
Как проверить диплом на антиплагиат и пройти проверку у дипломной комиссии
Наступил один из самых ярких периодов для любого студента ― сессия. А это значит, что совсем скоро кто-то будет защищать рефераты и курсовые, а некоторые счастливчики дипломы. Тут встаёт извечный вопрос: как проверить уникальность своей работы и убедиться, что в ней нет плагиата, из-за которого у студента могут возникнуть ощутимые проблемы. Редакция Synergy Times подобрала самые актуальные сетевые ресурсы, где можно «просканировать» свой текст, и сделала подборку лайфхаков по его улучшению.
Antiplagiat.ru. Сервис находит совпадения не только во всемирной паутине, но и в специальных базах, где хранятся научные и студенческие работы. Для деятельности на сайте потребуется регистрация. Имейте в виду: чтобы проверить текст, его необходимо перевести в формат txt.
Be1. Текст объёмом до 1 тысячи символов позволяет проверить без регистрации. После авторизации можно залить объём до 10 тысяч знаков. Ресурс показывает уникальность материала, наличие спама и «воду».
Ресурс показывает уникальность материала, наличие спама и «воду».
Text.ru. Здесь можно проверить уникальность текста, орфографию и провести SEO-анализ. В день сайт позволяет проверить статьи объёмом до 15 тысяч знаков. Сканирование производится в порядке очереди. Пройдя бесплатную регистрацию, на Text.ru в день можно проверить 50 тысяч символов.
Content Watch. При использовании бесплатной версии можно проверить до 3 текстов в день длиной по 10 тысяч знаков каждый.
Нужно ли менять диплом при смене имени или фамилии: отвечает специалист
Читать подробнееAdvego Plagiatus. Платформа способна выявить плагиат, дубликаты, некачественный рерайт, а также заимствования. Существует ограничение ― 95 тысяч символов. Но можно установить бесплатную десктопную программу для Windows и сканировать тексты любого объёма.
eTXT.ru. Площадка функционирует в двух режимах. Первый находит дословные совпадения, второй ― признаки рерайта.
Руконтекст. Необходима регистрация. Бесплатно тут можно проверить файлы объёмом не более 10 кб или текст размером до 10 тысяч символов. Однако между проверками нужно соблюсти интервал в два часа.
Написать качественный диплом — задача не из лёгких. Изображение от Freepik.Если результаты проверки показали, что вы безжалостный копипастер и перспектива успешно защитить диплом/курсовую становится всё более туманной, то уникальность текста можно повысить. Вот несколько способов:
1. Пересказ своими словами. Этот способ хорошо могут использовать гуманитарии. Ведь если переписать каждый абзац, текст станет полностью уникальным.
2. Использование иностранных источников. Если взять оттуда информацию, текст при переводе на русский станет оригинальным. Причём можно использовать не только англоязычные ресурсы. Например, подойдут тексты на белорусском или чешском языках.
3. Добавление своих примеров. Ключевые мысли и основные тезисы можно взять из официальных источников, а примеры придумать самому по аналогии.
4. Подбор синонимов. На данный момент этот способ ещё работает. Однако современные программы уже научились распознавать такую хитрость. У вас будет больше шансов на успех, если будете искать синонимы самостоятельно, а не с помощью профильных сервисов. Есть у этого приёма и минус: подобрать синонимы для технических текстов весьма непросто.
7 лайфхаков, как готовиться к экзаменам без нервотрёпки
Читать подробнее5. Удаление спорных фрагментов. Если после проверки некоторые куски вашего текста оказались выделены красным, их можно просто вырезать. Если, кончено, они существенного не меняют смысл. А ещё лучше заменить их оригинальным текстом.
6. Увеличение числа источников. На процент уникальности влияет количество пунктов в списке литературы. Информацию можно брать из книг, учебников, электронных библиотек, научных журналов.
Информацию можно брать из книг, учебников, электронных библиотек, научных журналов.
7. Выбор удачной темы. Правда этот нюанс надо продумывать заранее. Трудно создать уникальный контент на тему, которую уже освещало огромное количество авторов. А если взять для исследования редкое направление, то подобрать к нему «незасвеченные» источники будет полегче.
При написании курсовой работы или диплома главное не поддаваться эмоциям. Изображение от stockking на Freepik.А так повысить уникальность текста не получится, эти приёмы не работают:
1. Смена знаков препинания. Таким образом улучшить контент не получится, поскольку эти символы в общей статистике не учитываются.
2. Перестановка местами слов, абзацев и предложений. Когда-то так можно было обмануть сервисы. Но со временем ресурсы антиплагиата стали умнее.
3. Кодирование текста. Бесполезно скрывать символы, использовать специальные программы для повышения оригинальности, менять русские символы на латинские.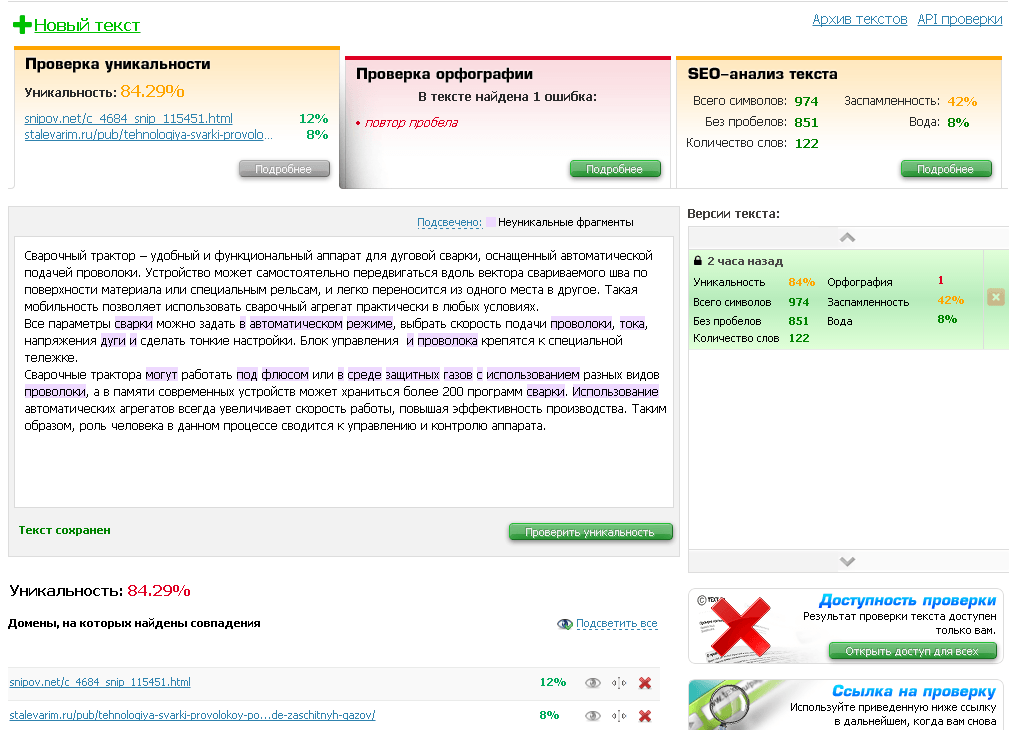 Подобные ходы не заиграют, поскольку платформа может отметить работу как подозрительную.
Подобные ходы не заиграют, поскольку платформа может отметить работу как подозрительную.
И, главное, не забывайте, что перед тем, как начать эксперименты с текстом, нужно обязательно сохранить его исходник! Иначе может получиться так, что первый вариант со всеми вашими бесценными мыслями безвозвратно пропадёт.
Студент потерял зачётку во время сессии. Что делать?
Вова разводит розы, а Саша колет дрова: студенты рассказали, как снимают стресс от сессии
Как вести конспект: основные правила и методы, которые помогут запомнить информацию
Проверка курсовой на уникальность
Из-за особенностей системы российского образования, проверка на уникальность нужна даже в том случае, если ты писал работу сам. Важно понимать, что процент оригинальности — формальный показатель, который зависит и от самой программы проверки.
Что неизбежно снижает уникальность
Даже если ты написал работу полностью сам, небольшой процент заимствований неизбежен. Эти четыре вещи негативно влияют на уникальность:
Эти четыре вещи негативно влияют на уникальность:
- Титульный лист. Титульные листы почти всегда есть в открытом доступе, а в некоторых университетах требуют прикреплять к курсовой работе 3-4 страницы такого общедоступного текста. Огромное количество титульных листов — не твоя проблема, и об этом нужно говорить.
- Список литературы. Обширный список литературы — огромный плюс, но список из 30-50 источников может существенно снизить оригинальность. Сокращать количество источников ради процента в программе не нужно — нужно доказывать научному руководителю, что ты прав.
- Формулы и стандартные формулировки. В некоторых работах никуда не деться от использования текстов законов. Если в курсовой работе нужна спецификация, то от снижения уникальности тоже никуда не деться. Не бойся доказывать, что проверять на уникальность нужно только то, что ты делал сам. То же самое касается таблиц — если в методичке даны шаблоны со словами «делать так и никак иначе», то оригинальность гарантированно упадёт.

- Приложения. В приложениях может быть всё, что угодно — от паспорта оборудования до огромной таблицы с бухгалтерской отчётностью компании за последние 10 лет. Чтобы избежать конфликтов, лучше использовать скриншоты или сканированные версии документов (сохраняя оригинал на случай возможных правок).

Процент оригинальности в отрыве от самой работы не отражает её качества. Если ты понимаешь, что писал всё честно, и в курсовой нет ничего, кроме твоего анализа проблемы, а уникальность снижают список литературы и титульный лист, то нужно доказывать свою правоту. Твоя курсовая — это не проценты в программе.
Системы проверки
Как уже было сказано, доступ к «Антиплагиат.вуз» получить практически невозможно, и итоговый процент уникальности самостоятельно ты узнать не сможешь. Но это не значит, что проверить уникальность самому нельзя (но и первой попавшейся системе проверки доверять не стоит). Самостоятельно проверить уникальность можно тут:
- Бесплатная версия сервиса «Антиплагиат. ру». Для курсовой, написанной честно, бесплатной проверки будет достаточно.
- eTXT Антиплагиат. Главное достоинство сервиса — полный отчёт о проверке тут можно получить абсолютно бесплатно. Советуем скачать десктопную версию, там доступна даже проверка с учётом перефразирования.
 ру». Для курсовой, написанной честно, бесплатной проверки будет достаточно.
ру». Для курсовой, написанной честно, бесплатной проверки будет достаточно.Чтобы перестраховаться, лучше проверять свои работы максимально строго. Помни, что именно ты должен стать своим самым строгим критиком. И это касается не только текста курсовой.
Мы рассмотрели всё, что касается работы с текстом курсовой работы. Теперь ты знаешь, как писать, чтобы не было правок или претензий к уникальности.
Проверка уникальности свойства — Wiki — Сообщество активных ролей
Описание
Этот скрипт проверяет значение атрибута, он гарантирует, что значение будет уникальным.
Скрипт
#********************************************* *******************************************
# ЭТОТ КОД И ИНФОРМАЦИЯ ПРЕДОСТАВЛЕНЫ «КАК ЕСТЬ» БЕЗ КАКИХ-ЛИБО ГАРАНТИЙ,
# ЯВНЫХ ИЛИ ПОДРАЗУМЕВАЕМЫХ, ВКЛЮЧАЯ, ПОМИМО ПРОЧЕГО, ПОДРАЗУМЕВАЕМЫЕ
# ГАРАНТИИ КОММЕРЧЕСКОЙ ПРИГОДНОСТИ И/ИЛИ ПРИГОДНОСТИ ДЛЯ ОПРЕДЕЛЕННОЙ ЦЕЛИ.
#
# ЕСЛИ ВЫ ХОТИТЕ УСЛОВНО ПОДДЕРЖАТЬ ЭТУ ФУНКЦИЮ,
# ПОЖАЛУЙСТА, ОБРАЩАЙТЕСЬ В ONE IDENTITY PROFESSIONAL SERVICES.
#****************************************************** *********************************
функция onCheckPropertyValues($Request)
{
$objectClass = [строка]$PolicyEntry.Parameter(«Имя класса объекта LDAP»)
if ($Request.Class -ne $objectClass) { return }
$attrName = [string]$PolicyEntry.Parameter(«Имя атрибута LDAP») 900 04
$ объем = [строка]$PolicyEntry.Parameter(«Область уникальности»)
) { возврат }
$founds = Get-QADObject -SearchRoot $scope -SearchAttributes @{$attrName=$attrValue;»objectClass»=$objectClass}
if ($founds -eq $null) { return}
if ($founds. DN -eq $Request.Name) { return } # найдено только self
DN -eq $Request.Name) { return } # найдено только self
900 05
$имена =»»
$founds | %{ $names+= «`n» + $_.CanonicalName }
$Request.SetPolicyComplianceInfo($attrName,
$constants.EDS_POLICY_COMPLIANCE_ERROR,
«Значение ‘$attrValue’ было найдено в объекты:$names»,$false)
}
функция onInit($context)
{
$par1 = $Context.AddParameter(«Имя атрибута LDAP»)
$par1.MultiValued = $False
$par1.Description = «Значение имени атрибута LDAP для проверки уникально.»
$par1.Defaultvalue = «»
$par2 = $Context.AddParameter(«Имя LDAP класса объекта»)
$par2. MultiValued = $False
MultiValued = $False
$par2.Description = «Класс объекта, значения атрибутов которого должны быть проверены на уникальность.»
$par2.Defaultvalue = «пользователь»
$par3 = $Context.AddParameter(«Область уникальности»)
9 0003 $par3.MultiValued = $False
$par3 .Description = «Домен, подразделение или другая область в Active Directory, где» +
«значение атрибута должно быть уникальным».
$par3.Defaultvalue = «CN=Active Directory»
$par3.Syntax = «DN»
900 03 }
#****** КОНЕЦ КОДА * ******************************************************* ************
Примеры пользовательских проверок | Документация Soda
Последнее изменение 05 июля 23
Язык Soda Checks Language (SodaCL) по умолчанию создает несколько встроенных метрик и проверок, таких как row_count , который можно использовать для определения проверок качества данных. Если встроенные метрики, которые предлагает Soda, не совсем покрывают некоторые из ваших более конкретных или сложных потребностей, вы можете использовать определяемые пользователем проверки и проверки ошибочных строк.
Если встроенные метрики, которые предлагает Soda, не совсем покрывают некоторые из ваших более конкретных или сложных потребностей, вы можете использовать определяемые пользователем проверки и проверки ошибочных строк.
Определенные пользователем проверки и проверки неудачных строк позволяют определить собственные показатели, которые можно использовать при проверке SodaCL. Вы также можете использовать эти проверки, чтобы просто определить SQL-запросы или общие табличные выражения (CTE), которые Soda выполняет во время сканирования, что и делает большинство этих примеров.
В приведенных ниже примерах представлены примеры того, как вы можете определить пользовательские проверки в файле проверок YAML, если используете Soda Library, или в рамках соглашения, если используете Soda Cloud, для извлечения более сложных, настраиваемых, специфичных для бизнеса измерений из вашего данные.
Установка приемлемого порога для дельты количества строк
Поиск дубликатов в наборе данных без столбца с уникальным идентификатором
Проверка бизнес-логики на уровне строк
Проверка неправильно сопоставленных значений в столбцах
Сравнение дат для проверки последовательности событий
Идти дальше
Установить приемлемый порог для дельты количества строк
Хотя вы можете использовать встроенную перекрестную проверку для сравнения количества строк между наборами данных в одном и том же или разных источниках данных, вы можете добавить немного больше сложность сравнения, как в следующем примере. Замените значения в двойных фигурных скобках {{ }} собственными соответствующими значениями.
Замените значения в двойных фигурных скобках {{ }} собственными соответствующими значениями.
Если вы хотите сравнить количество строк между двумя наборами данных и учесть некоторую приемлемую разницу между значениями, используйте следующий запрос.
✅ Amazon Redshift ✅ GCP Big Query ✅ PostgreSQL ✅ Snowflake
проверяет dim_product:
- row_delta > {{acceptance_threshold}}:
запрос row_delta: |
с таблицей1 как (
выберите count(*) как table_1_rows из {{ table_1 }}
),
таблица2 как (
выберите count(*) как table_2_rows из {{ table_2 }}
),
промежуточный как (
выбирать
(выберите table_1_rows из table1) как table_1_rows,
(выберите table_2_rows из table2) как table_2_rows
),
расчёт_разности как (
выбирать
АБС (таблица_1_строки - таблица_2_строки)
как row_delta
от промежуточного
)
выбирать
row_delta
из разницы_расчета
Объясните SQL- Сначала запрос подсчитывает строки в каждом из двух наборов данных.
- Затем он определяет промежуточную таблицу для хранения временных значений количества строк для каждой таблицы, чтобы можно было использовать эти значения в вычислениях.
- Затем запрос использует данные в промежуточной таблице для выполнения вычисления, которое сравнивает значения количества строк в наборах данных и создает значение, представляющее разницу в количестве строк, которое он помечает как
row_delta. - Наконец, он фиксирует значение, рассчитанное для
row_delta, для сравнения со значением, которое вы установили дляaccept_thresholdв определяемой пользователем проверке, или величиной несогласованности количества строк, которую вы готовы принять между наборами данных. Если вы хотите, чтобы значения количества строк были равны, установите пороговое значение0,0.

Поиск дубликатов в наборе данных без столбца с уникальным идентификатором
Вы можете использовать встроенную метрику дубликата_счета, чтобы проверить содержимое столбца на наличие повторяющихся значений, и Soda автоматически отправляет любые ошибочные строки, то есть строки, содержащие повторяющиеся значения, в Soda Cloud для изучения.
Однако, если ваш набор данных не содержит столбца с уникальным идентификатором, как в случае с денормализованным набором данных или набором данных, полученным из нескольких объединений, вам может потребоваться определить уникальность с помощью комбинации столбцов. В этом примере используется проверка неудачных строк с запросами SQL, чтобы выйти за рамки простой проверки одного столбца. Замените значения в двойных фигурных скобках {{ }} собственными соответствующими значениями.
В идеале вы должны сгенерировать суррогатный ключ из объединения столбцов в рамках преобразования, например, с помощью этой утилиты dbt Core™, которая генерирует суррогатный_ключ . Однако, если это невозможно, вы можете использовать следующий пример для проверки уникальности с помощью составного ключа.
✅ Amazon Redshift ✅ GCP Big Query ✅ PostgreSQL ✅ Snowflake
проверяет dim_product:
- неудачные строки:
неудачный запрос: |
с дублированными_записями как (
выбирать
{{столбец_а}},
{{ столбец_b }}
из {{ таблицы }}
сгруппировать по {{ column_a }}, {{ column_b }}
имея количество (*)> 1
)
выбирать
с. *
из {{ таблицы }} q
присоединяйтесь к дубликатам duplicated_records
на q.{{ column_a }} = дубликат.{{ column_a }}
и q.{{ column_b }} = дубликат.{{ column_b }}
Объясните SQL *
из {{ таблицы }} q
присоединяйтесь к дубликатам duplicated_records
на q.{{ column_a }} = дубликат.{{ column_a }}
и q.{{ column_b }} = дубликат.{{ column_b }}
*
из {{ таблицы }} q
присоединяйтесь к дубликатам duplicated_records
на q.{{ column_a }} = дубликат.{{ column_a }}
и q.{{ column_b }} = дубликат.{{ column_b }}
- Во-первых, общее табличное выражение (CTE)
Duplicated_recordsперечисляет все идентификаторы, которые встречаются в наборе данных более одного раза, что позволяет создать шаблон, подтверждающий уникальность с использованием более чем одного столбца. В примере используются два столбца, но вы можете добавить столько, сколько вам нужно. Если вы добавите больше, обязательно добавьте их в объединение в конце запроса. - Затем он присоединяется к
Duplicated_recordsобратно к самому набору данных, чтобы он мог идентифицировать и отправлять ошибочные строки для этих повторяющихся идентификаторов в Soda Cloud.
Проверка бизнес-логики на уровне строк
Используйте один из следующих примеров, чтобы проверить, соответствуют ли данные в записях в вашем источнике данных вашим ожиданиям.
Первый пример — скелетный запрос, в который можно вставлять различные условия; другие предлагают примеры того, как вы можете использовать запрос. Замените значения в двойных фигурных скобках {{ }} собственными соответствующими значениями.
✅ Amazon Redshift ✅ GCP Big Query ✅ PostgreSQL ✅ Snowflake
проверки dim_product:
- неудачные строки:
условие отказа: не ({{ condition_logic }})
Объясните SQL CTE определяет набор данных, в котором можно найти записи, не соответствующие условиям, заданным вами в выражении , а не .Проверка суммы значений столбцов
✅ Amazon Redshift ✅ GCP Big Query ✅ PostgreSQL ✅ Snowflake
проверяет dim_product:
- неудачные строки:
условие отказа: нет (credit_card_amount + wire_transfer = total_order_value)
Объясните SQL CTE проверяет, соответствует ли сумма двух столбцов в наборе данных значению в третьем столбце, и идентифицирует те строки, которые не совпадают.
Подтверждение полной оплаты
✅ Amazon Redshift ✅ GCP Big Query ✅ PostgreSQL ✅ Snowflake
проверяет dim_product:
- неудачные строки:
условие отказа: не (полный_дедлайн_платежа < датадобавления (месяц, количество_рассрочек, первая_дата_платежа))
Объясните SQL CTE проверяет, что заказ, оплачиваемый в рассрочку, будет полностью оплачен к установленному сроку, и идентифицирует те строки, которые не соответствуют сроку.Проверка на наличие неправильно сопоставленных значений в столбцах
Если набор данных не проверяет свое содержимое при вводе, вы можете захотеть подтвердить, что записи правильно сопоставляются со стандартными значениями. Например, когда конечные пользователи вводят значение в произвольной форме для поля страны, вы можете использовать SQL-запрос, чтобы убедиться, что запись правильно сопоставляется с кодом страны ISO, как показано в следующей таблице.
| название_страны | код_страны |
|---|---|
| Голландия | NL |
| Нидерланды | NL |
| Великобритания | Великобритания |
| США |
Используйте один из следующих примеров пользовательских показателей для конкретных источников данных в ваш проверяет файл YAML. Замените значения в двойных фигурных скобках {{ }} собственными соответствующими значениями.
Замените значения в двойных фигурных скобках {{ }} собственными соответствующими значениями.
✅ Amazon Redshift ✅ PostgreSQL
проверяет dim_product:
- неудачные строки:
неудачный запрос: |
// этот запрос возвращает ошибочные строки
выбирать
*
от(
выбирать
*,
количество ({{ столбец_2 }}) более (
раздел по {{column_1}}
) как number_duplicated_records_per_key
из {{ таблицы }}
) как Mapping_aggregations
где number_duplicated_records_per_key > 1
упорядочить по {{ column_1 }}, {{ column_2 }}
;
// этот запрос возвращает только отдельные ошибочные сопоставления
выбрать отдельный
{{ столбец_1 }},
{{ столбец_2 }}
от(
выбирать
*,
количество ({{ столбец_2 }}) более (
раздел на {{ column_1 }}
) как number_duplicated_records_per_key
из {{ таблицы }}
) как Mapping_aggregations
где number_duplicated_records_per_key > 1
упорядочить по {{ column_1 }}, {{ column_2 }}
;
Объясните SQL- Первый запрос подсчитывает количество строк, в которых значения в одном из столбцов различаются по отношению к содержимому другого столбца, и отображает полное содержимое ошибочных строк, содержащих различные значения.
- Второй запрос аналогичен первому, но отображает только уникальные значения, которые появляются в любом столбце.

✅ GCP Big Query
проверяет dim_product:
- неудачные строки:
неудачный запрос: |
// этот запрос возвращает ошибочные строки
выбирать
*,
из {{ таблицы }}
где 1 = 1
квалифицировать count(*) over (partition by {{ column_1 }} order by {{ column_2 }}) > 1;
// этот запрос возвращает только отдельные ошибочные сопоставления
выбрать отдельный
{{ столбец_1 }},
{{ столбец_2 }}
из {{ таблицы }}
где 1 = 1
квалифицировать count(*) over (partition by {{ column_1 }} order by {{ column_2 }}) > 1;
Объясните SQL- Первый запрос подсчитывает количество строк, в которых значения в одном из столбцов различаются по отношению к содержимому другого столбца, и отображает полное содержимое ошибочных строк, содержащих различные значения.
- Второй запрос аналогичен первому, но отображает только уникальные значения, которые появляются в любом столбце.

✅ Снежинка
чеки на dim_product:
- неудачные строки:
неудачный запрос: |
// этот запрос возвращает ошибочные строки
выбирать
*
из {{ таблицы }}
квалифицировать count(*) over (разделить на {{ column_1 }} порядок на {{ column_2 }}) > 1
// этот запрос возвращает только отдельные ошибочные сопоставления
выбирать
отчетливый
{{ столбец_1 }},
{{ столбец_2 }}
из {{ таблицы }}
квалифицировать count(*) over (разделить на {{ column_1 }} порядок на {{ column_2 }}) > 1
Объясните SQL- Первый запрос подсчитывает количество строк, в которых значения в одном из столбцов различаются по отношению к содержимому другого столбца, и отображает полное содержимое ошибочных строк, содержащих различные значения.
- Второй запрос аналогичен первому, но отображает только уникальные значения, которые появляются в любом столбце.

Сравнение дат для проверки последовательности событий
Вы можете использовать определяемую пользователем метрику для сравнения значений дат в одном и том же наборе данных. Например, вы можете сравнить значение start_date от до end_date , чтобы подтвердить, что событие не заканчивается до его начала, как во второй строке ниже.
индекс ; Дата начала ; Дата окончания 1; 01.01.2020 ; 2021-03-13 2; 01.01.2022 ; 2019-03-13
✅ GCP Big Query
проверяет exchange_operations:
- ОбновленнаяДатаОк = 1:
имя: Убедитесь, что если есть дата обновления, она больше, чем дата создания
Запрос UpdatedDateOk: |
ВЫБИРАТЬ
СЛУЧАЙ
КОГДА (updated_at_ts > '2017-10-01' И updated_at_ts < current_timestamp И updated_at_ts >= created_at_ts) ИЛИ updated_at_ts равно NULL THEN 1
ИНАЧЕ 0
КОНЕЦ как rdo
ИЗ exchange_operations
Дальше
- Нужна помощь? Присоединяйтесь к сообществу Soda в Slack.
