
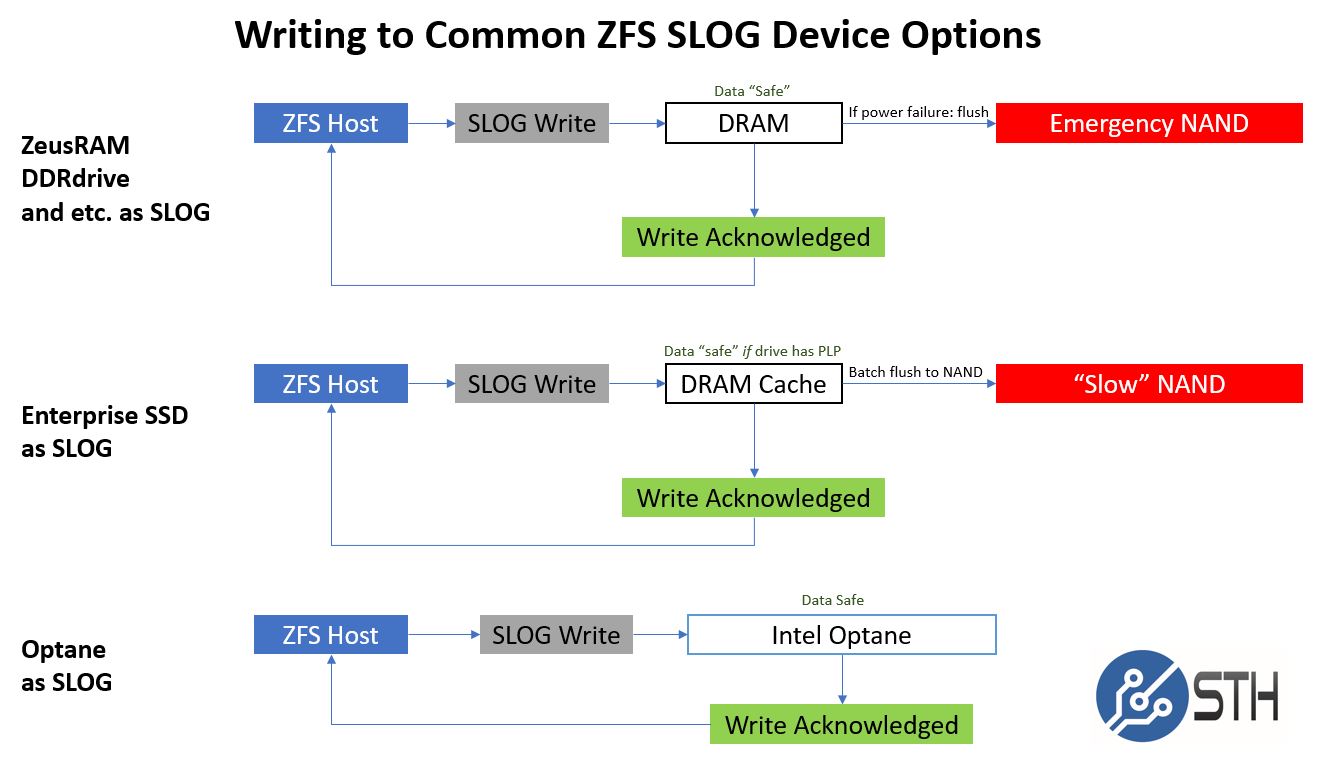
FreeNAS + ZFS: Raid-Z or RaidZ2
Я что-то не понял, USB отключается, и не происходит необходимых проверок на ошибки и восстановления? Кто ж так строит? Ну и это.
USB: раз в два дня происходит вот такое:
— End of security output — А несколько раз вот такое:
> (da3:umass-sim0:0:0:0): WRITE(16). CDB: 8a 00 00 00 00 01 34 42 cc 78 00 00 00 08 00 00 — End of security output — Софт enterprise grade. Железо server grade почти всё, кроме некоторых дисков (которые я постепенно заменяю на server grade), PCIe USB 3.0 карточки и external USB 3.0 enclosure. Софт явно говорит «не используй USB» 🙂
Тем более, если софт с железом хором поют «не используй меня, а то козлёночком станешь» 🙂
Крамольную вещь скажу.
Тормозня же будет адская.
Это был сарказм. Горький.
По существу вопроса — всё равно никуда не деться от ручной классификации данных, с выносом холодных куда-нибудь (да хоть в те же облака).
 Кто-то хочет реорганизовать всё, чтобы было логичнее — идёт нафиг. Система только растёт, но она не реорганизуется, и всем хорошо. Иногда отдельные комоненты системы заменяют новыми, и тогда есть шанс для частичной реорганизации. Но все эти реорганизационные costs берут на себя большие команды людей. Кто-то хочет реорганизовать всё, чтобы было логичнее — идёт нафиг. Система только растёт, но она не реорганизуется, и всем хорошо. Иногда отдельные комоненты системы заменяют новыми, и тогда есть шанс для частичной реорганизации. Но все эти реорганизационные costs берут на себя большие команды людей.Дома однородности куда меньше, а ресурс по управлению данными всего один — это ты. И время от времени нужно таки реорганизовывать всё, иначе оно плохо scale’ится (неудобства накапливаются одно на другое и повышают цену доступа). Большинство людей Ещё несколько довольно важных проблем — это группировка данных их важности, по их чувствительности к privacy, и фундаментальный недостаток файловой системы — одна иерархия. Хочется что-то вроде attribute-based store с произвольными выборками и множественными иерархиями, но нет экосистемы, которая бы это давала, не теряя удобств, performance и др.
Дима, NAS, который при таком оверхэде и вкачивании бабла может выдавать такие результаты – это как бы, прости, нелепость какая-то. Я всё понимаю, ZFS, надёжная защита от сбоя дисков, то-сё… Но если оно не защищено от других уязвимостей, приводящих к повреждению сохранённой инфы – да ну его нафиг, это энтерпрайз решение. Это не NAS. А оно ещё и обслуживания требует какого-то нехилого судя по твоим словам. Я бы решил, что эксперимент затянулся, и продал бы это кому-нибудь ) Edited at 2015-03-06 09:16 pm (UTC)
Такие мысли приходят, но у меня ещё есть немного терпения. Что касается как USB, так и Raid-Z vs Raid-Z2, то ответ, понятно, в моей жадности. Я хорошо понимал, что USB диски с FreeNAS’ом никто не использует, а Raid-Z почти никто*. Но я самоуверенно решил, что типа, я такой аккуратный, не буду трогать провода и USB прокатит. Насчёт Raid-Z: для Raid-Z2 такого же объёма нужен на 1 диск больше, т.е. +сто баксов. Пожадничал. *) Если некоторая конфигурация почти не используется, то, скорее всего, она не будет работать, или будет глючная с очень геморным саппортом. Этот общий принцип я хорошо знаю, мне осталось только научиться его применять везде и всюду 🙂
Нормальный инженерный авось. Меня сакральная мысль о том, что энтерпрайз не лучше чем «для дома», он просто не для дома, настигла примерно в похожем случае. У меня когда-то дома было два винсервера и оба контроллеры домена. И снюхивались они по вайфаю – хотя это мягко говоря не рекомендуется. И я так же решил, что я умный и всё устрою. Когда я как-то раз протрахался как-то очень долго, пытаясь зайти в ноут, я снёс это всё к чёртовой бабушке.
По количеству геморасаппорта энтерпрайз стопудово хуже, чем «для дома». Проблема в том, что «для дома» не дают нормальных железок и дают сильно меньше фич. Насчёт доменя — я помню очень похожий experience, мне хватило одного домен контроллера без синхронизации 🙂 чтобы понять что всё это к чёртовой матери, куда легче жить, если создавать юзеров с такими же паролями на всех тачках и без домен контроллера вовсе.
Это энтерпрайз левел железяк, но не решения. Ты можешь поставить ECC на материнку хоум-премиум, наверняка такие есть, но потом ты будешь искать, чем прикрыть геморрой, связанный с горбатостью самой материнки – потому что нет ничего хуже, чем сегмент хоум-премиум. Ну и тд. Энтерпрайз-левел решение вполне можно сделать из говна и палок, главное их правильно расставить. Элон Маск тебе в пример – там спейс-левел решения из говна и палок. Положа руку на сердце, ты же видишь как в самом деле изнутри устроен софт. Edited at 2015-03-06 10:07 pm (UTC)
По секрету. Где-то вот уже лет десять 90% усилий в энтерпрайзе как раз и уходит на то, чтобы это самое говно с палками как-то работало. Остальные 10% прилагаются к замене говна и палок на нормальное железо у особо-важных кастомеров.
ECC на материнку хоум-премиум я, скорее всего, не поставлю. «Это энтерпрайз левел железяк, но не решения.» Ты же понимаешь, что так или иначе это экосистема, ты (в общем случае) не можешь взять одного уровня железку и другого уровня решение. Скажем, на серверную железку у workstation-версии винды может не найтись железяк. Или софт который тебе нужен, на неё не встанет, т.к. ему нужен server-specific OS support, какие-нибудь DLL-ки отсутствующие. Вообще ставить Windows на NAS это отвратительно как минимум из-за необходимости перегружаться чтобы ставить апдейты. Любые голые *nix-ы уже автоматом мегагемор по конфигурации. Solutions типа Synology NAS — там ECC-enabled железка стоит вдвое дороже, чем я суммарно потратил на свой setup, и при этом я не защищён от багов, в случае которых мне нужно давать удалённый доступ к своему массиву каким-то странным людям, которым я не доверяю. FreeNAS не такое уж большое зло на этом фоне. Правильное решение, конечно, в принципе, иметь настолько меньше shit’а, чтобы можно было хранить на workstation’ах и использовать только бэкап. Я всё жду, когда подешевеют SSD настолько, чтобы можно было поставить обычный mirror на два 5TB диска с SSD, и это бы решило множество проблем в форм-факторе обычного disk enclosure, а не сервера. Кроме, пожалуй, ECC 🙂 Но, может, для file level integrity можно найти или написать софтинку, которая будет регулярно checksum’ить и говорить, если вдруг какое файло оказалось побито и его следует восстановить из бэкапа. По поводу идеи, что выбор железяки тянет за собой всю экосистему, могу привести мою любимую аналогию с бабами. Вот, допустим, тебе требуется такой функционал: Девушки описанной конфигурации, несомненно, существуют, но за каждую фичу (а особенно за их комбинацию) ты будешь по полной программе платить maintenance. Если она гламурная, ей нужен целый арсенал для макияжа, куча времени, и возможность ходить на всякие процедуры. Кроме того, её нужно выгуливать out в разные места, где она будет всё это показывать. Чтобы она была эрудированная и харизматичная, у неё должно быть много друзей + она должна проводить много времени с ними, ходить out, опять же. Работа, ум, профессия, хобби варить борщи, партнёрство? За всё это ты заплатишь равноправным участием в её жизни, и так, что кроме неё вообще ни на что не будет сил и времени. Короче, бесплатный сыр бывает только в мышеловке 🙂
У тебя «транзакционная» модель – всё сразу в одном месте – или ничего. Я за распределённые системы – девчонок надо просто несколько, ога
Отличная мысль !
У девочек будет девочковая варсия CAP теоремы:
Я пытаюсь соптимизировать суммарные накладные расходы.
Ты в самом деле увеличиваешь накладные расходы. Ты можешь иметь гоночную тачку и трак – или гоночный трак. Попробуй угадать, в каком случае у тебя будут накладные расходы выше ) А overall-применимость, юзабилити – ниже.
http://googleprojectzero.
да-да, я видел 🙂 sweet
Предлагаю RAID 1. Или RAID10 (если дисков больше 2-х).
RAID 1 это мой 3-й вариант, а RAID10 это второй. Склоняюсь всё-таки к Raid-Z2 (это stripe с двумя дисками для избыточности). | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

 У меня 2+2+3+3 диски, два диска на 5 в rotation’е для off-site бэкапа. Соответственно, в отношении места больше 5 мне смысла нет (с Raid-Z было 6, т.к. 3 диски пришлось считать как за 2). Есть несколько вариантов, которые я рассматриваю:
У меня 2+2+3+3 диски, два диска на 5 в rotation’е для off-site бэкапа. Соответственно, в отношении места больше 5 мне смысла нет (с Raid-Z было 6, т.к. 3 диски пришлось считать как за 2). Есть несколько вариантов, которые я рассматриваю: Benefits: double read IOPS, но sequential read speed может быть в 1.5-2 раза ниже гигабита. Диски будут узким местом. По сравнению с предыдущим вариантом — чуть лучше по безпасности: если умирают 2 диска и с вероятностью 1/3 это происходит на одной паре, то теряешь только эту пару, а не весь массив. Кроме того, массив фундаментально проще, в случае багов можно будет легко восстановить файлы с отдельных дисков без требования целостности оригинального массива. С местом будет нормально (5).
Benefits: double read IOPS, но sequential read speed может быть в 1.5-2 раза ниже гигабита. Диски будут узким местом. По сравнению с предыдущим вариантом — чуть лучше по безпасности: если умирают 2 диска и с вероятностью 1/3 это происходит на одной паре, то теряешь только эту пару, а не весь массив. Кроме того, массив фундаментально проще, в случае багов можно будет легко восстановить файлы с отдельных дисков без требования целостности оригинального массива. С местом будет нормально (5). .. Если даже хорошее консумерское железо такое говно и софт такое говно, то вот и ответ на вопрос, почему нихера никакие бэкапы не работают толком, и не так уж сильно народ парится по этому поводу. Комбинация говна со средним уровнем кривизны рук и прямоты извилин просто не может работать. Или я ошибаюсь?
.. Если даже хорошее консумерское железо такое говно и софт такое говно, то вот и ответ на вопрос, почему нихера никакие бэкапы не работают толком, и не так уж сильно народ парится по этому поводу. Комбинация говна со средним уровнем кривизны рук и прямоты извилин просто не может работать. Или я ошибаюсь? local kernel log messages:
local kernel log messages: Выкинуть нах железо, хранить всё в облаке.
Выкинуть нах железо, хранить всё в облаке. Так что место особо и не нужно, во всяком случае не в таком количестве.
Так что место особо и не нужно, во всяком случае не в таком количестве. фич.
фич. С моими requirements огребание гемора будет в любом случае.
С моими requirements огребание гемора будет в любом случае.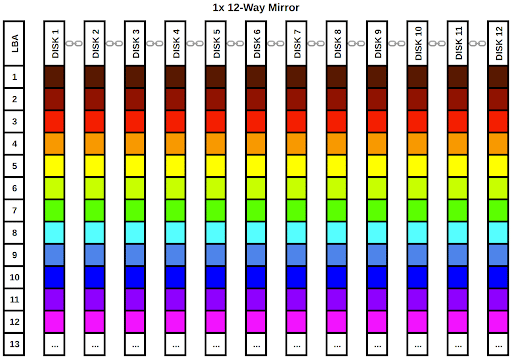
 Самый минимум это ECC-память (а я точно знаю, что она нужна, я видел своими глазами bit rot в домашних файлах). Х— вам. Это сразу enterprise level.
Самый минимум это ECC-память (а я точно знаю, что она нужна, я видел своими глазами bit rot в домашних файлах). Х— вам. Это сразу enterprise level.
 Для неё нужен mother board support & CPU support.
Для неё нужен mother board support & CPU support. Consumer-grade backup soft+железки вполне справляются с парой терабайт.
Consumer-grade backup soft+железки вполне справляются с парой терабайт.

 Отдельные девочки это отдельный overhead на каждую, который складывается. Ну или это нужно каждую обламывать в тех других вещах, которые она хочет (наращивать жёсткость?). Или искать таких, у которых всё есть, кроме вот ровно того, что ты хочешь от неё взять, а она может дать (прокачивать удачливость?).
Отдельные девочки это отдельный overhead на каждую, который складывается. Ну или это нужно каждую обламывать в тех других вещах, которые она хочет (наращивать жёсткость?). Или искать таких, у которых всё есть, кроме вот ровно того, что ты хочешь от неё взять, а она может дать (прокачивать удачливость?). blogspot.com/2015/03/exploiting-dram-rowhammer-bug-to-gain.html
blogspot.com/2015/03/exploiting-dram-rowhammer-bug-to-gain.html
Виконую встановлення, налаштування, супроводження серверів. Для деталей використовуйте форму зворотнього звʼязку
Зіштовхнувся нещодавно з тим, що у Solaris немає ‘proc_setgid’ privilege, який, наприклад, вимагає powerdns при старті, якщо запускати не від root’a. Помилка наступна:
Помилка наступна:
pdns_server[401190]: missing privilege "proc_setid" (euid = 0, syscall = "setgid") at setgid+0xcf
Каже, що немає proc_setid, але воно є, а далі вже йде уточнення, що треба не setid, а саме setgid, але у Solaris цього немає. Чому? Не знають навіть у Solaris community. Workaround – стартувати сервіс від root’a.
Цей запис оприлюднено у Misc, staff, other, Solaris о автором skeletor.Нам потрібно отримати лише список сервісів, які з якихось причин не запустилися через помилки
Solarissvcs -xv
systemctl --failed

В даній статті розглянемо відключення цих безпекових методів. Що це таке – написано тут. Відключати я це не рекомендується, але в деяких випадках це треба, враховуючи, що продуктивність може досягати до 30%.
Читати далі →
Цей запис оприлюднено у FreeBSD, Linux, Solaris о автором skeletor.Після оновлення MS від жовтня 2022 Outlook частково перестав працювати через SSL/TLS. Проблема в тому, що Outlook перестав приймати session ticket. Нижче є тимчасовий workaround для цього.
exim
Додаємо в exim.conf:
openssl_options = +no_ticket
postfix
Додаємо в master.cf:
submission inet n - n - - smtpd .Цей запис оприлюднено у Misc, staff, other о автором skeletor... -o tls_ssl_options=NO_TICKET .... smtps inet n - n - - smtpd .... -o tls_ssl_options=NO_TICKET ...
 ..
-o tls_ssl_options=NO_TICKET
....
smtps inet n - n - - smtpd
....
-o tls_ssl_options=NO_TICKET
...
..
-o tls_ssl_options=NO_TICKET
....
smtps inet n - n - - smtpd
....
-o tls_ssl_options=NO_TICKET
...
Виникло завдання зробити зовнішлю авторизацію через LDAP для сервіса, який її не підтримував, зате підтримував авторизацію через Radius. А у radius’a виявився модуль LDAP.
Тестовий стенд: Debian Linux 11.6 + Freeradius.
Нам знадобляться пакети freeradius-ldap, freeradius-utils (для локального тесту через утиліту radtest).
Читати далі →
Цей запис оприлюднено у Misc, staff, other, Security о автором skeletor.Якщо коротко, то ashift = степінь 2-ки результат якого дорівнює block size.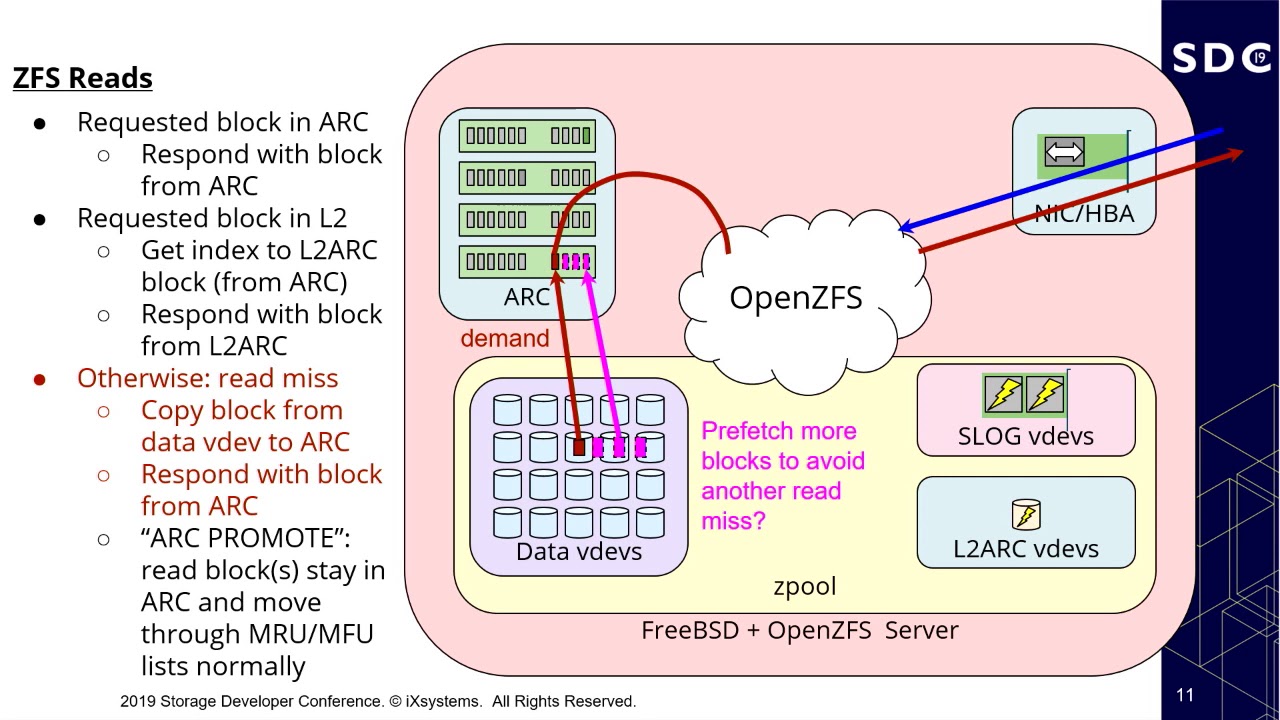 12=4096). Для старих дисків все ще використовується ashift = 9. Чим більше ashift тим буде продуктивніше працювати пул, бо за 1 раз буде більше зчитуватися даних. Але є і інша сторона – зайняте місце. Справа в тому, що якщо у вас багато маленьких файлів, по декілька КБ, то при виборі більшого ashift’y буде більше зайнятого місця. В середньому (якщо порівнювати з ashift=9) це буде в 3 рази більше зайнятого місця. Тому, при виборі ashift треба бути уважним. Головний нюанс в тому, що ashift можна змінити лише при створенні zfs pool.
12=4096). Для старих дисків все ще використовується ashift = 9. Чим більше ashift тим буде продуктивніше працювати пул, бо за 1 раз буде більше зчитуватися даних. Але є і інша сторона – зайняте місце. Справа в тому, що якщо у вас багато маленьких файлів, по декілька КБ, то при виборі більшого ashift’y буде більше зайнятого місця. В середньому (якщо порівнювати з ashift=9) це буде в 3 рази більше зайнятого місця. Тому, при виборі ashift треба бути уважним. Головний нюанс в тому, що ashift можна змінити лише при створенні zfs pool.
Читати далі →
Цей запис оприлюднено у Misc, staff, other о автором skeletor.В данній статті розглянемо, як можна логувати сесії NAT в різних файерволах.
iptables
Тут є декілька варіантів, почнемо з найнадійнішого:
conntrack -E --event-mask NEW --any-nat >> /var/log/nat_log
Є ще класичний варіант
iptables -t nat -I PREROUTING 1 -j LOG
iptables -t nat -I POSTROUTING 1 -j LOG
iptables -t nat -I OUTPUT 1 -j LOG
але, як пишуть у мережі, частина пакетів може не попадати в лог, якщо використовувати маркування або додаткову обробку.
pf
Є застарілий проект , який працює виключно на BSD-системах (на Solaris – ні)
ipfw
Тут мені не вдалося нічого знайти.
Цей запис оприлюднено у Misc, staff, other, Routers, GW, Internet о автором skeletor.Зʼявилася задача повідомляти про ticket’и jira у slack. На вигляд завдання просте, але є нюанси. google каже, що треба створити новий app у slack’y, згенерувати webhook URL, створити новий webhook у jira вставити його туди.
І… воно не працює. Точніше, якщо тестово відправлєш через curl, то все приходить у slack, а якщо через jira – то отримуєш 400 помилку. Щоб дізнатися, що саме не так, треба ввімкнути debug для webhook’ів у jira. Робиться це так:
Робиться це так:
Читати далі →
Цей запис оприлюднено у Misc, staff, other, www о автором skeletor.Нещодавно до мене звернувся один користувач з проблемою SPF. Його поштовий сервер видава помилку на прийом пошти від одного домену baddomain.com:
Not authorized by SPF
При цьому, клієнт каже, що якщо перевірити цей baddomain.com на https://mxtoolbox.com, то там немає жодної помилки.
Читати далі →
Цей запис оприлюднено у Mail systems, Misc, staff, other о автором skeletor.Знайшов нещодавно досить цікавий проект, який дозволяє використовувати потужності віддаленого сервера, не встановлюючи при цьому ПЗ (програмного забезпечення) на ньому.
Припустимо, у вас є якесь ПЗ, але вам не вистачає потужності поточного серверу, але є інший сервер. При цьому, на іншому потужнішому сервері зовсім не треба ставити це ПЗ, достатньо поставити лише outrun:
При цьому, на іншому потужнішому сервері зовсім не треба ставити це ПЗ, достатньо поставити лише outrun:
pip3 install outrun
Які обмеження при використанні:
- Linux only (насправді, можна ще і BSD, але можуть бути нюанси)
- підтримка fuse (ось із-за цього і обмеження Linux/BSD)
- ssh root access (так, бо після запуску на віддаленій машині виконується chroot)
Домашня сторінка
Цей запис оприлюднено у Linux, Misc, staff, other о автором skeletor.Reddit — Погрузитесь во что угодно
Привет — я не могу найти четкого ответа на этот вопрос в Интернете. Кажется, что нет жестких правил, больше похоже на рекомендации, когда речь идет о raidz2 и ширине вашего виртуального устройства.
У нас есть система ZFS с использованием raidz2 с 27 дисками.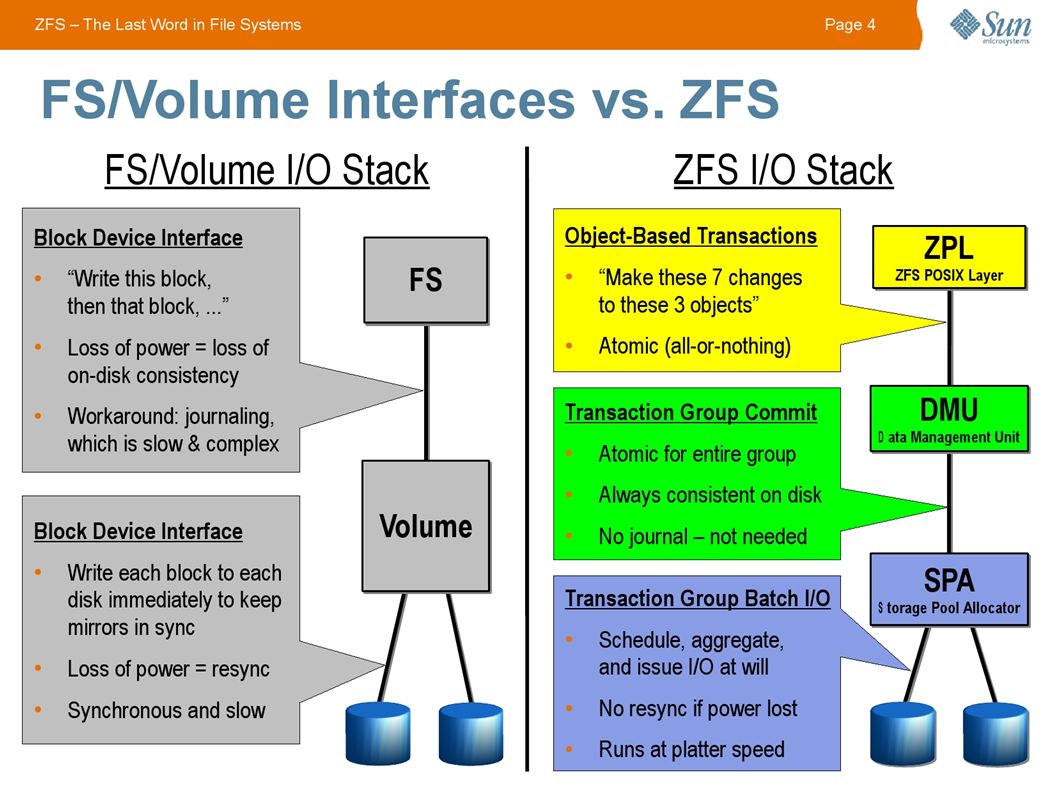 Это случилось недавно:
Это случилось недавно:
конфигурация:
ИМЯ СОСТОЯНИЕ ЧТЕНИЕ ЗАПИСЬ CKSUM
zpool ДЕГРАДИРОВАН 0 0 0
raidz2-0 ДЕГРАДАЦИЯ 0 0 0
sda УДАЛЕНО 0 0 0 (повторное серебрение)
sdb DEGRADED 0 0 0 слишком много ошибок
sdc DEGRADED 0 0 0 слишком много ошибок
sdd DEGRADED 0 0 0 слишком много ошибок
sde DEGRADED 0 0 0 слишком много ошибок
sdf DEGRADED 0 0 0 слишком много ошибок
sdg DEGRADED 0 0 0 слишком много ошибок
sdh DEGRADED 0 0 0 слишком много ошибок
sdi DEGRADED 0 0 0 слишком много ошибок
sdj DEGRADED 0 0 0 слишком много ошибок
sdk DEGRADED 0 0 0 слишком много ошибок
sdl DEGRADED 0 0 0 слишком много ошибок
sdm DEGRADED 0 0 0 слишком много ошибок
sdn DEGRADED 0 0 0 слишком много ошибок
sdo DEGRADED 0 0 0 слишком много ошибок
sdp DEGRADED 0 0 0 слишком много ошибок
sdq DEGRADED 0 0 0 слишком много ошибок
sdr DEGRADED 0 0 0 слишком много ошибок
sds DEGRADED 0 0 0 слишком много ошибок
sdt DEGRADED 0 0 0 слишком много ошибок
sdu DEGRADED 0 0 0 слишком много ошибок
sdv DEGRADED 0 0 0 слишком много ошибок
sdw DEGRADED 0 0 0 слишком много ошибок
sdx DEGRADED 0 0 0 слишком много ошибок
sdz DEGRADED 0 0 0 слишком много ошибок
sdaa DEGRADED 0 0 0 слишком много ошибок
sdab ОНЛАЙН 0 0 9(повторное серебрение)
запчасти
sdal FAULTED поврежденные данные
ошибки: 20595 ошибок данных, используйте '-v' для списка
Недавно у нас произошел сбой двух дисков, и повторная обработка, похоже, привела к сбою всего пула. Мы собираемся разрушить бассейн и восстановить его.
Мы собираемся разрушить бассейн и восстановить его.
Из того, что я прочитал, я придерживаюсь мнения, что у нас должно быть несколько vdev-устройств raidz2 вместо одного гигантского, подобного этому. Таким образом, когда один из них выходит из строя, он не переводит весь пул в автономный режим и/или не делает сервер неработоспособным/невыносимо медленным, когда он перестраивается.
Я прав в этом мышлении?
Является ли этот единственный 27-дисковый vdev причиной того, что повторное использование серебра так и не было завершено?
Разве несколько vdev не обеспечивают лучшую производительность записи благодаря тому, как работает ZFS?
Я читал, что ваш vdev не должен быть «слишком широким» — конечно, это случай слишком широкого?
Не было бы лучше, если бы у нас были эти диски в 3 виртуальных устройствах, например.

.
рейдз2-0 сда сдб sdc и т. д. рейдз2-1 sdf СДГ шдх и т. д. рейдз2-3 сдкс сды сдз и т. д.
Мой коллега хочет максимально увеличить пространство для хранения, но я не хочу, чтобы это повторилось. Если место для хранения является проблемой, нам нужно купить больше места для хранения.
Раньше у нас была эта установка в зеркале, и это работало фантастически. Но, очевидно, это уменьшило наши возможности вдвое. например
зеркало0 сда сдб зеркало 1 sdc сдд зеркало2 сде sdf зеркало3 СДГ шдх зеркало4 сди sdj и т. д...
ZFS RAIDZ2 — достижение 157 ГБ/с
ZFS RAIDZ2 — достижение 157 ГБ/с
Обновление: см. примечание 5 ниже. 157 ГБ/с — это вводящая в заблуждение пропускная способность из-за того, как библиотека fio lib обрабатывает параметр —filename. Фактическая пропускная способность составляет примерно 22 ГБ/с, что все еще очень впечатляет.
Я построил новый сервер, который также будет использоваться в качестве NAS. Он состоит из 8 NVMe-накопителей Samsung (970 Evo 2 ТБ) общей емкостью 10,2 ТБ в конфигурации RAIDZ2 (резервирование на 2 диска).
Спецификации сервера:
| Спецификации сервера Neil’s Lab | |
|---|---|
| Модель процессора | Intel® Xeon® Gold 6326, 16 ядер (32 потока), 2,90 ГГц (базовая), 3,50 ГГц (турбо) |
| Охладитель процессора | Noctua NH-U12S DX-4189 |
| Материнская плата | Супермикро X12SPi |
| ОЗУ | Samsung 6×16 ГБ (96 ГБ) DDR4-3200 RDIMM ECC PC4-25600R двухранговый |
| Сетевая карта (на плате) | Intel X550 2x 10G Base-T |
| Сетевая карта (PCIe) | Супермикро AOC-SGP-I4 4x 1GbE |
| ОС NVMe | 2×1 ТБ (2 ТБ) Samsung 970 Pro |
| Носитель ОС NVMe | Supermicro AOC-SLG3-2M2 PCIe x8 |
| Сетевой накопитель NVMe | 8×2 ТБ (16 ТБ) Samsung 970 Evo |
| Носитель NAS NVMe | 2x Quad Gigabyte GC-4XM2G4 PCIe x16 |
| Блок питания | EVGA 750 Вт 210-GQ-0750-V1 |
| Шасси | NZXT H510i поток |
Разделение PCIe
Я использую 2 платы-носителя Gigabyte GC-4XM2G4 PCIe M. 2, каждая из которых может вмещать до 4 дисков NVMe. Эти карты имеют родной режим бифуркации
2, каждая из которых может вмещать до 4 дисков NVMe. Эти карты имеют родной режим бифуркации 4x4x4x4 в Supermicro BIOS. Это означает, что они представлены операционной системе как отдельные 4-канальные устройства PCIe, в отличие от карт HBA или RAID. Все 32 линии PCIe напрямую подключены к вводу-выводу ЦП, без необходимости проходить через набор микросхем южного моста.
Создание рейда ZFS на сервере Ubuntu 20.04:
Все диски NVMe находятся в режиме PCIe Passthrough на VMWare ESXi:
VMWare ESXi PCIe Passthrough ConfigurationУстановка утилит ZFS:
sudo apt установить zfsutils-linux
Проверить, установлен ли он:
[электронная почта защищена]:~$ lsmod | grep zfs зфс 4034560 6 зуникод 331776 1 zfs zlua 147456 1 zfs завл 16384 1 зфс icp 303104 1 zfs zобщий 2 zfs, icp znvpair 81920 2 zfs, zобщий spl 126976 5 zfs, icp, znvpair, zcommon, zavl
Проверить физические диски:
[электронная почта защищена]:~$ lsblk НАИМЕНОВАНИЕ MAJ:MIN RM РАЗМЕР RO ТИП ТОЧКА КРЕПЛЕНИЯ loop0 7:0 0 70.
 3M 1 цикл /snap/lxd/21029
loop1 7:1 0 55.4M 1 цикл /snap/core18/2128
loop2 7:2 0 32.3M 1 цикл /snap/snapd/12704
sda 8:0 0 100G 0 диск
├─sda1 8:1 0 1M 0 часть
├─sda2 8:2 0 1G 0 часть /загрузка
└─sda3 8:3 0 99G 0 часть
└─ubuntu--vg-ubuntu--lv 253:0 0 99G 0 lvm /
nvme0n1 259:0 0 1.8T 0 диск
nvme5n1 259:1 0 1.8T 0 диск
nvme4n1 259:2 0 1.8T 0 диск
nvme2n1 259:3 0 1.8T 0 диск
nvme1n1 259:4 0 1.8T 0 диск
nvme6n1 259:5 0 1.8T 0 диск
nvme3n1 259:6 0 1.8T 0 диск
nvme7n1 259:7 0 1.8T 0 диск
3M 1 цикл /snap/lxd/21029
loop1 7:1 0 55.4M 1 цикл /snap/core18/2128
loop2 7:2 0 32.3M 1 цикл /snap/snapd/12704
sda 8:0 0 100G 0 диск
├─sda1 8:1 0 1M 0 часть
├─sda2 8:2 0 1G 0 часть /загрузка
└─sda3 8:3 0 99G 0 часть
└─ubuntu--vg-ubuntu--lv 253:0 0 99G 0 lvm /
nvme0n1 259:0 0 1.8T 0 диск
nvme5n1 259:1 0 1.8T 0 диск
nvme4n1 259:2 0 1.8T 0 диск
nvme2n1 259:3 0 1.8T 0 диск
nvme1n1 259:4 0 1.8T 0 диск
nvme6n1 259:5 0 1.8T 0 диск
nvme3n1 259:6 0 1.8T 0 диск
nvme7n1 259:7 0 1.8T 0 диск
При желании проверьте наличие плохих блочных секторов на диске (я пропустил этот шаг, так как он занимает много времени):
плохие блоки sudo -b 512 -sw /dev/nvme7n1 Тестирование с паттерном 0xaa: выполнено 3,68%, прошло 0:57. (0/0/0 ошибок)
Найти диски по ID:
[электронная почта защищена]:~$ ls -lh /dev/disk/by-id lrwxrwxrwx 1 root root 10 Dec 6 04:45 dm-name-ubuntu--vg-ubuntu--lv -> ../../dm-0 lrwxrwxrwx 1 root root 10 6 декабря 04:45 dm-uuid-LVM-Iw3mFxuF9uwlCMJ0yucrWHZwG82z1I6uX0tK6D7CT0Yfb4GXANWiCSjy3E4BoNos -> .
 ./../dm-0
lrwxrwxrwx 1 root root 10 6 декабря 04:45 lvm-pv-uuid-In8DDs-U2jd-TdgQ-BZM3-iACR-HPF3-PT61BX -> ../../sda3
lrwxrwxrwx 1 root root 13 6 декабря 04:45 nvme-eui.00253858119138c7 -> ../../nvme1n1
lrwxrwxrwx 1 root root 13 6 декабря 05:12 nvme-eui.00253858119138ca -> ../../nvme7n1
lrwxrwxrwx 1 root root 13 6 декабря 04:45 nvme-eui.0025385811913a89 -> ../../nvme5n1
lrwxrwxrwx 1 root root 13 6 декабря 04:45 nvme-eui.002538581191b1f1 -> ../../nvme3n1
lrwxrwxrwx 1 root root 13 6 декабря 04:45 nvme-eui.002538581191b32b -> ../../nvme4n1
lrwxrwxrwx 1 root root 13 6 декабря 04:45 nvme-eui.002538581191c362 -> ../../nvme6n1
lrwxrwxrwx 1 root root 13 6 декабря 04:45 nvme-eui.002538581191c369 -> ../../nvme0n1
lrwxrwxrwx 1 root root 13 6 декабря 04:45 nvme-eui.002538581191c472 -> ../../nvme2n1
./../dm-0
lrwxrwxrwx 1 root root 10 6 декабря 04:45 lvm-pv-uuid-In8DDs-U2jd-TdgQ-BZM3-iACR-HPF3-PT61BX -> ../../sda3
lrwxrwxrwx 1 root root 13 6 декабря 04:45 nvme-eui.00253858119138c7 -> ../../nvme1n1
lrwxrwxrwx 1 root root 13 6 декабря 05:12 nvme-eui.00253858119138ca -> ../../nvme7n1
lrwxrwxrwx 1 root root 13 6 декабря 04:45 nvme-eui.0025385811913a89 -> ../../nvme5n1
lrwxrwxrwx 1 root root 13 6 декабря 04:45 nvme-eui.002538581191b1f1 -> ../../nvme3n1
lrwxrwxrwx 1 root root 13 6 декабря 04:45 nvme-eui.002538581191b32b -> ../../nvme4n1
lrwxrwxrwx 1 root root 13 6 декабря 04:45 nvme-eui.002538581191c362 -> ../../nvme6n1
lrwxrwxrwx 1 root root 13 6 декабря 04:45 nvme-eui.002538581191c369 -> ../../nvme0n1
lrwxrwxrwx 1 root root 13 6 декабря 04:45 nvme-eui.002538581191c472 -> ../../nvme2n1
Создайте файл /etc/zfs/vdev_id.conf и добавьте следующие псевдонимы:
псевдоним nvme0 /dev/disk/by-id/nvme-Samsung_SSD_970_EVO_Plus_2TB_S59CNM0R849603J псевдоним nvme1 /dev/disk/by-id/nvme-Samsung_SSD_970_EVO_Plus_2TB_S59CNM0R835621F псевдоним nvme2 /dev/disk/by-id/nvme-Samsung_SSD_970_EVO_Plus_2TB_S59CNM0R849868J псевдоним nvme3 /dev/disk/by-id/nvme-Samsung_SSD_970_EVO_Plus_2TB_S59CNM0R846665V псевдоним nvme4 /dev/disk/by-id/nvme-Samsung_SSD_970_EVO_Plus_2TB_S59CNM0R846979M псевдоним nvme5 /dev/disk/by-id/nvme-Samsung_SSD_970_EVO_Plus_2TB_S59CNM0R836071F псевдоним nvme6 /dev/disk/by-id/nvme-Samsung_SSD_970_EVO_Plus_2TB_S59CNM0R849596Y псевдоним nvme7 /dev/disk/by-id/nvme-Samsung_SSD_970_EVO_Plus_2TB_S59CNM0R835624D
Запустите sudo udevadm trigger или просто перезагрузите компьютер. Псевдонимы, которые мы создали, теперь будут отображаться под
Псевдонимы, которые мы создали, теперь будут отображаться под /dev/disk/by-vdev 9.0143 .
[электронная почта защищена]:~$ ls -lh /dev/disk/by-vdev
lrwxrwxrwx 1 root root 13 6 декабря 05:35 nvme0 -> ../../nvme0n1
lrwxrwxrwx 1 root root 13 6 декабря 05:35 nvme1 -> ../../nvme1n1
lrwxrwxrwx 1 root root 13 6 декабря 05:35 nvme2 -> ../../nvme2n1
lrwxrwxrwx 1 root root 13 6 декабря 05:35 nvme3 -> ../../nvme3n1
lrwxrwxrwx 1 root root 13 6 декабря 05:35 nvme4 -> ../../nvme4n1
lrwxrwxrwx 1 root root 13 6 декабря 05:35 nvme5 -> ../../nvme5n1
lrwxrwxrwx 1 корень корень 13 дек 6 05:35 nvme6 -> ../../nvme6n1
lrwxrwxrwx 1 root root 13 6 декабря 05:35 nvme7 -> ../../nvme7n1
Создать zpool .
[электронная почта защищена]:/dev/disk/by-vdev$ ls
nvme0 nvme1 nvme2 nvme3 nvme4 nvme5 nvme6 nvme7
[электронная почта защищена]:/dev/disk/by-vdev$ sudo zpool create tank raidz2 nvme0 nvme1 nvme2 nvme3 nvme4 nvme5 nvme6 nvme7
[электронная почта защищена]:/dev/disk/by-vdev$ статус zpool
бассейн: танк
состояние: ОНЛАЙН
скан: не запрошено
конфигурация:
ИМЯ СОСТОЯНИЕ ЧТЕНИЕ ЗАПИСЬ CKSUM
бак ОНЛАЙН 0 0 0
raidz2-0 ОНЛАЙН 0 0 0
nvme0 ОНЛАЙН 0 0 0
nvme1 ОНЛАЙН 0 0 0
nvme2 ОНЛАЙН 0 0 0
nvme3 ОНЛАЙН 0 0 0
nvme4 ОНЛАЙН 0 0 0
nvme5 ОНЛАЙН 0 0 0
nvme6 ОНЛАЙН 0 0 0
nvme7 ОНЛАЙН 0 0 0
ошибки: Нет известных ошибок данных
[электронная почта защищена]:/dev/disk/by-vdev$
Для подробного состояния запустите zpool list -v :
[электронная почта защищена]:/dev/disk/by-id$ zpool list -v
НАЗВАНИЕ РАЗМЕР ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
бак 14. 5T 274K 14.5T - - 0% 0% 1.00x ОНЛАЙН -
raidz2 14.5T 274K 14.5T - - 0% 0.00% - ОНЛАЙН
nvme0 - - - - - - - - ОНЛАЙН
nvme1 - - - - - - - - ОНЛАЙН
nvme2 - - - - - - - - ОНЛАЙН
nvme3 - - - - - - - - ОНЛАЙН
nvme4 - - - - - - - - ОНЛАЙН
nvme5 - - - - - - - - ОНЛАЙН
nvme6 - - - - - - - - ОНЛАЙН
nvme7 - - - - - - - - ОНЛАЙН
 5T 274K 14.5T - - 0% 0% 1.00x ОНЛАЙН -
raidz2 14.5T 274K 14.5T - - 0% 0.00% - ОНЛАЙН
nvme0 - - - - - - - - ОНЛАЙН
nvme1 - - - - - - - - ОНЛАЙН
nvme2 - - - - - - - - ОНЛАЙН
nvme3 - - - - - - - - ОНЛАЙН
nvme4 - - - - - - - - ОНЛАЙН
nvme5 - - - - - - - - ОНЛАЙН
nvme6 - - - - - - - - ОНЛАЙН
nvme7 - - - - - - - - ОНЛАЙН
5T 274K 14.5T - - 0% 0% 1.00x ОНЛАЙН -
raidz2 14.5T 274K 14.5T - - 0% 0.00% - ОНЛАЙН
nvme0 - - - - - - - - ОНЛАЙН
nvme1 - - - - - - - - ОНЛАЙН
nvme2 - - - - - - - - ОНЛАЙН
nvme3 - - - - - - - - ОНЛАЙН
nvme4 - - - - - - - - ОНЛАЙН
nvme5 - - - - - - - - ОНЛАЙН
nvme6 - - - - - - - - ОНЛАЙН
nvme7 - - - - - - - - ОНЛАЙН
Отлично. Теперь у нас есть zpool .
Создайте файловую систему ZFS:
Теперь, когда у нас есть zpool с именем tank , мы можем создать файловую систему, включить сжатие lz4 и смонтировать ее для тестирования производительности:
[электронная почта защищена]:/dev/disk/by-vdev$ sudo zfs create tank/fs
[электронная почта защищена]:/dev/disk/by-vdev$ список zfs
ИМЯ ИСПОЛЬЗУЕТСЯ ДОСТУПНО ССЫЛКА ТОЧКА МОНТАЖА
танк 229К 10.5Т 47.1К /танк
танк/фс 47.1К 10.5Т 47.1К /танк/фс
[электронная почта защищена]:/dev/disk/by-vdev$ sudo zfs установить сжатие=lz4 tank/fs
[электронная почта защищена]:/dev/disk/by-vdev$ sudo zfs set mountpoint=/home/neil/mnt/disk tank
Отлично. У нас должна быть файловая система
У нас должна быть файловая система fs , расположенная по адресу ~/mnt/disk/fs .
Тестирование производительности с использованием FIO:
Комплект тестирования FIO весьма удобен для выполнения всех видов тестирования ввода-вывода.
Установить инструменты FIO:
sudo apt установить фио
И запустите тест с размером блока 512k и 28 воркерами:
sudo fio --name=read_test \
--filename=/home/neil/mnt/disk/dummy \
--filesize=20G \
--ioengine=libaio \
--direct=1 \
--синхронизация=1 \
--bs=512k \
--иоглубина=1 \
--rw=читать \
--numjobs=28 \
--group_reporting
157 ГБ/с — это безумие (последовательное чтение). Это со сжатием lz4 и конфигурацией RAIDZ2! Запустить службу обмена, такую как nfs , afp или smb в Ubuntu, несложно. Нет необходимости в FreeNAS или TrueNAS.
Тест диска FIO — 157 ГБ/с при последовательном чтении Я не думаю, что мы близки к насыщению пропускной способности PCIe, но использование большего количества виртуальных ЦП не помогает с пропускной способностью. Таким образом, это может быть связано с ограничениями контроллеров NVMe.
Надеюсь, этот NAS прослужит лет десять или около того. ZFS очень портативна, и даже если я потеряю образ VMWare ESXi или что-то пойдет не так с системой, я могу вытащить карты PCIe, содержащие диски NVMe, вставить их в другую систему, и она будет работать.
Это ни в коем случае не комплексный тест диска. Я возился со многими различными ручками: numjobs , blocksize , direct , sync и т. д. Большинство тестов были на скорости около 70-100 ГБ/с при последовательном чтении. Я подозреваю, что часть скорости связана с кэшированием в оперативной памяти, что объясняет абсурдность 157 ГБ/с. Что ж, еще более впечатляет то, что ZFS может это делать! YMMV.
Я бы хотел провести более полный тест, но эта штука должна быть постоянно смонтирована, и мне нужно перенести данные с ужасного [1] QNAP NAS. Он издает сварливые звуки SATA.
Спасибо Уиллу Ягеру и Стиву Раффу за помощь в этом приключении!
[1] Не из-за производительности, а из-за того, насколько он действительно раздут. Загрузка занимает буквально 10 минут. С такой высокой поверхностью атаки (все виды приложений, докеров, плагинов, QNAP-облачных штуковин и т. д.) это совершенно нелепо, и я не могу дождаться, чтобы избавиться от него.
Примечание 1
Я не уверен, я думаю, что некоторые из них кэшируются в оперативной памяти. Я провел более продолжительный тест и получил около 70 ГБ/с с файлом размером 200 ГБ — это определенно больше, чем 64 ГБ ОЗУ. Это связано с компрессией lz4? Извлечение меньших блоков с диска, а затем их распаковка, что увеличивает пропускную способность?
Исходный файл был создан с параметром fio rw=randwrite, поэтому фиктивные данные являются случайными. Я проверил с помощью ext4 fs на одном диске NVMe, и независимо от того, какие ручки я поворачиваю, я получаю около 3,5 ГБ/с.
Примечание 2
Я только что провел еще один тест файлов объемом 100 ГБ с помощью fio, полный дамп, как показано ниже, получил около 80 ГБ/с. Этот тест был запущен заново после перезагрузки системы и очистки диска (без кеша). Как это работает?:
[электронная почта защищена]:~/mnt/disk/fs$ sudo fio --name=read_test --filename=/home/neil/mnt/disk/fs/dummy --filesize=100G - -ioengine=libaio --direct=1 --sync=1 --bs=512k --iodepth=1 --rw=read --numjobs=28 --group_reporting
read_test: (g=0): rw=read, bs=(R) 512 КБ-512 КБ, (W) 512 КБ-512 КБ, (T) 512 КБ-512 КБ, ioengine=libaio, iodepth=1
...
фио-3.16
Запуск 28 процессов
read_test: Разметка файла IO (1 файл / 102400МиБ)
Задания: 28 (f=28): [R(28)][100,0%][r=78,0ГиБ/с][r=160k IOPS][эта 00м:00с]
read_test: (groupid = 0, jobs = 28): err = 0: pid = 405516: понедельник, 13 декабря, 06:00:25 2021
чтение: IOPS=152k, BW=74,4GiB/s (790,8 ГБ/с) (2800 ГБ/37653 мс)
планка (usec): мин. =20, макс.=107934, среднее=180,88, стандартное отклонение=1535,31
clat (нсек): мин.=248, макс.=9018,5 тыс., среднее=1114,70, стандартное отклонение=9262,53
lat (usec): min=20, max=107938, avg=182,57, stdev=1535,47
процентили клата (нсек):
| 1.00=[334], 5.00=[422], 10.00=[494], 20.00=[620],
| 30.00=[708], 40.00=[796], 50.00=[892], 60.00=[996],
| 70.00=[ 1112], 80.00=[ 1272], 90.00=[ 1512], 95.00=[ 1768],
| 99.00th=[ 2800], 99,50=[8640], 99,90=[32128], 99,95=[47872],
| 99,99=[116224]
bw ( МиБ / с): мин = 46896, макс = 93840, per = 99,96%, avg = 76117,26, стандартное отклонение = 463,15, выборки = 2100
IOPS: мин.=93792, макс.=187680, среднее=152233,31, стандартное отклонение=926,29, выборки=2100
широта (нс): 250 = 0,01%, 500 = 10,55%, 750 = 23,97%, 1000 = 25,87%
лат (усек): 2 = 36,82%, 4 = 2,02%, 10 = 0,35%, 20 = 0,24%, 50 = 0,14%
лат (усек): 100=0,03%, 250=0,01%, 500=0,01%, 750=0,01%, 1000=0,01%
широта (мс): 2 = 0,01%, 4 = 0,01%, 10 = 0,01%
процессор: usr=1,59%, sys=54,53%, ctx=3119239, majf=0, minf=3916
Глубина ввода-вывода: 1=100,0%, 2=0,0%, 4=0,0%, 8=0,0%, 16=0,0%, 32=0,0%, >=64=0,0%
отправить: 0=0,0%, 4=100,0%, 8=0,0%, 16=0,0%, 32=0,0%, 64=0,0%, >=64=0,0%
завершено: 0=0,0%, 4=100,0%, 8=0,0%, 16=0,0%, 32=0,0%, 64=0,0%, >=64=0,0%
выпущено rwts: всего=5734400,0,0,0 коротко=0,0,0,0 удалено=0,0,0,0
задержка: цель = 0, окно = 0, процентиль = 100,00%, глубина = 1
Выполнить группу состояния 0 (все задания):
ЧТЕНИЕ: bw=74,4 ГБ/с (79,8 ГБ/с), 74,4 ГБ/с-74,4 ГБ/с (790,8 ГБ/с-79,8 ГБ/с), io=2800 ГБ (3006 ГБ), run=37653-37653 мс
[электронная почта защищена]:~/mnt/disk/fs$
Примечание 3
Запуск всей виртуальной машины с 2 ГБ ОЗУ раскрывает историю. Cbs: 28 (f=28): [R(28)][22,6%][r=17,5ГиБ/с][r=35,9k IOPS][эта 02 мин:55 с]
fio: завершение по сигналу 2
read_test: (groupid = 0, jobs = 28): err = 0: pid = 4712: понедельник, 13 декабря, 06:11:57 2021
чтение: IOPS = 41,2 тыс., BW = 20,1 ГБ/с (21,6 ГБ/с) (1042 ГБ/51742 мс)
планка (usec): мин.=22, макс.=115406, среднее=674,35, стандартное отклонение=1331,96
clat (нсек): мин.=296, макс.=7427,7 тыс., среднее=1850,79, стандартное отклонение=14919,02
lat (usec): min=23, max=115409, avg=677,17, stdev=1332,58
процентили клата (нсек):
| 1.00th=[ 548], 5.00th=[ 676], 10.00th=[772], 20.00th=[916],
| 30.00=[ 1032], 40.00=[ 1176], 50.00=[ 1320], 60.00=[ 1496],
| 70.00=[ 1688], 80.00=[ 1944], 90.00=[ 2320], 95.00=[ 2672],
| 99,00=[7584], 99,50=[14656], 99,90=[88576], 99,95=[144384],
| 99,99=[301056]
bw ( МиБ / с): мин = 11908, макс = 59509, per = 100,00%, среднее = 20627,88, стандартное отклонение = 256,00, образцы = 2884
IOPS: минимум = 23815, максимум = 119018, средний = 41255,16, стандартное отклонение = 512,00, образцы = 2884
широта (нс): 500 = 0,49%, 750 = 8,39%, 1000 = 18,05%
лат (усек): 2 = 55,11%, 4 = 16,39%, 10 = 0,82%, 20 = 0,35%, 50 = 0,21%
лат (усек): 100=0,10%, 250=0,07%, 500=0,01%, 750=0,01%, 1000=0,01%
широта (мс): 2 = 0,01%, 4 = 0,01%, 10 = 0,01%
процессор: usr=0,66%, sys=25,64%, ctx=4108148, majf=0, minf=3923
Глубина ввода-вывода: 1=100,0%, 2=0,0%, 4=0,0%, 8=0,0%, 16=0,0%, 32=0,0%, >=64=0,0%
отправить: 0=0,0%, 4=100,0%, 8=0,0%, 16=0,0%, 32=0,0%, 64=0,0%, >=64=0,0%
завершено: 0=0,0%, 4=100,0%, 8=0,0%, 16=0,0%, 32=0,0%, 64=0,0%, >=64=0,0%
выпущено rwts: всего = 2133831,0,0,0 коротко = 0,0,0,0 удалено = 0,0,0,0
задержка: цель = 0, окно = 0, процентиль = 100,00%, глубина = 1
Выполнить группу состояния 0 (все задания):
ЧТЕНИЕ: bw=20,1 ГБ/с (21,6 ГБ/с), 20,1 ГБ/с – 20,1 ГБ/с (21,6 ГБ/с – 21,6 ГБ/с), io=1042 ГБ (1119 ГБ/с). ГБ), пробег=51742-51742 мс
[электронная почта защищена]:~/mnt/disk/fs$
Note 4
Вращение lz4 сжатие особой разницы не дало.
Последний вход: Пн, 13 декабря, 06:09:18 2021 из 10.0.0.42
[электронная почта защищена]:~$ sudo zfs установить сжатие=off tank/fs
[sudo] пароль для Нила:
[электронная почта защищена]:~$ sudo fio --name=read_test --filename=/home/neil/mnt/disk/fs/dummy --filesize=100G --ioengine=libaio --direct=1 --sync=1 --bs=512k --iodepth=1 --rw=read --numjobs=28 --group_reporting
read_test: (g=0): rw=read, bs=(R) 512 КБ-512 КБ, (W) 512 КБ-512 КБ, (T) 512 КБ-512 КБ, ioengine=libaio, iodepth=1
...
фио-3.16
Запуск 28 процессов
Задания: 28 (f=28): [R(28)][100,0%][r=78,4ГиБ/с][r=161k IOPS][эта 00м:00с]
read_test: (groupid=0, jobs=28): err=0: pid=4520: Пн, 13 декабря, 06:29:25 2021
чтение: IOPS = 156 тыс., BW = 76,2 ГБ/с (81,8 ГБ/с) (2800 ГБ/36751 мс)
планка (usec): мин.=19, макс.=105788, среднее=176,71, стандартное отклонение=1535,16
clat (нсек): мин. =247, макс.=16074k, среднее=993,84, стандартное отклонение=11978,23
lat (usec): мин.=20, макс.=105793, среднее=178,24, стандартное отклонение=1535,33
процентили клата (нсек):
| 1.00=[330], 5.00=[398], 10.00=[462], 20.00=[564],
| 30.00=[ 644], 40.00=[ 716], 50.00=[ 788], 60.00=[ 884],
| 70.00=[988], 80.00=[1128], 90.00=[1352], 95.00=[ 1576],
| 99,00=[2256], 99,50=[4448], 99,90=[27776], 99,95=[47872],
| 99,99=[128512]
bw (МиБ/с): мин.=20186, макс.=96350, per=100,00%, среднее=78083,60, стандартное отклонение=532,92, образцы=2044
IOPS: минимум = 40373, максимум = 192700, средний = 156166,03, стандартное отклонение = 1065,84, выборки = 2044
широта (нсек): 250=0,01%, 500=13,73%, 750=31,22%, 1000=25,80%
лат (усек): 2 = 27,66%, 4 = 1,06%, 10 = 0,22%, 20 = 0,16%, 50 = 0,09%
лат (усек): 100=0,03%, 250=0,01%, 500=0,01%, 750=0,01%, 1000=0,01%
широта (мс): 2 = 0,01%, 4 = 0,01%, 10 = 0,01%, 20 = 0,01%
процессор: usr=1,54%, sys=54,57%, ctx=2605775, majf=0, minf=3927
Глубина ввода-вывода: 1=100,0%, 2=0,0%, 4=0,0%, 8=0,0%, 16=0,0%, 32=0,0%, >=64=0,0%
отправить: 0=0,0%, 4=100,0%, 8=0,0%, 16=0,0%, 32=0,0%, 64=0,0%, >=64=0,0%
завершено: 0=0,0%, 4=100,0%, 8=0,0%, 16=0,0%, 32=0,0%, 64=0,0%, >=64=0,0%
выпущено rwts: всего=5734400,0,0,0 коротко=0,0,0,0 удалено=0,0,0,0
задержка: цель = 0, окно = 0, процентиль = 100,00%, глубина = 1
Выполнить группу состояния 0 (все задания):
ЧТЕНИЕ: bw=76,2 ГБ/с (81,8 ГБ/с), 76,2 ГБ/с-76,2 ГБ/с (81,8 ГБ/с-81,8 ГБ/с), io=2800 ГБ (3006 ГБ), run=36751-36751 мс
[электронная почта защищена]:~$
Note 5
Мне удалось докопаться до сути этого безумия.

 Я проверил с помощью ext4 fs на одном диске NVMe, и независимо от того, какие ручки я поворачиваю, я получаю около 3,5 ГБ/с.
Я проверил с помощью ext4 fs на одном диске NVMe, и независимо от того, какие ручки я поворачиваю, я получаю около 3,5 ГБ/с. =20, макс.=107934, среднее=180,88, стандартное отклонение=1535,31
clat (нсек): мин.=248, макс.=9018,5 тыс., среднее=1114,70, стандартное отклонение=9262,53
lat (usec): min=20, max=107938, avg=182,57, stdev=1535,47
процентили клата (нсек):
| 1.00=[334], 5.00=[422], 10.00=[494], 20.00=[620],
| 30.00=[708], 40.00=[796], 50.00=[892], 60.00=[996],
| 70.00=[ 1112], 80.00=[ 1272], 90.00=[ 1512], 95.00=[ 1768],
| 99.00th=[ 2800], 99,50=[8640], 99,90=[32128], 99,95=[47872],
| 99,99=[116224]
bw ( МиБ / с): мин = 46896, макс = 93840, per = 99,96%, avg = 76117,26, стандартное отклонение = 463,15, выборки = 2100
IOPS: мин.=93792, макс.=187680, среднее=152233,31, стандартное отклонение=926,29, выборки=2100
широта (нс): 250 = 0,01%, 500 = 10,55%, 750 = 23,97%, 1000 = 25,87%
лат (усек): 2 = 36,82%, 4 = 2,02%, 10 = 0,35%, 20 = 0,24%, 50 = 0,14%
лат (усек): 100=0,03%, 250=0,01%, 500=0,01%, 750=0,01%, 1000=0,01%
широта (мс): 2 = 0,01%, 4 = 0,01%, 10 = 0,01%
процессор: usr=1,59%, sys=54,53%, ctx=3119239, majf=0, minf=3916
Глубина ввода-вывода: 1=100,0%, 2=0,0%, 4=0,0%, 8=0,0%, 16=0,0%, 32=0,0%, >=64=0,0%
отправить: 0=0,0%, 4=100,0%, 8=0,0%, 16=0,0%, 32=0,0%, 64=0,0%, >=64=0,0%
завершено: 0=0,0%, 4=100,0%, 8=0,0%, 16=0,0%, 32=0,0%, 64=0,0%, >=64=0,0%
выпущено rwts: всего=5734400,0,0,0 коротко=0,0,0,0 удалено=0,0,0,0
задержка: цель = 0, окно = 0, процентиль = 100,00%, глубина = 1
Выполнить группу состояния 0 (все задания):
ЧТЕНИЕ: bw=74,4 ГБ/с (79,8 ГБ/с), 74,4 ГБ/с-74,4 ГБ/с (790,8 ГБ/с-79,8 ГБ/с), io=2800 ГБ (3006 ГБ), run=37653-37653 мс
[электронная почта защищена]:~/mnt/disk/fs$
=20, макс.=107934, среднее=180,88, стандартное отклонение=1535,31
clat (нсек): мин.=248, макс.=9018,5 тыс., среднее=1114,70, стандартное отклонение=9262,53
lat (usec): min=20, max=107938, avg=182,57, stdev=1535,47
процентили клата (нсек):
| 1.00=[334], 5.00=[422], 10.00=[494], 20.00=[620],
| 30.00=[708], 40.00=[796], 50.00=[892], 60.00=[996],
| 70.00=[ 1112], 80.00=[ 1272], 90.00=[ 1512], 95.00=[ 1768],
| 99.00th=[ 2800], 99,50=[8640], 99,90=[32128], 99,95=[47872],
| 99,99=[116224]
bw ( МиБ / с): мин = 46896, макс = 93840, per = 99,96%, avg = 76117,26, стандартное отклонение = 463,15, выборки = 2100
IOPS: мин.=93792, макс.=187680, среднее=152233,31, стандартное отклонение=926,29, выборки=2100
широта (нс): 250 = 0,01%, 500 = 10,55%, 750 = 23,97%, 1000 = 25,87%
лат (усек): 2 = 36,82%, 4 = 2,02%, 10 = 0,35%, 20 = 0,24%, 50 = 0,14%
лат (усек): 100=0,03%, 250=0,01%, 500=0,01%, 750=0,01%, 1000=0,01%
широта (мс): 2 = 0,01%, 4 = 0,01%, 10 = 0,01%
процессор: usr=1,59%, sys=54,53%, ctx=3119239, majf=0, minf=3916
Глубина ввода-вывода: 1=100,0%, 2=0,0%, 4=0,0%, 8=0,0%, 16=0,0%, 32=0,0%, >=64=0,0%
отправить: 0=0,0%, 4=100,0%, 8=0,0%, 16=0,0%, 32=0,0%, 64=0,0%, >=64=0,0%
завершено: 0=0,0%, 4=100,0%, 8=0,0%, 16=0,0%, 32=0,0%, 64=0,0%, >=64=0,0%
выпущено rwts: всего=5734400,0,0,0 коротко=0,0,0,0 удалено=0,0,0,0
задержка: цель = 0, окно = 0, процентиль = 100,00%, глубина = 1
Выполнить группу состояния 0 (все задания):
ЧТЕНИЕ: bw=74,4 ГБ/с (79,8 ГБ/с), 74,4 ГБ/с-74,4 ГБ/с (790,8 ГБ/с-79,8 ГБ/с), io=2800 ГБ (3006 ГБ), run=37653-37653 мс
[электронная почта защищена]:~/mnt/disk/fs$
 Cbs: 28 (f=28): [R(28)][22,6%][r=17,5ГиБ/с][r=35,9k IOPS][эта 02 мин:55 с]
fio: завершение по сигналу 2
read_test: (groupid = 0, jobs = 28): err = 0: pid = 4712: понедельник, 13 декабря, 06:11:57 2021
чтение: IOPS = 41,2 тыс., BW = 20,1 ГБ/с (21,6 ГБ/с) (1042 ГБ/51742 мс)
планка (usec): мин.=22, макс.=115406, среднее=674,35, стандартное отклонение=1331,96
clat (нсек): мин.=296, макс.=7427,7 тыс., среднее=1850,79, стандартное отклонение=14919,02
lat (usec): min=23, max=115409, avg=677,17, stdev=1332,58
процентили клата (нсек):
| 1.00th=[ 548], 5.00th=[ 676], 10.00th=[772], 20.00th=[916],
| 30.00=[ 1032], 40.00=[ 1176], 50.00=[ 1320], 60.00=[ 1496],
| 70.00=[ 1688], 80.00=[ 1944], 90.00=[ 2320], 95.00=[ 2672],
| 99,00=[7584], 99,50=[14656], 99,90=[88576], 99,95=[144384],
| 99,99=[301056]
bw ( МиБ / с): мин = 11908, макс = 59509, per = 100,00%, среднее = 20627,88, стандартное отклонение = 256,00, образцы = 2884
IOPS: минимум = 23815, максимум = 119018, средний = 41255,16, стандартное отклонение = 512,00, образцы = 2884
широта (нс): 500 = 0,49%, 750 = 8,39%, 1000 = 18,05%
лат (усек): 2 = 55,11%, 4 = 16,39%, 10 = 0,82%, 20 = 0,35%, 50 = 0,21%
лат (усек): 100=0,10%, 250=0,07%, 500=0,01%, 750=0,01%, 1000=0,01%
широта (мс): 2 = 0,01%, 4 = 0,01%, 10 = 0,01%
процессор: usr=0,66%, sys=25,64%, ctx=4108148, majf=0, minf=3923
Глубина ввода-вывода: 1=100,0%, 2=0,0%, 4=0,0%, 8=0,0%, 16=0,0%, 32=0,0%, >=64=0,0%
отправить: 0=0,0%, 4=100,0%, 8=0,0%, 16=0,0%, 32=0,0%, 64=0,0%, >=64=0,0%
завершено: 0=0,0%, 4=100,0%, 8=0,0%, 16=0,0%, 32=0,0%, 64=0,0%, >=64=0,0%
выпущено rwts: всего = 2133831,0,0,0 коротко = 0,0,0,0 удалено = 0,0,0,0
задержка: цель = 0, окно = 0, процентиль = 100,00%, глубина = 1
Выполнить группу состояния 0 (все задания):
ЧТЕНИЕ: bw=20,1 ГБ/с (21,6 ГБ/с), 20,1 ГБ/с – 20,1 ГБ/с (21,6 ГБ/с – 21,6 ГБ/с), io=1042 ГБ (1119 ГБ/с).
Cbs: 28 (f=28): [R(28)][22,6%][r=17,5ГиБ/с][r=35,9k IOPS][эта 02 мин:55 с]
fio: завершение по сигналу 2
read_test: (groupid = 0, jobs = 28): err = 0: pid = 4712: понедельник, 13 декабря, 06:11:57 2021
чтение: IOPS = 41,2 тыс., BW = 20,1 ГБ/с (21,6 ГБ/с) (1042 ГБ/51742 мс)
планка (usec): мин.=22, макс.=115406, среднее=674,35, стандартное отклонение=1331,96
clat (нсек): мин.=296, макс.=7427,7 тыс., среднее=1850,79, стандартное отклонение=14919,02
lat (usec): min=23, max=115409, avg=677,17, stdev=1332,58
процентили клата (нсек):
| 1.00th=[ 548], 5.00th=[ 676], 10.00th=[772], 20.00th=[916],
| 30.00=[ 1032], 40.00=[ 1176], 50.00=[ 1320], 60.00=[ 1496],
| 70.00=[ 1688], 80.00=[ 1944], 90.00=[ 2320], 95.00=[ 2672],
| 99,00=[7584], 99,50=[14656], 99,90=[88576], 99,95=[144384],
| 99,99=[301056]
bw ( МиБ / с): мин = 11908, макс = 59509, per = 100,00%, среднее = 20627,88, стандартное отклонение = 256,00, образцы = 2884
IOPS: минимум = 23815, максимум = 119018, средний = 41255,16, стандартное отклонение = 512,00, образцы = 2884
широта (нс): 500 = 0,49%, 750 = 8,39%, 1000 = 18,05%
лат (усек): 2 = 55,11%, 4 = 16,39%, 10 = 0,82%, 20 = 0,35%, 50 = 0,21%
лат (усек): 100=0,10%, 250=0,07%, 500=0,01%, 750=0,01%, 1000=0,01%
широта (мс): 2 = 0,01%, 4 = 0,01%, 10 = 0,01%
процессор: usr=0,66%, sys=25,64%, ctx=4108148, majf=0, minf=3923
Глубина ввода-вывода: 1=100,0%, 2=0,0%, 4=0,0%, 8=0,0%, 16=0,0%, 32=0,0%, >=64=0,0%
отправить: 0=0,0%, 4=100,0%, 8=0,0%, 16=0,0%, 32=0,0%, 64=0,0%, >=64=0,0%
завершено: 0=0,0%, 4=100,0%, 8=0,0%, 16=0,0%, 32=0,0%, 64=0,0%, >=64=0,0%
выпущено rwts: всего = 2133831,0,0,0 коротко = 0,0,0,0 удалено = 0,0,0,0
задержка: цель = 0, окно = 0, процентиль = 100,00%, глубина = 1
Выполнить группу состояния 0 (все задания):
ЧТЕНИЕ: bw=20,1 ГБ/с (21,6 ГБ/с), 20,1 ГБ/с – 20,1 ГБ/с (21,6 ГБ/с – 21,6 ГБ/с), io=1042 ГБ (1119 ГБ/с). ГБ), пробег=51742-51742 мс
[электронная почта защищена]:~/mnt/disk/fs$
ГБ), пробег=51742-51742 мс
[электронная почта защищена]:~/mnt/disk/fs$  =247, макс.=16074k, среднее=993,84, стандартное отклонение=11978,23
lat (usec): мин.=20, макс.=105793, среднее=178,24, стандартное отклонение=1535,33
процентили клата (нсек):
| 1.00=[330], 5.00=[398], 10.00=[462], 20.00=[564],
| 30.00=[ 644], 40.00=[ 716], 50.00=[ 788], 60.00=[ 884],
| 70.00=[988], 80.00=[1128], 90.00=[1352], 95.00=[ 1576],
| 99,00=[2256], 99,50=[4448], 99,90=[27776], 99,95=[47872],
| 99,99=[128512]
bw (МиБ/с): мин.=20186, макс.=96350, per=100,00%, среднее=78083,60, стандартное отклонение=532,92, образцы=2044
IOPS: минимум = 40373, максимум = 192700, средний = 156166,03, стандартное отклонение = 1065,84, выборки = 2044
широта (нсек): 250=0,01%, 500=13,73%, 750=31,22%, 1000=25,80%
лат (усек): 2 = 27,66%, 4 = 1,06%, 10 = 0,22%, 20 = 0,16%, 50 = 0,09%
лат (усек): 100=0,03%, 250=0,01%, 500=0,01%, 750=0,01%, 1000=0,01%
широта (мс): 2 = 0,01%, 4 = 0,01%, 10 = 0,01%, 20 = 0,01%
процессор: usr=1,54%, sys=54,57%, ctx=2605775, majf=0, minf=3927
Глубина ввода-вывода: 1=100,0%, 2=0,0%, 4=0,0%, 8=0,0%, 16=0,0%, 32=0,0%, >=64=0,0%
отправить: 0=0,0%, 4=100,0%, 8=0,0%, 16=0,0%, 32=0,0%, 64=0,0%, >=64=0,0%
завершено: 0=0,0%, 4=100,0%, 8=0,0%, 16=0,0%, 32=0,0%, 64=0,0%, >=64=0,0%
выпущено rwts: всего=5734400,0,0,0 коротко=0,0,0,0 удалено=0,0,0,0
задержка: цель = 0, окно = 0, процентиль = 100,00%, глубина = 1
Выполнить группу состояния 0 (все задания):
ЧТЕНИЕ: bw=76,2 ГБ/с (81,8 ГБ/с), 76,2 ГБ/с-76,2 ГБ/с (81,8 ГБ/с-81,8 ГБ/с), io=2800 ГБ (3006 ГБ), run=36751-36751 мс
[электронная почта защищена]:~$
=247, макс.=16074k, среднее=993,84, стандартное отклонение=11978,23
lat (usec): мин.=20, макс.=105793, среднее=178,24, стандартное отклонение=1535,33
процентили клата (нсек):
| 1.00=[330], 5.00=[398], 10.00=[462], 20.00=[564],
| 30.00=[ 644], 40.00=[ 716], 50.00=[ 788], 60.00=[ 884],
| 70.00=[988], 80.00=[1128], 90.00=[1352], 95.00=[ 1576],
| 99,00=[2256], 99,50=[4448], 99,90=[27776], 99,95=[47872],
| 99,99=[128512]
bw (МиБ/с): мин.=20186, макс.=96350, per=100,00%, среднее=78083,60, стандартное отклонение=532,92, образцы=2044
IOPS: минимум = 40373, максимум = 192700, средний = 156166,03, стандартное отклонение = 1065,84, выборки = 2044
широта (нсек): 250=0,01%, 500=13,73%, 750=31,22%, 1000=25,80%
лат (усек): 2 = 27,66%, 4 = 1,06%, 10 = 0,22%, 20 = 0,16%, 50 = 0,09%
лат (усек): 100=0,03%, 250=0,01%, 500=0,01%, 750=0,01%, 1000=0,01%
широта (мс): 2 = 0,01%, 4 = 0,01%, 10 = 0,01%, 20 = 0,01%
процессор: usr=1,54%, sys=54,57%, ctx=2605775, majf=0, minf=3927
Глубина ввода-вывода: 1=100,0%, 2=0,0%, 4=0,0%, 8=0,0%, 16=0,0%, 32=0,0%, >=64=0,0%
отправить: 0=0,0%, 4=100,0%, 8=0,0%, 16=0,0%, 32=0,0%, 64=0,0%, >=64=0,0%
завершено: 0=0,0%, 4=100,0%, 8=0,0%, 16=0,0%, 32=0,0%, 64=0,0%, >=64=0,0%
выпущено rwts: всего=5734400,0,0,0 коротко=0,0,0,0 удалено=0,0,0,0
задержка: цель = 0, окно = 0, процентиль = 100,00%, глубина = 1
Выполнить группу состояния 0 (все задания):
ЧТЕНИЕ: bw=76,2 ГБ/с (81,8 ГБ/с), 76,2 ГБ/с-76,2 ГБ/с (81,8 ГБ/с-81,8 ГБ/с), io=2800 ГБ (3006 ГБ), run=36751-36751 мс
[электронная почта защищена]:~$
