент Free Robots.txt Generator .
- Установите Статус по умолчанию на Разрешено или Запретить .
- Выберите Crawl-Delay и добавьте URL-адрес карты сайта (если доступен).
- Затем установите статус поисковых роботов в соответствии с вашими потребностями.
- Определите ограниченные каталоги , которые вы освобождаете от сканирования.
- Затем с помощью кнопки Создать/Сохранить создайте и сохраните файл Robots.txt.
Особенности:
- Этот инструмент охватывает 15 поисковых роботов, которым вы можете разрешить или запретить.
- Позволяет добавить несколько каталогов с ограниченным доступом.
- Параметры для копирования и загрузки сгенерированного файла Robots.txt.
Домашняя страница
SearchEngineReports.net
SearchEngineReports предлагает бесплатный онлайн-генератор Robots.txt . Вы можете использовать этот инструмент для создания файла Robots.txt для своего веб-сайта. Он позволяет выбрать разрешение по умолчанию для поисковых роботов, сканирующих ваш сайт. Затем вы можете разрешить или запретить использование популярных поисковых роботов в соответствии с вашими потребностями. Кроме того, вы можете добавить обход и отметить каталоги веб-сайта, которые вы не хотите сканировать ни одному поисковому роботу. Этот инструмент генерирует данные Robots.txt и показывает их на экране. Оттуда вы можете скопировать данные в буфер обмена или экспортировать их в файл TXT.
Как сгенерировать Robots.txt онлайн на SearchEngineReports?
- Перейдите к этому генератору Robots.txt , используя ссылку, указанную ниже.
- Установите Статус по умолчанию на Разрешено или Отказано .
- Выберите Crawl-Delay и добавьте URL-адрес карты сайта (необязательно).
- Затем установите статус поисковых роботов в соответствии с вашими требованиями.
- Добавьте ограниченных каталогов , которые вы освобождаете от сканирования.
- Затем используйте кнопку Create Robots.txt для создания и сохранения файла Robots.txt.
Особенности:
- Этот инструмент охватывает 15 поисковых роботов, которым вы можете разрешить или запретить.
- Позволяет добавить задержку сканирования и несколько каталогов с ограниченным доступом.
- Параметры для копирования и загрузки сгенерированного файла Robots.txt.
Домашняя страница
SmallSEOTools.com
SmallSEOTools — еще один бесплатный веб-сайт для создания файла Robots.txt в режиме онлайн. Процесс генерации довольно прост и похож на другие подобные инструменты. Вы можете указать, хотите ли вы, чтобы поисковые роботы сканировали ваши сайты или нет. Вы можете установить разрешения по умолчанию или выбрать разные разрешения для разных поисковых роботов. Если вы хотите исключить что-либо из сканирования, вы можете добавить это в каталог с ограниченным доступом. Этот простой инструмент создает файл Robots.txt с разрешениями. Вы можете скопировать его в буфер обмена или экспортировать в файл TXT и сохранить на своем компьютере.
Как сгенерировать Robots.txt онлайн в SmallSEOTools?
- Используйте приведенную ниже ссылку, чтобы открыть этот генератор Robots. txt .
- Начните с установки Статус по умолчанию на Разрешено или Отказано .
- Затем выберите Crawl-Delay и добавьте URL-адрес карты сайта (необязательно).
- После этого установите статус поисковых роботов в соответствии с вашими требованиями.
- Добавить каталоги с ограниченным доступом , который вы освобождаете от сканирования.
- Затем используйте кнопку Create Robots.txt для создания и сохранения файла Robots.txt.
Особенности:
- Этот инструмент охватывает 15 поисковых роботов, которым вы можете разрешить или запретить.
- Позволяет добавить задержку сканирования и несколько каталогов с ограниченным доступом.
- Параметры для копирования и экспорта сгенерированного файла Robots.txt.
Домашняя страница
KeySearch.co
KeySearch — еще один веб-сайт с онлайн-генератором Robots. txt. Этот инструмент позволяет создать файл Robots.txt, чтобы разрешить/запретить поисковым роботам на вашем веб-сайте сканирование веб-страниц. Это позволяет вам установить разрешение по умолчанию для всех роботов. Кроме того, вы можете индивидуально установить разрешения для 15 популярных поисковых роботов. Если вы хотите, чтобы какая-либо страница вашего веб-сайта не сканировалась, вы можете добавить каталог этой страницы в каталоги с ограниченным доступом. Таким образом, вы можете создать файл robots.txt с нужными конфигурациями.
Как сгенерировать Robots.txt онлайн на KeySearch?
- Откройте этот генератор Robots.txt , используя ссылку, указанную ниже.
- Установите Статус по умолчанию для всех роботов.
- Настройте Crawl-Delay и добавьте URL-адрес карты сайта (если доступно).
- Затем установите статус поисковых роботов в соответствии с вашими потребностями.
- Определите ограниченные каталоги , которые вы освобождаете от сканирования.
- Тогда используйте Кнопка Create/Download для создания и сохранения файла Robots.txt.
Особенности:
- Этот инструмент охватывает 15 поисковых роботов, которым вы можете разрешить или запретить.
- Позволяет добавить несколько каталогов с ограниченным доступом.
- Параметры для копирования и сохранения сгенерированного файла Robots.txt.
Домашняя страница
Похожие сообщения
Написать комментарий
Роботы txt File Checker | PageDart
Воспользуйтесь нашей программой проверки файла robots.txt ниже, чтобы проверить, работает ли ваш файл robots.txt.
Скопируйте и вставьте файл robots.txt в текстовое поле ниже. Вы можете найти файл robots, добавив /robots.txt на свой веб-сайт. Например, https://example.com/robots.txt .
Строка: ${error.index}
`; список результатов.innerHTML += ли; } если (ошибки.длина > 0) { resultsTitle. innerHTML = errors.length + «Ошибки»
результаты.скрытый = ложь;
} еще {
resultsTitle.innerHTML = «Нет ошибок»
результаты.скрытый = ложь;
}
вернуть ложь;
}
window.onload = функция () {
document.getElementById(«отправить»).onclick = проверить;
}Для создания этого инструмента мы проанализировали более 5000 файлов robots. В ходе нашего исследования мы обнаружили 7 распространенных ошибок.
Как только мы обнаружили эти ошибки, мы научились их исправлять. Ниже вы найдете подробные инструкции о том, как исправить все ошибки.
Продолжайте читать, чтобы узнать, почему мы создали этот инструмент и как мы завершили исследование.
Почему мы создали инструмент
Когда поисковый робот посещает ваш сайт, например Googlebot, он читает файл robots.txt, прежде чем просматривать любую другую страницу.
Он будет использовать файл robots.txt, чтобы проверить, куда он может пойти, а куда нет.
Он также будет искать вашу карту сайта, в которой будут перечислены все страницы вашего сайта.
Каждая строка в файле robots.txt — это правило, которому должен следовать сканер.
Если в правиле есть ошибка, сканер проигнорирует это правило.
Этот инструмент предоставляет простой способ быстро проверить наличие ошибок в файле robots.txt.
Мы также даем вам список того, как это исправить.
Более подробно о том, насколько важен файл robots.txt, можно прочитать в публикации Robots txt для SEO.
Как мы проанализировали более 5000 файлов robots.txt
Мы получили список из 1 миллиона лучших веб-сайтов по версии Alexa.
У них есть CSV-файл со списком всех URL-адресов, который вы можете скачать.
Мы обнаружили, что не на каждом сайте есть или нужен файл robots.txt.
Чтобы получить более 5000 файлов robots.txt, нам пришлось просмотреть более 7500 веб-сайтов.
Это означает, что из 7541 самых популярных веб-сайтов в Интернете 24% сайтов не имеют файла robots.txt.
Из 5000+ файлов robots. txt, которые мы проанализировали, мы обнаружили 7 распространенных ошибок:
- Шаблон должен быть пустым, начинаться с «/» или «*»’
- «$» следует использовать только в конце шаблона
- Пользовательский агент не указан
- Неверный протокол URL карты сайта
- Неверный URL-адрес карты сайта
- Неизвестная директива
- Синтаксис не понят
Мы рассмотрим каждую из этих ошибок и способы их исправления ниже.
Но вот что мы обнаружили в результате нашего анализа.
Из 5732 проанализированных нами файлов robots.txt только 188 содержали ошибки.
Мы также обнаружили, что в 51 % случаев было более одной ошибки. Часто повторялась одна и та же ошибка.
Давайте посмотрим, сколько раз возникала каждая ошибка:
| Ошибка | Граф |
|---|---|
| Шаблон должен быть пустым, начинаться с «/» или «*»‘ | 11660 |
| «$» следует использовать только в конце шаблона | 15 |
| Пользовательский агент не указан | 461 |
| Неверный протокол URL карты сайта | 0 |
| Неверный URL-адрес карты сайта | 29 |
| Неизвестная директива | 144 |
| Синтаксис не понят | 146 |
Как видите, шаблон должен быть пустым, начинаться с «/» или «*». — самая распространенная ошибка.
Получив данные, мы смогли понять и исправить ошибки.
Шаблон должен быть пустым, начинаться с «/» или «*»
Это была самая распространенная ошибка, которую мы обнаружили при анализе, и в этом нет ничего удивительного.
Эта ошибка относится к правилам Разрешить и Запретить . Эти правила чаще всего встречаются в файле robots.txt.
Если вы получаете эту ошибку, это означает, что первый символ после двоеточия не является «/» или «*».
Например, Разрешить: администратор вызовет эту ошибку.
Правильный способ форматирования: Разрешить: /admin .
Подстановочный знак (*) используется, чтобы разрешить все или запретить все. Например, часто можно увидеть это, когда вы хотите остановить сканирование сайта:
Запретить: *
Чтобы исправить эту ошибку, убедитесь, что после двоеточия стоит символ «/» или «*».
«$» следует использовать только в конце шаблона
В файле robots.txt может быть знак доллара.
Вы можете использовать это, чтобы заблокировать определенный тип файла.
Например, если мы хотим заблокировать сканирование всех файлов .xls , вы можете использовать:
Агент пользователя: * Запретить: /*.xls$
Знак $ сообщает сканеру, что это конец URL-адреса. Таким образом, это правило запрещает:
https://example.com/pink.xls
Но разрешить:
https://example.com/pink.xlsocks
Если у вас нет знака доллара в конце строки, например:
Агент пользователя: * Запретить: /*$.xls
Это вызовет это сообщение об ошибке. Для исправления переместите в конец:
Агент пользователя: * Запретить: /*.xls$
Так что используйте только знак $ в конце URL для соответствия типам файлов.
Пользовательский агент не указан
В файле robots.txt необходимо указать хотя бы один User-agent . Вы используете User-agent для идентификации и нацеливания на определенные поисковые роботы.
Если бы мы хотели настроить таргетинг только на поисковый робот Googlebot, вы бы использовали:
Агент пользователя: Googlebot Запретить: /
Используется довольно много сканеров:
- Гуглбот
- Бингбот
- Хлеб
- УткаУткаБот
- Байдуспайдер
- ЯндексБот
- фейсбот
- ia_archiver
Если вы хотите иметь разные правила для каждого, вы можете перечислить их следующим образом:
Агент пользователя: Googlebot Запретить: / Агент пользователя: Bingbot Разрешить: /
Вы также можете использовать «*», это подстановочный знак, означающий, что он будет соответствовать всем поисковым роботам.
Агент пользователя: * Разрешить: /
Убедитесь, что у вас установлен хотя бы один User-agent .
Неверный протокол URL-адреса карты сайта
При ссылке на карту сайта из файла robot.txt необходимо указать полный URL-адрес.
Этот URL-адрес должен быть абсолютным URL-адресом, например https://www.example.com/sitemap.xml .
Протокол — это https часть URL-адреса. В качестве URL-адреса карты сайта вы можете использовать HTTPS , HTTP или FTP . Если у вас есть что-то еще, вы увидите эту ошибку.
Неверный URL-адрес карты сайта
Вы можете сделать ссылку на карту сайта из файла robots.txt. Это должен быть полный (абсолютный) URL. Например, https://www.example.com/sitemap.xml будет абсолютным URL.
Если у вас нет абсолютного URL-адреса, например:
Агент пользователя: * Разрешать: / Карта сайта: /sitemap.
Это вызовет эту ошибку. Чтобы исправить это, измените абсолютный URL-адрес:
.Агент пользователя: * Разрешать: / Карта сайта: https://www.example.com/sitemap.xml
Неизвестная директива
При написании правила вы можете использовать только фиксированное количество «директив». Это команды, которые вы вводите перед двоеточием «:». Разрешить и Запретить — обе директивы.
Вот список всех допустимых директив:
- Карта сайта
- Агент пользователя
- Разрешить
- Запретить
- Задержка сканирования
- Чистый параметр
- Хост
- Скорость запросов
- Время посещения
- Без индекса
Если у вас есть что-то еще за пределами списка выше, вы увидите эту ошибку.
Согласно нашему исследованию, наиболее распространенной причиной этой проблемы является опечатка в написании директивы.
Исправьте опечатку и повторите проверку.
Синтаксис не понят
Вы увидите эту ошибку, если в строке нет двоеточия.
В каждой строке должно стоять двоеточие, отделяющее директиву от значения.
Это вызовет ошибку:
Агент пользователя: * Разрешить /
Чтобы исправить, добавьте двоеточие (найдите разницу):
Агент пользователя: * Разрешить: /
Поместите двоеточие после директивы, чтобы устранить проблему.
Подведение итогов, проверка файлов txt для роботов
Этот инструмент может помочь вам проверить наличие наиболее распространенных ошибок в файлах robots.txt.
Скопировав и вставив файл robots.txt в указанный выше инструмент, вы можете проверить, не содержит ли он ошибок.
Проверяем на 7 ошибок в том числе:
- Шаблон должен быть пустым, начинаться с «/» или «*»’
- «$» следует использовать только в конце шаблона
- Пользовательский агент не указан
- Неверный протокол URL карты сайта
- Неверный URL-адрес карты сайта
- Неизвестная директива
- Синтаксис не понят
Как только вы узнаете, в какой строке ошибка, вы можете исправить ее, используя предоставленные советы.