
Robots.txt директивы и настройки индексации сайта
Содержание
- Что такое файл robots.txt?
- Функции robots.txt
- Где хранить файл robots.txt?
- Плюсы и минусы robots.txt
- Синтаксис robots.txt
- Как использовать групповые символы/регулярные выражения
- Валидация robots.txt
Файл robots.txt — это один из основных способов сообщить поисковой системе
, к каким частям сайта она может получить доступ, а к каким нет. Данное руководство охватывает практически все возможные нюансы, связанные с robots.txt. Несмотря на то, что настройка файла robots.txt выглядит простой и незамысловатой, все-таки ошибки в нем могут нанести серьезный вред сайту.
Что такое файл robots.txt?
Robots.txt — это текстовый файл, с точным синтаксисом, который предназначен для чтения поисковыми системами. Эти системы также называют роботами, отсюда и одноименное название файла. Точность синтаксиса объясняется тем, что файл читается компьютером.
Robots.txt (известный также как «протокол исключений» (Robots Exclusion Protocol), был согласован разработчиками первых поисковых роботов. Файл не был стандартизирован какой-либо официальной организацией, но для всех крупных поисковых систем robots.txt, по сути, является стандартом.
Функции robots.txt
Поисковые системы индексируют веб-сайты за счет сканирования страниц. При этом осуществляются переходы по ссылкам с сайта «А» на сайт «Б», «В» и т.д. Прежде чем поисковая система начнет сканирование любой страницы в домене, с которым она прежде не сталкивалась, происходит открытие файла robots.txt этого домена. В свою очередь, файл robots.txt сообщает поисковой системе, какие URL на этом сайте разрешены для индексации.
Поисковая система кэширует контент robots.txt и обновляет его несколько раз в день, таким образом изменения отображаются очень быстро.
Где хранить файл robots.txt?
Файл robots.txt должен всегда находиться в корневой папке домена. Так, если адрес домена — www.example.com, тогда файл должен присутствовать здесь: http://www.example.com/robots.txt.
Так, если адрес домена — www.example.com, тогда файл должен присутствовать здесь: http://www.example.com/robots.txt.
Если домен отображается без www, таким же должен быть и robots.txt. Это же касается http и https.
Еще очень важно, чтобы файл назывался именно как robots.txt.
Плюсы и минусы robots.txt
Плюс: бюджет
Каждый сайт допускает сканирование определенного количества страниц. Блокируя доступ поисковой системы к разделам сайта, вы тем самым экономите средства, которые могут пойти на другие разделы. В особенности на сайтах, где требуется достаточно много работы по части SEO, может быть очень уместно сразу же заблокировать доступ к определенным разделам.
Блокировка параметров запросов
Одна из ситуаций, когда могут понадобиться дополнительные средства — сайт использует множество параметров в строке запроса для фильтрации и сортировки. Допустим, есть 10 разных параметров запросов и разных значений, которые могут использоваться в любой комбинации.
В результате получаются сотни, если не тысячи вариаций. Блокировка всех параметров запросов позволит сделать так, чтобы поисковая система сканировала только основные URL сайта.
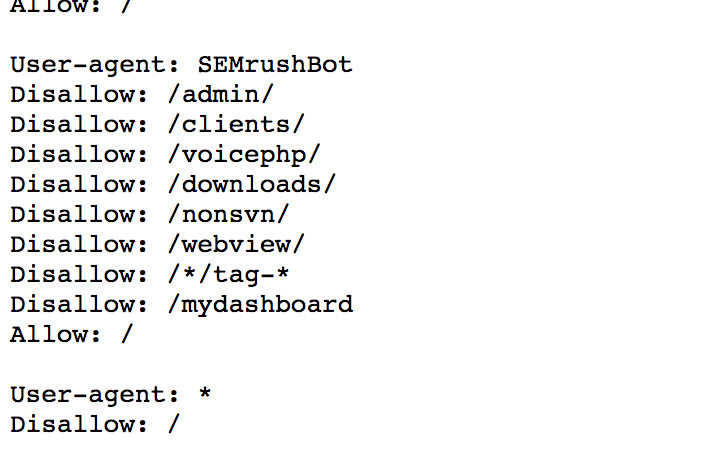
Линия, блокирующая все URL сайта, с запросом:
Disallow: /*?*
 В результате получаются сотни, если не тысячи вариаций. Блокировка всех параметров запросов позволит сделать так, чтобы поисковая система сканировала только основные URL сайта.
В результате получаются сотни, если не тысячи вариаций. Блокировка всех параметров запросов позволит сделать так, чтобы поисковая система сканировала только основные URL сайта. Минус: страница не удаляется из результатов поиска
Файл robots.txt сообщает поисковому пауку, в какую часть сайта он не может проникнуть. Но невозможно указать поисковой системе на то, какие URL не следует показывать в поисковых результатах. Это означает, что если поисковой системе запретить доступ к определенному URL, ссылка все еще может появляться в поисковых результатах. Если поисковая система обнаружит достаточно много ссылок, ведущих к этому URL, он будет добавлен, но при этом поисковая система не будет «знать» что на этой странице.
Если вы хотите сделать так, чтобы страница не появлялась в результатах поиска, понадобится атрибут noindex. Это означает, что у поисковой системы должна быть возможность индексировать страницу и найти атрибут noindex, поэтому страница не должна блокироваться в файле robots. txt.
txt.
Синтаксис robots.txt
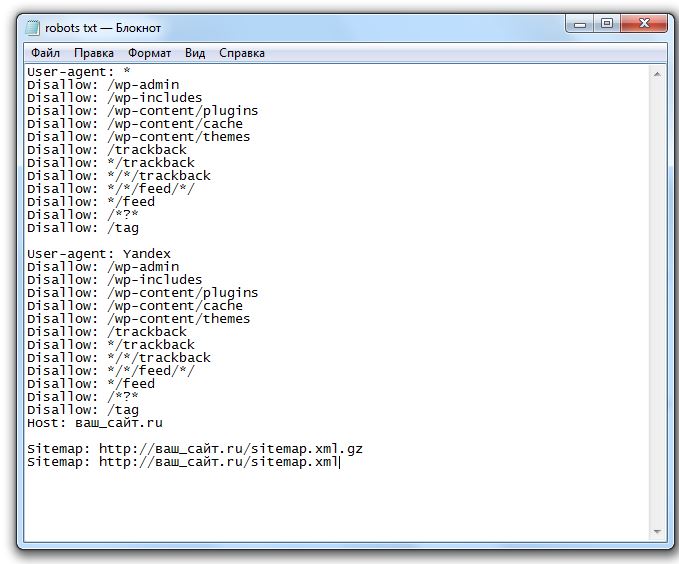
WordPress robots.txt
Файл robots.txt включает в себя один и больше блоков директив, каждый начинается с линии user-agent. «User-agent» — это название специфического робота. У вас может быть один блок для всех поисковых систем, использующих групповой символ для user-agent, или специфические блоки для поисковых систем. Поисковый робот всегда будет выбирать наиболее точное название блока.
Эти блоки выглядят следующим образом:
User-agent: *
Disallow: /
User-agent: Googlebot
Disallow:
User-agent: bingbot
Disallow: /not-for-bing/
Директивы Allow и Disallow не должны быть чувствительны к регистру (прописных или строчных букв). Но при выборе значения параметров все же следует учитывать состояние регистра. /photo/ — не то же самое, что /Photo/. Директивы пишутся прописными для удобочитаемости файла.
Директива User-agent
Первая часть любого блока директив — user-agent — идентифицирует определенного робота/паука. Поле user-agent сопоставляется со специфическим полем user-agent робота (обычно более длинным).
Поле user-agent сопоставляется со специфическим полем user-agent робота (обычно более длинным).
Например:
Mozilla/5.0 (compatible; Googlebot/2.1;
+http://www.google.com/bot.html)
Относительно простой линии User-agent: Googlebot будет вполне достаточно, если вы хотите сообщить роботу о том, что необходимо сделать.
У большинства поисковых систем имеется несколько роботов, которые используются для индексации, рекламных кампаний, изображений, видео и т.д.
Поисковые системы всегда будут выбирать самые специфические блоки директив, из тех, которые обнаружат. Например, есть три набора директив: одна для *, одна для Googlebot и еще одна — для Googlebot-News. Если блок определяет, кому принадлежит юзер-агент Googlebot-Video, будут соблюдены ограничения Googlebot. Бот с юзер-агентом Googlebot-News будет использовать более специфические директивы Googlebot-News.
Самые распространенные юзер-агенты для поисковых роботов:
Ниже представлен список юзер-агентов, которые можно использовать в файле robots. txt для сопоставления с самыми распространенными поисковыми системами:
txt для сопоставления с самыми распространенными поисковыми системами:
| Поисковая система | Поле | User-agent |
| Baidu | General | baiduspider |
| Baidu | Images | baiduspider-image |
| Baidu | Mobile | baiduspider-mobile |
| Baidu | News | baiduspider-news |
| Baidu | Video | baiduspider-video |
| Bing | General | bingbot |
| Bing | General | msnbot |
| Bing | Images & Video | msnbot-media |
| Bing | Ads | adidxbot |
| General | Googlebot | |
| Images | Googlebot-Image | |
| Mobile | Googlebot-Mobile | |
| News | Googlebot-News | |
| Video | Googlebot-Video | |
| AdSense | Mediapartners-Google | |
| AdWords | AdsBot-Google | |
| Yahoo! | General | slurp |
| Yandex | General | yandex |
Директива Disallow
Вторая линия в любом блоке директив — это линия Disallow. У вас может быть одна или несколько таких линий, определяющих те разделы сайта, к которым робот определенной системы не может получить доступ. Пустая линия Disallow означает, что запрещенных разделов нет, и что поисковому роботу предоставлен доступ ко всему сайту целиком.
У вас может быть одна или несколько таких линий, определяющих те разделы сайта, к которым робот определенной системы не может получить доступ. Пустая линия Disallow означает, что запрещенных разделов нет, и что поисковому роботу предоставлен доступ ко всему сайту целиком.
User-agent: *
Disallow: /
Эта линия блокирует доступ всех поисковых систем к вашему сайту.
User-agent: *
Disallow:
Эта линия разрешит всем поисковым системам сканировать весь ваш сайт.
User-agent: googlebot
Disallow: /Photo
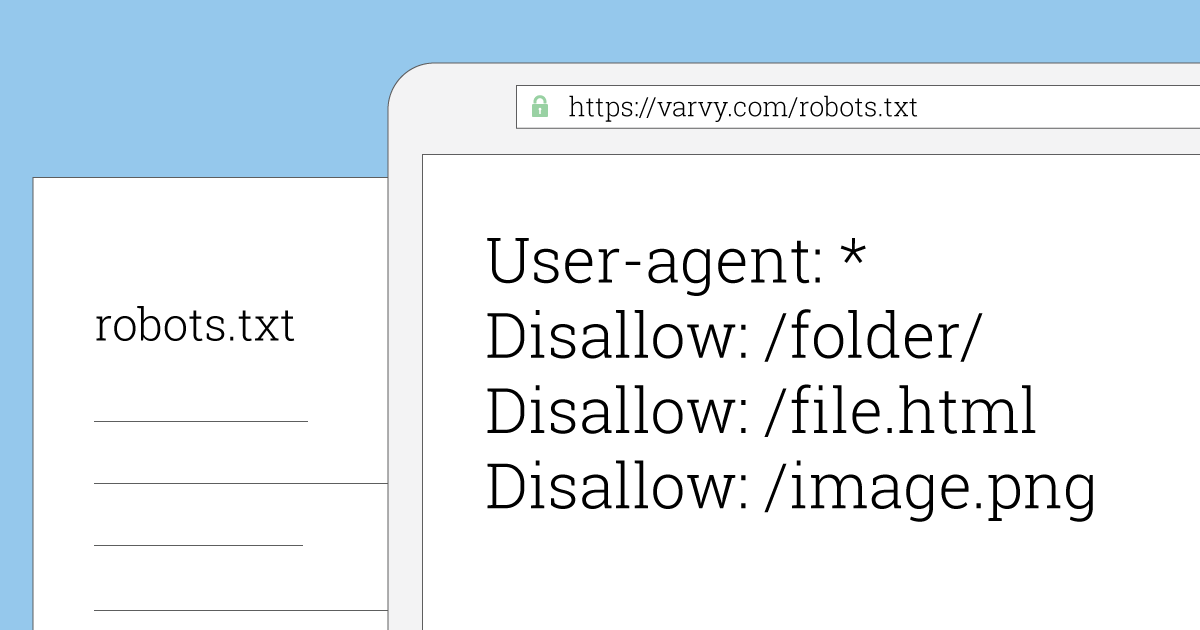
Эта линия запретит Google сканировать директорию Photo на вашем сайте и все ее содержимое. Все поддиректории /Photo также не будут сканироваться. Но эта линия не закроет Google доступ к директории photo, т.к. линии учитывают состояние регистра прописных и строчных символов.
Как использовать групповые символы/регулярные выражения
«Официально» стандарт robots. txt не поддерживает ни регулярные выражения, ни групповые символы. Однако все крупные поисковые системы их понимают. А это значит, что вы можете использовать такие линии, чтобы блокировать группы файлов:
txt не поддерживает ни регулярные выражения, ни групповые символы. Однако все крупные поисковые системы их понимают. А это значит, что вы можете использовать такие линии, чтобы блокировать группы файлов:
Disallow: /*.php
Disallow: /copyrighted-images/*.jpg
В приведенном выше примере * расширяется до названия совпадающего файла. Остальная часть лини не чувствительна к регистру, поэтому не будет блокироваться доступ поискового робота к файлу /copyrighted-images/example.JPG.
Некоторые системы, такие как Google, разрешают использование более усложненных регулярных выражений. Однако стоит учитывать, что не все поисковые системы способны понять такую логику. Самая полезная особенность — $, что указывает на конец URL.
Disallow: /*.php$
Это означает, что /index.php нельзя индексировать, но /index.php?p=1 — возможно. Конечно, данная особенность применима лишь особых ситуациях, и ее использование сопряжено с определенным риском: легко допустить ошибку и разблокировать то, что не нужно.
Нестандартные директивы robots.txt
Кроме директив Disallow и User-agent существуют ряд других, которые вы можете использовать. Эти директивы не поддерживаются всеми краулерами поисковых систем, поэтому следует учитывать такое ограничение.
Директива Allow
Это неоригинальная «спецификация», тем не менее большинство поисковых систем ее понимают, что дает возможность формировать очень простые и читабельные директивы:
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Единственно возможный способ достичь того же результата без директивы allow — специально добавить disallow к каждому файлу в папке wp-admin.
Директива noindex
Это одна из наименее известных директив, но Google ее фактически поддерживает. Однако использование метода блокировки, который только лишь убирает страницу из Google, означает, что эта страница останется открытой для других поисковых систем.
Стоит иметь в виду, что директива noindex официально не поддерживается Google, т.е. если она работает сейчас, в будущем ситуация может измениться.
Директива host
Поддерживается Яндексом (но не Google, даже несмотря на то, что в некоторых публикациях утверждается обратное), эта директива позволяет решить, будет ли поисковая система высвечивать адрес example.com или www.example.com.
Простой линии host: example.com будет достаточно.
На эту директиву не стоит полагаться, т.к. она поддерживается только Yandex. К тому же она не позволяет выбрать — http или https. Более подходящее решение, которое применимо для всех поисковых систем, — перенаправление 301 для всех названий хостов, которые вы не хотите индексировать.
www.example.com -> example.com
Директива crawl-delay
Директива crawl-delay поддерживается Yahoo!, Bing и Yandex — она позволяет несколько замедлить эти три системы, которые порой проявляют чрезмерную активность по части сканирования сайтов. Способы чтения директив у этих поисковых систем разные, но конечный результат принципиально не отличается.
Способы чтения директив у этих поисковых систем разные, но конечный результат принципиально не отличается.
crawl-delay: 10
Эта линия приведет к тому, что Yahoo! и Bing будет ждать 10 секунд после сканирующего действия.
Yandex будет получать доступ к вашему сайту через каждые десять секунд.
Устанавливая crawl delay на 10 секунд, вы позволяете этим поисковым системам индексировать только 8,640 страниц в день. Для маленького сайта это довольно много, но не для большого. С другой стороны, если вы не получаете трафик от упомянутых систем, это неплохой способ снизить нагрузку на полосу пропускания.
Директива sitemap для XML Sitemaps
С помощью директивы sitemap вы можете сообщить поисковой системе (в частности, Bing, Yandex и Google), где расположены XML-файлы. Конечно же, у вас есть возможность предоставить XML Sitemaps каждой поисковой системе, используя соответствующий инструментарий веб-мастера. Инструменты веб-мастера поисковых систем предоставляют очень ценную информацию о сайте. Если вы не хотите этого делать, как альтернативный вариант можете добавить sitemap в robots.txt.
Если вы не хотите этого делать, как альтернативный вариант можете добавить sitemap в robots.txt.
Валидация robots.txt
Существует множество инструментов, которые позволяют провести валидацию robots.txt. Однако когда необходимо подтвердить директивы, лучше обратиться к первоисточнику. У Google имеется тестовый инструмент для robots.txt в Google Search Console (меню Crawl):
И, конечно же, целесообразнее тщательно протестировать изменения перед их запуском.
Владельцу сайта нужно позаботиться о том, чтобы в поиск не попала конфиденциальная информация — например, личные данные пользователей, их переписка или счета. Такие страницы нужно запрещать индексировать, рекомендуется закрывать страницы со служебной информацией и страницы-дубликаты так как это напрямую влияет на продвижение сайта в поиске.
robots.txt · Курс молодого CTF бойца v 1.5
Стандарт исключений для роботов (robots.txt) — файл ограничения доступа к содержимому роботам на http-сервере.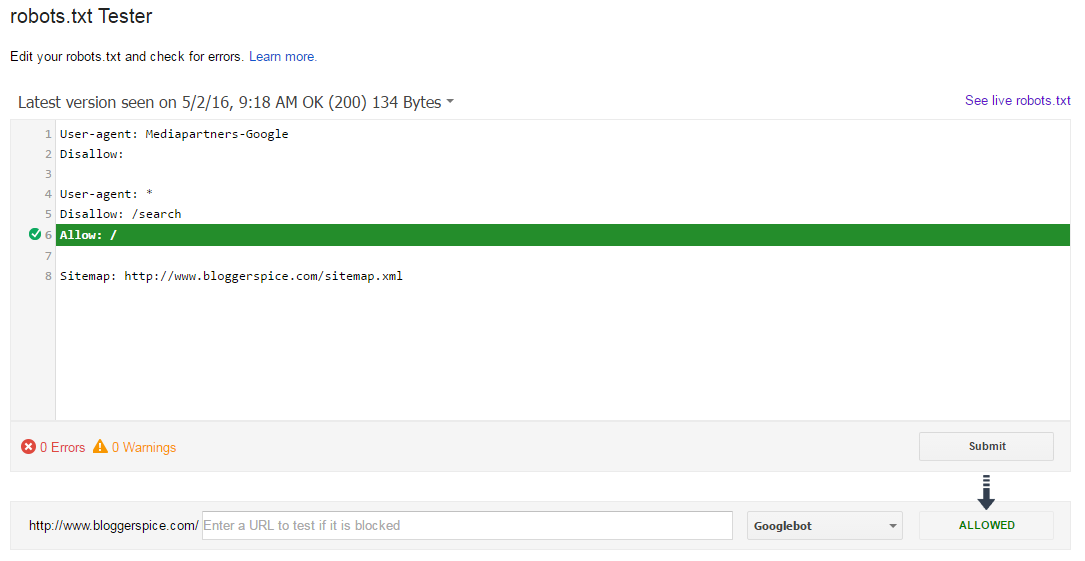 Файл должен находиться в корне сайта (то есть иметь путь относительно имени сайта /robots.txt). При наличии нескольких поддоменов файл должен располагаться в корневом каталоге каждого из них.
Файл должен находиться в корне сайта (то есть иметь путь относительно имени сайта /robots.txt). При наличии нескольких поддоменов файл должен располагаться в корневом каталоге каждого из них.
Файл robots.txt используется для частичного управления индексированием сайта поисковыми роботами. Этот файл состоит из набора инструкций для поисковых машин, при помощи которых можно задать файлы, страницы или каталоги сайта, которые не должны индексироваться.
Описание структуры Файл состоит из записей. Записи разделяются одной или более пустых строк (признак конца строки: символы CR, CR+LF, LF). Каждая запись содержит непустые строки следующего вида:
<поле>:<необязательный пробел> <значение><необязательный пробел>
где поле — это либо User-agent, либо Disallow. Примеры Запрет доступа всех роботов ко всему сайту:
User-agent: * Disallow: /
Запрет доступа определенного робота к каталогу /private/:
User-agent: googlebot Disallow: /private/
Нестандартные директивы Crawl-delay: устанавливает время, которое робот должен выдерживать между загрузкой страниц. Если робот будет загружать страницы слишком часто, это может создать излишнюю нагрузку на сервер. Впрочем, современные поисковые машины по умолчанию задают достаточную задержку в 1-2 секунды.
Если робот будет загружать страницы слишком часто, это может создать излишнюю нагрузку на сервер. Впрочем, современные поисковые машины по умолчанию задают достаточную задержку в 1-2 секунды.
User-agent: * Crawl-delay: 10
Allow: имеет действие, обратное директиве Disallow — разрешает доступ к определенной части ресурса. Поддерживается всеми основными поисковиками. В следующем примере разрешается доступ к файлу photo.html, а доступ поисковиков ко всей остальной информации в каталоге /album1/ запрещается.
Allow: /album1/photo.html Disallow: /album1/
Решение тасков Итак, открываем таск и видим:
Обращаем внимание на название и описание к таску — «Are you robot?». Так, обычно, организаторы пытаются указать нам путь решения, и, я думаю, что после такой подсказки вариантов решение остается немного:) Далее переходим по ссылке указанной в задании: Ну и далее пробуем воспользоваться подсказкой из задания: Смотрим файл robots.
Ну и получаем флаг. Таск решен.
Robots.txt Рекомендации по миграции HTTPS
Файл robots.txt
Файл robot.txt содержит поисковые роботы, такие как Googlebot, с инструкциями по взаимодействию с вашим сайтом. При переносе вашего сайта на HTTPS очень важно, как робот Googlebot взаимодействует с вашим сайтом.
Что нужно знать о файле robots.txt при переходе на HTTPS
При планировании перехода на HTTPS важно знать четыре конкретных момента о статусе файла robots.txt.
- Если существует
- Что там написано
- Если упоминается карта сайта
- Если он блокирует ресурсы страницы
1.
 Если он существует
Если он существуетФайл robots.txt есть не на каждом сайте, но он находится в одном месте на всех сайтах, которые его используют.
http://www.example.com/robots.txt
Чтобы узнать, есть ли у вас файл robots.txt, просто замените указанный выше домен своим доменом. Если у вас есть файл robots.txt, вы увидите его по этому адресу.
2. Что там написано
Многие файлы robots.txt очень просты. Типичный файл, предоставляющий полный доступ, будет выглядеть так:
User-agent: *
Disallow:
Некоторые файлы robots.txt сложные и длинные:
User-agent: *
Disallow: /wp-content/uploads /2014/
Запретить: /wp-content/uploads/2015/
Запретить: /wp-login.php
Запретить: /wp-admin/
Запретить: /send-to/
Запретить: /page/
Запретить: / 2015/
Запретить: /2016/
Disallow: /2017/
Disallow: /*?*
Noindex: /wp-login.php
Noindex: /wp-admin/
Noindex: /send-to/
Noindex: /page/
Noindex: /2015/
Noindex: /2016/
Noindex: /2017/
Noindex: /*?*
Noindex: /ml-thanks/
Noindex: /downloads/
Noindex: /robots. txt
txt
Важно убедиться, что вы понимаете что делает ваш файл robots.txt, независимо от того, простой он или сложный. Если вы не понимаете, что делает ваш robots.txt, вам следует обратиться за советом, поскольку содержимое вашего файла robots.txt может сильно повлиять на успех вашей миграции HTTPS.
3. Если в нем упоминается карта сайта
Когда файл robots.txt указывает на карту сайта, это выглядит так:
User-agent: *
Disallow: /wp-content/uploads/2009/
Disallow: /wp -content/uploads/2010/
Карта сайта: https://example.com/sitemap.xml
Последняя строка приведенного выше примера начинается со слова «Карта сайта:» и сопровождается URL-адресом. Именно так файлы robots.txt указывают на карты сайта. Если в вашем файле есть такая строка, это указывает на карту сайта.
4. Если блокирует ресурсы страницы
Если ваш файл robots.txt блокирует ресурсы страницы, такие как файлы CSS или Javascript, это может негативно повлиять на ваш рейтинг. В рекомендациях Google для веб-мастеров указано, что вы не должны блокировать ресурсы страницы.
В рекомендациях Google для веб-мастеров указано, что вы не должны блокировать ресурсы страницы.
Заблокированные ресурсы могут повлиять на успешное переключение HTTPS.
Проверка статуса файла robots.txt в Google Search Console
Вы можете получить отличный обзор статуса файла robots.txt в Google Search Console.
На странице тестера robots.txt отображаются инструкции к файлу robot.txt, а также любые ошибки и предупреждения.
Если у вас есть какие-либо ошибки или предупреждения, их следует устранить до перехода на HTTPS.
Подготовка файла robots.txt для HTTPS
Перед переключением на HTTPS у вас должен быть готов к работе файл robots.txt.Единственная разница между файлами robot.txt HTTP и HTTPS на данном этапе должна состоять в ссылке на карту сайта.
Ваш HTTPS robots.txt должен указывать на вашу карту сайта HTTPS (карта сайта HTTPS должна только включать URL-адреса HTTPS).
Мы рекомендуем отдельные файлы robots.
Веб-мастера Google
 txt для HTTP и HTTPS, указывая на отдельные файлы карты сайта для HTTP и HTTPS. Мы также рекомендуем указать конкретный URL-адрес только в одном файле карты сайта.
txt для HTTP и HTTPS, указывая на отдельные файлы карты сайта для HTTP и HTTPS. Мы также рекомендуем указать конкретный URL-адрес только в одном файле карты сайта.Самый идеальный файл robots.txt для коммутатора HTTPS
Правда в том, что пустой файл robots.txt или файл, специально разрешающий сканирование всех пользовательских агентов, является наиболее идеальным для перехода на HTTPS.
Это не всегда возможно, и большинство людей думают, что это безумие. Давайте посмотрим, что Google рекомендует для перехода на HTTPS…
На исходном сайте удалите все директивы robots.txt. Это позволяет роботу Googlebot обнаруживать все перенаправления на новый сайт и обновлять наш индекс.
На целевом сайте убедитесь, что файл robots.txt разрешает сканирование. Это включает в себя сканирование изображений, CSS, JavaScript и других ресурсов страницы, кроме URL-адресов, которые вы точно не хотите сканировать.
Справочная документация Google
В справочной документации Google переход с HTTP на HTTPS считается «перемещением сайта с изменением URL». Это означает, что этапы миграции с HTTP на HTTPS несколько «сведены» в ту же документацию, которая охватывает другие перемещения сайта (например, изменение имени вашего домена). Иногда это вызывает путаницу.
Потратьте время, чтобы убедиться, что вы знаете инструкции для своего робота.
Многие веб-сайты используют файл robots.txt и содержат сложные, хорошо продуманные и спланированные инструкции для роботов. Тем не менее, если бы мы следовали справочной документации Google, мы, по сути, потеряли бы всю эту структуру, и это вызвало бы некоторый хаос.
Лучше всего знать, о чем говорится в инструкциях вашего робота и почему эти инструкции существуют.
Если вы уверены, что ваш файл robots.txt надежен и не оказывает негативного влияния на ваш рейтинг или индексацию, вы можете оставить его таким, какой он есть для вашего HTTPS-переключателя.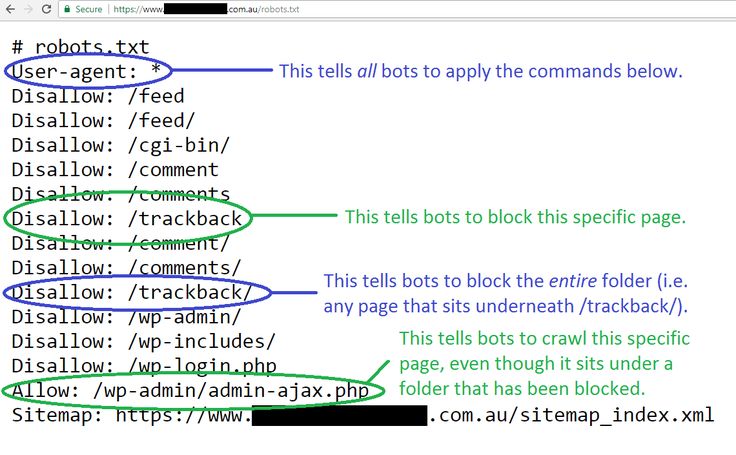 Это то, что делает большинство людей.
Это то, что делает большинство людей.
Как указано выше, единственное реальное изменение между файлами robots.txt HTTP и robots.txt HTTPS — это ссылка на карту сайта.
Bottom Line
Важно, чтобы вы были знакомы с файлом robots.txt и были уверены, что он соответствует вашим требованиям.
Во время переключения HTTPS робот Googlebot будет сканировать и повторно сканировать все ваши URL-адреса и файлы. Файл robots.txt содержит инструкции для робота Googlebot и поэтому имеет решающее значение для того, как пройдет ваша миграция HTTP.
Если вы обнаружите ошибки, предупреждения или заблокированный контент, вероятно, стоит потратить время на их исправление до переноса HTTPS. Это позволит представить более идеальную версию вашего сайта для индексации по протоколу HTTPS.
Дополнительные статьи о HTTPS
Редактирование файла robots.txt вашего сайта | Справочный центр
Файл robots.txt сообщает поисковым системам, какие страницы вашего сайта включать или пропускать в результатах поиска. Поисковые системы проверяют файл robots.txt вашего сайта, когда сканируют и индексируют ваш сайт. Это не гарантирует, что поисковые системы будут или не будут сканировать страницу или файл, но может помочь предотвратить менее точные попытки индексации.
Поисковые системы проверяют файл robots.txt вашего сайта, когда сканируют и индексируют ваш сайт. Это не гарантирует, что поисковые системы будут или не будут сканировать страницу или файл, но может помочь предотвратить менее точные попытки индексации.
Если вы хотите лучше контролировать запросы на сканирование вашего сайта, вы можете отредактировать файл robots.txt.
Из этой статьи вы узнаете больше о:
Что такое файл robots.txt
Файл robots.txt содержит инструкции по разрешению или запрещению определенных запросов от поисковых систем. Команда «разрешить» сообщает сканерам ссылки, по которым они могут переходить, а команда «запретить» сообщает сканерам ссылки, по которым они не могут переходить. Он также включает URL-адрес файла карты сайта вашего сайта.
Вы можете просмотреть файл robots.txt своего сайта, добавив «/robots.txt» в корневой домен. Например: https://www.mystunningwebsite.com/robots.txt .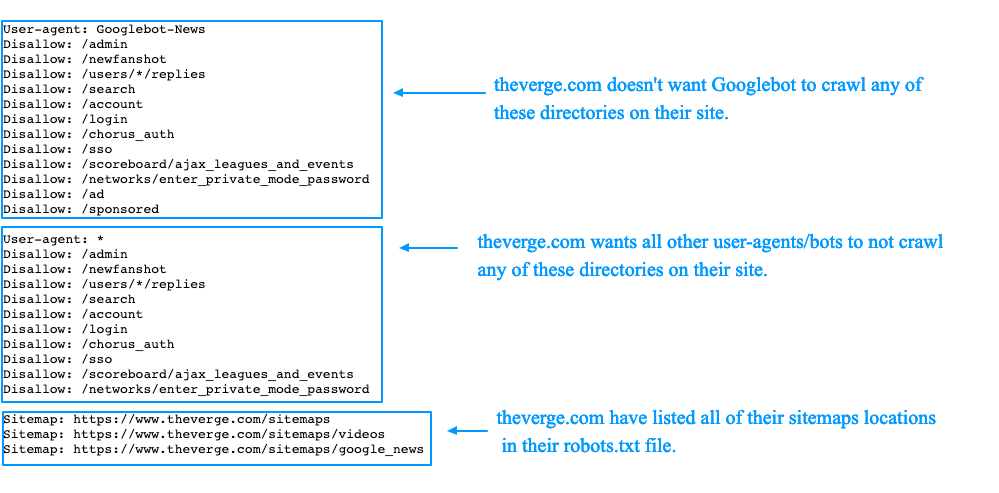
Редактирование файла robots.txt
Вы можете редактировать файл robots.txt своего сайта с помощью редактора Robots.txt в разделе инструментов SEO на панели инструментов вашего сайта. Файл robots.txt вашего сайта по умолчанию позволяет ботам выполнять поиск на всех страницах вашего сайта. Исключениями являются:
Прежде чем вносить изменения в файл robots.txt, рекомендуем ознакомиться с рекомендациями и ограничениями Google для файлов robot.txt.
Чтобы отредактировать файл robots.txt:
- Перейдите к инструментам SEO на панели инструментов вашего сайта.
- Нажмите Редактор Robots.txt .
- Нажмите Просмотреть файл .
- Добавьте информацию о файле robots.txt, написав директивы под Это ваш текущий файл .
- Нажмите Сохранить изменения .
- Щелкните Сохранить .
Сброс файла robots.
 txt
txtЕсли вы изменили файл robots.txt своего сайта и хотите вернуть его обратно, вы можете восстановить его состояние по умолчанию с помощью редактора Robots.txt в разделе инструментов SEO на панели управления вашего сайта.
Чтобы сбросить файл robots.txt:
- Перейдите к инструментам SEO на панели инструментов вашего сайта.
- Нажмите Редактор Robots.txt .
- Нажмите Просмотреть файл .
- Нажмите Восстановить настройки по умолчанию .
- Нажмите Сброс .
Ошибка robots.txt в Wix Site Inspection или Google Search Console
Иногда вы можете видеть такие ошибки, как Blocked by robots.txt , в отчете Wix Site Inspection или в вашей учетной записи Google Search Console.
Если вы видите подобную ошибку, вам не нужно редактировать файл robot.txt, особенно если вы никогда не редактировали его раньше.