
Битрикс robots.txt
Все современные поисковые системы используют файл robots.txt. Этот файл позволяет задавать поведение определенным поисковым ботам, указываемым в строке User-agent. В случае отсутствия такого файла поисковые системы посчитают, что доступ к вашему сайту неограничен, и будут индексировать все его страницы. Это может негативно отразиться на видимости вашего сайта в интернете. К примеру, стандартная страница отфильтрованного каталога в CMS Битрикс выглядит так:
www.site.com/catalog/?arrFilter_ff%5BNAME%5D=&arrFilter_pf%5BLAST%5D=&arrFilter_pf%5BTO_DATA%5D=&arrFilter_cf%5B8%5D%5BLEFT%5D=100&arrFilter_cf%5B8%5D%5BRIGHT%5D=500&set_filter=Y
очень часто множество таких страниц попадают в индекс поисковой системы, тем самым, уменьшая значимость других, оптимизированных страниц. Также в индекс могут попасть файлы, которые там совсем не нужны, и которые могут повлиять на безопасность вашего сайта.
Для того, чтобы этого избежать, существует файл
 txt
txt
Рассмотрим пример файла robots.txt для битрикс:
User-agent: * Disallow: /test/ Disallow: /dostavka/ Disallow: /information Disallow: /conf.php Disallow: /usl.php Disallow: /price/ Disallow: /contacts Disallow: /personal/ Disallow: /ext/ Disallow: /auth/ Disallow: /login/ Disallow: /include/ Disallow: /scripts/ Disallow: /sitemap/ Disallow: /*CODE Disallow: /index.php?id=* Disallow: *?clear_cache=Y Disallow: /*&sort= Disallow: *?r1=* Disallow: *?r2=* Disallow: /*action Disallow: /*showpath Disallow: /*shownotavail Disallow: /*arrFilter Disallow: /*PAGEN_ Disallow: /*SECTION_CODE Disallow: /*SHOWALL_ Disallow: /account.php/* Disallow: /checkout.php Disallow: /search/ Disallow: /news/rss/ Disallow: /specification/ Disallow: /brands/?letter=* Disallow: /index.php/manufacturers* Disallow: /index.php/* Disallow: *filter* Disallow: *letter* Host: https://www.site.ru Sitemap: https://www.site.ru/sitemap.xml
 php/manufacturers*
Disallow: /index.php/*
Disallow: *filter*
Disallow: *letter*
Host: https://www.site.ru
Sitemap: https://www.site.ru/sitemap.xml
php/manufacturers*
Disallow: /index.php/*
Disallow: *filter*
Disallow: *letter*
Host: https://www.site.ru
Sitemap: https://www.site.ru/sitemap.xml
Это типичный robots.txt битрикс, например директива:
Disallow: /*PAGEN_
закрывает от индексации повторяющиеся страницы пагинации (1,2,3 и т д) каталога, оставляя только главную.
Также закрыты все страницы фильтра: *filter*
Таким образом, можно в разы снизить количество индексируемых страниц, отдаваемых в поисковик. Следует сказать, что файл robots.txt не обязателен к исполнению поисковиками, т.е. нет 100% гарантии, что закрытые таким образом страницы не попадут в сеть.
Возможно, следовало бы добавить директиву Disallow: /bitrix/*, чтобы закрыть от индексации системные файлы, но таким образом мы покажем потенциальному взломщику то, что наша CMS – битрикс.
Robots.txt для 1С Битрикс | Bitrix Boost
Официальный сертифицированный
хостинг для продуктов 1С Битрикс
Тематика страницы
СайтСправка
robots. txt битрикс
txt битрикс
26.11.2018
В данной статье собраны примеры robots.txt, которые помогут составить корректный файл для различных популярных CMS и фрэймворков: 1C-Битрикс, Joomla, Drupal, WordPress, OpenCart, NetCat, UMI CMS, HostCMS, MODX.
Файл robots.txt – это текстовый файл с технической информаций, размещаемый в корне вашего сайта, он сообщает поисковым системам порядок индексации сайта. Наборы директив (строк) сообщают поисковому роботу, какие разделы сайта запретить или разрешить к индексации. Для ряда поисковых систем, в файле robots.txt могут быть прописаны дополнительные параметры, обрабатываемые только определенной поисковой системой.
Нужно понимать, что приведенные ниже директивы являются лишь примерами и файлы не гарантируют 100% правильную работу, так как в них могут быть не предусмотрены специальные разделы, типы файлов, которые должны быть закрыты или открыты на вашем сайте. В некоторых случаях может потребоваться тонкая коррекция настроек под ваш проект, поэтому рекомендуем дополнительно консультироваться по настройке robots. txt с программистом и\или администратором вашего проекта, который знаком с его спецификой и «узкими местами».
txt с программистом и\или администратором вашего проекта, который знаком с его спецификой и «узкими местами».
Обратите внимание: значение site.ru нужно заменить на ваш домен.
Как загрузить файл robots.txt на сайта через ISPmanager?
- Авторируйтесь в панели хостинга и в ISPmanager перейдите в Менеджер файлов — www — каталог Вашего сайта и на панели нажмите «Закачать».
- Перед Вами откроется окно загрузки файла, в котором нужно выбрать robots.txt с локального компьютера и загрузить на сервер.
Проверка robots.txt
Проверить успешную загрузку файла на сайта можно открыв его браузере по адресу http://site.ru/ robots.txt , где site.ru — имя Вашего сайта.
После загрузки robots.txt на сайт проверяем корректность работы файла по инструкциям:
Для Яндекс – через Яндекс.Вебмастер, без регистрации.
Для Google – через Google Вебмастер, с регистрацией.
Для robots.txt рекомендуется устанавливать права 444.
robots.txt для 1С-Битрикс
User-agent: *
Allow: /map/
Allow: /search/map.php
Allow: /bitrix/templates/
Disallow: */index.php
Disallow: /*action=
Disallow: /*print=
Disallow: /*/gallery/*order=
Disallow: /*/search/
Disallow: /*/slide_show/
Disallow: /*?utm_source=
Disallow: /*ADD_TO_COMPARE_LIST
Disallow: /*arrFilter=
Disallow: /*auth=
Disallow: /*back_url_admin=
Disallow: /*BACK_URL=
Disallow: /*back_url=
Disallow: /*backurl=
Disallow: /*bitrix_*=
Disallow: /*bitrix_include_areas=
Disallow: /*building_directory=
Disallow: /*bxajaxid=
Disallow: /*change_password=
Disallow: /*clear_cache_session=
Disallow: /*clear_cache=
Disallow: /*count=
Disallow: /*COURSE_ID=
Disallow: /*forgot_password=
Disallow: /*ID=
Disallow: /*index.php$
Disallow: /*login=
Disallow: /*logout=
Disallow: /*modern-repair/$
Disallow: /*MUL_MODE=
Disallow: /*ORDER_BY
Disallow: /*PAGE_NAME=
Disallow: /*PAGE_NAME=detail_slide_show
Disallow: /*PAGE_NAME=search
Disallow: /*PAGE_NAME=user_post
Disallow: /*PAGEN_
Disallow: /*print_course=
Disallow: /*print=
Disallow: /*q=
Disallow: /*register=
Disallow: /*register=yes
Disallow: /*set_filter=
Disallow: /*show_all=
Disallow: /*show_include_exec_time=
Disallow: /*show_page_exec_time=
Disallow: /*show_sql_stat=
Disallow: /*SHOWALL_
Disallow: /*sort=
Disallow: /*sphrase_id=
Disallow: /*tags=
Disallow: /access. log
log
Disallow: /admin
Disallow: /api
Disallow: /auth
Disallow: /auth.php
Disallow: /auto
Disallow: /bitrix
Disallow: /bitrix/
Disallow: /cgi-bin
Disallow: /club/$
Disallow: /club/forum/search/
Disallow: /club/gallery/tags/
Disallow: /club/group/search/
Disallow: /club/log/
Disallow: /club/messages/
Disallow: /club/search/
Disallow: /communication/blog/search.php
Disallow: /communication/forum/search/
Disallow: /communication/forum/user/
Disallow: /content/board/my/
Disallow: /content/links/my/
Disallow: /error
Disallow: /e-store/affiliates/
Disallow: /e-store/paid/detail.php
Disallow: /examples/download/download_private/
Disallow: /examples/my-components/
Disallow: /include
Disallow: /personal
Disallow: /search
Disallow: /temp
Disallow: /tmp
Disallow: /upload
Disallow: /*/*ELEMENT_CODE=
Disallow: /*/*SECTION_CODE=
Disallow: /*/*IBLOCK_CODE
Disallow: /*/*ELEMENT_ID=
Disallow: /*/*SECTION_ID=
Disallow: /*/*IBLOCK_ID=
Disallow: /*/*CODE=
Disallow: /*/*ID=
Disallow: /*/*IBLOCK_EXTERNAL_ID=
Disallow: /*/*SECTION_CODE_PATH=
Disallow: /*/*EXTERNAL_ID=
Disallow: /*/*IBLOCK_TYPE_ID=
Disallow: /*/*SITE_DIR=
Disallow: /*/*SERVER_NAME=
Sitemap: http://site.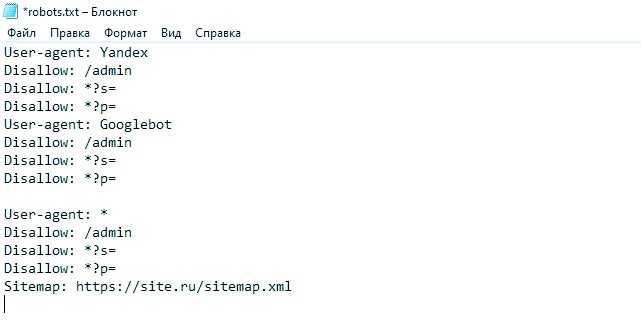 ru/sitemap_index.xml
ru/sitemap_index.xml
Sitemap: http://site.ru/sitemap.xml
Host: site.ru
Концепция и все материалы с сайта btrxboost.com включающие в себя текстовую, графическую, видео, аудио и маркетинговую информацию, защищены российским и международным законодательством. В соответствии с соглашением об охране авторских прав и интеллектуальной собственности (ст. №1259, №1260, гл. 70 “Авторское право” ГК РФ от 18.12.2006 № 230-ФЗ) и согласно сертификату собственности авторских прав на информационные материалы RID 07N-4M-48 от 12.08.2012, а также сертификата DMCA id: f25cb914-aba8-4988-a116-13afb399bba2 от 21.06.2019.
В случае нарушений данных правил, применяются следующие меры: подача официального заявления в судебные органы в т.ч. с эскалацией запроса хостинг-провайдеру на котором расположен сайт-нарушитель, а также подача запроса на исключение сайта-нарушителя из поисковых систем согласно “Online Copyright Infringement Liability Limitation Act” по ч. II, раздел 512 к закону об авторском праве по DMCA.
| User-agent: Яндекс | |
| Разрешить: /search/map.php | |
| Запретить: /*&bxajaxid= | |
| Запретить: /*&print= | |
| Запретить: /*/галерея/*заказ=* | |
| Запретить: /*/поиск/ | |
| Запретить: /*/slide_show/ | |
| Запретить: /*?bxajaxid= | |
| Запретить: /*?print= | |
| Запретить: /*?utm_source= | |
| Запретить: /*действие= | |
| Запретить: /*аутентификация= | |
| Запретить: /*back_url= | |
| Запретить: /*BACK_URL= | |
| Запретить: /*back_url_admin= | |
| Запретить: /*backurl= | |
| Запретить: /*BACKURL= | |
| Запретить: /*bitrix_*= | |
| Запретить: /*change_password= | |
| Запретить: /*clear_cache*= | |
| Запретить: /*forgot_password= | |
| Запретить: /*логин= | |
| Запретить: /*выход= | |
| Запретить: /*ORDER_BY | |
| Запретить: /*PAGE_NAME= | |
| Запретить: /*PAGEN_* | |
| Запретить: /*print | |
| Запретить: /*регистр= | |
| Запретить: /*show_all= | |
| Запретить: /*show_include_exec_time= | |
| Запретить: /*show_page_exec_time= | |
| Запретить: /*show_sql_stat= | |
| Запретить: /*ПОКАЗАТЬ | |
| Запретить: /auth/ | |
| Запретить: /bitrix/ | |
| Запретить: /личный/ | |
Хост: domain. ru ru | |
| # Хост: https://domain.ru | |
| Агент пользователя: * | |
| Разрешить: /search/map.php | |
| Запретить: /*&bxajaxid= | |
| Запретить: /*&print= | |
| Запретить: /*/галерея/*заказ=* | |
| Запретить: /*/поиск/ | |
| Запретить: /*/slide_show/ | |
| Запретить: /*?bxajaxid= | |
| Запретить: /*?print= | |
| Запретить: /*?utm_source= | |
| Запретить: /*действие= | |
| Запретить: /*аутентификация= | |
| Запретить: /*back_url= | |
| Запретить: /*BACK_URL= | |
| Запретить: /*back_url_admin= | |
| Запретить: /*backurl= | |
| Запретить: /*BACKURL= | |
| Запретить: /*bitrix_*= | |
| Запретить: /*change_password= | |
| Запретить: /*clear_cache*= | |
| Запретить: /*forgot_password= | |
| Запретить: /*логин= | |
| Запретить: /*выход= | |
| Запретить: /*ORDER_BY | |
| Запретить: /*PAGE_NAME= | |
| Запретить: /*PAGEN_* | |
| Запретить: /*print | |
| Запретить: /*регистр= | |
| Запретить: /*show_all= | |
| Запретить: /*show_include_exec_time= | |
| Запретить: /*show_page_exec_time= | |
| Запретить: /*show_sql_stat= | |
| Запретить: /*ПОКАЗАТЬ | |
| Запретить: /auth/ | |
| Запретить: /bitrix/ | |
| Запретить: /личный/ |
Руководство по Robots.
 txt — как создать идеальный файл robots.txt для SEO
txt — как создать идеальный файл robots.txt для SEOЧто такое robots.txt?
Robots.txt — это текстовый файл, содержащий рекомендации по сканированию для ботов. Это часть протокола исключения роботов (REP), группы веб-стандартов, которые регулируют то, как боты просматривают, получают доступ, индексируют и представляют контент пользователям. Файл содержит инструкции (директивы), с помощью которых вы можете ограничить доступ ботов к определенным разделам, страницам и файлам или указать адрес Sitemap.
Большинство основных поисковых систем, таких как Google, Bing и Yahoo, начинают сканирование веб-сайтов, проверяя файл robots.txt и следуя предписанным рекомендациям.
Почему файл robots.txt важен?
Большинству веб-сайтов, ориентированных в основном на Google, может не понадобиться файл robots.txt. Это связано с тем, что Google рассматривает их исключительно как рекомендации, а Googlebot обычно находит и индексирует все важные страницы независимо от них.
Robots.txt содержит рекомендации для поисковых ботов по навигации по сайту
Следовательно, если этот файл не будет создан, это не будет критической ошибкой. В этом случае поисковые роботы будут считать, что ограничений нет, и они могут свободно сканировать.
Несмотря на это, есть 3 основные причины, по которым вы действительно должны использовать robots.txt:
- Он оптимизирует краулинговый бюджет . Если у вас большой сайт, важно, чтобы поисковые роботы просканировали все важные страницы. Однако иногда сканеры находят и индексируют вспомогательные страницы, например страницы фильтров, игнорируя при этом основные. Вы можете исправить эту ситуацию, заблокировав несущественные страницы через robots.txt.
- Скрывает непубличные страницы . Не все на вашем сайте нужно индексировать. Хорошим примером являются страницы авторизации или тестирования. Хотя объективно они должны существовать, вы можете заблокировать их с помощью файла robots. txt, чтобы они не попадали в индекс поисковых систем и были недоступны для случайных людей.
- Предотвращает индексирование изображений и PDF-файлов . Есть несколько способов предотвратить индексацию страниц без использования robots.txt. Однако ни один из них не работает хорошо, когда дело доходит до медиафайлов. Поэтому, если вы не хотите, чтобы поисковые системы индексировали изображения или PDF-файлы на вашем сайте, проще всего заблокировать их с помощью файла robots.txt.
 txt, чтобы они не попадали в индекс поисковых систем и были недоступны для случайных людей.
txt, чтобы они не попадали в индекс поисковых систем и были недоступны для случайных людей.Требования к файлу
Для корректной обработки файла поисковыми ботами необходимо соблюдать следующие правила:
- Он должен находиться в корневом каталоге сайта.
- Он должен называться robots.txt и быть доступен по адресу https://yoursite.com/robots.txt.
- Допускается только один такой файл на сайт.
- Кодировка UTF-8.
Синтаксис robots.txt
Директивы
Файл robots. txt включает две основные директивы — User-agent и Disallow , но есть и дополнительные, такие как Allow и Sitemap . Давайте подробнее рассмотрим, какую информацию они передают и как правильно ее добавить.
txt включает две основные директивы — User-agent и Disallow , но есть и дополнительные, такие как Allow и Sitemap . Давайте подробнее рассмотрим, какую информацию они передают и как правильно ее добавить.
С помощью правильных директив вы можете заблокировать отдельные страницы или весь сайт
User-agent
Это обязательная директива. Он определяет, к каким поисковым ботам применяются правила.
Существует множество роботов, способных сканировать веб-сайты, наиболее распространенными из которых являются боты поисковых систем.
Некоторые из ботов Google включают:
- Googlebot;
- Googlebot-изображение;
- Googlebot-Новости.
Полный список User-Agent , используемый поисковыми системами, можно найти в их документации. Для Google это выглядит так.
Имейте в виду, что некоторые сканеры могут иметь более одного токена пользовательского агента. Для корректного применения правила важно, чтобы маркер соответствовал только одному сканеру.
Чтобы обратиться к конкретному боту, например Googlebot Image, вам необходимо ввести его имя в поле Агент пользователя строка:
Агент пользователя: Googlebot-Image
Если вы хотите применить правила ко всем ботам, используйте звездочку (*). Пример:
User-agent: *
Disallow
Указывает на страницу и каталог корневого домена, которые указанный User-agent не может сканировать. Используйте директиву Disallow , чтобы запретить доступ ко всему сайту, каталогу или определенной странице.
1. Если вы хотите ограничить доступ ко всему сайту, добавьте косую черту ( /). Например, чтобы запретить всем роботам доступ ко всему сайту, в файле robots.txt необходимо указать следующее:
User-agent: * Disallow: /
Вам может понадобиться использовать такую комбинацию, если ваш сайт находится на ранних стадиях разработки, когда вы хотите, чтобы он отображался в результатах поиска полностью завершенным.
2. Чтобы ограничить доступ к содержимому каталога, используйте его имя, за которым следует косая черта. Например, чтобы запретить всем ботам доступ к каталог блога, в файле нужно написать следующее:
User-agent: * Disallow: /blog/
3. Если вам нужно закрыть конкретную страницу, вы должны указать ее URL без хоста. Например, чтобы закрыть страницу https://yoursite.com/blog/website.html , вы должны написать в файле следующее:
User-agent: * Запретить: /blog/website.html
Разрешить
Указывает страницу и каталог корневого домена, которые могут быть просканированы указанным User-agent и считается необязательной директивой. Если ограничение не указано, то по умолчанию боты могут беспрепятственно сканировать сайт. Таким образом, следующее является совершенно необязательным:
User-agent: * Разрешить: /
Однако вам нужно будет использовать эту директиву, чтобы переопределить ограничение директивы Disallow. По сути, его можно использовать для сканирования части ограниченного раздела или сайта. Например, если вы хотите ограничить доступ ко всем страницам в /blog/ каталог кроме https://yoursite.com/blog/website.html , вам нужно будет указать следующее:
По сути, его можно использовать для сканирования части ограниченного раздела или сайта. Например, если вы хотите ограничить доступ ко всем страницам в /blog/ каталог кроме https://yoursite.com/blog/website.html , вам нужно будет указать следующее:
User-agent: * Запретить: /блог/ Разрешить: /blog/website.html
Карта сайта
Эта необязательная директива служит для указания местоположения файла Sitemap.xml сайта. Если на вашем сайте несколько файлов Sitemap, вы можете указать их все.
Обязательно укажите полный URL-адрес файла Sitemap.xml. Директиву можно разместить в любом месте файла, но чаще всего это делается в самом конце. Файл robots.txt со ссылками на несколько Sitemap.xml будет выглядеть так:
Агент пользователя: * Карта сайта: https://yoursite.com.com/sitemap1.xml Карта сайта: https://yoursite.com.com/sitemap2.xml
Специальные символы $, *, /, #
1. Символ звездочки (*) обозначает любую последовательность символов. В приведенном ниже примере использование звездочки запрещает доступ ко всем URL-адресам, содержащим слово веб-сайт :
В приведенном ниже примере использование звездочки запрещает доступ ко всем URL-адресам, содержащим слово веб-сайт :
User-agent: * Disallow: /*website
Этот специальный символ добавляется в конце каждой строки по умолчанию. Таким образом, два приведенных ниже примера означают, по сути, одно и то же:
Агент пользователя: * Disallow: /website*
Пользовательский агент: * Disallow: /website
2. Чтобы переопределить звездочку (*), вы должны включить знак доллара ($) в конце правила.
Например, чтобы запретить доступ к /website , но разрешить его /website.html , вы можете написать:
User-agent: * Disallow: /website$
3. Косая черта — это основной символ, обычно встречающийся в каждой директиве Allow и Disallow. С его помощью вы можете запретить доступ к /blog/ и ее содержимое или все страницы, начинающиеся с /blog .
Пример директивы, запрещающей доступ ко всей /блог/ категории:
User-agent: * Disallow: /blog/
Пример директивы, запрещающей доступ ко всем страницам, начинающимся с /blog :
User-agent: * Запретить: /blog
4. Знак номера (#) используется для добавления комментариев внутри файла для себя, пользователей или других веб-мастеров. Поисковые роботы проигнорируют эту информацию.
Знак номера (#) используется для добавления комментариев внутри файла для себя, пользователей или других веб-мастеров. Поисковые роботы проигнорируют эту информацию.
Агент пользователя: * Запретить: /блог #это не так сложно, как может показаться :)
Пошаговое руководство по созданию robots.txt
1. Создайте файл robots.txt
Для этого можно использовать любой текстовый редактор, например как блокнот. Если ваш текстовый редактор предложит вам выбрать кодировку при сохранении файла, обязательно выберите UTF-8.
2. Добавить правила для роботов
Правила — это инструкции для поисковых ботов, указывающие, какие разделы сайта можно сканировать. В своих рекомендациях Google рекомендует учитывать следующее:
- Файл robots.txt содержит одну или несколько групп.
- Каждая группа начинается со строки User-agent . Это определяет, к какому роботу относятся правила.
- Каждая группа может включать несколько директив, но по одной на строку.
- Поисковые роботы обрабатывают группы сверху вниз. Пользовательский агент может следовать только одному наиболее подходящему для него набору правил, который будет обрабатываться в первую очередь.
- По умолчанию агенту пользователя разрешено сканировать любые страницы и каталоги, которые не заблокированы правилом запрета.
- Правила чувствительны к регистру.
- Строки, не соответствующие ни одной из директив, будут игнорироваться.
 Это определяет, к какому роботу относятся правила.
Это определяет, к какому роботу относятся правила.3. Загрузите файл robots.txt в корневой каталог
После создания сохраните файл robots.txt на компьютере, затем загрузите его в корневой каталог вашего сайта и сделайте его доступным для поисковых систем.
4. Проверить наличие и правильность файла robots.txt
Чтобы проверить, доступен ли файл, вам необходимо открыть браузер в режиме инкогнито и посетить https://yoursite. com/robots.txt . Если вы видите содержимое и оно соответствует тому, что вы указали, вы можете приступить к проверке корректности директив.
com/robots.txt . Если вы видите содержимое и оно соответствует тому, что вы указали, вы можете приступить к проверке корректности директив.
Вы можете протестировать файл robots.txt с помощью специального инструмента в Google Search Console. Имейте в виду, что его можно использовать только для файлов robots.txt, которые уже доступны на вашем сайте.
Проверив Google Search Console, вы можете убедиться, что все директивы добавлены правильно
Шаблоны robots.txt для различных CMS
Если на вашем сайте установлена CMS, обратите внимание на страницы, которые она генерирует, особенно на те, которые не должны индексироваться поисковыми системами. Чтобы этого не произошло, нужно закрыть их в robots.txt. Поскольку это распространенная проблема, существуют шаблоны файлов для сайтов, использующих различные популярные CMS. Вот некоторые из них.
Robots.txt для WordPress
User-Agent: * Запретить: /wp-login.
 php
Запретить: /wp-register.php
Запретить: /xmlrpc.php
Запретить: /template.html
Запретить: /wp-admin
Запретить: /wp-includes
Запретить: /wp-контент
Разрешить: /wp-content/uploads/
Запретить: /тег
Запретить: /категория
Запретить: /архив
Запретить: */трекбэк/
Запретить: */канал/
Запретить: */комментарии/
Запретить: /?feed=
Запретить: /?s=
Разрешить: /wp-content/*.css*
Разрешить: /wp-content/*.jpg
Разрешить: /wp-content/*.gif
Разрешить: /wp-content/*.png
Разрешить: /wp-content/*.js*
Разрешить: /wp-includes/js/
Карта сайта: http://yoursite.com/sitemap.xml
php
Запретить: /wp-register.php
Запретить: /xmlrpc.php
Запретить: /template.html
Запретить: /wp-admin
Запретить: /wp-includes
Запретить: /wp-контент
Разрешить: /wp-content/uploads/
Запретить: /тег
Запретить: /категория
Запретить: /архив
Запретить: */трекбэк/
Запретить: */канал/
Запретить: */комментарии/
Запретить: /?feed=
Запретить: /?s=
Разрешить: /wp-content/*.css*
Разрешить: /wp-content/*.jpg
Разрешить: /wp-content/*.gif
Разрешить: /wp-content/*.png
Разрешить: /wp-content/*.js*
Разрешить: /wp-includes/js/
Карта сайта: http://yoursite.com/sitemap.xml Robots.txt для Joomla
User-agent: * Запретить: /администратор/ Запретить: /кеш/ Запретить: /компоненты/ Запретить: /изображения/ Запретить: /включает/ Запретить: /установка/ Запретить: /язык/ Запретить: /библиотеки/ Запретить: /медиа/ Запретить: /модули/ Запретить: /плагины/ Запретить: /шаблоны/ Запретить: /tmp/ Запретить: /xmlrpc/ Разрешить: /templates/*.css Разрешить: /templates/*.
 js
Разрешить: /media/*.png
Разрешить: /media/*.js
Разрешить: /modules/*.css
Разрешить: /modules/*.js
Карта сайта: http://yoursite.com/sitemap.xml
js
Разрешить: /media/*.png
Разрешить: /media/*.js
Разрешить: /modules/*.css
Разрешить: /modules/*.js
Карта сайта: http://yoursite.com/sitemap.xml Robots.txt для Битрикс
User-agent: * Запретить: /*index.php$ Запретить: /bitrix/ Запретить: /авторизация/ Запретить: /личные/ Запретить: /загрузить/ Запретить: /поиск/ Запретить: /*/поиск/ Запретить: /*/slide_show/ Запретить: /*/галерея/*порядок=* Запретить: /*?* Запретить: /*&print= Запретить: /*регистр= Запретить: /*forgot_password= Запретить: /*change_password= Запретить: /*логин= Запретить: /*выйти= Запретить: /*аутентификация= Запретить: /*действие=* Запретить: /*bitrix_*= Запретить: /*backurl=* Запретить: /*BACKURL=* Запретить: /*back_url=* Запретить: /*BACK_URL=* Запретить: /*back_url_admin=* Запретить: /*print_course=Y Запретить: /*COURSE_ID= Разрешить: /bitrix/*.css Разрешить: /bitrix/*.js Карта сайта: http://yoursite.com/sitemap.xml
Некоторые практические вещи, о которых вы могли не знать
Проиндексировано, но заблокировано robots.
 txt
txtИногда вы можете увидеть это предупреждение в Google Search Console. Это происходит, когда Google воспринимает директивы, изложенные в robots.txt, как рекомендации, а не как правила, и фактически игнорирует их. И хотя представители Google не видят в этом критической проблемы, на самом деле это может привести к тому, что будет проиндексировано множество ненужных страниц.
Экран «Проиндексировано, но заблокировано robots.txt» в Google Search Console
Чтобы решить эту проблему, следуйте этим рекомендациям:
❓ Определите, нужно ли индексировать эти страницы. Посмотрите, какую информацию они содержат и нужны ли они для привлечения пользователей из поиска.
✅ Если вы не хотите, чтобы эти страницы блокировались, найдите директиву, отвечающую за это, в вашем файле robots.txt. Если ответ не очевиден без сторонних инструментов, вы можете сделать это с помощью тестового инструмента robots.txt.
Результаты после проверки того, какая директива блокирует URL-адрес
Обновите файл robots. txt, не включая эту директиву. Кроме того, вы можете указать URL-адрес, который вы хотите проиндексировать, с помощью Разрешить , если вам нужно скрыть другие менее полезные URL-адреса.
txt, не включая эту директиву. Кроме того, вы можете указать URL-адрес, который вы хотите проиндексировать, с помощью Разрешить , если вам нужно скрыть другие менее полезные URL-адреса.
❌Robots.txt — не самый надежный механизм, если вы хотите заблокировать эту страницу для поиска Google. Чтобы избежать индексации, удалите предыдущую строку, использовавшуюся для этого, в файле robots.txt и добавьте на страницу метамета «noindex» .
Важно! Для без индекса , файл robots.txt не должен блокировать доступ к странице для поисковых роботов. В противном случае боты не смогут обработать код страницы и не обнаружат метатег noindex . В результате содержимое этой страницы по-прежнему будет отображаться в результатах поиска, если, например, другие сайты предоставляют на него ссылки.
Если вам нужно закрыть сайт на время с кодом 503, не делайте этого для robots.txt
Когда сайт находится на капитальном обслуживании или есть другие важные причины, вы можете временно приостановить или отключить его, таким образом предотвращая доступ как для ботов, так и для пользователей.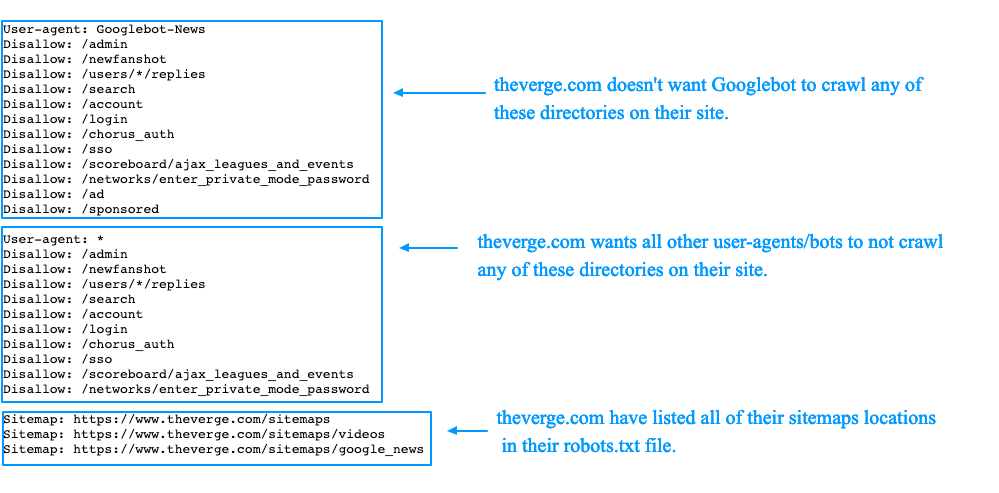 Для этого они используют 503 код ответа сервера.
Для этого они используют 503 код ответа сервера.
Однако Джон Мюллер, советник по поиску в Google, показал в теме Twitter, что вам нужно сделать и проверить, чтобы временно приостановить работу вашего сайта.
По словам Джона, файл robots.txt никогда не должен возвращать 503 , поскольку робот Google будет считать, что сайт полностью заблокирован через robots.txt. Для этого файл robots.txt должен возвращать 200 OK, имея в файле все необходимые директивы, или 404 .
Если файл robots.txt передается с ошибкой 503, роботы будут считать, что сайт полностью заблокирован robots.txt
Заключение
Robots.txt — полезный инструмент для формирования взаимодействия между роботами поисковых систем и вашим сайтом. При правильном использовании это может положительно повлиять на рейтинг сайта, позволяя вам эффективно управлять индексацией ваших документов.
Мы надеемся, что это руководство поможет вам понять, как работают файлы robots.