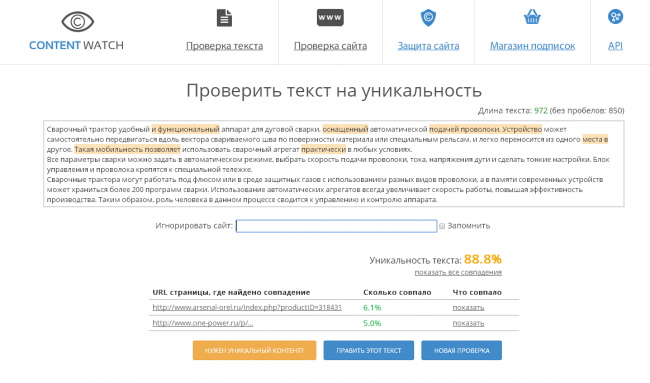
KB5008382 — проверка уникальности имени пользователя, основного имени службы и его псевдонима (CVE-2021-42282)
Windows Server 2022 Windows Server 2019 Windows Server 2016, all editions Windows Server 2012 R2 Windows Server 2012 Windows Server 2008 R2 Windows Server 2008 Service Pack 2 Еще…Меньше
Аннотация
Windows обновлений CVE-2021–42282, выпущенных 9 ноября 2021 г., добавляют следующие проверки атрибутов в Active Directory (AD):
-
Уникальность имени директора-пользователя (UPN) и имени директора-службы (SPN) (новые возможности Windows 8, Windows Server 2012 и более ранних версий)
-
Уникальность псевдонима SPN (новое для всех Windows версий)
Уникальность имени директора-пользователя и имени основной службы
Эта функция гарантирует уникальность доменных имен в лесу, из-за чего компьютеры и контроллеры доменов не могут добавлять повторяющиеся доменные имена.
Уникальность псевдонима SPN
Существующий атрибут AD определяет псевдонимы для многих общих классов служб с эквивалентом HOST SPN для таких служб, как CIFS, HTTP и RPC. Атрибут AD определяется как список в контексте именования конфигурации леса Active Directory. Пользователь, у которого нет прав администратора, не может перена назначенное неявным образом имя spn другой учетной записи с помощью этого псевдонима.
Примечание. Эта проверка реализована в дополнение к проверке уникальности upn и SPN.
Проверки уникальности псевдонима SPN по умолчанию находятся в режиме. Чтобы отключить эти проверки, измените 21-й знак атрибута
dSHeuristics , который интерпретируется как ряд символов. Атрибут dSHeuristics по умолчанию не существует, но его можно добавить под именем «CN=Directory Service,CN=Windows NT,CN=Services,CN=Configuration,DC=support,DC=local». Возможные параметры и соответствующие им битовые значения:
Возможные параметры и соответствующие им битовые значения:
-
Значение 0 — означает принудительное выполнение всех (без бит, установленных 000) Значение по умолчанию
-
Значение 1 — означает отключение проверки уникальности upN (бит 0 set — 001)
Значение 2 — означает отключение проверки уникальности SPN (бит 1 множество — 010)
-
Значение 3 — означает отключение проверки уникальности upN и уникальности SPN.
 (бит 0 и 1 набор — 011)
(бит 0 и 1 набор — 011) -
Значение 4 — означает отключение проверки уникальности псевдонима SPN (бит 2 set — 100)
-
Значение 5 — означает отключение проверки уникальности псевдонима SPN И upN (бит 2 и бит 0, множество — 101)
-
Значение 6 — означает отключение псевдонима SPN И уникальности SPN (бит 2 и 1 набора — 110)
-
Значение 7 — означает Отключить все (для всех бит за установлено значение 111).
 (бит 0 и 1 набор — 011)
(бит 0 и 1 набор — 011)Примере: Если в вашем лесу не включены другие параметры dSHeuristics и вы хотите отключить проверку уникальности псевдонима SPN, атрибут dSHeuristics должен иметь такой параметр: «000000000100000000024»
В этом случае заданной символами являются:
10-й символ: должен быть установлен 1, если атрибут dSHeuristics имеет не менее 10 символов
20-й символ: должен быть установлен 2, если атрибут
21-й символ: значение должно быть установлено в списке выше; Значение 4 означает отключение уникальности псевдонима SPN.
Примечание. Если атрибут dSHeuristics уже за установлен, необходимо объединить существующие параметры в новую строку атрибута dSHeuristics и убедиться, что 10-й, 20-й и 21-й символы задаются как выше. Другие уже застроимые символы должны оставаться без изменений.
Дополнительные сведения о настройке символов dSHeuristics можно найти в следующих документах:
-
Спецификация атрибута dSHeuristics
-
Сведения об атрибутах dSHeuristics и Version-Specific ОС
Дополнительная информация
Что такое имя основной службы?
Имя основной службы (SPN) — это уникальный идентификатор для экземпляра службы. Проверка подлинности Kerberos использует spNs для связывания экземпляра службы с учетной записью для входов в службу. Это позволяет клиентского приложения запрашивать проверку подлинности учетной записи службой, даже если у клиента нет имени учетной записи. Дополнительные сведения см. в списке Имена основных служб.
Проверка подлинности Kerberos использует spNs для связывания экземпляра службы с учетной записью для входов в службу. Это позволяет клиентского приложения запрашивать проверку подлинности учетной записи службой, даже если у клиента нет имени учетной записи. Дополнительные сведения см. в списке Имена основных служб.
Что такое имя основного пользователя?
Имя директора пользователя (UPN) — это имя для входов в почтовый ящик пользователя, основанное на стандарте RFC 822 в Интернете. Дополнительные сведения см. в атрибуте User-Principal-Name.
Типичные вопросы
Вопрос1 Что делать, если нужно зарегистрировать повторяющийся псевдоним HOST SPN для учетной записи?
A1 Зарегистрируйте обязательное spn в качестве администратора.
Вопрос 2 Что произойдет, если отключить уникальность spn или UPN?
A2 Мы не рекомендуем делать это..jpg) Если они не являются уникальными, это значит, что все они являются дубликатами, не зарегистрированы. Регистрация дубликата spn действует так же, как и при регистрации исходного. Если имя пользователя-пользователя не является уникальным, при подступах пользователей с использованием дублирующихся пользователей-пользователей сбой.
Если они не являются уникальными, это значит, что все они являются дубликатами, не зарегистрированы. Регистрация дубликата spn действует так же, как и при регистрации исходного. Если имя пользователя-пользователя не является уникальным, при подступах пользователей с использованием дублирующихся пользователей-пользователей сбой.
Вопрос 3 Что произойдет, если отключить уникальность псевдонима SPN?
A3 Мы не рекомендуем делать это. Администратор может изменить разрешение существующего псевдонима SPN с текущего разрешения на компьютер, не управляющего администратором. Этот компьютер может выступать в качестве этой службы, так как проверка подлинности на сервере, которая предоставляется Kerberos, будет принимать новую учетную запись как правильный хост для службы, а не как исходную учетную запись сN HOST.
Вопрос 4. Как администратор домена может найти в сети дублирующиеся доменные имена (SPNs) или UPNs?

Вопрос 5 Что произойдет, если у меня есть несколько контроллеров доменов, которые были обновлены, а не обновили или не несоответствия параметров между контроллерами домена?
A5 Репликация не блокируется из-за повторяютого upNs или SPNs. Таким образом, дубликаты могут реплицироваться на другие контроллеры доменов, если на контроллере домена, который не имеет обновления, созданы повторяющиеся имена имен-доменов или spNs.
Postgres Pro Standard : Документация: 10: 56.5. Проверки уникальности в индексе : Компания Postgres Professional
RU
EN
RU EN
Postgres Pro реализует ограничения уникальности SQL, применяя уникальные индексы, то есть такие индексы, которые не принимают несколько записей с одинаковыми ключами. Для метода доступа, поддерживающего это свойство, устанавливается признак
amcanunique. (В настоящее время это поддерживают только В-деревья.) Столбцы, указанные в предложении
(В настоящее время это поддерживают только В-деревья.) Столбцы, указанные в предложении INCLUDE, не учитываются при контроле уникальности.Вследствие особенностей MVCC, всегда необходимо допускать физическое сосуществование в индексе дублирующихся записей: такие записи могут относиться к последовательным версиям одной логической строки. На самом деле мы хотим добиться только того, чтобы никакой снимок MVCC не мог содержать две строки с одинаковыми ключами индекса. Из этого вытекают следующие ситуации, которые необходимо отследить, добавляя новую строку в уникальный индекс:
Если конфликтующая строка была удалена текущей транзакцией, это не проблема. (В частности из-за того, что UPDATE всегда удаляет старую версию строки, прежде чем вставлять новую, операцию UPDATE можно выполнять со строкой, не меняя её ключ.)
Если конфликтующая строка была добавлена ещё не зафиксированной транзакцией, запрос, претендующий на добавление новой строки, должен подождать, пока эта транзакция не будет зафиксирована.
Если она откатывается, конфликт исчезает. Если она фиксируется и при этом оставляет конфликтующую строку, возникает нарушение уникальности. (На практике мы просто ждём завершения другой транзакции и затем пересматриваем проверку видимости.)Подобным образом, если конфликтующая строка была удалена ещё не зафиксированной транзакцией, запрос, претендующий на добавление новой строки, должен дождаться фиксации или отката этой транзакции, а затем повторить проверку.
 Если она откатывается, конфликт исчезает. Если она фиксируется и при этом оставляет конфликтующую строку, возникает нарушение уникальности. (На практике мы просто ждём завершения другой транзакции и затем пересматриваем проверку видимости.)
Если она откатывается, конфликт исчезает. Если она фиксируется и при этом оставляет конфликтующую строку, возникает нарушение уникальности. (На практике мы просто ждём завершения другой транзакции и затем пересматриваем проверку видимости.)Более того, непосредственно перед тем как сообщать о нарушении уникальности согласно вышеприведённым правилам, метод доступа должен перепроверить, продолжает ли существовать добавляемая строка. Если она признана «мёртвой», о предвиденном нарушении он сообщать не должен. (Такого не должно быть при обычном сценарии добавления строки текущей транзакцией, однако это может произойти в процессе CREATE UNIQUE INDEX CONCURRENTLY.)
Мы требуем, чтобы метод доступа выполнял эти проверки сам, и это означает, что он должен обратиться к основным данным и проверить состояние фиксации всех строк, которые согласно содержимого индекса содержат дублирующиеся ключи. Это без сомнения некрасивый и немодульный подход, но он избавляет от излишней работы: если бы мы делали отдельную пробу, то поиск конфликтующей строки по индексу пришлось бы по сути повторять, пытаясь найти место, куда вставить запись для новой строки. Более того, не представляется возможным избежать условий гонки, если проверка конфликта не будет неотъемлемой частью процедуры добавления новой записи индекса.
Это без сомнения некрасивый и немодульный подход, но он избавляет от излишней работы: если бы мы делали отдельную пробу, то поиск конфликтующей строки по индексу пришлось бы по сути повторять, пытаясь найти место, куда вставить запись для новой строки. Более того, не представляется возможным избежать условий гонки, если проверка конфликта не будет неотъемлемой частью процедуры добавления новой записи индекса.
Если ограничение уникальности откладываемое, возникает дополнительная сложность: нам нужна возможность добавлять запись индекса для новой строки, но отложить выводы о нарушении уникальности до конца оператора или даже позже. Чтобы избежать ненужного повторного поиска по индексу, метод доступа должен произвести предварительную проверку уникальности во время изначального добавления строк. Если при этом окажется, что никакие кортежи не конфликтуют, на этом проверка заканчивается. В противном случае мы планируем перепроверку на время, когда это ограничение начинает действовать. Если во время перепроверки продолжают существовать и вставленный кортеж, и какой-либо другой с тем же ключом, должна выдаваться ошибка. (Заметьте, что в данном случае под «существованием» понимается «существование любого кортежа в цепочке HOT записей индекса».) Для реализации этой схемы в
(Заметьте, что в данном случае под «существованием» понимается «существование любого кортежа в цепочке HOT записей индекса».) Для реализации этой схемы в aminsert передаётся параметр checkUnique, принимающий одно из следующих значений:
UNIQUE_CHECK_NOуказывает, что проверка уникальности не должна выполняться (это не уникальный индекс).UNIQUE_CHECK_YESуказывает, что это неоткладываемый уникальный индекс и проверку уникальности нужно выполнить немедленно, как описано выше.UNIQUE_CHECK_PARTIALуказывает, что это откладываемое ограничение уникальности. Postgres Pro выбирает этот режим для добавления записи индекса для каждой строки. Метод доступа должен допускать добавление в индекс дублирующихся записей и сообщать о возможных конфликтах, возвращая FALSE изaminsert. Для каждой такой строки (для которой возвращается FALSE) будет запланирована отложенная перепроверка.Метод доступа должен отметить все строки, которые могут нарушать ограничение уникальности, но не будет ошибкой, если он допустит ложное срабатывание. Это позволяет произвести проверку, не дожидаясь завершения других транзакций; конфликты, выявленные на этой стадии, не считаются ошибками и будут перепроверены позже, когда они могут быть уже исчерпаны.
UNIQUE_CHECK_EXISTINGуказывает, что это отложенная перепроверка строки, которая была отмечена как возможно нарушающая ограничение. Хотя для этой проверки вызываетсяaminsert, метод доступа не должен добавлять новую запись индекса в данном случае, так как эта запись уже существует. Вместо этого, метод доступа должен проверить, нет ли в индексе другой такой же записи. Если она находится и соответствующая ей строка продолжает существовать, должна выдаваться ошибка.Для варианта
UNIQUE_CHECK_EXISTINGв методе доступа рекомендуется дополнительно проверить, что для целевой строки действительно имеется запись в индексе и сообщить об ошибке, если это не так. Это хорошая идея, так как значения кортежа индекса, передаваемые в aminsert, будут рассчитаны заново. Если в определении индекса задействованы функции, которые на самом деле не постоянные, мы можем проверять неправильную область индекса. Дополнительно убедившись в существовании целевой строки при перепроверке, мы можем быть уверены, что сканируются те же значения кортежа, что передавались при изначальном добавлении строки.
 Это хорошая идея, так как значения кортежа индекса, передаваемые в
Это хорошая идея, так как значения кортежа индекса, передаваемые в Глава 3 Доступность и уникальность
В этой главе показано, как проверить, доступны ли записи и/или полным в отношении набора ключей, и являются ли они уникальными. Описанные здесь проверки обычно полезны для данных в «длинном» формате, где один столбец содержит значение, а все остальные столбцы определяют это значение.
- Для проверки отсутствующих значений в отдельных переменных см. также 2.2.
- Чтобы проверить, заполнены ли записи или их части, см. 4.1.
Данные
В этой главе используется набор данных samplonomy , который поставляется с проверкой упаковка.
библиотека (подтвердить) данные (самплономия) head(samplonomy, 3)
## регион частота период значение измерения ## 1 Agria A 2014 г.в.п. 600000 ## 2 Agria A 2014 импорт 210000 ## 3 Agria A 2014 export 222000
3.1 Длинные данные
Набор данных выборки структурирован в «полной форме». Это означает, что каждый
запись имеет сингл значение столбец и один или несколько столбцов, содержащих
значения символов, которые вместе описывают, что означает значение.
головка(самплономия,3)
## регион частота период значение измерения ## 1 Agria A 2014 г.в.п. 600000 ## 2 Agria A 2014 импорт 210000 ## 3 Agria A 2014 export 222000
Набор данных содержит несколько временных рядов для нескольких показателей вымышленной страны Самплония. Есть временные ряды для нескольких субрегионы Самплонии.
Данные длинного формата обычно используются в качестве транспортного формата: они могут
массовая загрузка данных в системы баз данных на основе SQL или для передачи данных между
организации однозначно.
Данные в длинной форме, как правило, гораздо сложнее проверить и обработать для статистической цели, чем данные в широком формате, где каждая переменная хранится в отдельный столбец. Причина в том, что в длинноформатных отношениях между различные переменные разбросаны по записям, и эти записи не обязательно упорядочены каким-либо особым образом перед обработкой. Это делает интерпретация валидации по своей сути терпит неудачу для длинных данных, чем для широкоформатных данных.
Набор данных samplonomy имеет особенно неприятную структуру. Он содержит оба
годовые и квартальные временные ряды ВВП, импорта, экспорта и баланса
Торговля (экспорт минус импорт). Таким образом, столбец периода содержит как ежеквартальные
и годовые этикетки. Кроме того, существуют временные ряды для всего
Самплония (регион Самплония), для каждой из двух его провинций (регионы Агрия и
Индастон) и для каждого из его районов в Агрии (Уитон и Гринхэм) и
Индастон (Смокли, Мадуотер, Ньюбей и Окдейл).
Естественно, мы ожидаем, что комбинации клавиш уникальны, что все временные ряды непрерывны и полны, что торговый баланс равен экспорту за вычетом импорта. везде значения этих районов складываются с провинциями, и эта провинция значения складываются в общую сумму Samplonia. Наконец, квартальные временные ряды должны в сумме соответствовать годовым значениям.
3.2 Уникальность
Функция is_unique() проверяет, являются ли комбинации переменных (обычно
ключевые переменные) однозначно идентифицируют запись. Он принимает любое положительное число
имена переменных и возвращает ЛОЖЬ для каждой записи, которая дублируется с
относительно обозначенных переменных.
Здесь мы проверяем, однозначно ли регион, период и показатель определяют значение в
набор данных samplonomy .
правило <- validator(is_unique(регион, период, мера)) out <- конфронтация (самплономия, правило) # показываем 7 столбцов вывода для удобочитаемости summary(out)[1:7]
## name items pass failed nNA error warning ## 1 V1 1199 1197 2 0 ЛОЖЬ ЛОЖЬ
2 сбоя. После извлечения личности
значения для каждой записи, мы можем найти дубликаты, используя
функция удобства от
После извлечения личности
значения для каждой записи, мы можем найти дубликаты, используя
функция удобства от подтвердите .
нарушение(самплономия, выход)
## регион частота период значение измерения ## 870 Induston Q 2 кв. 2018 экспорт 165900 ## 871 Induston Q 2018Q2 export 170000
При интерпретации уникальности следует помнить о двух тонкостях. первое связано с пропущенными значениями, а второе связано с группировкой. Чтобы начать с проблемы пропущенного значения, взгляните на следующие две записи. кадр данных.
df <- data.frame(x = c(1,1), y = c("A",NA))
df ## х у ## 1 1 А ## 2 1
Как определить, уникальны ли эти две записи? Заманчивый вариант такой
сказать, что первая запись уникальна, и вернуть NA для второй записи
поскольку он содержит пропущенное значение: R имеет привычку возвращать NA из
расчеты, когда входное значение равно NA . Этот выбор не является недействительным, но он
будет иметь последствия для определения того, является ли первая запись уникальной, поскольку
Что ж. В конце концов, можно заполнить значение в отсутствующем поле, например
что две записи дублируются. Следовательно, если бы кто-то вернул
В конце концов, можно заполнить значение в отсутствующем поле, например
что две записи дублируются. Следовательно, если бы кто-то вернул NA для
вторая запись, правильно будет также вернуть NA для первой
записывать. В R выбор сделан для обработки NA как фактического значения при проверке
для дубликатов или уникальных записей (см. — дубликат из базы R). Чтобы увидеть это
проверьте следующий код и вывод.
df <- data.frame(x=rep(1,3), y = c("A", NA, NA))
is_unique(df$x, df$y) ## [1] TRUE FALSE FALSE
Вторая тонкость связана с группировкой. Вы можете проверить, является ли
столбец уникален, учитывая одну или несколько других переменных. Соблазнительно думать
что для этого требуется подход «разделить-применить-объединить», при котором набор данных сначала
разделить по одной или нескольким группирующим переменным, проверить уникальность
столбец в каждой группе, а затем объедините результаты. Однако такой подход
в этом нет необходимости, так как вы можете просто добавить группирующие переменные в список
переменные, которые вместе с должны быть уникальными.
В качестве примера рассмотрим вывод следующих двух подходов.
# y уникален при данном x. Но не сам по себе df <- data.frame(x=rep(буквы[1:2],каждый=3), y=rep(1:3,2)) # подход "разделить-применить-объединить" unsplit(tapply(df$y, df$x, is_unique), df$x)
## [1] TRUE TRUE TRUE TRUE TRUE TRUE
# комбинированный подход is_unique(df$x, df$y)
## [1] ИСТИНА ИСТИНА ИСТИНА ИСТИНА ИСТИНА ИСТИНА ИСТИНА
3.3 Доступность записей
Этот раздел находится на проверке на наличие полных записей. Тестирование для отдельных пропущенные значения (NA) рассматривается в 2.2.
Мы хотим убедиться, что для каждого региона и каждой переменной периоды 2014,
2015, \(\ldots\), 2019 присутствуют. Используя contains_at_least , мы можем установить
это.
правило <- валидатор(
содержит_по крайней мере(
ключи = data.frame(период = as.character(2014:2019))
, by=список(регион, мера))
)
out <- конфронтация (самплономия, правило)
# показываем 7 столбцов вывода для удобочитаемости
итог(выход)[1:7] ## элементы имени не проходят проверку, предупреждение об ошибке nNA ## 1 V1 1199 1170 29 0 FALSE FALSE
Функция contains_at_least разбивает набор данных samplonomy на блоки
по значениям регион и мерка . Далее проверяется, что в каждом
блок переменной
Далее проверяется, что в каждом
блок переменной период содержит как минимум значения 2014–2019.
Возвращаемое значение представляет собой логический вектор, в котором количество элементов равно
количество просматриваемых строк в наборе данных. это ИСТИНА для каждого блока
где присутствуют все годы, и ЛОЖЬ для каждого блока, где один из
лет отсутствует. В этом случае 29 записей помечены как FALSE. Эти
можно найти следующим образом.
головка(нарушение(самплономия, выход))
## регион частота период значение измерения ## 1 Agria A 2014 г.в.п. 600000 ## 5 Agria Q1 2014Q1 ВВП 60000 ## 9 Agria Q2014 Q2 ВВП 120000 ## 13 Agria Q 2014Q3 ВВП 300000 ## 17 Agria Q4 2014Q4 ВВП 120000 ## 204 Agria Q1 2015Q1 ВВП 58200
Проверка этих записей показывает, что в этом блоке для Agria ВВП
для "2015" отсутствует.
Мы можем выполнить более строгую проверку и проверить, все ли для каждой меры кварталы "2014Q1" \(\ldots\) "2019Q4" присутствуют для каждой провинции ( Agria и Индастон ). Сначала создайте набор ключей для тестирования.
Сначала создайте набор ключей для тестирования.
лет <- as.character(2014:2019)
четверти <- paste0("Q",1:4)
набор ключей <- expand.grid(
регион = c("Агрия", "Индастон")
, период = sapply (годы, paste0, кварталы))
головка(набор ключей) ## регион период ## 1 Агрия 2014Q1 ## 2 Индастон 2014Q1 ## 3 Агрия 2 кв. 2014 г. ## 4 Индастон, 2 кв. 2014 г. ## 5 Агрия 3 кв. 2014 г. ## 6 Induston 2014Q3
Этот набор ключей будет указан в правиле и передан против в качестве ссылки
данные.
правило <- валидатор(
содержит_по крайней мере (ключи = минимальные_ключи, по = мера)
)
out <- конфронтация(самплономия, правило
, ссылка = список (минимальные_ключи = набор ключей))
# показываем 7 столбцов вывода для удобочитаемости
итог(выход)[1:7] ## элементы имени не проходят проверку, предупреждение об ошибке nNA ## 1 V1 1199 899 300 0 FALSE FALSE
300 ошибок. Проверяя набор данных, как указано выше, мы
см. , что для Induston
, что для Induston export отсутствует в "2018Q3" .
Наконец, мы проводим строгий тест, чтобы проверить, что для каждого измерения все периоды и
сообщаются все регионы. Мы также требуем, чтобы не было больше и не меньше
записей, чем для каждой отдельной меры. Для этого функция contains_exactly можно использовать.
Сначала создайте набор ключей.
лет <- as.character(2014:2019)
четверти <- paste0("Q",1:4)
набор ключей <- expand.grid(
регион = с(
"Агрия"
, "Краудон"
, "Гринхэм"
, "Индастон"
, "Грязевая вода"
, "Ньюбэй"
, "Окдейл"
, "Самплония"
, "Смокли"
, "Уитон"
)
, период = с (годы, период (годы, паста0, кварталы))
)
головка (набор ключей) ## регион период ## 1 Агрия 2014 ## 2 Краудон 2014 ## 3 Гринхэм 2014 ## 4 Индастон 2014 ## 5 Грязевая вода 2014 ## 6 Ньюбэй 2014
Набор ключей передается правилу в качестве справочных данных с использованием и .
правило <- валидатор (содержит_точно (все_ключи, по = мере))
out <- конфронтация(самплономия, правило
, ссылка = список (all_keys = набор ключей))
# показываем 7 столбцов вывода для удобочитаемости
summary(out)[1:7] ## name items pass failed nNA error warning ## 1 V1 1199 0 1199 0 FALSE FALSE
Чтобы найти, где находятся ошибки, мы сначала выбираем записи с ошибкой и затем найдите уникальные меры, встречающиеся в этих записях.
ошибочные_записи <- нарушение(самплономия, вне) unique(erroneous_records$measure)
## [1] "gdp" "import" "export" "balance"
Итак, здесь в блоках, содержащих GDP и Export, отсутствуют целые записи.
3.4 Пробелы в (временных) рядах
Для временных рядов или, возможно, других рядов желательно, чтобы
существует постоянное расстояние между каждыми двумя элементами ряда.
Математический термин для такого ряда называется линейной последовательностью .
Вот несколько примеров линейных рядов.
- Натуральные числа: \(1,2,3,\ldots\)
- Четные натуральные числа \(2, 4, 6, \ldots\)
- Кварталы:
"2020Q1","2020Q2", \(\ldots\) - лет (это просто натуральные числа): \(2019, 2020, \ldots\)
проверка функций is_linear_sequence и in_linear_sequence проверка
представляет ли переменная линейный ряд, возможно, в блоках, определяемых
категориальные переменные. Они могут использоваться интерактивно или, как правило, в
объект валидатора. Сначала мы покажем, как работают эти функции, а затем дадим
пример с 9Набор данных 0015 samplonomy .
is_linear_sequence(c(1,2,3,4))
## [1] ИСТИНА
is_linear_sequence(c(8,6,4,2))
## [1] ИСТИНА
is_linear_sequence( c(2,4,8,16))
## [1] FALSE
Для символьных данных функция способна распознавать определенные форматы для периодов времени.
is_linear_sequence(c("2020Q1","2020Q2","2020Q3","2020Q4")) ## [1] TRUE
См.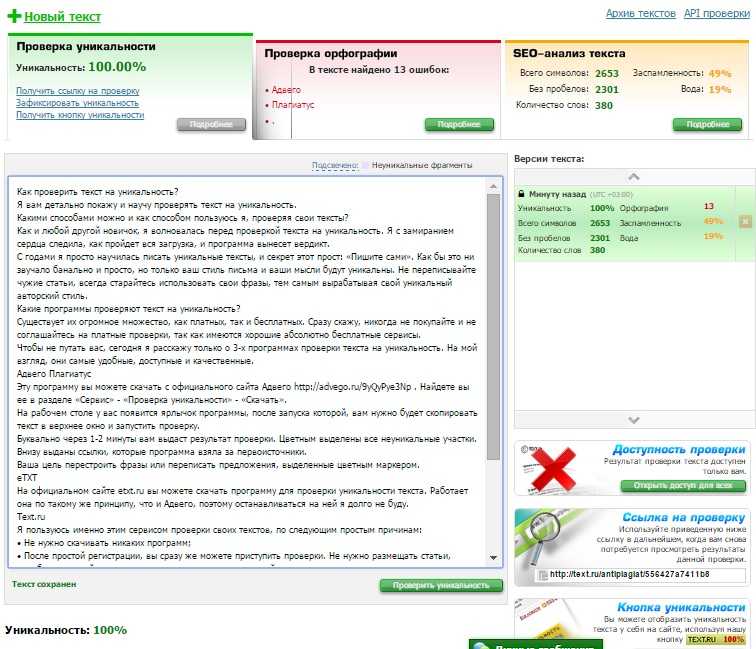
?is_linear_sequence для полной спецификации поддерживаемых
форматы даты и времени.
Нет необходимости сортировать данные, чтобы их можно было распознать как линейная последовательность.
is_linear_sequence(c("2020Q4","2020Q2","2020Q3","2020Q1")) ## [1] TRUE
Можно также задать начальную и/или конечную точку последовательности.
is_linear_sequence(c("2020Q4","2020Q2","2020Q3","2020Q1")
, begin = "2020Q2") ## [1] FALSE
Наконец, можно разделить переменную по одному или нескольким другим столбцам и проверьте, представляет ли каждый блок линейную последовательность.
ряд <- с(1,2,3,4,1,2,3,3)
блоки <- rep(c("a","b"), каждый = 4)
is_linear_sequence(series, by = blocks) ## [1] FALSE
Теперь этот результат не очень полезен, так как теперь неизвестно, какой блок
не является линейным рядом. Здесь на помощь приходит функция in_linear_sequence .
in_linear_sequence(series, by = blocks)
## [1] TRUE TRUE TRUE TRUE FALSE FALSE FALSE FALSE
Есть некоторые тонкости.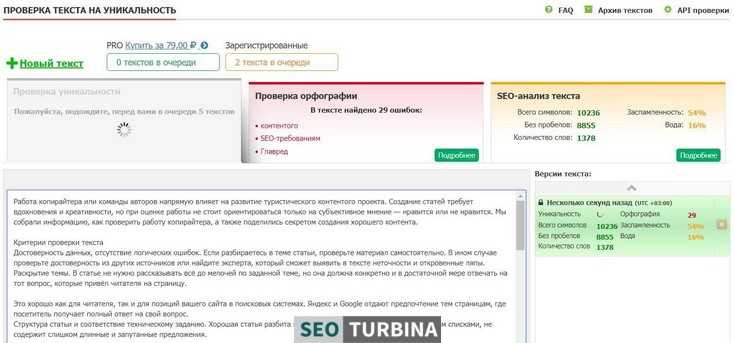 Отдельный элемент также является линейной последовательностью (длины 1).
Отдельный элемент также является линейной последовательностью (длины 1).
is_linear_sequence(5)
## [1] TRUE
Это может привести к сюрпризам в случае блоков длиной 1.
блоков[8] <- "c" data.frame(серия = серия, блоки = блоки)
## блоки серии ## 1 1 а ## 2 2 а ## 3 3 а ## 4 4 а ## 5 1 б ## 6 2 б ## 7 3 б ## 8 3 c
in_linear_sequence(серии, блоки)
## [1] ИСТИНА ИСТИНА ИСТИНА ИСТИНА ИСТИНА ИСТИНА ИСТИНА ИСТИНА ИСТИНА
Теперь у нас есть три линейных ряда, а именно
- Для
"а":1,2,3,4 - Для
"б":1,2,3 - Для
"с":3.
Мы можем обойти это, задав явные границы.
in_linear_sequence(серии, блоки, начало = 1, конец = 4)
## [1] ИСТИНА ИСТИНА ИСТИНА ИСТИНА ИСТИНА ЛОЖЬ ЛОЖЬ ЛОЖЬ ЛОЖЬ ЛОЖЬ
Теперь вернемся к набору данных samplonomy .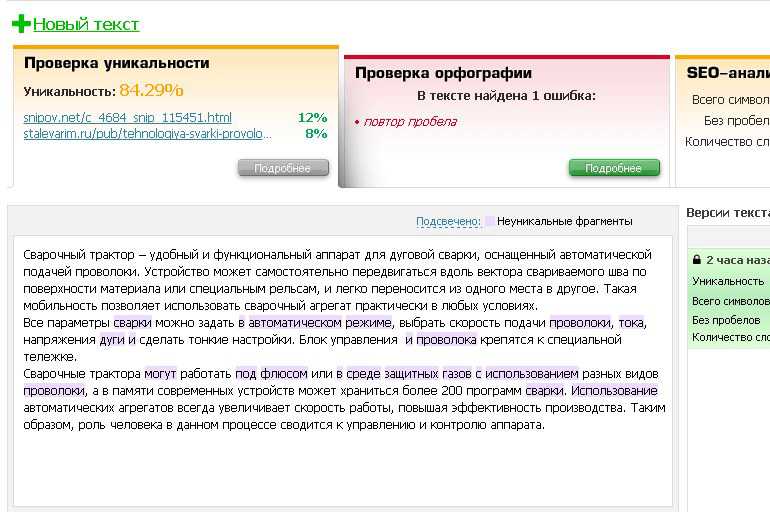 Мы хотим проверить это для
каждая мера и каждая область, временные ряды являются линейными рядами. С тех пор
являются временными рядами разных частот, нам нужно разделить данные по частоте
также.
Мы хотим проверить это для
каждая мера и каждая область, временные ряды являются линейными рядами. С тех пор
являются временными рядами разных частот, нам нужно разделить данные по частоте
также.
правило <- валидатор(
in_linear_sequence (период
, по = список (область, частота, мера))
)
out <- конфронтация (самплономия, правило)
summary(out)[1:7] ## name items pass failed nNA error warning ## 1 V1 1199 1170 29 0 FALSE FALSE
Блоки, в которых записи идут не по порядку, можно найти следующим образом (выводить не напечатано здесь для краткости).
нарушение(выборка, вне)
Проверка выбранных записей показывает, что для Agria ВВП за 2015 г. отсутствует, а для Induston экспорт за 2018Q3 отсутствует, а экспорт для 2018Q2 встречается дважды (но с разными значениями)
Проверка уникальности индекса
Проверка уникальности индекса PostgreSQL
применяет ограничения уникальности SQL, используя уникальные индексы , которые являются индексами, запрещающими множественные записи с одинаковыми ключами. Метод доступа, который поддерживает эти наборы функций.
pg_am
.
amcanunique
истинный. (В настоящее время его поддерживает только b-tree.)
Метод доступа, который поддерживает эти наборы функций.
pg_am
.
amcanunique
истинный. (В настоящее время его поддерживает только b-tree.)
Из-за MVCC всегда необходимо допускать, чтобы в индексе физически существовали повторяющиеся записи: записи могут ссылаться на последовательные версии одной логической строки. Поведение, которое мы на самом деле хотим обеспечить, заключается в том, что ни один снимок MVCC не может включать две строки с одинаковыми ключами индекса. Это разбивается на следующие случаи, которые необходимо проверять при вставке новой строки в уникальный индекс:
Если конфликтующая допустимая строка была удалена текущей транзакцией, все в порядке. (В частности, поскольку ОБНОВЛЕНИЕ всегда удаляет старую версию строки перед вставкой новой версии, это позволит ОБНОВИТЬ строку без изменения ключа.)
Если конфликтующая строка была вставлена еще не подтвержденной транзакцией, потенциальный вставщик должен подождать, чтобы убедиться, что эта транзакция зафиксирована.
Если откатится, то конфликта нет. Если он фиксируется без повторного удаления конфликтующей строки, происходит нарушение уникальности. (На практике мы просто ждем завершения другой транзакции, а затем полностью повторяем проверку видимости.)Точно так же, если конфликтующая допустимая строка была удалена еще не подтвержденной транзакцией, потенциальный вставщик должен дождаться фиксации или отмены этой транзакции, а затем повторить тест.
 Если откатится, то конфликта нет. Если он фиксируется без повторного удаления конфликтующей строки, происходит нарушение уникальности. (На практике мы просто ждем завершения другой транзакции, а затем полностью повторяем проверку видимости.)
Если откатится, то конфликта нет. Если он фиксируется без повторного удаления конфликтующей строки, происходит нарушение уникальности. (На практике мы просто ждем завершения другой транзакции, а затем полностью повторяем проверку видимости.)Кроме того, непосредственно перед нарушением уникальности в соответствии с приведенными выше правилами метод доступа должен перепроверить живучесть вставляемой строки. Если он зафиксирован мертвым, ошибка не должна возникать. (Этот случай не может произойти во время обычного сценария вставки строки, только что созданной текущей транзакцией. Это может произойти во время СОЗДАВАЙТЕ УНИКАЛЬНЫЙ ИНДЕКС ОДНОВРЕМЕННО , однако.)
Нам требуется, чтобы метод доступа к индексу сам применял эти тесты, а это означает, что он должен обратиться к куче, чтобы проверить статус фиксации любой строки, которая, как показано, имеет дублирующийся ключ в соответствии с содержимым индекса.