
какие данные нужно скрывать и как проверить работу запрета. — Топвизор–Журнал
Содержание
В статье о том, зачем и как закрыть сайт от индексации в robots.txt, что можно скрыть и как проверить, что вы всё сделали правильно.
Эта статья — часть нашего бесплатного курса по SEO для начинающих, с ней помогал главный эксперт курса Александр Сопоев. Если хотите разобраться, как продвигать сайты в ТОП поисковых систем, заходите на курс. В конце — сертификат от Топвизора!
Зачем закрывать сайт от индексации
Когда поисковые роботы просканировали и проиндексировали страницы сайта, они начинают показываться в поисковых системах.
При этом сайт может состоять из множества разных страниц, и некоторые из них пользователям и поисковым системам видеть не нужно. Например, служебные страницы, дубли страниц и другой малополезный контент. Страницы с таким контентом поисковые системы могут и сами «выбрасывать» из индекса или понижать их позиции, но тогда это может отразиться на ранжировании всего сайта.
Кроме того, стоит учитывать и краулинговый бюджет сайта — лимит на количество страниц сайта, которые поисковые роботы смогут обойти за сутки. И этот лимит может тратиться на неважные страницы сайта, в то время как важные целевые страницы могут долго быть непроиндексированными. Подробнее об этом мы писали в статье «Как оптимизировать краулинговый бюджет».
Что можно закрыть от индексации
Дубль
Это страницы сайта, которые отличаются URL‑адресом, но содержат одинаковый или практически одинаковый контент.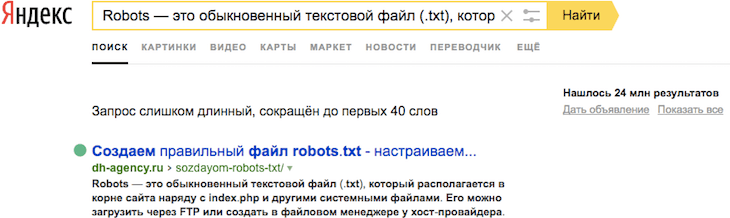
снижение скорости индексирования новых страниц. Индексирующий робот может медленнее доходить до новых страниц, из‑за того что будет обходить дубли;
поисковая система «склеит» дубли и сама выберет среди них основную страницу. При этом есть риск, что эта выбранная страница не будет вашей целевой;
в индексе останутся все дубли. Тогда все они могут конкурировать между собой, «моргать» в выдаче и т. д. Это может влиять на положение сайта в поиске.
Подробнее про дубли в Яндекс.Справке
Документ для скачивания
В некоторых случаях может быть нужно закрыть от индексации документы, например в формате pdf, docx и т. п. С помощью robots.txt это можно сделать.
С одной стороны, когда документы можно скачать из выдачи, не переходя на сайт, это может приводить к потере трафика, с другой стороны, может, наоборот, положительно повлиять на посещаемость сайта.
Страницы, которые находятся в разработке
Если на странице нет контента или есть, но он дублирует другую страницу, если на странице идёт редизайн или доработка и мы пока не хотим её выкатывать и в других подобных случаях можно запретить её индексацию.
Если оставить такие страницы доступными для индексации, то ПС может сама понизить или исключить их из индекса, что может сказаться на оценке сайта в целом.
Техническая страница
Все служебные, технические страницы не содержат полезного контента для пользователей или вовсе могут быть пустыми. Поэтому их стоит закрыть от индексации.
Такими страницами, в зависимости от конкретного сайта и особенностей проекта, могут быть: страницы регистрации, авторизации, результаты поиска по страницам сайта, Личный кабинет, Корзина, Избранное и т. д.
Папка
Файлы сайта обычно распределяются по папкам, например по категориям, каталогам, разделам, подразделам и т. д. Если какой‑то раздел на сайте устарел целиком, то можно скрыть от индексации всю папку, а не только отдельные страницы.
д. Если какой‑то раздел на сайте устарел целиком, то можно скрыть от индексации всю папку, а не только отдельные страницы.
Картинка
Помимо закрытия страниц сайта, можно также закрыть от индексации отдельный тип контента, например все картинки определённого формата или фотографии.
Если вы размещаете информативные и полезные изображения, закрывать их от индексации нежелательно.
Ссылка
С помощью robots.txt мы не можем запретить индексацию одной ссылки. Чтобы робот не переходил по ссылкам на странице, мы можем закрыть от индексации страницу, на которой размещена ссылка, или страницу, на которую она ведёт.
Чтобы скрыть от индексирования конкретную ссылку, Яндекс рекомендует использовать атрибут rel.
Блок на сайте
Мы не можем закрывать в robots.txt отдельные блоки на странице.
Запретить индексирование части текста в Яндексе можно с помощью тега noindex, но Google данный тег не поддерживает.
Как запретить индексацию в robots.
 txt
txtФайл robots.txt — это текстовый документ формата .txt, в котором прописаны специальные правила (директивы) для поисковых роботов. Они помогают управлять индексацией сайта.
С помощью этих правил можно указать поисковым роботам, какие страницы и файлы сайта не должны присутствовать в поисковой выдаче, а какие, наоборот, должны.
В файле robots.txt можно:
разрешить или запретить индексацию страниц или разделов сайта;
указать ссылку на карту сайта Sitemap.xml;
заблокировать показ изображений, видеороликов и аудиофайлов в результатах поиска.
В robots.txt мы обычно закрываем страницы массово: весь каталог, конкретные типы страниц, страницы или файлы с определёнными характеристиками.
Если у сайта есть robots.txt, то обычно он хранится он в корневой папке сайта — там, куда загружаются каталоги и другие файлы.
Кроме того, на некоторых сайтах robots.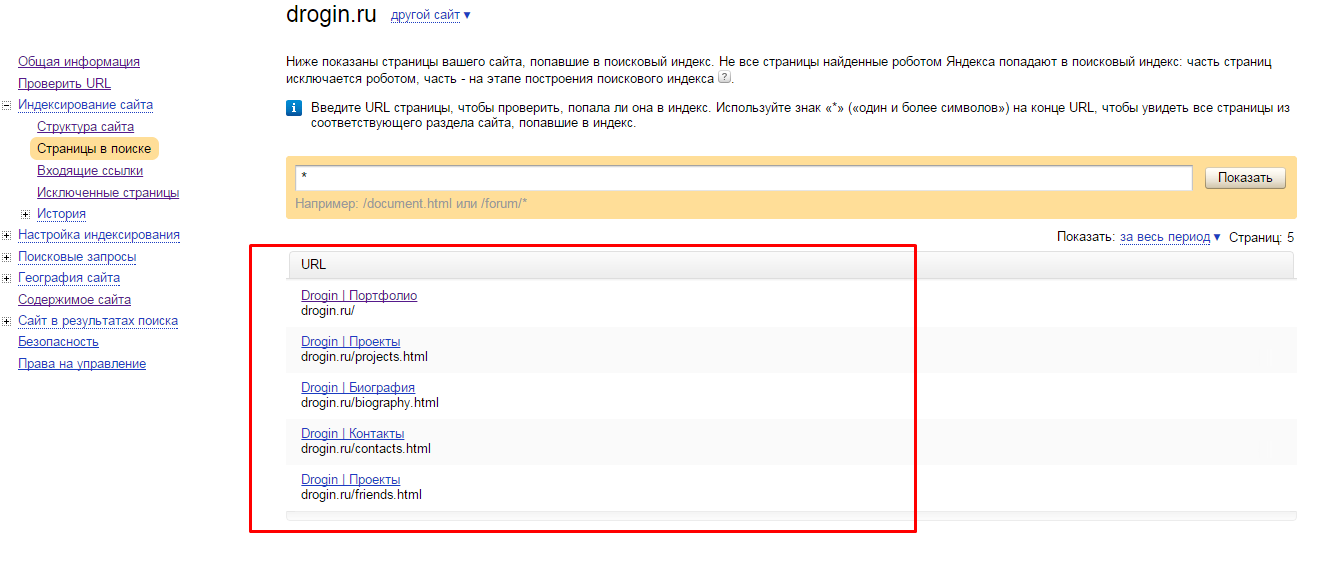 txt можно найти по ссылке site.ru/robots.txt, где site.ru — это ваш сайт. Например, https://topvisor.com/robots.txt.
txt можно найти по ссылке site.ru/robots.txt, где site.ru — это ваш сайт. Например, https://topvisor.com/robots.txt.
Если файла нет, значит, скорее всего, сейчас для индексации доступны все страницы сайта и у поисковых роботов нет специальных указаний.
Поэтому файл нужно создать самостоятельно. Сделать это можно в Блокноте или другом текстовом редакторе. В файле нужно прописать специальные директивы, о которых расскажем ниже.
После этого сохраняем документ в формате .txt с названием robots и загружаем в корневую папку сайта.
Основные директивы robots.txt
В файле эта строка будет выглядеть так:
User‑agent:
После двоеточия мы прописываем название бота, к которому будут обращены последующие правила.
Чаще всего используем такие:
- * — когда обращаемся ко всем поисковым роботам;
- Googlebot — когда обращаемся к роботам Google;
- Yandex — когда обращаемся к роботам Яндекса.
Записи в файле будут выглядеть так:
User‑agent: * или: User‑agent: Yandex или: User‑agent: Googlebot
Список User‑agent поисковых роботов Google
Список User‑agent поисковых роботов Яндекса
Перед каждой новой директивой User‑agent, которую вы прописываете в документе, необходимо ставить дополнительный пропуск строки.
Например, если бы нам нужно было закрыть весь сайт от индексации для Яндекса и Google, мы бы написали так:
User‑agent: Googlebot Disallow: / User‑agent: Yandex Disallow: /
Disallow — этой директивой мы можем запретить роботу индексировать определённые разделы сайта, страницы или файлы. Здесь могут закрываться от индексации, например:
технические страницы: страницы регистрации, авторизации и др.
 , у интернет‑магазинов это могут быть страницы «Корзина», «Избранное» и др.;
, у интернет‑магазинов это могут быть страницы «Корзина», «Избранное» и др.;страницы сортировок, которые изменяют вид отображения информации;
страницы внутреннего поиска и т. д.
 , у интернет‑магазинов это могут быть страницы «Корзина», «Избранное» и др.;
, у интернет‑магазинов это могут быть страницы «Корзина», «Избранное» и др.;Правила указания директивы такие:
Сначала указываем саму директиву и двоеточие. Например: Disallow:
После этого указываем раздел или страницу в корневой папке текущего сайта без указания самого домена. Например: /ru/marketing/.
Например, чтобы запретить роботам Яндекса индексацию всего раздела «Маркетинг» в Топвизор‑Журнале, мы бы написали в robots.txt так:
User‑agent: Yandex Disallow: /ru/marketing/
Allow — директива указывает поисковому роботу, какие разделы сайта можно индексировать. Обычно используется для указания подправила директивы Disallow, например, когда мы хотим разрешить сканирование какой‑то страницы или каталога внутри закрытого директивой Disallow раздела.
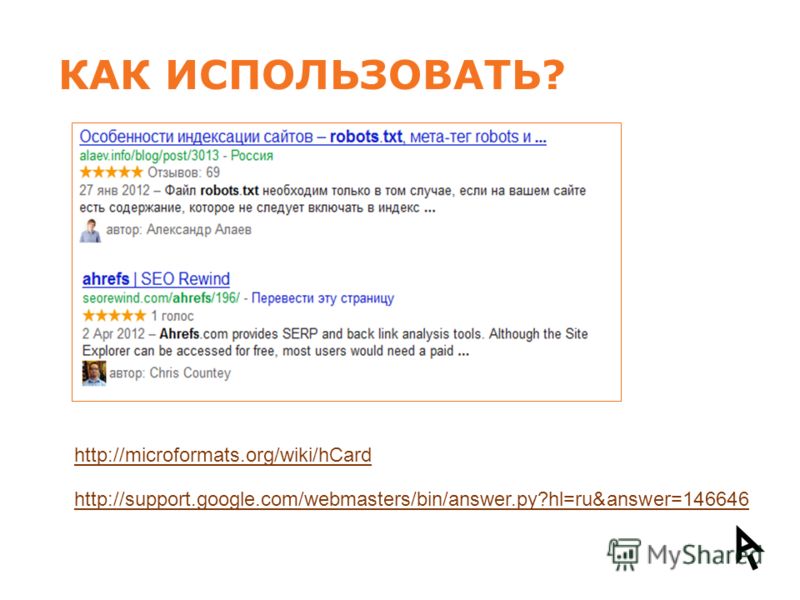
User‑agent: Yandex Disallow: /catalog/ Allow: /catalog/auto/ # запрещает скачивать страницы, начинающиеся с '/catalog/', # но разрешает скачивать страницы, начинающиеся с '/catalog/auto/'
Если в документе одновременно указаны директивы Allow и Disallow для одного и того же элемента, то предпочтение отдаётся директиве Allow — элемент будет проиндексирован.
О директиве Disallow и Allow у Яндекса
О директиве Disallow и Allow у Google
Дополнительно
При указании пути к разделу, странице или файлам может использоваться спецсимвол «*».
Он означает любую (в том числе пустую) последовательность символов. Может ставиться как префикс в начале адреса или как суффикс в конце.
Например:
Disallow: /catalog/*/shopinfo — запрещает индексацию любых страниц в разделе catalog, в URL которых есть shopinfo.
Disallow: *shopinfo — запрещает индексацию всех страниц, содержащих в URL “shopinfo”, например: /ru/marketing/shopinfo.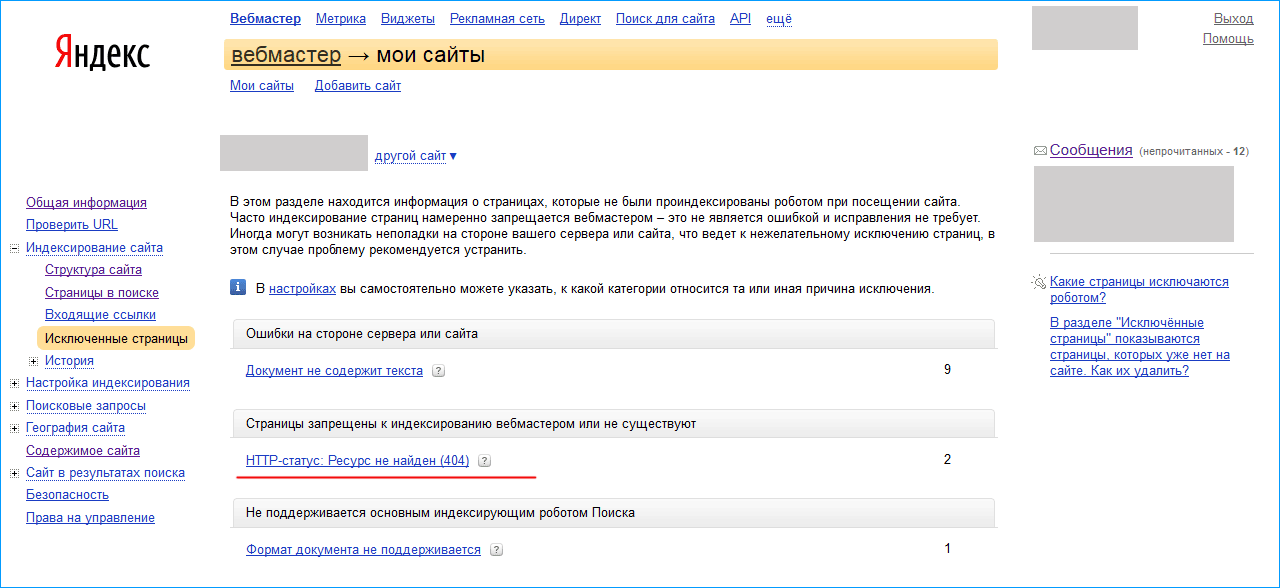
Подробнее о спецсимволах и правилах их использования в Яндексе
Спецсимволы работают в том числе и с директивой Allow.
Путь указывается через директиву Sitemap, а сам путь должен быть полным, с указанием домена, как в браузере:
Sitemap: https://site.com/sitemaps1.xml
Если карт сайта несколько, директиву можно повторять несколько раз с новой строки.
Директива считается межсекционной: поисковые роботы увидят путь к карте сайта вне зависимости от места в файле robots.txt, где он указан.
О директиве Sitemap в Яндекс.Справке
О директиве Sitemap в Google Справке
Яндекс предупреждает, что если не закрыть страницы с параметрами через Clean‑param, то в поиске могут появиться многочисленные дубли страниц, что может негативно отразиться на ранжировании.
Синтаксис и правила оформления:
файл должен называться robots.txt;
размер файла не больше 500 КБ;
на сайте должен быть только один такой файл;
файл размещён в корневом каталоге сайта, но не в подкаталоге.
Нужно вот так: https://www.example.com/robots.txt, а так нельзя: https://example.com/pages/robots.txt;файл отдаёт ответ сервера 200 OK.
 Нужно вот так: https://www.example.com/robots.txt, а так нельзя: https://example.com/pages/robots.txt;
Нужно вот так: https://www.example.com/robots.txt, а так нельзя: https://example.com/pages/robots.txt;Подробные правила оформления robots.txt у Яндекса.
Подробные правила оформления robots.txt у Google.
Дополнительно про файл robots.txt:
есть директивы, которые одни ПС воспринимают, а другие нет. Например, Clean‑param для Яндекса;
те страницы, которые вы запретили в файле, всё равно могут быть проиндексированы. Например, Google говорит, что страницы могут попасть в индекс, если поисковый робот нашёл их по ссылке с других сайтов или страниц. Чтобы полностью скрыть информацию от краулеров, стоит использовать другие способы, например метатег robots и HTTP‑заголовок X‑Robots‑Tag и др.
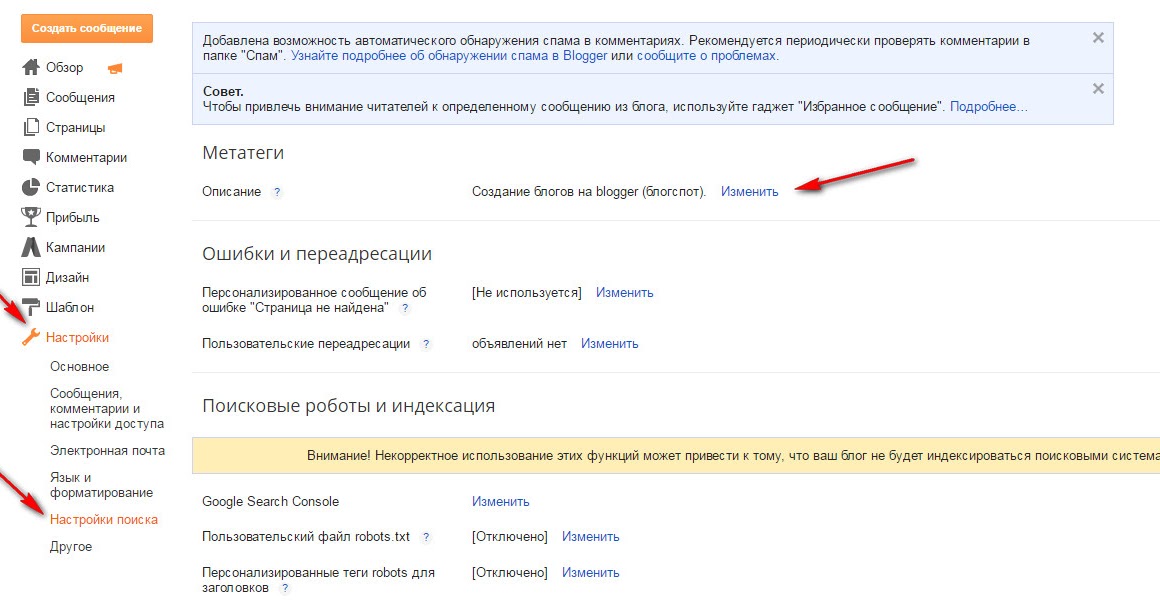
Как проверить запрет
После создания из загрузки файла на сайт убедитесь, что он существует, размещён в корневом каталоге сайта и без проблем открывается. Для проверки введите в строку браузера адрес сайта с указанием файла в формате https://site.ru/robots.txt.
Для проверки введите в строку браузера адрес сайта с указанием файла в формате https://site.ru/robots.txt.
После этого можно проверить файл в панелях веб‑мастеров Яндекс.Вебмастер и Google Search Console.
Яндекс.Вебмастер
В Вебмастере открываем «Инструменты» → «Анализ robots.txt». Обычно содержимое файла сразу будет отображаться в строке. Если нет, копируем из браузера и вставляем сюда. Затем нажимаем кнопку «Проверить»:
Проверка файла в ВебмастереЕсли в файле будут ошибки, Вебмастер подскажет, как их исправить.
Google Search Console
Для того чтобы проверить файл robots.txt с помощью валидатора Google, необходимо:
1. Зайти в аккаунт Google Search Console.
2. Перейти в инструмент проверки robots.txt.
3. В открывшемся окне вы увидите уже подгруженную информацию из файла. Если нет, вставьте её из браузера.
GSC покажет, есть ли в файле ошибки и как их исправить.
Проверка файла в GSCКраткий конспект
На сайте может быть необходимо скрыть некоторые страницы, например:
Закрывать от индексации можно как сайт полностью, так и отдельные страницы, файлы, изображения.
В robots.txt с помощью специальных директив мы обычно закрываем страницы массово: весь каталог, конкретные типы страниц, страницы или файлы с определёнными характеристиками.
После создания правил для индексирования сайта в robots.txt важно его проверить. Сделать это можно бесплатно в панелях веб‑мастеров Яндекс.Вебмастер и Google Search Console.
Как запретить индексацию нужных страниц
Как запретить индексацию определенных страниц?
Разрешения и запрещения на индексацию берутся всеми поисковыми системами из файла robots.txt, находящегося в корневом каталоге сервера. Запрет на индексацию ряда страниц может появиться, например, из соображений секретности или из желания не индексировать одинаковые документы в разных кодировках. Чем меньше ваш сервер, тем быстрее робот его обойдет. Поэтому запретите в файле robots.txt все документы, которые не имеет смысла индексировать (например, файлы статистики или списки файлов в директориях). Обратите особое внимание на CGI или ISAPI скрипты — наш робот индексирует их наравне с другими документами.
Обратите особое внимание на CGI или ISAPI скрипты — наш робот индексирует их наравне с другими документами.
В простейшем виде (разрешено все, кроме директории скриптов) файл robots.txt выглядит следующим образом:
User-Agent: *
Disallow: /cgi-bin/
Детальное описание спецификации файла можно прочитать на странице: «Стандарт исключений для роботов».
При написании robots.txt обратите внимание на следующие часто встречающиеся ошибки:
1. Строка с полем User-Agent является обязательной и должна предшествовать строкам с полем Disallow. Так, приведенный ниже файл robots.txt не запрещает ничего:
Disallow: /cgi-bin
Disallow: /forum
2. Пустые строки в файле robots.txt являются значимыми, они разделяют записи, относящиеся к разным роботам. Например, в следующем фрагменте файла robots.txt строка Disallow: /forum игнорируется, поскольку перед ней нет строки с полем User-Agent.
User-Agent: *
Disallow: /cgi-bin
Disallow: /forum
3. Строка с полем Disallow может запретить индексирование документов только с одним префиксом. Для запрета нескольких префиксов нужно написать несколько строк. Например, нижеприведенный файл запрещает индексирование документов, начинающихся с “/cgi-bin /forum”, которых, скорее всего, не существует (а не документов с префиксами /cgi-bin и /forum).
Строка с полем Disallow может запретить индексирование документов только с одним префиксом. Для запрета нескольких префиксов нужно написать несколько строк. Например, нижеприведенный файл запрещает индексирование документов, начинающихся с “/cgi-bin /forum”, которых, скорее всего, не существует (а не документов с префиксами /cgi-bin и /forum).
User-Agent: *
Disallow: /cgi-bin /forum
4. В строках с полем Disallowзаписываются не абсолютные, а относительные префиксы. То есть файл
User-Agent: *
Disallow: www.myhost.ru/cgi-bin
запрещает, например, индексирование документа http://www.myhost.ru/www.myhost.ru/cgi-bin/counter.cgi, но НЕ запрещает индексирование документа http://www.myhost.ru/cgi-bin/counter.cgi.
5. В строках с полем Disallowуказываются именно префиксы, а не что-нибудь еще. Так, файл:
User-Agent: *
Disallow: *
запрещает индексирование документов, начинающихся с символа «*» (которых в природе не существует), и сильно отличается от файла:
User-Agent: *
Disallow: /
который запрещает индексирование всего сайта.
Если вы не можете создать/изменить файл robots.txt, то еще не все потеряно — достаточно добавить дополнительный тег <META> в HTML-код вашей страницы (внутри тега <HEAD>):
<META NAME="ROBOTS" CONTENT="NOINDEX">
Тогда данный документ также не будет проиндексирован.
Вы также можете использовать тэг
<META NAME="ROBOTS" CONTENT="NOFOLLOW">
Он означает, что робот поисковой машины не должен идти по ссылкам с данной страницы.
Для одновременного запрета индексирования страницы и обхода ссылок с нее используется тэг
<META NAME="ROBOTS" CONTENT="NOINDEX,NOFOLLOW">
Как запретить индексацию определенных частей текста?
Чтобы запретить индексирование определенных фрагментов текста в документе, пометьте их тегами
<NOINDEX></NOINDEX>
Внимание! Тег NOINDEX не должен нарушать вложенность других тегов.![]() Если указать следующую ошибочную конструкцию:
Если указать следующую ошибочную конструкцию:
<NOINDEX>
…код1…
<TABLE><TR><TD>
…код2…
</NOINDEX>
…код3…
</TD></TR></TABLE>
запрет на индексирование будет включать не только «код1» и «код2», но и «код3».
Как выбрать главный виртуальный хост из нескольких зеркал?
Если ваш сайт находится на одном сервере (одном IP), но виден во внешнем мире под разными именами (зеркала, разные виртуальные хосты), Яндекс рекомендует вам выбрать то имя, под которым вы хотите быть проиндексированы. В противном случае Яндекс выберет главное зеркало самостоятельно, а остальные имена будут запрещены к индексации.
Для того, чтобы индексировалось выбранное вами зеркало, достаточно запретить индексацию всех остальных зеркал при помощи robots.txt. Это можно сделать, используя нестандартное расширение robots.txt — директиву Host, в качестве ее параметра указав имя основного зеркала. Если www.glavnoye-zerkalo.ru — основное зеркало, то robots.txt должен выглядеть примерно так:
Если www.glavnoye-zerkalo.ru — основное зеркало, то robots.txt должен выглядеть примерно так:
User-Agent: *
Disallow: /forum
Disallow: /cgi-bin
Host: www.glavnoye-zerkalo.ru
В целях совместимости с роботами, которые не полностью следуют стандарту при обработке robots.txt, директиву Host необходимо добавлять в группе, начинающейся с записи User-Agent, непосредственно после записей Disallow.
Аргументом директивы Host является доменное имя с номером порта (80 по умолчанию), отделенным двоеточием. Если какой-либо сайт не указан в качестве аргумента для Host, для него подразумевается наличие директивы Disallow: /, т.е. полный запрет индексации (при наличии в группе хотя бы одной корректной директивы Host). Таким образом, файлы robots.txt вида
User-Agent: *
Host: www.myhost.ru
и
User-Agent: *
Host: www. myhost.ru:80
myhost.ru:80
эквивалентны и запрещают индексирование как www.otherhost.ru, так и www.myhost.ru:8080.
Параметр директивы Host обязан состоять из одного корректного имени хоста (т.е. соответствующего RFC 952 и не являющегося IP-адресом) и допустимого номера порта. Некорректно составленные строчки Host игнорируются.
# Примеры игнорируемых директив Host
Host: www.myhost-.ru
Host: www.-myhost.ru
Host: www.myhost.ru:0
Host: www.my_host.ru
Host: .my-host.ru:8000
Host: my-host.ru.
Host: my..host.ru
Host: www.myhost.ru/
Host: www.myhost.ru:8080/
Host: http://www.myhost.ru
Host: www.mysi.te
Host: 213.180.194.129
Host: www.firsthost.ru,www.secondhost.ru
Host: www.firsthost.ru www.secondhost.ru
Если у вас сервер Apache, то можно вместо использования директивы Host задать robots.txt с использованием директив SSI:
<!--#if expr=" "${HTTP_HOST}" != "www.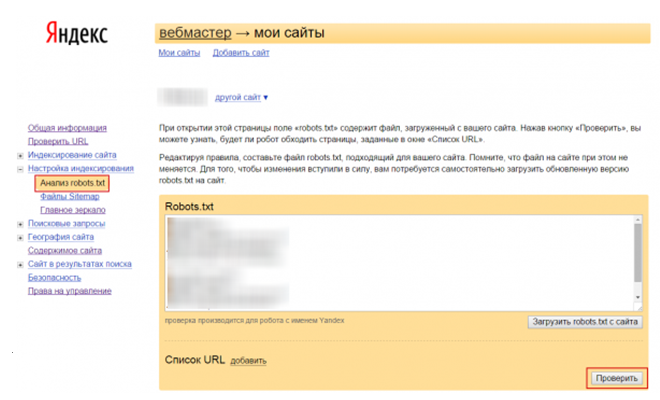 главное_имя.ru" " -->
главное_имя.ru" " -->
User-Agent: *
Disallow: /
<!--#endif -->
В этом файле роботу запрещен обход всех хостов, кроме www.главное_имя.ru
Как включать SSI, можно прочесть в документации по вашему серверу или обратиться к вашему системному администратору. Проверить результат можно, просто запросив страницы:
http://www.главное_имя.ru/robots.txtи т.д. Результаты должны быть разные.
http://www.другое_имя.ru/robots.txt
Рекомендации для веб-сервера Русский Apache
В robots.txt на сайтах с русским апачем должны быть запрещены для роботов все кодировки, кроме основной.
Если кодировки разложены по портам (или серверам), то надо выдавать на разных портах (серверах) РАЗНЫЙ robots.txt. А именно, во всех файлах robots.txt для всех портов/серверов, кроме «основного», должно быть написано:
User-Agent: *
Disallow: /
Для этого можно использовать механизм SSI, описанный выше.
Если кодировки в вашем Apache выделяются по именам «виртуальных» директорий, то надо написать один robots.txt, в котором должны быть примерно такие строчки (в зависимости от названий директорий):
User-Agent: *
Disallow: /dos
Disallow: /mac
Disallow: /koi
Удачки.
09.07.2007 17:56
Как исправить ошибку «Индексировано, хотя и заблокировано robots.txt» (2 метода)
Может быть обескураживающе видеть снижение рейтинга вашего сайта в поиске. Когда ваши страницы больше не сканируются Google, эти более низкие рейтинги могут привести к меньшему количеству посетителей и конверсий.
Ошибка «Проиндексировано, но заблокировано robots.txt» может означать проблему со сканированием вашего сайта поисковыми системами. Когда это происходит, Google проиндексировал страницу, которую не может просканировать. К счастью, вы можете редактировать свои robots.txt файл, указывающий, какие страницы следует или не следует индексировать.
В этом посте мы расскажем об ошибке «Проиндексировано, но заблокировано robots.txt» и как проверить ваш сайт на наличие этой проблемы. Затем мы покажем вам два разных метода исправления. Давайте начнем!
Посмотрите наше видео-руководство по исправлению ошибки «Проиндексировано, хотя и заблокировано robots.txt»
Что такое «Проиндексировано, хотя и заблокировано robots.txt»?
Как владелец веб-сайта, Google Search Console может помочь вам проанализировать эффективность вашего сайта во многих важных областях. Этот инструмент может отслеживать скорость страницы, безопасность и «сканируемость», чтобы вы могли оптимизировать свое присутствие в Интернете:
Google Search Console Например, отчет об индексировании Search Console может помочь вам улучшить поисковую оптимизацию вашего сайта (SEO). Он проанализирует, как Google индексирует ваш онлайн-контент, и вернет информацию о распространенных ошибках, таких как предупреждение «Проиндексировано, но заблокировано robots. txt»:
txt»:
Чтобы понять эту ошибку, давайте сначала обсудим robots. txt файл. По сути, он информирует сканеры поисковых систем, какие файлы вашего веб-сайта должны или не должны быть проиндексированы. С хорошо структурированной robots.txt , вы можете убедиться, что сканируются только важные веб-страницы.
Если вы получили предупреждение «Проиндексировано, но заблокировано robots.txt», сканеры Google нашли страницу, но заметили, что она заблокирована в вашем файле robots.txt . Когда это происходит, Google не уверен, хотите ли вы проиндексировать эту страницу.
В результате эта страница может появиться в результатах поиска, но не будет отображать описание. Он также исключит изображения, видео, PDF-файлы и файлы, отличные от HTML. Поэтому вам необходимо обновить robots.txt файл, если вы хотите отобразить эту информацию.
Снижение рейтинга вашего веб-сайта в поисковых системах может обескураживать. 📉 Этот пост поможет вам 💪Нажмите, чтобы твитнуть
📉 Этот пост поможет вам 💪Нажмите, чтобы твитнутьВозможные проблемы с индексированием страниц
Вы можете намеренно добавить в файл robots.txt директивы, которые блокируют страницы от сканеров. Однако эти директивы не могут полностью удалить страницы из Google. Если внешний веб-сайт ссылается на страницу, это может вызвать ошибку «Проиндексировано, но заблокировано robots.txt».
Google (и другие поисковые системы) должны проиндексировать ваши страницы, прежде чем они смогут точно ранжировать их. Чтобы в результатах поиска отображался только релевантный контент, важно понимать, как работает этот процесс.
Хотя некоторые страницы должны быть проиндексированы, они могут быть не проиндексированы. Это может быть вызвано несколькими причинами:
- Директива в файле robots.txt , запрещающая индексирование
- Неработающие ссылки или цепочки перенаправления
- Канонические теги в заголовке HTML
С другой стороны, некоторые веб-страницы не должны индексироваться.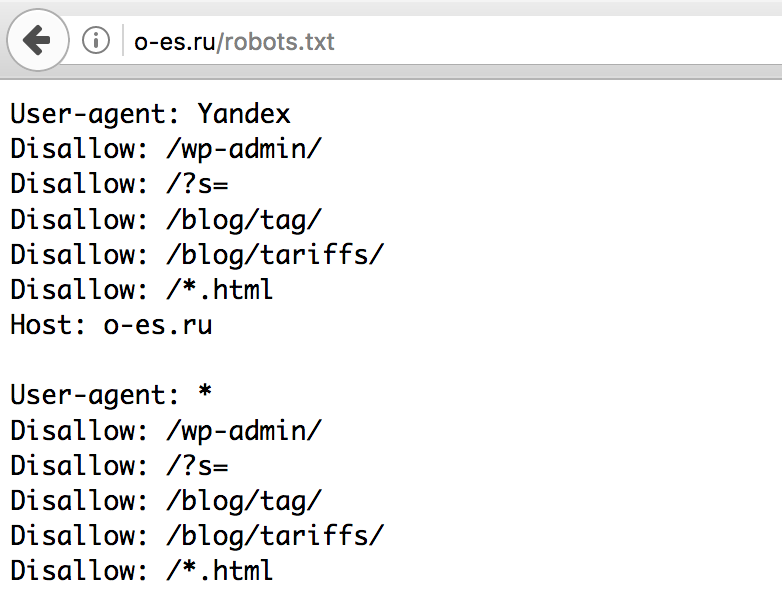 Они могут быть случайно проиндексированы из-за следующих факторов:
Они могут быть случайно проиндексированы из-за следующих факторов:
- Неправильные директивы noindex
- Внешние ссылки с других сайтов
- Старые URL в индексе Google
- Нет robots.txt файл
Если проиндексировано слишком много ваших страниц, ваш сервер может быть перегружен поисковым роботом Google. Кроме того, Google может тратить время на индексацию нерелевантных страниц вашего сайта. Поэтому вам нужно будет создать и отредактировать robots.txt Файл правильный.
Поиск источника ошибки «Проиндексировано, но заблокировано robots.txt»
Одним из эффективных способов выявления проблем с индексированием страниц является вход в Google Search Console. После того, как вы подтвердите право собственности на сайт, вы сможете получить доступ к отчетам о его эффективности.
В разделе Index перейдите на вкладку Valid with warnings . Это откроет список ваших ошибок индексации, включая любые предупреждения «Проиндексировано, но заблокировано robots. txt». Если вы ничего не видите, скорее всего, на вашем сайте нет этой проблемы.
txt». Если вы ничего не видите, скорее всего, на вашем сайте нет этой проблемы.
Кроме того, вы можете использовать тестер Google robots.txt. С помощью этого инструмента вы можете сканировать файл robots.txt на наличие синтаксических предупреждений и других ошибок:
Google Search Console robots.txt testerВнизу страницы введите определенный URL-адрес, чтобы проверить, не заблокирован ли он. Вам нужно будет выбрать пользовательский агент из выпадающего меню и выбрать Тест :
Проверить заблокированный URL-адресВы также можете перейти к domain.com/robots.txt . Если у вас уже есть robots.txt , это позволит вам просмотреть его:
Визуальный файл robots.txt KinstaЗатем найдите операторы disallow. Администраторы сайтов могут добавлять эти утверждения, чтобы указать поисковым роботам, как получить доступ к определенным файлам или страницам.
Если оператор disallow блокирует все поисковые системы, это может выглядеть так:
Disallow: /
Он также может блокировать определенный пользовательский агент:
Пользовательский агент: * Disallow: /
С помощью любого из этих инструментов вы сможете выявить любые проблемы с индексацией вашей страницы. Затем вам нужно будет принять меры, чтобы обновить robots.txt файл.
Затем вам нужно будет принять меры, чтобы обновить robots.txt файл.
Как исправить ошибку «Проиндексировано, но заблокировано robots.txt»
Теперь, когда вы знаете больше о файле robots.txt и о том, как он может предотвратить индексирование страниц, пришло время исправить ошибку «Проиндексировано, хотя и заблокировано». по ошибке robots.txt». Однако перед использованием этих решений обязательно оцените, нужно ли индексировать заблокированную страницу.
Способ 1: отредактируйте robots.txt напрямую
Если у вас есть веб-сайт WordPress, у вас, вероятно, будет виртуальный0005 robots.txt файл. Вы можете посетить его, выполнив поиск domain.com/robots.txt в веб-браузере (заменив domain.com на ваше доменное имя). Однако этот виртуальный файл не позволит вам вносить изменения.
Чтобы начать редактирование robots.txt , вам необходимо создать файл на своем сервере. Сначала выберите текстовый редактор и создайте новый файл. Обязательно назовите его «robots.txt»:
Сначала выберите текстовый редактор и создайте новый файл. Обязательно назовите его «robots.txt»:
Затем вам нужно будет подключиться к SFTP-клиенту. Если вы используете учетную запись хостинга Kinsta, войдите в MyKinsta и перейдите к Sites > Info :
Учетные данные MyKinsta SFTP для входаЗдесь вы найдете свое имя пользователя, пароль, хост и номер порта. Затем вы можете загрузить SFTP-клиент, например FileZilla. Введите свои учетные данные для входа в SFTP и нажмите Quickconnect :
Подключиться к FileZillaНаконец, загрузите файл robots.txt в корневой каталог (для сайтов WordPress он должен называться public_html ). Затем вы можете открыть файл и внести необходимые изменения.
Вы можете использовать операторы allow и disallow для настройки индексации вашего сайта WordPress. Например, вы можете захотеть, чтобы определенный файл сканировался без индексирования всей папки. В этом случае вы можете добавить этот код:
В этом случае вы можете добавить этот код:
User-agent: * Запретить: /wp-admin/ Разрешить: /wp-admin/admin-ajax.php
Не забудьте настроить таргетинг на страницу, вызывающую ошибку «Проиндексировано, но заблокировано robots.txt» во время этого процесса. В зависимости от вашей цели вы можете указать, должен ли Google сканировать страницу или нет.
Когда закончите, сохраните изменения. Затем вернитесь в Google Search Console, чтобы узнать, устранил ли этот метод ошибку.
Способ 2. Использование плагина SEO
Если у вас активирован плагин SEO, вам не нужно создавать совершенно новый файл robots.txt . Во многих случаях инструмент SEO создаст его для вас. Кроме того, он также может предоставлять способы редактирования файла, не выходя из панели управления WordPress.
Yoast SEO
Одним из самых популярных SEO-плагинов является Yoast SEO. Он может предоставить подробный SEO-анализ на странице, а также дополнительные инструменты для настройки индексации вашей поисковой системой.
Чтобы начать редактирование файла robots.txt , перейдите в Yoast SEO > Инструменты на панели управления WordPress. Из списка встроенных инструментов выберите Редактор файлов :
Выберите редактор файлов Yoast SEOYoast SEO не будет автоматически создавать файл robots.txt . Если у вас его еще нет, нажмите Создайте файл robots.txt :
Создайте файл robots.txt с помощью Yoast SEOЭто откроет текстовый редактор с содержимым вашего нового robots.txt файл. Как и в первом методе, вы можете добавить операторы allow на страницы, которые хотите проиндексировать. В качестве альтернативы используйте операторы запрета для URL-адресов, чтобы избежать индексации:
Отредактируйте файл robots.txt Yoast SEOПосле внесения изменений сохраните файл. Yoast SEO предупредит вас, когда вы обновите файл robots.txt .
Rank Math
Rank Math — еще один бесплатный плагин, который включает редактор robots. txt . После активации инструмента на вашем сайте WordPress перейдите к пункту 9.0005 Rank Math > Общие настройки > Редактировать robots.txt :
txt . После активации инструмента на вашем сайте WordPress перейдите к пункту 9.0005 Rank Math > Общие настройки > Редактировать robots.txt :
В редакторе кода вы увидите некоторые правила по умолчанию, включая вашу карту сайта. Чтобы обновить его настройки, вы можете вставить или удалить код по мере необходимости.
В процессе редактирования необходимо соблюдать несколько правил:
- Используйте одну или несколько групп, каждая из которых содержит несколько правил.
- Начните каждую группу с пользовательского агента, а затем с определенными каталогами или файлами.
- Предположим, что любая веб-страница разрешает индексирование, если на ней нет запрещающего правила.
Имейте в виду, что этот метод возможен только в том случае, если у вас еще нет файла robots.txt в корневом каталоге. Если вы это сделаете, вам придется отредактировать файл robot.txt напрямую с помощью SFTP-клиента.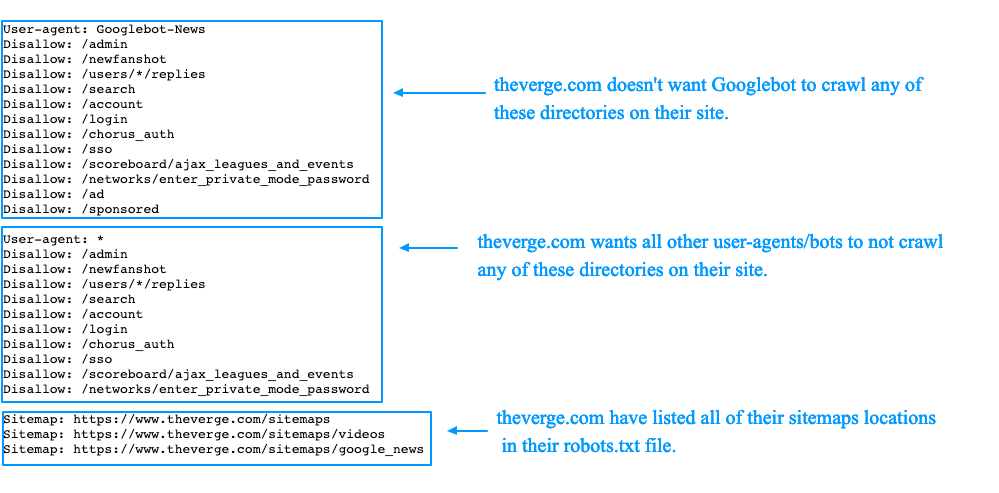 Кроме того, вы можете удалить этот уже существующий файл и использовать вместо него редактор Rank Math.
Кроме того, вы можете удалить этот уже существующий файл и использовать вместо него редактор Rank Math.
После того, как вы запретите страницу в robots.txt , вы также должны добавить директиву noindex. Это защитит страницу от поиска Google. Для этого перейдите на Rank Math > Заголовки и метаданные > Сообщения :
Откройте настройки сообщений Rank MathПрокрутите вниз до Post Robots Meta и включите его. Затем выберите Нет индекса :
Включить неиндексирование для сообщенийНаконец, сохраните изменения. В Google Search Console найдите предупреждение «Проиндексировано, но заблокировано robots.txt» и нажмите Проверить исправление . Это позволит Google повторно просканировать указанные URL-адреса и устранить ошибку.
Squirrly SEO
Используя плагин Squirrly SEO , вы можете аналогичным образом редактировать robots.txt . Чтобы начать, нажмите Squirrly SEO > SEO Configuration . Откроются настройки Tweaks and Sitemap :
Откроются настройки Tweaks and Sitemap :
С левой стороны выберите вкладку Файл роботов . Затем вы увидите редактор файла robots.txt , похожий на другие плагины SEO:
Squirrly SEO файл robots.txtС помощью текстового редактора вы можете добавить разрешающие или запрещающие операторы для настройки файла robots.txt 9.0006 файл. Продолжайте добавлять столько правил, сколько вам нужно. Когда вы довольны тем, как выглядит этот файл, выберите Сохранить настройки .
Кроме того, вы можете добавить правила noindex для определенных типов записей. Для этого вам просто нужно отключить параметр Разрешить индексировать Google на вкладке Автоматизация . По умолчанию SEO Squirrly оставит это включенным.
Не позволяйте этой надоедливой ошибке повлиять на ваш с трудом завоеванный поисковый рейтинг. 🙅♀️ Начните исправлять это с помощью этого руководства ✅Нажмите, чтобы твитнуть
Резюме
Как правило, Google находит ваши веб-страницы и индексирует их в результатах поиска.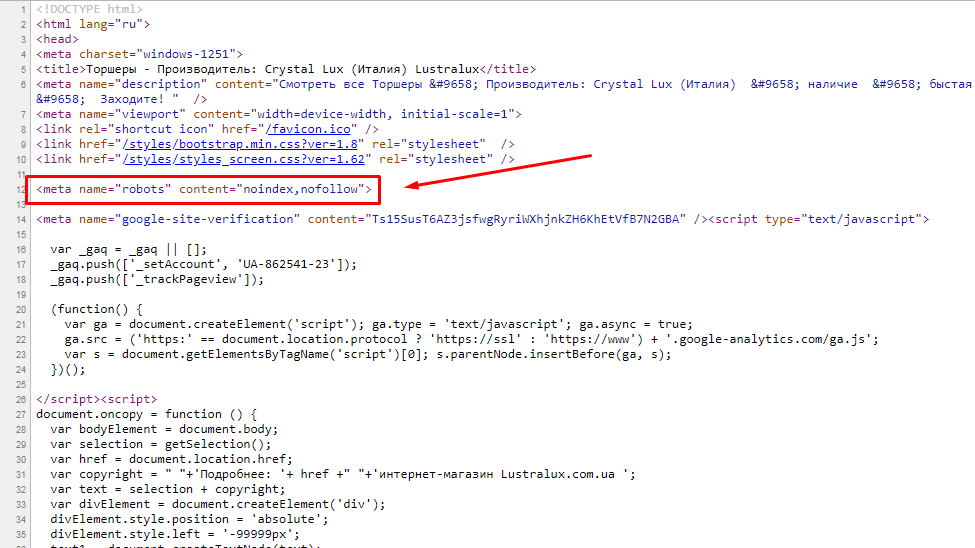 Однако плохо настроенный файл robots.txt может ввести поисковые системы в заблуждение относительно того, следует ли игнорировать эту страницу при сканировании. В этом случае вам нужно будет уточнить инструкции по сканированию, чтобы продолжить максимизировать SEO на вашем веб-сайте.
Однако плохо настроенный файл robots.txt может ввести поисковые системы в заблуждение относительно того, следует ли игнорировать эту страницу при сканировании. В этом случае вам нужно будет уточнить инструкции по сканированию, чтобы продолжить максимизировать SEO на вашем веб-сайте.
Вы можете редактировать robots.txt напрямую с помощью SFTP-клиента, такого как FileZilla. Кроме того, многие плагины SEO, включая Yoast, Rank Math и Squirrly SEO, включают robots.txt редакторов в их интерфейсах. Используя любой из этих инструментов, вы сможете добавлять разрешающие и запрещающие операторы, чтобы помочь поисковым системам правильно индексировать ваш контент.
Чтобы помочь вашему веб-сайту подняться на вершину результатов поиска, мы рекомендуем выбрать SEO-оптимизированный веб-хостинг. В Kinsta наши планы управляемого хостинга WordPress включают инструменты SEO, такие как мониторинг времени безотказной работы, SSL-сертификаты и управление перенаправлением. Ознакомьтесь с нашими планами на сегодня!
Ознакомьтесь с нашими планами на сегодня!
Получите все свои приложения, базы данных и сайты WordPress онлайн и под одной крышей. Наша многофункциональная высокопроизводительная облачная платформа включает в себя:
- Простая настройка и управление в панели управления MyKinsta
- Экспертная поддержка 24/7
- Лучшее оборудование и сеть Google Cloud Platform на базе Kubernetes для максимальной масштабируемости
- Интеграция Cloudflare корпоративного уровня для скорости и безопасности
- Глобальный охват аудитории до 35 центров обработки данных и 275 точек присутствия по всему миру
Начните с бесплатной пробной версии нашего хостинга приложений или хостинга баз данных. Ознакомьтесь с нашими планами или поговорите с отделом продаж, чтобы найти наиболее подходящий вариант.
«Заблокировано robots.txt» и «Проиндексировано, но заблокировано robots.txt»: различия и как их исправить Статусы Search Console.
 Они указывают на то, что затронутые страницы не сканировались, поскольку вы заблокировали их в файле robots.txt.
Они указывают на то, что затронутые страницы не сканировались, поскольку вы заблокировали их в файле robots.txt.Однако разница между этими двумя проблемами заключается в следующем:
- С «Заблокировано robots.txt» ваши URL-адреса не будут отображаться в Google,
- В свою очередь, с параметром «Проиндексировано, хотя и заблокировано robots.txt» вы можете видеть уязвимые URL-адреса в результатах поиска, даже если они заблокированы директивой Disallow в файле robots.txt. Другими словами, «Проиндексировано, хотя и заблокировано robots.txt» означает, что Google не сканировал ваш URL, но тем не менее проиндексировал его.
Поскольку устранение этих проблем лежит в основе создания эффективной стратегии сканирования и индексации вашего веб-сайта, давайте проанализируем, когда и как их следует решать.
Какое отношение индексация имеет к файлу robots.txt?
Хотя взаимосвязь между файлом robots.txt и процессом индексирования может сбивать с толку, позвольте мне помочь вам глубже разобраться в этой теме. Это облегчит понимание окончательного решения.
Это облегчит понимание окончательного решения.
Как работают обнаружение, сканирование и индексирование?
Прежде чем страница будет проиндексирована, роботы поисковых систем должны сначала обнаружить и просканировать ее.
На этапе обнаружения сканер узнает, что данный URL-адрес существует. Во время сканирования Googlebot посещает этот URL-адрес и собирает информацию о его содержании. Только после этого URL попадает в индекс и его можно найти среди других результатов поиска.
Псст. Этот процесс не всегда проходит гладко, но вы можете узнать, как помочь ему, прочитав наши статьи:
- Как исправить статус «Обнаружено — в настоящее время не проиндексировано» в GSC и
- Как исправить статус «Просканировано — пока не проиндексировано» в GSC.
Что такое robots.txt?
Robots.txt — это файл, который можно использовать для управления тем, как робот Googlebot сканирует ваш веб-сайт. Всякий раз, когда вы добавляете в него директиву Disallow, робот Googlebot знает, что не может посещать страницы, к которым применяется эта директива.
Но robots.txt не управляет индексацией.
Подробные инструкции по изменению и управлению файлом см. в нашем руководстве robots.txt.
Что вызывает сообщение «Проиндексировано, но заблокировано robots.txt» в Google Search Console?
Иногда Google решает проиндексировать обнаруженную страницу, несмотря на то, что не может ее просканировать и понять ее содержание.
В этом сценарии Google обычно мотивирован множеством ссылок, ведущих на страницу, заблокированную robots.txt.
Ссылки преобразуются в оценку PageRank. Google вычисляет его, чтобы оценить, насколько важна данная страница. Алгоритм PageRank учитывает как внутренние, так и внешние ссылки.
Когда в ваших ссылках беспорядок и Google видит, что запрещенная страница имеет высокое значение PageRank, он может решить, что страница достаточно значима, чтобы поместить ее в индекс.
Однако в индексе будет храниться только пустой URL-адрес без информации о содержимом, так как содержимое не было просканировано.
Почему «Проиндексировано, но заблокировано robots.txt» плохо для SEO?
Статус «Проиндексирован, но заблокирован robots.txt» — серьезная проблема. Это может показаться относительно безобидным, но это может саботировать вашу поисковую оптимизацию двумя важными способами.
Плохое отображение в поиске
Если вы заблокировали данную страницу по ошибке, то «Проиндексирована, но заблокирована robots.txt» не означает, что вам повезло, и Google исправил вашу ошибку.
Страницы, проиндексированные без сканирования, не будут выглядеть привлекательно в результатах поиска. Google не сможет отобразить:
- Тег заголовка (вместо этого он автоматически сгенерирует заголовок из URL-адреса или информации, предоставленной страницами, которые ссылаются на вашу страницу),
- Мета-описание,
- Любая дополнительная информация в виде расширенных результатов.
Без этих элементов пользователи не будут знать, чего ожидать после входа на страницу, и могут выбрать конкурирующие веб-сайты, резко снизив ваш CTR.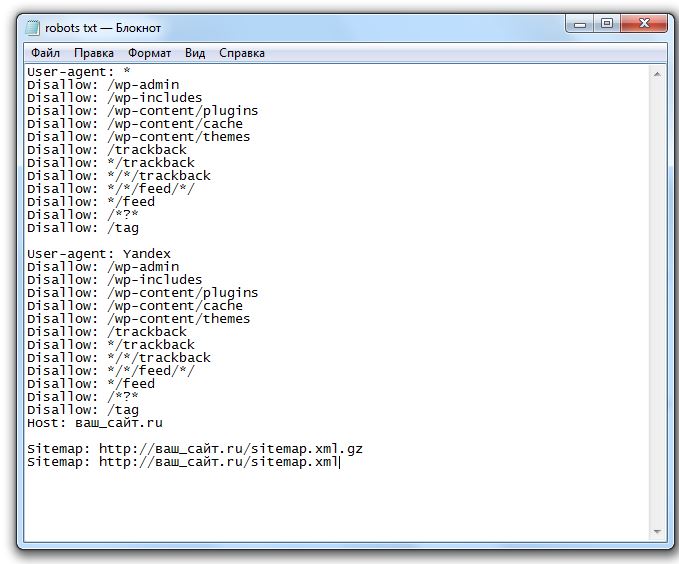
Вот пример — один из собственных продуктов Google:
Google Jamboard заблокирован от сканирования, но с почти 20000 ссылок с других сайтов (по данным Ahrefs) Google все равно проиндексировал его.
Пока страница ранжируется, она отображается без какой-либо дополнительной информации. Это потому, что Google не смог просканировать его и собрать какую-либо информацию для отображения. Он показывает только URL-адрес и основной заголовок, основанный на том, что Google нашел на других веб-сайтах, которые ссылаются на Jamboard.
Чтобы узнать, есть ли на вашей странице та же проблема и есть ли «Индексировано, хотя и заблокировано robots.txt», перейдите в консоль поиска Google и проверьте ее в инструменте проверки URL.
Нежелательный трафик
Если вы намеренно использовали директиву Disallow в файле robots.txt для определенной страницы, вы не хотите, чтобы пользователи могли найти эту страницу в Google. Предположим, например, что вы все еще работаете над содержанием этой страницы, и оно еще не готово для всеобщего просмотра.
Но если страница будет проиндексирована, пользователи смогут найти ее, зайти на нее и сформировать отрицательное мнение о вашем сайте.
Как исправить «Проиндексировано, но заблокировано robots.txt?»
Во-первых, найдите статус «Проиндексировано, но заблокировано robots.txt» в нижней части отчета об индексировании страниц в вашей консоли поиска Google.
Там вы можете увидеть таблицу «Улучшить внешний вид страницы».
Нажав на статус, вы увидите список затронутых URL-адресов и диаграмму, показывающую, как их количество менялось с течением времени.
Список можно фильтровать по URL-адресу или URL-пути. Если у вас есть много URL-адресов, затронутых этой проблемой, и вы хотите просмотреть только некоторые части своего веб-сайта, используйте символ пирамиды с правой стороны.
Прежде чем приступить к устранению неполадок, подумайте, действительно ли URL-адреса в списке должны быть проиндексированы. Содержат ли они контент, который может быть полезен вашим посетителям?
Если вы хотите, чтобы страница была проиндексирована
Если страница была запрещена в robots. txt по ошибке, вам необходимо изменить файл.
txt по ошибке, вам необходимо изменить файл.
После удаления директивы Disallow, блокирующей сканирование вашего URL-адреса, робот Googlebot, скорее всего, просканирует его при следующем посещении вашего веб-сайта.
Если вы хотите деиндексировать страницу
Если страница содержит информацию, которую вы не хотите показывать пользователям, посещающим вас через поисковую систему, вы должны сообщить Google, что не хотите индексировать страницу.
Robots.txt не следует использовать для управления индексацией. Этот файл блокирует сканирование Googlebot. Вместо этого используйте тег noindex.
Google всегда учитывает noindex, когда находит его на странице. Используя его, вы можете гарантировать, что Google не покажет вашу страницу в результатах поиска.
Вы можете найти подробные инструкции по его реализации на своих страницах в нашем руководстве по тегу noindex.
Не забудьте разрешить Google просканировать вашу страницу, чтобы обнаружить этот тег HTML. Это часть содержимого страницы.
Это часть содержимого страницы.
Если вы добавите тег noindex, но оставите страницу заблокированной в файле robots.txt, Google не обнаружит этот тег. И страница останется «Проиндексирована, но заблокирована robots.txt».
Когда Google просканирует страницу и увидит тег noindex, она будет удалена из индекса. Консоль поиска Google отобразит другой статус индексации при проверке этого URL-адреса.
Имейте в виду, что если вы хотите скрыть какую-либо страницу от Google и ее пользователей, всегда будет самым безопасным выбором реализовать HTTP-аутентификацию на вашем сервере. Таким образом, только пользователи, которые вошли в систему, могут получить к нему доступ. Это необходимо, например, если вы хотите защитить конфиденциальные данные.
Если вам нужно долгосрочное решение
Приведенные выше решения помогут вам на некоторое время решить проблему «Проиндексирован, хотя и заблокирован robots.txt». Однако возможно, что в будущем он появится и на других страницах.
Такой статус указывает на то, что вашему веб-сайту может потребоваться тщательная проверка внутренних ссылок или проверка обратных ссылок.
Что означает «Заблокировано robots.txt» в Google Search Console?
«Заблокировано robots.txt» означает, что Google не просканировал ваш URL-адрес, потому что вы заблокировали его с помощью директивы Disallow в robots.txt. Это также означает, что URL-адрес не был проиндексирован.
Помните, что робот Googlebot не может сканировать некоторые URL-адреса, особенно если ваш сайт становится больше. Некоторые из них не актуальны для поисковых систем по разным причинам.
Решение о том, какие страницы вашего веб-сайта следует и не следует сканировать, является обязательным шагом в создании надежной стратегии индексации вашего веб-сайта.
Как исправить «Заблокировано robots.txt?»
Во-первых, перейдите к таблице «Почему страницы не индексируются» под диаграммой в отчете об индексации страниц, чтобы разобраться с проблемами «Блокировано robots. txt.
txt.
Решение этой проблемы требует другого подхода в зависимости от того, заблокировали ли вы свою страницу по ошибке или намеренно.
Позвольте мне рассказать вам, как действовать в этих двух ситуациях:
Когда вы использовали директиву Disallow по ошибке
В этом случае, если вы хотите исправить «Заблокировано robots.txt», удалите блокировку директивы Disallow сканирование заданной страницы.
Благодаря этому робот Googlebot, скорее всего, просканирует ваш URL-адрес при следующем сканировании вашего веб-сайта. Без дальнейших проблем с этим URL Google также проиндексирует его.
Если у вас много URL-адресов, затронутых этой проблемой, попробуйте отфильтровать их в GSC. Нажмите на статус и перейдите к символу перевернутой пирамиды над списком URL-адресов.
Вы можете отфильтровать все затронутые страницы по URL-адресу (или только части пути URL-адреса) и дате последнего обхода.
Если вы видите сообщение «Заблокировано robots. txt», это может также означать, что вы намеренно заблокировали весь каталог, но непреднамеренно включили страницу, которую хотите просканировать. Чтобы устранить эту проблему:
txt», это может также означать, что вы намеренно заблокировали весь каталог, но непреднамеренно включили страницу, которую хотите просканировать. Чтобы устранить эту проблему:
- Включите в директиву Disallow как можно больше фрагментов пути URL, чтобы избежать возможных ошибок или
- Используйте директиву Allow, чтобы разрешить ботам сканировать определенный URL-адрес в запрещенном каталоге.
При изменении файла robots.txt я предлагаю вам проверить свои директивы с помощью тестера robots.txt в Google Search Console. Инструмент загружает файл robots.txt для вашего веб-сайта и помогает вам проверить, правильно ли ваш файл robots.txt блокирует доступ к заданным URL-адресам.
Тестер robots.txt также позволяет проверить, как ваши директивы влияют на конкретный URL-адрес в домене для данного агента пользователя, например, Googlebot. Благодаря этому вы можете поэкспериментировать с применением различных директив и посмотреть, заблокирован или принят URL-адрес.
Однако вы должны помнить, что инструмент не будет автоматически изменять ваш файл robots.txt. Поэтому, когда вы закончите тестирование директив, вам нужно вручную внести все изменения в свой файл.
Дополнительно я рекомендую использовать расширение Robots Exclusion Checker в Google Chrome. При просмотре любого домена инструмент позволяет обнаружить страницы, заблокированные файлом robots.txt. Он работает в режиме реального времени, поэтому поможет вам быстро реагировать, проверять и работать с заблокированными URL-адресами в вашем домене.
Посмотрите мою ветку в Твиттере, чтобы узнать, как я использую этот инструмент выше.
Что делать, если вы продолжаете блокировать важные страницы в robots.txt? Вы можете значительно ухудшить свою видимость в результатах поиска.
Когда вы намеренно использовали директиву Disallow
Вы можете игнорировать статус «Заблокировано robots.txt» в Google Search Console, если вы не запрещаете какие-либо ценные URL-адреса в файле robots. txt.
txt.
Помните, что запретить ботам сканировать низкокачественный или дублирующийся контент — это совершенно нормально.
Принятие решения о том, какие страницы должны и не должны сканировать боты, имеет решающее значение для:
- создания стратегии сканирования вашего веб-сайта и
- Значительно поможет вам оптимизировать и сэкономить краулинговый бюджет.
СЛЕДУЮЩИЕ ШАГИ
Вот что вы можете сделать сейчас:
- Свяжитесь с нами.
- Получите от нас индивидуальный план решения ваших проблем.
- Раскройте потенциал сканирования и индексирования вашего веб-сайта!
Все еще не уверены, стоит ли писать нам? Обратитесь за услугами по оптимизации краулингового бюджета, чтобы улучшить сканирование вашего веб-сайта.
Основные выводы
- Директива Disallow в файле robots.txt запрещает Google сканировать вашу страницу, но не индексировать ее.
- Наличие страниц, которые одновременно проиндексированы и не просканированы, плохо влияет на SEO.
