
Как проверить тег X-Robots на наличие директив Noindex (инструменты Google, расширения Chrome и сторонние сканеры)
Обновлено: апрель 2022 г. Тег x-robots для директив noindex. В список входят инструменты непосредственно от Google, расширения Chrome и сторонние инструменты сканирования.
——
Ранее я уже писал о силе (и опасности) метатега robots. Это одна строка кода, которая может препятствовать индексации страниц более низкого качества, а также говорит движкам не переходить по каким-либо ссылкам на странице (т. е. не передавать никаких сигналов ссылок на целевую страницу).
Это полезно, когда это необходимо, но мета-тег robots также может разрушить вашу SEO-оптимизацию при неправильном использовании. Например, если вы по ошибке добавите метатег robots на страницы, используя noindex. Если это произойдет, и если это будет широко распространено, ваши страницы могут начать выпадать из индекса Google. И когда это произойдет, вы можете потерять рейтинг этих страниц и последующий трафик. В худшем случае ваш органический поисковый трафик может резко упасть почти как у Панды. Другими словами, он может упасть с обрыва.
В худшем случае ваш органический поисковый трафик может резко упасть почти как у Панды. Другими словами, он может упасть с обрыва.
И прежде чем вы смеетесь над этим сценарием, я могу сказать вам, что за свою карьеру я несколько раз видел, как это случалось с компаниями. Это может быть человеческая ошибка, проблемы с CMS, возврат к старой версии сайта и т. д. Вот почему крайне важно проверять наличие метатега robots, чтобы убедиться, что используются правильные директивы.
Но вот беда. Это не единственный способ выпускать директивы noindex, nofollow. В дополнение к метатегу robots вы также можете использовать тег x-robots-tag в ответе заголовка. Используя этот подход, вам не нужно добавлять метатег к каждому URL-адресу, и вместо этого вы можете предоставлять директивы через ответ сервера.
Вот два примера тега x-robots в действии:
Опять же, эти директивы не содержатся в html-коде. Они находятся в заголовке ответа, который невооруженным глазом не виден. Вам нужно специально проверить ответ заголовка, чтобы увидеть, используется ли тег x-robots и какие директивы используются.
Вам нужно специально проверить ответ заголовка, чтобы увидеть, используется ли тег x-robots и какие директивы используются.
Как вы можете догадаться, это может легко ускользнуть, если вы специально не ищете это. Представьте, что вы проверяете сайт на метатег robots, думая, что все в порядке, когда вы его не видите, но тег x-robots используется с «noindex, nofollow» для каждого URL-адреса. Не хорошо, мягко говоря.
Как проверить тег X-Robots в заголовке Response
Основываясь на том, что я объяснил выше, я решил написать этот пост, чтобы объяснить несколько различных способов проверки тега x-robots. Добавив это в свой контрольный список, вы можете убедиться, что важные директивы верны и что вы не индексируете и не следите за правильными страницами на своем сайте (а также за теми, которые привлекают много трафика из Google и/или Bing). В приведенном ниже списке содержатся инструменты непосредственно от Google, расширения Chrome и сторонние инструменты сканирования для массовой проверки URL-адресов. Давайте прыгнем.
Давайте прыгнем.
1. Инструменты непосредственно от Google
Инструмент проверки URL-адресов Google
Нет ничего лучше, чем обратиться прямо к источнику. С помощью Инструмента проверки URL-адресов Google вы можете проверить определенные URL-адреса, чтобы узнать, индексируются ли они. И, как вы можете догадаться, инструмент укажет, доставляется ли noindex через x-robots-tag (через ответ заголовка).
API проверки URL-адресов
Вы также можете использовать API проверки URL-адресов Google для массового тестирования URL-адресов. После запуска URL-адресов через API вы можете увидеть, не индексируются ли они, с помощью тега x-robots-tag. Вы можете проверить мой учебник по созданию системы мониторинга индексации нескольких сайтов, чтобы узнать больше о том, как использовать API.
Тест для мобильных устройств
Тест Google для мобильных устройств также может показать вам, не индексируется ли страница с помощью тега x-robots. А поскольку инструмент может проверять любой общедоступный URL-адрес, вам не нужно проверять сайт в GSC.
А поскольку инструмент может проверять любой общедоступный URL-адрес, вам не нужно проверять сайт в GSC.
2. Расширения Chrome
Плагин веб-разработчика
Плагин веб-разработчика — один из моих любимых плагинов для проверки ряда важных элементов, он доступен как для Firefox, так и для Chrome. Просто щелкнув плагин в своем браузере, затем «Информация», а затем выбрав «Заголовки ответа», вы можете просмотреть значения заголовка http для имеющегося URL-адреса. И если используется тег x-robots, вы увидите перечисленные значения.
Расширение Detailed SEO для Chrome
Расширение Detailed SEO предоставляет множество SEO-информации на основе анализируемой вами страницы. И да, он включает тег x-robots. Один быстрый щелчок, и вы можете увидеть, не индексируется ли страница с помощью тега x-robots. Я настоятельно рекомендую этот плагин в целом и для проверки тега x-robots. Я думаю, вы это выкопаете.
Проверка исключения роботов
Это еще одно из моих любимых расширений Chrome. Средство проверки исключения роботов проверит статус файла robots.txt, метатега robots, x-robots-tag и тега канонического URL. Я часто использую этот плагин, и он очень хорошо работает для проверки тега x-robots.
Средство проверки исключения роботов проверит статус файла robots.txt, метатега robots, x-robots-tag и тега канонического URL. Я часто использую этот плагин, и он очень хорошо работает для проверки тега x-robots.
3. Инструменты сканирования
Теперь, когда я рассмотрел инструменты Google и некоторые расширения Chrome для проверки x-robots-tag, давайте проверим некоторые надежные сторонние инструменты сканирования. Например, если вы хотите массово сканировать множество URL-адресов (например, страниц размером 10 КБ, 100 КБ или более 1 млн) для проверки наличия тега x-robots, следующие инструменты могут быть чрезвычайно полезными.
DeepCrawl
Если вам нужен надежный механизм сканирования корпоративного уровня, то DeepCrawl для вас. Обратите внимание: я был настолько большим сторонником DeepCrawl, что много лет входил в консультативный совет клиентов. Так что да, я фанат. 🙂
После сканирования сайта вы можете легко проверить отчет «Неиндексированные страницы», чтобы просмотреть все страницы, которые не индексируются, с помощью метатега robots, ответа заголовка x-robots-tag или с помощью noindex в файле robots. txt. Вы можете экспортировать список, а затем отфильтровать в Excel, чтобы изолировать неиндексированные страницы с помощью тега x-robots.
txt. Вы можете экспортировать список, а затем отфильтровать в Excel, чтобы изолировать неиндексированные страницы с помощью тега x-robots.
Screaming Frog
Я тоже долгое время был большим поклонником Screaming Frog. Это важный инструмент в моем SEO-арсенале, и я часто использую Screaming Frog в сочетании с DeepCrawl. Например, я могу просканировать крупный сайт с помощью DeepCrawl, а затем изолировать определенные области для хирургического сканирования с помощью Screaming Frog.
После сканирования сайта с помощью Screaming Frog вы можете просто щелкнуть вкладку Directives и найти столбец x-robots. Если какие-либо страницы используют тег x-robots, вы увидите, какие директивы используются для каждого URL-адреса.
Sitebulb
Sitebulb — еще один отличный инструмент для сканирования, который также предоставляет информацию на основе тега x-robots. Вы можете найти эту информацию в разделе «Индексируемость», а затем в отчете об отсутствии индекса. Я часто использую Sitebulb при анализе веб-сайтов.
Я часто использую Sitebulb при анализе веб-сайтов.
JetOctopus
Я также начал использовать JetOctopus для сканирования веб-сайтов, это еще один отличный инструмент для сканирования корпоративного уровня. И, как вы можете догадаться, он также сообщает о теге x-robots. Не так много людей в отрасли знают о JetOctopus, но это надежный инструмент для сканирования, который я использую все больше и больше.
Резюме. Есть несколько способов запретить индексацию страницы…
Хорошо, теперь нет оправдания отсутствию тега x-robots во время SEO-аудита. 🙂 Если вы заметили, что какие-то страницы не индексируются, а метатег robots отсутствует в html-коде, то обязательно проверьте наличие x-robots-тега. Вы просто можете обнаружить, что важные страницы не индексируются через ответ заголовка. И опять же, это может быть скрытая проблема, которая вызывает серьезные проблемы с SEO.
В дальнейшем я рекомендую ознакомиться с различными инструментами, расширениями Chrome и поисковыми роботами, которые я перечислил в этом посте. Все это может помочь вам выявить важные директивы, которые могут повлиять на ваши усилия по SEO.
Все это может помочь вам выявить важные директивы, которые могут повлиять на ваши усилия по SEO.
GG
Когда следует использовать теги Meta Robots NoIndex?
Хотя боты Google постоянно сканируют Интернет, это не означает, что они должны сканировать и индексировать каждую страницу вашего сайта.
На самом деле, есть некоторые страницы, которые Google не должен индексировать, и единственный язык, который он понимает, — это метадирективы robots.
В этой статье я покажу вам, как (и когда) правильно использовать метатеги robots, включая тег no-index.
Что такое метатеги роботов?
В отличие от файла robots.txt, который указывает роботам, как сканировать ваш веб-сайт, метатеги robots определяют, как ваши страницы индексируются и отображаются в поисковой выдаче.
Это фрагменты HTML, вставленные в заголовок вашей страницы (
). На практике это фрагмент кода, который выглядит примерно так (если мы хотим запретить Google индексировать эту страницу): В зависимости от того, какую директиву вы хотите использовать, вы можете просто заменить значение «noindex» на свою директиву или добавить дополнительные директивы, разделив их запятыми.
В чем разница между файлом robots.txt и метатегами Robots?
| | Метатеги роботов | файл robots.txt |
Типы файлов | HTML | Любые файлы |
Объем | Уровень страницы | Уровень веб-сайта |
На какие поисковые действия они влияют? | Индексирование и сканирование | Сканирование и (как правило, но есть исключения) индексирование |
Короче говоря, если вы хотите не индексировать страницу или иметь более детальный контроль над тем, как Google воспринимает конкретную страницу на вашем веб-сайте, используйте метатег robots.
Если вы хотите предоставить более широкие директивы для группы страниц или всего вашего веб-сайта или запретить их сканирование ботами, используйте файл robots.txt.
Когда следует использовать метатег Robots No-Index
Используйте метатеги robots no-index, если:
- У вас есть страницы, которые вы не хотите индексировать. Например, страницы подтверждения, страницы политики конфиденциальности и т. д.
- Вы хотите защитить свой серверный, промежуточный или конфиденциальный контент.
- Держите контент закрытым. Например, если некоторый контент доступен только вашим подписчикам, специальным клиентам или является частью эксклюзивного предложения.
- Вы хотите предотвратить дублирование. Например, если у вас есть почти идентичные страницы продуктов, на которые вы отправляете рекламный трафик, и вы не хотите, чтобы Google индексировал их или помечал одну из них как дубликат.
Как использовать метатеги разных роботов
В дополнение к метатегу без индекса существует множество других тегов, которые вам могут понадобиться.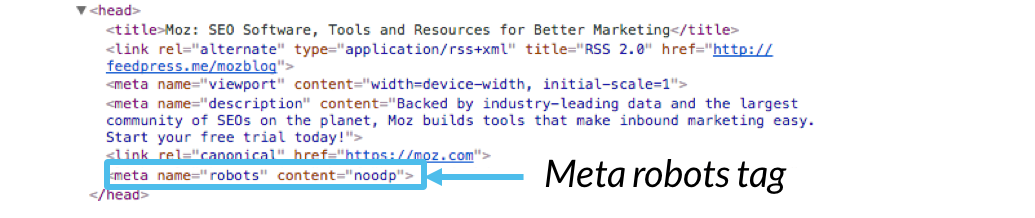 Вот некоторые из них, которые появляются чаще всего:
Вот некоторые из них, которые появляются чаще всего:
Как использовать тег Meta Robots «noindex,follow»
Если вы не хотите, чтобы поисковые системы индексировали вашу страницу, но все же хотите, чтобы они переходили по ссылкам на ней, вы должны использовать указанную выше директиву.
Это типичный вариант использования замененных страниц. Например, страницы продуктов, которых нет в наличии, которые были заменены новым вариантом, но на их исходных страницах все еще есть ценные внутренние ссылки.
Однако указывать это необязательно. Поисковые системы будут автоматически переходить по ссылкам на вашей странице (если вы не укажете им иное).
Meta Robots Теги «noindex,nofollow» и «none»
Используйте этот тег, если хотите, чтобы поисковые системы не индексировали и не переходили по ссылкам на вашей странице.
Используется так же, как следующий метатег:
Оба тега содержат одну и ту же директиву.
Варианты использования тега Meta Robots «noarchive»
Поисковые системы обычно архивируют и обслуживают кэшированные версии страниц. Используйте эту директиву, чтобы убедиться, что ваша страница не сохраняется в архивах поисковых ботов или кэшируется перед отображением.
Например, вы можете использовать это для часто изменяемых страниц.
Пропустить фрагмент с тегом «nosnippet» и атрибутом «data-nosnippet»
Если вы не хотите, чтобы поисковые системы отображали метаописание или фрагмент под заголовком вашей страницы, используйте директиву nosnippet.
(Это значение по умолчанию при наличии ошибок индексирования, таких как «Проиндексировано, хотя и заблокировано robots.txt.») атрибут data-nosnippet.
Например, если вы создали клиффхэнгер с заголовком своей страницы, вы можете не захотеть, чтобы Google выдавал ваш большой секрет до того, как пользователи нажмут на нее.
Мы отобразим этот но мы не хотим, чтобы этот контент отображался в поисковой выдаче.
Метатег «Noimageindex»
Используйте метатег robots noimageindex, если вы не хотите, чтобы Google индексировал изображения на вашей странице.
Метатег «Не переводить»
Поскольку Google предлагает переводить страницы из результатов поиска, вы можете использовать эту директиву, чтобы убедиться, что он не предоставляет переводы для вашей страницы.
А как насчет тега X-Robots?
Тег X-robots используется, когда вы хотите запретить поисковым системам индексировать ресурсы, отличные от HTML, такие как видео, изображения и файлы. Вы также можете использовать его, когда хотите добавить директивы массово, например, не индексировать всю папку.
Тег X-robots находится в заголовке HTTP-ответа вашего веб-сайта.
Тем не менее, поскольку использование тега X-robots требует изменения кода вашего веб-сайта, убедитесь, что вы знаете, как реализовать его на вашем конкретном типе сервера, или свяжитесь с разработчиком.
Небольшие ошибки могут повлиять на весь ваш веб-сайт, поэтому будьте осторожны.
Часто задаваемые вопросы
1. Что произойдет, если есть конфликтующие директивы?
Зависит от поисковой системы. Например, Google по умолчанию всегда будет использовать наиболее ограничительную директиву, а другие — нет.
2. Могу ли я использовать robots.txt и метатеги robots, чтобы не индексировать свою страницу?
Нет. Это может привести к ошибкам и путанице.
Например, если запретить страницу в файле robots.txt и добавить к ней тег noindex, поисковые роботы ее даже не обнаружат.
Точно так же не удаляйте страницы из вашей XML-карты сайта, пока поисковые системы не увидят директиву.
3. Могу ли я не индексировать канонические и переведенные страницы?
Если на ваших страницах есть канонические теги или теги hreflang, не пытайтесь их не индексировать.