
В чем разница dofollow и nofollow ссылки. Все правила применения атрибута nofollow в SEO в 2022
Споры о том, нужны ли nofollow-ссылки для SEO — бесконечны. Главный тезис спора
Если nofollow-ссылки не передают ссылочный вес, а значит не влияют на продвижение сайта, зачем их добывать?
Если вы согласны с этим мнением, то сегодня ваш мир изменится 😉
В этой статье мы разберем, что такое dofollow-ссылка и nofollow-ссылка, чем они отличаются и нужно ли использовать nofollow-ссылки при продвижении сайта в 2021.
Но обо всем по порядку …
Содержание:
- Что такое dofollow-ссылки?
- Что такое nofollow-ссылки?
- В чем разница между dofollow-ссылкой и nofollow-ссылкой?
- Зачем нужны nofollow ссылки в линкбилдинге?
- Аргумент №1: доверяем лидерам
- Аргумент № 2: сайтов со 100% dofollow ссылками нет
- Аргумент № 3: огромное количество топовых площадок размещают только nofollow
- Что вам дает использование nofollow ссылок?
- Как понять, что ссылка nofollow? И что такое nofollow noopener?
- Nofollow в Google
- Зачем вообще нужны ссылки бизнесу?
- Повышение узнаваемости
- Лидогенерация
- Ссылки порождают ссылки
- Где взять лучшие nofollow-ссылки?
- Видеохостинги
- Социальные сети
- Форумы
- Q/A
- Вместо заключения
Что такое dofollow-ссылки?
Техническое определение:
Dofollow — гиперссылки, ведущие на определенный сайт или страницу. Дуфоллоу-ссылки дают роботам поисковых систем сигнал к переходу и сканированию страницы, на которой расположены.
Дуфоллоу-ссылки дают роботам поисковых систем сигнал к переходу и сканированию страницы, на которой расположены.
Пример:
<a href="url" rel="dofollow">текст ссылки</a>
Что такое nofollow-ссылки?
Техническое определение:
Nofollow — это значение атрибута rel для HTML-тега «a» (rel="nofollow").
Пример:
<a href="http://site.com/" rel="nofollow">текст ссылки</a>
В чем разница между dofollow-ссылкой и nofollow-ссылкой?
Дуфоллоу-ссылки 100% учитываются поисковыми системами, а нофоллоу учитываются выборочно. Они больше работают как подсказки при ранжировании.
Поэтому при ссылочном продвижении сайта, специалисты стараются добыть с внешних площадок больше dofollow-ссылок. Но если вы хотите максимально естественный ссылочный профиль, стоит добывать ссылки разных видов.
Зачем нужны nofollow ссылки в линкбилдинге?
Последнее время я все чаще сталкиваюсь с мнением, что nofollow ссылки — это плохо.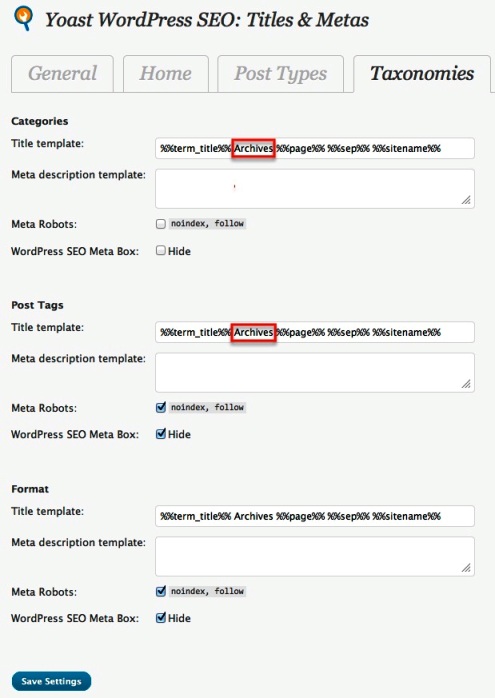 Большинство наших клиентов указывают в ТЗ к крауд-кампании 100% dofollow. Меня это настораживает, особенно, если заказчик — молодой сайт.
Большинство наших клиентов указывают в ТЗ к крауд-кампании 100% dofollow. Меня это настораживает, особенно, если заказчик — молодой сайт.
Зачем нужны нофоллоу ссылки сайту? Да и нужны ли они вообще, может они бесполезны и нужно их максимально избегать или стараться вообще не получать. На эти вопросы отвечу в видео:
Для тех, кто предпочитает текстовый формат, ниже коротко и по сути 😉
Аргумент №1: доверяем лидерам
Первый аргумент в пользу того, зачем все-таки нужно использовать nofollow ссылки — это справка Google.
Существует мнение, что если присвоить атрибут nofollow ссылке, то google не будет по ней переходить. Если дословно перевести, “nofollow” означает “не следовать”.
Мы как бы запрещаем поисковым роботам переходить по этой ссылке. Соответственно, она не будет проиндексирована и учтена. Но! Как мы видим, в справке Google добавлено фраза “как правило”. А это не значит “всегда”.
Я глубоко убежден, что nofollow ссылки учитываются. Особенно, если они трафиковые и стоят в нужном месте. Такие ссылки безусловно важны и работают. Вы можете с этим спорить, но если это написано в справке Google, то, скорее всего, так и есть. Тем более, эта корректировка была внесена в справку недавно.
Такие ссылки безусловно важны и работают. Вы можете с этим спорить, но если это написано в справке Google, то, скорее всего, так и есть. Тем более, эта корректировка была внесена в справку недавно.
Аргумент № 2: сайтов со 100% dofollow ссылками нет
При внедрении крауд-маркетинга, гостевых публикаций и т.д., все хотят dofollow ссылки с коммерческими анкорами. Это, конечно, здорово, но далеко от реальности.
А реальность такова, что практически не существует сайтов, у которых 0% nofollow ссылок. Как правило, их достаточно много. Для примера, давайте возьмем запрос “кадастровые работы в Москве”.
Выгружаем топ по этому запросу и с ahrefs берем показатели этих сайтов.
Как мы видим, у этих площадок разные показатели DR. При этом, они достаточно посредственные. Кроме этого, видим разное количество доменов, ссылок и т.д. И у всех сайтов абсолютно разные пропорции dofollow/nofollow ссылок.
Сразу скажу, что в этих замерах может быть неточность в связи с тем, что я замерял не по одной ссылке с домена, а в общем количестве. Поэтому цифры могут быть разные. Но моя задача была не высчитать конкретный процент, а просто показать, что nofollow ссылок достаточно много и что в любом ссылочном профиле они присутствуют. Их не 0, их там 10, 20, 30%…
Поэтому цифры могут быть разные. Но моя задача была не высчитать конкретный процент, а просто показать, что nofollow ссылок достаточно много и что в любом ссылочном профиле они присутствуют. Их не 0, их там 10, 20, 30%…
На скриншоте выше видно, что где-то nofollow ссылок может быть 1%, а где-то цифра переваливает за 45%. Разлет широкий, но сами ссылки присутствуют в любом ссылочном профиле. Это нормально и с этим нет смысла бороться.
Количество nofollow ссылок в профиле зависит от того, каким методам ссылочного продвижения вы отдаете предпочтение. Если вы только начали работать с сайтом, регистрируйте его в каталогах и работаете с форумами, то на таких площадках априори доля nofollow и redirect ссылок выше.
Если вы базируетесь на крауд-маркетинге и у вас 100% dofollow ссылок — это странно, потому, что такого точно не бывает. Такая ситуация точно привлечет внимание поисковых систем, что может привести к наложению санкций на сайт.
Аргумент № 3: огромное количество топовых площадок размещают только nofollow
Существует огромное количество крутых площадок, которые размещают только nofollow ссылки и нет причины с такими площадками не работать. Они дают вам переходы на целевой сайт, узнаваемость компании в сети и, собственно, клиентов.
Они дают вам переходы на целевой сайт, узнаваемость компании в сети и, собственно, клиентов.
Да, они не дадут вам dofollow ссылку, но nofollow линка, которую они разместят даст вам переходы заинтересованной целевой аудитории. Обратите внимание на пару примеров из строительной ниши:
forum.vashdom(.)ru. Трафик у форума более 711 тысяч посетителей в месяц, согласно данным SimilarWeb:
Теперь возьмем для примера ссылку на какую-то блоговую статью.
Видим, что она с атрибутом nofollow. При этом хорошая трафиковая площадка и много комментариев в обсуждении.
best-stroy(.)ru/forum. Трафик у форума более 672 тысяч посетителей в месяц, согласно данным SimilarWeb:
Крутая площадка в своей нише. Что мы видим в профиле? Тоже nofollow ссылка. При этом, очень активное обсуждение, большая аудитория.
Следующая площадка из компьютерной индустрии — forum.ixbt(.)com. Это прям флагманская площадка, одна из старейших в рунете в данной нише. Я ее знаю и читаю очень давно.
Я ее знаю и читаю очень давно.
Здесь мы видим тоже самое — nofollow ссылка.
В этом нет ничего плохого. Если вы не используете nofollow ссылки — вы теряете возможности.
Что вам дает использование nofollow ссылок?
- Безопасность ссылочного профиля. Если вы будете стараться размещать максимальное количество dofollow ссылок — это будет выглядеть странно на фоне других сайтов вашей ниши.
- Естественность. При работе над ссылочным, нужно помнить о том, что “показательный” профиль без nofollow и redirect ссылок, обратит на себя внимание поисковых систем и, в будущем, может привести к попаданию под фильтры.
- Больше возможностей. Это самое главное. Не боясь получить nofollow ссылки, перед вами открываются новые возможности: работа с лучшими площадками, трафиковыми, трастовыми, интересными.
Использование nofollow ссылок откроет перед вашим сайтом новые горизонты. Только представьте, если вы будете избегать таких ссылок, а ваши конкуренты — наоборот? Они будут размещаться на самых топовых площадках и общаться на крутых форумах со своей целевой аудиторией, а вы нет. Потому, что у вас в голове обосновался миф о том, что nofollow — это плохо.
Потому, что у вас в голове обосновался миф о том, что nofollow — это плохо.
Я рекомендую вам отходить от этого стереотипа и все же использовать потенциал nofollow ссылок.
Как понять, что ссылка nofollow? И что такое nofollow noopener?
Выбирая площадки для получения ссылок, нужно уметь определять dofollow, nofollow, redirect ссылки.
Самый простой способ это найти внешнюю ссылку и посмотреть ее в коде.
Открываем контекстное меню:
Жмем Inspect и смотрим, что в коде:
Видим тег rel="nofollow noopener"
Еще один вариант, это использовать расширение для браузера RDS Bar, либо другие аналогичные.
Выставьте в настройках подсветку nofollow ссылок:
Заходя на сайты с этим тегом, вы будете видеть зачеркнутые ссылки:
Установили себе уже RDS Bar?
Больше полезных расширений для SEO вы найдете по ссылке.

Сейчас переходим к интересному, к тому как поисковые системы воспринимают nofollow.
Вы ведь этого ждали? 😉
Nofollow в Google
Осенью 2019 года по всему миру прошла неожиданная новость! Google официально заявил, что будет учитывать nofollow-ссылки. Об этом говорится в его официальном блоге:
Кроме этого, поисковая система ввела два новых атрибута: rel=»sponsored» и rel=»ugc». Первый рекомендуется использовать для купленных ссылок (ссылок в рекламных постах, спонсорском контенте), второй — для ссылок в органическом пользовательском контенте (к примеру, в комментариях).
Подробнее о новых атрибутах Google и о том, как их использовать при продвижении сайта крауд-маркетингом можно узнать из нашей статьи.
Рекомендуем быть с новыми атрибутами максимально осторожными. Если вы используете атрибут rel=»ugc» на платных ссылках, то это может привести ваш сайт к санкциям.
А в случае, когда вам нужно скрыть от индексации спонсорскую ссылку, то вы вполне можете применить сочетание rel=“sponsored nofollow”. Главное не перепутать 😄
Главное не перепутать 😄
Ранее в SEO-кругах бытовало утверждение, что если закрыть все исходящие ссылки от индексации, то сайт будет лучше ранжироваться.
Google считает его неправильными и аргументирует это тем, что закрытие всех исходящих ссылок в nofollow может навредить сайту, то есть понизить позиции в поисковой выдаче.
Подробнее об этом в видео:
Зачем вообще нужны ссылки бизнесу?
Вне зависимости от того, передают nofollow, redirect, span ссылки какой-то вес или нет, главное, что они выполняют свою основную функцию — переводят пользователя с одной страницы на другую.
Повышение узнаваемости
Это значит, что люди будут попадать на ваш сайт, проводить на нем время, касаться вашего бизнеса.
Если у вас качественный продукт, удобный сайт, то вы получите хорошие поведенческие факторы страниц, что непременно повлияет на SEO. Вы получите брендовый и прямой трафик, который имеет большое значение для поисковых систем.
Лидогенерация
Если вы размещаете ссылки на релевантных страницах, то вы получите переходы аудитории, которой интересен ваш продукт и если он качественный, то однозначно получите лиды и заказы.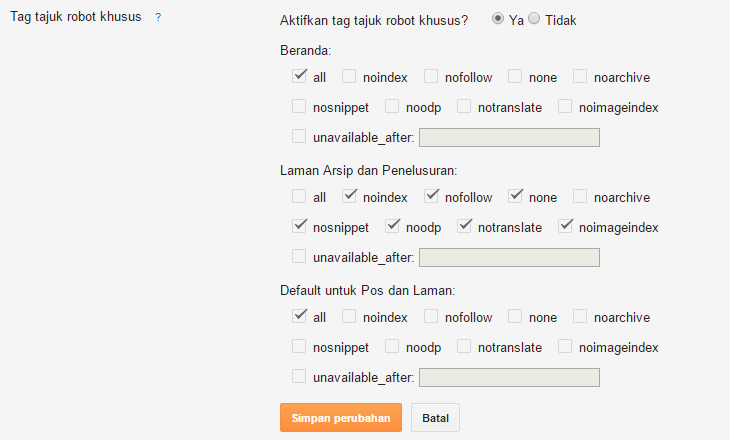
Ссылки порождают ссылки
Ссылки размещенные в социальных сетях могут не дать вам ожидаемый SEO-эффект, но могут спровоцировать инфоповод и принести ссылки с других площадок.
Не самый приятный кейс, но…
Федор Овчинников (CEO dodopizza) опубиковал пост:
который спровоцировал большое количество публикаций в СМИ:
- https://secretmag.ru/news/fyodor-ovchinnikov-rasskazal-o-doprose-iz-za-narkotikov-v-dodo-pizza-30-01-2018.htm
- https://vc.ru/32524-osnovatel-dodo-piccy-rasskazal-o-nastoychivyh-vyzovah-na-dopros-iz-za-odnoy-moskovskoy-piccerii
- http://www.bbc.com/russian/news-42985879
- https://www.novayagazeta.ru/articles/2018/02/08/75435-ugolovnoe-delo-idet-po-stsenariyu
И так далее. Сотни публикаций 🤯
Если вы способны сгенерировать такой инфоповод, какая разница как будут реализованы ссылки?
Где взять лучшие nofollow-ссылки?
Лучшая ссылка = трафиковая.
Если по ссылке переходит релевантная аудитория — это полезная ссылка.
 Если по ссылке переходит релевантная аудитория — это полезная ссылка.
Если по ссылке переходит релевантная аудитория — это полезная ссылка.Видеохостинги
Youtube — самый популярный видеохостинг в мире и вы думаете, что Гугл не учитывает ссылки, которые стоят под популярными видео?
Или vimeo:
Рекомендации от видеоблогеров могут дать большой объем трафика с очень хорошими поведенческими:
Социальные сети
Twitter, flickr.com, tumblr.com и десятки других социальных сетей позволяют поставить ссылку и получить аудиторию:
The @Tesla Model 3 is a love letter to the road (by @etherington) https://t.co/Nd9KXftYbJ pic.twitter.com/qmfymUiaZa
— TechCrunch (@TechCrunch) March 8, 2018
Хотите узнать больше о том, как эффективнее всего продвигать сайт в социальных сетях? Тогда обязательно прочтите это.
Форумы
Многие лидирующие форумы закрывают свои ссылки в nofollow или noindex, но это абсолютно не повод не работать с ними.
Например, форум Винского (крупнейший туристический форум с аудиторией 5-10 миллионов в месяц):
Но если вы хотите dofollow-ссылку, то конечно же исключайте его из своего списка подходящих площадок 😜
Больше о том как правильно отбирать обсуждения для размещения крауд-маркетинговых ссылок рассказывает Игорь Рудник на youtube-канале referr:
Q/A
- reddit.com
- quora.com
- otvet.mail.ru
Это платформы с миллиардным месячным трафиком и у них также ссылки в nofollow, а у quora ссылки реализованы через span. Но я не думаю, что поисковые системы не учитывают эти ссылки. Это не логично.
Пример ссылки quora.com:
И таких платформ сотни и тысячи, которые вы исключаете из-за SEO мифов.
Рекомендуем также прочесть про грамотное ссылочное продвижение сайта на quora и reddit.
Вместо заключения
Главная цель поисковых систем — улучшить результаты выдачи, существенно подняв экспертный контент. Однако тот факт, что ссылки с Википедии и других трастовых ресурсов не учитывались по причине того, что они nofollow, создал замкнутый круг.
Однако тот факт, что ссылки с Википедии и других трастовых ресурсов не учитывались по причине того, что они nofollow, создал замкнутый круг.
После того, как Google пересмотрел свое отношение к таким ссылкам, можно смело утверждать, что они работают и будут работать в дальнейшем.
Поэтому, не стоит опасаться nofollow. Если вы добываете их с качественных площадок — это пойдет только на пользу ссылочному профилю вашего сайта.
Хотите получать ссылки уже сегодня? Просто зарегистрируйтесь в referr-service.com. Наши менеджеры помогут вам во всем разобраться и запустить крауд-маркетинговую кампанию.
Можем с уверенностью сказать, что у нас самые лучшие менеджеры в нише крауд-маркетинга и мы поможем решить вам абсолютно любую задачу!
Что такое dofollow и nofollow-ссылки: что нужно знать
Автор Webline Promotion На чтение 5 мин. Просмотров 4.9k. Опубликовано
Dofollow — это атрибут тега rel, который дает роботам поисковых систем разрешение к переходу на страницу, на которой размещены ссылки.
Ссылочная масса – важная часть SEO, которая помогает поднять сайт в выдаче, придать ему «вес» в глазах поисковых систем. Google оперирует понятием PageRank, «ссылочный сок». Он активно влияет на ранжирование интернет-площадки, особенно если сайты-доноры – авторитетные площадки. С повышением роли PR в SEO появилась масса спам-линков, которые размещались в комментариях к записям и постам, на авторитетных форумах. Это привело к неразберихе с ранжированием. В 2005 году Джейсоном Шелленом и Мэттом Каттсом был введен атрибут nofollow. В чем отличие параметра от dofollow?
Содержание
- Разница между понятиями, обозначение
- Почему закрывают ссылки
- Открывать или закрывать?
- Как определить, закрыта ли ссылка
- Открытые форумы
- Полезные ресурсы с закрытой линковкой
Разница между понятиями, обозначение
- Dofollow – гиперссылки, ведущие на определенный сайт или страницу. Увеличение их количества повышает «ссылочный сок» ресурса в рейтинге Google. Логическая схема: на сайт (или отдельную страницу) ссылаются сотни людей – материал интересен, полезен. Поисковые роботы считают все линки по умолчанию dofollow, если не указан другой параметр.
- Nofollow – атрибут тега, указывающий поисковику, что переходить по линку не нужно. PageRank донора не меняется при переходе, ссылочный вес сайта-источника не учитывается. WordPress и некоторые другие движки автоматически прописывают этот атрибут всем ссылкам, которые размещают пользователи (например, в комментариях). Аналогичная система работает и в Википедии.
 Логическая схема: на сайт (или отдельную страницу) ссылаются сотни людей – материал интересен, полезен. Поисковые роботы считают все линки по умолчанию dofollow, если не указан другой параметр.
Логическая схема: на сайт (или отдельную страницу) ссылаются сотни людей – материал интересен, полезен. Поисковые роботы считают все линки по умолчанию dofollow, если не указан другой параметр.Почему закрывают ссылки
Чем больше входящих и исходящих линков связано с конкретной площадкой, тем выше ссылочная масса и PageRank в поисковике Google. Результат закономерен – привлекательная позиция в выдаче. Однако линкбилдинг может использоваться как инструмент «черного SEO»: публикация линков на качественных площадках приводит к повышению рейтинга сайта, на который они ведут. Если же этот сайт попадает под Гугл-фильтры, то страдает и ресурс-донор.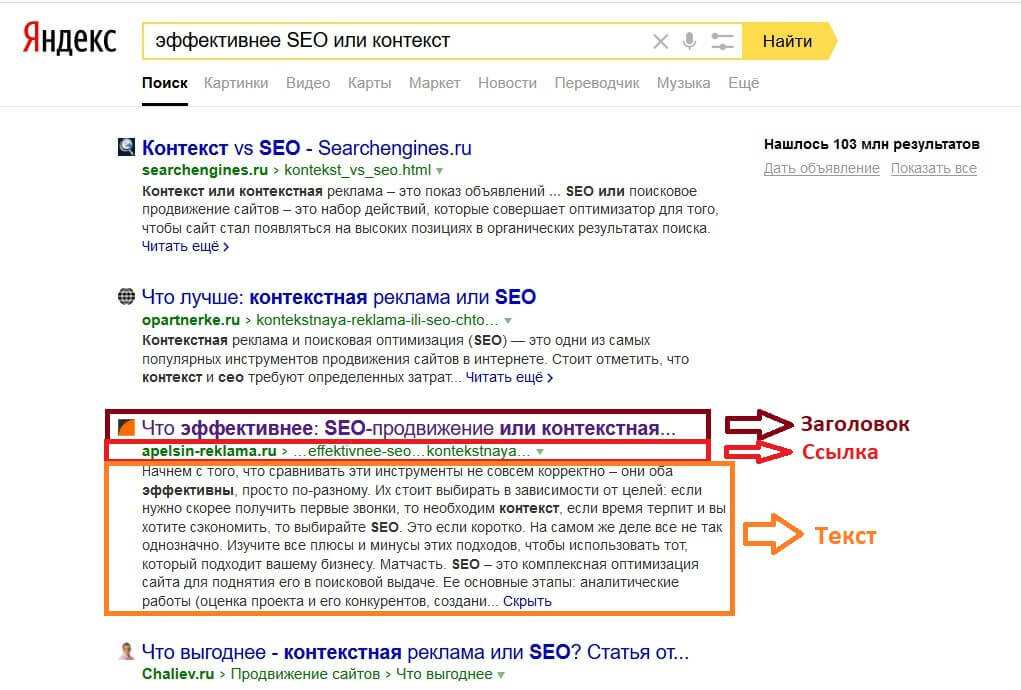 Чтобы избежать такой ситуации, используют nofollow, который особенно актуален для блогеров. Это позволило сократить объемы спама и нерелевантных линков при комментировании.
Чтобы избежать такой ситуации, используют nofollow, который особенно актуален для блогеров. Это позволило сократить объемы спама и нерелевантных линков при комментировании.
Сегодня чаще всего закрывают такие виды линков:
- на «непроверенный» (незащищенный с точки зрения Google) контент;
- в комментариях;
- на форумах.
Также Гугл рекомендует закрывать платные линки.
Открывать или закрывать?
Реакция поисковиков на обнаружение nofollow различается:
- Google переходит по цепочке, но не учитывает ее в качестве обратной;
- MSN не всегда переходит, но учитывает линк при подсчете позиции;
- Yahoo следует, но не принимает в расчет при вычислении релевантности;
- Яндекс отправляет своего робота при такой линковке, учитывая этот показатель в позиционировании выдачи.
Если вы хотите увеличить трафик и привлечь максимум посетителей в блог или на форум, можно использовать dofollow. Это своеобразное награждение за активность, однако оно может привести к наплыву ботов. Изменить атрибут можно в любое время, для этого достаточно использовать специальные плагины, позволяющие закрыть линки и в старых записях комментаторов.
Изменить атрибут можно в любое время, для этого достаточно использовать специальные плагины, позволяющие закрыть линки и в старых записях комментаторов.
При использовании цитат рекомендуется давать открытую ссылку на первоисточник – это показатель уважения к источнику и способ повысить PageRank. Русскоязычные ресурсы такой метод применяют редко, но в англоязычной Сети это востребованная практика. Такая линковка не «ударит» по ранжированию самой площадки с цитатой.
По закрытым ссылкам пользователи могут совершать переходы, что способно увеличить трафик. Это косвенно влияет на вес страницы и ее место в выдаче, поэтому совсем неактуальными nofollow назвать нельзя. Если их разместить на авторитетных ресурсах, в правильном контексте, это положительно скажется на ранжировании.
Внутренняя перелинковка должна быть открытой. Если не нужно переиндексировать страницу, применяют дополнительный тег – noindex, который не мешает роботу отслеживать линковку. Его указывают в описании архивных материалов, чтобы не дублировать страницы.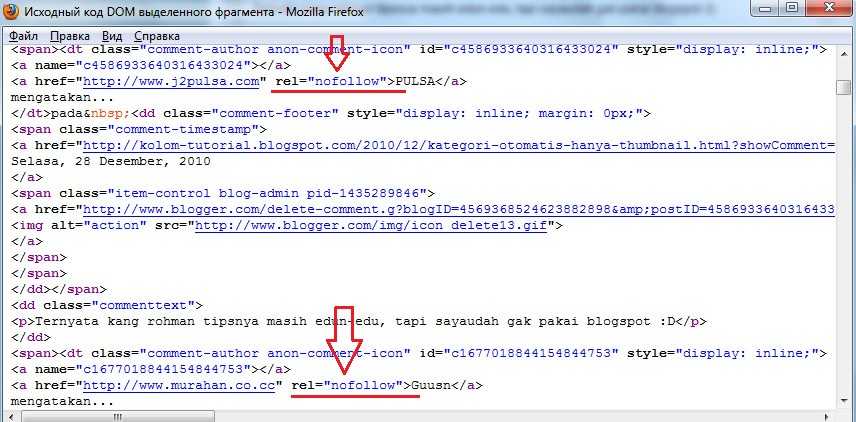 Исходящие линки, которые указывают на продающие площадки, лучше закрывать.
Исходящие линки, которые указывают на продающие площадки, лучше закрывать.
Как определить, закрыта ли ссылка
Проще всего сделать это при помощи контекстного меню. Откройте код страницы и просмотрите его. При отслеживании большой массы ресурсов можно воспользоваться специальными плагинами и расширениями для браузеров, которые подсвечивают закрытые линки.
Открытые форумы
В русскоязычном интернете осталось не так много открытых форумов и блогов, особенно бесплатных. Англоязычных ресурсов больше, но при размещении комментариев на них стоит учитывать релевантность. Иногда авторы и владельцы блогов специально открывают возможность линковки для комментаторов. Это может быть как способ поощрения, так и вариант заработка (разместить комментарий со ссылочной массой можно только после внесения оплаты).
Если линковка открытая и бесплатная, комментарии должны быть полезными, поддерживать и расширять тему поста. Спам-комментарии удаляются блогерами и могут привести к бану.
Для продвижения сайта можно и нужно использовать nofollow-линки. Если они органично вписаны в текст, эффект от их применения будет заметнее, чем от dofollow на сомнительном одностраничнике.
- Видеохостинги. Лучший вариант – это упоминание вашего сайта видеоблогерами под роликом. На ранжирование влияет несущественно, но повышает интерес аудитории, привлекает трафик и улучшает конверсию.
- Социальные сети. Весомый аргумент для поисковых роботов – ссылки с Твиттера или Фейсбука, даже с атрибутом закрытости, положительно расцениваются поисковиками. Это инструмент «два-в-одном», который повышает PR и привлекает новую аудиторию.
- Форумы с миллионными аудиториями.
Линкбилдинг – важный SEO-инструмент. Но, кроме nofollow и dofollow, на ранжирование влияет релевантность. Линковка со статьи о рыбе на магазин, продающий тапочки, не понравится поисковым системам и не приведет новых посетителей. Такая «разножанровость» может негативно повлиять на сайт, привести к штрафным санкциям и попаданию под фильтры.
Подпишись на рассылку дайджеста новостей от Webline Promotion
Email*
Предоставлено SendPulse
html теги для текста | SEO продвижение сайта в Санкт-Петербурге
Сегодня поговорим о том, что такое html теги для текста, чем они отличаются от простых метатегов.
html теги для текста и метатеги — в чем разница
Пришло время прояснить некоторую путаницу вокруг метатегов и HTML-метатегов. Разница между двумя типами тегов в значительной степени условна, а синтаксис метатега HTML означает, что он будет содержать слово meta, тогда как у тега, определенного как метатег, его может не быть.
Решение, где какой тег, принимается валидатором W3C и может изменяться с течением времени, однако важно помнить, что оба они выполняют одну и ту же цель – используются для обеспечения поисковых систем информацией о веб-странице.
Примечание: Некоторые люди включают теги title в метатеги, но поскольку они описывают один элемент страницы, а не содержимое страницы в целом, мы решили их не включать.
 Однако, само собой разумеется, что оптимизация тегов title поможет поисковым системам и, что еще важнее, пользователям понять, о чем же ваш контент.
Однако, само собой разумеется, что оптимизация тегов title поможет поисковым системам и, что еще важнее, пользователям понять, о чем же ваш контент.Теперь, когда мы это выяснили, можно приступить к делу и взглянуть на подборку тегов как HTML, так и метатегов, которые, по нашему мнению, полезны для SEO продвижения.
Hreflang
Итак, для начала следует сказать, что тег Hreflang технически не тег. Это атрибут, но атрибут важный, который сообщит Google, какой язык вы используете на веб-странице.
Если у вашего сайта есть несколько переводов или он обслуживает разные территории, вы должны обязательно использовать Hreflang для обеспечения правильной языковой версии в правильных версиях Google.
Это может помочь поисковым системам лучше оценить ваш контент и, что еще более важно, обеспечить пользователям из разных точек земного шара правильный выбор.
Пример фрагмента кода для таргетинга веб-страницы на пользователей из Великобритании, использующих английский язык:
<link rel=”alternate” href=”http://example.
 com” hreflang=”en-gb” />
com” hreflang=”en-gb” />Тег canonical
Другой очень важный тег — тег canonical. Установите его неправильно, и вы рискуете пропасть из результатов поиска, что вызовет реальные проблемы для SEO сайта. Однако если он используется правильно, это будет отличным способом сказать поисковым системам, что URL-адрес веб-страницы является её оригинальной версией.
Так вы избежите проблем с дублированным контентом на вашем сайте, что вызвано поисковиками, которые сканируют несколько URL-адресов, содержащих одинаковый или почти идентичный контент.
Обычно, если поисковая система находит несколько URL-адресов с одинаковым контентом, ей будет сложнее определить, что является оригиналом, а что дубликатом. Это может привести к снижению рейтинга для обоих, или, что еще хуже, важная страница не будет ранжироваться.
Пример фрагмента кода с использованием тега canonical:
<link rel=”canonical” href=”https://www.example.
 com” />
com” />Тег content-type
Тег content-type используется для определения типа содержимого страниц и набора символов, который он использует. Его использование помогает вашему браузеру понять и расшифровать страницу, и поэтому он важен.
Пример фрагмента кода для тега content-type:
<meta http-equiv=”Content-Type” content=”text/html; charset=utf-8 />
Тег title
Вероятно, один из наиболее узнаваемых и используемых тегов для тех, кто занимается SEO. Тег title используется для указания того, что представляет собой веб-страница. Он отображается на вкладке браузера, чтобы пользователь понял, о чем контент, и, что еще важнее, используется поисковыми системами для генерирования результатов, которые мы видим в поиске.
С точки зрения SEO оптимизация тега title, чтобы он содержал тему/ключевые слова контента на странице, может помочь улучшить ваше ранжирование по этим темам/ключевым словам. В настоящее время вы можете ожидать, что Google отобразит от 50 до 60 символов названия до его усечения, поэтому при написании следите за длиной.
В настоящее время вы можете ожидать, что Google отобразит от 50 до 60 символов названия до его усечения, поэтому при написании следите за длиной.
Пример фрагмента кода для тега title, который находится внутри основного тега в верхней части веб-страницы:
<title>Example.com | Лучшие примеры в Интернете</title>
Метатег description
Подобно тегу title, тег description хорошо известен и дает вам возможность рассказать поисковым системам и пользователям в результатах поиска, о чем контент вашей веб-страницы. Хотя это не прямой фактор ранжирования, вы должны оптимизировать свое метаописание, чтобы интересно и кратко сообщить о содержании ваших веб-страниц.
Если Google не считает, что вы проделали достаточно хорошую работу, он может заменить ваш метатег description своей собственной версией, часто используя контент из нескольких начальных параграфов вашего сайта.
Пример фрагмента кода для метатега description:
<meta name=”description” content=” Это мета-описание”>
Тег viewport
Тег viewport – полезный HTML тег, который помогает браузерам понять и контролировать размеры вашей веб-страницы.
Раньше в этом теге не было необходимости, поскольку все просматривали сайты на рабочем столе с дисплеев одинакового размера, но с ростом использования смартфонов и планшетов, многие из которых имеют разные размеры, теперь более важно обеспечить, что вы сообщаете браузеру эту информацию, обеспечивая сайту хорошую кросбраузерность.
Правильное внедрение тега viewport гарантирует, что пользователи будут правильно работать с вашим сайтом.
Пример фрагмента кода для метатега viewport:
<meta name=”viewport” content=”width=device-width, initial-scale=1>
Метатеги для роботов
Существует большое количество метатегов для роботов, которые вы можете использовать, и все они помогут поисковым роботам выполнять свою работу по сканированию и индексированию веб-страниц в Интернете. Не все поисковики будут следовать всем командам, но ниже приведено несколько примеров метатегов для роботов и то, что они сообщают сканерам:
Nofollow
Тэг nofollow сообщает сканерам не следовать ни по одной из ссылок, перечисленных на этой странице, а также не передавать какого-либо права странице по ссылке
Noindex
Noindex сообщает сканерам не индексировать эту страницу
Noimageindex
Noimageindex сообщает сканерам не индексировать изображения с этой страницы
Noarchive
Noarchive сообщает сканерам не включать кешированную версию
Пример фрагмента HTML кода метатега для роботов:
<meta name=”robot” content=”noindex, nofollow”>
Метатеги Open graph (OG) для соцсетей
И наконец, существуют метатеги OG для соцсетей. Хотя это меньше относится к SEO, правильно реализуйте метатеги OG для соцсетей – и вы можете помочь вашему контенту хорошо выглядеть, когда им делятся, что улучшит взаимодействие пользователей с постами и в конечном итоге увеличит трафик.
Хотя это меньше относится к SEO, правильно реализуйте метатеги OG для соцсетей – и вы можете помочь вашему контенту хорошо выглядеть, когда им делятся, что улучшит взаимодействие пользователей с постами и в конечном итоге увеличит трафик.
<meta property=”og:title” content=”Статья о тегах”/>
<meta property=”og:image” content=”https://example.com/img/facebooklogo.png”/>
<meta property=”og:site_name” content=”Блог о SEO”/>
<meta property=”og:description” content=”В этой статье будет говориться о тегах”/>
Излишне говорить, что есть целый ряд других html тегов для текста, которые вы можете использовать на своем сайте, и этот список не является исчерпывающим. Но все же, надеемся, он даст вам руководство по некоторым из наиболее важных и полезных тегов, которые вы можете использовать для вашего WEB-проекта, чтобы сделать этот опыт лучше для поисковых систем и сканеров.
Вместо заключения
Хотите выйти в ТОП10 Яндекс и долго там оставаться? Продвигайте свои сайты и интернет-магазины исключительно белыми SEO методами! Не умеете? Могу научить! Тем, кто хочет разобраться во всех премудростях SEO, предлагаю посетить мои курсы по SEO обучению, которые я провожу индивидуально, в режиме онлайн по скайпу.
Записаться на SEO обучение
Для тех, у кого нет времени проходить обучение и самостоятельно заниматься продвижением своих интернет-магазинов, предлагаю и в этом вопросе помощь. Я могу взять ваш сайт на SEO продвижение и за несколько месяцев вывести его в ТОП10 Яндекс.
Для того чтобы убедиться в моей экспертности, предлагаю ознакомиться с моими последними SEO кейсами и только после этого заказать у меня SEO продвижение. Ниже на видео один из примеров успешного продвижения строительного сайта в Санкт-Петербурге.
Заказать SEO продвижение сайта
SEO продвижение сайта по России:
Рейтинг моего сайта в Яндекс:
Screaming Frog Seo Spider — подробное руководство по программе
Attention! Много букв! Много скринов! Много смысла!
Доброго времени суток, друзья. Сегодня я хочу рассказать вам о настройке Screaming Frog (он же SF, он же краулер, он же паук, он же парсер — сразу определимся со всеми синонимами, ок?).
Сегодня я хочу рассказать вам о настройке Screaming Frog (он же SF, он же краулер, он же паук, он же парсер — сразу определимся со всеми синонимами, ок?).
SF — очень полезная программа для анализа внутрянки сайтов. С помощью этой утилиты можно быстро выцепить технические косяки сайта, чтобы составить грамотное ТЗ на доработку. Но чтобы увидеть проблему, надо правильно настроить краулера, верно? Об этом мы сегодня с вами и поговорим.
- Примечание автора: сразу скажу — программа имеет много вкладок и настроек, которые по сути не нужны рядовому пользователю, потому я подробно опишу только наиболее важные моменты, а второстепенные пройдем вскользь… хотя кого я обманываю, когда это у меня были статьи меньше 30 к символов? *Зануда mode on*
- Примечание автора 2: при написании статьи я пользовался дополнительными материалами в виде официального мануала от разработчиков. Если что, почитать его можно тут https://www.screamingfrog.
- Примечание автора 3: я люблю оставлять примечания…
 co.uk/seo-spider/user-guide/. Не пугайтесь английского, Google-переводчик в помощь — вполне себе сносная адаптация получается.
co.uk/seo-spider/user-guide/. Не пугайтесь английского, Google-переводчик в помощь — вполне себе сносная адаптация получается.- File
- Configuration
- Spider — настройки парсинга сайта
- Robots.txt — определяем каким правилам следовать при парсинге
- URL Rewriting — функция перезаписи URL
- CDNs — парсим поддомены
- Include/Exclude — сканирование/удаление определенных папок
- Speed — регулируем скорость парсинга сайта
- User-Agent — выбираем под кого маскируемся
- HTTP Header — настройка реагирования на разные http-заголовки
- Custom — дополнительные настройки поиска
- User Interface — обнуление настроек для колонок таблицы
- API Access — интеграция с разными сервисами
- Authentification — настройки аутентификации
- System — внутренние настройки самой программы
- Mode
- Bulk export
- Reports
- Sitemaps
- Visualisations
- Crawl Analysis
- License
- Help
Настройка Screaming Frog по шагам
Рассмотрим основное меню программы, для того чтобы понимать что где лежит и что за что отвечает (тавтология… Вова может в копирайт!).
Верхнее меню — управление парсингом, выгрузкой и многое другое
File
Из названия понятно, что это работа с файлами программы (загрузка проектов, конфиги, планирование задач — что-то вроде того).
- Open — открыть файл с уже проведенным парсингом.
- Open Recent — открыть последний парсинг (если вы его сохраняли отдельным файлом).
- Save — собственно, сохранить парсинг.
- Configuration — загрузка/сохранение специальных настроек парсинга вроде выведения дополнительных параметров проверки и т.д. (про то, как задавать эти настройки, я далее расскажу подробнее).
- Crawl Recent — повторно парсить один из последних сайтов, который уже проверялся в этой программе.
- Scheduling — отложенное планирование задач для программы… ни разу не пользовался этой опцией…стыдно.
- Exit — призвать к ответу Друзя… нет, ну серьезно,тут все очевидно.
Configuration
Один из самых интересных и важных пунктов меню, тут мы задаем настройки парсинга.
Ох, сейчас будет сложно — у многих пунктов есть подпункты, у этих подпунктов всплывающие окна с вкладками и кучей настроек…в общем крепитесь, ребята, будет много инфы.
Spider — собственно, настройки парсинга сайта
Вкладка Basic — выбираем что парсить
- Check Images — в отчет включаем анализ картинок.
- Check CSS — в отчет включаем анализ css-файлов (скрипты).
- Check JavaScript — в отчет включаем анализ JS-файлов (скрипты).
- Check SWF — в отчет включаем анализ Flash-анимации.
- Check External Link — в отчет включаем анализ ссылок с сайта на другие ресурсы.
- Check Links Outside of Start Folder — проверка ссылок вне стартовой папки. Т.е. отчет будет только по стартовой папке, но с учетом ссылок всего сайта.
- Follow internal “nofollow” — сканировать внутренние ссылки, закрытые в тег “nofollow”.
- Follow external “nofollow” — сканировать ссылки на другие сайты, закрытые в тег “nofollow”.
- Crawl All Subdomains — парсить все поддомены сайта, если ссылки на них встречаются на сканируемом домене.
- Crawl Outside of Start Folder — позволяет сканировать весь сайт, однако проверка начинается с указанной папки.
- Crawl Canonicals — выведение в отчете атрибута rel=”canonical” при сканировании страниц.
- Crawl Next/Prev — выведение в отчете атрибутов rel=”next”/”prev” при сканировании страниц пагинации.
- Extract hreflang/Crawl hreflang — при сканировании учитываются языковой атрибут hreflang и отображаются коды языка и региона страницы + формирование отчета по таким страницам.
- Extract AMP Links/Crawl AMP Links — извлечение в отчет ссылок с атрибутом AMP (определение версии контента на странице).
- Crawl Linked XML Sitemap — сканирование карты сайта. Тут краулер либо берет sitemap из robots.txt (Auto Discover XML Sitemap via robots.txt), либо берет карту по указанному пользователем пути (Crawl These Sitemaps).


Ну что, сложно? На самом деле просто нужна привычка и немного практики, чтобы освоить основные настройки SF и понять что нужно использовать в конкретных случаях, а от чего можно отказаться. Все, передохнули, теперь дальше… будет проще (нет).
Вкладка Limits — определяем лимиты парсинга
- Limit Crawl Total — задаем лимиты страниц для сканирования. Сколько всего страниц выгружаем для одного проекта.
- Limit Crawl Depth — задаем глубину парсинга. До какого уровня может дойти краулер при сканировании проекта.
- Limit Max Folder Depth — можно контролировать глубину парсинга вплоть до уровня вложенности папки.
- Limit Number of Query Strings — тут, если честно, сам не до конца разобрался, потому объясню так, как понял — мы ограничиваем лимит страниц с параметрами. Другими словами, если на одной статической странице есть несколько фильтров, то их комбинация может породить огромное количество динамических страниц. Вот чтобы такие “полезные” страницы не парсились (увеличивает время анализа в разы, а толковой информации по сути ноль), мы и выводим лимиты по Query Strings. Пример динамики — site.ru/?query1&query2&query3&queryN+1.
- Max Redirects to Follow — задаем максимальное количество редиректов, по которым паук может переходить с одного адреса.
- Max URL Length to Crawl — максимальная длина URL для обхода (указываем в символах, я так понимаю).
- Max Links per URL to Crawl — максимальное количество ссылок на URL для обхода (указываем в штуках).
- Max Page Size (KB) to Crawl — максимальный размер страницы для обхода (указываем в килобайтах).
 Вот чтобы такие “полезные” страницы не парсились (увеличивает время анализа в разы, а толковой информации по сути ноль), мы и выводим лимиты по Query Strings. Пример динамики — site.ru/?query1&query2&query3&queryN+1.
Вот чтобы такие “полезные” страницы не парсились (увеличивает время анализа в разы, а толковой информации по сути ноль), мы и выводим лимиты по Query Strings. Пример динамики — site.ru/?query1&query2&query3&queryN+1.Вкладка Rendering — настраиваем параметры рендеринга (только для JS)
На выбор три опции — “Text Only” (паук анализирует только текст страницы, без учета Аякса и JS), “Old AJAX Crawling Scheme” (проверяет по устаревшей схеме сканирования Аякса) и “JavaScript” (учитывает скрипты при рендеринге). Детальные настройки есть только у последнего, их и рассмотрим.
Детальные настройки есть только у последнего, их и рассмотрим.
- Enable Rendered Page Screen Shots — SF делает скриншоты анализируемых страниц и сохраняет их в папке на ПК.
- AJAX Timeout (secs) — лимиты таймаута. Как долго SEO Spider должен разрешать выполнение JavaScript, прежде чем проверять загруженную страницу.
- Window Size — выбор размера окна (много их — смотрим скриншот).
- Sample — пример окна (зависит от выбранного Window Size).
- Чекбокс Rotate — повернуть окно в Sample.
Вкладка Advanced — дополнительные опции парсинга
- Allow Cookies — учитывать Cookies, как это делает поисковый бот.
- Pause on High Memory Used — тормозит сканирование сайта, если процесс забирает слишком много оперативной памяти.
- Always Follows Redirect — разрешаем краулеру идти по редиректам вплоть до финальной страницы с кодом 200, 4хх, 5хх (по факту все ответы сервера, кроме 3хх).
- Always Follows Canonicals — разрешаем краулеру учитывать все атрибуты “canonical” вплоть до финальной страницы. Полезно, если на страницах сайта бардак с настройкой этого атрибута (например, после нескольких переездов).
- Respect Noindex — страницы с “noindex” не отображаются в отчете SF.
- Respect Canonical — учет атрибута “canonical” при формировании итогового отчета. Полезно, если у сайта много динамических страниц с настроенным rel=”canonical” — позволяет убрать из отчета дубли по метаданным (т.к. на страницах настроен нужный атрибут).
- Respect Next/Prev — учет атрибутов rel=”next”/”prev” при формировании итогового отчета. Полезно, если у сайта есть страницы пагинации с настроенными “next”/”prev”- позволяет убрать из отчета дубли по метаданным (т.к. на страницах настроен нужный атрибут).
- Extract Images from img srscet Attribute — изображения извлекаются из атрибута srscet тега <img>. SRSCET — атрибут, который позволяет вам указывать разные типы изображений для разных размеров экрана/ориентации/типов отображения.
- Respect HSTS Policy — если чекбокс активен, SF будет выполнять все будущие запросы через HTTPS, даже если перейдет по ссылке на URL-адрес HTTP (в этом случае код ответа будет 307). Если же чекбокс неактивен, краулер покажет «истинный» код состояния за перенаправлением (например, постоянный редирект 301).
- Respect Self Referencing Meta Refresh — учитывать принудительную переадресацию на себя же (!) по метатегу Refresh.
- Response Timeout — время ожидания ответа страницы, перед тем как парсер перейдет к анализу следующего урла. Можно сделать больше (для медленных сайтов), можно меньше.
- 5хх Response Retries — количество попыток “достучаться” до страниц с 5хх ответом сервера.
- Store HTML — можно сохранить статический HTML-код каждого URL-адреса, просканированного SEO Spider, на диск и просмотреть его до того, как JavaScript “вступит в игру”.
- Store Rendered HTML — позволяет сохранить отображенный HTML-код каждого URL-адреса, просканированного SEO Spider, на диск и просмотреть DOM после обработки JavaScript.
- Extract JSON-LD — извлекаем микроразметку сайта JSON-LD. При выборе — дополнительные чекбоксы с типами валидации микроразметки (Schema.org, Google Validation, Case-Sensitive).
- Extract Microdata — извлекаем микроразметку сайта Microdata. При выборе — дополнительные чекбоксы с типами валидации микроразметки (Schema.org, Google Validation, Case-Sensitive).
- Extract RDFa — извлекаем микроразметку сайта RDFa. При выборе — дополнительные чекбоксы с типами валидации микроразметки (Schema.org, Google Validation, Case-Sensitive).


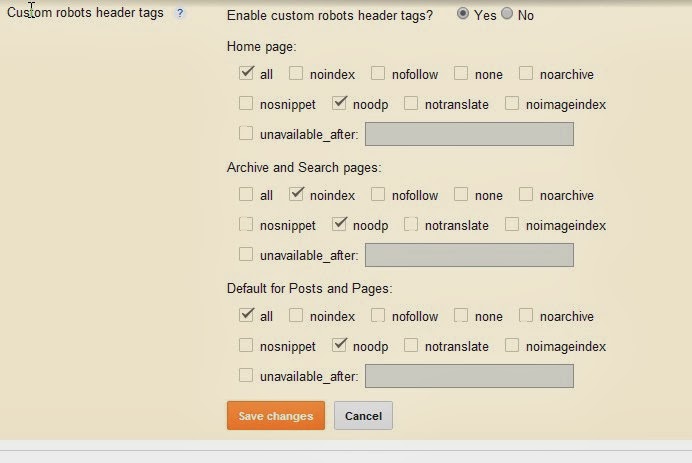
Вкладка Preferences — так называемые “предпочтения”
Здесь задаем желаемые параметры для некоторых сканируемых элементов (title, description, url, h2, h3, alt картинок, размер картинок). Соответственно, если сканируемые элементы сайта не будут соответствовать нашим предпочтениям, программа нам об этом сообщит в научно-популярной форме. Совершенно необязательные настройки — каждый прописывает для себя свой идеал… или вообще их не трогает, от греха подальше (как делаю я).
- Page Title Width — оптимальная ширина заголовка страницы. Указываем желаемые размеры от и до в пикселях и в символах.
- Meta Description Width — оптимальная ширина описания страницы. Аналогично, как и с тайтлом, указываем желаемые размеры.
- Other — сюда входит максимальная желаемая длина урл-адреса в символах (Max URL Length Chars), максимальная длина h2 в символах (Max h2 Length Chars), максимальная длина h3 в символах (Max h3 Length Chars), максимальная длина ALT картинок в символах (Max Image Length Chars) и максимальный вес картинок в КБ (Max Image Size Kilobytes).
Robots.txt — определяем каким правилам следовать при парсинге
Вкладка Settings — настраиваем парсинг относительно правил robots.txt
- Respect robots.txt — следуем всем правилам, прописанным в robots.txt. Т.е. учитываем в анализе те папки и файлы, которые открыты для робота.
- Ignore robots.txt — не учитываем robots. txt сайта при парсинге. В отчет попадают все папки и файлы, относящиеся к домену.
- Ignore robots.txt but report status — не учитываем robots.txt сайта при парсинге, однако в дополнительном меню выводится статус страницы (индексируемая или не индексируемая).
- Show internal/external URLs blocked by robots.txt — отмечаем в чекбоксах хотим ли мы видеть в итоговом отчете внутренние и внешние ссылки, закрытые от индексации в robots.txt. Данная опция работает только при условии выбора “Respect robots.txt”.
 txt сайта при парсинге. В отчет попадают все папки и файлы, относящиеся к домену.
txt сайта при парсинге. В отчет попадают все папки и файлы, относящиеся к домену.Вкладка Custom — ручное редактирование robots.txt в пределах текущего парсинга
Удобно, если вам нужно при парсинге сайта учитывать (или исключить) только определенные папки, либо же добавить правила для поддоменов. Кроме того, можно быстро сформировать и проверить свой рабочий robots, чтобы потом залить его на сайт.
Шаг 1. Прописать анализируемый домен в основной строке
Шаг 2. Кликнуть на Add, чтобы добавить robots..png) txt домена
txt домена
Тут на самом деле все очень просто, поэтому я по верхам пробегусь по основным опциям (а в конце будет видео, где я бездумно прокликиваю все кнопки).
- Блок Subdomains — сюда, собственно, можно добавлять домены/поддомены, robots.txt которых мы хотим учитывать при парсинге сайта.
- Окно справа — для редактирования выгруженного robots.txt. Итоговый вариант будет считаться каноничным для парсера.
- Окошко снизу — проверка индексации url в зависимости от настроенного robots.txt. Справа выводится статус страницы (Allowed или Disallowed).
URL Rewriting — функция перезаписи URL «на лету»
Тут мы можем настроить перезапись урл-адресов домена прямо в ходе парсинга. Полезно, когда нужно заменить определенные регулярные выражения, которые засоряют итоговый отчет по парсингу.
Вкладка Remove Parameters
Вручную вводим параметры, которые нужно удалять из url при анализе сайта, либо исключить вообще все возможные параметры (чекбокс “Remove all”). Полезно, если у страниц сайта есть идентификаторы сеансов, отслеживание контекста (utm_source, utm_medium, utm_campaign) или другие фишки.
Вкладка Regex Replace
Изменяет все сканируемые урлы с использованием регулярных выражений. Применений данной настройки масса, я приведу только несколько самых распространенных примеров:
- Изменение всех ссылок с http на https (Регулярное выражение: http Заменить: https).
- Изменение всех ссылок на site.by на site.ru (Регулярное выражение: .by Заменить: .ru).
- Удаление всех параметров (Регулярное выражение: \?. * Заменить: ).
- Добавление параметров в URL (Регулярное выражение: $ Заменить: ?ПАРАМЕТР).
Вкладка Options
Вы рассчитывали увидеть здесь еще 100500 дополнительных опций для суперточной настройки URL Rewriting, я прав? Как бы странно это ни звучало, но здесь мы всего лишь определяем перезаписывать все прописные url-адреса в строчные или нет… вот как-то так, не спрашивайте, я сам не знаю почему для этой опции сделали целую отдельную вкладку.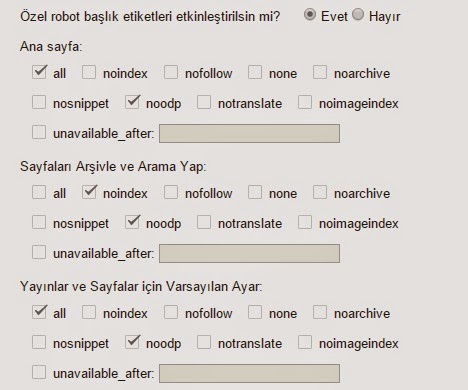
Вкладка Test
Тут мы можем предварительно протестировать видоизменение url перед началом парсинга и, соответственно, подправить регулярные выражения, чтобы на выходе не получилось какой-нибудь ерунды.
CDNs — парсим поддомены, не отходя от кассы
Использование настройки CDNs позволяет включать в парсинг дополнительные домены/поддомены/папки, которые будут обходиться пауком и при этом считаться внутренними ссылками. Полезно, если нужно проанализировать массив сайтов, принадлежащих одному владельцу (например, крупный интернет-магазин с сетью сайтов под регионы). Также можно прописывать регулярные выражения на конкретные пути сканирования — т.е. парсить только определенные папки.
Во вкладке Test можно посмотреть как будут определяться урлы в зависимости от используемых параметров (Internal или External).
Include/Exclude — сканирование/удаление определенных папок
Можно регулярными выражениями задать пути, которые будут сканироваться внутри домена. Также можно запретить парсинг определенных папок. Единственный нюанс в настройках — при использовании Include будут парситься только УКАЗАННЫЕ папки, если же мы добавляем урлы в Exclude, сканироваться будут все папки, КРОМЕ УКАЗАННЫХ.
Также можно запретить парсинг определенных папок. Единственный нюанс в настройках — при использовании Include будут парситься только УКАЗАННЫЕ папки, если же мы добавляем урлы в Exclude, сканироваться будут все папки, КРОМЕ УКАЗАННЫХ.
Выбираем папки для парсинга
Удаляем папки из парсинга
Примеры регулярных выражений для Exclude:
- http://site.by/obidnye-shutki-pro-seo.html (исключение конкретной страницы).
- http://site.by/obidnye-shutki-pro-seo/.* (исключение целой папки).
- http://site.by/.*/obidnye-shutki-pro-seo/.* (исключение всех страниц, после указанной).
- .*\?price.* (исключение страниц с определенным параметром).
- .*jpg$ (исключение файлов с определенным расширением).
- .*seo.* (исключение страниц с вхождением в url указанного слова).
- .*https.* (исключение страниц с https).
- http://site.by/.* (исключение всех страниц домена/поддомена).
Speed — регулируем скорость парсинга сайта
Можно выставить как количество потоков (по умолчанию 5), так и число одновременно сканируемых адресов.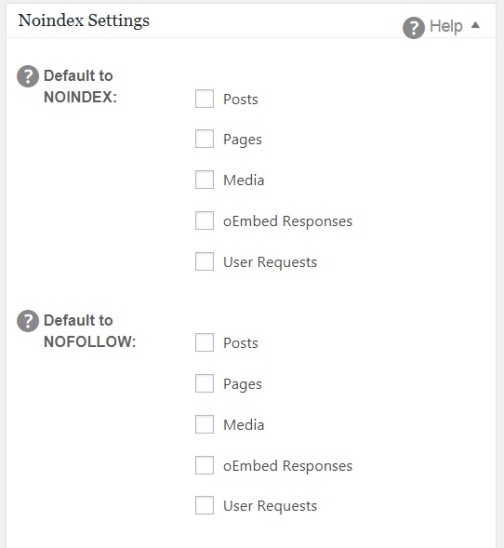 Влияет на скорость парсинга и вероятность бана бота, так что тут лучше не усердствовать.
Влияет на скорость парсинга и вероятность бана бота, так что тут лучше не усердствовать.
User-Agent — выбираем под кого маскируемся
В списке user-agent можно выбрать от лица какого бота будет происходить парсинг сайта. Удобно, если в настройках сайта есть директивы, блокирующие того или иного бота (например, запрещен google-bot). Также полезно иногда прокраулить сайт гугл-ботом для смартфона, чтобы проверить косяки адаптива или мобильной версии.
Скажу сразу — это опция очень индивидуальна, лично я ее не пользую, потому что чаще всего незачем. В любом случае, настройка реагирования на http-заголовки позволяет определить, как паук будет их обрабатывать (если указаны нюансы в настройках). По крайней мере я так это понял.
Т.е. можно индивидуально настроить, например, какого формата контент обрабатывать, учитывать ли cookie и т.д. Нюансов там довольно много.
Custom — дополнительные настройки поиска по исходному коду
Custom Search
По сути обычный фильтр, с помощью которого можно вытягивать дополнительные данные, например, страницы, в которых вместо тега <strong> используется <bold> или еще лучше — страницы, которые НЕ содержат определенного контента (например, без кода счетчика метрики). Фактически в настройках можно задать все что угодно.
Фактически в настройках можно задать все что угодно.
Custom Extraction
Это пользовательское извлечение любых данных из html (например, текстовое содержимое).
User Interface — обнуление настроек для колонок таблицы
Просто сбрасывает сортировку столбцов, ничего особенного, проходим дальше, граждане, не толпимся.
API Access — интеграция с разными сервисами
Для того чтобы получать больше данных по сайту, можно настроить интеграцию с разными сервисами статистики типа Google Analytics или Majestic, при условии того, что у вас есть аккаунт в этом сервисе.
При этом для каждого сервиса отдельные настройки выгрузки по типам данных.
На примере GA
Authentification — настройки аутентификации (если есть запрос от сайта)
Есть два вида аутентификации — Standart Based и Form Based. По умолчанию используется Standart Base — если при парсинге от сайта приходит запрос на аутентификацию, в программе появляется соответствующее окно.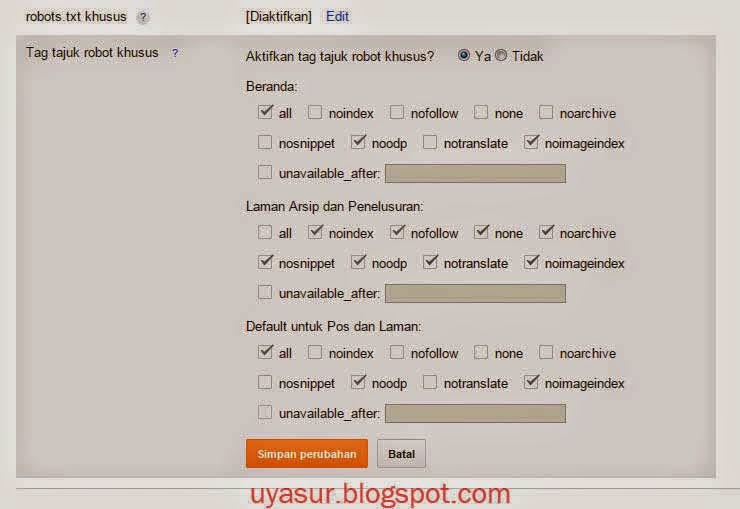
Form Based — использование для аутентификации встроенного в SF браузера (полезно, когда для подтверждения аутентификации нужно, например, пройти капчу). В данном случае необходимо вручную вводить урл сайта и в открывшемся окне браузера вводить логин/пароль, кликать recaptcha и т.д.
System — внутренние настройки самой программы
Настройки работы самой программы — сколько оперативной памяти выделять на процесс, куда сохранять экспорт и т.д.
Давайте как обычно — подробнее о каждом пункте.
- Memory — выделяем лимиты оперативной памяти для парсинга. По дефолту стоит 2GB, но можно выделить больше (если ПК позволяет).
- Storage — выбор базы для хранения данных. Либо сохранение в ОЗУ (для этого у SF есть свой движок), либо в указанной папке на ПК пользователя.
- Proxy — подключение прокси-сервера для парсинга.
- Embedded Browser — использование встроенного в программу браузера (вкл/выкл).

Mode
- Spider (Режим паука) — классический парсинг сайта по внутренним ссылкам. Просто вводим нужный домен в адресную строку программы и запускаем работу.
- List — парсим только предварительно собранный список урл-адресов! Адреса можно выгрузить из файла (From a file), вбить вручную (Enter Manually), подтянуть их из карты сайта (Download Sitemap) и т.д. Если честно, этих трех способов получения списка урлов должно быть более чем достаточно.
- SERP Mode — в этом режиме нет сканирования, зато здесь можно загружать мета-данные сайта, редактировать их и предварительно понимать как они будут отображаться в браузере. Делать все это можно пакетно, что вполне себе удобно.
 Делать все это можно пакетно, что вполне себе удобно.
Делать все это можно пакетно, что вполне себе удобно.Bulk export
В этом пункте меню висят все опции SF, отвечающие за массовый экспорт данных из основного и дополнительного меню отчета…сейчас покажу на скриншоте.
В общем и целом с помощью bulk export можно вытянуть много разной полезной информации для последующей постановки ТЗ на доработки. Например, выгрузить в excel страницы, на которых найдены ссылки с 3хх ответом сервера + сами 3хх-ссылки, что позволяет сформировать задание для программиста или контент-менеджера (зависит от того, где зашиты 3хх-ссылки) на замену этих 3хх-ссылок на прямые с кодом 200. Теперь подробнее про то, что можно экспортировать при помощи Bulk Export.
- All Inlinks — получаем все входящие ссылки на каждый URI, с которым столкнулся краулер при сканировании сайта.
- All Outlinks — получаем все исходящие ссылки с каждого URI, с которым столкнулся краулер при сканировании сайта.
- All Anchor Text — выгрузка анкоров всех ссылок.
- All Images — выгрузка всех картинок (урл-адресами, естественно).
- Screenshots — экспорт снимков экрана.
- All Page Source — получаем статический HTML-код или обработанный HTML-код просканированных страниц (рендеринг HTML доступен только в режиме рендеринга JavaScript) .
- External Links — все внешние ссылки со всех просканированных страниц.
- Response Codes — все страницы в зависимости от выбранного кода ответа сервера (закрытые от индекса, с кодом 200, с кодом 3хх и т.д.).
- Directives — все страницы с директивами в зависимости от выбранной (Index Inlinks, Noindex Inlinks, Nofollow Inlinks и т.д.).
- Canonicals — страницы, содержащие канонические атрибуты, страницы без указания этих атрибутов, каноникализированные (*перекрестился*) страницы и т.д.
- AMP — страницы с AMP, ссылки с AMP (но код ответа не 200) и т.д.
- Structured Data — выгрузка страниц с микроразметкой.
- Images — выгрузка картинок без альт-текста, тяжелых картинок (в соответствии с указанным в настройках размером).
- Sitemaps — выгрузка всех страниц в карте сайта, неиндексируемых страниц в карте сайта и проч.
- Custom — выгрузка пользовательских фильтров.


Reports
Здесь содержится множество различных отчетов, которые также можно выгрузить.
- Crawl Overview — в этом отчете содержится сводная информация о сканировании, включая такие данные, как количество найденных URL-адресов, заблокированных robots.txt, число сканированных, тип контента, коды ответов и т. д.
- Redirect & Canonical Chains — отчет о перенаправлении и канонических цепочках. Здесь отображаются цепочки перенаправлений и канонических символов, показывается количество переходов по пути и идентифицируется источник, а также цикличность (если есть).
- Non-Indexable Canonicals — здесь можно получить выгрузку, в которой освещаются ошибки и проблемы с canonical. В частности, этот отчет покажет любые канонические файлы, которые не отдают корректного ответа сервера — заблокированы файлом robots.txt, с перенаправлением 3хх, ошибкой 4хх или 5хх (вообще все что угодно, кроме ответа «ОК» 200).
- Pagination — ошибки и проблемы с атрибутами rel=”next” и rel=”prev”, которые используются для обозначения содержимого, разбитого на пагинацию.
- Hreflang — проблемы с атрибутами hreflang (некорректный ответ сервера, страницы, на которые нет гиперссылок, разные коды языка на одной странице и т.д.).
- Insecure Content — показаны любые защищенные (HTTPS) URL-адреса, на которых есть небезопасные элементы, такие как внутренние ссылки HTTP, изображения, JS, CSS, SWF или внешние изображения в CDN, профили социальных сетей и т. д.
- SERP Summary — этот отчет позволяет быстро экспортировать URL-адреса, заголовки страниц и мета-описания с соответствующими длинами символов и шириной в пикселях.
- Orphan Pages — список потерянных страниц, собранных из Google Analytics API, Google Search Console (Search Analytics API) и XML Sitemap, которые не были сопоставлены с URL-адресами, обнаруженными во время парсинга.
- Structured Data — отчет содержит данные об ошибках валидации микроразметки страниц.
 В частности, этот отчет покажет любые канонические файлы, которые не отдают корректного ответа сервера — заблокированы файлом robots.txt, с перенаправлением 3хх, ошибкой 4хх или 5хх (вообще все что угодно, кроме ответа «ОК» 200).
В частности, этот отчет покажет любые канонические файлы, которые не отдают корректного ответа сервера — заблокированы файлом robots.txt, с перенаправлением 3хх, ошибкой 4хх или 5хх (вообще все что угодно, кроме ответа «ОК» 200).
Sitemaps
С помощью этого пункта можно сгенерировать XML-карту сайта (страницы и картинки).
Все просто — выбираем что будем генерировать. В появившемся окне при необходимости выбираем нужные параметры и создаем карту сайта, которую потом заливаем в корневой каталог сайта.
Рассмотрим подробнее параметры, которые нам предлагают выбрать при генерации карты сайта.
Вкладка Pages — выбираем какие типы страниц включить в карту сайта.
- Noindex Pages — страницы, закрытые от индексации.
- Canonicalised — каноникализированные (опять это страшное слово!) страницы . Другими словами, динамика, у которой есть rel=”canonical”.
- Paginated URLs — страница пагинации.
- PDFs — PDF-документы.
- No response — страницы с кодом ответа сервера 0 (не отвечает).
- Blocked by robots. txt — страницы закрытые от индекса в robots.txt.
- 2xx — страницы с кодом 2хх (они будут в карте в любом случае).
- 3хх — страницы с кодом ответа 3хх (редиректы).
- 4хх — страницы с кодом ответа 4хх (битые ссылки на несуществующие страницы).
- 5хх — страницы с кодом ответа 5хх (проблема сервера при загрузке).
 txt — страницы закрытые от индекса в robots.txt.
txt — страницы закрытые от индекса в robots.txt.Вкладка Last Modified — выставляем дату последнего обновления карты.
- nclude <lastmod> tag — использовать в sitemap тег <lastmod> (дата последнего обновления карты).
- Use server report — использовать ответ сервера при создании карты, либо проставить дату вручную.
Вкладка Priority — выставляем приоритет ссылки в зависимости от глубины залегания страницы.
- Include <priority> tag — добавляет в карту сайта тег <priority>, показывающий приоритет страницы.
- Crawl Depth 0-5+ — в зависимости от глубины залегания страницы, можно проставить ее приоритет сканирования для поискового робота.

Вкладка Change Frequency — выставляем вероятную частоту обновления страниц.
- Include <changefreq> tag — использовать тег <changefreq> в карте сайта. Показывает частоту обновления страницы.
- Calculate from Last Modified header — рассчитать тег по последнему измененному заголовку.
- Use crawl depth settings — проставить тег в зависимости от глубины страницы.
Вкладка Images — добавляем картинки в карту сайта.
- Include Images — выводить в общей карте сайта картинки.
- Include Noindex Images — добавить картинки, закрытые от индекса.
- Include only relevant Images with up to … inlinks — добавить только картинки с заданным числом входящих ссылок.
- Regex list of CDNs hosting images to be included — честно, так и не понял что это такое… возможно настройка выгрузки в карту сайта картинок из хостинга (т.е. можно вбить списком несколько хостов и оттуда подтянуть картинки), но это всего лишь мои предположения.

Вкладка Hreflang — использовать в sitemap атрибут <hreflang> (или не использовать).
Visualisations
Это выбор интерактивной визуализации структуры сайта в программе. Можно получить отображение дерева сканирования и дерева каталогов. Основная фишка в том, что открываются эти карты и диаграммы во встроенном браузере программы, что позволяет эффективнее с ними работать (настраивать выведение, масштабировать, перескакивать к нужным урлам через поиск и т.д.).
Crawl Tree Graph — визуализация сканирования. По факту после завершения краулинга показывает текущую структуру сайта на основании анализа.
Directory Tree Graph — показывает ВСЕ каталоги после сканирования. Т.е. отличие от Crawl Tree Graph в том, что в этом отчете показываются, например, папки, закрытые от индекса.
Назначение Crawl Tree Graph и Directory Tree Graph в основном заключается в упрощении анализа структуры текущего сайта, можно глазами пробежаться по всем папкам, зацепиться за косяки (т.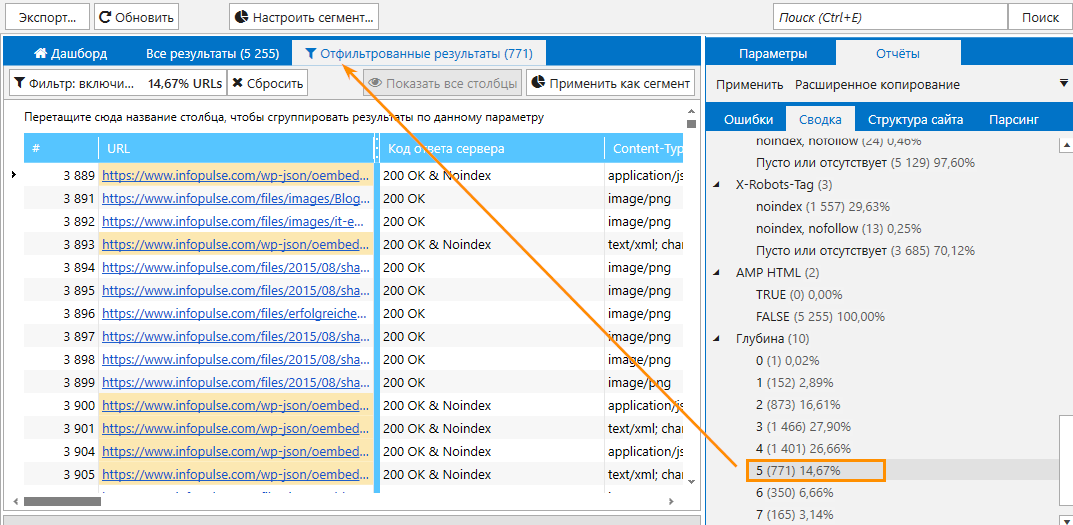 к. они выделены цветом). При наведении на папку, показывается ее данные (url, title, h2, h3 и т.д.).
к. они выделены цветом). При наведении на папку, показывается ее данные (url, title, h2, h3 и т.д.).
Force Directed Crawl-Diagram — по сути то же самое, что и Crawl Tree Graph, только оформленное по-другому + показывает сканирование сайта относительно главной страницы (ну или стартовой). Кому-то покажется нагляднее, хотя по мне, выглядит гораздо сложнее для восприятия.
Force Directed Tree-Diagram — аналогично, другой тип визуализации дерева каталогов сайта.
Inlink Anchor Text Word Cloud — визуализация анкоров (ссылочного текста) внутренней ссылки. Анализирует каждую страницу по-отдельности. Помогает понять какими анкорами обозначена страница, как их много, насколько разнообразны и т.д.
Р- Разнообразие
Body Text Word Cloud — визуализация плотности отдельных слов на странице. По сути выглядит так же, как и Inlink Anchor Text Word Cloud, так что отдельный скрин делать смысла особого нет — обычное облако слов, по размеру можно определить какое слово встречается чаще, по общему числу посмотреть разнообразие слов на странице и т. д.
д.
Каждая визуализация имеет массу настроек вывода данных, маркировки — про них я писать не буду, если станет интересно, сами поиграетесь, ок? Там ничего сложного.
Crawl Analysis
Большинство параметров сайта вычисляется пауком в ходе сбора статистики, однако некоторые данные (Link Score, некоторые фильтры и прочее) нуждаются в дополнительном анализе, чтобы попасть в финальный отчет. Данные, которые нуждаются в Crawl Analysis, помечены соответствующим образом в правом меню навигации.
Crawl Analysis запускается после основного парсинга. Перед запуском дополнительного анализа, можно настроить его (какие данные выводить в отчет).
- Link Score — присвоение оценок всем внутренним ссылкам сайта.
- Pagination — показывает петлевые пагинации, а также страницы, которые обнаружены только через атрибуты rel=”next”/”prev”.
- Hreflang — урлы hreflang без гиперссылки, битые ссылки.
- AMP — страницы без тегов “html amp”, теги не с 200 кодом ответа.
- Sitemaps — неиндексируемые страницы в карте сайта, урлы в нескольких картах сайта, потерянные страницы (например, есть в Google Analytics, есть в sitemap, не обнаружено при парсинге), страницы, которых нет в карте сайта, страницы в карте сайта.
- Analytics — потерянные страницы (есть в аналитике, нет в парсинге).
- Search Console — потерянные страницы (есть в вебмастере, нет в парсинге).
License
Исходя из названия, логично предположить, что этот пункт меню отвечает за разного рода манипуляции с активацией продукта…иии так оно и есть!
Buy a License — купить лицензию. При клике переход на соответствующую страницу официалов https://www.screamingfrog.co.uk/seo-spider/licence/. Стоимость ключа для одного ПК — 149 фунтов стерлинга. Есть пакеты для нескольких ПК, там, как обычно, идут скидки за опт.
Enter License — ввести логин и ключ лицензии, чтобы активировать полный функционал парсера.
Заметили, да? Лицензия покупается на год, не бессрочная
Help
Помощь юзеру — гайды, FAQ, связь с техподдержкой, в общем все, что связано с работой программы, ее багами и их решением.
- User Guide — мануал по работе с программой. Собственно, его я использовал, как один из источников, для написания этой статьи. При желании, можете ознакомиться, если я что-то непонятно рассказал или не донес. Еще раз оставлю ссылку https://www.screamingfrog.co.uk/seo-spider/user-guide/.
- FAQ — часто задаваемые вопросы по работе с SF и ответы на них https://www.screamingfrog.co.uk/seo-spider/faq/.
- Support — обратная связь с техподдержкой https://www.screamingfrog.co.uk/seo-spider/support/. Если программа ведет себя некрасиво (например, не принимает ключ лицензии), можно пожаловаться куда надо и все починят.
- Feedback — обратная связь. Та же самая страница, что и в Support. Т.е. можно не только жаловаться, но и вносить предложения по работе программы, предлагать партнерку, сказать банальное “спасибо” за такой крутой сервис (думаю ребятам будет приятно).
- Check for Updates и Auto Check for Updates — проверка на наличие обновлений программы. Screaming Frog нерегулярно, но довольно часто дорабатывается, поэтому есть смысл периодически проверять апдейты. Но лучше поставить галочку на Auto Check for Updates и программа сама будет автоматически предлагать обновиться при выходе нового апа.
- Debug — отчет о текущем состоянии программы. Нужно, если вы словили какой-то баг и хотите о нем сообщить разработчику. Там еще дополнительно есть настройки дебага, но я думаю, нет смысла заострять на этом внимание.
- About — собственно, краткая информация о самой программе (копирайт, сервисы, которые использовались при разработке).

Итог
Screaming Frog — очень гибкая в плане настройке утилита, с помощью которой можно вытянуть массу данных для анализа, нужно только (только… ха-ха) правильно настроить парсинг. Я надеюсь, мой мануал поможет вам в этом, хотя и не все я рассмотрел как надо, есть пробелы, но основные функции должны быть понятны.
Теперь от себя — текста много, скринов много, потому, если вы начинающий SEO-специалист, рекомендую осваивать SF поэтапно, не хватайтесь за все сразу, ибо есть шанс упустить важные нюансы.
Ну вот и все, ребята, я отчаливаю за новым материалом для нашего крутого блога. Подписывайтесь, чтобы не пропустить интересные публикации от меня и моих коллег. Всем удачи, всем пока!
Владимир Еленский
Практикующий SEO-специалист MAXI.BY media. Опыт работы более 5-ти лет. Хороший человек и просто красавчик.
Теги Noindex и Nofollow — в чем разница, зачем нужны и примеры использования
На каждом сайте есть контент, который владельцы не хотят показывать поисковым системам или не хотят, чтобы он оказывал какое-либо влияние на продвижение. Чаще всего мы хотим скрыть от индексации исходящие ссылки, чтобы не повышать заспамленность сайта ссылками. Вот для этих целей и применяются тег noindex и атрибут nofollow.
Прежде чем мы начнем говорить об использовании наших тегов, хотелось бы отметить несколько важных моментов. Необходимость скрывать от роботов поисковых систем различные фрагменты кода страниц была всегда. Разработчики и оптимизаторы сайтов уже много лет знают, что есть вещи, которые поисковикам лучше не показывать.
Необходимость скрывать от роботов поисковых систем различные фрагменты кода страниц была всегда. Разработчики и оптимизаторы сайтов уже много лет знают, что есть вещи, которые поисковикам лучше не показывать.
Но пик популярность пришелся на эпоху роста рынка купли-продажи ссылок и активизации поисковых систем в направлении борьбы с ними.
Noindex и nofollow это самые первые и простые инструменты, которые позволяют сказать поисковику, что нужно индексировать, а что трогать не стоит. И несмотря на то, что эти теги активно используются владельцами сайтов уже много лет, отказываться от них сегодня никто не собирается, и популярность они ни сколько не потеряли.
При использовании этих тегов нет никаких негативных последствий. Более того, Яндекс даже рекомендует применять noindex и nofollow для настройки индексации сайта и оптимизации контента на страницах.
В сервисе Яндекс.Вебмастер в разделе «Помощь» существует специальная страница, на который представители поисковой системы рассказывают обо всех возможностях использования данных инструментов.
Применение этих тегов не требует каких-либо особых знаний и навыков работы с программным html кодом. Даже новички без проблем смогут использовать эти теги.
Что делает тег noindex
Для начала очень важная особенность. Все мы знаем, что сегодня в Рунете существует два самых главных поставщика поискового трафика на наши с вами сайты — это Яндекс и Google.
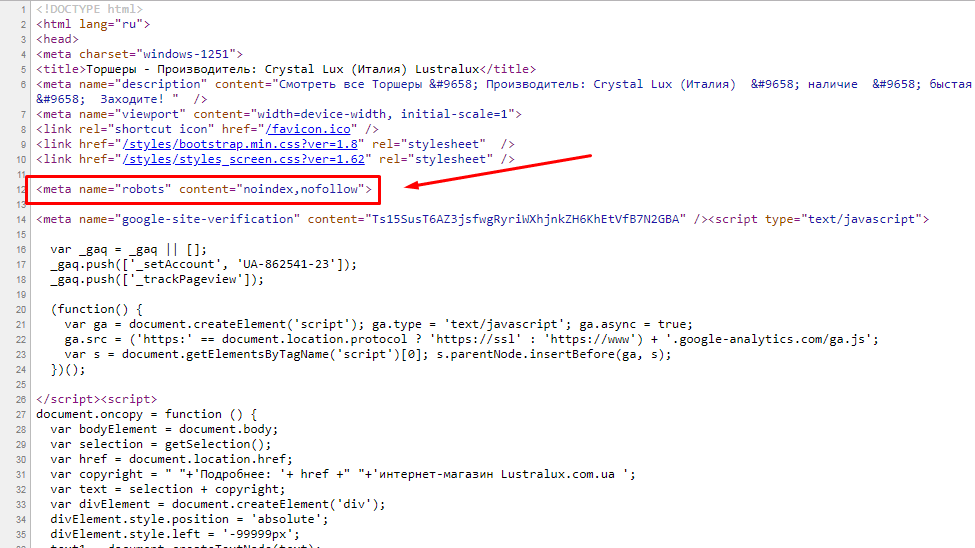
Тег noindex работает только для поисковой системы Яндекс и указывает на ту часть кода, который поисковая система не должна индексировать (добавлять в свою базу) и который не должен влиять на ранжирование страницы в результатах поиска. Google мета тег не видит и никак не учитывает.
Применять тег noindex нужно следующим образом:
<noindex><a href="http://DmitriyZhilin.ru">Проверка ссылок</a></noindex>
Сначала идет открывающийся тег — <noindex>, затем прописывается часть текста или программного кода, которую нужно скрыть от индексации Яндексом, и затем уже закрывающийся тег — </noindex>.
C помощью данного инструмента можно скрывать не только исходящие ссылки на сайте, но и любой программный код или текст. Просто помещаем нужный нам фрагмент между открывающим и закрывающим тегом, и готово.
Когда нам нужно скрывать программный код от индексации? Когда он не связан напрямую с темой вашей статьи и может неправильно повлиять на понимание текста поисковиком. Чаще всего это какой-нибудь опрос, несколько счетчиков, код для анализа поведенческих факторов или еще что-то в таком роде.
Что делает атрибут nofollow
Хотя эти два параметра часто употребляются вместе и многие думают, что это одно и то же, только для разных поисковых систем, разница между noindex и nofollow огромна.
Nofollow является параметром тега «rel» и может запрещать индексировать только ссылки, даже не индексировать, а переходить по ним поисковику (передавать ссылочный вес), сам анкорный текст будет спокойно читаться роботами. Этот параметр можно применять только к HTML ссылкам (<a>).
Другими словами, данный параметр не cможет cпрятать фрагменты программного кода или же часть какого-то текста, как это делает noindex.
Применяется параметр nofollow следующим образом:
<a href="http://DmitriyZhilin.ru" rel="nofollow">Проверка ссылок</a>
Я вам привел обычный программный код, которым выводим на страницах наших сайтов исходящие ссылки, где:
http://DmitriyZhilin.ru/ — ссылка, которую мы закрываем от индексации роботами Google.
rel=”nofollow” — присваиваем тегу «rel» значение nofollow.
Текст “Проверка ссылок” — это анкор скрываемой ссылки.
Для того, чтобы закрыть ссылку от индексации полностью, можно воспользоваться и тегом noindex, и параметром nofollow одновременно. В этом случае программный код будет выглядеть следующим образом:
<noindex><a href="http://DmitriyZhilin.ru" rel="nofollow">Проверка ссылок</a></noindex>
Получается тег noindex закрывает текст ссылки от индексации, а параметр nofollow запрещает передачу ссылочного веса.
Как я уже сказал выше, использование этих инструментов для закрытия ссылок это очень старый и проверенный метод.
Сегодня уже существует целый ряд альтернативных способов закрытия ссылок, например с помощью JavaScript, они сложнее в реализации, поэтому еще не так распространены.
Применение Noindex и Nofollow для всей страницы
Еще один способ применения данных тегов – это запрет на индексацию всей страницы и запрет на учет всех ссылок с неё.
Для этого используется мета тег в разделе head кода сайта, выглядит он следующим образом:
<meta name="robots" content="noindex,nofollow" />
Задача такой конструкции в запрете на попадание в поиск различных дублей страниц, которые могут создаваться на сайте, например, архивы в WordPress.
Теперь вы знаете, когда и как нужно применять теги noindex и nofollow и в чем между ними разница.
Мета тег Robots и файл Robots.txt – как управлять индексацией страниц сайта ~ SEO простым языком
[yandex2]
Доброго времени суток, уважаемые читатели. Задумала я тут поделиться с вами одним интересным материалом на тему внутренней оптимизации WordPress, а именно про установку мета тегов, и поняла, что чтобы получился хороший материал, необходимо прояснить ситуацию с тем, что такое мета тег Robots. Когда и для чего применяется. В чем разница использования файла Robots.txt и мета тега Robots.
Задумала я тут поделиться с вами одним интересным материалом на тему внутренней оптимизации WordPress, а именно про установку мета тегов, и поняла, что чтобы получился хороший материал, необходимо прояснить ситуацию с тем, что такое мета тег Robots. Когда и для чего применяется. В чем разница использования файла Robots.txt и мета тега Robots.
Robots.txt – это файл, с помощью которого мы можем управлять индексацией своего блога, указывая запрещающие директивы непосредственно в файле как для отдельных страниц, так и для целых каталогов. Более подробно об этом файле я писала применительно к WordPress в статье от 28 декабря 2011 года Файл Robots.txt.
Метатег Robots – это тег, с помощью которого мы можем управлять индексацией своего блога, указывая запрещающие команды для каждой отдельной страницы.
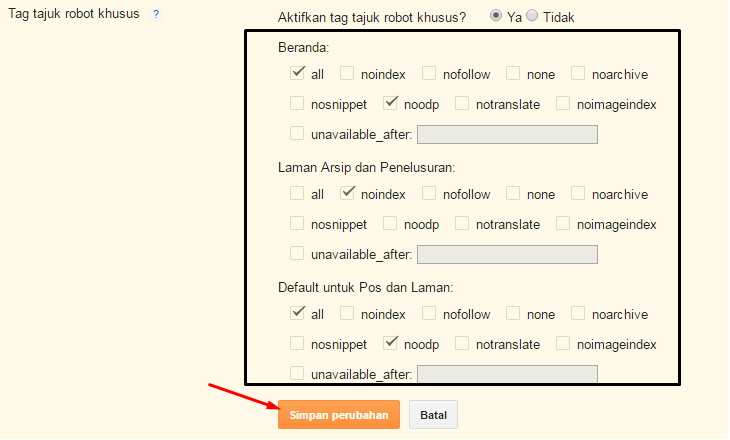
К слову, нет единого написания слова «мета тег». Даже Яндекс и Google по разному их пишут в своих справочных материалах. Мета тег, Мета-тег и Метатег – все это одно слово и используется в сети одновременно. При этом в справке Яндекс он имеет написание Мета-тег, а в Google – Метатег. Давайте сначала разберемся, каким вообще бывает мета тег Robots. Независимо от того, указываете вы этот метатег или нет, его значение всегда — «all», что означает индексировать. Т.е. есть три «состояния» данного мета тега:
При этом в справке Яндекс он имеет написание Мета-тег, а в Google – Метатег. Давайте сначала разберемся, каким вообще бывает мета тег Robots. Независимо от того, указываете вы этот метатег или нет, его значение всегда — «all», что означает индексировать. Т.е. есть три «состояния» данного мета тега:
- Полное его отсутствие.
- <meta name=»robots» content=»all» />
- <meta name=»robots» content=»index, follow» />
Все это означает, что страница будет проиндексирована. Поэтому если вам не нужно запрещать страницу к индексации, то используется первый вариант, т.е. вообще ничего не используем. Если же вы хотите полностью запретить страницу к индексации, то запись будет такой:
<meta name=»robots» content=»noindex, nofollow»/>
или более короткий вариант
<meta name=»robots» content=»none»/>
Как вы думаете, почему значение имеет два параметра – index/noindex и follow/nofollow?
- Значение index/noindex применяется только к тексту страницы.
- Значение follow/nofollow применяется только к ссылкам на странице.
Вот в этом, а также в самом определении кроется одно значительное преимущество мета тега Robots перед одноименным файлом.
Если вы сравните оба определения, то увидите, что они, практически, одинаковые. Но при этом имеют небольшое различие.
Да, оба способа – создание файла или указание мета тега – одно и тоже, выполняют абсолютно одинаковые функции и обладают абсолютно одинаковой значимостью. Другими словами нельзя сказать, что одно важнее другого. Они абсолютно равнозначны. Но как уже сказала, в них есть некоторые различия.
Вообще метатеги были придуманы не в противовес файлу, а для облегчения жизни тем вебмастерам, которые не имеют доступа к корневым папкам своего сайта, как это, например, происходит на Blogger. Т.е. сами поисковики рекомендуют настраивать файл Robots.txt когда есть доступ к папкам сайта, если же такого доступа нет, то рекомендуется использовать метатег.
Преимущества файла Robots.
 txt перед мета тегом
txt перед мета тегомНа мой взгляд преимущество заключается в том, что в файле Robots.txt мы можем указывать целые каталоги своего сайта, запретить к индексации сразу все теги, рубрики и любые другие каталоги. При чем данный запрет выставляется единой строкой. Если же мы хотим запретить весь каталог, но при этом разрешить к индексации одну-две страницы, то так же в файле мы можем настроить исключения. Обо всем этом я писала в статье, на которую дала ссылку выше, поэтому сейчас кратко передаю суть.
Как же дела обстоят с мета тегом? Мета тег невозможно выставить один раз сразу всему каталогу, он устанавливается для каждой страницы в отдельности. Т.е. им удобно пользоваться тогда, когда на вашем сайте вы с каждой новой публикацией решаете, разрешать поисковому роботу индексировать данную страницу или нет.
Лично мне сложно представить такой сайт, где могло бы это понадобиться. Но факт остается фактом. Если вы не настраиваете файл Robots.txt, но при этом многие страницы закрываете от индексации, то каждый раз вам нужно быть начеку, чтобы не забыть закрыть страницу от индексации. Согласитесь, это неудобно.
Согласитесь, это неудобно.
Если вы свободны от такой рутины, то всегда значительно удобней и проще настроить один раз и навсегда файл Robots.txt и больше об этом не думать.
Преимущества мета тега Robots перед файлом или, когда лучше использовать мета тег
Я уже обратила ваше внимание на то, что мета тег можно выставлять каждой отдельной странице, так же значительное преимущество нам могут дать разные команды index/noindex и follow/nofollow, которые можно применять в мета теге, и при определенных обстоятельствах все это является большим преимуществом перед файлом.
[yandex]
Ситуация 1. Вы публикуете неуникальный контент. Не обязательно это должен быть копипаст (ворованный контент), это могут быть какие-то официальные документы, законодательные акты, статьи кодексов, т.е. любые материалы, которые создадут на вашем сайте большое количество неуникального контента, при этом страницы с неуникальным контентом не имеют отдельного каталога, а размещаются в вперемешку с основным контентом. Такие страницы вы можете запретить к индексации, как полностью, указав мета тег
Такие страницы вы можете запретить к индексации, как полностью, указав мета тег
<meta name=»robots» content=»none»/>
так и частично, запретив индексировать только контент, но разрешив индексировать ссылки.
<meta name=»robots» content=»noindex, follow»/>
или просто
<meta name=»robots» content=»noindex»/>
Ситуация 2. Второй случай, когда имеет смысл использовать метатег – это при публикации большого количества ссылок на странице. Например, вы хотите поделиться со своими пользователями интересными ссылками, но при этом не хотите скомпрометировать себя перед поисковыми системами, публикуя большой объем внешних ссылок. В таком случае можно запретить страницу к индексации, при этом она будет доступна вашим посетителям. Только не делайте так, если вы обмениваетесь ссылками с кем-то, а именно тогда, когда ни перед никем не обязаны. Опять же, полный запрет к индексации будет таким:
<meta name=»robots» content=»none»/>
если же вы хотите, чтобы текстовое содержание страницы индексировалось, а ссылки нет, то запись должна быть такой
<meta name=»robots» content=»index, nofollow»/>
или равнозначная ей запись
<meta name=»robots» content=»nofollow»/>
Ситуация 3 по сути тоже самое, что и в ситуации 1, но я решила выделить ее отдельно, т. к. она может иметь большое значение. Все мы знаем, что архивы, рубрики и ярлыки создают дублирование контента. Но совсем не обязательно закрывать эти страницы от индексации полностью, ведь на них содержатся ссылки на наши же страницы, и эти ссылки могут участвовать во внутренней перелинковке, передавая свой вес страницам со статьями, главной и другим.Т.е. в метатеге Robots мы можем сообщить поисковику, чтобы он не индексировал текст, т.к. это создает дублирование на сайте, но при этом разрешить переходить по ссылкам на этих страницах. Таким образом не будет нарушаться внутренняя перелинковка на сайте, а даже наоборот, это создает нам дополнительный инструмент для увеличения статического веса страниц внутри сайта.
к. она может иметь большое значение. Все мы знаем, что архивы, рубрики и ярлыки создают дублирование контента. Но совсем не обязательно закрывать эти страницы от индексации полностью, ведь на них содержатся ссылки на наши же страницы, и эти ссылки могут участвовать во внутренней перелинковке, передавая свой вес страницам со статьями, главной и другим.Т.е. в метатеге Robots мы можем сообщить поисковику, чтобы он не индексировал текст, т.к. это создает дублирование на сайте, но при этом разрешить переходить по ссылкам на этих страницах. Таким образом не будет нарушаться внутренняя перелинковка на сайте, а даже наоборот, это создает нам дополнительный инструмент для увеличения статического веса страниц внутри сайта.
Таким образом вы можете использовать значение мета тега из ситуации 1 для внутренней перелинковки на сайте. КАк правильно рассчитать внутренний вес страниц и сделать перелинковку, я писала в статье Как проверить и сделать правильно перелинковку на сайте, если же вы ещё не знаете, что такое перелинковка, то рекомендую сначала ознакомиться со статьей – Секреты перелинковки.
Если вы изучите справочные материалы поисковых систем, в частности Яндекс и Google об этом мета теге, то узнаете, что он может иметь и другие значения, помимо index и follow (индексировать и не индексировать).
Так, например Яндекс и Google, помимо озвученных мета Robots, понимает ещё и команду noarchive
<meta name=»robots» content=»noarchive»/>
Вы можете применять данное значение в том случае, если не хотите, чтобы пользователям поисковых систем в результатах поиска показывалась ссылка копия (Яндекс) и Сохраненная копия (Google), которая ведет на сохраненную копию вашей страницы.Помимо всего перечисленного Google понимает ещё некоторые значения, с которыми я рекомендую вам ознакомиться самостоятельно.
И последнее, на что я хочу обратить ваше внимание особенно.
Для любой поисковой системы абсолютно не важно, каким образом вы указываете команды для индексации, в файле robots.txt или в метатеге robots, а вот если вы в разных случаях используете противоречащие друг другу команды, например в файле robots. txt страница запрещена к индексации, а вы вручную проставляете мета тег со значением «all» или наоборот, то поисковый робот учтет более строгую команду и это всегда будет noindex, т.е. робот учтет запрещающую директиву и не будет индексировать страницу. Поэтому будьте внимательны, если одновременно используете на сайте оба варианта robots.
txt страница запрещена к индексации, а вы вручную проставляете мета тег со значением «all» или наоборот, то поисковый робот учтет более строгую команду и это всегда будет noindex, т.е. робот учтет запрещающую директиву и не будет индексировать страницу. Поэтому будьте внимательны, если одновременно используете на сайте оба варианта robots.
[ads1]Итак, все это я объясняла для того, чтобы вы понимали разницу между файлом robots.txt и мета тегом robots. Умение управлять своим сайтом является важной ступенью в общей раскрутке сайта в интернете. Чтобы вы могли самостоятельно решать, какой из способов и когда использовать на своем сайте. А также эти знания вам помогут при прочтении моей следующей статьи, ради которой я и затеяла эту. Так что не пропустите, будет интересно.
Что это такое и как их использовать?
Главная / Noindex, Nofollow и Disallow
Узнайте, как использовать директивы сканирования и индексации для улучшения SEO. Покрытие директив nofollow, noindex и disallow.
Сэм Марсден
SEO и контент-менеджер
Теги
Управление роботами
Давайте делиться
Три приведенных выше слова могут звучать как SEO-тарабарщина, но их определенно стоит знать, поскольку понимание того, как их использовать, означает, что вы можете командовать роботом Googlebot. Что весело.
Итак, давайте начнем с основ: есть три способа сообщить, какие части вашего сайта поисковые системы должны сканировать и индексировать:
- Noindex : указывает поисковым системам не включать ваши страницы в результаты поиска. Чтобы боты увидели этот сигнал, страница должна быть доступна для сканирования.
- Disallow : запрещает поисковым системам сканировать ваши страницы. Это не гарантирует, что страница не будет проиндексирована.
- Nofollow : сообщает поисковым системам не переходить по ссылкам на вашей странице.
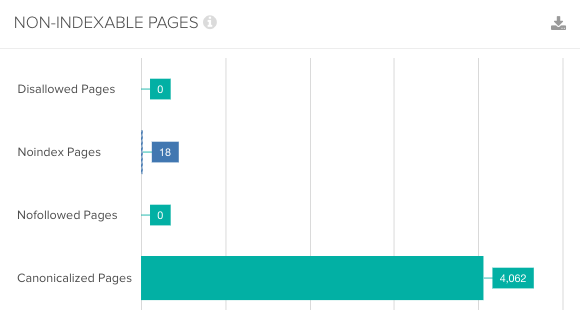
Что такое метатег
noindex ?Тег noindex указывает поисковым системам не включать страницу в результаты поиска.
Самый распространенный способ неиндексирования страницы — добавить тег в раздел заголовка HTML или в заголовки ответов. Чтобы поисковые системы могли видеть эту информацию, страница еще не должна быть заблокирована (запрещена) в файле robots.txt. Если страница заблокирована с помощью вашего файла robots.txt, Google никогда не увидит тег noindex, и страница может по-прежнему отображаться в результатах поиска.
Чтобы запретить поисковым системам индексировать вашу страницу, просто добавьте в раздел
следующее:
Вторая часть содержимого тег здесь указывает, что все ссылки на этой странице должны быть пройдены, что мы обсудим ниже.
Кроме того, тег noindex можно использовать в X-Robots-Tag в заголовке HTTP:
X-Robots-Tag: noindex
Для получения дополнительной информации см. сообщение разработчиков Google о метатеге robots и x -robots-tag спецификация HTTP-заголовка.
сообщение разработчиков Google о метатеге robots и x -robots-tag спецификация HTTP-заголовка.
Что такое директива
disallow ?Запрет страницы означает, что вы говорите поисковым системам не сканировать ее, что должно быть сделано в файле robots.txt вашего сайта. Это полезно, если у вас есть много страниц или файлов, которые бесполезны для пользователей, так как это означает, что поисковые системы не будут тратить время на сканирование этих страниц. Часто это может быть полезно для максимизации краулингового бюджета.
Чтобы добавить директиву disallow, просто объедините ее с относительным путем URL и добавьте в файл robots.txt:
Запретить: /your-page-url
Целые каталоги вашего сайта также могут быть запрещены. Завершите правило символом /, чтобы это вступило в силу:
Disallow: /directory/
Пользовательский агент должен быть указан где-то над этой строкой. Используйте звездочку в этом поле, чтобы сопоставить все поисковые роботы (кроме Adsbot, имя которого необходимо указать явно). Например:
Например:
Агент пользователя: *
Директива disallow просто запрещает ботам сканировать содержимое этих URL-адресов. Запрещенная страница все еще может появиться в индексе, например, если поисковые системы могут найти ее по входящим внешним ссылкам. Поскольку страница остается недоступной для сканирования, эти страницы обычно отображают сообщение «нет доступной информации для этой страницы», когда они появляются в поисковой выдаче.
Можно ли сочетать noindex и disallow?
Директивы Disallow не следует сочетать с тегами noindex. Это связано с тем, что предотвращение сканирования страницы поисковыми системами также не позволяет им видеть тег noindex. Страница не будет просканирована, но есть шанс, что она будет проиндексирована, если она будет найдена из других источников.
Если вы действительно не хотите, чтобы страница появлялась в поисковой выдаче, вам подойдет тег noindex.
Что такое тег nofollow?
А Тег nofollow на ссылке указывает поисковым системам не передавать ссылочный вес с исходной страницы на целевой сайт. Они также предназначены для предотвращения перехода поисковых систем по ссылке и обнаружения по ней большего количества контента.
Они также предназначены для предотвращения перехода поисковых систем по ссылке и обнаружения по ней большего количества контента.
Обычно nofollow используется для ссылок в комментариях и сообщениях на форумах, а также в любом другом контенте, который вы не контролируете. Их также можно найти во многих платных ссылках, встраиваниях, таких как виджеты или инфографика, ссылки в гостевых постах или что-то не по теме, на что вы все еще хотите связать людей, но не обязательно хотите, чтобы поисковые системы следили и сканировали.
Исторически SEO-специалисты также выборочно использовали nofollow-ссылки, чтобы направить внутренний PageRank на более важные страницы.
Теги nofollow можно добавить в одном из двух мест:
- страницы (для nofollow всех ссылок на этой странице):
- Код ссылки (для перехода по отдельной ссылке): пример страницы
Nofollow не предотвратит полное сканирование связанной страницы; это просто предотвращает его сканирование по этой конкретной ссылке. Наши собственные и другие тесты показали, что Google не будет сканировать URL-адрес, найденный по ссылке nofollow.
Наши собственные и другие тесты показали, что Google не будет сканировать URL-адрес, найденный по ссылке nofollow.
Google заявляет, что если другой сайт ссылается на ту же страницу без использования тега nofollow или страница появляется в карте сайта, страница может по-прежнему отображаться в результатах поиска. Точно так же, если это URL-адрес, о котором поисковые системы уже знают, добавление ссылки nofollow не удалит его из индекса.
В сентябре 2019 года Google объявил об обновлении своей директивы nofollow и ввел два новых атрибута ссылки, а именно:
- rel=»sponsored» — атрибут спонсируемый должен использоваться для идентификации ссылок, предназначенных для рекламных целей, если спонсорство и компенсационные соглашения существуют.
- rel=»ugc» — в качестве атрибута пользовательского контента это значение рекомендуется для ссылок на сайтах с пользовательским контентом, например, сообщения на форуме и комментарии в блогах.
Кроме того, все ссылки, помеченные как nofollow, спонсируемые или UGC, теперь рассматриваются как подсказки относительно того, какие ссылки следует учитывать при поиске и сканировании, а не просто как сигнал, как это использовалось ранее для nofollow. Вы можете узнать больше об этом обновлении в нашем посте, в котором также рассказывается об их влиянии, а также о экспертных выводах.
Что такое noindex, nofollow?
Как упоминалось выше, добавление тега nofollow на страницу не предотвратит ее сканирование. Чтобы предотвратить индексацию URL-адреса, вам также понадобится тег noindex. Это позволит Google просканировать страницу, но она не появится в индексе. Чтобы запретить Google полностью сканировать страницу, вы должны запретить это через robots.txt.
Другие директивы, которые необходимо знать: канонические теги, нумерация страниц и hreflang
Существуют и другие способы сообщить Google и другим поисковым системам, как обрабатывать URL-адреса, — их тоже стоит знать! Ознакомьтесь с приведенными ниже ресурсами, чтобы узнать больше.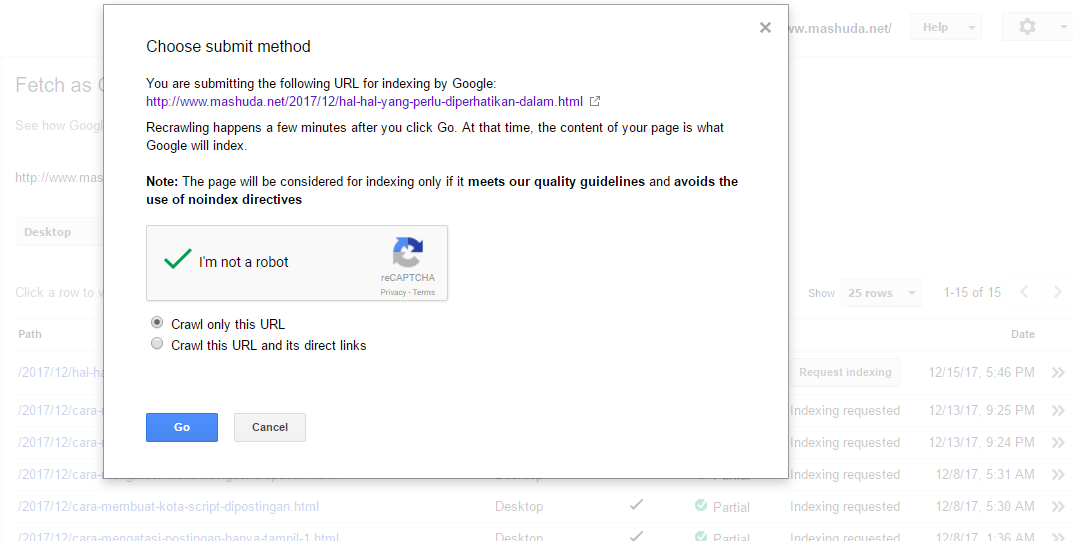
- Канонические теги сообщают поисковым системам, какую страницу из группы похожих страниц следует проиндексировать. Канонизированные (т.е. вторичные страницы, направляющие поисковые системы на основную версию) не включаются в индекс. Если у вас есть отдельные мобильные и настольные сайты, вы должны канонизировать свои мобильные URL-адреса на настольные.
- Разбивка на страницы группирует несколько страниц вместе, чтобы поисковые системы знали, что они являются частью набора. Поисковые системы должны отдавать приоритет первой странице каждого набора при ранжировании страниц, но все страницы в наборе останутся в индексе.
- Hreflang сообщает поисковым системам, какие международные версии одного и того же контента относятся к какому региону, чтобы они могли отдавать приоритет правильной версии для каждой аудитории. Все эти версии останутся в индексе.
Сколько времени вы должны потратить на сокращение краулингового бюджета?
Вы можете услышать много разговоров на форумах SEO о том, насколько важны для SEO эффективность сканирования и бюджет сканирования. Хотя общепринятой практикой является запрет и запрет на индексирование страниц, которые не приносят пользы поисковым системам или пользователям (например, внутренний код, который используется только для работы сайта, или некоторые типы дублированного контента), решение о том, следует ли скрывать отдельных страниц, вероятно, не лучшее использование времени и усилий. Если нет особой причины скрывать страницу от поисковых систем, обычно лучше оставить решение за ними.
Хотя общепринятой практикой является запрет и запрет на индексирование страниц, которые не приносят пользы поисковым системам или пользователям (например, внутренний код, который используется только для работы сайта, или некоторые типы дублированного контента), решение о том, следует ли скрывать отдельных страниц, вероятно, не лучшее использование времени и усилий. Если нет особой причины скрывать страницу от поисковых систем, обычно лучше оставить решение за ними.
Проверка ваших директив с помощью Lumar
Поиск всех неиндексируемых страниц с помощью LumarОтчет о неиндексируемых страницах включает сведения обо всех страницах с неиндексируемым статусом. Вы можете увидеть их общее количество, а также разбивку правил, которые заставляют их классифицироваться как неиндексируемые:
Отсюда погрузитесь в отдельные отчеты, чтобы убедиться, что правильные правила применяются к правильные URL-адреса.
Индексация > Страницы без индекса
В этом отчете будут показаны все страницы, содержащие тег noindex в метаинформации, заголовке HTTP или файле robots.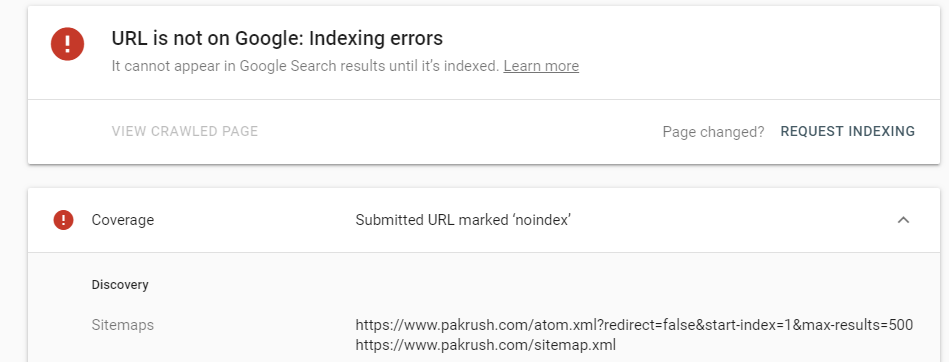 txt.
txt.
Индексация > Запрещенные страницы
Этот отчет содержит все URL-адреса, сканирование которых невозможно из-за правила запрета в файле robots.txt.
Протестируйте новый файл robots.txt с помощью Lumar
Используйте функцию перезаписи robots.txt Lumar в дополнительных настройках, чтобы заменить текущий файл пользовательским.
При следующем запуске сканирования существующий файл robots.txt будет перезаписан новыми правилами. Это позволяет вам убедиться, что нужные URL-адреса запрещены, прежде чем внедрять изменения на действующий сайт.
Для получения дополнительной информации прочитайте наше руководство по управлению изменениями robots.txt с помощью Lumar.
Дополнительные технические учебные ресурсы по SEO
Мы надеемся, что вы нашли этот пост полезным для получения дополнительной информации о noindex, nofollow и запрете на управление сканированием и индексированием вашего сайта.
Вы можете больше узнать об этих темах в нашей Технической SEO-библиотеке, а если вы хотите узнать, как проводить технический SEO-аудит, прочтите наше руководство. У нас также есть большой выбор регулярно обновляемых электронных книг по техническим темам SEO, которые помогут вам быть в курсе последних обновлений Google и передовых методов SEO.
* Примечание. Это сообщение было обновлено 26 августа 2022 г.
Сэм Марсден
SEO и контент-менеджер
Сэм Марсден — бывший менеджер Lumar по поисковой оптимизации и контенту, а в настоящее время — руководитель отдела SEO в Busuu. Сэм регулярно выступает на маркетинговых конференциях, таких как SMX и BrightonSEO, и является автором отраслевых изданий, таких как Search Engine Journal и State of Digital.
Что это такое и как им пользоваться?
Главная / Noindex, Nofollow и Disallow
Узнайте, как использовать директивы сканирования и индексации для улучшения SEO. Покрытие директив nofollow, noindex и disallow.
Покрытие директив nofollow, noindex и disallow.
Сэм Марсден
SEO и Content Manager
Теги
Управление роботами
Давайте делиться
Три приведенных выше слова могут звучать как тарабарщина для SEO, но их определенно стоит знать, поскольку понимание того, как их использовать, означает, что вы можете командовать роботом Google. Что весело.
Итак, давайте начнем с основ: есть три способа указать, какие части вашего сайта поисковые системы должны сканировать и индексировать:
- Noindex : указывает поисковым системам не включать ваши страницы в результаты поиска. Чтобы боты увидели этот сигнал, страница должна быть доступна для сканирования.
- Disallow : запрещает поисковым системам сканировать ваши страницы. Это не гарантирует, что страница не будет проиндексирована.
- Nofollow : сообщает поисковым системам не переходить по ссылкам на вашей странице.

Что такое метатег
noindex ?Тег noindex указывает поисковым системам не включать страницу в результаты поиска.
Самый распространенный способ неиндексирования страницы — добавить тег в раздел заголовка HTML или в заголовки ответов. Чтобы поисковые системы могли видеть эту информацию, страница еще не должна быть заблокирована (запрещена) в файле robots.txt. Если страница заблокирована с помощью вашего файла robots.txt, Google никогда не увидит тег noindex, и страница может по-прежнему отображаться в результатах поиска.
Чтобы запретить поисковым системам индексировать вашу страницу, просто добавьте в раздел
следующее:
Вторая часть тега контента здесь указывает, что нужно переходить по всем ссылкам на этой странице, о чем мы поговорим ниже.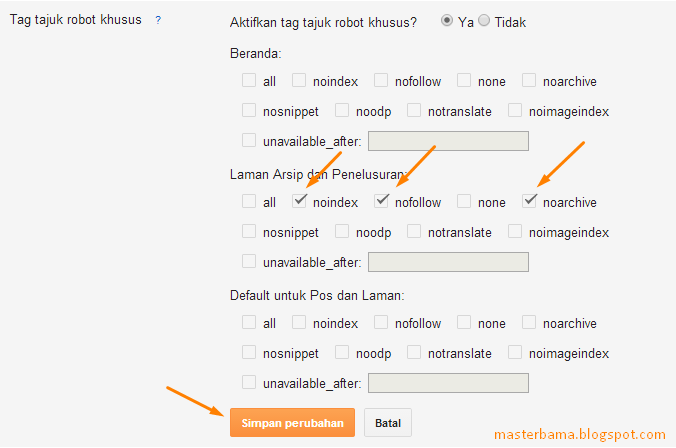
Кроме того, тег noindex можно использовать в X-Robots-Tag в заголовке HTTP:
X-Robots-Tag: noindex
Для получения дополнительной информации см. сообщение разработчиков Google о метатеге robots и x -robots-tag спецификация HTTP-заголовка.
Что такое директива
disallow ?Запрет страницы означает, что вы говорите поисковым системам не сканировать ее, что должно быть сделано в файле robots.txt вашего сайта. Это полезно, если у вас есть много страниц или файлов, которые бесполезны для пользователей, так как это означает, что поисковые системы не будут тратить время на сканирование этих страниц. Часто это может быть полезно для максимизации краулингового бюджета.
Чтобы добавить директиву disallow, просто объедините ее с относительным путем URL и добавьте в файл robots.txt:
Запретить: /your-page-url
Целые каталоги вашего сайта также могут быть запрещены. Завершите правило символом /, чтобы это вступило в силу:
Disallow: /directory/
Пользовательский агент должен быть указан где-то над этой строкой.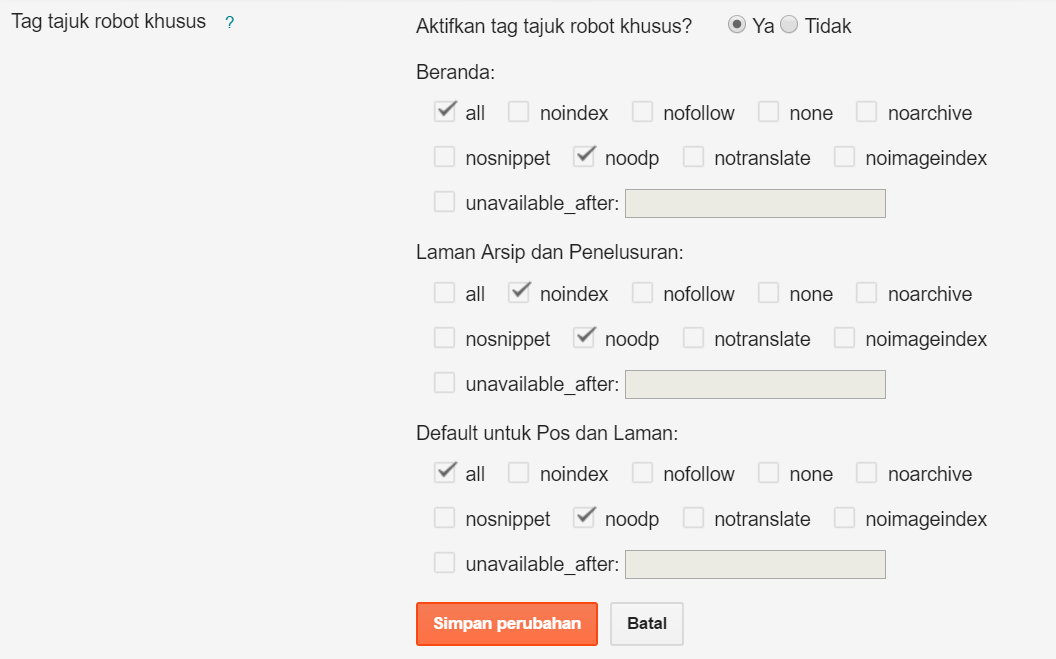 Используйте звездочку в этом поле, чтобы сопоставить все поисковые роботы (кроме Adsbot, имя которого необходимо указать явно). Например:
Используйте звездочку в этом поле, чтобы сопоставить все поисковые роботы (кроме Adsbot, имя которого необходимо указать явно). Например:
Агент пользователя: *
Директива disallow просто запрещает ботам сканировать содержимое этих URL-адресов. Запрещенная страница все еще может появиться в индексе, например, если поисковые системы могут найти ее по входящим внешним ссылкам. Поскольку страница остается недоступной для сканирования, эти страницы обычно отображают сообщение «нет доступной информации для этой страницы», когда они появляются в поисковой выдаче.
Можно ли сочетать noindex и disallow?
Директивы Disallow не следует сочетать с тегами noindex. Это связано с тем, что предотвращение сканирования страницы поисковыми системами также не позволяет им видеть тег noindex. Страница не будет просканирована, но есть шанс, что она будет проиндексирована, если она будет найдена из других источников.
Если вы действительно не хотите, чтобы страница появлялась в поисковой выдаче, вам подойдет тег noindex.![]()
Что такое тег nofollow?
А Тег nofollow на ссылке указывает поисковым системам не передавать ссылочный вес с исходной страницы на целевой сайт. Они также предназначены для предотвращения перехода поисковых систем по ссылке и обнаружения по ней большего количества контента.
Обычно nofollow используется для ссылок в комментариях и сообщениях на форумах, а также в любом другом контенте, который вы не контролируете. Их также можно найти во многих платных ссылках, встраиваниях, таких как виджеты или инфографика, ссылки в гостевых постах или что-то не по теме, на что вы все еще хотите связать людей, но не обязательно хотите, чтобы поисковые системы следили и сканировали.
Исторически SEO-специалисты также выборочно использовали nofollow-ссылки, чтобы направить внутренний PageRank на более важные страницы.
Теги nofollow можно добавить в одном из двух мест:
- страницы (для nofollow всех ссылок на этой странице):
- Код ссылки (для перехода по отдельной ссылке):
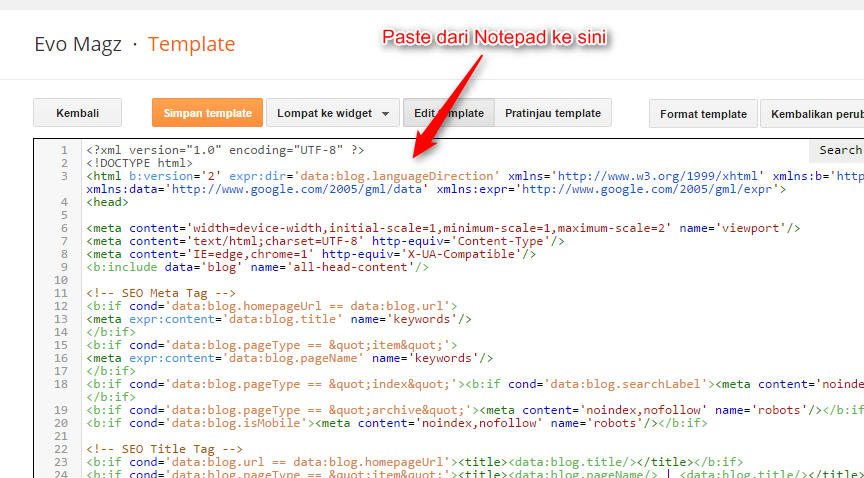 html» rel=»nofollow»>пример страницы
html» rel=»nofollow»>пример страницы
Nofollow не предотвратит полное сканирование связанной страницы; это просто предотвращает его сканирование по этой конкретной ссылке. Наши собственные и другие тесты показали, что Google не будет сканировать URL-адрес, найденный по ссылке nofollow.
Google заявляет, что если другой сайт ссылается на ту же страницу без использования тега nofollow или страница появляется в карте сайта, страница может по-прежнему отображаться в результатах поиска. Точно так же, если это URL-адрес, о котором поисковые системы уже знают, добавление ссылки nofollow не удалит его из индекса.
В сентябре 2019 года Google объявил об обновлении своей директивы nofollow и ввел два новых атрибута ссылки, а именно:
- rel=»sponsored» — атрибут спонсируемый должен использоваться для идентификации ссылок, предназначенных для рекламных целей, если спонсорство и компенсационные соглашения существуют.
- rel=»ugc» — в качестве атрибута пользовательского контента это значение рекомендуется для ссылок на сайтах с пользовательским контентом, например, сообщения на форуме и комментарии в блогах.
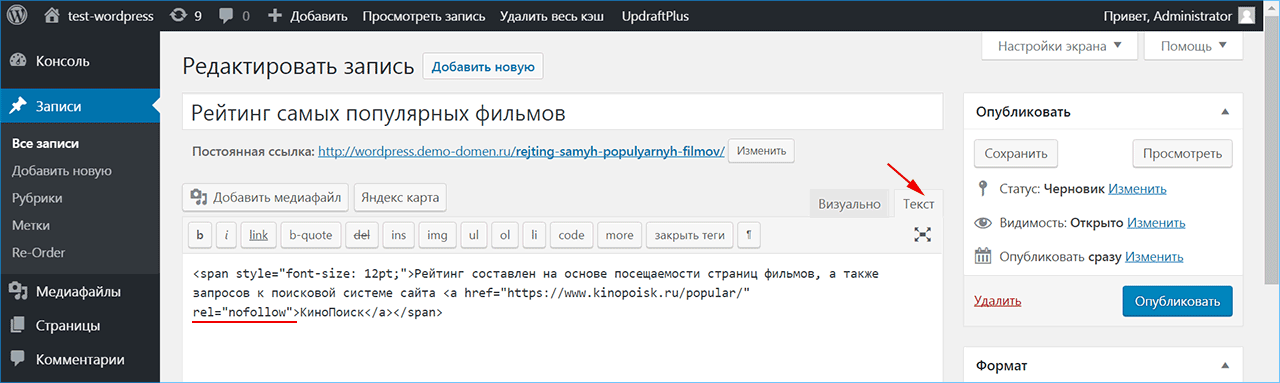
Кроме того, все ссылки, помеченные как nofollow, спонсируемые или UGC, теперь рассматриваются как подсказки относительно того, какие ссылки следует учитывать при поиске и сканировании, а не просто как сигнал, как это использовалось ранее для nofollow. Вы можете узнать больше об этом обновлении в нашем посте, в котором также рассказывается об их влиянии, а также о экспертных выводах.
Что такое noindex, nofollow?
Как упоминалось выше, добавление тега nofollow на страницу не предотвратит ее сканирование. Чтобы предотвратить индексацию URL-адреса, вам также понадобится тег noindex. Это позволит Google просканировать страницу, но она не появится в индексе. Чтобы запретить Google полностью сканировать страницу, вы должны запретить это через robots.txt.
Другие директивы, которые необходимо знать: канонические теги, нумерация страниц и hreflang
Существуют и другие способы сообщить Google и другим поисковым системам, как обрабатывать URL-адреса, — их тоже стоит знать! Ознакомьтесь с приведенными ниже ресурсами, чтобы узнать больше.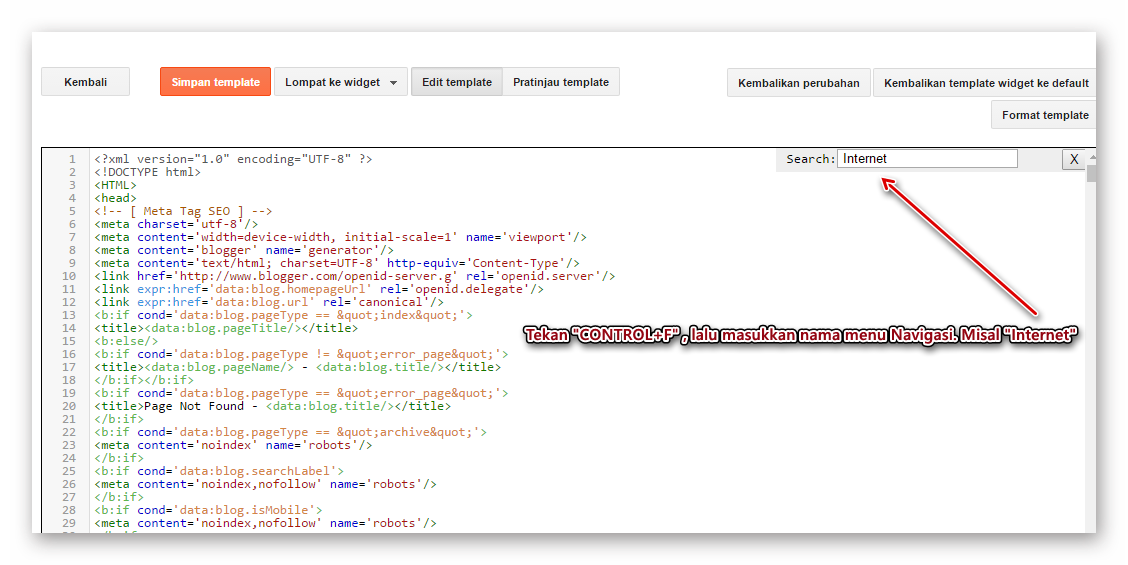
- Канонические теги сообщают поисковым системам, какую страницу из группы похожих страниц следует проиндексировать. Канонизированные (т.е. вторичные страницы, направляющие поисковые системы на основную версию) не включаются в индекс. Если у вас есть отдельные мобильные и настольные сайты, вы должны канонизировать свои мобильные URL-адреса на настольные.
- Разбивка на страницы группирует несколько страниц вместе, чтобы поисковые системы знали, что они являются частью набора. Поисковые системы должны отдавать приоритет первой странице каждого набора при ранжировании страниц, но все страницы в наборе останутся в индексе.
- Hreflang сообщает поисковым системам, какие международные версии одного и того же контента относятся к какому региону, чтобы они могли отдавать приоритет правильной версии для каждой аудитории. Все эти версии останутся в индексе.
Сколько времени вы должны потратить на сокращение краулингового бюджета?
Вы можете услышать много разговоров на форумах SEO о том, насколько важны для SEO эффективность сканирования и бюджет сканирования. Хотя общепринятой практикой является запрет и запрет на индексирование страниц, которые не приносят пользы поисковым системам или пользователям (например, внутренний код, который используется только для работы сайта, или некоторые типы дублированного контента), решение о том, следует ли скрывать отдельных страниц, вероятно, не лучшее использование времени и усилий. Если нет особой причины скрывать страницу от поисковых систем, обычно лучше оставить решение за ними.
Хотя общепринятой практикой является запрет и запрет на индексирование страниц, которые не приносят пользы поисковым системам или пользователям (например, внутренний код, который используется только для работы сайта, или некоторые типы дублированного контента), решение о том, следует ли скрывать отдельных страниц, вероятно, не лучшее использование времени и усилий. Если нет особой причины скрывать страницу от поисковых систем, обычно лучше оставить решение за ними.
Проверка ваших директив с помощью Lumar
Поиск всех неиндексируемых страниц с помощью LumarОтчет о неиндексируемых страницах включает сведения обо всех страницах с неиндексируемым статусом. Вы можете увидеть их общее количество, а также разбивку правил, которые заставляют их классифицироваться как неиндексируемые:
Отсюда погрузитесь в отдельные отчеты, чтобы убедиться, что правильные правила применяются к правильные URL-адреса.
Индексация > Страницы без индекса
В этом отчете будут показаны все страницы, содержащие тег noindex в метаинформации, заголовке HTTP или файле robots. txt.
txt.
Индексация > Запрещенные страницы
Этот отчет содержит все URL-адреса, сканирование которых невозможно из-за правила запрета в файле robots.txt.
Протестируйте новый файл robots.txt с помощью Lumar
Используйте функцию перезаписи robots.txt Lumar в дополнительных настройках, чтобы заменить текущий файл пользовательским.
При следующем запуске сканирования существующий файл robots.txt будет перезаписан новыми правилами. Это позволяет вам убедиться, что нужные URL-адреса запрещены, прежде чем внедрять изменения на действующий сайт.
Для получения дополнительной информации прочитайте наше руководство по управлению изменениями robots.txt с помощью Lumar.
Дополнительные технические учебные ресурсы по SEO
Мы надеемся, что вы нашли этот пост полезным для получения дополнительной информации о noindex, nofollow и запрете на управление сканированием и индексированием вашего сайта.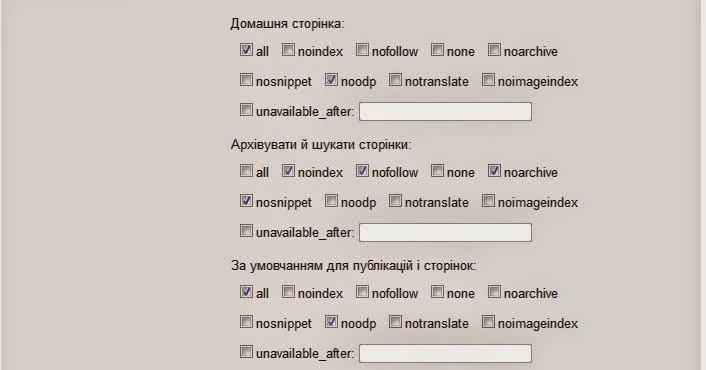
Вы можете больше узнать об этих темах в нашей Технической SEO-библиотеке, а если вы хотите узнать, как проводить технический SEO-аудит, прочтите наше руководство. У нас также есть большой выбор регулярно обновляемых электронных книг по техническим темам SEO, которые помогут вам быть в курсе последних обновлений Google и передовых методов SEO.
* Примечание. Это сообщение было обновлено 26 августа 2022 г.
Сэм Марсден
SEO и контент-менеджер
Сэм Марсден — бывший менеджер Lumar по поисковой оптимизации и контенту, а в настоящее время — руководитель отдела SEO в Busuu. Сэм регулярно выступает на маркетинговых конференциях, таких как SMX и BrightonSEO, и является автором отраслевых изданий, таких как Search Engine Journal и State of Digital.
Что это такое и как им пользоваться?
Главная / Noindex, Nofollow и Disallow
Узнайте, как использовать директивы сканирования и индексации для улучшения SEO.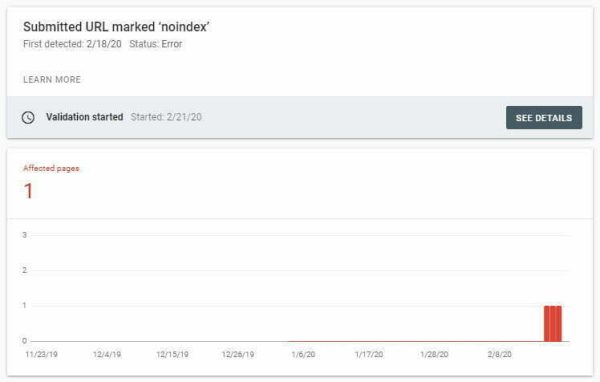 Покрытие директив nofollow, noindex и disallow.
Покрытие директив nofollow, noindex и disallow.
Сэм Марсден
SEO и Content Manager
Теги
Управление роботами
Давайте делиться
Три приведенных выше слова могут звучать как тарабарщина для SEO, но их определенно стоит знать, поскольку понимание того, как их использовать, означает, что вы можете командовать роботом Google. Что весело.
Итак, давайте начнем с основ: есть три способа указать, какие части вашего сайта поисковые системы должны сканировать и индексировать:
- Noindex : указывает поисковым системам не включать ваши страницы в результаты поиска. Чтобы боты увидели этот сигнал, страница должна быть доступна для сканирования.
- Disallow : запрещает поисковым системам сканировать ваши страницы. Это не гарантирует, что страница не будет проиндексирована.
- Nofollow : сообщает поисковым системам не переходить по ссылкам на вашей странице.

Что такое метатег
noindex ?Тег noindex указывает поисковым системам не включать страницу в результаты поиска.
Самый распространенный способ неиндексирования страницы — добавить тег в раздел заголовка HTML или в заголовки ответов. Чтобы поисковые системы могли видеть эту информацию, страница еще не должна быть заблокирована (запрещена) в файле robots.txt. Если страница заблокирована с помощью вашего файла robots.txt, Google никогда не увидит тег noindex, и страница может по-прежнему отображаться в результатах поиска.
Чтобы запретить поисковым системам индексировать вашу страницу, просто добавьте в раздел
следующее:
Вторая часть тега контента здесь указывает, что нужно переходить по всем ссылкам на этой странице, о чем мы поговорим ниже.
Кроме того, тег noindex можно использовать в X-Robots-Tag в заголовке HTTP:
X-Robots-Tag: noindex
Для получения дополнительной информации см. сообщение разработчиков Google о метатеге robots и x -robots-tag спецификация HTTP-заголовка.
Что такое директива
disallow ?Запрет страницы означает, что вы говорите поисковым системам не сканировать ее, что должно быть сделано в файле robots.txt вашего сайта. Это полезно, если у вас есть много страниц или файлов, которые бесполезны для пользователей, так как это означает, что поисковые системы не будут тратить время на сканирование этих страниц. Часто это может быть полезно для максимизации краулингового бюджета.
Чтобы добавить директиву disallow, просто объедините ее с относительным путем URL и добавьте в файл robots.txt:
Запретить: /your-page-url
Целые каталоги вашего сайта также могут быть запрещены. Завершите правило символом /, чтобы это вступило в силу:
Disallow: /directory/
Пользовательский агент должен быть указан где-то над этой строкой.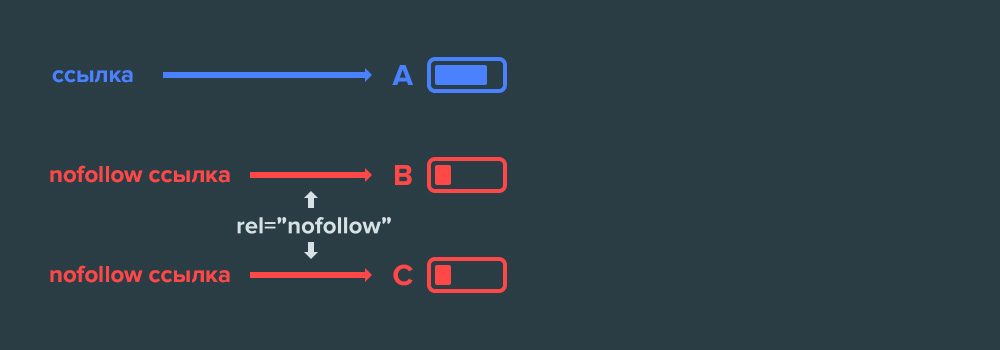 Используйте звездочку в этом поле, чтобы сопоставить все поисковые роботы (кроме Adsbot, имя которого необходимо указать явно). Например:
Используйте звездочку в этом поле, чтобы сопоставить все поисковые роботы (кроме Adsbot, имя которого необходимо указать явно). Например:
Агент пользователя: *
Директива disallow просто запрещает ботам сканировать содержимое этих URL-адресов. Запрещенная страница все еще может появиться в индексе, например, если поисковые системы могут найти ее по входящим внешним ссылкам. Поскольку страница остается недоступной для сканирования, эти страницы обычно отображают сообщение «нет доступной информации для этой страницы», когда они появляются в поисковой выдаче.
Можно ли сочетать noindex и disallow?
Директивы Disallow не следует сочетать с тегами noindex. Это связано с тем, что предотвращение сканирования страницы поисковыми системами также не позволяет им видеть тег noindex. Страница не будет просканирована, но есть шанс, что она будет проиндексирована, если она будет найдена из других источников.
Если вы действительно не хотите, чтобы страница появлялась в поисковой выдаче, вам подойдет тег noindex.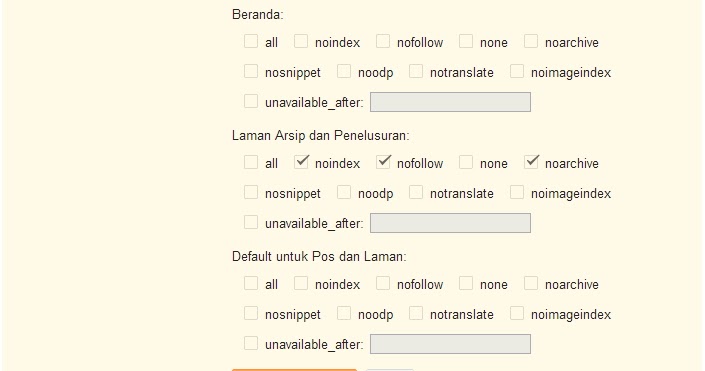
Что такое тег nofollow?
А Тег nofollow на ссылке указывает поисковым системам не передавать ссылочный вес с исходной страницы на целевой сайт. Они также предназначены для предотвращения перехода поисковых систем по ссылке и обнаружения по ней большего количества контента.
Обычно nofollow используется для ссылок в комментариях и сообщениях на форумах, а также в любом другом контенте, который вы не контролируете. Их также можно найти во многих платных ссылках, встраиваниях, таких как виджеты или инфографика, ссылки в гостевых постах или что-то не по теме, на что вы все еще хотите связать людей, но не обязательно хотите, чтобы поисковые системы следили и сканировали.
Исторически SEO-специалисты также выборочно использовали nofollow-ссылки, чтобы направить внутренний PageRank на более важные страницы.
Теги nofollow можно добавить в одном из двух мест:
- страницы (для nofollow всех ссылок на этой странице):
- Код ссылки (для перехода по отдельной ссылке):
 html» rel=»nofollow»>пример страницы
html» rel=»nofollow»>пример страницы
Nofollow не предотвратит полное сканирование связанной страницы; это просто предотвращает его сканирование по этой конкретной ссылке. Наши собственные и другие тесты показали, что Google не будет сканировать URL-адрес, найденный по ссылке nofollow.
Google заявляет, что если другой сайт ссылается на ту же страницу без использования тега nofollow или страница появляется в карте сайта, страница может по-прежнему отображаться в результатах поиска. Точно так же, если это URL-адрес, о котором поисковые системы уже знают, добавление ссылки nofollow не удалит его из индекса.
В сентябре 2019 года Google объявил об обновлении своей директивы nofollow и ввел два новых атрибута ссылки, а именно:
- rel=»sponsored» — атрибут спонсируемый должен использоваться для идентификации ссылок, предназначенных для рекламных целей, если спонсорство и компенсационные соглашения существуют.
- rel=»ugc» — в качестве атрибута пользовательского контента это значение рекомендуется для ссылок на сайтах с пользовательским контентом, например, сообщения на форуме и комментарии в блогах.

Кроме того, все ссылки, помеченные как nofollow, спонсируемые или UGC, теперь рассматриваются как подсказки относительно того, какие ссылки следует учитывать при поиске и сканировании, а не просто как сигнал, как это использовалось ранее для nofollow. Вы можете узнать больше об этом обновлении в нашем посте, в котором также рассказывается об их влиянии, а также о экспертных выводах.
Что такое noindex, nofollow?
Как упоминалось выше, добавление тега nofollow на страницу не предотвратит ее сканирование. Чтобы предотвратить индексацию URL-адреса, вам также понадобится тег noindex. Это позволит Google просканировать страницу, но она не появится в индексе. Чтобы запретить Google полностью сканировать страницу, вы должны запретить это через robots.txt.
Другие директивы, которые необходимо знать: канонические теги, нумерация страниц и hreflang
Существуют и другие способы сообщить Google и другим поисковым системам, как обрабатывать URL-адреса, — их тоже стоит знать! Ознакомьтесь с приведенными ниже ресурсами, чтобы узнать больше.
- Канонические теги сообщают поисковым системам, какую страницу из группы похожих страниц следует проиндексировать. Канонизированные (т.е. вторичные страницы, направляющие поисковые системы на основную версию) не включаются в индекс. Если у вас есть отдельные мобильные и настольные сайты, вы должны канонизировать свои мобильные URL-адреса на настольные.
- Разбивка на страницы группирует несколько страниц вместе, чтобы поисковые системы знали, что они являются частью набора. Поисковые системы должны отдавать приоритет первой странице каждого набора при ранжировании страниц, но все страницы в наборе останутся в индексе.
- Hreflang сообщает поисковым системам, какие международные версии одного и того же контента относятся к какому региону, чтобы они могли отдавать приоритет правильной версии для каждой аудитории. Все эти версии останутся в индексе.
Сколько времени вы должны потратить на сокращение краулингового бюджета?
Вы можете услышать много разговоров на форумах SEO о том, насколько важны для SEO эффективность сканирования и бюджет сканирования.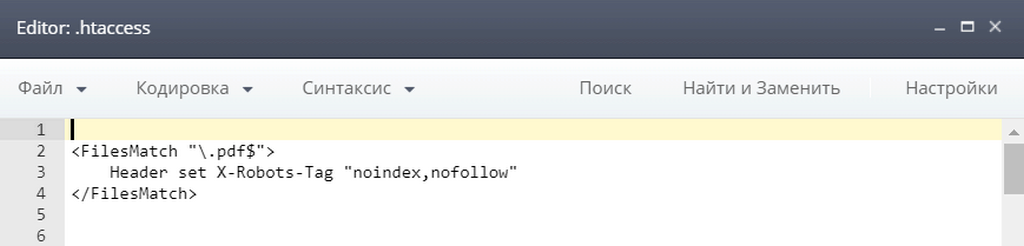 Хотя общепринятой практикой является запрет и запрет на индексирование страниц, которые не приносят пользы поисковым системам или пользователям (например, внутренний код, который используется только для работы сайта, или некоторые типы дублированного контента), решение о том, следует ли скрывать отдельных страниц, вероятно, не лучшее использование времени и усилий. Если нет особой причины скрывать страницу от поисковых систем, обычно лучше оставить решение за ними.
Хотя общепринятой практикой является запрет и запрет на индексирование страниц, которые не приносят пользы поисковым системам или пользователям (например, внутренний код, который используется только для работы сайта, или некоторые типы дублированного контента), решение о том, следует ли скрывать отдельных страниц, вероятно, не лучшее использование времени и усилий. Если нет особой причины скрывать страницу от поисковых систем, обычно лучше оставить решение за ними.
Проверка ваших директив с помощью Lumar
Поиск всех неиндексируемых страниц с помощью LumarОтчет о неиндексируемых страницах включает сведения обо всех страницах с неиндексируемым статусом. Вы можете увидеть их общее количество, а также разбивку правил, которые заставляют их классифицироваться как неиндексируемые:
Отсюда погрузитесь в отдельные отчеты, чтобы убедиться, что правильные правила применяются к правильные URL-адреса.
Индексация > Страницы без индекса
В этом отчете будут показаны все страницы, содержащие тег noindex в метаинформации, заголовке HTTP или файле robots. txt.
txt.
Индексация > Запрещенные страницы
Этот отчет содержит все URL-адреса, сканирование которых невозможно из-за правила запрета в файле robots.txt.
Протестируйте новый файл robots.txt с помощью Lumar
Используйте функцию перезаписи robots.txt Lumar в дополнительных настройках, чтобы заменить текущий файл пользовательским.
При следующем запуске сканирования существующий файл robots.txt будет перезаписан новыми правилами. Это позволяет вам убедиться, что нужные URL-адреса запрещены, прежде чем внедрять изменения на действующий сайт.
Для получения дополнительной информации прочитайте наше руководство по управлению изменениями robots.txt с помощью Lumar.
Дополнительные технические учебные ресурсы по SEO
Мы надеемся, что вы нашли этот пост полезным для получения дополнительной информации о noindex, nofollow и запрете на управление сканированием и индексированием вашего сайта.
Вы можете больше узнать об этих темах в нашей Технической SEO-библиотеке, а если вы хотите узнать, как проводить технический SEO-аудит, прочтите наше руководство. У нас также есть большой выбор регулярно обновляемых электронных книг по техническим темам SEO, которые помогут вам быть в курсе последних обновлений Google и передовых методов SEO.
* Примечание. Это сообщение было обновлено 26 августа 2022 г.
Сэм Марсден
SEO и контент-менеджер
Сэм Марсден — бывший менеджер Lumar по поисковой оптимизации и контенту, а в настоящее время — руководитель отдела SEO в Busuu. Сэм регулярно выступает на маркетинговых конференциях, таких как SMX и BrightonSEO, и является автором отраслевых изданий, таких как Search Engine Journal и State of Digital.
В чем разница между этими директивами поисковой системы? – Blogging Karma
Noindex – это команда, которая указывает поисковым системам не помещать веб-страницу в свои индексы. Это означает, что они не могут сохранить эту информацию в своих записях. Таким образом, страница не будет отображаться в результатах поиска.
Это означает, что они не могут сохранить эту информацию в своих записях. Таким образом, страница не будет отображаться в результатах поиска.
С другой стороны, nofollow — это директива, предписывающая поисковым системам не переходить по ссылке, найденной на веб-странице. И из-за этого любой SEO или авторитет, который есть у этой страницы, не просачивается на страницу с гиперссылкой.
Что такое индексация?
У Google, в частности, есть роботы, которые сканируют всю сеть. Этих роботов называют пауками, и они читают каждую страницу, которую могут найти. Как только они его прочитают, они сообщают об этом основному алгоритму, а затем алгоритм индексирует данные.
Если пользователь вводит определенное ключевое слово, алгоритм проверяет индекс и затем показывает лучший контент. Индекс — это источник данных о том, что поисковые системы предлагают пользователям.
Некоторые веб-разработчики не хотят, чтобы их веб-сайт индексировался — они не хотят, чтобы их веб-сайт отображался на страницах результатов поисковых систем. Вот почему они используют команду noindex.
Вот почему они используют команду noindex.
Очевидно, что это редкий случай. Люди, у которых есть веб-сайт, особенно те, кто зарабатывает на жизнь аффилированным маркетингом, хотят, чтобы их контент индексировался, чтобы получать бесплатный или органический трафик.
Что дальше?
Допустим, Google нашел вашу страницу; он будет сканировать содержимое этой веб-страницы. Где-то на вашей странице есть ссылка на другой сайт. Если роботы-пауки Google увидят это, они «откроют» эту ссылку и пойдут туда, куда она их ведет.
Оттуда они могут создать информационную сеть и решить, о чем ваш сайт. Google любит веб-сайты, которые приносят пользу читателям, и одна из этих ценностей — делиться информацией, которая может принести пользу читателю.
Это то, что мы называем подпиской, потому что Google переходит по гиперссылке. Итак, предположим, что популярный веб-сайт, такой как CNET, имеет гиперссылку на вашу веб-страницу. Если это произойдет, CNET, по сути, говорит людям и Google перейти по этой гиперссылке на вашу веб-страницу, потому что есть информация, которая может им помочь.
В этом случае авторитет сайта CNET как бы просачивается к вам. Google будет думать, что, поскольку CNET направил своих читателей на ваш сайт, вы также должны быть надежным источником информации.
Короче говоря, Google нашел ваш веб-сайт, а также улучшил рейтинг вашей веб-страницы благодаря рекомендации CNET — CNET направляет читателей к вам.
Некоторым разработчикам сайтов это совсем не нравится. Они усердно работали над своим рейтингом и не хотят, чтобы их сайт был источником Google для поиска вас. В связи с этим CNET напишет команду, сообщающую Google не переходить по ссылке, ведущей на ваш сайт.
Если подумать, это немного эгоистично. Однако не спешите судить.
Обратные ссылки могут повлиять на то, как Google видит CNET. Если алгоритм Google считает, что обратная ссылка на вас является спамом, он понизит рейтинг CNET — и все потому, что ваш контент является спамом.
Итак, решение состоит в том, чтобы запретить Google переходить по ссылке к вам. CNET сохранит доверие к себе, и CNET по-прежнему сможет связываться с вами без какого-либо ущерба или вреда, причиненного им.
CNET сохранит доверие к себе, и CNET по-прежнему сможет связываться с вами без какого-либо ущерба или вреда, причиненного им.
Другая причина, по которой они делают это, заключается в том, что они не знают, будет ли ваша веб-страница всегда активной. Если авторитетный веб-сайт имеет десятки тысяч обратных ссылок, и одна из этих обратных ссылок, ведущая на вас, мертва, Google это не понравится.
Google это не понравится, потому что CNET отправляет пользователей на мертвый сайт. Опять же, это повлияет на их рейтинг. Поэтому лучше просто сказать Google, чтобы он не переходил к вам по этой ссылке.
Когда следует использовать noindex?
У веб-мастера есть несколько веских причин, по которым вы не хотите, чтобы Google индексировал вашу страницу. Позвольте мне показать вам некоторые.
- Малоценный контент — это веб-страницы или контент, которые никто особенно не ищет, или они не представляют большой ценности. Примеры таких тонких страниц.
- Маркетинговый контент — это страницы, которые вы используете для своих объявлений, например онлайн-версии вашей маркетинговой кампании по электронной почте или правила вашего конкурса.
- Пользовательский контент – например, форумы.
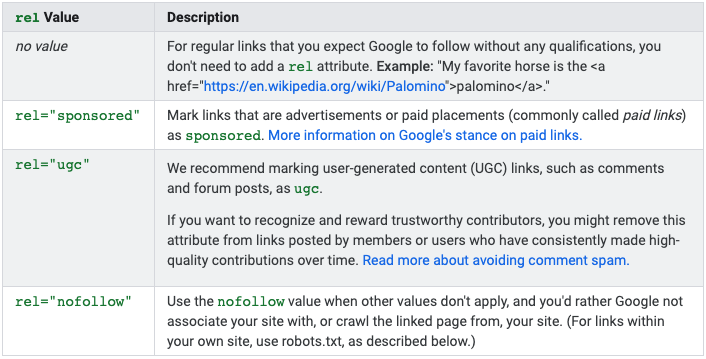
Некоторые форумы отлично подходят для индексации, если веб-сайт сам по себе является форумом. В большинстве случаев вы не хотите, чтобы Google индексировал форум, потому что когда люди нажимают на страницу и уходят, это может повлиять на ваш рейтинг — у вас высокий показатель отказов, и Google это может не понравиться.
Когда следует использовать nofollow?
Как и в случае с командой noindex, для nofollow есть несколько отличных применений, и ниже приведены несколько примеров.
- Платные ссылки и реклама
- Партнерские ссылки
- Ссылки, которые могут исчезнуть
Вы не хотите, чтобы Google переходил по ссылкам, ведущим к платной рекламе или партнерским ссылкам. Google знает, как определить эти вещи, и это может повлиять на то, как Google смотрит на ваш сайт. Если вы продолжите отправлять людей на партнерские сайты, Google в конечном итоге сочтет ваш сайт спамом.
Google знает, как определить эти вещи, и это может повлиять на то, как Google смотрит на ваш сайт. Если вы продолжите отправлять людей на партнерские сайты, Google в конечном итоге сочтет ваш сайт спамом.
Кроме того, вы не хотите, чтобы Google переходил по ссылкам на сайты, которые однажды могут умереть. Вы взяли интервью у человека, у которого есть веб-сайт, и вы связались с ним.
Веб-сайт этого человека может однажды закрыться и стать недоступным. Если вы ссылаетесь на мертвые или недоступные сайты, это также негативно повлияет на ваш SEO-рейтинг.
Резюме
Noindex и nofollow — это две разные команды для Google. Команда noindex указывает Google не перечислять конкретную веб-страницу, найденную на вашем сайте. Вы не хотите, чтобы он был указан, потому что это не то, что вы хотите, чтобы пользователи находили, или это может повлиять на ваш рейтинг.
Nofollow — это то, что вы используете, чтобы указать Google не переходить по гиперссылке, которую вы разместили на своих веб-страницах.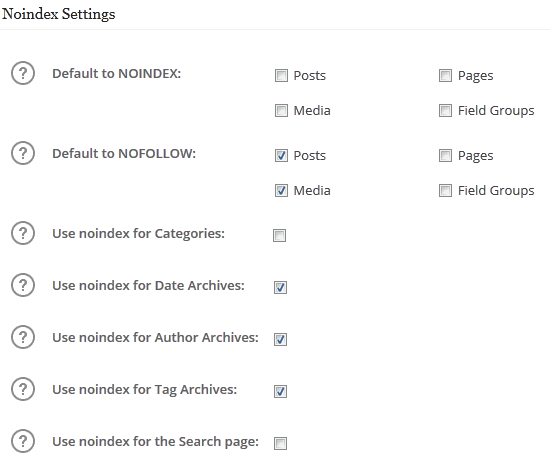 Вы не хотите передавать свои полномочия другим сайтам или хотите убедиться, что низкое качество этих страниц не повлияет на ваш сайт.
Вы не хотите передавать свои полномочия другим сайтам или хотите убедиться, что низкое качество этих страниц не повлияет на ваш сайт.
Твитнуть
Эл. адрес
Распечатать
Recent Posts
ссылка на Как маркетинг может достичь целей в области устойчивого развитияКак маркетинг может достичь целей в области устойчивого развития
Многие потребители разделили или отрицательно относятся к методам маркетинга. Неустойчивый маркетинг порождает недоверие — будь то ложное обещание большей ценности или убеждение клиентов покупать…
Продолжить чтение
ссылка на Зачем вам нужен управляемый хостинг WordPress?Зачем вам нужен управляемый хостинг WordPress?
Наиболее значительными инвестициями, о которых следует подумать, является веб-хостинг, чтобы получить больше трафика и более высокую производительность и успешно запускать свой веб-сайт после его создания. Поэтому очень важно выбрать лучшее…
Поэтому очень важно выбрать лучшее…
Продолжить чтение
Разница между noindex и nofollow? | SEO Форум
Ваш браузер не поддерживает JavaScript. В результате ваши впечатления от просмотра будут уменьшены, и вы будете переведены в режим только для чтения .
Загрузите браузер, поддерживающий JavaScript, или включите его, если он отключен (например, NoScript).
- Дом
- SEO-тактика
- Техническое SEO
 org/ListItem»> Разница между noindex и nofollow?
org/ListItem»> Разница между noindex и nofollow?Эта тема была удалена. Его могут видеть только пользователи с правами управления вопросами.
В чем на самом деле разница между noindex и nofollow и почему/когда вы хотите их использовать? Создал свой первый сайт на WordPress, и «сообщения» в блоге, которые составляют мою домашнюю страницу, смущают меня… что касается передачи сока ссылок на мой домашний URL… не знаю, о чем я здесь спрашиваю! Как мне использовать nofollow/noindex или проблема, на которую мне следует обратить внимание, это 301/canonical. Или ни то, ни другое?
Спасибо! Полезно и по делу? Можете ли вы сделать то же самое для 301 и канонического? Я смотрел видео в блогах, читал и т. д. Каков простой ответ? ты обалденный! Спасибо.
.. но как насчет того, чтобы WordPress рассматривал каждое сообщение на моей домашней странице как собственный URL-адрес… Я просто хочу, чтобы домашняя страница правильно получала «ссылочный вес»?-
Noindex = Вы говорите Google не индексировать эту страницу. Обычно это не очень хорошо, если вы хотите, чтобы контент был найден в поисковых системах. Если это конкретная страница, изображение или что-то еще, что вы не хотите индексировать Google, используйте NoIndex. Если вы хотите, чтобы его можно было найти, не используйте его.
Nofollow используется в ссылках. Это говорит поисковой системе, что вы не хотите, чтобы она переходила по ссылке, которую вы публикуете. Если ссылка имеет nofollow прикрепленный PageRank или якорный текст, он не передается.
 org/Comment»>
org/Comment»> Привет, Кортни
Нет, вы не просто хотите, чтобы главная страница получила «ссылочный вес», вы хотите, чтобы весь сайт был виден для поисковых систем или, по крайней мере, все страницы и сообщения, которые вы хотите, чтобы люди могли видеть читать бесплатно.
Помните, что каждое слово, которое вы пишете в своем блоге, может привлечь больше людей на ваш сайт, поэтому чем больше страниц вы сможете проиндексировать и ранжировать в Google, тем больше у вас шансов получить трафик.
Надеюсь, это поможет
Шон
 .. но как насчет того, чтобы WordPress рассматривал каждое сообщение на моей домашней странице как собственный URL-адрес… Я просто хочу, чтобы домашняя страница правильно получала «ссылочный вес»?
.. но как насчет того, чтобы WordPress рассматривал каждое сообщение на моей домашней странице как собственный URL-адрес… Я просто хочу, чтобы домашняя страница правильно получала «ссылочный вес»?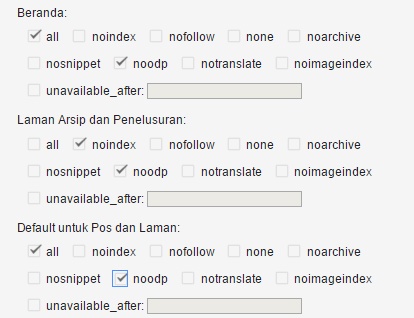
У вас есть животрепещущий вопрос по SEO?
Подпишитесь на Moz Pro, чтобы получить полный доступ к вопросам и ответам, отвечать на вопросы и задавать свои.
Начать бесплатную пробную версию
Есть вопрос?
Обзор вопросов
Посмотреть Все вопросыНовые (нет ответов)ОбсуждениеОтветыПоддержка продуктаБез ответа
От Все времяПоследние 30 днейПоследние 7 днейПоследние 24 часа
Сортировка по Последние вопросыНедавняя активностьБольше всего лайковБольшинство ответовМеньше всего ответовСамые старые вопросы
С категорией All CategoriesAffiliate MarketingAlgorithm UpdatesAPIBrandingCommunityCompetitive ResearchContent DevelopmentConversion Rate OptimizationDigital MarketingFeature RequestsGetting StartedImage & Video OptimizationIndustry EventsIndustry NewsIntermediate & Advanced SEOInternational SEOJobs and OpportunitiesKeyword ExplorerKeyword ResearchLink BuildingLink ExplorerLocal ListingsLocal SEOLocal Website OptimizationMoz BarMoz LocalMoz NewsMoz ProMoz ToolsOn-Page OptimizationOther SEO ToolsPaid Search MarketingProduct SupportReporting & AnalyticsResearch & TrendsReviews and RatingsSearch BehaviorSEO ТактикаТренды поисковой выдачиСоциальные сетиТехническое SEOВеб-дизайнБелое/черное SEO
Связанные вопросы
 schema.org/ItemList» data-nextstart=»» data-set=»»>
schema.org/ItemList» data-nextstart=»» data-set=»»>Я вижу, что конкурент может изменить структуру своего URL/хлебных крошек в Google и на сайте. Google показывает бункер из 3-4 категорий для страницы, но после того, как вы нажали, страница не является корневой. Как ты мог это сделать?
Техническое SEO | | ТикетСити
0
 org/ListItem»> Подход для существующего сайта, который хочет предоставлять различный контент для регионов в одной стране/языке
org/ListItem»> Подход для существующего сайта, который хочет предоставлять различный контент для регионов в одной стране/языке Привет, ребята!
У меня есть установленный сайт, который в настоящее время предоставляет один и тот же контент для всех регионов — запада и востока — в одной стране на одном языке.
Сейчас мы пытаемся изменить контент в западном и восточном регионах — не сильно, но предлагаемые продукты будут немного отличаться.
Из того, что я понял, изменение URL-адреса лучше всего подходит для стран, поэтому кажется излишним для регионов в одной стране. У меня также вряд ли будет очень уникальный контент, помимо разнообразных продуктов, поэтому я не забываю о дублирующемся/похожем контенте, но я знаю, что могу использовать канонические теги для адресации.
У меня есть довольно современная CMS, которая может ориентироваться на контент в зависимости от региона, но помня о том, что Google может расстроиться; показ контента, отличного от того, с чем может столкнуться бот, при условии, что это все еще актуально.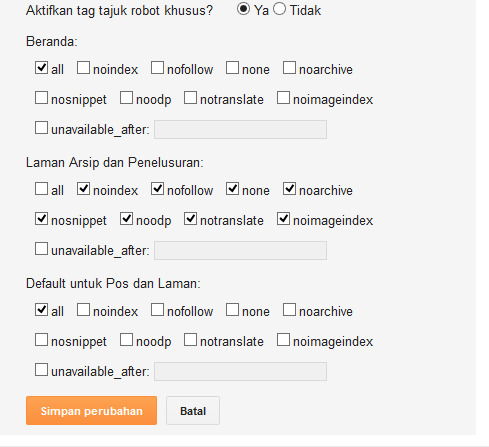 Итак, три вопроса с точки зрения SEO:
Нужно ли мне действительно сосредоточиться на изменении моей структуры URL-адресов, тем более, что я уже зарекомендовал себя на конкурентном рынке, или я принесу больше вреда, чем пользы? Является ли регион в URL сильным сигналом?
Если мне нужно внести некоторые изменения в URL-адрес и/или метаданные, какие наиболее эффективные изменения вы бы сделали?
Как Google Local вписывается в это? Это отдельный процесс с помощью инструментов для веб-мастеров или он соответствует указанным выше изменениям?
Ваше здоровье!!!
Джез
Итак, три вопроса с точки зрения SEO:
Нужно ли мне действительно сосредоточиться на изменении моей структуры URL-адресов, тем более, что я уже зарекомендовал себя на конкурентном рынке, или я принесу больше вреда, чем пользы? Является ли регион в URL сильным сигналом?
Если мне нужно внести некоторые изменения в URL-адрес и/или метаданные, какие наиболее эффективные изменения вы бы сделали?
Как Google Local вписывается в это? Это отдельный процесс с помощью инструментов для веб-мастеров или он соответствует указанным выше изменениям?
Ваше здоровье!!!
Джез
Техническое SEO | | jez000
0

У меня несколько цветов одного и того же товара, но в результате я получаю предупреждения о дублирующемся содержании. Я хочу сохранить все эти разные продукты на своих собственных страницах, чтобы цвет можно было легко определить, просматривая страницу категории. Какие-либо предложения?
Техническое SEO | | бобджон1
0
Мы работаем над уменьшением проблемы со ссылками на странице. На страницах определенного типа проблема возникла из-за того, что мы автоматически ссылаемся на релевантный контент. Когда мы добавили nofollow к этому контенту, это решило проблему для некоторых, но не для всех, и мы не можем понять, почему это не удалось для всех. Вы видите какие-либо проблемы?
Пример страницы, где nofollow не работал для…
http://www.andor.com/learning-academy/4-5d-микроскопия-an-overview-of-andor’s-solutions-for-4-5d-микроскопия
Когда мы добавили nofollow к этому контенту, это решило проблему для некоторых, но не для всех, и мы не можем понять, почему это не удалось для всех. Вы видите какие-либо проблемы?
Пример страницы, где nofollow не работал для…
http://www.andor.com/learning-academy/4-5d-микроскопия-an-overview-of-andor’s-solutions-for-4-5d-микроскопия
Техническое SEO | | тоникелли
0
Canonical» и «Hreflang» на этих новых страницах, чтобы показать версию G для разных регионов и языков (en-us). Тогда должны ли аналогичные страницы оригинального/основного сайта иметь канонические теги и теги href?
Страница основного/исходного сайта Я действительно не хочу ориентироваться на конкретную страну (хотя существующие сигналы (хостинг и т. д.) будут Великобритания (основная цель основного сайта), но страницы также отображаются при поиске в других странах (что мы и хотим).
Я полагаю, что можно оставить исходный/основной сайт таким, какой он есть в настоящее время, хотя формулировки в блоге Google/центральных статьях для веб-мастеров и т. д. немного сбивают с толку, поэтому я прошу чье-либо мнение/вклад по этому поводу.
Также есть ли какое-либо преимущество (или просто лучшая практика) использовать «www.example.com/en-us/…» в URL-адресе подкаталога, а не просто «www.example.com/us/».
заранее большое спасибо всем комментаторам 🙂
Тогда должны ли аналогичные страницы оригинального/основного сайта иметь канонические теги и теги href?
Страница основного/исходного сайта Я действительно не хочу ориентироваться на конкретную страну (хотя существующие сигналы (хостинг и т. д.) будут Великобритания (основная цель основного сайта), но страницы также отображаются при поиске в других странах (что мы и хотим).
Я полагаю, что можно оставить исходный/основной сайт таким, какой он есть в настоящее время, хотя формулировки в блоге Google/центральных статьях для веб-мастеров и т. д. немного сбивают с толку, поэтому я прошу чье-либо мнение/вклад по этому поводу.
Также есть ли какое-либо преимущество (или просто лучшая практика) использовать «www.example.com/en-us/…» в URL-адресе подкаталога, а не просто «www.example.com/us/».
заранее большое спасибо всем комментаторам 🙂
Техническое SEO | | Дэн-Лоуренс
0
 org/ListItem»> Одна и та же страница из разных мест имеет немного разные URL-адреса, является ли это негативной практикой SEO?
org/ListItem»> Одна и та же страница из разных мест имеет немного разные URL-адреса, является ли это негативной практикой SEO? Привет, Недавно мы внесли изменения в логику генерации ссылок на наш веб-сайт, и теперь я могу получить доступ к одной и той же странице с разных страниц с немного разными URL-адресами, например: http://www.showme.com/sh/?h=wlZJNya&by=Featured_ShowMe а также http://www.showme.com/sh/?h=wlZJNya&by=Topic Просто интересно, это плохая практика, и мы должны избегать этого? Спасибо, Карен
Техническое SEO | | Покажите мне
0
 noindex.follow для страниц с разбивкой на страницы
noindex.follow для страниц с разбивкой на страницы Я работаю на сайте недвижимости, который имеет несколько страниц со списками, например, http://www.hhcrealestate.com/manhattan-beach-mls-real-estate- списки Я пытаюсь заставить главную страницу результатов ранжироваться по этому конкретному ключевому слову, то есть «дома на Манхэттен-Бич на продажу». Я хочу убедиться, что все отдельные списки на страницах с разбивкой на страницы, 2, 3, 4 и т. д. по-прежнему индексируются. лучше добавить ко всем страницам с разбивкой на страницы, т. е. manhattan-beach-mls-real-estate-listings-2, manhattan-beach-mls-real-estate-listings-3, manhattan-beach-mls-real-estate-listings-4 и т.д. или лучше добавить noindex,follow на эти страницы?
Техническое SEO | | fthead9
1
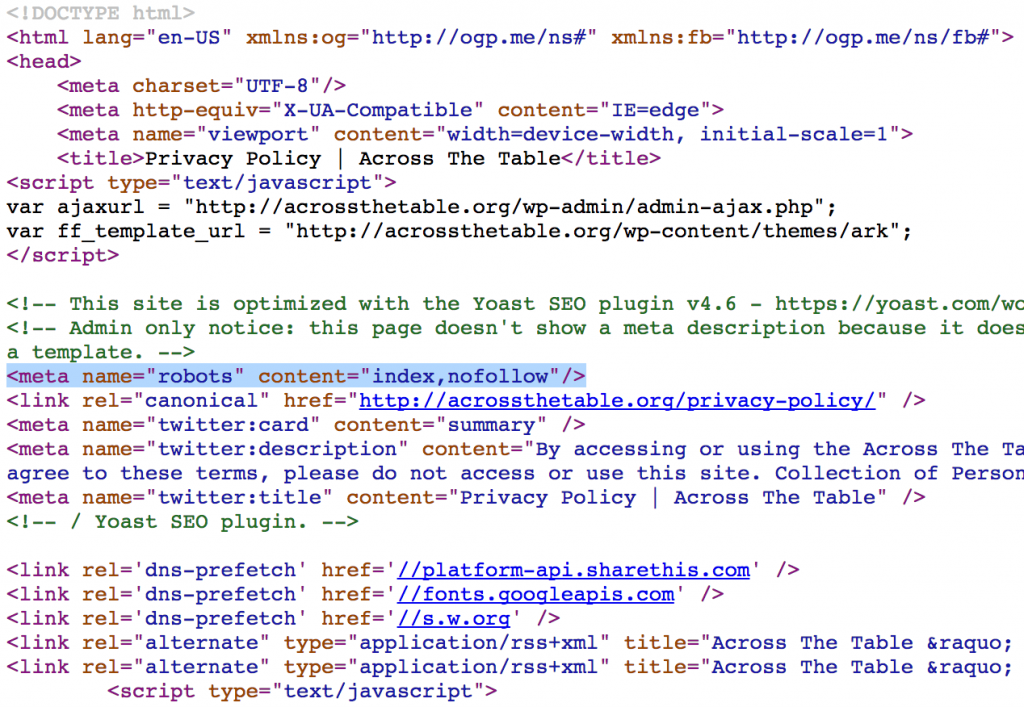 org/ListItem»> После того, как весь сайт не будет проиндексирован, как долго он будет восстанавливаться?
org/ListItem»> После того, как весь сайт не будет проиндексирован, как долго он будет восстанавливаться? Программисты «случайно» поместили «name=»robots» content=»noindex» />» на каждую страницу одного из моих сайтов (статьи, целевые страницы, домашнюю страницу и т. д.). Это произошло в понедельник, а мы заметили только сегодня. Фу… Мы исправили проблему; сколько времени займет переиндексация? Сохраним ли мы сразу те же позиции по ключевым словам? Какие-нибудь советы?
Техническое SEO | | Эрик Пасифико
0
Ссылки Follow и Nofollow: что нужно знать — SEO-маркетинг
Разница между ссылками Follow и nofollow и их влияние на SEO чтобы максимизировать вашу цифровую производительность. Добавление их в свой набор инструментов SEO может помочь повысить профиль вашего веб-сайта. Давайте рассмотрим, что это такое, почему они используются и как они могут помочь вам лучше общаться с вашей целевой аудиторией.
Давайте рассмотрим, что это такое, почему они используются и как они могут помочь вам лучше общаться с вашей целевой аудиторией.
Ссылки для перехода — это обратные ссылки (или входящие ссылки), которые сообщают роботам поисковых систем о переходе по гиперссылке. Этот тип входящей ссылки сигнализирует сканерам о релевантной и полезной ссылке. По сути, автор ручается за связанный сайт и говорит читателям: «Эй, я нашел эту страницу полезной. Возможно, ты тоже захочешь это проверить».
Их также часто называют ссылками «подписаться». Они говорят поисковым роботам перейти по ссылке, просканировать страницу и отдать должное ссылающейся странице. С каждой последующей ссылкой с других страниц связанная страница получает «голоса» за доверие. Чем больше голосов у страницы, тем больше вероятность того, что она получит повышение рейтинга в поисковой выдаче.
Это лучшие из лучших, когда речь идет о внешних ссылках.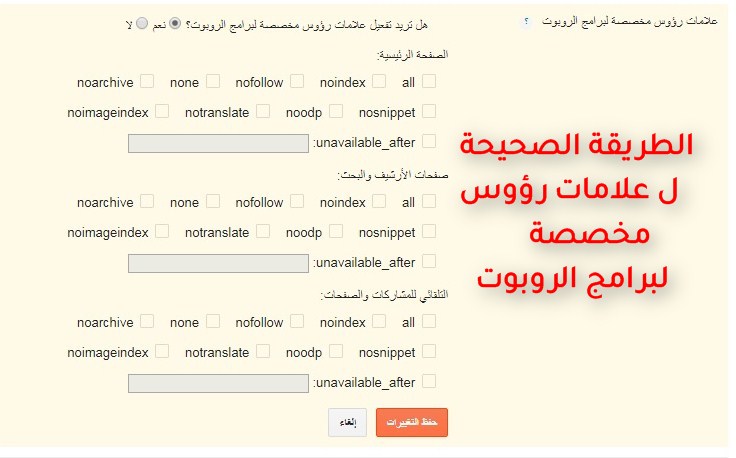 Они нужны вам, потому что они направляют читателей на вашу страницу, а поисковых роботов — на ваш контент. Они также дают вам почувствовать вкус невероятно сладкого ссылочного сока, который нужен каждому сайту (подробнее об этом позже).
Они нужны вам, потому что они направляют читателей на вашу страницу, а поисковых роботов — на ваш контент. Они также дают вам почувствовать вкус невероятно сладкого ссылочного сока, который нужен каждому сайту (подробнее об этом позже).
Это другой вид входящих ссылок. В отличие от dofollow, они имеют атрибут nofollow в HTML-теге, сообщающий сканерам , а не , переходить по ссылке. С другой стороны, читатели видят то же самое, что и ссылка «подписаться». Это гиперссылка, которая открывает новую страницу при нажатии на нее. Единственный способ увидеть разницу — посмотреть на HTML-тег.
Другим заметным отличием от dofollow-ссылок является то, что nofollow-ссылки не начисляют баллы за доверие. Для поисковых систем такие ссылки ненадежны. По какой-то причине ссылающийся сайт не желает ручаться за понравившийся сайт. Поэтому они просто не переходят по гиперссылке.
По крайней мере, так было до недавнего времени. В 2019 году Google изменил свою стратегию и теперь рассматривает атрибуты nofollow как «подсказки», а не указания игнорировать.
В 2019 году Google изменил свою стратегию и теперь рассматривает атрибуты nofollow как «подсказки», а не указания игнорировать.
Переходя на модель подсказок, мы больше не теряем эту важную информацию, но при этом позволяем владельцам сайтов указывать, что некоторым ссылкам не следует придавать вес одобрения первой стороны». — Гугл
Зачем использовать ссылки Nofollow?
Если сканеры поисковых систем не «подсчитывают» nofollow-ссылки так же, как они подсчитывают ссылки для подписки, почему они вообще существуют?
Первоначально nofollow-ссылки были созданы для борьбы со спамом и злоупотреблением обратными ссылками.
В начале 2000-х блоги начали зарекомендовать себя как прибыльный сектор онлайн-мира. Увидев это, спамеры воспользуются возможностью прокомментировать сообщения со ссылками на свой сайт. Это оказалось эффективной тактикой, и она распространилась со скоростью лесного пожара, нанеся ущерб поисковой выдаче.
Пользователи больше не могли получать информацию, которую они искали, из искаженных результатов поиска.
Спам в комментариях сбил алгоритмы поисковых систем и привел к тому, что спамерские сайты заняли высокие позиции. Поскольку качественные сайты опустились в рейтинге, Google должен был найти способ предотвратить спам в комментариях и поддерживать достоверные результаты поиска. Итак, в 2005 году они помогли разработать своего рода супергероя: HTML-тег nofollow link.
Общие Nofollow ссылки:
- Комментарии
- Форумы
- Виджеты
- Платные ссылки / Рекламный контент
Когда использовать rel=»ugc» и rel=»sponsored»
Ссылки Nofollow развивались с момента их создания. Теперь есть способы указывать исходящие ссылки с атрибутами HTML rel=»ugc» и rel=»sponsored».
Rel=»ugc» предназначен для пользовательского контента. Комментарии и форумы — это типы пользовательского контента.
Rel=»sponsored» для спонсируемого контента.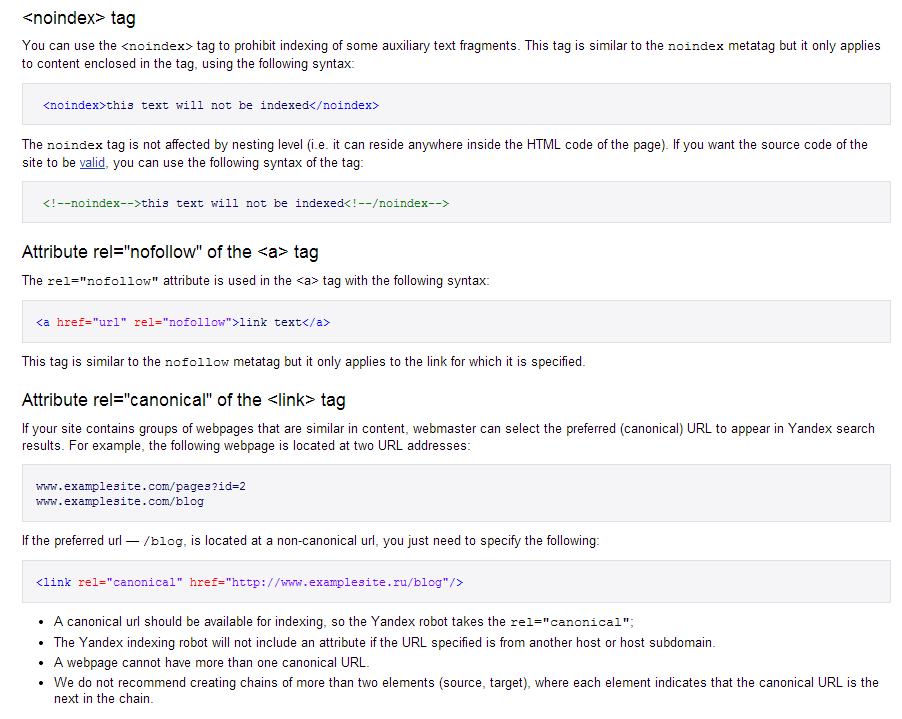 Используйте это для рекламы, партнерских ссылок или в любое время, когда ссылки обмениваются на деньги или товары.
Используйте это для рекламы, партнерских ссылок или в любое время, когда ссылки обмениваются на деньги или товары.
Сканирование, индексирование и ранжирование
Поисковые системы выполняют три основные функции: сканирование, индексирование и ранжирование.
Сканирование
Это когда Google развертывает роботов для проверки Интернета. Этих роботов часто называют «краулерами» или «пауками». Они сканируют содержимое и HTML-коды каждого URL-адреса, с которым могут столкнуться.
Важно отметить, что поисковые роботы обнаруживают URL-адреса веб-сайтов по ссылкам. Они начинают с проверки нескольких страниц и переходят по обратным ссылкам на этих страницах, чтобы найти новые.
Кроме того, они могут найти страницы с помощью файла карты сайта, который должен регулярно обновляться веб-мастером.
Индексирование
После обнаружения содержимого оно индексируется. Это означает сохранение его для ссылки, когда пользователь инициирует поиск.
Не весь контент нуждается в индексировании. Одним из примеров этого является административная страница на веб-сайте, такая как политика конфиденциальности или страница доставки.
Используя HTML-код noindex, веб-мастер может предотвратить индексацию нерелевантных страниц.
Ранжирование
Ранжирование — это когда поисковая система упорядочивает проиндексированное содержимое от наиболее релевантного к наименее релевантному каждый раз, когда пользователь выполняет поиск.
Агентство цифрового маркетинга, работающее над оптимизацией поисковых систем, стремится повысить рейтинг компаний в поисковой выдаче. Бизнес хочет достичь своих потенциальных клиентов через Интернет. Однако цель поисковой системы — предоставить пользователю наиболее релевантный и полезный контент.
Как только все три работают в гармонии, ранжирование становится естественным и имеет смысл.
Почему важны обратные ссылки? Проще говоря: потому что они сообщают поисковым роботам, что сайт подтвержден и считается надежным источником.
Чем больше веб-сайтов ссылается на ваш контент, тем больше вы доверяете пользователям и Интернету в целом. Поисковые системы считают обратные ссылки «голосами». Чем больше у вас их, тем надежнее ваш сайт и, следовательно, выше вероятность того, что рейтинг вашего сайта повысится. Более высокий рейтинг означает больший трафик, больше посетителей, больше продаж и больше успеха.
Как создать обратные ссылкиМы знаем, что они являются важной частью создания успешного веб-сайта, но как их получить?
Создавайте качественный контент
Это лучший способ органически получать обратные ссылки. Если вы публикуете исключительный контент, другие захотят дать на него ссылку.
Вот список примеров качественного контента, составленный генеральным директором NeoMam Studio Жизель Наварро. Группы в списке создавали инновационный контент, который заставлял людей делиться своими страницами с помощью обратных ссылок.
Если вы можете создавать привлекающий внимание, заставляющий задуматься и достойный ссылок контент, другие это заметят.