
Почему RAID-5 — «mustdie»? / Habr

В последнее время в мировой компьютерной прессе стало появляться довольно много статей на тему: «Почему RAID-5 это плохо» (пример раз, два, и другие)
Постараюсь, без ныряния в инженерные и терминологические дебри объяснить, почему до сих пор RAID-5 вроде работал, а теперь вдруг перестал.
Емкость жестких дисков за последние несколько лет растет без особых тенденций к остановке. Однако, хотя емкость дисков чуть ли не удваивается каждый год, прирост их быстродействия, то есть скорости передачи данных, за тот же срок увеличивается всего в проценты. Да, действительно, на дисках появляются интерфейсы SATA, SATA-II, и ждем уже SATA-III, но стали ли диски быстрее работать, а не просто получили новый интерфейс с бубенчиками и новыми круглыми цифрами теоретических показателей вида «цифра максимальной скорости на спидометре «Запорожца»?
Практика говорит нам, что — нет.
Если мы сравним быстродействие, в особенности на небольших случайных операциях, для массовых дисков SATA за несколько лет, то мы увидим, что заметного, сравнимого с ростами объемов, прироста производительности нет.
Когда RAID-5 появился, в 1987 году, типичный жесткий диск был размером 21MB, и имел скорость вращения 3600 RPM. Сегодня типичный диск SATA это 1TB, то есть прирост емкости составил 50 тысяч раз! Но скорость вращения при этом увеличилась всего вдвое.
Если бы скорость передачи данных за эти годы росла бы такими же темпами что и емкость, то сегодняшние диски имели бы показатели передачи данных в районе 30 гигабайт в секунду.
Теперь вспомним о том, что такое есть RAID, и его реализация — RAID-5.
RAID, или Redundant Array of Independent Disks, это модель организации группы дисков в отказоустойчивую структуру таким образом, чтобы она сохранял доступность информации даже в случае повреждения или полного выхода из строя части из этих дисков.
RAID-10 хорош многим. Да почти всем. И надежностью, и быстродействием, за исключением того, что на его создание уходит 50% всей емкости дисков, половина. Довольно таки «бандитский процент».
Действительно, в RAID-5 мы платим за отказоустойчивость емкостью всего одного диска, то есть емкость RAID-5 равна (n-1)*hddsize, где n — число дисков, а hddsize — их размер.
Данные «размазаны» по всем входящим в RAID-группу дискам, их блоки дополнены служебной информацией, которая дает возможность восстановить потерю данных в размере любого одного диска, причем сама эта служебная информация не занимает какой-то выделенный диск, а просто часть объема этой группы, равную как раз емкость одного диска. Но она также размазана по всем дискам.
Когда происходит выход из строя (полный или частичный) одного из дисков группы типа RAID-5, то RAID-группа переходит в состояние degraded, но наши данные остаются доступными, так как недостающая часть их может быть восстановлена за счет избыточной информации того самого «дополнительного объема, размером в один диск». Правда обычно быстродействие дисковой группы резко падает, так как при чтении и записи выполняются дополнительные операции вычислений избыточности и восстановления целостности данных. Если мы вставим вместо вышедшего из строя новый диск, то умный RAID-контроллер начнет процедуру rebuild, «перестроения», для чего начнет считывать со всех дисков оставшиеся данные, и, на основании избыточной информации, заполнит новый, ранее пустой диск недостающей, пропавшей вместе со сдохшим диском частью.
Если вы еще не сталкивались с процессом ребилда RAID-5, вы, возможно, будете неприятно поражены тем, насколько длительным этот процесс может быть. Длительность эта зависит от многих факторов, и, кроме количества дисков в RAID-группе, и их заполненностью, что очевидно, в значительной степени зависит от мощности процессора RAID-контроллера и производительности диска на чтение/запись. А также от рабочей нагрузки на дисковый массив во время проведения ребилда, и от приоритета процесса ребилда по сравнению с приоритетом рабочей нагрузки.
А с выходом все более и более емких дисков, уровни быстродействия которых, как мы помним, почти не растут, в сравнении с емкостью, время ребилда растет угрожающими темпами, ведь, как уже писалось выше, скорость считывания с дисков, от которой напрямую зависит скорость прохождения ребилда, растет гораздо медленнее, чем емкость дисков и объем, который нужно считать.
Так, в интернете легко можно найти истории, когда сравнительно небольшой 4-6 дисковый RAID-5 из 500GB дисков восстанавливал данные на новый диск в течении суток, и более.

Источник: Adaptec
«a RAID 5 array with five 500 GB SATA drives took approximately 24 hours to rebuild» Источник:
«The testing used a 3.5TB array composed of 16 250GB SATA disks configured as RAID 5… 3ware took… over a day to repair a RAID 5 array when under a file server workload.»Источник:
«I’m now at 80% of rebuilding my RAID-5 array with 3x 1TB harddrives, I’ve calculated that the total time needed to rebuild the array will be 66 hours!»Источник:
«On my filer I run a software raid 5 across eight 500 GB sata drives, which works great… Recovery time is about 20 hours. Athlon X2 4200+ and nvidia chipset.»Источник:
С использованием же терабайтных и двухтерабайтных дисков приведенные цифры можно смело умножать в 2-4 раза!
И вот тут начинаются страсти.
Дело в том, и это надо себе трезво уяснить, что на время ребилда RAID-5 вы остаетесь не просто с RAID лишенным отказоустойчивости. Вы получаете на все время ребилда RAID-0
(решил удалить откровенно спорные положения статьи 🙂 С удовольствием приму помощь от компетентного математика-«вероятниста» в правильном вычислении показателей надежности, впрочем основного посыла в ненадежности RAID-0 это не изменяет)
В случае любого отказа, даже самого маленького, даже, быть может, не отказа диска целиком, а просто сбоя чтения из за помехи, или проблем с кабелями, вы теряете всю на нем информацию.
Допустим.
Но нынешние диски выглядят достаточно надежными, не так ли? Уж поди сутки ребилда они протянут без сбоев, не все так плохо, и не настолько же мы неудачники, чтобы у нас на руках дохли два подряд диска. Такое бывает, но может пронесет?
Вот что говорят о надежности дисков материалы самих вендоров.
(Сводная таблица по основным сериям дисков)
В настоящее время практически все производители выпускают жесткие диски двух основных классов.
Это так называемые Desktop-диски, для настольных систем, и диски Enterprise, предназначенные для серверов и прочих критичных случаев. Кроме того, диски класса Enterprise также делятся на диски SATA (скорость оборотов 7200RPM) и SAS или FC (со скоростями вращения 10K и 15K RPM).
Надежность процесса передачи данных принято измерять параметром BER — Bit Error Rate(Ratio). Это вероятность сбоя, из расчета некоего объема прочитанных головками диска бит.
Как правило, диски Desktop-class имеют указанную производителем величину BER равную 10^14 степени, постепенно для все больших дисков, в особенности новых серий, указывают величины надежности в 10^15. Это число означает, что производитель прогнозирует вероятность сбоя при чтении не хуже, чем одного сбойного бита на 10^14 степени прочитанных диском бит. Единица с 14 нулями. Сто тысяч миллиардов бит.
Цифра огромная, казалось бы. Но так ли велика она на самом деле?
Несложная математика уровня calc.exe говорит нам, что 10^14 бит это всего лишь около 11TB данных. Это означает, что производитель жестких дисков говорит нам таким образом, что считав с диска с параметром BER 10^14, то есть обычного, десктопного класса диска, примерно 11TB, мы, с точки зрения производителя, наверняка получим где-нибудь сбойный бит. По крайней мере он, производитель, на это у себя рассчитывает.
Сбойный бит чтения означает сбойный блок, размером 512 байт, на который он пришелся. И пошло-поехало.
11 терабайт это же уже и не так много?
И это не означает, что надо прочитать ровно 11TB, BER это только вероятность, которая стремится к 100% к 11-му терабайту. На меньших объемах она просто пропорционально уменьшается.
Да, диски с BER равным 10^15 имеют вероятность ошибки в 10 раз лучше (110TB считанного на один сбойный бит), но и это только временное улучшение. Как мы помним, емкость дисков удваивается с каждым новым поколением, то есть примерно каждые полтора-два года, растут и емкости RAID, а BER10^15 для SATA достигнут только в последний год-полтора.
Так, например, для 6-дискового RAID-5 с дисками 1TB величина отказа по причине BER оценивается в 4-5%, а для 4TB дисков она же будет достигать уже 16-20%.

Источник: Hitachi Data Systems: Why growing business need RAID-6.
Эта холодная цифра означает, что с 16-20-процентной вероятностью вы получите отказ диска во время ребилда (и, следовательно, потеряете все данные на RAID). Ведь для ребилда, как правило, RAID-контроллеру придется прочитать все диски, входящие в RAID-группу, для 6 дисков по 1TB объем прочитанного RAID-контроллером потока данных с дисков достигает 6TB, для 4TB он уже станет равным 24TB.
24TB это, при BER 10^15, четверть от 110TB.
Но даже и это еще не все.
Как показывает практика, примерно 70-80% данных, хранимых на дисках, это так называемые cold data. Это файлы, доступ к которым сравнительно редок. С увеличением емкости дисков их объем в абсолютном исчислении также растет. Огромный объем данных лежит, зачастую, нетронутый никем, даже антивирусом (зачем ему проверять гигабайтные рипы и mp3?), месяцами, а возможно и годами.
Ошибка данных, пришедшаяся на массив cold data обнаружится только лишь в процессе полного чтения содержимого диска, на процесс ребилда.
Большие и «умные» системы хранения обычно постоянно занимаются в секунды простоя так называемым disk scrubbing-ом, постоянно считывая и контролируя характеристики чтения для всего объема дисков. Но уверен, что ваш недорогой «домашний» RAID-контроллер этого не делает.
Следовательно, вы узнаете о появившемся неделю назад bad block где-то в пространстве cold data в тот момент, когда скрестив пальцы будете с замиранием следить за прогресс-баром процесса ребилда.
Вот какая неприятная правда скрывается за несколько скандальными статьями о «смерти RAID-5».
Возможно, что для архива порнухи домашней видеоколлекции потеря ее в считанные секунды и не будет такой уж большой катастрофой, особенно если вы хорошо владеете собой. Но уж точно пришла пора отказаться от RAID-5 на чуть более критичных задачах, чем «домашнее хранилище BD-рипов накачаных из торрента».
Выводы (для тех, кто ниасилил):
- Резкий рост объемов дисков, при гораздо более медленном приросте скоростей передачи данных с диска привел к тому, что время восстановления RAID-5 катастрофически удлиннилось и продолжает расти с выходом все более емких дисков. Как следствие, неприемлимо увеличивается период времени, когда данные остаются полностью незащищеными.
- Отсутствие средств контроля областей cold data (редко обновляемых и считываемых данных) в недорогих контроллерах RAID-5 может привести к обнаружению давно возникшей проблемы считывания в критический момент ребилда RAID, когда он полностью незащищен от сбоев, и приведет в полной потере данных.
- Повышенная нагрузка на диски в период восстановления потенциально еще повышает вероятность сбоя.
- Современные диски Desktop-class уже приблизились по объемам к показателям определяемого их изготовителями параметра BER (Bit Error Rate), что еще более повышает вероятность сбоя в ходе массированного считывания всего объема диска.
Все перечисленное доказывает необходимость отказа от использования RAID-5 в качестве отказоустойчивого решения для хранения важных и критичных данных.
Решение:
- Для данных, скорость доступа (и в особенности записи) к которым не так важна — RAID-6. Тип RAID устойчивый к сбою двух дисков. При выходе из строя одного диска, защищающий на время ребилда, от случайных ошибок чтения при восстановлении. Недостаток — относительно невысокая скорость на запись.
- Для данных, к которым требуется максимально быстрый доступ как на запись, так и на чтение — RAID-10. При использовании RAID-10 время ребилда резко сокращается, так как не требуется чтения полного объема RAID, а только копирование содержимого «зеркального» к вышедшему из строя диска. Недостатки — большой расход дисков на обеспечение отказоустойчивости.
- По возможности не экономить, используя для хранения критичной информации не предназначенные для работе в RAID диски Desktop-class, а использовать специальные серверные Enterprise-серии, надежность чтения которых на один-два порядка выше.
habr.com
Виды RAID и их характеристики
Виды RAID и их характеристики
Что такое RAID мы рассмотрели в первой статье. Теперь посмотрим какие есть виды и чем они отличаются.
Калифорнийский университет в Беркли представил следующие уровни спецификации RAID, которые были приняты как стандарт де-факто:
- RAID 0 — дисковый массив повышенной производительности с чередованием, без отказоустойчивости;
- RAID 1 — зеркальный дисковый массив;
- RAID 2 зарезервирован для массивов, которые применяют код Хемминга;
- RAID 3 и 4 — дисковые массивы с чередованием и выделенным диском чётности;
- RAID 5 — дисковый массив с чередованием и «невыделенным диском чётности»;
- RAID 6 — дисковый массив с чередованием, использующий две контрольные суммы, вычисляемые двумя независимыми способами;
- RAID 10 — массив RAID 0, построенный из массивов RAID 1;
- RAID 50 — массив RAID 0, построенный из массивов RAID 5;
- RAID 60 — массив RAID 0, построенный из массивов RAID 6.
Виды RAID и их характеристики
Аппаратный RAID-контроллер может поддерживать несколько разных RAID-массивов одновременно, суммарное количество жёстких дисков которых не превышает количество разъёмов для них. При этом контроллер, встроенный в материнскую плату, в настройках BIOS имеет всего два состояния (включён или отключён), поэтому новый жёсткий диск, подключённый в незадействованный разъём контроллера при активированном режиме RAID, может игнорироваться системой, пока он не будет ассоциирован как ещё один RAID-массив типа JBOD (spanned), состоящий из одного диска.
RAID 0 (striping — «чередование»)
Режим, при использовании которого достигается максимальная производительность. Данные равномерно распределяются по дискам массива, дискиобъединяются в один, который может быть размечен на несколько. Распределенные операции чтения и записи позволяют значительно увеличить скорость работы, поскольку несколько дисков одновременно читают/записывают свою порцию данных. Пользователю доступен весь объем дисков, но это снижает надежность хранения данных, поскольку при отказе одного из дисков массив обычно разрушается и восстановить данные практически невозможно. Область применения — приложения, требующие высоких скоростей обмена с диском, например видеозахват, видеомонтаж. Рекомендуется использовать с высоконадежными дисками.
RAID 0 (striping — «чередование»)
RAID 1 (mirroring — «зеркалирование»)
массив из двух дисков, являющихся полными копиями друг друга. Не следует путать с массивами RAID 1+0, RAID 0+1 и RAID 10, в которых используется более двух дисков и более сложные механизмы зеркалирования.
Обеспечивает приемлемую скорость записи и выигрыш по скорости чтения при распараллеливании запросов.
Имеет высокую надёжность — работает до тех пор, пока функционирует хотя бы один диск в массиве. Вероятность выхода из строя сразу двух дисков равна произведению вероятностей отказа каждого диска, т.е. значительно ниже вероятности выхода из строя отдельного диска. На практике при выходе из строя одного из дисков следует срочно принимать меры — вновь восстанавливать избыточность. Для этого с любым уровнем RAID (кроме нулевого) рекомендуют использовать диски горячего резерва.
RAID 1
RAID 1E
Похожий на RAID10 вариант распределения данных по дискам, допускающий использование нечётного числа дисков (минимальное количество — 3)
RAID 2, 3, 4
различные варианты распределенного хранения данных с дисками, выделенными под коды четности и различными размерами блока. В настоящее время практически не используются из-за невысокой производительности и необходимости выделять много дисковой емкости под хранение кодов ЕСС и/или четности.
RAID_3
RAID_4
RAID 5
Основным недостатком уровней RAID от 2-го до 4-го является невозможность производить параллельные операции записи, так как для хранения информации о чётности используется отдельный контрольный диск. RAID 5 не имеет этого недостатка. Блоки данных и контрольные суммы циклически записываются на все диски массива, нет асимметричности конфигурации дисков. Под контрольными суммами подразумевается результат операции XOR (исключающее или). Xor обладает особенностью, которая даёт возможность заменить любой операнд результатом, и, применив алгоритм xor, получить в результате недостающий операнд. Например: a xor b = c (где a, b, c — три диска рейд-массива), в случае если a откажет, мы можем получить его, поставив на его место c и проведя xor между c и b: c xor b = a. Это применимо вне зависимости от количества операндов: a xor b xor c xor d = e. Если отказывает c тогда e встаёт на его место и проведя xor в результате получаем c: a xor b xor e xor d = c. Этот метод по сути обеспечивает отказоустойчивость 5 версии. Для хранения результата xor требуется всего 1 диск, размер которого равен размеру любого другого диска в raid.
Достоинства
RAID5 получил широкое распространение, в первую очередь, благодаря своей экономичности. Объём дискового массива RAID5 рассчитывается по формуле (n-1)*hddsize, где n — число дисков в массиве, а hddsize — размер наименьшего диска. Например, для массива из четырех дисков по 80 гигабайт общий объём будет (4 — 1) * 80 = 240 гигабайт. На запись информации на том RAID 5 тратятся дополнительные ресурсы и падает производительность, так как требуются дополнительные вычисления и операции записи, зато при чтении (по сравнению с отдельным винчестером) имеется выигрыш, потому что потоки данных с нескольких дисков массива могут обрабатываться параллельно.
Недостатки
Производительность RAID 5 заметно ниже, в особенности на операциях типа Random Write (записи в произвольном порядке), при которых производительность падает на 10-25% от производительности RAID 0 (или RAID 10), так как требует большего количества операций с дисками (каждая операция записи, за исключением так называемых full-stripe write-ов, сервера заменяется на контроллере RAID на четыре — две операции чтения и две операции записи). Недостатки RAID 5 проявляются при выходе из строя одного из дисков — весь том переходит в критический режим (degrade), все операции записи и чтения сопровождаются дополнительными манипуляциями, резко падает производительность. При этом уровень надежности снижается до надежности RAID-0 с соответствующим количеством дисков (то есть в n раз ниже надежности одиночного диска). Если до полного восстановления массива произойдет выход из строя, или возникнет невосстановимая ошибка чтения хотя бы на еще одном диске, то массив разрушается, и данные на нем восстановлению обычными методами не подлежат. Следует также принять во внимание, что процесс RAID Reconstruction (восстановления данных RAID за счет избыточности) после выхода из строя диска вызывает интенсивную нагрузку чтения с дисков на протяжении многих часов непрерывно, что может спровоцировать выход какого-либо из оставшихся дисков из строя в этот наименее защищенный период работы RAID, а также выявить ранее не обнаруженные сбои чтения в массивах cold data (данных, к которым не обращаются при обычной работе массива, архивные и малоактивные данные), что повышает риск сбоя при восстановлении данных.
Минимальное количество используемых дисков равно трём.
RAID 5
RAID 5EE
массив, аналогичный RAID5, однако кроме распределенного хранения кодов четности используется распределение резервных областей — фактически задействуется жесткий диск, который можно добавить в массив RAID5 в качестве запасного (такие массивы называют 5+ или 5+spare). В RAID 5 массиве резервный диск простаивает до тех пор, пока не выйдет из строя один из основных жестких дисков, в то время как в RAID 5EE массиве этот диск используется совместно с остальными HDD все время, что положительно сказывается на производительность массива. К примеру, массив RAID5EE из 5 HDD сможет выполнить на 25% больше операций ввода/вывода за секунду, чем RAID5 массив из 4 основных и одного резервного HDD. Минимальное количество дисков для такого массива — 4.
RAID 5EE
RAID 6
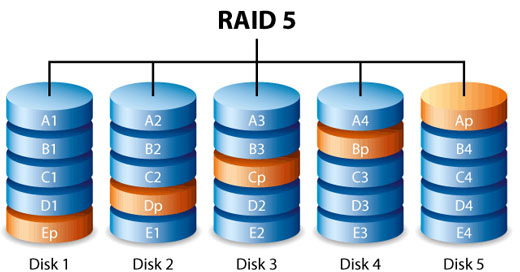
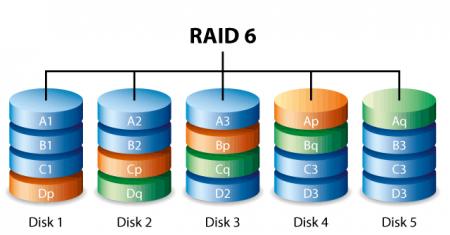
RAID 6 — похож на RAID 5, но имеет более высокую степень надёжности — под контрольные суммы выделяется ёмкость 2-х дисков, рассчитываются 2 суммы по разным алгоритмам. Требует более мощный RAID-контроллер. Обеспечивает работоспособность после одновременного выхода из строя двух дисков — защита от кратного отказа. Для организации массива требуется минимум 4 диска. Обычно использование RAID-6 вызывает примерно 10-15% падение производительности дисковой группы, относительно RAID 5, что вызвано большим объёмом обработки для контроллера (необходимость рассчитывать вторую контрольную сумму, а также читать и перезаписывать больше дисковых блоков при записи каждого блока).
RAID 6
RAID 0+1
Под RAID 0+1 может подразумеваться в основном два варианта:
- два RAID 0 объединяются в RAID 1;
- в массив объединяются три и более диска, и каждый блок данных записывается на два диска данного массива; таким образом, при таком подходе, как и в «чистом» RAID 1, полезный объём массива составляет половину от суммарного объёма всех дисков (если это диски одинаковой ёмкости).
RAID 10 (1+0)
RAID 10 — зеркалированный массив, данные в котором записываются последовательно на несколько дисков, как вRAID 0. Эта архитектура представляет собой массив типа RAID 0, сегментами которого вместо отдельных дисков являются массивы RAID 1. Соответственно, массив этого уровня должен содержать как минимум 4 диска (и всегда чётное количество). RAID 10 объединяет в себе высокую отказоустойчивость и производительность.
Утверждение, что RAID 10 является самым надёжным вариантом для хранения данных вполне обосновано тем, что массив будет выведен из строя после выхода из строя всех накопителей в одном и том же массиве. При одном вышедшем из строя накопителе, шанс выхода из строя второго в одном и том же массиве равен 1/3*100=33%. RAID 0+1 выйдет из строя при двух накопителях, вышедших из строя в разных массивах. Шанс выхода из строя накопителя в соседнем массиве равен 2/3*100=66%, однако так как накопитель в массиве с уже вышедшим из строя накопителем уже не используется, то шанс того, что следующий накопитель выведет из строя массив целиком равен 2/2*100=100%
RAID 1 (Mirror)
RAID 5EE
массив, аналогичный RAID5, однако кроме распределенного хранения кодов четности используется распределение резервных областей — фактически задействуется жесткий диск, который можно добавить в массив RAID5 в качестве запасного (такие массивы называют 5+ или 5+spare). В RAID 5 массиве резервный диск простаивает до тех пор, пока не выйдет из строя один из основных жестких дисков, в то время как в RAID 5EE массиве этот диск используется совместно с остальными HDD все время, что положительно сказывается на производительность массива. К примеру, массив RAID5EE из 5 HDD сможет выполнить на 25% больше операций ввода/вывода за секунду, чем RAID5 массив из 4 основных и одного резервного HDD. Минимальное количество дисков для такого массива — 4.
RAID 5EE
RAID 50
объединение двух(или более, но это крайне редко применяется) массивов RAID5 в страйп, т.е. комбинация RAID5 и RAID0, частично исправляющая главный недостаток RAID5 — низкую скорость записи данных за счёт параллельного использования нескольких таких массивов. Общая ёмкость массива уменьшается на ёмкость двух дисков, но, в отличие от RAID6, без потери данных такой массив переносит отказ лишь одного диска, а минимально необходимое число дисков для создания массива RAID50 равно 6. Наряду с RAID10, это наиболее рекомендуемый уровень RAID для использования в приложениях, где требуется высокая производительность в сочетании приемлемой надёжностью.
RAID 50
RAID 60
объединение двух массивов RAID6 в страйп. Скорость записи повышается примерно в два раза, относительно скорости записи в RAID6. Минимальное количество дисков для создания такого массива — 8. Информация не теряется при отказе двух дисков из каждого RAID 6 массива
RAID 60
RAID 00
RAID 00 встречается весьма редко, я с ним познакомился на контроллерах LSI. Группа дисков RAID 00 — это составная группа дисков, которая создает чередующийся набор из серии
дисковых массивов RAID 0. RAID 00 не обеспечивает избыточности данных, но наряду с RAID 0, предлагает лучшую производительность любого уровня RAID. RAID 00 разбивает данные на меньшие сегменты, а затем чередует сегменты данных на каждом диске в сторадж группе. Размер каждого сегмента данных определяется размером полосы. RAID 00 предлагает высокая пропускная способность. Уровень RAID 00 не является отказоустойчивым. Если диск в группе дисков RAID 0 выходит из строя, весь
виртуальный диск (все диски, связанные с виртуальным диском) выйдет из строя. Разбивая большой файл на более мелкие сегменты, контроллер RAID может использовать оба SAS
контроллера для чтения или записи файла быстрее. RAID 00 не предполагает четности расчеты усложняют операции записи. Это делает RAID 00 идеальным для
приложения, которые требуют высокой пропускной способности, но не требуют отказоустойчивости. Может состоять от 2 до 256 дисков.
Что быстрее RAID 0 или RAID 00?
Я провел свое тестирование описанное в статье про оптимизацию скорости твердотельных дисков на LSI контроллерах и получил вот такие вот цифры на массивах из 6-ти SSD
pyatilistnik.org
Уровни RAID. Коротко и ясно
Технология RAID разработаная в 1980-х годах задумывалась как обьединение нескольких дисков в дисковый массив с целью увеличения емкости, повышения надежности и доступности данных. Рассмотрим вкратце основные уровни RAID
RAID0: Чередование (Striping)
Описание: Данные распределены по всем дискам массива равномерно. В массиве участвуют два или более дисков
Производительность: Одновременно может быть записан и прочитан бит данных
Плюсы: Быстродействие чтения/записи
Минусы: Нет резервирования. Любой диск вышедший из строя приведет к разрушению массива и как следствие потере всех данных
Использование: Приложения, которым необходим скоросной обмен данными, хранилище временных файлов, некритичные данные
RAID1: Зеркалирование (Mirroring)
Описание: Запись/чтение данных происходит одновременно на два или более дисков массива
Производительность: Операции чтения выполняются бстрее т.к. данные считываются со всех дисков массива одновременно. Операции записи медленнее т.к. запись выполняется дважды или более раз (зависит от количества дисков в массиве)
Плюсы: Выход из строя любого количества дисков массива кроме последнего не приводит к потере данных
Минусы: Стоимость. Пропорциональна количеству дисков в массиве
Использование: Системные разделы, разделы с важными данными, приложения использующие транзакции
RAID3: Чередование с выделенным диском чётности (Virtual disk blocks)
Описание: Данные чередуются по дискам массива на уровне байтов. Необходим дополнительный диск на котором хранится информация о четности. Минимально три диска в массиве
Производительность: Низкая на операциях записи
Плюсы: Данные остаются полностью доступными при выходе из строя одного диска
Минусы: Производительность
Использование: Редко меняющиеся, часто считываемые данные
RAID4: Чередование с выделенным диском чётности (Dedicated parity disk)
Описание: Данные чередуются на уровне блоков. Необходим дополнительный диск на котором хранится информация о четности. Минимально три диска в массиве
Производительность: Низкая на операциях записи
Плюсы: Это лучше чем RAID3. Данные остаются полностью доступными при выходе из строя одного диска. В массив можно добавить любое количество дисков
Минусы: Узкое место такого массива — выделенный диск четности. Данные не считаются записанными, пока не будет записана контрольная сумма на диск четности
Использование: Не подходит для высокопроизводительных систем с активной записью/чтением
RAID5: Чередование чётности (Striped parity)
Описание: В отличии от RAID4 данные и четность чередуются по всем дискам массива. Очень хорошо иметь дополнительный вакантный диск (hot spare disk) на случай если один из дисков массива выйдет из строя. Тогда контроллер подхватит вакантный диск и массив будет перестроен. Минимально три диска в массиве
Производительность: Лучше, чем в RAID4 т.к. решена проблема выделенного диска четности
Плюсы: Достигнут баланс чтения/записи/резервирования
Минусы: Просадка производительности во время перестройки массива. Если не используется кеш записи (рейд-контроллер не оборудован батарейкой и не настроен), то просадка будет особенно чуствительна
Использование: Веб-сервера, файловые сервера где используется интенсивное чтение данных
RAID6: Двойное чередование чётности (Dual parity)
Описание: Похож на RAID5 с той разницей, что в массиве присутствует два диска контроля четности, что повышает надежность системы. Минимально четыре диска в массиве
Производительность: Хуже на 10%-15% чем в RAID5 из-за более сложного алгоритма рассчета контрольных сумм. Больше операций чтения/записи
Плюсы: Повышена надежность сохранности данных. Система останется в работе при двух отказавших дисках
Минусы: Стоимость. Просадка производительности во время перестройки массива
Использование: Резервные хранилища данных с повышенной надежностью
RAID10
Описание: Из групп массивов RAID1 строится RAID0
Производительность: Считается самым быстрым и надежным массивом
Плюсы: Повышена надежность сохранности данных. Массив будет жизнеспособен пока в каждой группе массивов RAID1 будет рабочим последний диск
Минусы: Стоимость, один из самых дорогих
Использование: Веб-сервера с активным чтением данных, приложения используюшие транзакции
RAID50
Описание: Из групп массивов RAID5 строится RAID0
Производительность: Обьединение массивов RAID5 в RAID0 увеличивает пропускную способность данных
Плюсы: Повышена производительность и надежность сохранности данных при большей емкости массива чем в RAID10
Минусы: Стоимость — один из самых дорогих
Использование: Приложения где необходимо сочетание экономии дискового пространства и производительности
перевод Александр Черных
системный администратор
4admin.info
RAID для «чайников» и не только
KDV, iBase.ru, 26.11.2004, последнее обновление – 27.02.2009.
Со времени первой публикации статьи, на forum.ibase.ru в ее обсуждении появилась масса интересных сообщений. Так что после чтения статьи рекомендую обязательно просмотреть топик на форуме.
В интернете есть масса статей с описанием RAID. Например, эта описывает все очень подробно. Но как обычно, читать все не хватает времени, поэтому надо что-нибудь коротенькое для понимания – а надо оно или нет, и что лучше использовать применительно к работе с СУБД (InterBase, Firebird или что то иное – на самом деле все равно). Перед вашими глазами – именно такой материал.
Примечание. Сейчас есть хорошая статья о RAID в Википедии.
В первом приближении RAID это объединение дисков в один массив. SATA, SAS, SCSI, SSD – неважно. Более того, практически каждая нормальная материнская плата сейчас поддерживает возможность организации SATA RAID. Пройдемся по списку, какие бывают RAID и зачем они. (Хотел бы сразу заметить, что в RAID нужно объединять одинаковые диски. Объединение дисков от разных производителей, от одного но разных типов, или разных размеров – это баловство для человека, сидящего на домашнем компьютере).
RAID 0 (Stripe)
Грубо говоря, это последовательное объединение двух (или более) физических дисков в один «физический» диск. Годится разве что для организации огромных дисковых пространств, например, для тех, кто работает с редактированием видео. Базы данных на таких дисках держать нет смысла – в самом деле, если даже у вас база данных имеет размер 50 гигабайт, то почему вы купили два диска размером по 40 гигабайт, а не 1 на 80 гигабайт? Хуже всего то, что в RAID 0 любой отказ одного из дисков ведет к полной неработоспособности такого RAID, потому что данные записываются поочередно на оба диска, и соответственно, RAID 0 не имеет средств для восстановления в случае сбоев.Конечно, RAID 0 дает ускорение в работе из-за чередования чтения/записи.
RAID 0 часто используют для размещения временных файлов.
RAID 1 (Mirror)
Зеркалирование дисков. Если Shadow в IB/FB это программное зеркалирование (см. Operations Guide.pdf), то RAID 1 – аппаратное зеркалирование, и ничего более. Упаси вас от использования программного зеркалирования средствами ОС или сторонним ПО. Надо или «железный» RAID 1, или shadow.При сбое тщательно проверяйте, какой именно диск сбойнул. Самый частый случай погибания данных на RAID 1 – это неверные действия при восстановлении (в качестве «целого» указан не тот диск).
Насчет производительности – по записи выигрыш 0, по чтению – возможно до 1.5 раз, т. к. чтение может производиться «параллельно» (поочередно с разных дисков) . Для баз данных ускорение мало, в то время как при параллельном обращении к разным (!) частям (файлам) диска ускорение будет абсолютно точно.
RAID 1+0
Под RAID 1+0 имеют в виду вариант RAID 10, когда два RAID 1 объединяются в RAID 0. Вариант, когда два RAID 0 объединяются в RAID 1 называется RAID 0+1, и «снаружи» представляет собой тот же RAID 10.RAID 2-3-4
Эти RAID являются редкими, т. к. в них используются коды Хэмминга, либо разбиение байт на блоки + контрольные суммы и т. п., но общее резюме таково – эти RAID дают только надежность, при 0-вом увеличении производительности, и иногда даже ее ухудшении.RAID 5
Для него нужно минимально 3 диска. Данные четности распределяются по всем дискам массиваОбычно говорится, что «RAID5 использует независимый доступ к дискам, так что запросы к разным дискам могут выполняться параллельно». Следует иметь в виду, что речь идет, конечно, о параллельных запросах на ввод-вывод. Если такие запросы идут последовательно (в SuperServer), то конечно, эффекта распараллеливания доступа на RAID 5 вы не получите. Разумеется, RAID5 даст прирост производительности, если с массивом будут работать операционная система и другие приложения (например, на нем будет находиться виртуальная память, TEMP и т. п.).
Вообще RAID 5 раньше был наиболее часто используемым массивом дисков для работы с СУБД. Сейчас такой массив можно организовать и на SATA дисках, причем он получится существенно дешевле, чем на SCSI. Цены и контроллеры вы можете посмотреть в статьях
Причем, следует обратить внимание на объем покупаемых дисков – например, в одной из упомянутых статей RAID5 собирается из 4-х дисков объемом 34 гиг, при этом объем «диска» получается 103 гигабайта.
Тестирование пяти контроллеров SATA RAID – http://www.thg.ru/storage/20051102/index.html.
Adaptec SATA RAID 21610SA в массивах RAID 5 – http://www.ixbt.com/storage/adaptec21610raid5.shtml.
Почему RAID 5 — это плохо — https://geektimes.ru/post/78311/
Внимание! При закупке дисков для RAID5 обычно берут 3 диска, по минимуму (скорее из-за цены). Если вдруг по прошествии времени один из дисков откажет, то может возникнуть ситуация, когда не удастся приобрести диск, аналогичный используемым (перестали выпускаться, временно нет в продаже, и т. п.). Поэтому более интересной идеей кажется закупка 4-х дисков, организация RAID5 из трех, и подключение 4-го диска в качестве резервного (для бэкапов, других файлов и прочих нужд).
Объем дискового массива RAID5 расчитывается по формуле (n-1)*hddsize, где n – число дисков в массиве, а hddsize – размер одного диска. Например, для массива из 4-х дисков по 80 гигабайт общий объем будет 240 гигабайт.Статья RAID-5 must die. И еще о потерях данных на RAID5.
Примечание. На 05.09.2005 стоимость SATA диска Hitachi 80Gb составляет 60 долларов.
RAID 10, 50
Дальше идут уже комбинации из перечисленных вариантов. Например, RAID 10 это RAID 0 + RAID 1. RAID 50 – это RAID 5 + RAID 0.Интересно, что комбинация RAID 0+1 в плане надежности оказывается хуже, чем RAID5. В копилке службы ремонта БД есть случай сбоя одного диска в системе RAID0 (3 диска) + RAID1 (еще 3 таких же диска). При этом RAID1 не смог «поднять» резервный диск. База оказалась испорченной без шансов на ремонт.
Для RAID 0+1 требуется 4 диска, а для RAID 5 – 3. Подумайте об этом.
RAID 6
В отличие от RAID 5, который использует четность для защиты данных от одиночных неисправностей, в RAID 6 та же четность используется для защиты от двойных неисправностей. Соответственно, процессор более мощный, чем в RAID 5, и дисков требуется уже не 3, а минимум 5 (три диска данных и 2 диска контроля четности). Причем, количество дисков в raid6 не имеет такой гибкости, как в raid 5, и должно быть равно простому числу (5, 7, 11, 13 и т. д.)Допустим одновременный сбой двух дисков, правда, такой случай является весьма редким.
По производительности RAID 6 я данных не видел (не искал), но вполне может быть, что из-за избыточного контроля производительность может быть на уровне RAID 5.
См. неплохую статью про RAID 6.
Rebuild time
У любого массива RAID, который остается работоспособным при сбое одного диска, существует такое понятие, какВо время «подключения» нового диска, например, для RAID 5, контроллер может допускать работу с массивом. Но скорость работы массива в этом случае будет весьма низкой, как минимум потому, что даже при «линейном» наполнении нового диска информацией запись на него будет «отвлекать» контроллер и головки диска на операции синхронизации с остальными дисками массива.
Время восстановления функционирования массива в нормальном режиме напрямую зависит от объема дисков. Например, Sun StorEdge 3510 FC Array при размере массива 2 терабайта в монопольном режиме делает rebuild в течение 4.5 часов (при цене железки около $40000). Поэтому, при организации массива и планировании восстановления при сбое нужно в первую очередь думать именно о rebuild time. Если ваша база данных и бэкапы занимают не более 50 гигабайт, и рост в год составляет 1-2 гигабайта, то вряд ли имеет смысл собирать массив из 500-гигабайтных дисков. Достаточно будет и 250-гигабайтных, при этом даже для raid5 это будет минимум 500 гигабайт места для размещения не только базы данных, но и фильмов. Зато rebuild time для 250 гигабайтных дисков будет примерно в 2 раза меньше, чем для 500 гигабайтных.
Резюме
Получается, что самым осмысленным является использование либо RAID 1, либо RAID 5. Однако, самая частая ошибка, которую делают практически все – это использование RAID «подо все». То есть, ставят RAID, на него наваливают все что есть, и … получают в лучшем случае надежность, но никак не улучшение производительности.Еще часто не включают write cache, в результате чего запись на raid происходит медленнее, чем на обычный одиночный диск. Дело в том, что у большинства контроллеров эта опция по умолчанию выключена, т.к. считается, что для ее включения желательно наличие как минимум батарейки на raid-контроллере, а также наличие UPS.
Текст
В старой статье hddspeed.htmLINK (и в doc_calford_1.htmLINK) показано, как можно получить существенное увеличение производительности путем использования нескольких физических дисков, даже для IDE. Соответственно, если вы организуете RAID – положите на него базу, а остальное (temp, OS, виртуалка) делайте на других винчестерах. Ведь все равно, RAID сам по себе является одним «диском», пусть даже и более надежным и быстродействующим.
признан устаревшим. Все вышеупомянутое вполне имеет право на существование на RAID 5. Однако перед таким размещением необходимо выяснить – каким образом можно делать backup/restore операционной системы, и сколько по времени это будет занимать, сколько времени займет восстановление «умершего» диска, есть ли (будет ли) под рукой диск для замены «умершего» и так далее, т. е. надо будет заранее знать ответы на самые элементарные вопросы на случай сбоя системы.
Я все-таки советую операционную систему держать на отдельном SATA-диске, или если хотите, на двух SATA-дисках, связанных в RAID 1. В любом случае, располагая операционную систему на RAID, вы должны спланировать ваши действия, если вдруг прекратит работать материнская плата – иногда перенос дисков raid-массива на другую материнскую плату (чипсет, raid-контроллер) невозможен из-за несовместимости умолчательных параметров raid.
Размещение базы, shadow и backup
Несмотря на все преимущества RAID, категорически не рекомендуется, например, делать backup на этот же самый логический диск. Мало того что это плохо влияет на производительность, но еще и может привести к проблемам с отсутствием свободного места (на больших БД) – ведь в зависимости от данных файл backup может быть эквивалентным размеру БД, и даже больше. Делать backup на тот же физический диск – еще куда ни шло, хотя самый оптимальный вариант – backup на отдельный винчестер.Объяснение очень простое. Backup – это чтение данных из файла БД и запись в файл бэкапа. Если физически все это происходит на одном диске (даже RAID 0 или RAID 1), то производительность будет хуже, чем если чтение производится с одного диска, а запись – на другой. Еще больше выигрыш от такого разделения – когда backup делается во время работы пользователей с БД.
То же самое в отношении shadow – нет никакого смысла класть shadow, например, на RAID 1, туда же где и база, даже на разные логические диски. При наличии shadow сервер пишет страницы данных как в файл базы так и в файл shadow. То есть, вместо одной операции записи производятся две. При разделении базы и shadow по разным физическим дискам производительность записи будет определяться самым медленным диском.
Обсудить статью на форуме
www.ibase.ru
Массивы RAID0 и RAID5 из винчестеров против твердотельных накопителей
Методика тестирования накопителей образца 2016 года
В первых персональных компьютерах винчестеров вообще не было. Чуть позднее они стали штатным оборудованием. Еще позднее в основном были решены проблемы совместимости, мешающие использованию одновременно и поддерживаемой в теории пары устройств, а к концу 90-х годов прошлого века конфигурация среднестатистического компьютера потенциально могла включать в себя уже и четыре винчестера. С этого момента многие пользователи заинтересовались уже использованием накопителей не по-отдельности, а в составе единого массива — как во «взрослых системах». В последних, впрочем, чаще всего применялся SCSI-интерфейс, доступный и владельцу обычной «персоналки», но излишне дорогой — требовались дешевые решения. И они появились в виде контроллеров IDE RAID.
Заметим, что наиболее часто используемым вариантом был RAID0, строго говоря, к «RAID-массивам» не относящийся, поскольку избыточность данных он не обеспечивает. Надежность хранения сравнительно с одиночным диском даже снижает. Но иногда было просто некуда деваться, поскольку винчестеры тех лет были слишком медленными для некоторых сфер применения, а альтернативных решений с более высокой производительностью не было вовсе. Использование же чередования позволяло их заметно «пришпорить». Но применялись (да и сейчас применяются) и «зеркала» (RAID1) — для повышения надежности. А наиболее обеспеченные граждане могли объединить достоинства обоих подходов посредством создания массива RAID10, что позволяло повысить и скорость, и надежность. Других режимов в те времена в массовых контроллерах «не водилось»: слишком сложными были для программной реализации — с учетом вычислительных возможностей систем того времени.
Через некоторое время дискретные RAID-контроллеры начали устанавливать и на топовые системные платы — надо же было чем-то выделяться их производителям. В итоге к массивам стали приглядываться и пользователи, ранее о них не задумывавшиеся — раз уж возможность есть. В итоге идею подхватили сами производители чипсетов, так что возможность создания RAID-массивов стала стандартной для последних. Как минимум — для старших модификаций. Причем к числу возможных вариантов добавился и RAID5, на первый взгляд выглядящий очень привлекательно: более экономным расходованием дискового пространства, чем у RAID10, но при обеспечении необходимой для надежности хранения избыточности.
А позднее начались новые времена — винчестеры перестали быть основным и единственным типом накопителей, применяющихся в компьютере. Внедрение твердотельных накопителей прервало эволюцию, оказавшись революционным шагом с точки зрения производительности. Правда было оно достаточно медленным — просто потому, что и стоимость хранения информации первое время была очень высокой. Довольно быстро снижалась, но и сейчас до паритета с винчестерами еще далеко — особенно если рассматривать «настольные» модели. Да и с абсолютной емкостью тоже пока все не просто: теоретически флэш-памяти в стандартный корпус «напихать» можно очень много, а практически это будет слишком уж дорого. Собственно, поэтому до сих пор подавляющее большинство компьютеров продается лишь с одним-единственным винчестером в качестве накопителя «для всего»: и для программ, и для данных. В принципе, даже устройств этого класса минимальной на сегодня емкости достаточно для того, чтобы полностью закрыть все потребности среднестатистического пользователя, поэтому в бюджетном сегменте такой вариант долго еще будет преобладающим, несмотря на низкую производительность. А вот чуть выше решений минимальной стоимости у покупателя есть выбор, часто приводящий его к одному из гибридных вариантов системы хранения данных. Самым дешевым (но пока до конца не изученным и освоенным) способом является кэширование посредством технологии Optane Memory. Более дорогим, но предсказуемым и совместимым со старыми системами — использование SSD невысокой емкости для операционной системы и приложений в паре с тихоходным, но очень емким винчестером для хранения данных. В итоге про RAID-массивы в бытовых персоналках все как-то и забыли. Хотя некоторые пользователи считают, что зря — все-таки и емкость самая большая (в пределах фиксированного бюджета), и производительность должна быть более высокой, чем у одиночного накопителя. Пусть, даже, и не на столько, как обеспечивают твердотельные накопители, но ведь дешево же — а вдруг и этого хватит на практике. Поэтому мы сегодня решили немного отклониться от основной линейки тестов и посмотреть — как ведут себя лучшие винчестеры в т. ч. и в массивах из двух-трех дисков, сравнительно с разными твердотельными накопителями.
Участники тестирования
Поскольку в наших руках оказалось одновременно три не совсем идентичных, но почти идентичных винчестера Seagate, они и выступили в роли «подопытных кроликов». Было бы сразу четыре — можно было бы и RAID10 организовать, а так пришлось ограничиться RAID0 из двух и RAID5 из трех дисков (три-четыре диска в RAID0 это уже за границей добра и зла, которую без необходимости мы стараемся не переступать), имеющие одинаковый объем в 20 ТБ. Собственно, чем RAID5 многим и кажется привлекательным — «пропадает» всего один накопитель в массиве, а не половина, как в «зеркалах» (RAID1, 10 и подобных). RAID0 еще «гуманнее», но ценой потенциальных проблем с надежностью. Сами же винчестеры — одни из лучших на сегодняшний день: модели на 10 ТБ со скоростью вращения 7200 об/мин, использующие заполнение гермоблока гелием. Понятно, что в роли системного и единственного накопителя даже один такой винчестер выглядит странно (мягко говоря), однако дает оценку сверху того, что вообще можно получить от массивов. Недорогие устройства малой емкости просто медленнее, в чем мы уже не раз убеждались.
С кем будем сравнивать? Во-первых, интересна разница в пределах группы. Во-вторых, для части тестов мы отобрали следующую четверку твердотельных накопителей:
Можно было бы ограничиться и меньшим количеством, но мы решили пойти навстречу читателям, жалующимся на то, что в статьях сайта редко сравниваются твердотельные накопители разных классов или, тем более, твердотельные с механическими. Просили? Сами виноваты 🙂
Тестирование
Методика тестирования
Методика подробно описана в отдельной статье. Там можно познакомиться с используемым аппаратным и программным обеспечением. Для данной статьи нам ее пришлось, немного доработать, поскольку участие в тестировании сегодня принимают и винчестеры, и твердотельные накопители, но касается это в основном использования результатов (благо тестовые программы в основном пересекаются) и их группировки.
Последовательные операции
Для начала начнем с «чисто винчестерных» тестов, в которых твердотельные накопители по понятным причинам не участвуют — для них нет зависимости скорости от конкретной области данных.

Как и предполагается априори, скорость чтения удваивается. Точнее, для RAID0 из двух дисков это очевидно. Для RAID5 на трех дисках — в общем-то тоже: для данных используется то же самое чередование. В итоге даже минимальная скорость чтения оказалась выше средней одиночного диска, а средняя — выше максимальной. Идеальный случай.

Потому что при записи все уже не так просто. Точнее, для RAID0 — по-прежнему просто и быстро, на что любят упирать «любители» этого типа массивов (который, строго говоря, RAID-массивом и не является, как уже было сказано выше). Все также работает чередование блоков с данными, так что два винчестера (или большее их количество) работают, по сути параллельно.
А вот ситуация с RAID5 печальна. Однако легко объяснима: специфика организации этого типа массивов такова, что практически любая операция записи превращается в две операции чтения и две записи, которые должны «отработать» практически одновременно. Итоговая производительность в случае «чипсетного» контроллера, фактически лишенного собственных «мозгов», так что реализующего всю необходимую функциональность на базе программного драйвера, оказывается удручающе низкой. «Нормальный аппаратный» контроллер способен ослабить проблему, но не решить ее полностью — RAID5 все равно остается одним из самых медленных типов массивов в любых условиях. Радикальным способом решения проблемы (да и практически единственно-возможным для программной реализации) является использование RAID10, сочетающего в себе и производительность, и отказоустойчивость, но… Но ценой потери уже половины потенциального пространства, т. е. для создания массива в те же 20 ТБ потребуется уже не три, а четыре диска по 10 ТБ, о чем было сказано в начале статьи. Впрочем, можно «выжать» и из чипсетного RAID5 немного больше: подбором размера блока чередования и кластера файловой системы, чем мы не занимались, оставив значения по-умолчанию. Однако повысить скорость записи до уровня хотя бы одиночного винчестера и это не позволяет — в отличие от RAID10, обеспечивающего ее удвоение (пусть и высокой ценой). В лучшем случае получается повысить скорость примерно до 100 МБ/с, т. е. RAID5 на практике даже при тонкой настройке снижает производительность операций записи. Где-нибудь в NAS это не важно: данные записываются редко, а читаются часто, да и лимитирует производительность сам по себе сетевой интерфейс (как раз значениями в районе сотни мегабайт в секунду, а то и меньше), так что высокая емкость и отказоустойчивость выходят на первый план. А вот в персональном компьютере или рабочей станции массивы такого типа просто не интересны. Точнее, интересны еще меньше, чем RAID0 или RAID1. А ведь и у первых уже появились серьезные конкуренты, но об этом чуть ниже.
Время доступа

Если при чтении данных латентность практически неизменна, то при записи в массиве RAID0 она резко снижается. В чем, впрочем, заслуга, скорее, не его, а алгоритмов кэширования, применяемых контроллером для массивов. Но, как видим, RAID5 и это никак не помогает. Даже наоборот, что вполне согласуется с логикой его работы.
Последовательные операции (Crystal Disk Mark)
Поскольку HD Tune Pro при тестировании твердотельных накопителей мы не используем, а вот Crystal Disk Mark «прогоняется» везде, посмотрим на его результаты.

Как и положено, производительность при чтении данных примерно удваивается. Забавный результат в многопоточном режиме связан с тем, что при использовании ограниченной области данных (в программе, напомним, мы используем лишь 2 ГБ) и современных алгоритмов внутреннего кэширования винчестеров, вкупе с нынешними емкостями кэш-памяти, данные зачастую в ней и будут оказываться еще до соответствующего запроса. Остается только передать нужный блок по интерфейсу, что происходит очень быстро. Это позволяет с легкостью опережать SATA SSD (поскольку их сдерживает именно интерфейс), да и в однопоточном режиме от них практически не отставать. Но только в «тепличных условиях» — внешние дорожки (на внутренних скорость вдвое ниже, что уже было показано выше), небольшие объемы данных. Что бывает в более сложных случаях — посмотрим чуть позже.

С записью же все намного хуже: чем-то подстегнуть многопоточный режим не получается, так что он не только медленнее однопоточного, но и удвоения скорости сравнительно с одиночным накопителем уже не наблюдается. Но в один поток потягаться с SATA SSD хотя бы можно. Во всяком случае, при использовании RAID0 из двух дисков. Если бы мы объединили в такой массив три имеющихся винчестера — было бы еще быстрее, хотя и слишком перпендикулярно здравому смыслу. А с RAID5 все традиционно плохо. Поэтому в последующих тестах мы его использовать не будем — и без того картина ясна.
Работа с большими файлами

Как и следовало ожидать на основании низкоуровневых тестов, в однопоточном режиме хотя бы на внешних дорожках скорость чтения сравнима с SATA SSD. Но если нужно считать 32 ГБ в 32-х файлах по 1 ГБ, производительность резко падает почти до уровня одиночного винчестера (кэширование же при таких объемах ничем помочь уже не может). Для твердотельных же накопителей, напротив, это идеальный случай. А если они не ограничены интерфейсом — тем более.

Чем, все-таки, до сих пор привлекательны механические накопители — симметричностью производительности при записи и чтении, чего для флэш-памяти и близко нет. Соответственно, на операциях записи даже некоторые NVMe-накопители могут оказаться медленнее одиночного современного винчестера. Двух — тем более. Но если не рассматривать самые медленные из устройств, то опять ничего похожего на «честную конкуренцию» не наблюдается.

А запись одновременно с чтением — хороший случай для большинства SSD и плохой для винчестеров. Причем твердотельным накопителям и (псевдо)случайный режим «жизнь не портит», в отличие от. Таким образом, быстро прочитать или записать большой объем данных современные винчестеры могут — если есть куда или откуда. Объединенными в массив RAID0 сделают это быстрее. Но поскольку обработка данных предполагает обычно и запись, и чтение, и далеко не всегда последовательные — для этой цели уже лучше использовать твердотельные накопители. Если, конечно, объемы позволяют. А вот хранить данные лучше там, где это обходится дешевле.
Производительность в приложениях
Но основной темой сегодняшней статьи было вовсе не исследование вопросов хранения и обработки больших массивов данных, хотя и это тоже интересно. Еще важнее — оценить перспективность использования RAID0 для ускорения обычной работы за компьютером. Когда-то это позволяло что-то выиграть сравнительно с одиночным винчестером, но тогда и программы были другими, да и операционные системы тоже. Да и сравнивать сейчас уже нужно не только «механику с механикой». Вот и сравним 🙂

Тестируя SSD, мы временами жаловались на то, что с точки зрения тестов высокого уровня они слишком похожи. Тестируя винчестеры — аналогично. Но они «по-разному похожи»: это два непересекающихся мира. А одиночный винчестер и RAID0 из винчестеров — один мир. Совсем один. Потенциальное ускорение от чередования к настоящему моменту по сути рассосалось: современные операционные системы и с одиночным винчестером работают настолько эффективно, насколько он позволяет (чему сильно помогает развитое кэширование данных в оперативной памяти, радикально улучшившееся в современных версиях Windows — пусть это и вызывает жалобы некоторых пользователей, привыкших к примитивной Windows XP и более ранним, на «расход памяти»). Снижение задержек пригодилось бы, но его при чтении данных (что важно для тестов высокого уровня) как раз и нет.

И даже по низкоуровневому баллу появляются различия между разными моделями твердотельных накопителей, но не более того. Винчестеры (что с ними не делай) намного медленнее. Причем в этом случае и порядки-то величин разные, что «замаскировать» получается лишь потому, что реальная работа приложений «упирается» и в другие компоненты компьютера. А иногда и в самого пользователя, что и не всегда позволяет реализовать потенциальные возможности накопителей. Твердотельных. У «механики» таковых и не водится.

Кстати, и предыдущая версия тестового пакета ведет себя аналогично. Когда-то, кстати, PCMark на массивы реагировал хорошо — но это было под управлением других ОС и на трассах, имитирующих другие приложения. А сейчас уже так. Подробные результаты, думаем, уже не нужны.
Рейтинги

Как видим, с точки зрения тестов низкого уровня, ориентированных в первую очередь на SSD (так что изобилующими операциями со случайным доступом) сравнивать «механику» (что с ней не делай) и SSD большого смысла нет. Но и ничего удивительного в этом тоже уже нет — для винчестеров лучший сценарий это однопоточный последовательный, однако, как уже было показано выше, и в этом случае о прямой конкуренции говорить не всегда приходится. Иногда при записи, разве что, но и при этом «потолок» винчестеров (и массивов из них) сопоставим лишь с «полом» твердотельных накопителей с SATA-интерфейсом (eMMC-модули — отдельная история; но они и используются чаще всего там, куда никакие другие накопители просто «не лезут»).

Да и «подмешивание» к оценке результатов тестов высокого уровня не слишком меняет картину. По совокупности разные SSD при этом отличаются друг от друга примерно вдвое, поскольку мы взяли один из самых медленных и один из самых быстрых из протестированных накопителей, радикально различающихся конструктивно. Однако при этом и «самый медленный» быстрее массива RAID0 из пары топовых винчестеров даже не в два, а в два с половиной раза. Комментарии излишни.
Итого
В общем и целом, картина понятная. Равно как понятно и то, почему тема RAID-массивов в персональных компьютерах практически сошла на нет. Во всяком случае, в их «винчестерной» ипостаси — с массивами из SSD некоторые энтузиасты продолжают баловаться, чему способствуют производители, реализовав, в частности, возможность создания RAID из NVMe-устройств. Да и в топовых ноутбуках нет-нет да и встречаются RAID0 из пары твердотельных накопителей — в основном, конечно, чтобы блистать в обзорах. На этом всё. В тех сферах, где технология RAID-массивов зарождалась, она по-прежнему является нужной и полезной, но в ПК ей делать особо нечего. С одной стороны, современные ОС способны и из одиночного винчестера «выжимать» все, на что он способен, так что улучшением части характеристик «подстегнуть» производительность не получится. С другой — доступными стали более быстрые накопители. В том числе, существенно более быстрые в тех сценариях, ради которых до сих пор имеет смысл использовать RAID-массивы с увеличением производительности (благодаря чередованию). А «настоящие» RAID (т. е. с избыточностью хранения данных) по-прежнему полезны, но в бюджетном исполнении силами программного обеспечения они могут заметно понизить производительность. Кроме того, RAID в любом случае не заменяет резервного копирования данных, так что начинать надо с него, а не наоборот.
www.ixbt.com
RAID-массивы: классификация, особенности, применение | Записки Web-разработчика
RAID (англ. redundant array of independent disks — избыточный массив независимых жёстких дисков) — массив из нескольких дисков, управляемых контроллером, взаимосвязанных скоростными каналами и воспринимаемых внешней системой как единое целое. В зависимости от типа используемого массива может обеспечивать различные степени отказоустойчивости и быстродействия. Служит для повышения надёжности хранения данных и/или для повышения скорости чтения/записи информации. Изначально, подобные массивы строились в качестве резерва носителям на оперативной (RAM) памяти, которая в то время была дорогой. Со временем, аббревиатура приобрела второе значение – массив уже был из независимых дисков, подразумевая использование нескольких дисков, а не разделов одного диска, а также дороговизну (теперь уже относительно просто нескольких дисков) оборудования, необходимого для построения этого самого массива.
Рассмотрим, какие бывают RAID массивы. Сперва рассмотрим уровни, которые были представлены учёными из Беркли, потом их комбинации и необычные режимы. Стоит заметить, что если используются диски разного размера (что не рекомендуется), то работать они буду по объёму наименьшего. Лишний объем больших дисков просто будет недоступен.
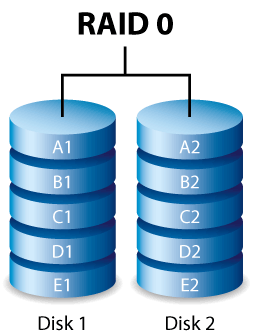
RAID 0. Дисковый массив с чередованием без отказоустойчивости/чётности (Stripe)
Является массивом, где данные разбиваются на блоки (размер блока можно задавать при создании массива) и затем записываются на отдельные диски. В простейшем случае – есть два диска, один блок пишется на первый диск, другой на второй, затем опять на первый и так далее. Также этот режим называется «чередование», поскольку при записи блоков данных чередуются диски, на которые осуществляется запись. Соответственно, читаются блоки тоже поочерёдно. Таким образом, происходит параллельное выполнение операций ввода/вывода, что приводит к большей производительности. Если раньше за единицу времени мы могли считать один блок, то теперь можем сделать это сразу с нескольких дисков. Основным плюсом данного режима как раз и является высокая скорость передачи данных.
Однако чудес не бывает, а если бывают, то нечасто. Производительность растёт всё же не в N раз (N – число дисков), а меньше. В первую очередь, увеличивается в N раз время доступа к диску, и без того высокое относительно других подсистем компьютера. Качество контроллера оказывает не меньшее влияние. Если он не самый лучший, то скорость может едва заметно отличаться от скорости одного диска. Ну и немалое влияние оказывает интерфейс, которым RAID контроллер соединён с остальной системой. Всё это может привести не только к меньшему, чем N увеличению скорости линейного чтения, но и к пределу количества дисков, установка выше которого прироста давать уже не будет вовсе. Или, наоборот, будет слегка снижать скорость. В реальных задачах, с большим числом запросов шанс столкнуться с этим явлением минимален, ибо скорость весьма сильно упирается в сам жёсткий диск и его возможности.
Как видно, в этом режиме избыточности нет как таковой. Используется всё дисковое пространство. Однако, если один из дисков выходит из строя, то, очевидно, теряется вся информация.
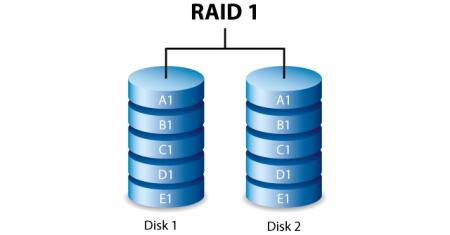
RAID 1. Зеркалирование (Mirror)
Суть данного режима RAID сводится к созданию копии (зеркала) диска с целью повышения отказоустойчивости. Если один диск выходит из строя, то работа не прекращается, а продолжается, но уже с одним диском. Для этого режима требуется чётное число дисков. Идея этого метода близка к резервному копированию, но всё происходит «на лету», равно как и восстановление после сбоя (что порой весьма важно) и нет необходимости тратить время на это.
Минусы – высокая избыточность, так как нужно вдвое больше дисков для создания такого массива. Ещё одним минусом является то, что отсутствует какой-либо прирост производительности – ведь на второй диск просто пишется копия данных первого.
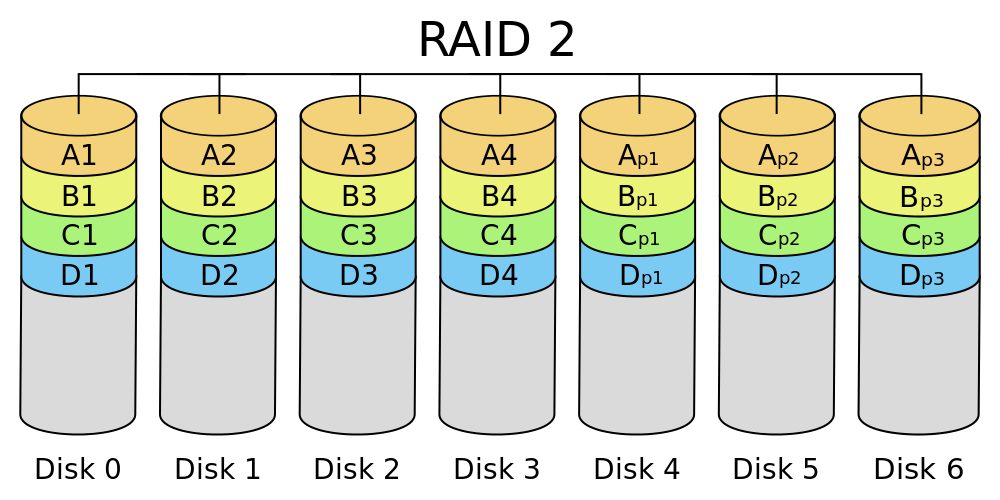
RAID 2 Массив с использованием ошибкоустойчивого кода Хемминга.
Данный код позволяет исправлять и обнаруживать двойные ошибки. Активно используется в памяти с коррекцией ошибок (ECC). В этом режиме диски разбиваются на две группы – одна часть используется для хранения данных и работает аналогично RAID 0, разбивая блоки данных по разным дискам; вторая часть используется для хранения ECC кодов.
Из плюсов можно выделить исправление ошибок «на лету», высокую скорость потоковой передачи данных.
Главным минусом является высокая избыточность (при малом числе дисков она почти двойная, n-1). При увеличении числа дисков удельное число дисков хранения ECC кодов становится меньше (снижается удельная избыточность). Вторым минусом является низкая скорость работы с мелкими файлами. Из-за громоздкости и высокой избыточности с малым числом дисков, данный уровень RAID в данное время не используется, сдав позиции более высоким уровням.
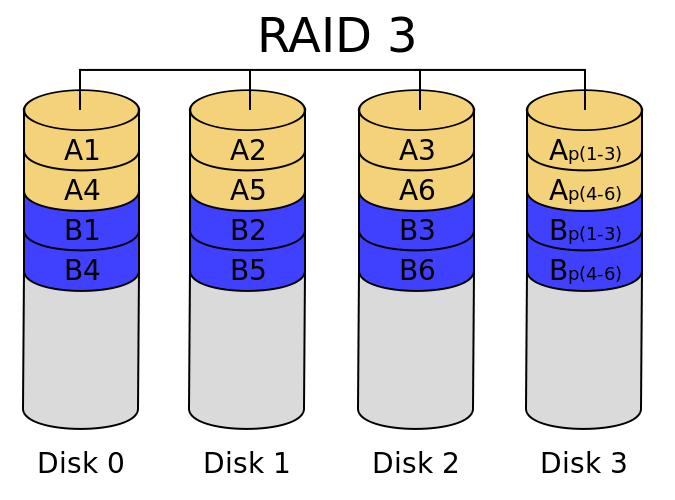
RAID 3. Отказоустойчивый массив с битовым чередованием и чётностью.
Данный режим записывает данные по блокам на разные диски, как RAID 0, но использует ещё один диск для хранения четности. Таким образом, избыточность намного ниже, чем в RAID 2 и составляет всего один диск. В случае сбоя одного диска, скорость практически не меняется.
Из основных минусов надо отметить низкую скорость при работе с мелкими файлами и множеством запросов. Связано это с тем, что все контрольные коды хранятся на одном диске и при операциях ввода/вывода их необходимо переписывать. Скорость этого диска и ограничивает скорость работы всего массива. Биты чётности пишутся только при записи данных. А при чтении – они проверяются. По причине этого наблюдается дисбаланс в скорости чтения/записи. Одиночное чтение небольших файлов также характеризуется невысокой скоростью, что связано с невозможностью параллельного доступа с независимых дисков, когда разные диски параллельно выполняют запросы.
RAID 4
Данные записываются блоками на разные диски, один диск используется для хранения битов чётности. Отличие от RAID 3 заключается в том, что блоки разбиваются не по битам и байтам, а по секторам. Преимущества заключаются в высокой скорости передачи при работе с большими файлами. Также высока скорость работы с большим числом запросов на чтение. Из недостатков можно отметить доставшиеся от RAID 3 – дисбаланс в скорости операций чтения/записи и существование условий, затрудняющих параллельный доступ к данным.
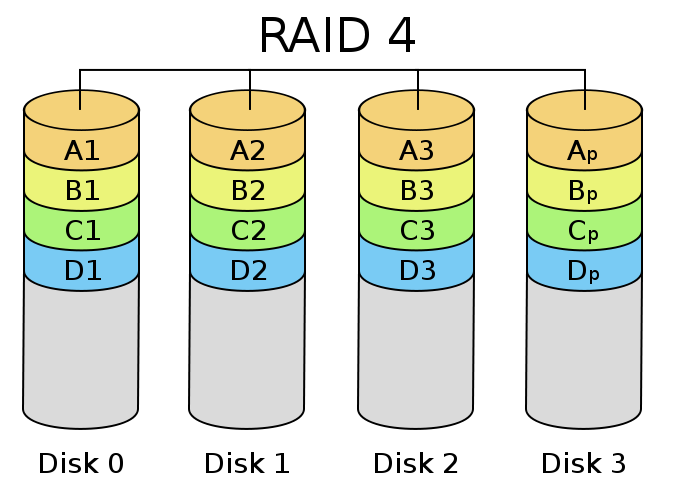
RAID 5. Дисковый массив с чередованием и распределённой чётностью.
Метод похож на предыдущий, но в нём для битов чётности выделяется не отдельный диск, а эта информация распределяется между всеми дисками. То есть, если используется N дисков, то будет доступен объём N-1 диска. Объём одного будет выделен под биты чётности, как и в RAID 3,4. Но они хранятся не на отдельном диске, а разделены. На каждом диске есть (N-1)/N объёма информации и 1/N объёма заполнено битами чётности. Если в массиве выходит из строя один диск, то он остаётся работоспособным (данные, хранившиеся на нём, вычисляются на основе чётности и данных других дисков «на лету»). То есть, сбой проходит прозрачно для пользователя и порой даже с минимальным падением производительности (зависит от вычислительной способности RAID контроллера). Из преимуществ отметим высокие скорости чтения и записи данных, как при больших объёмах, так и при большом числе запросов. Недостатки – сложное восстановление данных и более низкая, чем в RAID 4 скорость чтения.
RAID 6. Дисковый массив с чередованием и двойной распределённой чётностью.
Всё отличие сводится к тому, что используются две схемы чётности. Система устойчива к отказам двух дисков. Основной сложностью является то, что для реализации этого приходится делать больше операций при выполнении записи. Из-за этого скорость записи является чрезвычайно низкой.
Комбинированные (nested) уровни RAID.
Поскольку массивы RAID являются прозрачными для ОС, то вскоре пришло время и созданию массивов, элементами которых являются не диски, а массивы других уровней. Обычно они пишутся через плюс. Первая цифра означает то, массивы какого уровня входят в качестве элементов, а вторая цифра – то, какую организацию имеет верхний уровень, который объединяет элементы.
RAID 0+1
Комбинация, которая является массивом RAID 1, собранным на базе массивов RAID 0. Как и в массиве RAID 1, доступным будет только половина объёма дисков. Но, как и в RAID 0, скорость будет выше, чем с одним диском. Для реализации такого решения необходимо минимум 4 диска.
RAID 1+0
Также известен, как RAID 10. Является страйпом зеркал, то есть, массивом RAID 0, построенным из RAID 1 массивов. Практически аналогичен предыдущему решению.
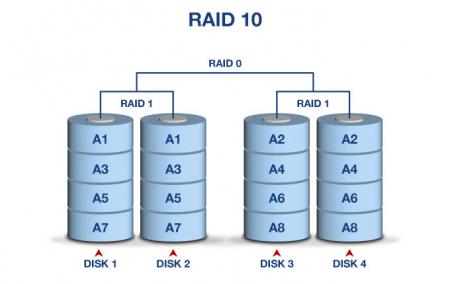
RAID 0+3
Массив с выделенной чётностью над чередованием. Является массивом 3-го уровня, в котором данные блоками разбиваются и пишутся на массивы RAID 0. Комбинации, кроме простейших 0+1 и 1+0 требуют специализированных контроллеров, зачастую достаточно дорогих. Надёжность данного вида ниже, чем у следующего варианта.
RAID 3+0
Также известен, как RAID 30. Является страйпом (массивом RAID 0) из массивов RAID 3. Обладает весьма высокой скорость передачи данных, вкупе с неплохой отказоустойчивостью. Данные сначала разделяются на блоки (как в RAID 0) и попадают на массивы-элементы. Там они опять делятся на блоки, считается их чётность, блоки пишутся на все диски кроме одного, на который пишутся биты чётности. В данном случае, из строя может выйти один из дисков каждого из входящих в состав RAID 3 массива.
RAID 5+0 (50)
Создаётся путём объединения массивов RAID 5 в массив RAID 0. Обладает высокой скоростью передачи данных и обработки запросов. Обладает средней скоростью восстановления данных и хорошей стойкостью при отказе. Комбинация RAID 0+5 также существует, но больше теоретически, так как даёт слишком мало преимуществ.
RAID 5+1 (51)
Сочетание зеркалирования и чередования с распределённой четностью. Также вариантом является RAID 15 (1+5). Обладает очень высокой отказоустойчивостью. Массив 1+5 способен работать при отказе трех дисков, а 5+1 – пяти из восьми дисков.
RAID 6+0 (60)
Чередование с двойной распределённой четностью. Иными словами – страйп из RAID 6. Как уже говорилось применительно к RAID 0+5, RAID 6 из страйпов не получил распространения (0+6). Подобные приёмы (страйп из массивов с четностью) позволяют повысить скорость работы массива. Ещё одним преимуществом является то, что так можно легко повысить объём, не усложняя ситуации с задержками, необходимыми на вычисление и запись большего числа битов четности.
RAID 100 (10+0)
RAID 100, также пишущийся как RAID 10+0, является страйпом из RAID 10. По своей сути, он схож с более широким RAID 10 массивом, где используется вдвое больше дисков. Но именно такой «трехэтажной» структуре есть своё объяснение. Чаще всего RAID 10 делают аппаратным, то есть силами контроллера, а уже страйп из них делают программно. К такой уловке прибегают, чтобы избежать проблемы, о которой говорилось в начале статьи – контроллеры имеют свои ограничения по масштабируемости и если воткнуть в один контроллер двойное число дисков, прироста можно при некоторых условиях вообще не увидеть. Программный же RAID 0 позволяет создать его на базе двух контроллеров, каждый из которых держит на борту RAID 10. Так, мы избегаем «бутылочного горлышка» в лице контроллера. Ещё одним полезным моментом является обход проблемы с максимальным числом разъёмов на одном контроллере – удваивая их число, мы удваиваем и число доступных разъёмов.
Нестандартные режимы RAID
Двойная четность
Распространённым дополнением к перечисленным уровням RAID является двойная четность, порой реализованная и потому называемая «диагональной четностью». Двойная четность уже внедрена в RAID 6. Но, в отличие от нее, четность считается над другими блоками данных. Недавно спецификация RAID 6 была расширена, потому диагональная четность может считаться RAID 6. Если для RAID 6 четность считается как результат сложения по модулю 2 битов, идущих в ряд (то есть сумма первого бита на первом диске, первого бита на втором и т.д.), то в диагональной четности идет смещение. Работа в режиме сбоя дисков не рекомендуется (ввиду сложности вычисления утраченных битов из контрольных сумм).
RAID-DP
Является разработкой NetApp RAID массива с двойной четностью и подпадает под обновленное определение RAID 6. Использует отличную от классической RAID 6 реализации схему записи данных. Запись ведется сначала на кеш NVRAM, снабжённый источником бесперебойного питания, чтобы предотвратить потерю данных при отключении электричества. Программное обеспечение контроллера, по возможности, пишет только цельные блоки на диски. Такая схема предоставляет большую защиту, чем RAID 1 и имеет более высокую скорость работы, нежели обычный RAID 6.
RAID 1,5
Был предложен компанией Highpoint, однако теперь применяется очень часто в контроллерах RAID 1, без каких-либо выделений данной особенности. Суть сводится к простой оптимизации – данные пишутся как на обычный массив RAID 1 (чем 1,5 по сути и является), а читают данные с чередованием с двух дисков (как в RAID 0). В конкретной реализации от Highpoint, применявшейся на платах DFI серии LanParty на чипсете nForce 2, прирост был едва заметным, а порой и нулевым. Связано это, вероятно, с невысокой скоростью контроллеров данного производителя в целом в то время.
RAID 1E
Комбинирует в себе RAID 0 и RAID 1. Создаётся минимум на трёх дисках. Данные пишутся с чередованием на три диска, а со сдвигом на 1 диск пишется их копия. Если пишется один блок на три диска, то копия первой части пишется на второй диск, второй части – на третий диск. При использовании четного числа дисков лучше, конечно, использовать RAID 10.
RAID 5E
Обычно при построении RAID 5 один диск оставляют свободным (spare), чтобы в случае сбоя система сразу стала перестраивать (rebuild) массив. При обычной работе этот диск работает вхолостую. Система RAID 5E подразумевает использование этого диска в качестве элемента массива. А объём этого свободного диска распределяется по всему массиву и находится в конце дисков. Минимальное число дисков – 4 штуки. Доступный объём равен n-2, объём одного диска используется (будучи распределенным между всеми) для четности, объем еще одного – свободный. При выходе из строя диска происходит сжатие массива до 3-х дисков (на примере минимального числа) заполнением свободного пространства. Получается обычный массив RAID 5, устойчивый к отказу ещё одного диска. При подключении нового диска, массив расжимается и занимает вновь все диски. Стоит отметить, что во время сжатия и распаковки диск не является устойчивым к выходу еще одного диска. Также он недоступен для чтения/записи в это время. Основное преимущество – большая скорость работы, поскольку чередование происходит на большем числе дисков. Минус – что нельзя данный диск назначать сразу к нескольким массивам, что возможно в простом массиве RAID 5.
RAID 5EE
Отличается от предыдущего только тем, что области свободного места на дисках не зарезервированы одним куском в конце диска, а чередуются блоками с битами четности. Такая технология значительно ускоряет восстановление после сбоя системы. Блоки можно записать прямо на свободное место, без необходимости перемещения по диску.
RAID 6E
Аналогично с RAID 5E использует дополнительный диск для повышения скорости работы и распределения нагрузки. Свободное место разделяется между другими дисками и находится в конце дисков.
RAID 7
Данная технология является зарегистрированной торговой маркой фирмы Storage Computer Corporation. Массив, основывающийся на RAID 3, 4, оптимизированный для повышения производительности. Основное преимущество заключается в использовании кеширования операций чтения/записи. Запросы на передачу данных осуществляются асинхронно. При построении используются диски SCSI. Скорость выше решений RAID 3,4 приблизительно в 1,5-6 раз.
Intel Matrix RAID
Является технологией, представленной Intel в южных мостах, начиная с ICH6R. Суть сводится к возможности комбинации RAID массивов разных уровней на разделах дисков, а не на отдельных дисках. Скажем, на двух дисках можно организовать по два раздела, два из них будут хранить на себе операционную систему на массиве RAID 0, а другие два – работая в режиме RAID 1 – хранить копии документов.
Linux MD RAID 10
Это RAID драйвер ядра Linux, предоставляющий возможность создания более продвинутой версии RAID 10. Так, если для RAID 10 существовало ограничение в виде чётного числа дисков, то этот драйвер может работать и с нечетным. Принцип для трех дисков будет тем же, что в RAID 1E, когда происходит чередование дисков по очереди для создания копии и чередования блоков, как в RAID 0. Для четырех дисков это будет эквивалентно обычному RAID 10. Помимо этого, можно задавать, на какой области диска будет храниться копия. Скажем, оригинал будет в первой половине первого диска, а его копия – во второй половине второго. Со второй половиной данных – наоборот. Данные можно дублировать несколько раз. Хранение копий на разных частях диска позволяет достичь большей скорости доступа в результате разнородности жесткого диска (скорость доступа меняется в зависимости от расположения данных на пластине, обычно разница составляет два раза).
RAID-K
Разработан компанией Kaleidescape для использования в своих медиа устройствах. Схож с RAID 4 с использованием двойной четности, но использует другой метод отказоустойчивости. Пользователь может легко расширять массив, просто добавляя диски, причём в случае, если он содержит данные, данные будут просто добавлены в него, вместо удаления, как это требуется обычно.
RAID-Z
Разработка компании Sun. Самой большой проблемой RAID 5 является потеря информации в результате отключения питания, когда информация из дискового кеша (который является энергозависимой памятью, то есть не хранит данные без электричества) не успела сохраниться на магнитные пластины. Такое несовпадение информации в кеше и на диске называют некогерентностью. Сама организация массива связана с файловой системой Sun Solaris – ZFS. Используется принудительная запись содержимого кеш-памяти дисков, восстанавливать можно не только весь диск, но и блок «на лету», когда контрольная сумма не совпала. Ещё немаловажным аспектом является идеология ZFS – она не меняет данные при необходимости. Вместо этого она пишет обновлённые данные и потом, убедившись, что операция прошла уже удачно, меняет указатель на них. Таким образом, удаётся избежать потери данных при модификации. Мелкие файлы дублируются вместо создания контрольных сумм. Это тоже делается силами файловой системы, поскольку она знакома со структурой данных (массивом RAID) и может выделять место под эти цели. Существует также RAID-Z2, которая, подобно RAID 6 способна выдержать отказ двух дисков с помощью использования двух контрольных сумм.
JBOD
То, что не является RAID в принципе, но часто вместе с ним употребляется. Дословно переводится как «просто набор дисков» (just a bunch of disks) Технология объединяет все диски, установленные в системе в один большой логический диск. То есть, вместо трех дисков будет виден один крупный. Используется весь суммарный объем дисков. Ускорения ни надежности, ни производительности нет.
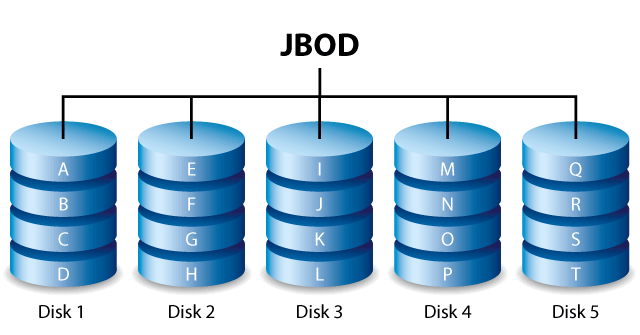
Drive Extender
Функция, заложенная в Window Home Server. Совмещает в себе JBOD и RAID 1. При необходимости создания копии, она не дублирует сразу файл, а ставит NTFS разделе метку, указывающую на данные. При простое система копирует файл так, чтобы место на дисках было максимальным (использовать можно диски разного объема). Позволяет достичь многих преимуществ RAID – отказоустойчивости и возможности простой замены вышедшего из строя диска и его восстановления в фоновом режиме, прозрачности местонахождения файла (вне зависимости от того, на каком диске он находится). Также можно проводить параллельный доступ с разных дисков с помощью вышеуказанных меток, получая сходную с RAID 0 производительность.
UNRAID
Разработана компанией Lime technology LLC. Эта схема отличается от обычных RAID массивов тем, что позволяет смешивать диски SATA и PATA в одном массиве и диски разных объема и скорости. Для контрольной суммы (четности) используется выделенный диск. Данные не чередуются между дисками. В случае отказа одного диска, теряются только файлы, на нём хранящиеся. Однако, с помощью четности они могут быть восстановлены. UNRAID внедрен как добавление к Linux MD (multidisk).
Большинство видов RAID массивов не получило распространения, часть используется в узких сферах применения. Наиболее массовыми, от простых пользователей до серверов начального уровня стали RAID 0, 1, 0+1/10, 5 и 6. Нужен ли вам рейд-массив для ваших задач – решать вам. Теперь вы знаете, в чём их отличия друг от друга.
Источник: http://www.ipcctv.by/index.php?option=com_content&view=article&id=92&Itemid=60
web-profi.by
RAID массивы — краткий ликбез
 RAID-массивы давно и прочно вошли в повседневную деятельность администраторов даже небольших предприятий. Трудно найти того, кто никогда не использовал хотя бы «зеркало», но тем не менее очень и очень многие с завидной периодичностью теряют данные или испытывают иные сложности при эксплуатации массивов. Не говоря уже о распространенных мифах, которые продолжают витать вокруг вроде бы давно избитой темы. Кроме того, современные условия вносят свои коррективы и то, чтобы было оптимальным еще несколько лет назад сегодня утратило свою актуальность или стало нежелательным к применению.
RAID-массивы давно и прочно вошли в повседневную деятельность администраторов даже небольших предприятий. Трудно найти того, кто никогда не использовал хотя бы «зеркало», но тем не менее очень и очень многие с завидной периодичностью теряют данные или испытывают иные сложности при эксплуатации массивов. Не говоря уже о распространенных мифах, которые продолжают витать вокруг вроде бы давно избитой темы. Кроме того, современные условия вносят свои коррективы и то, чтобы было оптимальным еще несколько лет назад сегодня утратило свою актуальность или стало нежелательным к применению.
Чем является и чем не является RAID-массив
Наиболее популярен миф, что RAID предназначен для защиты данных, многие настолько верят в это, что забывают про резервное копирование. Но это не так. RAID-массив никоим образом не защищает пользовательские данные, если вы захотите их удалить, зашифровать, отформатировать — наличие или отсутствие RAID вам абсолютно не помешает. Две основных задачи RIAD-массивов — это защита дисковой подсистемы от выхода из строя одного или нескольких дисков и / или улучшение ее параметров по сравнению с одиночным диском (получение более высокой скорости обмена с дисками, большего количества IOPS и т.д.).
Здесь может возникнуть некоторая путаница, ведь сначала мы сказали, что RAID не защищает, а потом выяснилось, что все-таки защищает, но никакой путаницы нет. Основную ценность для пользователя представляют данные, причем не некоторые абстрактные нули-единицы, кластеры и блоки, а вполне «осязаемые» файлы, которые содержат необходимую нам информацию, иногда очень дорогостоящую. Мы будем в последствии называть это пользовательскими данными или просто данными.
RAID-контроллер о данных ничего не знает, он оперирует с блочными устройствами ввода-вывода. И все что поступает к нему от драйвера — это просто поток байтов, который нужно определенным образом разместить на устройствах хранения. Сам набор блочных устройств объединенных некоторым образом отдается системе в виде некоторой виртуальной сущности, которую принято называть массивом, а в терминологии контроллера — LUN, для системы это выглядит как самый обычный диск, с которым мы можем делать все что угодно: размечать, форматировать, записывать данные.
Как видим, работа RAID-контроллера закончилась на формировании LUN и предоставлении его системе, поэтому защита контроллера распространяется только на этот самый LUN — т.е. логическая структура массива, которую система видит как жесткий диск, должна уцелеть при отказе одного или нескольких дисков составляющих этот массив. Ни более, ни менее. Все что находится выше уровнем: файловая система, пользовательские данные — на это «защита» контроллера не распространяется.
Простой пример. Из «зеркала» вылетает один из дисков, со второго система отказывается грузиться, так как часть данных оказалась повреждена (скажем BAD-блок). Сразу возникает масса «претензий» к RAID, он все они беспочвенны. Главную задачу контроллер выполнил — сохранил работоспособность массива. А в том, что размещенная на нем файловая система оказалась повреждена — это вина администратора, не уделившего должного внимания системе.
Поэтому следует запомнить — RAID-массив защищает от выхода из строя одного или нескольких дисков только самого себя, точнее тот диск, который вы видите в системе, но никак ни его содержимое.
BAD-блоки и неисправимые ошибки чтения
Раз мы коснулись содержимого, то самое время разобраться, что же с ним может быть «не так». Начнем с привычного зла, BAD-блоков. Есть мнение, что если на диске появился сбойный сектор — то диск «посыпался» и его надо менять. Но это не так. Сбойные сектора могут появляться на абсолютно исправных дисках, просто в силу технологии, и ничего страшного в этом нет, обнаружив такой сектор контроллер просто заменит его в LBA-таблице блоком из резервной области и продолжит нормально работать дальше.
Дальше простая статистика, чем выше объем диска — тем больше физических секторов он содержит, тем меньше их физический размер и тем выше вероятность появления сбойных секторов. Грубо говоря, если взять произведенные по одной технологии диски объемом в 1ТБ и 4 ТБ, то у последнего вероятность появления BAD-блока в четыре раза выше.
К чему это может привести? Про ситуацию, когда администратор не контролирует SMART и у диска давно закончилась резервная область мы всерьез говорить не будем, тут и так все понятно. Это как раз тот случай, когда диск реально посыпался и его нужно менять. Большую опасность представляет иная ситуация. Согласно исследованиям, достаточно большие объемы данных составляют т.н. cold data — холодные или замороженные данные — это массивы данных доступ к которым крайне редок. Этом могут быть какие-нибудь архивы, домашние фото и видеоколлекции и т.д. и т.п., они могут месяцами и годами лежать не тронутыми никем, даже антивирусом.
Если в этой области данных возникнет сбойный сектор, то он вполне себе может остаться необнаруженным до момента реконструкции (ребилда) массива или попыток слить данные с массива с отказавшей избыточностью. В зависимости от типа массива такой сектор может привести от невозможности выполнить ребилд до полной потери массива во время его реконструкции. По факту невозможность считать данные с еще одного диска в массиве без избыточности можно рассматривать как отказ еще одного диска со всеми вытекающими.
Кроме физически поврежденных секторов на диске могут быть логические ошибки. Чаще всего они возникают, когда контроллер без резервной батарейки использует кеширование записи на диск. При неожиданной потере питания может выйти, что контроллер уже сообщил системе о завершении записи, но сам не успел физически записать данные, либо сделал это некорректно. Попав в область с холодными данными, такая ошибка тоже может жить очень долго, проявив себя в аварийной ситуации.
Ну и наконец самое интересное: неисправимые ошибки чтения — URE (Unrecoverable Read Error) или BER (Bit Error Ratio) — величина, показывающая вероятность сбоя на количество прочитанных головками диска бит. На первый взляд это очень большая величина, скажем для бытовых дисков типичное значение 10^14 (10 в 14 степени), но если перевести ее в привычные нам единицы измерения, то получим примерно следующее:
- HDD массовых серий — 10^14 — 12,5 ТБ
- HDD корпоративных серий — 10^15 — 125 ТБ
- SSD массовых серий — 10^16 — 1,25 ПБ
- SSD корпоративных серий — 10^17 — 12,5 ПБ
В данном случае в качестве единицы измерения мы использовали десятичные единицы измерения объема, т.е. те, что написаны на этикетке диска, исходя из того, что 1 КБ = 1000 Б.
Что это значит? Это значит, что для массовых дисков вероятность появления ошибки чтения стремится к единице на каждые прочитанные 12,5 ТБ, что по сегодняшним меркам не так уж и много. Если такая ошибка будет получена во время ребилда — это, как и в случае со сбойным сектором, эквивалентно отказу еще одного диска и может привести к самым печальным последствиям.
MTBF — наработка на отказ
Еще один важный параметр, который очень многими трактуется неправильно. Если мы возьмем значение наработки на отказ для современного массового диска, скажем Seagate Barracuda 2 Тб ST2000DM008, то это будет 1 млн. часов, для диска корпоративной серии Seagate Enterprise Capacity 3.5 2 Тб ST2000NM0008 — 2 млн. часов. На первый взгляд какие-то запредельные цифры и судя по ним диски никогда не должны ломаться. Однако этот показатель определяет не срок службы устройства, а среднее вермя между отказами — MTBF ( Mean time between failures ) — а в качестве времени подразумевается время работы устройства.
Если у вас есть 1000 дисков, то при MTBF в 1 млн. часов вы будете получать в среднем один отказ на 1000 часов. Т.е. большие значения оказываются не такими уж и большими. Для оценки вероятности отказа применяется иной показатель — AFR (Annual failure rate) — годовая частота отказов. Ее несложно рассчитать по формуле, где n — количество дисков:
AFR = 1 - exp(-8750*n/MTBF)Так для одиночного диска массовой серии годовая частота отказов составит 0,87%, а для корпоративных дисков 0,44%, вроде бы немного, но если сделать расчет для массива из 5 дисков, то мы получим уже 4,28% / 2,16%. Согласитесь, что вероятность отказа в 5% достаточно велика, чтобы сбрасывать ее со счетов. В тоже время такое знание позволяет обоснованно подходить к закупке комплектующих, теперь вы можете не просто апеллировать к тому, что вам нужны корпоративные диски, потому что они «энтерпрайз и все такое…», а грамотно обосновать свое мнение с цифрами в руках.
Но в реальной жизни не все так просто, годовая величина отказов не является статичной величиной, а подчиняется законам статистики, учитывающим совокупность реальных факторов. Не углубляясь в теорию мы приведем классическую кривую интенсивности отказов:
 Как можно видеть, в самом начале эксплуатации вероятность отказов наиболее велика, постепенно снижаясь. Этот период, обозначенный на графике t0 — t1, называется периодом приработки. В этот момент вскрывается производственный брак, ошибки в планировании системы, неверные режимы и условия эксплуатации. Повышенная нагрузка увеличивает вероятность отказов, так как позволяет быстрее выявить брак и ошибки эксплуатации.
Как можно видеть, в самом начале эксплуатации вероятность отказов наиболее велика, постепенно снижаясь. Этот период, обозначенный на графике t0 — t1, называется периодом приработки. В этот момент вскрывается производственный брак, ошибки в планировании системы, неверные режимы и условия эксплуатации. Повышенная нагрузка увеличивает вероятность отказов, так как позволяет быстрее выявить брак и ошибки эксплуатации.
За ним следует период нормальной эксплуатации t1-t2, вероятность отказов в котором невелика и соответствует расчетным значениям (т.е. тем показателям, которые мы вычислили выше).
Правее отметки t2 на графике начинается период износовых отказов, когда оборудование начинает выходить из строя выработав свой ресурс, повышенная нагрузка будет только усугублять этот показатель. Также обратите внимание, что функция износа изменяется не линейно, по отношении ко времени, а по логарифмической функции. Т.е. в периоде износа отказы будут увеличиваться не постепенно, а не сразу, но, с какого-то момента стремительно.
К чему это может привести? Скажем, если вы эксплуатируете массив, находящийся в периоде износовых отказов и у него выходит из строя один из дисков, то повышенная нагрузка во время ребилда способна привести к новым отказам, что чревато полной потерей массива и данных.
Для жестких дисков и SSD, согласно имеющейся статистики, период приработки где-то равен 3-6 месяцам. А период износовых отказов следует начинать отсчитывать с момента окончания срока гарантии производителя. Для большинства дисков это два года. Это хорошо укладывается в ту же статистику, которая фиксирует увеличение количества отказов на 3-4 году эксплуатации.
Мы не будем сейчас делать выводы и давать советы, приведенных нами теоретических данных вполне достаточно, чтобы каждый мог самостоятельно оценить собственные риски.
Немного терминологии
Прежде чем двигаться дальше — следует определиться с используемыми терминами, тем более что с ними не все так однозначно. Путаницу вносят сами производители, используя различные термины для обозначения одних и тех же вещей, а перевод на русский часто добавляет неопределенности. Мы не претендуем на истину в последней инстанции, но в дальнейшем будем придерживаться описанной ниже системы.
Весь входящий поток данных разбивается контроллером на блоки определенного размера, которые последовательно записываются на диски массива. Каждый такой блок является минимальной единицей данных, с которой оперирует RAID-контроллер. На схеме ниже мы схематично представили массив из трех дисков (RAID 5).
 Каждая шайба на схеме представляет один такой блок, для обозначения которого используют термины: Strip, Stripe Unit, Stripe Size или Chunk, Сhunk Size. В русскоязычной терминологии это может быть блок, «страйп», «чанк». Мы, во избежание путаницы с другой сущностью, предпочитаем использовать для его обозначения термин Chunk (чанк, блок), в тоже время встроенный во многие материнские платы Intel RAID использует термин Stripe Size.
Каждая шайба на схеме представляет один такой блок, для обозначения которого используют термины: Strip, Stripe Unit, Stripe Size или Chunk, Сhunk Size. В русскоязычной терминологии это может быть блок, «страйп», «чанк». Мы, во избежание путаницы с другой сущностью, предпочитаем использовать для его обозначения термин Chunk (чанк, блок), в тоже время встроенный во многие материнские платы Intel RAID использует термин Stripe Size.
Группа блоков (чанков) расположенная по одинаковым адресам на всех дисках массива обозначается в русскоязычных терминах как лента или полоса. В англоязычной снова используется Stripe, а также «страйп» в переводах, что в ряде случаев способно внести путаницу, поэтому при трактовании термина всегда следует учитывать контекст его употребления.
Каждая полоса содержит либо набор данных, либо данные и их контрольные суммы, которые вычисляются на основе данных каждой такой полосы. Глубиной или шириной полосы (Stripe width/depth) называется объем данных, содержащийся в каждой полосе.
Так если размер чанка равен 64 КБ (типовое значение для многих контроллеров), то вычислить ширину полосы мы можем, умножив это значение на количество дисков с данными в массиве. Для RAID 5 из трех дисков — это два, поэтому ширина полосы будет 128 КБ, для RAID 10 из четырех дисков — это четыре и ширина полосы будет 256 КБ.
RAID 0
Перейдем, наконец от теории, к разбору конкретных реализаций RAID. Из всех вариантов RAID 0 — единственный тип массива, который не содержит избыточности, также его еще называют чередующимся массивом или страйпом (Stripe).
 Принцип работы чередующегося массива прост — поток данных делится на блоки (чанки), которые по очереди записываются на все диски массива. При этом ни один диск массива не содержит полной копии данных, зато за счет одновременных операций чтения / записи достигается практически кратный количеству дисков прирост скорости. Объем массива равен сумме объема всех дисков.
Принцип работы чередующегося массива прост — поток данных делится на блоки (чанки), которые по очереди записываются на все диски массива. При этом ни один диск массива не содержит полной копии данных, зато за счет одновременных операций чтения / записи достигается практически кратный количеству дисков прирост скорости. Объем массива равен сумме объема всех дисков.
Несложно заменить, что отказ даже одного диска будет для массива фатальным, поэтому в чистом виде он практически не используется, разве что в тех случаях, когда на первый взгляд выходит быстродействие, при низких требованиях к сохранности данных. Например, рабочие станции, которые размещают на таких массивах только рабочий набор данных, который обрабатывается в текущий момент.
RAID 1
Один из самых популярных видов массивов, знакомый, пожалуй, каждому. RAID 1, он же зеркало (Mirror), состоит обычно из двух дисков, данные на которых дублируют друг друга.
 Входящие данные также разбиваются на блоки и каждый блок записывается на все диски массива, тем самым обеспечивая избыточность. При отказе одного из дисков на втором у нас остается полная копия данных. Дополнительный плюс в том, что для восстановления таких данных не требуется никаких дополнительных операций, вы можете просто присоединить диск к любому ПК и выполнить с него чтение, что важно, если ребилд массива по какой-либо причине сделать не удастся.
Входящие данные также разбиваются на блоки и каждый блок записывается на все диски массива, тем самым обеспечивая избыточность. При отказе одного из дисков на втором у нас остается полная копия данных. Дополнительный плюс в том, что для восстановления таких данных не требуется никаких дополнительных операций, вы можете просто присоединить диск к любому ПК и выполнить с него чтение, что важно, если ребилд массива по какой-либо причине сделать не удастся.
Но за это приходится платить большими потерями емкости — емкость массива равна емкости одного диска, поэтому зеркала с более чем двумя дисками на практике не используют. Также это негативно сказывается на быстродействии. Вспомним, что еще одной причиной объединения дисков в массивы является увеличение быстродействия, при этом важна не линейная скорость записи / чтения, а количество операций ввода вывода в секунду — IOPS — которые может предоставить диск.
В первом приближении общее количество IOPS массива — это суммарное количество IOPS его дисков, но на практике оно будет меньше за счет накладных расходов в самом массиве. В RAID 1 для выполнения одной операции записи массив производит две записи данных, по одной на каждый диск. Этот параметр называется RAID-пенальти и показывает сколько операций ввода вывода делает массив для обеспечения одной операции записи. Операции чтения не подвержены пенальти.
Для RAID 1 пенальти равно двум. Поэтому его производительность на запись не отличается от производительности одиночного жесткого диска. На чтение, теоретически, можно достичь двойной производительности за счет одновременного чтения с разных дисков, но на практике такая функция в контроллерах не реализуется. Поэтому чтение с зеркала также не отличается по производительности от одиночного диска.
Как видим, RAID 0 предоставляет нам высокую производительность при отсутствии надежности, а RAID 1 — высокую надежность без увеличения производительности. Поэтому существуют комбинированные уровни RAID, сочетающие достоинства нескольких типов массивов.
RAID 01 (0+1)
Этот тип массива часто путают с RAID 10, но это неверно, первым числом в наименовании массива всегда указывается вложенный массив, а вторым — внешний. Таким образом RAID 01 — зеркало из страйпов, а RAID 10 — страйп из зеркал. Какая разница? А вот сейчас и посмотрим.
 Так как внешним массивом является RAID 1 — зеркало, то на оба вложенных чередующихся массива подается одинаковый набор данных, который распределяется без избыточности по дискам массива. В итоге получаем два одинаковых RAID 0 массива, которые собраны в зеркало.
Так как внешним массивом является RAID 1 — зеркало, то на оба вложенных чередующихся массива подается одинаковый набор данных, который распределяется без избыточности по дискам массива. В итоге получаем два одинаковых RAID 0 массива, которые собраны в зеркало.
Что случится при отказе одного диска? Ничего страшного, массив выдерживает такой отказ. А если выйдут из строя два? В этом случае возможны варианты:

Для массива из четырех дисков (а это минимальное количество для этого уровня RAID) у нас есть шесть вариантов отказа двух дисков. Исходя из того, что отказ из любого диска RAID 0 является для него фатальным, то получаем 4 отказа из 6 или 66,67%. Т.е. при потере двух дисков вы потеряете свои данные с вероятностью 66,67%, что довольно-таки много.
RAID 10
«Десятка» также собирается минимум из 4 дисков, но внутренняя структуре ее зеркально отличается от 0+1:
 Массив верхнего уровня RAID 0 — делит входящие данные и распределяет их между низлежащими массивами RAID 1. В итоге получаем чередующийся массив из нескольких зеркал. В чем тут принципиальная разница с предыдущим массивом? А вот в чем, снова рассмотрим ситуацию отказа сразу двух дисков:
Массив верхнего уровня RAID 0 — делит входящие данные и распределяет их между низлежащими массивами RAID 1. В итоге получаем чередующийся массив из нескольких зеркал. В чем тут принципиальная разница с предыдущим массивом? А вот в чем, снова рассмотрим ситуацию отказа сразу двух дисков:
 В отличие от страйпа, для отказа зеркала нужен выход из строя обоих диском массива и только эта ситуация приведет к полному отказу RAID 10, из 6 вариантов это произойдет только в двух случаях, т.е. вероятность потери данных при отказе двух дисков в RAID 10 равна 33,33%. А теперь сравните это с 66,77% у RAID 0+1, поэтому в настоящее время применяется исключительно RAID 10, так как при одинаковых показателях производительности обеспечивает гораздо более высокую надежность.
В отличие от страйпа, для отказа зеркала нужен выход из строя обоих диском массива и только эта ситуация приведет к полному отказу RAID 10, из 6 вариантов это произойдет только в двух случаях, т.е. вероятность потери данных при отказе двух дисков в RAID 10 равна 33,33%. А теперь сравните это с 66,77% у RAID 0+1, поэтому в настоящее время применяется исключительно RAID 10, так как при одинаковых показателях производительности обеспечивает гораздо более высокую надежность.
Пенальти RAID 10, также, как и RAID 1 равно двум, но за счет наличия четырех дисков он обеспечивает скоростные показатели аналогичные RAID 0 при надежности сопоставимой с RAID 1, емкость массива равна емкости половины его дисков.
На сегодня RAID 10 — наиболее производительный RAID-массив с высокой надежностью, его единственный и довольно существенный недостаток — высокие накладные расходы — 50% (половина дисков используется для создания избыточности).
RAID 5
Существует распространенное заблуждение, что RAID 5 (и RAID 6) — это более «крутые» уровни RAID, правда редко кто при этом может пояснить чем они «круче», но миф продолжает жить и очень часто администраторы выбирают уровень RAID исходя из таких вот заблуждений, а не реальных показателей.
Устройство RAID 5 более сложно, чем у «младших» уровней RAID и здесь появляется понятие контрольной суммы, на же Рarity, четность. В основу алгоритма положена логическая функция XOR (исключающее ИЛИ), так для трех переменных будет справедливо равенство:
a XOR b XOR c = pГде p — контрольная сумма или четность. При этом мы всегда можем вычислить любую из переменных зная четность и остальные значения, т.е.:
a = p XOR b XOR c
b = a XOR p XOR c
c = a XOR b XOR pДанные формулы остаются справедливы для любого количества переменных, позволяя обходится единственным значением четности. Таким образом минимальное количество дисков в RAID 5 будет равно трем: два диска для данных и один диск для четности. Раньше существовали реализации RAID 3 и 4, которые использовали для хранения блоков четности отдельный диск, что приводило к высокой нагрузке на него, в RAID 5 поступили иначе.
 Здесь данные точно также разбиваются на блоки и распределяются по дискам, как в RAID 0, но появляется еще и понятие полосы, для каждой полосы данных вычисляется контрольная сумма и записывается в той же полосе на отдельном диске, т.е. один из дисков полосы выполняет роль диска для хранения четности. В следующей полосе происходит чередование дисков, теперь два других диска будут хранить данные, а третий четность. Таким образом достигается равномерное использование всех дисков, что снижает нагрузку на диски и повышает производительность массива в целом.
Здесь данные точно также разбиваются на блоки и распределяются по дискам, как в RAID 0, но появляется еще и понятие полосы, для каждой полосы данных вычисляется контрольная сумма и записывается в той же полосе на отдельном диске, т.е. один из дисков полосы выполняет роль диска для хранения четности. В следующей полосе происходит чередование дисков, теперь два других диска будут хранить данные, а третий четность. Таким образом достигается равномерное использование всех дисков, что снижает нагрузку на диски и повышает производительность массива в целом.
Основным стимулом создания RAID 5 было более оптимальное использование дисков в массиве, так в массиве из 3 дисков накладные расходы RAID 5 составят 33%, из 4 дисков — 25 %, из 6 дисков — 16%. Но при этом вырастает пенальти, в RAID 5 на одну операцию записи приходятся операции: чтение данных, чтение четности, запись новых данных, запись четности. Таким образом пенальти для RAID 5 составляет четыре.
Это означает, что производительность на запись массивов из небольшого числа дисков (менее 5) будет ниже, чем у одиночного диска, но производительность чтения будет сравнима с RAID 0. При этом массив допускает отказ любого одного диска.
В этом месте мы подходим к развенчанию одного из мифов, что RAID 5 «круче», нет, он не «круче», а по производительности даже уступает тому же RAID 10 (а иногда даже и зеркалу). Но по соотношению производительности, накладных расходов и надежности данный уровень RAID представлял наиболее разумный компромисс, что и обеспечило его популярность.
Внимательный читатель заметит, что в прошлом абзаце мы высказались о преимуществах RAID 5 в прошедшем времени, действительно это так, но, чтобы понять почему, следует поговорить о недостатках, которые наиболее ярко проявляются при выходе из строя одного из дисков.
В отличие от RAID 1 / 10 при отказе диска RAID 5 не будет содержать полной копии данных, только их часть плюс контрольные суммы. Это означает что у нас появится пенальти на чтение — для чтения недостающего фрагмента данных нам потребуется полностью считать полосу и провести ряд вычислений для восстановления отсутствующих значений. Это резко снижает производительность массива и увеличивает нагрузку на него, что может привести к выходу из строя оставшихся дисков.
При отказе одного диска массив переходит в режим деградации, при этом по его надежность начинает соответствовать RAID 0, т.е. отказ еще одного диска, BAD-блок или ошибка URE могут стать для него фатальными. При замене неисправного диска массив переходит в режим реконструкции (ребилда), который сопряжен с высокой нагрузкой на оборудование, так как для восстановления контроллер должен прочитать весь объем данных массива. Любой сбой в процессе ребилда также может привести к полному разрушению массива.
А теперь вспомним значение URE для современных массовых дисков — 10^14, что это значит в нашем случае? А то, что собрав RAID 5 из четырех дисков на 4 ТБ (с объемом данных 12 ТБ) вы с вероятностью очень близкой к 100% получите невосстановимую ошибку чтения при ребилде и потеряете массив полностью.
Но это не значит, что RAID 5 изначально имел столь критические недостатки. Вернемся на 10 лет назад, основной объем ходовых моделей дисков тогда составлял 250-500 ГБ, URE для популярной тогда серии Barracuda 7200.10 был теми же 10^14, а MTBF был немного ниже — 700 тыс. часов.
Допустим мы собрали тогда массив из 4 дисков по 750 ГБ (топовые диски на тот момент), объем данных такого массива составит 2,25 ТБ, вероятность получить URE будет в районе 18%. В общем и целом — немного, большинство успешно реконструировало массив, а голоса тех, кому не повезло, тонули в общем хоре тех, у кого все было хорошо.
Но сегодня RAID 5 в принципе неприменим с массовыми сериями дисков, и с определенными оглядками применим на корпоративных сериях. Не смотря на более высокое значение URE последних, не будем забывать о возможных сбойных областях в зоне холодных данных, а чем больше объем дисков, тем больше секторов, тем больше вероятность сбоя в одном из них.
Также это хорошая иллюстрация пагубности мифов, так как собрав сегодня «крутой» массив RAID 5 вы с очень большой вероятностью просто угробите все свои данные при отказе одного из дисков.
RAID 5E
Как мы уже успели выяснить, ситуация с отказом одного из дисков является для RAID 5 критической — массив переходит в режим деградации с серьезным падением производительности и существенным ростом нагрузки на диски, а его надежность падает до уровня RAID 0 и любая ошибка способна полностью разрушить массив с полной потерей данных. Поэтому чем быстрее мы заменим сбойный диск — тем скорее выведем массив из зоны риска.
Первоначально этот вопрос решался, да и решается до сих пор, выделением диска горячей замены. Такой диск может быть выделенным, т.е. привязанным к указанному массиву, или разделяемым, тогда в случае отказа он будет использован одним из отказавших массивов. Но у этого подхода есть серьезный недостаток — фактически мы никак не используем резервный диск, а так как отказы происходят не каждый день, то его ресурс просто тратится впустую.
RAID 5E предлагает иной подход, пространство резервного диска разделяется между остальными дисками и остается неразмеченным в конце каждого диска массива.
 Такой подход связан с некоторыми ограничениями, а именно — один раздел на один массив. Из плюсов — более высокая производительность за счет использования дополнительного диска. Что происходит при отказе? Массив автоматически начинает реконструкцию размещая данные в неразмеченной области (производит сжатие), после чего массив фактически превращается в простой RAID 5 и способен выдержать отказ еще одного диска (но не во время перестроения).
Такой подход связан с некоторыми ограничениями, а именно — один раздел на один массив. Из плюсов — более высокая производительность за счет использования дополнительного диска. Что происходит при отказе? Массив автоматически начинает реконструкцию размещая данные в неразмеченной области (производит сжатие), после чего массив фактически превращается в простой RAID 5 и способен выдержать отказ еще одного диска (но не во время перестроения).
При замене неисправного диска массив переносит данные из резервной области на новый диск и снова начинает работать как RAID 5E (производит развертывание), при этом операция развертывания не сопряжена с дополнительными рисками, отказ диска или ошибка в данной ситуации не будут фатальными.
RAID 5EE
Дальнейшее развитие RAID 5E, в котором отказались из за размещения резервной области в конце диска (самая медленная его часть), а разбили ее на блоки и также как и блоки четности начали чередовать между дисками. Основное преимущество такого подхода — это более быстрый процесс реконструкции, а так как в этом состоянии массив особо уязвим, то уменьшение времени ребилда — это повышение надежности всего массива.
 Кроме того, такой подход позволяет выровнять нагрузку по дискам, что должно положительно сказываться на надежности. Ограничения остались те же — один раздел на один массив.
Кроме того, такой подход позволяет выровнять нагрузку по дискам, что должно положительно сказываться на надежности. Ограничения остались те же — один раздел на один массив.
Также ни RAID 5E, ни RAID 5EE не лишились недостатка простого RAID 5 — на современных объемах массивов вероятность успешного ребилда такого массива очень невелика.
RAID 6
В отличие от RAID 5 этот массив использует две контрольные суммы и два диска четности, поэтому для него понадобятся 4 диска, при этом допускается выход из строя двух из них. Также, как и у RAID 5 алгоритм позволяет использовать всего две контрольные суммы вне зависимости от ширины полосы и общий объем массива всегда будет равен объему всех дисков за вычетом двух. При отказе одного диска RAID 6 выдерживает отказ еще одного, либо ошибку чтения без фатальных последствий.

Казалось бы, вот он — новый компромисс, замена RAID 5 в современных условиях и т.д. и т.п., но за все надо платить. Одна операция записи на такой массив требует большего количества операций внутри массива: чтение данных, чтение четности 1, чтение четности 2, запись данных, запись четности 1, запись четности 2 — итого 6 операций, таким образом пенальти RAID 6 равен шести.
В общем, повысив надежность, данный массив существенно потерял в производительности настолько, что многие поставщики не рекомендуют его использование кроме как для хранения холодных данных.
И снова вернемся к мифам: RAID 6 это «круто»? Может быть, во всяком случае за свои данные можно не беспокоиться. А почему так медленно? Так это плата за надежность…
RAID 6E
По сути, тоже самое, что и RAID 5E. Резервный диск точно также распределяется в виде неразмеченного пространства в конце дисков, с теми же самыми ограничениями — один раздел на один массив. Ну и добавьте еще один диск в минимальное количество для массива, для RAID 5E это было 4, для RAID 6E — 5.
RAID 50 и RAID 60
Комбинированные массивы, аналогичные RAID 10, только вместо зеркала используется чередование нескольких массивов RAID 5 или RAID 6. Основная цель при создании таких массивов — более высокая производительность, надежность их в минимальном варианте соответствует надежности внутреннего массива, но в зависимости от ситуации может выдерживать отказ и большего количества дисков.
Заключение
Данная статья в первую очередь предназначена для исключения пробелов в знаниях и не претендует на какие-либо рекомендации. Тем не менее кое какие выводы можно сделать. RAID 5 в современных условиях применять не следует, скорее всего вы потеряете свои данные в любой нештатной ситуации.
RAID 10 остается наиболее производительным массивом, но имеет большие накладные расходы — 50%.
RAID 6 имеет наиболее разумное сочетание надежности и накладных расходов, но его производительность оставляет желать лучшего.
При этом мы оставили за кадром многие технологии, скажем RAID DP — реализацию RAID 6 от производителя систем хранения NetApp, которая предлагает все достоинства RAID 6 вкупе в высокой производительностью, на уровне RAID 0. Или RAID-Z — систем на основе ZFS, которые являются программными реализациями и для обзора которых потребуется отдельная статья.
Также мы надеемся, что данный материал поможет вам в осознанном выборе уровня RAID-массива согласно вашим требованиям.
interface31.ru