
Robots.txt — инструкция для SEO
24173 222
| SEO | – Читать 12 минут |
Прочитать позже
ЧЕК-ЛИСТ: ТЕХНИЧЕСКАЯ ЧАСТЬ — ROBOTS.TXT
Ильхом Чакканбаев
Автор блога Seopulses.ru
Файл robots.txt — это текстовый файл, в котором содержаться инструкции для поисковых роботов, в частности каким роботам и какие страницы допускается сканировать, а какие нет. В данной статье рассмотрим, где можно найти robots.txt, как его редактировать и какие правила по его использовать в SEO-продвижении.
Содержание
1. Зачем robots.txt нужен на сайте
2. Где можно найти файл robots.txt и как его создать или редактировать
3. Как создать и редактировать robots.txt
4. Инструкция по работе с robots.txt
5. Синтаксис в robots.txt
6. Директивы в Robots.txt
— Disallow
— Allow
— Sitemap
— Clean-param
— Crawl-delay
7. Как проверить работу файла robots. txt
txt
— В Яндекс.Вебмастер
— В Google Search Console
Заключение
Зачем robots.txt нужен на сайте
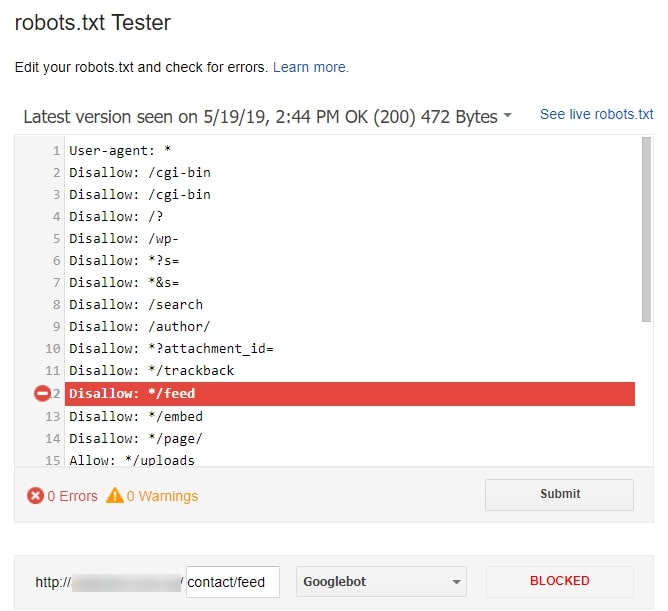
Командами robots.txt называются директивы, которые разрешают либо запрещают сканировать отдельные участки веб-ресурса. С помощью файла вы можете разрешать или ограничивать сканирование поисковыми роботами вашего веб-ресурса или его отдельных страниц, чем можете повлиять на позиции сайта. Пример того, как именно директивы будут работать для сайта:
На картинке видно, что доступ к определенным папкам, а иногда и отдельным файлам, не допускает к сканированию поисковыми роботами. Директивы в файле носят рекомендательный характер и могут быть проигнорированы поисковым роботом, но как правило, они учитывают данное указание. Техническая поддержка также предупреждает вебмастеров, что иногда требуются альтернативные методы для запрета индексирования:
Какие страницы нужно закрыть от индексации
| Читать |
Где можно найти файл robots.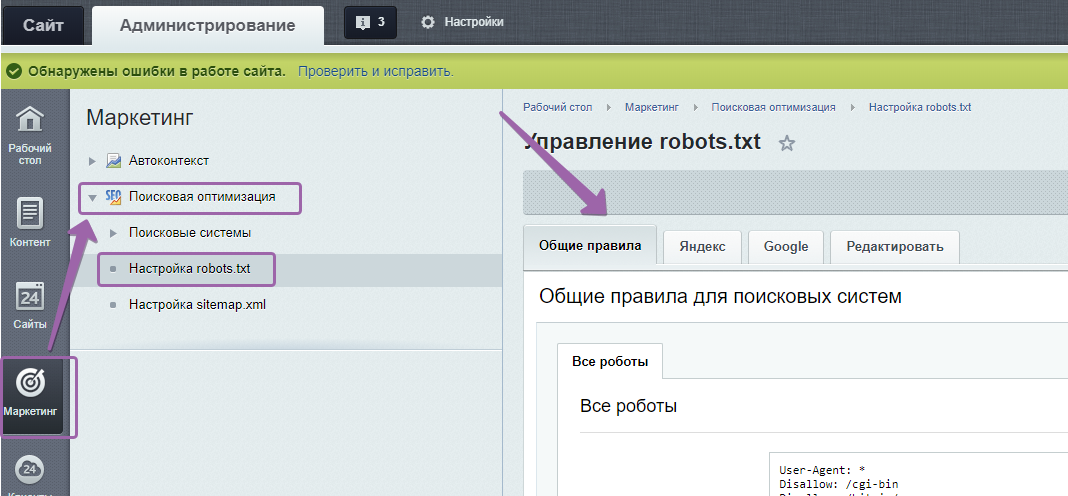 txt и как его создать или редактировать
txt и как его создать или редактировать
Чтобы проверить файл robots.txt сайта, следует добавить к домену «/robots.txt», примеры:
https://seopulses.ru/robots.txt
https://serpstat.com/robots.txt
https://netpeak.net/robots.txt
Как провести анализ индексации сайта
| Читать |
Как создать и редактировать robots.txt
Вручную
Данный файл всегда можно найти, подключившись к FTP сайта или в файлом редакторе хостинг-провайдера в корневой папке сайта (как правило, public_html):
Далее открываем сам файл и можно его редактировать.
Если его нет, то достаточно создать новый файл.
После вводим название документа и сохраняем.
Через модули/дополнения/плагины
Чтобы управлять данный файлом прямо в административной панели сайта следует установить дополнительный модуль:
Для 1С-Битрикс;
WordPress;
Для Opencart;
Webasyst.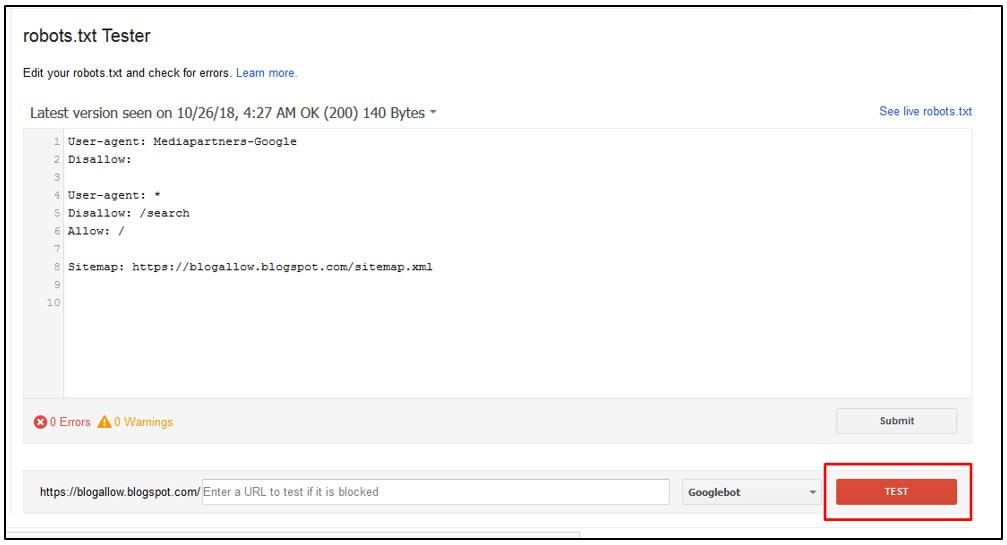
Самые распространенные SEO-ошибки на сайте: инфографика
| Читать |
Инструкция по работе с robots.txt
В первую очередь записывается User-Agent, указывая на то, к какому роботу идет обращение, например:
User-agent: Yandex — для обращения к поисковому роботу Яндекса;
User-agent: Googlebot — в случае с краулером Google;
User-agent: YandexImages — при работе с ботом Яндекс.Картинок.
Обращения в robots.txt для Яндекса:
Чтобы обозначить обращение для поисковых роботов данной системы применяют такие значения:
Yandex Bot — основной робот, который будет индексировать ваш ресурс;
Yandex Media — робот, который специализируется на сканировании мультимедийной информации;
Yandex Images — индексатор для Яндекс.Картинок;
Yandex Direct — робот, который сканирует страницы веб-площадок, имеющих отношение к рекламе в Яндексе;
Yandex Blogs — робот для поиска в блогах и форумах, который индексирует комментарии в постах;
Yandex News — бот собирающий данные по Яндекс Новостям;
Yandex Pagechecker — робот, который обращается к странице с целью валидировать микроразметку.
Обращения в robots.txt для Google:
Имена используемые для краулеров от Google:
Googlebot — краулер, индексирующий страницы веб-сайта;
Googlebot Image — сканирует изображения и картинки;
Googlebot Video — сканирует всю видео информацию;
AdsBot Google — анализирует качество размещенной рекламы на страницах для компьютеров;
AdsBot Google Mobile — анализирует качество рекламы мобильных версий сайта;
Googlebot News — оценивает страницы для использования в Google Новости;
AdsBot Google Mobile Apps — расценивает качество рекламы для приложений на андроиде, аналогично AdsBot.
Полный список роботов Яндекс и Google.
Синтаксис в robots.txt
В первую очередь записывается User-Agent, указывая на то, к какому роботу идет обращение, например:
# — отвечает за комментирование;
* — указывает на любую последовательность символов после этого знака. По умолчанию указывается при любого правила в файле;
По умолчанию указывается при любого правила в файле;
$ — отменяет действие *, указывая на то что на этом элементе необходимо остановиться.
Почему сайт не индексируется или
как проверить индексацию сайта в Google и Яндекс
| Читать |
Директивы в Robots.txt
Disallow
Disallow запрещает индексацию отдельной страницы или группы (в том числе всего сайта). Чаще всего используется для того, чтобы скрыть технические страницы, динамические или временные страницы.
Пример #1
# Полностью закрывает весь сайт от индексации
User-agent: *
Disallow: /
Пример #2
# Блокирует для скачивания все страницы раздела /category1/, например, /category1/page1/ или caterogy1/page2/
Disallow: /category1/
Пример #3
# Блокирует для скачивания страницу раздела /category2/
User-agent: *
Disallow: /category2/$
Пример #4
# Дает возможность сканировать весь сайт просто оставив поле пустым
User-agent: *
Disallow:
Важно! Следует понимать, что регистр при использовании правил имеет значение, например, Disallow: /Category1/ не запрещает посещение страницы /category1/.
Директива Allow указывает на то, что роботу можно сканировать содержимое страницы/раздела, как правило, используется, когда в полностью закрытом разделе, нужно дать доступ к определенному документу.
Пример #1
# Дает возможность роботу скачать файл site.ru//feed/turbo/ несмотря на то, что скрыт раздел site.ru/feed/.
Disallow: */feed/*
Allow: /feed/turbo/
Пример #2
# разрешает скачивание файла doc.xml
Allow: /doc.xml
Sitemap
Директива Sitemap указывает на карту сайта, которая используется в SEO для вывода списка URL, которые нужно проиндексировать в первую очередь.
Важно понимать, что в отличие от стандартных директив у нее есть особенности в записи:
Следует указывать полный URL, когда относительный адрес использовать запрещено;
На нее не распространяются остальные правила в файле robots. txt;
txt;
XML-карта сайта должна иметь в URL-адресе домен сайта.
Пример
Sitemap.xml или карта сайта: как создать и настроить для Google и Яндекс
| Читать |
Clean-param
Используется когда нужно указать Яндексу (в Google она не работает), что страница с GET-параметрами (например, site.ru?param1=2¶m2=3) и метками (в том числе utm) не влияющие на содержимое сайта, не должна быть проиндексирована.
Пример #1
#для адресов вида:
www.example1.com/forum/showthread.php?s=681498b9648949605&t=8243
www.example1.com/forum/showthread.php?s=1e71c4427317a117a&t=8243
#robots.txt будет содержать:
User-agent: Yandex
Disallow:
Clean-param: s /forum/showthread.php
Пример #2
#для адресов вида:
www.example2.com/index.php?page=1&sid=2564126ebdec301c607e5df
www. example2.com/index.php?page=1&sid=974017dcd170d6c4a5d76ae
example2.com/index.php?page=1&sid=974017dcd170d6c4a5d76ae
#robots.txt будет содержать:
User-agent: Yandex
Disallow:
Clean-param: sid /index.php
Подробнее о данной директиве можно прочитать здесь.
Crawl-delay
Важно! Данная директива не поддерживается в Яндексе с 22 февраля 2019 года и в Google 1 сентября 2019 года, но работает с другими роботами. Настройки скорости скачивания можно найти в Яндекс.Вебмастер и Google Search Console.
Crawl-delay указывает временной интервал в секундах, в течение которого роботу разрешается делать только 1 сканирование. Как правило, необходима лишь в случаях, когда у сайта наблюдается большая нагрузка из-за сканирования.
Пример
# Допускает скачивание страницы лишь раз в 3 секунды
Crawl-delay: 3
Хотите узнать, как использовать Serpstat для поиска ошибок на сайте?
Заказывайте бесплатную персональную демонстрацию сервиса, и наши специалисты вам все расскажут! 😉
| Оставить заявку! |
| Узнать подробнее! |
Как проверить работу файла robots. txt
txt
В Яндекс.Вебмастер
В Яндекс.Вебмастер в разделе «Инструменты→ Анализ robots.txt» можно увидеть используемый поисковиком свод правил и наличие ошибок в нем.
Также можно скачать другие версии файла или просто ознакомиться с ними.
Чуть ниже имеется инструмент, который дает возможно проверить сразу до 100 URL на возможность сканирования.
В нашем случае мы проверяем эти правила.
Как видим из примера все работает нормально.
Также если воспользоваться сервисом «Проверка ответа сервера» от Яндекса также будет указано, запрещен ли для сканирования документ при попытке обратиться к нему.
В Google Search Console
В случае с Google можно воспользоваться инструментом проверки Robots.txt, где потребуется в первую очередь выбрать нужный сайт.
Важно! Ресурсы-домены в этом случае выбирать нельзя.
Теперь мы видим:
Сам файл;
Кнопку, открывающую его;
Симулятор для проверки сканирования.
Если в симуляторе ввести заблокированный URL, то можно увидеть правило, запрещающее сделать это и уведомление «Недоступен».
Однако, если ввести заблокированный URL в страницу поиска в новой Google Search Console (или запросить ее индексирование), то можно увидеть, что страница заблокирована в файле robots.txt.
Заключение
Robots.txt необходим для ограничения сканирования определенных страниц вашего сайта, которые не нужно включать в индекс, так как они носят технический характер. Для создания такого документа можно воспользоваться Блокнотом или Notepad++.
Пропишите к каким поисковым роботам вы обращаетесь и дайте им команду, как описано выше.
Далее, проверьте его правильность через встроенные инструменты Google и Яндекс. Если не возникает ошибок, сохраните файл в корневую папку и еще раз проверьте его доступность, перейдя по ссылке http://yoursiteadress.com/robots.txt. Активная ссылка говорит о том, что все сделано правильно.
Помните, что директивы носят рекомендательный характер, а для того чтобы полностью запретить индексирование страницы нужно воспользоваться другими методами.
«Список задач» — готовый to-do лист, который поможет вести учет
о выполнении работ по конкретному проекту. Инструмент содержит готовые шаблоны с обширным списком параметров по развитию проекта, к которым также можно добавлять собственные пункты.
| Начать работу со «Списком задач» |
Сэкономьте время на изучении Serpstat
Хотите получить персональную демонстрацию сервиса, тестовый период или эффективные кейсы использования Serpstat?
Оставьте заявку и мы свяжемся с вами 😉
Оцените статью по 5-бальной шкале
4.71 из 5 на основе 13 оценок
Нашли ошибку? Выделите её и нажмите Ctrl + Enter, чтобы сообщить нам.
Рекомендуемые статьи
SEO
Анатолий Бондаренко
Основные ошибки в оптимизации сайта и как их выявить
SEO
Ilkhom Chakkanbaev
Идеальная оптимизация страницы сайта: наглядное руководство [Инфографика]
SEO
Анастасия Кочеткова
Краулинговый или рендеринговый бюджет: не вместо, а вместе
Кейсы, лайфхаки, исследования и полезные статьи
Не успеваешь следить за новостями? Не беда! Наш любимый редактор подберет материалы, которые точно помогут в работе. Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити 🙂
Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити 🙂
Нажимая кнопку, ты соглашаешься с нашей политикой конфиденциальности.
Поделитесь статьей с вашими друзьями
Вы уверены?
Спасибо, мы сохранили ваши новые настройки рассылок.
Сообщить об ошибке
Отменить
правильный пример на WordPress для Яндекса и Google
Всем привет! Сегодня я бы хотел Вам рассказать про файл robots.txt. Да, про него очень много чего написано в интернете, но, если честно, я сам очень долгое время не мог понять, как же создать правильный robots.txt. В итоге я сделал один и он стоит на всех моих блогах. Проблем с индексацией сайта я не замечаю, robots.txt работает просто великолепно.
Robots.txt для WordPress
А зачем, собственно говоря, нужен robots.txt? Ответ все тот же – продвижение сайта в поисковых системах. То есть составление robots.txt – это одно из частей поисковой оптимизации сайта (кстати, очень скоро будет урок, который будет посвящен всей внутренней оптимизации сайта на WordPress.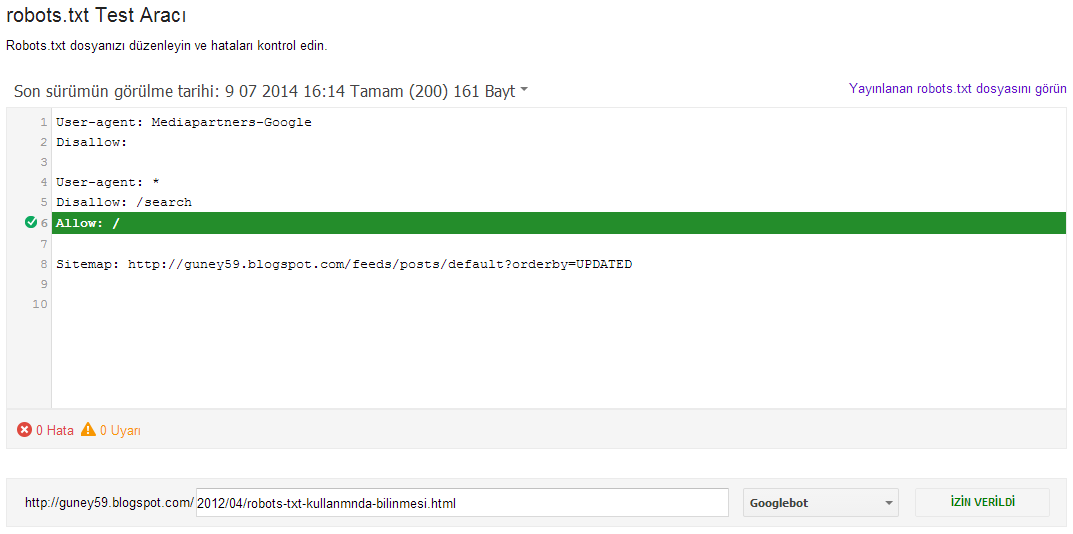 Поэтому не забудьте подписаться на RSS, чтобы не пропустить интересные материалы.).
Поэтому не забудьте подписаться на RSS, чтобы не пропустить интересные материалы.).
Одна из функций данного файла – запрет индексации ненужных страниц сайта. Также в нем задается адрес карты сайта sitemap.xml и прописывается главное зеркало сайта (сайт с www или без www).
Примечание: для поисковых систем один и тот же сайт с www и без www совсем абсолютно разные сайты. Но, поняв, что содержимое этих сайтов одинаковое, поисковики “склеивают” их. Поэтому важно прописать главное зеркало сайта в robots.txt. Чтобы узнать, какое главное (с www или без www), просто наберите адрес своего сайта в браузере, к примеру, с www, если Вас автоматически перебросит на тот же сайт без www, значит главное зеркало Вашего сайта без www. Надеюсь правильно объяснил.
Было:
Стало (после перехода на сайт, www автоматически удалились, и сайт стал без www):
Так вот, этот заветный, по-моему, правильный robots.txt для WordPress Вы можете увидеть ниже.
Правильный Robots.txt для WordPress
User-agent: *
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /*?*
Disallow: /tag
User-agent: Yandex
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /*?*
Disallow: /tag
Host: wpnew.ru
Sitemap: https://wpnew.ru/sitemap.xml.gz
Sitemap: https://wpnew.ru/sitemap.xml
Все что дано выше, Вам нужно скопировать в текстовой документ с расширением .txt, то есть, чтобы название файла было robots.txt. Данный текстовой документ Вы можете создать, к примеру, с помощью программы Notepad++. Только, не забудьте, пожалуйста, изменить в последних трех строчках адрес wpnew.ru на адрес своего сайта. Файл robots.txt должен располагаться в корне блога, то есть в той же папке, где находятся папки wp-content, wp-admin и др. .
Данный текстовой документ Вы можете создать, к примеру, с помощью программы Notepad++. Только, не забудьте, пожалуйста, изменить в последних трех строчках адрес wpnew.ru на адрес своего сайта. Файл robots.txt должен располагаться в корне блога, то есть в той же папке, где находятся папки wp-content, wp-admin и др. .
Те, кому же лень создавать данный текстовой файл, можете просто скачать robots.txt и также там подкорректировать 3 строчки.
Хочу отметить, что в техническими частями, о которых речь пойдет ниже, себя сильно загружать не нужно. Привожу их для “знаний”, так сказать общего кругозора, чтобы знали, что и зачем нужно.
Итак, строка:
User-agent
задает правила для какого-то поисковика: к примеру “*” (звездочкой) отмечено, что правила для всех поисковиков, а то, что ниже
User-agent: Yandex
означает, что данные правила только для Яндекса.
Disallow
Здесь же Вы “засовываете” разделы, которые НЕ нужно индексировать поисковикам. К примеру, на странице https://wpnew.ru/tag/seo у меня идет дубль статей (повторение) с обычными статьями, а дублирование страниц отрицательно сказывается на поисковом продвижении, поэтому, крайне желательно, данные секторы нужно закрыть от индексации, что мы и делаем с помощью этого правила:
К примеру, на странице https://wpnew.ru/tag/seo у меня идет дубль статей (повторение) с обычными статьями, а дублирование страниц отрицательно сказывается на поисковом продвижении, поэтому, крайне желательно, данные секторы нужно закрыть от индексации, что мы и делаем с помощью этого правила:
Disallow: /tag
Так вот, в том robots.txt, который дан выше, от индексации закрыты почти все ненужные разделы сайта на WordPress, то есть просто оставьте все как есть.
Host
Здесь мы задаем главное зеркало сайта, о котором я рассказывал чуть выше.
Sitemap
В последних двух строчках мы задаем адрес до двух карт сайта, созданные с помощью плагина Google XML Sitemaps.
Возможные проблемы
Если у Вас на блоге не стоит ЧПУ (именно так у меня происходит с тем сайтом, которого я занимаюсь продвижением), то с тем robots.txt, который дан выше, могут быть проблемы. Напомню, что без ЧПУ ссылки на сайте на посты выглядят примерно следующим образом:
А вот из-за этой строчки в robots. txt, у меня перестали индексироваться посты сайта:
txt, у меня перестали индексироваться посты сайта:
Disallow: /*?*
Как видите, эта самая строка в robots.txt запрещает индексирование статей, что естественно нам нисколько не нужно. Чтобы исправить это, просто нужно удалить эти 2 строчки (в правилах для всех поисковиков и для Яндекса) и окончательный правильный robots.txt для WordPress сайта без ЧПУ будет выглядеть следующим образом:
User-agent: *
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /tag
User-agent: Yandex
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /tag
Host: wpnew. ru
ru
Sitemap: https://wpnew.ru/sitemap.xml.gz
Sitemap: https://wpnew.ru/sitemap.xml
Анализ robots.txt
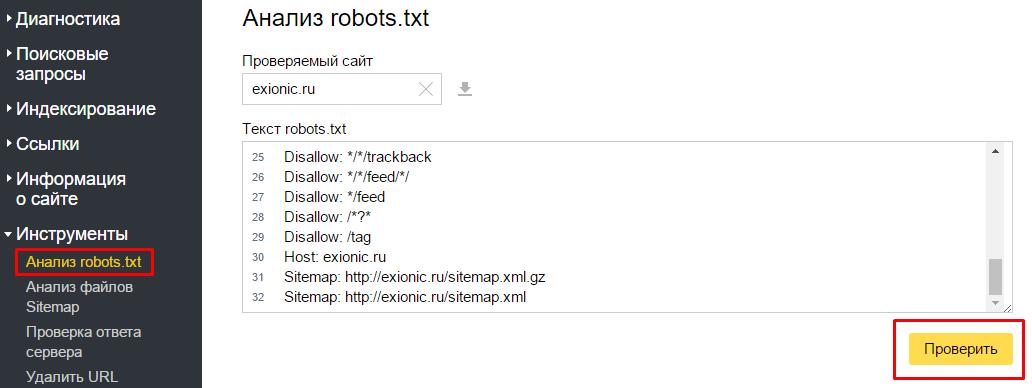
Чтобы проверить, правильно ли мы составили файл robots.txt я рекомендую Вам воспользоваться сервисом Яндекс Вебмастер (как регистрироваться в данном сервисе я рассказывал тут).
Заходим в раздел Настройки индексирования –> Анализ robots.txt:
Уже там нажимаете на кнопку “Загрузить robots.txt с сайта”, а затем нажимаете на кнопку “Проверить”:
Если Вы увидите примерно следующее сообщение, значит у Вас правильный robots.txt для Яндекса:
Также Вы можете в “Список URL” добавить адрес любой статьи сайта, чтобы проверить не запрещает ли robots.txt индексирование данной страницы:
Как видите, никакого запрета на индексирование страницы со стороны robots.txt мы не видим, значит все в порядке :).
Надеюсь больше вопросов, типа: как составить robots.txt или как сделать правильным данный файл у Вас не возникнет. В этом уроке я постарался показать Вам правильный пример robots.txt:
В этом уроке я постарался показать Вам правильный пример robots.txt:
Вы можете посмотреть другие варианты, как еще можно составлять robots.txt.
До скорой встречи!
P.s. Совсем недавно я добавил блог в Яндекс Каталог, что же интересного произошло? 🙂
Что такое файл robots.txt? – iSEO
Файл robots.txt («роботс тэ-экс-тэ») – текстовый файл, который представляет собой основной способ управления сканированием и индексацией сайта поисковыми системами. Размещается строго в корневой папке сайта. Имя файла должно быть прописано в нижнем регистре.
Зачем нужен robots.txt?
Поисковый робот, попадая на сайт обращается к файлу robots.txt, чтобы получить информацию о том, какие разделы и страницы сайта нужно игнорировать, а также информацию о расположении XML-карты сайта и другие параметры.
Данный файл позволяет убрать из поиска дубли страниц и служебные страницы, на которые не должны попадать посетители из поисковых систем. Помогает улучшить позиции сайта в поиске и комфортность для посетителей в использовании сайта.
Помогает улучшить позиции сайта в поиске и комфортность для посетителей в использовании сайта.
Для создания robots.txt достаточно воспользоваться любым текстовым редактором. Его необходимо заполнить в соответствии с определенными правилами (о них расскажем далее) и загрузить в корневой каталог сайта.
Если файла robots.txt на сайте нет или он пустой – поисковые системы могут пытаться сканировать и индексировать весь сайт.
Основные директивы в robots.txt
Комментарии
В файле robots.txt можно оставлять комментарии – они будут игнорироваться поисковыми системами. Комментарии помогают структурировать файл, указывать какие-то важные пометки и т. п. Строка с комментарием должна начинаться с символа решетки – #.
Пример:
# Это комментарий
User-agent
Указывает для какого робота предназначены следующие за ней инструкции. Файл robots.txt может состоять из нескольких блоков инструкций, каждая из которых предназначена для определенной поисковой системы.
Наименования роботов для User-agent можно найти, например, в справке поисковых систем. В Рунете чаще всего используются три:
- * – указывает, что следующие инструкции предназначены для всех роботов. Если робот не найдет в файле robots.txt секции конкретно для него, то будет учитывать эту секцию.
- Yandex – робот Яндекса.
- Googlebot – робот Google.
Примеры:
# Секция для всех роботов, которая разрешает индексировать весь сайт User-agent: * Disallow: # Секция для Google, которая запрещает индексировать папку /secret/ User-agent: Googlebot Disallow: /secret/
Disallow и Allow
Основные директивы, которые указывают, что можно и что нельзя индексировать:
- Disallow – запрещает индексацию
- Allow – разрешает
Поскольку, изначальная стандартная функция robots. txt это именно запрещать индексацию, то чаще используются директивы Disallow. Директива Allow появилась позднее и её могут поддерживать не все поисковые системы. Но Яндекс и Google – поддерживают.
txt это именно запрещать индексацию, то чаще используются директивы Disallow. Директива Allow появилась позднее и её могут поддерживать не все поисковые системы. Но Яндекс и Google – поддерживают.
Директива Allow применяется если вам нужно разрешить к индексированию что-то, что было запрещено директивами Disallow. Например, если какая-то папка запрещена к индексированию, но определенный файл/страницу в ней нужно разрешить.
В каждой из директив указывается префикс URL (т. е. начало адреса страницы), для которого должно применяться это правило. Также есть специальные символы:
- * – любая последовательность символов (в том числе, пустая). В конце инструкций ставить этот символ не нужно, т. к. по умолчанию директивы интерпретируются так, что как будто он там уже есть.
- $ – конец строки. Отменяет подразумеваемый символ * на конце строки.
Если в файле используются одновременно директивы Allow и Disallow, то приоритет будет иметь та, префикс URL у которой длиннее.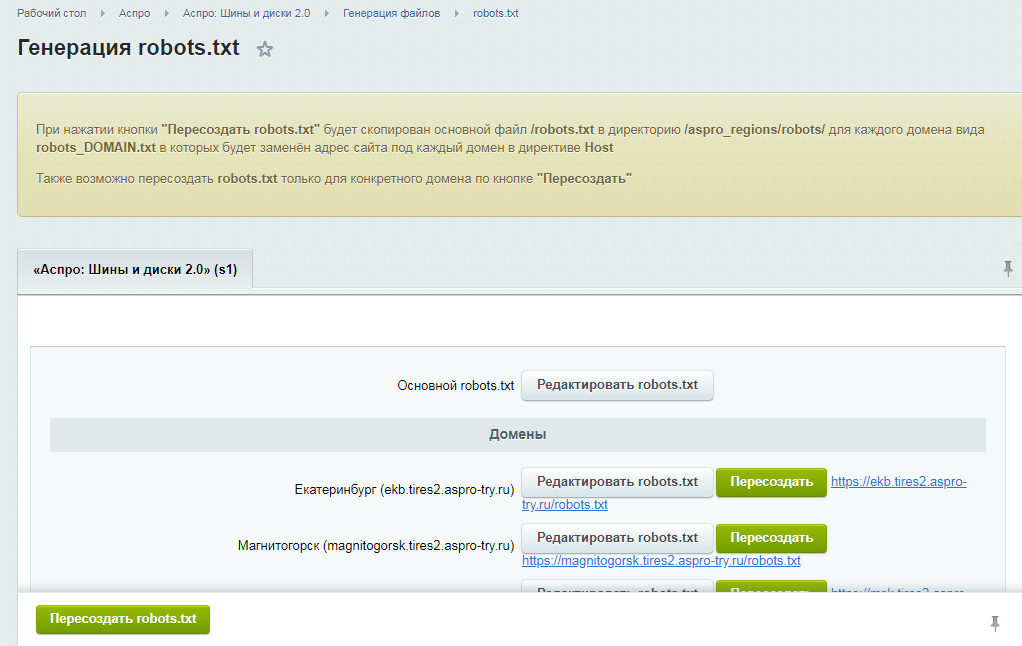 Правила применяются по возрастанию длины префикса.
Правила применяются по возрастанию длины префикса.
Пример:
# Секция для Яндекса, которая запрещает индексировать папку /secret/ # но разрешает индексировать страницу /secret/not-really/ # при этом не разрешает индексировать всё остальное в папке /secret/not-really/ User-agent: Yandex Disallow: /secret/ Allow: /secret/not-really/$ # Секция для всех роботов, которая запрещает индексировать весь сайт User-agent: * Disallow: / # Секция для Google, которому можно индексировать только страницы с параметрами в URL User-agent: Googlebot Disallow: / Allow: /*?*=
Clean-param
Директива, которую поддерживает Яндекс. Используется для указания параметров в URL, которые следует игнорировать (т. е. считать страницы с такими параметрами одной и той же страницей).
Синтаксис:
Clean-param: param1[¶m2¶m3&..¶mN] [path]
Где param1…paramN это список параметров, разделенных символом &, а [path] это опциональный префикс URL для которого нужно применять это правило (по аналогии с Allow/Disallow).
Директив может быть несколько. Длина правила – не более 500 символов.
Пример:
# Разрешить Яндексу индексировать всё # кроме страниц с параметром session_id в папке /catalog/ User-agent: Yandex Disallow: Clean-param: session_id /catalog/
Sitemap
Указывает на расположение XML-карт сайта. Таких директив может быть несколько.
Директива Sitemap является межсекционной – не важно в каком блоке User-agent или месте файла она будет указана. Все роботы будут учитывать все директивы Sitemap в вашем файле robots.txt.
Пример:
Sitemap: https://www.site.ru/sitemap_index.xml
Host
Межсекционная директива для указания основного хоста. Раньше поддерживалась Яндексом. Теперь поддерживается только роботом поиска Mail.ru. Ее наличие в файле не является какой-то ошибкой, но и пользы от нее немного, т. к. доля органического трафика с поиска Mail.ru обычно очень низкая (порядка 1%).
Пример:
Host: https://www.site.ru
Crawl-delay
Устаревшая директива, которая использовалась для указания задержки между обращениями робота к сайту. Теперь управлять нагрузкой робота на сайте можно в Яндекс Вебмастере и Google Search Console. Директиву Crawl-delay не поддерживает ни Яндекс, ни Google.
Что еще важно знать про robots.txt
- Регистр букв имеет значение.
- Кириллица – не поддерживается. Как она не поддерживается в URL и в названиях доменов. В файле robots.txt кириллические папки/файлы и названия доменов должны быть указаны в закодированном виде.
- Google считает, что файл robots.txt управляет сканированием, а не индексацией. На практике это значит, что если какие-то страницы сайта Google уже нашел и проиндексировал (например, на них были ссылки с других сайтов), то запрет их индексации в robots.
 txt не поможет исключить их из индекса. Для этого нужно применять метатег robots на самой странице. При этом, чтобы Google это тег увидел и учёл – страница не должна быть закрыта в robots.txt. Звучит это довольно абсурдно, но работает именно так, к сожалению.
txt не поможет исключить их из индекса. Для этого нужно применять метатег robots на самой странице. При этом, чтобы Google это тег увидел и учёл – страница не должна быть закрыта в robots.txt. Звучит это довольно абсурдно, но работает именно так, к сожалению. - Прежде чем залить файл на «боевой» домен – проверьте его правильность с помощью соответствующих инструментов в Яндекс Вебмастере и Google Search Console.
 txt не поможет исключить их из индекса. Для этого нужно применять метатег robots на самой странице. При этом, чтобы Google это тег увидел и учёл – страница не должна быть закрыта в robots.txt. Звучит это довольно абсурдно, но работает именно так, к сожалению.
txt не поможет исключить их из индекса. Для этого нужно применять метатег robots на самой странице. При этом, чтобы Google это тег увидел и учёл – страница не должна быть закрыта в robots.txt. Звучит это довольно абсурдно, но работает именно так, к сожалению.Подробнее о файле robots.txt в справке поисковых систем:
- https://yandex.ru/support/webmaster/controlling-robot/robots-txt.html
- https://developers.google.com/search/docs/advanced/robots/intro?hl=ru
настройки сканирования без бубна — SEO на vc.ru
Как показывает практика, база технического SEO – файл robots.txt, – многими вебмастерами не только заполняется неправильно, но и без понимания, зачем этот файл и как он работает. Статей на эту тему – объективно, тонны, но есть смысл расставить некоторые акценты.
3376 просмотров
Для чего вообще нужен robots.txt
В интернете можно найти много глупых советов по настройкам robots.txt. Люди советуют управлять с его помощью доступами, предлагают какие-то типовые шаблонные списки инструкций, пытаются что-то удалять таким образом из индекса.
robots.txt предназначен для единственной цели: управлять сканированием сайта на базе «Стандарта исключений для роботов». Это не инструмент для управления индексацией, и если вы попытаетесь управлять с его помощью попаданием ваших страниц в индекс, неизбежно получите ошибки и проблемы. И чем больше и сложнее ваш сайт – тем больше будет ошибок. Для управления индексацией используйте предназначенные для этого инструменты:
С его помощью можно указать поисковым роботам, какие URL не должны сканироваться, а какие сканировать можно и нужно. Это не команды: поисковые роботы могут проигнорировать запрещающие и разрешающие директивы, если получат более весомые сигналы это сделать. Простой пример: если на страницу ведёт достаточное количество ссылок, она появится в выдаче – хотя саму страницу поисковик скачивать и не будет.
Простой пример: если на страницу ведёт достаточное количество ссылок, она появится в выдаче – хотя саму страницу поисковик скачивать и не будет.
Важно понимать: robots.txt – не закон для роботов, а просто список пожеланий с достаточно противоречивой историей. Несмотря на необязательность директив, например, гуглобот не станет сканировать ваш сайт, если сервер ответит технической ошибкой на запрос «роботс». И вместе с тем, легко проигнорирует запреты, если получит сигналы о важности какого-то URL в рамках сайта (наличие ссылок, настройка перенаправлений, постоянный пользовательский трафик и т.п.).
Что не нужно сканировать
Системные папки на сервере
Дубли: сортировки, UTM-метки, фильтры и прочие URL с параметрами
- Страницы пользовательских сессий, результаты поиска по сайту, динамические URL
- Служебные URL
- Административная часть сайта
К чему должен быть обязательный доступ
Посадочные страницы
- Служебные файлы, отвечающие за рендеринг страницы (js, css, шрифты, графика)
Особое внимание обращу на обязательное наличие разрешений на сканирование JS и CSS. Если поисковые системы не смогут отрисовать страницы сайта в том виде, в каком их получает посетитель-человек, это приведёт к следующим проблемам:
Если поисковые системы не смогут отрисовать страницы сайта в том виде, в каком их получает посетитель-человек, это приведёт к следующим проблемам:
Зачем нужны отдельные секции для поисковых роботов
Оставлять единый блок директив для всех поисковых роботов – плохая идея, и вот почему.
Поисковые роботы Яндекса и Гугла в ряде случаев совершенно по-разному воспринимают директивы, потому и что и правила сканирования у них разные. Вот лишь несколько главных отличий.
Яндекс плохо работает с метатегами robots и каноническими адресами. Директивы в robots.txt для него важнее. Если вы разрешите ему сканировать то, что не должно попасть в индекс, он с большой степенью вероятности проигнорирует всё остальное, и может начать ранжировать вовсе не то, что вам надо. Скажем, нецелевую страницу пагинации — просто потому, что ему что-то не понравилось на целевой странице.
- Яндекс использует директивы, которые не признаёт Google, например, Clean-param. Есть и директивы, которые понимает только гуглобот.
- Хорошая идея — минимально блокировать сканирование для гуглобота, индексацией управляя только на уровне страницы. Таким образом Гугл будет лучше понимать ваш сайт, а алгоритмы там достаточно умные, чтобы и без вашего участия разобраться, что к чему. Если же по логам вы отмечаете ненормальную активность гуглобота там, где не надо – это повод подумать, что не так с сайтом.
- Если гуглобот зайдёт на сайт и не сможет скачать robots.txt, он уйдёт. Яндекс-бот в такой придирчивости не замечен.
 Есть и директивы, которые понимает только гуглобот.
Есть и директивы, которые понимает только гуглобот.Общий принцип: открывайте для Яндекса по необходимости. Для Гугл – по необходимости закрывайте.
Для Яндекса вы должны понимать, что у вас должно быть в индексе. Для Гугл – наоборот, чего в индексе быть не должно.
Активность Яндекс-бота в рунете кратно превышает активность гуглобота, которая в принципе лимитирована. Это ещё одно условие, которое надо учитывать при составлении директив для robots.txt.
Это ещё одно условие, которое надо учитывать при составлении директив для robots.txt.
Можно ли блокировать на уровне robots.txt зловредных ботов и парсеры
Каждый сайт посещает множество роботов, и не все они вам нужны. Это могут быть роботы-парсеры, которые используют ваши конкуренты для извлечения информации, многочисленные SEO-сервисы, которые могут предоставлять информацию о вашем сайте конкурентам и т.п. Пользы для сайта от них нет, а нагрузку на сервер они создают. Стоит ли пытаться запрещать им сканирование в robots.txt?
Нет. Набор инструкций на базе стандарта исключений имеет рекомендательный характер, и фактически ограничить ничего не может. Если вы хотите заблокировать посторонних роботов – делать это надо на уровне сервера. Чаще всего в robots.txt пытаются заблокировать самых известных официальных ботов типа AhrefsBot, MJ12bot, Slurp, SMTBot, SemrushBot, DotBot, BLEXBot и т.п. Смысла это не имеет, но вы можете попробовать.
Что будет, если robots. txt не заполнен или заполнен неправильно
txt не заполнен или заполнен неправильно
Недоступность файла с директивами по техническим причинам (ошибки 5**) может привести к тому, что гуглобот не станет сканировать сайт. Отсутствие же файла приведет к тому, что роботы будут обходить всё подряд и накидают в индекс тонны мусора. Чаще всего это не очень страшно. А вот ошибки в директивах могут привести к достаточно широкому спектру проблем. Вот типовые:
Поисковая система не сможет отрисовать адаптивную вёрстку вашего сайта, потому что не может получить доступ к файлам шаблона, и решит, что сайт не подходит для просмотра на смартфонах.
- Часть контента или оформления не будет просканирована или учтена, если выводится она средствами JS, а доступ к ним заблокирован.
- Если в robots.txt запрещено сканирование страниц, которые вы хотели бы удалить из индекса, деиндексированы они не будут – робот просто не увидит ваших указаний в рамках страницы, а в панели вебмастеров вы увидите соответствующее уведомление («Проиндексировано, несмотря на блокировку в файле robots. txt»).
- Без запрета на сканирование определенных страниц (пользовательских, с параметрами) поисковая система будет вносить в индекс явный мусор, который через время будет выбрасывать. В случае Яндекса это может быть чревато переклейкой запросов на нецелевые страницы, рост страниц, рассматриваемых как некачественные, и как следствие – снижения доверия к сайту на уровне хоста.
 txt»).
txt»).Ошибки в настройках сканирования – и вот уже поисковому роботу недоступен целый блок, куда выводится портфолио веб-студии.
Простенькие сайты на той же «Тильде» чаще всего вообще не нуждаются в правках robots.txt – там разрешено всё, и нет никаких проблем ни с отрисовкой сайта, ни с попаданием в индекс поискового мусора. Интерпретаторы современных ПС довольно снисходительно относятся к возможным ошибкам, однако надеяться на это не стоит.
Основные правила
Заполнение файла директив должно соответствовать правилам, игнорирование которых может привести к критическим ошибкам сканирования и непредсказуемым багам обхода сайта. Перечислим основные.
Перечислим основные.
Файл может называться только «robots.txt» с названием в нижнем регистре, быть в кодировке UTF-8 без BOM, и находиться в корне сайта.
- Никакой кириллицы в robots.txt быть не должно! Если вы используете домен в зоне РФ или кириллические адреса – для настроек robots.txt используйте конвертацию таких URL в пуникод. Например, директива Sitemap в данном случае будет выглядеть примерно так:
Sitemap: http://xn--80aswg.xn--p1ai/sitemap.xml - Каждая новая директива начинается с новой строки.
- Блок директив для каждого User-agent отделяется от других блоков пустой строкой. Пустая строка между директивами обрывает список, после пустой строки начинается новый блок.
- Все запрещающие или разрешающие директивы относятся только к боту, указанному для заданного блока.
- Порядок размещения разрешающих и запрещающих директив особого значения не имеет. В настоящий момент это свойственно и роботам Яндекса, и Google.
 В настоящий момент это свойственно и роботам Яндекса, и Google.
В настоящий момент это свойственно и роботам Яндекса, и Google.Регулярные выражения и подстановочные знаки
Регулярные выражения и подстановочные знаки значительно упрощают процесс настройки сканирования. Официально они не поддерживаются стандартами, и тем не менее, понимают их все роботы. Ваша задача – составить регулярное выражение, блокирующее сканирование всего поискового мусора и разрешить необходимые URL, а не вносить туда десятки и даже сотни URL (как иногда пытаются делать). Отдельные URL, ненужные в выдаче по каким-то причинам, нужно просто запрещать индексировать метатегом.
Пример заполнения robots.txt в стиле «Знай наших» школы SEO-кунгфу «Раззудись плечо» — и это ещё не весь список
Для формирования регулярных выражений в рамках «роботс» используется всего два знака: * и $.
Знак * означает любую последовательность символов, «что угодно». Примеры.
User-agent: * Disallow: /*?
Это означает, что для любого робота (если для него нет отдельного набора директив) запрещено сканирование любых страниц фильтров.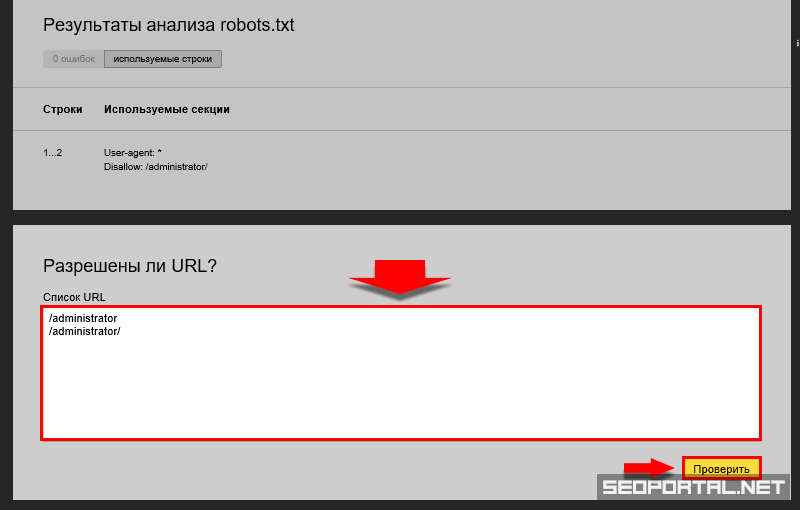
User-agent: * Allow: */*.jpg*
Разрешено сканирование файлов JPG с любым названием в любой доступной папке сайта, включая кэшированные файлы.
Знак $ соответствует концу заданного URL. Те URL, что содержат какие-то знаки после знака $, могут быть просканированы. Пример:
User-agent: * Disallow: */*.pdf$
Эта директива запрещает сканировать любой файл в формате PDF в рамках сайта. Ещё один пример:
Disallow: */ofis$
Будет заблокирован URL https://сайт-ру/catalog/muzhchinam/ofis
Но URL https://сайт-ру/catalog/muzhchinam/ofis?sort=rate&page=1 будет доступен.
Как составить правильный robots.txt для своего сайта
Как уже было сказано выше, гуглобот не станет сканировать сайт, если не найдёт robots.txt, поэтому для начала можно использовать даже шаблонный «роботс» (как многие и поступают). Однако это явно не оптимальный вариант.
Чтобы составить правильный robots.txt для своего сайта, вы должны чётко понимать два момента:
На первый вопрос вам поможет ответить семантическое ядро и структура сайта, созданная на его основе. Мы не будем разбирать здесь вопросы структурирования.
Мы не будем разбирать здесь вопросы структурирования.
На второй же вопрос вам поможет ответить парсер сайта, способный эмулировать заданных поисковых роботов, показать наглядно, как поисковых робот отрисовывает страницу по актуальным правилам, справляется ли он с рендерингом адаптивной версии сайта и т.п. С этой целью я использую Screaming Frog SEO Spider. Думаю, эти возможности есть и у его конкурентов.
Полноценный рендеринг сайта позволит вам увидеть его глазами поискового робота
Можно начинать парсинг. По окончании запустите Crawl Analysis, и можно приступать к изучению результатов.
Поскольку нас в данном случае интересует список проблем с файлом robots.txt начнём с вкладки Rendered Page — там можно посмотреть, как видит робот выбранную страницу.
Если всё совсем плохо, вы увидите тлен и безнадёжность: отсутствие внятной вёрстки, пустые блоки, абсолютно нечитабельный контент.
Как вариант – контент может быть в основном доступен, просто без ожидаемого дизайна, дырками на месте картинок и т. п. Здесь же можно сразу посмотреть, что именно заблокировано и мешает роботу увидеть сайт так, как видите его вы. Если в списке заблокированных ресурсов вы видите js, css, файлы изображений, веб-шрифты – вносите их в список разрешающих директив.
п. Здесь же можно сразу посмотреть, что именно заблокировано и мешает роботу увидеть сайт так, как видите его вы. Если в списке заблокированных ресурсов вы видите js, css, файлы изображений, веб-шрифты – вносите их в список разрешающих директив.
В левом окне мы видим заблокированные папки, содержащие файлы шаблона. Их отсутствие приводит к тому, что робот видит сайт так, как показано в правом окне.
Внимательно изучите все страницы, которые так или иначе помечены как дубли – по тайтлам, по сходству контента и т.п. Вероятно, среди них действительно могут оказаться дубли и поисковый мусор. Дубли могут быть как чисто техническими (например, товары могут выводиться плиткой, а могут списком), а могут быть и качественными, когда полезного контента на странице недостаточно, и она похожа на другие страницы, такие же некачественные с точки зрения ПС. В данном случае вам предстоит решить, что делать: закрыть мусор от сканирования, запретить индексацию метатегом, или оперативно внести правки и отправить URL на переобход.
На следующем шаге вам предстоит изучить данные из панелей вебмастеров. Достаточно удобно и наглядно это реализовано в Яндекс-Вебмастере. Заходим в «Индексирование», «Страницы в поиске», вкладка «Исключенные» – и внимательно оцениваем URL, помеченные как неканонические, дубли, а также МПК. Среди них, как правило, большую часть представляют страницы сортировок, фильтров, пагинации и т.п. Их чаще всего можно смело вносить в список для запрета на сканирование.
Инструменты для тестирования
Любые внесенные правки должны проверяться с помощью соответствующих инструментов поисковых систем.
В Гугл – https://www.google.com/webmasters/tools/robots-testing-tool
В Яндексе – https://webmaster.yandex.ru/tools/robotstxt/
Принцип действия прост: вы видите актуальную кэшированную версию файла, анализатор, инструмент проверки заданных URL. Если URL заблокирован – вы увидите строку, которая его блокирует.
Заключение
Подытожим основные тезисы.
UPD. Для настроек индексирования сайта рекомендую использовать метатег Robots, HTTP-заголовок X-Robots-Tag, настройки тега Canonical, а также вполне традиционные средства – редиректы, sitemap.xml и т.п.
Файл robots.txt для сайта в 2022: пошаговая инструкция
Файл robots.txt — это текстовый файл, в котором содержаться инструкции для поисковых роботов, в частности каким роботам и какие страницы допускается сканировать, а какие нет. В данной статье рассмотрим, где можно найти robots.txt, как его редактировать и какие правила по его использовать в SEO-продвижении.
- Где найти;
- Как создать;
- Инструкция по работе;
- Синтаксис;
- Директивы;
- Как проверить.
Где можно найти файл robots.txt и как его создать или редактировать
Чтобы проверить файл robots.txt сайта, следует добавить к домену «/robots.txt», примеры:
https://seopulses.ru/robots.txt
https://serpstat.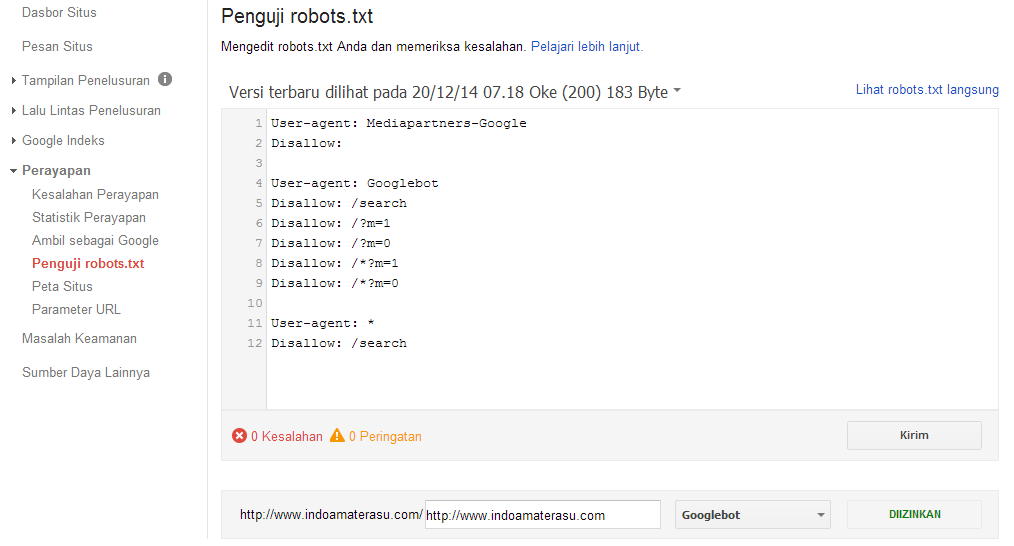.png) com/robots.txt
com/robots.txt
https://netpeak.net/robots.txt
Как создать и редактировать robots.txt
Вручную
Данный файл всегда можно найти, подключившись к FTP сайта или в файлом редакторе хостинг-провайдера в корневой папке сайта (как правило, public_html):
Далее открываем сам файл и можно его редактировать.
Если его нет, то достаточно создать новый файл.
После вводим название документа и сохраняем.
Через модули/дополнения/плагины
Чтобы управлять данный файлом прямо в административной панели сайта следует установить дополнительный модуль:
- Для 1С-Битрикс;
https://dev.1c-bitrix.ru/learning/course/?COURSE_ID=139&LESSON_ID=5814
- WordPress;
Virtual Robots.txt
- Для Opencart;
https://opencartforum.com/files/file/5141-edit-robotstxt/
- Webasyst.
https://support.webasyst.ru/shop-script/149/shop-script-robots-txt/
Инструкция по работе с robots.
 txt
txtВ первую очередь записывается User-Agent, указывая на то, к какому роботу идет обращение, например:
- User-agent: Yandex — для обращения к поисковому роботу Яндекса;
- User-agent: Googlebot — в случае с краулером Google;
- User-agent: YandexImages — при работе с ботом Яндекс.Картинок.
Полный список роботов Яндекс:
https://yandex.ru/support/webmaster/robot-workings/check-yandex-robots.html#check-yandex-robots
И Google:
https://support.google.com/webmasters/answer/1061943?hl=ru
Синтаксис в robots.txt
- # — отвечает за комментирование;
- * — указывает на любую последовательность символов после этого знака. По умолчанию указывается при любого правила в файле;
- $ — отменяет действие *, указывая на то что на этом элементе необходимо остановиться.
Директивы в Robots.txt
Disallow
Disallow запрещает индексацию отдельной страницы или группы (в том числе всего сайта). Чаще всего используется для того, чтобы скрыть технические страницы, динамические или временные страницы.
Пример #1
# Полностью закрывает весь сайт от индексации
User-agent: *
Disallow: /
Пример #2
# Блокирует для скачивания все страницы раздела /category1/, например, /category1/page1/ или caterogy1/page2/
Disallow: /category1/
Пример #3
# Блокирует для скачивания страницу раздела /category2/
User-agent: *
Disallow: /category1/$
Пример #4
# Дает возможность сканировать весь сайт просто оставив поле пустым
User-agent: *
Disallow:
Важно! Следует понимать, что регистр при использовании правил имеет значение, например, Disallow: /Category1/ не запрещает посещение страницы /category1/.
Allow
Директива Allow указывает на то, что роботу можно сканировать содержимое страницы/раздела, как правило, используется, когда в полностью закрытом разделе, нужно дать доступ к определенному документу.
Пример #1
# Дает возможность роботу скачать файл site.ru//feed/turbo/ несмотря на то, что скрыт раздел site. ru/feed/.
ru/feed/.
Disallow: */feed/*
Allow: /feed/turbo/
Пример #2
# разрешает скачивание файла doc.xml
# разрешает скачивание файла doc.xml
Allow: /doc.xml
Sitemap
Директива Sitemap указывает на карту сайта, которая используется в SEO для вывода списка URL, которые нужно проиндексировать в первую очередь.
Важно понимать, что в отличие от стандартных директив у нее есть особенности в записи:
- Следует указывать полный URL, когда относительный адрес использовать запрещено;
- На нее не распространяются остальные правила в файле robots.txt;
- XML-карта сайта должна иметь в URL-адресе домен сайта.
Пример
# Указывает карту сайта
Sitemap: https://serpstat.com/sitemap.xml
Clean-param
Используется когда нужно указать Яндексу (в Google она не работает), что страница с GET-параметрами (например, site.ru?param1=2¶m2=3) и метками (в том числе utm) не влияющие на содержимое сайта, не должна быть проиндексирована.
Пример #1
#для адресов вида:
www.example1.com/forum/showthread.php?s=681498b9648949605&t=8243
www.example1.com/forum/showthread.php?s=1e71c4427317a117a&t=8243
#robots.txt будет содержать:
User-agent: Yandex
Disallow:
Clean-param: s /forum/showthread.php
Пример #2
#для адресов вида:
www.example2.com/index.php?page=1&sid=2564126ebdec301c607e5df
www.example2.com/index.php?page=1&sid=974017dcd170d6c4a5d76ae
#robots.txt будет содержать:
User-agent: Yandex
Disallow:
Clean-param: sid /index.php
Подробнее о данной директиве можно прочитать здесь:
https://serpstat.com/ru/blog/obrabotka-get-parametrov-v-robotstxt-s-pomoshhju-direktivy-clean-param/
Crawl-delay
Важно! Данная директива не поддерживается в Яндексе с 22 февраля 2019 года и в Google 1 сентября 2019 года, но работает с другими роботами. Настройки скорости скачивания можно найти в Яндекс. Вебмастер и Google Search Console.
Вебмастер и Google Search Console.
Crawl-delay указывает временной интервал в секундах, в течение которого роботу разрешается делать только 1 сканирование. Как правило, необходима лишь в случаях, когда у сайта наблюдается большая нагрузка из-за сканирования.
Пример
# Допускает скачивание страницы лишь раз в 3 секунды
Crawl-delay: 3
Как проверить работу файла robots.txt
В Яндекс.Вебмастер
В Яндекс.Вебмастер в разделе «Инструменты→ Анализ robots.txt» можно увидеть используемый поисковиком свод правил и наличие ошибок в нем.
Также можно скачать другие версии файла или просто ознакомиться с ними.
Чуть ниже имеется инструмент, который дает возможно проверить сразу до 100 URL на возможность сканирования.
В нашем случае мы проверяем эти правила.
Как видим из примера все работает нормально.
Также если воспользоваться сервисом «Проверка ответа сервера» от Яндекса также будет указано, запрещен ли для сканирования документ при попытке обратиться к нему.
В Google Search Console
В случае с Google можно воспользоваться инструментом проверки Robots.txt, где потребуется в первую очередь выбрать нужный сайт.
Важно! Ресурсы-домены в этом случае выбирать нельзя.
Теперь мы видим:
- Сам файл;
- Кнопку, открывающую его;
- Симулятор для проверки сканирования.
Если в симуляторе ввести заблокированный URL, то можно увидеть правило, запрещающее сделать это и уведомление «Недоступен».
Однако, если ввести заблокированный URL в страницу поиска в новой Google Search Console (или запросить ее индексирование), то можно увидеть, что страница заблокирована в файле robots.txt.
Зачем вам нужен robots.txt
Почти в каждом материале по разработке и продвижению мы упоминаем robots.txt. Сегодня не будем упоминать, а всю статью будем рассказывать про него, про правильный robots. txt в 2021 году.
txt в 2021 году.
Вот так выглядит robots.txt Google. Примерно так же выглядит и robots.txt вашего сайта. По сути, это текстовый файл со списком исключений для поисковых роботов. Исключения запрещают индексировать одни разделы сайта и разрешают другие. Это необходимо, чтобы защитить конфиденциальную информацию, административные файлы или страницы, которые в силу требований SEO не должны попасть в поиск.
Инструкции
Поисковые роботы законопослушны. Они четко следуют инструкциям robots.txt и сканируют только те ссылки, которые разрешены. Инструкции в файле называются директивами, и в дальнейшем мы будем употреблять именно этот термин.
Директива User-agent для разграничения команд
Все robots.txt начинаются с user-agent. Это своеобразный маршрутизатор, который определяет адресата последующих команд. К ботам Яндекса и Гугла user-agent обращается по-разному — User-agent:Yandex и User-agent:GoogleBot, соответственно. User-agent из файла Google начинается с символа * и это значит, что дальнейшие команды относятся ко всем поисковым ботам.
User-agent из файла Google начинается с символа * и это значит, что дальнейшие команды относятся ко всем поисковым ботам.
Сразу отвечаем на закономерно возникающий вопрос: «Зачем указывать отдельные директивы для Яндекса и Гугла, если можно сделать универсальный список?». Поисковых ботов несколько. У одного только Гугла их семь: анализатор рекламы на десктопах и мобильных, индексатор картинок и видео, новостной сканер, бот по оценке рекламы для приложений на Android. Подставляя в user-agent имя нужного бота, можно определить список директив именно для него. Например, запретить индексацию картинок. Плюс у поисковых ботов разный подход к сканированию. Так, команду clean-param воспринимает только Яндекс и бесполезно указывать ее в блоке указаний для Гугла — не поймет.
Для больших сайтов с разными стратегиями продвижения имеет смысл прописывать директивы под конкретных ботов. Маленьким несложным ресурсам мы обычно рекомендует обращаться сразу ко всем индексаторам и использовать User-agent с символом *.
Директива disallow
Disallow — команда запрета. Она запрещает индексировать отдельные файлы, страницы или целые разделы. Обычно, disallow закрывают страницу входа в панель администрирования, документы PDF, DOC, XLS, формы регистрации, корзины, страницы с персональными данными клиентов и пр.
В robots.txt для Bitrix, например, disallow выглядит так:
User-agent: *
Disallow: /wp-admin/
Это в случае, когда мы закрываем доступ к панели управления.
Или так:
User-agent: *
Disallow: /images/
Такая комбинация запретит боту индексировать иллюстрации.
В структуре команды символ / обозначает, что нужно закрыть от индексации, а знак * боты понимают как «любой текст».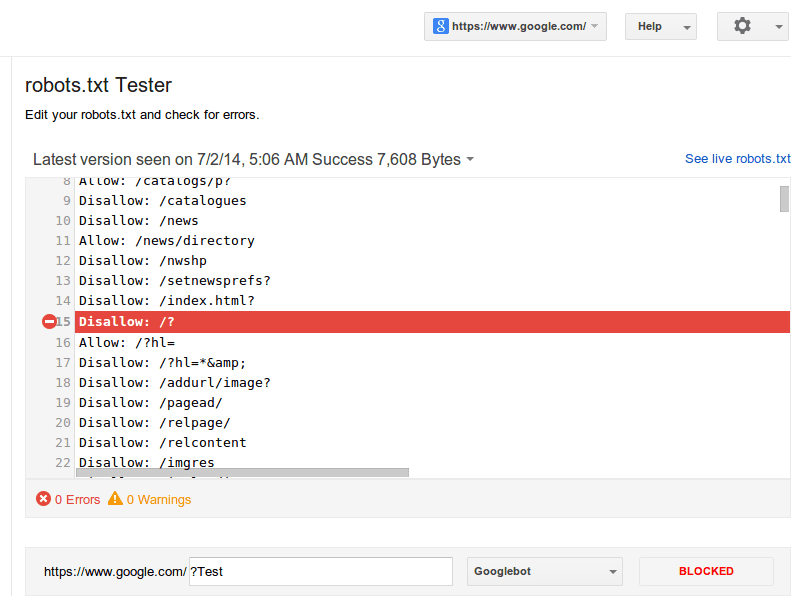
Важно! Disallow закрывает доступ поисковым роботам, но не людям, поэтому конфиденциальную информацию на сайте рекомендуем обязательно защищать аутентификацией.
Директивы allow и sitemap
Allow разрешает все, что не запрещает disallow. Это может показаться странным, ведь бот и без того может индексировать все, что не закрыто от сканирования. На самом деле allow нужна для выборочной индексации файлов или документов в закрытом разделе. Допустим, у вас есть закрытый с помощью disallow раздел для дистрибьюторов:
User-agent: *
Disallow: /distributoram/
Он будет выглядеть так, когда вы полностью закрываете индексацию раздела. Но допустим, в закрытом каталоге есть страница или файл, который имеет смысл показать пользователям. Вот тут на сцену выходит allow. Получается так:
Получается так:
User-agent: *
Disallow: /distributoram/
Allow: /distributoram/usloviya.html
При такой расстановке боты поймут, что из всего раздела distributoram они могут сканировать только контент страницы usloviya.html.
Sitemap одновременно и карта сайта, и директива. Про карту сайта в другой раз, а в роли директивы sitemap используется во всех случаях, когда вы хотите направить роботов на определенные разделы сайта.
Директиву sitemap поисковые боты воспринимают как указатель на приоритетные разделы, но если Яндекс понимает ее как рекомендацию, то GoogleBot как обязательное требование. Само собой, используя в robots.txt команду sitemap, саму карту в корневом каталоге необходимо поддерживать в актуальном состоянии.
Создаем и проверяем robots.txt
Для создания файла подойдет любой текстовый редактор, тот же «Блокнот». На первое место ставим адресную директиву user-agent, потом блоками вносим disallow и allow. Примеры и руководства есть у обоих поисковиков. У Яндекса в разделе «Помощь вебмастеру». У Google в Центре Google Поиска.
На первое место ставим адресную директиву user-agent, потом блоками вносим disallow и allow. Примеры и руководства есть у обоих поисковиков. У Яндекса в разделе «Помощь вебмастеру». У Google в Центре Google Поиска.
Чтобы прописать robots.txt на сайте, файл сохраняем в текстовом формате и загружаем в корень. После загрузки проверьте правильность установки — robots.txt должен открываться по адресу вашсайт/robots.txt. Для проверки работоспособности вставьте ссылку на сайт и код файла в специальные поля сервиса https://webmaster.yandex.ru/tools/robotstxt/ Яндекса и выберите подтвержденный ресурс в https://www.google.com/webmasters/tools/robots-testing-tool в Google.
Зачем проверять robots.txt
В случае с robots ошибки проводят к выпадению из индекса одного раздела и попаданию в выдачу другого, совершенно лишнего и абсолютно ненужного. Кроме того, поисковые системы регулярно меняют правила индексации и добавляют/убирают отдельные директивы. Так, с 22 февраля 2018 года Яндекс перестал учитывать crawl-delay, но у многих сайтов в robots.txt она до сих пор есть и SEO-менеджеры до сих пор уверены, что управляют скоростью обхода.
Так, с 22 февраля 2018 года Яндекс перестал учитывать crawl-delay, но у многих сайтов в robots.txt она до сих пор есть и SEO-менеджеры до сих пор уверены, что управляют скоростью обхода.
Держите руку на пульсе и не пренебрегайте базовыми правилами защиты сайта. Тем более, что с маленьким фалом robots.txt это совсем несложно.
Дальше: Составляем CJM (Customer Journey Map)
Анализ robots txt yandex
Поисковые роботы — краулеры начинают знакомство с сайтом с чтения файла robots.txt. В нем содержится вся важная для них информация. Владельцы сайтов должны создавать и периодически просматривать файл robots.txt. От корректности его работы зависит скорость индексации страниц и место в результатах поиска.
Не является обязательным элементом сайта, но его наличие желательно, т.к. используется владельцами сайтов для управления поисковыми роботами. Установить разные уровни доступа к сайту, запрет на индексацию всего сайта, отдельных страниц, разделов или файлов. Для ресурсов с высокой посещаемостью ограничьте время индексации и запретите доступ роботам, не относящимся к основным поисковым системам. Это снизит нагрузку на сервер.
Для ресурсов с высокой посещаемостью ограничьте время индексации и запретите доступ роботам, не относящимся к основным поисковым системам. Это снизит нагрузку на сервер.
Создание. Создайте файл в текстовом редакторе, таком как Блокнот или аналогичный. Убедитесь, что размер файла не превышает 32 КБ. Выберите для файла кодировку ASCII или UTF-8. Обратите внимание, что файл должен быть уникальным. Если сайт создан на CMS, то он будет сгенерирован автоматически.
Поместите созданный файл в корневой каталог сайта рядом с основным файлом index.html. Для этого используйте FTP-доступ. Если сайт сделан на CMS, то файл обрабатывается через административную панель. Когда файл создан и работает правильно, он доступен в браузере.
При отсутствии файла robots.txt поисковые роботы собирают всю информацию, относящуюся к сайту. Не удивляйтесь, увидев в результатах поиска пустые страницы или служебную информацию. Определите, какие разделы сайта будут доступны пользователям, а остальные закройте от индексации.
Экспертиза. Периодически проверяйте, все ли работает правильно. Если краулер не получает ответа 200 OK, то он автоматически предполагает, что файл не существует, а сайт полностью открыт для индексации. Коды ошибок следующие:
3xx — перенаправить ответы. Робот перенаправляется на другую страницу или на главную. Создавайте до пяти редиректов на одной странице. Если их больше, робот пометит такую страницу как ошибку 404. То же самое относится и к редиректам, основанным на принципе бесконечного цикла;
4xx — ответы об ошибках сайта. Если сканер получает ошибку 400 из файла robots.txt, он делает вывод, что файл не существует и все содержимое доступно. Это также относится к ошибкам 401 и 403;
5xx — ответы об ошибках сервера. Искатель будет «стучать», пока не получит ответ, отличный от 500-го.
Правила создания
Начнем с приветствия. Каждый файл должен начинаться с приветствия агента пользователя. С его помощью поисковые системы будут определять уровень открытости.
| Код | Значение |
| Агент пользователя: * | Доступно всем |
| Агент пользователя: Яндекс | Доступен роботу Яндекса |
| Агент пользователя: Googlebot | Доступно роботу Googlebot |
| Агент пользователя: Mail.ru | Доступен роботу Mail.ru |
Добавьте отдельные директивы для роботов. При необходимости добавьте директивы для специализированных поисковых ботов Яндекса.
Однако в этом случае директивы * и Яндекс учитываться не будут.
У Google есть свои боты:
Сначала запрещаем, потом разрешаем. Действовать двумя директивами: Allow — разрешаю, Disallow — запрещаю. Обязательно включите директиву disallow, даже если доступ разрешен ко всему сайту. Эта директива является обязательной. Если он отсутствует, сканер может неправильно прочитать остальную информацию.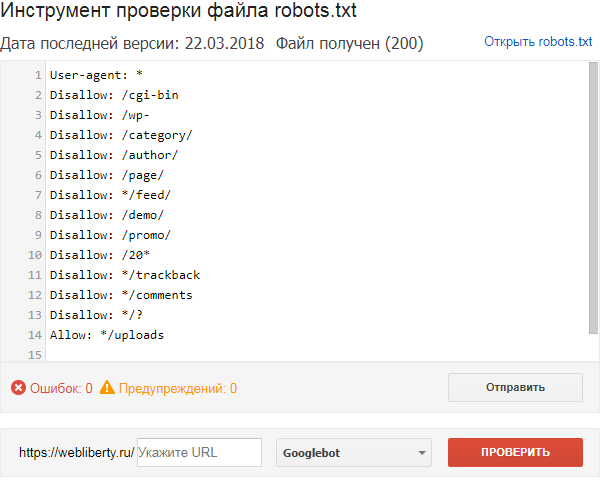 Если на сайте нет контента с ограниченным доступом, оставьте директиву пустой.
Если на сайте нет контента с ограниченным доступом, оставьте директиву пустой.
Работа с разными уровнями. В файле можно указать настройки на четырех уровнях: сайт, страница, папка и тип контента. Допустим, вы хотите скрыть изображения от индексации. Это можно сделать на уровне:
- папки — запретить: /images/
- тип содержимого — запретить: /*.jpg
Группировать директивы в блоки и разделять их пустой строкой. Не записывайте все правила в одну строку. Используйте отдельное правило для каждой страницы, краулера, папки и т.д. Также не путайте инструкции: пишите бота в юзер-агенте, а не в директиве allow/disallow.
| Не | Да |
| Запретить: Яндекс | Агент пользователя: Яндекс disallow: / |
| Запретить: /css/ /images/ | Запретить: /css/ Запретить: /images/ |
С учетом регистра. Введите имя файла строчными буквами. Яндекс в пояснительной документации указывает, что регистр для его ботов не важен, но Google просит учитывать регистр. Также возможно, что имена файлов и папок чувствительны к регистру.
Введите имя файла строчными буквами. Яндекс в пояснительной документации указывает, что регистр для его ботов не важен, но Google просит учитывать регистр. Также возможно, что имена файлов и папок чувствительны к регистру.
Укажите редирект 301 на главное зеркало сайта . Раньше для этого использовалась директива Host, но с марта 2018 года она больше не нужна. Если он уже есть в файле robots.txt, удалите его или оставьте на свое усмотрение; роботы игнорируют эту директиву.
Чтобы указать главное зеркало, поставьте 301 редирект на каждую страницу сайта. Если редиректа нет, поисковик самостоятельно определит, какое зеркало считать основным. Чтобы исправить зеркало сайта, просто введите переадресацию 301 страницы и подождите несколько дней.
Написать директиву Sitemap (карта сайта). Файлы sitemap.xml и robots.txt дополняют друг друга. Проверить, чтобы:
- файлы не противоречили друг другу; Из обоих файлов исключена
- страница; В обоих файлах разрешена
- страница.
При анализе содержимого robots.txt обратите внимание, включена ли карта сайта в одноименную директиву. Пишется так: Карта сайта: www.yoursite.ru/sitemap.xml
Укажите комментарии с помощью символа #. Все, что пишется после этого, игнорируется сканером.
Проверка файлов
Анализ robots.txt с помощью инструментов разработчика: Яндекс.Вебмастер и Google Robots Testing Tool. Обратите внимание, что Яндекс и Google проверяют только соответствие файла их собственным требованиям. Если файл корректен для яндекса, это не значит, что он корректен для роботов гугла, так что проверяйте в обеих системах.
Если вы обнаружите ошибки и исправите файл robots.txt, поисковые роботы не смогут мгновенно прочитать изменения. Обычно повторное сканирование страницы происходит раз в день, но часто занимает гораздо больше времени. Через неделю проверьте файл, чтобы убедиться, что поисковые системы используют новую версию.
Регистрация в Яндекс.
 Вебмастере
ВебмастереСначала подтвердите права на сайт. После этого он появится в панели Вебмастера. Введите название сайта в поле и нажмите проверить. Результат проверки будет доступен ниже.
Дополнительно проверьте отдельные страницы. Для этого введите адреса страниц и нажмите «проверить».
Тестирование в Google Robots Testing Tool
Позволяет проверить и отредактировать файл в административной панели. Выдает сообщение о логических и синтаксических ошибках. Исправьте текст файла прямо в редакторе Google. Но обратите внимание, что изменения не сохраняются автоматически. После исправления robots.txt скопируйте код из веб-редактора и создайте новый файл с помощью блокнота или другого текстового редактора. Затем загрузите его на сервер в корневой каталог.
Запомнить
Файл robots.txt помогает поисковым роботам индексировать сайт. Закрывайте сайт на время разработки, в остальное время — весь сайт или его часть должны быть открыты. Правильно работающий файл должен возвращать ответ 200.
Файл создан в обычном текстовом редакторе. Во многих CMS в административной панели предусмотрено создание файла. Убедитесь, что размер не превышает 32 КБ. Поместите его в корневой каталог сайта.
Заполнить файл по правилам. Начните с кода «User-agent:». Пишите правила блоками, разделяя их пустой строкой. Следуйте принятому синтаксису.
Разрешить или запретить индексирование для всех или выбранных поисковых роботов. Для этого укажите название поискового робота или поставьте значок *, что означает «для всех».
Работа с разными уровнями доступа: сайт, страница, папка или тип файла.
Включить в файл указание на главное зеркало с помощью постраничной переадресации 301 и карту сайта с помощью директивы sitemap.
Используйте инструменты разработчика для анализа файла robots.txt. Это Яндекс.Вебмастер и Google Robots Testing Tools. Сначала подтвердите права на сайт, потом проверяйте. В гугле сразу отредактируйте файл в веб-редакторе и уберите ошибки. Отредактированные файлы не сохраняются автоматически. Загрузите их на сервер вместо оригинального файла robots.txt. Через неделю проверьте, используют ли поисковые системы новую версию.
Отредактированные файлы не сохраняются автоматически. Загрузите их на сервер вместо оригинального файла robots.txt. Через неделю проверьте, используют ли поисковые системы новую версию.
Материал подготовила Светлана Сирвида-Льоренте.
Каждый день в Интернете появляются решения той или иной проблемы. Нет денег на дизайнера? Используйте один из тысяч бесплатных шаблонов. Не хотите нанимать SEO-специалиста? Воспользуйтесь услугами какого-нибудь известного бесплатного сервиса, сами прочитайте пару статей.
Уже давно нет необходимости писать тот же robots.txt с нуля. Кстати, это специальный файл, который есть практически на любом сайте, и в нем содержатся инструкции для поисковых роботов. Синтаксис команды очень прост, но на создание собственного файла все равно потребуется время. Лучше посмотреть на другом сайте. Здесь есть несколько предостережений:
Сайт должен быть на том же движке, что и ваш. В принципе, сегодня в интернете очень много сервисов, где можно узнать название cms практически любого веб-ресурса.
Это должен быть более-менее успешный сайт, хорошо работающий с поисковым трафиком. Это означает, что файл robots.txt в порядке.
Итак, чтобы просмотреть этот файл, вам нужно набрать в адресной строке: domain-name.zone/robots.txt
Все невероятно просто, правда? Если адрес не найден, значит такого файла нет на сайте, либо доступ к нему закрыт. Но в большинстве случаев вы увидите перед собой содержимое файла:
В принципе, даже не особо разбирающийся в коде человек быстро поймет, что тут писать. Команда allow разрешает что-либо индексировать, а команда disallow запрещает это. User-agent — это указание поисковых роботов, которым адресованы инструкции. Это необходимо, когда вам нужно указать команды для конкретной поисковой системы.
Что делать дальше?
Скопируйте все и измените для своего сайта. Как изменить? Я уже говорил, что движки сайтов должны совпадать, иначе менять что-либо бессмысленно — нужно переписывать абсолютно все.
Итак, вам нужно будет пройтись по строкам и определить, какие из них присутствуют на вашем сайте, а какие нет. На скриншоте выше вы видите пример файла robots.txt для сайта wordpress, а в отдельной директории находится форум. Выход? Если у вас нет форума, все эти строчки надо удалить, так как таких разделов и страниц у вас просто нет, зачем тогда их закрывать?
На скриншоте выше вы видите пример файла robots.txt для сайта wordpress, а в отдельной директории находится форум. Выход? Если у вас нет форума, все эти строчки надо удалить, так как таких разделов и страниц у вас просто нет, зачем тогда их закрывать?
Простейший robots.txt может выглядеть так:
User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content Разрешить: /wp-content/uploads/
Агент пользователя: * Запретить: /wp-admin Запретить: /wp-includes Запретить: /wp-content Разрешить: /wp-content/uploads/ |
Все вы, наверное, знаете стандартную структуру папок в wordpress, если хоть раз устанавливали этот движок. Это папки wp-admin, wp-content и wp-includes. Обычно все 3 закрыты от индексации, т.к. содержат чисто технические файлы, необходимые для работы движка, плагинов и шаблонов.
Открыт каталог загрузки, так как он содержит изображения, и они обычно индексируются.
В общем надо пройтись по скопированному robots.txt и посмотреть, что на самом деле написано у вас на сайте, а что нет. Самому, конечно, будет сложно определить. Могу только сказать, что если что-то не удалять, то ничего страшного, просто будет лишняя строка, что не навредит (потому что раздела нет).
Действительно ли настройка robots.txt так важна?
Конечно, вы должны иметь этот файл и хотя бы закрывать через него основные каталоги. Но так ли уж важно его составить? Как показывает практика, нет. Я лично вижу сайты на одних и тех же движках с совершенно разными robots.txt, которые одинаково успешно продвигаются в поисковых системах О.
Я не спорю, что можно сделать какую-то ошибку. Например, закройте изображения или оставьте ненужную директорию открытой, но ничего сверхстрашного не произойдет. Во-первых, потому что поисковые системы сегодня умнее и могут игнорировать некоторые инструкции из файла. Во-вторых, про настройку robots.txt написаны сотни статей, и из них можно кое-что понять.
Я видел файлы, в которых было 6-7 строк, запрещающих индексацию пары каталогов. Еще я видел файлы с сотней-двумя строками кода, где было закрыто все, что можно было. Оба сайта работали хорошо.
В wordpress есть так называемые дубликаты. Это плохо. Многие борются с этим, закрывая такие дубликаты, как это:
Disallow: /wp-feed Disallow: */trackback Disallow: */feed Disallow: /tag/ Disallow: /archive/
Disallow: /wp-feed Здесь надо бороться иначе. Например, с помощью редиректов или плагинов, которые уничтожат дубликаты. Впрочем, это тема для отдельной статьи. Где находится robots.txt?Этот файл всегда находится в корне сайта, поэтому мы можем получить к нему доступ, введя адрес сайта и имя файла через косую черту. На мой взгляд, здесь все максимально просто. В общем, сегодня мы рассмотрели вопрос, как посмотреть содержимое файла robots.txt, скопировать его и изменить под свои нужды. |
 Также в ближайшее время напишу еще 1-2 статьи по настройке, т.к. в этой статье мы не все осветили. Кстати, много информации по продвижению сайтов-блогов вы также можете найти у нас. И на этом я прощаюсь с вами.
Также в ближайшее время напишу еще 1-2 статьи по настройке, т.к. в этой статье мы не все осветили. Кстати, много информации по продвижению сайтов-блогов вы также можете найти у нас. И на этом я прощаюсь с вами.Правильно составленный файл robots.txt помогает корректно проиндексировать сайт и устраняет дублированный контент, обнаруженный в любой CMS. Я знаю, что многих авторов просто пугает необходимость лазить куда-то в корневые папки блога и что-то менять в «служебных» файлах. Но этот ложный страх необходимо преодолеть. Поверьте мне, ваш блог не рухнет, даже если вы поместите свой собственный портрет в robots.txt (т.е. испортите его!). Но, любые выгодные изменения повысят его статус в глазах поисковых систем.
Что такое файл robots.txt
Не буду претендовать на звание эксперта, мучая вас терминами. Просто поделюсь своим довольно простым пониманием функций этого файла:
robots.txt — это инструкция, дорожная карта для поисковых роботов, посещающих наш блог с проверкой. Нам просто нужно сказать им, какой контент является, так сказать, услугой, а какой является наиболее ценным контентом, к которому читатели стремятся (или должны стремиться) нам. И именно эта часть контента должна индексироваться и попадать в результаты поиска!
Нам просто нужно сказать им, какой контент является, так сказать, услугой, а какой является наиболее ценным контентом, к которому читатели стремятся (или должны стремиться) нам. И именно эта часть контента должна индексироваться и попадать в результаты поиска!
А что будет, если нам наплевать на такие инструкции? Все индексируется. А так как пути алгоритмов поисковых систем практически неисповедимы, анонс статьи, открывающейся по адресу архива, может показаться более актуальным для Яндекса или Google, чем полный текст статьи, находящейся по другому адресу. И посетитель, заглянув в блог, увидит совсем не то, что он хотел и что хотелось бы вам: не поста, а списки всех статей месяца… Итог ясен — скорее всего, он оставлять.
Хотя есть примеры сайтов, которые вообще не имеют робота, но занимают приличные позиции в поисковой выдаче, но это конечно исключение, а не правило.
Из чего состоит файл robots.txt
А вот переписыванием заниматься не хочу. Есть вполне понятные пояснения из первых рук — например, в разделе помощи Яндекса. Я настоятельно рекомендую прочитать их не один раз. Но я постараюсь помочь вам преодолеть первое оцепенение перед обилием терминов, описав общую структуру файла robots.txt.
Есть вполне понятные пояснения из первых рук — например, в разделе помощи Яндекса. Я настоятельно рекомендую прочитать их не один раз. Но я постараюсь помочь вам преодолеть первое оцепенение перед обилием терминов, описав общую структуру файла robots.txt.
В самом верху в начале robots.txt заявляем для кого пишем инструкцию:
User agent: Яндекс
Конечно у каждого уважающего себя поисковика есть куча роботов — именных и безымянный. Пока вы не освоите мастерство robots.txt, лучше всего делать вещи простыми и обобщаемыми. Поэтому предлагаю отдать должное Яндексу, а всех остальных объединить, прописав общее правило:
User-Agent: * — это все, любые, роботы
Также указываем основное зеркало сайта — адрес, который будет участвовать в поиске. Это особенно верно, если у вас есть несколько зеркал. Вы также можете указать некоторые другие параметры. Но самое главное для нас, все-таки, это возможность закрыть служебные части блога от индексации.
Вот примеры запрета индексации:
Запретить: /cgi-bin* — файлы скриптов;
Запретить: /wp-admin* — административная консоль;
Запретить: /wp-includes* — служебные папки;
Запретить: /wp-content/plugins* — служебные папки;
Запретить: /wp-content/cache* — служебные папки;
Запретить: /wp-content/themes* — служебные папки;
Запретить: */feed
Запретить: /comments* — комментарии;
Запретить: */comments
Запретить: /*/?replytocom=* — ответы на комментарии
Запретить: /tag/* — теги
Запретить: /archive/* — архивы
Запретить: /category/* — категории
Как создать свой файл robots.
 txt
txtСамый простой и очевидный способ — найти пример готового файла robots.txt в каком-нибудь блоге и торжественно переписать его под себя. Хорошо, если при этом авторы не забудут заменить адрес блога примера на адрес своего детища.
Роботы любого сайта доступны по адресу:
https://website/robots.txt
Я сделал то же самое и не считаю себя вправе отговаривать вас. Единственное, что я прошу, это: разберись что написано в скопированном файле robots.txt! Воспользуйтесь помощью Яндекса, любых других источников информации — расшифруйте все строки. Тогда вы наверняка увидите, что какие-то правила не подходят для вашего блога, а каких-то правил, наоборот, не хватает.
Теперь посмотрим, как проверить правильность и эффективность нашего файла robots.txt.
Поскольку все, что связано с файлом robots.txt, поначалу может показаться слишком туманным и даже опасным, хочу показать вам простой и понятный инструмент для его проверки.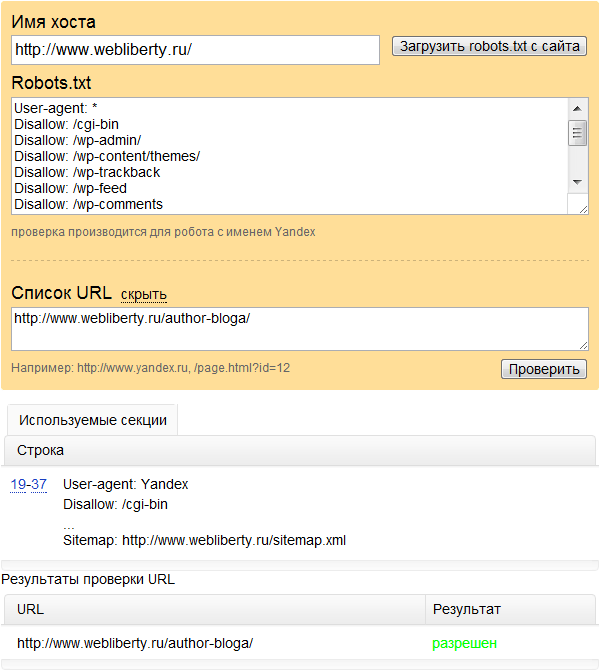 Это очевидный способ помочь вам не только проверить, но и подтвердить ваш robots.txt, заполнить его всеми необходимыми инструкциями и убедиться, что роботы поисковых систем понимают, что вы от них хотите.
Это очевидный способ помочь вам не только проверить, но и подтвердить ваш robots.txt, заполнить его всеми необходимыми инструкциями и убедиться, что роботы поисковых систем понимают, что вы от них хотите.
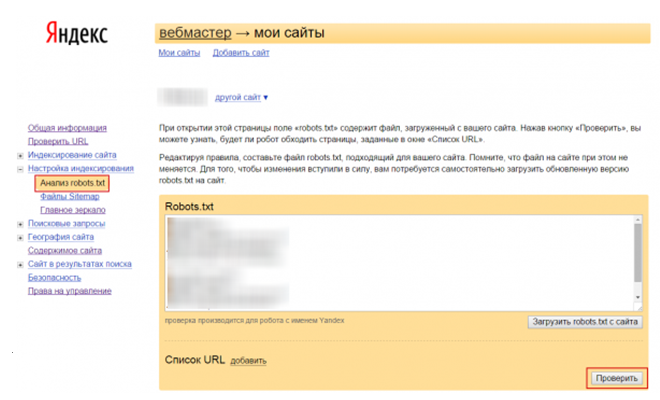
Проверка файла robots.txt в Яндексе
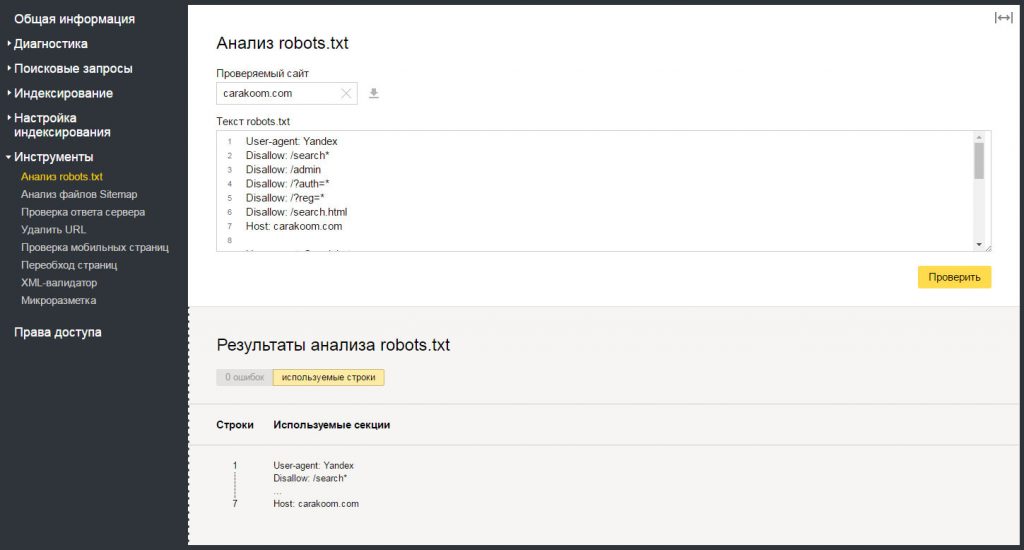
Яндекс Вебмастер позволяет узнать отношение поискового робота этой системы к нашему творению. Для этого, очевидно, нужно открыть информацию, относящуюся к блогу и:
- перейти на вкладку Сервис->Анализ robots.txt
- нажать кнопку «загрузить» и будем надеяться, что вы разместили robots. txt куда нужно и робот его найдет 🙂 (если не найдет, проверьте, где находится ваш файл: он должен быть в корне блога, где папки wp -admin, wp- include и т.д., а ниже отдельные файлы — среди них должен быть robots.txt)
- нажмите «Проверить».
Но самая важная информация находится в соседней вкладке — «Используемые разделы»! Ведь на самом деле нам важно, чтобы робот понимал основную часть информации — а все остальное пропускал:
На примере мы видим, что Яндекс понимает все, что касается его робота (строки с 1 по 15 и 32) — это здорово!
Проверка файла robots.
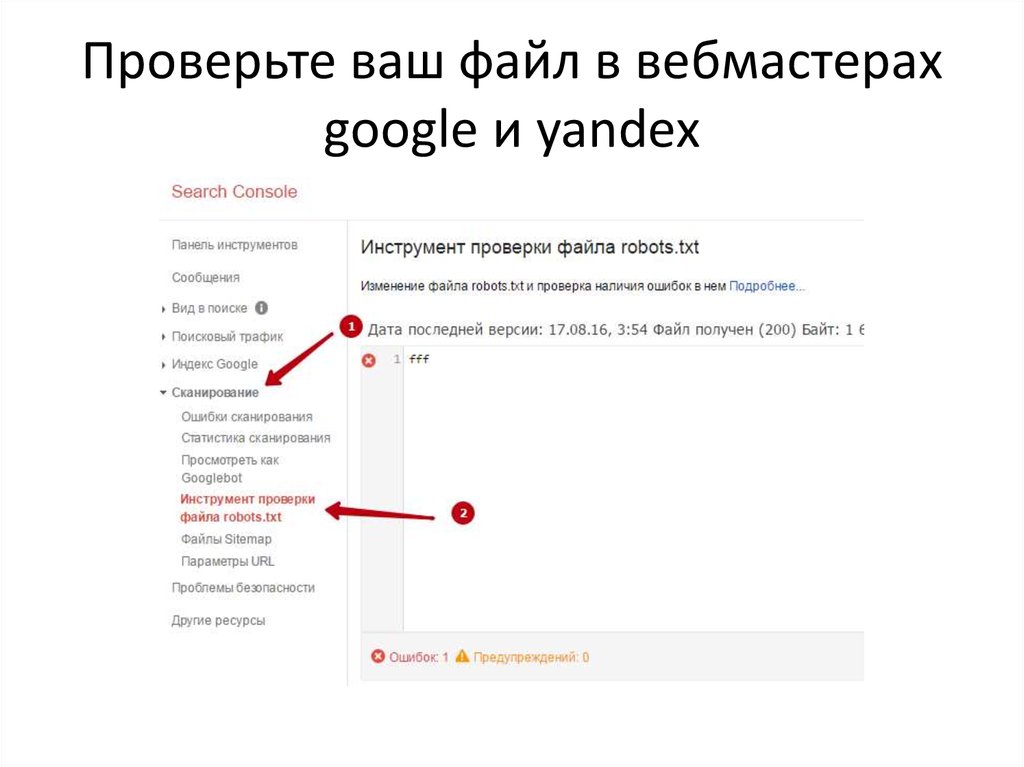 txt в Google
txt в GoogleУ Google также есть инструмент проверки, который покажет нам, как эта поисковая система видит (или не видит) наш robots.txt:
- Инструменты Google для веб-мастеров (где ваш блог также должен быть зарегистрирован) имеют собственную службу для проверки файла robots.txt. Он находится на вкладке «Сканирование».
- Найдя файл, система анализирует его и выводит информацию об ошибках. Все просто.
На что следует обратить внимание при анализе файла robots.txt
Мы не зря рассмотрели инструменты анализа от двух важнейших поисковых систем — Яндекс и Google. Ведь нам нужно сделать так, чтобы каждый из них прочитал рекомендации, данные нами в robots.txt.
В приведенных здесь примерах видно, что Яндекс понимает инструкции, которые мы оставили его роботу, и игнорирует все остальные (хотя везде написано одно и то же, только директива User-agent: другая:)))
Важно понимать, что любые изменения в robots.txt необходимо вносить непосредственно в файл, находящийся в корневой папке вашего блога. То есть вам нужно открыть его в любом блокноте, чтобы переписать, удалить, добавить любые строки. Затем нужно сохранить его обратно в корень сайта и перепроверить реакцию на изменения в поисковых системах.
То есть вам нужно открыть его в любом блокноте, чтобы переписать, удалить, добавить любые строки. Затем нужно сохранить его обратно в корень сайта и перепроверить реакцию на изменения в поисковых системах.
Нетрудно понять, что в нем написано, что нужно добавить. А заниматься продвижением блога без правильной настройки файла robots.txt (так, как вам нужно!) — усложните себе задачу.
Карта сайта значительно упрощает индексацию вашего блога. Карта сайта должна быть обязательной для каждого сайта и блога. Но также на каждом сайте и блоге должен быть файл robots. текст . Файл robots.txt содержит набор инструкций для поисковых роботов. Можно сказать — правила поведения поисковых роботов на вашем блоге. А также этот файл содержит путь к карте сайта вашего блога. И, действительно, при правильно составленном файле robots.txt поисковый робот не тратит драгоценное время на поиск карты сайта и индексацию ненужных файлов.
Что такое файл robots.txt?
robots.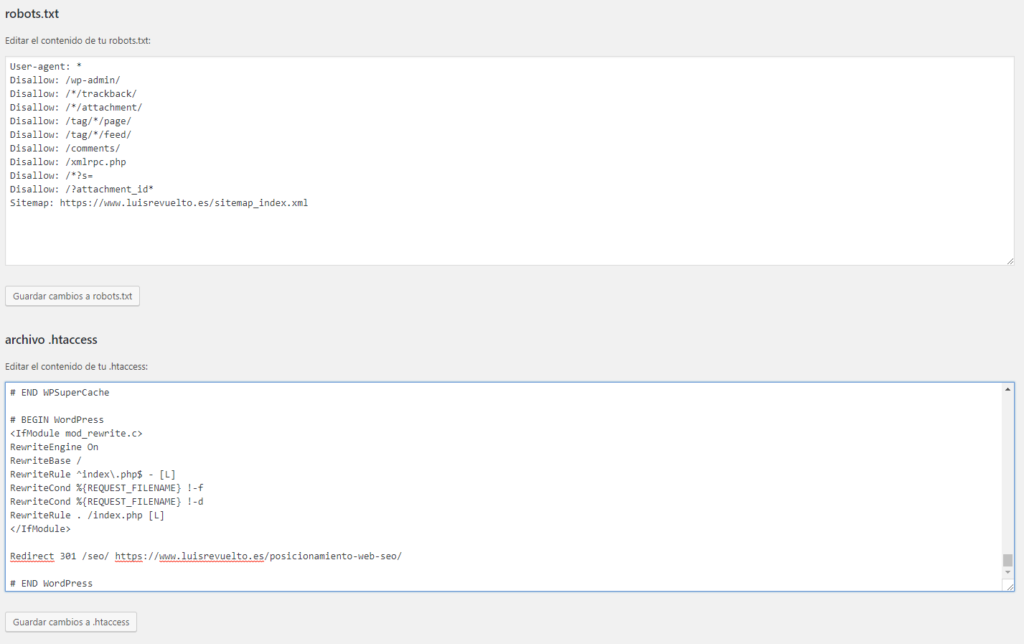 txt — этот текстовый файл, может быть создан в обычном «блокноте» расположенном в корне вашего блога с инструкциями для поисковых роботов.
txt — этот текстовый файл, может быть создан в обычном «блокноте» расположенном в корне вашего блога с инструкциями для поисковых роботов.
Эти инструкции не позволяют поисковым роботам случайным образом индексировать все файлы вашего бога и нацелены на индексирование именно тех страниц, которые должны быть в поисковой выдаче.
С помощью данного файла вы можете отключить индексацию файлов движка WordPress. Или, скажем, секретный раздел вашего блога. Вы можете указать путь к карте вашего блога и главному зеркалу вашего блога. Под этим я подразумеваю ваше доменное имя с www и без www.
Индексация сайта с помощью и без robots.txt
На этом скриншоте хорошо видно, как файл robots.txt запрещает индексацию определенных папок на сайте. Без файла роботу доступно все на вашем сайте.
Основные директивы robots.txt
Чтобы понять инструкции, содержащиеся в файле robots.txt, вам необходимо понять основные команды (директивы).
user-agent — эта команда указывает доступ роботов к вашему сайту. Используя эту директиву, вы можете создавать инструкции индивидуально для каждого робота.
Используя эту директиву, вы можете создавать инструкции индивидуально для каждого робота.
User-agent: Яндекс — правила для робота Яндекса
User-agent: * — правила для всех роботов
Запретить и разрешить — директивы запрета и разрешения. С помощью директивы Disallow индексирование запрещается, а с помощью Allow разрешается.
Пример бана:
User-agent: *
Disallow: / — запрет всему сайту.
Агент пользователя: Яндекс
Запретить: /admin — запрещает роботу Яндекса доступ к страницам в папке администратора.
Пример разрешения:
User-agent: *
Разрешить: /photo
Запретить: / — запрет на весь сайт, кроме страниц, расположенных в папке фото.
Внимание! директива Disallow: без параметра разрешает все, а директива Allow: без параметра все запрещает. И директивы Allow без Disallow быть не должно.
Карта сайта — указывает путь к карте сайта в формате xml.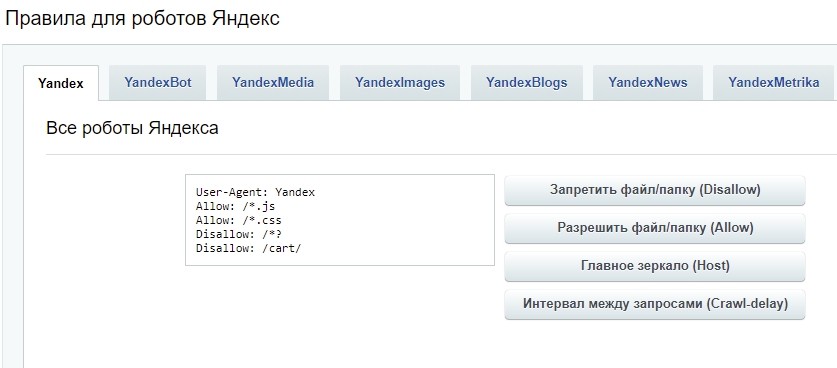
Карта сайта: https://site/sitemap.xml.gz
Карта сайта: https://site/sitemap.xml
Хост — директива определяет главное зеркало вашего блога. Считается, что эта директива прописана только для роботов Яндекса. Эту директиву следует разместить в самом конце файла robots.txt.
Агент пользователя: Яндекс
Запретить: /wp-includes
хост: сайт
Внимание! адрес главного зеркала указывается без указания протокола передачи гипертекста (http://).
Как создать robots.txt
Теперь, когда мы ознакомились с основными командами файла robots.txt, мы можем приступить к созданию нашего файла. Чтобы создать собственный файл robots.txt со своими настройками, вам нужно знать структуру своего блога.
Мы рассмотрим создание стандартного (универсального) файла robots.txt для блога WordPress. Вы всегда можете добавить в него свои настройки.
Итак, приступим. Нам понадобится обычный «блокнот», который есть в каждой операционной системе Windows. Или TextEdit на MacOS.
Или TextEdit на MacOS.
Откройте новый документ и вставьте в него следующие команды:
Агент пользователя: * Запретить: Карта сайта: https://site/sitemap.xml.gz Карта сайта: https://site/sitemap.xml Агент пользователя: Яндекс Запретить: /wp-login.php Запретить: /wp-register .php Запретить: /cgi-bin Запретить: /wp-admin Запретить: /wp-includes Запретить: /xmlrpc.php Запретить: /wp-content/plugins Запретить : /wp-content/cache Disallow: /wp-content/themes Disallow: /wp-content/languages Disallow: /category/*/* Disallow: /trackback Disallow: */trackback Disallow: */*/trackback Disallow : /tag/ Disallow: /feed/ Disallow: */*/feed/ */ Disallow: */feed Disallow: */*/feed Disallow: /?feed= Disallow: /*?* Disallow: /?s= Host : сайт
Не забудьте заменить параметры директив Sitemap и Host на свои.
Важно! при написании команд допускается только один пробел. Между директивой и параметром. Ни в коем случае не делайте пробелы после параметра или где угодно.

Пример : Disallow:/feed/
Этот пример файла robots.txt является универсальным и подходит для любого блога WordPress с URL-адресами CNC. Почитайте, что такое ЧПУ. Если вы не настроили ЧПУ, рекомендую удалить Disallow: /*?* Disallow: /?s= из предложенного файла
Загрузка файла robots.txt на сервер
Лучший способ для такого рода манипуляций — FTP-соединение. Читайте о том, как настроить FTP-соединение для TotolCommander. Или вы можете использовать файловый менеджер на вашем хостинге.
Я буду использовать FTP-подключение к TotolCommander.
Сеть > Подключиться к FTP-серверу.
Выберите нужное подключение и нажмите кнопку «Подключить».
Откройте корень блога и скопируйте наш файл robots.txt, нажав клавишу F5.
Скопируйте robots.txt на сервер
Теперь ваш файл robots.txt будет выполнять свои функции. Но я все же рекомендую разобрать robots.txt, чтобы убедиться в отсутствии ошибок.
Для этого вам потребуется войти в аккаунт вебмастера Яндекс или Google. Рассмотрим на примере Яндекс. Здесь можно провести анализ, даже не подтверждая права на сайт. Вам достаточно иметь почтовый ящик на Яндексе.
Открываем аккаунт Яндекс.Вебмастер.
На главной странице кабинета вебмастера открыть ссылку «Проверить роботов. txt» .
Для анализа вам нужно будет ввести адрес вашего блога и нажать кнопку « Скачать robots. txt с сайта «. После загрузки файла нажмите кнопку «Проверить».
Отсутствие записей с предупреждениями указывает на правильность создания файла robots.txt.
Результат будет показан ниже. Где ясно и понятно, какие материалы разрешено показывать поисковым роботам, а какие — запрещены.
Результат разбора файла robots.txt
Здесь вы также можете вносить изменения в robots.txt и экспериментировать, пока не получите желаемый результат. Но помните, файл, расположенный в вашем блоге, не меняется. Для этого нужно скопировать полученный здесь результат в блокнот, сохранить как robots.txt и скопировать блог себе.
Но помните, файл, расположенный в вашем блоге, не меняется. Для этого нужно скопировать полученный здесь результат в блокнот, сохранить как robots.txt и скопировать блог себе.
Кстати, если вам интересно, как выглядит файл robots.txt в чьем-то блоге, вы можете легко найти его. Для этого нужно просто добавить /robots.txt к адресу сайта
https://website/robots.txt
Теперь ваш robots.txt готов. И помните, не откладывайте создание файла robots.txt, от этого будет зависеть индексация вашего блога.
Если вы хотите создать правильный robots.txt и при этом быть уверенным, что в индекс поисковика попадут только нужные страницы, то это можно сделать автоматически с помощью плагина.
Это все для меня. Желаю всем успехов. Если у вас есть вопросы или дополнения, пишите в комментариях.
До скорой встречи.
С уважением, Максим Зайцев.
Подписывайтесь на новые статьи!
Индексация txt робота отключена. Как запретить индексацию нужных страниц.
 Запретить индексацию всех страниц со строкой запроса
Запретить индексацию всех страниц со строкой запросаНу, например, вы решили изменить дизайн блога и не хотите, чтобы поисковые боты в это время посещали ресурс. Или вы только что создали сайт и установили на него движок, поэтому если на ресурсе нет полезной информации, то не стоит показывать ее поисковым ботам. В этой статье вы узнаете, как закрыть сайт от индексации в Яндексе, Гугле или сразу во всех поисковиках. Но перед этим вы также можете прочитать другую подобную статью: «?» А теперь приступим.
1. Закрываем сайт от индексации с помощью файла robots.txt.
Для начала вам понадобится . Для этого создайте на своем компьютере обычный текстовый документ с именем robots и расширением .txt. Вот я его только что создал:
Теперь этот файл нужно загрузить в . Если ресурс сделан на движке WordPress, то корневая папка находится там, где находятся папки wp-content, wp-includes и т.д.
Итак, мы залили на хостинг пустой файл, теперь нам нужно использовать этот файл, чтобы как-то закрыть блог от индексации. Это можно сделать, как я уже писал только для яндекса, гугла или всех поисковиков сразу. Обо всем по порядку.
Это можно сделать, как я уже писал только для яндекса, гугла или всех поисковиков сразу. Обо всем по порядку.
Как закрыть сайт от индексации только для Яндекса?
В файле robots.txt пропишите следующую строку:
Агент пользователя: Яндекс
disallow: /
Для того, чтобы убедиться, что вы запретили Яндексу индексировать ваш ресурс, сначала добавьте сайт, если у вас есть еще не сделали этого, а затем перейдите на эту страницу. Далее введите несколько страниц вашего сайта и нажмите на кнопку «Проверить». Если страницы запрещены к индексации, то вы увидите примерно следующее:
Как запретить индексацию сайта только для Google?
Откройте файл robots.txt и пропишите там следующую строку:
Агент пользователя: Googlebot
disallow: /
Для того, чтобы проверить, что Google не индексирует сайт, создайте , добавьте свой ресурс в Google Webmaster и иди к нему. Здесь также нужно ввести несколько страниц и нажать на кнопку «проверить».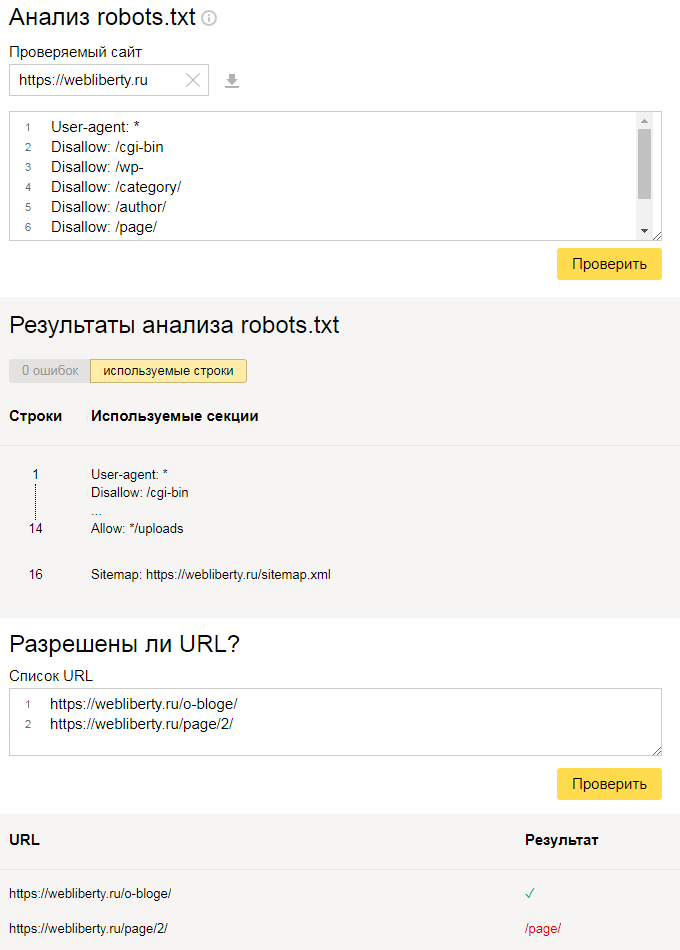
Я заметил, что поисковик Google индексирует даже те документы, которые запрещены в файле robots.txt и ставит их в дополнительный индекс, так называемые «сопли». Почему, не знаю, но вы должны понимать, что нельзя на 100% забанить сайт или отдельную страницу с помощью файла robots.txt. Этот файл, я так понимаю, только рекомендация для Гугла, а он уже решает, что индексировать, а что нет.
Как заблокировать сайт от индексации всеми поисковыми системами?
Чтобы ваш ресурс не индексировали сразу все поисковые системы, пропишите в robots.txt строку:
User-agent: *
disallow: /
Теперь вы также можете зайти на Яндекс или Гугл Вебмастер и проверить запрет на индексацию.
Посмотреть ваш файл robots.txt можно по этому адресу:
Вашдомен.ru/robots.txt
Все, что вы написали в этом файле, должно отображаться в браузере. Если при переходе по этому адресу он всплывает перед вами, значит, вы загрузили свой файл не туда.
Кстати, мой robots.txt находится в формате . Если ваш ресурс сделан на движке wordpress, то его можно просто скопировать. Он правильно настроен, чтобы поисковые боты индексировали только нужные документы и чтобы на сайте не было дубликатов.
2. Закрываем сайт от индексации с помощью панели инструментов.
Этот способ подходит только тем, чей ресурс сделан на WordPress. Заходим в «Панель управления» — «Настройки» — «Чтение». Здесь нужно поставить галочку напротив надписи «Рекомендовать поисковым системам не индексировать сайт».
Обратите внимание, внизу есть очень интересная надпись: «Поисковики сами решают, следовать ли вашему запросу». Это именно то, что я написал выше. Яндекс, скорее всего, не будет индексировать запрещенные к индексации страницы, а вот с Google могут возникнуть проблемы.
3. Закрываем сайт от индексации вручную.
При закрытии всего ресурса или страницы от индексации в исходном коде автоматически появляется следующая строка:
meta name=»robots» content=»noindex,follow»
Она сообщает поисковым роботам, что документ не может быть проиндексирован. Вы можете просто вручную написать эту строчку в любом месте вашего сайта, главное чтобы она отображалась на всех страницах и тогда ресурс будет закрыт от индексации.
Вы можете просто вручную написать эту строчку в любом месте вашего сайта, главное чтобы она отображалась на всех страницах и тогда ресурс будет закрыт от индексации.
Кстати, если вы создаете ненужный документ на своем сайте, и не хотите, чтобы его индексировали поисковые боты, вы также можете вставить эту строку в исходный код.
После обновления откройте исходный код страницы (CTRL+U) и посмотрите, появилась ли там эта строка. Если есть, то все в порядке. На всякий случай еще можно проверить с помощью инструментов для веб-мастеров от Яндекса и Google.
На сегодня все. Теперь вы знаете, как заблокировать сайт от индексации. Я надеюсь, что эта статья была вам полезна. Все пока.
Одним из этапов оптимизации сайта для поисковых систем является создание файла robots.txt. С помощью этого файла вы можете запретить некоторым или всем поисковым роботам индексировать ваш сайт или определенные его части, не предназначенные для индексации. В частности, вы можете отключить индексирование дублированного контента, например печатных версий страниц.
Перед индексацией поисковые роботы всегда обращаются к файлу robots.txt в корневом каталоге вашего сайта, например, http://site.ru/robots.txt, чтобы знать, в каких разделах сайта находится робот не разрешено индексировать. Но даже если вы не собираетесь ничего запрещать, то этот файл все же рекомендуется создать.
Как видно по расширению robots.txt, это текстовый файл. Для создания или редактирования этого файла лучше использовать самые простые текстовые редакторы вроде Notepad (Блокнот). robots.txt должен быть размещен в корневом каталоге сайта и имеет собственный формат, который мы рассмотрим ниже.
Формат файла robots.txt
Файл robots.txt должен содержать не менее двух обязательных записей. Сначала идет директива User-agent, которая указывает, какой сканер должен следовать приведенным ниже инструкциям. Значением может быть имя робота (гуглбот, яндекс, стекрамблер) или символ *, если вы обращаетесь ко всем роботам сразу. Например:
Агент пользователя: googlebot
Имя робота можно найти на сайте соответствующей поисковой системы. Далее должна быть одна или несколько директив Disallow. Эти директивы сообщают роботу, какие файлы и папки нельзя индексировать. Например, следующие строки запрещают роботам индексировать файл Feedback.php и каталог cgi-bin:
Далее должна быть одна или несколько директив Disallow. Эти директивы сообщают роботу, какие файлы и папки нельзя индексировать. Например, следующие строки запрещают роботам индексировать файл Feedback.php и каталог cgi-bin:
Запретить: /feedback.php Запретить: /cgi-bin/
Вы также можете использовать только начальные символы файлов или папок. Строка Disallow: /forum запрещает индексацию всех файлов и папок в корне сайта, имя которых начинается на forum, например, файл http://site.ru/forum.php и файл http://site. ru/forum/ папка со всем ее содержимым. Если Disallow пуст, это означает, что робот может индексировать все страницы. Если значением Disallow является символ /, это означает, что весь сайт не может быть проиндексирован.
Должно быть хотя бы одно поле Disallow для каждого поля User-agent. То есть, если вы не собираетесь ничего запрещать для индексации, то в файле robots.txt должны быть следующие записи:
User-agent: * Disallow:
Дополнительные директивы
Кроме регулярных выражений, Яндекс и Гугл разрешить использование директивы Allow, которая противоположна Disallow, то есть указывает, какие страницы можно индексировать. В следующем примере Яндексу запрещено индексировать все, кроме адресов страниц, начинающихся с /articles:
В следующем примере Яндексу запрещено индексировать все, кроме адресов страниц, начинающихся с /articles:
Агент пользователя: Яндекс Разрешить: /articles Запретить: /
В данном примере директива Allow должна быть написана перед Disallow, иначе Яндекс воспримет это как полный запрет на индексацию сайта. Пустая директива Allow также полностью отключает индексацию сайта:
User-agent: Yandex Allow:
равносильно
User-agent: Яндекс Запретить: /
Нестандартные директивы нужно указывать только для тех поисковых систем, которые их поддерживают. В противном случае робот, который не понимает эту запись, может некорректно обработать ее или весь файл robots.txt. Подробнее о дополнительных директивах и вообще о понимании команд файла robots.txt отдельным роботом вы можете узнать на сайте соответствующей поисковой системы.
Регулярные выражения в robots.
 txt
txtБольшинство поисковых систем учитывают только явно указанные имена файлов и папок, но есть и более продвинутые поисковые системы. Googlebot и Yandexbot поддерживают использование простых регулярных выражений в robots.txt, что значительно сокращает объем работы веб-мастеров. Например, следующие команды запрещают роботу Googlebot индексировать все файлы с расширением .pdf:
. Пользовательский агент: googlebot Запретить: *.pdf$
В приведенном выше примере символ * — это любая последовательность символов, а $ указывает на конец ссылки.
Агент пользователя: Яндекс Разрешить: /articles/*.html$ Запретить: /
Приведенные выше директивы позволяют Яндексу индексировать только файлы в папке /articles/ с расширением «.html». Все остальное запрещено для индексации.
карта сайта
Вы можете указать расположение XML карты сайта в файле robots.txt:
Агент пользователя: googlebot Disallow: Карта сайта: http://site.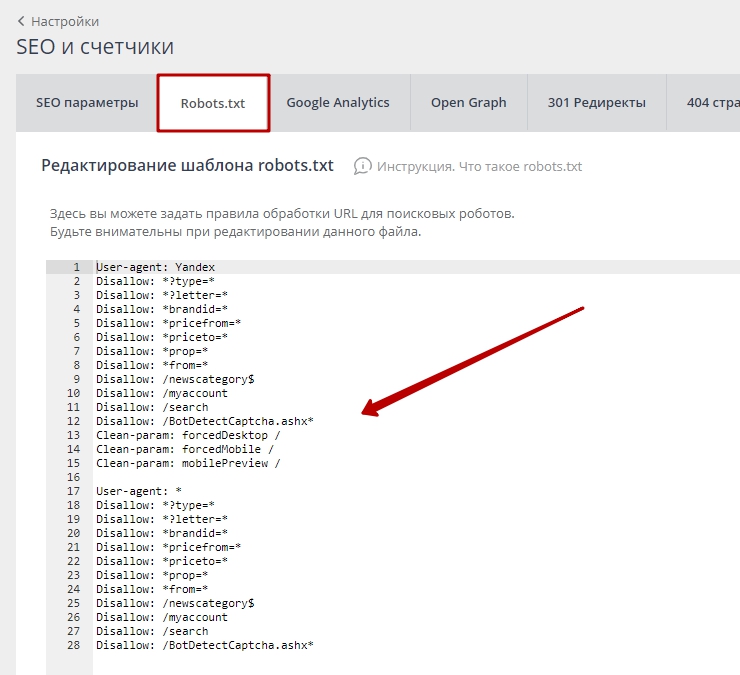 ru/sitemap.xml
ru/sitemap.xml
Если у вас очень большое количество страниц на сайте и вам пришлось разбить карту сайта на части, то вам необходимо указать все части карты в файле robots.txt:
User-agent: Яндекс Disallow: Карта сайта: http://mysite.ru/my_sitemaps1.xml Карта сайта: http://mysite.ru/my_sitemaps2.xml
Зеркала сайта
Как известно, обычно один и тот же сайт можно зайти по двум адресам: как с www, так и без него. Для поискового робота site.ru и www.site.ru — это разные сайты, но с одинаковым содержанием. Их называют зеркалами.
В связи с тем, что страницы сайта имеют ссылки как с www, так и без, вес страниц можно разделить между www.site.ru и site.ru. Чтобы этого не произошло, поисковику нужно указать главное зеркало сайта. В результате «склейки» весь вес будет принадлежать одному основному зеркалу и сайт сможет занять более высокие позиции в поисковой выдаче.
Вы можете указать главное зеркало для Яндекса прямо в файле robots. txt с помощью директивы Host:
txt с помощью директивы Host:
User-agent: Яндекс Disallow: /feedback.php Disallow: /cgi-bin/ Хост: www.site.ru
После склейки зеркалу www.site.ru будет принадлежать весь вес и оно будет занимать более высокие позиции в результатах поиска. А site.ru вообще не будет индексироваться поисковой системой.
Для других поисковых систем выбор основного зеркала — это постоянный редирект на стороне сервера (код 301) с дополнительных зеркал на основное. Это делается с помощью файла .htaccess и модуля mod_rewrite. Для этого кладем файл .htaccess в корень сайта и пишем там следующее: 9(.*)$ http://www.site.ru/$1
В результате все запросы с site.ru будут уходить на www.site.ru, т.е. site.ru/page1.php будут перенаправляться на www.site.ru/page1.php.
Метод перенаправления будет работать для всех поисковых систем и браузеров, но для Яндекса все же рекомендуется добавить директиву Host в файл robots.txt.
Комментарии в robots.
 txt
txtВы также можете добавлять комментарии в файл robots.txt — они начинаются с символа # и заканчиваются переводом строки. Комментарии желательно писать отдельной строкой, но лучше их вообще не использовать.
Пример использования комментариев:
User-agent: StackRambler Disallow: /garbage/ # ничего полезного в этой папке Disallow: /doc.xhtml # и на этой странице # и все комментарии в этом файле тоже бесполезны
Образцы файлов robots.txt
1. Разрешаем всем роботам индексировать все документы сайта:
User-agent: * Disallow:
User-agent: * Disallow: /
3. Запрещаем роботу поисковой системы Google для индексации файла Feedback.php и содержимого каталога cgi-bin:
Агент пользователя: googlebot Disallow: /cgi-bin/ Disallow: /feedback.php
4. Разрешаем всем роботам индексировать весь сайт, а роботу поисковой системы Яндекс запрещаем индексировать файл Feedback.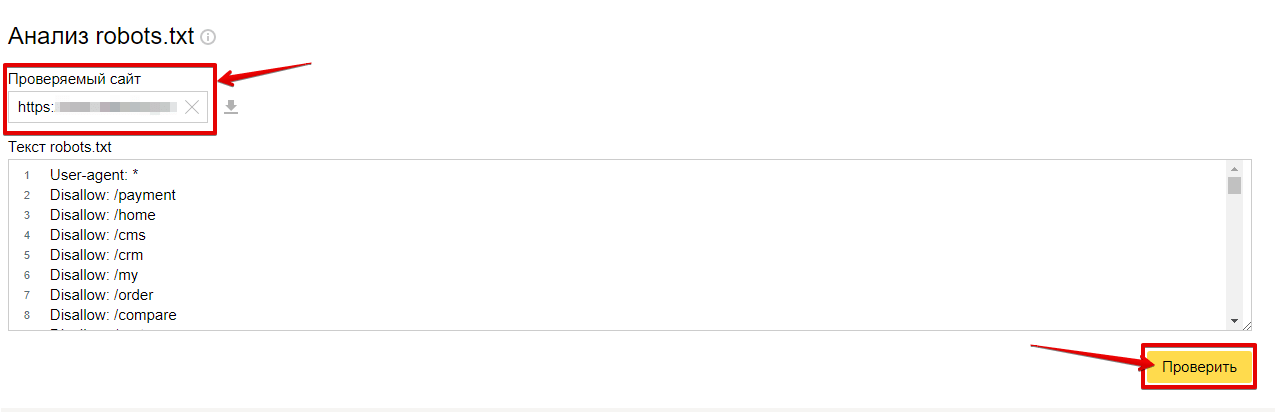 php и содержимое директории cgi-bin:
php и содержимое директории cgi-bin:
User-agent: Яндекс Disallow: /cgi-bin/ Disallow: /feedback.php Host: www.site.ru User-agent: * Disallow:
5. Разрешаем всем роботам индексировать весь сайт, а роботу Яндекса разрешаем индексировать только предназначенную для него часть сайта:
User-agent: Яндекс Разрешить: /yandex Disallow: / Хост: www.site.ru User-agent: * Disallow:
Пустые строки разделяют пределы для разных роботов. Каждый блок ограничений должен начинаться со строки с полем User-Agent, указывающим на робота, к которому применяются данные правила индексации сайта.
Распространенные ошибки
Необходимо учитывать, что пустая строка в файле robots.txt является разделителем между двумя записями для разных роботов. Кроме того, вы не можете указать несколько директив в одной строке. При отключении индексации файла веб-мастера часто опускают / перед именем файла.
Не нужно прописывать в robots. txt запрет на индексацию сайта для различных программ, которые предназначены для полной загрузки сайта, например ТелепортПро. Ни загрузчики, ни браузеры никогда не смотрят этот файл и не следуют написанным там инструкциям. Он предназначен исключительно для поисковых систем. Также не стоит блокировать админку своего сайта в robots.txt, так как если на нее нигде нет ссылки, то она не будет проиндексирована. Вы будете раскрывать расположение админки только тем людям, которые не должны об этом знать. Также стоит помнить, что слишком большой файл robots.txt может быть проигнорирован поисковиком. Если у вас слишком много страниц, не предназначенных для индексации, то лучше просто удалить их с сайта или переместить в отдельный каталог и запретить индексацию этого каталога.
txt запрет на индексацию сайта для различных программ, которые предназначены для полной загрузки сайта, например ТелепортПро. Ни загрузчики, ни браузеры никогда не смотрят этот файл и не следуют написанным там инструкциям. Он предназначен исключительно для поисковых систем. Также не стоит блокировать админку своего сайта в robots.txt, так как если на нее нигде нет ссылки, то она не будет проиндексирована. Вы будете раскрывать расположение админки только тем людям, которые не должны об этом знать. Также стоит помнить, что слишком большой файл robots.txt может быть проигнорирован поисковиком. Если у вас слишком много страниц, не предназначенных для индексации, то лучше просто удалить их с сайта или переместить в отдельный каталог и запретить индексацию этого каталога.
Проверка файла robots.txt на наличие ошибок
Обязательно проверьте, как поисковые системы понимают ваш файл robots. Вы можете использовать инструменты Google для веб-мастеров, чтобы проверить Google. Если вы хотите узнать, как Яндекс понимает ваш файл robots. txt, вы можете воспользоваться сервисом Яндекс.Вебмастер. Это позволит вовремя исправить допущенные ошибки. Также на страницах этих сервисов можно найти рекомендации по составлению файла robots.txt и много другой полезной информации.
txt, вы можете воспользоваться сервисом Яндекс.Вебмастер. Это позволит вовремя исправить допущенные ошибки. Также на страницах этих сервисов можно найти рекомендации по составлению файла robots.txt и много другой полезной информации.
Копирование статьи запрещено.
Robots.txt — это специальный файл, расположенный в корневом каталоге сайта. Вебмастер указывает в нем, какие страницы и данные закрыть от индексации поисковыми системами. Файл содержит директивы, описывающие доступ к разделам сайта (так называемый стандарт исключений роботов). Например, с его помощью можно задавать различные параметры доступа для поисковых роботов, предназначенных для мобильных устройств и обычных компьютеров. Очень важно правильно его настроить.
Требуется ли файл robots.txt?
С помощью robots.txt вы можете:
- запретить индексацию похожих и ненужных страниц, чтобы не тратить впустую лимит сканирования (количество URL-адресов, которые поисковый робот может обойти за одно сканирование). Те. робот сможет индексировать более важные страницы.
- скрыть изображения из результатов поиска.
- закрыть неважные скрипты, файлы стилей и другие некритические ресурсы страницы от индексации.
 Те. робот сможет индексировать более важные страницы.
Те. робот сможет индексировать более важные страницы.Если это не позволяет поисковым роботам Google или Yandex анализировать страницы, не блокируйте файлы.
Где находится файл Robots.txt?
Если вы просто хотите посмотреть, что находится в файле robots.txt, то просто введите в адресной строке браузера: site.ru/robots.txt.
Физически файл robots.txt находится в корневой папке сайта на хостинге. У меня хостинг beget.ru, поэтому покажу расположение файла robots.txt на этом хостинге.
Как создать правильный файл robots.txt
Файл robots.txt состоит из одного или нескольких правил. Каждое правило блокирует или разрешает индексацию путей на сайте.
- В текстовом редакторе создайте файл robots.txt и заполните его в соответствии с приведенными ниже правилами.
- Файл robots.txt должен быть текстовым файлом в кодировке ASCII или UTF-8. Использование символов в других кодировках запрещено.
- На сайте должен быть только один такой файл.
- Файл robots.txt должен быть помещен в корневой каталог сайта. Например, чтобы управлять индексацией всех страниц на http://www.example.com/, поместите файл robots.txt по адресу http://www.example.com/robots.txt. Он не должен находиться в подкаталоге (например, по адресу http://example.com/pages/robots.txt). Если у вас возникли проблемы с доступом к корневому каталогу, обратитесь к своему хостинг-провайдеру. Если у вас нет доступа к корневому каталогу сайта, используйте альтернативный метод блокировки, например метатеги.
- Файл robots.txt можно добавить на адреса с поддоменами (например, http:// веб-сайт .example.com/robots.txt) или нестандартными портами (например, http://example.com : 8181 /robots.txt).
- Проверить файл в Яндекс. Вебмастере и Google Search Console.
- Загрузите файл в корневой каталог вашего сайта.

 Вебмастере и Google Search Console.
Вебмастере и Google Search Console.Вот пример файла robots.txt с двумя правилами. Ниже приводится его объяснение.
Агент пользователя: Googlebot Запретить: /nogooglebot/ Агент пользователя: * Разрешить: / Карта сайта: http://www.example.com/sitemap.xml
Пояснение
- Пользовательский агент с именем Googlebot не должен проиндексируйте каталог http://example.com/nogooglebot/ и его подкаталоги.
- Все остальные пользовательские агенты имеют доступ ко всему сайту (можно опустить, результат тот же, так как по умолчанию предоставляется полный доступ).
- Карта сайта для этого сайта находится по адресу http://www.example.com/sitemap.xml.
Директивы Disallow и Allow
Для запрета индексации и доступа робота к сайту или отдельным его разделам используйте директиву Disallow.
User-agent: Yandex Disallow: / # блокирует доступ ко всему сайту User-agent: Yandex Disallow: /cgi-bin # блокирует доступ к страницам, # начинающимся с «/cgi-bin»
Стандарт рекомендует вставлять пустую новую строку перед каждой директивой User-agent.
Символ # используется для описания комментариев. Все после этого символа и до первой новой строки игнорируется.
Чтобы разрешить роботу доступ к сайту или некоторым его разделам, используйте директиву Allow
User-agent: Яндекс Разрешить: /cgi-bin Disallow: / # запрещает загрузку всего, кроме страниц, # начинающихся с «/cgi-bin »
Пустые символы новой строки между директивами User-agent, Disallow и Allow не допускаются.
Директивы Allow и Disallow из соответствующего блока User-agent сортируются по длине префикса URL (от меньшего к большему) и применяются последовательно. Если для данной страницы сайта подходят несколько директив, то робот выбирает последнюю по порядку появления в отсортированном списке. Таким образом, порядок директив в файле robots.txt не влияет на то, как робот их использует. Примеры:
# Исходный robots.txt: User-agent: Яндекс Разрешить: /catalog Disallow: / # Отсортированный robots.txt: User-agent: Яндекс Disallow: / Разрешить: /catalog # разрешить загрузку только страниц, # начинающихся с «/ catalog» # Оригинальный robots.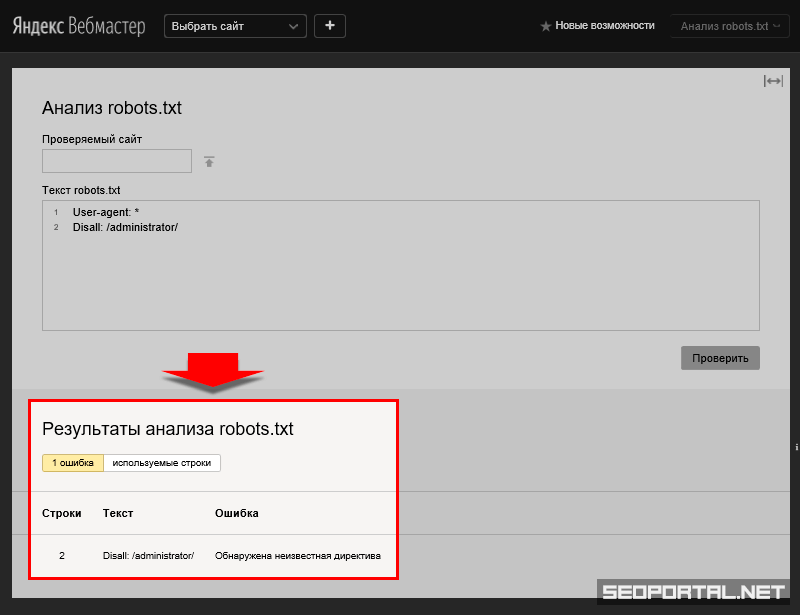 txt: User-agent: Яндекс Разрешить: / Разрешить: /catalog/auto Запретить: /catalog # Отсортированный robots.txt: User-agent: Яндекс Разрешить: / Запретить: /catalog Разрешить: /catalog/auto # запрещает загрузку страниц, начинающихся с «/catalog», # но разрешает загрузку страниц, начинающихся с «/catalog/auto».
txt: User-agent: Яндекс Разрешить: / Разрешить: /catalog/auto Запретить: /catalog # Отсортированный robots.txt: User-agent: Яндекс Разрешить: / Запретить: /catalog Разрешить: /catalog/auto # запрещает загрузку страниц, начинающихся с «/catalog», # но разрешает загрузку страниц, начинающихся с «/catalog/auto».
В случае конфликта между двумя директивами с префиксами одинаковой длины приоритет имеет директива Allow.
Использование специальных символов * и $
При указании путей директив Allow и Disallow можно использовать специальные символы * и $, тем самым задавая определенные регулярные выражения.
Специальный символ * означает любую (включая пустую) последовательность символов.
Специальный символ $ означает конец строки, символ перед ним — последний.
Агент пользователя: Яндекс Disallow: /cgi-bin/*.aspx # запрещает «/cgi-bin/example.aspx» # и «/cgi-bin/private/test.aspx» Disallow: /*private # запрещает не только «/private», # но и «/cgi-bin/private»
Директива карты сайта
Если вы используете описание структуры сайта с помощью карты сайта, укажите путь к файлу в качестве параметра директивы карты сайта ( если файлов несколько, укажите все). Пример:
Пример:
Агент пользователя: Яндекс Разрешить: /sitemap: https://example.com/site_structure/my_sitemaps1.xml карта сайта: https://example.com/site_structure/my_sitemaps2.xml
Директива является сквозной, поэтому она будет использоваться роботом вне зависимости от того места в файле robots.txt, где она указана.
Робот запомнит путь к файлу, обработает данные и использует результаты при последующем формировании сеансов загрузки.
Директива Crawl-delay
Если сервер сильно загружен и не успевает обрабатывать запросы роботов, используйте директиву Crawl-delay. Позволяет задать минимальный промежуток времени (в секундах) для поискового робота между окончанием загрузки одной страницы и началом загрузки следующей.
Прежде чем менять скорость сканирования сайта, узнайте, на какие страницы робот заходит чаще.
- Анализ журналов сервера. Свяжитесь с лицом, ответственным за сайт, или с вашим хостинг-провайдером.
- Посмотреть список адресов на странице Индексирование → Статистика обхода в Яндекс. Вебмастере (установить переключатель Все страницы).
 Вебмастере (установить переключатель Все страницы).
Вебмастере (установить переключатель Все страницы).Если вы обнаружите, что робот обращается к служебным страницам, отключите их индексацию в файле robots.txt с помощью директивы Disallow. Это поможет сократить количество ненужных вызовов робота.
Clean-param Директива
Директива работает только с роботом Яндекс.
Если адреса страниц сайта содержат динамические параметры, не влияющие на их содержание (идентификаторы сеансов, идентификаторы пользователей, идентификаторы рефереров и т. д.), вы можете описать их с помощью директивы Clean-param.
Робот Яндекса, используя эту директиву, не будет повторно загружать повторяющуюся информацию. Таким образом, эффективность сканирования вашего сайта повысится, а нагрузка на сервер снизится.
Например, на сайте есть страницы:
www.example.com/some_dir/get_book.pl?ref=site_1&book_id=123 www.example.com/some_dir/get_book.pl?ref=site_2&book_id=123 www.example. com/some_dir/get_book.pl?ref=site_3&book_id= 123
com/some_dir/get_book.pl?ref=site_3&book_id= 123
Параметр ref используется только для отслеживания с какого ресурса был сделан запрос и не меняет содержание, та же страница с книгой book_id=123 будет показана по адресу все три адреса. Затем, если вы укажете директиву следующим образом:
User-agent: Yandex Disallow: Clean-param: ref /some_dir/get_book.pl
робот Яндекса сократит все адреса страниц до одного:
www.example.com/some_dir/get_book.pl?book_id=123
Если такая страница есть на сайте, она будет участвовать в результатах поиска.
Синтаксис директивы
Clean-param: p0[&p1&p2&..&pn]
В первом поле через символ & перечислены параметры, которые роботу не нужно учитывать. Во втором поле указывается префикс пути к страницам, для которых вы хотите применить правило.
Примечание. Директива Clean-Param является сквозной, поэтому ее можно указать в любом месте файла robots.txt. Если указаний несколько, все они будут учтены роботом.
Префикс может содержать регулярное выражение в формате, аналогичном файлу robots.txt, но с некоторыми ограничениями: можно использовать только символы A-Za-z0-9.-/*_. В этом случае символ * обрабатывается так же, как и в файле robots.txt: символ * всегда неявно добавляется в конец префикса. Например:
Чистый параметр: s /forum/showthread.php
Регистрация соблюдается. Длина правила ограничена 500 символами. Например:
Параметр очистки: abc /forum/showthread.php Параметр очистки: sid&sort /forum/*.php Параметр очистки: someTrash&otherTrash
Директива HOST
На данный момент Яндекс прекратил поддержку этой директивы.
Правильный robots.txt: настройка
Содержимое файла robots.txt различается в зависимости от типа сайта (интернет-магазин, блог), используемой CMS, особенностей структуры и ряда других факторов. Поэтому созданием этого файла для коммерческого сайта, особенно если речь идет о сложном проекте, должен заниматься SEO-специалист с достаточным опытом.
Неподготовленный человек, скорее всего, не сможет принять правильное решение, какую часть контента лучше заблокировать от индексации, а какую разрешить показывать в результатах поиска.
Правильный пример Robots.txt для WordPress
User-agent: * # общие правила для роботов, кроме Яндекса и Гугла, # потому что правила для них ниже Disallow: /cgi-bin # папка хостинга Disallow: /? # все параметры запроса на главной странице Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins Disallow: /wp/ # если есть поддиректория /wp/, где CMS установлена (если нет, # правило можно удалить) Disallow: *?s= # поиск Disallow: *&s= # поиск Disallow: /search/ # поиск Disallow: /author/ # авторский архив Disallow: /users/ # авторский архив Disallow: */ trackback # трекбэки, оповещения в комментариях при появлении открытой # ссылки на статью Disallow: */feed # все ленты Disallow: */rss # rss лента Disallow: */embed # все вставки Disallow: */wlwmanifest.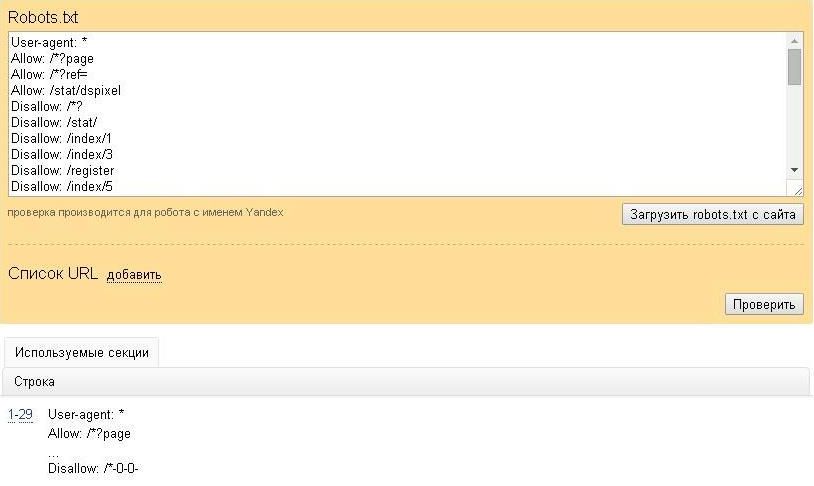 xml # файл манифеста xml Windows Live Writer (если не используется, # можно удалить) Disallow: /xmlrpc.php # файл WordPress API Disallow: *utm*= # ссылки с тегами utm Disallow: *openstat= # ссылки с тегами openstat Разрешить : */uploads # открыть папку с файлами закачки Карта сайта: http://site.ru/sitemap.xml # адрес карты сайта User-agent: GoogleBot # правила для Google (не дублировать комментарии) Disallow: /cgi-bin Disallow: / ? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */ rss Disallow: */embed Disallow: */wlwmanifest.xml Disallow: /xmlrpc.php Disallow: *utm*= Disallow: *openstat= Allow: */uploads Allow: /*/*.js # открываем скрипты js внутри /wp — (/*/ — для приоритета) Разрешить: /*/*.css # открывать файлы css внутри /wp- (/*/ — для приоритета) Разрешить: /wp-*.png # изображения в плагинах, папке кеша и т.д. Разрешить: /wp-*.jpg # изображения в плагинах, папке кеша и т.
xml # файл манифеста xml Windows Live Writer (если не используется, # можно удалить) Disallow: /xmlrpc.php # файл WordPress API Disallow: *utm*= # ссылки с тегами utm Disallow: *openstat= # ссылки с тегами openstat Разрешить : */uploads # открыть папку с файлами закачки Карта сайта: http://site.ru/sitemap.xml # адрес карты сайта User-agent: GoogleBot # правила для Google (не дублировать комментарии) Disallow: /cgi-bin Disallow: / ? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */ rss Disallow: */embed Disallow: */wlwmanifest.xml Disallow: /xmlrpc.php Disallow: *utm*= Disallow: *openstat= Allow: */uploads Allow: /*/*.js # открываем скрипты js внутри /wp — (/*/ — для приоритета) Разрешить: /*/*.css # открывать файлы css внутри /wp- (/*/ — для приоритета) Разрешить: /wp-*.png # изображения в плагинах, папке кеша и т.д. Разрешить: /wp-*.jpg # изображения в плагинах, папке кеша и т. д. Разрешить: /wp-*.jpeg # изображения в плагинах, папке кеша и т. д. Разрешить: /wp-*.gif # картинки в плагинах, кеше папка и т.д. Разрешить: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS User-agent: Yandex # правила для Яндекса (не дублировать комментарии) Disallow: /cgi-bin Disallow: / ? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */ rss Запретить: */embed Запретить: */wlwmanifest.xml Запретить: /xmlrpc.php Разрешить: */uploads Разрешить: /*/*.js Разрешить: /*/*.css Разрешить: /wp-*.png Разрешить: /wp-*.jpg Разрешить: /wp-*.jpeg Разрешить: /wp-*.gif Разрешить: /wp-admin/admin-ajax.php Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать # из индексации, а удалять параметры тега, # Google не поддерживает такие правила Clean-Param: openstat # аналогичный
д. Разрешить: /wp-*.jpeg # изображения в плагинах, папке кеша и т. д. Разрешить: /wp-*.gif # картинки в плагинах, кеше папка и т.д. Разрешить: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS User-agent: Yandex # правила для Яндекса (не дублировать комментарии) Disallow: /cgi-bin Disallow: / ? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */ rss Запретить: */embed Запретить: */wlwmanifest.xml Запретить: /xmlrpc.php Разрешить: */uploads Разрешить: /*/*.js Разрешить: /*/*.css Разрешить: /wp-*.png Разрешить: /wp-*.jpg Разрешить: /wp-*.jpeg Разрешить: /wp-*.gif Разрешить: /wp-admin/admin-ajax.php Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать # из индексации, а удалять параметры тега, # Google не поддерживает такие правила Clean-Param: openstat # аналогичный
Пример Robots.txt для Joomla
User-agent: *
Disallow: /administrator/
Disallow: /cache/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries /
Запретить: /media/
Запретить: /modules/
Запретить: /plugins/
Запретить: /templates/
Запретить: /tmp/
Запретить: /xmlrpc/
Пример robots.
 txt для Битрикс агент: *
txt для Битрикс агент: * Запретить: /*index.php$
Запретить: /bitrix/
Запретить: /auth/
Запретить: /personal/
Запретить: /upload/
Запретить: /search/
Запретить: /*/search/
Запретить: /*/slide_show/
Запретить: / */gallery/*order=*
Запретить: /*?print=
Запретить: /*&print=
Запретить: /*register=
Запретить: /*forgot_password=
Запретить: /*change_password=
Запретить: /*login =
Запретить: /*logout=
Запретить: /*auth=
Запретить: /*?action=
Запретить: /*action=ADD_TO_COMPARE_LIST
Запретить: /*action=DELETE_FROM_COMPARE_LIST
Запретить: /*action=ADD2BASKET
Запретить: /*action=BUY
Запретить: /*bitrix_*=
Запретить: /*backurl=*
Запретить: /*BACKURL=*
Запретить : /*back_url=*
Запретить: /*BACK_URL=*
Запретить: /*back_url_admin=*
Запретить: /*print_course=Y
Запретить: /*COURSE_ID=
Запретить: /*?COURSE_ID=
Запретить: /* ?PAGEN
Запретить: /*PAGEN_1=
Запретить: /*PAGEN_2=
Запретить: /*PAGEN_3=
Запретить: /*PAGEN_4=
Запретить: /*PAGEN_5=
Запретить: /*PAGEN_6=
Запретить: /*PAGEN_7=
Запретить: /*PAGE_NAME=search
Запретить: /*PAGE_NAME=user_post
Запретить: /* PAGE_NAME=detail_slide_show
Запретить: /*SHOWALL
Запретить: /*show_all=
Карта сайта: http://путь к вашей XML-карте сайта
Пример robots.
 txt для MODx
txt для MODx Агент пользователя: *
Запретить: /assets/cache /
Запретить: /assets/docs/
Запретить: /assets/export/
Запретить: /assets/import/
Запретить: /assets/modules/
Запретить: /assets/plugins/
Запретить: /assets/snippets/
Запретить: /install/
Запретить: /manager/
Карта сайта: http:/ /site.ru/sitemap.xml
Пример Robots.txt для Drupal
User-agent: *
Disallow: /database/
Disallow: /includes/
Disallow: /misc/
Disallow: /modules/
Disallow: /sites/
Запретить: /themes/
Запретить: /scripts/
Запретить: /updates/
Disallow: /profiles/
Disallow: /profile
Disallow: /profile/*
Disallow: /xmlrpc.php
Disallow: /cron.php
Disallow: /update.php
Disallow: /install.php
Disallow: / index.php
Запретить: /admin/
Запретить: /comment/reply/
Запретить: /contact/
Запретить: /logout/
Запретить: /search/
Запретить: /user/register/
Запретить: /user/password /
Запретить: *регистрация*
Запретить: *логин*
Запретить: /top-rated-
Запретить: /messages/
Запретить: /book/export/
Запретить: /user2userpoints/
Запретить: /myuserpoints/
Запретить: /tagadelic/
Запретить: /referral/
Запретить: /aggregator/
Запретить: /files/ pin/
Запретить: /your-votes
Запретить: /comments/recent
Запретить: /*/edit/
Запретить: /*/delete/
Запретить: /*/export/html/
Запретить: /taxonomy/term/ */0$
Запретить: /*/edit$
Запретить: /*/outline$
Запретить: /*/revisions$
Запретить: /*/contact$
Запретить: /*downloadpipe
Запретить: /node$
Запретить: /node/*/track$
Запретить: /*&
Запретить: /*%
Запретить: /*?page= 0
Запретить: /*section
Запретить: /* порядок
Запретить: /*?sort*
Запретить: /*&sort*
Запретить: /*votesupdown
Запретить: /*calendar
Запретить: /*index. php
php
Разрешить : /*?page=
Запретить: /*?
Карта сайта: http://путь к вашей XML карте сайта
ВНИМАНИЕ!
CMS постоянно обновляются. Возможно, вам придется закрыть другие страницы от индексации. В зависимости от цели запрет на индексацию может быть снят или, наоборот, добавлен.
Проверить robots.txt
У каждой поисковой системы свои требования к оформлению файла robots.txt.
Для того, чтобы проверить robots.txt на правильность синтаксиса и структуры файла, вы можете воспользоваться одним из онлайн-сервисов. Например, Яндекс и Google предлагают собственные сервисы анализа сайтов для веб-мастеров, которые включают в себя robots.txt parsing:
Проверка robotx.txt для краулера Яндекса
Это можно сделать с помощью специального инструмента от Яндекса — Яндекс.Вебмастер, и тут тоже два варианта.
Вариант 1:
Верхний правый выпадающий список — выберите Парсинг robots.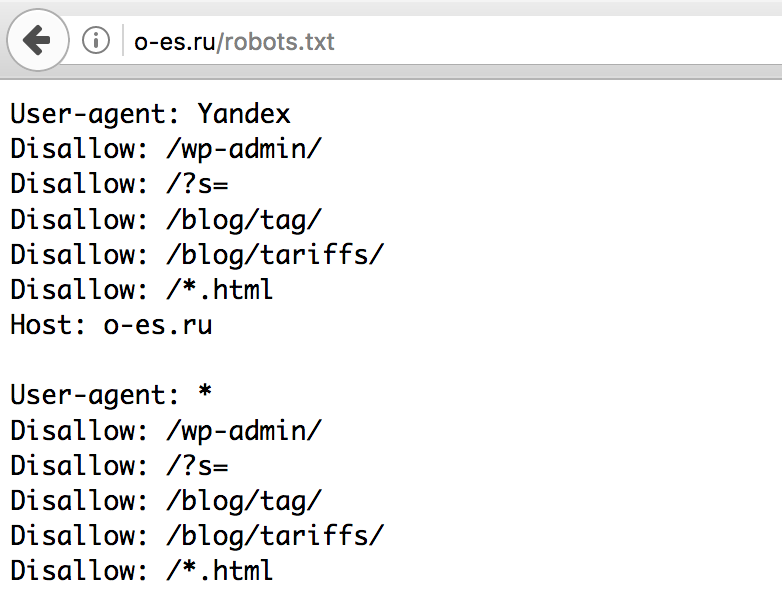 txt или перейдите по ссылке http://webmaster.yandex.ru/robots.xml
txt или перейдите по ссылке http://webmaster.yandex.ru/robots.xml
Не забывайте, что все изменения, которые вы вносите в файл robots.txt, он будет доступен не сразу, а только через некоторое время.
Проверка файла robotx.txt для поискового робота Google
- В Google Search Console выберите свой сайт, перейдите к инструменту проверки и просмотрите содержимое файла robots.txt. Синтаксическая и головоломка ошибки в ней будут подсвечены, а их количество указано под окном редактирования.
- Внизу страницы интерфейса введите нужный URL в соответствующее окно.
- В раскрывающемся меню справа выберите робот .
- Нажмите кнопку ПРОВЕРИТЬ .
- Статус будет отображаться ДОСТУПНО или НЕДОСТУПНО . В первом случае гугл-боты могут зайти на указанный вами адрес, а во втором — нет.
- При необходимости внесите изменения в меню и проверьте еще раз. Внимание! Эти исправления не будут автоматически добавлены в файл robots. txt на вашем сайте.
- Скопируйте измененное содержимое и добавьте его в файл robots.txt на своем веб-сервере.
 txt на вашем сайте.
txt на вашем сайте.Помимо верификационных сервисов от Яндекса и Гугла в сети есть много других. валидаторов robots.txt.
генераторы robots.txt
- Сервис от SEOlib.ru. С помощью этого инструмента можно быстро получить и проверить ограничения в файле Robots.txt.
- Генератор от pr-cy.ru. В результате работы генератора Robots.txt вы получите текст, который необходимо сохранить в файл с именем Robots.txt и загрузить в корневую директорию вашего сайта.
Поисковые роботы сканируют всю информацию в Интернете, но владельцы сайтов могут ограничить или запретить доступ к своему ресурсу. Для этого нужно закрыть сайт от индексации через служебный файл robots.txt.
Если вам не нужно закрывать сайт полностью, запретите индексацию отдельных страниц. Пользователи не должны видеть в поиске служебные разделы сайта, личные кабинеты, устаревшую информацию из раздела акций или календаря.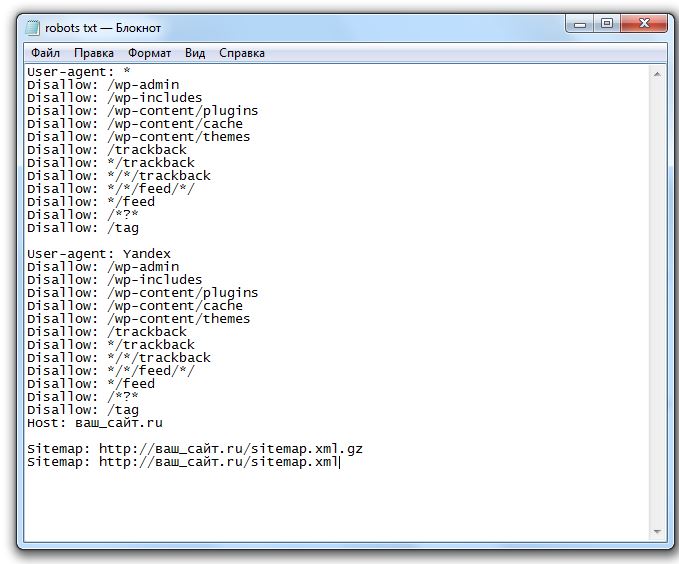 Дополнительно нужно закрыть от индексации скрипты, всплывающие окна и баннеры, тяжелые файлы. Это поможет сократить время индексации и снизить нагрузку на сервер.
Дополнительно нужно закрыть от индексации скрипты, всплывающие окна и баннеры, тяжелые файлы. Это поможет сократить время индексации и снизить нагрузку на сервер.
Как полностью закрыть сайт
Обычно ресурс полностью закрывается от индексации во время или . Также закрывают сайты, на которых веб-мастера учатся или проводят эксперименты.
Вы можете отключить индексацию сайта для всех поисковиков, для одного робота или запретить для всех, кроме одного.
Как закрыть отдельные страницы
Небольшие сайты-визитки обычно не требуют скрытия отдельных страниц. Для ресурсов с большим количеством служебной информации закройте страницы и целые разделы:
- административная панель;
- служебных каталогов;
- Личный кабинет; регистрационные формы
- ; бланки заказов
- ;
- сравнение товаров;
- избранное;
- корзина;
- капча;
- всплывающих окон и баннеров;
- поиск по сайту;
- идентификатор сеанса.

Желательно запретить индексацию т.н. мусорные страницы. Это старые новости, акции и спецпредложения, события и события в календаре. На информационных сайтах закрывать статьи с устаревшей информацией. В противном случае ресурс будет восприниматься как неактуальный. Чтобы не закрывать статьи и материалы, регулярно обновляйте данные в них.
Запрет индексации
Как закрыть прочую информацию
Файл robots.txt позволяет закрывать на сайте папки, файлы, скрипты, utm теги. Их можно скрыть полностью или выборочно. Укажите запрет на индексацию для всех роботов или отдельных.
Запрет индексации
Как закрыть сайт с помощью метатегов
Альтернативой файлу robots.txt является метатег robots. Запишите его в исходный код сайта в файле index.html. Поместить в контейнер
. Укажите, для каких поисковых роботов сайт закрыт от индексации. Если для всех, напишите robots. Если для одного робота, укажите его имя.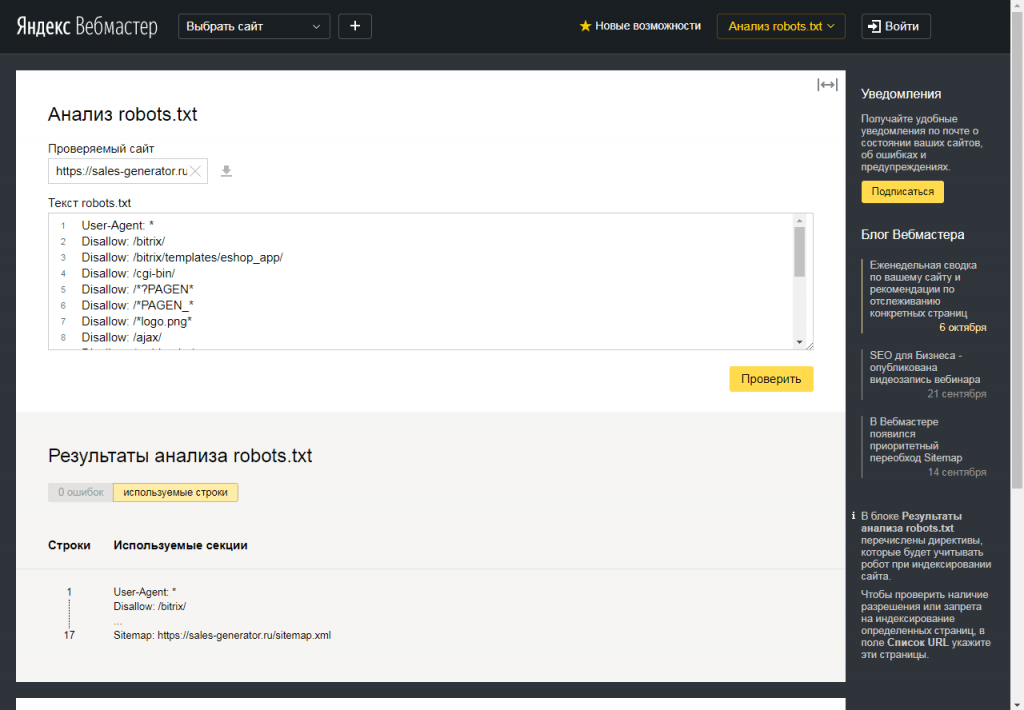 Для Google — Googlebot, для Яндекса — Яндекс. Существует два варианта написания метатега.
Для Google — Googlebot, для Яндекса — Яндекс. Существует два варианта написания метатега.
Вариант 1.
Вариант 2.
Атрибут «content» имеет следующие значения:
- none — запрещена индексация, в том числе noindex и nofollow;
- noindex — запрещена индексация контента;
- nofollow — индексация ссылок запрещена;
- follow — разрешена индексация ссылок;
- index — разрешена индексация;
- все — индексация контента и ссылок разрешена.
Таким образом, можно запретить индексацию контента, но разрешить ссылки. Для этого укажите content=»noindex, follow». На такой странице ссылки будут проиндексированы, а текст — нет. Используйте комбинации значений для разных случаев.
При закрытии сайта от индексации через метатеги отдельно создавать robots.txt не нужно.
Какие ошибки возникают
головоломка — когда правила противоречат друг другу.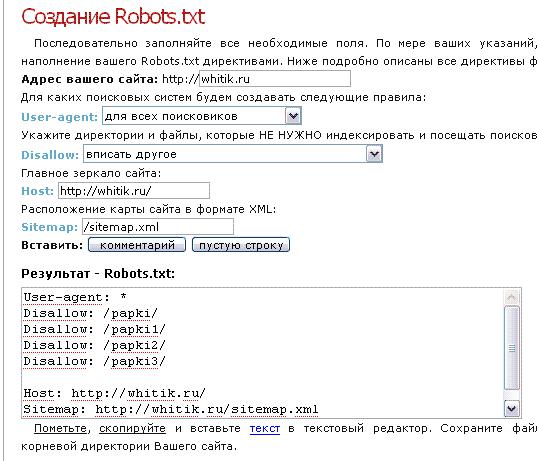 Выявляйте логические ошибки, проверяя файл robots.txt в Яндекс.Вебмастере и Google Robots Testing Tool.
Выявляйте логические ошибки, проверяя файл robots.txt в Яндекс.Вебмастере и Google Robots Testing Tool.
Синтаксический — когда неправильно прописаны правила в файле.
Наиболее часто встречающиеся:
- ввод без учета регистра;
- написание заглавными буквами;
- список всех правил в одной строке;
- отсутствие пустой строки между правилами;
- с указанием обходчика в директиве;
- перечисление набора вместо закрытия всего раздела или папки;
- отсутствие обязательной директивы запрета.
Шпаргалка
Есть два варианта отключения индексации сайта. Создайте файл robots.txt и укажите запрет через директиву disallow для всех сканеров. Другой вариант — прописать бан через метатег robots в файле index.html внутри тега.
Закрыть служебную информацию, устаревшие данные, скрипты, сессии и utm-метки. Создайте отдельное правило для каждого запрета. Запретить всем поисковым роботам через * или указать имя конкретного краулера. Если хотите разрешить только одного робота, пропишите правило через disallow.
Если хотите разрешить только одного робота, пропишите правило через disallow.
При создании файла robots.txt избегайте логических и синтаксических ошибок. Проверьте файл с помощью Яндекс.Вебмастера и Google Robots Testing Tool.
Материал подготовила Светлана Сирвида-Льоренте.
Эта статья посвящена практическому использованию файла robots.txt для удаления нежелательных страниц из . Какие страницы удалять, как их искать, как сделать так, чтобы полезный контент не блокировался. На самом деле в статье речь идет об использовании только одной директивы — Disallow. Подробная инструкция по использованию файла robots и других директив в Справке Яндекса.
В большинстве случаев закрываем ненужные страницы для всех поисковых роботов, то есть указываем правила Disallow для User-agent: *.
User-agent: *
Disallow: /cgi-bin
Что нужно закрыть от индексации?
С помощью директивы Disallow в файле robots.txt нужно закрыть от индексации поисковыми ботами:
Как искать страницы, которые нужно закрыть от индексации?
ComparseR
Просканировать сайт и справа во вкладке «Структура» построить дерево сайта:
Посмотреть все вложенные «ветви» дерева.
Получить во вкладках «Яндекс» и «Google» страницы в индексе поисковых систем. Потом в статистике обхода посмотреть в «Найдено в яндексе, не найдено на сайте» и «Найдено в гугле не найдено на сайте».
Яндекс.Вебмастер
В разделе «Индексирование» — «Структура сайта» просмотреть все «ветви» структуры.
Проверить, не был ли случайно заблокирован полезный контент
robots.txt
Посмотреть содержимое файла robots.txt.
Comparser (проверка роботов на закрывающий метатег)
В настройках Comparser перед сканированием снимите галочку:
Анализ результатов сканирования справа:
Search Console (проверьте полезные заблокированные ресурсы)
Важно убедиться, что робот Googlebot имеет доступ к файлам стилей и изображениям, используемым для отображения страниц. Для этого вам необходимо выборочно просканировать страницы с помощью инструмента «Просмотреть как Googlebot», нажав кнопку «Получить и обработать».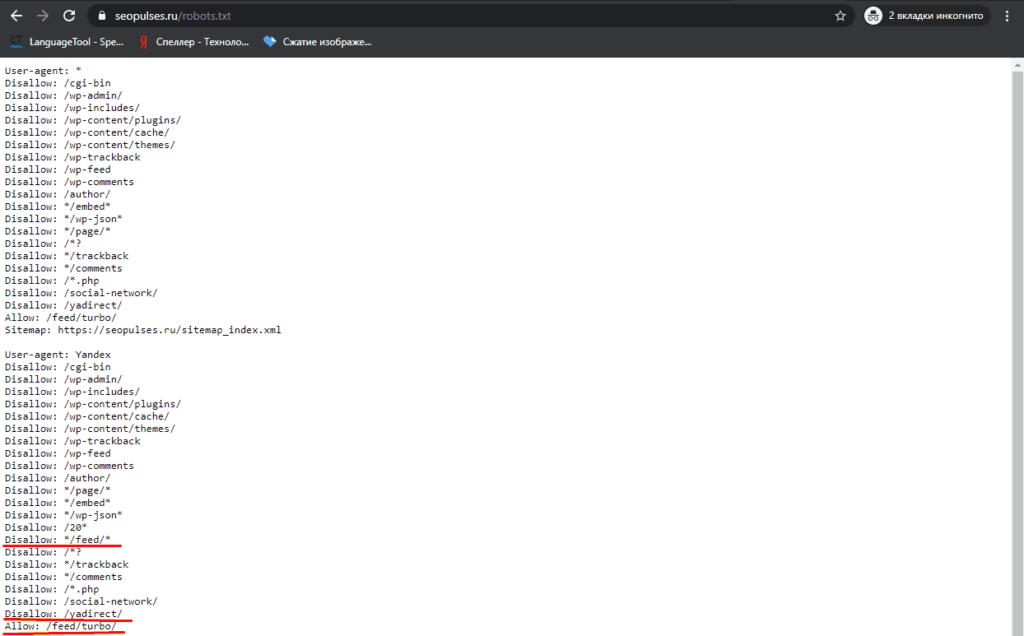 Полученные два изображения «Вот как Googlebot увидел эту страницу» и «Вот как посетитель сайта увидит эту страницу» должны выглядеть практически одинаково. Пример проблемной страницы:
Полученные два изображения «Вот как Googlebot увидел эту страницу» и «Вот как посетитель сайта увидит эту страницу» должны выглядеть практически одинаково. Пример проблемной страницы:
Вы можете увидеть заблокированные части страницы в таблице ниже:
Подробнее о результатах сканирования читайте в справке консоли. Все заблокированные ресурсы необходимо разблокировать в файле robots.txt с помощью директивы Allow (разблокировать нельзя только внешние ресурсы). В этом случае вам нужно в режиме «точка-точка» разблокировать только необходимые ресурсы. В приведенном выше примере боту Google отказано в доступе к папке /templates/, но он открыт для некоторых типов файлов внутри этой папки:
Агент пользователя: Googlebot
Разрешено: /templates/*.css
Разрешено: /templates/*.js
Разрешено: /templates/*.png
Разрешено: /templates/*.jpg
Разрешено: /templates/*.woff
Разрешить: /templates/*.ttf
Разрешить: /templates/*.svg
Запретить: /templates/
>> Подстановочные знаки Robots.
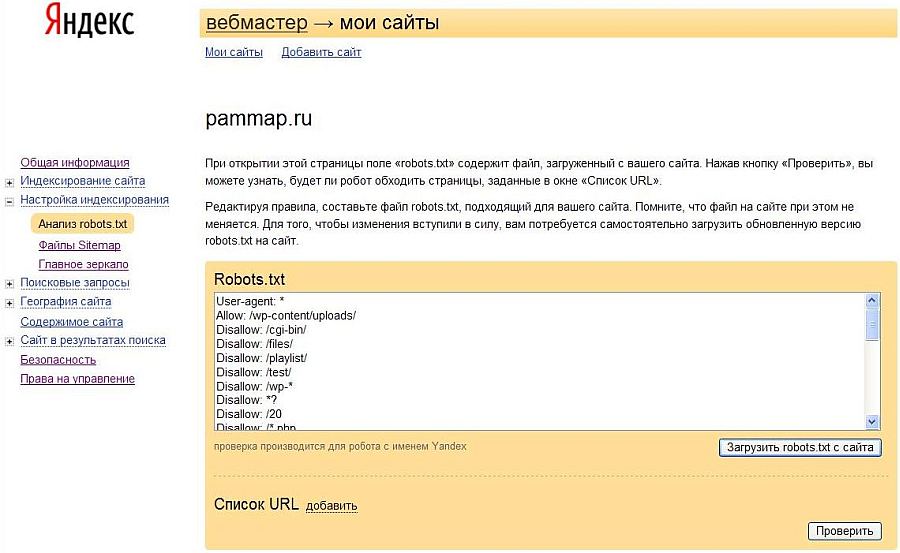 txt: как использовать подстановочные знаки в Robots.txt
txt: как использовать подстановочные знаки в Robots.txtФайл robots.txt используется для управления тем, какой контент поисковым системам разрешен к доступу на вашем сайте. Это отлично подходит для контроля дублирующегося контента и направления краулингового бюджета на самые важные страницы. Важно понимать, что если у вас есть контент, который вы хотите удалить из индекса Google, запрет контента в вашем файле robots.txt только предотвратит повторный доступ Google к нему, он не удалит контент из индекса — сделать это вам нужно будет использовать тег noindex. Я в порядке, давайте перейдем к тому, как использовать подстановочные знаки robots.txt
Также стоит отметить, что Google делает категорическое заявление о том, что большинству людей не нужно беспокоиться о краулинговом бюджете:
Во-первых, мы хотели бы подчеркнуть, что краулинговый бюджет, как описано ниже, не является чем-то, что есть у большинства издателей. беспокоиться о. Если новые страницы, как правило, сканируются в тот же день, когда они опубликованы, веб-мастерам не нужно сосредотачиваться на краулинговом бюджете.
 Аналогичным образом, если на сайте менее нескольких тысяч URL-адресов, в большинстве случаев он будет сканироваться эффективно.
Аналогичным образом, если на сайте менее нескольких тысяч URL-адресов, в большинстве случаев он будет сканироваться эффективно.Хотя вышеизложенное может быть верно для большинства веб-сайтов, оно, скорее всего, неверно для любого веб-сайта, который достаточно велик, чтобы нанять SEO-специалиста. Обратите внимание, что в своем заявлении Google говорит, что вам не нужно беспокоиться о краулинговом бюджете… если на вашем сайте меньше нескольких тысяч URL-адресов…. Бюджет обхода — важный фактор, который следует учитывать, чтобы убедиться, что ресурсы обхода сосредоточены на важных страницах.
Использование подстановочных знаков robots.txt очень важно для эффективного контроля сканирования поисковыми системами. В то время как обычное форматирование в robots.txt предотвратит сканирование страниц в каталоге или определенном URL-адресе, использование подстановочных знаков в вашем файле robots.txt позволит вам запретить поисковым системам доступ к контенту на основе шаблонов в URL-адресах, таких как параметр или повторение символа. Прежде чем углубляться в детали использования подстановочных знаков в robots.txt, давайте рассмотрим основы robots.txt (я в порядке, давайте перейдем к тому, как использовать подстановочные знаки в robots.txt).
Основы Robots.txt
Если мы хотим разрешить всем поисковым системам доступ ко всему на сайте, это можно сделать тремя способами: с помощью Disallow: , Allow: / или просто оставив файл robots.txt пустым. Любой из них позволит поисковым системам делать на вашем сайте все, что они хотят.
Агент пользователя: * Disallow:
или
User-agent: * Разрешить: /
И наоборот, если вы хотите запретить поисковым системам доступ к любому контенту на вашем сайте, вы должны использовать команду Disallow: /. Это отлично подходит для сайтов разработки и сайтов, которые строятся, к которым вы пока не хотите разрешать доступ поисковым системам, но вы почти никогда не хотите использовать эту команду на своем работающем сайте.
Агент пользователя: * Disallow: /
Если вы хотите разрешить определенным поисковым системам различный доступ, вы можете использовать для этого команду user-agent. В приведенных выше примерах мы просто говорим «user-agent: *», что означает, что все поисковые системы должны подчиняться следующим командам. Пример ниже позволяет Google получить доступ ко всему сайту, в то время как Яндекс не имеет доступа ни к чему.
Агент пользователя: Googlebot Запретить: User-agent: Яндекс: Disallow: /
Чтобы предотвратить сканирование каталога, просто укажите каталог, а не корень, /.
Агент пользователя: * Disallow: /directory/
Как использовать подстановочные знаки в robots.txt
Хорошо, теперь, когда мы рассмотрели, почему вам может понадобиться использовать подстановочные знаки robots.txt, и несколько основных примеров robots.txt, давайте углубимся в то, как использовать подстановочные знаки robots.txt. Есть несколько вещей, которые нам нужно знать об использовании подстановочного знака в robots.txt заранее. Во-первых, вам не нужно добавлять подстановочный знак к каждой строке в файле robots.txt. Подразумевается, что если вы заблокируете /directory-z/, вы хотите заблокировать все в этом каталоге и не должны включать подстановочный знак (например, /directory-z/*). Во-вторых, вам нужно знать, что на самом деле Google поддерживает два разных типа подстановочных знаков: 9.0003
* подстановочные знаки
Подстановочный знак * будет просто соответствовать любой последовательности символов. Это полезно, когда есть четкие шаблоны URL, которые вы хотите запретить, такие как фильтры и параметры.
Подстановочные знаки $
Подстановочный знак $ используется для обозначения конца URL-адреса. Это полезно для сопоставления определенных типов файлов, таких как .pdf.
Ниже приведены несколько распространенных вариантов использования подстановочных знаков robots.txt:
Запретить поисковым системам доступ к любому URL-адресу, который имеет ? в нем:
Агент пользователя: * Запретить: /*?
Запретить поисковым системам сканировать любой URL-адрес страницы результатов поиска (query?kw=)
Агент пользователя: * Запретить: /query?kw=*
Запретить поисковым системам сканировать любой URL-адрес с параметром ?color=, за исключением ?color=blue
Агент пользователя: * Запретить: /*?цвет Разрешить: /*?color=blue
Запретить поисковым системам сканировать каналы комментариев в WordPress
Агент пользователя: * Запретить: /comments/feed/
Блокировать поисковым системам сканирование URL-адресов в общем дочернем каталоге
Агент пользователя: * Disallow: /*/child/
Запретить поисковым системам сканировать URL-адреса в определенном каталоге, которые содержат 3 или более дефиса
Агент пользователя: * Запретить: /directory/*-*-*-
Запретить поисковым системам сканировать любой URL-адрес, который заканчивается на «. pdf». Обратите внимание: если к URL-адресу добавлены параметры, этот подстановочный знак не будет препятствовать сканированию, поскольку URL-адрес не более длинный заканчивается на «.pdf»
Агент пользователя: * Disallow: /*.pdf$
Всегда проверяйте подстановочные знаки robots.txt перед отправкой Live
Всегда рекомендуется дважды проверять подстановочные знаки robots.txt, прежде чем переключать переключатель и вносить какие-либо обновления в файл robots.txt. . Поскольку простое добавление / в ваш файл robots.txt потенциально может помешать поисковым системам проиндексировать весь ваш сайт, погрешность отсутствует. Ошибки могут иметь катастрофические последствия и могут потребовать длительного времени восстановления. Лучший способ перепроверить свою работу — использовать Google Robots.txt Testing Tool.
Поисковые роботы — 10 самых популярных
Бен Итон
Опубликовано 19 августа 2022 г.
Во всемирной паутине есть как плохие, так и хорошие боты. Вы определенно хотите избежать плохих ботов, поскольку они потребляют вашу пропускную способность CDN, занимают ресурсы сервера и крадут ваш контент. С другой стороны, с хорошими ботами (также известными как поисковые роботы) следует обращаться с осторожностью, поскольку они являются жизненно важной частью индексации вашего контента поисковыми системами, такими как Google, Bing и Yahoo. В этом сообщении блога мы рассмотрим десятку самых популярных поисковых роботов.
Что такое поисковые роботы?
Веб-сканеры — это компьютерные программы, которые методично и автоматически просматривают Интернет. Их также называют роботами, муравьями или пауками.
Поисковые роботы посещают веб-сайты и читают их страницы и другую информацию, чтобы создать записи для индекса поисковой системы. Основная цель поискового робота — предоставить пользователям полный и актуальный индекс всего доступного онлайн-контента.
Кроме того, поисковые роботы также могут собирать определенные типы информации с веб-сайтов, например контактную информацию или данные о ценах. Используя поисковые роботы, компании могут поддерживать актуальность и эффективность своего присутствия в Интернете (например, SEO, оптимизация внешнего интерфейса и веб-маркетинг).
Поисковые системы, такие как Google, Bing и Yahoo, используют сканеры для правильного индексирования загруженных страниц, чтобы пользователи могли быстрее и эффективнее находить их при поиске. Без поисковых роботов не было бы ничего, что могло бы сказать им, что на вашем сайте есть новый и свежий контент. Карты сайта также могут играть роль в этом процессе. Так что поисковые роботы, по большей части, это хорошо.
Однако иногда возникают проблемы с планированием и загрузкой, поскольку поисковый робот может постоянно опрашивать ваш сайт. И здесь в игру вступает файл robots.txt. Этот файл может помочь контролировать сканирующий трафик и гарантировать, что он не перегрузит ваш сервер.
Поисковые роботы идентифицируют себя для веб-сервера с помощью заголовка запроса User-Agent в HTTP-запросе, и каждый сканер имеет свой уникальный идентификатор. В большинстве случаев вам нужно будет просматривать журналы реферера вашего веб-сервера, чтобы просмотреть трафик поискового робота.
Robots.txt
Поместив файл robots.txt в корень вашего веб-сервера, вы можете определить правила для поисковых роботов, например разрешить или запретить сканирование определенных ресурсов. Поисковые роботы должны следовать правилам, определенным в этом файле. Вы можете применить общие правила ко всем ботам или сделать их более детализированными и указать их конкретные User-Agent строка.
Пример 1
Этот пример предписывает всем роботам поисковых систем не индексировать содержимое веб-сайта. Это определяется путем запрета доступа к корневому каталогу / вашего веб-сайта.
Агент пользователя: * Запретить: /
Пример 2
Этот пример противоположен предыдущему. В этом случае инструкции по-прежнему применяются ко всем пользовательским агентам. Однако в инструкции Disallow ничего не определено, а это означает, что все может быть проиндексировано.
Агент пользователя: * Запретить:
Чтобы увидеть больше примеров, обязательно ознакомьтесь с нашим подробным сообщением о том, как использовать файл robots.txt.
10 лучших поисковых роботов и поисковых роботов
Существуют сотни поисковых роботов и поисковых роботов, прочесывающих Интернет, но ниже приведен список из 10 популярных поисковых роботов и поисковых роботов, которые мы собрали на основе тех, которые мы регулярно видим в логи нашего веб-сервера.
1. GoogleBot
Являясь крупнейшей в мире поисковой системой, Google использует поисковые роботы для индексации миллиардов страниц в Интернете. Googlebot — это поисковый робот, который Google использует именно для этого.
Googlebot — это два типа поисковых роботов: настольный поисковый робот, который имитирует человека, просматривающего компьютер, и мобильный поисковый робот, который выполняет те же функции, что и iPhone или телефон Android.
Строка пользовательского агента запроса может помочь вам определить подтип Googlebot. Googlebot Desktop и Googlebot Smartphone, скорее всего, будут сканировать ваш веб-сайт. С другой стороны, оба типа сканеров принимают один и тот же токен продукта (токен пользовательского агента) в файле robots.txt. Вы не можете использовать robots.txt для выборочного таргетинга Googlebot Smartphone или Desktop.
Googlebot — очень эффективный поисковый робот, который может быстро и точно индексировать страницы. Однако у него есть некоторые недостатки. Например, робот Googlebot не всегда сканирует все страницы веб-сайта (особенно если веб-сайт большой и сложный).
Кроме того, робот Googlebot не всегда сканирует страницы в режиме реального времени, а это означает, что некоторые страницы могут быть проиндексированы только через несколько дней или недель после их публикации.
User-Agent Googlebot
Полный
User-Agent stringMozilla/5.
Пример робота Googlebot в файле robots.txt
В этом примере заданные инструкции немного более детализированы. Здесь инструкции относятся только к Googlebot. В частности, он говорит Google не индексировать определенную страницу ( /no-index/your-page.html ).
Агент пользователя: Googlebot Запретить: /no-index/your-page.html
Помимо поискового робота Google, у них на самом деле есть 9additional web crawlers:
| Web crawler | User-Agent string |
|---|---|
| Googlebot News | Googlebot-News |
| Googlebot Images | Googlebot-Image/1.0 |
| Googlebot Видео | Googlebot-Video/1.0 |
| Google Mobile (рекомендуемый телефон) | SAMSUNG-SGH-E250/1.0 Profile/MIDP-2.0 Configuration/CLDC-1.1 UP.Browser/6. 2.3.3.c.1.101 (GUI) ) MMP/2.0 (совместимый; Googlebot-Mobile/2.1; +http://www.google.com/bot.html) |
| Смартфон Google | Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (совместимый; Googlebot/2.1; +http://www.google.com/bot.html) |
| Google Mobile Adsense | (совместимо; Mediapartners-Google/2.1; +http://www.google.com/bot.html) |
| Google Adsense | Mediapartners-Google |
| Google AdsBot (качество целевой страницы PPC) | AdsBot-Google (+http://www.google.com/adsbot.html) |
| Поисковый робот Google (получение ресурсов для мобильных устройств) | AdsBot-Google-Mobile-Apps |
Вы можете используйте инструмент Fetch в Google Search Console, чтобы проверить, как Google сканирует или отображает URL-адрес на вашем сайте. Узнайте, может ли робот Googlebot получить доступ к странице на вашем сайте, как он отображает страницу и заблокированы ли какие-либо ресурсы страницы (например, изображения или сценарии) для робота Googlebot.
Вы также можете просмотреть статистику сканирования Googlebot за день, количество загруженных килобайт и время, затраченное на загрузку страницы.
См. документацию robots.txt для робота Google.
2. Bingbot
Bingbot — это поисковый робот, развернутый Microsoft в 2010 году для предоставления информации их поисковой системе Bing. Это замена того, что раньше было ботом MSN.
Агент пользователя Bingbot
Full
User-Agent stringMozilla/5.0 (совместимый; Bingbot/2.0; +http://www.bing.com/bingbot.htm)
У Bing также есть инструмент, очень похожий на Google, который называется Fetch as Bingbot в Инструментах для веб-мастеров Bing. Fetch As Bingbot позволяет запросить сканирование страницы и показать ее вам так, как ее увидит наш сканер. Вы увидите код страницы так, как его увидит Bingbot, что поможет вам понять, видят ли они вашу страницу так, как вы предполагали.
См. документацию Bingbot robots. txt.
3. Slurp Bot
Результаты поиска Yahoo поступают от поискового робота Yahoo Slurp и поискового робота Bing, так как многие Yahoo работают на базе Bing. Сайты должны разрешать доступ Yahoo Slurp, чтобы они отображались в результатах поиска Yahoo Mobile.
Кроме того, Slurp делает следующее:
- Собирает контент с партнерских сайтов для включения в такие сайты, как Yahoo News, Yahoo Finance и Yahoo Sports.
- Доступ к страницам сайтов в Интернете для подтверждения точности и улучшения персонализированного контента Yahoo для наших пользователей.
User-Agent Slurp
Full
User-Agent stringMozilla/5.0 (совместимый; Yahoo! Slurp; http://help.yahoo.com/help/us/ysearch/slurp)
См. документацию Slurp robots.txt.
4. DuckDuckBot
DuckDuckBot — это веб-сканер для DuckDuckGo, поисковой системы, которая стала довольно популярной, поскольку известна своей конфиденциальностью и отсутствием слежки за вами. Теперь он обрабатывает более 93 миллионов запросов в день. DuckDuckGo получает результаты из разных источников. К ним относятся сотни вертикальных источников, предоставляющих нишевые мгновенные ответы, DuckDuckBot (их поисковый робот) и краудсорсинговые сайты (Википедия). У них также есть более традиционные ссылки в результатах поиска, которые они получают от Yahoo! и Бинг.
Агент пользователя DuckDuckBot
Полный
User-Agent stringDuckDuckBot/1.0; (+http://duckduckgo.com/duckduckbot.html)
It respects WWW::RobotRules and originates from these IP addresses:
- 72.94.249.34
- 72.94.249.35
- 72.94.249.36
- 72.94.249.37
- 72.94.249.38
5. Baiduspider
Baiduspider — это официальное название паука китайской поисковой системы Baidu. Он сканирует веб-страницы и возвращает обновления в индекс Baidu. Baidu — ведущая китайская поисковая система, на долю которой приходится 80% всего рынка поисковых систем материкового Китая.
Агент пользователя Baiduspider
Full
User-Agent stringMozilla/5.0 (совместимо; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)
Besides Baidu’s web search crawler, they actually have 6 additional web crawlers:
| Web crawler | User-Agent string |
|---|---|
| Image Search | Baiduspider-image |
| Video Search | Baiduspider-video |
| News Search | Baiduspider-news |
| Baidu wishlists | Baiduspider-favo |
| Baidu Union | Baiduspider-cpro |
| Business Search | Baiduspider -ads |
| Другие страницы поиска | Baiduspider |
См. документацию Baidu robots.txt.
6. Яндекс Бот
YandexBot — поисковый робот для одной из крупнейших российских поисковых систем Яндекс.
User-Agent ЯндексБот
Full
User-Agent stringMozilla/5.0 (совместимо; YandexBot/3.0; +http://yandex.com/bots)
Существует множество различных строк User-Agent, которые ЯндексБот может отображать в логах вашего сервера. См. полный список роботов Яндекса и документацию Яндекса robots.txt.
7. Паук Согоу
Sogou Spider — это поисковый робот для Sogou.com, ведущей китайской поисковой системы, которая была запущена в 2004 году.
Примечание. чрезмерное ползание.
User-Agent Sogou Pic Spider/3.0 (http://www.sogou.com/docs/help/webmasters.htm#07) Головной паук Sogou/3.0 (http://www.sogou.com/docs/help/webmasters.htm#07) Веб-паук Sogou/4.0 (+http://www.sogou.com/docs/help/webmasters.htm#07) Паук Sogou Orion/3.0 (http://www.sogou.com/docs/help/webmasters.htm#07) Sogou-Test-Spider/4.0 (совместимый; MSIE 5.5; Windows 98)
8. Exabot
Exabot — поисковый робот для Exalead, поисковой системы, базирующейся во Франции. Он был основан в 2000 году и имеет более 16 миллиардов проиндексированных страниц.
User-Agent Mozilla/5.0 (совместимый; Konqueror/3.5; Linux) KHTML/3.5.5 (как Gecko) (Exabot-Thumbnails) Mozilla/5.0 (совместимо; Exabot/3.0; +http://www.exabot.com/go/robot)
См. документацию Exabot robots.txt.
9. Facebook external hit
Facebook позволяет своим пользователям отправлять ссылки на интересный веб-контент другим пользователям Facebook. Часть того, как это работает в системе Facebook, включает временное отображение определенных изображений или деталей, связанных с веб-контентом, таких как название веб-страницы или встроенный тег видео. Система Facebook извлекает эту информацию только после того, как пользователь предоставит ссылку.
Одним из их основных сканирующих ботов является Facebot, предназначенный для повышения эффективности рекламы.
User-Agent фейсбот facebookexternalhit/1.0 (+http://www.
См. документацию Facebot robots.txt.
10. Applebot
Бренд компьютерных технологий Apple использует поисковый робот Applebot, в частности Siri и Spotlight Suggestions, для предоставления персонализированных услуг своим пользователям.
Агент пользователя Applebot
Full
User-Agent stringMozilla/5.0 (Device; OS_version) AppleWebKit/WebKit_version (KHTML, как Gecko) Версия/Safari_версия Safari/WebKit_версия (Applebot/Applebot_version)
Другие популярные поисковые роботы
Apache Nutch
Apache Nutch — поисковый робот с открытым исходным кодом, написанный на Java. Он выпущен под лицензией Apache и управляется Apache Software Foundation.
Nutch может работать на одной машине, но чаще используется в распределенной среде. На самом деле, Nutch был разработан с нуля, чтобы быть масштабируемым и легко расширяемым.
Орех очень гибкий и может использоваться для различных целей. Например, Nutch можно использовать для обхода всего Интернета или только определенных веб-сайтов. Кроме того, Nutch можно настроить на индексацию страниц в режиме реального времени или по расписанию.
Одним из основных преимуществ Apache Nutch является его масштабируемость. Nutch можно легко масштабировать для обработки больших объемов данных и трафика. Например, большой веб-сайт электронной коммерции может использовать Apache Nutch для сканирования и индексации своего каталога продуктов. Это позволит клиентам искать продукты на своем веб-сайте с помощью внутренней поисковой системы компании.
Кроме того, Apache Nutch можно использовать для сбора данных о веб-сайтах. Компании могут использовать Apache Nutch для сканирования веб-сайтов конкурентов и сбора информации об их продуктах, ценах и контактной информации. Затем эта информация может быть использована для улучшения их присутствия в Интернете.
Однако у Apache Nutch есть некоторые недостатки. Например, это может быть сложно настроить и использовать. Кроме того, Apache Nutch не так широко используется, как другие поисковые роботы, а это означает, что для него доступна меньшая поддержка.
Screaming Frog
Screaming Frog SEO Spider — это настольная программа (ПК или Mac), которая сканирует ссылки, изображения, CSS, скрипты и приложения веб-сайтов с точки зрения SEO.
Он извлекает ключевые элементы сайта для SEO, представляет их на вкладках по типам и позволяет вам фильтровать общие проблемы SEO или нарезать данные так, как вам нравится, экспортируя их в Excel.
Вы можете просматривать, анализировать и фильтровать данные сканирования по мере их сбора и извлечения в режиме реального времени с помощью простого интерфейса.
Программа бесплатна для небольших сайтов (до 500 URL). Для больших сайтов требуется лицензия.
Screaming Frog использует Chromium WRS для сканирования динамических веб-сайтов с большим количеством JavaScript, таких как Angular, React и Vue. js. Создание карты сайта WordPress, извлечение XPath и визуализация архитектуры сайта — другие важные функции.
Платформа обслуживает такие корпорации, как Apple, Amazon, Disney и даже Google. Screaming Frog также является популярным инструментом среди владельцев агентств и SEO-специалистов, которые управляют SEO для нескольких клиентов.
Deepcrawl
Deepcrawl — это облачный поисковый робот, который позволяет пользователям сканировать веб-сайты и собирать данные об их структуре, содержании и производительности.
DeepCrawl предоставляет пользователям несколько функций и опций, в том числе возможность сканировать веб-сайты на основе JavaScript, настраивать процесс сканирования и создавать подробные отчеты.
Одной из самых уникальных функций Deepcrawl является его способность сканировать веб-сайты, созданные с помощью JavaScript. Это возможно, потому что Deepcrawl использует безголовый браузер (например, Chrome) для отображения содержимого веб-сайта перед его сканированием.
Это означает, что Deepcrawl может сканировать и собирать данные о веб-сайтах, которые не всегда могут быть доступны другим поисковым роботам.
Помимо гибких API, данные Deepcrawl интегрируются с Google Analytics, Google Search Console и другими популярными инструментами. Это позволяет пользователям легко сравнивать данные своего веб-сайта с данными конкурентов. Это также позволяет им связывать бизнес-данные (например, данные о продажах) с данными своего веб-сайта, чтобы получить полное представление о том, как работает их веб-сайт.
Deepcrawl лучше всего подходит для компаний с большими веб-сайтами с большим количеством контента и страниц. Платформа менее подходит для небольших веб-сайтов или тех, которые не меняются очень часто.
Deepcrawl предлагает три разных продукта:
- Центр автоматизации: этот продукт интегрируется с конвейером CI/CD и автоматически сканирует ваш веб-сайт с более чем 200 правилами тестирования SEO QA.
- Центр аналитики: Этот продукт позволяет вам получать полезную информацию из данных вашего веб-сайта и улучшать SEO вашего веб-сайта.
- Концентратор мониторинга: этот продукт отслеживает изменения на вашем веб-сайте и предупреждает вас о появлении новых проблем.
Предприятия используют эти три продукта для улучшения SEO своего веб-сайта, отслеживания изменений и сотрудничества с командами разработчиков.
Octoparse
Octoparse — это удобное клиентское программное обеспечение для сканирования веб-страниц, которое позволяет извлекать данные со всего Интернета. Программа специально разработана для людей, не являющихся программистами, и имеет простой интерфейс «укажи и щелкни».
С Octoparse вы можете запускать запланированные облачные извлечения для извлечения динамических данных, создавать рабочие процессы для автоматического извлечения данных с веб-сайтов и использовать его API парсинга веб-страниц для доступа к данным.
Его прокси-серверы IP позволяют сканировать веб-сайты без блокировки, а встроенная функция Regex автоматически очищает данные.
Благодаря готовым шаблонам скрейпера вы можете начать извлекать данные с популярных веб-сайтов, таких как Yelp, Google Maps, Facebook и Amazon, за считанные минуты. Вы также можете создать свой собственный парсер, если его нет в наличии для ваших целевых веб-сайтов.
HTTrack
Вы можете использовать бесплатное ПО HTTrack для загрузки целых сайтов на свой компьютер. Благодаря поддержке Windows, Linux и других систем Unix этот инструмент с открытым исходным кодом может использоваться миллионами.
Средство копирования веб-сайтов HTTrack позволяет загружать веб-сайты на компьютер, чтобы вы могли просматривать их в автономном режиме. Программу также можно использовать для зеркалирования веб-сайтов, что означает, что вы можете создать точную копию веб-сайта на своем сервере.
Программа проста в использовании и имеет множество функций, в том числе возможность возобновлять прерванные загрузки, обновлять существующие веб-сайты и создавать статические копии динамических веб-сайтов.
Вы можете получить файлы, фотографии и HTML-код с зеркального веб-сайта и возобновить прерванную загрузку.
Хотя HTTrack можно использовать для загрузки веб-сайтов любого типа, он особенно полезен для загрузки веб-сайтов, которые больше не доступны в сети.
HTTrack — отличный инструмент для тех, кто хочет загрузить весь веб-сайт или создать его зеркальную копию. Однако следует отметить, что программу можно использовать для загрузки нелегальных копий веб-сайтов.
Таким образом, вы должны использовать HTTrack только в том случае, если у вас есть разрешение от владельца веб-сайта.
SiteSucker
SiteSucker — это приложение для macOS, которое загружает веб-сайты. Он асинхронно копирует веб-страницы сайта, изображения, PDF-файлы, таблицы стилей и другие файлы на ваш локальный жесткий диск, дублируя структуру каталогов сайта.
Вы также можете использовать SiteSucker для загрузки определенных файлов с веб-сайтов, таких как файлы MP3.
Программа может использоваться для создания локальных копий веб-сайтов, что делает ее идеальной для просмотра в автономном режиме.
Это также полезно для загрузки целых сайтов, чтобы вы могли просматривать их на своем компьютере без подключения к Интернету.
Одним из недостатков SiteSucker является то, что он не может обрабатывать Javascript (хотя может обрабатывать Flash). Тем не менее, он по-прежнему полезен для загрузки веб-сайтов на ваш Mac.
Webz.io
Пользователи могут использовать веб-приложение Webz.io для получения данных в режиме реального времени путем сканирования онлайн-источников по всему миру в различных удобных форматах. Этот поисковый робот позволяет сканировать данные и извлекать ключевые слова на нескольких языках на основе многочисленных критериев из различных источников.
Архив позволяет пользователям получать доступ к историческим данным. Пользователи могут легко индексировать и искать структурированные данные, просканированные Webhose, используя его интуитивно понятный интерфейс/API. Вы можете сохранять очищенные данные в форматах JSON, XML и RSS. Кроме того, Webz.io поддерживает до 80 языков с результатами сканирования данных.
Freemium бизнес-модель Webz.io должна подойти для предприятий с базовыми требованиями к сканированию. Для предприятий, которым требуется более надежное решение, Webz.io также предлагает поддержку мониторинга СМИ, угроз кибербезопасности, анализа рисков, финансового анализа, веб-аналитики и защиты от кражи личных данных.
Они даже поддерживают решения API даркнета для бизнес-аналитики.
UiPath
UiPath — это приложение Windows, которое можно использовать для автоматизации повторяющихся задач. Это полезно для парсинга веб-страниц, поскольку оно может автоматически извлекать данные с веб-сайтов.
Программа проста в использовании и не требует знаний в области программирования. Он имеет визуальный интерфейс перетаскивания, который упрощает создание сценариев автоматизации.
С помощью UiPath вы можете извлекать табличные данные и данные на основе шаблонов с веб-сайтов, PDF-файлов и других источников. Программу также можно использовать для автоматизации таких задач, как заполнение онлайн-форм и загрузка файлов.
Коммерческая версия инструмента предоставляет дополнительные возможности сканирования. При работе со сложными пользовательскими интерфейсами этот подход очень успешен. Инструмент очистки экрана может извлекать данные из таблиц как по отдельным словам, так и по группам текста, а также по блокам текста, таким как RSS-каналы.
Кроме того, вам не нужны навыки программирования для создания интеллектуальных веб-агентов, но если вы хакер .NET, вы сможете полностью контролировать их данные.
Плохие боты
Хотя большинство поисковых роботов безопасны, некоторые из них могут использоваться в злонамеренных целях. Эти вредоносные веб-сканеры, или «боты», могут использоваться для кражи информации, проведения атак и совершения мошенничества. Также все чаще обнаруживается, что эти боты игнорируют директивы robots.txt и переходят непосредственно к сканированию веб-сайтов.
Некоторые выдающиеся плохие боты приведены ниже:
- Petalbot
- Semrushbot
- Majestic
- Dotbot
- Ahrefsbot
Профилает свой сайт от Malicoe Websbot
. брандмауэр веб-приложений (WAF) для защиты вашего сайта от ботов и других угроз. WAF — это часть программного обеспечения, которое находится между вашим веб-сайтом и Интернетом и фильтрует трафик до того, как он попадет на ваш сайт.CDN также может помочь защитить ваш сайт от ботов. CDN — это сеть серверов, которые доставляют контент пользователям в зависимости от их географического положения.
Когда пользователь запрашивает страницу с вашего веб-сайта, CDN направляет запрос на сервер, ближайший к местоположению пользователя. Это может помочь снизить риск атаки ботов на ваш сайт, поскольку им придется нацеливаться на каждый сервер CDN в отдельности.
У KeyCDN есть отличная функция, которую вы можете включить на своей панели инструментов, которая называется «Блокировка плохих ботов». KeyCDN использует полный список известных вредоносных ботов и блокирует их на основе их User-Agent строка.
При добавлении новой зоны для функции Блокировать плохих ботов устанавливается значение отключено . Этот параметр можно установить на с включенным , если вы хотите, чтобы плохие боты автоматически блокировались.
Ресурсы бота
Возможно, вы видите некоторые строки пользовательского агента в своих журналах, которые вас беспокоят. Вот несколько хороших ресурсов, на которых вы можете найти популярных плохих ботов, сканеров и парсеров.
- BotReports.com
У Кайо Алмейды также есть довольно хороший список в его проекте GitHub для поисковых агентов.
Резюме
Существуют сотни различных поисковых роботов, но, надеюсь, вы уже знакомы с несколькими наиболее популярными из них. Опять же, вы должны быть осторожны при блокировании любого из них, так как они могут вызвать проблемы с индексацией. Всегда полезно проверить журналы вашего веб-сервера, чтобы узнать, как часто они сканируют ваш сайт.
Какой ваш любимый поисковый робот? Дайте нам знать в комментариях ниже.
Ознакомьтесь с некоторыми менее известными директивами поиска robots.txt
На этой неделе я получил несколько 667 964 /robots.txt файлов исключения роботов из Alexa Top 1 Million доменов. Вот что я узнал о некоторых менее известных директивах для роботов, которые они содержали.
Некоторые быстрые и грязные данные: 66,79 % доменов в топ-миллионном списке имеют файл robots. 5,29 % доменов вернули файлов HTML (в основном HTTP 404 Not Found страниц ошибок), 1,55 % вернули пустые файлы, а 0,15 % доменов вернули файлы других типов.
Наиболее распространенной причиной ошибочного синтаксического анализа было включение комментариев HTML с отладочной информацией. Большинство из этих комментариев были уникальными, за исключением плагина WP Super Cache для WordPress, который один отвечал за размещение комментариев в 0,08% всех файлов robots (исправление предоставлено проекту).
0,008 % доменов вежливо встречают роботов с той или иной вариацией комментария «# привет робот! ». Некоторые даже приветствуют их на их родном языке: «# бип-блуп-бип ».
Я предполагаю, что любой, кто читает это, уже знаком с директивами User-agent , Disallow , Allow и Sitemap . Тем не менее, некоторые из наиболее часто встречающихся ошибок в написании директивы « Disallow » включают 5001 домен с написанием « Disalow », 765 « dissalow », 381 « dissallow », […], и 31 просто пошло с « желтый ».
Если вы уже знакомы с основными директивами и их написанием, давайте подробнее рассмотрим самые популярные среди обнаруженных мной необычных директив.
Задержка сканирования Устанавливает задержку между каждым новым запросом на сайт. Например, Crawl-delay: 12 указывает сканеру ждать 12 секунд между каждым запросом; ограничивая его не более чем пятью запросами страниц в минуту.
Данную директиву признают Bing, Яндекс (45 % рынка в России и 20 % в Украине), Naver (40 % рынка в Южной Корее) и Mail.Ru (5 % рынка в России).
Из-за распределенного характера поисковых искателей вы можете увидеть больше запросов, чем ожидалось, поскольку неясно, применяется ли ограничение ко всему пулу искателей или к каждому отдельному искателю. Bing указывает, что ограничение применяется ко всему их пулу искателей, но ни одна из других поисковых систем не предоставляет никакой документации по этому поводу.
Агент пользователя: * Запретить: # разрешить все Crawl-задержка: 6
Яндекс поддерживает дробные значения, обеспечивающие более точное управление, чем целые секунды. Я бы рекомендовал придерживаться целых чисел, поскольку ни один из других поисковых роботов не рекламирует поддержку чего-либо, кроме целых секунд. Придерживаться наименьшего общего знаменателя кажется способом избежать проблем.
40 % просканированного набора данных файлов robots используют 10-секундную задержку сканирования, а средняя задержка сканирования составляет 12,78 секунды. 30 секунд — это максимальная задержка, признанная большинством поисковых систем. Среднее значение было скорректировано, чтобы отразить максимальную задержку в 30 секунд.
Эта директива была замечена на 78 516 доменах. Дробные значения были найдены на 1266 доменах. Документация предоставлена Яндексом, Naver (на корейском) и Mail.Ru (на русском).
Хост Устанавливает каноническое доменное имя для текущего сервера, который обслуживал файл robots. Директиву используют Google, Яндекс и Mail.Ru.
Агент пользователя: * Запретить: # разрешить все Хост: www.example.com
Эта директива была замечена на 42 408 доменах. Документация предоставлена Яндексом и Mail.Ru (на русском языке).
2999 доменов предоставили URI , а не имя хоста. Половина из них использует Протокол HTTPS . Это использование полностью недокументировано, но тестер robots.txt Яндекса не выдает никаких ошибок по этому поводу.
Чистый параметр Указывает параметры запроса, не влияющие на содержимое (например, отслеживание), которые следует удалить из URL s. Например, « Clean-param: referral/» преобразует «/document?referral=advert » в канонический адрес «/document ».
Данную директиву используют Яндекс и Mail.Ru. По сути, это другой взгляд на инициативы Google по канонизации адресов с использованием тегов ссылок. Основное отличие от тега канонической ссылки заключается в том, что он снижает активность поискового робота на вашем сервере, так как поисковый робот выполняет канонизацию адреса. Поисковые роботы даже не должны запрашивать дубликаты страниц.
Агент пользователя: * Запретить: # разрешить все Чистый параметр: utm_campaign/ Чистота-параметр: реферал /
Эта директива была обнаружена на 2651 домене. Документация предоставлена Яндексом и Mail.Ru (на русском языке).
Расширенное исключение роботов «Стандарт»
Предлагаемый расширенный стандарт исключения роботов был разработан Шоном Коннером в конце 90-х годов, но не получил должного внимания. Seznam контролирует около 20 % поискового рынка в Чехии, а их SeznamBot — единственная известная реализация в крупной поисковой системе.
Стандарт включает общие User-agent , Disallow и Allow директивы. Он расширяет стандарт следующими дополнительными директивами:
Скорость запросов Разновидность Crawl-delay , которая устанавливает скорость запроса, а не задержку между каждым запросом. Например, Request-rate: 5/1m не эквивалентно Crawl-delay: 12 , так как все пять запросов могут быть выполнены за первые несколько секунд в течение одной минуты. ( Скорость запроса: 1/12 с будет эквивалентно).
Агент пользователя: * Запретить: # разрешить все Частота запросов: 10/1м
Эта директива была обнаружена на 1315 доменах. Документация предоставлена Seznam.
Время посещения Устанавливает время суток, когда сканеры должны получать доступ к сайту. В предложении по стандартам не проясняется намерение, но, вероятно, оно предназначалось для ограничения доступа сканеров к сайту только в ночное время.
Это не масштабируется, так как всем хотелось бы, чтобы роботы работали ночью, освобождая ресурсы для людей в течение дня. Предложение не касается часовых поясов, но SeznamBot — как единственный известный пользователь — указывает часовой пояс как UTC .
Агент пользователя: * Запретить: # разрешить все Время посещения: 01:45-08:30
Эта директива была обнаружена на 864 доменах.
Обновление( ): Seznam удалил все упоминания о 9Директива 2033 Visit-time из их документации, что означает, что в настоящее время нет известных разработчиков.
Если вы используете директиву Crawl-delay , не помешает предоставить ту же информацию и через директиву Request-rate . Однако указывать Visit-time кажется совершенно бессмысленным.
Индексная страница 360 Search (ранее HoaSou) получает около 20% ежедневных поисковых запросов в Китае. Их 360Spider (иногда HaoSouSpider) использует эту уникальную директиву для роботов в качестве индикатора для часто обновляемых страниц, таких как индексные страницы подфорума, газетные разделы и другие типы страниц, которые служат часто обновляемыми индексами новых страниц.
360 Search указывает, что они используют их в качестве подсказок, чтобы определить, как часто следует выбирать страницы для обнаружения нового контента. Как и директива Sitemap, директива Indexpage должна использовать абсолютный URL-адрес , а не относительный URL-адрес .
Агент пользователя: * Запретить: # разрешить все Индексная страница: https://www.example.com/articles/archive/ Индексная страница: https://www.example.com/forum/?order=newest Индексная страница: https://www.example.com/videos/*-category$
В отличие от Baidu (доля рынка 60%), 360 Search не предлагает машинный перевод с английского на китайский, поэтому стоит ли принимать эту директиву, зависит от вашего желания выйти на китайский рынок и вашего типа контента. Включение его в конец файла robots не помешает.
Тем не менее, я проводил эксперимент на этом веб-сайте в течение месяца и практически не заметил увеличения трафика с поиска 360 после принятия этой директивы. Однако количество страниц, проиндексированных их роботом, выросло с ~ 30 % до 82 % страниц на этом домене за тот же период времени. Это может указывать на определенный уровень предпочтения сайтов, которые включают эту директиву.
Эта директива была обнаружена только на 12 доменах. Документация предоставлена 360 Search (на китайском языке).
Теперь о некоторых директивах, которые ни на что не влияют, никогда ни на что не влияли и, вероятно, никогда ни на что не повлияют. Это всего лишь выдуманные директивы без известной реализации, которые по какой-то причине были приняты.
Без индекса Эта якобы «секретная и недокументированная» директива была сфабрикована « SEO Специалисты», нуждающиеся в наполнении своих блогов новым и интересным контентом. Вероятно, это произошло из-за неправильного понимания метатега noindex .
Предполагается, что она более мощная, чем директива « Disallow », поскольку поисковые роботы по-прежнему могут запрашивать страницы и находить ссылки на другие страницы, не включая саму страницу в результаты поиска. Ни один из известных сканеров не использует эту директиву, и это совершенно бессмысленно, но эй – легко SEO баллов!
Эта директива была замечена на 26 423 доменах. Я не буду приводить здесь какие-либо источники, потому что не хочу, чтобы они привлекали лишний трафик и внимание к этому сомнительному «новшеству».
Автоматизированный протокол доступа к контенту
ASCP-crawler , ASCP-disallow-crawl и ASCP-allow-crawl точно эквивалентны User-agent , Disallow и Allow . Они служат той же цели, но имеют аббревиатуру группы интересов правообладателей в качестве префикса и суффикс «-crawl[er]. Инновационный. Нет известных разработчиков; почему бы и нет?
Эти директивы были обнаружены на 245 доменах. Документация предоставлена IPTC .
Думаю, стоит принять любую из этих директив, которая покажется вам интересной (кроме Noindex , конечно). Не так много поисковых роботов, которые поддерживают эти менее известные директивы, но поисковые системы будут принимать новые директивы, как только они начнут активно их использовать.
Возможно, стоит изучить различные варианты и посмотреть, сможет ли ваш сайт выйти на новые рынки, увеличив свое присутствие в поиске по всему миру. Не помешает принять новые директивы. Строки в файлах robots, содержащие директивы, непонятные сканерам, будут просто игнорироваться. (Предполагается, что сканер следует спецификации robots. txt.)
Размещение малоизвестных директив в конце файла robots может помочь гарантировать, что любая ошибка синтаксического анализа произойдет после того, как более популярные директивы уже будут приняты их процессорами.
Вы можете увидеть пример использования многих из этих директив в комбинации, просмотрев ctrl.blog/robots.txt . Они могут не слишком широко поддерживаться, но нет никакого реального вреда в указании большего количества директив.
Список одного миллиона самых популярных доменных имен был предоставлен Alexa Internet. Доля рынка настольных поисковых систем предоставлена StatCounter GlobalStats.
87.250.224.146 | ООО «Яндекс» | AbuseIPDB
Проверьте IP-адрес, доменное имя или подсеть
например. 176.9.44.166 , microsoft.com , или 5.188.10.0/24
87.250.224.146 был найден в нашей базе данных! Об этом IP сообщили 64 раз. Уверенность в жестоком обращении 0% : ?
| Интернет-провайдер | ООО «Яндекс» |
|---|---|
| Тип использования | Поисковый паук |
| Имя хоста(ов) | 87-250-224-146.spider.yandex.com |
| Имя домена | яндекс.нет |
| Страна | Российская Федерация |
| Город | Москва, Москва |
IP-информация, включая интернет-провайдера, тип использования и местоположение, предоставленная IP2Location. Обновляется ежемесячно.
Важное примечание: 87.250.224.146 — это IP-адрес из нашего белого списка. Сетевые блоки из белого списка обычно принадлежат доверенным организациям, таким как Google или Microsoft, которые могут использовать их для поисковых роботов. Однако эти же организации иногда также предоставляют облачные серверы и почтовые службы, которыми легко злоупотреблять. Будьте особенно внимательны, доверяя или не доверяя этим IP-адресам.
По нашим данным, этот IP принадлежит подсети 87.250.224.0/19, идентифицированной как: «Яндекс»
Отчет 87.250.224.146
Whois 87.250.224.146
Отчеты о злоупотреблениях IP для
87.250.224.146 :Об этом IP-адресе сообщили в общей сложности 64 раз из 19 различных источников. Впервые о 87.250.224.146 сообщили , а последнее сообщение было .
Последние отчеты: Мы получили сообщения о неправомерных действиях с этого IP-адреса за последнюю неделю. Потенциально он по-прежнему активно занимается оскорбительной деятельностью.
| Репортер | Дата | Комментарий | Категории | |
|---|---|---|---|---|
| Байтмарк | 87.250.224.146 — — [20/сен/2022:01:24:59 +0100] «GET /курс/доступ-к-диплому/встроенная-среда/ … показать еще87.250.224.146 — — [ 20/Sep/2022:01:24:59 +0100] «GET /course/access-to-he-diploma/built-environment/option-2 HTTP/1.1» 404 7277 «-» «Mozilla/5.0 (совместимый; ЯндексБот/3.0; +http://yandex.com/bots)» свернуть | Грубая сила Атака веб-приложений | ||
| Байтмарк | 87.250.224.146 — — [18/Sep/2022:00:08:00 +0100] «GET / HTTP/1.1» 200 13749 «-» «Mozilla/5.0 (совместим … показать еще87.250.224.146 — — [18/Sep/2022:00:08:00 +0100] «GET / HTTP/1.1» 200 13749 «-» «Mozilla/5.0 (совместимо; YandexBot/3.0; +http://yandex.com/bots)» показать меньше | Грубая сила Атака веб-приложений | ||
| Байтмарк | 87.250.224.146 — — [15/сен/2022:16:12:41 +0100] «GET /viewtopic.php?f=21&t=5043 HTTP/1.1» 200 14284 … показать еще87.250.224.146 — — [15/Sep/2022:16:12:41 +0100] «GET /viewtopic.php?f=21&t=5043 HTTP/1.1» 200 14284 «-» «Mozilla/5.0 (совместимо; YandexBot/3.0; +http: //yandex.com/bots)» свернуть | Грубая сила Атака веб-приложений | ||
| Анонимный | сканирование портов и подключение, tcp 80 (http) | Сканирование портов | ||
| Байтмарк | 87.250.224.146 — — [13/сен/2022:14:47:56 +0100] «GET /robots. | Грубая сила Атака веб-приложений | ||
| Байтмарк | 87.250.224.146 — — [11/сен/2022:12:23:05 +0100] «GET /robots.txt HTTP/1.1» 200 7139 «-» «Mozilla/5.0 … показать еще87.250.224.146 — — [11/Sep/2022:12:23:05 +0100] «GET /robots.txt HTTP/1.1» 200 7139 «-» «Mozilla/5.0 (совместимо; YandexBot/3.0; +http://yandex.com /bots)» | Грубая сила Атака веб-приложений | ||
| Байтмарк | 87.250.224.146 — — [04/сен/2022:21:02:18 +0100] «GET /robots.txt HTTP/1.1» 200 7139 «-» «Mozilla/5.0 … показать еще87.250.224.146 — — [04/Sep/2022:21:02:18 +0100] «GET /robots.txt HTTP/1.1» 200 7139 «-» «Mozilla/5.0 (совместимо; YandexBot/3.0; +http://yandex.com /боты)» | Грубая сила Атака веб-приложений | ||
| Байтмарк | 87.250.224.146 — — [02/Сент/2022:19:38:26 +0100] «GET /viewtopic.php?t=5741&start=15 HTTP/1.1» 200 13 … показать еще87.250.224.146 — — [02/Sep/2022:19:38:26 +0100] «GET /viewtopic.php?t=5741&start=15 HTTP/1.1» 200 13610 «-» «Mozilla/5. | Грубая сила Атака веб-приложений | ||
| Байтмарк | 87.250.224.146 — — [31/Aug/2022:19:11:12 +0100] «GET /robots.txt HTTP/1.1» 200 7139 «-» «Mozilla/5.0 … показать еще87.250.224.146 — — [31/Aug/2022:19:11:12 +0100] «GET /robots.txt HTTP/1.1» 200 7139 «-» «Mozilla/5.0 (совместимо; YandexBot/3.0; +http://yandex.com /bots)» | Грубая сила Атака веб-приложений | ||
| Байтмарк | 87. | Грубая сила Атака веб-приложений | ||
| Байтмарк | 87.250.224.146 — — [25/Aug/2022:16:52:13 +0100] «GET /phpBB3/viewtopic.php?f=71&t=9070 HTTP/1.1» 301 … показать еще87.250.224.146 — — [25/Aug/2022:16:52:13 +0100] «GET /phpBB3/viewtopic.php?f=71&t=9070 HTTP/1.1» 301 7063 «-» «Mozilla/5.0 (совместимый; YandexBot/3.0; +http://yandex. | Грубая сила Атака веб-приложений | ||
| Клаппер | (mod_security) mod_security (id:980001) инициировано 87.250.224.146 (RU/Russia/87-250-224-146.spider … показать еще(mod_security) mod_security (id:980001) инициировано 87.250.224.146 (RU /Russia/87-250-224-146.spider.yandex.com): 5 за последние 14400 сек ID: rub показать меньше | Грубая сила Плохой веб-бот | ||
| Байтмарк | 87. | Грубая сила Атака веб-приложений | ||
| рх34 | (apache-useragents) Неудачный запуск apache-useragents с совпадением [удалено] с 87.250.224.146 (RU/R … показать больше(apache-useragents) Неудачный запуск apache-useragents с совпадением [удален] с 87.250.224.146 (RU /Russia/87-250-224-146.spider.yandex.com) скрыть | Плохой веб-бот | ||
| ozisp.com.au | RU_YANDEX-MNT_<33>1660984650 [1:2032979:1] ET SCAN User-Agent Yandex Webcrawler (YandexBot) [Классификация . |