Запрет индексации в файле robots.txt
Перейти к содержанию
В этой статье мы разберем файл «Robots.txt», для чего он необходим, и как ним работать.
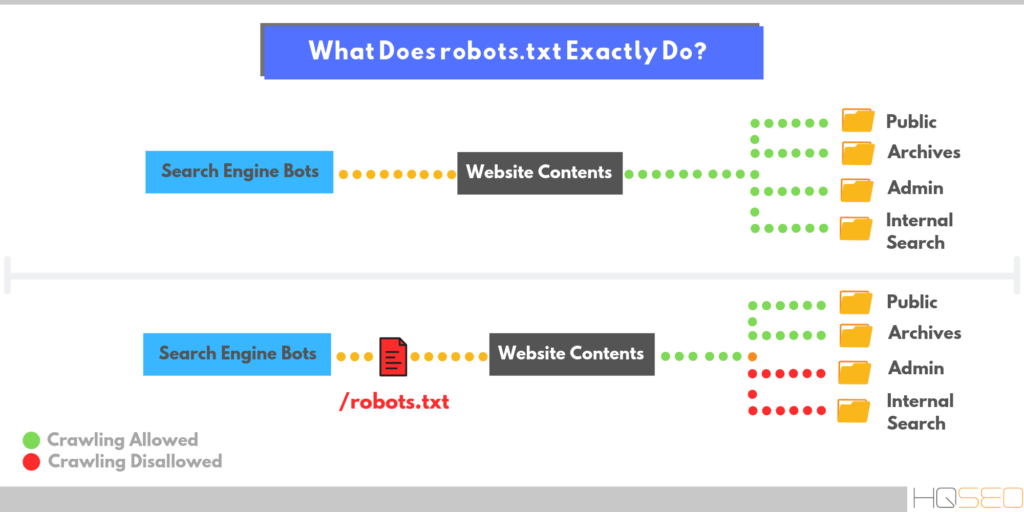
Robots.txt это файл в формате «.txt», который содержит директивы для индексации определенного сайта. Другими словами, этот файл указывает поисковым системам, какие страницы веб-ресурса нужно проиндексировать, а какие запретить к индексации.
Веб-индексирование — это добавления данных о сайте ботом, системы поиска, в базу данных, которая в дальнейшем используется для поиска информации на проиндексированных сайтах.
Сведенья о сайте это — ключевые слова , статьи, ссылки, документы, изображения, аудио файлы и т. д.
Использование «robots.txt» и карты сайта( «Sitemap xml») позволяют управлять индексацией Вашего сайта и скрыть, страницы, которые не относятся к основной направленности сайта, например: служебные страницы, дубликаты, информацию для печати и т.п..
Содержание
- Как управлять индексированием
- Ошибки
- Длительность индексации
Как управлять индексированием
Файл «robots» находится в коревой папке сайта, просмотреть его можно по адресу: http://vash_site. com/robots.txt.
com/robots.txt.
Если Вам потребовалось закрыть от индексации в Google страницу , например http:// vash_site.com /page-for-robots/. Для этого нужно применить директиву Disallow :
User-agent: GoogleDisallow: /page-for-robots/Host: vash_site.com
Если же нужно скрыть от индексации весь сайт кроме определенного раздела, например http:// vash_site.com /category/case/, нужно сделать следующим образом:
User-agent: Google
Disallow: /
Allow: /category/case/
Host: vash_site.com
Если же нужно скрыть от индексации весь сайт кроме определенного раздела, например, http:// vash_site.com /category/case/, нужно сделать следующим образом:
User-agent: Google
Disallow: /
Allow: /category/case/
Host: vash_site. com
com
Как вы уже поняли, директива «Allow» указывает какую страницу/ раздел/ файл нужно проиндексировать.
Еще один способ скрыть страницу или сайт – мета – тег NAME=»ROBOTS» #.
Для закрытия от индексации внутри тегов <head> </head> документа прописывается такой код:
<meta name="robots" content="noindex, nofollow"/>
Или<meta name="robots" content="none"/>
Так же можно вместо name=»robots» использовать имя конкретного робота, например:
Для паука Google: <meta name="googlebot" content="noindex, nofollow"/>
Или для Яндекса: <meta name="yandex" content="none"/>
Директива «User-agent» содержит название поискового робота. При помощи нее в файле «robots. txt» можно настроить индексацию сайта для каждого конкретной поисковой системы.
txt» можно настроить индексацию сайта для каждого конкретной поисковой системы.
В каждой системе поиска бот имеет свое название, ниже мы приведем список роботов самых популярных поисковиков:
Google http://www.google.com Googlebot
Yahoo! http://www.yahoo.com Slurp (или Yahoo! Slurp)
AOL http://www.aol.com Slurp
MSN http://www.msn.com MSNBot
Live http://www.live.com MSNBot
Ask http://www.ask.com Teoma
AltaVista http://www.altavista.com Scooter
Alexa http://www.alexa.com ia_archiver
Lycos http://www.lycos.com Lycos
Яндекс http://www. ya.ru Yandex
ya.ru Yandex
Рамблер http://www.rambler.ru StackRambler
Мэйл.ру http://mail.ru Mail.Ru
Aport http://www.aport.ru Aport
Вебальта http://www.webalta.ru WebAlta (WebAlta Crawler/2.0)
Можно написать универсальные правила индексации, которые будут применимы ко всем поисковикам, используя « User-agent: *»
User-agent: *
Disallow: /
Allow: /category/case/
Host: vash_site.com
Одной из важных считается директива Host, в ней нужно прописать основное зеркало сайта. Что бы это сделать, нужно выяснить какое зеркало является основным.
Для этого нужно ввести в поисковик адрес Вашего сайта, навести курсор на URL в выдаче и внизу слева будет прописан домен с «www» или без него.
Например:
После того как Вы определили главное зеркало сайта, его нужно прописать в Robots.txt:
Host: vash_site.com.
Ошибки
Даже если веб-мастер хорошо разбирается в командах, это не означает, что он застрахован от ошибок. У неопытных разработчиков сайтов прослеживается целый ряд типичных ошибок. Многие часто путают значения директив, так как не понимают их значений. К примеру, не там ставят знак «/» или вписывают имя робота после директивы Disallow.
Зачастую перечисляют запрещенные страницы друг за другом, тогда директиву к каждой странице следует писать отдельно. Множество ошибок связано с именем файла. Его следует писать маленькими буквами, без заглавных букв.
Длительность индексации
Файлы robots индексирует ресурсы согласно информации. Срок проведения процедуры может составлять от одной до двух, трех недель, особенно на сайте Яндекса. На сегодняшний день самым медленным считается поисковик Гугл, который еще не так давно (2012 г) занимал первое место.
Если сайт размещен, однако постоянно изменяется, корректируется и на нем видна свежая информация, индексации страниц ускоряется.
Виды поисковых роботов
Варианты поисковых роботов меняются в зависимости от предопределения программы.
- «Зеркальными», так как работают на схожих сайтах;
- Мобильными — для мобильных вариаций интернета;
- Ультрадействующими — быстро рассматривают новую информацию;
- Ссылочными, рассматривают и подсчитывают ссылки;
- «Шпионскими» — так как отыскивают страницы, не отображающие в ПС;
- «Дятлами» — это те, кто время от времени заходят на сайты для проверки;
- Национальными — контролируют только веб-ресурсы одной страны, например,
- Глобальными — рассматривают ресурсы всей паутины, всего мира.
Хотя такие поисковые системы как Гугл и Яндекс являются лидерами, существуют множество систем, имеющих своих роботов. На деле весь процесс запрета или исключения достаточно прост, но если нет уверенности в своих силах, лучше оставить все на индексацию, система сама выберет то, что посчитает важным.
Go to Top
Robots.txt для Joomla — инструкция для SEO
Файл robots.txt предоставляет важную информацию для поисковых роботов, которые сканируют интернет. Перед тем как пройтись по страницам вашего сайта, поисковые роботы проверяют данный файл.
Это позволят им с большей эффективностью сканировать сайт, так как вы помогаете роботам сразу приступать к индексации действительно важной информации на вашем сайте (это при условии, что вы правильно настроили robots.txt).
Но, как директивы в robots.txt, так и инструкция noindex в мета-теге robots являются лишь рекомендацией для роботов, поэтому они не гарантируют что закрытые страницы не будут проиндексированы и не будут добавлены в индекс.
Если вам нужно действительно закрыть часть сайта от индексации, то, например, можно дополнительно воспользоваться закрытие директорий паролем.
Основной синтаксисUser-Agent: робот для которого будут применяться следующие правила (например, «Googlebot»)
Disallow: страницы, к которым вы хотите закрыть доступ (можно указать большой список таких директив с каждой новой строки)
Каждая группа User-Agent / Disallow должны быть разделены пустой строкой. Но, не пустые строки не должны существовать в рамках группы (между User-Agent и последней директивой Disallow).
Но, не пустые строки не должны существовать в рамках группы (между User-Agent и последней директивой Disallow).
Символ хэш (#) может быть использован для комментариев в файле robots.txt: для текущей строки всё что после # будет игнорироваться. Данные комментарий может быть использован как для всей строки, так в конце строки после директив.
Каталоги и имена файлов чувствительны к регистру: «catalog», «Catalog» и «CATALOG» – это всё разные директории для поисковых систем.
Host: применяется для указание Яндексу основного зеркала сайта. Поэтому, если вы хотите склеить 2 сайта и делаете постраничный 301 редирект, то для файла robots.txt (на дублирующем сайте) НЕ надо делать редирект, чтобы Яндекс мог видеть данную директиву именно на сайте, который необходимо склеить.
Crawl-delay: можно ограничить скорость обхода вашего сайта, так как если у вашего сайта очень большая посещаемость, то, нагрузка на сервер от различных поисковых роботов может приводить к дополнительным проблемам.
Регулярные выражения: для более гибкой настройки своих директив вы можете использовать 2 символа
- * (звездочка) – означает любую последовательность символов
- $ (знак доллара) – обозначает конец строки
Пример:
Disallow: /catalog/ #запрещаем сканировать каталог
«*» — означает любую последовательность символов в файле.
«$» — ограничивает действия «*», представляет конец строки.
«/» — показывает, что закрывают для сканирования.
«/catalog/» — закрывают раздел каталога;
«/catalog» — закрывают все ссылки, которые начинаются с «/catalog».
«#» — используют для комментариев, боты игнорируют текст с этим символом.
Инструкции отделяют друг от друга переносом строки.
Директивы robots.txt
Директивы, которые распознают все краулеры:
User-agent
На первой строчке прописывают правило User-agent — указание того, какой робот должен реагировать на рекомендации. Если запрещающего правила нет, считается, что доступ к файлам открыт.
Для разного типа контента поисковики используют разных ботов:
- Google: основной поисковый бот называется Googlebot, есть Googlebot News для новостей, отдельно Googlebot Images, Googlebot Video и другие;
- Яндекс: основной бот называется YandexBot, есть YandexDirect для РСЯ, YandexImages, YandexCalendar, YandexNews, YandexMedia для мультимедиа, YandexMarket для Яндекс.Маркета и другие.
Для отдельных ботов можно указать свою директиву, если есть необходимость в рекомендациях по типу контента.
User-agent: * — правило для всех поисковых роботов;
User-agent: Googlebot — только для основного поискового бота Google;
User-agent: YandexBot — только для основного бота Яндекса;
User-agent: Yandex — для всех ботов Яндекса. Если любой из ботов Яндекса обнаружит эту строку, то другие правила User-agent: * учитывать не будет.
Sitemap
Указывает ссылку на карту сайта — файл со структурой сайта, в котором перечислены страницы для индексации:
User-agent: * Sitemap: http://site.com/sitemap.xml
 com/sitemap.xml
com/sitemap.xml
Некоторые веб-мастеры не делают карты сайтов, это не обязательное требование, но лучше составить Sitemap — этот файл краулеры воспринимают как структуру страниц, которые не можно, а нужно индексировать.
Disallow
Правило показывает, какую информацию ботам сканировать не нужно.
Если вы еще работаете над сайтом и не хотите, чтобы он появился в незавершенном виде, можно закрыть от сканирования весь сайт:
User-agent: * Disallow: /
После окончания работы над сайтом не забудьте снять блокировку.
Разрешить всем ботам сканировать весь сайт:
User-agent: * Disallow:
Для этой цели можно оставить robots.txt пустым.
Чтобы запретить одному боту сканировать, нужно только прописать запрет с упоминанием конкретного бота. Для остальных разрешение не нужно, оно идет по умолчанию:
Пользователь-агент: BadBot Disallow: /
Чтобы разрешить одному боту сканировать сайт, нужно прописать разрешение для одного и запрет для остальных:
User-agent: Googlebot Disallow: User-agent: * Disallow: /
Запретить ботам сканировать страницу:
User-agent: * Disallow: /page.
 html
htmlЗапретить сканировать конкретную папку с файлами:
User-agent: * Disallow: /name/
Запретить сканировать все файлы, которые заканчиваются на «.pdf»:
User-agent: * Disallow: /*.pdf$
Запретить сканировать раздел http://site.com/about/:
User-agent: * Disallow: /about/
Запись формата «Disallow: /about» без закрывающего «/» запретит доступ и к разделу http://site.com/about/, к файлу http://site.com/about.php и к другим ссылкам, которые начинаются с «/about».
Если нужно запретить доступ к нескольким разделам или папкам, для каждого нужна отдельная строка с Disallow:
User-agent: * Disallow: /about Disallow: /info Disallow: /album1
Allow
Директива определяет те пути, которые доступны для указанных поисковых ботов. По сути, это Disallow-наоборот — директива, разрешающая сканирование. Для роботов действует правило: что не запрещено, то разрешено, но иногда нужно разрешить доступ к какому-то файлу и закрыть остальную информацию.
Разрешено сканировать все, что начинается с «/catalog», а все остальное запрещено:
User-agent: * Allow: /catalog Disallow: /
Сканировать файл «photo.html» разрешено, а всю остальную информацию в каталоге /album1/ запрещено:
User-agent: * Allow: /album1/photo.html Disallow: /album1/
Заблокировать доступ к каталогам «site.com/catalog1/» и «site.com/catalog2/» но разрешить к «catalog2/subcatalog1/»:
User-agent: * Disallow: /catalog1/ Disallow: /catalog2/ Allow: /catalog2/subcatalog1/
Бывает, что для страницы оказываются справедливыми несколько правил. Тогда робот будет отсортирует список от меньшего к большему по длине префикса URL и будет следовать последнему правилу в списке.
Директивы, которые распознают боты Яндекса:
Clean-param
Некоторые страницы дублируются с разными GET-параметрами или UTM-метками, которые не влияют на содержимое. К примеру, если в каталоге товаров использовали сортировку или разные id.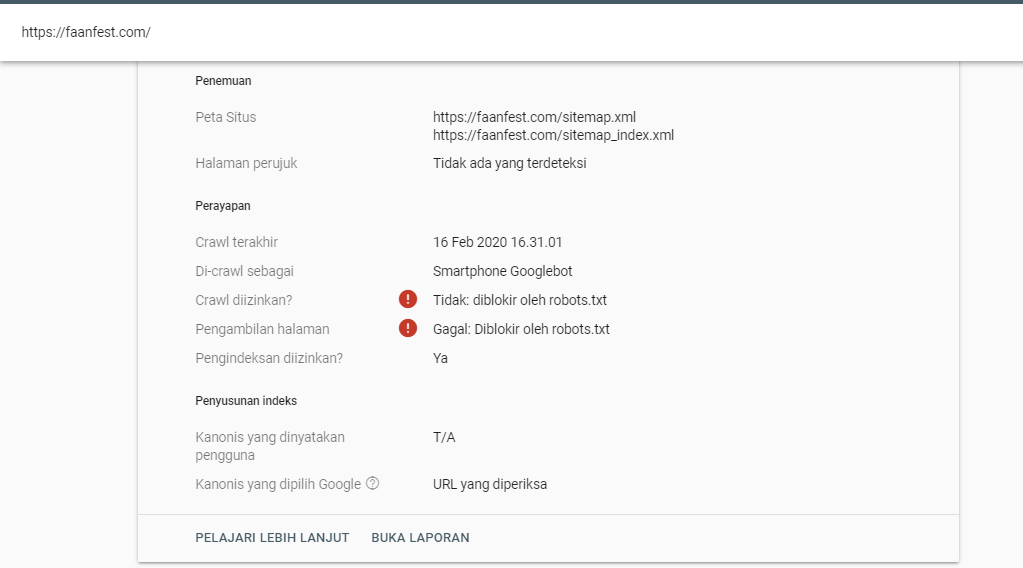
Чтобы отследить, с какого ресурса делали запрос страницы с книгой book_id=123, используют ref:
«www.site. com/some_dir/get_book.pl?ref=site_1& book_id=123»
«www.site. com/some_dir/get_book.pl?ref=site_3& book_id=123»
Страница с книгой одна и та же, содержимое не меняется. Чтобы бот не сканировал все варианты таких страниц с разными параметрами, используют правило Clean-param:
User-agent: Yandex Disallow: Clean-param: ref/some_dir/get_book.pl
Робот Яндекса сведет все адреса страницы к одному виду:
«www.example. com/some_dir/get_book.pl? book_id=123»
Для адресов вида:
«www.example2. com/index.php? page=1&sid=2564126ebdec301c607e5df»
«www.example2. com/index.php? page=1&sid=974017dcd170d6c4a5d76ae»
robots.txt будет содержать:
User-agent: Yandex Disallow: Clean-param: sid/index.php
Для адресов вида
«www.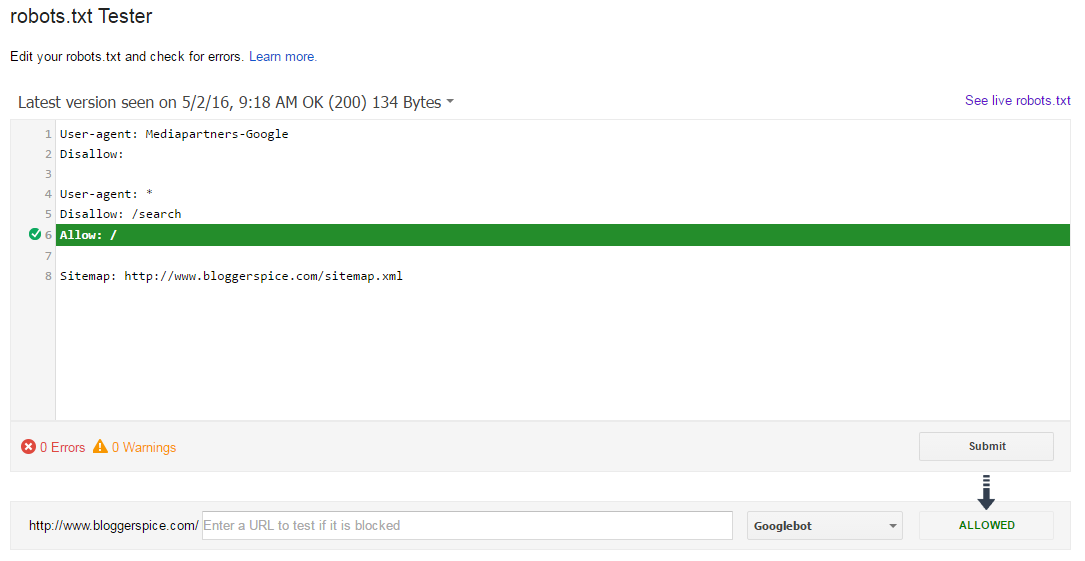
«www.example1. com/forum/showthread.php? s=1e71c4427317a117a&t=8243»
robots.txt будет содержать:
User-agent: Yandex Disallow: Clean-param: s/forum/showthread.php
Если переходных параметров несколько:
«www.example1.com/forum_old/showthread.php?s=681498605&t=8243&ref=1311»
«www.example1.com/forum_new/showthread.php?s=1e71c417a&t=8243&ref=9896»
robots.txt будет содержать:
User-agent: Yandex Disallow: Clean-param: s&ref/forum*/showthread.php
Host
Правило показывает, какое зеркало учитывать при индексации. URL нужно писать без «http://» и без закрывающего слэша «/».
User-agent: Yandex Disallow: /about Host: www.site.com
Сейчас эту директиву уже не используют, если в ваших robots.txt она есть, можно удалять. Вместо нее нужно на всех не главных зеркалах сайта поставить 301 редирект.
Crawl-delay
Раньше частая загрузка страниц нагружала сервер, поэтому для ботов устанавливали Crawl-delay — время ожидания робота в секундах между загрузками. Эту директиву можно не использовать, мощным серверам она не требуется.
Время ожидания — 4 секунды:
User-agent: * Allow: /album1 Disallow: / Crawl-delay: 4
Только латиница
Напомним, что все кириллические ссылки нужно перевести в Punycode с помощью любого конвертера.
Неправильно:
User-agent: Yandex Disallow: /каталог
Правильно:
User-agent: Yandex Disallow: /xn--/-8sbam6aiv3aОсновные примеры использования robots.txt
Запрет на индексацию всего сайта
User-agent: *
Disallow: /
Эту инструкцию важно использовать, когда вы разрабатываете новый сайт и выкладываете доступ к нему, например, через поддомен.
Очень часто разработчики забывают таким образом закрыть от индексации сайт и получаем сразу полную копию сайта в индексе поисковых систем. Если это всё-таки произошло, то надо сделать постраничный 301 редирект на ваш основной домен.
Если это всё-таки произошло, то надо сделать постраничный 301 редирект на ваш основной домен.
А такая конструкция ПОЗВОЛЯЕТ индексировать весь сайт:
User-agent: *
Disallow:
Запрет на индексацию определённой папки
User-agent: Googlebot
Disallow: /no-index/
Запрет на посещение страницы для определенного робота
User-agent: Googlebot
Disallow: /no-index/this-page.html
Запрет на индексацию файлов определенного типа
User-agent: *
Disallow: /*.pdf$
Разрешить определенному поисковому роботу посещать определенную страницу
User-agent: *
Disallow: /no-bots/block-all-bots-except-rogerbot-page.html
User-agent: Yandex
Allow: /no-bots/block-all-bots-except-Yandex-page.html
Ссылка на Sitemap
User-agent: *
Disallow:
Sitemap: http://www.site.com/none-standard-location/sitemap.xml
Нюансы с использованием данной директивы: если у вас на сайте постоянно добавляется уникальный контент, то
- лучше НЕ добавлять в robots. txt ссылку на вашу карту сайта,
- саму карту сайта сделать с НЕСТАНДАРТНЫМ названием sitemap.xml (например, my-new-sitemap.xml и после этого добавить эту ссылку через «вебмастерсы» поисковых систем),
 txt ссылку на вашу карту сайта,
txt ссылку на вашу карту сайта,так как, очень много недобросовестных вебмастеров парсят с чужих сайтов контент и используют для своих проектов.
Что лучше использовать robots.txt или noindex?Если вы хотите, чтобы страница не попала в индекс, то лучше использовать noindex в мета-теге robots. Для этого на странице в секции <head> необходимо добавить следующий метатег:
<meta name=”robots” content=”noindex, follow”>.
Это позволит вам
- убрать из индекса страницу при следующем посещение поискового робота (и не надо будет делать в ручном режиме удаление данной страницы, через вебмастерс)
- позволит вам передать ссылочный вес страницы
Через robots.txt лучше всего закрывать от индексации:
- админку сайта
- результаты поиска по сайту
- страницы регистрации/авторизации/восстановление пароля
 txt?
txt?После того, как вы окончательно сформировали файл robots.txt необходимо проверить его на ошибки. Для этого можно воспользоваться инструментами проверки от поисковых систем:
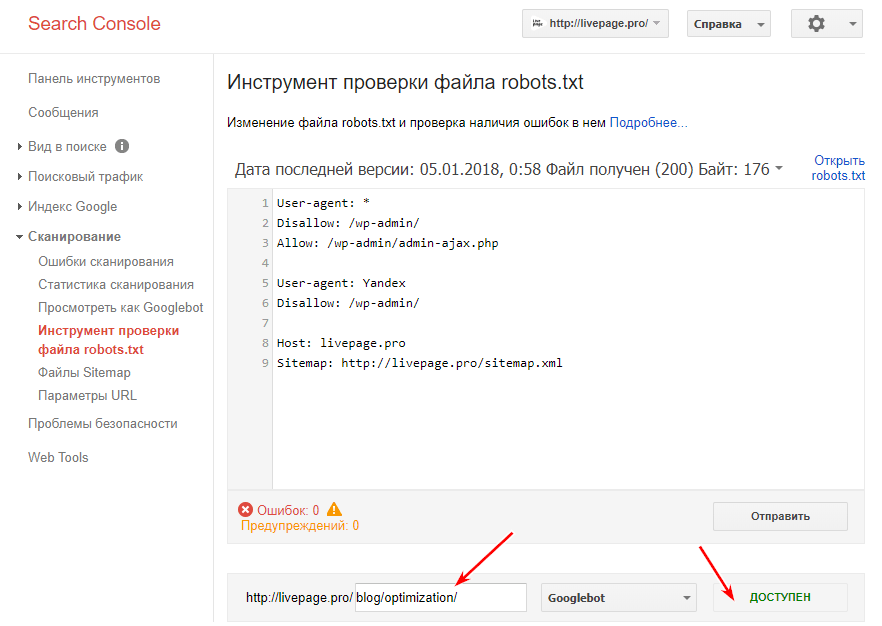
Google Вебмастерс: войти в аккаунт с подтверждённым в нём текущим сайтом, перейти на Сканирование -> Инструмент проверки файла robots.txt.
В данном инструменте вы можете:
- сразу увидеть все свои ошибки и возможные проблемы,
- прямо в этом инструменте провести все правки и сразу проверить на ошибки, чтобы потом уже перенести готовый файл себе на сайт,
- проверить правильно ли вы закрыли все не нужные для индексации страницы и открыты ли все нужные страницы.
Яндекс Вебмастер:
Этот инструмент почти аналогичный предыдущему с тем небольшим отличием, что:
- тут можно не авторизоваться и нет необходимости в подтверждении прав на сайт, а поэтому, можно сразу приступать к проверке вашего файла robots. txt,
- для проверки сразу можно задать список страниц, а не вбивать их по одному,
- точно убедиться, что Яндекс правильно понял ваши инструкции.
 txt,
txt,Для проверки файла robots.txt на ошибки у поисковиков есть собственные инструменты:
Инструмент проверки файла robots.txt от Google позволит проверить, как бот видит конкретный URL. В поле нужно ввести проверяемый URL, а инструмент покажет, доступна ли ссылка.
Инструмент проверки от Яндекса покажет, правильно ли заполнен файл. Нужно указать сайт, для которого создан robots.txt, и перенести его содержимое в поле.
В заключениеСоздание и настройка robots.txt является в списке первых пунктов по внутренней оптимизации сайта и началом поискового продвижения.
Важно его настроить грамотно, чтобы нужные страницы и разделы были доступны к индексации поисковых систем. А не нужные были закрыты.
Примеры для Joomla 3
Изначально robots.txt имеет такой вид
User-agent: *
Disallow: /administrator/
Disallow: /bin/
Disallow: /cache/
Disallow: /cli/
Disallow: /components/
Disallow: /images/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /layouts/
Disallow: /libraries/
Disallow: /logs/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
User-agent — это имя робота, для которого предназначена инструкция.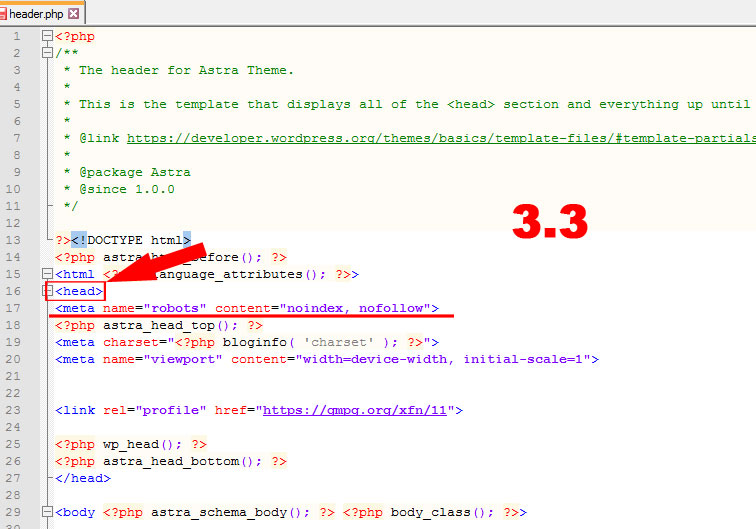 По умолчанию в Joomla стоит * (звёздочка) — это означает, что инструкция предназначена для абсолютно всех поисковых роботов.
По умолчанию в Joomla стоит * (звёздочка) — это означает, что инструкция предназначена для абсолютно всех поисковых роботов.
Disallow — запрещает индексировать содержимое указанной папки или URL.
Пример:
Disallow: /images/ — запрет индексации всего содержимого папки images
Disallow: /index.php* — запрет индексации всех URL адресов, начинающихся с index.php
Allow — наоборот, разрешает индексацию папки или URL.
Пример:
Allow: /index.php?option=com_xmap&sitemap=1&view=xml — разрешает индексацию карты сайта, созданной при помощи Xmap.
Такая директива необходима если у вас стоит запрет на индексацию адресов с index.php, а чтобы робот мог получить доступ к карте сайта, нужно разрешить этот конкретный URL.
Host — указание основного зеркала сайта (с www или без www)
Пример:
Host: www.site.ru — основной адрес этого сайта с www
Sitemap — указание на адрес по которму находиться карта сайта
Пример:
Sitemap: http://www.site. ru/index.php?option=com_xmap&sitemap=1&view=xml
ru/index.php?option=com_xmap&sitemap=1&view=xml
По этому адресу находится карта сайта в формате xml
Clean-param — специальная директива, которая запрещает роботам Яндекса индексировать URL адреса с динамическими параметрами.
Динамические параметры, это различные переменные и цифры, которые подставляются к адресу, например при поиске по сайту.
Пример таких параметров:
http://www.site.ru/poisk?searchword=robots.txt&ordering=newest&searchphrase=all&limit=20
И чтобы Яндекс не учитывал такие служебные страницы, в robots.txt задаётся директива Clean-param.
Всё тот же пример с поиском по сайту:
Clean-param: searchword / — директива запрещает индексировать все URL с параметром ?searchword
Crawl-delay — директива пока знакомая только Яндексу. Она указывает с каким интервалом сканировать страницы, интервал задаётся в секундах.
Может быть полезно если у вас много страниц и достаточно высокая нагрузка на сервер, поскольку каждое обращение робота к странице вашего сайта — это нагрузка на сервер. Робот может сканировать по несколько страниц в секунду и тем самым загрузить сервер.
Робот может сканировать по несколько страниц в секунду и тем самым загрузить сервер.
Пример:
Crawl-delay: 5 — интервал для загрузки страницы — 5 секунд.
Пример с использованием sitemap.xml
User-agent: *
Disallow: /administrator/
Disallow: /bin/
Disallow: /cache/
Disallow: /cli/
Disallow: /components/
Disallow: /component/
Disallow: /images/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /layouts/
Disallow: /libraries/
Disallow: /logs/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /index.php*
Disallow: /index2.php*
Disallow: /*com_mailto
Disallow: /*pop=
Disallow: /*format=
Disallow: /*print=
Disallow: /*user/
Disallow: /index2.php
Disallow: /index.php
Disallow: /*%
Disallow: /*?
Disallow: /*&
Disallow: /*tag
Disallow: /*=atom #RSS
Disallow: /*=rss #RSS
Disallow: /*?view=featured
Disallow: /component/users/
Disallow: /component/content/?view=featured
Allow: /images/
Allow: /templates/*.
Allow: /templates/*.js
Allow: /*.js
Allow: /*.css
Allow: /*.jpg
Allow: /*.gif
Allow: /*.png
Host: https://sitemap.ru
Sitemap: https://sitemap.ru/sitemap.xml
Clean-param: searchword /
Crawl-delay: 5
 css
cssПример с использованием генератора карты сайта JMap
User-agent: *
Disallow: /administrator/
Disallow: /bin/
Disallow: /cache/
Disallow: /cli/
Disallow: /components/
Disallow: /component/
Disallow: /images/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /layouts/
Disallow: /libraries/
Disallow: /logs/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /index.php*
Disallow: /index2.php*
Disallow: /*com_mailto
Disallow: /*pop=
Disallow: /*format=
Disallow: /*print=
Disallow: /*user/
Disallow: /index2.php
Disallow: /index.php
Disallow: /*?
Disallow: /*%
Disallow: /*&
Disallow: /*tag
Disallow: /*=atom #RSS
Disallow: /*=rss #RSS
Disallow: /*?view=featured
Disallow: /component/users/
Disallow: /component/content/?view=featured
Allow: /*.
Allow: /*.css*
Allow: /*.png*
Allow: /*.jpg*
Allow: /*.gif*
Allow: /images/
Allow: /templates/*.css
Allow: /templates/*.js
Allow: /index.php?option=com_jmap&view=sitemap&format=xml
Host: https://site.ru
Sitemap: https://www.site.ru/index.php?option=com_jmap&view=sitemap&format=xml
Clean-param: searchword /
Crawl-delay: 5
 js*
js*Пример с использованием генератора карты сайта Osmap
User-agent: *
Disallow: /administrator/
Disallow: /bin/
Disallow: /cache/
Disallow: /cli/
Disallow: /components/
Disallow: /component/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /layouts/
Disallow: /libraries/
Disallow: /logs/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /index.php*
Disallow: /index2.php*
Disallow: /*com_mailto
Disallow: /*pop=
Disallow: /*format=
Disallow: /*print=
Disallow: /*user/
Disallow: /index2.
Disallow: /index.php
Disallow: /*%
Disallow: /*&
Disallow: /*?
Disallow: /*tag
Disallow: /*=atom #RSS
Disallow: /*=rss #RSS
Disallow: /*?view=featured
Allow: /images/
Allow: /templates/*.css
Allow: /templates/*.js
Allow: /*.js
Allow: /*.css
Allow: /*.jpg
Allow: /*.gif
Allow: /*.png
Allow: /*.ico
Allow: /index.php?option=com_osmap&view=xml&tmpl=component&id=1
Host: https://site.ru
Sitemap: https://site.ru/index.php?option=com_osmap&view=xml&tmpl=component&id=1
Clean-param: searchword /
Crawl-delay: 5
 php
phpПример с использованием компонента K2
User-agent: *
Disallow: /administrator/
Disallow: /bin/
Disallow: /cache/
Disallow: /cli/
Disallow: /components/
Disallow: /component/
Disallow: /images/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /layouts/
Disallow: /libraries/
Disallow: /logs/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /index.
Disallow: /index2.php*
Disallow: /*com_mailto
Disallow: /*pop=
Disallow: /*format=
Disallow: /*print=
Disallow: /*user/
Disallow: /*?start=*
Disallow: /index2.php
Disallow: /index.php
Disallow: /*%
Disallow: /*&
Disallow: /*tag
Disallow: /*=atom #RSS
Disallow: /*=rss #RSS
Disallow: /*?view=featured
Disallow: /component/users/
Disallow: /component/content/?view=featured
Disallow: /component/k2/item/*
Disallow: /component/k2/itemlist/*
Allow: /images/
Allow: /templates/*.css
Allow: /templates/*.js
Allow: /*.js
Allow: /*.css
Allow: /*.jpg
Allow: /*.gif
Allow: /*.png
Allow: /index.php?option=com_xmap&sitemap=1&view=xml
Host: https://site.ru
Sitemap: https://site.ru/index.php?option=com_xmap&sitemap=1&view=xml
Clean-param: searchword /
Crawl-delay: 5
 php*
php*Пример для компонента интернет-магазина Joomshopping
User-agent: *
Disallow: /administrator/
Disallow: /bin/
Disallow: /cache/
Disallow: /cli/
Disallow: /components/
Disallow: /component/
Disallow: /images/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /layouts/
Disallow: /libraries/
Disallow: /logs/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /index.
Disallow: /index2.php*
Disallow: */cart/*
Disallow: /wishlist.html
Disallow: /log-in.html
Disallow: /my-cart.html
Disallow: /my-wishlist.html
Disallow: /my-cart/view.html
Disallow: /shop/cart/*
Disallow: /*com_mailto
Disallow: /*pop=
Disallow: /*format=
Disallow: /*print=
Disallow: /*user/
Disallow: /index2.php
Disallow: /index.php
Disallow: /*?
Disallow: /*%
Disallow: /*&
Disallow: /*tag
Disallow: /*=atom #RSS
Disallow: /*=rss #RSS
Disallow: /*?view=featured
Disallow: /component/users/
Disallow: /component/content/?view=featured
Allow: /*.js*
Allow: /*.css*
Allow: /*.png*
Allow: /*.jpg*
Allow: /*.gif*
Allow: /images/
Allow: /templates/*.css
Allow: /templates/*.js
Allow: /components/com_jshopping/files/img_categories/
Allow: /components/com_jshopping/files/img_products/
Allow: /site.ru/index.php?option=com_jmap&view=sitemap&format=xml
Host: https://site.
Sitemap: https://site.ru/index.php?option=com_jmap&view=sitemap&format=xml
Clean-param: searchword /
Crawl-delay: 5
 php*
php* ru
ruПример — закрыть от индексации весь сайт
User-agent: *
Disallow: /
Важно!!! Все примеры указаны для включенной функции SEF в настройках сайта Joomla и они не являются абсолютом.
Веб-студия WebTend делает подробный аудит сайта и включает в robots.txt дополнительные позиции Disallow и Allow.
Правильный robots.txt для CMS Joomla 4
User-agent: *
Disallow: /administrator/
Disallow: /api/
Disallow: /bin/
Disallow: /cache/
Disallow: /cli/
Disallow: /components/
Disallow: /component/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /layouts/
Disallow: /libraries/
Disallow: /logs/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /*archive
Disallow: /index.
Disallow: /index2.php*
Disallow: /*com_mailto
Disallow: /*pop=
Disallow: /*format=
Disallow: /*print=
Disallow: /*user/
Disallow: /index2.php
Disallow: /index.php
Disallow: /*?
Disallow: /*%
Disallow: /*&
Disallow: /*tag
Disallow: /*=atom #RSS
Disallow: /*=rss #RSS
Disallow: /*?view=featured
Disallow: /component/users/
Disallow: /component/content/?view=featured
Disallow: /*feed*
Disallow: /*search
Disallow: /*tags
Disallow: /*uncategorised
Disallow: /*users
Disallow: /*?format
Disallow: /*?itemid
Disallow: /*?searchword
Disallow: /*?start
Disallow: /*?tagid
Disallow: /*?tmpl=component
Disallow: /*?type
Disallow: /*?view=article
Disallow: /*?view=category
Disallow: /*?view=registration
Allow: /images/
Allow: /media/*.css
Allow: /media/*.js
Allow: /*.js
Allow: /*.css
Allow: /*.png
Allow: /*.jpg
Allow: /*.gif
Allow: /*.
Allow: /templates/*.css
Allow: /templates/*.js
Allow: /templates/*.jpg
Allow: /templates/*.png
Allow: /templates/*.jpg
Allow: /templates/*.gif
Allow: /templates/*.ico
Allow: /images/
Allow: /index.php?option=com_jmap&view=sitemap&format=xml
Host: https://site.ru
Sitemap: https://site.ru/index.php?option=com_jmap&view=sitemap&format=xml
Clean-param: searchword /
Crawl-delay: 5
 php*
php*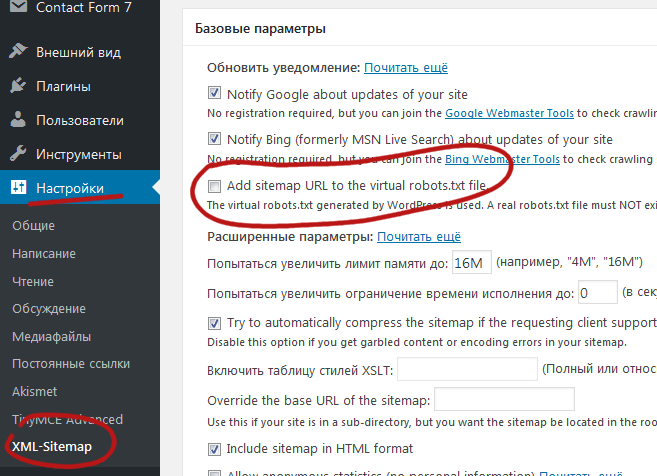 ico
icoОтключить индексацию поддоменов в robots.txt на виртуальных хостах — Маркетинг — Форумы SitePoint
john_zakaria
#1
я создаю поддомен для использования на своем веб-сайте, например:
example.com — test.example.com
, но я использую в одном файле robots, потому что это виртуальный поддомен только
так как в мой файл robots, чтобы включить индексирование example. com, но одновременно отключить test.example.com
com, но одновременно отключить test.example.com
, потому что, когда в поиске я набираю «свяжитесь с нами», он дает результаты для example.com/contact-us и test.example.com/contact-us
я хочу отображать только результаты example.com и не индексировать тест .example.com, чтобы отключить его отображение в результатах поиска
, поэтому я удалил ссылки в поисковой консоли Google, но мне нужно отредактировать robots.txt
TechnoBear
#2
Google рекомендует использовать метатеги «noindex» или каталог, защищенный паролем, чтобы страницы не сканировались.
Разработчики GoogleRobots.txt Введение и руководство | Центр поиска Google | …
Robots.txt используется для управления трафиком поисковых роботов. Изучите это вводное руководство по robots.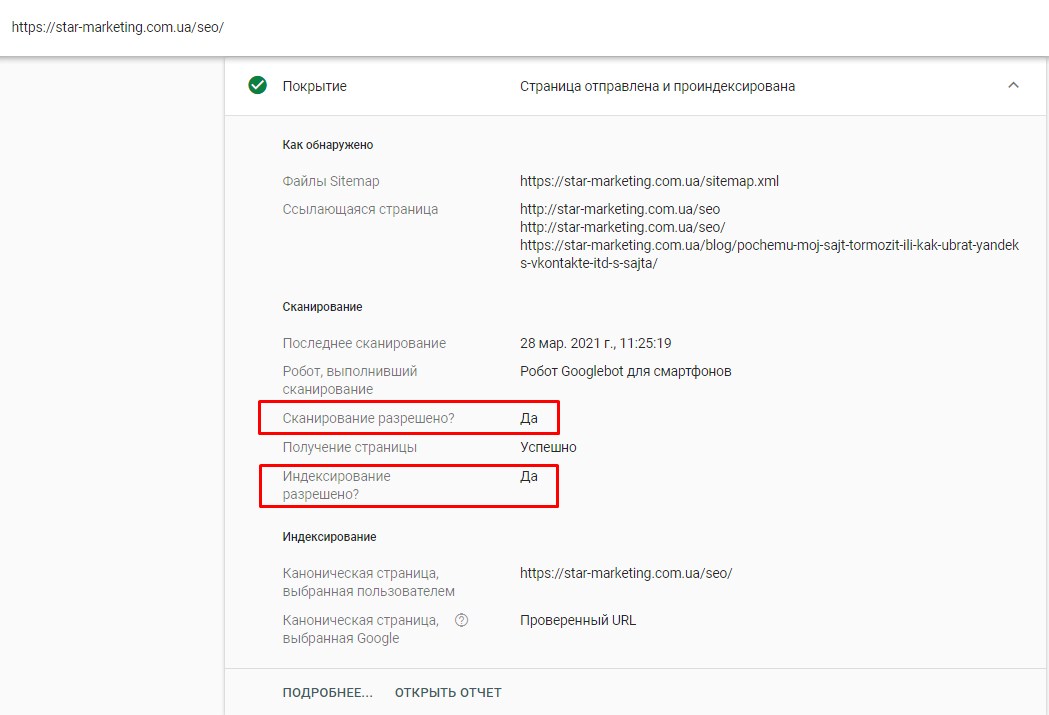 txt, чтобы узнать, что такое файлы robots.txt и как их использовать.
txt, чтобы узнать, что такое файлы robots.txt и как их использовать.
джон_закария
#3
это хорошее решение?
я добавил в htaccess эти строки
RewriteCond %{HTTP_HOST} test.example.com
RewriteRule /robots.txt /subdomainRobots.txt [L,NC,QSA]
и сделал все в disallowRobots для поддоменов
Джон_Закария
#4
и основной домен, и поддомен ищут одни и те же файлы и один и тот же robots.txt
это только URL-имя, которое использует субдомен, но веб-сайт тот же
, поэтому я не могу ставить теги, потому что он будет отражать как ссылки оригинал, так и субдомен
, не могли бы вы проверить мой другой комментарий в качестве решения ? это полезно
TechnoBear
#5
Если у вас есть доступ к одному и тому же контенту с двух разных URL-адресов, правильным подходом будет использование канонических URL-адресов.
Разработчики GoogleКанонизация URL и тег Canonical | Центр поиска Google…
Если на сайте есть дублированный контент, Google выбирает канонический URL. Узнайте больше о канонических URL-адресах и о том, как объединять повторяющиеся URL-адреса.
системаЗакрыто
#6
Эта тема была автоматически закрыта 91 дней после последнего ответа. Новые ответы больше не допускаются.
Если я отключу индексирование из файла robots.
 txt сервера CDN, создаст ли это проблему SEO?
txt сервера CDN, создаст ли это проблему SEO?спросил
Изменено 1 год, 5 месяцев назад
Просмотрено 428 раз
У меня есть 1 собственный веб-сайт и 1 сервер CDN. У меня есть CSS, JS и изображения на моем сервере CDN. Все CSS, JS и изображения на моем собственном веб-сайте поступают с сервера CDN.
Если я заблокирую свой CDN-сервер с помощью файла robots.txt, будут ли проиндексированы изображения на моем собственном веб-сайте, URL-адреса которых находятся в CDN? Кроме того, игнорирует ли робот Google файлы CSS и JS?
- seo
- robots.txt
- cdn
- Technical-seo
Стандарт robots.txt относится к домену/поддомену. Таким образом, файл по адресу cdn. будет управлять доступом к ресурсам по адресу  example/robots.txt
example/robots.txt cdn.example , а файл по адресу yoursite.example/robots.txt будет контролировать доступ к ресурсам на yoursite.example .
Это означает, что, например, если cdn.example/robots.txt имеет директиву User-agent : * ⏎ Disallow: / , все ресурсы на cdn.example , включая изображения, будут заблокированы. Таким образом, в этом случае, если у вас есть веб-страница на yoursite.example , которая пытается загрузить эти изображения CDN как часть страницы, доступ к этим изображениям будет заблокирован сканером, поэтому сканер отобразит вашу страницу без изображений.
Бот Google использует файлы CSS и JS для правильного отображения и ранжирования вашей страницы. Он будет жаловаться, если вы не разрешите ему доступ, и может несколько понизить ваш сайт из-за невозможности проверить его на удобство для мобильных устройств, время загрузки страницы (часть «опыта страницы») и т.