Калькулятор RAID
Уровень RAID
0 1 3 4 5 6 DP TEC DDP 10 50 60
RAID 0 — массив дисков с чередованием данных (страйп). Подробнее
Подробнее
RAID 1 — зеркалированный массив дисков (зеркало). Подробнее
RAID 3 — массив дисков с побайтным чередованием с одним выделенным диском четности на группу. Подробнее
RAID 4 — массив дисков с поблочным чередованием с одним выделенным диском четности на группу. Подробнее
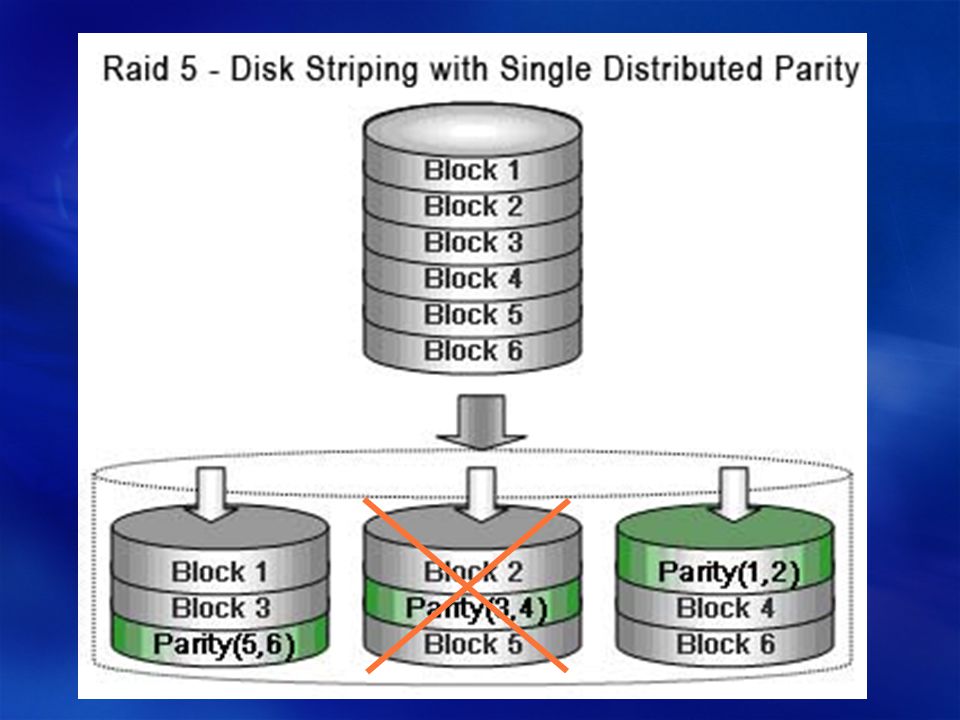
RAID 5 — массив дисков с поблочным чередованием с одной контрольной суммой. Подробнее
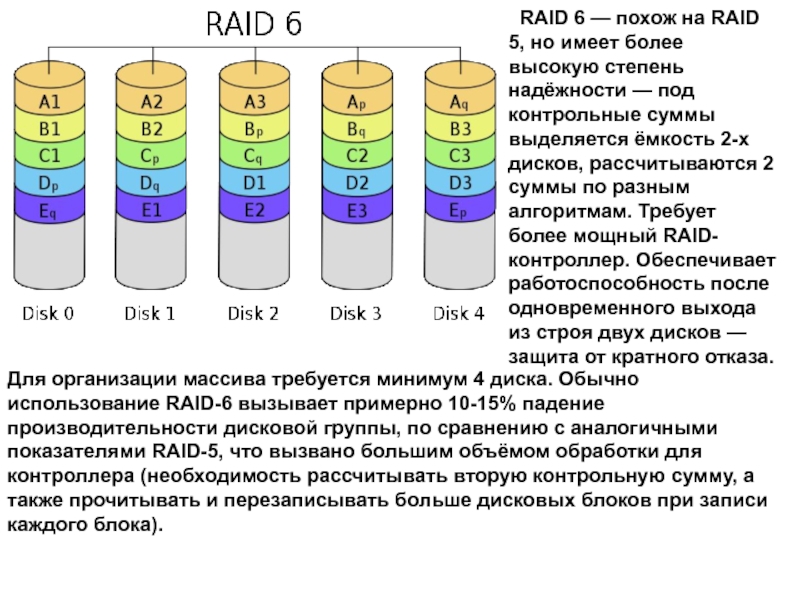
RAID 6 — массив дисков с поблочным чередованием с двумя контрольными суммами. Подробнее
RAID DP — модификация RAID 6 в линейке продукции FAS компании NetApp, под контрольные суммы выделяются два отдельных диска. Подробнее
RAID TEC — массив дисков с тройной четностью в линейке продукции FAS компании NetApp. Подробнее
DDP — массив DDP. Подробнее
RAID 10 — массив дисков с зеркалированием и чередованием. Подробнее
Подробнее
RAID 50 — массив дисков, состоящий из чередования массивов RAID 5. Подробнее
RAID 60 — массив дисков, состоящий из чередования массивов RAID 6. Подробнее
Емкость диска
NL SAS / SATA 3.5″ SAS 2.5″ SSD 2.5″
Для RAID 1 рекомендуется использовать SAS или SSD.
Для RAID 4 рекомендуется использовать SAS или SSD.
Для RAID 5 рекомендуется использовать SAS или SSD.
Для RAID 6 рекомендуется использовать NL-SAS / SATA.
Для RAID DDP рекомендуется использовать NL-SAS / SATA и SAS.
Для RAID 10 рекомендуется использовать NL-SAS / SATA и SAS.
1 терабайт (TB) = 1000 гигабайт (GB), 1 гигабайт (GB) = 1000 мегабайт (MB)
Для RAID 1 рекомендуемый объем: от 128 до 600 GB.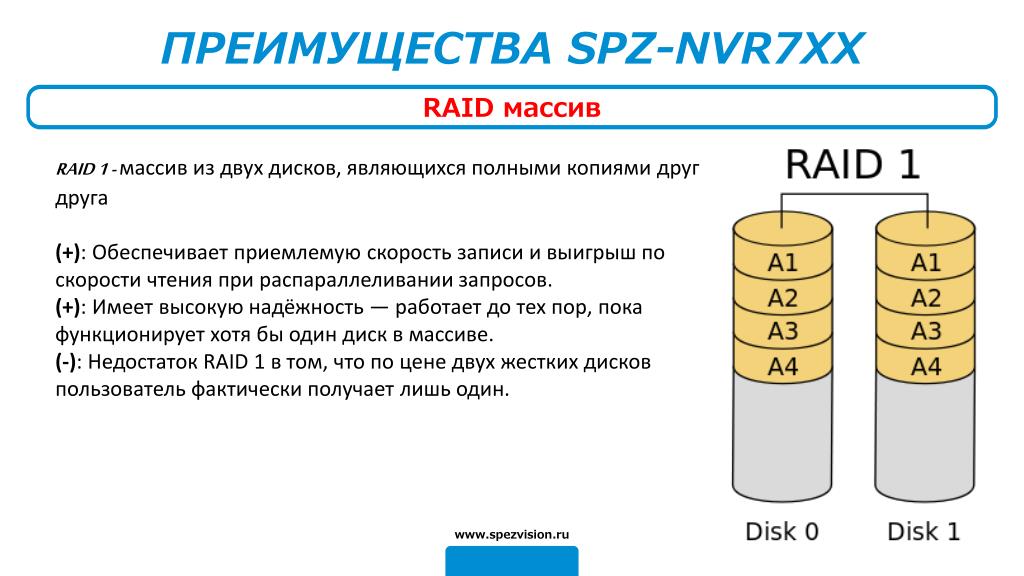
Для RAID 3 рекомендуемый объем: от 900 до 3840 GB.
Для RAID 4 рекомендуемый объем: менее 1000 GB.
Для RAID 5 рекомендуемый объем: менее 2000 GB.
Для RAID 6 рекомендуемый объем: 4000 GB и более.
Для RAID DP рекомендуемый объем: не более 7500 GB.
Для RAID TEC рекомендуемый объем: 6000 GB и более.
Для RAID 10 рекомендуемый объем: не более 2400 GB.
Количество дисков
Указать размер RAID группыМаксимальное количество дисков в RAID группе.
Максимальное количество дисков в RAID группе.
Рекомендуемое количество: от 9 до 17 дисков.
Ограничение большинства производителей: не более 24 дисков.
Рекомендуемое количество: от 4 до 12 дисков.
Ограничение большинства производителей: не более 14 дисков.
Рекомендуемое количество: от 9 до 17 дисков.
Ограничение большинства производителей: не более 30 дисков.
Рекомендуемое количество: от 10 до 18 дисков.
Ограничение большинства производителей: не более 30 дисков.
Рекомендуемое количество: от 6 до 16 дисков.
Ограничение большинства производителей: не более 28 дисков.
Рекомендуемое количество: от 21 до 29 дисков.
Ограничение большинства производителей: не более 29 дисков.
Рекомендуемое количество: от 24 до 48 дисков.
Ограничение большинства производителей: не более 480 дисков.
Рекомендуемое количество: от 12 до 36 дисков.
Ограничение большинства производителей: не более 48 дисков.
Максимальное количество дисков в RAID группе.
Максимальное количество дисков в RAID группе.
Доступный объем: —
Недоступный объем: —
Расчет
Общий объем
—
Общий физический объем дисков
Эффективный объем с учетом WAFL
—
Объем, видимый файловой системой
Эффективность использования дискового пространства
—
Отказоустойчивость
—
Допустимое количество дисков RAID-массива, которое может одновременно выйти из строя без потери данных
RAID для «чайников» и не только
KDV, iBase.
 ru, 26.11.2004, последнее обновление – 27.02.2009. Со времени первой публикации статьи, на forum.ibase.ru в ее обсуждении появилась масса интересных сообщений. Так что после чтения статьи рекомендую обязательно просмотреть топик на форуме.
ru, 26.11.2004, последнее обновление – 27.02.2009. Со времени первой публикации статьи, на forum.ibase.ru в ее обсуждении появилась масса интересных сообщений. Так что после чтения статьи рекомендую обязательно просмотреть топик на форуме.В интернете есть масса статей с описанием RAID. Например, эта описывает все очень подробно. Но как обычно, читать все не хватает времени, поэтому надо что-нибудь коротенькое для понимания – а надо оно или нет, и что лучше использовать применительно к работе с СУБД (InterBase, Firebird или что то иное – на самом деле все равно). Перед вашими глазами – именно такой материал.
Примечание. Сейчас есть хорошая статья о RAID в Википедии.
В первом приближении RAID это объединение дисков в один массив. SATA, SAS, SCSI, SSD – неважно. Более того, практически каждая нормальная материнская плата сейчас поддерживает возможность организации SATA RAID. Пройдемся по списку, какие бывают RAID и зачем они. (Хотел бы сразу заметить, что в RAID нужно объединять одинаковые диски.
RAID 0 (Stripe)
Грубо говоря, это последовательное объединение двух (или более) физических дисков в один «физический» диск. Годится разве что для организации огромных дисковых пространств, например, для тех, кто работает с редактированием видео. Базы данных на таких дисках держать нет смысла – в самом деле, если даже у вас база данных имеет размер 50 гигабайт, то почему вы купили два диска размером по 40 гигабайт, а не 1 на 80 гигабайт? Хуже всего то, что в RAID 0 любой отказ одного из дисков ведет к полной неработоспособности такого RAID, потому что данные записываются поочередно на оба диска, и соответственно, RAID 0 не имеет средств для восстановления в случае сбоев. Конечно, RAID 0 дает ускорение в работе из-за чередования чтения/записи.RAID 0 часто используют для размещения временных файлов.
RAID 1 (Mirror)
Зеркалирование дисков. Если Shadow в IB/FB это программное зеркалирование (см. Operations Guide.pdf), то RAID 1 – аппаратное зеркалирование, и ничего более. Упаси вас от использования программного зеркалирования средствами ОС или сторонним ПО. Надо или «железный» RAID 1, или shadow.
Если Shadow в IB/FB это программное зеркалирование (см. Operations Guide.pdf), то RAID 1 – аппаратное зеркалирование, и ничего более. Упаси вас от использования программного зеркалирования средствами ОС или сторонним ПО. Надо или «железный» RAID 1, или shadow.При сбое тщательно проверяйте, какой именно диск сбойнул. Самый частый случай погибания данных на RAID 1 – это неверные действия при восстановлении (в качестве «целого» указан не тот диск).
Насчет производительности – по записи выигрыш 0, по чтению – возможно до 1.5 раз, т. к. чтение может производиться «параллельно» (поочередно с разных дисков) . Для баз данных ускорение мало, в то время как при параллельном обращении к разным (!) частям (файлам) диска ускорение будет абсолютно точно.
RAID 1+0
Под RAID 1+0 имеют в виду вариант RAID 10, когда два RAID 1 объединяются в RAID 0. Вариант, когда два RAID 0 объединяются в RAID 1 называется RAID 0+1, и «снаружи» представляет собой тот же RAID 10.RAID 2-3-4
Эти RAID являются редкими, т. к. в них используются коды Хэмминга, либо разбиение байт на блоки + контрольные суммы и т. п., но общее резюме таково – эти RAID дают только надежность, при 0-вом увеличении производительности, и иногда даже ее ухудшении.
к. в них используются коды Хэмминга, либо разбиение байт на блоки + контрольные суммы и т. п., но общее резюме таково – эти RAID дают только надежность, при 0-вом увеличении производительности, и иногда даже ее ухудшении.RAID 5
Для него нужно минимально 3 диска. Данные четности распределяются по всем дискам массиваОбычно говорится, что «RAID5 использует независимый доступ к дискам, так что запросы к разным дискам могут выполняться параллельно». Следует иметь в виду, что речь идет, конечно, о параллельных запросах на ввод-вывод. Если такие запросы идут последовательно (в SuperServer), то конечно, эффекта распараллеливания доступа на RAID 5 вы не получите. Разумеется, RAID5 даст прирост производительности, если с массивом будут работать операционная система и другие приложения (например, на нем будет находиться виртуальная память, TEMP и т. п.).
Вообще RAID 5 раньше был наиболее часто используемым массивом дисков для работы с СУБД. Сейчас такой массив можно организовать и на SATA дисках, причем он получится существенно дешевле, чем на SCSI. Цены и контроллеры вы можете посмотреть в статьях
Цены и контроллеры вы можете посмотреть в статьях
- http://old.computerra.ru/2004/540/204913/
- http://www.thg.ru/storage/20040625/index.html
Тестирование пяти контроллеров SATA RAID – http://www.thg.ru/storage/20051102/index.html.
Adaptec SATA RAID 21610SA в массивах RAID 5 – http://www.ixbt.com/storage/adaptec21610raid5.shtml.
Почему RAID 5 — это плохо — https://geektimes.ru/post/78311/
Внимание! При закупке дисков для RAID5 обычно берут 3 диска, по минимуму (скорее из-за цены). Если вдруг по прошествии времени один из дисков откажет, то может возникнуть ситуация, когда не удастся приобрести диск, аналогичный используемым (перестали выпускаться, временно нет в продаже, и т. п.). Поэтому более интересной идеей кажется закупка 4-х дисков, организация RAID5 из трех, и подключение 4-го диска в качестве резервного (для бэкапов, других файлов и прочих нужд).
Есть интересное мнение по поводу «непригодности» RAID5 для баз данных. Как минимум его можно рассматривать с той точки зрения, что для получения хорошей производительности RAID5 необходимо использовать специализированный контроллер, а не то, что есть по умолчанию на материнской плате.
Статья RAID-5 must die. И еще о потерях данных на RAID5.
Примечание. На 05.09.2005 стоимость SATA диска Hitachi 80Gb составляет 60 долларов.
RAID 10, 50
Дальше идут уже комбинации из перечисленных вариантов. Например, RAID 10 это RAID 0 + RAID 1. RAID 50 – это RAID 5 + RAID 0.Интересно, что комбинация RAID 0+1 в плане надежности оказывается хуже, чем RAID5. В копилке службы ремонта БД есть случай сбоя одного диска в системе RAID0 (3 диска) + RAID1 (еще 3 таких же диска). При этом RAID1 не смог «поднять» резервный диск. База оказалась испорченной без шансов на ремонт.
При этом RAID1 не смог «поднять» резервный диск. База оказалась испорченной без шансов на ремонт.
Для RAID 0+1 требуется 4 диска, а для RAID 5 – 3. Подумайте об этом.
RAID 6
В отличие от RAID 5, который использует четность для защиты данных от одиночных неисправностей, в RAID 6 та же четность используется для защиты от двойных неисправностей. Соответственно, процессор более мощный, чем в RAID 5, и дисков требуется уже не 3, а минимум 5 (три диска данных и 2 диска контроля четности). Причем, количество дисков в raid6 не имеет такой гибкости, как в raid 5, и должно быть равно простому числу (5, 7, 11, 13 и т. д.)Допустим одновременный сбой двух дисков, правда, такой случай является весьма редким.
По производительности RAID 6 я данных не видел (не искал), но вполне может быть, что из-за избыточного контроля производительность может быть на уровне RAID 5.
См. неплохую статью про RAID 6.
Rebuild time
У любого массива RAID, который остается работоспособным при сбое одного диска, существует такое понятие, как rebuild time. Разумеется, когда вы заменили сдохший диск на новый, контроллер должен организовать функционирование нового диска в массиве, и на это потребуется определенное время.
Разумеется, когда вы заменили сдохший диск на новый, контроллер должен организовать функционирование нового диска в массиве, и на это потребуется определенное время.Во время «подключения» нового диска, например, для RAID 5, контроллер может допускать работу с массивом. Но скорость работы массива в этом случае будет весьма низкой, как минимум потому, что даже при «линейном» наполнении нового диска информацией запись на него будет «отвлекать» контроллер и головки диска на операции синхронизации с остальными дисками массива.
Время восстановления функционирования массива в нормальном режиме напрямую зависит от объема дисков. Например, Sun StorEdge 3510 FC Array при размере массива 2 терабайта в монопольном режиме делает rebuild в течение 4.5 часов (при цене железки около $40000). Поэтому, при организации массива и планировании восстановления при сбое нужно в первую очередь думать именно о rebuild time. Если ваша база данных и бэкапы занимают не более 50 гигабайт, и рост в год составляет 1-2 гигабайта, то вряд ли имеет смысл собирать массив из 500-гигабайтных дисков. Достаточно будет и 250-гигабайтных, при этом даже для raid5 это будет минимум 500 гигабайт места для размещения не только базы данных, но и фильмов. Зато rebuild time для 250 гигабайтных дисков будет примерно в 2 раза меньше, чем для 500 гигабайтных.
Достаточно будет и 250-гигабайтных, при этом даже для raid5 это будет минимум 500 гигабайт места для размещения не только базы данных, но и фильмов. Зато rebuild time для 250 гигабайтных дисков будет примерно в 2 раза меньше, чем для 500 гигабайтных.
Резюме
Получается, что самым осмысленным является использование либо RAID 1, либо RAID 5. Однако, самая частая ошибка, которую делают практически все – это использование RAID «подо все». То есть, ставят RAID, на него наваливают все что есть, и … получают в лучшем случае надежность, но никак не улучшение производительности.Еще часто не включают write cache, в результате чего запись на raid происходит медленнее, чем на обычный одиночный диск. Дело в том, что у большинства контроллеров эта опция по умолчанию выключена, т.к. считается, что для ее включения желательно наличие как минимум батарейки на raid-контроллере, а также наличие UPS.
Текст
В старой статье hddspeed.htmLINK (и в doc_calford_1.htmLINK) показано, как можно получить существенное увеличение производительности путем использования нескольких физических дисков, даже для IDE. Соответственно, если вы организуете RAID – положите на него базу, а остальное (temp, OS, виртуалка) делайте на других винчестерах. Ведь все равно, RAID сам по себе является одним «диском», пусть даже и более надежным и быстродействующим.
Соответственно, если вы организуете RAID – положите на него базу, а остальное (temp, OS, виртуалка) делайте на других винчестерах. Ведь все равно, RAID сам по себе является одним «диском», пусть даже и более надежным и быстродействующим.
признан устаревшим. Все вышеупомянутое вполне имеет право на существование на RAID 5. Однако перед таким размещением необходимо выяснить – каким образом можно делать backup/restore операционной системы, и сколько по времени это будет занимать, сколько времени займет восстановление «умершего» диска, есть ли (будет ли) под рукой диск для замены «умершего» и так далее, т. е. надо будет заранее знать ответы на самые элементарные вопросы на случай сбоя системы.
Я все-таки советую операционную систему держать на отдельном SATA-диске, или если хотите, на двух SATA-дисках, связанных в RAID 1. В любом случае, располагая операционную систему на RAID, вы должны спланировать ваши действия, если вдруг прекратит работать материнская плата – иногда перенос дисков raid-массива на другую материнскую плату (чипсет, raid-контроллер) невозможен из-за несовместимости умолчательных параметров raid.
Размещение базы, shadow и backup
Несмотря на все преимущества RAID, категорически не рекомендуется, например, делать backup на этот же самый логический диск. Мало того что это плохо влияет на производительность, но еще и может привести к проблемам с отсутствием свободного места (на больших БД) – ведь в зависимости от данных файл backup может быть эквивалентным размеру БД, и даже больше. Делать backup на тот же физический диск – еще куда ни шло, хотя самый оптимальный вариант – backup на отдельный винчестер.Объяснение очень простое. Backup – это чтение данных из файла БД и запись в файл бэкапа. Если физически все это происходит на одном диске (даже RAID 0 или RAID 1), то производительность будет хуже, чем если чтение производится с одного диска, а запись – на другой. Еще больше выигрыш от такого разделения – когда backup делается во время работы пользователей с БД.
То же самое в отношении shadow – нет никакого смысла класть shadow, например, на RAID 1, туда же где и база, даже на разные логические диски.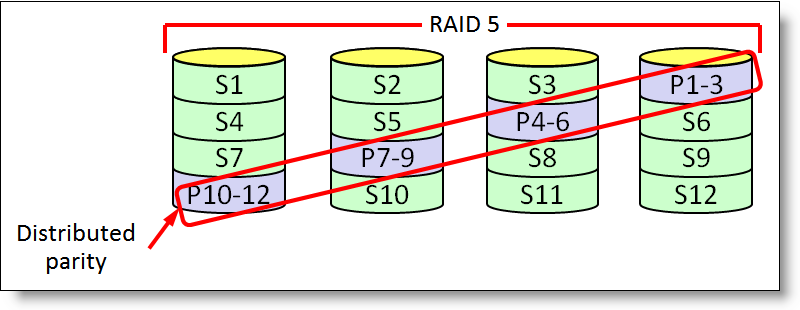 При наличии shadow сервер пишет страницы данных как в файл базы так и в файл shadow. То есть, вместо одной операции записи производятся две. При разделении базы и shadow по разным физическим дискам производительность записи будет определяться самым медленным диском.
При наличии shadow сервер пишет страницы данных как в файл базы так и в файл shadow. То есть, вместо одной операции записи производятся две. При разделении базы и shadow по разным физическим дискам производительность записи будет определяться самым медленным диском.
Обсудить статью на форуме
404: Страница не найдена
ХранилищеСтраница, которую вы пытались открыть по этому адресу, похоже, не существует. Обычно это результат плохой или устаревшей ссылки. Мы извиняемся за любые неудобства.
Что я могу сделать сейчас?
Если вы впервые посещаете TechTarget, добро пожаловать! Извините за обстоятельства, при которых мы встречаемся. Вот куда вы можете пойти отсюда:
Поиск- Узнайте последние новости.
- Наша домашняя страница содержит последнюю информацию о технологиях хранения данных.
- Наша страница «О нас» содержит дополнительную информацию о сайте, на котором вы находитесь, Хранилище.
- Если вам нужно, пожалуйста, свяжитесь с нами, мы будем рады услышать от вас.


Просмотр по категории
Аварийное восстановление- 10 революционных тенденций аварийного восстановления
Последние тенденции в области ИИ, программ-вымогателей и регулирования данных оказывают серьезное влияние на группы аварийного восстановления. Не позволяйте быстро …
- 20-летняя эволюция системы управления критическими событиями Everbridge
Управление важными событиями Everbridge достигло Украины и пользователей, работающих из любого места. Генеральный директор Дэвид Вагнер объясняет, как он руководил …
- 10 вопросов по аварийному восстановлению, которые нужно задать в 2023 году и далее
Существует множество факторов, влияющих на бесперебойную работу плана аварийного восстановления. Вот 10 вопросов, на которые группы аварийного восстановления должны ответить…
- Rubrik делает кейс Security Cloud для своих клиентов Polaris
Во время своей первой остановки в мировом турне компания Rubrik представила клиентам Polaris платформу Security Cloud SaaS, рекламируя новую .
.. - Veeam стремится расширить охват и повысить безопасность данных
Конференция пользователей Veeam, посвященная киберустойчивости, готовности и предотвращению программ-вымогателей, с новыми партнерами и …
- Как правило резервного копирования 3-2-1-1-0 отражает современные потребности
Правило резервного копирования 3-2-1-1-0 отвечает современным требованиям защиты данных, таким как защита от программ-вымогателей и резервное копирование в облаке. Узнайте…
 ..
..- Навигация по стандарту и сертификации центров обработки данных Energy Star
Организации могут использовать центры обработки данных стандарта Energy Star и сертифицированные активы для повышения энергоэффективности. Обратите внимание на Energy Star…
- Понимание использования блокчейна в центрах обработки данных
Блокчейн
наиболее известен своими криптовалютными приложениями, но центры обработки данных могут использовать его для различных бизнес-приложений .
.. - Сделайте операции мэйнфреймов эффективными с помощью этих стратегий
Мэйнфреймы влияют на итоговые показатели организации. Эксперт описывает некоторые ключевые стратегии для поддержания надежности при сохранении …
 ..
..404: Страница не найдена
Страница, которую вы пытались открыть по этому адресу, похоже, не существует. Обычно это результат плохой или устаревшей ссылки. Мы извиняемся за любые неудобства.
Что я могу сделать сейчас?
Если вы впервые посещаете TechTarget, добро пожаловать! Извините за обстоятельства, при которых мы встречаемся. Вот куда вы можете пойти отсюда:
Поиск- Узнайте последние новости.
- Наша домашняя страница содержит самую свежую информацию об информационных технологиях.
- Наша страница «О нас» содержит дополнительную информацию о сайте ComputerWeekly.com, на котором вы находитесь.
- Если вам нужно, пожалуйста, свяжитесь с нами, мы будем рады услышать от вас.

Просмотр по категории
ИТ-директор- Meta Fine подчеркивает проблемы обмена данными между ЕС и США
До нового соглашения ЕС-США. Создана структура конфиденциальности данных, штраф Meta в размере 1,2 миллиарда евро должен послужить предупреждением для США …
- Штаты действуют, в то время как Конгресс тормозит правила ИИ
Штаты предпринимают шаги по регулированию искусственного интеллекта, в то время как Конгресс обсуждает наилучший путь вперед.
- Блокчейн против базы данных: сходство, объяснение различий
Выбор между блокчейном и традиционными базами данных или их совместное использование требует знания того, как каждая из них обрабатывает данные …
- Злоумышленники используют драйверы ядра в новых атаках
Fortinet подробно описала кампанию с использованием вредоносного драйвера в атаках на организации на Ближнем Востоке, а Trend Micro .
.. - Как использовать Wfuzz для поиска уязвимостей веб-приложений
Изучив, как использовать Wfuzz для нечеткого тестирования веб-приложений, охотники за ошибками могут автоматизировать обнаружение уязвимостей. Узнать…
- Как стать охотником за ошибками: начало работы
Поиск, использование уязвимостей и сообщение об уязвимостях могут быть как прибыльными, так и образовательными. Исследователь безопасности Вики Ли объясняет…
 ..
..- 9 способов заставить модернизацию сети работать
Больше облачных вычислений, контейнерных сетей и пропускной способности сети — вот некоторые из способов, с помощью которых компании могут модернизировать свои сети. …
- SONiC NOS сталкивается с проблемами, связанными с мейнстримом
По оценкам Gartner, менее 200 предприятий используют SONiC из потенциального рынка ЦОД в 100 000 предприятий.
Один… - 12 распространенных сетевых протоколов и объяснение их функций
Работа в сети заставляет Интернет работать, но ни один из них не может быть успешным без протоколов. Общие сетевые протоколы и их функции …
 Один…
Один…- Навигация по стандарту и сертификации центров обработки данных Energy Star
Организации могут использовать центры обработки данных стандарта Energy Star и сертифицированные активы для повышения энергоэффективности. Обратите внимание на Energy Star…
- Понимание использования блокчейна в центрах обработки данных
Блокчейн наиболее известен своими приложениями для криптовалюты, но центры обработки данных могут использовать его для различных бизнес-приложений …
- Сделайте операции мэйнфреймов эффективными с помощью этих стратегий
Мэйнфреймы влияют на итоговые показатели организации.