
Как и зачем проверять тексты на уникальность
Профессия
Мнение
Оксана Силантьева мультимедийный продюсер sila.media
Теги:
советы
инструменты
Недобросовестно сделанный контент не должен попадать на полосы и мониторы. И это редакторская зона ответственности
Редактор — это человек, который держит планку качества. От его / ее отношения к вопросу копипаста зависит, смогут авторы публиковать под своим именем чужие тексты или нет. Те самые пресловутые «тексты из интернета». Автор может быть добросовестным, а может и «срезать на поворотах», скопировав пару-тройку тысяч знаков на просторах Сети. Получив при этом гонорар за все килобайты, свои и чужие.
«Я не понимаю, о каких проблемах контента онлайн-СМИ вы тут, Оксана, говорите. Мои журналисты берут в интернете информацию, публикуют в газете, потом мы эти материалы выкладываем на свой сайт. У нас все хорошо».
На том семинаре нам не удалось найти общий язык с этим редактором.
Легче всего ответить на вопрос: «Как проверять текст на уникальность?» Уже есть много сетевых инструментов выявления плагиата. Большая часть функций таких сервисов бесплатна. Можно настроить работу так, чтобы каждый текст, который попадает к редактору, проверялся на процент заимствований. Можно даже полуавтоматизировать этот процесс и пропускать через сервис все тексты, которые приходят от штатных и внештатных авторов, копирайтеров, колумнистов.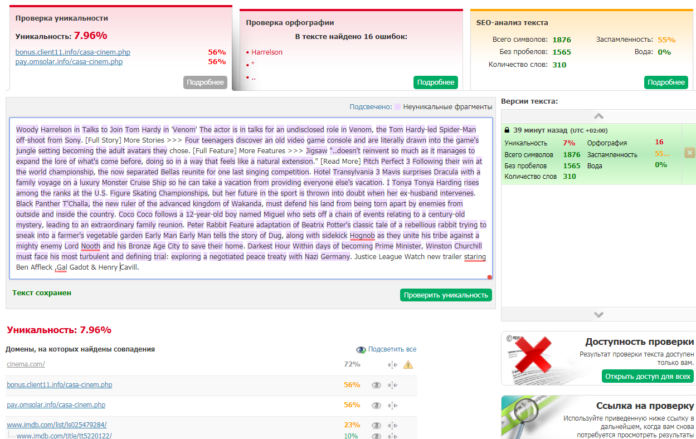
Куда сложнее с вопросом: «Зачем проверять на плагиат?» Потому что на чаше весов всегда с одной стороны принципы и стандарты, а с другой — реальность и требуемые объемы контента. И если редактору силами пяти сотрудников нужно сделать еженедельную газету, информационный сайт, пару групп в соцсетях и спецпроект, то «Оксана, ты ж понимаешь, о каком эксклюзивном контенте мы говорим». Если планку новостей и общественно-политических материалов, интервью еще можно удерживать, то все, что касается потребительских тем, вечно востребованных рецептов, лайфхаков и советов молодой хозяйке, часто спускается на тормозах. Рерайт и компиляция. Два спасительных слова, когда текстов нужно много.
И есть только один человек, который принимает решение, что в издании допустимо, а что нет, — редактор. Плагиат чаще всего вспоминают, когда речь идет о студенческих работах или деятельности сообщества «Диссернет». И каждый раз столкновение с копипастом вызывает возмущение: ну как так, ну это же твой текст, на нем стоит твое имя, неужели не стыдно? Апелляция к чувству вины, к сожалению, не меняет ситуацию.
ОДИН ВОПРОС МЕНЯ ВОЛНУЕТ ДО СИХ ПОР. СКОЛЬКО ИЗДАНИЙ ПОСЛЕ ИСТОРИИ С ПЕСКОВОЙ ВНЕДРИЛИ У СЕБЯ ОБЯЗАТЕЛЬНУЮ ПРОВЕРКУ КОНТЕНТА НА ПЛАГИАТ?
Еще в конце 90-х годов я разговаривала с возмущенным преподавателем экономического факультета барнаульского вуза:
— Какие ужасные студенты! Представляешь, в прошлом году приносили диплом про Алтайский моторный завод. В этом году другой приносит этот диплом слово в слово, только год поменял. Наглецы!
— Ну и как, защитился тот, который в этом году?
— Конечно, а что мы можем поделать?
— Тогда почему вы жалуетесь? Кафедра, факультет имеют власть не пропускать через себя некачественные работы. Ученый совет определяет стандарты допустимого, ставит планку качества и фильтрует то, что не дотягивает до стандарта. Никто другой.
Сейчас в некоторых вузах выпускные работы и диссертации проходят обязательную проверку на плагиат. Работа не допускается к защите, если в ней авторского текста меньше нормы. Невероятное сопротивление пришлось преодолеть, но если вуз переживает за качество и репутацию, то есть ответ на вопрос: «Зачем проверять на плагиат?»
Точно такая же ситуация в медиа. Апеллировать к честности можно, но не продуктивно. Производственный процесс должен быть выстроен так, чтобы недобросовестно сделанный контент не попадал на полосы и мониторы. И это целиком и полностью редакторская зона ответственности. Редактор принимает решение, какую проверку проходят авторские материалы. Перепроверяем ли мы факты, цифры, выводы, корректность цитат, имена и фамилии. Редактор определяет, кто за какую часть этой верификации отвечает. Именно редактор принимает решение, хочет он знать, насколько контент издания уникален, или не хочет.
Апеллировать к честности можно, но не продуктивно. Производственный процесс должен быть выстроен так, чтобы недобросовестно сделанный контент не попадал на полосы и мониторы. И это целиком и полностью редакторская зона ответственности. Редактор принимает решение, какую проверку проходят авторские материалы. Перепроверяем ли мы факты, цифры, выводы, корректность цитат, имена и фамилии. Редактор определяет, кто за какую часть этой верификации отвечает. Именно редактор принимает решение, хочет он знать, насколько контент издания уникален, или не хочет.
Осенью 2017 года случайно стала причиной небольшого всплеска интереса к теме плагиата в медиа. Я занимаюсь темой развития дистанционного образования, поэтому ко мне стекается разнообразная информация об этом. И вот на сайте Forbes.ru я увидела авторскую колонку Лизы Песковой, дочери пресс-секретаря президента, где она рассуждает о преимуществах очного образования перед обучением онлайн. Мой тренированный глаз сразу заметил несостыковки в стиле текста. Это один из самых первых звоночков в голове редактора — автора не должно постоянно кидать из просторечной лексики в пафосные многосложные грамматические конструкции.
Это один из самых первых звоночков в голове редактора — автора не должно постоянно кидать из просторечной лексики в пафосные многосложные грамматические конструкции.
Дело трех минут — прогнать текст через систему антиплагиата. В результате наглядно видно, какой кусок был скопирован из публикации портала Mel.fm, какой — копипаст из материала 2011 года passion.ru, а какой — из реферата по педагогике на портале сами знаете каких рефератов.
Проверка на плагиат колонки Елизаветы Песковой, опубликованной на forbes.ru
Многие студенты так делают. Меняют глаголы, переставляют местами части предложения, подчас по дороге теряя смысл. Но курсовая работа остается в недрах вуза, ее читают немногие. А в медиа копипаст публикуется под брендом издания и остается в архивах Сети надолго.
Я связалась с замредактора «Форбс», мы поговорили о ситуации. К моменту моего поста колонка Лизы уже разлетелась в репостах и перепечатках — звездность автора улучшает дистрибуцию. Удалять с портала? У меня не очень много вопросов было к автору колонки, уровень ее экспертизы в вопросе дистанционного образования невысок.
История с плагиатом получилась достаточно громкой, многие крупные издания не прошли мимо, можно набрать в поиске «силантьева пескова» и посмотреть на результат.
Но один вопрос меня волнует до сих пор. Сколько изданий после этой истории внедрили у себя обязательную проверку контента на плагиат?
ОНЛАЙН-СЕРВИСЫ ДЛЯ ПРОВЕРКИ АВТОРСКОГО ТЕКСТА НА УНИКАЛЬНОСТЬ
CONTENT WATCH
Умеет проверять на уникальность загруженные тексты и страницы сайтов в интернете.
Бесплатно разрешается сделать 7 проверок в день. Можно проверять текст, скопировав его в окно, или указать ссылку на сайт. И тот и другой варианты называются ручной проверкой. Чтобы сервис проверил текст, его длина должна быть от 50 до 10 000 знаков, включая пробелы. Тексты меньшего и большего размера не пройдут: всплывающее уведомление попросит увеличить либо сократить количество символов.
После проверки текста Content Watch показывает степень уникальности загруженного текста, ссылки на страницы в интернете и процент заимствования текста.
TEXT.RU
Ищет дубликаты текстов, а также учитывает изменение падежей и времен — уловки рерайтеров не пройдут незамеченными. На сайте есть словарь синонимов: он поможет найти замену заезженным словам.
Проверить текст на уникальность можно бесплатно и без регистрации. В поисковую форму можно вставлять текст в 15 000 символов без пробелов. Если хотите больше — придется зарегистрироваться. Алгоритм выявляет плагиат, орфографические ошибки и делает SEO- анализ. Количество проверок в сутки не ограничено.
ANTIPLAGIAT.RU
На бесплатном тарифе установлено ограничение — проверка одного документа в 6 минут. В отчете будут данные о степени заимствования, оригинальности и цитировании, поиск будет проводиться только по модулю «Интернет».
Другие модули подключаются за плату: можно подключить модуль поиска по авторефератам и диссертациям РГБ, поиск по законодательным и нормативным актам или выбрать другую коллекцию. На платном тарифе скорость проверки станет выше, спадет ограничение на частоту проверок и появится доступ к полному отчету.
Иллюстрация: shutterstock.com
Сообщить об ошибке
Подписаться на журнал
Подписаться на рассылку
Июн 27, 2019
Как проверить текст на уникальность: ТОП-5 сервисов
Один из наиболее часто задаваемых вопросов среди наших клиентов: «Как проверить текст на уникальность и какой сервис для этого лучше использовать?». Отвечаем кратким обзором самых популярных сервисов, которые испробовал наш редактор.
Сразу хотим отметить, что один и тот же текст в различных сервисах может иметь разный процент уникальности. Это связано с тем, что каждый сервис использует свой уникальный алгоритм поиска совпадений текста в интернете.
Наш ТОП-5 сервисов для проверки уникальности текста.
1. Text.ru. Сервис, который мы в WHAT agency ценим и юзаем чаще всего. Удобный и простой в пользовании, быстро осуществляет проверку. Неуникальные фрагменты подсвечивает цветом.
Счетчик очереди показывает сколько текстов проверяется перед вашим, а если пройти быструю бесплатную регистрацию, ваши тексты получают приоритетность в общей очереди.
Достоинства:
- Неограниченное количество проверок в день (нужна регистрация).
- Услуги проверки на уникальность бесплатные.
- Встроена функция проверки текста на орфографию.
- Встроены функции SEO-анализа текста (заспамленность, вода).
- Также доступны бесплатные услуги подбора синонимов слов, проверки уникальности документа прямо из файла.
Недостатки:
- Если проверять текст без регистрации, процесс проверки довольно медленный.

- Услуга проверки сайта на уникальность платная.
- Максимальная длина 1 текста: 15 тыс. символов.
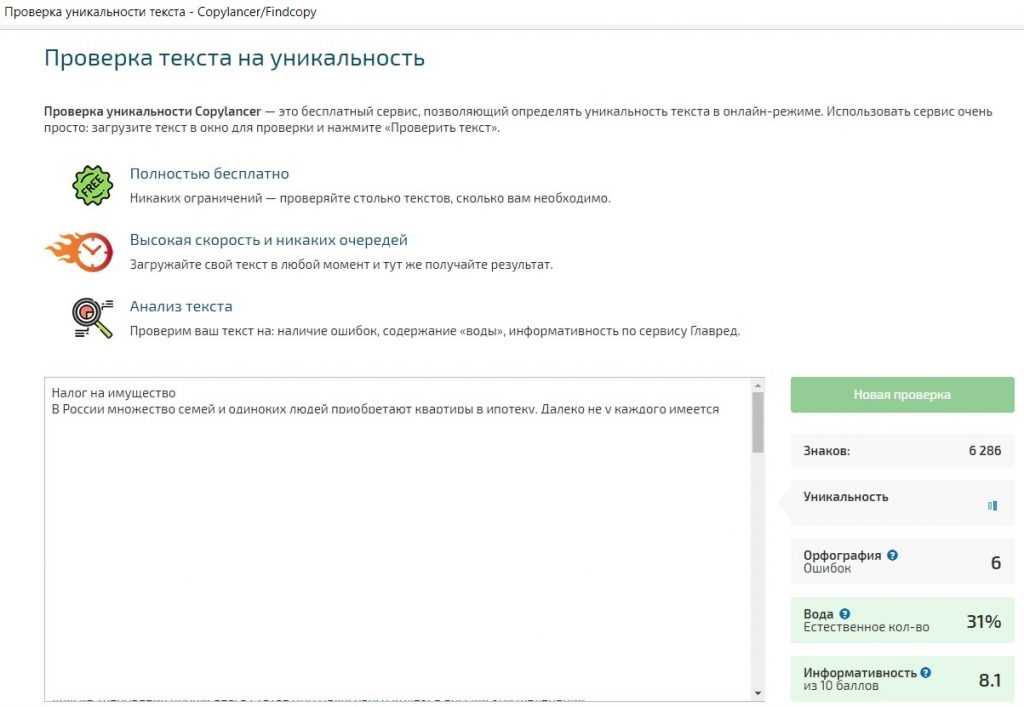
2. Content-watch.ru. Данный сервис проверяет тексты в более быстром режиме без регистрации, чем Текст.ру, но имеет ограничения по количеству символов и проверок в день. Зарегистрированный пользователь может проверить на уникальность сайт или определенные страницы, но опять же ограниченное количество раз.
Этот сервис хорош для небольшого количества проверок в день, или если вы готовы купить платный пакет услуг (есть еще один способ, который позволяет «обойти» ограничения по количеству проверок, но мы не можем поделиться им здесь из соображений безопасности. Интересующихся просим в личные сообщения или чат в правом углу экрана:).
Достоинства:
- Проверка быстрая даже без регистрации (очередь отсутствует).
- Есть возможность проверить уникальность уже опубликованных текстов, для этого нужно ввести в строку «Игнорировать сайт» ссылку на страницу текста. Эта функция удобна, если вы, например, решили усовершенствовать существующий текст сайта и хотите проверить, насколько уникальной получилась новая версия.
- Бесплатная проверка сайта или отдельных страниц.
- В платной версии есть возможность установки плагинов на самые популярные CSM, которые позволяют автоматически проверять тексты прямо на сайте.
 Эта функция удобна, если вы, например, решили усовершенствовать существующий текст сайта и хотите проверить, насколько уникальной получилась новая версия.
Эта функция удобна, если вы, например, решили усовершенствовать существующий текст сайта и хотите проверить, насколько уникальной получилась новая версия.
Недостатки
- В день можно проверить не более 7 текстов объемом до 10 тыс. символов (бесплатная версия)
- Ограничения для проверки сайта на уникальность: до 3 в день.
3. Advego Antiplagiatus. Когда-то была программой №1 для проверки текстов на плагиат. №1 потому что имеет массу достоинств и функций. Была — потому что с момента блокировки в Украине российских сервисов, в том числе Яндекса, украинские пользователи не могут получить релевантный результат проверки с программы Advego. Программа не может подключиться к поиску в Яндексе и не учитывает выдачу с этой поисковой системы. В результате выдает высокий процент уникальности даже для тех текстов, которые таковыми не являются.
В результате выдает высокий процент уникальности даже для тех текстов, которые таковыми не являются.
Помимо этого, прекрасное ПО для проверки. Для пользователей остальных стран работает отлично.
Кстати, у сервиса есть еще онлайн-версия с теми же функциями, но она имеет ограничения по объему проверок (до 10 тыс. символов в день только для зарегистрированных пользователей).
Достоинства
- Установка программы бесплатна.
- Не имеет ограничений по количеству и объему проверок (программа).
- Можно проверять большие тексты — до 100 тыс. символов.
- Можно проверять тексты в различных режимах: быстрой и глубокой проверки.
- Изменять параметр длины шингла, то есть совпадения по фразам — сколько слов подряд во фразе считать как совпадение (плагиат).
- Текст проверяется и на SEO- параметры: заспамленность, водность, семантическое ядро с процентным соотношением.
- Присутствует функция «Игнорировать сайт» для проверки опубликованных текстов.

Недостатки
- Не проверяет совпадения в Яндексе, поэтому для пользователей Украины результаты проверки будут неточными.
- Программа устанавливается только на Windows.
- Для проверки через онлайн-сервис обязательна регистрация, ограничения по объему: до 10 тыс. символов в день.
Для англоязычного контента
Хоть и три вышеперечисленных сервиса подходят и для проверки текста на английском языке, иногда есть смысл дополнительно проверять англоязычный контент через зарубежные сервисы.
4. Copyscape. Этот сервис больше подходит для проверки отдельных страниц сайта, так вы сможете отслеживать уникальность опубликованного контента. Если ваш контент дублируется на каких-либо страницах в интернете, сервис покажет список этих ресурсов с ссылками.
Проверка на уникальность страниц сайта здесь бесплатна, а вот за каждую проверку текста нужно заплатить 0,05$.
Преимущества
- Бесплатная проверка страниц сайта
Недостатки
- Ограниченное количество проверок страниц сайта в день.
- Платная проверка отдельного текста (0,05$ за каждую проверку).
- Для проверки текста регистрация обязательна.
5. Duplichecker. Многофункциональный сервис, который кроме проверки текста на уникальность предлагает массу полезных инструментов: проверку грамматики и орфографии (англ. язык), плотность ключевых слов и др.
Текст на уникальность можно проверять путем вставки или загрузки вордовского файла.
Преимущества
- Неограниченное количество проверок для зарегистрированных пользователей (бесплатно).
- Широкий функционал проверки текста (SEO-параметры, орфография и грамматика — что особенно актуально для англоязычного контента).
Недостатки
- Для незарегистрированных пользователей действует ограничение по количеству проверок — до 3 в день.
- Ограничения по объему — текст должен быть не более 1000 слов.
Попробуйте воспользоваться несколькими сервисами из нашего списка и выберите для себя наиболее удобный. Надеемся, теперь проверка контента на уникальность не будет вызывать у вас вопросов. А заказать уникальный текст лучше всего у нас — в агентстве копирайтинга WHAT agency.
Обнаружение плагиата
Процесс рецензирования лежит в основе научных публикаций. В рамках обязательств Elsevier по защите целостности научных записей Elsevier считает своим долгом поддерживать научное сообщество во всех аспектах исследовательской и издательской этики.
Мы вкладываем средства во многие ресурсы, чтобы помочь исследователям научиться избегать этических проблем, выявлять любые проблемы в процессе редактирования, поддерживать редакторов в работе с обвинениями в этике публикации и, при необходимости, исправлять научные записи.
О проверке сходства перекрестных ссылок
Случаи подозрения на плагиат редко ограничиваются одним журналом или издателем. Поэтому программные решения требуют сотрудничества между (в идеале) всеми издательствами. В 2008 году Crossref и издательское сообщество STM объединились для разработки Crossref Similarity Check — сервиса, помогающего редакторам проверять подлинность статей. Проверка подобия Crossref основана на программном обеспечении Ithenticate от iParadigms, известной в академическом сообществе как поставщик Turnitin.
Поэтому программные решения требуют сотрудничества между (в идеале) всеми издательствами. В 2008 году Crossref и издательское сообщество STM объединились для разработки Crossref Similarity Check — сервиса, помогающего редакторам проверять подлинность статей. Проверка подобия Crossref основана на программном обеспечении Ithenticate от iParadigms, известной в академическом сообществе как поставщик Turnitin.
Более 200 членов CrossRef, включая Elsevier, сотрудничают, предоставляя полнотекстовые журнальные статьи и главы из книг для создания уникальной базы данных, содержащей более 50 миллионов статей. Обратите внимание, что даже эта база данных не является полностью исчерпывающей: исследования, опубликованные неучаствующими издателями или до цифровой эры, могут отсутствовать. Вклад Elsevier состоит из 10 миллионов статей и 7000 книг и постоянно увеличивается по мере добавления всех новых опубликованных статей.
Чтобы найти список всех участвующих издателей с возможностью поиска, посетите: https://www. ithenticate.com/crossref-members
ithenticate.com/crossref-members
Чем могут воспользоваться редакторы
Все новые материалы, поступающие во многие журналы Elsevier, автоматически проверяются с помощью проверки сходства Crossref в редакционной системе. Редакторы также могут запустить отчет о сходстве в любой другой момент в процессе рецензирования или после публикации с помощью автономного инструмента. Чтобы запросить учетную запись, просто обратитесь к своему контактному лицу по публикации в Elsevier.
Представление отчета о сходстве по умолчанию дает процент текста рукописи, который перекрывается с одной или несколькими опубликованными статьями. Рисунки и уравнения в настоящее время не могут быть проверены. Обратите внимание, что высокая оценка сходства не обязательно указывает на плагиат текста. Показатель схожести 30% может означать, что 30% текста совпадает с одним источником, но в равной степени может означать 1% текста, общего с 30 различными источниками. Повторно использованный текст, который был законно процитирован, библиографический текст и тексты методов могут внести свой вклад в оценку сходства. Предметные знания редакторского эксперта жизненно важны для интерпретации отчета о проверке подобия и определения наличия каких-либо оснований для беспокойства.
Предметные знания редакторского эксперта жизненно важны для интерпретации отчета о проверке подобия и определения наличия каких-либо оснований для беспокойства.
Рекомендуемое чтение для редакторов
Прежде чем использовать функцию проверки сходства в первый раз, мы настоятельно рекомендуем всем редакторам прочитать короткую статью «Понимание показателя сходства» и наше краткое руководство «Советы и рекомендации». Мы предлагаем множество дополнительных ресурсов поддержки и обучения для редакторов, в том числе:
- Посетить обучающий веб-семинар в режиме реального времени
- Слайд-презентация по использованию функции проверки сходства
- Отправить запрос в службу поддержки iThenticate
- Подробное руководство пользователя
Редакционный менеджер Проверка отправки дубликатов
Редакционный менеджер (EM) предлагает проверку дубликатов отправки, которая сравнивает аннотацию, название и имя автора заявки с исторической базой данных журнала (т.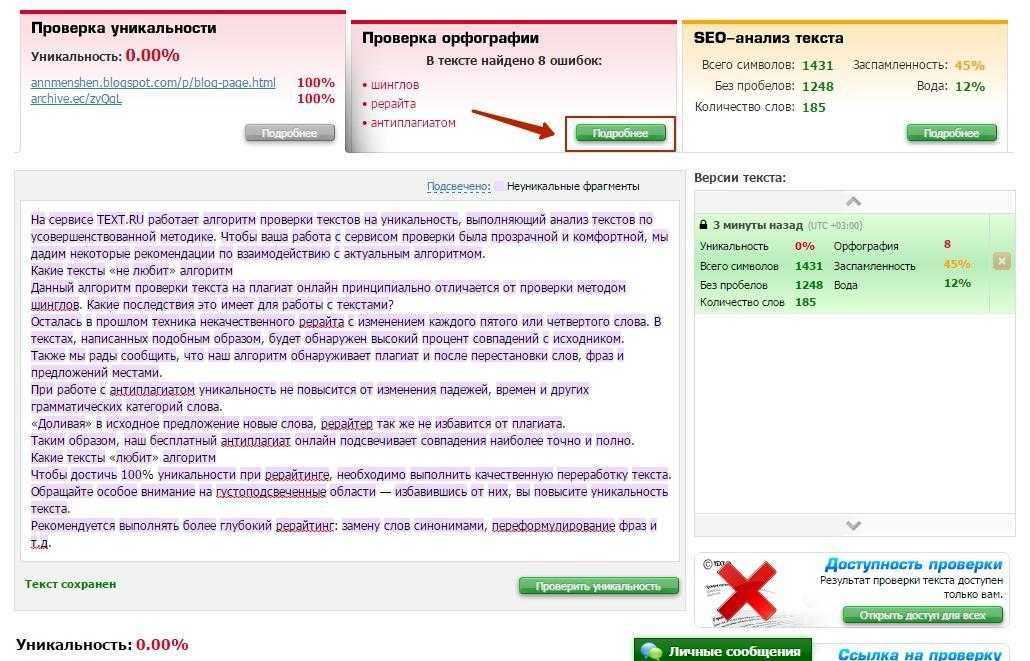 е. сравнивает внутри журнала) для создания общей оценки на основе трех взвешенных оценок. Это дополняет проверку сходства перекрестных ссылок на базе iThenticate, которая сравнивает полный текст заявки с опубликованной литературой. Проверка на сходство не сравнивает представленные материалы с рукописями, все еще находящимися в процессе редактирования.
е. сравнивает внутри журнала) для создания общей оценки на основе трех взвешенных оценок. Это дополняет проверку сходства перекрестных ссылок на базе iThenticate, которая сравнивает полный текст заявки с опубликованной литературой. Проверка на сходство не сравнивает представленные материалы с рукописями, все еще находящимися в процессе редактирования.
Дополнительные ресурсы по этике публикаций
Python — Поиск уникальных слов в текстовом файле
- Python File Operations
- Python — Read Text File
- Python — Create New File
- Python — Write String 4 7 0 Text
to8 File
или удалить файл - Python — Создать каталог
- Python — проверить, является ли указанный путь файлом или Каталог
- Python — рекурсивно получить список всех файлов в каталоге и его подкаталогах.
- Python — Добавить Текст в файл
- Python — Заменить строку в текстовом файле
- Python — Заменить нескольких пробелов одним пробелом в текстовом файле
- Python — подсчитать Количество слов в a Текстовый файл
- Python — количество количество символов в текстовом файле
Содержание
- Введение
- Действия по поиску уникальных слов
- Пример 1. Поиск уникальных слов в текстовом файле
- Резюме
 Поиск уникальных слов в текстовом файле
Поиск уникальных слов в текстовом файлеПоиск уникальных слов в текстовом файле требует очистки текста , а затем нахождение уникального.
В этом уроке мы научимся находить уникальные слова в текстовом файле.
Действия по поиску уникальных слов
Чтобы найти уникальные слова в текстовом файле, выполните следующие действия.
- Чтение текстового файла в режиме чтения.
- Преобразование текста в нижний или верхний регистр. Мы не хотим, чтобы «яблоко» отличалось от «яблока».
- Разделить содержимое файла на список слов.
- Очистить слова, зараженные знаками препинания. Что-то вроде удаления из слов точек, запятых и т. д.
- Также удалите апострофы и .
- Здесь вы также можете добавить дополнительные этапы очистки текста.
- Теперь найдите уникальные слова в списке, используя Python For Loop и оператор членства Python.
- Найдя уникальные слова, отсортируйте их для представления.
При очистке текста вы также можете удалить вспомогательные глаголы и т. д.
Пример 1: Поиск уникальных слов в текстовом файле
Теперь мы применим все вышеперечисленные шаги к работе с использованием программы Python.
Учтите, что мы берем следующий текстовый файл.
Apple — очень крупная компания. Яблоко в день держит доктора далеко. Рядом с кабинетом врача дорогу перебежал большой толстый кот. Доктор владеет устройством Apple.
Программа Python
text_file = open('data.txt', 'r')
текст = text_file.read()
#уборка
текст = текст.нижний()
слова = текст.split()
слова = [word.strip('.,!;()[]') для слова в словах]
слова = [word.replace("s", '') для слова в словах]
#поиск уникального
уникальный = []
для слова словами:
если слово не уникально:
уникальный.добавлять(слово)
#Сортировать
уникальный.sort()
#Распечатать
print(unique) Output
['а', 'поперек', 'ан', 'яблоко', 'в гостях', 'рядом', 'большой', 'пришел', 'кот', 'компания ', 'день', 'устройство', 'доктор', 'толстый', 'есть', 'держит', 'офис', 'владеет', 'дорога', 'то', 'очень']
Перевод шагов в код Python
Ниже приведен список концепций Python, которые мы использовали в приведенной выше программе для поиска уникальных слов.