
Директивы Meta Robots и как их использовать
Meta Robots — это метатег, который позволяет настроить инструкции по индексации сайта. Его плюсы заключаются в надёжности и простоте установки. Но многие вебмастера и SEO-специалисты зачастую ограничиваются лишь директивами noindex и nofollow, указывающими на запрет индексации страниц сайта и содержащихся на них ссылок.

Я решил подробнее ознакомиться с возможностями Meta Robots, а потому в рамках данной статьи разберу и другие способы использования Meta Robots, которые вы сможете применить для SEO-продвижения вашего сайта.
Директивы Meta Robots и какие поисковые системы их учитывают
Всего существует чуть больше десятка основных директив Meta Robots, которые можно комбинировать между собой:
noindex— запрещает индексирование страницы.nofollow— запрещает роботу переходить по ссылкам с этой страницы.none— аналогичен комбинации noindex, nofollow.all— нет ограничений на индексирование и показ контента. Директива используется по умолчанию и не влияет на работу поисковых роботов, если нет других указаний.noimageindex— не индексировать изображения на этой странице.noarchive— запрещает показывать ссылку «Сохраненная копия» для определенной страницы.nocache— указывает на необходимость отправить запрос на сервер для валидации ресурса перед использованием кэшированных данных.nosnippet— запрещает показывать видео или фрагмент текста в результатах поиска.notranslate— запрещает предлагать перевод этой страницы в результатах поиска.unavailable_after: [RFC-850 date/time]— указывает точную дату и время, когда нужно прекратить сканирование и индексирование этой страницы.noodp— не использовать метаданные из проекта Open Directory для заголовков или фрагментов этой страницы.noydir— не брать название сайта и его описание из Yahoo! Directory (каталога Yahoo!).noyaca— не использовать описание из Яндекс.Каталога для сниппета в результатах поиска.
Некоторые из директив по-разному воспринимаются роботами тех или иных поисковых систем. В таблице ниже собрана информация о том, как боты систем Google, Yahoo, Bing и Яндекс работают с директивами Meta Robots.
| Директивы | Yahoo | Bing | Яндекс | |
|---|---|---|---|---|
| index | Да* | Да* | Да* | Да |
| noindex | Да | Да | Да | Да |
| follow | Да* | Да* | Да* | Да |
| nofollow | Да | Да | Да | Да |
| none | Да | ? | ? | Да |
| all | Да | ? | ? | Да |
| noimageindex | Да | Нет | Нет | Нет |
| noarchive | Да | Да | Да | Да |
| nocache | Нет | Нет | Да | Нет |
| nosnippet | Да | Нет | Да | Нет |
| notranslate | Да | Нет | Нет | Нет |
| unavailable_after | Да | Нет | Нет | Нет |
| noodp | Нет | Да** | Да** | Нет |
| noydir | Нет | Да** | Нет | Нет |
| noyaca | Нет | Нет | Нет | Да |
* Поисковая система не имеет официальной документации, которая бы подтверждала поддержку этой директивы. Но предполагается, что поддержка исключающего значения (например, nofollow) подразумевает поддержку положительного (например, follow).
** Теги noodp и noydir перестали поддерживаться, и, вероятно, не работают.
Директивы Meta Robots, которые стоит использовать в SEO
Как мы видим из предыдущей таблицы, не все атрибуты метатега Robots поддерживаются поисковой системой Google, под которую оптимизируют сайты большинство разработчиков и SEO-специалистов. Поэтому рассмотрим те атрибуты метатега Robots, которые поддерживаются Google:
- nosnippet,
- noimageindex,
- noarchive,
- unavailable_after.
Все они прописываются в блоке <head> страницы, к которой вы хотите применить те или иные инструкции по индексации.
Nosnippet
Эта директива может понадобиться, если, например, вы хотите предотвратить попадание контента вашего сайта в блоки с готовыми ответами Google (Featured Snippet). Несмотря на то, что фрагмент контента в Featured Snippet, как правило, позволяет повысить конверсию, всё же он может отвлекать внимание от самого сайта. То есть, у пользователей, получивших ответ на свой вопрос, пропадает надобность кликать по ссылке.

Для решения проблемы вам следует использовать инструкцию следующего вида:
<meta name="robots" content="nosnippet">Также важно учитывать, что атрибут nosnippet отключает и отображение расширенных сниппетов в результатах поиска.
К тому же, исследование HubSpot показало, что сниппеты с расширенной информацией получают в два раза больше кликов. Соответственно, отключение сниппета может стать причиной снижения CTR вашего сайта или отдельных его страниц.
Noimageindex
Директива noimageindex позволит скрыть графический контент на вашем сайте из результатов поиска по картинкам. Это может быть полезно, если вы, к примеру, хотите разместить на своём блоге уникальные изображения и при этом минимизировать риск воровства.
Чтобы запретить поисковым системам индексировать изображения, задайте в блоке <head> html-документа следующую директиву:
<meta name = "robots" content = "noimageindex">Действие необходимо повторить с каждой страницей, которая содержит изображения, которые вы хотите скрыть от поисковиков. Учитывайте, что если другие сайты уже ссылались на ваши изображения, поисковики могут продолжать индексировать их.
Запрещая индексацию изображений, не забывайте о том, что поиск по картинкам может приносить хороший дополнительный трафик вашему сайту.
Noarchive
Директива может пригодиться тем, кто работает с интернет-магазинами. К примеру, на вашем сайте есть страницы с товарами и указанной на них стоимостью. Так как цены с определённой периодичностью меняются, кэшированные страницы товаров могут быстро терять свою актуальность. Для предотвращения кэширования поместите в <head>
<meta name="robots" content="noarchive">Вопреки распространённому мнению, директива noarchive никак не влияет на ранжирование — эту информацию подтвердил в своем Твиттере ведущий аналитик компании Google, специалист отдела качества поиска по работе с вебмастерами Джон Мюллер (John Mueller).
Директива unavailable_after наиболее актуальна для страниц с акционными предложениями. Так как по истечению времени действия акции они теряют свою актуальность, вы можете указать поисковикам дату крайнего срока индексации контента. Дату и время нужно указывать в формате RFC 850.
К примеру, если вам нужно исключить возможность индексации страницы после 25 марта 2019 года, используйте метатег следующего вида:
<meta name="googlebot" content="unavailable_after: 25-Mar-2019 00:00:00 EST">Отдельно отметим, что для правильного функционирования тега необходимо, чтобы он был прописан до первого обхода роботом. В таком случае запрос на удаление из поисковой выдачи займёт примерно сутки после указанной даты.
Проверка правильности Meta Robots и его содержимого в Netpeak Spider
Перед проверкой атрибутов Meta Robots важно узнать, какие страницы индексируются на сайте, иначе не будет смысла внедрять вышеописанные атрибуты.
Программа доступна для операционных систем Microsoft Windows и Mac OS, поддержка платформы Linux в данный момент не доступна, но находится в разработке. Вы можете пользоваться бесплатной версией в течение 14 дней без каких либо ограничений.
Воспользуйтесь промокодом c6c39672 при оформлении заказа и получите специальную скидку 10% на покупку Netpeak Spider и Netpeak Checker!
С помощью Netpeak Spider вы можете найти запрещённые к индексации страницы. На таких страницах программа делает особый акцент, отмечая ошибками:
- Заблокировано в Meta Robots. Показывает страницы, запрещённые к индексации с помощью инструкции
<meta name="robots" content="noindex"><head>. - Nofollow в Meta Robots. Показывает страницы, содержащие инструкции
<meta name="robots" content="nofollow">в блоке<head>.
Для проверки сайта откройте программу и перейдите на вкладку «Параметры» на боковой панели. Найдите раздел «Индексация» и проверьте, отмечен ли галочкой пункт «Meta Robots». Если пункт не будет отмечен, программа не проанализирует метатег, и вы в финальном отчёте не увидите данных о нём.

Для сканирования всего сайта введите его начальный URL в адресную строку и нажмите кнопку «Старт». Если вам необходимо просканировать список страниц, зайдите в меню «Список URL» и выберите удобный вам способ добавления URL (ввести вручную, загрузить из файла или Sitemap, вставить из буфера обмена), после чего запустите сканирование.

По завершению сканирования получить информацию о Meta Robots вы можете несколькими путями:
1. В основной таблице на вкладке «Все результаты». В столбце Meta Robots просмотрите директивы, которые содержатся в соответствующем теге каждой из просканированных страниц.

2. На вкладке «Ошибки» боковой панели. Найдите ошибки, связанные с Meta Robots, и кликните по их названию. В таблице отфильтрованных результатов вы увидите полный список страниц, на которых были найдены эти ошибки.

3. На вкладке «Дашборд». Вы можете просмотреть данные в виде диаграмм об индексируемых страницах на сайте, а также узнать причины их неиндексируемости. Кликните на интересующую вас область, чтобы получить список страниц, соответствующих тому или иному значению.

4. На вкладке «Сводка» на боковой панели. Здесь вы можете ознакомиться как закрытыми от индексации страницами, так и посмотреть, какие ещё значения помимо noindex, nofollow заданы в метатеге Robots. Найдите пункт «Meta Robots» со списком всех имеющихся на сайте директив. Кликните на любую из них, чтобы ознакомиться со страницами, на которых они были найдены.
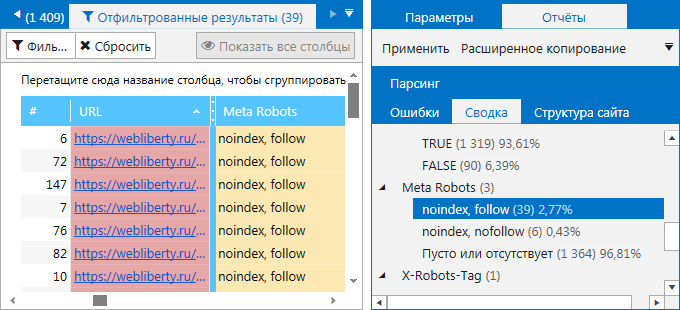
При необходимости вы можете воспользоваться функцией «Экспорт», чтобы выгрузить отфильтрованные результаты в отдельный файл формата .xlsx на свой компьютер. Нажмите на кнопку «Экспорт» в левом верхнем углу над результатами сканирования или выберите в соответствующем меню команду «Результаты в текущей таблице».
Коротко о главном
Meta Robots — удобный инструмент, который позволяет управлять инструкциями по индексации сайта и его отдельных страниц. Однако зачастую его использование ограничивается атрибутами запрета индексации — noindex, nofollow.
На деле же он может использоваться как минимум с 4 директивами, которые полноценно воспринимаются поисковыми роботами Google и помогают решить разного рода SEO-задачи. В их числе — nosnippet, noimageindex, noarchive и unavailable_after.

Проверить директивы метатега Robots всего сайта или списка определённых URL удобнее всего с помощью Netpeak Spider. Программа покажет все возможные ошибки, связанные с метатегами, и предоставит данные об атрибутах в максимально наглядном виде.
Краулер программы выполняет глубокий анализ сайта в автоматическом режиме, получает полную его структуру и находит ошибки технической оптимизации. Умеет находить битые ссылки и редиректы, обнаруживать дублирование страниц, Title, Description, заголовков h2 и т.д — проверяет более 50 ключевых параметров. Настоятельно рекомендую!
webliberty.ru
Метатег robots (meta name robots) – что это такое
Метатег robots – это код гипертекстовой разметки, позволяющий контролировать индексирование и показ страниц сайта в результатах поиска. Код можно писать на любой странице сетевого ресурса в специально отведенном для него месте. Роботы поисковых систем в процессе индексирования будут читать значение этого метатега и учитывать его в дальнейшей работе над сетевым ресурсом. Временное или постоянное внедрение этого кода может понадобиться в разных ситуациях. Например, он позволяет скрыть от поисковых роботов определенные ссылки или контент, который не должен попасть в выдачу поисковых систем. Этим тегом пользуются при оптимизации сайта, поисковом продвижении, наполнении ресурса уникальными статьями.

Использование
Код вписывают в заголовок каждой страницы, которую посещает робот. HTML-код выглядит следующим образом:
<html>
<head>
</head>
</html>
Все, что пользователь впишет между тегами <head> и </head> будет находиться в заголовке гипертекстовой разметки страницы.
Обсуждаемый код выглядит так:
<meta name=»robots» content=» » />
Между кавычками нужно указать команду, которую вы хотите отдать поисковому роботу.
Список стандартных значений метатега
Index и noindex. Разрешает или запрещает поисковику индексировать содержимое страницы соответственно. Полезно использовать при продвижении сайта и работе над ним в целом.
Follow и nofollow. Первое значение разрешает роботу переходить по ссылкам в пределах страницы, а второе запрещает. Также используется при SEO-оптимизации сетевых ресурсов.
Nosnippet. Директива запрещает роботу выводить в поисковой выдаче содержимое сниппета – краткое описание страницы.
Noarchive. Код запрещает роботу выводить в результатах поиска ссылку на сохраненную в кеше копию страницы.
All/none. Значение тега разрешает или запрещает индексацию всей страницы.
Noimageindex. Команда запрещает роботу индексировать опубликованные на странице фото.
Существуют и другие специальные указания, запрещающие или разрешающие поисковым роботам совершать определенные действия при индексировании содержимого страницы. Если тег отсутствует, то робот автоматически индексирует весь контент и все ссылки на странице. Если написано несколько тегов, значения которых противоречат друг другу, то поисковая система примет разрешающую директиву.
Значения метатега можно комбинировать, записывая команды через запятую. Записывать параметры можно без учета регистра. Если в атрибуте тега name стоит значение robots, то все поисковые системы будут учитывать его значение в процессе индексации. При желании можно дать команду конкретной поисковой системе, указав в атрибуте название робота. Например, значение Googlebot позволит запретить или разрешить определенные действия только поисковой системе Google.
Пример метатега:
<meta name=»googlebot» content=» » />
Если пользователь знает названия всех роботов, используемых поисковыми системами, то сможет давать команды каждому из них. Например, чтобы страница появилась в основном поиске Google, но не в новостях этого поисковика, нужно написать следующее:
<meta name=»googlebot-news» content=»noindex» />
Для передачи нескольких команд одной или нескольким поисковым системам или отдельным роботам можно писать несколько метатегов с разными или одинаковыми значениями. Если пользователь запутается и напишет команды, противоречащие друг другу, то робот выберет более строгую из них.

Причины использования метатега robots
Разработчики и пользователи сетевых ресурсов знают, что существует файл robots.txt, который помогает при СЕО-оптимизации, позволяя разрешать или запрещать роботам совершать определенные действия. Метатег robots дает возможность:
- закрывать содержимое страницы, оставляя ссылки доступными для индексирования;
- давать команды поисковым роботам при недоступности корневой директории сайта;
- открыть доступ роботу к просмотру содержимого некоторых страниц при закрытии от индексации каталогов.
Тег robots применяют совместно с файлом robots.txt для более тонкой настройки параметров индексации.
wiki.rookee.ru
Руководство по метатегам Robots и X-robots-tag
Перед вами дополненный (конечно же, выполненный с любовью) перевод статьи Robots Meta Tag & X-Robots-Tag: Everything You Need to Know c блога Ahrefs. Дополненный, потому что в оригинальном материале «Яндекс» упоминается лишь вскользь, а в главе про HTTP-заголовки затрагивается только сервер Apache. Мы дополнили текст информацией по метатегам «Яндекса», а в части про X-Robots-Tag привели примеры для сервера Nginx. Так что этот перевод актуален для наиболее популярных для России поисковых систем и веб-серверов. Круто, правда?
Приятного чтения!
Направить поисковые системы таким образом, чтобы они сканировали и индексировали ваш сайт именно так, как вы того хотите, порой может быть непросто. Хоть robots.txt и управляет доступностью вашего контента для ботов поисковых систем, он не указывает краулерам на то, стоит индексировать страницы или нет.
Для этой цели существуют метатеги robots и HTTP-заголовок X-Robots-Tag.
Давайте проясним одну вещь с самого начала: вы не можете управлять индексацией через robots.txt. Распространенное заблуждение — считать иначе.
Правило noindex в robots.txt официально никогда не поддерживалось Google. 2 июля 2019 года Google опубликовал новость, в которой описал нерелевантные и неподдерживаемые директивы файла robots.txt. С 1 сентября 2019 года такие правила, как noindex в robots.txt, официально не поддерживаются.
Из этого руководства вы узнаете:
- что такое метатег robots;
- почему robots важен для поисковой оптимизации;
- каковы значения и атрибуты метатега robots;
- как внедрить robots;
- что такое X-Robots-Tag;
- как внедрить X-Robots-Tag;
- когда нужно использовать метатег robots, а когда — X-Robots-Tag;
- как избежать ошибок индексации и деиндексации.
Что такое метатег robots
Это фрагмент HTML-кода, который указывает поисковым системам, как сканировать и индексировать определенную страницу. Robots помещают в контейнер <head> кода веб-страницы, и выглядит это следующим образом:
<meta name="robots" content="noindex" />
Почему метатег robots важен для SEO
Метатег robots обычно используется для того, чтобы предотвратить появление страниц в выдаче поисковых систем. Хотя у него есть и другие возможности применения, но об этом позже.
Есть несколько типов контента, который вы, вероятно, хотели бы закрыть от индексации поисковыми системами. В первую очередь это:
- страницы, ценность которых крайне мала для пользователей или отсутствует вовсе;
- страницы на стадии разработки;
- страницы администратора или из серии «спасибо за покупку!»;
- внутренние поисковые результаты;
- лендинги для PPC;
- страницы с информацией о грядущих распродажах, конкурсах или запуске нового продукта;
- дублированный контент. Не забывайте настраивать тег canonical для того, чтобы предоставить поисковым системам наилучшую версию для индексации.
В общем, чем больше ваш веб-сайт, тем больше вам придется поработать над управлением краулинговой доступностью и индексацией. Еще вы наверняка хотели бы, чтобы Google и другие поисковые системы сканировали и индексировали ваш сайт с максимально возможной эффективностью. Да? Для этого нужно правильно комбинировать директивы со страницы, robots.txt и sitemap.
Какие значения и атрибуты есть у метатега robots
Метатег robots содержит два атрибута: name и content.
Следует указывать значения для каждого из этих атрибутов. Их нельзя оставлять пустыми. Давайте разберемся, что к чему.
Атрибут name и значения user-agent
Атрибут name уточняет, для какого именно бота-краулера предназначены следующие после него инструкции. Это значение также известно как user-agent (UA), или «агент пользователя». Ваш UA отражает то, какой браузер вы используете для просмотра страницы, но вот у Google UA будет, например, Googlebot или Googlebot-image.
Значения user-agent, robots, относится только к ботам поисковых систем. Цитата из официального руководства Google:
Тег
<meta name="robots" content="noindex" />и соответствующая директива применяются только к роботам поисковых систем. Чтобы заблокировать доступ другим поисковым роботам, включая AdsBot-Google, возможно, потребуется добавить отдельные директивы для каждого из них, например<meta name="AdsBot-Google" content="noindex" />.
Вы можете добавить столько метатегов для различных роботов, сколько вам нужно. Например, если вы не хотите, чтобы картинки с вашего сайта появлялись в поисковой выдаче Google и Bing, то добавьте в шапку следующие метатеги:
<meta name="googlebot-image" content="noindex" /><meta name="MSNBot-Media" content="noindex" />
Примечание: оба атрибута — name и content — нечувствительны к регистру. То есть абсолютно не важно, напишите ли вы их с большой буквы или вообще ЗаБоРчИкОм.
Атрибут content и директивы сканирования и индексирования
Атрибут content содержит инструкции по поводу того, как следует сканировать и индексировать контент вашей страницы. Если никакие метатеги не указаны или указаны с ошибками, и бот их не распознал, то краулеры расценят гнетущую тишину их отсутствия как «да», т. е. index и follow. В таком случае страница будет проиндексирована и попадет в поисковую выдачу, а все исходящие ссылки будут учтены. Если только ссылки непосредственно не завернуты в тег rel=»nofollow» .
Ниже приведены поддерживаемые значения атрибута content.
all
Значение по умолчанию для index, follow. Вы спросите: зачем оно вообще нужно, если без этой директивы будет равным образом то же самое? И будете чертовски правы. Нет абсолютно никакого смысла ее использовать. Вообще.
<meta name="robots" content="all" />
noindex
Указывает ПС на то, что данную страницу индексировать не нужно. Соответственно, в SERP она не попадет.
<meta name="robots" content="noindex" />
nofollow
Краулеры не будут переходить по ссылкам на странице, но следует заметить, что URL страниц все равно могут быть просканированы и проиндексированы, в особенности если на них ведут внешние ссылки.
<meta name="robots" content="nofollow" />
none
Комбинация noindex и nofollow как кофе «два в одном». Google и Yandex поддерживают данную директиву, а вот, например, Bing — нет.
<meta name="robots" content="none" />
noarchive
Предотвращает показ кешированной версии страницы в поисковой выдаче.
<meta name="robots" content="noarchive" />
notranslate
Говорит Google о том, что ему не следует предлагать перевод страницы в SERP. «Яндексом» не поддерживается.
<meta name="robots" content="notranslate" />
noimageindex
Запрещает Google индексировать картинки на странице. «Яндексом» не поддерживается.
<meta name="robots" content="noimageindex" />
Указывает Google на то, что страницу нужно исключить из поисковой выдачи после указанной даты или времени. В целом это отложенная директива noindex с таймером. Бомба деиндексации с часовым механизмом, если изволите. Дата и время должны быть указаны в формате RFC 850. Если время и дата указаны не будут, то директива будет проигнорирована. «Яндекс» ее тоже не знает.
<meta name="robots" content="unavailable_after: Sunday, 01-Sep-19 12:34:56 GMT" />
nosnippet
Отключает все текстовые и видеосниппеты в SERP. Кроме того, работает и как директива noarchive. «Яндексом» не поддерживается.
<meta name="robots" content="nosnippet" />
Важное примечание
С октября 2019 года Google предлагает более гибкие варианты управления отображением сниппетов в поисковой выдаче. Сделано это в рамках модернизации авторского права в Евросоюзе. Франция стала первой страной, которая приняла новые законы вместе со своим обновленным законом об авторском праве.
Новое законодательство хоть и введено только в Евросоюзе, но затрагивает владельцев сайтов повсеместно. Почему? Потому что Google больше не показывает сниппеты вашего сайта во Франции (пока только там), если вы не внедрили на страницы новые robots-метатеги.
Мы описали каждый из нововведенных тегов ниже. Но вкратце: если вы ищете быстрое решение для исправления сложившейся ситуации, то просто добавьте следующий фрагмент HTML-кода на каждую страницу сайта. Код укажет Google на то, что вы не хотите никаких ограничений по отображению сниппетов. Поговорим об этом более подробно далее, а пока вот:
<meta name="robots" content=”max-snippet:-1, max-image-preview:large, max-video-preview:-1" />
Заметьте, что если вы используете Yoast SEO, этот фрагмент кода уже добавлен на все ваши страницы, при условии, что они не отмечены директивами noindex или nosnippet.
Нижеуказанные директивы не поддерживаются ПС «Яндекс».
max-snippet
Уточняет, какое максимальное количество символов Google следует показывать в своих текстовых сниппетах. Значение «0» отключит отображение текстовых сниппетов, а значение «-1» укажет на то, что верхней границы нет.
Вот пример тега, указывающего предел в 160 символов (стандартная длина meta description):
<meta name="robots" content="max-snippet:160" />
max-image-preview
Сообщает Google, какого размера картинку он может использовать при отображении сниппета и может ли вообще. Есть три опции:
- none — картинки в сниппете не будет вовсе;
- standart — в сниппете появится (если появится) картинка обыкновенного размера;
- large — может быть показана картинка максимального разрешения из тех, что могут влезть в сниппет.
<meta name="robots" content="max-image-preview:large" />
max-video-preview
Устанавливает максимальную продолжительность видеосниппета в секундах. Аналогично текстовому сниппету значение «0» выключит опцию показа видео, значение «-1» укажет, что верхней границы по продолжительности видео не существует.
Например, вот этот тег скажет Google, что максимально возможная продолжительность видео в сниппете — 15 секунд:
<meta name="robots" content="max-video-preview:15" />
noyaca
Запрещает «Яндексу» формировать автоматическое описание с использованием данных, взятых из «Яндекс.Каталога». Для Google не поддерживается.
Примечание относительно использования HTML-атрибута data-nosnippet
Вместе с новыми директивами по метатегу robots, представленными в октябре 2019 года, Google также ввел новый HTML-атрибут data-nosnippet. Атрибут можно использовать для того, чтобы «заворачивать» в него фрагменты текста, который вы не хотели бы видеть в качестве сниппета.
Новый атрибут может быть применен для элементов <div>, <span> и <section>. Data-nosnippet — логический атрибут, то есть он корректно функционирует со значениями или без них.
Вот два примера:
<p>Фрагмент этого текста может быть показан в сниппете <span data-nosnippet>за исключением этой части.</span></p><div data-nosnippet>Этот текст не появится в сниппете.</div><div data-nosnippet="true">И этот тоже.</div>
Использование вышеуказанных директив
В большинстве случаев при поисковой оптимизации редко возникает необходимость выходить за рамки использования директив noindex и nofollow, но нелишним будет знать, что есть и другие опции.
Вот таблица для сравнения поддержки различными ПС упомянутых ранее директив.
| Директива | «Яндекс» | Bing | |
|---|---|---|---|
| all | ✅ | ✅ | ❌ |
| noindex | ✅ | ✅ | ✅ |
| nofollow | ✅ | ✅ | ✅ |
| none | ✅ | ✅ | ❌ |
| noarchive | ✅ | ✅ | ✅ |
| nosnippet | ✅ | ❌ | ✅ |
| max-snippet | ✅ | ❌ | ❌ |
| max-snippet-preview | ✅ | ❌ | ❌ |
| max-video-preview | ✅ | ❌ | ❌ |
| notranslate | ✅ | ❌ | ❌ |
| noimageindex | ✅ | ❌ | ❌ |
| unavailable_after: | ✅ | ❌ | ❌ |
| noyaca | ❌ | ✅ | ❌ |
| index|follow|archive | ✅ | ✅ | ✅ |
Вы можете сочетать различные директивы.
И вот здесь очень внимательно
Если директивы конфликтуют друг с другом (например, noindex и index), то Google отдаст приоритет запрещающей, а «Яндекс» — разрешающей директиве. То есть боты Google истолкуют такой конфликт директив в пользу noindex, а боты «Яндекса» — в пользу index.
Примечание: директивы, касающиеся сниппетов, могут быть переопределены в пользу структурированных данных, позволяющих Google использовать любую информацию в аннотации микроразметки. Если вы хотите, чтобы Google не показывал сниппеты, то измените аннотацию соответствующим образом и убедитесь, что у вас нет никаких лицензионных соглашений с ПС, таких как Google News Publisher Agreement, по которому поисковая система может вытягивать контент с ваших страниц.
Как настроить метатеги robots
Теперь, когда мы разобрались, как выглядят и что делают все директивы этого метатега, настало время приступить к их внедрению на ваш сайт.
Как уже упоминалось выше, метатегам robots самое место в head-секции кода страницы. Все, в принципе, понятно, если вы редактируете код вашего сайта через разные HTML-редакторы или даже блокнот. Но что делать, если вы используете CMS (Content Management System, в пер. — «система управления контентом») со всякими SEO-плагинами? Давайте остановимся на самом популярном из них.
Внедрение метатегов в WordPress с использованием плагина Yoast SEO
Тут все просто: переходите в раздел Advanced и настраивайте метатеги robots в соответствии с вашими потребностями. Вот такие настройки, к примеру, внедрят на вашу страницу директивы noindex, nofollow:

Строка meta robots advanced дает вам возможность внедрять отличные от noindex и nofollow директивы, такие как max-snippet, noimageindex и так далее.
Еще один вариант — применить нужные директивы сразу по всему сайту: открывайте Yoast, переходите в раздел Search Appearance. Там вы можете указать нужные вам метатеги robots на все страницы или на выборочные, на архивы и структуры сайта.

Примечание: Yoast — вовсе не единственный способ управления вашим метатегами в CMS WordPress. Есть альтернативные SEO-плагины со сходным функционалом.
Что такое X-Robots-Tag
Метатеги robots замечательно подходят для того, чтобы закрывать ваши HTML-страницы от индексирования, но что делать, если, например, вы хотите закрыть от индексирования файлы типа изображений или PDF-документов? Здесь в игру вступает X-Robots-Tag.
X-Robots-Tag — HTTP-заголовок, но, в отличие от метатега robots, он находится не на странице, а непосредственно в файле конфигурации сервера. Это позволяет ему сообщать ботам поисковых систем инструкции по индексации страницы даже без загрузки содержимого самой страницы. Потенциальная польза состоит в экономии краулингового бюджета, так как боты ПС будут тратить меньше времени на интерпретацию ответа страницы, если она, например, будет закрыта от индексации на уровне ответа веб-сервера.
Вот как выглядит X-Robots-Tag:

Чтобы проверить HTTP-заголовок страницы, нужно приложить чуть больше усилий, чем требуется на проверку метатега robots. Например, можно воспользоваться «дедовским» методом и проверить через Developer Tools или же установить расширение на браузер по типу Live HTTP Headers.
Последнее расширение мониторит весь HTTP-трафик, который ваш браузер отправляет (запрашивает) и получает (принимает ответы веб-серверов). Live HTTP Headers работает, так сказать, в прямом эфире, так что его нужно включать до захода на интересующий сайт, а уже потом смотреть составленные логи. Выглядит все это следующим образом:

Как правильно внедрить X-Robots-Tag
Конфигурация установки в целом зависит от типа используемого вами сервера и того, какие страницы вы хотите закрыть от индексирования.
Строчка искомого кода для веб-сервера Apache будет выглядеть так:
Header set X-Robots-Tag «noindex»Для nginx — так:
add_header X-Robots-Tag «noindex, noarchive, nosnippet»;Наиболее практичным способом управления HTTP-заголовками будет их добавление в главный конфигурационный файл сервера. Для Apache обычно это httpd.conf или файлы .htaccess (именно там, кстати, лежат все ваши редиректы). Для nginx это будет или nginx.conf, где лежат общие конфигурации всего сервера, или файлы конфигурации отдельных сайтов, которые, как правило, находятся по адресу etc/nginx/sites-available.
X-Robots-Tag оперирует теми же директивами и значениями атрибутов, что и метатег robots. Это из хороших новостей. Из тех, что не очень: даже малюсенькая ошибочка в синтаксисе может положить ваш сайт, причем целиком. Так что два совета:
- при каких-либо сомнениях в собственных силах, лучше доверьте внедрение X-Robots-Tag тем, кто уже имеет подобный опыт;
- не забывайте про бекапы — они ваши лучшие друзья.
Подсказка: если вы используете CDN (Content Delivery Network), поддерживающий бессерверную архитектуру приложений для Edge SEO, вы можете изменить как метатеги роботов, так и X-Robots-теги на пограничном сервере, не внося изменений в кодовую базу.
Когда использовать метатеги robots, а когда — X-Robots-tag
Да, внедрение метатегов robots хоть и выглядит более простым и понятным, но зачастую их применение ограничено. Рассмотрим три примера.
Файлы, отличные от HTML
Ситуация: нужно впихнуть невпихуемое.
Фишка в том, что у вас не получится внедрить фрагмент HTML-кода в изображения или, например, в PDF-документы. В таком случае X-Robots-Tag — безальтернативное решение.
Вот такой фрагмент кода задаст HTTP-заголовок со значением noindex для всех PDF-документов на сайте для сервера Apache:
Header set X-Robots-Tag «noindex»А такой — для nginx:
location ~* \.pdf$ { add_header X-Robots-Tag «noindex»; }Масштабирование директив
Если есть необходимость закрыть от индексации целый домен (поддомен), директорию (поддиректорию), страницы с определенными параметрами или что-то другое, что требует массового редактирования, ответ будет один: используйте X-Robots-Tag. Можно, конечно, и через метатеги, но так будет проще. Правда.
Изменения заголовка HTTP можно сопоставить с URL-адресами и именами файлов с помощью различных регулярных выражений. Массовое редактирование в HTML с использованием функции поиска и замены, как правило, требует больше времени и вычислительных мощностей.
Трафик с поисковых систем, отличных от Google
Google поддерживает оба способа — и robots, и X-Robots-Tag. «Яндекс» хоть и с отставанием, но в конце концов научился понимать X-Robots-Tag и успешно его поддерживает. Но, например, чешский поисковик Seznam поддерживает только метатеги robots, так что пытаться закрыть сканирование и индексирование через HTTP-заголовок не стоит. Поисковик просто не поймет вас. Придется работать с HTML-версткой.
Как избежать ошибок доступности краулинга и деиндексирования страниц
Вам, естественно, нужно показать пользователям все ваши страницы с полезным контентом, избежать дублированного контента, всевозможных проблем и не допустить попадания определенных страниц в индекс. А если у вас немаленький сайт с тысячами страниц, то приходится переживать еще и за краулинговый бюджет. Это вообще отдельный разговор.
Давайте пробежимся по распространенным ошибкам, которые допускают люди в отношении директив для роботов.
Ошибка 1. Внедрение noindex-директив для страниц, закрытых через robots.txt
Официальные инструкции основных поисковых систем гласят:
 «Яндекс»
«Яндекс» Google
GoogleНикогда не закрывайте через disallow в robots.txt те страницы, которые вы пытаетесь удалить из индекса. Краулеры поисковых систем просто не будут переобходить такие страницы и, следовательно, не увидят изменения в noindex-директивах.
Если вас не покидает чувство, что вы уже совершили подобную ошибку в прошлом, то не помешает выяснить истину через Ahrefs Site Audit. Смотрите на страницы, отмеченные ошибкой noindex page receives organic traffic («закрытые от индексации страницы, на которые идет органический трафик»).

Если на ваши страницы с директивой noindex идет органический трафик, то очевидно, что они все еще в индексе, и вполне вероятно, что робот их не просканировал из-за запрета в robots.txt. Проверьте и исправьте, если это так.
Ошибка 2. Плохие навыки работы с sitemap.xml
Если вы пытаетесь удалить контент из индекса, используя метатеги robots или X-Robots-Tag, то не стоит удалять их из вашей карты сайта до момента их деиндексации. В противном случае переобход этих страниц может занять у Google больше времени.

— …ускоряет ли процесс деиндексации отправка Sitemap.xml с URL, отмеченным как noindex?
— В принципе все, что вы внесете в sitemap.xml, будет рассмотрено быстрее.
Для того чтобы потенциально ускорить деиндексацию ваших страниц, установите дату последнего изменения вашей карты сайта на дату добавления тега noindex. Это спровоцирует переобход и переиндексацию.

Еще один трюк, который вы можете проделать, — загрузить sitemap.xml с датой последней модификации, совпадающей с датой, когда вы отметили страницу 404, чтобы вызвать переобход.
Джон Мюллер говорит здесь про страницы с ошибкой 404, но можно полагать, что это высказывание справедливо и для директив noindex.
Важное замечание
Не оставляйте страницы, отмеченные директивой noindex, в карте сайта на долгое время. Как только они выпадут из индекса, удаляйте их.
Если вы переживаете, что старый, успешно деиндексированный контент по каким-то причинам все еще может быть в индексе, проверьте наличие ошибок noindex page sitemap в Ahrefs Site Audit.

Ошибка 3. Оставлять директивы noindex на страницах, которые уже не находятся на стадии разработки
Закрывать от сканирования и индексации все, что находится на стадии разработки, — это нормальная, хорошая практика. Тем не менее, иногда продукт выходит на следующую стадию с директивами noindex или закрытым через robots.txt доступом к нему. Органического трафика в таком случае вы не дождетесь.
Более того, иногда падение органического трафика может протекать незамеченным на фоне миграции сайта через 301-редиректы. Если новые адреса страниц содержат директивы noindex, или в robots.txt прописано правило disallow, то вы будете получать органический трафик через старые URL, пока они будут в индексе. Их деиндексация поисковой системой может затянуться на несколько недель.

Чтобы предотвратить подобные ошибки в будущем, стоит добавить в чек-лист разработчиков пункт о необходимости удалять правила disallow в robots.txt и директивы noindex перед отправкой в продакшен.
Ошибка 4. Добавление «секретных» URL в robots.txt вместо запрета их индексации
Разработчики часто стараются спрятать страницы о грядущих промоакциях, скидках или запуске нового продукта через правило disallow в файле robots.txt. Работает это так себе, потому что кто угодно может открыть такой файл, и, как следствие, информация зачастую сливается в интернет.
Не запрещайте их в robots.txt, а закрывайте индексацию через метатеги или HTTP-заголовки.
Заключение
Правильное понимание и правильное управление сканированием и индексацией вашего сайта крайне важны для поисковой оптимизации. Техническое SEO может быть довольно запутанным и на первый взгляд сложным, но метатегов robots уж точно бояться не стоит. Надеемся, что теперь вы готовы применять их на практике!
racurs.agency
Мета-тег Robots — Robots.Txt по-русски
МЕТА-тег “Robots” позволяет указывать Роботам, можно ли индексировать данную страницу и можно ли использовать ссылки, приведенные на странице. Этот тег указывается на каждой конкретной странице, доступ к которой требуется ограничить.
В этом простом примере:
META NAME=»ROBOTS» CONTENT=»NOINDEX, NOFOLLOW»
робот не должен ни индексировать документ, ни анализировать стоящие на нем ссылки.
МЕТА-тег “Robots” – это простой инструмент для указания роботам, может ли страница быть проиндексирована и можно ли следовать по ссылкам со страницы.
Он отличается от Стандарта исключения для роботов тем, что вам не нужно тратить много усилий или получать доступ у Администратора cервера.
Куда писать META-тег “Robots”
Как и любой META-тег он должен быть помещен в область HEAD HTML страницы:
<html>
<head>
<meta name=“robots” content=“noindex,nofollow”>
<meta name=“description” content=“Эта страница ….”>
<title>…</title>
</head>
<body>
…
Что писать в META-теге “Robots”
META-тег “Robots” содержит указания, разделенные запятыми. В настоящее время определены существующие указания [NO]INDEX и [NO]FOLLOW. Директивы INDEX указывают, может ли робот индексировать страницу. Директива FOLLOW указывает роботу, может ли он следовать по ссылкам со страницы. Значения по умолчанию – INDEX и FOLLOW. Значения ALL и NONE обозначают активность всех директив и, соответственно, наоборот: ALL=INDEX,FOLLOW и NONE=NOINDEX,NOFOLLOW.
Несколько примеров:
<meta name=“robots” content=“index,follow”>
<meta name=“robots” content=“noindex,follow”>
<meta name=“robots” content=“index,nofollow”>
<meta name=“robots” content=“noindex,nofollow”>
Следует учесть, что параметр content тега “robots” нечувствителен к регистру.
Вы не должны включать конфликтующие и повторяющиеся директивы, как например:
<meta name=“robots” content=“INDEX,NOINDEX,NOFOLLOW,FOLLOW,FOLLOW”>
Правильный синтаксис атрибутов META-тега “Robots”:
content = all | none | directives
all = «ALL»
none = «NONE»
directives = directive [«,» directives]
directive = index | follow
index = «INDEX» | «NOINDEX»
follow = «FOLLOW» | «NOFOLLOW»
это программы, помогающие пользователям – например в выборе продукта, заполнении форм или даже в поиске. Такие программы имеют очень небольшое отношение к сетевому взаимодействию.
Дополнительно
Несколько ссылок по теме – постепенно надо будет добавить информацию из них на эту страницу.
Мета-тег Robots в стандарте HTML 4 на W3C
Как разные поисковики обрабатывают noindex
Запрет использования в выдаче описания из ODP
robotstxt.org.ru
Мета тег Robots и файл Robots.txt – как управлять индексацией страниц сайта
Доброго времени суток, уважаемые читатели. Задумала я тут поделиться с вами одним интересным материалом на тему внутренней оптимизации WordPress, а именно про установку мета тегов, и поняла, что чтобы получился хороший материал, необходимо прояснить ситуацию с тем, что такое мета тег Robots. Когда и для чего применяется. В чем разница использования файла Robots.txt и мета тега Robots. Robots.txt – это файл, с помощью которого мы можем управлять индексацией своего блога, указывая запрещающие директивы непосредственно в файле как для отдельных страниц, так и для целых каталогов. Более подробно об этом файле я писала применительно к WordPress в статье от 28 декабря 2011 года Файл Robots.txt.Что такое мета тег Robots
Метатег Robots – это тег, с помощью которого мы можем управлять индексацией своего блога, указывая запрещающие команды для каждой отдельной страницы.
К слову, нет единого написания слова «мета тег». Даже Яндекс и Google по разному их пишут в своих справочных материалах. Мета тег, Мета-тег и Метатег – все это одно слово и используется в сети одновременно. При этом в справке Яндекс он имеет написание Мета-тег, а в Google – Метатег. Давайте сначала разберемся, каким вообще бывает мета тег Robots. Независимо от того, указываете вы этот метатег или нет, его значение всегда — «all», что означает индексировать. Т.е. есть три «состояния» данного мета тега:
- Полное его отсутствие.
- <meta name=»robots» content=»all» />
- <meta name=»robots» content=»index, follow» />
Все это означает, что страница будет проиндексирована. Поэтому если вам не нужно запрещать страницу к индексации, то используется первый вариант, т.е. вообще ничего не используем. Если же вы хотите полностью запретить страницу к индексации, то запись будет такой:
<meta name=»robots» content=»noindex, nofollow»/>
или более короткий вариант
<meta name=»robots» content=»none»/>
Как вы думаете, почему значение имеет два параметра – index/noindex и follow/nofollow?- Значение index/noindex применяется только к тексту страницы.
- Значение follow/nofollow применяется только к ссылкам на странице.
Вот в этом, а также в самом определении кроется одно значительное преимущество мета тега Robots перед одноименным файлом.
Если вы сравните оба определения, то увидите, что они, практически, одинаковые. Но при этом имеют небольшое различие.
Да, оба способа – создание файла или указание мета тега – одно и тоже, выполняют абсолютно одинаковые функции и обладают абсолютно одинаковой значимостью. Другими словами нельзя сказать, что одно важнее другого. Они абсолютно равнозначны. Но как уже сказала, в них есть некоторые различия.
Вообще метатеги были придуманы не в противовес файлу, а для облегчения жизни тем вебмастерам, которые не имеют доступа к корневым папкам своего сайта, как это, например, происходит на Blogger. Т.е. сами поисковики рекомендуют настраивать файл Robots.txt когда есть доступ к папкам сайта, если же такого доступа нет, то рекомендуется использовать метатег.
Преимущества файла Robots.txt перед мета тегом
На мой взгляд преимущество заключается в том, что в файле Robots.txt мы можем указывать целые каталоги своего сайта, запретить к индексации сразу все теги, рубрики и любые другие каталоги. При чем данный запрет выставляется единой строкой. Если же мы хотим запретить весь каталог, но при этом разрешить к индексации одну-две страницы, то так же в файле мы можем настроить исключения. Обо всем этом я писала в статье, на которую дала ссылку выше, поэтому сейчас кратко передаю суть.
Как же дела обстоят с мета тегом? Мета тег невозможно выставить один раз сразу всему каталогу, он устанавливается для каждой страницы в отдельности. Т.е. им удобно пользоваться тогда, когда на вашем сайте вы с каждой новой публикацией решаете, разрешать поисковому роботу индексировать данную страницу или нет.
Лично мне сложно представить такой сайт, где могло бы это понадобиться. Но факт остается фактом. Если вы не настраиваете файл Robots.txt, но при этом многие страницы закрываете от индексации, то каждый раз вам нужно быть начеку, чтобы не забыть закрыть страницу от индексации. Согласитесь, это неудобно.
Если вы свободны от такой рутины, то всегда значительно удобней и проще настроить один раз и навсегда файл Robots.txt и больше об этом не думать.
Преимущества мета тега Robots перед файлом или, когда лучше использовать мета тег
Я уже обратила ваше внимание на то, что мета тег можно выставлять каждой отдельной странице, так же значительное преимущество нам могут дать разные команды index/noindex и follow/nofollow, которые можно применять в мета теге, и при определенных обстоятельствах все это является большим преимуществом перед файлом.
Ситуация 1. Вы публикуете неуникальный контент. Не обязательно это должен быть копипаст (ворованный контент), это могут быть какие-то официальные документы, законодательные акты, статьи кодексов, т.е. любые материалы, которые создадут на вашем сайте большое количество неуникального контента, при этом страницы с неуникальным контентом не имеют отдельного каталога, а размещаются в вперемешку с основным контентом. Такие страницы вы можете запретить к индексации, как полностью, указав мета тег
<meta name=»robots» content=»none»/>
так и частично, запретив индексировать только контент, но разрешив индексировать ссылки.
<meta name=»robots» content=»noindex, follow»/>
или просто
<meta name=»robots» content=»noindex»/>
Ситуация 2. Второй случай, когда имеет смысл использовать метатег – это при публикации большого количества ссылок на странице. Например, вы хотите поделиться со своими пользователями интересными ссылками, но при этом не хотите скомпрометировать себя перед поисковыми системами, публикуя большой объем внешних ссылок. В таком случае можно запретить страницу к индексации, при этом она будет доступна вашим посетителям. Только не делайте так, если вы обмениваетесь ссылками с кем-то, а именно тогда, когда ни перед никем не обязаны. Опять же, полный запрет к индексации будет таким:
<meta name=»robots» content=»none»/>
если же вы хотите, чтобы текстовое содержание страницы индексировалось, а ссылки нет, то запись должна быть такой
<meta name=»robots» content=»index, nofollow»/>
или равнозначная ей запись
<meta name=»robots» content=»nofollow»/>
Ситуация 3 по сути тоже самое, что и в ситуации 1, но я решила выделить ее отдельно, т.к. она может иметь большое значение. Все мы знаем, что архивы, рубрики и ярлыки создают дублирование контента. Но совсем не обязательно закрывать эти страницы от индексации полностью, ведь на них содержатся ссылки на наши же страницы, и эти ссылки могут участвовать во внутренней перелинковке, передавая свой вес страницам со статьями, главной и другим.Т.е. в метатеге Robots мы можем сообщить поисковику, чтобы он не индексировал текст, т.к. это создает дублирование на сайте, но при этом разрешить переходить по ссылкам на этих страницах. Таким образом не будет нарушаться внутренняя перелинковка на сайте, а даже наоборот, это создает нам дополнительный инструмент для увеличения статического веса страниц внутри сайта.Таким образом вы можете использовать значение мета тега из ситуации 1 для внутренней перелинковки на сайте. КАк правильно рассчитать внутренний вес страниц и сделать перелинковку, я писала в статье Как проверить и сделать правильно перелинковку на сайте, если же вы ещё не знаете, что такое перелинковка, то рекомендую сначала ознакомиться со статьей – Секреты перелинковки.
Если вы изучите справочные материалы поисковых систем, в частности Яндекс и Google об этом мета теге, то узнаете, что он может иметь и другие значения, помимо index и follow (индексировать и не индексировать).
Так, например Яндекс и Google, помимо озвученных мета Robots, понимает ещё и команду noarchive
<meta name=»robots» content=»noarchive»/>
Вы можете применять данное значение в том случае, если не хотите, чтобы пользователям поисковых систем в результатах поиска показывалась ссылка копия (Яндекс) и Сохраненная копия (Google), которая ведет на сохраненную копию вашей страницы.Помимо всего перечисленного Google понимает ещё некоторые значения, с которыми я рекомендую вам ознакомиться самостоятельно.И последнее, на что я хочу обратить ваше внимание особенно.
Для любой поисковой системы абсолютно не важно, каким образом вы указываете команды для индексации, в файле robots.txt или в метатеге robots, а вот если вы в разных случаях используете противоречащие друг другу команды, например в файле robots.txt страница запрещена к индексации, а вы вручную проставляете мета тег со значением «all» или наоборот, то поисковый робот учтет более строгую команду и это всегда будет noindex, т.е. робот учтет запрещающую директиву и не будет индексировать страницу. Поэтому будьте внимательны, если одновременно используете на сайте оба варианта robots.
Итак, все это я объясняла для того, чтобы вы понимали разницу между файлом robots.txt и мета тегом robots. Умение управлять своим сайтом является важной ступенью в общей раскрутке сайта в интернете. Чтобы вы могли самостоятельно решать, какой из способов и когда использовать на своем сайте. А также эти знания вам помогут при прочтении моей следующей статьи, ради которой я и затеяла эту. Так что не пропустите, будет интересно.amateurblogger.ru
Что такое мета-тег Robots (meta name robots)? 7 основных вариантов + варианты GoogleBot


Указания поисковому роботу
При проведении SEO-оптимизации страниц сайта, иногда нужно изменить поведение поискового робота на конкретной странице. Например, запретить ему индексировать её содержание. Или же индексацию разрешить, но не позволять ему переходить по ссылкам. Сделать это можно при помощи специального мета-тега meta name robots.
«Способ применения» данного тега несколько отличается от использования файла Robots.txt — в данном файле можно дать указания поисковому роботу сразу для всего сайта, используя специальные регулярные выражения.
Но если вы хотите скрыть от поисковиков определённую страницу и не прописывать её в Robots.txt (чтобы вообще никто о ней не знал), то лучше прописать на самой странице данный мета-тег.
Что такое мета-тег Robots и как его использовать?
Это один из многочисленных тегов, используемых для сообщения роботам и/или браузерам т.н. метаданных (т.е. информации об информации). Среди самых известных и часто используемых:
Что прописывать в тег robots?
Выглядит он так:

Вместо многоточия может быть 7 основных вариантов. Каждый вариант — это комбинации специальных указаний index/noindex и follow/nofollow, а также archive/noarchive:
- index, follow. Это сообщает поисковикам о том, что нужно произвести индексацию данной страницы (index), а также следовать (follow) по ссылкам, которые есть на странице.
- all. Аналогично предыдущему пункту.
- noindex,follow или просто noindex. Запрещает индексировать данную страницу, но разрешает роботу переходить по ссылкам, расположенным на ней.
- index,nofollow или просто nofollow. Запрещает переходить по ссылкам, но разрешает индексировать страницу — т.е. содержимое страницы будет отправлено в поисковый индекс, но другие страницы, на которые стоят ссылки, в индекс не попадут (при условии, что робот иными способами до них не доберётся).
- noindex, nofollow. Указание не индексировать документ и не переходить по ссылкам, содержащимся в нём.
- none. Аналогично предыдущему пункту.
- noarchive. Данное указание запрещает показывать ссылку на сохранённую копию страницы в результатах выдачи:

Ссылка на сохранённую копию страницы в Яндексе

Если мета-тег Robots не указан, то принимается значение по умолчанию:

То же самое происходит, если на странице указано несколько этих тегов.
Все вышеперечисленные варианты понимаются большинством поисковых систем и, в частности, Яндексом. Google тоже хорошо распознаёт эти комбинации, но также вводит кое что ещё:
- Вместо name=robots можно указать name=googlebot — «обращение» конкретно к роботу Google.
- content=nosnippet (запрещает показывать сниппеты в поисковой выдаче) и content=noodp (запрещает брать содержимое сниппетов из описания сайта в каталоге DMOZ).
- content=noimageindex. При поиске по картинкам запрещает отображение ссылки на источник картинки.
- content=unavailable_after:[date]. В качестве date следует указать дату и время, после которой Гугл перестанет индексировать эту страницу. Едва ли это когда-нибудь пригодится
В общем, Google несколько расширяет содержимое мета-тега Robots.
Куда прописывать meta name robots?
Традиционно, все мета-теги прописываются между «head» и «/head» в HTML-коде страницы.
В WordPress они легко выставляются при помощи популярного плагина All in One Seo Pack:

Мета Robots в All in One Seo Pack
Таким образом, если вам необходимо «спрятать» определённую страницу от поисковых роботов — используйте данный мета-тег.
 Loading…
Loading… 
web-ru.net
Что такое мета-тег Robots и зачем он нужен?
Мета-тег robots поможет найти общий язык с поисковыми роботами
Даже не зная, зачем нужен мета-тег robots, только исходя из его названия, уже можно сделать выводы о том, что он имеет какое-то отношение к роботам поисковых систем. И это действительно так.
Внедрение мета-тега robots в код веб-страницы дает возможность указать поисковым ботам свои пожелания по поводу индексирования ее содержимого и ссылок, расположенных на ней.
Это может пригодится в многих ситуациях. Например, при наличии на сайте дублирования контента или для предотвращения передачи веса страничек по ссылкам, расположенным на них.
Как воспользоваться возможностями мета-тега robots
Страница, к которой нужно применить желаемые условия индексирования, должна содержать внутри тега <head> своего html-кода правильно оформленный мета-тег robots.
Структура его довольно проста:

Чтобы он был правильно воспринят ботами поисковиков, в данной конструкции содержимое атрибута content (‘’ххххххххх’’) должно состоять из одной или нескольких (через запятую) стандартных директив:
- index/noindex – указывает на необходимость индексации/игнорирования содержимого страницы.
- follow/nofollow – анализировать/игнорировать ссылки в пределах веб-страницы.
- all/none – индексировать/игнорировать страницу полностью.
- noimageindex – запрет индексации присутствующих на странице изображений.
- noarchive – запрет на вывод в результатах поиска ссылки «Сохраненная копия», которая дает возможность просматривать сохраненную в кэше поисковика копию страницы (даже если она временно недоступна или удалена с сайта).
- nosnippet – запрет на вывод в поисковой выдаче под названием страницы фрагмента текста (сниппета), описывающего ее содержание.
- noodp – директива, которая сообщает Google-боту о запрете использования в качестве сниппета страницы, описания из каталога Open Directory Project (он же DMOZ).
Особенности использования мета-тега robots
Некоторые поддерживаемый этим мета-тегом комбинации директив взаимозаменяемы (тождественны). Например, если нужно запретить индексирование содержимого странички и всех ссылок на ней, можно использовать в мета-теге robots ‘’noindex, nofollow’’ или же директиву ‘’none’’.

В обратном случае, когда нужно индексировать всё (в параметре content мета-тега robots – ‘’index, follow’’ или ‘’all’’), появляется еще и третий вариант – вообще не внедрять этот тег в код страницы.

Бывают и частные случаи, в которых указания по поводу индексирования нужно сообщить только роботу какой-нибудь одной поисковой системы. Для этого нужно вместо ‘’robots’’ указать имя бота, которого касаются содержащиеся в мета-теге директивы. Например, если Google должен внести в свой индекс содержимое странички, но при этом не анализировать ссылки на ней:

Важно, чтобы в содержимом атрибута content не было повторений или присутствия противоречащих друг другу директив, поскольку в этом случае мета-тег может быть проигнорирован поисковым ботом.
Еще один момент, на почве которого довольно часто спорят веб-мастера – регистр, в котором прописывается содержимое мета-тега. Одни считают, что правильно использовать только прописные, другие – только строчные. Но на самом деле приемлемы оба варианта, поскольку мета-тег нечувствителен к регистру.
Зачем нужен мета-тег robots, если есть файл robots.txt?
Да, действительно на первый взгляд может показаться, что применение этого мета-тега предоставляет те же возможности, что и настройка файла robots.txt. Но несколько отличий все же есть. И они вполне могут быть причинами, чтобы отдать предпочтение использованию мета-тега:
- Мета-тег robots используется для более тонкой настройки индексации – можно закрыть контент, но оставить открытыми ссылки (в параметре content мета-тега robots – ‘’noindex, follow’’) и наоборот. В robots.txt такой возможности нет.
- В ситуациях, когда нет возможности получить доступ к корневой директории веб-сайта, редактировать robots.txt не представляется возможным. Вот тогда-то и приходит на помощь одноименный мета-тег.
- В robots.txt можно закрыть от индексации целый каталог, чтобы запретить доступ ботов ко всем, содержащимся в нем страницам, тогда как мета-тег придется использовать для каждой из них. Получается, что в таком случае удобнее произвести настройки в файле. Но если некоторые страницы внутри каталога все же нужно оставить открытыми, удобнее использовать мета-тег.

Для управления индексацией страниц веб-сайта допустимо одновременно использовать мета-тег robots и файл robots.txt. Они могут отвечать за указания поисковым ботам по поводу разных веб-страниц или же дублировать команды друг друга.
А вот если в них будут присутствовать противоречащие директивы по поводу одних и тех же страниц, роботы поисковиков будут принимать не всегда верное решение – по умолчанию выбирается более строгое указание. Получается, что страницы (или ссылки на них), по поводу которых между robots.txt и мета-тегом robots имеются разногласия, индексироваться не будут.
Возможность управления индексацией веб-сайта – очень полезный инструмент для SEO-продвижения. Главное, научиться правильно определять, в какой ситуации эффективнее использовать тот или иной из теперь известных Вам способов.
seo-akademiya.com