Метатег
Robots с примерами кода
Метатег роботов с примерами кода
Всем привет, в этом посте мы рассмотрим, как решить проблему метатега роботов на языке программирования.
Ниже приведен список различных подходов, которые можно использовать для решения проблемы с метатегами роботов.
Noindex: указывает поисковой системе не индексировать страницу.
Индекс: указывает поисковой системе индексировать страницу. Обратите внимание, что вам не нужно добавлять этот метатег; это значение по умолчанию.
Следовать: даже если страница не проиндексирована, сканер должен переходить по всем ссылкам на странице и передавать доступ к связанным страницам.
Nofollow: указывает сканеру не переходить ни по каким ссылкам на странице и не передавать какой-либо ссылочный вес.
Noimageindex: указывает сканеру не индексировать изображения на странице.
Нет: эквивалентно одновременному использованию тегов noindex и nofollow. Мы представили множество наглядных примеров, чтобы показать, как можно решить проблему с метатегами роботов, а также объяснили, как это сделать.
Как роботы используют метатеги? Если вы используете оба файла robots. Если вы заблокируете страницу с помощью robots. txt, робот Googlebot никогда не просканирует страницу и не прочитает какие-либо метатеги на странице.
Что лучше: метатеги роботов или robots txt? Роботы. txt лучше всего подходят для запрета целого раздела сайта, например категории, тогда как метатег более эффективен для запрета отдельных файлов и страниц. Вы можете использовать как метатег robots, так и файл robots.
Как мне найти метатег робота? После сканирования сайта вы можете легко проверить отчет «Неиндексированные страницы», чтобы просмотреть все страницы, которые не индексируются, с помощью метатега robots, ответа заголовка x-robots-tag или с помощью noindex в robots.08-Nov- 2015
Что такое пример метатега? Поисковые системы, такие как Google, используют метаданные из метатегов для понимания дополнительной информации о веб-странице. Они могут использовать эту информацию для целей ранжирования, для отображения фрагментов в результатах поиска, а иногда могут игнорировать метатеги.
и <description>.24 июля 2019 г.</p><h3><span class="ez-toc-section" id="_HTML-_robots"> Что такое HTML-тег robots? </span></h3><p> Метатег robots — это HTML-тег, который идет в теге заголовка страницы и содержит инструкции для ботов. Как роботы. txt, он сообщает поисковым роботам, разрешено ли им индексировать страницу.</p><h3><span class="ez-toc-section" id="i-4"> Что означают метароботы? </span></h3><p> Мета-тег robots — это тег, который сообщает поисковым системам, чему следует следовать, а чему — нет. Это фрагмент кода в разделе<head> вашей веб-страницы. Это простой код, который дает вам возможность решить, какие страницы вы хотите скрыть от сканеров поисковых систем и какие страницы вы хотите, чтобы они проиндексировали и просматривали.</p><h3><span class="ez-toc-section" id="_robots"> Что такое текстовый файл robots на веб-сайте? </span></h3><p> Файл robots.txt сообщает сканерам поисковых систем, к каким URL-адресам на вашем сайте они могут получить доступ. Это используется в основном для того, чтобы не перегружать ваш сайт запросами; это не механизм защиты веб-страницы от Google.<img class="lazy lazy-hidden" loading='lazy' src="//russia-dropshipping.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/http/hitechwork.com/wp-content/uploads/2016/05/no-index-no-follow-meta-tag-1024x562.jpg' /><noscript><img loading='lazy' src='/800/600/http/hitechwork.com/wp-content/uploads/2016/05/no-index-no-follow-meta-tag-1024x562.jpg' /></noscript> Чтобы веб-страница не попала в Google, заблокируйте индексирование с помощью noindex или защитите страницу паролем.</p><h3><span class="ez-toc-section" id="_robots_txt-2"> Как мне использовать robots txt на своем веб-сайте? </span></h3><p> Основные рекомендации по созданию роботов. txt</p><ul><li> Создайте файл с именем robots. текст.</li><li> Добавить правила для файла robots. текстовый файл.</li><div id="yandex_rtb_5" class="yandex-adaptive classYandexRTB"></div> <script type="text/javascript">if(rtbW>=960){var rtbBlockID="R-A-744204-3";}
else{var rtbBlockID="R-A-744204-5";}
window.yaContextCb.push(()=>{Ya.Context.AdvManager.render({renderTo:"yandex_rtb_5",blockId:rtbBlockID,pageNumber:5,onError:(data)=>{var g=document.createElement("ins");g.className="adsbygoogle";g.style.display="inline";if(rtbW>=960){g.style.width="580px";g.style.height="400px";g.setAttribute("data-ad-slot","9935184599");}else{g.style.width="300px";g.style.height="600px";g.setAttribute("data-ad-slot","9935184599");}
g.setAttribute("data-ad-client","ca-pub-1812626643144578");g.setAttribute("data-alternate-ad-url",stroke2);document.getElementById("yandex_rtb_5").appendChild(g);(adsbygoogle=window.adsbygoogle||[]).push({});}})});window.addEventListener("load",()=>{var ins=document.getElementById("yandex_rtb_5");if(ins.clientHeight =="0"){ins.innerHTML=stroke3;}},true);</script> <li> Загрузить роботов. txt на свой сайт.</li><li> Протестируйте роботов. текстовый файл.</li></ul><h3><span class="ez-toc-section" id="i-5"> Какие продвинутые мета роботы? </span></h3><p> На вкладке «Дополнительно» в Yoast SEO вы можете определить, как поисковые системы сканируют и индексируют вашу запись, страницу или другой тип контента.</p><h3><span class="ez-toc-section" id="i-6"> Как узнать, что сайт не индексируется? </span></h3><p> Таким образом, способ проверки на наличие noindex состоит в том, чтобы выполнить оба действия: Проверить X-Robots-Tag, содержащий «noindex» или «none» в ответах HTTP (попробуйте curl -I https://www.example.com, чтобы увидеть как они выглядят) Получите HTML и просмотрите метатеги на наличие «noindex» или «none» в атрибуте содержимого.<img class="lazy lazy-hidden" loading='lazy' src="//russia-dropshipping.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/http/i.pinimg.com/originals/e0/dd/93/e0dd93a57f63db153b57aa459ec4c41f.png' /><noscript><img loading='lazy' src='/800/600/http/i.pinimg.com/originals/e0/dd/93/e0dd93a57f63db153b57aa459ec4c41f.png' /></noscript> 14 февраля 2017 г.</p> Категории Без категорий<p> Copyright © Все права защищены. Тех</p> Метатег<h2><span class="ez-toc-section" id="Robots_X-Robots"> Robots и теги X-Robots </span></h2><p> Существуют две директивы, которым сканеры поисковых систем выполняют команды перед сканированием и индексированием. Это Robots.txt и метатег Robots. В котором robots.txt помогает разрешить или запретить веб-страницы или веб-сайты для каждого поискового робота.</p><center><ins class="adsbygoogle"
style="display:inline-block;width:580px;height:400px"
data-ad-client="ca-pub-1812626643144578"
data-ad-slot="8813674614"></ins> <script>(adsbygoogle=window.adsbygoogle||[]).push({});</script></center><p> Напротив, метатег robots дает команду сканеру индексировать или исключать из индексации, передавая вес ссылки.</p><p> Давайте начнем использовать полную концепцию тега robots и HTTP-заголовка X-Robots-tag.</p><p><h3><span class="ez-toc-section" id="i-7"> Что такое метатег роботов? </span></h3></p><p> Тег robots — это код мета-директивы, присутствующий в разделе заголовка (<head>…</head>) HTML-файла любой веб-страницы. Этот HTML-код помогает поисковым роботам либо индексировать, либо не индексировать веб-страницу.</p><p> Мета-директивы предоставляют сканерам набор инструкций о том, как и что сканировать и индексировать.<img class="lazy lazy-hidden" loading='lazy' src="//russia-dropshipping.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/http/emarketingblogger.com/wp-content/uploads/2014/04/robots-and-meta-noindex-google.jpg' /><noscript><img loading='lazy' src='/800/600/http/emarketingblogger.com/wp-content/uploads/2014/04/robots-and-meta-noindex-google.jpg' /></noscript> Любой веб-сайт или веб-страницы без этих директив, вероятно, будут проиндексированы или закончатся нежелательными страницами индексации.</p><p> Он также содержит дополнительные директивы, которыми мы поделимся в другом разделе. И robots.txt, и метатег robots играют роль в управлении работой поисковых роботов, но оба они конфликтуют друг с другом в процессе.</p><div id="yandex_rtb_4" class="yandex-adaptive classYandexRTB"></div> <script type="text/javascript">if(rtbW>=960){var rtbBlockID="R-A-744204-3";}
else{var rtbBlockID="R-A-744204-5";}
window.yaContextCb.push(()=>{Ya.Context.AdvManager.render({renderTo:"yandex_rtb_4",blockId:rtbBlockID,pageNumber:4,onError:(data)=>{var g=document.createElement("ins");g.className="adsbygoogle";g.style.display="inline";if(rtbW>=960){g.style.width="580px";g.style.height="400px";g.setAttribute("data-ad-slot","9935184599");}else{g.style.width="300px";g.style.height="600px";g.setAttribute("data-ad-slot","9935184599");}
g.setAttribute("data-ad-client","ca-pub-1812626643144578");g.setAttribute("data-alternate-ad-url",stroke2);document.getElementById("yandex_rtb_4").appendChild(g);(adsbygoogle=window.adsbygoogle||[]).push({});}})});window.addEventListener("load",()=>{var ins=document.getElementById("yandex_rtb_4");if(ins.clientHeight =="0"){ins.innerHTML=stroke3;}},true);</script> <p> При этом robots.txt – это файл, который должен быть включен в базовый файл веб-сайта, он должен содержать директивы и XML-карту сайта. Напротив, тег robots — это просто фрагмент HTML-кода.</p><p> В файле HTML это выглядит следующим образом:</p><pre> <head> <br/> <meta name="robots" content="index,follow"> <br/> </head> </pre><p> Существует два типа метадиректив роботов. Один из них — метатег robots, а другой — тег X-Robots в HTTP-заголовке веб-сервера.</p><p><h3><span class="ez-toc-section" id="_Robots_SEO"> Почему метатег Robots используется в SEO? </span></h3></p><p> HTML-теги robots используются для включения или исключения веб-страниц из индексации поисковыми системами.<img class="lazy lazy-hidden" loading='lazy' src="//russia-dropshipping.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/http/495p3ynf80l2rq8ud44wk2f6-wpengine.netdna-ssl.com/wp-content/uploads/2019/04/Yoast-SEO.jpg' /><noscript><img loading='lazy' src='/800/600/http/495p3ynf80l2rq8ud44wk2f6-wpengine.netdna-ssl.com/wp-content/uploads/2019/04/Yoast-SEO.jpg' /></noscript></p><p> Вот важные роли, которые роботы метатегируют, чтобы помочь веб-страницам предотвратить индексацию</p><ul><li> Исключение веб-сайта из индексации в тестовой среде.</li><li> Тонкие страницы или страницы-дубликаты</li><center><ins class="adsbygoogle"
style="display:block"
data-ad-client="ca-pub-1812626643144578"
data-ad-slot="3076124593"
data-ad-format="auto"
data-full-width-responsive="true"></ins> <script>(adsbygoogle=window.adsbygoogle||[]).push({});</script></center><li> Страницы администратора и входа.</li><li> Добавить в корзину, инициировать оформление заказа и страницу благодарности.</li><li> Целевые страницы, которые используются для кампаний PPC.</li><li> Поиск по страницам сайта.</li><li> Рекламные страницы, страницы конкурса или запуска продукта.</li><li> Веб-страницы с внутренними и конфиденциальными данными.</li><li> Категория, тэг веб-страниц.</li><li> Кэшированные веб-страницы.</li></ul><p> Вы должны понимать полную концепцию атрибутов, директив и фрагментов кода, чтобы давать указания сканерам в соответствии с рекомендациями для веб-мастеров.</p><p><h3><span class="ez-toc-section" id="_X-Robots"> Что такое тег X-Robots? </span></h3></p><p> Метатег robots позволяет сканерам управлять индексом/неиндексированием веб-страницы, но <em> x-robots-tag </em> может препятствовать индексированию всего веб-сайта или части веб-страниц, поскольку он присутствует в заголовке HTTP сервера.<img class="lazy lazy-hidden" loading='lazy' src="//russia-dropshipping.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/http/i.ytimg.com/vi/kgXIwAIclmQ/hqdefault.jpg' /><noscript><img loading='lazy' src='/800/600/http/i.ytimg.com/vi/kgXIwAIclmQ/hqdefault.jpg' /></noscript><div id="yandex_rtb_3" class="yandex-adaptive classYandexRTB"></div> <script type="text/javascript">if(rtbW>=960){var rtbBlockID="R-A-744204-3";}
else{var rtbBlockID="R-A-744204-5";}
window.yaContextCb.push(()=>{Ya.Context.AdvManager.render({renderTo:"yandex_rtb_3",blockId:rtbBlockID,pageNumber:3,onError:(data)=>{var g=document.createElement("ins");g.className="adsbygoogle";g.style.display="inline";if(rtbW>=960){g.style.width="580px";g.style.height="400px";g.setAttribute("data-ad-slot","9935184599");}else{g.style.width="300px";g.style.height="600px";g.setAttribute("data-ad-slot","9935184599");}
g.setAttribute("data-ad-client","ca-pub-1812626643144578");g.setAttribute("data-alternate-ad-url",stroke2);document.getElementById("yandex_rtb_3").appendChild(g);(adsbygoogle=window.adsbygoogle||[]).push({});}})});window.addEventListener("load",()=>{var ins=document.getElementById("yandex_rtb_3");if(ins.clientHeight =="0"){ins.innerHTML=stroke3;}},true);</script> файл.</p><p> Теги X-robot обычно доступны в файлах сервера, файлах header.php или .htaccess.</p><p> И тег robots, и x-robots-tag используют одни и те же директивы, такие как index, noindex, follow, nofollow, nosnippet, noimageindex, imageindex и т. д. По сравнению с метатегами x-robots имеют более специфические и гибкие функции.</p><p> X-роботы могут выполнять директивы сканирования для файлов, отличных от HTML, поскольку они используют регулярные выражения с глобальными параметрами.</p><p> Рассмотрите возможность использования тега x robots в следующих случаях:</p><ol><li> Вы хотите предотвратить индексирование изображений, видео или PDF-файлов на странице, а не самой веб-страницы.</li><li> Для индексации или исключения из индексации любого файла веб-страницы, отличного от кодов HTML.</li><li> Если у вас нет доступа для редактирования или модерации заголовка HTML-файла, вы можете получить доступ к тегу X-Robots с сервера, чтобы включить директивы.</li></ol><pre> <Files ~ "\.<img class="lazy lazy-hidden" loading='lazy' src="//russia-dropshipping.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/http/searchengineland.com/wp-content/seloads/2018/04/janet5.png' /><noscript><img loading='lazy' src='/800/600/http/searchengineland.com/wp-content/seloads/2018/04/janet5.png' /></noscript><center><div class="advv"><ins class="adsbygoogle"
style="display:inline-block;width:336px;height:280px"
data-ad-client="ca-pub-1812626643144578"
data-ad-slot="9935184599"></ins> <script>(adsbygoogle=window.adsbygoogle||[]).push({});</script></div></center><center><div class="advv"><ins class="adsbygoogle"
style="display:inline-block;width:336px;height:280px"
data-ad-client="ca-pub-1812626643144578"
data-ad-slot="9935184599"></ins> <script>(adsbygoogle=window.adsbygoogle||[]).push({});</script></div></center> videos$"> <br/> Набор заголовков X-Robots-Tag "noindex, follow" <br/> </Files> </pre><p><h3><span class="ez-toc-section" id="i-8"> Директивы метатегов роботов: </span></h3></p><p> Чтобы лучше понять директивы, давайте еще раз посмотрим на структуру метатега robots.</p><p><meta name="robots" content="index,follow"></p><p> Здесь у вас есть два атрибута, и все используемые директивы должны быть указаны под этими двумя атрибутами.</p><ol><li> Имя.</li><li> Содержание.</li></ol><p><h4><span class="ez-toc-section" id="i-9"> Атрибуты имени: </span></h4></p><p> Команда общего доступа к атрибутам имени, для которого или какого поискового робота применяются следующие HTML-коды тега robots. Он действует так же, как пользовательский агент в файле robots.txt.</p><p> <em> name=»robots» </em> -Эта команда предназначена для всех поисковых роботов, обращающихся к веб-странице.</p><p> <em> name = «Googlebot» </em> — Команда предназначена только для робота Googlebot.</p><p> Большинство экспертов по поисковой оптимизации обычно используют директиву «роботы» в атрибутах имени, которые применяются метатегом и контролируют все поисковые роботы.<img class="lazy lazy-hidden" loading='lazy' src="//russia-dropshipping.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/http/cultofweb.com/blog/wp-content/uploads/2018/02/meta-robots-tag-example-1.jpg' /><noscript><img loading='lazy' src='/800/600/http/cultofweb.com/blog/wp-content/uploads/2018/02/meta-robots-tag-example-1.jpg' /></noscript><div id="yandex_rtb_2" class="yandex-adaptive classYandexRTB"></div> <script type="text/javascript">if(rtbW>=960){var rtbBlockID="R-A-744204-3";}
else{var rtbBlockID="R-A-744204-5";}
window.yaContextCb.push(()=>{Ya.Context.AdvManager.render({renderTo:"yandex_rtb_2",blockId:rtbBlockID,pageNumber:2,onError:(data)=>{var g=document.createElement("ins");g.className="adsbygoogle";g.style.display="inline";if(rtbW>=960){g.style.width="580px";g.style.height="400px";g.setAttribute("data-ad-slot","9935184599");}else{g.style.width="300px";g.style.height="600px";g.setAttribute("data-ad-slot","9935184599");}
g.setAttribute("data-ad-client","ca-pub-1812626643144578");g.setAttribute("data-alternate-ad-url",stroke2);document.getElementById("yandex_rtb_2").appendChild(g);(adsbygoogle=window.adsbygoogle||[]).push({});}})});window.addEventListener("load",()=>{var ins=document.getElementById("yandex_rtb_2");if(ins.clientHeight =="0"){ins.innerHTML=stroke3;}},true);</script> </p><p> Код может состоять из нескольких строк, если атрибуты имени используются для определенных поисковых роботов или пользовательских агентов.</p><p> Вот наиболее распространенные атрибуты имени или пользовательские агенты, используемые во всем мире.</p><p> <strong> Роботы </strong> -> Все сканеры <br/> <strong> Googlebot </strong> -> Поисковые роботы Google для настольных компьютеров <br/> <strong> Googlebot-новый </strong> -> Поисковые роботы Google News <br/> <strong> Googlebot-изображения </strong> -> Поисковые роботы Google Image <br/> <strong> Смартфон Googlebot-мобильный </strong> -> Googlebot для мобильных устройств <br/> <strong> Adsbot-Google </strong> -> Google Ads Bot для ПК <br/> <strong> Adsbot-Google-мобильная версия </strong><center><ins class="adsbygoogle"
style="display:block; text-align:center;"
data-ad-layout="in-article"
data-ad-format="fluid"
data-ad-client="ca-pub-1812626643144578"
data-ad-slot="4491286225"></ins> <script>(adsbygoogle=window.adsbygoogle||[]).push({});</script></center> -> Google Ads Bot для мобильных устройств <br/> <strong> Mediapartners-Google </strong> -> Adsense Bot <br/> <strong> Googlebot-Video </strong> -> Google Bot для видео <br/> <strong> BingBot </strong> -> Поисковые роботы Bing для компьютеров и мобильных устройств <br/> <strong> MSNBot-Media </strong> -> Бот Bing для сканирования изображений и видео.<img class="lazy lazy-hidden" loading='lazy' src="//russia-dropshipping.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/http/avmaphoto.com/wp-content/uploads/2019/01/2.png' /><noscript><img loading='lazy' src='/800/600/http/avmaphoto.com/wp-content/uploads/2019/01/2.png' /></noscript> <br/> <strong> Baiduspider </strong> -> Поисковые роботы Baidu для компьютеров и мобильных устройств. <br/> <strong> Slurp </strong> -> Yahoo Crawlers <br/> <strong> DuckDuckBot </strong> -> DuckDuckGo Crawlers</p><p><h4><span class="ez-toc-section" id="i-10"> Атрибуты содержимого: </span></h4></p><p> Атрибуты содержимого — это команда, дающая указание программе-обходчику, упомянутой в атрибутах имени.</p><p> Было бы полезно, если бы вы плохо понимали различные директивы тегов роботов, чтобы следовать идеальной стратегии SEO. Значение по умолчанию в соответствии с метатегом robots — «индексировать, следовать».</p><div id="yandex_rtb_1" class="yandex-adaptive classYandexRTB"></div> <script type="text/javascript">if(rtbW>=960){var rtbBlockID="R-A-744204-3";}
else{var rtbBlockID="R-A-744204-5";}
window.yaContextCb.push(()=>{Ya.Context.AdvManager.render({renderTo:"yandex_rtb_1",blockId:rtbBlockID,pageNumber:1,onError:(data)=>{var g=document.createElement("ins");g.className="adsbygoogle";g.style.display="inline";if(rtbW>=960){g.style.width="580px";g.style.height="400px";g.setAttribute("data-ad-slot","9935184599");}else{g.style.width="300px";g.style.height="600px";g.setAttribute("data-ad-slot","9935184599");}
g.setAttribute("data-ad-client","ca-pub-1812626643144578");g.setAttribute("data-alternate-ad-url",stroke2);document.getElementById("yandex_rtb_1").appendChild(g);(adsbygoogle=window.adsbygoogle||[]).push({});}})});window.addEventListener("load",()=>{var ins=document.getElementById("yandex_rtb_1");if(ins.clientHeight =="0"){ins.innerHTML=stroke3;}},true);</script> <p> Вот наиболее часто используемые директивы в атрибутах содержимого.</p><p> <strong> все </strong> -> Это то же самое, что и настройка по умолчанию для команды index, follow (можно использовать как ярлык)</p><p> <strong> нет </strong> -> Ярлык для noindex, nofollow</p><p> <strong> index </strong> -> Команды для индексирования веб-страница</p><p> <strong> noindex </strong> -> Дайте указание имени (пользовательскому агенту) исключить веб-страницу из сканирования.<img class="lazy lazy-hidden" loading='lazy' src="//russia-dropshipping.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/http/znet.ru/wp-content/uploads/2017/02/kak-propisat.png' /><noscript><img loading='lazy' src='/800/600/http/znet.ru/wp-content/uploads/2017/02/kak-propisat.png' /></noscript></p><p> <strong> следовать </strong> -> Помогает поисковым роботам обнаруживать новые веб-страницы, на которые есть ссылки, и передавать ссылочный вес.</p><p> <strong> nofollow </strong> -> Блокирует поиск новых веб-страниц и ссылок.</p><p> <strong> nosnippet </strong> -> Эта команда исключает метаописание и другие расширенные результаты, видимые в поисковой выдаче.</p><p> <strong> noimageindex </strong><center><ins class="adsbygoogle"
style="display:block"
data-ad-client="ca-pub-1812626643144578"
data-ad-slot="3076124593"
data-ad-format="auto"
data-full-width-responsive="true"></ins> <script>(adsbygoogle=window.adsbygoogle||[]).push({});</script></center> -> Указывает поисковым роботам не индексировать изображения на веб-странице.</p><p> <strong> noarchive </strong> -> Не показывать кешированную версию страницы в поисковой выдаче</p><p> <strong> nocache </strong> -> то же, что и noarchive, но используется только для MSN.</p><p> <strong> notranslate </strong> -> Указывает сканерам не отображать переведенную версию веб-страницы в SERP (странице результатов поисковой системы).</p><p> <strong> nositelinkssearchbox </strong> -> Эта команда не позволяет отображать окно поиска сайта в поисковой выдаче.</p><p> <strong> нет страниц читать вслух </strong> -> Исключает сканеры, не читающие веб-страницу во время голосового поиска.<img class="lazy lazy-hidden" loading='lazy' src="//russia-dropshipping.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/http/seoprofy.ua/wp-content/uploads/2016/04/ci-5.png' /><noscript><img loading='lazy' src='/800/600/http/seoprofy.ua/wp-content/uploads/2016/04/ci-5.png' /></noscript></p><p> <strong> unavailable_after </strong> -> Указывает поисковым роботам деиндексировать веб-страницу через определенное время.</p><p> <strong> Noodyp/noydir </strong> -> С помощью этого тега поисковые системы не могут использовать описание DMOZ в качестве фрагмента SERP</p><p> Вы можете просмотреть полный список всех директив, поддерживаемых Google и Bing.</p><p><h3><span class="ez-toc-section" id="i-11"> Мета-роботы Примеры тегов: </span></h3></p><p> Вот примеры метатегов robots, которые могут улучшить методы поисковой оптимизации.</p><p> <strong> 1. Индексируйте и переходите по ссылкам на другие страницы: </strong></p><pre> <meta name="robots" content="index, follow" /> </pre><p> или</p><pre> <meta name="robots" content="all" /> </pre><p> <strong> 2. Индексировать, но не разрешать переходить по ссылке: </strong></p><pre> <meta name="robots" content="index, nofollow" /> </pre><p> <strong> 3. Не индексировать и не разрешить перейти по ссылке: </strong></p><pre> <meta name="robots" content="noindex, nofollow" /> </pre><p> или</p><pre> <meta name="robots" content="none" /> </pre><p> <strong> 4.<img class="lazy lazy-hidden" loading='lazy' src="//russia-dropshipping.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/http/2.bp.blogspot.com/-7-stny6kEn0/Wmjplit7EsI/AAAAAAAAAS0/AVqrBAv3Ujww5KZ6cyvTcbMiWQnqmXcEgCPcBGAYYCw/s1600/meta-keyword-otomatis-di-blog.png' /><noscript><img loading='lazy' src='/800/600/http/2.bp.blogspot.com/-7-stny6kEn0/Wmjplit7EsI/AAAAAAAAAS0/AVqrBAv3Ujww5KZ6cyvTcbMiWQnqmXcEgCPcBGAYYCw/s1600/meta-keyword-otomatis-di-blog.png' /></noscript> Не индексировать, но разрешить перейти по ссылке на другие страницы: </strong></p><pre> <meta name="robots" content ="noindex, follow" /> </pre><p><h3><span class="ez-toc-section" id="_Robots"> Роль сниппетов и директив в метатеге Robots: </span></h3></p><p> Тег robots предназначен не только для управления индексацией и позволяет поисковым роботам переходить по ссылке. Это также помогает поддерживать видимость сниппетов в поисковой выдаче.</p><p> Вот наиболее распространенные директивы сниппета, используемые в метатеге robots.</p><p> <strong> nosnippet </strong> -> Указывает на исключение отображения фрагментов или метаописаний в поисковой выдаче.</p><p> <strong> max-snippet:[number] </strong> -> Этот фрагмент помогает контролировать максимальное количество символов, которое может содержать фрагмент.</p><p> <strong> max-video-preview:[число] </strong> -> Этот фрагмент помогает отображать видео в поисковой выдаче и содержит ограничение продолжительности.</p><p> <strong> максимальный предварительный просмотр изображения [настройка] </strong> -> Фрагмент кода указывает указать максимальный размер предварительного просмотра изображения: «нет», «стандартный» или «большой».<img class="lazy lazy-hidden" loading='lazy' src="//russia-dropshipping.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/http/searchengineland.com/wp-content/seloads/2018/07/barry7.png' /><noscript><img loading='lazy' src='/800/600/http/searchengineland.com/wp-content/seloads/2018/07/barry7.png' /></noscript></p><h4></h4><strong> Как использовать директивы сниппета в метатеге robots? </strong></h4><p> <strong> 1. Не показывать фрагменты веб-страницы в поисковой выдаче: </strong></p><pre> <meta name:"robots" content="nosnippet" /> </pre><p> <strong> 2. Установить максимальное количество символов в описании веб-страница: </strong></p><pre> <meta name="robot" content="max-snippet:156" /> </pre><p> <strong> 3. Установите размер изображения и просмотрите его в поисковой выдаче: </strong></p><pre> <meta name="robots" content="max-image-preview:large" /> </pre><p> Размер изображения может быть нулевым, стандартным , и большой</p><p> <strong> 4. Установите продолжительность в секундах и видимость видео в поисковой выдаче. </strong></p><pre> <meta name="robots" content="max-video-preview:20" /> </pre><p> <strong> 5. Использование всех фрагментов в одном коде: </strong></p><pre> <meta name="robots" content=" максимальный фрагмент: 156, максимальный предварительный просмотр видео: 20, максимальный предварительный просмотр изображения: большой" /> </pre><p> Используйте запятые для разделения каждого фрагмента при объединении каждого фрагмента в один код.<img class="lazy lazy-hidden" loading='lazy' src="//russia-dropshipping.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/http/i1.ytimg.com/vi/4rsOpkDFDtc/hqdefault.jpg' /><noscript><img loading='lazy' src='/800/600/http/i1.ytimg.com/vi/4rsOpkDFDtc/hqdefault.jpg' /></noscript></p><p><h3><span class="ez-toc-section" id="i-12"> Передовые методы оптимизации роботов Метатег: </span></h3></p><p> Сканирование и индексирование играют огромную роль в том, чтобы сделать ваш контент видимым в поисковой выдаче, это цель каждого эксперта по SEO. При работе с огромным веб-сайтом краулинговый бюджет играет роль в индексации потенциальных веб-страниц.</p><p> Тег robots играет огромную роль в управлении сканированием, и вот несколько советов, которые вам понадобятся для оптимизации метатега robots, который не повредит сканированию и индексированию.</p><p><h4><span class="ez-toc-section" id="_Robots_-_Robotstxt"> Никогда не добавляйте директивы тегов Robots на веб-страницы, заблокированные файлом Robots.txt </span></h4></p><p> Если какая-либо страница запрещена в robots.txt, поисковые системы обычно исключают веб-страницы из сканирования. Одновременно сканеры также читают директивы веб-страниц, указанные в метатеге robots и теге X-robots.</p><p> Убедитесь, что директивы тегов robots не указывают индексировать веб-страницу. Поскольку он отключает директивы, указанные в robots.<img class="lazy lazy-hidden" loading='lazy' src="//russia-dropshipping.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/http/seoservices-india.in/blog/wp-content/uploads/2020/08/robot.jpg' /><noscript><img loading='lazy' src='/800/600/http/seoservices-india.in/blog/wp-content/uploads/2020/08/robot.jpg' /></noscript> txt.</p><p> Поэтому мы рекомендуем никогда не добавлять на веб-страницу какие-либо директивы метатегов robots, которые заблокированы файлом robots.txt</p><p><h4><span class="ez-toc-section" id="_Meta_Robots_Robotstxt"> Никогда не используйте директивы тегов Meta Robots в Robots.txt: </span></h4></p><p> В 2019 году Google официально объявил, что никогда не поддерживает директивы тегов роботов, такие как index, noindex, follow и nofollow в robots.txt.</p><p> Поэтому не включайте эти директивы в файл robots.txt.</p><p><h4><span class="ez-toc-section" id="i-13"> Никогда не блокировать весь сайт от блокировки: </span></h4></p><p> Когда сайт перемещается на действующий сервер, директивы robots могут быть случайно оставлены на месте при использовании в промежуточной среде.</p><p> Прежде чем перемещать сайт из промежуточной среды в реальную среду, убедитесь, что все директивы для роботов верны.</p><p> Аналогичным образом можно случайно исключить весь сайт из индексации с помощью директив noindex в теге x-robots или метатеге robots.</p><p><h4><span class="ez-toc-section" id="_Noindex_Sitemap"> Никогда не удалять страницы с директивой Noindex из файлов Sitemap: </span></h4></p><blockquote><p dir="ltr" lang="en"> @nishanthstephen обычно все, что вы добавляете в карту сайта, будет получено раньше</p><p> — Гэри 鯨理/경리 Illyes (@methode) 13 октября 2015 г.<img class="lazy lazy-hidden" loading='lazy' src="//russia-dropshipping.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/http/searchengineland.com/wp-content/seloads/2018/07/barry10.png' /><noscript><img loading='lazy' src='/800/600/http/searchengineland.com/wp-content/seloads/2018/07/barry10.png' /></noscript></div><footer class="entry-footer"> <span><i class="fa fa-folder"></i> <a href="https://russia-dropshipping.ru/category/raznoe" rel="category tag">Разное</a></span><span><i class="fa fa-link"></i><a href="https://russia-dropshipping.ru/raznoe/robots-meta-tag-noindex-robots-meta-tags-specifications-google-search-central-documentation.html" rel="bookmark"> permalink</a></span></footer></article><nav class="navigation post-navigation clearfix" role="navigation"><h1 class="screen-reader-text">Post navigation</h1><div class="nav-links"><div class="nav-previous"><a href="https://russia-dropshipping.ru/raznoe/100-shablonov-100-shablonov-prezentaczij-powerpoint-kotorye-mozhno-skachat-besplatno.html" rel="prev"><i class="fa fa-long-arrow-left"></i> 100 шаблонов: 100 шаблонов презентаций PowerPoint, которые можно скачать бесплатно</a></div><div class="nav-next"><a href="https://russia-dropshipping.ru/raznoe/avtoposting-v-vk-instrukcziya-po-nastrojke-21-programma.html" rel="next">Автопостинг в вк: инструкция по настройке + 21 программа <i class="fa fa-long-arrow-right"></i></a></div></div></nav><div id="comments" class="comments-area"><div id="respond" class="comment-respond"><h3 id="reply-title" class="comment-reply-title">Добавить комментарий <small><a rel="nofollow" id="cancel-comment-reply-link" href="/raznoe/robots-meta-tag-noindex-robots-meta-tags-specifications-google-search-central-documentation.html#respond" style="display:none;">Отменить ответ</a></small></h3><form action="https://russia-dropshipping.ru/wp-comments-post.php" method="post" id="commentform" class="comment-form" novalidate><p class="comment-notes"><span id="email-notes">Ваш адрес email не будет опубликован.</span> <span class="required-field-message">Обязательные поля помечены <span class="required">*</span></span></p><p class="comment-form-comment"><label for="comment">Комментарий <span class="required">*</span></label><textarea id="comment" name="comment" cols="45" rows="8" maxlength="65525" required></textarea></p><p class="comment-form-author"><label for="author">Имя <span class="required">*</span></label> <input id="author" name="author" type="text" value="" size="30" maxlength="245" autocomplete="name" required /></p><p class="comment-form-email"><label for="email">Email <span class="required">*</span></label> <input id="email" name="email" type="email" value="" size="30" maxlength="100" aria-describedby="email-notes" autocomplete="email" required /></p><p class="comment-form-url"><label for="url">Сайт</label> <input id="url" name="url" type="url" value="" size="30" maxlength="200" autocomplete="url" /></p><p class="form-submit"><input name="submit" type="submit" id="submit" class="submit" value="Отправить комментарий" /> <input type='hidden' name='comment_post_ID' value='46069' id='comment_post_ID' /> <input type='hidden' name='comment_parent' id='comment_parent' value='0' /></p></form></div></div></main></div><div id="secondary" class="widget-area" role="complementary"><aside id="search-2" class="widget widget_search"><form role="search" method="get" class="search-form" action="https://russia-dropshipping.ru/"> <label> <span class="screen-reader-text">Найти:</span> <input type="search" class="search-field" placeholder="Поиск…" value="" name="s" /> </label> <input type="submit" class="search-submit" value="Поиск" /></form></aside><aside id="categories-3" class="widget widget_categories"><h3 class="widget-title">Рубрики</h3><ul><li class="cat-item cat-item-7"><a href="https://russia-dropshipping.ru/category/seo">Seo</a></li><li class="cat-item cat-item-15"><a href="https://russia-dropshipping.ru/category/instrument-2">Инструмент</a></li><li class="cat-item cat-item-9"><a href="https://russia-dropshipping.ru/category/instrument">Инструменты</a></li><li class="cat-item cat-item-16"><a href="https://russia-dropshipping.ru/category/program-2">Програм</a></li><li class="cat-item cat-item-4"><a href="https://russia-dropshipping.ru/category/program">Программы</a></li><li class="cat-item cat-item-14"><a href="https://russia-dropshipping.ru/category/prodvizh-2">Продвиж</a></li><li class="cat-item cat-item-5"><a href="https://russia-dropshipping.ru/category/prodvizh">Продвижение</a></li><li class="cat-item cat-item-3"><a href="https://russia-dropshipping.ru/category/raznoe">Разное</a></li><li class="cat-item cat-item-13"><a href="https://russia-dropshipping.ru/category/semant-2">Семант</a></li><li class="cat-item cat-item-8"><a href="https://russia-dropshipping.ru/category/semant">Семантика</a></li><li class="cat-item cat-item-17"><a href="https://russia-dropshipping.ru/category/sovet-2">Совет</a></li><li class="cat-item cat-item-11"><a href="https://russia-dropshipping.ru/category/sovet">Советы</a></li><li class="cat-item cat-item-12"><a href="https://russia-dropshipping.ru/category/sozdan-2">Создан</a></li><li class="cat-item cat-item-6"><a href="https://russia-dropshipping.ru/category/sozdan">Создание</a></li><li class="cat-item cat-item-18"><a href="https://russia-dropshipping.ru/category/sxem-2">Схем</a></li><li class="cat-item cat-item-10"><a href="https://russia-dropshipping.ru/category/sxem">Схемы</a></li></ul></aside></div></div><div id="sidebar-footer" class="footer-widget-area clearfix" role="complementary"><div class="container"></div></div><footer id="colophon" class="site-footer" role="contentinfo"><div class="site-info"><div class="container"> Copyright © 2025 <font style="text-align:left;font-size:15px;"><br> Дропшиппинг в России.<br> Сообщество поставщиков дропшипперов и интернет предпринимателей.<br>Все права защищены.<br>ИП Калмыков Семен Алексеевич. ОГРНИП: 313695209500032.<br>Адрес: ООО «Борец», г. Москва, ул. Складочная 6 к.4.<br>E-mail: mail@russia-dropshipping.ru. <span class="phone-none">Телефон: +7 (499) 348-21-17</span></font></div></div></footer></div> <noscript><style>.lazyload{display:none}</style></noscript><script data-noptimize="1">window.lazySizesConfig=window.lazySizesConfig||{};window.lazySizesConfig.loadMode=1;</script><script async data-noptimize="1" src='https://russia-dropshipping.ru/wp-content/plugins/autoptimize/classes/external/js/lazysizes.min.js'></script> <!-- noptimize -->
<style>iframe,object{width:100%;height:480px}img{max-width:100%}</style><script>new Image().src="//counter.yadro.ru/hit?r"+escape(document.referrer)+((typeof(screen)=="undefined")?"":";s"+screen.width+"*"+screen.height+"*"+(screen.colorDepth?screen.colorDepth:screen.pixelDepth))+";u"+escape(document.URL)+";h"+escape(document.title.substring(0,150))+";"+Math.random();</script>
<!-- /noptimize --> <script defer src="https://russia-dropshipping.ru/wp-content/cache/autoptimize/js/autoptimize_4cad87507949d1a2750fb90f494c0e55.js"></script></body></html><script src="/cdn-cgi/scripts/7d0fa10a/cloudflare-static/rocket-loader.min.js" data-cf-settings="66dbaa4d4145e4761399c227-|49" defer></script> 


 Если вы разрешите страницу с robots. txt, но заблокирует его индексацию с помощью метатега, робот Googlebot получит доступ к странице, прочитает метатег и впоследствии не будет ее индексировать.
Если вы разрешите страницу с robots. txt, но заблокирует его индексацию с помощью метатега, робот Googlebot получит доступ к странице, прочитает метатег и впоследствии не будет ее индексировать.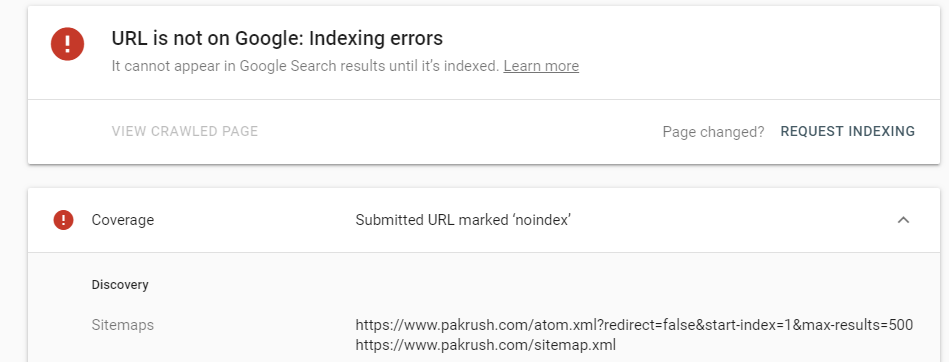 Примеры метатегов включают элементы
Примеры метатегов включают элементы