
Что такое Robots txt, как его составить и использовать во благо
Что такое Robots txt?
Robots txt. – файл, содержащий в себе правила индексирования страниц для поисковых роботов и сообщающий им, на какие страницы Вашего сайта заходить можно, а к каким доступ ограничен.
Он создан для того, чтобы скрыть ненужный для сканирования и индексации контент на сайте, значительно облегчить работу поисковым системам и, в конечном счете, направить роботов только на важные страницы.
Как в примере на картинке, наличие файла robots.txt позволит избежать сканирования и дальнейшей индексации системных страниц сайта, которые не несут никакой полезной информации для посетителей и должны быть скрыты
Яндекс и Google постоянно обращаются к robots txt чтобы получить рекомендации по сканированию сайта. Если файл robots txt не обнаружен, то поисковым роботам приходится сканировать весь сайт и тратить свои ресурсы, в том числе, на нерелевантные страницы, что может привести к израсходованию краулингового бюджета.
Краулинговый бюджет— Лимит на сканирование страниц сайта поисковыми роботами. Простыми словами, это системное ограничение числа страниц, которые поисковые системы выделяют для сканирования Вашего сайта за заданный промежуток времени.
Узнайте подробное о том, как краулинговый бюджет влияет на индексирование страниц и стоит ли Вам переживать за его значение.
Из чего состоит файл robots txt?
Стандартный вид файла robots txt:
Sitemap: [URL, с расположением карты сайта]
User-agent: *
[директива 1]
[директива 2]
[директива …]
User-agent: Yandex
[директива 1]
[директива 2]
[директива …]
С первого взгляда все может показаться сложно, но не пугайтесь, сейчас мы подробно расскажем про каждый элемент файла.
Все правила, которые прописаны в robots txt принято называть директивами, именно они указывают поисковым роботам, на какие страницы сайта можно заходить
User—agent – стандартная команда, указывающая для каких поисковых систем и роботов будут предназначены прописанные в ней директивы.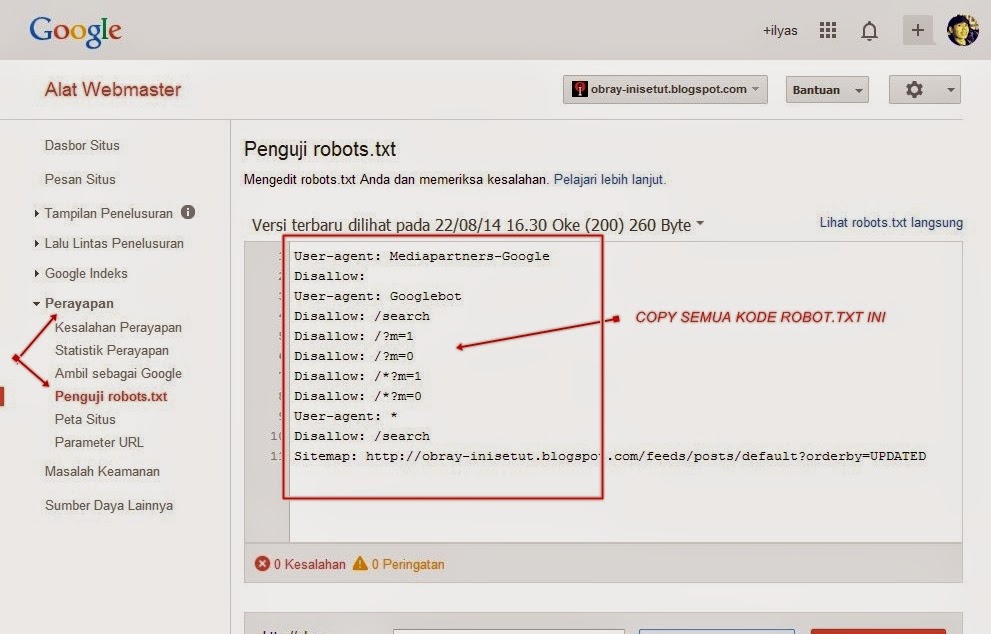
Например, в User—agent у нас прописана следующая команда:
User-agent: Googlebot
[Директива]
Это означает, что рекомендациям файла robots.txt будет следовать только Googlebot.
Вы можете прописать неограниченное количество User-agent для любых поисковых роботов, но чаще всего, в России используют User-agent: Googlebot и User-agent: Yandex. для Гугла и Яндекса соответственно.
User-agent: Googlebot
[Директива]
User-agent: Yandex
[Директива]
Значение * после user-agent открывает доступ к директивам для всех поисковых роботов.
User-agent: *
[Директива]
Есть мнение, что если мы указываем User-agent отдельно для каждого поискового робота, то мы увеличиваем свои шансы на успешное сканирование сайта.
Какие директивы robots txt существуют?
Директива Disallow – используется для того, чтобы закрыть от индексации определенные страницы и файлы. Например, если хотите закрыть доступ к странице с новостями, Ваш robots txt будет выглядеть так:
Например, если хотите закрыть доступ к странице с новостями, Ваш robots txt будет выглядеть так:
User-agent: *
Disallow: /news
Обязательство прописывайте путь к страницам, к которым закрываете доступ, иначе поисковые системы проигнорируют директиву Disallow.
Директива Allow – используется для того, чтобы сообщить поисковым системам, что они могут получить доступ к определенной странице из закрытого каталога в директории disallow. Например, запретили поисковым системам сканировать все записи на странице с новостями, кроме одной. В таком случае robots txt будет выглядеть так:
User-agent: *
Disallow: /news
Allow: /news/разрешенаая-запись
В таком случае, поисковые системы смогут зайти на страницу /news/разрешенная-запись , но не смогут получить доступ к остальным записям
/news/другая-запись
/news/новый-пост
Возможные конфликты между директивами robots txt
Разберем на примере
User—agent: *
Allow: /directory
Disallow: *. html
html
В теории, у поисковых систем могут возникнуть трудности, нужно обходить следующую страницу или нет? — http://www.domain.com/directory.html
Поисковые роботы пользуются простым правилом – принимать во внимание ту директиву, в которой больше символов.
Если количество символов одинаково, то они используют менее ограничивающую директиву, то есть в нашем примере, они получат доступ к сканированию страницы.
Директива Sitemap – используется для того, чтобы указать путь поисковым роботам к карте сайта. Sitemap выполняет роль навигатора для поисковых систем и содержит в себе все страницы, которые нужно индексировать.
Sitemap: https://www.domain.com/sitemap.xml
User-agent: *
Disallow: /news
Allow: /news/разрешенаая-запись
На самом деле, Если Вы добавили карту сайту в Яндекс вебмастер и google search console, для Яндекса и Гугла этого будет достаточно, но не стоит забывать, что существуют и другие поисковые системы, роботы которых пользуются рекомендацией этой директивы.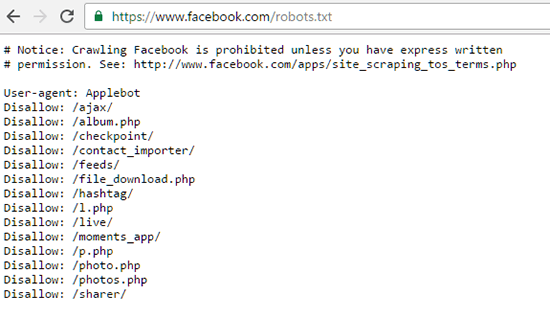
Директива Crawl-delay – в настоящее время не используется поисковыми роботами. Была предназначена для временного задела между сканированием страниц.
User—agent: Yandex
Crawl—delay: 5
Так мог выглядеть robots.txt если бы Вы хотели, чтобы поисковой робот Яндекса ждал 5 секунд после сканирования каждой страницы.
Вместо директивы Crawl-delay яндекс рекомендует настроить скорость обхода страницы в вебмастере.
Директива Clean-param – используется только роботами яндекса и позволяет исключить от иднексации страницы с изменяющимися параметрами URL (UTM метки, id страниц и так далее)
Разберем на примере двух страниц:
www.example.com/some_dir/get_book.pl?ref=site_1&book_id=123
www.example.com/some_dir/get_book.pl?ref=site_2&book_id=123
Если мы пропишем директиву
Clean-param: ref /some_dir/get_book.pl
Поисковой робот Яндекса приведет их к одному формату и проиндексирует страницу www.example.com/some_dir/get_book. pl?book_id=123
Как создать файл robots txt?
Для создания файла можно использовать любой текстовый редактор, который может сохранить документ с разрешением txt.
Один из самых популярных вариантов – стандартный блокнот windows.
Откройте пустой файл, вписывайте нужные директивы и сохраните его под названием robots.txt
Создание robots.txt очень ответственная работа, одна неверная директива может закрыть доступ к сканированию всего сайта. Если не уверены в своих знаниях и силах, обратитесь к профессионалам.
Где расположить файл robots.txt?
Robots.txt должен располагаться в корневом каталоге сайта для которого он применяется.
Если адрес вашего сайта www.test.ru , то файл с robots.txt должен быть доступен по адресу www.test.ru/robots.txt
Заключительные мысли
Robots.txt оказывает большую помощь поисковым роботам и по праву считается одним из ключевых инструментов seo продвижения.
Если у Вас еще не составлен файл robots, сейчас самое время это исправить!
Robots.
txt для различных CMS | JetoВ данной статье собраны примеры robots.txt, которые помогут составить корректный настройки файл для различных популярных CMS и фрэймворков: 1C-Битрикс, Joomla, Drupal, WordPress, OpenCart, NetCat, UMI CMS, HostCMS, MODX.
Файл robots.txt – это текстовый файл с технической информаций, размещаемый в корне вашего сайта, он сообщает поисковым системам орядок индексации сайта. Наборы директив (строк) сообщают поисковому роботу, какие разделы сайта запретить или разрешить к индексации. Для ряда поисковых систем, в файле robots.txt могут быть прописаны дополнительные параметры, обрабатываемые только определенной поисковой системой.
Нужно понимать, что приведенные ниже директивы являются лишь примерами и файлы не гарантируют 100% правильную работу, так как в них могуть не предусмотрены специальные разделы, типы файлов, которые должны быть закрыты или открыты на вашей сайте. В некоторых случаях может потребоваться тонкая коррекция настроек под ваш проект, поэтому рекомендуем дополнительно консультироваться по настройке robots. txt с программистом и\или администратором вашего проекта, который знаком с его спецификой и «узкими местами».
Обратите внимание: значение site.ru нужна заменить на ваш домен.
Авторируйтесь в панели хостина и в ISPmanager перейдите в Менеджер файлов — www — каталог Вашего сайта и на панели нажмите «Закачать».
Перед Вами откроется окно загрузки файла, в котором нужно выбрать robots.txt с локального компьютера и загрузить на сервер.
Проверка robots.txt
Проверить успешную загрузку файла на сайта можно открыв его браузере по адресу http://site.ru/ robots.txt , где site.ru — имя Вашего сайта.
После загрузки robots.txt на сайт проверяем корректность работы файла по инструкциям:
Для Яндекс – через Яндекс.Вебмастер, без регистрации.
Для Google – через Google Вебмастер, с регистрацией.
Для robots. txt рекомендуется устанавливать права 444.
robots.txt для 1С-Битрикс
User-agent: *
Allow: /map/
Allow: /search/map.php
Disallow: */index.php
Disallow: /*action=
Disallow: /*print=
Disallow: /*/gallery/*order=
Disallow: /*/search/
Disallow: /*/slide_show/
Disallow: /*?utm_source=
Disallow: /*ADD_TO_COMPARE_LIST
Disallow: /*arrFilter=
Disallow: /*auth=
Disallow: /*back_url_admin=
Disallow: /*BACK_URL=
Disallow: /*back_url=
Disallow: /*backurl=
Disallow: /*bitrix_*=
Disallow: /*bitrix_include_areas=
Disallow: /*building_directory=
Disallow: /*bxajaxid=
Disallow: /*change_password=
Disallow: /*clear_cache_session=
Disallow: /*clear_cache=
Disallow: /*count=
Disallow: /*COURSE_ID=
Disallow: /*forgot_password=
Disallow: /*ID=
Disallow: /*index.php$
Disallow: /*login=
Disallow: /*logout=
Disallow: /*modern-repair/$
Disallow: /*MUL_MODE=
Disallow: /*ORDER_BY
Disallow: /*PAGE_NAME=
Disallow: /*PAGE_NAME=detail_slide_show
Disallow: /*PAGE_NAME=search
Disallow: /*PAGEN_
Disallow: /*print_course=
Disallow: /*print=
Disallow: /*q=
Disallow: /*register=
Disallow: /*register=yes
Disallow: /*set_filter=
Disallow: /*show_all=
Disallow: /*show_include_exec_time=
Disallow: /*show_page_exec_time=
Disallow: /*show_sql_stat=
Disallow: /*SHOWALL_
Disallow: /*sort=
Disallow: /*sphrase_id=
Disallow: /*tags=
Disallow: /access.
logDisallow: /admin
Disallow: /api
Disallow: /auth
Disallow: /auth.php
Disallow: /auto
Disallow: /bitrix
Disallow: /bitrix/
Disallow: /cgi-bin
Disallow: /club/$
Disallow: /club/forum/search/
Disallow: /club/gallery/tags/
Disallow: /club/group/search/
Disallow: /club/log/
Disallow: /club/messages/
Disallow: /club/search/
Disallow: /communication/blog/search.php
Disallow: /communication/forum/search/
Disallow: /communication/forum/user/
Disallow: /content/board/my/
Disallow: /content/links/my/
Disallow: /error
Disallow: /e-store/affiliates/
Disallow: /e-store/paid/detail.php
Disallow: /examples/download/download_private/
Disallow: /examples/my-components/
Disallow: /include
Disallow: /personal
Disallow: /search
Disallow: /temp
Disallow: /tmp
Disallow: /upload
Disallow: /*/*ELEMENT_CODE=
Disallow: /*/*SECTION_CODE=
Disallow: /*/*IBLOCK_CODE
Disallow: /*/*ELEMENT_ID=
Disallow: /*/*SECTION_ID=
Disallow: /*/*IBLOCK_ID=
Disallow: /*/*CODE=
Disallow: /*/*ID=
Disallow: /*/*IBLOCK_EXTERNAL_ID=
Disallow: /*/*SECTION_CODE_PATH=
Disallow: /*/*EXTERNAL_ID=
Disallow: /*/*IBLOCK_TYPE_ID=
Disallow: /*/*SITE_DIR=
Disallow: /*/*SERVER_NAME=
Sitemap: http://site.
ru/sitemap_index.xmlSitemap: http://site.ru/sitemap.xml
Host: site.ru
robots.txt для WordPress
User-agent: *
Allow: /wp-content/uploads
Disallow: */comment-page-*
Disallow: */comments
Disallow: */feed
Disallow: */trackback
Disallow: /*?
Disallow: /?feed=
Disallow: /?s=
Disallow: /author
Disallow: /cgi-bin
Disallow: /comments
Disallow: /page
Disallow: /search
Disallow: /tag
Disallow: /trackback
Disallow: /webstat
Disallow: /wp-admin
Disallow: /wp-comments
Disallow: /wp-content/cache
Disallow: /wp-content/plugins
Disallow: /wp-content/themes
Disallow: /wp-feed
Disallow: /wp-includes
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /wp-trackback
Disallow: /xmlrpc.php
Sitemap: http://site.ru/sitemap.xml
Host: site.ru
robots.txt для Joomla
User-agent: *
Allow: /images
Allow: /index. php?option=com_xmap&sitemap=1&view=xml
Disallow: /*?sl*
Disallow: /*atom.html
Disallow: /*rss.html
Disallow: /administrator
Disallow: /bin
Disallow: /cache
Disallow: /cli
Disallow: /component
Disallow: /components
Disallow: /includes
Disallow: /index*
Disallow: /index2.php?option=com_content&task=emailform
Disallow: /installation
Disallow: /language
Disallow: /layouts
Disallow: /libraries
Disallow: /logs
Disallow: /media
Disallow: /modules
Disallow: /plugins
Disallow: /templates
Disallow: /tmp
Disallow: /trackback
Disallow: /xmlrpc
Sitemap: http://site.ru/sitemap.xml
Host: site.ru
robots.txt для OpenCart
User-agent: *
Disallow: /*filter_description=
Disallow: /*filter_name=
Disallow: /*filter_sub_category=
Disallow: /*keyword
Disallow: /*limit=
Disallow: /*manufacturer
Disallow: /*order=
Disallow: /*page=
Disallow: /*route=account/login
Disallow: /*route=affiliate
Disallow: /*route=checkout
Disallow: /*route=checkout/cart
Disallow: /*route=product/search
Disallow: /*sort=
Disallow: /*tracking=
Disallow: /admin
Disallow: /cache
Disallow: /cart
Disallow: /catalog
Disallow: /change-password
Disallow: /checkout
Disallow: /download
Disallow: /export
Disallow: /index.
php?route=accountDisallow: /index.php?route=account/account
Disallow: /index.php?route=account/login
Disallow: /index.php?route=checkout/cart
Disallow: /index.php?route=checkout/shipping
Disallow: /index.php?route=common/home
Disallow: /index.php?route=product/category
Disallow: /index.php?route=product/compare
Disallow: /index.php?route=product/manufacturer
Disallow: /index.php?route=product/product*&manufacturer_id=
Disallow: /index.php?route=product/search
Disallow: /login
Disallow: /my-account
Disallow: /order-history
Disallow: /request-return
Disallow: /search
Disallow: /search?filter_name=
Disallow: /search?tag=
Disallow: /system
Disallow: /vouchers
Disallow: /vqmod
Disallow: /wishlist
Sitemap: http://site.ru/sitemap.xml
Host: site.ru
robots.txt для MODX
User-agent: *
Disallow: /*?
Disallow: /*?id=
Disallow: /assets
Disallow: /assets/cache
Disallow: /assets/components
Disallow: /assets/docs
Disallow: /assets/export
Disallow: /assets/import
Disallow: /assets/modules
Disallow: /assets/plugins
Disallow: /assets/snippets
Disallow: /connectors
Disallow: /core
Disallow: /index. php
Disallow: /install
Disallow: /manager
Disallow: /profile
Disallow: /search
Sitemap: http://site.ru/sitemap.xml
Host: site.ru
robots.txt для Drupal
User-agent: *
Disallow: *comment*
Disallow: *login*
Disallow: *register*
Disallow: /*&sort*
Disallow: /*/delete
Disallow: /*/edit
Disallow: /*?sort*
Disallow: /*calendar
Disallow: /*index.php
Disallow: /*order
Disallow: /*section
Disallow: /*votesupdown
Disallow: /?q=admin
Disallow: /?q=admin/
Disallow: /?q=comment/reply
Disallow: /?q=contact
Disallow: /?q=filter/tips
Disallow: /?q=logout
Disallow: /?q=node/add
Disallow: /?q=search
Disallow: /?q=user/login
Disallow: /?q=user/logout
Disallow: /?q=user/password
Disallow: /?q=user/register
Disallow: /admin
Disallow: /admin/
Disallow: /archive/
Disallow: /book/export/html
Disallow: /CHANGELOG.txt
Disallow: /comment
Disallow: /comment/reply
Disallow: /comments/recent
Disallow: /contact
Disallow: /cron. php
Disallow: /filter/tips
Disallow: /forum
Disallow: /forum/active
Disallow: /forum/unanswered
Disallow: /includes
Disallow: /INSTALL.mysql.txt
Disallow: /INSTALL.pgsql.txt
Disallow: /install.php
Disallow: /INSTALL.sqlite.txt
Disallow: /INSTALL.txt
Disallow: /LICENSE.txt
Disallow: /logout
Disallow: /logout/
Disallow: /MAINTAINERS.txt
Disallow: /messages
Disallow: /misc
Disallow: /modules
Disallow: /node
Disallow: /node/add
Disallow: /print/node
Disallow: /profile
Disallow: /profiles
Disallow: /scripts
Disallow: /search
Disallow: /taxonomy
Disallow: /taxonomy/term*/feed
Disallow: /themes
Disallow: /update.php
Disallow: /UPGRADE.txt
Disallow: /user
Disallow: /user/
Disallow: /user/login
Disallow: /user/logout
Disallow: /user/password
Disallow: /user/register
Disallow: /xmlrpc.php
Sitemap: http://site.ru/sitemap.xml
Host: site.ru
robots. txt для NetCat
User-agent: *
Disallow: /*.swf
Disallow: /*?
Disallow: /eng
Disallow: /install
Disallow: /js
Disallow: /links
Disallow: /netcat
Disallow: /netcat_cache
Disallow: /netcat_dump
Disallow: /netcat_files
Sitemap: http://site.ru/sitemap.xml
Host: site.ru
robots.txt для UMI.CMS
User-agent: *
Disallow: /*?
Disallow: /?
Disallow: /admin
Disallow: /emarket/addToCompare
Disallow: /emarket/basket
Disallow: /files
Disallow: /go_out.php
Disallow: /images
Disallow: /images/lizing
Disallow: /images/ntc
Disallow: /index.php
Disallow: /install-libs
Disallow: /install-static
Disallow: /install-temp
Disallow: /search
Disallow: /users
Sitemap: http://site.ru/sitemap.xml
Host: site.ru
robots.txt для HostCMS
User-agent: *
Disallow: /403
Disallow: /404
Disallow: /admin
Disallow: /articles/tag
Disallow: /captcha. php
Disallow: /chmod.sh
Disallow: /config.php
Disallow: /config_db.php
Disallow: /data_templates
Disallow: /documents
Disallow: /download_file.php
Disallow: /glossary/tag
Disallow: /hostcmsfiles
Disallow: /lib
Disallow: /logs
Disallow: /main_classes.php
Disallow: /modules
Disallow: /news/tag
Disallow: /search
Disallow: /structure
Disallow: /templates
Disallow: /tmp
Disallow: /upload
Disallow: /xsl
Disallow: captcha.php
Disallow: download_file.php
Sitemap: http://site.ru/sitemap.xml
Host: site.ru
Как написать хороший robots.txt
Файл robots.txt похож на привратника вашего веб-сайта, который пропускает одних ботов и поисковых роботов, а других нет. Плохо написанный файл robots.txt может привести к проблемам с доступностью для поисковых роботов и падению трафика.
Протокол исключения роботов
Файл robots.txt был впервые определен в исходном документе «Стандарт для исключения роботов» 1994 года, а затем обновлен в спецификации Internet Draft 1996 года «Метод управления веб-роботами». Оба определяют очень строгий и, следовательно, подверженный ошибкам синтаксический анализ, который побудил основные поисковые системы, такие как Google, использовать, а затем указать более расслабленный метод синтаксического анализа и работать над тем, чтобы сделать его интернет-стандартом. Новые документы для протокола исключения роботов находятся в стадии разработки и получили некоторые последние обновления с 2019 года..
При строгом анализе неточные файлы robots.txt могут привести к неожиданному сканированию. Новый, более простой синтаксический анализ позволяет решить ряд проблем, обнаруженных в файлах robots.txt. Непринужденный синтаксический анализ, скорее всего, имел в виду веб-мастер, когда писал robots.txt.
Рассмотрим пример:
Файл robots.txt с
User-agent: * Disallow: /
можно интерпретировать как
User-agent: * Disallow:
со строгим толкованием оригинальных и обновленных документов и как
Агент пользователя: * Disallow: /
с использованием парсинга, указанного в последнем документе.
В этом крайнем примере обе интерпретации приводят к прямо противоположным результатам, и пользователь, вероятно, имел в виду смягченную интерпретацию. Как веб-мастер, вы хотите убедиться, что оба анализа идентичны. Вы можете сделать это, работая над проблемами, описанными ниже.
Базовый файл robots.txt
Написание файла robots.txt может быть очень простым, если вы не запрещаете сканирование и обрабатываете всех роботов одинаково. Это позволит всем роботам сканировать сайт без ограничений:
Агент пользователя: * Disallow:
Общие проблемы с файлами robots.txt
Проблемы начинаются, когда все становится сложнее. Например, вы можете обращаться к нескольким роботам, добавлять комментарии и использовать такие расширения, как задержка сканирования или подстановочные знаки. Не все роботы все понимают, и здесь все очень быстро становится запутанным.
Пустые строки
Черновик описывает формат файла следующим образом:
Формат логически состоит из непустого набора или записей, разделенных пустыми строками.
Записи состоят из набора строк вида: <Поле> «:» <значение>
Это означает, что записи разделены пустыми строками, и вам не разрешено иметь пустые строки в записи.
Агент пользователя: * Disallow: /
Если строго применять черновик, то это будет интерпретироваться как две записи. Обе записи неполные, первая не имеет правил, вторая не имеет пользовательского агента. Оба набора можно игнорировать, что приведет к созданию пустого файла robots.txt, который фактически будет таким же, как:
User-agent: * Disallow:
Это полностью противоположно тому, что было задумано. Однако некоторые роботы, такие как Googlebot, используют другой подход к разбору файлов robots.txt, удаляя пустые строки и интерпретируя их так, как это, вероятно, придумал веб-мастер:
Агент пользователя: * Disallow: /
Если вы хотите сэкономить, мы настоятельно рекомендуем не использовать пустые строки в записи. Таким образом, больше ботов будет интерпретировать файл robots. txt так, как он был создан.
С другой стороны, это тоже плохо, если у вас нет пустых строк для разделения записей:
User-agent: a Запретить: /путь2/ Пользовательский агент: b Disallow: /path3/
Это неубедительно. Его можно интерпретировать как:
User-agent: a Запретить: /путь2/ Запретить: /path3/
или
Агент пользователя: a Пользовательский агент: b Запретить: /путь2/ Disallow: /path3/
Веб-мастер, вероятно, имел в виду:
User-agent: a Запретить: /путь2/ Пользовательский агент: b Disallow: /path3/
Если вы хотите сэкономить, мы настоятельно рекомендуем разделить записи в этом случае.
Проанализируйте проблемы с разбором robots.txt в несколько кликов с Audisto
Наше программное обеспечение будет систематически проверять все хосты на соответствие файлам robots.txt и предупреждать вас о многих обнаруженных распространенных проблемах. Убедитесь, что ваши директивы robots управляют ботами, как задумано.
Заказать демонстрацию
Неполный набор записей
В черновике запись описана следующим образом:
Запись начинается с одной или нескольких строк агента пользователя, указывающих, к каким роботам относится запись, за которыми следуют инструкции «Запретить» и «Разрешить» для этого робота.
Это означает, что запись состоит из строки User-agent и директивы. Даже если вы хотите разрешить сканирование всего вашего сайта, вы должны добавить инструкцию.
Вместо использования:
Агент пользователя: *
Следует использовать:
Агент пользователя: * Disallow:
Многие плохо запрограммированные роботы имеют проблемы с комментариями. Черновик допускает комментарии в конце строки и в виде отдельных строк.
# robots.txt версия 1 User-agent: * # обрабатывать всех ботов Disallow: /
Есть несколько роботов, которые полностью запутались в разборе этого и обрабатывают его как:
User-agent: * Disallow:
Мы настоятельно рекомендуем не оставлять комментарии в файле robots. txt, чтобы он правильно обрабатывался большим количеством роботов.
Записи с более чем одним агентом пользователя
Черновик позволяет обращаться к нескольким агентам пользователя и иметь набор правил, которые применяются ко всем из них:
Агент пользователя: bot1 Агент пользователя: bot2 Disallow: /
Для некоторых ботов этот синтаксис слишком сложен, и мы видели, что это интерпретируется как:
User-agent: bot1 Запретить: Агент пользователя: bot2 Disallow: /
или еще хуже
User-agent: bot1 Запретить: Агент пользователя: bot2 Disallow:
Настоятельно рекомендуется адресовать каждому боту отдельную запись для повышения совместимости с плохо запрограммированными роботами. Если вы обращаетесь к более чем одному роботу с отдельным набором записей, вам необходимо использовать пустые строки для разделения записей.
Перенаправление на другой хост или протокол
В черновике очень конкретно указаны перенаправления:
При ответе сервера, указывающем перенаправление (код состояния HTTP 3XX), робот должен следовать перенаправлениям, пока не будет найден ресурс.
Однако в некоторых роботах это вообще не реализовано. Мы настоятельно рекомендуем вам не перенаправлять файл robots.txt в другое место. У вас должен быть отдельный файл robots.txt на каждом хосте и для каждого протокола/порта, который доступен напрямую, потому что это диапазон допустимости.
Проанализируйте проблемы с разбором robots.txt в несколько кликов с Audisto
Наше программное обеспечение будет систематически проверять все хосты на соответствие файлам robots.txt и предупреждать вас о многих обнаруженных распространенных проблемах. Убедитесь, что ваши директивы robots управляют ботами, как задумано.
Заказать демонстрацию
Усовершенствования чернового варианта, сделанные основными поисковыми системами
В дополнение к черновому варианту основные поисковые системы согласовали несколько улучшений, таких как подстановочные знаки, задержка сканирования и возможность ссылаться на карты сайта.
Проблема, конечно, в том, что некоторые роботы не поддерживают эти улучшения и не могут корректно с ними работать:
Агент пользователя: * Запретить: /*/secret.html Crawl-delay: 5
Мы настоятельно рекомендуем использовать улучшения только в записях для ботов, которые могут их обрабатывать, чтобы предотвратить ошибки синтаксического анализа.
Усовершенствования подстановочных знаков
Как упоминалось выше, подстановочные знаки поддерживаются основными поисковыми системами. Всякий раз, когда вы хотите заблокировать доступ к URL-адресам с определенным суффиксом, их невозможно обойти. Мы часто видим наборы правил, подобные этому:
Агент пользователя: * Disallow: .doc
Не блокирует доступ к файлам .doc, поскольку совпадает с
User-agent: * Disallow: /.doc
, и это блокирует доступ только к URL-адресам, начинающимся с /.doc. Чтобы заблокировать доступ ко всем файлам, заканчивающимся на .doc, вам нужно использовать:
User-agent: * Disallow: /*.
При использовании подстановочных знаков для блокировки параметров следует использовать что-то вроде этого:
User-agent: * Запретить: /*?параметр1 Запретить: /*&параметр1
в противном случае правило не соответствует, если параметр не является первым:
http://www.example.com/?parameter2¶meter1
Порядок записей
В черновике очень конкретно указано, в каком порядке применяются записи :
Эти маркеры имени используются в строках агента пользователя в файле /robots.txt, чтобы определить, к каким конкретным роботам относится запись. Робот должен подчиняться первой записи в /robots.txt, которая содержит строку User-Agent, значение которой содержит токен имени робота в качестве подстроки. Сравнение имен не зависит от регистра. Если такой записи не существует, она должна подчиняться первой записи со строкой User-agent со значением «*», если оно присутствует. Если ни одна запись не удовлетворяет ни одному из условий, или записи вообще отсутствуют, доступ неограничен.
Чтобы оценить, разрешен ли доступ к URL-адресу, робот должен попытаться сопоставить пути в строках «Разрешить» и «Запретить» с URL-адресом в том порядке, в котором они встречаются в записи. Используется первое найденное совпадение. Если совпадений не найдено, предполагается, что URL-адрес разрешен.
Однако существует множество ботов, которые не справляются с этим корректно. Мы настоятельно рекомендуем предварительно сортировать записи и разрешать и запрещать строки, чтобы уменьшить количество проблем во время синтаксического анализа.
Записи никогда не складываются
Некоторые веб-мастера считают, что записи складываются. Это фатально:
User-Agent: * Запретить: /url/1 Пользовательский агент: кто-то Запретить: /url/2 Пользовательский агент: кто-то Crawl-delay: 5
не приводит к тому, что «somebot» интерпретирует это как
User-Agent: somebot Запретить: /url/1 Запретить: /url/2 Crawl-delay: 5
, но обычно интерпретируется как
User-Agent: somebot Disallow: /url/2
Вам нужно продублировать правила, если вы хотите, чтобы бот применил их все.
Кодирование символов, отличных от US-ASCII
Кажется, многие упускают из виду тот факт, что путь к строке правил имеет ограниченный набор разрешенных символов. Символы, не входящие в набор символов US-ASCII, необходимо кодировать. Вместо использования
User-agent: * Disallow: /ä
вы должны использовать закодированную версию. Эта версия может отличаться для разных кодировок. Если вы используете UTF-8, вы должны использовать:
User-agent: * Запретить: /%C3%A4
Если вы используете ISO-8859-1 вы бы использовали:
Агент пользователя: * Disallow: /%E4
Из-за того, что пользователи могут копировать ваши URL-адреса в другие наборы символов, вам необходимо обрабатывать оба URL-адреса в вашем приложении и обязательно использовать обе закодированные версии, чтобы правильно их заблокировать:
User- агент: * Запретить: /%C3%A4 Disallow: /%E4
Формат файла, только символы US-ASCII
В черновике очень четко указан формат файла. Файл должен быть текстовым и содержать подробное описание в стиле BNF. Однако мы часто видим, что люди упускают эту часть.
В файле robots.txt разрешены только символы US-ASCII. Вам даже не разрешено использовать символы, отличные от US-ASCII, в комментариях.
Мы настоятельно рекомендуем использовать только символы US-ASCII, чтобы избежать проблем с анализом.
Кодировка Unicode и метка порядка байтов (BOM)
В черновике не указана кодировка содержимого. Мы видим много разных кодировок для файлов robots.txt. Однако это может привести к проблемам синтаксического анализа, особенно если файл robots.txt содержит символы, отличные от US-ASCII.
Во избежание проблем настоятельно рекомендуется использовать для файла robots.txt обычный текст в кодировке UTF-8. Это также формат файла, который ожидает Google.
Иногда люди также используют метку порядка байтов (BOM) в начале файла, и это может быть проблемой для парсеров robots.txt. Метка порядка байтов — это необязательный невидимый символ Unicode, используемый для обозначения порядка байтов текстового файла или потока.
Мы рекомендуем не использовать метку порядка байтов для повышения совместимости.
Размер файла
Даже крупные поисковые системы не обрабатывают большие файлы robots.txt. Google, например, имеет ограничение в 500 КБ, другие могут иметь меньшие ограничения. Имейте это в виду и постарайтесь свести размер к минимуму.
Другие проблемы с файлами robots.txt
Некоторые люди также склонны сталкиваться с проблемами, которые возникают из-за того, что некоторые роботы демонстрируют определенное поведение.
Коды состояния HTTP 401 и 403 для файлов robots.txt
Отправка кода состояния 401 или 403 для файла robots.txt, скорее всего, приведет к неожиданному сканированию, особенно если вы хотите ограничить доступ с помощью этих кодов состояния.
Роботы с реализацией, основанной на спецификации A Method for Web Robots Control от 1996 года, вероятно, будут рассматривать коды состояния 401 и 403 как ограничение доступа. В документе в разделе 3. 1 указано:
При ответе сервера с указанием ограничений доступа (код состояния HTTP 401 или 403) робот должен считать доступ к сайту полностью ограниченным.
Однако это только рекомендация, а не требование. Требования касаются только явного существования (коды состояния 2xx) и явного отсутствия (код состояния 404) файла robots.txt. Это оставляет много случаев открытыми для интерпретации.
Роботы с реализацией, основанной на спецификации протокола исключения роботов, будут рассматривать 401 и 403 как недоступные коды состояния, что может разрешить сканирование. В документе в разделе 2.3.1.3 указано:
Недоступно означает, что сканер пытается получить файл robots.txt, а сервер отвечает кодами состояния недоступности. Например, в контексте HTTP недоступные коды состояния находятся в диапазоне 400–499.
Если код состояния сервера указывает на то, что файл robots.txt недоступен для клиента, сканеры МОГУТ получить доступ к любым ресурсам на сервере или МОГУТ использовать кэшированную версию файла robots.
Здесь четко указано, что сканирование разрешено для кодов состояния 401 и 403, но поисковые роботы по-прежнему могут рассматривать это как ограничение доступа.
Рекомендация в старом документе и спецификация в новом документе противоречат друг другу. Использование кодов состояния HTTP для разрешения или ограничения доступа является плохой практикой и не имеет четкого определения. Вместо этого следует реализовать правильный файл robots.txt с кодом состояния 200.
Обработка запланированных простоев
Когда вы доставляете файл robots.txt с кодом состояния 503, роботы некоторых основных поисковых систем перестают сканировать веб-сайт. Даже во время запланированного простоя рекомендуется сохранить файл robots.txt с кодом состояния 200 и предоставлять только коды состояния 503 для всех остальных URL-адресов.
Изменение файла robots.txt на
User-agent: * Disallow: /
— худшее, что вы можете сделать во время простоя, и обычно вызывает проблемы, которые длятся довольно долго.
Блокировать контент, который не должен индексироваться
Блокировать URL-адреса, которые не должны индексироваться или сканироваться ботом, также не рекомендуется. Поисковые системы склонны перечислять известные страницы даже после того, как они были заблокированы. Вы должны использовать noindex в качестве заголовка или метатега, чтобы сначала удалить сайты из индекса.
Файлы robots.txt для каталогов
Некоторые также считают, что для каждого каталога можно создать отдельный файл robots.txt. Это не вариант!
Инструкции должны быть доступны через HTTP с сайта, к которому должны быть применены инструкции, как ресурс интернет-медиа. Введите «text/plain» по стандартному относительному пути на сервере: «/robots.txt».
Файл robots.txt необходимо поместить в корневой каталог хоста.
Проанализируйте проблемы с разбором robots.txt в несколько кликов с Audisto
Наше программное обеспечение будет систематически проверять все хосты на соответствие файлам robots. txt и предупреждать вас о многих обнаруженных распространенных проблемах. Убедитесь, что ваши директивы robots управляют ботами, как задумано.
Заказать демонстрацию
Файл robots.txt в Yoast SEO • Yoast
Файл robots.txt сообщает поисковой системе, где на вашем сайте разрешен доступ. В этой статье мы объясним, как файл robots.txt работает с Yoast SEO.
Вы можете улучшить сканирование вашего сайта поисковыми системами с помощью настроек оптимизации сканирования в Yoast SEO Premium! Они позволяют удалять ненужные URL-адреса, чтобы поисковые системы могли более эффективно сканировать ваш сайт!
Хотите узнать больше о том, что такое файл robots.txt и для чего он нужен? Ознакомьтесь с нашим полным руководством по robots.txt.
Директивы Yoast SEO по умолчанию
По умолчанию WordPress создает файл robots.txt со следующим содержимым:
Агент пользователя: * Запретить: /wp-admin/ Разрешить: /wp-admin/admin-ajax.
Когда вы создаете robots.txt с помощью Yoast SEO, мы заменим WordPress по умолчанию следующим:
# НАЧАТЬ БЛОК YOAST # ------------------------------------------ Пользовательский агент: * Запретить: Карта сайта: https://www.example.com/sitemap_index.xml # ------------------------------------------ # END YOAST BLOCK
Эти директивы позволяют всем поисковым системам сканировать ваш сайт. Кроме того, мы добавляем ссылку на вашу карту сайта, чтобы поисковые системы и (в частности, Bing) могли найти ее и более эффективно сканировать ваш сайт.
Как создать файл robots.txt в Yoast SEO
Самый простой способ создать или отредактировать файл robots.txt — через Yoast SEO на панели инструментов WordPress. Для этого выполните следующие действия.
- Войдите на свой сайт WordPress.
Когда вы войдете в систему, вы окажетесь в своей «Панель инструментов».
- Нажмите «Yoast SEO» в меню администратора.
- Нажмите «Инструменты».
- Нажмите «Редактор файлов».
Это меню не появится, если в вашей установке WordPress отключено редактирование файлов. Включите редактирование файла или отредактируйте файл через FTP. Если вы не знаете, как использовать FTP, вам может помочь ваш хост-провайдер.
- Нажмите кнопку Создать файл robots.txt.
- Просмотрите (или отредактируйте) файл, созданный Yoast SEO.
Вы увидите направления, которые Yoast SEO добавляет в файл по умолчанию. Вы также можете отредактировать файл здесь.
Создание или редактирование на вашем сервере
Если файл robots.txt недоступен для записи или ваша установка WordPress отключила редактирование файла, создание или редактирование robots.txt с помощью Yoast SEO может завершиться ошибкой. В этом случае вы можете редактировать на уровне сервера.