Sprinthost — robots.txt
robots.txt — текстовый файл, в котором указаны правила индексации сайта. С его помощью можно регулировать частоту обращений поисковых роботов, запретить индексирование отдельных страниц или всего сайта.
Разместите файл c именем robots.txt в корневой директории вашего сайта и наполните его правилами. Рассмотрим основные.
User-agent
В первой строке укажите директиву User-agent. Она определяет имена роботов, для которых составлены правила. Например: User-agent: Yandex только для ботов Яндекса; User-agent: * для всех существующих ботов.
Список имен поисковых роботов есть в документации Яндекса и Google.
Disallow, Allow
Директивы Disallow и Allow ограничивают доступ роботов к определенным страницам. С их помощью вы можете закрыть от индексирования административную часть и другие разделы сайта.
Disallow запрещает индексацию, Allow разрешает индексировать отдельные ссылки внутри запрещенных. Например:
Например: Allow: /public Правило запрещает индексировать все, кроме страниц вида domain.ru/public
Disallow: /
Директивы работают со специальными символами «*» и «$». Символ «*» задает последовательность из неограниченного количества символов (0 и более): Disallow: /catalog/*.html Правило запрещает доступ роботам ко всем страницам из раздела catalog с расширением .html.
При этом идентичными будут правила: Disallow: /catalog/*Disallow: /catalog/
Символ «$» жестко указывает на конец правила: Disallow: /catalog/boxs$ Такое правило запрещает индексирование страницы domain.ru/catalog/boxs , в то же время доступ к domain.ru/catalog/boxs.html роботы получить смогут.
Crawl-delay
Директива Crawl-delay определяет максимальное число запросов к сайту от робота. Она помогает избежать повышенного потребления ресурсов из-за активности поисковых ботов.
Достаточно направлять один запрос в 7 секунд: Crawl-delay: 7
Не все роботы следуют этому правилу. Для Яндекса и Google скорость обхода указывается в кабинете вебмастера.
Для Яндекса и Google скорость обхода указывается в кабинете вебмастера.
Clean-param
Порой в ссылках содержатся параметры (идентификаторы сессий, пользователей), которые не влияют на содержимое страницы.
Например, на странице domain.ru/catalog есть каталог товаров, которые можно отфильтровать. После применения фильтра получится следующий набор ссылок: domain.ru/catalog
domain.ru/catalog? =1domain.ru/catalog?product=2
Первый URL включает в себя весь каталог продуктов, индексация этой же страницы с параметрами не нужна. Используйте Clean-param, чтобы убрать лишние ссылки из поисковой выдачи: Clean-param: product /catalog
Указать несколько параметров можно через символ «&»: Clean-param: product&price /catalog
Clean-param ускоряет обход сайта поисковыми роботами и снижает нагрузку на сервер.
Host
Если ваш сайт имеет несколько доменов (алиасов), укажите основное имя с помощью директивы Host: Host: domain.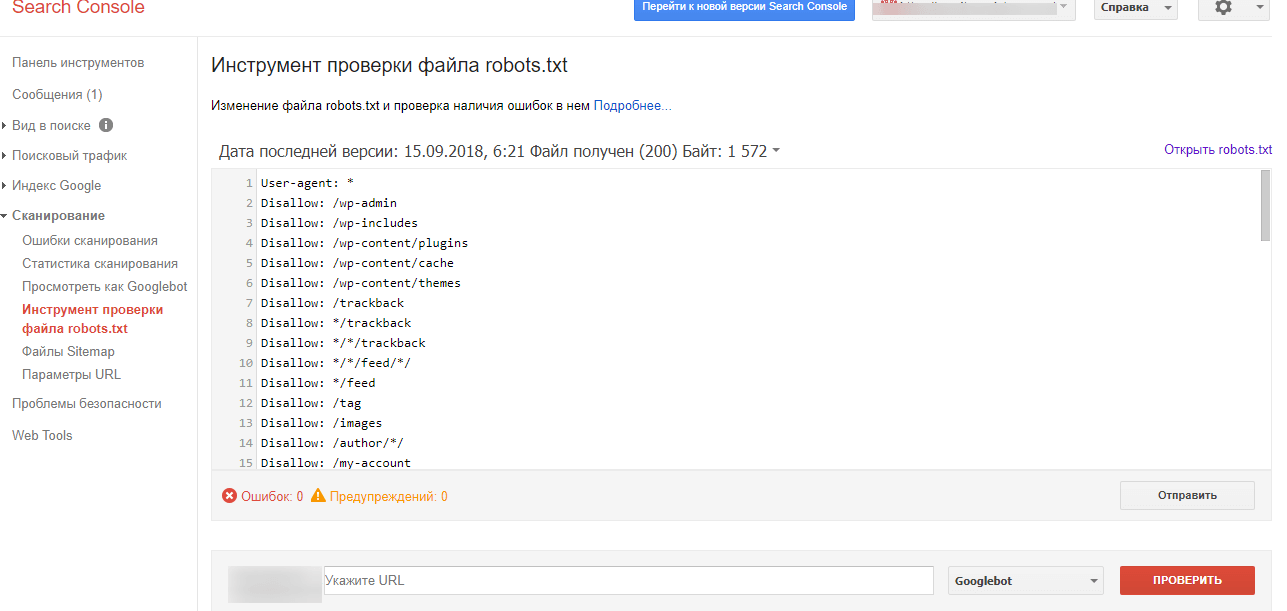 ru
ru
Sitemap
Sitemap указывает роботу расположение карты сайта: Sitemap: http://domain.ru/sitemap.xml
Как отключить индексацию
Если вы не хотите, чтобы сайт индексировался, укажите правило: User-agent: *
Disallow: /
При составлении файла robots.txt рекомендуем ознакомиться со справочной информацией поисковиков: некоторые правила могут не поддерживаться или игнорироваться роботами.
Была ли эта инструкция полезной?
что это, и как с помощью него управлять индексацией сайта
Каким бы древним ни было SEO, но такой инструмент как robots.txt всё ещё актуален, и останется таким ещё очень долго. Разберёмся, что это за инструмент и как им пользоваться правильно.
Robots.txt — это файл в корне продвигаемого сайта, в котором указываются правила для поисковых роботов по сканированию тех или иных разделов сайта.
Зачем нужен robots.
 txt?
txt?👉 Разрешать или запрещать поисковым роботам сканировать конкретные папки, разделы сайта, и соответственно размещать их в индекс поисковой системы.
Основные команды в robots.txt
- User-agent: — указывает для какого робота предназначены правила сканирования ниже. Если указывается конкретное название, то правила будут работать только для указываемого робота, если указано “*” — то для всех поисковых роботов.
- Disallow: — запрет для индексации указанного раздела или папки сайта.
- Allow: — разрешение для индексации указанного раздела сайта.
- Sitemap: — указание пути к карте сайта.
- Host: — главный домен сайта.
- Crawl-delay: — команда, которая указывает на тайм-ауты загрузки страниц роботом, и как правило, задаётся для больших сайтов. По информации многих источников, эта команда сейчас не актуальна, но по старинке прописываем.
Как закрыть сайт для индексации через robots.
 txt?
txt?User-agent: * Disallow: /
Этот “/” указывает, что всё начиная от корневой папки, закрыто для индексации.
Если Вам необходимо закрыть к индексации только конкретную папку, то указываете ее через “/”. В данном случае будет индексироваться весь сайт, кроме указанной папки.
User-agent: * Disallow: /admin
Если необходимо закрыть часть из структуры сайта, имеющую определенную закономерность в URL, то можно после «/» добавить конструкцию типа *parts_of_url*.
Это будет означать для робота, что URL сайта, которые содержат данный кусок индексироваться не будут.
Как открыть сайт для индексации через robots.txt?
User-agent: * Disallow:
Отсутствие “/”, разрешает роботу сканировать всё в границах данного домена.
Как открыть только отдельные папки для индексации через robots.txt?
User-agent: * Disallow: / Allow: /admin
В данном случае весь сайт, за исключением папки “admin”, закрыт к индексации.![]()
Обычно, “allow” используют при сложной структуре сайта, когда внутри закрытых папок необходимо что-то открыть для робота.
Как составить robots.txt?
Robots.txt, как правило создаётся вручную, исходя из следующих составляющих:
👉 анализ корня сайта;
👉 анализ URL-структуры сайта.
Обычно это делают SEO-специалисты, при запуске сайта. Если robots.txt не создать, то сайт в любом случае будет проиндексирован.
Как протестировать robots.txt?
Тест файла robots.txt осуществляется через специальный инструмент в Google Search Console, с возможностью проверки работоспособности директив:
Стоит отметить, что директивы robots.txt на запрет индексации не всегда на 100% выполняются. Поэтому, если хотите себя подстраховать, рекомендуем воспользоваться дополнительными инъекциями в html код, типа:
<meta name="robots" content="noindex, nofollow">
Данная команда сразу принимается роботом во внимание, при загрузке html кода страницы и сканировании, даже если робот не обратится к файлу robots.
Собственно, это основные важные моменты по работе с robots.txt. Это важный этап при запуске проекта и техническом SEO-аудите сайта, о котором не стоит забывать. Надеемся, этот материал был для Вас полезным. До новых встреч.
Robots.txt Обновление Noindex: все, что нужно знать SEO-специалистам
Рут Эверетт
Техническое SEO
Давайте делиться
| 4 минуты чтения Обновление
. С 1 сентября 2019 г. Google прекращает поддержку всего кода, который обрабатывает неподдерживаемые и неопубликованные правила в файле robots.txt, включая использование директивы noindex.
Как раньше работал Noindex в Robots.txt
Несмотря на то, что Google официально не документировал это, добавление директив noindex в файл robots. txt поддерживалось более десяти лет, а Мэтт Каттс впервые упомянул об этом еще в 2008 году. , Lumar (ранее Deepcrawl) также поддерживает его с 2011 года. Сочетание noindex и disallow в файле robots.txt помогло оптимизировать эффективность сканирования: директива noindex запрещает показ страницы в результатах поиска, а директива disallow предотвращает ее сканирование:
txt поддерживалось более десяти лет, а Мэтт Каттс впервые упомянул об этом еще в 2008 году. , Lumar (ранее Deepcrawl) также поддерживает его с 2011 года. Сочетание noindex и disallow в файле robots.txt помогло оптимизировать эффективность сканирования: директива noindex запрещает показ страницы в результатах поиска, а директива disallow предотвращает ее сканирование:
Disallow: /example-page-1/
Disallow: /example-page-2/
Noindex: /example-page-1/
Noindex: /example-page-2/
Обновление неподдерживаемых правил
1 июля 2019 года Google объявил, что протокол исключения роботов (REP) через 25 лет становится интернет-стандартом, а также теперь является открытым исходным кодом. После этого 2 июля они опубликовали официальную заметку о неподдерживаемых правилах в файлах robots.
В этом объявлении мы уведомлены о том, что с 1 сентября 2019 г., Google больше не будет поддерживать использование noindex в файле robots. txt.
txt.
Гэри Иллиес объяснил, что после анализа использования noindex в файлах robots.txt Google обнаружил, что «число сайтов, которые причиняют себе вред, очень велико». Он также подчеркнул, что обновление «предназначено для улучшения экосистемы, и те, кто правильно его использовал, найдут лучшие способы добиться того же».
Как и обещал несколько недель назад, я провел анализ noindex в robotstxt. Количество сайтов, которые наносили себе вред, очень велико. Я искренне верю, что это к лучшему для экосистемы, и те, кто использовал ее правильно, найдут лучшие способы добиться того же.
https://t.co/LvdhsN2pIE
— Гэри «鯨理» Иллиес (@methode) 2 июля 2019 г.
Альтернативные варианты директивы noindex в вашем файле robots.txt есть несколько альтернативных вариантов, перечисленных в официальном блоге Google;
- Метатеги роботов Noindex: Это наиболее эффективный способ удалить URL-адреса из индекса, но при этом разрешить сканирование.
 Эти теги поддерживаются как в заголовках ответов HTTP, так и в HTML и достигаются путем добавления директивы noindex для мета-роботов на самой веб-странице.
Эти теги поддерживаются как в заголовках ответов HTTP, так и в HTML и достигаются путем добавления директивы noindex для мета-роботов на самой веб-странице. - 404 и 410 Коды состояния HTTP: Эти коды состояния используются для информирования поисковых систем о том, что страница больше не существует, что приведет к удалению их из индекса после сканирования.
- Защита паролем: Предотвращение доступа Google к странице путем сокрытия ее за логином обычно приводит к ее удалению из индекса.
- Запретить в robots.txt: Блокировка сканирования страницы обычно предотвращает индексацию страниц, поскольку поисковые системы могут индексировать только те страницы, о которых они знают. Хотя страница может быть проиндексирована из-за ссылок, указывающих на нее с других страниц, Google будет стремиться сделать страницу менее заметной в результатах поиска.
- Search Console Инструмент удаления URL: Инструмент удаления URL в Google Search Console — это быстрый и простой способ временно удалить URL-адрес из результатов поиска Google.
 Эти теги поддерживаются как в заголовках ответов HTTP, так и в HTML и достигаются путем добавления директивы noindex для мета-роботов на самой веб-странице.
Эти теги поддерживаются как в заголовках ответов HTTP, так и в HTML и достигаются путем добавления директивы noindex для мета-роботов на самой веб-странице.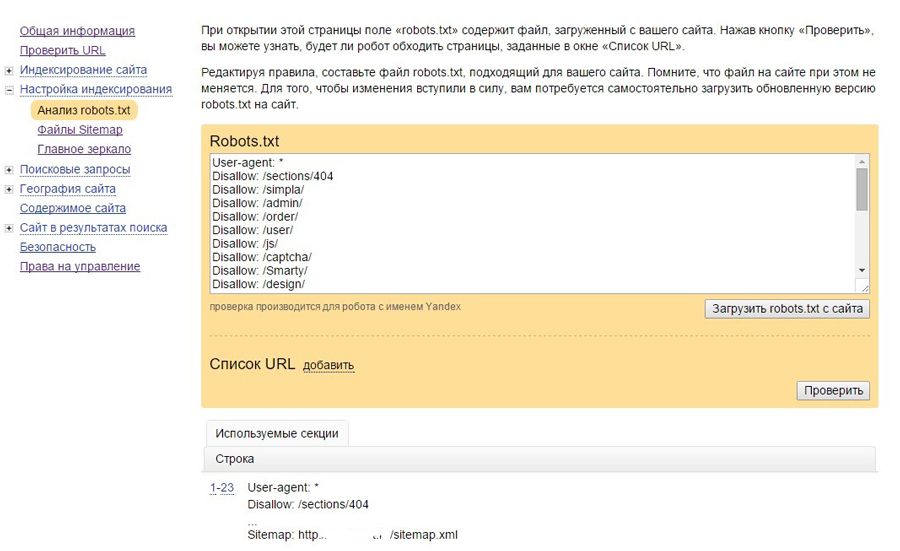
Идентификация и мониторинг безиндексных страниц robots.txt
В преддверии поддержки директив noindex robots.txt, заканчивающейся 1 сентября 2019 г., отчет о неиндексируемых страницах в Lumar (через Индексация > Неиндексируемые страницы > Неиндексируемые страницы) позволит вам проверить, какие из ваших страниц в настоящее время не индексируются и каким образом. В списке непроиндексированных страниц вы сможете увидеть, где они были не проиндексированы: через заголовок, метатег или robots.txt.
Откройте для себя этот и более 200 других отчетов, зарегистрировавшись в учетной записи Lumar.
Вы также можете проверить, как работает ваша директива noindex, в инструменте тестирования Search Console, как и в случае с любой другой директивой Robots.txt (в Сканировании > Тестировщик robots.txt).
Другие изменения в файле robots.txt
Это обновление — лишь одно из ряда изменений, внесенных в протокол robots. txt, поскольку он стремится стать интернет-стандартом. Google объяснил это подробнее в своем обновленном документе спецификаций robots.txt в блоге Google Developers.
txt, поскольку он стремится стать интернет-стандартом. Google объяснил это подробнее в своем обновленном документе спецификаций robots.txt в блоге Google Developers.
Хотите еще что-нибудь подобное?
Мы надеемся, что вы нашли этот пост полезным для получения дополнительной информации об обновлении протокола noindex robots.txt для контроля сканирования вашего сайта.
Подробнее об этой теме можно прочитать в руководствах нашей технической библиотеки SEO о директивах роботов на уровне URL и файле robots.txt.
Кроме того, если вы хотите быть в курсе последних обновлений и рекомендаций Google, почему бы не подписаться на нашу электронную почту?
Новостная рассылка
Получайте лучшие аналитические данные о цифровом маркетинге и SEO прямо в свой почтовый ящик
Дополнительные ресурсы:
Полное руководство по здоровью веб-сайтов
Вот как добиться успеха в поиске в будущем, включив здоровье веб-сайтов и SEO в свои более широкие маркетинговые стратегии.
Как сделать свой сайт мультипликатором производительности для формирования спроса
Узнайте, как использовать состояние веб-сайта и поисковую оптимизацию в качестве мультипликаторов эффективности для усилий маркетинговых групп по формированию спроса.
Рут Эверетт
Техническое SEO
Рут Эверетт — менеджер данных и аналитики в Code First Girls, а также бывший технический SEO-аналитик в Lumar. Чаще всего вы обнаружите, что она помогает клиентам улучшить их техническое SEO, пишет обо всем, что связано с SEO, и смотрит видео с собаками.
Руководство по Robots.txt — все, что нужно знать специалистам по поисковой оптимизации
Рэйчел Костелло
SEO и Content Manager
Давайте поделимся
В этом разделе нашего руководства по директивам robots. txt мы более подробно расскажем о текстовом файле robots.txt и о том, как его можно использовать для управления поиском. поисковые роботы двигателя. Этот файл особенно полезен для управлять бюджетом сканирования и следить за тем, чтобы поисковые системы эффективно проводили время на вашем сайте и сканировали только важные страницы.
txt мы более подробно расскажем о текстовом файле robots.txt и о том, как его можно использовать для управления поиском. поисковые роботы двигателя. Этот файл особенно полезен для управлять бюджетом сканирования и следить за тем, чтобы поисковые системы эффективно проводили время на вашем сайте и сканировали только важные страницы.
Для чего используется текстовый файл robots?
Файл robots.txt предназначен для того, чтобы сообщать поисковым роботам и роботам, какие URL-адреса на вашем веб-сайте им не следует посещать. Это важно, чтобы помочь им избежать сканирования некачественных страниц или застревания в ловушках сканирования, где потенциально может быть создано бесконечное количество URL-адресов, например, раздел календаря, который создает новый URL-адрес на каждый день.
Как Google объясняет в своем руководстве по спецификациям robots.txt , формат файла должен быть обычным текстом, закодированным в UTF-8.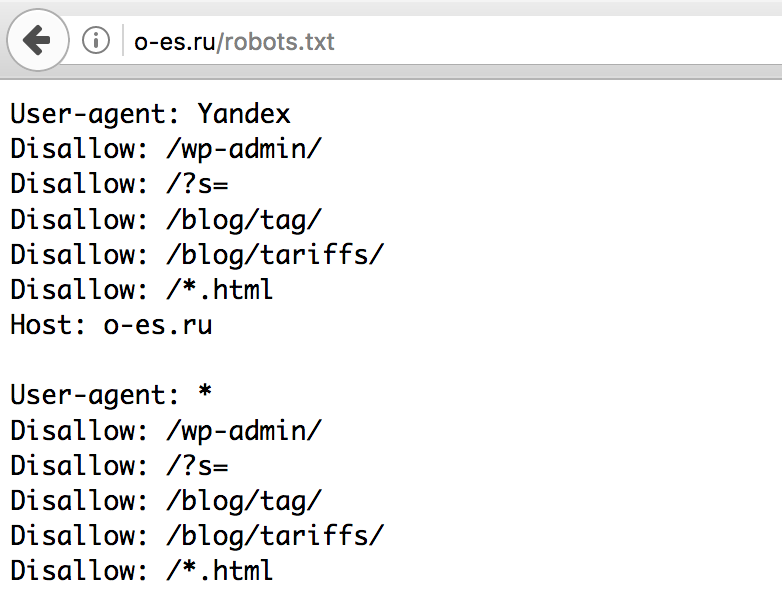 Записи файла (или строки) должны быть разделены символами CR, CR/LF или LF.
Записи файла (или строки) должны быть разделены символами CR, CR/LF или LF.
Следует помнить о размере файла robots.txt, так как у поисковых систем есть собственные ограничения на максимальный размер файла. Максимальный размер для Google составляет 500 КБ.
Где должен находиться файл robots.txt?
Файл robots.txt всегда должен находиться в корне домена, например:
Этот файл относится к протоколу и полному домену, поэтому robots.txt на https://www.example.com не влияет на сканирование https://www.example.com или https ://subdomain.example.com ; у них должны быть свои собственные файлы robots.txt.
Когда следует использовать правила robots.txt?
В общем, веб-сайты должны стараться использовать файл robots.txt как можно меньше для контроля сканирования. Гораздо лучшее решение — улучшить архитектуру вашего веб-сайта и сделать его чистым и доступным для поисковых роботов. Однако рекомендуется использовать robots.txt там, где это необходимо для предотвращения доступа сканеров к некачественным разделам сайта, если эти проблемы не могут быть устранены в краткосрочной перспективе.
Однако рекомендуется использовать robots.txt там, где это необходимо для предотвращения доступа сканеров к некачественным разделам сайта, если эти проблемы не могут быть устранены в краткосрочной перспективе.
Google рекомендует использовать robots.txt только в случае возникновения проблем с сервером или проблем с эффективностью сканирования, например, когда робот Googlebot тратит много времени на сканирование неиндексируемого раздела сайта.
Некоторые примеры страниц, сканирование которых нежелательно:
- Страницы категорий с нестандартной сортировкой , так как это обычно создает дублирование со страницей основной категории
- Пользовательский контент , который не может модерироваться
- Страницы с конфиденциальной информацией
- Страницы внутреннего поиска , так как может быть бесконечное количество этих страниц результатов, которые создают плохой пользовательский опыт и тратят впустую краулинговый бюджет
Когда не следует использовать robots.
 txt ?
txt ?Файл robots.txt — полезный инструмент при правильном использовании, однако бывают случаи, когда это не лучшее решение. Вот несколько примеров, когда не следует использовать файл robots.txt для управления сканированием:
1. Блокировка Javascript/CSS
Поисковые системы должны иметь доступ ко всем ресурсам на вашем сайте для правильного отображения страниц, что является необходимой частью поддержания хорошего рейтинга. Файлы JavaScript, которые резко изменяют взаимодействие с пользователем, но не могут быть просканированы поисковыми системами, могут привести к ручным или алгоритмическим штрафам.
Например, если вы показываете межстраничное объявление или перенаправляете пользователей с помощью JavaScript, к которому поисковая система не имеет доступа, это может рассматриваться как маскировка, и рейтинг вашего контента может быть скорректирован соответствующим образом.
2. Блокировка параметров URL
Вы можете использовать robots.txt для блокировки URL-адресов, содержащих определенные параметры, но это не всегда лучший способ действий.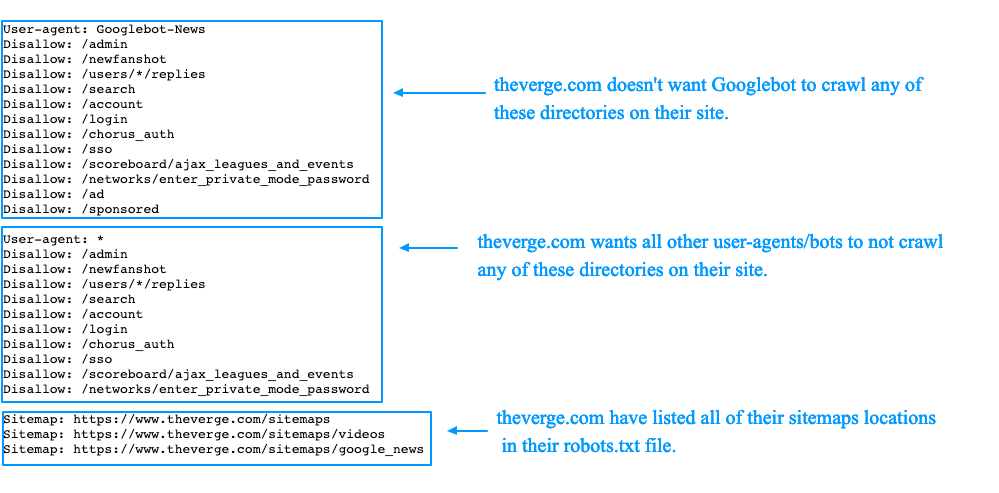 Лучше обрабатывать их в консоли поиска Google, так как там есть больше параметров для конкретных параметров, чтобы сообщить Google о предпочтительных методах сканирования.
Лучше обрабатывать их в консоли поиска Google, так как там есть больше параметров для конкретных параметров, чтобы сообщить Google о предпочтительных методах сканирования.
Вы также можете поместить информацию во фрагмент URL-адреса ( /page#sort=price ), так как поисковые системы его не сканируют. Кроме того, если необходимо использовать параметр URL, ссылки на него могут содержать атрибут rel=nofollow, чтобы сканеры не пытались получить к нему доступ.
3. Блокировка URL-адресов с обратными ссылками
Запрет URL-адресов в файле robots.txt предотвращает передачу ссылочного капитала на веб-сайт. Это означает, что если поисковые системы не могут переходить по ссылкам с других веб-сайтов, поскольку целевой URL-адрес запрещен, ваш веб-сайт не получит авторитета, который проходят эти ссылки, и, как следствие, ваш общий рейтинг может ухудшиться.
4. Деиндексация проиндексированных страниц
Использование Disallow не приводит к деиндексации страниц, и даже если URL-адрес заблокирован и поисковые системы никогда не сканировали страницу, запрещенные страницы все равно могут быть проиндексированы. Это связано с тем, что процессы сканирования и индексации в значительной степени разделены.
Это связано с тем, что процессы сканирования и индексации в значительной степени разделены.
Даже если вы не хотите, чтобы поисковые системы сканировали и индексировали страницы, вы можете захотеть, чтобы социальные сети могли получить доступ к этим страницам, чтобы можно было создать фрагмент страницы. Например, Facebook попытается посетить каждую страницу, которая публикуется в сети, чтобы предоставить соответствующий фрагмент. Учитывайте это при настройке правил robots.txt.
6. Блокировка доступа с промежуточных сайтов или сайтов разработки
Использование файла robots.txt для блокировки всего промежуточного сайта — не лучшая практика. Гугл рекомендует не индексирует страницы, но позволяет их сканировать, но в целом лучше сделать сайт недоступным из внешнего мира.
7. Когда вам нечего блокировать
Некоторые веб-сайты с очень чистой архитектурой не нуждаются в блокировке поисковых роботов на любых страницах. В этой ситуации вполне допустимо не иметь файла robots. txt и возвращать статус 404 по запросу.
txt и возвращать статус 404 по запросу.
Синтаксис и форматирование robots.txt
Теперь, когда мы узнали, что такое robots.txt и когда его следует и не следует использовать, давайте рассмотрим стандартизированный синтаксис и правила форматирования, которых следует придерживаться. при написании файла robots.txt.
Комментарии – это строки, полностью игнорируемые поисковыми системами и начинающиеся с # . Они существуют для того, чтобы вы могли писать заметки о том, что делает каждая строка вашего файла robots.txt, почему она существует и когда она была добавлена. Как правило, рекомендуется документировать назначение каждой строки файла robots.txt, чтобы его можно было удалить, когда он больше не нужен, и не изменять, пока он все еще необходим.
Указание агента пользователя
Блок правил может быть применен к определенным агентам пользователя с помощью « User-agent ” директива. Например, если вы хотите, чтобы определенные правила применялись к Google, Bing и Яндексу; но не Facebook и рекламные сети, этого можно добиться, указав токен пользовательского агента, к которому применяется набор правил.
У каждого сканера есть собственный токен пользовательского агента, который используется для выбора совпадающих блоков.
Сканеры будут следовать наиболее конкретным правилам пользовательского агента, установленным для них с именами, разделенными дефисами, а затем вернутся к более общим правилам, если точное соответствие не будет найдено. Например, Googlebot News будет искать совпадение « googlebot-news ’, затем ‘ googlebot ’, затем ‘*’.
Вот некоторые из наиболее распространенных токенов агента пользователя, с которыми вы столкнетесь:
- * — правила применяются к каждому боту, если нет более конкретного набора правил
- Googlebot — все поисковые роботы Google
- Googlebot-News – Поисковый робот Google News
- Googlebot-Image – Поисковый робот Google Images
- Mediapartners-Google – Google Adsense crawler
- Bingbot – Bing’s crawler
- Yandex – Yandex’s crawler
- Baiduspider – Baidu’s crawler
- Facebot – Facebook’s crawler
- Twitterbot – Twitter’s crawler
This list токенов пользовательского агента, ни в коем случае не является исчерпывающим, поэтому, чтобы узнать больше о некоторых сканерах, взгляните на документацию, опубликованную Google , Bing , Яндекс , Baidu , Facebook и Twitter .
При сопоставлении токена пользовательского агента с блоком robots.txt регистр не учитывается. Например. «googlebot» будет соответствовать токену пользовательского агента Google «Googlebot».
URL-адреса, соответствующие шаблону
У вас может быть определенная строка URL-адреса, которую вы хотите заблокировать от сканирования, так как это намного эффективнее, чем включение полного списка полных URL-адресов, которые необходимо исключить в файле robots.txt.
Чтобы уточнить URL-адреса, вы можете использовать символы * и $. Вот как они работают:
- * — это подстановочный знак, представляющий любое количество любых символов. Он может быть в начале или в середине URL-адреса, но не обязателен в конце. Вы можете использовать несколько подстановочных знаков в строке URL, например, « Disallow: */products?*sort= ». Правила с полными путями не должны начинаться с подстановочного знака.
- $ — этот символ означает конец строки URL, поэтому « Disallow: */dress$ » будет соответствовать только URL-адресам, оканчивающимся на « / dress », а не на « / dress?parameter ».

Стоит отметить, что правила robots.txt чувствительны к регистру, а это означает, что если вы запретите URL-адреса с параметром « search » (например, « Disallow: *?search= »), роботы все равно могут сканировать URL-адреса с другими заглавными буквами, например « ?Search=anything ».
Правила директивы соответствуют только путям URL и не могут включать протокол или имя хоста. Косая черта в начале директивы соответствует началу пути URL. Например. Disallow: /starts ” будет соответствовать www.example.com/starts .
Если вы не добавите соответствие директивы start a / или * , оно не будет соответствовать чему-либо. Например. « Disallow: запускает » никогда не будет соответствовать чему-либо.
Чтобы наглядно представить, как работают различные правила URL-адресов, мы собрали для вас несколько примеров:
Robots.txt Ссылка на карту сайта
Директива карты сайта в файле robots. txt сообщает поисковым системам, где найти XML-карту сайта, что помогает им обнаружить все URL-адреса на веб-сайте. Чтобы узнать больше о картах сайта, ознакомьтесь с нашими руководство по аудиту карты сайта и расширенной настройке .
txt сообщает поисковым системам, где найти XML-карту сайта, что помогает им обнаружить все URL-адреса на веб-сайте. Чтобы узнать больше о картах сайта, ознакомьтесь с нашими руководство по аудиту карты сайта и расширенной настройке .
При включении карт сайта в файл robots.txt следует использовать абсолютные URL-адреса (например, https://www.example.com/sitemap.xml ) вместо относительных URL-адресов (например, /sitemap.xml .) Это также стоит отметить, что карты сайта не обязательно должны находиться в одном корневом домене, они также могут размещаться на внешнем домене.
Поисковые системы обнаружат и могут сканировать карты сайта, указанные в файле robots.txt, однако эти карты сайта не будут отображаться в Google Search Console или Bing Webmaster Tools без отправки вручную.
Robots.txt блокирует
Правило «запретить» в файле robots.txt можно использовать несколькими способами для разных пользовательских агентов. В этом разделе мы рассмотрим несколько различных способов форматирования комбинаций блоков.
В этом разделе мы рассмотрим несколько различных способов форматирования комбинаций блоков.
Важно помнить, что директивы в файле robots.txt — это только инструкции. Вредоносные сканеры будут игнорировать ваш файл robots.txt и сканировать любую общедоступную часть вашего сайта, поэтому не следует использовать запрет вместо надежных мер безопасности.
Несколько блоков пользовательских агентов
Вы можете сопоставить блок правил с несколькими пользовательскими агентами, перечислив их перед набором правил, например, следующие правила запрета будут применяться как к Googlebot, так и к Bing в следующем блоке правил:
Агент пользователя: googlebot
Агент пользователя: bing
Запретить: /a
Расстояние между блоками директив
Google будет игнорировать пробелы между директивами и блоками. В этом первом примере будет выбрано второе правило, даже если есть пробел, разделяющий две части правила:
[код]
Агент пользователя: *
Disallow: /disallowed/
Disallow: /test1/robots_excluded_blank_line
[/code]
Во втором примере Googlebot-mobile унаследует те же правила, что и Bingbot3:
[код]
Агент пользователя: googlebot-mobile
Агент пользователя: bing
Запретить: /test1/deepcrawl_excluded
[/код]
Объединение отдельных блоков
Объединение нескольких блоков с одним и тем же агентом пользователя. Таким образом, в приведенном ниже примере верхний и нижний блоки будут объединены, и роботу Googlebot будет запрещено сканировать « /б » и «/а ».
Таким образом, в приведенном ниже примере верхний и нижний блоки будут объединены, и роботу Googlebot будет запрещено сканировать « /б » и «/а ».
Пользовательский агент: Googlebot
Diswalling: /BПользовательский агент: Bing
Diswally: /AПользователь-Агент: GoogleBot
DISLANK: /A
ROBOT.TXT. Правило .txt «разрешить» явно разрешает сканирование определенных URL-адресов. Хотя это значение по умолчанию для всех URL-адресов, это правило можно использовать для перезаписи правила запрета. Например, если «
/locations » запрещен, вы можете разрешить сканирование « /locations/london », имея специальное правило « Разрешить: /locations/london ».
Приоритезация файла robots.txt
Если к URL-адресу применяется несколько разрешающих и запрещающих правил, применяется правило с самым длинным соответствием.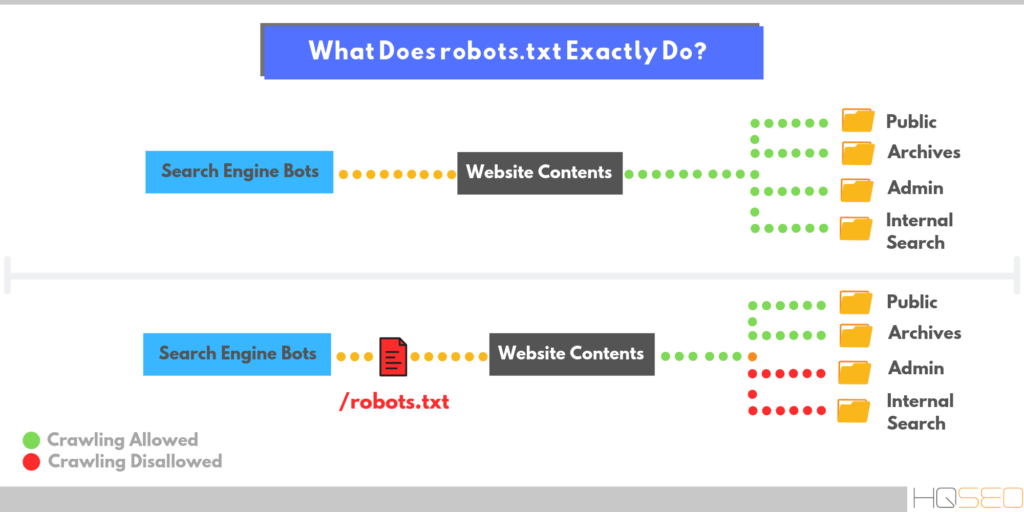 Давайте посмотрим, что произойдет для URL « /home/search/shirts » со следующими правилами:
Давайте посмотрим, что произойдет для URL « /home/search/shirts » со следующими правилами:
Запретить: /home
Разрешить: *search/*
Запретить: *shirts
В этом случае, URL-адрес разрешен для обхода, поскольку правило разрешения имеет 9символов, в то время как правило запрета имеет только 7. Если вам нужно разрешить или запретить конкретный URL-адрес, вы можете использовать *, чтобы сделать строку длиннее. Например:
Disallow: *******************/shirts
одинаковой длины, последует запрет. Например, URL « /search/shirts » будет запрещен в следующем сценарии:
Запретить: /search
Разрешить: *shirts
Директивы robots.txt
Директивы уровня страницы (которые мы рассмотрим позже в этом руководстве) — отличные инструменты, но проблема с ними заключается в том, что поисковые системы должны просканировать страницу, прежде чем будут в состоянии прочитать эти инструкции, которые могут расходовать краулинговый бюджет.
Директивы robots.txt могут помочь уменьшить нагрузку на бюджет сканирования, поскольку вы можете добавлять директивы непосредственно в файл robots.txt, а не ждать, пока поисковые системы просканируют страницы, прежде чем предпринимать какие-либо действия. Это решение намного быстрее и проще в управлении.
Следующие директивы robots.txt работают так же, как директивы allow и disallow, в том смысле, что вы можете указать подстановочные знаки ( * ) и использовать символ $ для обозначения конца строки URL.
Robots.txt noIndex
Robots.txt noindex — это полезный инструмент для управления индексацией поисковыми системами без расходования краулингового бюджета. Запрет страницы в robots.txt не означает ее удаление из индекса, поэтому директиву noindex гораздо эффективнее использовать для этой цели.
Google официально не поддерживает robots.txt noindex, и вам не следует полагаться на него, потому что, хотя он работает сегодня, он может не работать завтра. Этот инструмент может быть полезен, и его следует использовать в качестве краткосрочного исправления в сочетании с другими долгосрочными элементами управления индексами, но не в качестве критически важной директивы. Взгляните на тесты, проведенные ohgm и Stone Temple , которые доказывают, что функция работает эффективно.
Этот инструмент может быть полезен, и его следует использовать в качестве краткосрочного исправления в сочетании с другими долгосрочными элементами управления индексами, но не в качестве критически важной директивы. Взгляните на тесты, проведенные ohgm и Stone Temple , которые доказывают, что функция работает эффективно.
Вот пример использования файла robots.txt noindex:
[код]
Агент пользователя: *
NoIndex: /directory
NoIndex: /*?*sort=
[/code]
Помимо noindex, Google в настоящее время неофициально подчиняется нескольким другим директивам индексации, когда они помещается в файл robots.txt. Важно отметить, что не все поисковые системы и краулеры поддерживают эти директивы, а те, которые поддерживают, могут перестать их поддерживать в любое время — не стоит полагаться на их постоянную работу.
Распространенные проблемы с файлом robots.txt
Существует ряд ключевых проблем и соображений относительно файла robots. txt и его влияния на производительность сайта. Мы нашли время, чтобы перечислить некоторые ключевые моменты, которые следует учитывать при работе с robots.txt, а также некоторые из наиболее распространенных проблем, которых вы, надеюсь, сможете избежать.
txt и его влияния на производительность сайта. Мы нашли время, чтобы перечислить некоторые ключевые моменты, которые следует учитывать при работе с robots.txt, а также некоторые из наиболее распространенных проблем, которых вы, надеюсь, сможете избежать.
- Иметь резервный блок правил для всех ботов — Использование блоков правил для определенных строк пользовательского агента без резервного блока правил для всех остальных ботов означает, что ваш веб-сайт в конечном итоге столкнется с ботом, у которого нет наборов правил. следить.
- I Важно, чтобы файл robots.txt обновлялся . Относительно распространенная проблема возникает, когда файл robots.txt устанавливается на начальном этапе разработки веб-сайта, но не обновляется по мере роста веб-сайта. потенциально полезные страницы запрещены.
- Помните о перенаправлении поисковых систем через запрещенные URL-адреса — например, /product > /disallowed > /category
- Чувствительность к регистру может вызвать много проблем — Веб-мастера могут ожидать, что часть веб-сайта не будет просканирована, но эти страницы могут быть просканированы из-за альтернативных регистров, т. е. «Disallow: /admin» существует, но поисковые системы сканируют « /ADMIN ».
- Не запрещать URL-адреса с обратными ссылками — Это предотвращает попадание PageRank на ваш сайт от других, которые ссылаются на вас.
- Задержка сканирования может вызвать проблемы с поиском — Директива « Crawl-delay » заставляет сканеры посещать ваш веб-сайт медленнее, чем им хотелось бы, а это означает, что ваши важные страницы могут сканироваться реже, чем оптимально. Этой директиве не следуют ни Google, ни Baidu, но поддерживают Bing и Яндекс.
- Убедитесь, что файл robots.txt возвращает код состояния 5xx только в том случае, если весь сайт недоступен. Обычно это означает, что позже они снова попытаются просканировать веб-сайт.
- Запрет Robots.txt переопределяет инструмент удаления параметров . Помните, что ваши правила robots.txt могут переопределять обработку параметров и любые другие подсказки по индексации, которые вы могли дать поисковым системам.
- Разметка окна поиска дополнительных ссылок будет работать с заблокированными страницами внутреннего поиска. — страницы внутреннего поиска на сайте не должны быть доступными для сканирования, чтобы разметка поля поиска дополнительных ссылок работала.
- Запрет переноса домена повлияет на успех переноса — Если вы запретите перенос домена, поисковые системы не смогут отслеживать какие-либо перенаправления со старого сайта на новый, поэтому миграция маловероятна. быть успешным.
 е. «Disallow: /admin» существует, но поисковые системы сканируют « /ADMIN ».
е. «Disallow: /admin» существует, но поисковые системы сканируют « /ADMIN ».
Тестирование и аудит Robots.txt
Учитывая, насколько опасным может быть файл robots.txt, если содержащиеся в нем директивы обрабатываются неправильно, существует несколько различных способов проверить его, чтобы убедиться, что он настроен правильно. . Взгляните на это руководство о том, как проверять URL-адреса, заблокированные robots.txt , а также на следующие примеры: показать вам, какие страницы заблокированы от поисковых систем вашим файлом robots. txt.
txt.
Мониторинг изменений robots.txt
Когда над сайтом работает много людей, и с проблемами, которые могут возникнуть, если хотя бы один символ находится не на месте в файле robots.txt, постоянно отслеживая robots.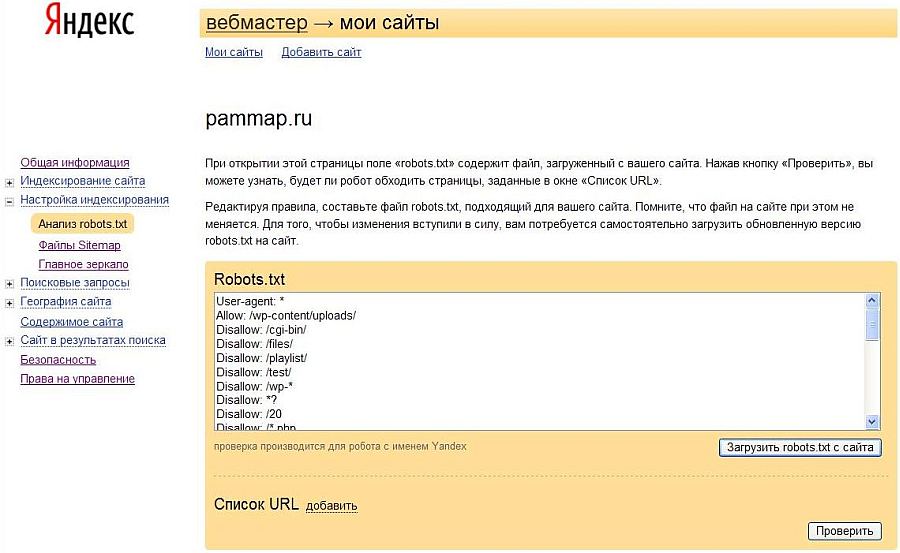 txt имеет решающее значение. Вот несколько способов проверить наличие проблем:
txt имеет решающее значение. Вот несколько способов проверить наличие проблем:
- Проверьте консоль поиска Google, чтобы увидеть текущий файл robots.txt, который использует Google. Иногда robots.txt может быть доставлен условно на основе пользовательских агентов, так что это единственный способ увидеть именно то, что видит Google.
- Проверьте размер файла robots.txt, если вы заметили значительные изменения, чтобы убедиться, что он не превышает установленного Google ограничения размера в 500 КБ.
- Перейдите к отчету о состоянии индекса Google Search Console в расширенном режиме, чтобы сверить изменения robots.txt с количеством запрещенных и разрешенных URL-адресов на вашем сайте.
- Запланируйте регулярное сканирование с помощью Lumar, чтобы постоянно видеть количество запрещенных страниц на вашем сайте и отслеживать изменения.
Далее: Директивы о роботах на уровне URL
Полное руководство по работе поисковых систем:
Как работают поисковые системы?
Как поисковые системы сканируют веб-сайты
Как работает индексирование в поисковых системах?
Каковы различия между поисковыми системами?
Что такое краулинговый бюджет?
Что такое Robots.