как правильный robots.txt сайт из Google удалил — SEO на vc.ru
{«id»:13821,»url»:»\/distributions\/13821\/click?bit=1&hash=c1a6336773903cd5a554138f89b3c2b4ec89b0ddd1b9d884ea297d09f027b6bf»,»title»:»\u041d\u0435\u043d\u0430\u0432\u0438\u0434\u0438\u0442\u0435 \u0433\u043e\u043b\u043e\u0441\u043e\u0432\u044b\u0435 \u0438 \u043a\u0440\u0443\u0436\u043e\u0447\u043a\u0438? \u042d\u0442\u0438 \u0432\u044b \u0442\u043e\u0447\u043d\u043e \u043f\u043e\u043b\u044e\u0431\u0438\u0442\u0435″,»buttonText»:»\u041f\u0440\u043e\u0432\u0435\u0440\u0438\u0442\u044c»,»imageUuid»:»dd81dff1-4549-5651-b661-51aa9164840c»,»isPaidAndBannersEnabled»:false}
Таки-здрасьте!
5385 просмотров
Пишу тут пост впервые, так что пинайте как можно сильнее и сопровождайте пинки как можно более сильными криками.
В данном посте я расскажу о том, как robots.txt, который на первый взгляд составлен правильно, полностью выбил сайт из поисковой системы Google.
Дано.
Сайт по велотуризму. Клиент у нас совсем недавно, поэтому на сайте пока что всё плохо. Клиент пожаловался, что сайт полностью вылетел из поисковой выдачи Google. Также заказчик сказал, что кто-то из его программистов что-то делал с robots.txt. ОК, будем посмотреть.
Клиент у нас совсем недавно, поэтому на сайте пока что всё плохо. Клиент пожаловался, что сайт полностью вылетел из поисковой выдачи Google. Также заказчик сказал, что кто-то из его программистов что-то делал с robots.txt. ОК, будем посмотреть.
Задача.
Вернуть сайт обратно в Google. Не обязательно в ТОП, достаточно чтобы он просто индексировался.
Что было сделано.
Самое первое, что я сделал — глянул текущий robots. На момент вмешательства он выглядел вот так (версия от 11 августа):
User-agent: *
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Disallow: *utm*=
Disallow: *openstat=
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.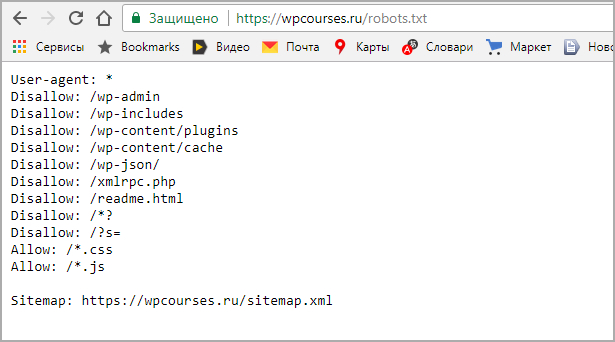 png
png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Sitemap: https://velotour-asia.ru/sitemap_index.xml
Как видите, никаких правил, которые запрещают индексирвание всего сайта ( или, скажем, главной страницы) тут нету. Подозрительно, однако!
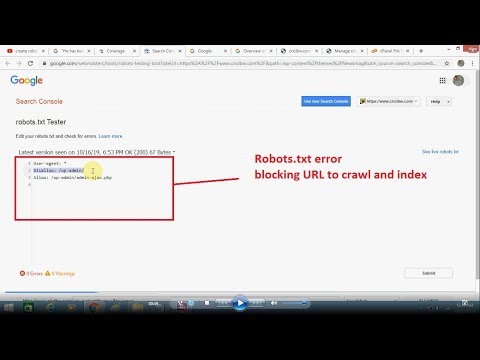
OK, Google, расскажи же, что не так! Идём в Search Console и пытаемся разобраться. И «от оно чо, Михалыч!» Противоречие однако!
Обратите внимание, что попытка сканирования была 19го числа, т.е. спустя несколько дней после последнего редактирования robots’а. Эй, какого яруса?! Роботс, вроде, в порядке, но Google на него ругается. Как так-то?
В коде страницы я никаких noindex’ов тоже не нашел, т.е. вариант с тегами отпадает.
Далее я просканировал сайт Screaming Frog’ом, предварительно выставив в настройках смартфонный гуглбот (именно смартфонный, т.к. Николай Васильевич Гуголь сканировал сайт именно им). Также в настройках было выставлено Respect robots, чтобы содержимое robots.
Как видите, все строки (кроме первой) отдают код 200 ОК и имеют статус Indexable. Т.е. со сканированием Фрог проблем не выявил. Странно.
ОК, тогда воспользуемся штатным инструментом Google для проверки robots.txt. Самое первое, что бросилось в глаза — все строки были помечены как ошибочные.
Всё страннее и страннее… Томить не буду. Проблему я, кстати, заметил далеко не сразу. Всё внимание на первую строку роботса:
Что это за символ — не понятно. Удаляем и…
… и все 26 ошибок исчезли. Далее я напрямую из Консоли скачал исправленный роботс, затем скачал с сайта исходный и стал сравнивать.
Если их просто открыть в блокноте, то они выглядят абсолютно идентично. Как говорится, «найдите 10 отличий». Если вместо Блокнота открывать через Notepad++ — будет то же самое.
Однако, размер файлов отличается, пусть даже всего на 3 байта:
Вот блин просто охренеть! Всего 1 символ, который не отображается ни в браузере, ни в блокноте, ни в Notepad++, и сайт вылетел из индекса Google! Как тебе такое, Илон Маск?
Что такое файл robots.
 txt? — Бюро Корректировки
txt? — Бюро Корректировки- Файл robots.txt — это простой текстовый файл, размещенный на вашем веб-сервере, который сообщает веб-сканерам, таким как Googlebot , должны ли они получить доступ к файлу или нет.
Основные примеры robots.txt
Вот некоторые распространенные настройки файла robots.txt (они будут подробно описаны ниже).
Разрешить полный доступ
User-agent: *
Disallow:
Заблокировать доступ
User-agent: *
Disallow: /
Заблокировать одну папку
User-agent: *
Disallow: /folder/
Заблокировать один файл
User-agent: * Disallow: /file.html
Почему вы должны узнать о robots.txt?
- Неправильное использование файла robots.txt может повредить вашему рейтингу.
- Файл robots.txt управляет тем, как поисковые роботы видят ваши веб-страницы и взаимодействуют с ними.
- Этот файл упоминается в нескольких руководствах Google.

- Этот файл и боты, с которыми они взаимодействуют, являются фундаментальными частями работы поисковых систем.

Поисковые пауки
Первое, на что обращает внимание поисковый робот, такой как Googlebot , при посещении страницы — это файл robots.txt.
Он делает это, потому что хочет знать, есть ли у него разрешение на доступ к этой странице или файлу. Если в файле robots.txt указано, что он может войти, паук поисковой системы переходит к файлам страниц.
Если у вас есть инструкции для поискового робота, вы должны сообщить ему эти инструкции. Это можно сделать с помощью файла robots.txt. 2
Приоритеты для вашего сайта
Есть три важные вещи, которые должен сделать любой веб-мастер, когда дело доходит до файла robots.txt.
- Определите, есть ли у вас файл robots.txt
- Если он у вас есть, убедитесь, что он не вредит вашему рейтингу и не блокирует контент, который вы не хотите блокировать.
- Определите, нужен ли вам файл robots. txt
 txt
txtОпределение наличия файла robots.txt
Файл robots.txt всегда находится в одном и том же месте на любом сайте, поэтому легко определить, есть ли он на сайте. Просто добавьте «/robots.txt» в конец имени домена, как показано ниже.
www.yourwebsite.com/robots.txt
Если у вас там есть файл, это ваш файл robots.txt. Вы либо найдете файл заполненным, либо найдете файл пустым, либо вообще не найдете файл.
Определите, блокирует ли файл robots.txt важные файлы.
Вы можете использовать консоль поиска Google для проверки файла robots.txt. Инструкции для этого можно найти здесь (инструмент не является общедоступным — требуется вход в систему).
Чтобы полностью понять, не блокирует ли ваш файл robots.txt то, что вы не хотите, чтобы он блокировал, вам необходимо понять, о чем он говорит. Мы расскажем об этом ниже.
Нужен ли вамфайл robots.txt?
Возможно, вам даже не понадобится файл robots.txt на вашем сайте. На самом деле часто бывает так, что он вам не нужен.
Причины, по которым вам может понадобиться файл robots.txt:
- У вас есть контент, который вы хотите заблокировать от поисковых систем
- Вы используете платные ссылки или рекламу, требующую специальных инструкций для роботов.
- Вы хотите точно настроить доступ к вашему сайту от авторитетных роботов
- Вы разрабатываете сайт, который работает, но пока не хотите, чтобы поисковые системы индексировали его
- Они помогают вам следовать некоторым рекомендациям Google в определенных ситуациях.
- Вам нужно что-то или все вышеперечисленное, но у вас нет полного доступа к вашему веб-серверу и его настройке.
Каждой из вышеперечисленных ситуаций можно управлять с помощью других методов, однако файл robots.txt является хорошим центральным местом, где можно позаботиться о них, и большинство веб-мастеров имеют возможность и доступ, необходимые для создания и использования файла robots.txt.
Причины, по которым вам может не понадобиться файл robots. txt:
txt:
- Это просто и без ошибок
- У вас нет файлов, которые вы хотите или должны заблокировать от поисковых систем.
- Вы не попадаете ни в одну из ситуаций, перечисленных в приведенных выше причинах, чтобы иметь файл robots.txt
Можно не иметь файла robots.txt.
Если у вас нет файла robots.txt, роботы поисковых систем, такие как Googlebot, будут иметь полный доступ к вашему сайту. Это нормальный и простой метод, который очень распространен.
Как сделать файл robots.txt
Если вы можете печатать или копировать и вставлять, вы также можете создать файл robots.txt.
Это просто текстовый файл, а это значит, что вы можете использовать блокнот или любой другой текстовый редактор для его создания. Вы также можете сделать их в редакторе кода. Вы даже можете «скопировать и вставить» их.
Вместо того, чтобы думать: «Я создаю файл robots.txt», просто подумайте: «Я пишу заметку», это практически один и тот же процесс.
Что должен сказать файл robots.
 txt?
txt?Это зависит от того, что вы хотите сделать.
Все инструкции robots.txt приводят к одному из следующих трех результатов.
- Полное разрешение: весь контент может быть просканирован.
- Полный запрет: контент не может быть просканирован.
- Условное разрешение: директивы в файле robots.txt определяют возможность сканирования определенного контента.
Давайте объясним каждый.
Полное разрешение — весь контент может быть просканирован
Большинство людей хотят, чтобы роботы посещали все на их веб-сайте. Если это относится к вам, и вы хотите, чтобы робот проиндексировал все части вашего сайта, есть три варианта сообщить роботам, что они приветствуются.
1) Нет файла robots.txt
Если на вашем сайте нет файла robots.txt, то происходит вот что…
В гости приходит такой робот, как Googlebot. Он ищет файл robots.txt. Он не находит его, потому что его там нет. Затем робот может свободно посещать все ваши веб-страницы и контент, потому что это то, на что он запрограммирован в этой ситуации.
2) Создайте пустой файл и назовите его robots.txt.
Если на вашем веб-сайте есть файл robots.txt, в котором ничего нет, то происходит вот что…
В гости приходит такой робот, как Googlebot. Он ищет файл robots.txt. Он находит файл и читает его. Читать нечего, поэтому робот может свободно посещать все ваши веб-страницы и контент, потому что это то, на что он запрограммирован в этой ситуации.
3) Создайте файл с именем robots.txt и напишите в нем следующие две строки…
User-agent: *
Disallow:
Если на вашем веб-сайте есть файл robots.txt с этими инструкциями, то происходит вот что…
В гости приходит такой робот, как Googlebot. Он ищет файл robots.txt. Он находит файл и читает его. Он читает первую строку. Затем он читает вторую строку. Затем робот может свободно посещать все ваши веб-страницы и контент, потому что это то, что вы сказали ему делать (я объясню это ниже).
Полный запрет — контент не может быть просканирован
Предупреждение. Это означает, что Google и другие поисковые системы не будут индексировать или отображать ваши веб-страницы.
Это означает, что Google и другие поисковые системы не будут индексировать или отображать ваши веб-страницы.
Чтобы заблокировать все авторитетные поисковые роботы на вашем сайте, в файле robots.txt должны быть следующие инструкции:
User-agent: *
Disallow: /
Делать это не рекомендуется, так как это приведет к тому, что ни одна из ваших веб-страниц не будет проиндексирована.
Инструкции robot.txt и их значение
Вот объяснение того, что означают разные слова в файле robots.txt.
User-agent
User-agent:
Часть «User-agent» предназначена для указания направления к конкретному роботу, если это необходимо. Есть два способа использовать это в вашем файле.
Если вы хотите сказать всем роботам одно и то же, поставьте «*» после «User-agent». Это будет выглядеть так…
User-agent: *
В приведенной выше строке говорится: «Эти указания применимы ко всем роботам».
Если вы хотите что-то сказать определенному роботу (в данном примере Googlebot), это будет выглядеть так. ..
..
User-agent: Googlebot
В приведенной выше строке говорится: «Эти указания относятся только к роботу Googlebot».
Disallow:
Часть «Disallow» предназначена для того, чтобы сообщить роботам, какие папки им не следует просматривать. Это означает, что если, например, вы не хотите, чтобы поисковые системы индексировали фотографии на вашем сайте, вы можете поместить эти фотографии в одну папку и исключить ее.
Допустим, вы поместили все эти фотографии в папку под названием «photos». Теперь вы хотите запретить поисковым системам индексировать эту папку.
Вот как должен выглядеть ваш файл robots.txt в этом случае:
User-agent: *
Disallow: /photos
Приведенные выше две строки текста в вашем файле robots.txt не позволят роботам посещать вашу папку с фотографиями. Часть «User-agent *» говорит «это относится ко всем роботам». Часть «Disallow: / photos» говорит «не посещать и не индексировать папку с моими фотографиями».
Конкретные инструкции Googlebot
Робот Google, который использует для индексации своей поисковой системы, называется Googlebot. Он понимает на несколько больше инструкций, чем другие роботы.
Он понимает на несколько больше инструкций, чем другие роботы.
В дополнение к «User-name» и «Disallow» робот Googlebot также использует инструкцию «Allow».
Allow
Allow:
Инструкции «Allow:» позволяют указать роботу, что он может видеть файл в папке, которая была «Запрещена» другими инструкциями. Чтобы проиллюстрировать это, давайте возьмем приведенный выше пример, говорящий роботу не посещать и не индексировать ваши фотографии. Мы поместили все фотографии в одну папку под названием «фотографии» и создали файл robots.txt, который выглядел так…
User-agent: *
Disallow: /photos
Теперь предположим, что в этой папке есть фотография с именем mycar.jpg, которую вы хотите проиндексировать роботом Googlebot. С помощью инструкции Allow: мы можем указать роботу Googlebot сделать это, это будет выглядеть так…
User-agent: *
Disallow: /photos
Allow: /photos/mycar.jpg
Это сообщит роботу Googlebot, что он может посетить файл «mycar.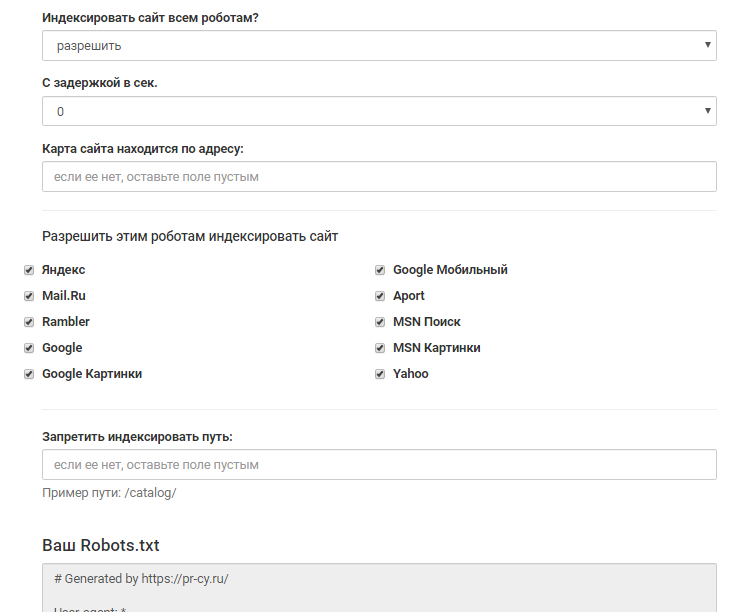 jpg» в папке с фотографиями, даже если в противном случае папка с фотографиями будет исключена.
jpg» в папке с фотографиями, даже если в противном случае папка с фотографиями будет исключена.
Ключевые понятия
- Если вы используете файл robots.txt, убедитесь, что он используется правильно.
- Неверный файл robots.txt может помешать роботу Googlebot проиндексировать вашу страницу.
- Убедитесь, что вы не блокируете страницы, которые нужны Google для ранжирования ваших страниц.
Как исправить «Заблокировано robots.txt» в Google Search Console
«Заблокировано robots.txt» — это статус Google Search Console. Это указывает на то, что Google не просканировал ваш URL-адрес, потому что вы заблокировали его с помощью директивы Disallow в файле robots.txt. Это также означает, что URL-адрес не был проиндексирован.
Устранение этой проблемы лежит в основе создания эффективной стратегии сканирования и индексации вашего веб-сайта.
1 Как исправить «Заблокировано robots.txt»
1.1 Когда вы использовали директиву Disallow по ошибке
1,2 Когда вы намеренно использовали директиву Disallow
2
«Заблокировано robots.
2.1 Изучите основы индексации!
3 Подведение итогов
3.1 Что такое robots.txt?
3.2 Почему робот Googlebot не должен сканировать все URL-адреса?
3.3 Как решить, какие страницы заблокировать с помощью robots.txt?
Как исправить «Заблокировано robots.txt»Решение этой проблемы требует другого подхода в зависимости от того, заблокировали ли вы свою страницу по ошибке или намеренно.
Позвольте мне рассказать вам, как действовать в этих двух ситуациях:
Когда вы по ошибке использовали директиву DisallowВ этом случае, если вы хотите исправить «Заблокировано robots.txt», удалите директиву Disallow директива, блокирующая сканирование данной страницы.
Благодаря этому робот Googlebot, скорее всего, просканирует ваш URL-адрес при следующем сканировании вашего веб-сайта. Без дальнейших проблем с этим URL Google также проиндексирует его.
Если у вас много URL-адресов, затронутых этой проблемой, попробуйте отфильтровать их в GSC. Нажмите на статус и перейдите к символу перевернутой пирамиды над списком URL-адресов.
Вы можете отфильтровать все затронутые страницы по URL-адресу (или только части пути URL-адреса) и дате последнего обхода.
Если вы видите сообщение «Заблокировано robots.txt», это может также означать, что вы намеренно заблокировали весь каталог, но непреднамеренно включили страницу, которую хотите просканировать. Чтобы устранить эту проблему:
- Включите как можно больше фрагментов URL-адреса в директиву Disallow , чтобы избежать возможных ошибок или
- Используйте директиву Allow, если вы хотите разрешить ботам сканировать определенный URL-адрес в запрещенном каталоге.
При изменении файла robots.txt я предлагаю вам проверить свои директивы с помощью тестера robots.txt в Google Search Console. Инструмент загружает файл robots.txt для вашего веб-сайта и помогает вам проверить, правильно ли ваш файл robots.
Тестер robots.txt также позволяет проверить, как ваши директивы влияют на конкретный URL-адрес в домене для данного User-agent, например, Googlebot. Благодаря этому вы можете поэкспериментировать с применением различных директив и посмотреть, заблокирован или принят URL-адрес.
Однако вы должны помнить, что инструмент не будет автоматически изменять ваш файл robots.txt. Поэтому, когда вы закончите тестирование директив, вам нужно вручную внести все изменения в свой файл.
Дополнительно я рекомендую использовать расширение Robots Exclusion Checker в Google Chrome. При просмотре любого домена инструмент позволяет обнаружить страницы, заблокированные файлом robots.txt. Он работает в режиме реального времени, поэтому поможет вам быстро реагировать, проверять и работать с заблокированными URL-адресами в вашем домене.
Посмотрите мою ветку в Твиттере, чтобы узнать, как я использую этот инструмент выше.
Что делать, если вы продолжаете блокировать важные страницы в robots. txt? Вы можете значительно ухудшить свою видимость в результатах поиска.
txt? Вы можете значительно ухудшить свою видимость в результатах поиска.
Вы можете игнорировать статус «Заблокировано robots.txt» в Google Search Console, если вы не запрещаете какие-либо ценные URL-адреса в файле robots.txt.
Помните, что запретить ботам сканировать низкокачественный или дублирующийся контент — это совершенно нормально.
Принятие решения о том, какие страницы должны и не должны сканировать боты, имеет решающее значение для:
- создания стратегии сканирования для вашего веб-сайта и
- Значительно поможет вам оптимизировать и сэкономить краулинговый бюджет.
СЛЕДУЮЩИЕ ШАГИ
Вот что вы можете сделать сейчас:
- Свяжитесь с нами.
- Получите от нас индивидуальный план решения ваших проблем.
- Раскройте потенциал сканирования вашего сайта!
Все еще не уверены, стоит ли писать нам? Обратитесь за услугами по оптимизации краулингового бюджета, чтобы улучшить сканирование вашего веб-сайта.
«Заблокировано robots.txt» можно легко спутать с другим статусом в отчете «Индексация страницы (покрытие индекса)» — « Проиндексировано, но заблокировано robots.txt».
Разница между этими двумя проблемами заключается в том, что с пометкой «Заблокировано robots.txt» ваш URL-адрес не будет отображаться в Google. В свою очередь, с « Проиндексировано, но заблокировано robots.txt» вы можете увидеть свой URL в результатах поиска.
Почему Google может захотеть проиндексировать ваш заблокированный URL? Потому что, когда многие ссылки указывают на конкретный URL-адрес с описательным якорным текстом, Google может счесть его достаточно важным для индексации без сканирования.
Кроме того, чтобы найти «Заблокировано robots.txt», перейдите к таблице «Почему страницы не индексируются» под диаграммой в отчете об индексации страниц.
В свою очередь, «Проиндексировано, но заблокировано robots.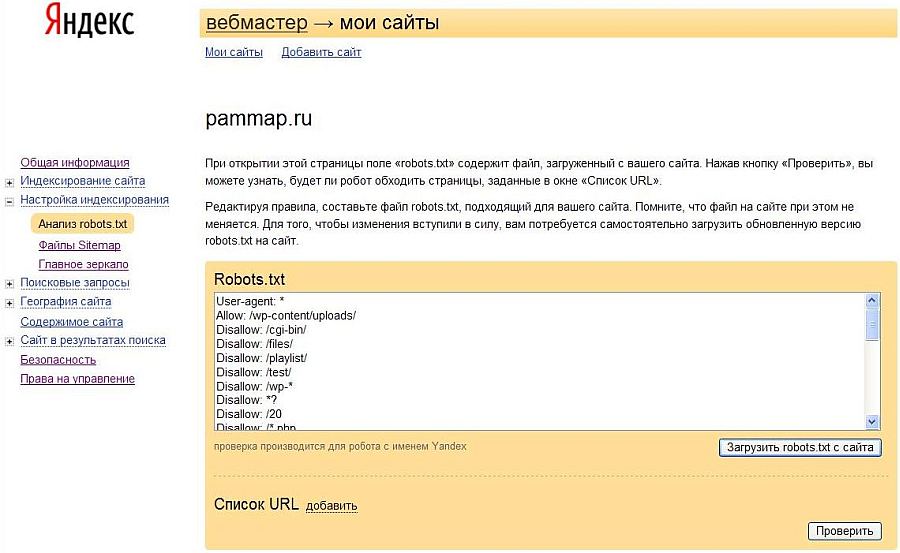 txt» является частью раздела «Улучшение внешнего вида страницы», который вы можете увидеть под таблицей «Почему страницы не индексируются».
txt» является частью раздела «Улучшение внешнего вида страницы», который вы можете увидеть под таблицей «Почему страницы не индексируются».
Помните, что директива Disallow в файле robots.txt не позволяет Google сканировать только ваши страницы. Он не может и не должен использоваться для управления индексацией. Чтобы запретить Google индексировать URL-адрес, убедитесь, что вы блокируете его индексирование с помощью тега noindex.
Изучите основы индексации!
Прочитайте наше окончательное руководство по тегу noindex для SEO и узнайте, как решить проблему «Исключено тегом noindex» в Google Search Console.
Подведение итоговСтатус «Заблокировано robots.txt» означает, что робот Googlebot обнаружил в вашем файле robots.txt директиву Disallow, применимую к этому URL-адресу.
Помните, что робот Googlebot не может сканировать некоторые URL-адреса, особенно если ваш сайт становится больше. Решение о том, какие страницы на вашем веб-сайте следует и не следует сканировать, является фиксированным шагом в создании надежной стратегии индексации вашего веб-сайта.
И поскольку правильное сканирование и индексирование — это основа SEO, хорошо организованный файл robots.txt — это лишь одна из его частей.
Свяжитесь с нами для тщательного технического SEO-аудита, чтобы решить ваши проблемы.
Часто задаваемые вопросы
Что такое robots.txt?Файл robots.txt содержит директивы для роботов Google и других поисковых систем. Прежде чем сканировать ваш веб-сайт, они посещают этот файл, чтобы узнать, к каким страницам они могут получить доступ, не нарушая ваших пожеланий. Узнайте, как изменить и протестировать файл robots.txt, в нашем окончательном руководстве по robots.txt.
Почему робот Googlebot не должен сканировать все URL-адреса? Не все URL-адреса на вашем веб-сайте одинаково ценны. Некоторые из них не актуальны для поисковых систем по разным причинам. Вы должны в первую очередь направлять робота Googlebot на наиболее ценные страницы, что включает в себя контроль бюджета сканирования.
Вы должны использовать robots.txt, чтобы заблокировать сканирование страниц, которые вы не хотите анализировать и индексировать Google, особенно когда вы боретесь с проблемами бюджета сканирования. Но помните, что директива Disallow в robots.txt сама по себе не управляет индексацией — вам также нужно использовать теги noindex.
Как исправить ошибку «Отправленный URL-адрес заблокирован robots.txt» в Google Search Console? » Rank Math
Если вы когда-либо видели ошибку «Отправленный URL-адрес заблокирован robots.txt» в вашей консоли поиска Google и в отчете о статусе индекса аналитики Rank Math, вы знаете, что это может быть довольно неприятно. В конце концов, вы соблюдали все правила и позаботились о том, чтобы ваш сайт был оптимизирован для поисковых систем, таких как Google или Bing. Так почему это происходит?
В этой статье базы знаний мы покажем вам, как исправить ошибку «Отправленный URL-адрес заблокирован robots.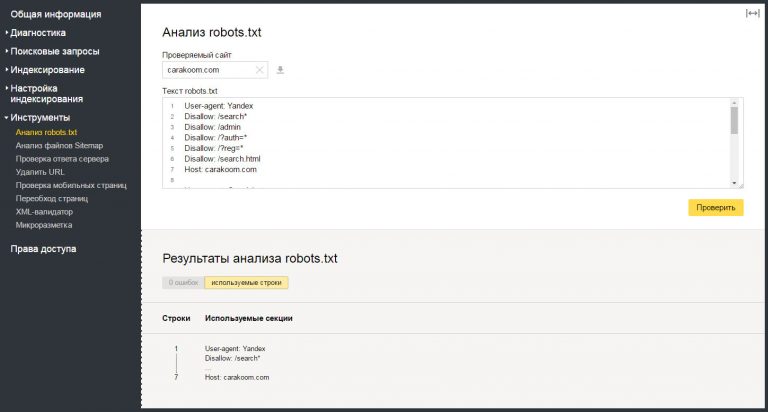 txt», а также объясним, что означает эта ошибка и как предотвратить ее повторение в будущем.
txt», а также объясним, что означает эта ошибка и как предотвратить ее повторение в будущем.
Начнем!
Содержание
- Что означает ошибка?
- Как найти ошибку «Отправленный URL-адрес заблокирован robots.txt»?
- Как исправить ошибку «Исправить отправленный URL, заблокированный robots.txt»?
- Как предотвратить повторение ошибки
- Заключение
1 Что означает ошибка?
Ошибка «Отправленный URL-адрес заблокирован robots.txt» означает, что файл robots.txt вашего веб-сайта блокирует сканирование страницы роботом Googlebot. Другими словами, Google пытается получить доступ к странице, но ему мешает файл robots.txt.
Это может произойти по ряду причин, но наиболее распространенной причиной является неправильная настройка файла robots.txt. Например, вы могли случайно заблокировать роботу Googlebot доступ к странице или включить директиву disallow в файл robots.txt, которая не позволяет роботу Googlebot сканировать страницу.
2 Как найти ошибку «Отправленный URL-адрес заблокирован robots.txt»?
К счастью, ошибку «Отправить URL-адрес, заблокированный robots.txt» довольно легко найти. Вы можете использовать консоль поиска Google или отчет о статусе индекса в аналитике Rank Math, чтобы найти эту ошибку.
2.1 Используйте Google Search Console, чтобы найти ошибку
Чтобы проверить, есть ли эта ошибка в вашей Google Search Console, просто перейдите на вкладку Coverage и найдите ошибку в разделе Error , как показано ниже:
Затем нажмите на ошибку Представленный URL-адрес, заблокированный файлом robots.txt , как показано ниже:
Если вы нажмете на ошибку, вы увидите список страниц, заблокированных вашим файлом robots.txt:
2.2 Использование аналитики Rank Math для выявления проблемных страниц
Вы также можете использовать отчет о состоянии индекса в Rank Math Analytics, чтобы определить страницы с проблемой.
Для этого перейдите к Rank Math > Analytics на панели управления WordPress. Затем перейдите на вкладку Index Status . На этой вкладке вы получите реальные данные/статус ваших страниц, а также их присутствие в Google.
Кроме того, вы можете отфильтровать статус индекса сообщения, используя раскрывающееся меню. Когда вы выбираете определенный статус, например «Отправленный URL-адрес заблокирован robot.txt», вы сможете увидеть все сообщения, которые имеют один и тот же статус индекса.
Получив список страниц, которые возвращают этот статус, вы можете приступить к устранению неполадок и устранению проблемы.
3 Как исправить ошибку «Отправленный URL-адрес, заблокированный robots.txt»?
Чтобы исправить это, вам нужно убедиться, что файл robots.txt вашего веб-сайта настроен правильно. Вы можете использовать инструмент тестирования robots.txt от Google, чтобы проверить свой файл и убедиться, что нет никаких директив, которые блокируют доступ робота Googlebot к вашему сайту.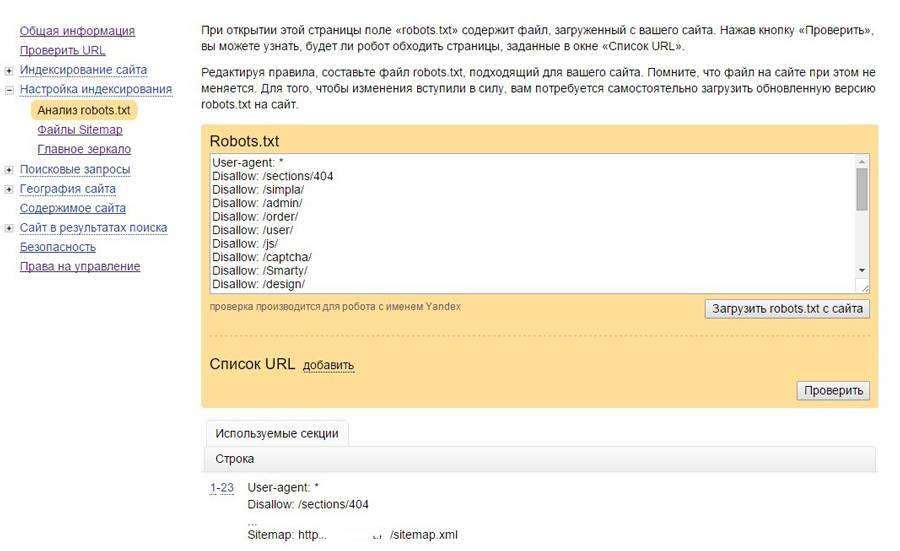
Если вы обнаружите, что в вашем файле robots.txt есть директивы, которые блокируют доступ робота Googlebot к вашему сайту, вам нужно будет удалить их или заменить более либеральными.
Давайте посмотрим, как вы можете протестировать файл robots.txt и убедиться, что никакие директивы не блокируют доступ робота Googlebot к вашему сайту.
3.1 Откройте тестер robots.txt
Сначала перейдите к тестеру robots.txt. Если ваша учетная запись Google Search Console связана с несколькими веб-сайтами, выберите свой веб-сайт из списка сайтов, показанного в правом верхнем углу. Теперь Google загрузит файл robots.txt вашего сайта.
Вот как это будет выглядеть.
3.2 Введите URL-адрес вашего сайта
В нижней части инструмента вы найдете возможность ввести URL-адрес вашего веб-сайта для тестирования.
3.3 Выберите агент пользователя
В раскрывающемся списке справа от текстового поля выберите агент пользователя, который вы хотите имитировать (в нашем случае Googlebot).
3.4 Проверить Robots.txt
Наконец, нажмите кнопку Проверить .
Сканер немедленно проверит, есть ли у него доступ к URL-адресу на основе конфигурации robots.txt, и, соответственно, тестовая кнопка окажется ПРИНЯТ или ЗАБЛОКИРОВАН .
Редактор кода, доступный в центре экрана, также выделит правило в файле robots.txt, которое блокирует доступ, как показано ниже.
3.5 Редактирование и отладка
Если тестер robots.txt обнаружит какое-либо правило, запрещающее доступ, вы можете попробовать отредактировать правило прямо в редакторе кода, а затем снова запустить тест.
Вы также можете обратиться к нашей специальной статье базы знаний о robots.txt, чтобы узнать больше о принятых правилах, и было бы полезно отредактировать правила здесь.
Если вам удастся исправить правило, то это здорово. Но обратите внимание, что это инструмент отладки, и любые внесенные вами изменения не будут отражены в robots. txt вашего веб-сайта, если вы не скопируете и не вставите содержимое в robots.txt своего веб-сайта.
txt вашего веб-сайта, если вы не скопируете и не вставите содержимое в robots.txt своего веб-сайта.
3.6 Редактирование файла robots.txt с помощью Rank Math
Для этого перейдите к файлу robots.txt в Rank Math, который находится в разделе Панель управления WordPress > Rank Math > Общие настройки > Редактировать robots.txt , как показано ниже:
Примечание: Если эта опция недоступна для вас, убедитесь, что вы используете расширенный режим в Rank Math.
В редакторе кода, расположенном посередине экрана, вставьте код, скопированный из robots.txt. Tester, а затем нажмите кнопку Сохранить изменения , чтобы отразить изменения.
Предупреждение: Будьте осторожны, внося существенные или незначительные изменения на свой веб-сайт с помощью файла robots.txt. Хотя эти изменения могут улучшить ваш поисковый трафик, они также могут принести больше вреда, чем пользы, если вы не будете осторожны.
Чтобы узнать больше, смотрите скриншоты ниже:
Вот и все! После внесения этих изменений Google сможет получить доступ к вашему веб-сайту, и ошибка «Отправленный URL-адрес заблокирован robots.txt» будет исправлена.
4 Как предотвратить повторное появление ошибки
Чтобы предотвратить повторение ошибки «Отправленный URL-адрес, заблокированный robots.txt» в будущем, мы рекомендуем регулярно просматривать файл robots.txt вашего веб-сайта. Это поможет убедиться, что все директивы точны и что ни одна страница не будет случайно заблокирована для сканирования роботом Googlebot.
Мы также рекомендуем использовать такие инструменты, как Инструменты Google для веб-мастеров, которые помогут вам управлять файлом robots.txt вашего веб-сайта. Инструменты для веб-мастеров позволят вам легко редактировать и обновлять файл robots.txt, а также отправлять страницы для индексации, просматривать ошибки сканирования и многое другое.
5 Заключение
В конце концов, мы надеемся, что эта статья помогла вам узнать, как исправить ошибку «Отправленный URL-адрес, заблокированный robots.