Google прекращает поддержку директивы noindex в robots.txt — SEO на vc.ru
{«id»:13685,»url»:»\/distributions\/13685\/click?bit=1&hash=c2e7afd19e4e46007aede99e91f5ec6f21fe38548f3a375b79fa2e3037f252db»,»title»:»\u0421\u043e\u0442\u043a\u0430, \u0437\u0430\u0431\u044b\u0442\u0430\u044f \u0432 \u0437\u0438\u043c\u043d\u0435\u0439 \u043a\u0443\u0440\u0442\u043a\u0435, \u0441\u043d\u043e\u0432\u0430 \u0432 \u0438\u0433\u0440\u0435!»,»buttonText»:»\u0427\u0442\u043e?»,»imageUuid»:»8ba3dedd-0a4d-507f-95a7-c1d8ea29ecba»,»isPaidAndBannersEnabled»:false}
После 1.09.2019 года, поисковый гигант прекратит следовать директивам, которые не поддерживаются и не опубликованы в robots exclusion protocol. Изменения были анонсированы в блоге компании (https://webmasters.googleblog.com/2019/07/a-note-on-unsupported-rules-in-robotstxt.html). Это значит, что Google не будет учитывать файлы robots с записанной внутри директивой “noindex”.
1730 просмотров
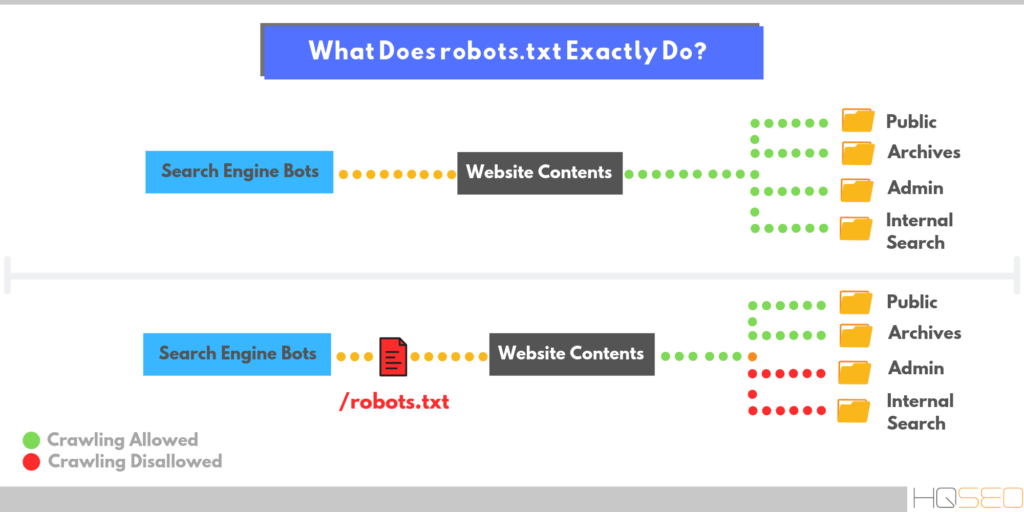
Что произошло? В течение многих лет файл robots позволял ограничивать доступ к некоторым (или всем) страницам сайта для разного рода роботов, парсеров, пауков или скраулеров.
- Директивы теперь используются для любого протокола: кроме HTTP/HTTPS, они распространяются на FTP и прочие;
- Поисковые пауки обязательно сканируют первые 512Кб файла robots.txt. Если файл большой, то дальше они могут его не сканировать..
- Все записи в файле кешируются сроком до 24 часов. Это сделано, чтобы не загружать сервер запросами, а также, чтобы SEO-специалист мог обновлять файл по мере необходимости и в удобные сроки. Срок кеширования можно задавать, используя директиву Cache-Control.
- Если файл по какой-то причине перестал сканироваться — правила продолжают работать. Согласно новой спецификации, в течение продолжительного времени используется последняя кэшированная копия.


Также, были пересмотрены правила для файла robots.txt. Теперь поисковой машиной Google не учитываются директивы, которые не указаны в стандарте. Первой записью, которая не попала в документ, стала директива noindex.
Каковы же альтернативы? Google такие варианты, которые, вероятно, уже использовались в любом случае:
1) noindex в метатегах. Данная директива, поддерживаемая в HTTP-ответах/HTML-коде — самый эффективный способ, чтобы удалить ссылки из индекса, если парсинг разрешен.
2) 404 и 410 коды ответов. Оба HTTP-ответа означают, что по данному URL отсутствует страница, и приведут к удалению страниц с такой ошибкой из поискового индекса если они будут или были просканированы.
3) Защита паролем. Если разметка не указывает на подписку или платный контент (https://developers.google.com/search/docs/data-types/paywalled-content), то сокрытая за формой авторизации страница со временем удалится из индекса Google.
4) Disallow в robots. txt. Поисковики индексируют известные им страницы. Поэтому, блокирование доступа к странице для краулеров означает, что контент никогда не будет проиндексирован. В то же время, поисковик также может индексировать URL-адрес, основываясь на переходах с других страниц (внутренних или внешних), не видя при этом непосредственно контент. Так что, при использовании директивы disallow рекомендую сделать страницы, закрытые ею, менее видимыми в целом.
txt. Поисковики индексируют известные им страницы. Поэтому, блокирование доступа к странице для краулеров означает, что контент никогда не будет проиндексирован. В то же время, поисковик также может индексировать URL-адрес, основываясь на переходах с других страниц (внутренних или внешних), не видя при этом непосредственно контент. Так что, при использовании директивы disallow рекомендую сделать страницы, закрытые ею, менее видимыми в целом.
5) Инструмент удаления URL в Google Search Console
(https://support.google.com/webmasters/answer/1663419). С его помощью можно легко и быстро (но временно) убрать страницы из результатов поиска.Новый стандарт. За день до этой новости, Google анонсировал, что компания также работает над разработкой стандарта, основанного на robots exclusion protocol, что является первым существенным изменением в данном направлении. Также, компания выложила исходный код парсера robots.txt в открытый доступ одновременно с новостью о разработке стандарта.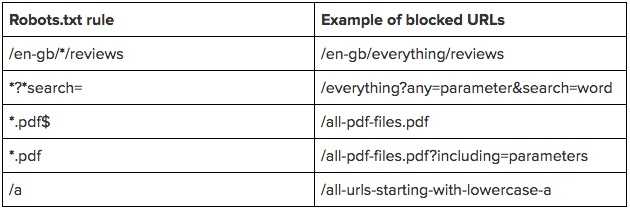
Почему Google вводит эти изменения сейчас? Поисковый гигант искал возможности для этих изменений в течение нескольких лет и со стандартизацией протокола он наконец-то может двигаться вперед. В Google сказали, что «провели анализ по использованию разных директив в файле robots» и теперь сфокусированы на удалении основных неподдерживаемых директив – crawl-delay, nofollow, noindex.
«Поскольку эти правила никогда официально не разъяснялись компанией, их использование может плохо влиять на сканирование Googlebot’а. Также, такие ошибки плохо влияют на присутствие сайтов в поисковой выдаче»
Стоит ли переживать? Самое главное на данный момент – избавиться от директивы noindex в файле robots.txt. Если же без нее никак, то стоит воспользоваться одной из перечисленных выше альтернатив до 1 сентября. Также, обратите внимание на использование nofollow или crawl-delay команд и если они есть, то переделайте также их с использованием поддерживаемых директив. Поисковый гигант дал достаточно времени для того, чтобы все ознакомились с вносимыми изменениями и поменяли свои файлы robots. txt, поэтому нет поводов для беспокойства.
txt, поэтому нет поводов для беспокойства.
Тем не менее, все равно интересно как коллеги решают данную проблему. Со статическими сайтами все понятно, там и в хедере можно написать все нужные метатеги. Но для SPA-сайтов было гораздо удобнее закрывать страницы по определенной маске (например https://ntile.app/some_id/*) или же скрывать целые разделы (например, https://ntile.app/taynaya-komnata-5d2ec134e12fd4000146d3ec-5d2ec134e12fd4000146d3ee, изначально созданный не для индексации, а для тестов по переспаму). С кодами ответов в заголовках много мороки получается. Да и скрывать всё за формой авторизации несколько усложняет разработку.
Подскажите, кто как решает такого рода проблемы?
Массовая проверка страниц на запрет noindex nofollow в robots.txt
Попробуйте бесплатно
Как проверить правила в robots.txt для каждой из страниц
Если у вас большое количество страниц с обратными ссылками которые вы хотели бы проверить на доступность для поисковых систем и наличие директив noindex и nofollow в файле robots. txt, то в ручном режиме это займет уйму времени. HyperChecker предлагает автоматизировать этот процесс и получить результаты проверки за несколько минут.
txt, то в ручном режиме это займет уйму времени. HyperChecker предлагает автоматизировать этот процесс и получить результаты проверки за несколько минут.
Для проверки правил файла robots.txt мы предлагаем два инструмента.
Первый инструмент — Массовая проверка страниц. Это простая одноразовая проверка страниц по ключевым СЕО параметрам:
- Директивы nofollow/noindex в Meta Tag и X-Robots-Tag;
- Количество исходящих ссылок;
- Статус индексации страниц в Google;
- Запрет на показ страницы через жалобы DMCA;
- Интегрированные данные из Ahrefs;
- Top-Level-Domain, IP адрес и страна размещения веб-сайта;
- Http статус код.
Второй инструмент — автоматический мониторинг обратных ссылок. Сюда входят те же проверки что и в первом случае, но еще добавлен поиск обратных ссылок на странице на ваш веб-сайт. В отчете вы увидите сколько и каких анкоров имеется у вашего проекта и доступны ли они для поисковых систем в атрибуте rel(nofollow/dofollow/sponsored и т.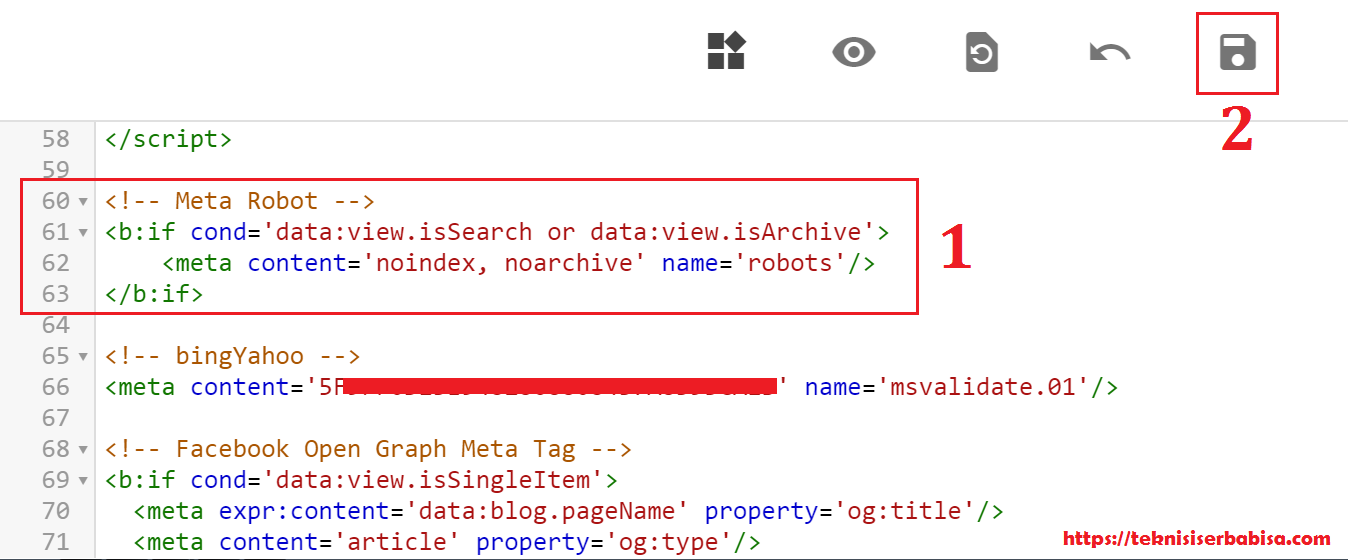
В настройках проекта можно настроить частоту проверки обратных ссылок чтобы всегда быть в курсе того, какие ссылки пропали, стали недоступны для поисковых систем или получили запрет на сканирование и индексацию для поисковых роботов согласно правил файла robots.txt.
Для чего линкбилдеру проверять правила файла robots.txt
Для проверки noindex nofollow в файле robots.txt есть несколько причин.
Оптимизация бюджета и восстановление работы обратных ссылок
Вебмастера, которые размещают гостевые посты на своих сайтах, часто вносят технические изменения в его работу. Не редки случаи когда по ошибке, либо намеренно, страница с вашим гостевым постом может получить запрет на сканирование и индексацию в файле robots.txt. Такая страница обязательно выпадет из поиска и перестанет передавать вес, что в дальнейшем приведет к понижению позиций вашего основного сайта в поисковых системах.
Пользы от таких гостевых постов — ноль, а деньги будут потрачены в пустую.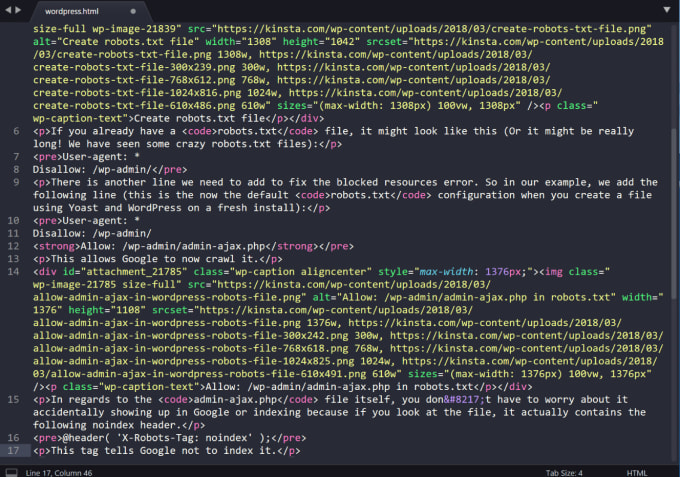 Необходимо регулярно и вовремя выявлять страницы которые запрещены в robots.txt и писать вебмастерам, чтобы они вернули исходные параметры страниц с вашими обратными ссылкам. В таком случае вы минимизируете негативный эффект на продвижение своего проекта. Если же вебмастер не идет на контакт, вы можете открыть диспут и затребовать возврат потраченных денег. Это отлично работает в денежной системе PayPal.
Необходимо регулярно и вовремя выявлять страницы которые запрещены в robots.txt и писать вебмастерам, чтобы они вернули исходные параметры страниц с вашими обратными ссылкам. В таком случае вы минимизируете негативный эффект на продвижение своего проекта. Если же вебмастер не идет на контакт, вы можете открыть диспут и затребовать возврат потраченных денег. Это отлично работает в денежной системе PayPal.
Повторение ссылочной массы как у конкурентов
Если вы хотите разместить обратные ссылки на тех же площадках, на которых размещаются конкуренты, то здесь инструмент HyperChecker подойдет как никогда. Обратные ссылки конкурента могут быть заблокированы в файле robots.txt либо иметь запрет на индексацию в мета тегах или X-Robots-Tag. Они не принесут никакой пользы для вас, а лишь истощат ваш бюджет.
Чтобы отсеять такие ссылки, необходимо загрузить их в чекер HyperChecker, и отфильтровать все то, что не разрешено в robots.txt и мета тегах. При желании можно воспользоваться фильтром по данным Ahrefs, исходящим ссылкам, по статусу индексации и т.
В итоге, вы не потратите деньги на безполезные гостевые посты и получите только те площадки, на которых ваши обратные ссылки будут приносить пользу для вашего проекта.
Попробуйте бесплатно
Robots.txt Обновление Noindex: все, что нужно знать SEO-специалистам
Рут Эверетт
Техническое SEO
| 4 минуты чтения Обновление
. С 1 сентября 2019 г. Google прекращает поддержку всего кода, который обрабатывает неподдерживаемые и неопубликованные правила в файле robots.txt, включая использование директивы noindex.
Как работал Noindex в Robots.txt
Несмотря на то, что Google официально не документировал это, добавление директив noindex в файл robots.txt поддерживалось более десяти лет, а Мэтт Каттс впервые упомянул об этом еще в 2008 году. Lumar (ранее Deepcrawl) также поддерживает его с 2011 года.
Lumar (ранее Deepcrawl) также поддерживает его с 2011 года.
В отличие от запрещенных страниц, непроиндексированные страницы не попадают в индекс и поэтому не отображаются в результатах поиска. Сочетание noindex и disallow в файле robots.txt помогло оптимизировать эффективность сканирования: директива noindex запрещает показ страницы в результатах поиска, а директива disallow предотвращает ее сканирование:
Disallow: /example-page-1/
Disallow: /example-page-2/
Noindex: /example-page-1/
Noindex: /example-page-2/
Обновление неподдерживаемых правил
1 июля 2019 года Google объявил, что протокол исключения роботов (REP) через 25 лет становится интернет-стандартом, а также теперь является открытым исходным кодом. После этого 2 июля они опубликовали официальную заметку о неподдерживаемых правилах в файлах robots.
В этом объявлении мы уведомлены о том, что с 1 сентября 2019 г., Google больше не будет поддерживать использование noindex в файле robots. txt.
txt.
Гэри Иллиес объяснил, что после анализа использования noindex в файлах robots.txt Google обнаружил, что «число сайтов, которые причиняют себе вред, очень велико». Он также подчеркнул, что обновление «предназначено для улучшения экосистемы, и те, кто правильно его использовал, найдут лучшие способы добиться того же».
Как и обещал несколько недель назад, я провел анализ noindex в robotstxt. Количество сайтов, которые наносили себе вред, очень велико. Я искренне верю, что это к лучшему для экосистемы, и те, кто использовал ее правильно, найдут лучшие способы добиться того же.
https://t.co/LvdhsN2pIE
— Гэри «鯨理» Иллиес (@methode) 2 июля 2019 г.
Альтернативные варианты директивы noindex альтернативных вариантов, перечисленных в официальном блоге Google;
- Метатеги роботов Noindex: Это наиболее эффективный способ удалить URL-адреса из индекса, но при этом разрешить сканирование. Эти теги поддерживаются как в заголовках ответов HTTP, так и в HTML и достигаются путем добавления директивы noindex для мета-роботов на самой веб-странице.
- Коды состояния 404 и 410 HTTP: Эти коды состояния используются для информирования поисковых систем о том, что страница больше не существует, что приведет к их удалению из индекса после сканирования.
- Защита паролем: Предотвращение доступа Google к странице путем сокрытия ее за логином обычно приводит к удалению ее из индекса.
- Запретить в robots.txt: Блокировка сканирования страницы обычно предотвращает индексацию страниц, поскольку поисковые системы могут индексировать только те страницы, о которых они знают. Хотя страница может быть проиндексирована из-за ссылок, указывающих на нее с других страниц, Google будет стремиться сделать страницу менее заметной в результатах поиска.
- Инструмент удаления URL-адресов в Search Console: Инструмент удаления URL-адресов в Google Search Console — это быстрый и простой способ временно удалить URL-адрес из результатов поиска Google.
 Эти теги поддерживаются как в заголовках ответов HTTP, так и в HTML и достигаются путем добавления директивы noindex для мета-роботов на самой веб-странице.
Эти теги поддерживаются как в заголовках ответов HTTP, так и в HTML и достигаются путем добавления директивы noindex для мета-роботов на самой веб-странице.
Идентификация и мониторинг безиндексных страниц robots.txt
В преддверии поддержки директив noindex для robots.txt, заканчивающейся 1 сентября 2019 г., отчет о неиндексируемых страницах в Lumar (через Индексация > Неиндексируемые страницы > Неиндексируемые страницы) будет позволяют вам проверить, какие из ваших страниц в настоящее время не индексируются и как. В списке непроиндексированных страниц вы сможете увидеть, где они были не проиндексированы: через заголовок, метатег или robots.txt.
Откройте для себя этот и более 200 других отчетов, зарегистрировавшись в учетной записи Lumar.
Вы также можете проверить, как работает ваша директива noindex, в инструменте тестирования Search Console, как и в случае с любой другой директивой Robots.txt (в Сканирование > Тестировщик robots.txt).
Другие изменения в файле robots.txt
Это обновление — лишь одно из ряда изменений, внесенных в протокол robots. txt, поскольку он стремится стать интернет-стандартом. Google объяснил это подробнее в своем обновленном документе спецификаций robots.txt в блоге Google Developers.
txt, поскольку он стремится стать интернет-стандартом. Google объяснил это подробнее в своем обновленном документе спецификаций robots.txt в блоге Google Developers.
Хотите еще что-нибудь подобное?
Мы надеемся, что вы нашли этот пост полезным для получения дополнительной информации об обновлении протокола noindex robots.txt для контроля сканирования вашего сайта.
Подробнее об этой теме можно прочитать в руководствах нашей технической библиотеки SEO о директивах роботов на уровне URL и файле robots.txt.
Кроме того, если вы хотите быть в курсе последних обновлений и рекомендаций Google, почему бы не подписаться на нашу электронную почту?
Включи меня!
Рут Эверетт
Техническое SEO
Рут Эверетт — менеджер данных и аналитики в Code First Girls, а также бывший технический SEO-аналитик в Lumar. Чаще всего вы обнаружите, что она помогает клиентам улучшить их техническое SEO, пишет обо всем, что связано с SEO, и смотрит видео с собаками.
индексация — noindex следует в Robots.txt
Спросил
Изменено 3 года, 3 месяца назад
Просмотрено 2k раз
1
Новинка! Сохраняйте вопросы или ответы и организуйте свой любимый контент.
Узнать больше.
У меня есть сайт wordpress, который проиндексирован поисковыми системами.
Я отредактировал файл robots.txt, чтобы исключить определенные каталоги и веб-страницы из поискового индекса.
Я умею только разрешать и запрещать, но не знаю, как использовать подписку и nofollow в файле Robots.txt.
Во время гугления я где-то читал, что у меня могут быть веб-страницы, которые не будут проиндексированы в Google, но будут просканированы для рангов страниц. Этого можно добиться, запретив веб-страницы в файле Robots.txt и используя подписку для веб-страниц.
Пожалуйста, дайте мне знать, как использовать follow и nofollow в файле Robots.txt.
Спасибо
SUMIT
- Индексирование
- Search-Engine
- Robots.txt
- Робот
- NOFOLLY
A). устанавливает общие правила сайта), а для тега мета-роботов на странице (устанавливает правила для этой конкретной страницы)
Дополнительная информация о Meta-Robots
b.) Google не будет сканировать запрещенные страницы, но может индексировать их в поисковой выдаче (используя информацию из внешних ссылок или каталогов веб-сайтов, таких как Dmoz).
Сказав это, вы не можете получить от этого никакого PR.
Дополнительная информация о поведении Googlebot при индексировании
Google действительно распознает директиву Noindex: внутри robots.txt. Об этом говорит Мэтт Каттс: http://www.mattcutts.com/blog/google-noindex-behavior/
Если вы поместите «Запретить» в robots.txt для страницы, которая уже находится в индексе Google, вы, как правило, обнаружите, что страница остается в индексе, как призрак, лишенный своих ключевых слов. Я полагаю, это потому, что они знают, что не будут его сканировать, и им не нужен индекс, содержащий битовую гниль. Поэтому они заменяют описание страницы на «Описание этого результата недоступно из-за файла robots.txt этого сайта — узнайте больше».
Я полагаю, это потому, что они знают, что не будут его сканировать, и им не нужен индекс, содержащий битовую гниль. Поэтому они заменяют описание страницы на «Описание этого результата недоступно из-за файла robots.txt этого сайта — узнайте больше».
Итак, проблема остается: как нам удалить эту ссылку из Google, так как «запретить» не работает? Как правило, вы хотите использовать метатег robots noindex на рассматриваемой странице, потому что Google фактически удалит страницу из индекса, если увидит это обновление, но с этой директивой Disallow в вашем файле robots они никогда не узнают об этом.
Таким образом, вы можете удалить правило Disallow этой страницы из robots.txt и добавить мета-тег robots noindex в заголовок страницы, но теперь вам нужно подождать, пока Google вернется и просмотрит страницу, о которой вы сказали им забыть. .
Вы можете создать новую ссылку на него со своей домашней страницы в надежде, что Google поймет подсказку, или вы можете избежать всего этого, просто добавив это правило Noindex непосредственно в файл robots.