
Что такое релевантный запрос и для чего он нужен
В наши дни обычному человеку нет необходимости копаться в библиотеках и архивах в поисках нужной информации. Развитие информационных технологий привело к тому, что практически все необходимое ныне можно найти в интернете. Для облегчения этой задачи существуют специальные поисковые алгоритмы, которые обеспечивают поиск и выдачу информации по запросам пользователей.
Содержание:
Понятие релевантности
В основу работы поисковых систем положен принцип релевантности информации. Релевантность – это одно из важнейших понятий в сфере поисковой оптимизации, уровень соответствия результата выдачи поисковому запросу. То есть, другими словами, насколько отвечает результат поиска потребностям пользователя. Релевантность можно рассмотреть на примерах.
Пользователю срочно понадобилась книга «А», но ни в одном из книжных магазинов он ее не нашел. Пользователь заходит на страницу поисковика и вводит в строку запроса «купить книгу «А». Если, перейдя по предложенным ссылкам, пользователь попадает на страницу книжного интернет-магазина, где ему будет предложена необходимая книга и цена за нее, то такой результат считается релевантным.
У пользователя не включается телефон, он вводит в строчку поиска фразу «сломался телефон». Результатов будет множество, но релевантным будет результат, где описываются возможные причины проблем с телефоном и способы их решения. Нерелевантным является тот результат, где вместо этого просто описываются модели телефонов.
То есть, релевантным результат считается если вы получили на свой запрос конкретный ответ, который вас полностью устраивает или искомую информацию. Тексты, не содержащие никакой конкретики, либо просто содержащие набор фраз релевантными считаться не могут.
Таким образом, релевантность – это главный критерий успеха. Пользователь, который переходит на страницу сайта из поисковика должен найти именно тот материал, который ищет. В другом случае, страница для него бесполезна, а значит нерелевантная запросу.

Как получить релевантную статью
Раньше, когда сфера поисковой оптимизации только начинала свое развитие, для того чтобы подняться в рейтинге выдачи можно было просто вставить в текст большое количество ключевых слов. Сейчас такой прием не работает. Вернее, сделать такое можно, но после этого гарантировано понижение в рейтинге, вплоть до исключения из индекса.
На сегодняшние день многие пытаются просто вставлять в текст несколько ключевых слов, которые идентичны популярным поисковым запросам. Но релевантной статью это не делает и пользователям такие страницы попросту не интересны. Поисковые системы тоже научились определять релевантность по поведению пользователей, в частности, по времени, проведенному на сайте. Если человек заходит на сайт и сразу же закрывает его, то информация считается не соответствующей запросу. Необходимо чтобы пользователь задержался на странице минимум сорок секунд.
Поисковые системы анализируют сам текст, размещенный на странице на предмет наличия определенных терминов и слов, которые употребляются в статьях подобной тематики.

Другими словами, на данный момент релевантность определяется не по ключевым словам. Несмотря на то что их продолжают использовать, этот метод является устаревшим. В первую очередь необходимо соответствие заявленным темам, это приведет к увеличению количества посетителей, и как следствие, повышению в рейтинге.
С уважением, Евгений Кузьменко.
Как измерить релевантность контента / Rookee.ru corporate blog / Habr
Оценка контента одна из главных составляющих формулы релевантности. Знание текстовых признаков и вклад каждого из них в оценку сайта позволит приблизиться к более профессиональной работе с ресурсом. В данной статье будет рассмотрена модель, позволяющая восстановить формулу ранжирования по каждому конкретному запросу, указана значимость определение тематики сайта при продвижении по определенному запросу, а также проработан вопрос, связанного с определением неестественного текста. Восстановление формулы ранжированияЕсли переводить данную задачу в область математики, то входные данные можно представить набором векторов, где каждый вектор – множество характеристик каждого сайта, а координаты в векторе – параметр, по которым оценивается сайт. В описанном векторном пространстве обязательно должна быть задана функция, определяющая отношение порядка двух объектов между собой. Эта функция позволяет ранжировать объекты между собой по принципу «больше — меньше», однако при этом сказать, насколько именно одно больше или меньше другого – нельзя. Такого вида задачи относятся к задачам оценки порядковой регрессии.
Наши сотрудники разработали алгоритм на основе модели линейной регрессии с регулируемой селективностью, который позволил с определенной долей погрешности восстановить ранги сайтов и спрогнозировать изменение выдачи при соответствующих корректировках параметров сайта. Первым шагом алгоритма является обучение модели. В данном случае обучающая выборка представляет собой результаты ранжирования сайтов в рамках одного поискового запроса. Упорядоченность сайтов в рамках поискового запроса фактически означает, что в признаковом пространстве существует некоторое направление, на которое объекты обучающей выборки должны проектироваться в нужном порядке. Это направление и является искомым в задаче восстановления формулы ранжирования. Однако судя по рис.1, таких направлений может быть много.
Рис. 1. Выбор направляющего вектора
Для решения данного вопроса был рассмотрен подход, лежащий в основе метода опорных точек, а именно – выбор такого направления, которое будет обеспечивать максимальное удаление объектов друг от друга.
Следующая задача, которая была решена — выбор стратегии обучения. Рассматривалось два варианта – сокращенная стратегия обучения, при которой учитывается порядок двух соответствующих элементов, и полная стратегия, которая учитывает весь порядок объектов. В результате экспериментов была выбрана сокращенная стратегия, которая заключается в решении следующего уравнения:(1)
— симметричная матрица
— вектор коэффициента
— разница векторов характеристик
Данный подход на различных выборках (100 признаков и 500 признаков на 20 различных множествах поисковых запросов) показал хорошие результаты (см. табл. 1).
Таблица 1. Результаты сокращенной модели
Рис. 2. Восстановленные коэффициенты регрессии при n=100
Рис. 3. Восстановленные коэффициенты регрессии при n=500
Если говорить о результатах на конкретных запросах, то проведенные эксперименты дают следующий показатель ошибка
Таблица 2. Ошибки вычислений
При работе над проектом данный подход использовался для прогнозирования позиций при конкретном изменении на сайте. Подобные эксперименты проводились на базе текстовых признаков. Первоначально были собраны данные по сайтам из ТОП20 по рассматриваемому запросу, затем данные подвергались стандартизации с помощью соответствующего алгоритма. После чего выполнялся алгоритм непосредственно по вычислению «релевантности» с помощью метода квадратичного программирования.
Полученные значения релевантности сайта сортируются и делается вывод о восстановленных позициях.
Таблица 3. Восстановление позиций
Было выявлено, что наибольшее влияние на позиции при ранжировании запроса «шиномонтажное оборудование» вносят признаки: наличие в Яндекс каталоге, вхождение первого слова из запроса «шиномонтажное», вхождение в h2 первого слова запроса «шиномонтажное», вхождение в title страницы второго слова запроса «оборудование».
Рис. 4. Программа, восстанавливающая формулу ранжирования
На сайте были произведены все эти изменения, после очередного апдейта сайт занял позиции, близкие к прогнозируемым. Первоначальная позиция была 50, после указанных изменений она составила ТОП20.
Рис.5. Результаты продвижения запроса «шиномонтажное оборудование»
Измерение тематики текста
В работе с восстановлением формулы ранжирования была подтверждена значимость измерения тематической близости тематики текста по отношению к тематике всего сайта. Подобную метрику можно построить на базе расчета косинуса между векторами соответствующих тематики страницы, релевантной запросу, и всего сайта: (2)
где и соответственно обозначение вектора тематичности сайта и рассматриваемого документа.
N – число слов в словаре коллекции. Вес каждого слова j в документе Di рассчитывается по формуле:(3)
где countij – число вхождений слова в документ, IDFwj — обратная частота слова в коллекции. После расчета веса каждого слова в документе, вектор нормируется:(4)
Аналогичным образом строится вектор и для всего сайта, при этом текст сайта получается объединением текстов всех входящих в него документов.
Таким образом, алгоритм определения тематической ценности документа можно представить в следующем виде:
1) Определяется словарь, в котором отсутствуют редкие и стоп-слова, т.е. IDF слов, формирующих словарь, лежит в диапазоне значимых слов.
2) Строится N-мерный вектор тематичности для рассматриваемого документа , используя формулы 3 и 4.
3) Строится N-мерный вектор тематичности для всего сайта , используя формулы 3 и 4.
4) С помощью (2) устанавливается близость векторов и . Чем ближе вектора, тем тематическая ценность документа выше.
На основе данной модели была написана программа, позволяющая определить тематическую схожесть рассматриваемого документа и текстовой составляющей самого сайта. Эксперименты проводились на базе 3 групп сайтов: с одинаковой тематикой, с близкой тематикой, с разной тематикой. Всего было обработано 200 статей. В результате обработки были получены следующие данные по 20 группам «1 тестовый документ / 9 обучающих документов», представленные в таблице.
Таблица 4. Результаты проверки тематической полноты
Из таблицы видно, что предложенный метод определения тематической полноты информационного ресурса работает на практике: проверяемые документы, расположенные на сайтах с более полно раскрывающейся тематикой, имеют более высокие показатели. Однако были выявлены и недочеты разработанной системы. Во-первых, на сайтах часто находятся неинформативные или малоинформативные страницы (формы заказов, обратной связи, контакты и т.п.). Во-вторых, при выборе случайно заданного количества обучающих текстов можно отобрать нетематические страницы. В-третьих, в качестве тестовых текстов могут попасться неспецифический контент, но близкие по тематике, например – правописание того или иного слова. В-четвертых, существуют сайты, которые охватывают разные тематические направления, при этом пересекающихся по смыслу (интернет-магазины, новостные сайты, банки рефератов).
Рис. 6. Рубрика, присвоенная в Каталоге.Яндекса
При использовании рассмотренного выше метода был сделан вывод, что тематическая полнота продвигаемых страниц не полная по отношению к запросам тематики «перевозка и доставка из Китая», но достаточная большая по отношению к тематике «оборудование». Соотношение страниц «логистика: оборудование» составляло соответственно «30:200». Соответственно, и позиции, и трафик был лишь у запросов, связанных с оборудованием. При этом приоритетна была «логистика». Для решения проблемы было написано письмо в Яндекс с целью получения развернутой информации. Однако был получен стандартный ответ «Платона» об улучшении и развитии сайта, но в целом все в порядке.
В качестве решения стоял выбор между развитием требуемой тематике на сайте и разнесением двух тематик на разные поддомены. Выиграла необходимость получить быстрый результат. Были составлены ТЗ на перенос направления «оборудование» на поддомен, а на основном сайте сохранена информация по «логистике», а так же на развитие ресурса путем добавления новых релевантных тематике страниц. Результат изменений представлен на рис. Запросы по оборудованию успешно перешли на поддомен и заняли положительные позиции. А после добавления тематических страниц по логистике и запросы по перевозкам, стали показывать положительную динамику.
Рис. 6. Результаты продвижения, после разведения тематик
Таким образом, за счет схемы «поддомен + домен» получилось без потерь разнести тематики и за счет этого повысить релевантность каждой из тематик по-отдельности и добиться положительную динамику по запросам.
Измерение естественности текста
Требования попадания в Яндекс.Каталог ужесточаются. В последнее время приходится сталкиваться с тем, что при проверки сайта, сотрудники яндекса сообщают о некачественном контенте. Выявить данный факт вручную на большом сайте представляется проблемой. Поэтому в настоящий момент ведутся работы по анализу признаков данных текстов. Расскажу о некоторых из них. Можно выделить два основных подхода в получении спам-текста: замена русских букв латинскими и генерация контента, лишенного смысла.
Первый подход вскрывается путем выявления измененных слов с помощью инвертированной частоты и сравнением с установленной эмпирическим путем критической величиной. Слова, образованные заменой русских букв аналогичными латинскими, являются редкими словами с точки зрения статистики употребления. С помощью инвертированной частоты по общей коллекции можно выявить такие слова. Каждому элементу текстового узла , ставится в соответствие значение с помощью функции инвертированной частоты fh:(5)
В качестве функции инвертированной частоты были рассмотрены:(6), (7), (8).
Здесь D – число документов в коллекции, DF – количество документов, в которых встречается лемма, CF – число вхождений леммы в коллекцию, TotalLemms – общее число вхождений всех лемм в коллекции. Из этих вариантов лучший результат в эксперименте, также как и в исследовании Гулина А. показал ICF (7), поэтому где – число вхождений леммы в рассматриваемом тексте, – общее число вхождений всех лемм во множестве.
Чем больше значение функции fh, тем реже слово встречается. Для получения интервала ICF значимых слов была написана программа, на вход которой подавались тексты различного содержания (устранение тематического влияния). Программа обработала порядка 500 МБ текстовой информации. В результате обработки был получен словарь обратных частот слов ICF в нормальной форме. Лемматизация слов была осуществлена с помощью парсера mystem, компании Яндекс. Все элементы словаря были отсортированы в порядке увеличения обратной частоты. В результате анализа данного словаря был получен интервал значимых слов: [500; 191703].
Для установления критерия выявления спам-текстов, также вводится критическая величина Hкрит и производится подсчет Hp процента слов, чья характеристика превышает установленную эмпирическим путем критическую величину Hкрит :(9)
В качестве критической отметки используется процент незначащих слов – 50% (наибольший показатель частоты служебных слов — 37.60%, а придуманных слов автором в среднем — 5.63%). Большой процент употребления в одном тексте таких словообразований Hp будет свидетельствовать о том, что документ является сгенерированным.
Однако сайтов с такими спам-текстами достаточно мало. Второй подход более распространен. Существует класс неестественных текстов, порожденных с помощью генераторов на основе цепей Маркова. На основе исследований Павлова А.С. была предложена модель, позволяющая выявлять такие тексты.
Вся текстовая составляющая B документа D имеет ряд признаков , трудно контролируемых автором. Для построения автоматического классификатора неестественных текстов используются выделенные признаки в машинном обучении. В качестве разрабатываемого подхода лежит алгоритм на основе деревьев решений C4.5. Сам алгоритм определения неестественного текста выглядит следующим образом:
Рис. 7. Алгоритм определения сгенерированного контента
Для получения дерева решений была подготовлена база естественных текстов в размере 2000 и база неестественных текстов объемом также 2000, часть найдена в интернете, часть сгенерирована, остальные получены путем синонимизации документов-образцов или путем перевода с иностранных языков. Исходной коллекцией стала коллекция ROMIP By.Web. Инструменты генерации и синонимизации были найдены в интернете (TextoGEN, Generating The Web 2.2, SeoGenerator и другие).
Полученный набор текстов делился на две равные части. Первая группа использовалась в качестве обучающей выборки, а вторая часть – тестовый набор. Обе выборки имели равное количество документов-образцов и порожденных текстов.
Для процесса обучения была написана программа, которая по каждому тексту строила вектор, оценивающий параметры, влияющие на определение естественности текста. Согласно исследованию Павлова А.С. наибольший вклад в обучение вносит список параметров, определяющих текстовое разнообразие и частоту использования частей речи. В таблице представлен список наиболее ценных признаков для классификации русскоязычных текстов, для каждого признака указана F-мера и тип признака.
Таблица 5. Наиболее ценные признаки для классификации текстов
По полученным векторам P каждого из документа D строилось дерево решений. Данная процедура проводилась с помощью аналитической платформы Deductor Studio Academic версии 5.2. В Deductor в основе обработчика «Дерево решений» лежит модифицированный алгоритм C4.5, решающий задачи классификации. В результате было построено дерево со 157 узлами и 79 правилами. На рис. представлена часть полученного дерева. Полученные правила использовались в основной программе при определении спам-текстов сайта.
Рис. 8. Дерево решений. Аналитическая платформа Deductor 5.2.
Рис. 9. Результат работы программы по анализу текстов
На практике данный подход помог обнаружить причину отсутствия динамики по запросам. Программа обнаружила сгенерированные тексты на всех страницах категорий сайта. При расследовании было выяснено, что они представляют контент машинного перевода этого же сайта, но английской версии.
Рис. 10. Тексты на страницах категорий
После редактирования данных текстов даже только на продвигаемых страницах, была получена хорошая динамику: запросы из ТОП500 сразу попали в ТОП10 за 9 недель.
Рис. 11. Пример измененного текста.
Рис. 12. Изменение позиций по неделям после выкладки.
В заключение необходимо отметить, что разработка рассмотренных функционалов — не обязательна! Она полезна при глобальных исследованиях поисковых машин. При продвижении сайта достаточно выработать подход, позволяющий точечно работать с запросами на основе анализа ТОПа. Для этого существует много естественных инструментов:
1) Проверьте, сколько по запросу релевантных страниц на сайте и сравните с конкурентами – сможете оценить текстовую полноту сайта
2) Обратите внимание на подсвеченные слова в многословных запросам в сохраненной копии – помощь при составлении текстов, на сколько далеко могут стоять друг от друга слова
3) Используйте язык запросов. Например, анализируя выдачу по точному запросу и без кавычек, можно выявить проблемы с текстовой составляющей
4) Через расширенный поиск ищите запрос по конкретным сайтам и анализируйте, какие страницы и почему выше продвигаемой
5) Результаты Вебмастера.Яндекса и Вебмастера.Гугл, данные метрики и GA также помогут выявить проблемы и провести работу с ними.
Целенаправленная деятельность по запросам всегда дает положительный результат.
Авторы статьи: Неелова Н.В. (к.т.н., руководитель отдела ПП Ingate), Поленова Е.А. (руководитель группы ПП Ingate).
Релевантность 100% — секреты поисковой оптимизации

Одной из самых сложных тематик в seo принято считать «релевантность». Ведь все мы знаем, что значимость контента для поисковика всегда находилась, да и будет находиться на первом месте. Простыми словами, слово «релевантность» означает степень совпадения поискового запроса контенту, содержащемуся на странице.
Но что такое релевантность с точки зрения поисковых алгоритмов и как правильно выстроить свой собственный текст, чтобы создать максимально возможные перспективы для ТОПовых позиций, ответить сможет не каждый.
Я сразу отмечу, что в интернете опубликовано множество статей на данную тематику, ну и каждый мало-мальский блоггер (часто даже не имеющий отношения к seo) считает обязательным вставить свои «пять копеек» по поводу релевантности запросов.
Я постараюсь вам показать всю внутреннюю и внешнюю структуру релевантности и логику основного робота при обходе и определении степени совпадения.
Хорошим примером для seo-новичков и всех тех, кто по каким-то причинам желает создать релевантный контент для собственного сайта, будет являться Wikipedia. Так уж сложилось, что Яндекс и Google считают данный сайт чуть ли не эталоном релевантности запросов. Для этого есть обоснованная причина, но разбирать её мы не будем. Поверим на слово и будем придерживаться некоторых принципов этой большой энциклопедии.
Совет для новичков: забудьте слово «релевантность», пишите хорошие статьи с качественным полезным контентом. Публикуйте то, чего ещё нет на просторах интернета. Дополняйте и пополняйте базу знаний сети! И тогда о релевантности вам и думать не придётся: Вас будут ценить за вашу уникальность, неповторимость и исключительность!
Но если вы уж решили окунуться в «кашу» современного seo, то данная статья поможет вам понять логику обработки данных поисковиками.
Любой робот, каковым является алгоритм поиска, всегда и без исключения действует по определённому алгоритму: обрабатывает данные согласно условиям и заданным характеристикам. Любой математик скажет вам, что, имея формулы, получить ответ не составит труда. Наша с вами задача — приблизиться к той формуле, которая сокрыта в тайне «релевантности». А поможет нам в этом обычная и самая простая логика!
Как составить релевантный текст
В основе любого контента заложен текст. Именно текст является основополагающим фактором для определения релевантности. Любой текст состоит из символов (букв, знаков цифр и т.д.), поисковики же собирают данные символы в слова, чаще всего понимая, что то или иное отдельное слово значит. С помощью слов-синонимов, морфологических форм и речевых оборотов определяют более точное значение многозначных слов. На основе частоты использования слов в тексте формируют общее представление о смысловой нагрузке контента в целом и каждого отдельного абзаца в частности. Так формируется релевантность на первом этапе обработки алгоритма.
Принято считать, что контент обрабатывается поисковиками по трём принципам:
- Закон Ципфа. Принцип данного закона гласит, что слова в тексте используются пропорционально рангу ключевого слова. То есть n-количество раз используемых ключевых слов делится для каждого последующего на два, три, четыре и т.д.
- Принцип формирования шинглов. Релевантность в данном случае складывается из последовательности вхождения ключевиков в абзацы. За расчёт берётся условная единица в 250 знаков (количество знаков в сниппете).
- Принцип прогрессивно уменьшающейся значимости. Заключается в том, что каждое последующее слово имеет меньшую значимость для релевантности, чем предыдущее.
Целевым указанием роботу на принадлежность того или иного контента ключевому слову являются специальные указатели, которые помогают алгоритмам сформировать более целостное представление о степени совпадении слов и смысла.
Самым главным и самым важным из них является <title> — это прямой и самый короткий ответ на вопрос, освещенный в вашем материале. Заголовок должен содержать в себе точное и короткое предложение, максимально характеризующее ваш текст, и никак по-другому!
Очень часто составить качественно и правильно текст длиной в 70 символов не представляется возможным, поэтому горе-seoшники включают в title весь набор ключевых фраз. Для этого существует второй по значимости указатель, дополняющий <title> — это <description>. Значение данного поля измеряется 220 символами — достаточным количеством, чтобы дополнить ваш title поясняющим описанием!
Особые отношения у поисковиков сложились с внутренними заголовками страниц (<h2>, <h3> и <h4>). Они также являются указателями для определения смысла контента и качества релевантности. Считается, что:
<h2> — основной заголовок статьи, должен содержать ключевую фразу;
<h3> — дополнительный заголовок, должен содержать словоформы и склонения ключевых фраз, а также расширенные ключевые фразы;
<h4> — слова синонимы и дополнения к ключевым фразам.
Важное значение поисковики отдают плотности слов и фраз в тексте, ведь именно они являются ключевым фактором определения значимости слово по отношению к общему объему текста. Достаточно знать простое правило: текст — это не игрушка. Не нужно прикручивать и вставлять фразы в контент: лаконичность и простота фраз, разнообразие лексики и сложные красивые обороты не дадут вам использовать ключевые фразы больше дозволенного количества раз. Ну, а уж если ориентируетесь на конкретные цифры, то релевантность — это 2-3% ключевиков к общему объему текста!
К значимому дополнительному указателю можно отнести медиа-контент. По большей части это иллюстрации, изображения и картинки. Именно они дают дополнительные сигналы алгоритмам о составляющей релевантности. Причём данный фактор может играть как положительную роль, так и отрицательную!
Большинство из вас знает, что поисковики рекомендуют размещать на своих страницах уникальные картинки и иллюстрации к тексту, и это может понизить вашу релевантность! Алгоритмы поисковых роботов, анализирующих изображения, далеки от совершенства, а обработка изображений основывается на тексте, размещенным возле картинок. Как следствие, уникальная картинка, даже с указанием alt и title в описании, даёт маленькое представление о изображении, а следовательно, и на релевантность влияют слабо.
Существует целая схема того, как быстро дать поисковику понять, что изображено на картинке. В данном случае в работу включаются ссылки. Самый простой способ — распространить иллюстрацию с нужным релевантным описанием в социальных сетях (в первую очередь pinterest), фото-хостингах и на самих сервисах поисковиков (Яндекс.Фото и Google+). Но данный процесс займёт некоторое время, порой несколько месяцев!
Для усиления релевантности я рекомендую использовать заимствованные изображения с других сайтов, которые уже имеют значение в базе поисковиков. Найти их можно в поиске Яндекса или Google по ключевому слову. Такие изображения уже имеют смысловые значения и, как следствие, дополняют ваш контент значимостью. Поисковики в таких случаях требуют снабжать картинки ссылками на первоисточники, что позволяет дополнительно усилить релевантность. Ссылка с релевантной страницы на релевантную помогают в понимании смысла как первоисточника, так ссылающейся страницы.
Большой редкостью для сайтов является микроразметка, а ведь именно она указывает поисковым роботам на те или иные элементы контенты на сайте. Чего уж проще: вы сами можете управлять действиями алгоритма с помощью специальных тегов. Несомненно, страницы с микроразметкой обрабатываются с сотни раз быстрее, и, как следствие релевантность определяется гораздо эффективнее!
Многие блоггеры очень часто замечали, что после написания большего количества комментариев на странице позиции начинают двигаться в противоположную сторону от ТОПа. Причиной тому является большой объём неоптимизированного контента. Микроразметка исключит данные случаи и укажет на значимость тех или иных частей контента для seo. Так, для обычного блога становится понятно, что является основным контентом (текст статьи), что картинкой — с описанием, что — ссылкой с дополняющими материалами, что — комментариями, а что сайдбаром. Таким образом вы показываете поисковому роботу, какой контент важен для релевантности, а какой учитывать ни в коем случае нельзя.
Последний важным фактором, влияющим на релевантность, являются ссылки. И не важно, какого формата: закрытые или открытые, ссылки с анкором или безанкорные. Даже ссылки на картинки несут значимость!
В формирование релевантности участвуют как исходящие ссылки, так и входящие.
К исходящим ссылкам можно отнести прямые релевантные запросы (чаще всего исходящие внешние), либо околорелевантные запросы (входящие внутренние) — похожие статьи, тематические материалы. Так, с помощью одной единственной ссылки с wikipedia можно получить 100% релевантность вашего запроса, либо же с помощью определенного количества входящих внешних и внутренних улучшить её.
Одним из самых эффективных способов улучшения релевантности является статейное продвижение, когда внешние ссылки проставляются с релевантных страниц. В данном случае даже общая тематика сайта-донора не играет роли. Ведь каждая страница на сайте рассматривается отдельно. Ярким примером могут послужить новостной портал, где тематика страниц может быть разнообразной, но тем не менее поисковики прекрасно понимают их значения!
Всё остальные средства, такие как: выделения контента, ключевые слова в url, meta keywords т.д. играют малозначимую роль и не стоят внимания.
Стоит отдельно заметить: meta keywords всё же является неким указателем, точнее, подсказкой, которая указывает на поисковые запросы, однако данный мета-тэг не влияет на релевантность.
Применяя данные методы на практике, вы сможете указывать поисковым алгоритмам правильное направление: направление на 100%-ную релевантность ваших страниц! Но не забывайте тот совет, которой я дал новичкам в начале статьи: полезный контент всегда важнее алгоритмов. Не засоряйте поисковую выдачу, если не уверены в качестве собственного контента. Возможно его стоит просто проработать и переписать?
Релевантность поиска — как определить соответствие запросов в выдаче
Релевантность (от англ. «relevant», т. е. «относящийся к теме») – это показатель соответствия документа тематическому запросу, или ожиданиям и потребностям пользователя. Чем выше релевантность запросов, тем больше показанные страницы удовлетворяют информационные потребности.
Пример: что означает релевантность
Содержание статьи
Допустим, мы ввели в поисковую строку «термин релевантность поисковой системы». В выдаче мы видим ссылки на сайты, где рассказывается именно о поисковом продвижении и работе соответствующих алгоритмов поисковиков. Мы получаем ответ на заданный вопрос, т. е. то, ради чего и заходили в поиск. Пользователи довольны – выдача соответствует их потребностям.
Если же в выдаче окажется, например, описание того, что означает слово релевантность с точки зрения неклассической логики, то эта ссылка является нерелевантной. И, скорей всего, в ближайшее время она будет удалена из ТОПа поисковика по выбранному запросу.
Такое иногда случается после первичного анализа соответствия слов в тексте страницы заданным параметрам. Исправляется эта ошибка сравнительно быстро на основе анализа поведенческих факторов. Почему это случается и как поисковики вообще анализируют документы и определяют их содержание, давайте разберемся подробнее.
Как определяется релевантность выдачи
Поисковые системы разрабатывают специальные алгоритмы анализа текстовой информации для определения тематики и подходящих поисковых запросов. При этом учитывается контент на странице, поисковые теги (title, description), содержимое тегов «alt» в картинках.
В первую очередь поисковые боты сверяют запросы с образцами документов, хранящихся в поисковом индексе. Е
Релевантность в SEO и поисковом маркетинге
Обновлено
Релевантность — соответствие намерения пользователя контенту сайта. Релевантность была, есть и будет одним из ключевых факторов успешного продвижения сайта. Как увеличить релевантность сайта? — Читайте в этой статье.
Почему релевантность важна для SEO
Релевантность — ключ к успеху поискового продвижения. Это именно та грань, где пересекаются задачи бизнеса и поисковая оптимизация. Если перед оптимизатором не стоит конкретных бизнес-задач, привязанных к KPI, то успех продвижения сайта будет стремиться к нулю. Почему?
Представим, что вы владелец офлайн-магазина. И вы нанимаете человека, который приводил бы к вам в магазин возможных покупателей. Человек приводит свою многочисленную родню, случайных прохожих, но никто из них ничего не покупает — и даже не планирует. Посетители без дела слоняются по магазину, травят анекдоты, проводят политические митинги, пьют вино, но даже не смотрят на товары. Ваш магазинчик становится проходным двором, привлекает внимание властей, у него появляется репутация какого-то странного клуба — и вы теряете шансы вообще что-то продавать даже в туманной перспективе.
Несмотря на абсурдность образа, то же самое происходит с множеством интернет-магазинов. Примеры.
- Оптовый продавец биохимических препаратов решает продвигаться с помощью информационных запросов, и получает тонны трафика по запросу «чем травить крыс». Зайдут ли на сайт клиенты? Маловероятно. А вот обрабатывать входящие звонки и почту становится всё сложнее.
- Другой пример: в погоне за трафиком продавец элитных вин решает продвигаться по запросам, соответствующим любому вину, включая дешевую «бормотуху» и откровенный контрафакт. Спустя пару месяцев поведенческие факторы с резким ростом отказов быстро расставляют всё на свои места: позиции потеряны, трафик упал.
Нет смысла вкладывать ресурсы (деньги и время) в «раскачку» позиций по какому-то ключу или абстрактное увеличение поискового трафика на сайт. Нужно понимать, зачем, и что это даст бизнесу. Оптимизация должна быть частью общей стратегии развития бизнеса онлайн. Только в этом случае можно ожидать, что результаты SEO принесут доход и не пропадут в краткосрочной перспективе.
Релевантность и персонализация поисковой выдачи
Теме релевантности в маркетинге посвящено много статей и книг. Если говорить о SEO (а это всё же поисковый маркетинг), то релевантность в терминах поисковой оптимизации формулируется просто. Пользователь поисковой системой понимается как коллекция запросов, сайт — как коллекция ответов. Релевантность возникает тогда, когда коллекция запросов соответствует коллекции ответов. Чем больше характерных для вас запросов пересекается с ответами на конкретном сайте, тем выше показатель соответствия. Так работает персонификация выдачи.
Фактически вы не можете повлиять на этот момент: единой выдачи больше нет, поисковая система самостоятельно сегментирует трафик на ваш сайт благодаря системе персонализации выдачи.
Тему персонализации поисковой выдачи мы рассмотрели ранее. Коротко повторим основные тезисы, важные для понимания концепции релевантности в поисковом маркетинге.
- Интеллект нейросетей на сегодняшнем этапе соответствует интеллекту ребенка, делящего всех на маму, папу, тётеньку, дяденьку, ляльку и бабайку. И хотя у него есть сотни различных факторов ранжирования и маркеров качества контента, он до сих пор не всегда способен самостоятельно понять, что именно предлагает конкретная посадочная страница. И в этом деле ему по-прежнему на помощь приходят люди — асессоры. Это либо штатные сотрудники поисковой системы, либо добровольные помощники (в Яндекс это сервис «Толока», объединяющий людей, за пару копеек выполняющих задания). Обмануть их, в отличие от поискового алгоритма, практически невозможно.
- Помимо хорошо известных всем факторов ранжирования (текстовых, поведенческих, ссылочных) развиваются совершенно новые способы оценки контента и качества сайтов, основанные на поисковых сущностях. Это своего рода метаданные, повлиять на формирование которых практически нельзя. Пример. Вы можете сколь угодно убеждать поисковые системы, что у вас на сайте можно купить подгузники дешево, прописывая соответствующий ключ в тайтлы, заголовки и тексты. Но сервисы Яндекса и Гугл, отслеживающие ваших посетителей, предложат им оценить ваш магазин, задавая простые вопросы: «Можно ли здесь купить дешевые подгузники?» — и если посетители будут отвечать отрицательно, вашего магазина по соответствующему запросу в выдаче уже не будет.
Самый важный вывод из этого таков: старые формы SEO уже не будут работать так эффективно, как это было раньше, и должны уступить место методам полноценного поискового маркетинга (SEM), основанного как на классических маркетинговых практиках, так и на самых современных, основанных на обработке Больших Данных. В первую очередь — на сборе данных о целевой аудитории, её интересах, сегментации и умении формулировать торговое предложение именно для этой аудитории.
Почему анализ данных станет главным инструментом оптимизатора
Если вы зарабатываете на жизнь электронной коммерцией или поисковой оптимизацией в частности, вам уже сейчас стоит задуматься о создании собственных баз данных, объединяющих информацию о ключевых словах и посетителях вашего сайта. Правила игры меняются, и не в вашу пользу. Общие тренды поисковых систем:
- Коммерциализация. И Гугл, и Яндекс становятся в большей мере коммерческими сервисами, чем поисковыми системами. И речь не только о банальной продаже рекламных объявлений: обе системы стремятся удовлетворить все потребности пользователя в рамках собственных сервисов.
- Перевод оценки и ранжирования интернет-ресурсов в мета-сферу, основанную на колоссальной базе данных, собранных поисковыми системами как о пользователях, так и о сайтах. Это закрытая сфера, и повлиять на неё извне едва ли возможно в принципе.
- Развитие собственной базы знаний поисковиков, основанной на информации из доверенных источников (подобной Google Knowledge Graph). Уже в 2019 половина всех обращений к поиску Google не сопровождается переходом на какой-либо сайт: пользователь уже получает всю необходимую информацию из поисковой выдачи.
Большой импульс для развития всех этих пугающих честного маркетолога тенденций дали мобильные устройства. Доля мобильного трафика уже составляет около 70%, а для многих пользователей интернета мобильное устройство — единственный доступ к интернету.
Что это означает для вас? — Прежде всего то, что поисковая система знает о пользователе практически всё: его интересы, привычки, местоположения, финансовое состояние, контакты, распорядок дня. И этими данными с вами делиться никто не будет. В очень усеченной версии вы можете получить такие данные из сервисов поисковых систем.
Но что будет, если владельцы Яндекс и Гугл решат перекрыть вам доступ? А это вполне ожидаемое развитие ситуации: любимые всеми «сеошниками» «Вордстат» и инструмент работы с ключевыми словами AdWords со временем могут стать недоступными, если кто-то решит, что вы как маркетолог — лишнее звено между поисковой системой и покупателем.
Единственный вариант, который поможет вам удержаться на плаву — это собственные базы данных, объединяющих всю необходимую информацию, и умение эту информацию обрабатывать. И если вы всё ещё рассчитываете плотность ключей по топу с помощью tf*idf, задумайтесь: может быть, уже стоит начать изучать Python или R, учиться работать с логами и составлять галереи пользовательских «персон»?
Как можно увеличить релевантность уже сейчас
Из мира мрачного будущего с диктатом поисковых систем вернемся в не менее печальное настоящее. Если речь не идёт о топе (забитом «вылизанными» сайтами, онлайн-гипермаркетами, агрегаторами, сервисами поисковиков) то среднестатистический сайт весьма далёк от самого понятия «релевантность» — особенно если на нём порезвился SEO-специалист старой школы, озабоченный плотностью ключевиков и количеством внешних ссылок.
- Действительно ли ваши посадочные страницы отвечают намерению посетителя? Если в вашем тайтле прописано «ремонт холодильников цена в Москве», то указана ли эта цена на странице прямо, или есть лишь несколько кнопок «Запросить цену» (или того хуже, в тексте-«простыне» плотно натыкано что-то типа «приятная цена, низкая стоимость, недорого, купить дешево» без всякой конкретики)?
- Насколько ваши товары или услуги соответствуют продвигаемому запросу? У вас действительно можно «купить постельное белье» на любой вкус и кошелек или вы ограничены каким-то одним сегментом или производителем?
- Пересмотрите свое семантическое ядро. Это нужно делать хотя бы раз в год (в идеале — чаще), удаляя ненужные запросы и добавляя актуальные. Те запросы, которые приводили к вам покупателей 10 лет назад, могут вести к вам мусорный трафик, создающий лишь лишнюю нагрузку на сервер и плохо влияющие на поведенческие факторы.
- Интегрируйте на сайт модель конверсионной воронки и научитесь работать с ней. Вы, как поисковый маркетолог или владелец сайта, должны понимать, кто приходит к вам на сайт, зачем, как он перемещается по страницам на пути к целевому действию, и на какой фазе он «сливается». Невозможно работать с конверсией без понимания целевой аудитории и полноценной работы с путями посетителей по сайту.
- Если вы покупаете ссылки — прекратите закупать или арендовать ссылки, по которым заведомо никто и никогда не пойдёт к вам на сайт. Судя по патентам Гугл, релевантность внешней ссылки определяется не только тематикой сайта, но и положением на странице, контекстном окружении, семантической связи исходной и целевой страницы. Ссылочный мусор не работает на ваше продвижение!
- Научитесь работать с панелями веб-мастеров поисковых систем, если вы ещё этим не занимаетесь. Помимо чисто технических параметров, системы аналитики предоставляют много информации об аудитории и её реальных запросах, а также о поведении этой аудитории на сайте.
Кейс: как смена семантического вектора повлияла на конверсию
Исходные данные
Интернет-магазин корейской косметики на новом домене, без истории и ссылочного профиля. Количество брендов и ассортимент — меньше, чем у сайтов из топа. Заказчика интересовали исключительно топовые позиции по двум ВЧ-запросам: «корейская косметика» и «купить корейскую косметику». Вопросы конверсии не поднимались, продвижение коммерческих запросов со средней и низкой частотностью заказчика не интересовало.
Что было сделано
Интегрировано большое количество посадочных страниц, соответствующих средне- и низкочастотным запросам с выраженным коммерческим характером, средней и малой конкурентностью. Оптимизация высокочастотных запросов, рассматриваемых заказчиком как основные, была отложено на более поздние этапы продвижения, и к моменту прекращения сотрудничества оба запроса находились всего лишь в топ-30. Спустя полгода после начала работ по оптимизации заказчик решил сменить оптимизатора, поскольку не увидел динамики в продвижении ВЧ-запросов.
Последствия
Новый подрядчик по SEO не заметил, что по техническим причинам основные посадочные страницы, приносящие много трафика по низкочастотным коммерческим запросам, начали выпадать из индекса. Новые посадочные страницы оптимизатором не добавлялись, падение позиций по коммерческим НЧ-запросам также было проигнорировано. Всё внимание с начала работ уделялось исключительно высокочастотным запросам.
Спустя 4 месяца эти два запроса вошли в топ-10.
Однако вместе с тем всё это время сайт закономерно начал терять трафик из поисковых систем (см. скриншот).
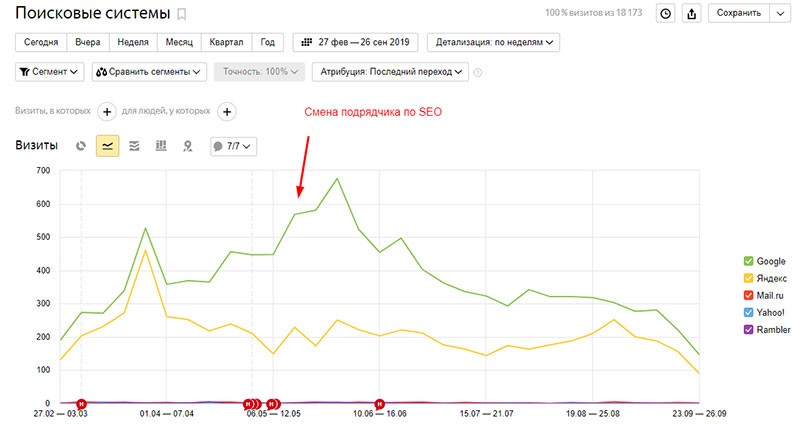
Вместе с тем топовые позиции по ВЧ не смогли улучшить продажи: конверсия всё это время также падала.

Выводы
Акцентирование высокочастотных запросов с низкими конверсионными характеристиками не способно заменить множество низкочастотных запросов, приносящих основной коммерческий трафик на сайт. Выбор нерелевантных запросов для продвижения интернет-магазина неизбежно приводит к снижению продаж.
Заключение
Манипуляции поисковыми алгоритмами (относящимися к «чёрным» и «серым» методам SEO) становятся всё сложнее. Да, накрутка поведенческих факторов, PBN и закупка ссылок всё ещё работают. Но со временем поисковые системы найдут способы с этим справляться. И уже сейчас вам нужно намного меньше ресурсов, чтобы сделать сайт соответствующим ожиданиям посетителей, чем вкладываться в обман поисковиков.
Релевантность — это ключ к топу!

Виктор Петров
SEO-специалист